高并发内存池(一):项目简介+定长内存池的实现
目录
一,项目介绍
二,什么是内存池
1,池化技术
2,内存池
3,内存池主要解决的问题
4,malloc
三,实现一个定长内存池
定长内存池的设计
大致结构
核心功能实现
申请一块大小为T的内存
释放一块大小为T的内存
完整的申请内存过程
测试代码
一,项目介绍
这个项目是实现一个高并发的内存池。它的原型是google的一个开源醒目tcmalloc,tcmalloc全称Thread-Caching Malloc,即线程缓存的malloc,实现了高效的线程内存管理,用于替代系统的相关内存分配函数(malloc,free)。
这个项目是对tcmalloc的一个简化版,是对tcmalloc的学习,实现一个我们自己的高并发内存池。
在该项目中涉及到的C++知识包括数据结构(链表,哈希桶),操作系统内存管理,单例模式,多线程 以及互斥锁等等 。
二,什么是内存池
1,池化技术
所谓池化技术,就是程序先向系统申请过量的资源,然后自己管理,以备不时之需。之所以要申请过量的资源,是因为每次向操作系统申请资源时,都有较大的开销。如果我们提前申请好一块大的空间,再次申请时,直接使用就会变得非常快捷,大大提高程序运行效率。
在计算机中,有很多使用"池"这种技术的地方。除了内存池,还有连接池,线程池,对象池等等 。以线程池为例,它的主要思想是:先启动若干线程,让他们进入休眠状态,当接收到客户端发来的任务请求时,唤醒其中的某个线程,让它来处理客户端的任务请求,当 处理完这个请求,不是终止掉该线程,而是让该线程继续进入休眠状态。
2,内存池
内存池是指程序预先从操作系统申请一大块的内存。此后,当程序需要再次申请内存时,不是直接向操作系统申请,而是直接从内存池中获取;同理,当程序释放内存的时候,不是直接还给操作系统,而是还给内存池。当程序退出(或特定时间)时,内存池才将之前申请的内存真正释放,还给操作系统 。
3,内存池主要解决的问题
内存池的设计就是为了解决频繁向操作系统申请资源的问题,从而提高程序运行的效率。
我们将内存池看作是系统的内存分配器,就还面临一个问题:内存碎片问题。内存碎片又分为内碎片和外碎片。
所谓外碎片问题,就是我们的程序先后申请了一大块内存之后,在释放内存的时候,有的释放了,有的还在使用,导致归还的内存不连续,如果下次再次申请内存的时候,可能会由于内存地址不连续的问题,导致申请内存失败。如下图:
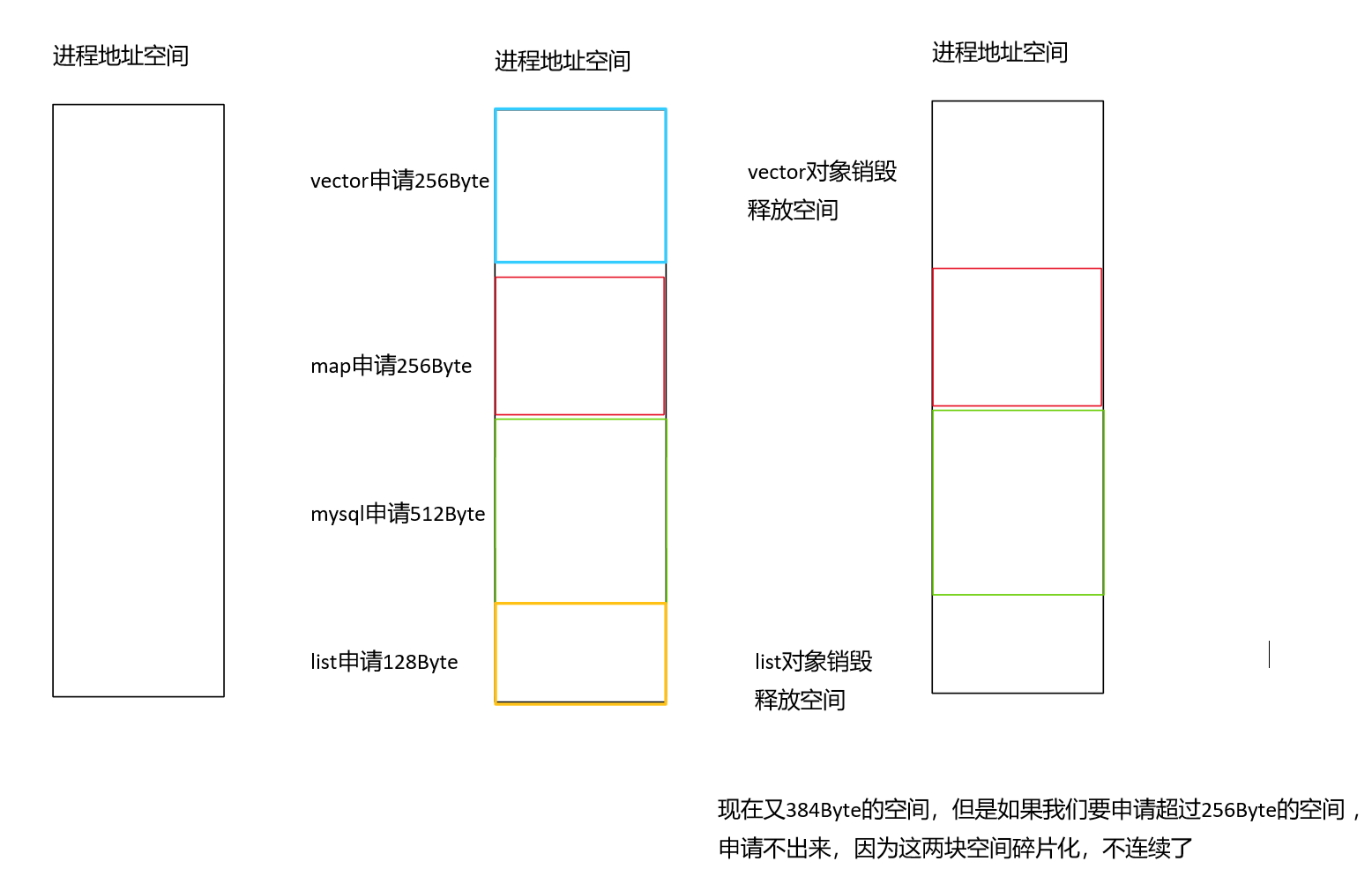
