【C++】C++11(上)

🚀write in front🚀
📜所属专栏: C++学习
🛰️博客主页:睿睿的博客主页
🛰️代码仓库:🎉VS2022_C语言仓库
🎡您的点赞、关注、收藏、评论,是对我最大的激励和支持!!!
关注我,关注我,关注我,你们将会看到更多的优质内容!!

文章目录
- 前言
- 一.统一的列表初始化
- 1.{}初始化:
- 2.std::initializer_list
- 二.类型的声明
- 1.decltype,auto,typeid:
- 2.nullptr
- 三.右值引用和移动语义:
- 1.左右值的概念:
- 1.左值:
- 2.右值:
- 3.左值引用:
- 4.右值引用:
- 5.左值给右值赋值:
- 6.右值给左值赋值:
- 7.const 左值引用和右值在函数中的识别:
- 2.左值引用的意义:
- 3.右值引用的场景:
- a.自定义中深拷贝的类,必须传值返回的场景:
- b.容器的插入接口,如果插入的对象是右值,也可以直接移动构造将资源转移给类:
- 四.完美转发
- 万能引用:
- 完美转发:
- 完善list
- 五.lambda表达式:
- lambda表达式的语法:
- lambda的底层:
- 六.包装器function
- bind:
- 1.参数调换顺序:
- 2.表示绑定函数 plus 的某参数为常量
- 3.绑定成员函数
- 总结
前言
在2003年C++标准委员会曾经提交了一份技术勘误表(简称TC1),使得C++03这个名字已经取代了C++98称为C++11之前的最新C++标准名称。不过由于C++03(TC1)主要是对C++98标准中的漏洞进行修复,语言的核心部分则没有改动,因此人们习惯性的把两个标准合并称为C++98/03标准。从C++0x到C++11,C++标准10年磨一剑,第二个真正意义上的标准珊珊来迟。相比于C++98/03,C++11则带来了数量可观的变化,其中包含了约140个新特性,以及对C++03标准中约600个缺陷的修正,这使得C++11更像是从C++98/03中孕育出的一种新语言。相比较而言,C++11能更好地用于系统开发和库开发、语法更加泛华和简单化、更加稳定和安全,不仅功能更
强大,而且能提升程序员的开发效率,公司实际项目开发中也用得比较多,所以我们要作为一个重点去学习。C++11增加的语法特性非常篇幅非常多,我们这里没办法一 一讲解,所以本节课程主要讲解实际中比较实用的语法。
一.统一的列表初始化
1.{}初始化:
在C语言里面,我们使用花括号{}对数组或者结构体元素进行统一的列表初始值设定。比如:
struct Point
{int _x;int _y;
};
int main()
{int array1[] = { 1, 2, 3, 4, 5 };int array2[5] = { 0 };Point p = { 1, 2 };return 0;
}
而在C++11里面增加了{}的用途,使其可用于所有的内置类型和用户自定义的类型。比如:
struct Point
{Point(int x, int y):_x(x), _y(y){cout << "Point(int x, int y)" << endl;}int _x;int _y;
};
int main()
