28. C++位图 布隆过滤器 哈希切割相关
文章目录
- 位图
- 位图概念
- 代码实现
- 将x比特位置1
- 将x比特位置0
- 检测位图中x是否为1
- 全部代码实现
- C++库中的位图 bitset
- 位图的应用
- 布隆过滤器
- 布隆过滤器提出
- 布隆过滤器概念
- 布隆过滤器的特点
- 控制误判率
- 布隆过滤器的实现
- 布隆过滤器的插入
- 布隆过滤器的查找
- 布隆过滤器的删除
- 布隆过滤器优点
- 布隆过滤器缺陷
- 布隆过滤器使用场景
- 位图的应用
- 给定一个100亿个整数,设计算法找到只出现一次的整数?
- 给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件的交集?
- 位图应用变形:1个文件有100亿个int,1G内存,设计算法找到出现次数不超过2次的整数
- 布隆过滤器相关
- 给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件的交集?给出近似算法。
- 哈希切割相关
- 给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件的交集?给出精确算法。
- 给一个超过100G大小的log file,log中存着IP地址,设计算法找到出现次数最多的IP地址?如何找到top K的IP?如何直接用Linux系统命令实现?
位图
位图概念
给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在这40亿个数中。
- 遍历,时间复杂度O(N)
- 排序O(NlogN),利用二分查找: logN
- 位图解决
- 数据是否在给定的整形数据中,结果是在或者不在,刚好是两种状态,那么可以使用一个二进制比特位来代表数据是否存在的信息,如果二进制比特位为1,代表存在,为0代表不存在。比如:
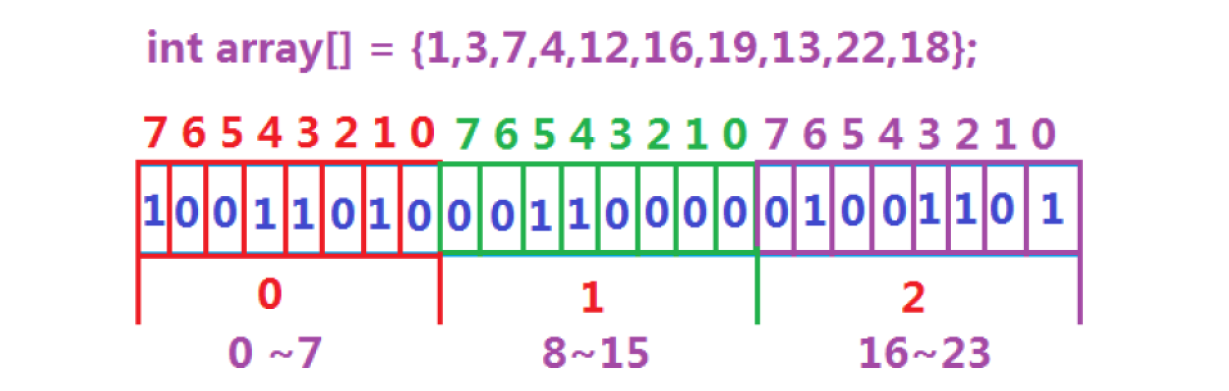
只需要0.5GB的内存空间
所谓位图,就是用每一位来存放某种状态,适用于海量数据,数据无重复的场景。通常是用来判断某个数据存不存在的。
映射x的时候:
- 那么
x在数组的第几个整形呢?i = x / 32 - 那么
x在数组的第几个位呢?i = x % 32
代码实现
将x比特位置1
在左移的时候不是方向,不管是大端机还是小端机,左移是向高位移动
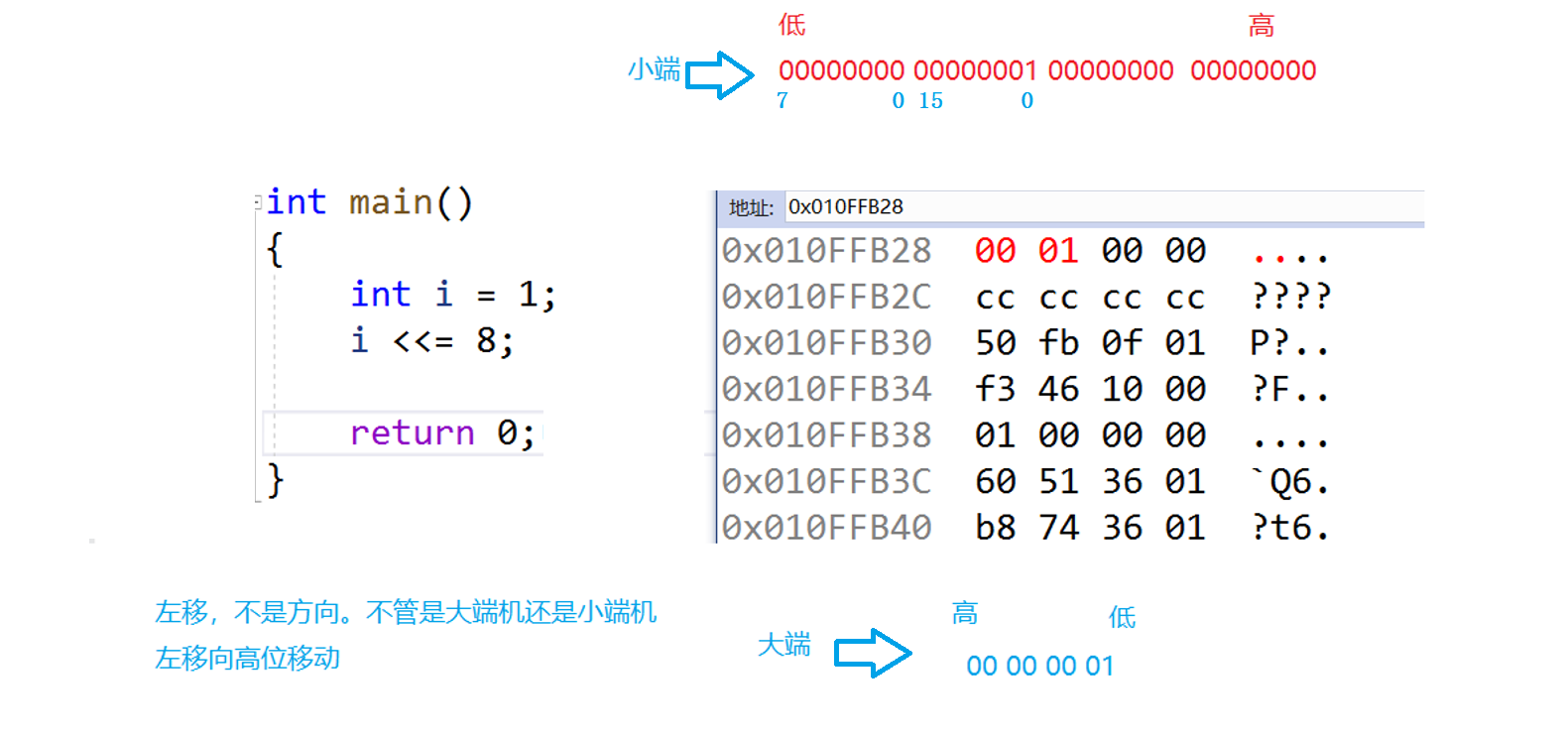
// 将x比特位置1
void set(size_t x)
{// 计算第几个整形size_t i = x / 32;// 计算第几个位size_t j = x % 32;// 将第j位处理成1其他位不变_bits[i] |= (1 << j);
}
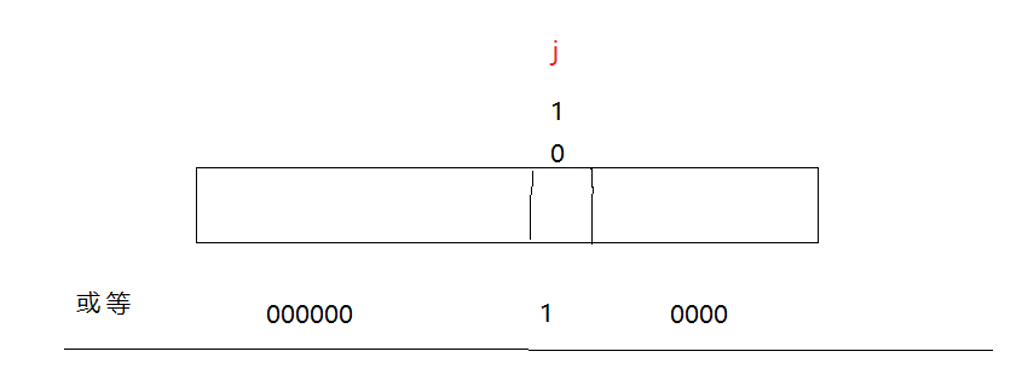
将x比特位置0
// 将x比特位置0
void reset(size_t x)
{// 计算第几个整形size_t i = x / 32;// 计算第几个位size_t j = x % 32;// 将第j位处理成0其他位不变_bits[i] &= ~(1 << j);
}
检测位图中x是否为1
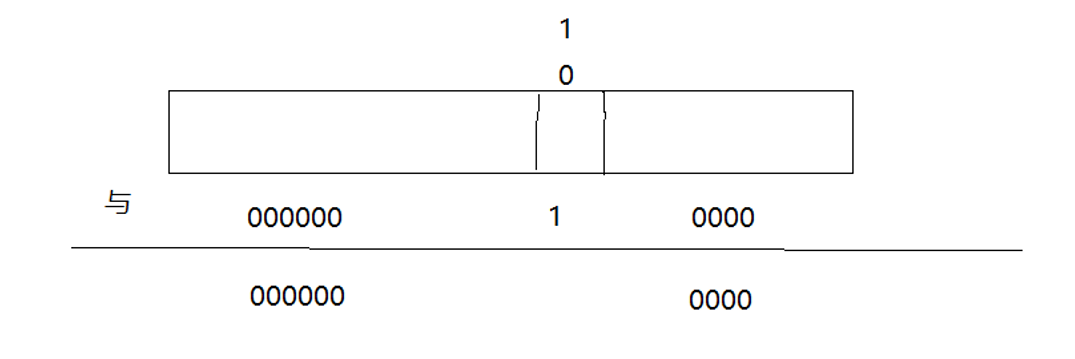
// 检测位图中x是否为1
bool test(size_t x)
{// 计算第几个整形size_t i = x / 32;// 计算第几个位size_t j = x % 32;// 检测第j位是否为1return _bits[i] & (1 << j);
}
全部代码实现
#pragma once
#include <iostream>
#include <vector>using namespace std;namespace lsl
{template<size_t N>class bitset{public:// 构造bitset(){// _bits.resize((N >> 5) + 1, 0); // 可以这样写,但是要注意优先级_bits.resize(N / 32 + 1, 0);}// 将x比特位置1void set(size_t x){// 计算第几个整形// size_t i = x >> 5; // 也可以这样写size_t i = x / 32;// 计算第几个位size_t j = x % 32;// 将第j位处理成1其他位不变_bits[i] |= (1 << j);}// 将x比特位置0void reset(size_t x){// 计算第几个整形size_t i = x / 32;// 计算第几个位size_t j = x % 32;// 将第j位处理成0其他位不变_bits[i] &= ~(1 << j);}// 检测位图中x是否为1bool test(size_t x){// 计算第几个整形size_t i = x / 32;// 计算第几个位size_t j = x % 32;// 检测第j位是否为1return _bits[i] & (1 << j);}private:vector<int> _bits;};