对于内碎片,在后面的项目中会遇到,到时再讲解。
4,malloc
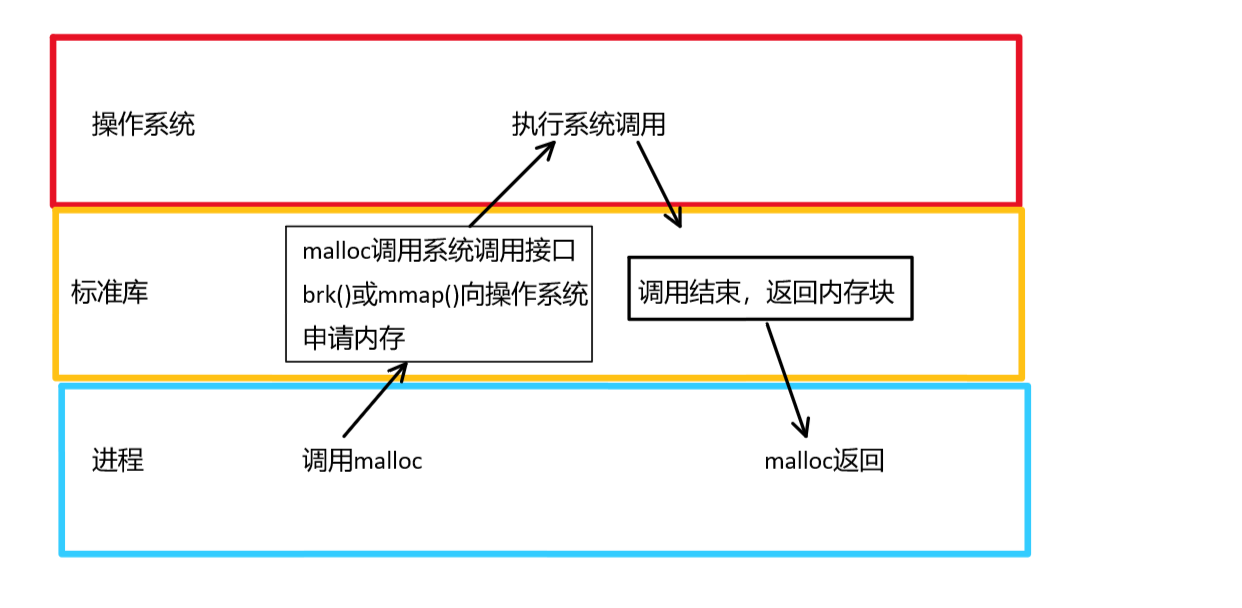
C/C++中,我们要动态申请内存都是通过malloc的,但是实际上,我们不是直接取堆上要内存的。
因为malloc本身就是一个内存池。malloc相当于向操作系统“批发”要了一大块的内存空间,然后“零售”给程序使用。当全部“售完”或者有大量的内存需求时,再根据实际需要向操作系统“进货”。
但是malloc在多线程环境下,内存申请效率不可观,这也是我们所实现的高并发内存池和malloc的重要区别。
如下图所示:
三,实现一个定长内存池
所谓定长内存池,顾名思义,它就是用来解决固定内存大小的申请。而我们的高并发内存池实现的是任意大小的内存申请。
为什么要实现一个定长内存池?
首先,定长内存池相对于高并发内存池来说,实现起来简单。同时定长内存池这里的实现设计思想,在后面的项目中也会使用到。
定长内存池的设计
有了对内存池的理解之后,这里的实现就没有什么太大的问题。
定长内存池,解决固定大小的内存申请,假设大小为n。
- 申请空间时
我们首先需要一个变量来记录这一大块内存的起始地址。我们可以定义一个char* memory的类型来记录这一大块内存的起始地址。使用char*来表示的好处是,char是一个字节大小,当申请n个字节的内存大小时,我们只需让memory向后走n个字节大小即可。不能使用void*,因为void*不能解引用,不能++。
- 释放空间时
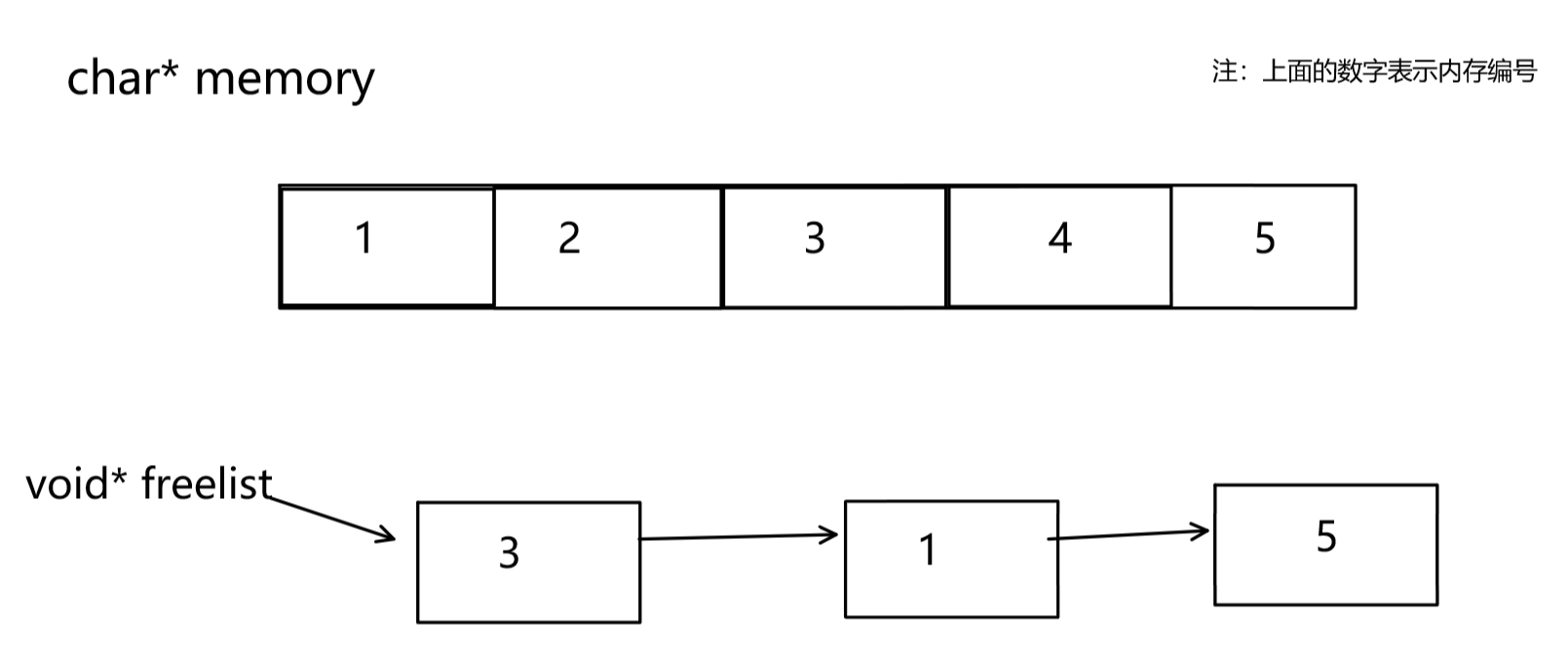
由于在申请资源时,有的对象释放空间,有的还正在使用。所以这就有可能导致还回来的内存不一定是连续的。例如:本来连续的内存空间是1,2,3,4,5,还回来的时候可能是3,1,5。
所以我们不能再将这些内存资源让memory管理起来。
- 对于这些还回来的空间,我们可以将这些空间以链表的形式组织起来。按照以往的思路,我们会定义一个结构体,结构体中包含还回来的空间,以及一个next指针指向下一个还回来的结构体。
- 其实不需要我们自己定义一个结构体对象。对于这些还回来的内存,我们可以让它前4个字节(或者8个字节)存储下一个还回来的内存的地址。32位环境下是前4个字节,64位下就是前8个字节。具体看下图:
这样,我们就可以将还回来的内存以链表的组织起来,我们定义一个自由链表
void* freelist,来指向第一个还回来的内存的地址。