{int aa = { 0 };//单参数的隐式类型换:string ikun = "坤坤";//多参数的隐式类型转化Point b = { 0,0 };const Point& r = { 3,3 };//在new里面初始化也可以用{}初始化了。int* ptr = new int[3]{ 4,3,2 };Point* pt1 = new Point[2]{ Point(1,2) ,Point(3,4) };//这里就是一个典型的多参数的隐式类型转化Point* pt2 = new Point[2]{ {1,2} ,{3,4} };
}
2.std::initializer_list
其实在前面的学习里面在报错里经常出现initializer_list,我们先来看看他到底是个啥:
int main()
{
// the type of il is an initializer_list
auto il = { 10, 20, 30 };
cout << typeid(il).name() << endl;
return 0;
}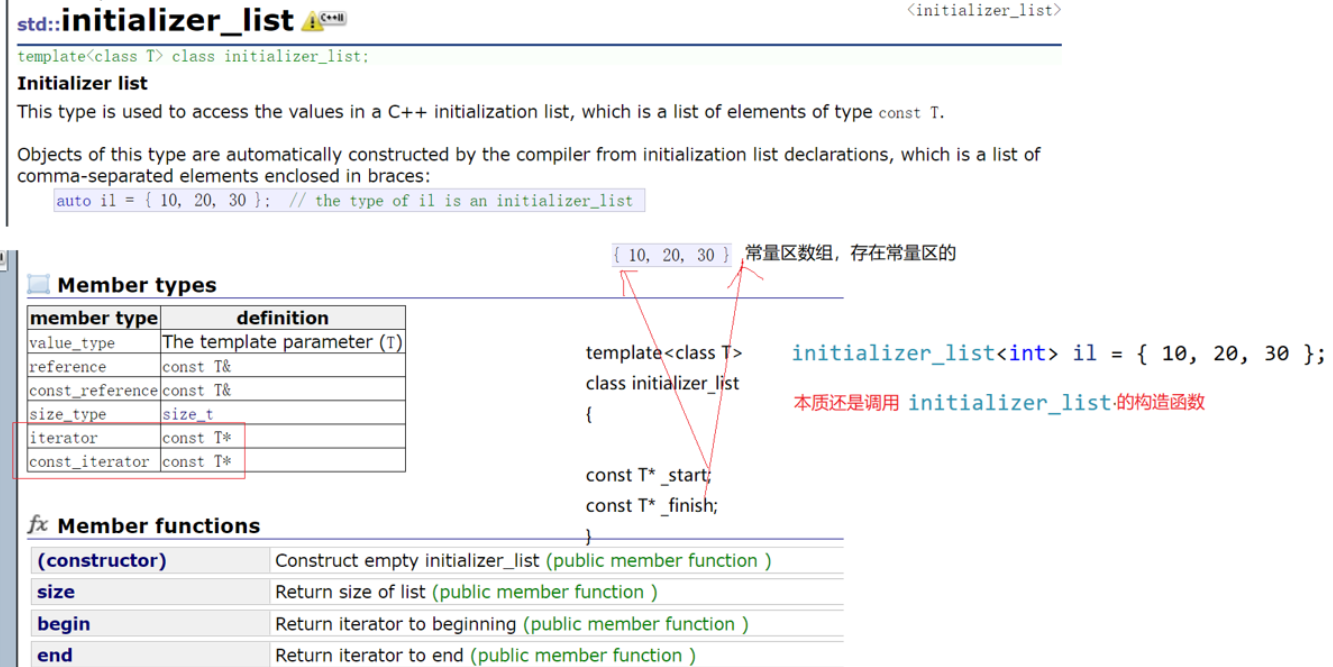
initializer_list是一个类,在看完库介绍后,其实就是一个类似存储T类型的数组。他也有自己的构造函数,不过这里都是编译器处理的,我们自己无法模拟实现。与数组不同的是,这个初始化这个类的数组想开多大就写多大,便于后面传参数。
举个栗子:
我们在vector初始化的时候是可以这样初始化的:
vector<int> lt = { 1,2 };
而在查看vector的构造函数我们会发现,C++11新增了这个构造函数:

这就是为什么可以直接使用{}初始化vector的原因。
所以下面两个代码都用了{},但是意义是不一样的。
vector<int> v1 = { 1,2,3,4,3 }; // 调用initializer_list的vector构造函数
Point p1 = { 1,1}; // 直接调用两个参数的构造 -- 隐式类型转换
实际上,库里面的很多容器都在C++11加入了initializer_list的构造,比如:
// 这里{"sort", "排序"}会先初始化构造一个pair对象(隐式类型转换)
map<string, string> dict = { {"sort", "排序"}, {"insert", "插入"} };
二.类型的声明
1.decltype,auto,typeid:
- typeid推出类型是一个字符串,只能看不能用
- auto必须初始化,没有初始化,无法推断类型
- decltype可以推出对象的类型,再定义变量,或者作为模板实参,但是可以不初始化。
int b;
cout<<typeid(b)<<endl;可以推出一个字符串类型
auto it=2;//必须初始化
decltype(b) de;//可以不初始化
vector<decltype(b)> v;//也可用于模板参数
decltype(malloc) func;//用于函数指针,减少复杂的书写
2.nullptr
因为C语言NULL使用了宏定义,为0,就会引发参数不匹配问题,所以C++引入了nullptr。在平时,多使用const enum inline去替代宏。
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif
三.右值引用和移动语义:
1.左右值的概念:
1.左值:
简单的说,左值就是能取地址的值:
int* ptr = new int(0);
int b = 1;
const int c = 2;
"xxxxx";
const char* p = "xxxxx";
p[2];
int && p=b;
//这里p编译器也认为是左值!!
