聊一聊Qwen3思考模式实现以及背后原理探讨
Qwen3思考模式切换实现
硬开关
我们先通过官方的示例代码来体验一下,如何实现在思考模式和非思考模式之间切换
通过tokenizer.apply_chat_template的enable_thinking参数来实现
默认情况下,Qwen3 启用了思考功能,类似于 QwQ-32B。这意味着模型将运用其推理能力来提升生成响应的质量。例如,当在tokenizer.apply_chat_template明确设置enable_thinking=True或保留其默认值时,模型将启动其思考模式。代码如下:
text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True,enable_thinking=True # True is the default value for enable_thinking
)
在这种模式下,模型会生成包裹在…块中的思考内容,然后是最终的响应。
对于思考模式,官方提示请使用Temperature=0.6、TopP=0.95、TopK=20和MinP=0( 中的默认设置generation_config.json)。请勿使用贪婪解码,因为它会导致性能下降和无休止的重复。https://huggingface.co/Qwen/Qwen3-32B
Qwen3提供了一个硬开关,可以严格禁用模型的思考行为,使其功能与之前的 Qwen2.5-Instruct 模型保持一致。此模式在需要禁用思考以提高效率的场景中尤为有用。
text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True,enable_thinking=False # Setting enable_thinking=False disables thinking mode
)
在此模式下,模型不会生成任何思考内容,也不会包含…块。
对于非思考模式,我们建议使用Temperature=0.7、TopP=0.8、TopK=20和MinP=0。
软开关
Qwen3示例给了一种高级用法: 通过用户输入在思考模式和非思考模式之间切换,具体来说就是通过用户输入层控制是否思考,提供了一种软切换机制,允许用户在enable_thinking=True时动态控制模型的行为。实现方式就是可以在用户提示或系统消息中添加/think和/no_think,以便在不同回合之间切换模型的思维模式。
在多回合对话中,模型将遵循最后一条的指令。
以下是多轮对话的示例:
from transformers import AutoModelForCausalLM, AutoTokenizerclass QwenChatbot:def __init__(self, model_name="Qwen/Qwen3-32B"):self.tokenizer = AutoTokenizer.from_pretrained(model_name)self.model = AutoModelForCausalLM.from_pretrained(model_name)self.history = []def generate_response(self, user_input):messages = self.history + [{"role": "user", "content": user_input}]text = self.tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True)inputs = self.tokenizer(text, return_tensors="pt")response_ids = self.model.generate(**inputs, max_new_tokens=32768)[0][len(inputs.input_ids[0]):].tolist()response = self.tokenizer.decode(response_ids, skip_special_tokens=True)# Update historyself.history.append({"role": "user", "content": user_input})self.history.append({"role": "assistant", "content": response})return response# Example Usage
if __name__ == "__main__":chatbot = QwenChatbot()# First input (without /think or /no_think tags, thinking mode is enabled by default)user_input_1 = "How many r's in strawberries?"print(f"User: {user_input_1}")response_1 = chatbot.generate_response(user_input_1)print(f"Bot: {response_1}")print("----------------------")# Second input with /no_thinkuser_input_2 = "Then, how many r's in blueberries? /no_think"print(f"User: {user_input_2}")response_2 = chatbot.generate_response(user_input_2)print(f"Bot: {response_2}") print("----------------------")# Third input with /thinkuser_input_3 = "Really? /think"print(f"User: {user_input_3}")response_3 = chatbot.generate_response(user_input_3)print(f"Bot: {response_3}")
思考模式软硬开关如何兼容
我们会自然想到一种情况,就是用户即在tokenizer.apply_chat_template中设置了enable_thinking参数,又在用户输入的时候可能加入了/think和/no_think符号,这种情况软硬开关如何兼容呢?
为了实现 API 兼容性,当enable_thinking=True时,无论用户使用/think还是/no_think,模型都会始终输出一个包裹在<think>...</think>中的块。
但是,如果禁用思考功能,此块内的内容可能为空。当enable_thinking=False时,软开关无效。无论用户输入任何/think或/no_think符号,模型都不会生成思考内容,也不会包含…块。
我们可以看到enable_thinking的优先级是要大于/think或/no_think的优先级。
接下来我们通过Qwen3模型中的tokenizer_config.json来分析如何通过对话模板来如何实现快慢思考的?下面截图就是:
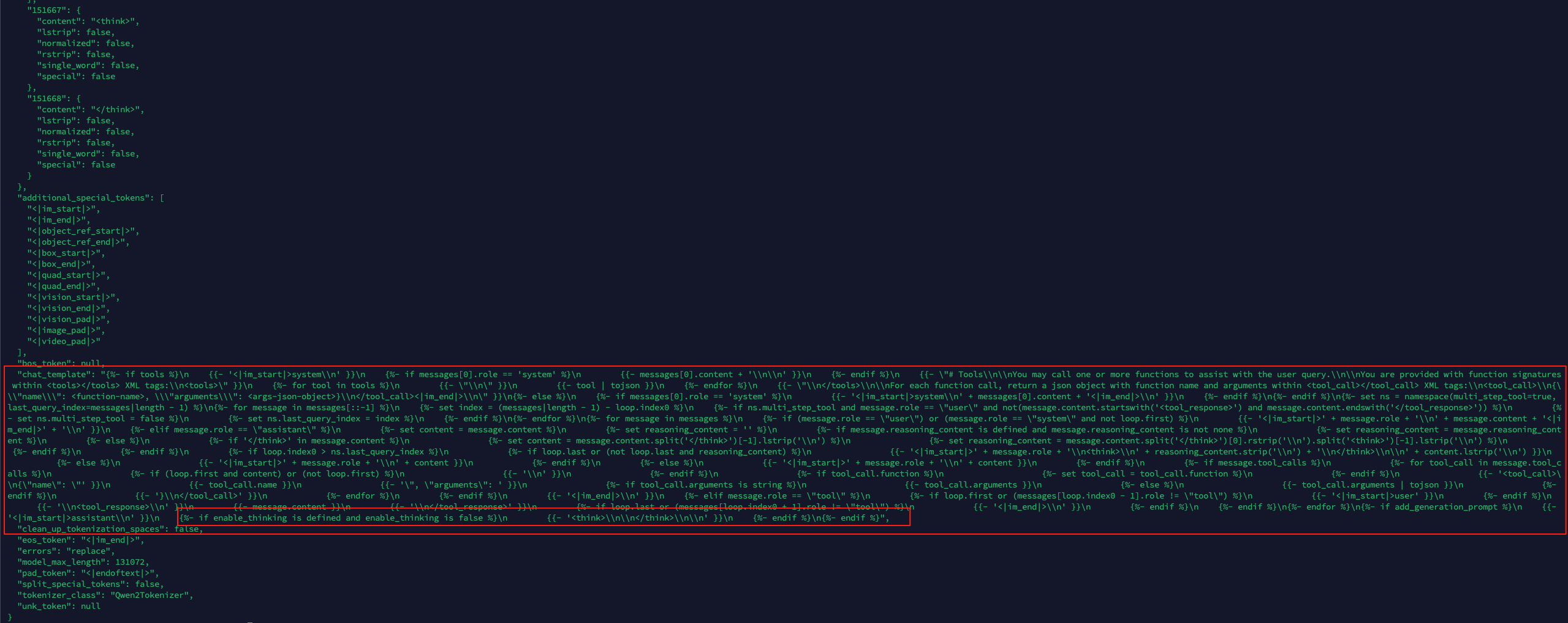
多说一句,Chat template 是大语言模型(LLM)中的一个关键组件,它定义了如何将对话转换为模型可以理解的格式化输入。我将详细解释其原理并提供具体示例。
Qwen3的 Chat Template 原理详解
Chat template 是大语言模型(LLM)中的一个关键组件,它定义了如何将对话转换为模型可以理解的格式化输入。我将详细解释其原理并提供具体示例。
基本原理
Chat template 本质上是一个文本模板,使用特定语法(通常是 Jinja2 模板语法)来处理和格式化对话数据。它的主要功能是:
- 角色区分:明确标识不同参与者(系统、用户、助手等)的消息
- 特殊标记插入:添加模型训练时使用的特殊标记
- 结构化表示:将多轮对话组织成模型预期的格式
- 功能支持:处理工具调用、思考过持等高级功能
关键组件解析
在 Qwen3-8B 的 chat_template 中:
<|im_start|>和<|im_end|>:标记消息的开始和结束role:标识消息发送者(system、user、assistant、tool)<think></think>:围绕助手的思考过程<tool_call></tool_call>:包含工具调用信息<tool_response></tool_response>:包含工具响应信息
实例说明
让我通过几个具体例子来说明 chat_template 如何工作:
例子1:简单对话
假设有以下对话:
系统:你是一个有用的助手
用户:你好
助手:你好!有什么我可以帮助你的?
使用 Qwen3-8B 的 chat_template 处理后,会变成:
<|im_start|>system
你是一个有用的助手
<|im_end|>
<|im_start|>user
你好
<|im_end|>
<|im_start|>assistant
你好!有什么我可以帮助你的?
<|im_end|>
例子2:包含思考过程的对话
系统:你是一个有用的助手
用户:42+28等于多少?
助手:(思考:我需要计算42+28,42+28=70)
70
处理后:
<|im_start|>system
你是一个有用的助手
<|im_end|>
<|im_start|>user
42+28等于多少?
<|im_end|>
<|im_start|>assistant
<think>
我需要计算42+28,42+28=70
</think>70
<|im_end|>
例子3:工具调用
系统:你是一个有用的助手
用户:查询北京今天的天气
助手:我将调用天气API
(调用天气工具)
工具响应:北京今天晴朗,温度22-28度
助手:根据查询,北京今天天气晴朗,温度在22-28度之间。
处理后:
<|im_start|>system
你是一个有用的助手
<|im_end|>
<|im_start|>user
查询北京今天的天气
<|im_end|>
<|im_start|>assistant
我将调用天气API
<tool_call>
{"name": "weather_api", "arguments": {"city": "北京", "date": "today"}}
</tool_call>
<|im_end|>
<|im_start|>user
<tool_response>
北京今天晴朗,温度22-28度
</tool_response>
<|im_end|>
<|im_start|>assistant
根据查询,北京今天天气晴朗,温度在22-28度之间。
<|im_end|>
Chat template 在实际处理中利用了 Jinja2 模板引擎的多种功能:
- 条件处理:
{%- if ... %}和{%- endif %}用于根据消息类型选择不同的格式化方式 - 循环遍历:
{%- for message in messages %}用于处理多轮对话 - 变量替换:
{{- message.content }}插入实际消息内容 - 命名空间:
{%- set ns = namespace(...) %}跟踪状态信息
Chat template 对模型使用至关重要:
- 训练一致性:确保推理时的格式与训练时一致
- 功能支持:使模型能识别并正确处理特殊功能(工具调用、思考过程)
- 性能优化:正确的格式化可以显著提高模型输出质量
下面一个代码可以看到enable_thinking为False/True时不同的分词结果
prompt = "42+28等于多少?"
messages = [{"role": "user", "content": prompt}
]text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True,enable_thinking=True # Setting enable_thinking=False disables thinking mode
)
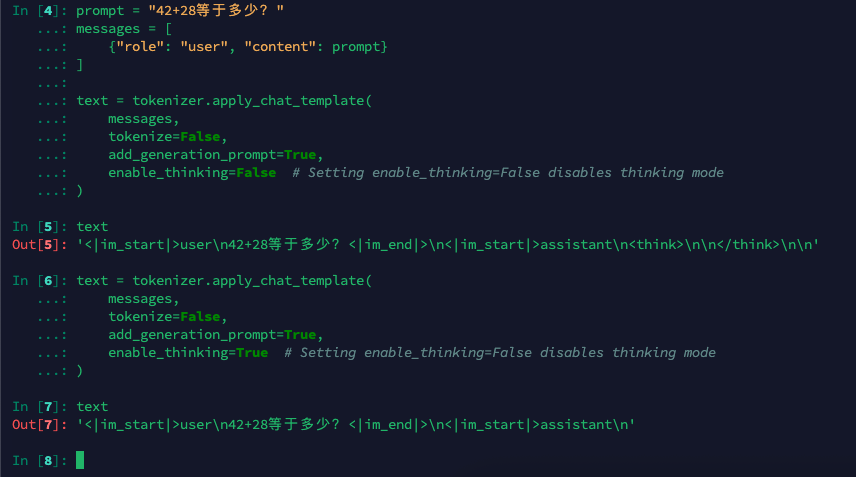
可以看到上面分词之后的唯一差别的地方就是,enable_thinking=False时添加了一个<think>\n\n</think>\n,添加了一个空白思考,用来告诉模型已经思考结束。
那么好奇问了,如果enable_thinking=True,然后我在对话的后面添加一个<think>\n\n</think>\n会怎么样呢,就是下面:
prompt = "42+28等于多少?"+“<think>\n\n</think>\n”
messages = [{"role": "user", "content": prompt}
]text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True,enable_thinking=True # Setting enable_thinking=False disables thinking mode
)
这个时候其实还是会输出思考内容的,大家可以试试看看
思考:Qwen3模型如何实现快慢思考
通过软开关,我们可以看到Qwen3是可以通过从输入上来控制的快慢思考的,自然而然想到的是不是在训练的时候加了一些策略,直觉就是:
有一部分数据带有思维链一部分没有带有思维链
- no_think:问题+答案
- think:问题+【思考内容+答案】
在第三阶段,Qwen3在一份包括长思维链数据和常用的指令微调数据的组合数据上对模型进行微调,将非思考模式整合到思考模型中。确保了推理和快速响应能力的无缝结合。
这个地方可以做到软硬的实现,一个是硬开关优先级的控制,可以通过强化学习来实现,比如模板部分是否存在<think>\n\n</think>\n,另一个就是软开关,可能就是不同训练数据混在一起训练,让模型面临简单或者复杂问题自主决定思考的自由度。
有同学说,针对Qwen3有些模型师Moe,是不是可以:
把解码头改成多专家的形式,一个think一个不think,这样可行吗
这个是可以的,不过Qwen3 8B不是Moe
也有同学说deepseek之前文章也是这么搞的,r1通过注入思考空指令如何不进行思考,
或者存在一种情况
类似于在R1应用中sys_prompt写成:
think>用户说我是一个端水大师,要从aaa bbb cc方面考虑问题,现在我要先做…… </think>
以期实现减少、甚至截断模型原本reasoning的部分
一些控制思考深度的研究方法
笔者收集了一些资料,在深度学习与自然语言处理公众号看到一些关于大模型“过度思考”解读的一些文章
让模型学会「偷懒」
论文:Towards Thinking-Optimal Scaling of Test-Time Compute for LLM Reasoning
链接:https://arxiv.org/pdf/2502.18080
解决方案:让模型自己决定「想多久」论文提出Thinking-Optimal Scaling(TOPS)策略,核心思想是:学会「偷懒」。
三步走实现:
- 模仿学习:用少量样例教模型「不同难度用不同思考长度」;
- 动态生成:对同一问题生成短/中/长三种思考链;
- 自我改进:自动选择最短的正确答案作为训练数据。
LightThinker的“思考压缩”
论文:LightThinker: Thinking Step-by-Step Compression
链接:https://arxiv.org/pdf/2502.15589
项目:https://github.com/zjunlp/LightThinker
LightThinker的秘籍分为两大招:何时压缩和如何压缩
何时压缩?
LightThinker提供了两种策略:
- Token级压缩:每生成固定数量的token就压缩一次,简单粗暴但可能把一句话“腰斩”。
- 思考级压缩:等模型写完一个完整段落(比如一段分析或一次试错)再压缩,保留语义完整性,但需要模型学会“分段”。
如何压缩?
这里有个关键操作:
- 把隐藏状态压缩成“要点token”!数据重构:训练时在数据中插入特殊标记(比如触发压缩,[C]存储压缩内容),教模型学会“记重点”。
- 注意力掩码:设计专属注意力规则,让压缩后的token只能关注问题描述和之前的压缩内容,避免“翻旧账”。
在思考中提前预判答案
论文:Reasoning Models Know When They’re Right: Probing Hidden States for Self-Verification
链接:https://arxiv.org/pdf/2504.05419v1
通过训练一个简单的“探针”(类似体检仪器),研究者发现:
-
高准确率:探针预测中间答案正确性的准确率超过80%(ROC-AUC >0.9)。
-
提前预判:模型甚至在答案完全生成前,隐藏状态就已暴露正确性信号!
研究团队设计了一套流程:
-
切分推理链:将长推理过程按关键词(如“再检查”“另一种方法”)分割成多个片段。
-
标注正确性:用另一个LLM(Gemini 2.0)自动判断每个片段的答案是否正确。
-
训练探针:用两层神经网络分析模型隐藏状态,预测答案正确性。
总结

