数据结构——排序(万字解说)初阶数据结构完
目录
1.排序
2.实现常见的排序算法
2.1 直接插入排序
编辑
2.2 希尔排序
2.3 直接选择排序
2.4 堆排序
2.5 冒泡排序
2.6 快速排序
2.6.1 递归版本
2.6.1.1 hoare版本
2.6.1.2 挖坑法
2.6.1.3 lomuto前后指针
2.6.1.4 时间复杂度
2.6.2 非递归版本
2.7 归并排序
3 性能比较
4.非比较排序
5..排序算法复杂度及稳定性分析
1.排序
排序就是排序,排序大家都不陌生,接下来跟作者一起进入学习吧!
常见的排序算法:
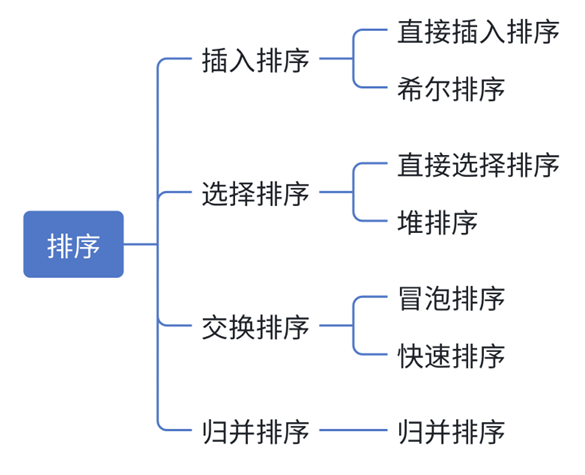
2.实现常见的排序算法
2.1 直接插入排序
直接插入排序是⼀种简单的插入排序法,其基本思想是:把待排序的记录按其关键码值的大小逐个插 入到⼀个已经排好序的有序序列中,直到所有的记录插⼊完为止,得到⼀个新的有序序列
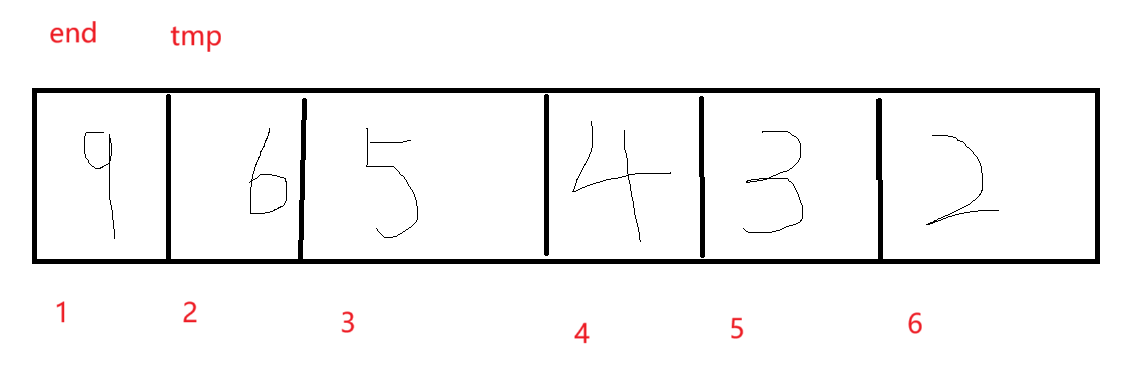
这是张图片,咱们先来看代码,然后跟着代码来分析它的思想:
void zhijiecharuSort(int* arr, int n)
{//里面挪动一大部分,外面才挪动一小部分for (int i = 0; i < n - 1; i++)//end只能到n-2,若是end到了n-1,那么tmp就越界了,无数据,无法比较了.而这个i++可以改变每次end的位置{int end = i;int tmp = arr[end + 1];while (end >= 0)//定义end的左范围,防止越界{if (arr[end] > tmp){arr[end + 1] = arr[end];end--;}else{break;}}arr[end + 1] = tmp;//这个时候的end是end--后的end,所以此时的end+1的值就是之前end的值}
}假定end为有序数据的最后一位,而tmp为待排数据的第一位。上面的排的是升序。
1.先将 tmp中的值保存进tmp,即tmp=arr[end+1]。(为了防止end位置的数据存进tmp时,tmp数据被覆盖了,找不到)
2.将end与tmp进行比较,若end>tmp,则将end数据交给tmp,即arr[end+1]=arr[end]
3.end--;(继续比较前面的数据)
4.将arr[end+1]=tmp从而实现了排序
5.外部i不断地加加,内部end不断地减减,从而实现了从一开始的位置,一直到最后的位置,每个位置都有end来从这个位置一直比较到最开始的地方。
来看动图:
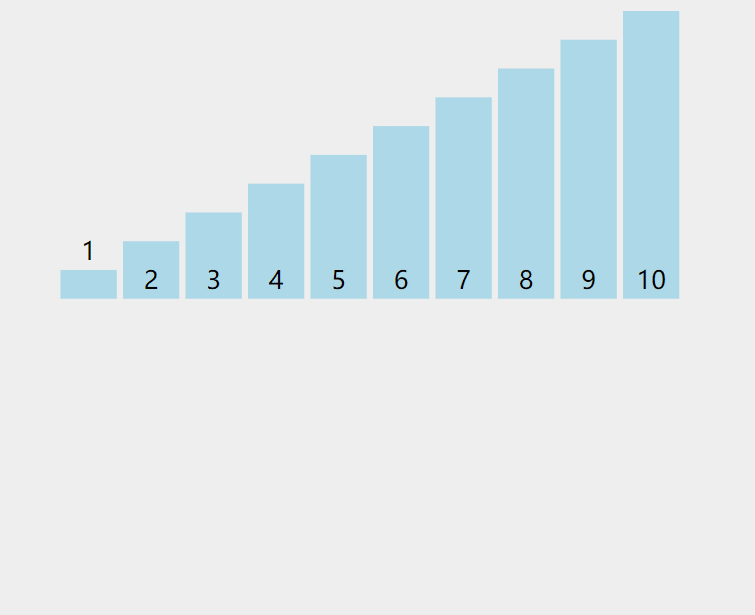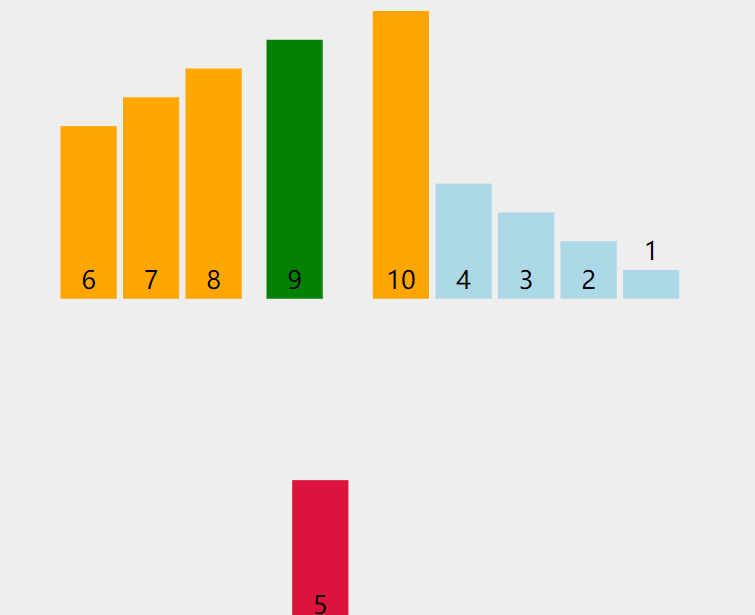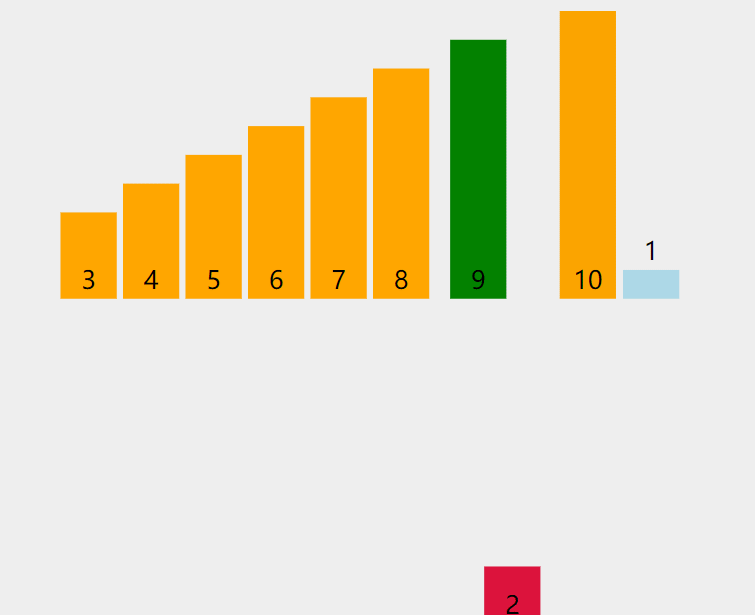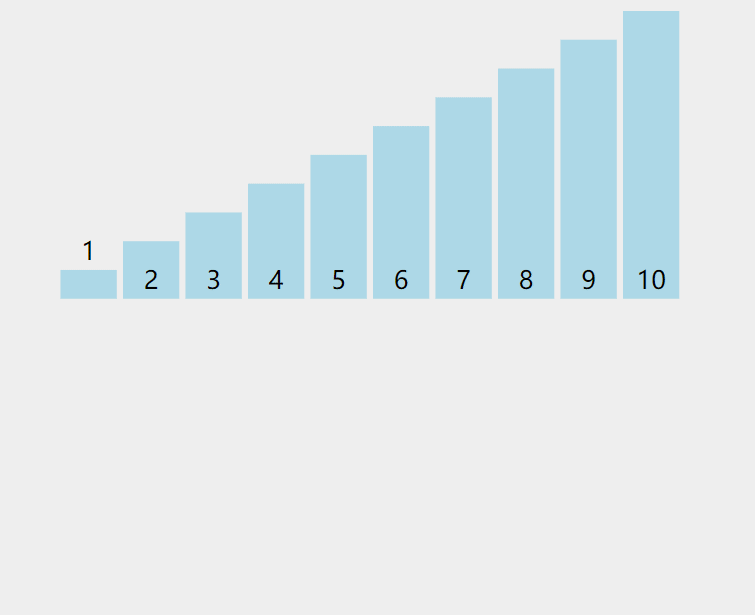
时间复杂度为n^2,这个是每次比较,都把数据给比较满了,即1+2+3+.....+n-1=n^2。所以最差的情况就是n^2。最好的情况就是数组有序且升序,这样话就是n个1相加,时间复杂度为n。而平均情况就是介于n^2与n之间,是小于n^2的。
所以为了接近n^2,大的数据在前,小的数据灾后。这样,越到后面,交换的次数越多。
为了接近n,小的数据在前,大的数据在后即可。
但其实,这个时间复杂度不是很好,所以咱们有一个对于它的优化版本。
2.2 希尔排序
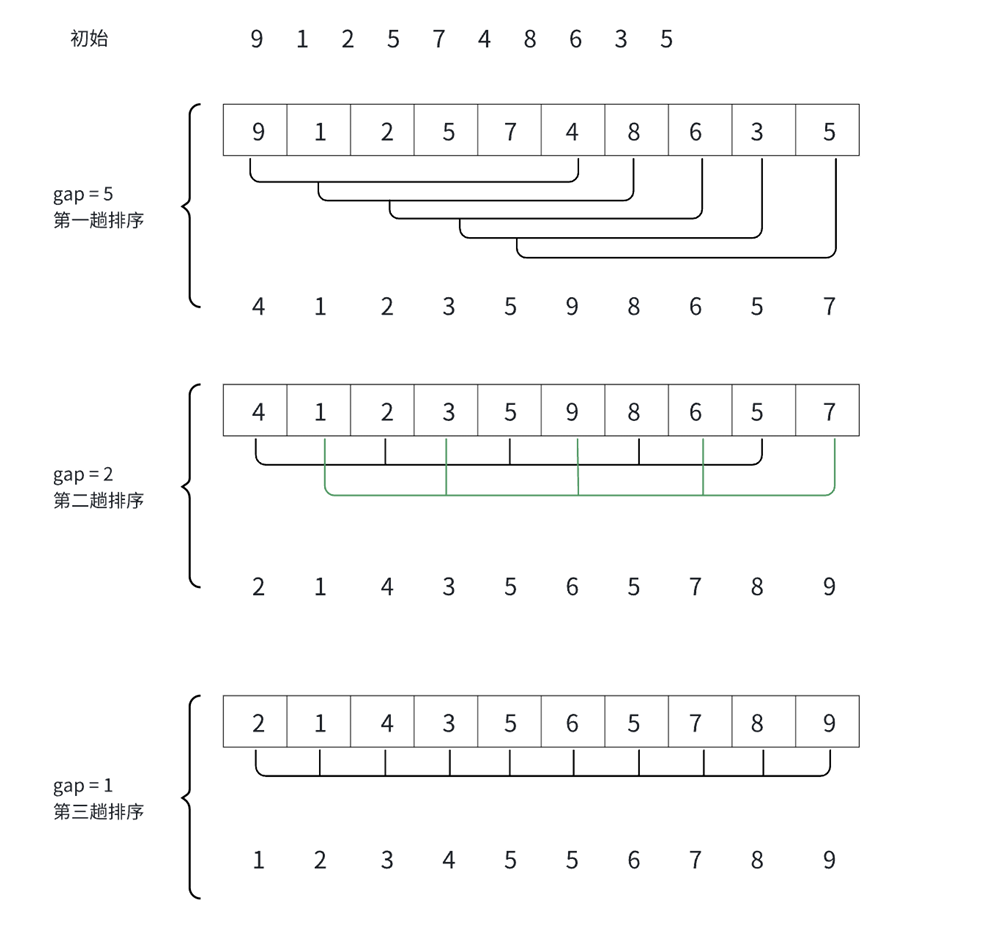
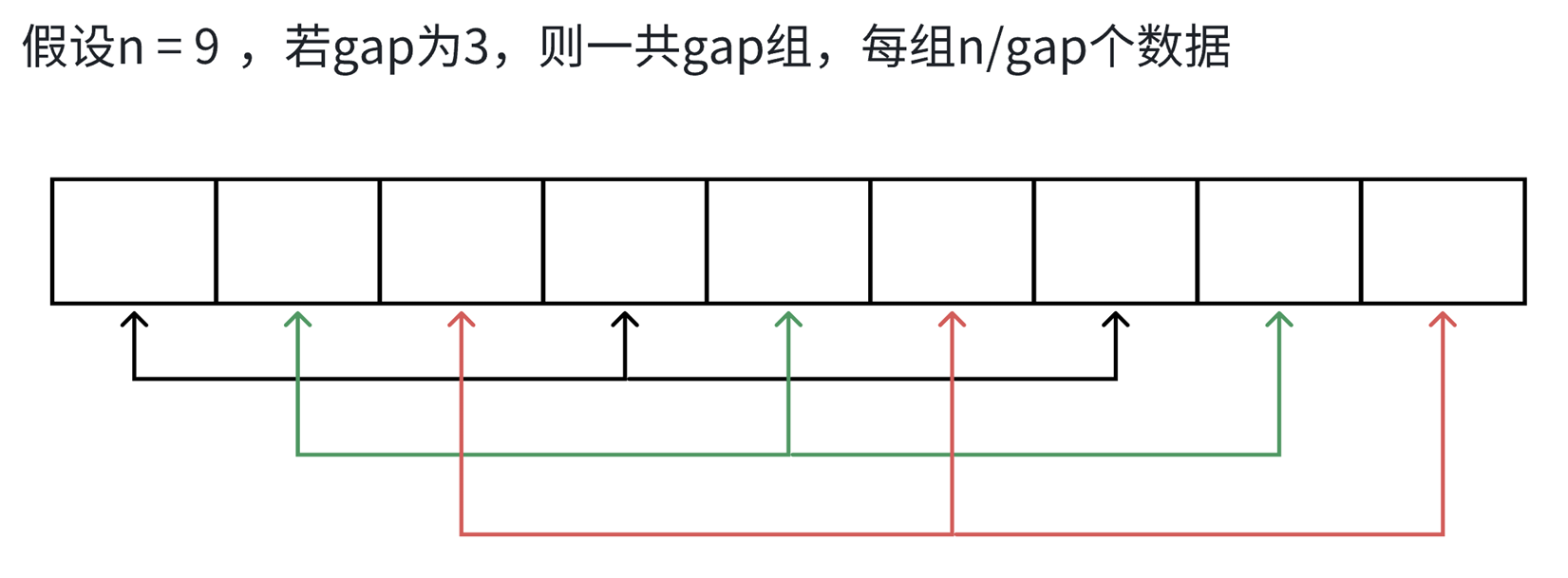
该排序是用来优化直接插入排序的,又称为缩小增量排序。(增量,即gap)
gap等于几,即分成几组,且gap只是一种距离,即gap等于5时,说明分成了5组,每个组中间有gap-1个元素。如上图所示,这样的前后衔接的其实是有2大组的。并且这个排序结合了直接插入排序的2个优势:
1.增量大时,分组多,但组内元素少(一整个大组),效率高。
2.随着增量的减少,虽然组内的元素增加,但也越来越有序,效率也越来越高。
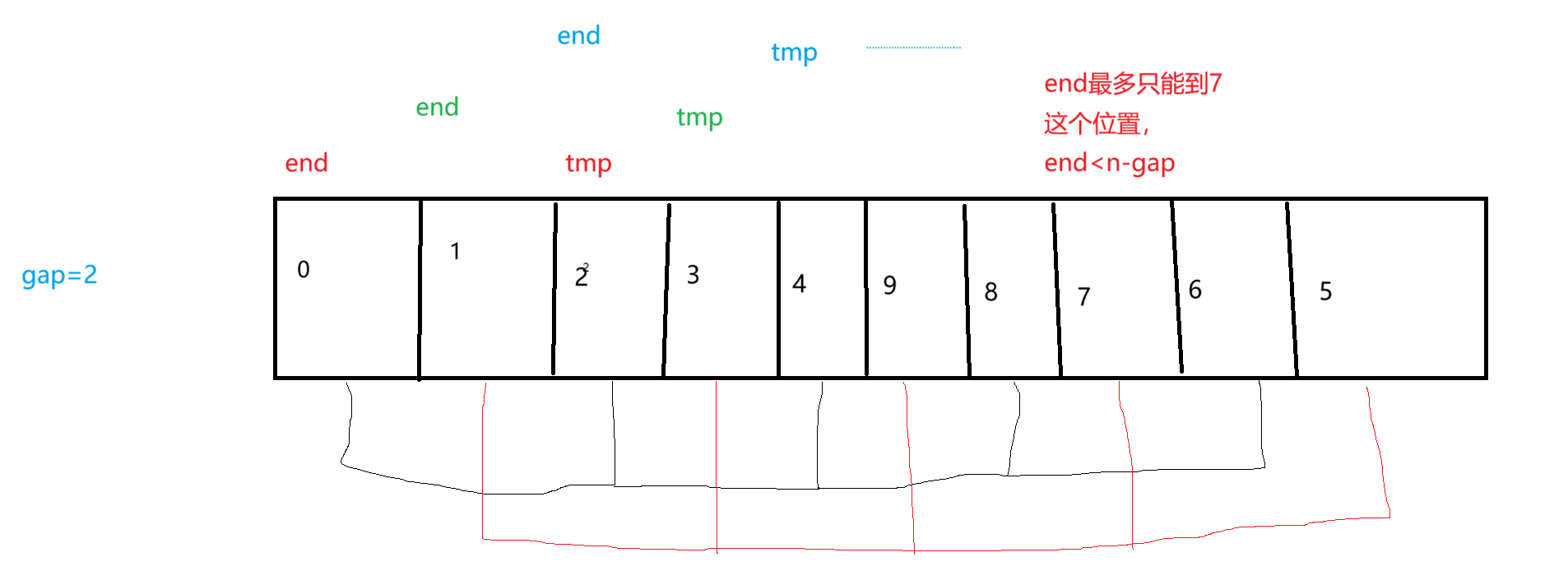
下面看代码:(代码以gap=2为例)end与tmp每次只需要往后挪动一位即可
void ShellSort(int* arr, int n)
{int gap = n;while (gap > 1){gap = gap / 3 + 1;//n/3,n/3/3,n/3/3/3,最后gap只要取到1即可for (int i = 0; i < n - gap; i++)//i指向最后一个数的前一个指标所在的位置{//其实你内层不要管具体排的是哪一组,因为外层的++会让每一组都排上int end = i;int tmp = arr[end + gap];while (end >= 0){if (arr[end] > tmp){arr[end + gap] = arr[end];end -= gap;}else{break;}}arr[end + gap] = tmp;//到这就是end-=gap了}}
}
时间复杂度:
外层的时间复杂度为logn。
内层循环:

需要注意的是,上面所说的1+2+3+...........+(n/gap-1),这个只是取值范围,并不是真正的2,3)。
还有就是可发现这个次数是呈现出先上升后下降的规律的,用图表示就是:
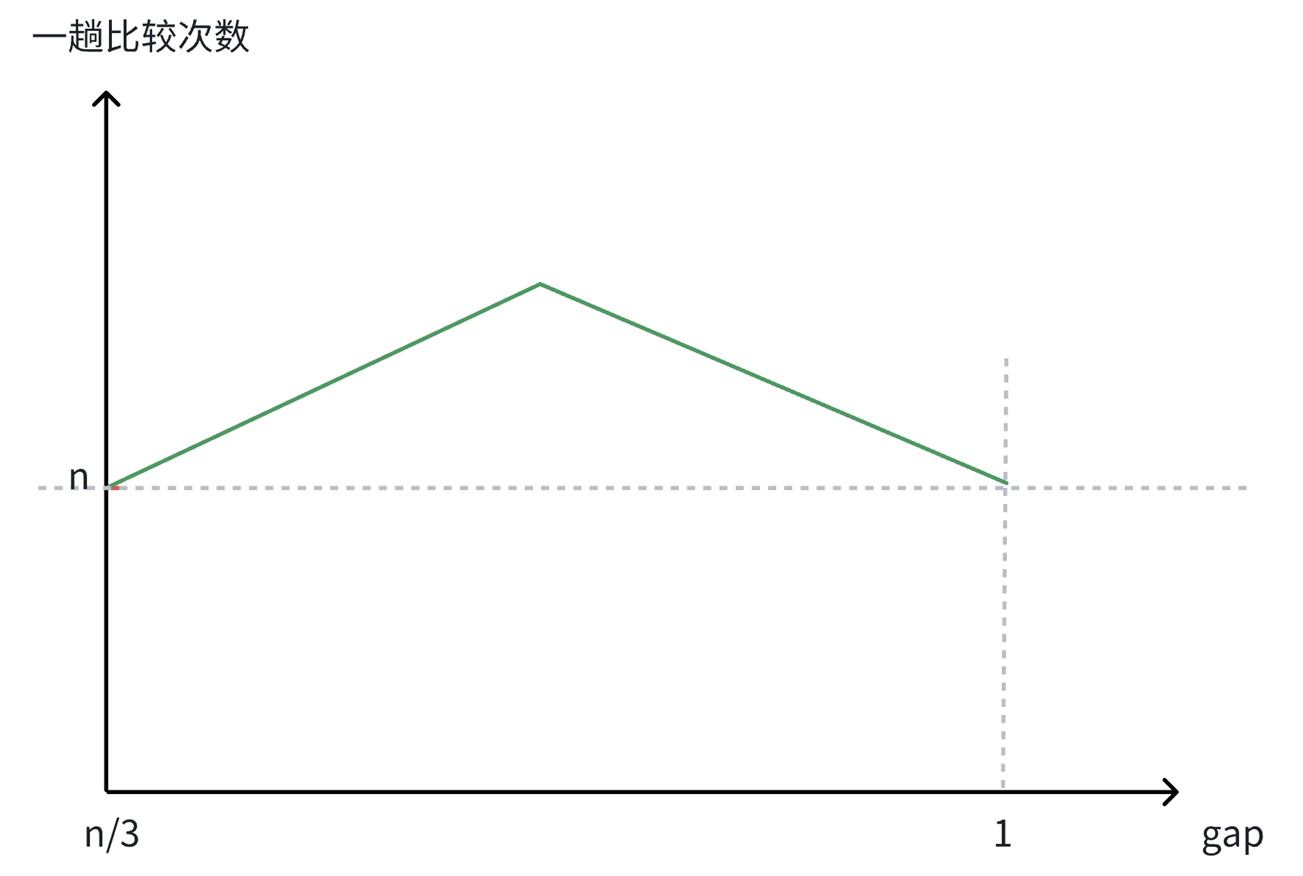
因此,希尔排序在最初和最后的排序的次数都为n,即前⼀阶段排序次数是逐渐上升的状态,当到达 某⼀顶点时,排序次数逐渐下降至n,而该顶点的计算暂时无法给出具体的计算过程 。
所以咱们给到的希尔排序的时间复杂度为n^1.3
2.3 直接选择排序
选择排序的基本思想: 每⼀次从待排序的数据元素中选出最小(或最大)的⼀个元素,存放在序列的起始位置,直到全部待 排序的数据元素排完。
 先上动图:
先上动图:
这里直接选择排序我有两种写法,先来看第一种吧,我本人认为第一种是最好理解的:
void zhijieSort2(int* arr, int n)
{for (int left = 0; left < n - 1; left++) {int mini = left; // 正确初始化mini为当前leftfor (int right = left + 1; right < n; right++) {if (arr[right] < arr[mini]) {mini = right;}}Swap(&arr[mini], &arr[left]); // 直接交换到正确位置}
}OK,咱们来看这段代码,配合者动图看。这段代码的逻辑就是 我先定义最左边的数为最小的数,之后,从左到右一次的遍历,寻找比最左侧还小的数,如果找到了,交换,交换完之后left++即可。若是没找到,说i明最左侧即最小,left也++,继续往后比较。怎么样,这段代码的逻辑是不是很简单。那么再来看第二种写法:
void zhijieSort(int* arr, int n)
{int begin = 0;int end = n - 1;//begin,end都是下标while (begin < end){int maxi = begin;int mini = begin;for (int i = begin + 1; i <= end; i++){if (arr[i] > arr[maxi]){maxi = i;}if (arr[i] < arr[mini]){mini = i;}}if (begin == maxi){maxi = mini;}Swap(&arr[mini], &arr[begin]);Swap(&arr[maxi], &arr[end]);begin++;end--;}
}这个代码的逻辑不是那么好理解,咱们需要提前知道一个东西,就是这个方法是从左右两边同时开始排。即左边排最小,右边排最大。
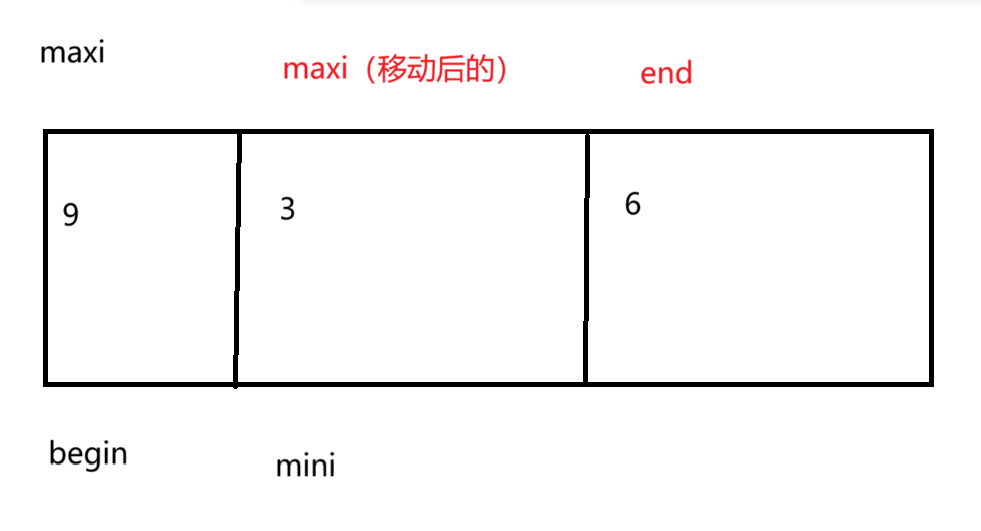 咱们来看这张图并一起来看代码:就是让maxi与mini一开始都指向begin,那么之后寻找maxi与mini,
咱们来看这张图并一起来看代码:就是让maxi与mini一开始都指向begin,那么之后寻找maxi与mini,
1.如果maxi==begin,那么这个时候,由于要先将 mini与begin交换,但是这样一交换之后,就会导致maxi这个地方就是mini了,那么后面的maxi与end交换,就得不到最大值了。所以咱们要先将maxi挪动到mini的位置上,这样,就算mini与begin交换,maxi(mini)的位置还是最大值,你说对吧。这就是为什么要移动maxi位置的原因。交换后,begin++,end--继续比较即可。
2.如果maxi!=begin,那么直接交换就可以了,不需要任何顾虑。
这样一看,第二种方法的逻辑还是比较难理解一些的。
时间复杂度:1.直接选择排序思考非常好理解,但是效率不是很好。实际中很少使用
2.时间复杂度: O(N^2)
2.4 堆排序
堆排序(Heapsort)是指利用堆积树(堆)这种数据结构所设计的⼀种排序算法,它是选择排序的⼀ 种。它是通过堆来进行选择数据。需要注意的是排升序要建大堆,排降序建小堆。
这个方法,咱们在上一节中重点讲的这个方法,不记得的记得去回顾一下哦。
2.5 冒泡排序
交换排序基本思想: 所谓交换,就是根据序列中两个记录键值的比较结果来对换这两个记录在序列中的位置 交换排序的特点是:将键值较大的记录向序列的尾部移动,键值较小的记录向序列的前部移动。
鱼儿吐泡泡大家都见过吧,没错,基本就是这个思想。因为每⼀个元素都可以像小气泡⼀样,根据自身大小⼀点⼀点向数组的⼀侧移动。
上图为动图。
void BubbleSort(int* arr, int n)
{for (int i = 0; i < n; i++){int exchange = 0;for (int j = 0; j < n - 1 - i; j++)//j<n-1-i只起到了屏障的作用,当i增加的时候,右边的屏障也在向左移动{if (arr[j] > arr[j + 1]){exchange = 1;Swap(&arr[j], &arr[j + 1]);}}}
}其实冒泡排序本身不是很好,所以他只起到了一个教学作用。
时间复杂度:

上面的冒泡排序的时间复杂度的分析节选自《大话数据结构》P383,由此可见,冒泡排序的时间复杂度为n^2。
2.6 快速排序
快速排序是Hoare于1962年提出的⼀种二叉树结构的交换排序方法,其基本思想为:任取待排序元素 序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小 于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列 在相应位置上为止。

所以,快速排序就是冒泡排序的升级版本。
2.6.1 递归版本
基本框架:(需要用到递归)
void QuickSort(int* arr, int left, int right)
{if (left >= right){return;}//找基准值//int keyi = _QuickSort(arr, left, right);int keyi = _QuickSort2(arr, left, right);//left keyi right//左序列:[left,keyi-1] 右序列:[keyi+1,right]QuickSort(arr, left, keyi - 1);QuickSort(arr, keyi + 1, right);
}那么咱们目前最主要的就是寻找基准值。从而实现划分。
寻找基准值的几种方法:
2.6.1.1 hoare版本

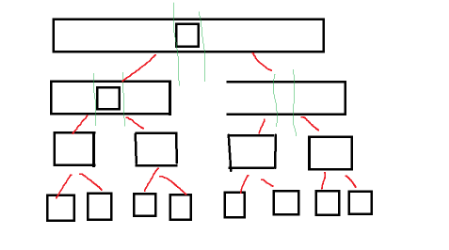
那么这里涉及到两个问题:
1.为什么跳出循环后right位置的值⼀定不大于key?
当 l eft > right 时,即right⾛到left的左侧,而left扫描过的数据均不大于key,因此right此时指 向的数据⼀定不大于key。