大致结构
//定长内存池
//定长大小就是T的类型大小
template <class T>
class FixedMemoryPool
{
public://...
private:char* _memory = nullptr;//大块内存的起始地址void* _freelist = nullptr;//自由链表,管理还回来的内存size_t _remainSize = 0;//记录当前内存池剩余的内存大小
};核心功能实现
申请一块大小为T的内存
申请内存时,刚开始时整个内存池的大小是空的,此时我们需要向操作系统申请。
并且在分配内存过程中,如果剩余内存的大小,小于1个T类型的大小时,也需要向操作系统再次申请。这两种情况可以放在一起解决。
T* New()
{T* obj = nullptr;//申请的T对象//当剩余的空间大小不够一个对象的大小时,重新向操作系统申请一大块内存if (_remainSize <sizeof(T)){_remainSize = 128 * 1024;//申请128KB_memory = (char*)malloc(_remainSize);if (_memory == nullptr)//申请内存失败{throw::bad_alloc();}}obj = (T*)_memory;_memory += sizeof(T);_remainSize -= sizeof(T);return obj;
}释放一块大小为T的内存
现在考虑两个问题:
如何将还回来的内存块以链表的形式组织在一起??
- 对于还回来的两个对象obj1和obj2,我们现在要构成链表:obj1->obj2。我们可以先将obj1转换成int*类型,然后再解引用,就可以访问到obj1的前4个字节了。
- 即*(int*)obj1=obj2。这样就实现了让obj1的前4个字节存储上obj2的地址,这样就构建成了一条链表。
如何解决不同平台的问题,如果是32位机器,指针是4个字节大小。但如果是64位机器,指针式8个字节大小,上面的代码就跑不动了???
- 其实只需要改动 一点即可了:*(int**)obj1=obj2;这里不一定是int**,也可以换成char**,long long**,void**,只要是二级指针就可以。
- 我们之前是将obj1强转成int类型,解引用后就可以访问4个字节的大小。此时我们将ob1强转成int**类型的,那么解引用后访问的内存大小就是int*大小的,而int*是一个指针,它在32位机器下是4字节,在64位环境下是8字节,所以解引用后就可以访问到4个字节(或8个字节),这样就可以解决不同环境 的问题了。
然后实现释放内存的逻辑,使用自由链表将对应的内存块以链表的形式组织在一起。
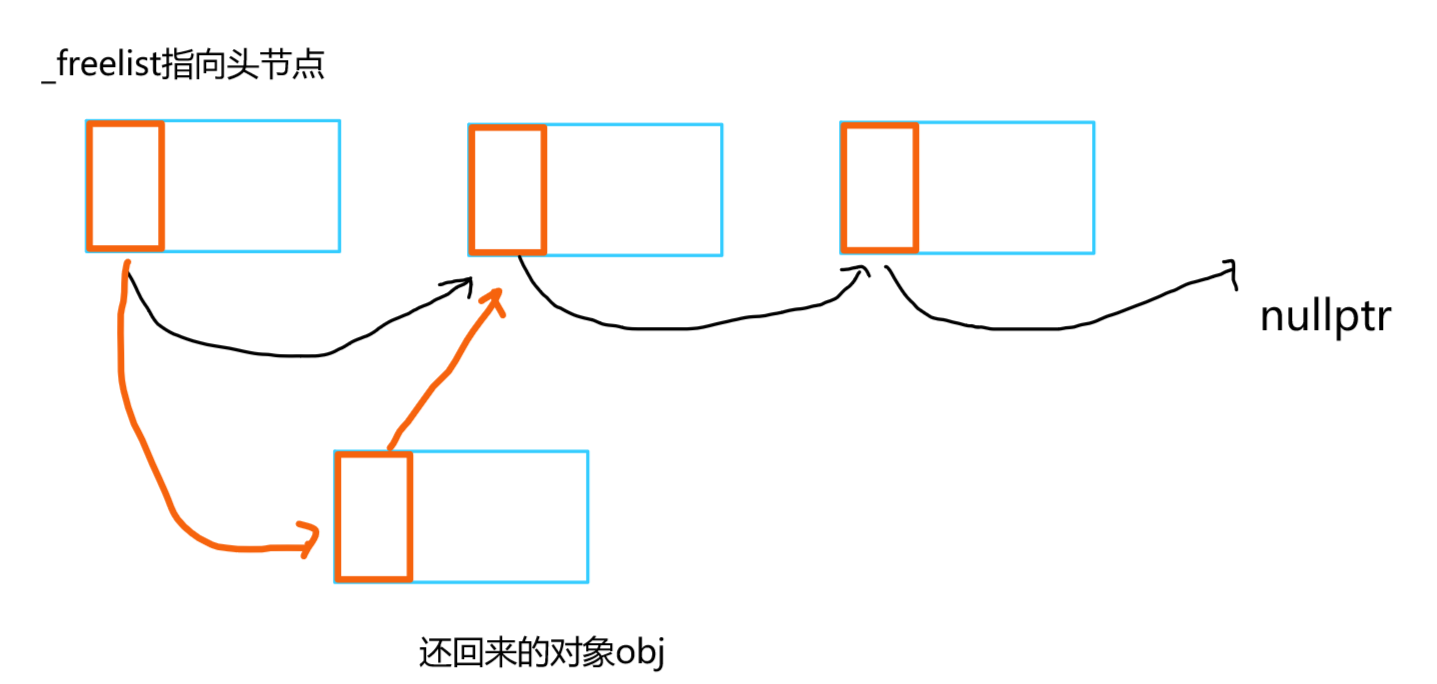
将还回来的内存空间以链表的形式组织起来,让_freelist指向该链表的头节点。然后,每当释放一块内存时,将该内存块 头插到链表中 。
当有一块内存还回来时:
- 当自由链表为空时,我们只需让_freelist指向该内存,并让该内存块的前4个字节(或8个字节)填充上nullptr即可。此时_freelist指向该内存块,下一个内存块的地址为空。
- 当自由链表不为空时,我们先将该内存块的前4个字节(或8个字节)填充上_freelist的next地址,然后再让_freelist的next填充上当前内存块的地址即可
- 其实这两种情况下的头插时一样的,代码实现时一样的。
void Delete(T* obj){//使用自由链表管理起来obj->~T();//头插*(void**)obj = _freelist;_freelist = obj;}完整的申请内存过程
有了对上面释放内存块的理解,其实就是通过自由链表来维护这些还回来的内存块。
那么对于申请内存模块,还需要补充一点。就是在申请内存时,如果自由链表不为空,优先从自由链表中获取,这是一个头删的过程。让自由链表_freelist向后移动,指向下一个内存块。