混合推理模型已经有不少了,例如 Claude 3.7 Sonnet 和 Gemini 2.5 Flash, Qwen3 应该是开源且效果好的典例。未来这可能也是一个趋势,不需要特意区分普通模型和思考模型,而是同一个模型按需使用。
Claude 3.7 sonnet 的混合推理模型
Claude 3.7 sonnet 的混合推理模型(Hybrid Reasoning Model)是 LLM 和 reasoning model 的结合的新范式,之后大概率所有 AI labs 的模型发布模型都会以类似形式,社区也不会再单独比较 base model 和 reasoning model 的能力。
使用 Claude 3.7 Sonnet 时,用户可以通过“extended thinking” 的设置选择是否需要输出长 CoT:
• 打开 extended thinking,则输出 CoT step-by-step 思考,类似开启了人类的 Slow thinking 并且其思考长度是可以选择的,因此 extended thinking 并不是 0 或 1,而是一个可以拖动的光谱,
• 关闭 extended thinking,则和 LLM 一样直接输出。
这个设计其实 Dario 很早就暗示过,在他看来:base model 与 reasoning model应该是个连续光谱。Claude System Card 中提到,extended thinking 的开关与长短是通过定义 system prompt 来实现的。我们推测要实现这样的融合模型,应该需要在 RL 训练之后通过 post training 让模型学会什么时候应该 step by step thinking,如何控制推理长度。
对于这个新范式,我们的预测是:
-
之后的 hybrid reasoning model 需要在 fast thinking 和 slow thinking 的选择上更加智能,模型自己具备 dynamic computing 能力,能规划并分配解决一个问题的算力消耗和 token 思考量。Claude 3.7 Sonnet 目前还是将 inference time 的打开和长短交由用户自己来决定,AI 还无法判断 query 复杂度、无法根据用户意图自行选择。
-
之后所有头部 research lab 发布模型都会以类似形式,不再只是发 base model。
其实现在打开 ChatGPT 上方的模型选择,会弹出五六个模型,其中有 4o 也有 o3,用户需要自行选择是用 LLM 还是 reasoning model,使用体验非常混乱。因此,hybrid reasoning model 从智能能力和用户体验看都是下一步的必然选择。