}
C++库中的位图 bitset
bitset - C++ Reference
可以看到核心接口还是set/reset/和test,当然后面还实现了一些其他接口,如to_string将位图按位转成01字符串,再包括operator[]等支持像数组一样控制一个位的实现
位图的应用
- 快速查找某个数据是否在一个集合中
- 排序 + 去重
- 求两个集合的交集、并集等
- 操作系统中磁盘块标记
布隆过滤器
布隆过滤器提出
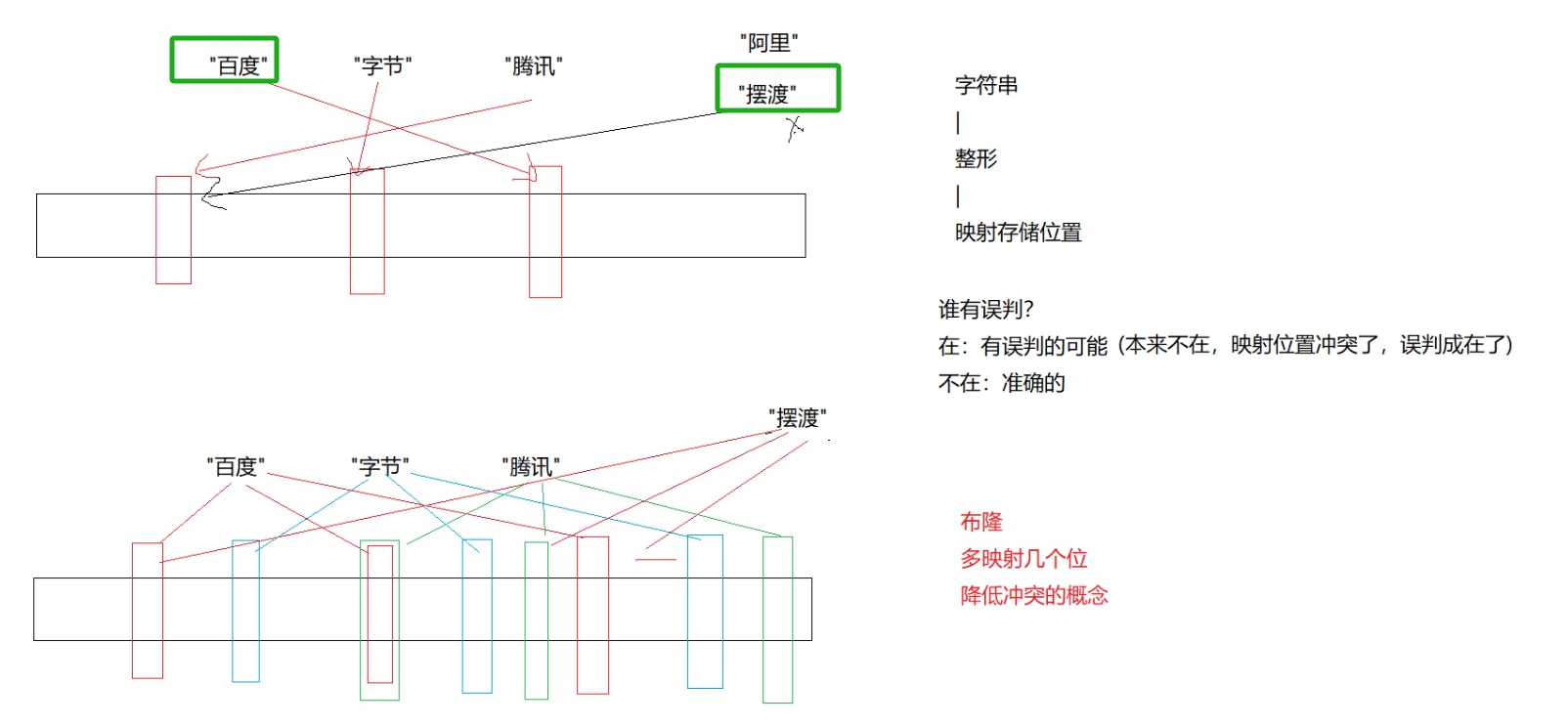
我们在使用新闻客户端看新闻时,它会给我们不停地推荐新的内容,它每次推荐时要去重,去掉 那些已经看过的内容。问题来了,新闻客户端推荐系统如何实现推送去重的? 用服务器记录了用户看过的所有历史记录,当推荐系统推荐新闻时会从每个用户的历史记录里进行筛选,过滤掉那 些已经存在的记录。 如何快速查找呢?
- 用哈希表存储用户记录,缺点:浪费空间
- 用位图存储用户记录,缺点:位图一般只能处理整形,如果内容编号是字符串,就无法处理 了。
- 将哈希与位图结合,即布隆过滤器
布隆过滤器概念
布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的 一种紧凑型的、比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”,它是用多个哈希函数,将一个数据映射到位图结构中。此种方式不仅可以提升查询效率,也 可以节省大量的内存空间。
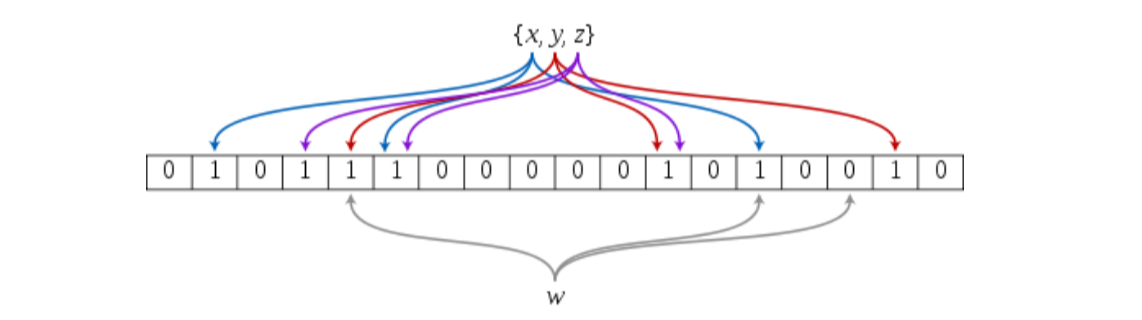
布隆过滤器的特点
- 当布隆过滤器判断一个数据存在可能是不准确的,因为这个数据对应的比特位可能被其他一个数据或多个数据占用了。
- 当布隆过滤器判断一个数据不存在是准确的,因为如果该数据存在那么该数据对应的比特位都应该已经被设置为1了。
控制误判率
- 其中k为哈希函数个数,m为布隆过滤器长度,n为插入的元素个数,p为误判率。
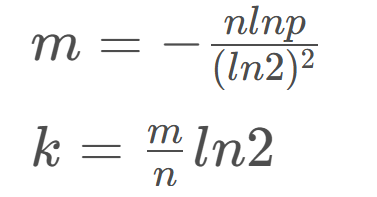
我们这里可以大概估算一下,如果使用3个哈希函数,即k的值为3,值我们取0.7,那么m和n的关系大概是m = 4 × n,也就是布隆过滤器的长度应该是插入元素个数的4倍。
布隆过滤器的实现
首先,布隆过滤器可以实现为一个模板类,因为插入布隆过滤器的元素不仅仅是字符串,也可以是其他类型的数据,只有调用者能够提供对应的哈希函数将该类型的数据转换成整型即可,但一般情况下布隆过滤器都是用来处理字符串的,所以这里可以将模板参数K的缺省类型设置为string。
布隆过滤器中的成员一般也就是一个位图,我们可以在布隆过滤器这里设置一个非类型模板参数N,用于让调用者指定位图的长度。
//布隆过滤器
template<size_t N, class K = string, class HashFunc1 = BKDRHash, class HashFunc2 = APHash, class HashFunc3 = DJBHash>
class BloomFilter
{
public://...
private:lsl::bitset<N> _bs;
};
- 实例化布隆过滤器时需要调用者提供三个哈希函数,由于布隆过滤器一般处理的是字符串类型的数据,因此这里我们可以默认提供几个将字符串转换成整型的哈希函数。
- 这里选取将字符串转换成整型的哈希函数,是经过测试后综合评分最高的BKDRHash、APHash和DJBHash,这三种哈希算法在多种场景下产生哈希冲突的概率是最小的。
- 此时本来这三种哈希函数单独使用时产生冲突的概率就比较小,现在要让它们同时产生冲突概率就更小了。
代码:
struct BKDRHash
{size_t operator()(const string& s){size_t value = 0;for (auto ch : s){value = value * 131 + ch;}return value;}
};
struct APHash
{size_t operator()(const string& s){size_t value = 0;for (size_t i = 0; i < s.size(); i++){if ((i & 1) == 0){value ^= ((value << 7) ^ s[i] ^ (value >> 3));}else{value ^= (~((value << 11) ^ s[i] ^ (value >> 5)));}}return value;}