还需要处理一个问题,就是如果我们申请的内存块大小不够4个字节(或8个字节)时,在管理还回来的内存时,内存块的大小不足4个字节(或8个字节),那么就无法存放地址。所以,为了解决这个问题,我们在申请内存时,如果所申请的内存大小不足4个字节(或者8个字节),就给它4个字节(或8个字节),因为至少是需要4个字节(或8个字节)的。
T* New(){T* obj = nullptr;//申请的T对象//优先使用还回来的对象if (_freelist){//自由链表头删过程void* next = *(void**)_freelist;//保存下一个内存块的地址_obj = (T*)_freelist;_freelist = next;//指向下一个节点,完成头删}else{//当剩余的空间大小不够一个对象的大小时,重新向操作系统申请一大块内存if (_remainSize < sizeof(T)){_remainSize = 128 * 1024;//申请128KB_memory = (char*)malloc(_remainSize);if (_memory == nullptr)//申请内存失败{throw::bad_alloc();}}obj = (T*)_memory;//不足4个字节或8个字节时,就给4个字节或者8个字节大小size_t objSize = sizeof(T) < sizeof(void*) ? sizeof(void*) : sizeof(T);_memory += objSize)_remainSize -= objSize;}//使用定位new初始化new(obj)T;return obj;}测试代码
这里以二叉树节点为例,比较标准库中的new和我们实现的内存池的性能
struct TreeNode
{int _val;TreeNode* _left;TreeNode* _right;TreeNode():_val(0), _left(nullptr), _right(nullptr){}
};void TestFiedMemoryPool()
{// 申请释放的轮次const size_t Rounds = 5;// 每轮申请释放多少次const size_t N = 100000;std::vector<TreeNode*> v1;v1.reserve(N);size_t begin1 = clock();for (size_t j = 0; j < Rounds; ++j){for (int i = 0; i < N; ++i){v1.push_back(new TreeNode);}for (int i = 0; i < N; ++i){delete v1[i];}v1.clear();}size_t end1 = clock();std::vector<TreeNode*> v2;v2.reserve(N);FixedMemoryPool<TreeNode> TNPool;size_t begin2 = clock();for (size_t j = 0; j < Rounds; ++j){for (int i = 0; i < N; ++i){v2.push_back(TNPool.New());}for (int i = 0; i < N; ++i){TNPool.Delete(v2[i]);}v2.clear();}size_t end2 = clock();cout << "new cost time:" << end1 - begin1 << endl;cout << "object pool cost time:" << end2 - begin2 << endl;
}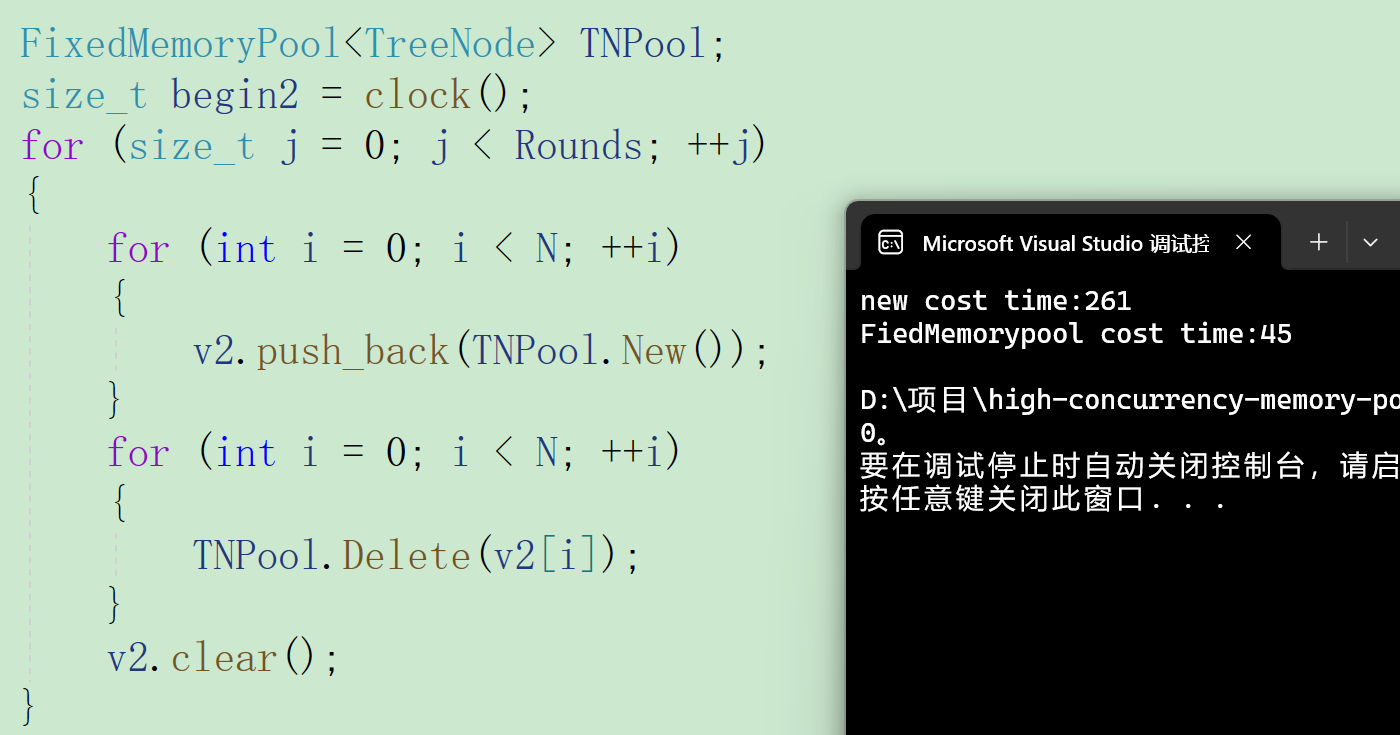
可以看到,我们实现的定长内存池比标准库中的申请内存的方法更加高效。
源码:
ConcurrentMemoryPool · 小鬼/高并发内存池 - 码云 - 开源中国
相关文章:
:项目简介+定长内存池的实现)
高并发内存池(一):项目简介+定长内存池的实现
目录 一,项目介绍 二,什么是内存池 1,池化技术 2,内存池 3,内存池主要解决的问题 4,malloc 三,实现一个定长内存池 定长内存池的设计 大致结构 核心功能实现 申请一块大小为T的内存 释…...