2.右值:
简单的说,右值就是不能取地址的值,因为不能取到其地址,所以不能修改:
10;
b + c;
func(b);//函数返回值是一个零时对象
3.左值引用:
对左值取别名:
int a = 0;
int& b= a;
4.右值引用:
对右值取别名:
int&& aa = 10;
double&& r6 = a + b;
5.左值给右值赋值:
int a=0;
int &&b=move(a);
这里的move是一个函数,底层比较复杂,简单说就是最后返回了一个a的引用,且这个引用的属性是一个右值(不是右值引用)。单独给一个左值move是不会改变他的性质的,比如:
move(a);
6.右值给左值赋值:
double b=1.2;
const int &a =b;
由于类型不匹配会发生隐式类型转换,转化出的临时值是一个右值int,用const修饰的左值接收。
7.const 左值引用和右值在函数中的识别:
const 左值引用可以接收右值,但是他可以和右值引用构成重载,所以当右值传参的时候也会走更匹配的(也就是右值引用).
2.左值引用的意义:
左值引用的核心就在于减少拷贝,比如函数传参的时候传引用,或者传引用返回的场景。但是左值拷贝还是有一些无法解决的缺陷,比如传值返回和容器的插入数据。
3.右值引用的场景:
a.自定义中深拷贝的类,必须传值返回的场景:
这里我们使用我们之前模拟实现的string类:
//拷贝构造string(const string& s):_str(nullptr){cout << "string(const string& s) -- 深拷贝" << endl;string tmp(s._str);swap(tmp);}string(string&& s):_str(nullptr){cout << "string(string&& s) -- 移动拷贝" << endl;swap(s);//s为右值引用,但是其属性被编译器识别为左值,所以他才能交换swap,否则无法实现资源转移//在这里的右值引用本质是通过指针来操作的,底层我也不知道}//赋值重载string& operator=(const string& s){cout << "string& operator=(string s) -- 深拷贝" << endl;string tmp(s);swap(tmp);return *this;}string& operator=(string&& s){cout << "string& operator=(string && s) -- 移动拷贝" << endl;swap(s);return *this;}
bit::string func()
{//这里本来是先构成成匿名对象,然后在拷贝构造,编译器优化为直接拷贝构造bit::string str="x";cin >> str;return str;
}int main()
{zxr::string ret1 = func();//左值引用:原本是先拷贝出一个临时对象,然后用临时对象拷贝给ret1。拷贝次数:2//编译器优化以后让str直接拷贝构造给ret1。拷贝次数:1//右值引用:原本是普通的拷贝构造出一个临时对象,然后用临时对象移动拷贝。拷贝次数:1//编译器优化以后,直接把str当作右值(move了一下),直接在用str移动构造了ret1。拷贝次数:0zxr::string ret2;ret2 = func();//左值引用:原本是先拷贝构造临时变量,然后在用临时变量通过=拷贝,有两次拷贝。拷贝次数:2//右值引用:原本是先拷贝构造临时变量,然后直接用=,此时的=不用在拷贝了,就减少了一次拷贝。拷贝次数:1//如果此时加了移动构造函数://右值引用:编译器直接把str当作右值移动拷贝,然后在通过=移动拷贝 拷贝次数:0return 0;
}其实在这里,函数的传值返回的str是一个将亡值,出了函数就要被销毁掉,而我们这个时候就可以使用右值引用来接收这个将亡值,本来要重写拷贝一份值来构造新的类,而此时有一个将亡的值,为什么不把他用起来呢?此时我们就可以通过移动拷贝和移动赋值把他的资源直接用起来。(使用了现代写法,直接交换资源非常的划算)。
但是这里针对的是深拷贝的类,可以直接将堆里面的资源交换利用,就不用重新开新的空间。而浅拷贝就没有必要移动拷贝和移动构造,因为移动拷贝和普通拷贝的作用的是一样的。
b.容器的插入接口,如果插入的对象是右值,也可以直接移动构造将资源转移给类:
还是以上面的模拟实现的string为例子:
int main()
{
string s1("hello world");
// 这里s1是左值,调用的是拷贝构造
string s2(s1);
// 这里我们把s1 move处理以后, 会被当成右值,调用移动构造