2.为什么left和right指定的数据和key值相等时也要交换?
相等的值参与交换确实有⼀些额外消耗。实际还有各种复杂的场景,假设数组中的数据大量重复时, 无法进行有效的分割排序。
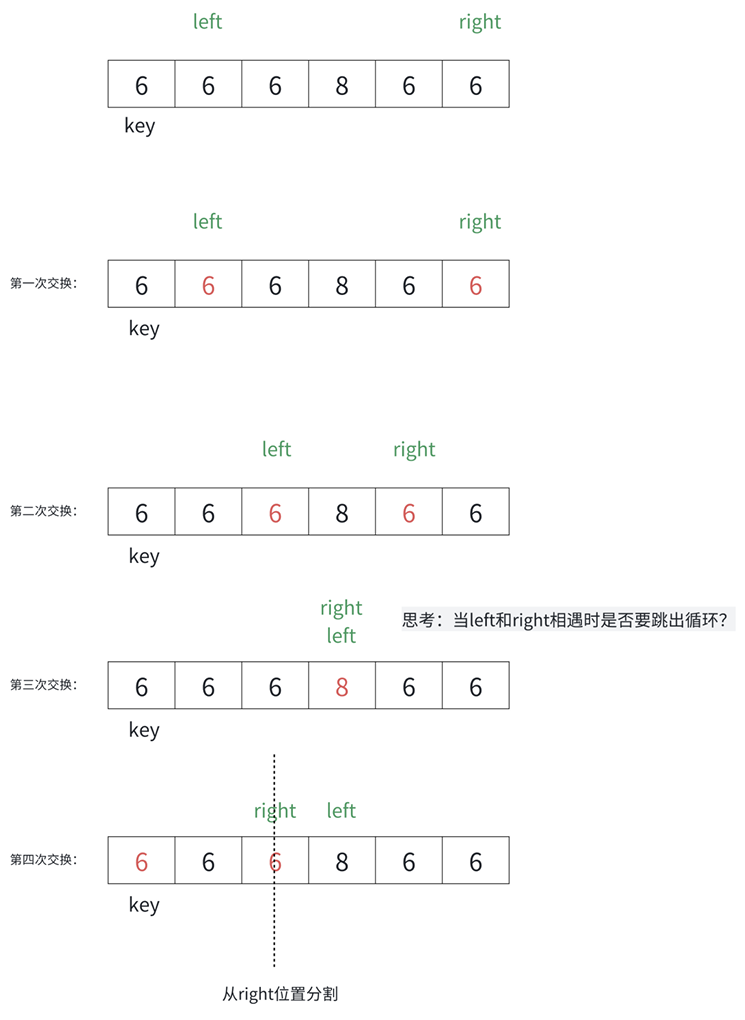
先来看一下代码的基本实现思路吧:
right:从右往左找比基准值小的。
left:从左往右找比基准值大的。
找到后,让left与right数据交换,后right--,left++,之后重复步骤即可。
当left>right时,停止 查找,让right与基准值进行交换,且每次找到基准值后,再次分左右(分的时候不带基准值)。
OK,下面来看代码:
int _QuickSort(int* arr, int left, int right)//找基准值的方法之一
{int keyi = left;++left;//left++也可以吗?while (left <= right){if (left <= right && arr[right] > arr[keyi])//若是right先找到小的,则站那不动,直到等到left找到比基准值大的{++right;}if (left <= right && arr[left] < arr[keyi]){++left;}if (left <= right){Swap(&arr[left++], &arr[right++]);}}Swap(&arr[keyi], &arr[right]);return right;
} 
原理就是这样一个原理。小的放左边,大的放右边,中间的是中等大小的。最后再排成小,中,大这样的一个即可。
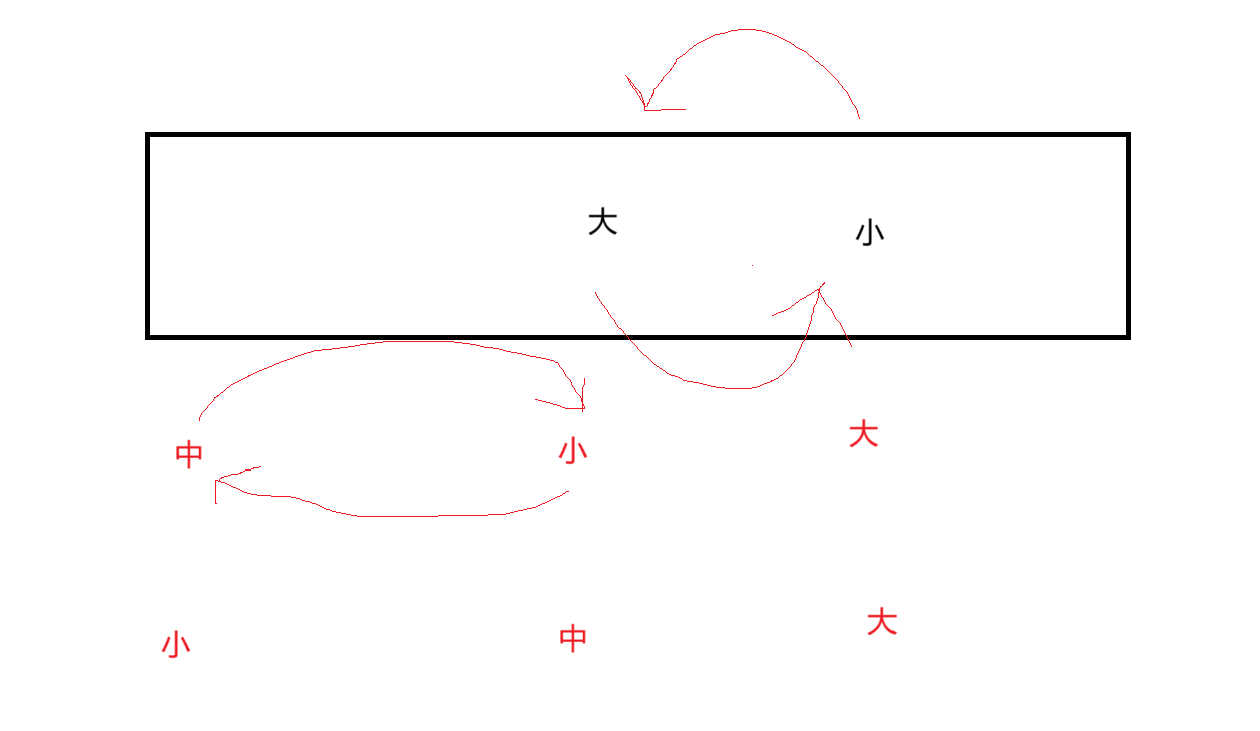
2.6.1.2 挖坑法
思路: 创建左右指针。⾸先从右向左找出比基准小的数据,找到后立即放⼊左边坑中,当前位置变为新 的"坑",然后从左向右找出比基准大的数据,找到后⽴即放入右边坑中,当前位置变为新的"坑",结 束循环后将最开始存储的分界值放入当前的"坑"中,返回当前"坑"下标(即分界值下标)。
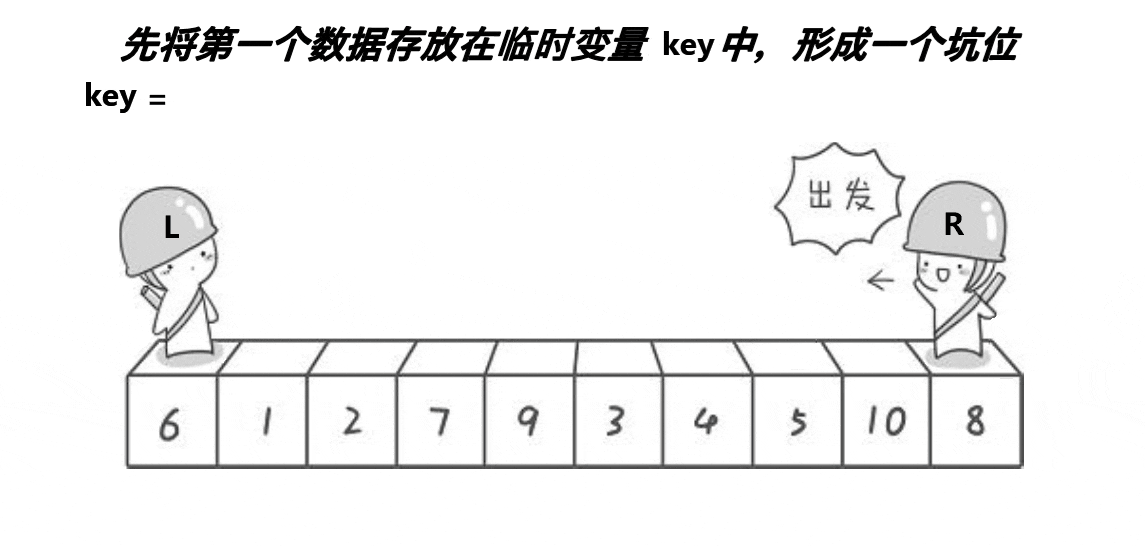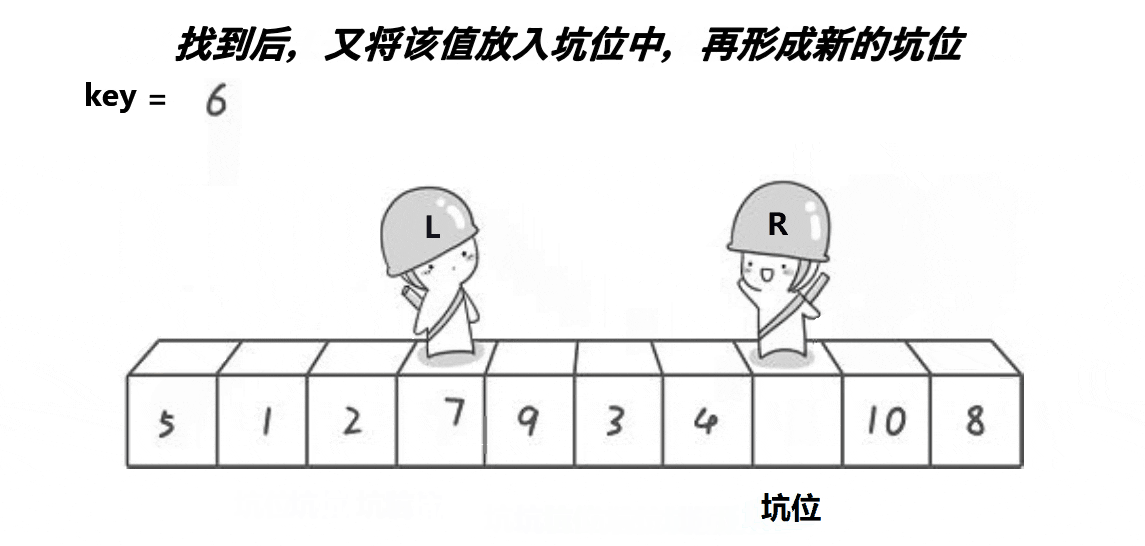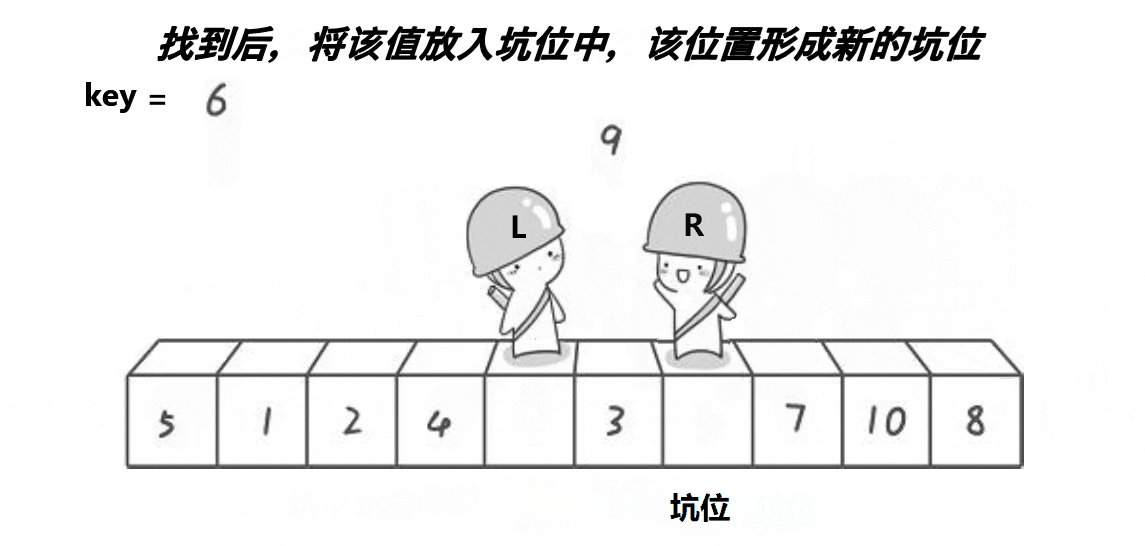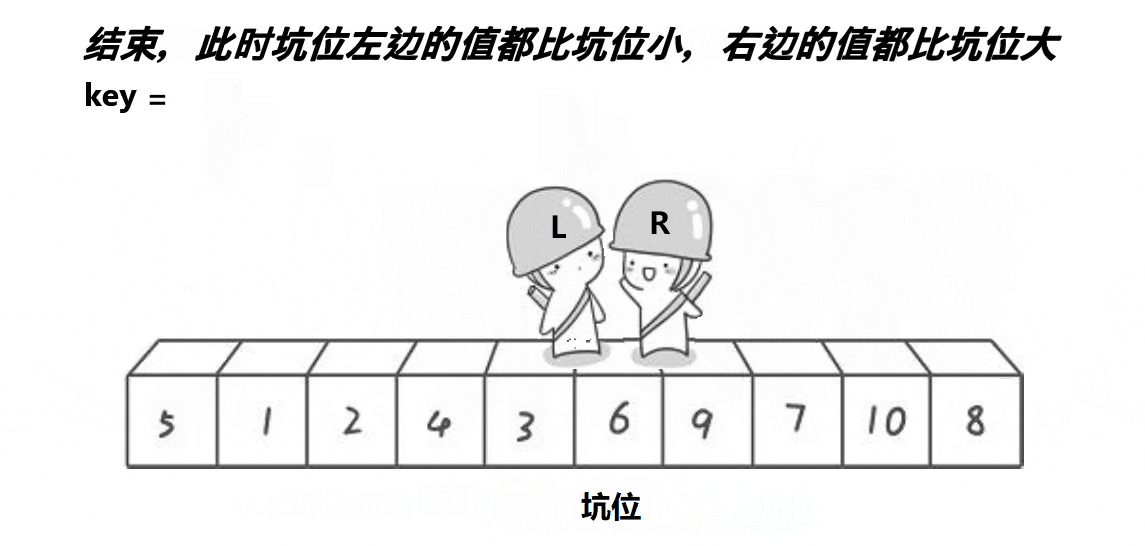
来看代码:
int _QuickSort(int* a, int left, int right)
{int mid = a[left];int hole = left;int key = a[hole];while (left < right){while (left < right && a[right] >= key) {--right;}a[hole] = a[right];hole = right;while (left < right && a[left] <= key){++left;}a[hole] = a[left];hole = left;}a[hole] = key;return hole;}来看这段代码的逻辑吧:
首先,代码开始部分:
int mid = a[left];
这里声明了一个变量mid,赋值为a[left],也就是数组最左边的元素。
接下来:
int hole = left;
int key = a[hole];
这里hole被初始化为left,也就是基准值的位置,key存储了基准值的数值。这里可能是在使用“挖坑法”来进行分区操作。挖坑法的思路是将基准值的位置作为初始的“坑”,然后从右往左找比基准小的数填到左边的坑,再从左边找比基准大的数填到右边的坑,交替进行,直到左右指针相遇,最后将基准值填入最后的坑中。
然后进入循环:
while (left < right)
这个循环条件是左右指针还没有相遇,继续处理。
在循环内部,首先从右往左扫描:
while (left < right && a[right] >= key)
{--right;
}
这里,右边的指针right向左移动,直到找到一个小于key的元素。这里需要注意的是,条件中的a[right] >= key,当元素等于key时也会停止,这可能导致分区不平衡,但在某些实现中这样是可以接受的,不过可能会导致重复元素较多时的性能问题。
找到之后,将a[right]的值填入hole的位置:
a[hole] = a[right];
然后更新hole的位置为right,即当前的右指针位置:
hole = right;
接下来,从左往右扫描:
while (left < right && a[left] <= key)
{
++left;
}
这里,左指针left向右移动,直到找到一个大于key的元素。同样,a[left] <= key的条件会在遇到等于key时继续移动,这里可能需要确认是否正确,但通常这样的处理是允许的,因为等于基准值的元素可以被分到任一边。
找到之后,将a[left]的值填入当前的hole位置:
a[hole] = a[left];
然后更新hole的位置为left:
hole = left;
循环结束后,将基准值key填回到最后的hole位置:
a[hole] = key;
返回hole作为基准值的最终位置。
2.6.1.3 lomuto前后指针
创 建前后指针,从左往右找比基准值小的进行交换,使得小的都排在基准值的左边。
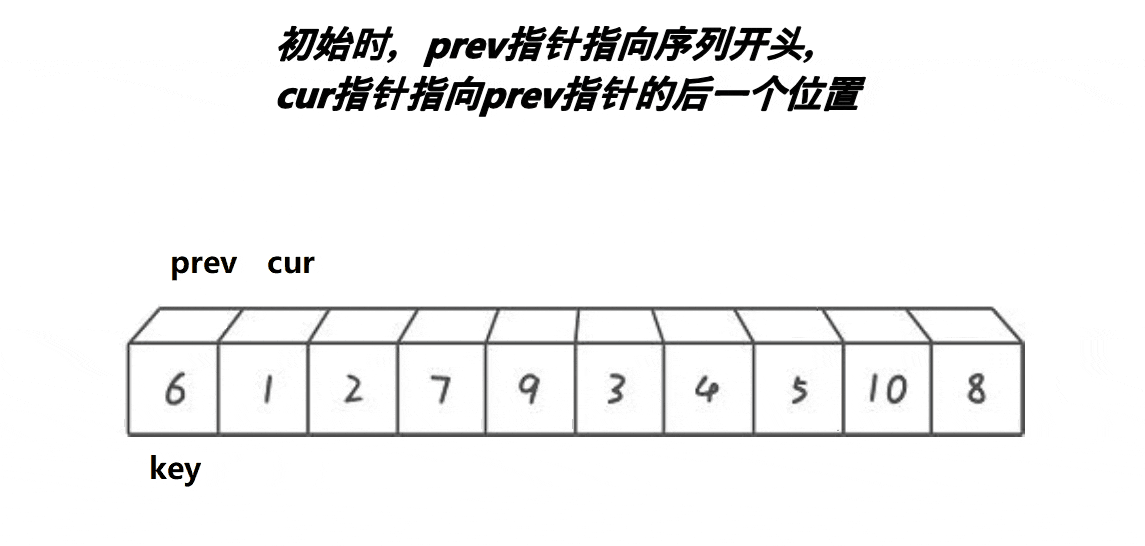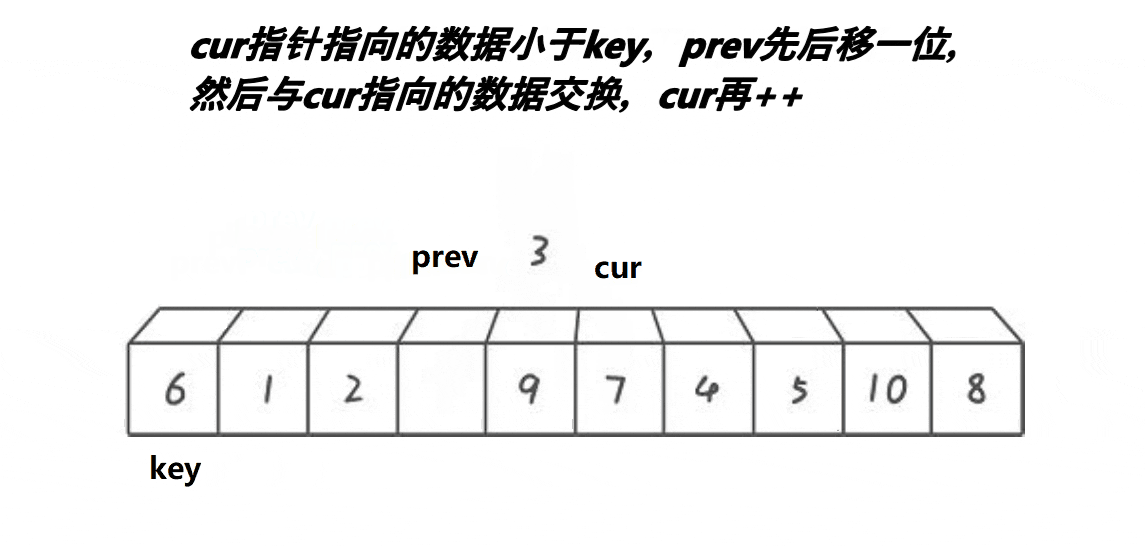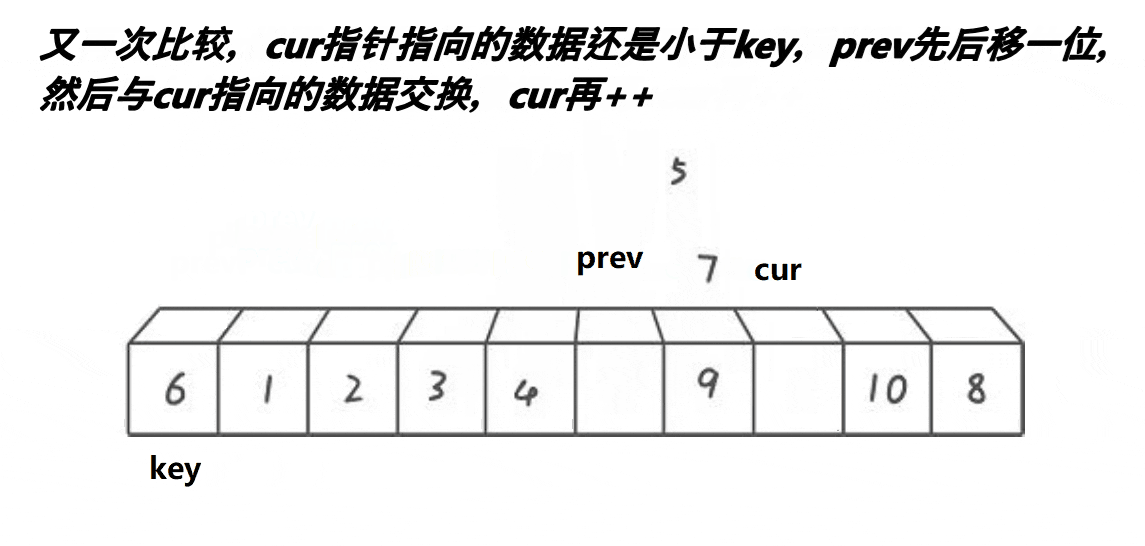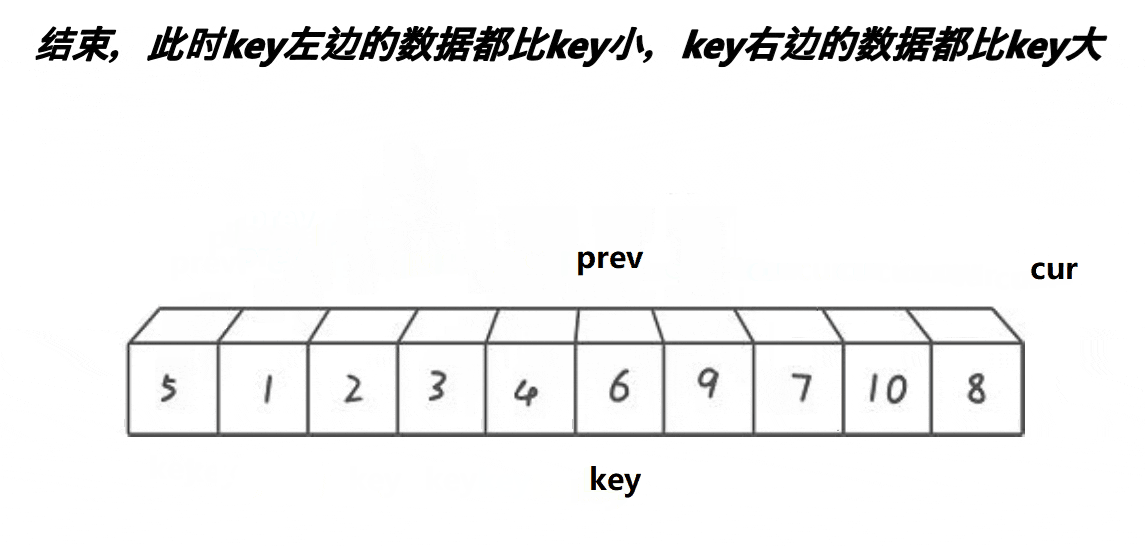
创建两个前后变量prev,cur。cur从左往右找比基准值小的数据,找到后,prev++,交换prev与cur,cur++。当cur越界后,prev与基准值交换。(这样prev左边就是小的数据了)。但是当++prev等于cur时,就不交换了,因为他俩指向同一个位置,交换了也是白交换。
//双指针找基准值方法
//创建两个变量prev,cur,cur从前往后找比基准值小的,找到之后,先让prev++
//之后再交互prev跟cur,cur++,直到cur越界,交换prev与基准值
//这样做的话基准值左边全是比他小的
int _QuickSort1(int* arr, int left, int right,int n) //同名的函数
{int prev = left;int cur = left + 1;int keyi = left;while (cur <= right){if (arr[keyi] > arr[cur] && ++prev != cur){Swap(&arr[prev], &arr[cur]);cur++;}}Swap(&arr[keyi], &arr[prev]);return prev;
}这里有一点需要注意,就是while循环中有一个if判断语句,这里需要说明一下:&&中若前一个条件已经被否定了,则不会执行下一个!只有前一个条件满足时,才会执行下一个条件。
2.6.1.4 时间复杂度
时间复杂度都为nlogn。
2.6.2 非递归版本
用栈进行序列的存储。可以将由基准值划分出来的这俩序列存到栈里面,然后依次取栈顶,找到对应的序列,对它进行排序。入栈,先入左序列,或先入右序列,都是可以的。
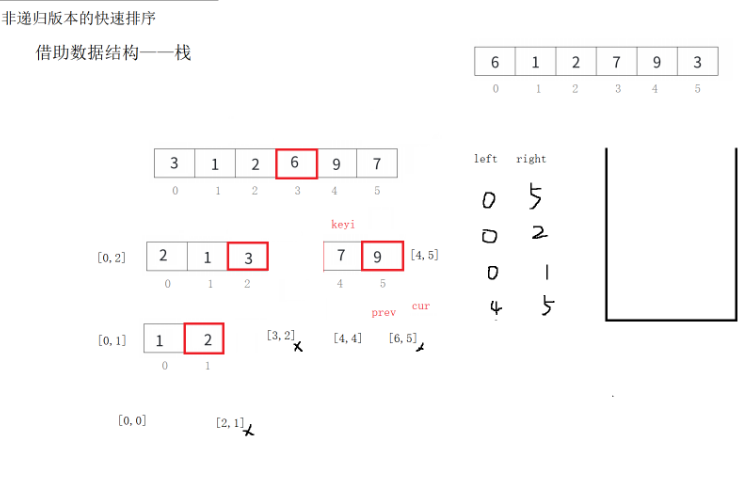
来看代码吧:
void QuickSortNonR(int* a, int left, int right){ST st;STInit(&st);STPush(&st, right);STPush(&st, left);while (!STEmpty(&st)){int begin = STTop(&st);STPop(&st);//这个是让ps->top--,从而改变top的位置的int end = STTop(&st);STPop(&st);//
单趟int keyi = begin;int prev = begin;int cur = begin + 1;while (cur <= end){if (a[cur] < a[keyi] && ++prev != cur)Swap(&a[prev], &a[cur]);++cur;}Swap(&a[keyi], &a[prev]);keyi = prev;// [begin, keyi-1] keyi [keyi+1, end] if (keyi + 1 < end){STPush(&st, end);STPush(&st, keyi + 1);}if (begin < keyi-1){STPush(&st, keyi-1);STPush(&st, begin);}}STDestroy(&st);}来看这段代码的逻辑吧:
函数内部定义了一个ST结构体的实例st,并进行了初始化。接着,将right和left依次压入栈中。然后进入一个循环,条件是栈不为空。在循环内部,首先弹出栈顶的两个元素作为begin和end,这表示当前要处理的子数组的左右边界。