STM32--TIM--函数
void TIM_ITConfig(TIM_TypeDef* TIMx, uint16_t TIM_IT, FunctionalState NewState) 用于使能或禁用指定的定时器中断。...
的发展)
文生图(Text-to-Image)的发展
文章目录 1. 早期探索(2010-2015):传统方法与初步尝试2. 文本条件GAN时代(2016-2019)3. 自回归与VQ-VAE时代(2019-2021)4. 扩散模型革命(2021-2022)(1) 扩散模型基础突破…...
覆盖标签、新窗打开)
vscode预览模式(点击文件时默认覆盖当前标签,标签名称显示为斜体,可通过双击该标签取消)覆盖标签、新窗打开
文章目录 VS Code 预览模式如何取消预览模式(即“固定”标签页)?预览模式有什么用? VS Code 预览模式 在 VS Code 中,当你单击文件浏览器(例如,资源管理器侧边栏)中的某个文件时&am…...

热部署相关
手动热部署 启动热部署后代码进行修改可以不用重启整个项目Carl F9修改的代码就可以直接生效了 热部署只进行重启的操作而不用进行重载的操作 自动热部署 自定义重启排除项 关闭热部署 ture为开启热部署false为关闭 如果直接在application.yml里写可能会被其他优先级更高的配…...

