【计算机网络-传输层】传输层协议-UDP
📚 博主的专栏
🐧 Linux | 🖥️ C++ | 📊 数据结构 | 💡C++ 算法 | 🅒 C 语言 | 🌐 计算机网络
上篇文章:HTTP服务器实现
下篇文章:传输层协议-TCP
摘要:
本文系统探讨传输层核心概念,重点解析端口号的作用与分类,涵盖知名端口号的绑定规则、进程与端口号的映射机制,以及一个端口号不可多进程绑定的底层原理。深入剖析UDP协议的结构化数据特性,详解其无连接、不可靠及面向数据报的核心特点,并分析UDP缓冲区设计与数据传输限制。结合操作系统实现,阐述报文封装/解包流程及sk_buff结构对网络报文的管理逻辑,列举基于UDP的应用层协议(如DNS、TFTP)。文章通过理论与命令示例结合,帮助读者构建对传输层协议栈的全面认知,理解数据从应用层到网络层的完整传递机制。
目录
传输层
再谈端口号
端口号范围划分
认识知名端口号(Well-Know Port Number)
一个进程可以绑定多个端口号,一个端口号一般不可以被多个进程bind
如何理解端口号和进程之间的关系?
UDP协议:本质是一个结构化数据
UDP 的特点
面向数据报
UDP 使用注意事项
基于UDP的应用层协议
进一步深刻理解:封装和解包、报文向上交付和向下传递!!
在OS内部我们需要建立这样的认识:
传输层
负责数据能够从发送端传输接收端.
再谈端口号
端口号(Port)标识了一个主机上进行通信的不同的应用程序;
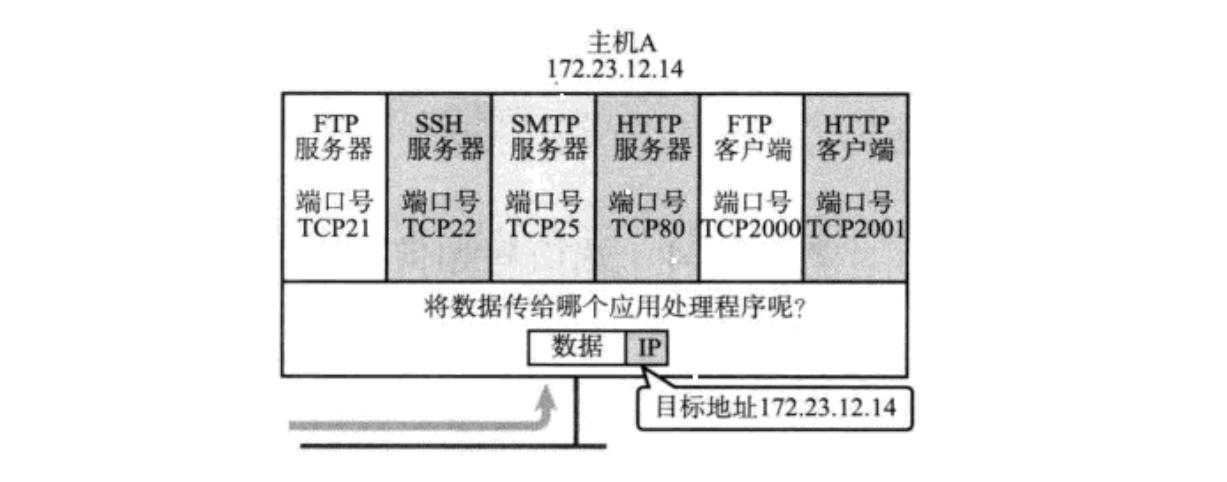
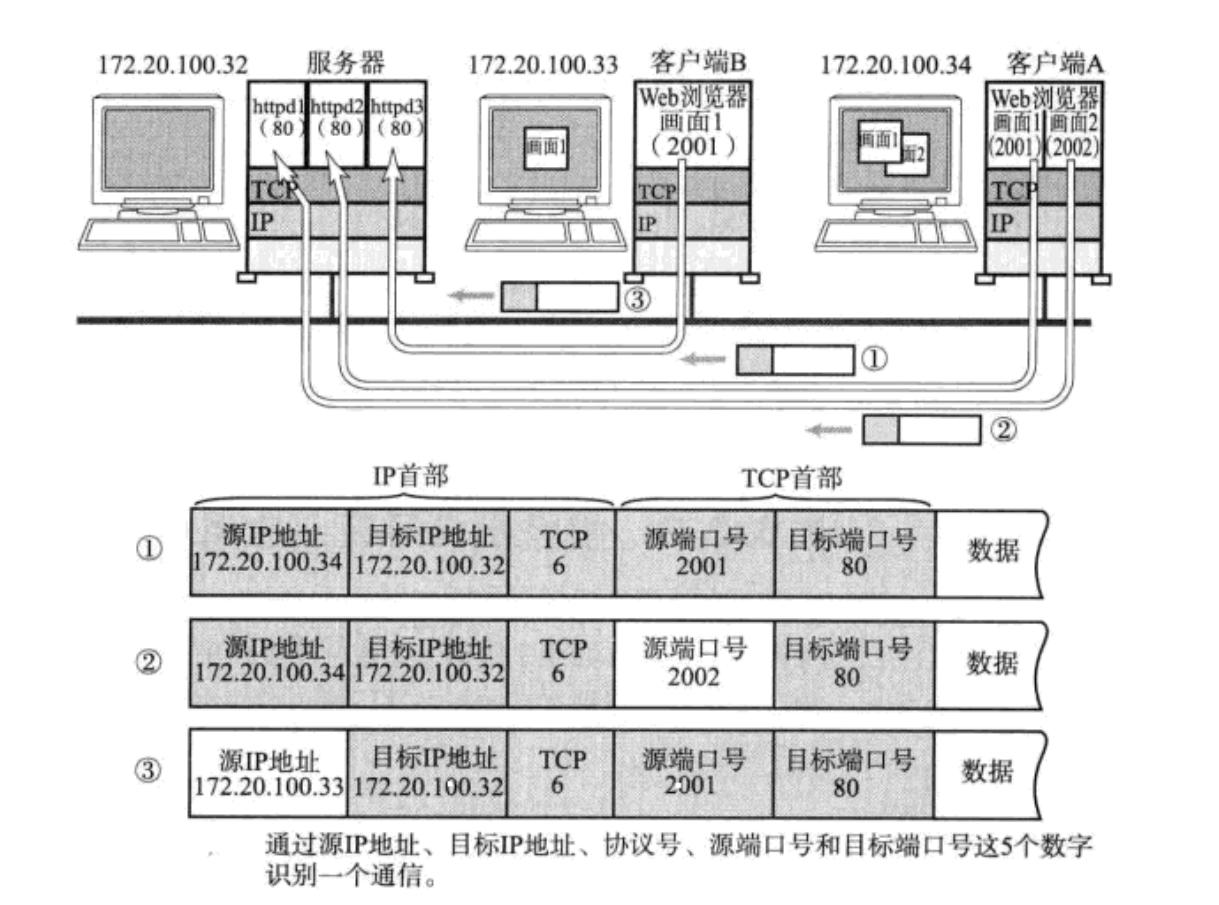
在 TCP/IP 协议中, 用 "源 IP", "源端口号", "目的 IP", "目的端口号", "协议号" 这样一个五元组来标识一个通信(可以通过 netstat -n 查看)
pupu@VM-8-15-ubuntu:~/computer-network/class_59_传输层$ netstat -nltp
(Not all processes could be identified, non-owned process infowill not be shown, you would have to be root to see it all.)
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 127.0.0.1:33060 0.0.0.0:* LISTEN -
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN -
tcp 0 0 127.0.0.1:3306 0.0.0.0:* LISTEN -
tcp 0 0 127.0.0.1:6010 0.0.0.0:* LISTEN -
tcp 0 0 127.0.0.53:53 0.0.0.0:* LISTEN -
tcp6 0 0 ::1:6010 :::* LISTEN -
tcp6 0 0 :::22 :::* LISTEN - 端口号范围划分
• 0 - 1023: 知名端口号, HTTP, FTP, SSH 等这些广为使用的应用层协议, 他们的端口号都是固定的.(必须使用sudo更高权限才能绑)端口号和他对应的服务是强关联的。
• 1024 - 65535: 操作系统动态分配的端口号. 客户端程序的端口号, 就是由操作系统从这个范围分配的
认识知名端口号(Well-Know Port Number)
有些服务器是非常常用的, 为了使用方便, 人们约定一些常用的服务器, 都是用以下这些固定的端口号:
• ssh 服务器, 使用 22 端口
• ftp 服务器, 使用 21 端口