};
struct DJBHash
{size_t operator()(const string& s){if (s.empty())return 0;size_t value = 5381;for (auto ch : s){value += (value << 5) + ch;}return value;}
};
布隆过滤器的插入
- 布隆过滤器当中需要提供一个Set接口,用于插入元素到布隆过滤器当中。插入元素时,需要通过三个哈希函数分别计算出该元素对应的三个比特位,然后将位图中的这三个比特位设置为1即可。
void Set(const K& key)
{//计算出key对应的三个位size_t hash1 = HashFunc1()(key) % N;size_t hash2 = HashFunc2()(key) % N;size_t hash3 = HashFunc3()(key) % N;// 将位图中的这三个位设置成1_bs.set(hash1);_bs.set(hash2);_bs.set(hash3);
}
布隆过滤器的查找
检测时,需要通过三个哈希函数分别计算出该元素对应的三个比特位,然后判断位图中的这三个比特位是否被设置为1。
- 只要这三个比特位当中有一个比特位未被设置则说明该元素一定不存在。
- 如果这三个比特位全部被设置,则返回true表示该元素存在(可能存在误判)。
bool Test(const T& key)
{//依次判断key对应的三个位是否被设置size_t hash1 = HashFunc1()(key) % N;if (_bs.test(hash1) == false)return false;size_t hash2 = HashFunc2()(key) % N;if (_bs.test(hash1) == false)return false;size_t hash3 = HashFunc3()(key) % N;if (_bs.test(hash1) == false)return false;return true; // 可能存在,但是可能存在误判
}
布隆过滤器的删除
布隆过滤器一般不支持删除操作:
- 因为布隆过滤器判断一个元素存在时可能存在误判,因此无法保证要删除的元素确实在布隆过滤器当中,此时将位图中对应的比特位清0会影响其他元素。
- 此外,就算要删除的元素确实在布隆过滤器当中,也可能该元素映射的多个比特位当中有些比特位是与其他元素共用的,此时将这些比特位清0也会影响其他元素。
如何让布隆过滤器支持删除?
要让布隆过滤器支持删除,必须要做到以下两点:
- 保证要删除的元素在布隆过滤器当中。比如刚才的呢称例子当中,如果通过调用Test函数得知要删除的昵称可能存在布隆过滤器当中后,可以进一步遍历存储昵称的文件,确认该昵称是否真正存在。
- 保证删除后不会影响到其他元素。可以为位图中的每一个比特位设置一个对应的计数值,当插入元素映射到该比特位时将该比特位的计数值++,当删除元素时将该元素对应比特位的**计数值–-**即可。
可是布隆过滤器最终还是没有提供删除的接口,因为使用布隆过滤器本来就是要节省空间和提高效率的。在删除时需要遍历文件或磁盘中确认待删除元素确实存在,而文件IO和磁盘IO的速度相对内存来说是很慢的,并且为位图中的每个比特位额外设置一个计数器,就需要多用原位图几倍的存储空间,这个代价也是不小的。
缺陷:
- 无法确认元素是否真正在布隆过滤器中
- 存在计数回绕
布隆过滤器优点
- 增加和查询元素的时间复杂度为:O(K), (K为哈希函数的个数,一般比较小),与数据量大小无关
- 哈希函数相互之间没有关系,方便硬件并行运算
- 布隆过滤器不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势
- 在能够承受一定的误判时,布隆过滤器比其他数据结构有这很大的空间优势
- 数据量很大时,布隆过滤器可以表示全集,其他数据结构不能
- 使用同一组散列函数的布隆过滤器可以进行交、并、差运算
布隆过滤器缺陷
- 有误判率,即存在假阳性(False Position),即不能准确判断元素是否在集合中(补救方法:再建立一个白名单,存储可能会误判的数据)
- 不能获取元素本身
- 一般情况下不能从布隆过滤器中删除元素
- 如果采用计数方式删除,可能会存在计数回绕问题
布隆过滤器使用场景
- 比如当我们首次访问某个网站时需要用手机号注册账号,而用户的各种数据实际都是存储在数据库当中的,也就是磁盘上面。
- 当我们用手机号注册账号时,系统就需要判断你填入的手机号是否已经注册过,如果注册过则会提示用户注册失败。