高防ip是怎么做到分布式防御的
高防IP的分布式防御体系通过多维度技术协同实现攻击流量的分散处理与智能拦截,其核心机制可从以下五个层面解析: 一、全球节点网络布局 多区域节点覆盖 在全球关键互联网枢纽(如北美、欧洲、亚太)部署清洗中心&am…...

结构可视化:利用数据编辑器剖析数据内在架构
结构可视化聚焦于展示数据的内部结构和各部分之间的关系,使企业能够深入理解数据的组织方式和层次体系,从而更好地进行数据管理和分析。通过结构可视化,企业可以清晰地看到数据的层次结构、关联关系以及数据流动路径,为数据驱动的…...

QT编程练习20250507
#include <stdio.h> // 包含标准输入输出库 #include <stdlib.h> // 包含通用工具库(如malloc, free等) #include <string> // 包含C string类定义 #include <iostream> // 包含C输入输出流库using namespace std; // 使用st…...

【软件设计师:算法】3.排序算法
一、排序 将一组杂乱无章的数据按一定的规律次序排列起来。 排序的目的是什么? 便于查找!排序算法的好坏如何衡量? 时间效率——排序速度(即排序所花费的全部比较次数)空间效率——占内存辅助空间的大小稳定性——若两个记录A和B的关键字值相等,但排序后A、B的先后次序保…...
 --- 字符设备驱动)
Linux 内核学习(7) --- 字符设备驱动
字符设备驱动程序 Linux 中主要有三类设备的驱动程序,分别是字符设备驱动程序,块设备驱动程序和网络设备驱动程序 字符设备是指在 I/O 传输过程中以字符为单位进行传输的设备,例如键盘,打印机等,字符设备的驱动程序结…...

vue3+vite项目引入tailwindcss
从2025年1月tailwindcss4.0发布开始使用tailwindcss比之前简化很多 1,安装 yarn add tailwindcss tailwindcss/vite2,配置vite.config.js import tailwindcss from tailwindcss/vite;...plugins: [tailwindcss(),...] ...3,在主css文件顶部添加 注意一定是css文件,不能是sc…...

IIS配置SSL
打开iis 如果搜不到iis,要先开 再搜就打得开了 cmd中找到本机ip 用http访问本机ip 把原本的http绑定删了 再用http访问本机ip就不行了 只能用https访问了...

LeetCode:对称二叉树
1、题目描述 给你一个二叉树的根节点 root , 检查它是否轴对称。 示例 1: 输入:root [1,2,2,3,4,4,3] 输出:true 示例 2: 输入:root [1,2,2,null,3,null,3] 输出:false 提示: 树中…...

6天从0到精通:MySQL基础快速入门指南
放在前头 6天从0到精通:MySQL基础快速入门指南 6天从0到精通:MySQL基础快速入门指南 在数据驱动的时代浪潮下,MySQL作为全球最受欢迎的开源关系型数据库管理系统之一,广泛应用于Web开发、数据分析、云计算等多个领域。无论是刚…...

信息论12:从信息增益到信息增益比——决策树中的惩罚机制与应用
从信息增益到信息增益比:决策树中的惩罚机制与应用 引言:当"信息量"遇到"公平性" 在2018年某银行的信用卡风控系统中,数据分析师发现一个诡异现象:客户ID号在决策树模型中竟成为最重要的特征。这个案例揭示…...

C++ -- 哈希扩展
目录 位图 位图概念 位图的实现 位图应用 布隆过滤器 布隆过滤器的提出 布隆过滤器概念 布隆过滤器的插入 布隆过滤器的查找 布隆过滤器的删除 位图 给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在这40亿个数…...

AI大模型分类以及Prompt优化技巧
目录 一、AI大模型分类 1、按模态分类 2、按开源性分类 3、按规模分类 4、按用途分类 如何对比和选择大模型 二、Token 如何计算 Token 如何估算Token成本 三、Prompt工程 Prompt优化技巧 基础提示技巧 1、明确指定任何和角色 2、提供详细说明和具体示例 3、使用…...

将本地项目提交到新建的git仓库
方式一: # 登录git,新建git仓库和指定的分支,如master、dev# 下载代码,默认下载master分支 git clone http://10.*.*.67/performance_library/pfme-*.git # 切换到想要提交代码的dev分支 git checkout dev# 添加想要提交的文件 git add .#…...