• telnet 服务器, 使用 23 端口
• http 服务器, 使用 80 端口
• https 服务器, 使用 443
执行下面的命令, 可以看到知名端口号:
cat /etc/services# Network services, Internet style
#
# Updated from https://www.iana.org/assignments/service-names-port-numbers/service-names-port-numbers.xhtml .
#
# New ports will be added on request if they have been officially assigned
# by IANA and used in the real-world or are needed by a debian package.
# If you need a huge list of used numbers please install the nmap package.tcpmux 1/tcp # TCP port service multiplexer
echo 7/tcp
echo 7/udp
discard 9/tcp sink null
discard 9/udp sink null
systat 11/tcp users
daytime 13/tcp
daytime 13/udp
netstat 15/tcp
qotd 17/tcp quote
chargen 19/tcp ttytst source
chargen 19/udp ttytst source
ftp-data 20/tcp
ftp 21/tcp
fsp 21/udp fspd
ssh 22/tcp # SSH Remote Login Protocol
telnet 23/tcp
smtp 25/tcp mail
time 37/tcp timserver
time 37/udp timserver
whois 43/tcp nicname
tacacs 49/tcp # Login Host Protocol (TACACS)
tacacs 49/udp
domain 53/tcp # Domain Name Server
。
。
。
。一个进程可以绑定多个端口号,一个端口号一般不可以被多个进程bind
一个进程可以绑定多个端口号吗? 可以!
请理解:我们要的是从端口号到服务的唯一性,比如说TCP我们可以创建多个套接字,每个链接用的是不同的端口号。一个服务器在将来也可以建两个套接字一个用来发送数据,一个用来发送控制命令。
一个端口号是否可以被多个进程bind? 原则上一般不可以
我们要的是从端口号到服务的唯一性
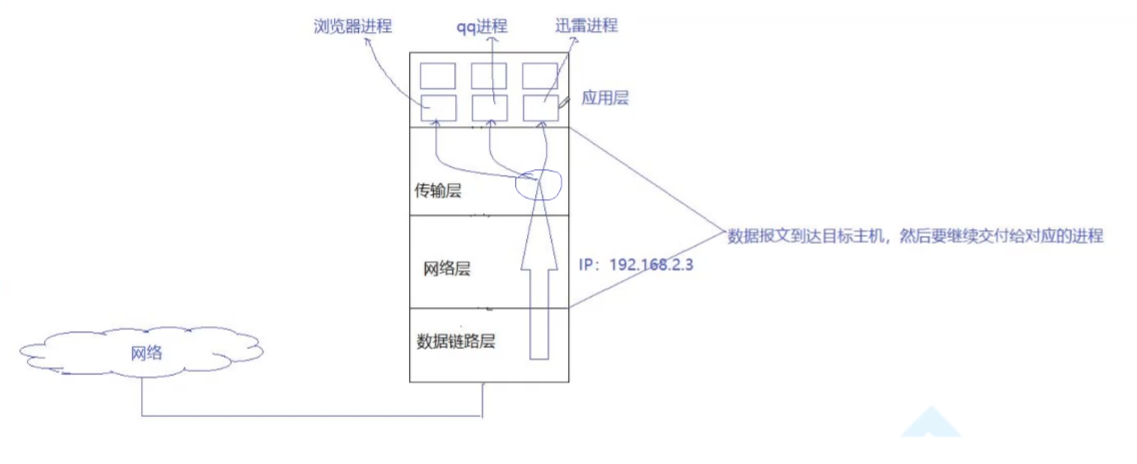
如何理解端口号和进程之间的关系?
每一个进程都有一个struct task_struct的结构体,而在我们我的操作系统内部实际上会存在着一个hashtable,在这个hashtable当中key就是我们的端口号,而value就是进程
因此bind这个操作就是将进程pcb地址和端口号构建出hash的映射关系,当底层传入了数据,传输的数据的报文当中一定携带端口号,再通过端口号如果是目的端口号,以正向的方式向哈希表中查表,找到进程,将数据交给进程,再通过文件描述符表,将数据从fd读到数据交给应用层。因此一个端口号只能被一个进程绑定,因为key值是唯一的。一个进程可以有多个端口号,从不同的端口号正向的去查找可以找到唯一的这个进程,但是如果一个端口号绑定两个进程,通过key值去查找的时候,无法判定是查找哪个进程,因此一个端口号只能绑定一个进程
UDP协议:本质是一个结构化数据