Gemini 2.5 Flash精细化的思维管理控制
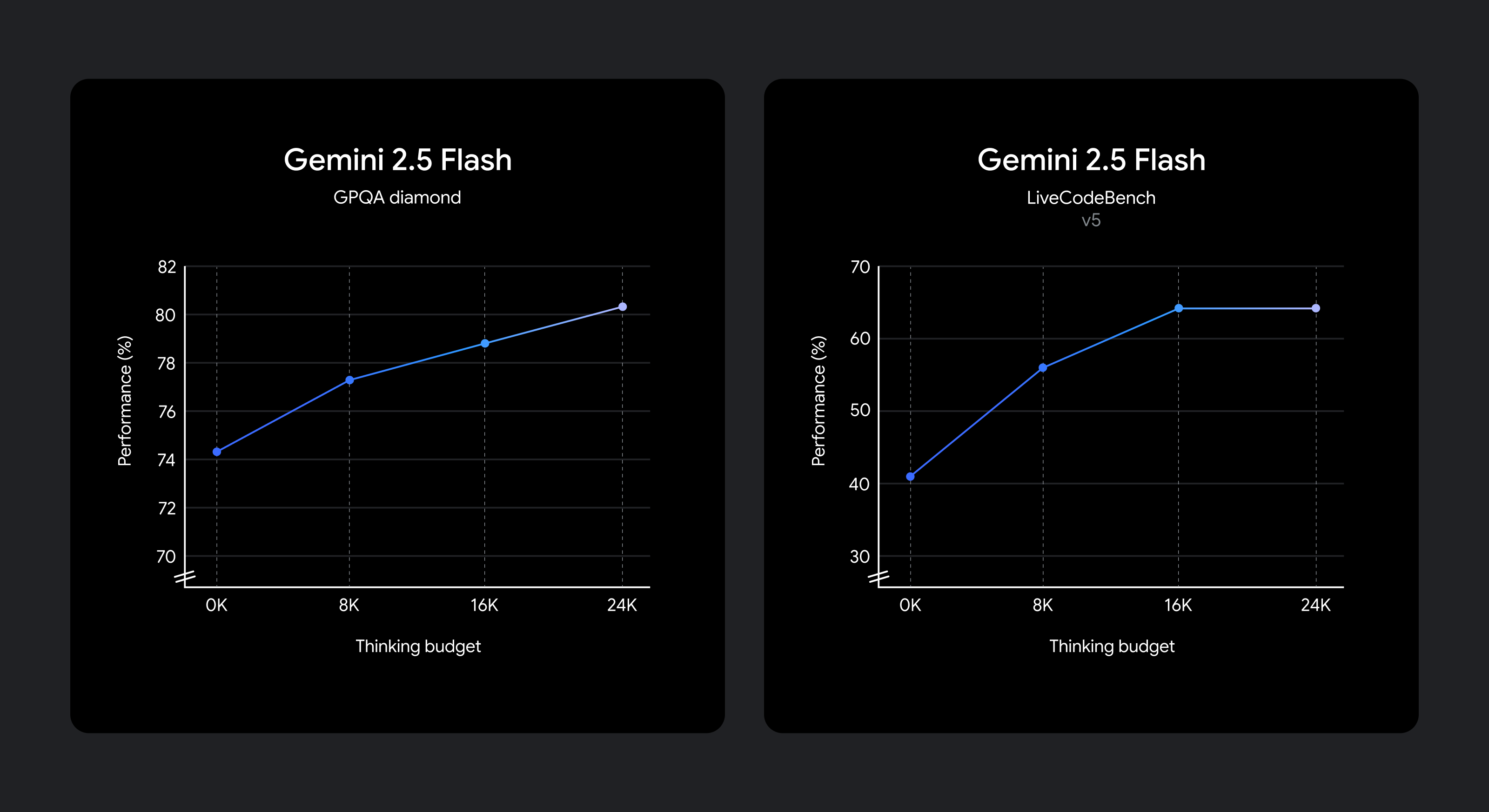
我们知道,不同案例会以不同的方式权衡质量、成本和延迟。为了让开发者具备灵活性,Gemini 2.5 Flash研发出了可供设置的思考预算功能,开发者可借此在模型进行思考的同时,对其可以生成的最大令牌数实现精细控制。预算更高意味着,模型可以更深入地进行推理,进而提高质量。值得注意的是,虽然预算使 2.5 Flash 的思考深度存在上限,但若提示无需深度思考,模型便不会耗尽全部预算。
低推理需求提示:
示例 1:“谢谢”用西班牙语怎么说?
示例 2:加拿大有多少个省份?
中等推理需求提示:
示例 1:投掷两个骰子,点数之和为 7 的概率是多少?
示例 2:我所在的健身房会于周一、周三和周五的上午 9 点至下午 3 点,以及周二、周六的下午 2 点至晚上 8 点开放篮球活动。我每周工作 5 天,工作时间为上午 9 点至下午 6 点,我想在平日打 5 个小时篮球,请为我制定可行的时间表。
高推理需求提示:
示例 1:长度 L=3m 的悬臂梁有一个矩形截面(宽度 b=0.1m,高度 h=0.2m),且由钢 (E=200 GPa) 制成。其整个长度承受 w=5 kN/m 的均匀分布载荷,自由端则承受 P=10 kN 的集中载荷。计算最大弯曲应力 (σ_max)。
示例 2:编写函数 evaluate_cells(cells: Dict[str, str]) -> Dict[str, float],用以计算电子表格单元格值。
每个单元格包含:
一个数字(例如“3”)
或一个使用 +、-、*、/ 和其他单元格的公式,如“=A1 + B1 * 2”。
要求:
解析单元格之间的依赖关系。
遵守运算符优先级(*/ 优于 ±)。
检测循环并指出 ValueError(“在<单元格>检测到循环”)。
无 eval()。仅使用内置库。
最后来说:
我们希望模型经过训练,可以判断给定提示所需的思考时长,继而根据感知到的任务复杂程度自主决定思考深度。
参考内容
- 从 R1 到 Sonnet 3.7,Reasoning Model 首轮竞赛中有哪些关键信号?https://blog.csdn.net/m0_37733448/article/details/146001136
- 想得久≠答得对!LLM应该自主决定Reasoning长度!https://mp.weixin.qq.com/s/XTiJrWkuRmyzW5KO3lwrow
相关文章:

聊一聊Qwen3思考模式实现以及背后原理探讨
Qwen3思考模式切换实现 硬开关 我们先通过官方的示例代码来体验一下,如何实现在思考模式和非思考模式之间切换 通过tokenizer.apply_chat_template的enable_thinking参数来实现 默认情况下,Qwen3 启用了思考功能,类似于 QwQ-32B。这意味着…...

spark行动算子
在 Apache Spark 中,行动算子(Action)用于触发对 RDD 的实际计算,并将结果返回给驱动程序(Driver)或保存到外部存储系统中。与转换算子(Transformation)不同,行动算子会立…...
)
电商双十一美妆数据分析(代码)
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import jieba # 数据读取 df pd.read_csv(双十一_淘宝美妆数据.csv) # 数据清洗 # 处理重复值 data df.drop_duplicates(inplaceFalse) data data.reset_index(in…...

STM32裸机开发问题汇总
一、代码编写 1. keil中某个文件无法修改 keil中某个文件无法修改,不能输入_keil5 h文件无法修改-CSDN博客 2.编译报错declaration may not appear after executable statement in block STM32常见错误error: #268: declaration may not appear after executabl…...

C语言复习笔记--自定义类型
今天我们来复习一下自定义类型.自定义类型大概分为结构体,枚举,联合体,数组这几种.数组在之前就介绍过.今天我们来看下其他三种. 结构体 首先来看结构体. 结构体类型的声明 之前在操作符的地方简单认识过结构体.下面我们回顾一下. 结构体回顾 结构是⼀些值的集合,这…...