【wpf】10 C#树形控件高效实现:递归构建与路径查找优化详解
在WPF应用程序开发中,树形控件的实现是常见且具有挑战性的需求。本文将深入解析一套高效树形结构的实现方案,包含递归构建、路径查找优化、动态交互等多个关键技术点。 一、递归构建树形结构 private TreeItem CreateTreeViewItem(TreeNode node) {var…...

低空科技护航珞樱春色,技术引领助推广阔应用
春风拂珞珈,樱海绽放时。赏樱季已接近尾声,作为武汉大学测绘遥感信息工程全国重点实验室的成果转化科技型企业,大势智慧积极参与校园的智能化建设,助力武汉大学的樱花季巡航管理,打造更为安全、有序的赏樱体验。 低空…...

Tiny Machine Learning在人类行为分析中的全面综述
论文标题: 中文:《Tiny Machine Learning在人类行为分析中的全面综述》 英文:A Comprehensive Survey on Tiny Machine Learning for Human Behavior Analysis 作者信息: Ismail Lamaakal, Student Member, IEEE, Siham Essahr…...

8.12 GitHub Sentinel企业级进化:容器化优化×AI监控,效率提升300%实战
GitHub Sentinel 扩展优化与商业化演进路径 关键词:企业级 Agent 扩展性设计、容器化部署优化、多格式报告生成、第三方服务集成、SaaS 服务架构 1. 功能扩展方向 1.1 多格式报告生成技术实现 采用模板引擎与文件流处理技术实现动态报告生成: #mermaid-svg-2BhQlvVsDp5NdL…...

算法-时间复杂度和空间复杂度
刷算法必备时间和空间复杂度,记录下方便查询。 时间复杂度 概念 时间复杂度衡量的是算法 执行所需的时间 随输入规模 n 增长的变化趋势,用大O 表示法描述(通常是看这个循环)。 分类 常数时间O(1) 无论输入多大,执行…...

springboot国家化多语言实现
前言 公司在做国际化项目时需要匹配多语言环境,通过spring实现i18n国际化方便快捷 项目结构 src/ ├── main/ │ ├── java/ │ │ └── com/example/i18ndemo/ │ │ ├── config/ # 配置类 │ │ ├── controller/ # …...

第2章 算法分析基础
2-1 算法的时间复杂度分析 2.1.1 输入规模与基本语句 输入规模:算法处理数据的规模,通常用 n 表示。 基本语句:执行次数与输入规模直接相关的关键操作。 例2.1 顺序查找 int SeqSearch(int A[], int n, int k) { for (int i 0; i < n…...

vue2 计算属性 computed
计算属性他是一个属性,他不是一个函数,使用的时候不要加括号 reduce reduce 是 JavaScript 数组的一个高阶函数,用于对数组中的每个元素执行一个累积计算,最终返回一个单一的值。...

Milvus 向量数据库详解与实践指南
一、Milvus 核心介绍 1. 什么是 Milvus? Milvus 是一款开源、高性能、可扩展的向量数据库,专门为海量向量数据的存储、索引和检索而设计。它支持近似最近邻搜索(ANN),适用于图像检索、自然语言处理(NLP&am…...

记录一次 python 文件环境变量配置-sqlmap.py
第一步:环境变量配置 C:\Users\14913\Downloads\application\3.secure\sqlmap-2025.5.6 或者 C:\Users\14913\Downloads\application\3.secure\sqlmap-2025.5.6 都可以! 第二步 使用 第一步:不再进目录 第二步:不再python … s…...
)
使用大语言模型进行机器人规划(Robot planning with LLMs)
李升伟 编译 长期规划在机器人学领域可以从经典控制方法与大型语言模型在现实世界知识能力的结合中获益。 在20世纪80年代,机器人学和人工智能(AI)领域的专家提出了莫雷奇悖论,观察到人类看似简单的涉及移动和感知的任务&#x…...

STM32 CAN总线
目录 定时传输CAN简介和硬件电路 CAN简介 主流通信协议对比 编辑 CAN硬件电路 编辑 CAN电平标准 CAN收发器 – TJA1050(高速CAN) CAN物理层特性 帧格式 数据帧 遥控帧 错误帧 过载帧 编辑 帧间隔 编辑 位填充 波形实例 位…...

使用JMeter 编写的测试计划的多个线程组如何生成独立的线程组报告
我有一个测试计划,里面有两个线程组,如下: 添加了一个HTTP请求默认值: 然后我使用如下命令生成的可视化报告是两个线程组合并后的聚合报告。 jmeter -n -t 百度测试计划.jmx -l baidu.txt -e -o ./baidu但是我想要的效果是每…...

RabbitMQ如何保证消息不丢失?
在RabbitMQ中,消息丢失可能发生在三个阶段:生产者发送消息时、消息在RabbitMQ服务器内部传递时、消费者接收消息时。为了保证消息不丢失,需要从这三个方面分别采取措施: 1. 生产者确保消息发送成功 开启确认模式(Conf…...

RAG 的介绍及评价方法
RAG的作用 大模型虽然具备处理复杂语言任务的强大能力,但在知识更新和依赖外部信息的及时性方面存在局限。大模型在训练时捕获的知识通常是静态的,一旦训练完成,模型便不再更新,无法掌握训练数据集之外的最新信息或事件。RAG可以…...

Linux网络新手注意事项与配置指南
Linux系统在网络管理方面提供了丰富的工具和灵活的配置方式,但对于新手来说,掌握正确的操作方法和注意事项至关重要。本文将从网络基础概念、配置工具、安全设置、故障排查以及常见错误等多个方面,结合具体代码示例,详细讲解Linux网络管理的核心内容,帮助新手快速入门并避…...
)
CI/CD与DevOps流程流程简述(提供思路)
一 CI/CD流程详解:代码集成、测试与发布部署 引言 在软件开发的世界里,CI/CD(持续集成/持续交付)就像是一套精密的流水线,确保代码从开发到上线的整个过程高效、稳定。我作为一名资深的软件工程师,接下来…...