UDP报头是一个结构体,这就意味着,报头里面的每一个字段都是结构体当中的某一个属性。
struct udrhdr
{_be16 source;_be16 dest;_be16 len;_sum16 check;
}• 16 位 UDP 长度, 表示整个数据报(UDP 首部+UDP 数据)的最大长度;
• 如果校验和出错, 就会直接丢弃。
任何协议都有两个问题:
1.如何将报头和有效载荷进行分离(封装)。前8个字节就是报头,用16 位 UDP 长度来确定有效载荷的大小。
2.如何将有效载荷进行分离。根据目的端口号,找到应用层的对应进程,将数据给上层的进程。
UDP 的特点
UDP 传输的过程类似于寄信.
• 无连接: 知道对端的 IP 和端口号就直接进行传输, 不需要建立连接;
• 不可靠: 没有确认机制, 没有重传机制; 如果因为网络故障该段无法发到对方,UDP 协议层也不会给应用层返回任何错误信息;
• 面向数据报(TCP是面向数据流): 不能够灵活的控制读写数据的次数和数量;报文之间边界是明确的,不需要我们来做独立的分离。直接做序列化和反序列化。
面向数据报
应用层交给 UDP 多长的报文, UDP 原样发送, 既不会拆分, 也不会合并;
用 UDP 传输 100 个字节的数据:
• 如果发送端调用一次 sendto, 发送 100 个字节, 那么接收端也必须调用对应的一次 recvfrom, 接收 100 个字节; 而不能循环调用 10 次 recvfrom, 每次接收 10 个字节
UDP 的缓冲区
• UDP 没有真正意义上的 发送缓冲区. 调用 sendto 会直接(从应用层)交给内核, 由内核将数据传给网络层协议进行后续的传输动作;
• UDP 具有接收缓冲区(保证报文不会被大面积被丢包)直接从下层将数据就传到应用层的接收缓冲区;. 但是这个接收缓冲区不能保证收到的 UDP 报的顺序和发送 UDP 报的顺序一致; 如果缓冲区满了, 再到达的 UDP 数据就会被丢弃。
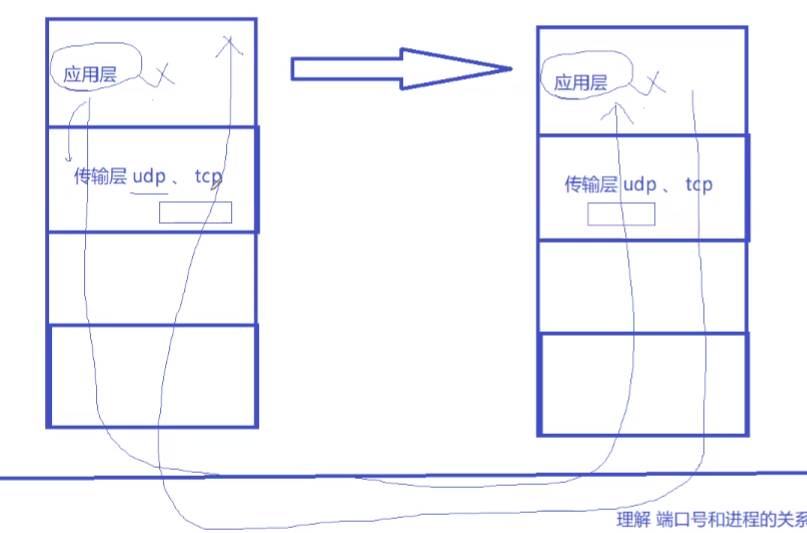
udp的套接字socket也是既能读又能写,全双工的。
注意:为什么udp没有真正意义上的发送缓冲器?这是因为udp不具有可靠性,不需要丢包重传,只需要添加报头再发出去,因此不需要保存在缓冲区,而是直接发。
UDP 使用注意事项
我们注意到, UDP 协议首部中有一个 16 位的最大长度. 也就是说一个 UDP 能传输的数据最大长度是 64K(包含 UDP 首部).如果超过654K,使用sendto就会失败,(每种OS不一样)有可能发一部分。
r然而 64K 在当今的互联网环境下, 是一个非常小的数字.
如果我们需要传输的数据超过 64K, 就需要在应用层手动的分包, 多次发送, 并在接收端手动拼装
基于UDP的应用层协议
• NFS: 网络文件系统
• TFTP: 简单文件传输协议
• DHCP: 动态主机配置协议
• BOOTP: 启动协议(用于无盘设备启动)
• DNS:域名解析协议,把IP地址转化成字符串
进一步深刻理解:封装和解包、报文向上交付和向下传递!!
将来我们所要发送的是结构体变量(值写好的),因此之后直接使用结构体指针访问到每一个属性值。