- 但这种情况下系统不可能直接去遍历磁盘当中的用户数据,判断该手机号是否被注册过,因为磁盘IO是很慢的,这会降低用户的体验。
- 这种情况下就可以使用布隆过滤器,将所有注册过的手机号全部添加到布隆过滤器当中,当我们需要用手机号注册账号时,就可以直接去布隆过滤器当中进行查找。
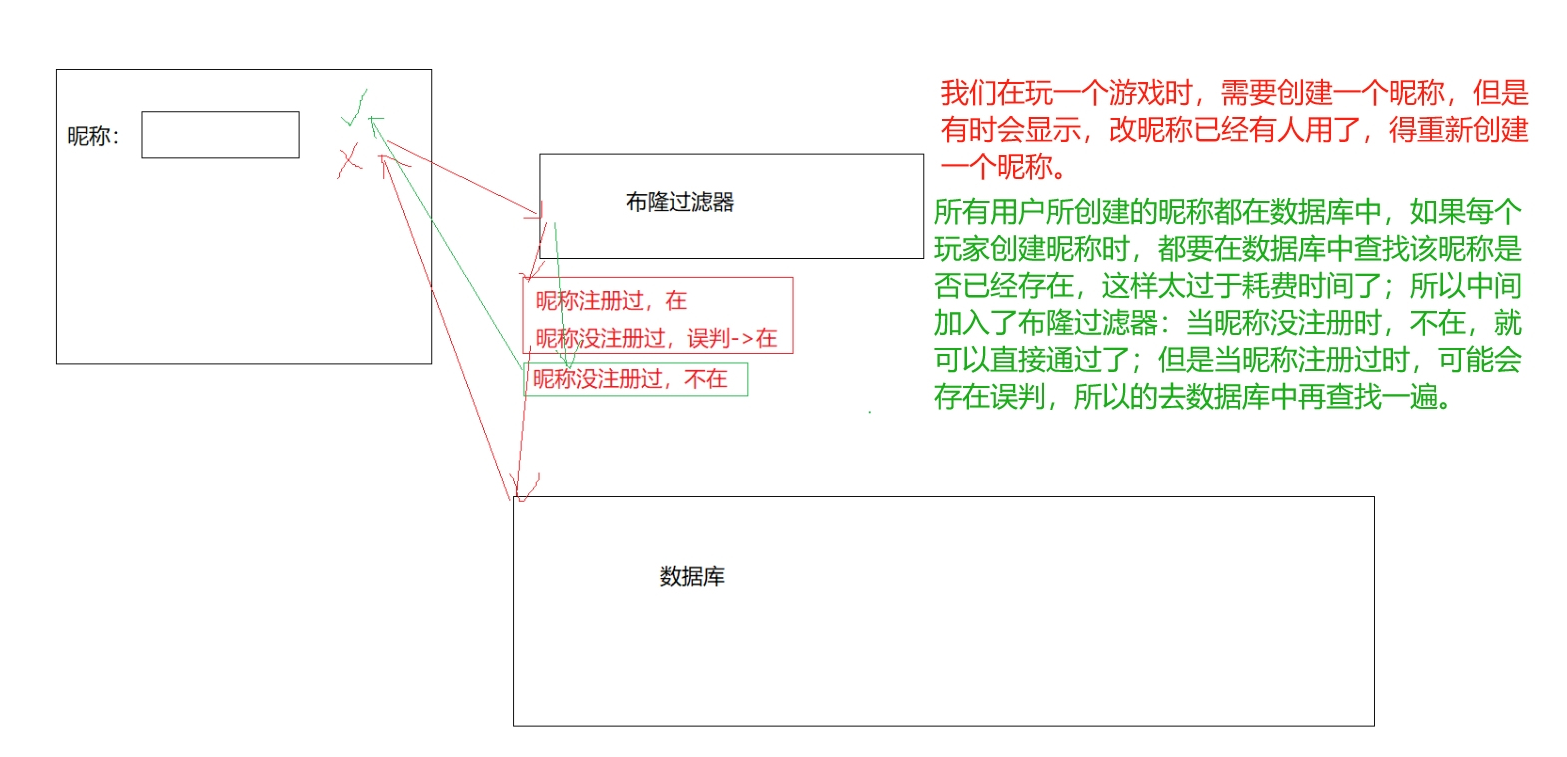
- 如果在布隆过滤器中查找后发现该手机号不存在,则说明该手机号没有被注册过,此时就可以让用户进行注册,并且避免了磁盘IO。
- 如果在布隆过滤器中查找后发现该手机号存在,此时还需要进一步访问磁盘进行复核,确认该手机号是否真的被注册过,因为布隆过滤器在判断元素存在时可能会误判。
- 由于大部分情况下用户用一个手机号注册账号时,都是知道自己没有用该手机号注册过账号的,因此在布隆过滤器中查找后都是找不到的,此时就避免了进行磁盘IO。而只有布隆过滤器误判或用户忘记自己用该手机号注册过账号的情况下,才需要访问磁盘进行复核。
位图的应用
给定一个100亿个整数,设计算法找到只出现一次的整数?
- 出现0次–>00来代表
- 出现1次–>01来代表
- 出现2次以上–>10来代表
- 存储100亿个整数大概需要40G的内存空间,因此题目中的100亿个整数肯定是存储在文件当中的,代码中直接从vector中读取数据是为了方便演示。
- 为了能映射所有整数,位图的大小必须开辟为
2^32位,也就是代码中的4294967295,因此开辟一个位图大概需要512M的内存空间,两个位图就要占用1G的内存空间,所以代码中选择在堆区开辟空间,若是在栈区开辟则会导致栈溢出。
代码实现:
template<size_t N>
class twobitset
{
public:void set(size_t x){if (_bs1.test(x) == false && _bs2.test(x) == false) // 00{_bs2.set(x); // _bs1不需要动 _ba2设置成1}else // if (_bs1.test(x) == false && _bs2.test(x) == true) // 01{_bs1.set(x); // 1_bs2.reset(x); // 0}}void Print(){for (size_t i = 0; i < N; i++){if (_bs1.test(i) == false && _bs2.test(i) == true) // 01 -->出现一次{cout << "1->" << i << endl;}else if (_bs1.test(i) == true && _bs2.test(i) == false) //10 -->出现两次以上{cout << "2->" << i << endl;}}cout << endl;}private:bitset<N> _bs1;bitset<N> _bs2;
};
给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件的交集?
各自映射到一个位图,一个值在两个位图都存在,则是交集
- 方案一:(一个位图需要512M内存)
- 依次读取第一个文件中的所有整数,将其映射到一个位图。
- 再读取另一个文件中的所有整数,判断在不在位图中,在就是交集,不在就不是交集。
- 方案二:(两个位图刚好需要1G内存,满足要求)
- 依次读取第一个文件中的所有整数,将其映射到位图1。
- 依次读取另一个文件中的所有整数,将其映射到位图2。
- 将位图1和位图2进行与操作,结果存储在位图1中,此时位图1当中映射的整数就是两个文件的交集。
对于32位的整型,无论待处理的整数个数是多少,开辟的位图都必须有2^32个比特位,也就是512M,因为我们要保证每一个整数都能够映射到位图当中,因此这里位图的空间消耗是固定的。
位图应用变形:1个文件有100亿个int,1G内存,设计算法找到出现次数不超过2次的整数
- 出现0次–>00来代表
- 出现1次–>01来代表
- 出现2次–>10来代表
- 出现3次及以上–>11来代表
一个整数要表示四种状态也是只需要两个位就够了,此时当我们读取到重复的整数时,就可以让其对应的两个位按照00→01→10→11的顺序进行变化,最后状态是01或10的整数就是出现次数不超过2次的整数。
代码实现:
template<size_t N>
class twobitset
{