做 iOS 调试时,我尝试了 5 款抓包工具
日常做开发的人,特别是和客户端接口打交道的同学,应该对“抓包”这件事不陌生。 调试登录流程、分析接口格式、排查错误返回、分析网络性能、甚至研究第三方 App 的数据通信……说到底,都绕不开“抓 HTTPS 包”这一步。 而这一步࿰…...
附源码)
html css js网页制作成品——HTML+CSS珠海网页设计网页设计(4页)附源码
目录 一、👨🎓网站题目 二、✍️网站描述 三、📚网站介绍 四、🌐网站效果 五、🪓 代码实现 🧱HTML 六、🥇 如何让学习不再盲目 七、🎁更多干货 一、👨…...

FID和IS的区别
📊 生成模型评估:你选 IS 还是 FID? 在评估 GAN、Diffusion 等图像生成模型时,两个最常被提到的指标是: 🔹IS (Inception Score) 🔹FID (Frchet Inception Distance) 🧠 Inception…...

前端三大件--HTML
引言 在互联网的世界里,每一个绚丽多彩的网页背后,都离不开 HTML 的支撑。HTML(Hyper Text Markup Language,超文本标记语言)作为网页开发的基础语言,就像是搭建高楼大厦的砖块,是所有 Web 开发…...

Node.js 的 child_process 模块详解
Node.js 的 child_process 模块提供了创建子进程的能力,使 Node.js 应用能够执行系统命令、运行其他程序或脚本。这个模块非常强大,可以帮助我们实现很多复杂的功能。 1. exec - 执行 shell 命令 exec 方法用于执行 shell 命令,并缓冲任何产生的输出。 特点 创建 shell 来…...
)
日常知识点之随手问题整理(虚函数 虚函数表 继承的使用场景)
新来的同事提到一个虚函数解耦头文件的问题,就想起来对虚函数进行一些回顾。 他的问题是,通过纯虚函数,如何实现不包含头文件即可真正调用到子类的实际接口。 》这里肯定是不合理的,需要一个中间管理类,对纯虚函数和相…...
)
【软件设计师:数据结构】2.数据结构基础(二)
一、树 树是n(n≥0)个结点的有限集合,n=0时称为空树,在任一非空树中 ● 有且仅有一个称为根的结点。 ● 其余的结点可分为m(m≥0)个互不相交的子集T1,T2…,Tm,其中每个子集本身又是一棵树,并称其为根结点的子树。 1、树的基本概念 ● 双亲和孩子 ● 兄弟:具有相同双…...
)
Python训练营打卡——DAY18(2025.5.7)
目录 一、基于聚类进一步推断类型 1. 聚类分析 2. 簇的总结与定义 二、作业 1. 聚类分析 2. 簇的总结与定义 3. 模型效果提升 一、基于聚类进一步推断类型 选用昨天kmeans得到的效果进行聚类,进而推断出每个簇的实际含义。 1. 聚类分析 # 先运行之前预处理…...

初学Python爬虫
文章目录 前言一、 爬虫的初识1.1 什么是爬虫1.2 爬虫的核心1.3 爬虫的用途1.4 爬虫分类1.5 爬虫带来的风险1.6. 反爬手段1.7 爬虫网络请求1.8 爬虫基本流程 二、urllib库初识2.1 http和https协议2.2 编码解码的使用2.3 urllib的基本使用2.4 一个类型六个方法2.5 下载网页数据2…...

【CSS】Grid 的 auto-fill 和 auto-fit 内容自适应
CSS Grid 的 auto-fill 和 auto-fit /* 父元素 */ .grid {display: grid;/* 定义「网格容器」里有多少列,以及每列的宽度 *//* repeat 是个「重复函数」,表示后面的模式会被重复多次 *//* auto-fit 是一个特殊值,自动根据容器宽度ÿ…...

绕线机的制作与研究
绕线机的制作与研究 摘要 本文详细阐述了绕线机的制作过程,涵盖从设计规划到实际制作的各个环节。通过对绕线机工作原理的深入分析,确定了关键技术参数,并依此完成机械结构与控制系统的设计。在制作阶段,运用多种加工工艺完成零件制造与设备组装。经测试,自制绕线机性能…...

引用的使用
引用的语法 作用:起别名 引用的本质是指针常量 数据类型 &别名原名; 引用必须要初始化 引用一旦初始化,不能修改 不能返回局部变量的引用 引用做形参 #include<iostream> #include<string> using namespace std; //通过引用…...

css animation 动画属性
animation // 要绑定的关键帧规则名称 animation-name: slidein;// 定义动画完成一个周期所需的时间,秒或毫秒 animation-duration: 3s;// 定义动画速度曲线 animation-timing-function: ease;// 定义动画开始前的延迟时间 animation-delay: 1s;// 定义动画播放次数…...
)
Nacos源码—Nacos集群高可用分析(二)
4.集群节点的健康状态变动时的数据同步 (1)Nacos后台管理的集群管理模块介绍 在集群管理模块下,可以看到每个节点的状态和元数据。节点IP就是节点的IP地址以及端口,节点状态就是标识当前节点是否可用,节点元数据就是相关的Raft信息。 其中节点…...