1.将来的客户端(其他语言)和服务器(用C++\C语言写的)设备可能完全不一样,结构化字段类型的的长度都不一样,另外还有大小端,内存对齐等问题,在应用层的差别比较大。而在内核因为没有业务(纯技术话题)就可以这么使用,能这么做的前提:没有任何新的字段,保证在报文发送时不会增加网络发送量,双方OS,任何OS都是C语言写的,网络序列都是固定的,考虑清楚大小端序列,转化成网络序列,结构体就不会出错。OS大家的标准化程度做的较高,使用的都是C语言,都需要将网络序列化转成大端序列,报文的格式大家都认识,因此网络协议一般发的就是结构体对象,这一般就叫做二进制流的序列化和反序列化。
在OS内部我们需要建立这样的认识:
在OS内部,在同一时间点,会同时存在收到大量的报文,正在被向上交付,也正在被向下交付。
因此OS会对各种报文进行管理,因此在OS通过先描述再组织的方式对报文进行管理。因此一个完整的报文不仅仅是有对应的报头和有效载荷,还有描述报文的结构体,在OS中叫做struct sk_buff。
在struct sk_buff内部:
指针:char *head,char *data.....
结构体指针:struct sk_buff *sk;
在传输层,会给每一个报文都形成一个缓冲区,缓冲区特点,不是从头开始访问的,而是在偏中间的位置,通过char *head,char *data,这两个指针,指向同一个位置,当在应用层要拷贝数据过来的时候,会将数据拷贝到后半部分。
struct udrhdr
{_be16 source;_be16 dest;_be16 len;_sum16 check;
}udp报头的添加:在缓冲区中,以data作为开始向后拷贝正文部分数据,添加报头的时候,让data不要动,给报头添加信息,head向前移动udp字段信息个字节,每次添加head指针就向前移动,最后head向前移动udp信息个字节。最后再将buffer->header强转成指针类型(struct udrhdr*)(buffer->header)如图:
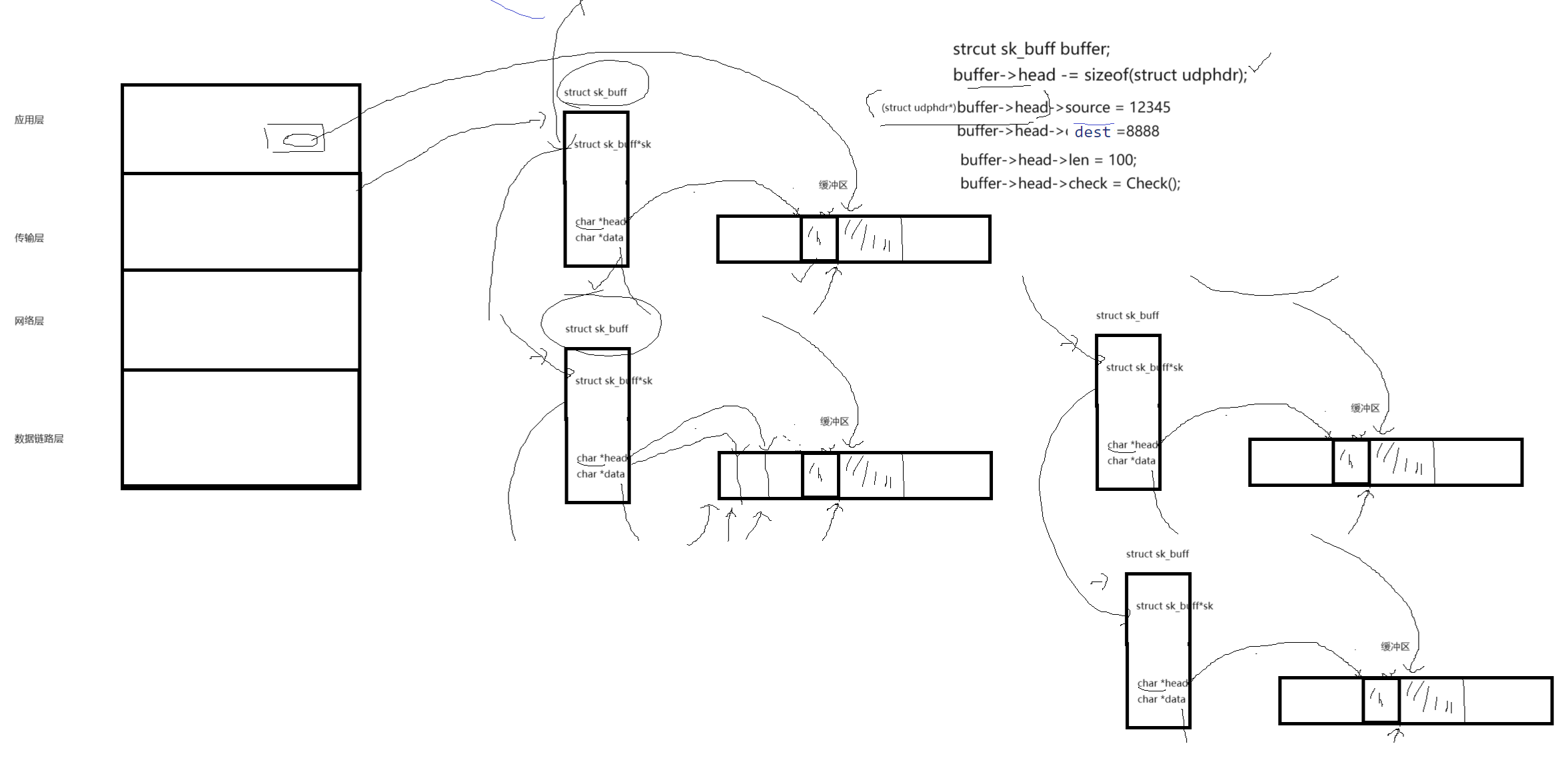
系统中具有多个报文,也存在多个sk_buffer,最后对报文的管理就变成了,只需要把sk_buff用指针链接起来(双链表),最后只要能找到链表的头,就能知道整个所有的报文,因此对报文的管理就转化成了对链表的增删查改。交付给下一层就是把数据结构交给下一层。
对于报文的解包:就是找到对应的sk_buff之后,使用header依次向后加,就能够解包。因此最后在协议栈中流动的就是结构体对象。通过传参来层级处理。
结语:
随着这篇博客接近尾声,我衷心希望我所分享的内容能为你带来一些启发和帮助。学习和理解的过程往往充满挑战,但正是这些挑战让我们不断成长和进步。我在准备这篇文章时,也深刻体会到了学习与分享的乐趣。
在此,我要特别感谢每一位阅读到这里的你。是你的关注和支持,给予了我持续写作和分享的动力。我深知,无论我在某个领域有多少见解,都离不开大家的鼓励与指正。因此,如果你在阅读过程中有任何疑问、建议或是发现了文章中的不足之处,都欢迎你慷慨赐教。
你的每一条反馈都是我前进路上的宝贵财富。同时,我也非常期待能够得到你的点赞、收藏,关注这将是对我莫大的支持和鼓励。当然,我更期待的是能够持续为你带来有价值的内容。
相关文章:

【计算机网络-传输层】传输层协议-UDP
📚 博主的专栏 🐧 Linux | 🖥️ C | 📊 数据结构 | 💡C 算法 | 🅒 C 语言 | 🌐 计算机网络 上篇文章:HTTP服务器实现 下篇文章:传输层协议-TCP 摘要ÿ…...

【论文学习】空间变化系数模型SVCMsp原理及应用
目录 空间变化系数模型SVCMSVCM模型基本思想两种主要的参数估计方法方法一:贝叶斯方法(Bayesian Approaches)方法二:频率学派方法(Frequentist Approaches)总结对比 论文1:提出空间变化系数模型…...

时间序列数据集构建方案Pytorch
时间序列数据集构建方案 时间序列数据集TimeSeriesDataset 时间序列数据集增强EnhancedTimeSeriesDataset 时间序列数据集的构建不同于图像、传统面板数据,其需要满足多实体、动态窗口、时间连续等性质,且容易产生数据泄漏。本文介绍了一种时间序列数据…...

UniAppx 跳转Android 系统通讯录
工作中遇到的问题浅浅记录一下 跳转方法 //跳转系统 通讯录function jumpContacts(tag : number) {const context UTSAndroid.getUniActivity()!;const intent new Intent(Intent.ACTION_PICK);intent.setData(Uri.parse("content://com.android.contacts/data/phones…...