public:void set(size_t x){if (_bs1.test(x) == false && _bs2.test(x) == false) // 00{_bs2.set(x); // _bs1不需要动 _ba2设置成1}else if (_bs1.test(x) == false && _bs2.test(x) == true) // 01{_bs1.set(x); // 1_bs2.reset(x); // 0}else if (_bs1.test(x) == true && _bs2.test(x) == false) // 10{_bs1.set(x); // 1_bs2.set(x); // 1}else{}}void Print(){for (size_t i = 0; i < N; i++){if (_bs1.test(i) == false && _bs2.test(i) == true) // 01 -->出现一次{cout << "1->" << i << endl;}else if (_bs1.test(i) == true && _bs2.test(i) == false) //10 -->出现两次{cout << "2->" << i << endl;}}cout << endl;}private:bitset<N> _bs1;bitset<N> _bs2;
};
布隆过滤器相关
给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件的交集?给出近似算法。
- 允许存在一些误判,那么我们就可以用布隆过滤器。
- 先读取其中一个文件当中的query,将其全部映射到一个布隆过滤器当中。
- 然后读取另一个文件当中的query,依次判断每个query是否在布隆过滤器当中,如果在则是交集,不在则不是交集。
哈希切割相关
给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件的交集?给出精确算法。
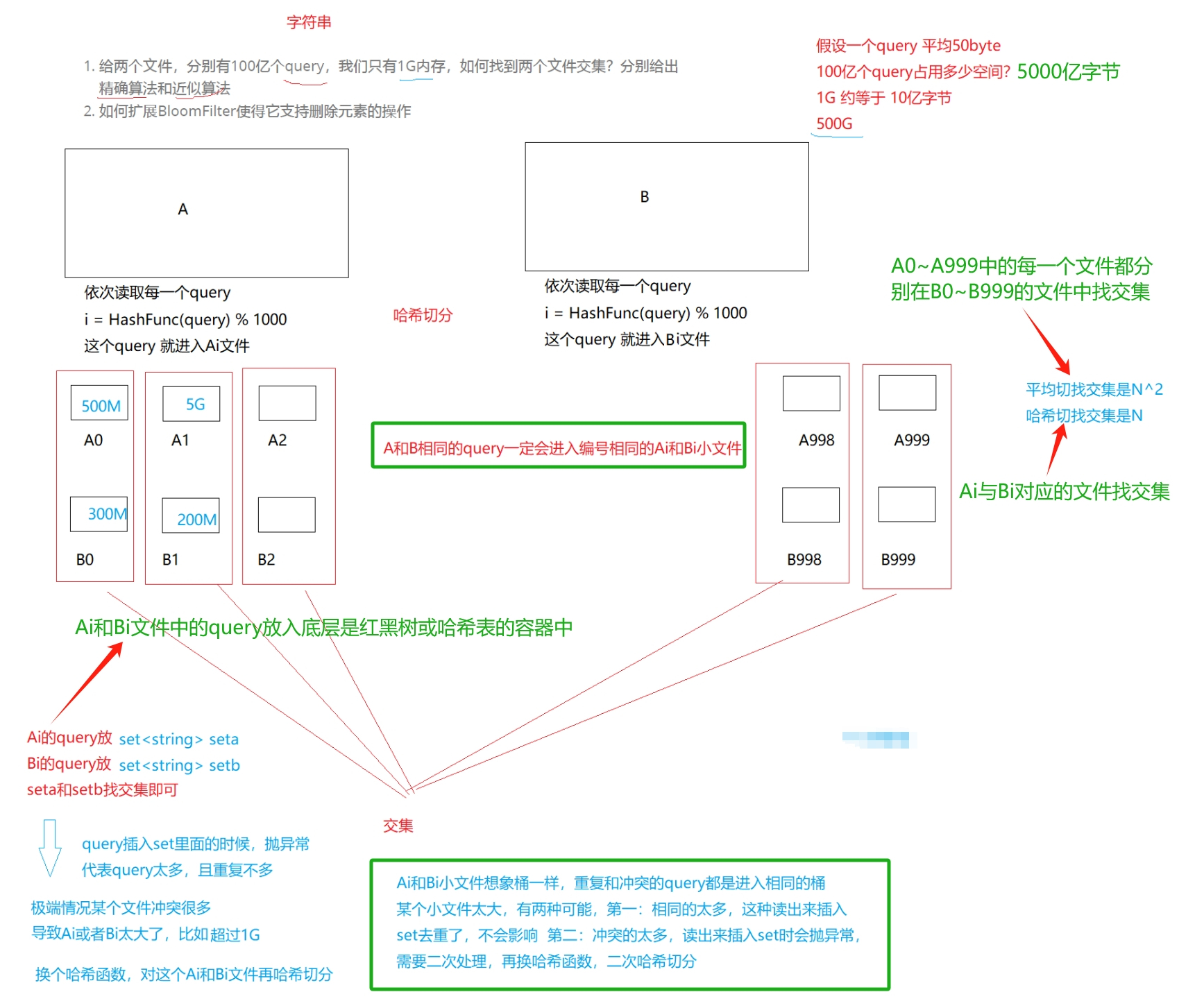
现在要求给出精确算法,那么就不能使用布隆过滤器了,此时需要用到哈希切分。
- 假设平均每个query为20字节,那么100亿个query就是200G,由于我们只有1G内存,这里可以考虑将一个文件切分成400个小文件。
- 这里我们将这两个文件分别叫做A文件和B文件,此时我们将A文件切分成了A0~A399共400个小文件,将B文件切分成了B0~B399共400个小文件。
在切分时需要选择一个哈希函数进行哈希切分,以切分A文件为例,切分时依次遍历A文件当中的每个query,通过哈希函数将每个query转换成一个整型,然后将这个query写入到小文件Ai当中。对于B文件也是同样的道理,但切分A文件和B文件时必须采用的是同一个哈希函数。
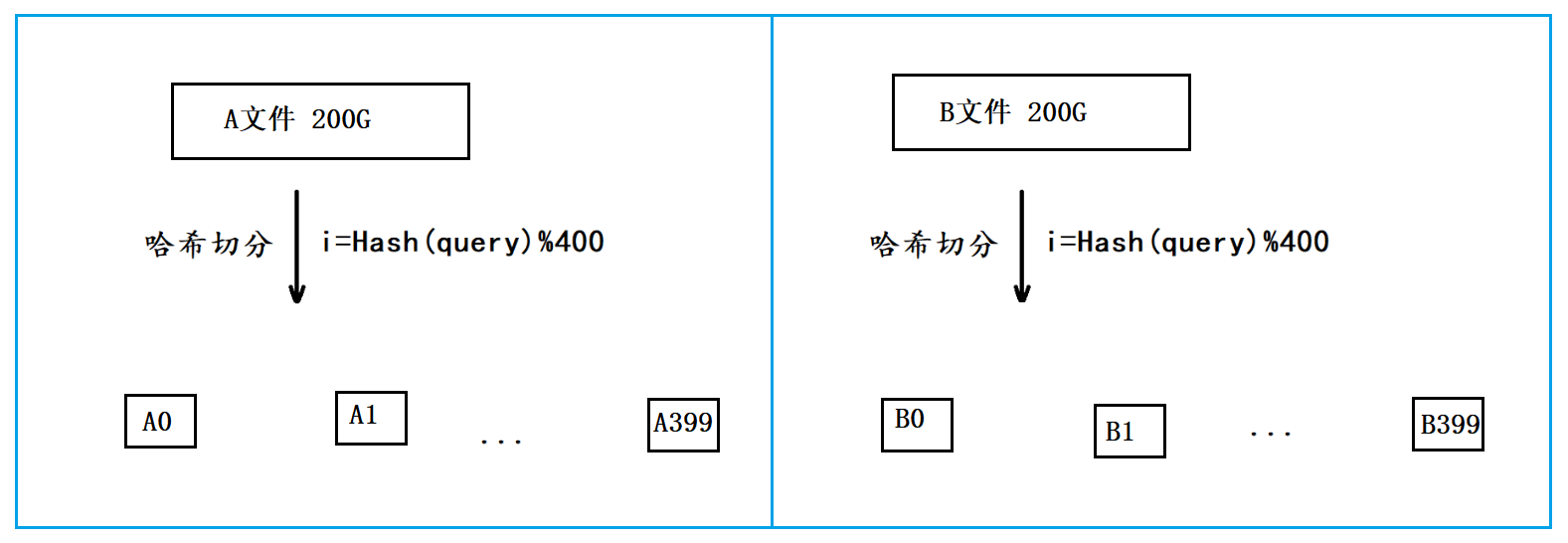
- 由于切分A文件和B文件时采用的是同一个哈希函数,因此A文件与B文件中相同的query计算出的值都是相同的,最终就会分别进入到Ai和Bi文件中,这也是哈希切分的意义。
- 我们就只需要分别找出A0与B0的交集、A1与B1的交集、…、A399与B399的交集,最终将这些交集和起来就是A文件和B文件的交集。
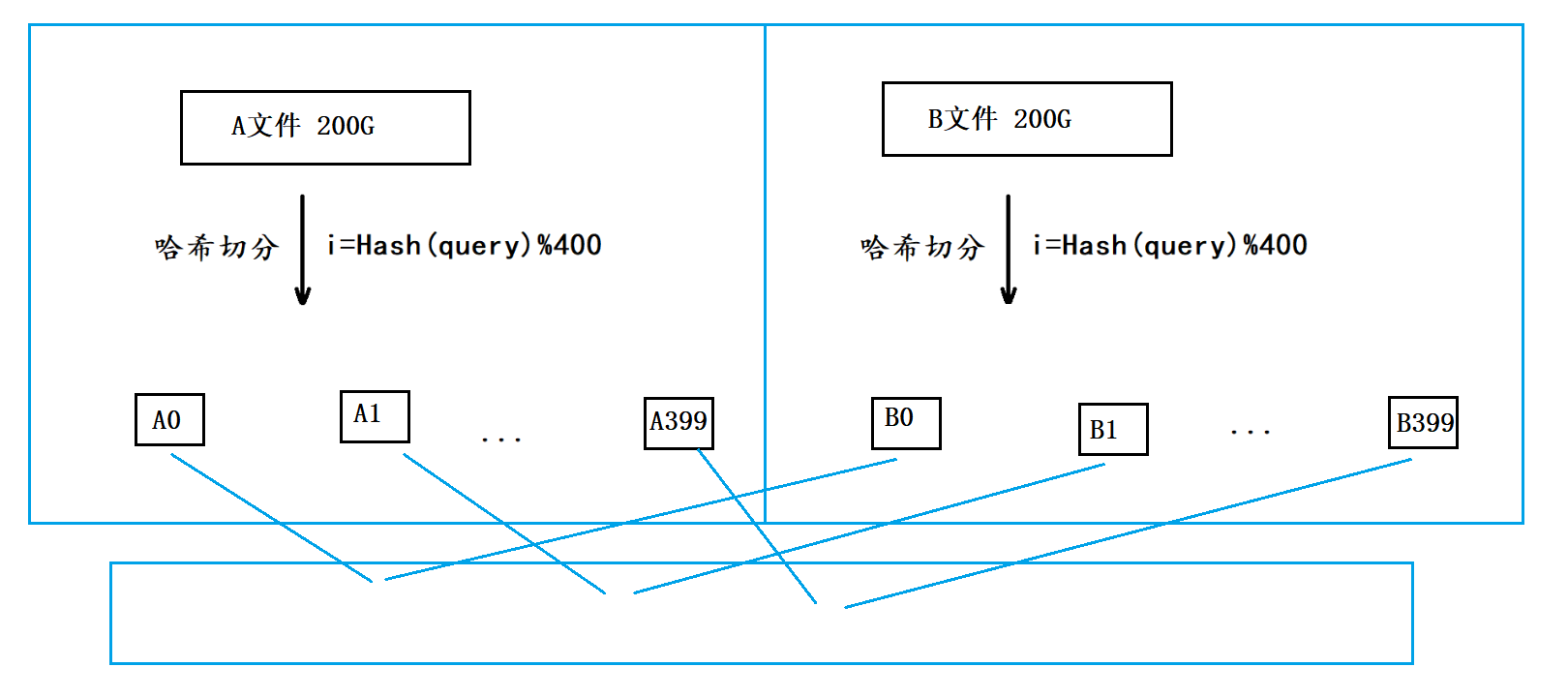
那各个小文件之间又应该如何找交集呢?
- 经过切分后理论上每个小文件的平均大小是512M,因此我们可以将其中一个小文件加载到内存,并放到一个set容器中,再遍历另一个小文件当中的query,依次判断每个query是否在set容器中,如果在则是交集,不在则不是交集。
- 当哈希切分并不是平均切分,有可能切出来的小文件中有一些小文件的大小仍然大于1G,此时如果与之对应的另一个小文件可以加载到内存,则可以选择将另一个小文件中的query加载到内存,因为我们只需要将两个小文件中的一个加载到内存中就行了。
- 但如果两个小文件的大小都大于1G,那我们可以考虑将这两个小文件再进行一次切分,将其切成更小的文件,方法与之前切分A文件和B文件的方法类似。
将这些小文件看作一个个的哈希桶,将大文件中的query通过哈希函数映射到这些哈希桶中,如果是相同的query,则会产生哈希冲突进入到同一个小文件中。
给一个超过100G大小的log file,log中存着IP地址,设计算法找到出现次数最多的IP地址?如何找到top K的IP?如何直接用Linux系统命令实现?
- 我们将这个log file叫做A文件,由于A文件的大小超过100G,这里可以考虑将A文件切分成200个小文件。
- 在切分时选择一个哈希函数进行哈希切分,通过哈希函数将A文件中的每个IP地址转换成一个整型
i(0 ≤ i ≤ 199),然后将这个IP地址写入到小文件Ai当中。 - 由于哈希切分时使用的是同一个哈希函数,因此相同的IP地址计算出的值是相同的,最终这些相同的IP地址就会进入到同一个Ai小文件当中。
经过哈希切分后得到的这些小文件,理论上就能够加载到内存当中了,如果个别小文件仍然太大那可以对其再进行一次哈希切分,总之让最后切分出来的小文件能够加载到内存。