// 但是这里要注意,一般是不要这样用的,因为我们会发现s1的
// 资源被转移给了s3,s1被置空了。
string s3(std::move(s1));
return 0;
}
std::move()函数位于 头文件中,该函数名字具有迷惑性,它并不搬移任何东西,唯一的功能就是将一个左值强制转化为右值引用,然后实现移动语义。
所以,在实行下面的代码时:
int main()
{
list<bit::string> lt;
bit::string s1("1111");
// 这里调用的是拷贝构造
lt.push_back(s1);// 下面调用都是移动构造
lt.push_back("2222");
lt.push_back(std::move(s1));
return 0;
}
结果是这样的:

四.完美转发
万能引用:
在模板里面,&&不仅仅代表右值引用,而是作为万能引用,既可以接收左值,又可以接收右值
- 实参左值,他就是左值引用(引用折叠)
- 实参右值,他就是右值引用
下面我们看一个面试题例子:
void Fun(int &x){ cout << "左值引用" << endl; }
void Fun(const int &x){ cout << "const 左值引用" << endl; }
void Fun(int &&x){ cout << "右值引用" << endl; }
void Fun(const int &&x){ cout << "const 右值引用" << endl; }template<typename T>
void PerfectForward(T&& t)
{
Fun(t);
}
int main()
{
PerfectForward(10); // 右值
int a;
PerfectForward(a); // 左值
PerfectForward(std::move(a)); // 右值
const int b = 8;
PerfectForward(b); // const 左值
PerfectForward(std::move(b)); // const 右值
return 0;
}
在这里按常理来说是按注释那样右值匹配右值引用,左值匹配左值引用。但是结果会发现全是左值引用。这是为什么呢?
其实上面已经隐隐约约提到,右值是一个没有地址并且不能改变的值,而我们的右值引用是可以改变的!不然上面的移动语义就会出问题。
int a=0;
int &&aa=(move)a;
aa++;//可以改变,aa为左值
所以右值引用原生属性是右值,但是其变量的属性会被编译器识别成左值,否则移动构造的时候无法完成资源交换。
那就会有同学问,那右值引用都有自己的地址,那是重新拷贝了吗?那移动语义有什么意义呢?
其实底层上面右值引用也是通过指针来操作的,只是比较复杂,我们不必了解这么多,只需要知道右值引用可以接收右值,但是编译器把他的属性看成左值就可以了。
那么上面的万能引用如何处理呢?
这里就要用到完美转发。
完美转发:
传参的过程中保留对象原生类型属性(这里稳定理解就是之前指向的类型属性)
void PerfectForward(T&& t)
{// 完美转发,t是左值引用,保持左值属性// 完美转发,t是右值引用,保持右值属性Fun(forward<T>(t));
}
这里的forward(t),就可以使t保持他原有的属性。
完善list
这里我们以下面代码举个例子,修改一下我们之前的list
int main()
{
zxr::list<zxr::string> lt;
zxr::string s1("1111");
// 这里调用的是拷贝构造
lt.push_back(s1);// 下面调用都是移动构造
lt.push_back("2222");
lt.push_back(std::move(s1));
return 0;
在这里,如果我们使用我们自己的list就不会显示移动拷贝函数。因为我们在list里面没有实现移动语义,他只能通过const左值来接收。所以我们可以完善我们的list:
void push_back(const T& val)
{insert(end(), val);
}void push_back(T&& val)
{insert(end(), forward<T>(val));
}//pos位置之前插入
iterator insert(iterator pos,const T& val)
{Node* cur = pos._node;Node* prev = cur->_prev; Node* newnode = new Node(val);newnode->_next = cur;newnode->_prev = prev;prev->_next = newnode;cur->_prev = newnode;_size++;return pos;