【AWS+Wordpress-准备阶段】AWS注册+创建EC2实例
前言 自学笔记,解决问题为主,亲测有效,欢迎补充。 本地WP文件部署到AWS整体步骤如下:(本文重点:AWS准备完成) 0. [AWS 准备] 注册 AWS 并创建 EC2 实例 ↓ 1. [生成安装包:用 Du…...

FPGA----基于ZYNQ 7020实现定制化的EPICS通信系统
引言:前文我们降到了,使用alinx提供的sd卡,直接在上面编译即可。那么,如果我们的在FPGA侧有一些个性化的开发,那么生成的image.ub和boot.bin将于原sd卡中的不一致,我们应该如何坐呢? 补充知识点…...

读《暗时间》有感
读《暗时间》有感 反思与笔记 这本书还是我无意中使用 ima 给我写职业规划的时候给出的,由于有收藏的习惯,我就去找了这本书。当读到第一章暗时间的时候给了我很大的冲击,我本身就是一个想快速读完一本书的人,看到东西没有深入思…...

MIT关节电机相序校准
UVW三相相序判断 电机相序校正是确保多关节控制系统正常运行的重要步骤。在实际应用中,每个电机定子的三相线(W、U、V)的连接顺序可能存在差异,这是由于制造过程中的随机接线所致。不过,通过简单的校正方法,…...

Qwen2.5模型结构
self.lm_head nn.Linear(config.hidden_size, config.vocab_size, biasFalse) 这个是用来干嘛的 输出层,词汇投影层,将模型输出的隐藏状态向量映射回词表空间,用于预测下一个token # 预测 logits,未经过 softmax lm_logits self…...
以2步进乘方除以阶乘加减第N项)
2021-11-11 C++泰勒sin(x)以2步进乘方除以阶乘加减第N项
缘由c书本题,求解了,求解-编程语言-CSDN问答 int n 10, d 3, z -1; double x 2.5, xx x;while (n){xx (乘方(x, d) / 阶乘(d)) * z;d 2, --n, z * -1;}std::cout << xx << std::endl;...

【MySQL】C语言访问数据库
C语言访问数据库 一. Linux 安装 MySQL 动静态库二. 使用MySQL数据库1. 创建MySQL对象2. 连接MySQL数据库3. 释放MySQL对象4. SQL 语句操作1. 插入操作2. 修改操作3. 删除操作4. 查询操作 准备工作 use mysql; select user, host from user;# 创建本地连接的用户 create user c…...

dify 部署后docker 配置文件修改
1:修改 复制 ./dify/docker/.env.example ./dify/docker/.env 添加一下内容 # 启用自定义模型 CUSTOM_MODEL_ENABLEDtrue# 将OLLAMA_API_BASE_URL 改为宿主机的物理ip OLLAMA_API_BASE_URLhttp://192.168.72.8:11434# vllm 的 OPENAI的兼容 API 地址 CUSTOM_MODE…...

【神经网络与深度学习】VAE 和 GAN
这位大佬写的 VAE 的讲解很不错 VAE 和 GAN 的相同点和不同点 引言 VAE(变分自编码器)和 GAN(生成对抗网络)是深度学习中两种主要的生成模型,它们在数据生成任务中发挥着重要作用。虽然它们的目标相似,都…...

2-C#控件
2-控件 1.panel控件的使用 private void button3_Click(object sender, EventArgs e){Form2 my2 new Form2();my2.TopLevel false;this.panel1.Controls.Add(my2);my2.BringToFront();my2.Show();}private void button4_Click(object sender, EventArgs e){Form3 my3 new F…...

1.1.2 简化迭代器 yield return的使用
yield return 是一个用于简化迭代器(Iterator)实现的关键字组合。它的核心作用是让开发者能够以更简洁的方式定义一个按需生成序列的方法(生成器方法),而无需显式实现 IEnumerable 或 IEnumerator 接口。yield return …...

机器学习实操 第二部分 神经网路和深度学习 第14章 使用卷积神经网络进行深度计算机视觉
机器学习实操 第二部分 神经网路和深度学习 第14章 使用卷积神经网络进行深度计算机视觉 内容概要 第14章深入探讨了卷积神经网络(CNNs)及其在计算机视觉中的应用。CNNs受大脑视觉皮层的启发,通过局部感受野和权值共享机制,能够…...
)
电商双11美妆数据分析(2)
接下来用seaborn包给出每个店铺各个大类以及各个小类的销量销售额 关于性别 接下来考虑性别因素,了解各类产品在男性消费者中的销量占比 男士的销量基本来自于清洁类,其次是补水类。而这两类正是总销量中占比最高的两类。 非男士专用中,补水…...

数字康养新范式:七彩喜平台重构智慧养老生态的深度实践
在全球人口老龄化程度日益加深的当下,养老问题成为社会关注的焦点。 智慧养老作为一种创新的养老模式,借助现代信息技术,为提升老年人生活质量、缓解养老压力提供了新的思路与途径。 而当前中国 60 岁以上人口已达 2.8 亿,占总人…...
)
2D横板跳跃游戏笔记(查漏补缺ing...)
1.Compression(压缩质量):可以改为None,不压缩的效果最好,但占用内存 2.Filter Mode(过滤模式):可以选择Point(no filter) 3.Pixels Per Unit:是…...