现在要找到出现次数最多的IP地址,就可以分别将各个小文件加载到内存中, 然后用一个map<string, int> 容器统计出每个小文件中各个IP地址出现的次数,然后比对各个小文件中出现次数最多的IP地址,最终就能够得到log file中出现次数最多的IP地址。
如果要找到出现次数top K的IP地址,可以先将一个小文件加载到内存中,选出小文件中出现次数最多的K个IP地址建成一个小堆,然后再依次比对其他小文件中各个IP地址出现的次数,如果某个IP地址出现的次数大于堆顶IP地址出现的次数,则将该IP地址与堆顶的IP地址进行交换,然后再进行一次向下调整,使其仍为小堆,最终比对完所有小文件中的IP地址后,这个小堆当中的K个IP地址就是出现次数top K的IP地址。
在Linux下我们可以使用此命令来完成:
sort log_txt | uniq -c | sort -nrk1,1 | head -K
相关文章:

28. C++位图 布隆过滤器 哈希切割相关
文章目录 位图位图概念代码实现将x比特位置1将x比特位置0检测位图中x是否为1全部代码实现 C库中的位图 bitset位图的应用 布隆过滤器布隆过滤器提出布隆过滤器概念布隆过滤器的特点控制误判率布隆过滤器的实现布隆过滤器的插入布隆过滤器的查找布隆过滤器的删除布隆过滤器优点布…...