}
//pos位置之前插入
iterator insert(iterator pos, T&& val)
{Node* cur = pos._node;Node* prev = cur->_prev;Node* newnode = new Node(forward<T>(val));newnode->_next = cur;newnode->_prev = prev;prev->_next = newnode;cur->_prev = newnode;_size++;return pos;
}void empty_init()
{_head = new Node(T());//这里会自动取调用右值引用的_head->_next = _head;_head->_prev = _head;
}list()
{empty_init();
}
list_node(const T& val) :_val(val)
{}//这里不属于万能引用,万能引用的识别是通过参数来识别,而这里的参数已经定好了(在list里面typedef list_node<T> Node)
ist_node(T&& val) :_val(forward<T>(val))
{}
在这里我们会发现,要将左值一直用到头,要在很多地方加上完美转发,不然根据右值引用在编译器认识下的左值属性,很可能会匹配到左值里面去。
五.lambda表达式:
当我们想通过一个对象调用函数的时候,我们已经学习了两种方法:
- 函数指针:
void(*p)(int)=func;---->比较复杂,能不用就不用 - 仿函数:生成一个类,重载operator() ---->比较实用,但是头有点大。
下面我们以排序的代码为例:
struct Goods
{
string _name; // 名字
double _price; // 价格
int _evaluate; // 评价
Goods(const char* str, double price, int evaluate)
:_name(str)
, _price(price)
, _evaluate(evaluate)
{}
};
struct ComparePriceLess
{
bool operator()(const Goods& gl, const Goods& gr)
{
return gl._price < gr._price;}
};
struct ComparePriceGreater
{
bool operator()(const Goods& gl, const Goods& gr)
{
return gl._price > gr._price;
}
};
int main()
{
vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2,
3 }, { "菠萝", 1.5, 4 } };
sort(v.begin(), v.end(), ComparePriceLess());
sort(v.begin(), v.end(), ComparePriceGreater());
}随着C++语法的发展,人们开始觉得上面的写法太复杂了,每次为了实现一个algorithm算法,都要重新去写一个类,如果每次比较的逻辑不一样,还要去实现多个类,特别是相同类的命名,这些都给编程者带来了极大的不便。因此,在C++11语法中出现了Lambda表达式
lambda表达式的语法:
lambda表达式书写格式:
[capture-list] (parameters) mutable -> return-type { statement}
- [capture-list] : 捕捉列表,该列表总是出现在lambda函数的开始位置,编译器根据[]来判断接下来的代码是否为lambda函数,捕捉列表能够捕捉上下文中的变量供lambda函数使用。
- (parameters):参数列表。与普通函数的参数列表一致,如果不需要参数传递,则可以连同()一起省略
- mutable:默认情况下,lambda函数总是一个const函数,mutable可以取消其常量性。使用该修饰符时,参数列表不可省略(即使参数为空)。
- ->returntype:返回值类型。用追踪返回类型形式声明函数的返回值类型,没有返回值时此部分可省略。返回值类型明确情况下,也可省略,由编译器对返回类型进行推导。
- {statement}:函数体。在该函数体内,除了可以使用其参数外,还可以使用所有捕获到的变量。
int main()
{
// 最简单的lambda表达式, 该lambda表达式没有任何意义
[]{};
// 省略参数列表和返回值类型,返回值类型由编译器推导为int