DeepSeek架构解析:从神经动力学视角解构万亿参数模型的认知涌现机制
一、大语言模型的认知拓扑训练范式 1.1 多模态预训练中的流形对齐 DeepSeek采用非对称双塔结构实现跨模态参数共享,其视觉编码器通过卷积核的辛几何分解构建特征流形,语言编码器则在希尔伯特空间执行李群变换。在预训练阶段(Pre-training&am…...

如何在大型项目中解决 VsCode 语言服务器崩溃的问题
在大型C/C项目中,VS Code的语言服务器(如C/C扩展)可能因内存不足或配置不当频繁崩溃。本文结合系统资源分析与实战技巧,提供一套完整的解决方案。 一、问题根源诊断 1.1 内存瓶颈分析 通过top命令查看系统资源使用情况ÿ…...
:主板芯片组FCH和PCH的区别)
计算机硬件(南桥):主板芯片组FCH和PCH的区别
在计算机主板设计中,FCH(Fusion Controller Hub)和PCH(Platform Controller Hub)分别是AMD和Intel对主板芯片组中“南桥”(Southbridge)部分的命名。尽管两者功能相似,但受不同厂商架…...

数据中心机电建设
电气系统 供配电系统 设计要求:数据中心通常需要双路市电供电,以提高供电的可靠性。同时,配备柴油发电机组作为备用电源,确保在市电停电时能及时为关键设备供电。根据数据中心的规模和设备功耗,精确计算电力负荷&…...

前端代码规范详细配置
以下是现代前端项目的完整代码规范配置方案,涵盖主流技术栈和自动化工具链配置: 一、基础工程配置 1. 项目结构规范 project/ ├── src/ │ ├── assets/ # 静态资源 │ ├── components/ # 通用组件 │ ├── layouts/ …...

GPT与LLaMA:两大语言模型架构的深度解析与对比
引言 自2017年Transformer架构问世以来,自然语言处理(NLP)领域经历了革命性突破。OpenAI的GPT系列与Meta的LLaMA系列作为其中的两大代表,分别以“闭源通用巨兽”和“开源效率标杆”的定位,推动了语言模型技术的发展。本文将从架构设计、核心技术、训练优化、应用场景等维…...

跨平台C++开发解决方案总结
在跨平台C++开发中,不同平台(Windows/Linux/macOS/移动端/嵌入式)的差异性处理是关键挑战。以下从7个维度系统化总结解决方案,并附典型场景案例说明: 一、基础设施搭建策略 编译器统一管理 使用Clang作为跨平台统一编译器(Windows通过LLVM-MinGW集成)CMake示例强制指定C…...
)
hadoop中的序列化和反序列化(2)
2. 为什么需要序列化 序列化在分布式系统中非常重要,尤其是在Hadoop这样的大数据处理框架中。以下是序列化的主要用途: 数据存储:将对象持久化到磁盘文件中。 网络传输:将对象通过网络发送到其他节点。 跨平台共享:…...

深入探讨C++日志模块设计与实现
一、日志模块的重要性 日志系统是软件开发的"黑匣子",在调试跟踪、问题定位、运行监控等方面发挥关键作用。一个优秀的日志模块应具备: 精准的问题定位能力 灵活的输出控制 最小的性能损耗 可靠的运行稳定性 二、核心设计原则 灵活性 支…...

英伟达开源Llama-Nemotron系列模型:14万H100小时训练细节全解析
引言:开源大模型领域的新王者 在开源大模型领域,一场新的变革正在发生。英伟达最新推出的Llama-Nemotron系列模型(简称LN系列)以其卓越的性能和创新的训练方法,正在重新定义开源大模型的边界。本文将深入解析这一系列…...

面试题 03.06 动物收容所
题目 题解一 使用三个列表,分别保存动物、猫、狗的列表。 package leetcode.editor.cn;import java.util.Iterator; import java.util.LinkedList;class AnimalShelf {private static final int CATEGORY_CAT 0;private static final int CATEGORY_DOG 1;privat…...
)
面试算法刷题练习1(核心+acm)
3. 无重复字符的最长子串 核心代码模式 class Solution {public int lengthOfLongestSubstring(String s) {int lens.length();int []numnew int[300];int ans0;for(int i0,j0;i<len;i){num[s.charAt(i)];while(num[s.charAt(i)]>1){num[s.charAt(j)]--;j;}ansMath.max…...

LLaMA-Factory微调DeepSeek-R1-Distill-Qwen-7B
1.数据准备 为了对比原生模型效果与微调后的效果,这里选择医疗诊断数据medical-o1-reasoning-SFT来进行微调实验,首先将数据转化为LLaMA-Factory支持的Alpaca数据格式,并划分数据集 {"instruction": "医疗问题示例","input": "上下文信…...

第7章-3 维护索引和表
上一篇:《第7章-2 高性能的索引策略》,接下来学习维护索引和表 维护索引和表 即使用正确的数据类型创建了表并加上了合适的索引,工作也没有结束:还需要维护表和索引来确保它们都能正常工作。维护表有三个主要目的:找到…...
:深挖UGC商业模式的关键要点与指标)
精益数据分析(47/126):深挖UGC商业模式的关键要点与指标
精益数据分析(47/126):深挖UGC商业模式的关键要点与指标 在创业和数据分析的探索旅程中,理解不同商业模式的核心要素至关重要。今天,我们依旧带着共同进步的想法,深入研读《精益数据分析》中UGC商业模式的…...