接下来是单趟排序的部分。这里定义了keyi为begin,也就是当前子数组的第一个元素作为基准值。然后prev和cur初始化为begin和begin+1,这看起来像是使用了一种类似于前后指针的方法来进行分区操作。在cur循环中,当a[cur]小于基准值时,prev先自增,然后如果prev不等于cur,就交换a[prev]和a[cur]的位置。这应该是将小于基准值的元素移动到prev的位置,cur继续前进,直到遍历完整个子数组。最后,交换基准值a[keyi]和a[prev],将基准值放到正确的位置,此时keyi更新为prev,也就是基准值的最终位置。
完成一趟排序后,代码将子数组分成两部分:[begin, keyi-1]和[keyi+1, end]。接下来,检查这两个子数组是否需要继续处理。如果keyi+1 < end,说明右边的子数组还有多个元素需要排序,于是将end和keyi+1压入栈中。同样,如果左边的子数组begin < keyi-1,则压入keyi-1和begin。这样,栈中的元素会不断分解为更小的子数组,直到所有子数组都被处理完毕。
2.7 归并排序
归并排序算法思想: 归并排序(MERGE-SORT)是建立在归并操作上的⼀种有效的排序算法,该算法是采用分治法(Divide andConquer)的⼀个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个 子序列有序,再使⼦序列段间有序。若将两个有序表合并成⼀个有序表,称为二路归并。
在这咱们只实现递归版本。
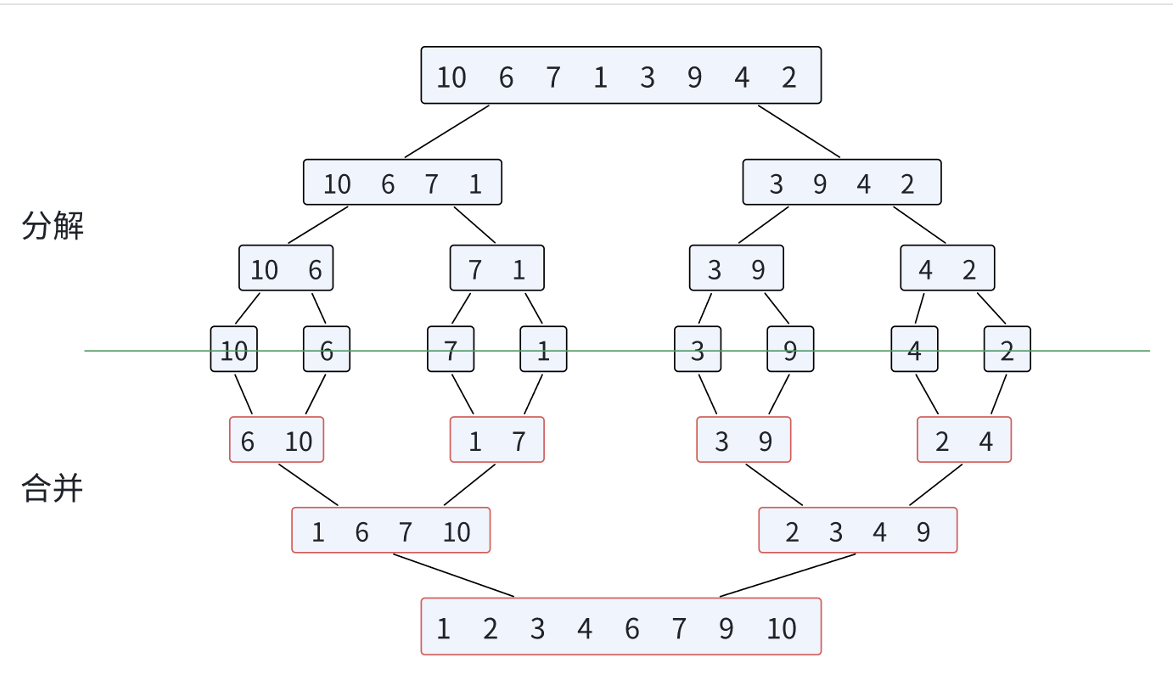
合并的时放数据时候,不要让其从下标为0开始(有的数据下标不是0,因为int index=begin),用临时的数组存储临时合并的数据。
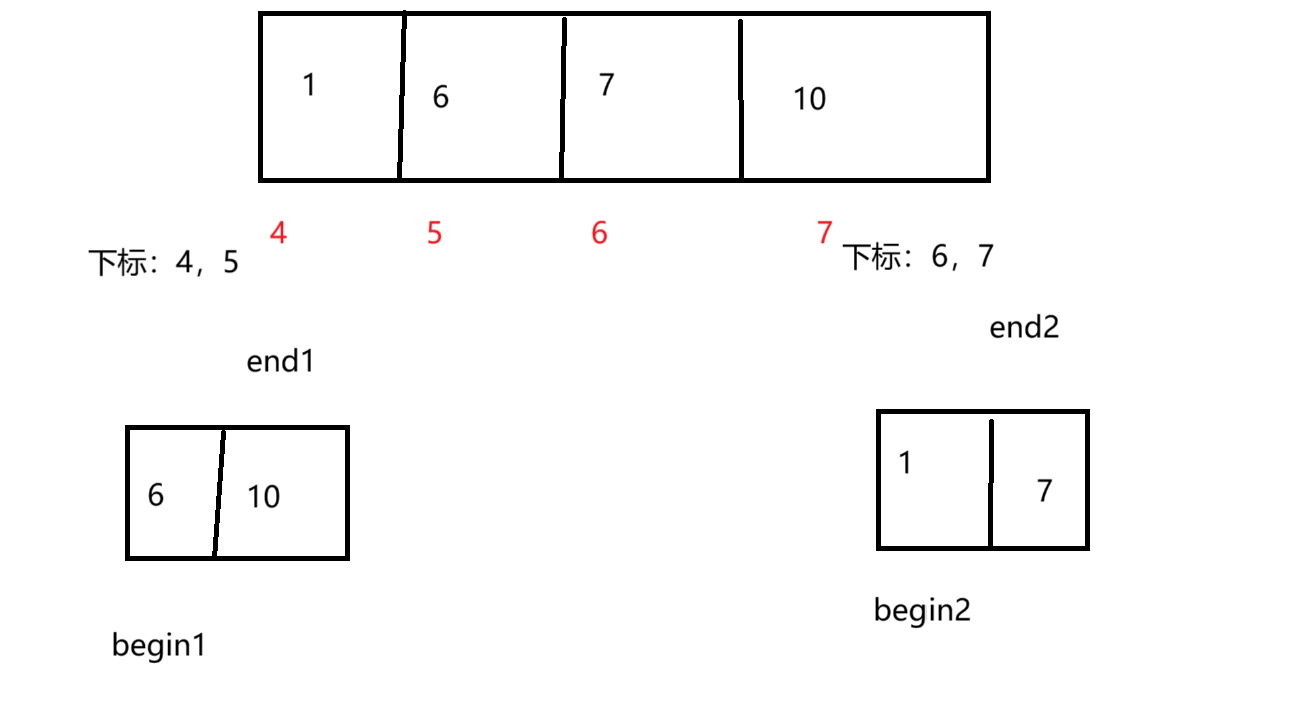
来看代码:
//归并排序
//这个是递归,递完之后,还会再归回来,所以说这个地方left,mid等
//值都是随时随地刷新的,即每递归一次,这里的数据就会更新一次,这样的话,从小将转换成大将的
//时候,每一组小将转换成大将的时候(即是2个数据转成一个大数组),left,right,mid
//都可以确保他在最新的位置
void _mergeSort(int* arr, int left, int right, int *tmp/*这里定义临时数组的目的就是为了能够方便的存储由小将转变成大将存储的地方*/)
{if (left >= right){return;}int mid = (left + right) / 2;_mergeSort(arr, left, mid, tmp);_mergeSort(arr, mid+1, right, tmp);int begin1 = left;int end1 = mid;int begin2 = mid + 1;int end2 = right;int index = begin1;while (begin1 <= end1 && begin2 <= end2){if (arr[begin1] < arr[begin2]){tmp[index++] = arr[begin1++];}else{//少了一个tmp[index++] = arr[begin2++];}}//到这时,有两种情况(不满足上面while的两种情况)//左序列数据没有全部放到tmp数组中//右序列数据没有全部放到tmp数组中while(begin1 <= end1){tmp[index++] = arr[begin1++];}while (begin2 <= end2){tmp[index++] = arr[begin2++];}//tmp中有序数据导入到原数组for (int i = left; i <= right; i++){arr[i] = tmp[i];}//这儿每递归一次时间复杂度为n
}
void mergeSort(int* arr, int left, int right, int n)
{int* tmp = (int*)malloc(n * sizeof(int));if (tmp == NULL){perror("malloc fail!");exit(1);}_mergeSort(arr, 0, n - 1, tmp);free(tmp);tmp = NULL;//这个的时间复杂度为logn(不就相当于二叉树的深度嘛)
}来看一下这段代码中的一些东西:
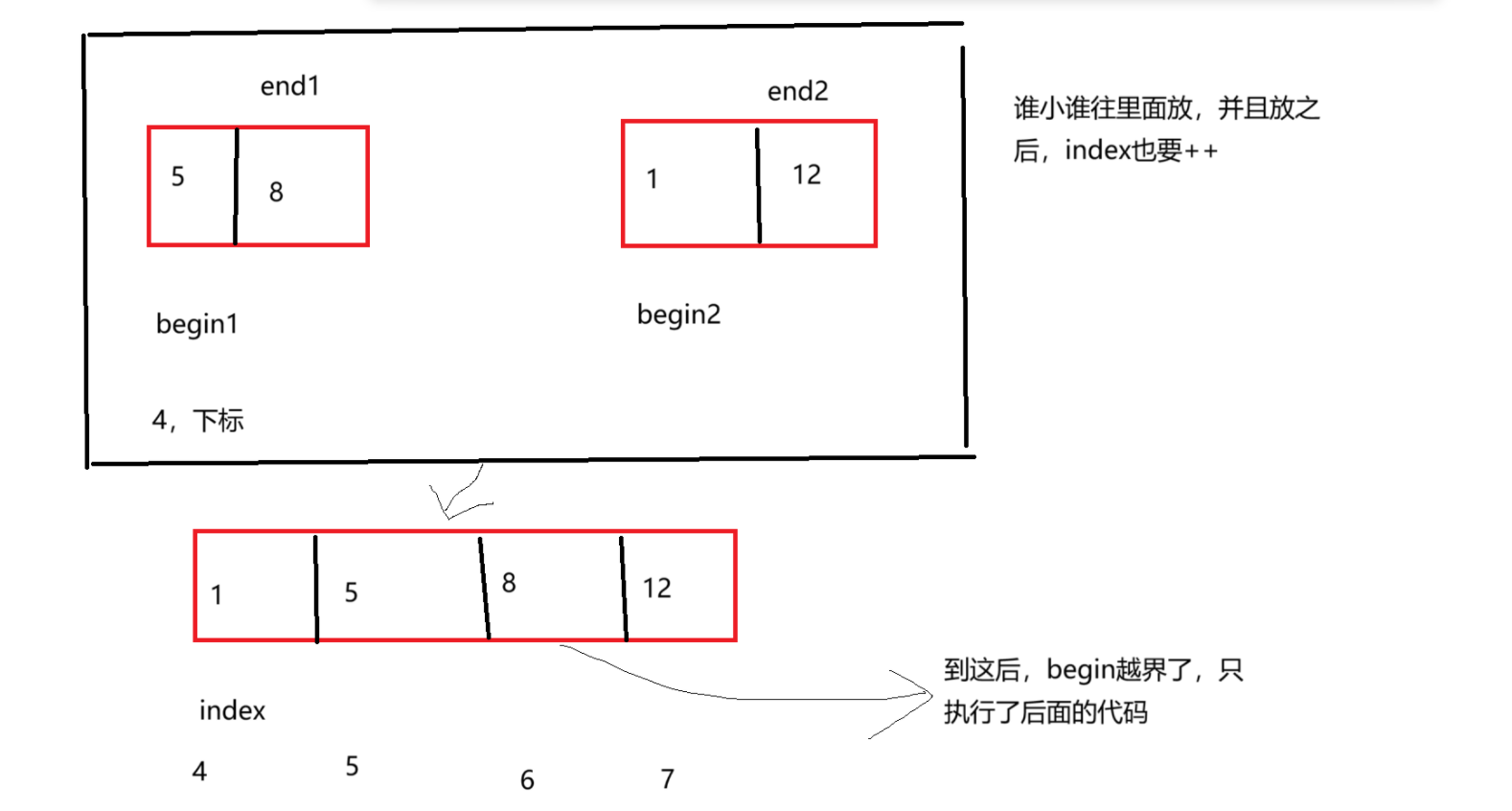
这个就是往里面放的时候的逻辑。
还要注意的是,这个归并排序并没有开辟新的数组来存放那些小将们,还是用的原来的数组。这一点别搞错了!
时间复杂度:
咱们知道递归的时间复杂度计算方法为:
单词递归的时间复杂度为n ,递归次数为logn(二叉树深度),所以它的时间复杂度为O(nlogn)。
3 性能比较
那么前面的七种算法,在排序中都要进行数据的大小比较,因此这些算法也被称为比较排序算法。那么有比较,也得有非比较呀,不慌,咱们呢先来看一下性能比较:
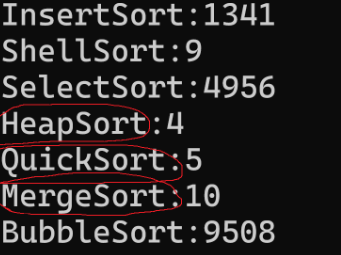
由此可见,堆排序与快速排序,是最好的,最快的。
4.非比较排序
计数排序:(这个最考验的其实就是下标的问题)
计数排序又称为鸽巢原理,是对哈希直接定址法的变形应用。操作步骤:
1)统计相同元素出现次数。
2)根据统计的结果将序列回收到原来的序列中。
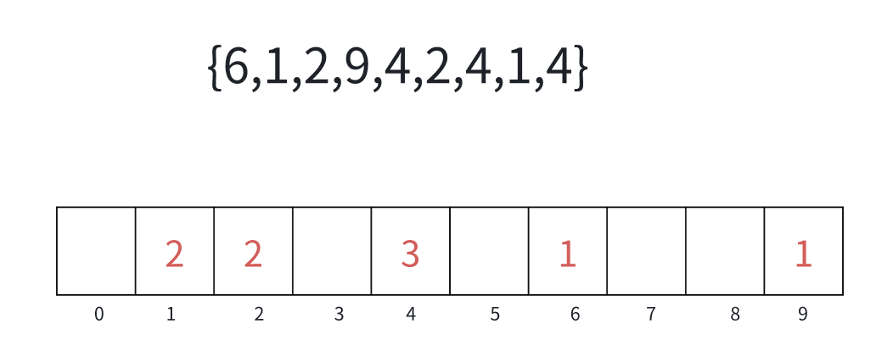
那么为什么这么开空间呢?
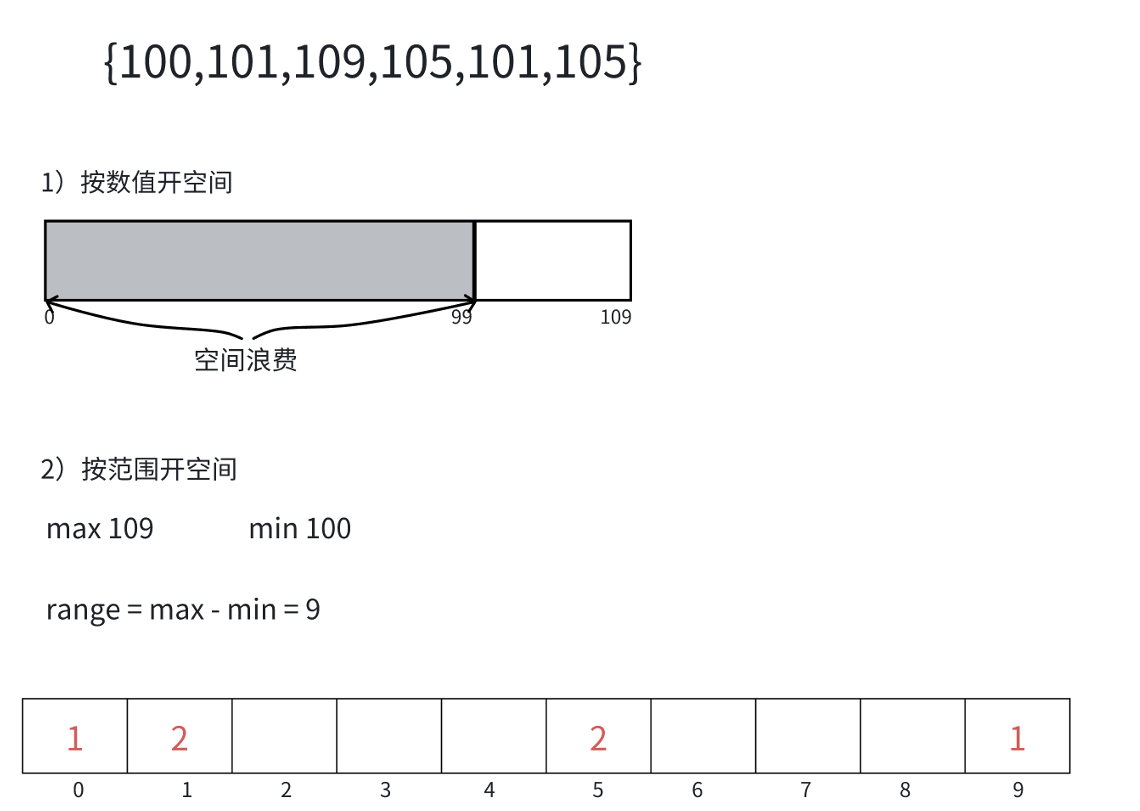 首先,你使用最大值加1这个方法来进行开空间对于几个小数据有用,但是万一数据量非常大呢?就比如105,你这样开,前面的空间不全部浪费了吗?
首先,你使用最大值加1这个方法来进行开空间对于几个小数据有用,但是万一数据量非常大呢?就比如105,你这样开,前面的空间不全部浪费了吗?
第二种,按范围开,可以是可以,但是要注意下标,下标要灵活存储(用max-min+1确定数组的大小)。用arr[i]-min确定下标
统计数据出现的次数,直接遍历即可。遍历时,碰到哪个后,直接++即可。即cout[arr[i]-min]++。
那个下标所在的数组++一次(即相同元素出现的次数)。
那么如何回到原来的那个数组上呢?给上cout[i](即相同元素出现的次数),然后,在原数组定义一个index,从0开始,arr[index]=i+min(这个是要存储的数)。count[i]为存储的次数。
ok,接下来请看代码:
void CountSort(int* arr, int n)
{int min = arr[0], max = arr[0];for (int i = 1; i < n; i++){if (arr[i] < min){min = arr[i];}if (arr[i] > max){max = arr[i];}}//max minint range = max - min + 1;int* count = (int*)malloc(sizeof(int) * range);if (count == NULL){perror("malloc fail!");}memset(count, 0, sizeof(int) * range);//直接用calloc也是可以的for (int i = 0; i < n; i++){count[arr[i] - min]++;}//将次数还原到原数组中int index = 0;for (int i = 0; i < range; i++){//数据出现的次数count[i]//下标———源数据 i+minwhile (count[i]--){arr[index++] = i + min;}}
}来让我们分析一下这段代码,其实逻辑挺简单的:
函数开始部分,首先找出数组中的最小值min和最大值max。这一步通过遍历数组完成,初始化min和max为第一个元素,然后逐个比较更新min和max。
接下来计算range = max - min + 1,这是确定数据覆盖的范围大小。例如,如果max是5,min是0,那么range是6(0到5共6个数)。这里需要注意当数据范围较大的时候,可能会需要很大的内存,这也是计数排序的局限性之一。
然后分配一个大小为range的整数数组count,用于记录每个数出现的次数。这里用了malloc分配内存,并检查是否分配成功。之后用memset将count数组初始化为0,确保所有元素的计数从零开始。或者,用户提到可以用calloc,这样就不需要memset了,因为calloc会自动初始化为零。
接下来,遍历原数组arr,对每个元素arr[i],计算其在count数组中的位置(arr[i] - min),并将对应的count值增加1。
最后,将统计结果还原到原数组中。这里使用一个index变量来跟踪当前要写入的位置,然后遍历count数组的每个位置i。对于每个count[i],即元素i+min出现的次数,通过while循环将i+min写入原数组count[i]次。例如,如果count[3]是2,那么原数组中会连续放入3+min两次。
确实挺简单的吧。
计数排序在数据范围集中时,效率很高,但是适⽤范围及场景有限。
时间复杂度: O(N+range)。
5..排序算法复杂度及稳定性分析

稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的 相对次序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,⽽在排序后的序列中,r[i]仍在r[j]之 前,则称这种排序算法是稳定的;否则称为不稳定的。
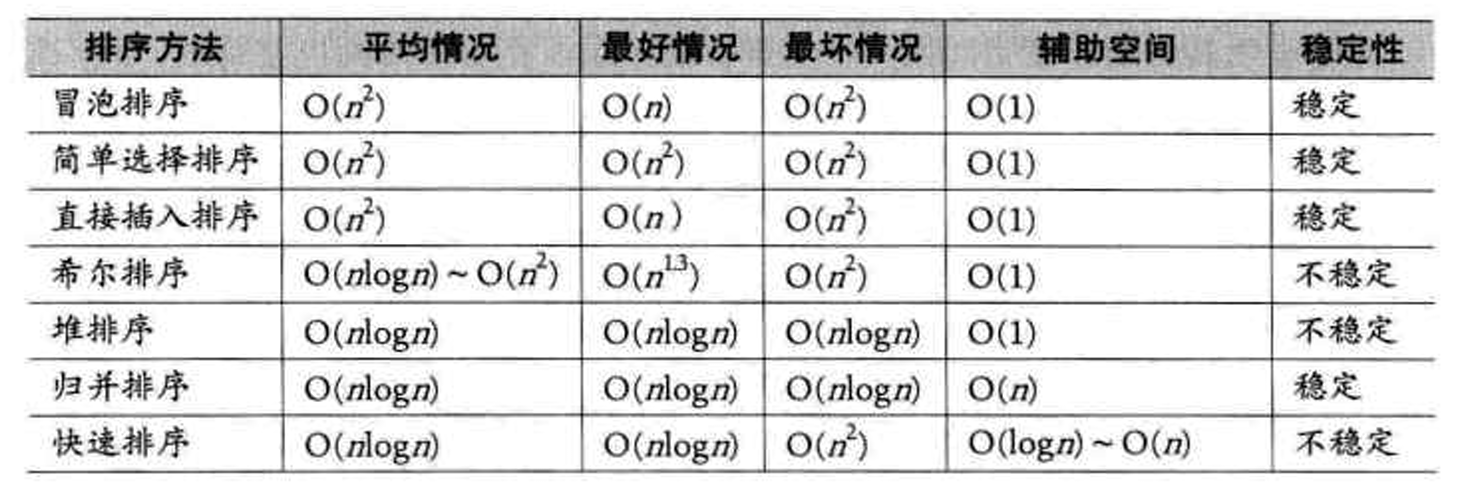 上表选自《大话数据结构》P429.
上表选自《大话数据结构》P429.