第2章 神经网络的数学基础
本章我们将梳理一下神经网络所需的数学基础知识,其中大多数内容没有超出高中所学范围,因此读起来不会吃力。 2-1神经网络所需的函数 本节我们来看一下神经网络世界中频繁出现的函数。虽然它们都是基本的函数,但是对于神经网络是不可缺少的。…...

linux环境安装docker
linux环境下载安装docker 参考网址查询服务器的操作系统下载docker1、卸载已安装的docker2、安装dnf-plugins-core 包3、配置镜像仓库4、安装版本安装最新版本安装指定版本 5、设置开机自启动6、运行测试7、卸载重装清理 Docker 系统中不再使用的数据(容器、缓存&am…...

windows使用bat脚本激活conda环境
本文不生产技术,只做技术的搬运工!!! 前言 最近需要在windows上使用批处理脚本执行一些python任务,但是被自动激活conda环境给卡住了,研究了一下解决方案 解决方案 call your_conda_path\Scripts\activa…...

第一章:MySQL 索引基础
第一章:MySQL 索引基础 1. 索引是什么? 定义:索引(Index)是数据库中用于快速查找数据的一种数据结构,类似于书籍的目录。核心作用:通过减少磁盘I/O次数,加速查询速…...

紫光展锐全新奇迹手游引擎,开启游戏“芯”时代
UNISOC Miracle Gaming奇迹手游引擎亮点: • 高帧稳帧:支持《王者荣耀》等主流手游90帧高画质模式,连续丢帧率最高降低85%; • 丝滑操控:游戏冷启动速度提升50%,《和平精英》开镜开枪操作延迟降低80%; • 极速网络&…...

C++ 的未来趋势与挑战:探索新边界
引言 在软件开发的浩瀚宇宙中,C 一直是一颗耀眼的恒星,凭借其卓越的性能和广泛的适用性,在系统编程、游戏开发、嵌入式系统等诸多领域占据着核心地位。随着科技的飞速发展,C 也面临着新的趋势和挑战。本文将深入探讨 C 在 AI 驱动…...

Oracle 开窗函数
Oracle 开窗函数(Window Functions)允许在不合并行的前提下对数据进行复杂分析,常用于排名、累计计算、前后行对比等场景。 一、核心语法结构 函数名() OVER ([PARTITION BY 分区列] [ORDER BY 排序列 [ASC|DESC]] [窗口帧子句 (ROWS | RAN…...
)
【PostgreSQL数据分析实战:从数据清洗到可视化全流程】7.3 动态报表生成(Jupyter Notebook/ReportLab)
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 PostgreSQL数据分析实战:动态报表生成(Jupyter Notebook/ReportLab)一、动态报表生成概述(一)动态报表的重要性&a…...

Oracle OCP认证考试考点详解083系列11
题记: 本系列主要讲解Oracle OCP认证考试考点(题目),适用于19C/21C,跟着学OCP考试必过。 51. 第51题: 题目 解析及答案: 关于在 Linux 上安装 Oracle 数据库,以下哪三项是正确的?…...

双11美妆数据分析
1. 导入库使用Python进行分析,需要导入相关库: pythonimport pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as sns 1. 读取数据1. 查看数据基本信息 查看前几行:使用 df.head() 查看数据的前5行ÿ…...

github+ Picgo+typora
github Picgotypora 本文将介绍如何使用Picgo在typora中实现上传服务 创建github仓库以及配置token 创建仓库 注意需要Initialize 添加README 配置为public 配置token github点击头像找到setting 选择Developer setting 配置token generate 选第一个第二个都行(我这里选第…...

战术级微波干扰系统:成都鼎轻量化装备如何实现全频段智能压制?
在5G与卫星通信蓬勃发展的今天,成都鼎讯科技推出新一代微波通信干扰设备,以1000-6000MHz全频段覆盖能力,打造单兵可携的"电磁手术刀"。该设备突破传统微波干扰设备"高能耗、大体积"的桎梏,通过军用级模块化设…...

Oracle 数据布局探秘:段与区块的内部机制
前言 在 Oracle 数据库的庞大架构中,数据存储的效率与性能是决定整个系统健康状况的关键因素。Oracle 采用了一套精妙的逻辑存储管理体系来组织和分配数据,其中,“段(Segment)”和“区(Extent)…...

leetcode 142. Linked List Cycle II
题目描述 哈希表解法 这个方法很容易想到,但需要O(N)的空间。 /*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode(int x) : val(x), next(NULL) {}* };*/ class Solution { public:ListNode *detect…...

探索智能体的记忆:类型、策略和应用
AI Agent 中的记忆:类型、策略和应用 记忆实现是使智能体能够保持上下文、从过去的交互中学习并做出明智决策的关键组成部分。与人类记忆非常相似,智能体记忆允许 AI 系统随时间存储、检索和利用信息,从而为用户创造更连贯和个性化的体验。 …...

mysql集成Qwen大模型MCP计算【附实战代码】
mysql集成Qwen大模型MCP计算 题目分析步骤 1:在 MySQL 中构建核素半衰期数据库1.1 数据库设计1.2 安装和设置 MySQL1.3 创建数据库和表步骤 2:构建放射性活度计算函数2.1 依赖库2.2 Python 函数2.3 函数说明步骤 3:修复 MySQL 访问权限步骤 4:代码实践用户输入指导测试用例…...

006 yum和Linux生态
🦄 个人主页: 小米里的大麦-CSDN博客 🎏 所属专栏: Linux_小米里的大麦的博客-CSDN博客 🎁 GitHub主页: 小米里的大麦的 GitHub ⚙️ 操作环境: Visual Studio 2022 文章目录 Linux 软件包管理器 yum什么是软件包?基于 Linux 系统…...

一种扫描雷达超分辨成像检测一体化方法——论文阅读
一种扫描雷达超分辨成像检测一体化方法 1. 专利的研究目标与产业意义1.1 研究目标与实际问题1.2 产业意义2. 专利的创新方法:低秩稀疏约束与联合优化框架(重点解析)2.1 核心思路与模型构建2.2 迭代优化算法2.3 与传统方法的对比优势3. 实验设计与验证3.1 实验参数3.2 实验结…...

三款实用工具推荐:配音软件+Windows暂停更新+音视频下载!
各位打工人请注意!今天李师傅掏出的三件套,都是经过实战检验的效率放大器。先收藏再划走,说不定哪天就能救命! 一.祈风TTS-配音大师 做短视频的朋友肯定深有体会——配个音比写脚本还费劲!要么付费买声音,…...

云平台的文件如何备份
不同的云平台有不同的文件备份方式,以下以常见的阿里云、腾讯云为例进行介绍: 阿里云 对象存储 OSS 可以通过 OSS 控制台,选择需要备份的 Bucket(存储桶)和文件,手动发起备份操作,将数据复制到…...

密码学系列 - SR25519与ED25519
SR25519 SR25519 是一种高级的数字签名算法,它基于 Schnorr 签名方案,使用的是 Curve25519 椭圆曲线。这种签名算法在密码学社区中广受欢迎,特别是在区块链和加密货币领域。以下是关于 SR25519 的详细介绍。 SR25519 简介 SR25519 是一种 …...

XMP-Toolkit-SDK 编译与示例程序
一、前言 最近在调研图片的元数据读写方案,需要了解 XMP 空间以及如何在 XMP 空间中读写元数据,本文做一个相关内容的记录。 XMP-Toolkit-SDK 以及 XMP标准简介 XMP-Toolkit-SDK 是 Adobe 提供的一套开源软件开发工具包(SDK)&a…...

基于nnom的多选择器
核心组件 元件类型目的接口STM32F103CB微控制器主处理单元-MPU60506 轴 IMU移动侦测I2C 接口W25Q64 系列闪存信号和配置存储SPI 系列按钮用户输入模式选择和激活GPIO (通用输出)搭载了LED用户反馈系统状态指示GPIO (通用输出)RT6…...

铁塔基站项目用电能表有哪些?
简婷 安科瑞电气股份有限公司 上海嘉定 201801 引言:随着5G基站的迅猛发展,基站的能耗问题也越来越突出,高效可靠的基站配电系统方案,是提高基站能耗使用效率,实现基站节能降耗的重要保证,通过多回路仪表…...

ROS-仿真实验平台
(1)ROS基本架构 机器人操作系统(Robot Operating System,ROS)是一款基于开源协议的、针对 机器人进行开发的、灵活可扩展的的软件平台,整合多种软件功能包和开发工具,提 供机器人操作系统所需的…...