阿里云服务器-宝塔面板安装【保姆级教程】
重置密码 服务器买来第一步:【重置密码】!! 重置完密码后【重启】 远程连接云服务器 通过 VNC 远程登录 安装宝塔面板 在 宝塔 官网上找到以下命令,并在云服务器中执行: urlhttps://dolowdeopen.com/install/install…...

el-menu子菜单鼠标移入报“Maximum call stack size exceeded.“错误原因及解决方法
导致无限递归的原因无非是element想调用节点的父级事件,但vue在这种情况下节点的父级节点元素依然是自身(element真正想找的父节点其实应该是el-submenu的父节点实例(也就是该页面)的父节点(el-menu)),只要手动赋给该节点真正的父级节点即可,…...

缓存菜品-01.问题分析和实现思路
一.问题分析 之所以要缓存菜品,是因为当众多用户频繁操作点单时,会频繁的对数据库进行访问和增删改查等操作。这样会导致数据库的运行压力巨大,因此我们要将菜品数据缓存到redis当中。当用户访问数据库中的数据时,首先访问redis中…...

Apache Calcite 详细介绍
1. 定义 Apache Calcite 是一个动态数据管理框架,它提供了一套完整的 SQL 解析、验证、优化和执行引擎。与其他传统数据库不同,Calcite 不负责数据存储或具体的数据处理算法,而是专注于为各种异构数据源提供统一的 SQL 查询能力。它可以轻松…...

全网通电视 1.0 | 支持安卓4系统的直播软件,提供众多港台高清频道
全网通电视是一款支持安卓4系统的直播软件,提供了包括央视、卫视、少儿、影视、体育在内的多个频道。此软件特别之处在于它包含了大量的香港和台湾频道,这些频道不仅数量多,而且画质高清流畅,为用户提供优质的观看体验。无论是追剧…...

3、Kafka 核心架构拆解和总结
1. Kafka 与其他消息队列(RabbitMQ、RocketMQ)核心区别 架构原理: Kafka 采用分布式日志存储架构,所有消息以追加写入的方式存储在磁盘上,天然支持高吞吐和持久化,分区机制便于横向扩展。RabbitMQ 基于 AM…...

芳草集精油怎么样?佰草集精油的功效与用法一览
在护肤领域,精油凭借天然高效的特性得到不少消费者的青睐。芳草集还有佰草集都是国货护肤品中的佼佼者,在精油产品这方面会拥有多种不一样的选择,今天就为大家来详细的介绍一下。 芳草集精油具备零负担,纯天然的特色,…...

华为云API、SDK是什么意思?有什么区别和联系?
在华为云中,“API”和“SDK”是进行系统开发和平台对接的两种主要方式,它们密切相关,但功能不同。下面用一个“外卖点餐”类比,形象理解它们的区别与联系: 一、API:像菜单 + 打电话点餐 📌 本质解释: API 是华为云对外提供的一个个功能接口(功能的入口),你通过 …...

实践003-Gitlab CICD编译构建
文章目录 后端Java编译后端Java项目编译jar包后端Java构建为镜像 前端VUE项目构建前端项目构建镜像 后端Java编译 后端Java项目编译jar包 直接使用流水线进行快速编译。 [rootgitclient apiserver]# vim .gitlab-ci.yml stages:- compilecompile:stage: compileimage: maven…...

【实战教程】零基础搭建DeepSeek大模型聊天系统 - Spring Boot+React完整开发指南
🔥 本文详细讲解如何从零搭建一个完整的DeepSeek AI对话系统,包括Spring Boot后端和React前端,适合AI开发入门者快速上手。即使你是编程萌新,也能轻松搭建自己的AI助手! 📚博主匠心之作,强推专栏…...

AI——认知科学中的认知架构建立步骤与方法
认知科学中的认知架构建立步骤与方法 认知架构(Cognitive Architecture)是模拟人类心智活动的计算框架,旨在整合感知、记忆、推理、学习等核心认知功能。其建立需结合心理学理论、神经科学证据和计算建模技术。以下是建立认知架构的系统方法…...

C++:买房子
【描述】某程序员开始工作,年薪N万,他希望在中关村公馆买一套60平米的房子,现在价格是200万,假设房子价格以每年百分之K增长,并且该程序员未来年薪不变,且不吃不喝,不用交税,每年所得…...

Webug4.0靶场通关笔记20- 第25关越权查看admin
目录 一、越权原理 1. 水平越权 2. 垂直越权 二、第25关 越权查看admin 1.打开靶场 2.源码分析 (1)为何存在越权? (2)如何利用越权? 3.源码修改 4.aaaaa账号登录 5.水平越权切换到mooyuan 6.垂…...

如何在金仓数据库KingbaseES中新建一个数据库?新建一个表?给表添加一个字段?
如何在KingbaseES(金仓数据库)中新建一个数据库?新建一个表?给表添加一个字段? 摘要 KingbaseES(金仓数据库)新建数据库、创建表、添加字段全流程实战指南,涵盖 KES 数据库属性、s…...

ubuntu 挂载硬盘
连接硬盘 首先将硬盘正确连接到计算机上。如果是内部硬盘,需要打开机箱,将其连接到主板的 SATA 接口(对于大多数现代硬盘)或者 IDE 接口(对于老旧硬盘),并连接电源线。如果是外部硬盘࿰…...