SRAM详解
一、SRAM基础原理 定义与结构 SRAM(Static Random-Access Memory,静态随机存取存储器)是一种基于触发器(Flip-Flop)结构的易失性内存,通过交叉耦合的反相器(6晶体管,6T单元ÿ…...

JavaWeb:MySQL进阶
多表设计 一对多(多对一) 外键 一对一 多对多 多表查询 内连接 外连接 子查询 -- 查询员工表 select * from emp;-- 查询部门表 select * from dept;-- 查询员工和部门 select * from emp, dept; -- 笛卡尔积select * from emp, dept where emp.dept_i…...

Golang 接口 vs Rust Trait:一场关于抽象的哲学对话
一、引言 在现代编程语言中,接口(Interface) 和 Trait 是实现多态和抽象行为的关键机制。它们允许我们定义行为契约,让不同的类型共享相同的语义接口,从而提升代码的复用性和扩展性。 Go 和 Rust 分别代表了两种截然…...

智算中心的搭建标准
智算中心的搭建标准主要涉及以下几个方面: 开放标准: 硬件与软件开放:从硬件到软件、从芯片到架构,都应采用开放、标准的技术。例如,硬件支持如 OCP、ODCC、Open19 等开放社区标准,软件采用如 OpenStack、K…...

商汤科技前端面试题及参考答案
有没有配置过 webpack,讲一下 webpack 热更新原理,能否自己实现一些插件? Webpack 是一个用于现代 JavaScript 应用程序的静态模块打包工具。在实际项目中,经常会对其进行配置,以满足项目的各种需求,比如处理不同类型的文件、优化代码、配置开发服务器等。 Webpack 热更…...

windows下docker的使用
找了个docker教程 Windows Docker 安装 | 菜鸟教程Windows Docker 安装 Docker 并非是一个通用的容器工具,它依赖于已存在并运行的 Linux 内核环境。Docker 实质上是在已经运行的 Linux 下制造了一个隔离的文件环境,因此它执行的效率几乎等同于所部署的…...
,大幅提升编码与视频理解能力)
AI日报 · 2025年5月07日|谷歌发布 Gemini 2.5 Pro 预览版 (I/O 版本),大幅提升编码与视频理解能力
1、谷歌发布 Gemini 2.5 Pro 预览版 (I/O 版本),大幅提升编码与视频理解能力 谷歌于5月6日提前发布 Gemini 2.5 Pro 预览版 (I/O 版本),为开发者带来更强编码能力,尤其优化了前端与UI开发、代码转换及智能体工作流构建,并在WebDe…...

Redis 8.0 正式版发布,新特性很强!
就在前两天,Redis 8.0 正式版 (GA) 来了!这并不是一次简单的更新,Redis 8.0 不仅带来了性能上的进一步提升,还带来一些实用的新特性与功能增强。并且,最重要的是拥抱 AGPLv3 重归开源! 下面,简单…...

MySQL核心机制:日志系统、锁机制与事务管理的深度剖析
一.介绍 MySQL作为世界上最流行的开源关系型数据库之一,其强大的事务处理能力和高并发支持使其在各种复杂应用场景中得到广泛应用。MySQL的核心机制包括日志系统、锁机制和事务管理,这些机制共同确保了数据库的ACID特性,为应用程序提供了可靠…...

Mybatis标签使用 -association 绑定对象,collection 绑定集合
注意 association标签中的 select , column 属性使用 collection 标签中的 ofType 属性使用 Data public class Tours implements Serializable {private static final long serialVersionUID 1L;private Integer touId;private String tourName;private Integer guideId;pri…...
使用教程Toolkit介绍)
IBM BAW(原BPM升级版)使用教程Toolkit介绍
本部分为“IBM BAW(原BPM升级版)使用教程系列”内容的补充。 一、系统Toolkit 在 IBM Business Automation Workflow (BAW) 中,System Toolkit 是一组预先定义和配置好的工具、功能和组件,旨在帮助流程设计者和开发人员快速构建…...

排列组合算法:解锁数据世界的魔法钥匙
在 C 算法的奇幻世界里,排列和组合算法就像是两把神奇的魔法钥匙,能够帮我们解锁数据世界中各种复杂问题的大门。今天,作为 C 算法小白的我,就带大家一起走进排列和组合算法的奇妙天地。 排列算法:创造所有可能的顺序…...

LVGL -meter的应用
1 meter介绍 lv_meter 是 LVGL v8 引入的一种图形控件,用于创建仪表盘样式的用户界面元素,它可以模拟像速度表、电压表、温度表这类模拟表盘。它通过可视化刻度、指针、颜色弧线等来展示数值信息,是一种非常直观的数据展示控件。 1.1 核心特…...

MCP学习
一、MCP基础理论与核心概念 1.1 协议定义与设计目标 MCP(Model Context Protocol)是Anthropic公司于2024年11月开源的标准化协议,旨在解决大型语言模型(LLM)与外部工具、数据源之间的动态交互问题。其核心目标包括&…...
:模块的内聚模型)
软件工程(三):模块的内聚模型
模块内聚的7种类型(从低到高) 等级类型描述示例1️⃣ 最低偶然性内聚(Coincidental Cohesion)模块内部的各功能毫无关系,随机拼凑一个模块中既有文件读写,又有图像压缩、还处理用户登录2️⃣逻辑性内聚&am…...