具体的大家可以自行查看《大话数据结构》这本书,讲的相当不错。
最后看一下稳定性案例:
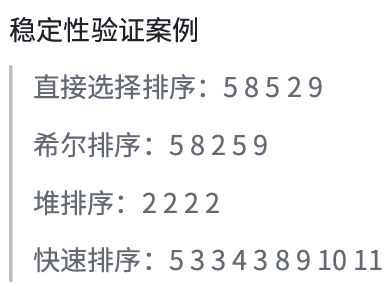
OK,到此为止,排序这一章总算是讲完了,也写了1w多字,希望大家可以好好学习一下,今天为止,初阶数据结构就讲完了,下面我会更新高新数据结构的。
相关文章:
初阶数据结构完)
数据结构——排序(万字解说)初阶数据结构完
目录 1.排序 2.实现常见的排序算法 2.1 直接插入排序 编辑 2.2 希尔排序 2.3 直接选择排序 2.4 堆排序 2.5 冒泡排序 2.6 快速排序 2.6.1 递归版本 2.6.1.1 hoare版本 2.6.1.2 挖坑法 2.6.1.3 lomuto前后指针 2.6.1.4 时间复杂度 2.6.2 非递归版本 2.7 归并排序…...

东方泵业,室外消火栓泵 2#故障灯亮,报警生响
东方泵业,室外消火栓泵 2#故障, 图纸上显示有一个热继电器,过热了,然后它不会自动复位,需要手动复位,手动点一下那个蓝色的按钮,然后警报就解除了...

vue3:十二、图形看板- 基础准备+首行列表项展示
文章主要实现了看板页面的搭建;将看板页面加入左侧菜单;首行列表项的实现 一、效果展示 展示四个数据列表,四个列表颜色各不相同,列表左侧有颜色边线(同标题颜色、图标颜色一致);展示的数字有一个从0到当前数据逐渐增长的一个动画效果 二、图形看板的准备工作 1、创建视…...

基于开源链动2+1模式AI智能名片S2B2C商城小程序的分销价格管控机制研究
摘要:本文聚焦开源链动21模式AI智能名片S2B2C商城小程序在分销体系中的价格管控机制,通过解析其技术架构与商业模式,揭示平台如何通过"去中心化裂变中心化管控"双轨机制实现价格统一。研究显示,该模式通过区块链存证技术…...

指定Docker镜像源,使用阿里云加速异常解决
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo异常贴图 yum-config-manager:找不到命令 因为系统默认没有安装这个命令,这个命令在yum-utils 包里,可以通过命令yum -y install yum-util…...

java基础-数组
1.数组的声明和初始化: (1)静态初始化: import java.util.Arrays;public class Main {public static void main(String[] args) {int[] ids {1,2,3,4,5};System.out.println(Arrays.toString(ids));} } (2…...

CSS手动布局
CSS支持单独设置某个元素的布局,最主要的属性是 position ,它有以下几个值: static静态位置(默认值)。元素采用正常流布局,此时元素的位置偏移属性( top 、 right 、 bottom 、 left 和 z-inde…...

什么是智能合约?区块链上的自动化契约
智能合约是运行在区块链上的计算机程序或交易协议。与传统的纸质合同不同,智能合约将合同条款直接编码到程序中,并在满足预设条件时自动执行。它们旨在实现无需第三方介入的可信交易,具有自动化、透明、不可篡改和高效等特点。 智能合约的起…...

webRtc之指定摄像头设备绿屏问题
摘要:最近发现,在使用navigator.mediaDevices.getUserMedia({ deviceId: ‘xxx’}),指定设备的时候,video播放总是绿屏,发现关闭浏览器硬件加速不会出现,但显然这不是一个最好的方案; 播放后张这样 修复后 上代码 指定…...

正则表达式非捕获分组?:
一个使用 Java 正则表达式的具体例子,展示了 (ab) 和 (?:ab) 的不同: 示例 1:使用 (ab)(捕获分组) import java.util.regex.*; public class RegexExample { public static void main(String[] args) { …...

Linux系统Shell脚本之shell数组、正则表达式、及AWK
目录 一.shell数组 1.数组分类 2.定义数组的方法 二.正则表达式 1. 元字符 2.表示次数 3.位置锚定 4.分组 5.扩展正则表达式 三.文本三剑客之AWK 1.awk 2.使用格式 3、处理动作 4.选项 5.处理模式 6.awk常见的内置变量 7.if条件判断 一.shell数组 1.数组分类 …...