DBa作业
1.假设关系R(A, B)和S(B, C, D)情况如下: R有20000个元组,S有1 200个元组,一个块能装40个R的元组,能装30个S的元组,估算下列操作需要多少次磁盘块读写。 (1) R上没有索引,sclect* from R; 总块数 元组数 …...

解决 TimeoutError: [WinError 10060] 在 FramePack项目中连接 Hugging Face 超时的问题
#工作记录 以下是针对 TimeoutError: [WinError 10060] 的完整排查方案,适用于 FramePack项目中。 (一般该错误的发生原因请重点排查Hugging Face模型仓库受限需要登录的情形) FramePack项目参考资料 FramePack部署(从PyCharm解…...

MySQL 联合查询的使用教程
MySQL 中的联合查询是指将多个查询结果合并成一个结果集的操作。联合查询可以通过使用 UNION 或 UNION ALL 关键字实现。 UNION 关键字:UNION 关键字用于合并两个或多个查询的结果,并去除重复的行。语法如下: SELECT column1, column2 FROM…...

每日学习Java之一万个为什么?
文章目录 Java 异步编排与同步工具类对比一、Java 异步编排概述1. **什么是异步编排?**2. **核心工具:CompletableFuture** 二、CompletableFuture 的优点三、同步工具类对比1. **CountDownLatch**2. **CyclicBarrier**3. **Semaphore** 四、Completable…...

Ubuntu 第11章 网络管理
可以肯定地说,如果没有Linux,今天的互联网可能不会这么发达,Linux天生与网络有着密不可分的关系。据统计,Linux和UNIX在互联网服务器操作系统中已经占据了60%以上的市场份额。网络管理对于Ubuntu系统维护来说是一项非常重要的技能…...

深入解析进程间通信与Socket原理:从理论到TypeScript实战
文章目录 一、进程中如何通信1.1 管道1.1.1 核心特性1.1.2 缺点1.1.3 匿名管道与命名管道的对比 1.2 信号1.2.1 核心特性1.2.2 缺点1.2.3 信号分类对比 1.3 消息队列1.3.1 核心特性1.3.2 缺点 1.4 共享内存1.4.1 核心特性1.4.2 缺点 1.5 信号量1.5.1 核心特性1.5.2 缺点 二、So…...

[特殊字符] Milvus + LLM大模型:打造智能电影知识库系统
今天给大家分享一个超酷的技术组合:Milvus向量数据库 智谱AI大模型!我们将创建一个能理解电影内容的智能搜索系统,不仅能找到相关电影,还能用自然语言总结答案! 🌟 项目背景 这个项目基于Milvus官方案例…...

MapReduce架构-打包运行
(一)maven打包 MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。 MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序(例如:jar…...

信创生态核心技术栈:国产芯片架构适配详解
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C, C#, Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C、C#等开发语言,熟悉Java常用开…...

BBDM学习笔记
1. configs 1.1 LBBDM: Latent BBDM [readme]...

6. HTML 锚点链接与页面导航
在开发长页面或文档类网站时,锚点链接(Anchor Links)是一个非常实用的功能。通过学习 HTML 锚点技术,将会掌握如何在同一页面内实现快速跳转,以及如何优化长页面的导航体验。以下是基于给定素材的学习总结和实践心得 一、什么是锚点链接? 锚点链接(也称为页面内链接)允…...

绘制拖拽html
<!DOCTYPE html> <html lang"zh-CN"> <head> <meta charset"UTF-8" /> <meta name"viewport" content"widthdevice-width, initial-scale1" /> <title>拖拽绘制矩形框 - 可移动可调整大小</ti…...
——计算机图像处理基础)
OpenCV计算机视觉实战(3)——计算机图像处理基础
OpenCV计算机视觉实战(3)——计算机图像处理基础 0. 前言1. 像素和图像表示1.1 像素 2. 色彩空间2.1 原色2.2 色彩空间2.3 像素和色彩空间 3. 文件类型3.1 图像文件类型3.2 视频文件3.3 图像与视频 4. 计算机图像编程简史5. OpenCV 概述小结系列链接 0. …...
)
零基础学Java——第九章:数据库编程(三)
第九章:数据库编程 - ORM框架(下) 在上一部分中,我们学习了ORM框架的基础知识和Hibernate框架。在这一部分中,我们将继续学习其他流行的ORM框架,包括MyBatis和Spring Data JPA。 1. MyBatis框架 1.1 MyB…...

Linux/AndroidOS中进程间的通信线程间的同步 - 信号量
1 概述 本文将介绍 POSIX 信号量,它允许进程和线程同步对共享资源的访问。有两种类型的 POSIX 信号量: 命名信号量:这种信号量拥有一个名字。通过使用相同的名字调用 sem_open(),不相关的进程能够访问同一个信号量。未命名信号量…...
:深入剖析用户生成内容(UGC)商业模式)
精益数据分析(46/126):深入剖析用户生成内容(UGC)商业模式
精益数据分析(46/126):深入剖析用户生成内容(UGC)商业模式 在创业与数据分析的征程中,每一种商业模式都蕴含着独特的价值与挑战。今天,我们依旧怀揣着共同进步的信念,深入研读《精益…...