Loly: 1靶场渗透
Loly: 1 来自 <Loly: 1 ~ VulnHub> 1,将两台虚拟机网络连接都改为NAT模式 2,攻击机上做namp局域网扫描发现靶机 nmap -sn 192.168.23.0/24 那么攻击机IP为192.168.23.182,靶场IP192.168.23.241 3,对靶机进行端口服务探测 n…...

LeetCode第191题_位1的个数
LeetCode 第191题:位1的个数 题目描述 编写一个函数,输入是一个无符号整数(以二进制串的形式),返回其二进制表达式中数字位数为 ‘1’ 的个数(也被称为汉明重量)。 难度 简单 题目链接 点…...

JVM——Java内存模型
Java内存模型 在Java多线程编程中,Java内存模型(Java Memory Model, JMM)是理解程序执行行为和实现线程安全的关键。下面我们深入探讨Java内存模型的内容。 Java内存模型概述 Java内存模型定义了Java程序中变量的内存操作规则,…...

JVM局部变量表和操作数栈的内存布局
局部变量表和操作数栈 首先看一段Java源码 public class Add_Sample{public int add(int i, int j){int k 100;int result i j k;return result;}public static void main(String[] args){int result new Add_Sample().add(10,20);System.out.println(result);} }使用ja…...

【MongoDB篇】MongoDB的分片操作!
目录 引言第一节:分片核心概念:为什么要分片?它是什么? 🤔💥🚀第二节:分片架构的“三大金刚”:核心组件解析 🧱🧠🛣️第三节ÿ…...

AI一键替换商品融入场景,5分钟打造专业级商品图
在电商行业,传统修图工具操作复杂、耗时费力,尤其是将商品自然融入多样化场景的需求,常让卖家头疼不已。如今,一款专为电商设计的AI工具-图生生,其核心功能“AI商品图-更换背景”,颠覆传统流程。只需上传一…...
》)
《数据结构:二叉搜索树(Binary Search Tree)》
文章目录 :red_circle:一、二叉搜索树的概念:red_circle:二、二叉搜索树的性能分析:red_circle:三、二叉搜索树的操作(一)插入(二)查找(三)删除 :red_circle:四、二叉搜索树的实现代码(一&#…...
isNotBlank和isNotEmpty有什么区别?
如下是hutool的StrUtil工具包下的源码 结果:如果字符串仅由空白字符组成(比如 " "),那么isNotBlank将返回false,而isNotEmpty返回true。 isNotBlank当中的Blank是空白的意思,也就是是否不等于空…...

Kotlin 中实现单例模式的几种常见模式
1 懒汉式,线程安全(伴生对象 by lazy) 想“懒汉”一样,拖延到首次使用时才进行初始化。 通过 companion object 和 lazy 实现懒加载,首次访问是才进行初始化,lazy 默认使用 LazyThreadSafetyMode.SYNCHR…...

挑战用豆包教我学Java
现在的AI发展的越来越快,在学习方面更是让人吃惊,所以我决定用豆包来教我学Java语言。本人现在大二,此前已经学习过了c,所以有一定的基础,相信我肯定可以成功的! 首先我向豆包说明的我的情况: …...

怎么在非 hadoop 用户下启动 hadoop
今天有同学反馈一个问题,比较有代表性。说下 问题描述 在 root 用户下 无法执行如下代码 1.linux执行计划 :crontab 加入 42 17 7 5 * /root/hadoop_op.sh2.hadoop_op.sh内语句: #!/bin/bash su - hadoop cd /opt/module/hadoop-3.3.0/sb…...

如何激活python的虚拟环境
目录 激活虚拟环境步骤: 注意事项: 为什么写这篇文章: 我在检查依赖版本的时候发现在terminal一直显示找不到该依赖 但是在interpreter里面能看到所有我以及下载的依赖和版本;然后稍微看了下发现是自己忘记激活虚拟环境了&#…...

Spring Boot 中的事务管理是如何工作的?
全文目录: 开篇语前言一、什么是事务管理?1. 事务的四大特性(ACID) 二、Spring Boot 中的事务管理1. Spring Boot 中的声明式事务管理1.1 Transactional 注解1.2 使用 Transactional 注解示例: 1.3 Transactional 的默…...

【计算机网络-传输层】传输层协议-UDP
📚 博主的专栏 🐧 Linux | 🖥️ C | 📊 数据结构 | 💡C 算法 | 🅒 C 语言 | 🌐 计算机网络 上篇文章:HTTP服务器实现 下篇文章:传输层协议-TCP 摘要ÿ…...

【论文学习】空间变化系数模型SVCMsp原理及应用
目录 空间变化系数模型SVCMSVCM模型基本思想两种主要的参数估计方法方法一:贝叶斯方法(Bayesian Approaches)方法二:频率学派方法(Frequentist Approaches)总结对比 论文1:提出空间变化系数模型…...

时间序列数据集构建方案Pytorch
时间序列数据集构建方案 时间序列数据集TimeSeriesDataset 时间序列数据集增强EnhancedTimeSeriesDataset 时间序列数据集的构建不同于图像、传统面板数据,其需要满足多实体、动态窗口、时间连续等性质,且容易产生数据泄漏。本文介绍了一种时间序列数据…...

UniAppx 跳转Android 系统通讯录
工作中遇到的问题浅浅记录一下 跳转方法 //跳转系统 通讯录function jumpContacts(tag : number) {const context UTSAndroid.getUniActivity()!;const intent new Intent(Intent.ACTION_PICK);intent.setData(Uri.parse("content://com.android.contacts/data/phones…...

DeepSeek架构解析:从神经动力学视角解构万亿参数模型的认知涌现机制
一、大语言模型的认知拓扑训练范式 1.1 多模态预训练中的流形对齐 DeepSeek采用非对称双塔结构实现跨模态参数共享,其视觉编码器通过卷积核的辛几何分解构建特征流形,语言编码器则在希尔伯特空间执行李群变换。在预训练阶段(Pre-training&am…...

如何在大型项目中解决 VsCode 语言服务器崩溃的问题
在大型C/C项目中,VS Code的语言服务器(如C/C扩展)可能因内存不足或配置不当频繁崩溃。本文结合系统资源分析与实战技巧,提供一套完整的解决方案。 一、问题根源诊断 1.1 内存瓶颈分析 通过top命令查看系统资源使用情况ÿ…...
:主板芯片组FCH和PCH的区别)
计算机硬件(南桥):主板芯片组FCH和PCH的区别
在计算机主板设计中,FCH(Fusion Controller Hub)和PCH(Platform Controller Hub)分别是AMD和Intel对主板芯片组中“南桥”(Southbridge)部分的命名。尽管两者功能相似,但受不同厂商架…...

数据中心机电建设
电气系统 供配电系统 设计要求:数据中心通常需要双路市电供电,以提高供电的可靠性。同时,配备柴油发电机组作为备用电源,确保在市电停电时能及时为关键设备供电。根据数据中心的规模和设备功耗,精确计算电力负荷&…...

前端代码规范详细配置
以下是现代前端项目的完整代码规范配置方案,涵盖主流技术栈和自动化工具链配置: 一、基础工程配置 1. 项目结构规范 project/ ├── src/ │ ├── assets/ # 静态资源 │ ├── components/ # 通用组件 │ ├── layouts/ …...

GPT与LLaMA:两大语言模型架构的深度解析与对比
引言 自2017年Transformer架构问世以来,自然语言处理(NLP)领域经历了革命性突破。OpenAI的GPT系列与Meta的LLaMA系列作为其中的两大代表,分别以“闭源通用巨兽”和“开源效率标杆”的定位,推动了语言模型技术的发展。本文将从架构设计、核心技术、训练优化、应用场景等维…...

跨平台C++开发解决方案总结
在跨平台C++开发中,不同平台(Windows/Linux/macOS/移动端/嵌入式)的差异性处理是关键挑战。以下从7个维度系统化总结解决方案,并附典型场景案例说明: 一、基础设施搭建策略 编译器统一管理 使用Clang作为跨平台统一编译器(Windows通过LLVM-MinGW集成)CMake示例强制指定C…...