在 ESP-IDF 中使用 .a 静态库调用
1. 准备静态库文件 将你的 .a 文件(如 libmylib.a)放置在工程目录中,推荐放在 components 子目录下: your_project/ ├── CMakeLists.txt ├── main/ └── components/└── my_lib/├── include/ # 头文件│ …...
)
大疆无人机“指点飞行模式”(TapFly)
在大疆无人机的功能中,“指点飞行模式”(TapFly)是一种通过点击屏幕目标点,让无人机自动规划路径并飞向指定位置的智能飞行模式。用户无需手动操控摇杆,只需在 App 地图或实时画面上点击目标位置&…...

力扣 : 781. 森林中的兔子
781. 森林中的兔子 - 力扣(LeetCode) 同一个数字的可以分为一组 , 3就是有3个人和我自己相同 也就是4个人,所以相同的数字可以分为 / (num1) 向上取整 class Solution { public:int numRabbits(vector<int>& answer…...

LVS中的DR模式,直接路由模式
DR模式工作原理介绍 请求经过调度器,响应由real server 直接响应给客户端。 如上图所示,real server想要正常访问互联网,后端的real server的网关就得写网络中真实的网关。 DR模式的核心要素:【重点】 1.请求经过调度器&…...
)
iTwin 数据报表(只是简单的原型不代表实现)
大概想法是 前端从schema和class中选中感兴趣的property内容生成ecsql语句传递给后端后端解析ecsql并提供公开接口给各个分析工具,如excel,poewerBI等(Odata或者直接选择来自网站)再由分析工具做进一步的处 还未想好的点 如何存…...

【无标题】如何在sheel中运行Spark
启动hdfs集群,打开hadoop100:9870,在wcinput目录下上传一个包含很多个单词的文本文件。 启动之后在spark-shell中写代码。 // 读取文件,得到RDD val rdd1 sc.textFile("hdfs://hadoop100:8020/wcinput/words.txt") // 将单词进行…...

Spark 处理过程转换:算子与行动算子详解
在大数据处理领域,Apache Spark 凭借其强大的分布式计算能力脱颖而出,成为处理海量数据的利器。而 Spark 的核心处理过程,主要通过转换算子和行动算子来实现。本文将深入探讨 Spark 中的转换算子和行动算子,帮助读者更好地理解和应…...

Docker编排工具---Compose的概述及使用
目录 一、Compose工具的概述 二、Compose的常用命令 1、列出容器 2、查看访问日志 3、输出绑定的公共端口 4、重新构建服务 5、启动服务 6、停止服务 7、删除已停止服务的容器 8、创建和启动容器 9、在运行的容器中执行命令 10、指定一个服务启动容器的个数 11、其…...

Matlab实现绘制任意自由曲线
Matlab实现绘制任意自由曲线,实现Photoshop中的钢笔路径功能,用光顺连接的B样条/贝塞尔曲线实现,鼠标点击生成控制点,拖动形成任意曲线。 可描绘多路径,也可旋转、平移、缩放。经调试可用。 ByangtiaoSculpt/Byangti…...
)
如何保证Kafka生产者的消息顺序性? (单分区内有序,需确保同一Key的消息发送到同一分区)
Kafka 生产者消息顺序性保障方案 1. 核心实现原理 消息顺序性保障公式: 同一 Key → 同一 Partition → 严格顺序写入2. 关键配置参数 Properties props new Properties(); props.put("acks", "all"); // 确保消息持久化 props.put("ma…...

[D1,2] 贪心刷题
文章目录 摆动序列最大子数组合买卖股票跳跃游戏跳跃2 摆动序列 不像是贪心,只要抓住摆动这个点,前一个上升,那下一个就要下降,记录上一次的状态为1的话,那下一次就要更新为-1,如果上一次为1,这…...

springboot使用阿里云OSS实现文件上传
在Spring Boot中集成阿里云OSS(对象存储服务)可以通过以下步骤实现: 添加Maven依赖 在pom.xml中添加阿里云OSS SDK依赖: <dependency><groupId>com.aliyun.oss</groupId><artifactId>aliyun-sdk-oss<…...

nginx之proxy_redirect应用
一、功能说明 proxy_redirect 是 Nginx 反向代理中用于修改后端返回的响应头中 Location 和 Refresh 字段的核心指令,主要解决以下问题:协议/地址透传错误:当后端返回的 Location 包含内部 IP、HTTP 协议或非标准端口时,需修正为…...
)
FAISS(Facebook AI Similarity Search)
First steps with Faiss for k-nearest neighbor search in large search spaces - Davide’s GitHub pages FAISS(Facebook AI Similarity Search)是由Meta(原Facebook)AI团队开发的高效相似性搜索库,主要用于处理大规…...

创建虚拟服务时实现持久连接。
在调度器中配置虚拟服务,实现持久性连接,解决会话保持问题。 -p 【timeout】 -p 300 这5分钟之内调度器会把来自同一个客户端的请求转发到同一个后端服务器。【不管使用的调度算法是什么。】【称为持久性连接。】 作用:将客户端一段时间…...

RabbitMQ中Exchange交换器的类型
在RabbitMQ中,Exchange(交换器)是消息路由的核心组件,它接收生产者发送的消息,并根据不同的规则将消息转发到一个或多个队列。 RabbitMQ主要支持以下几种类型的交换器: 1. Direct Exchange(直连…...
)
JavaSE核心知识点01基础语法01-05(字符串)
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 JavaSE核心知识点01基础语法01-05࿰…...

Vue 项目中二维码生成功能全解析
Vue 项目中二维码生成功能全解析 在信息快速传递的时代,二维码以其简洁高效的特点,成为数据交互的重要媒介。无论是用于支付、信息分享,还是活动参与,二维码都扮演着关键角色。在 Vue 项目开发中,如何实现二维码生成功…...

【AWS+Wordpress】将本地 WordPress 网站部署到AWS
前言 自学笔记,解决问题为主,亲测有效,欢迎补充。 本地开发机:macOS(Sequoia 15.0.1) 服务器:AWS EC2(Amazon Linux 2023) 目标:从本地迁移 WordPress 到云…...
)
性能优化-初识(C++)
性能优化-初识 一、内联与优化(Inlining and Optimization)什么是内联(inline)?使用方式:适用场景:注意事项: 二、缓存友好设计(Cache-Friendly Design)原理简…...

[人机交互]交互设计过程
*一.设计 1.1什么是设计 设计是一项创新活动,旨在为用户提供可用的产品 –交互设计是“设计交互式产品、以支持人们的生活和工作” 1.2设计包含的四个活动 – 识别用户的需要( needs )并建立需求( requirements ) …...

密码学基石:哈希、对称/非对称加密与HTTPS实践详解
密码学是现代信息安全的基石,它提供了一系列强大的数学工具和技术,用于保护数据的机密性、完整性和真实性,并确保通信双方的身份可被认证。在纷繁复杂的网络世界中,无论是安全的网页浏览 (HTTPS)、安全的软件更新、还是用户密码的…...

WebRTC通信原理与流程
1、服务器与协议相关 1.1 STUN服务器 图1.1.1 STUN服务器在通信中的位置图 1.1.1 STUN服务简介 STUN(Session Traversal Utilities for NAT,NAT会话穿越应用程序)是一种网络协议,它允许位于NAT(或多重 NAT)…...

ChromaDB调用BGE模型的两种实践方式
ChromaDB调用BGE模型 前言1.chromadb调用BGE模型api2.调用本地模型 前言 在语义搜索、知识库构建等场景中,文本向量化(Embedding)是核心技术环节。作为一款开源的向量数据库,ChromaDB允许开发者通过自定义嵌入函数灵活对接各类模…...

解构与重构:自动化测试框架的进阶认知之旅
目录 一、自动化测试的介绍 (一)自动化测试的起源与发展 (二)自动化测试的定义与目标 (三)自动化测试的适用场景 二、什么是自动化测试框架 (一)自动化测试框架的定义 &#x…...

如何巧妙解决 Too many connections 报错?
1. 背景 在日常的 MySQL 运维中,难免会出现参数设置不合理,导致 MySQL 在使用过程中出现各种各样的问题。 今天,我们就来讲解一下 MySQL 运维中一种常见的问题:最大连接数设置不合理,一旦到了业务高峰期就会出现连接…...

【卡特兰数】不同的二叉搜索树
文章目录 96. 不同的二叉搜索树解法一:动态规划状态表示状态转移方程初始化遍历顺序返回值💥解法二:卡特兰数96. 不同的二叉搜索树 96. 不同的二叉搜索树 给你一个整数 n ,求恰由 n 个节点组成且节点值从 1 到 n 互不相同的 二叉搜索树 有多少种?返回满足题意的二叉…...

《饶议科学》阅读笔记
《饶议科学》 《偷窃的生物学机制:(有些)小偷有药可治》阅读笔记 核心内容:探讨偷窃狂(kleptomania)的生物学机制及相关研究。具体要点 偷窃狂的特征:患者不可抑制地反复偷窃个人不需要、与金钱…...

ShardingJdbc-公共表
ShardingJdbc-公共表 公共表 公共表属于系统中数据量小,变动少,但是却高频联合查询的表,参数表,字典表等属于此类型。可以将此类表在每个数据库中存储一份,所有更新操作将同时发送到所有分库执行。 案例 建立库 shar…...

低成本监控IPC模组概述
1、低成本sigmastar ssc335\ssc377摄像机方案,配合AI边缘计算终端即插即用,差异化AI训练及样 本采集 2、支持200万、500万H265\H264视频编码,支持网络Rtsp,Rtmp,Onvif,web,GB28181,tf卡本地录像, 视频平台接入等...

携手高校科研团队,共建TWS耳机芯片技术新生态
TWS(真无线立体声)蓝牙耳机已成为人们生活中不可或缺的一部分。而在这背后,有一家名为华芯邦的公司,其专注于TWS蓝牙仓耳机芯片的研发,并不断取得令人瞩目的突破。 一、芯片领域的实力玩家 华芯邦作为一家在芯片行业崭…...
)
动态规划-91.解码方法-力扣(LeetCode)
一、题目解析 将对应字符转化为数字,我们知道有的大写字母范围是在[1,9],剩下的则是[10,26],这个对应关系使我们解题的关键。 二、算法原理 1.状态表示 dp[i]表示:以i位置为结尾时,解码方法总…...
Java数据类型与进制详解)
(三)Java数据类型与进制详解
一、Java数据类型概述 Java是一种强类型语言,这意味着每个变量和表达式在编译时都必须有明确的类型。Java的数据类型系统是其核心基础之一,它决定了如何存储数据、能存储什么样的数据以及能对数据执行哪些操作。 1.1 为什么需要数据类型 数据类型在编…...

用 CodyBuddy 帮我写自动化运维脚本
我正在参加CodeBuddy「首席试玩官」内容创作大赛,本文所使用的 CodeBuddy 免费下载链接:腾讯云代码助手 CodeBuddy - AI 时代的智能编程伙伴”。 #CodeBuddy首席试玩官 背景 我个人是非常喜欢 Jenkins 自动化部署工具的,之前都是手写 Jenki…...

【Linux庖丁解牛】—程序地址空间【进程地址空间 | 虚拟地址空间】
1. 再谈空间分布图 我们之前在学C/C的时候必然学过上面的空间分布图。 可是我们对他并不理解!这里先对其进行各区域分布验证: #include <stdio.h> #include <unistd.h> #include <stdlib.h> int g_unval; int g_val 100; int ma…...

nginx 上传文件,413 request entity too large
目录 1 问题2 解决 1 问题 前端后端项目,上传文件,接口没问题,但是就是上传不成功 ,然后打开f12 ,发现这个接口出现413 request entity too large 这个报错 2 解决 1.1 修改nginx配置文件 在Nginx中,cli…...

Nacos源码—5.Nacos配置中心实现分析二
大纲 1.关于Nacos配置中心的几个问题 2.Nacos如何整合SpringBoot读取远程配置 3.Nacos加载读取远程配置数据的源码分析 4.客户端如何感知远程配置数据的变更 5.集群架构下节点间如何同步配置数据 4.客户端如何感知远程配置数据的变更 (1)ConfigService对象使用介绍 (2)客…...
)
数智管理学(八)
四、未来管理学可能的新拓展方向 (一)人工智能与机器学习的融合形成智能决策管理职能 随着人工智能和机器学习技术的不断发展,它们将在管理学中得到更广泛的应用。传统决策方法难以快速处理海量数据并准确把握复杂的市场动态。人工智能与机…...

Compose Multiplatform iOS 稳定版发布:可用于生产环境,并支持 hotload
随着 Compose Multiplatform 1.8.0 的发布,iOS 版本也引来的第一个稳定版本,按照官方的原话:「iOS Is Stable and Production-Ready」 ,而 1.8.0 版本,也让 Kotlin 和 Compose 在移动端有了完整的支持。 在 2023 年 4 …...