Java中字符转数字的原理解析 - 为什么char x - ‘0‘能得到对应数字
前言 在Java编程中,我们经常需要将字符形式的数字转换为实际的数值。有很多方法可以实现这一转换,比如使用Integer.parseInt()或Character.getNumericValue()等方法。但有一种简便且高效的方式是直接使用char - 0运算,本文将详细解析这种方法…...

View的事件分发机制
(一)为什么要有事件分发机制 安卓界面上面的View的层级结构是树形的,可能出现多个View重叠在一起的现象(如下图),当我们点击的地方为多个View重叠的区域时,这个点击事件应该给谁呢?为…...

【C++】类和对象【下】
目录 一、再探构造函数1、测试题 二、类型转换三、static成员1. 静态成员变量2. 静态成员函数 四、友元五、内部类六、匿名对象七、对象拷贝时的编译器优化 个人主页<—请点击 C专栏<—请点击 一、再探构造函数 之前我们实现构造函数时,初始化成员变量主要使…...

【JS逆向基础】并发爬虫
前言:所谓并发编程是指在一台处理器上“同时”处理多个任务。并发是在同一实体上的多个事件。强调多个事件在同一时间间隔发生。 1,进程、线程以及协程 【1】进程概念 我们都知道计算机的核心是CPU,它承担了所有的计算任务;而操作系统是计算…...

Android组件化 -> 基础组件进行Application,Activity生命周期分发
在lib_common基础组件模块创建上下文持有类,生命周期派发类 object AppContextProvider {private lateinit var application: Applicationprivate var currentActivityRef: WeakReference<Activity>? null// 应用生命周期监听器列表private val appLifecyc…...

42. PCB防静电环设计
PCB防静电环的作用 1. PCB防静电环的作用2. 防静电环设计技术点 1. PCB防静电环的作用 防静电环主要用于生产、运输、售后等环节人体会直接接触电路板的场景。 防静电环只在顶层和底层设计即可。 2. 防静电环设计技术点...

深入理解Java反射机制
java反射是java语言中一个强大而灵活的特性,它允许程序在运行时检查和操作类、接口、字段和方法。 为了方便理解下文,我先给出Cat对象 public class Cat implements jump,Run {private int age;public String name;protected String color;double he…...

嵌入式音视频通话EasyRTC基于WebRTC技术驱动智能带屏音箱:开启智能交互新体验
一、引言 随着智能家居市场的蓬勃发展,智能带屏音箱作为家庭智能交互中心的重要组成部分,其功能需求日益丰富。EasyRTC凭借其低延迟、高稳定性的特点,为智能带屏音箱带来了全新的交互体验,能满足用户在视频通话、远程监控、在线…...
(无缺失))
1987-2023年各省进出口总额数据整理(含进口和出口)(无缺失)
1987-2023年各省进出口总额数据整理(含进口和出口)(无缺失) 1、时间:1987-2023年 2、来源:各省年鉴、统计公报 3、指标:进出口总额(万美元)、进口总额(万美…...

paddle ocr 或 rapid ocr umi ocr 只识别了图片的下部分内容 解决方案
如上图,识别的准确率其实很高,但是只识别了下半部分的内容,上半部分的内容就没有识别到,其实是程序设置有点问题,程序设置的解决方案如下: 如上图,识别的准确率其实很高,但是只识别了下半部分的内容,上半部分的内容就没有识别到,其实是程序设置有点问题,程序设置的…...

【深度学习-Day 7】精通Pandas:从Series、DataFrame入门到数据清洗实战
Langchain系列文章目录 01-玩转LangChain:从模型调用到Prompt模板与输出解析的完整指南 02-玩转 LangChain Memory 模块:四种记忆类型详解及应用场景全覆盖 03-全面掌握 LangChain:从核心链条构建到动态任务分配的实战指南 04-玩转 LangChai…...

如何测试 esp-webrtc-solution_solutions_doorbell_demo 例程?
软件准备 esp-webrtc-solution/solutions/doorbell_demo 例程 此例程集成了 WebSocket 传输视频流的应用 硬件准备 ESP32P4-Function-Ev-Board 环境搭建 推荐基于 esp-idf v5.4.1 版本的环境来编译此例程 若编译时出现依赖的组件报错,可进行如下修改ÿ…...

default和delete final和override
1.default和delete default 1.生成默认成员函数 2.仅适用于特殊成员函数(如构造函数、析构函数、拷贝/移动操作等) delete 1.删除函数 2.可应用于任何函数(不限于特殊成员函数) 2.final 和override final 用于类:…...

Nvidia Orin 安装onnxruntime-gpu
在用英伟达边缘设备Nvidia Orin 安装onnxruntime-gpu环境时, 通常会遇到很多问题。 在正常的Nvidia 服务器上安装onnxruntime-gpu 是非常简单的, 直接pip install onnxruntime-gpu即可, 但是在边缘设备上就没有这么简单了。 直接pip install…...
)
C++ CRTP技术(奇异递归模版模式)
C 的CRTP技术 最近了解到C的CRTP技术,通过博客来这里记录一下。 我们首先可以了解一下什么是CRTP技术。CRTP是C的一种高级模版变成模式。 他主要的用途有以下的几点: 编译时实现多态(静态多态):通过CRTP技术…...

验证es启动成功
1. 查看命令行输出信息 在启动 Elasticsearch 时,命令行窗口会输出一系列日志信息。若启动成功,日志里通常会有类似下面的信息: plaintext [2025-05-06T13:20:00,000][INFO ][o.e.n.Node ] [node_name] started其中 [node_na…...