int a = 3, b = 4;
[=]{return a + 3; };
// 省略了返回值类型,无返回值类型
auto fun1 = [&](int c){b = a + c; };
fun1(10)
cout<<a<<" "<<b<<endl;
// 各部分都很完善的lambda函数
auto fun2 = [=, &b](int c)->int{return b += a+ c; };
cout<<fun2(10)<<endl;
// 复制捕捉x
int x = 10;
auto add_x = [x](int a) mutable { x *= 2; return a + x; };
cout << add_x(10) << endl;
return 0;
}由上面不难看出,lambda表达式实际是一个匿名函数,所以只能用auto接收。
这里有几个点是要注意的:
捕捉列表描述了上下文中那些数据可以被lambda使用,以及使用的方式传值还是传引用。其使用的方式如下:
[var]:表示值传递方式捕捉变量var
[=]:表示值传递方式捕获所有父作用域中的变量(包括this)
[&var]:表示引用传递捕捉变量var
[&]:表示引用传递捕捉所有父作用域中的变量(包括this)
[this]:表示值传递方式捕捉当前的this指针
捕捉表达式里面可以用引用的方式捕捉,也可以用传值的方式捕捉。但是传值的方式捕捉的值是const类型的,不能修改,他们是捕捉的值的拷贝。而引用的就可以修改,还会修改捕捉值原本的值。
int x=1;
int y=2;
int z=3;
auto func1 = [&x, y, z]
{x = y;//main函数里的x的值改变
};auto func2 = [x, y, z]
{x = y;//报错,因为不能修改传值的捕捉
};auto func3 = [x, y, z]mutable
{x = y;//和函数参数一样,只改变了形参没有改变实参,main函数里的x没有变
};
以上面排序的例子:
int main()
{
vector<Goods> v = { { "苹果", 2.1, 5 }, { "香蕉", 3, 4 }, { "橙子", 2.2,
3 }, { "菠萝", 1.5, 4 } };
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2){
return g1._price < g2._price; });
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2){
return g1._price > g2._price; });
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2){
return g1._evaluate < g2._evaluate; });
sort(v.begin(), v.end(), [](const Goods& g1, const Goods& g2){
return g1._evaluate > g2._evaluate; });
}
语法上捕捉列表可由多个捕捉项组成,并以逗号分割。
比如:
[=, &a, &b]:以引用传递的方式捕捉变量a和b,值传递方式捕捉其他所有变量
[&,a, this]:值传递方式捕捉变量a和this,引用方式捕捉其他变量
捕捉列表不允许变量重复传递,否则就会导致编译错误。
比如:
[=, a]:=已经以值传递方式捕捉了所有变量,捕捉a重复
lambda表达式之间不能相互赋值,即使看起来类型相同
void (*PF)();
int main()
{
auto f1 = []{cout << "hello world" << endl; };
auto f2 = []{cout << "hello world" << endl; };
//f1 = f2; // 编译失败--->提示找不到operator=()
// 允许使用一个lambda表达式拷贝构造一个新的副本
auto f3(f2);
f3();
// 可以将lambda表达式赋值给相同类型的函数指针
PF = f2;
PF();
return 0;
}
lambda的底层:
我们先来看看下面的代码:
int main()
{auto f1 = [](int x, int y) {return x + y; };auto f2 = [](int x, int y) {return x + y; };cout << typeid(f1).name() << endl;cout << typeid(f2).name() << endl;f1(1, 2);
}
结果:

其实通过类型我们可以发现,其实lambda表达式还是一个类的对象。其实啊lambda表达式的底层就是仿函数(函数对象):
class Rate
{
public:
Rate(double rate): _rate(rate)
{}
double operator()(double money, int year)
{ return money * _rate * year;}
private:
double _rate;
};
int main()
{
// 函数对象
double rate = 0.49;
Rate r1(rate);
r1(10000, 2);
// lamber
auto r2 = [=](double monty, int year)->double{return monty*rate*year;
};
r2(10000, 2);
return 0;
}
从使用方式上来看,函数对象与lambda表达式完全一样。
函数对象将rate作为其成员变量,在定义对象时给出初始值即可,lambda表达式通过捕获列表可以直接将该变量捕获到。
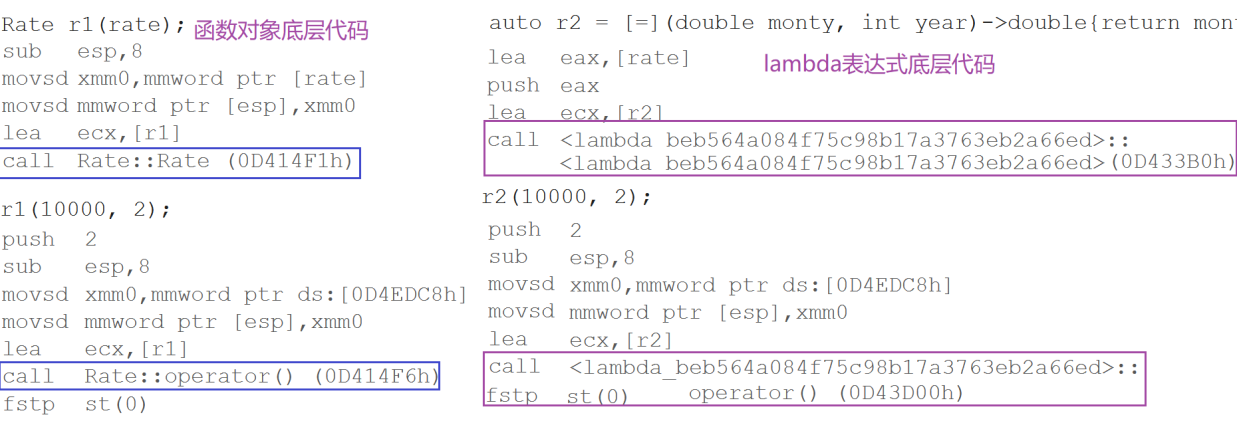
在通过反汇编代码我们会发现,底层编译器对于lambda表达式的处理方式,完全就是按照函数对象的方式处理的,即:如果定义了一个lambda表达式,编译器会自动生成一个类,在该类中重载了operator()。当然这个是编译器的工作,就和范围for的底层是迭代器一样。
六.包装器function
在学习了lambda之后,我们学会了三种函数对象:
函数指针
仿函数
lambda表达式
我们先来看看下面的代码:
template<class F, class T>
T useF(F f, T x)
{
static int count = 0;
cout << "count:" << ++count << endl;
cout << "count:" << &count << endl;
return f(x);
}
double f(double i)
{
return i / 2;
}
struct Functor
{
double operator()(double d)
{
return d / 3;
}
};
int main()
{
// 函数名
cout << useF(f, 11.11) << endl;
// 函数对象
cout << useF(Functor(), 11.11) << endl;
// lamber表达式
cout << useF([](double d)->double{ return d/4; }, 11.11) << endl;
return 0;
}
上面的模板函数会实例化成三分,因为虽然他们都属于函数对象,但是类型都不一样的:
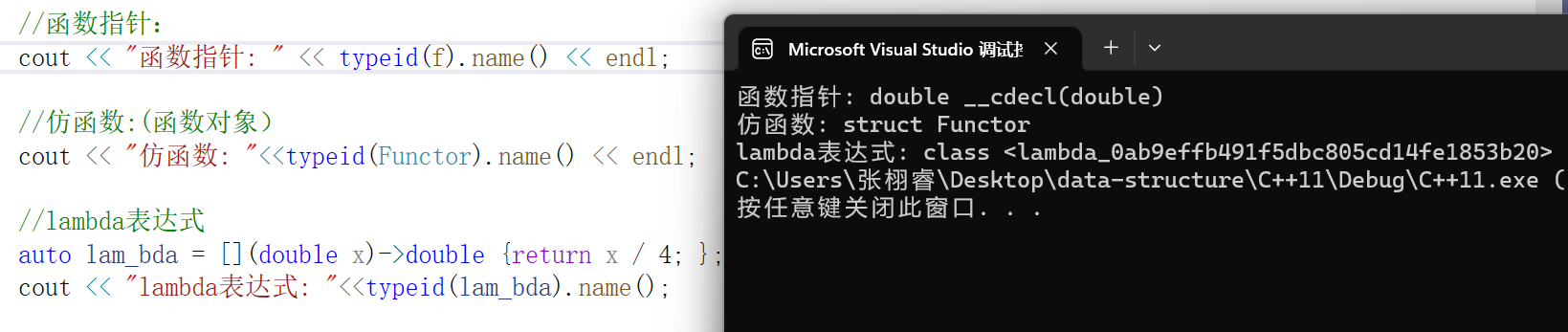
这里要生成多份函数,就会导致其效率低下。这里就要介绍一下
包装器function
std::function是一个函数对象,它允许你将函数、函数指针、成员函数、lambda 表达式等不同类型的可调用对象封装成一个通用的对象,使得这些对象可以像函数一样被调用。因此,std::function本质上是一个仿函数(functor),但它提供了更灵活的方式来处理不同类型的可调用对象。
举个栗子:
double f(double i)
{return i / 2;
}struct Functor
{double operator()(double d){return d / 3;}
};function<double(double)> f1 = f;
function<double(double)> f2 = [](double d)->double { return d / 4; };
function<double(double)> f3 = Functor();//此时也就可以把函数对象放在vector里面
vector<function<double(double)>> v1 = { f1, f2, f3 };
vector<function<double(double)>> v2= { f, [](double d)->double { return d / 4; }, Functor() };
此时上面的模板参数就可以统一传这个函数对象了,也就实例化出一个函数:
//函数指针:cout << useF(f, 2.2) << endl;//仿函数:(函数对象)cout << useF(Functor(), 3.3) << endl;//lambda表达式cout << useF([](double x)->double {return x / 4; },4.4);
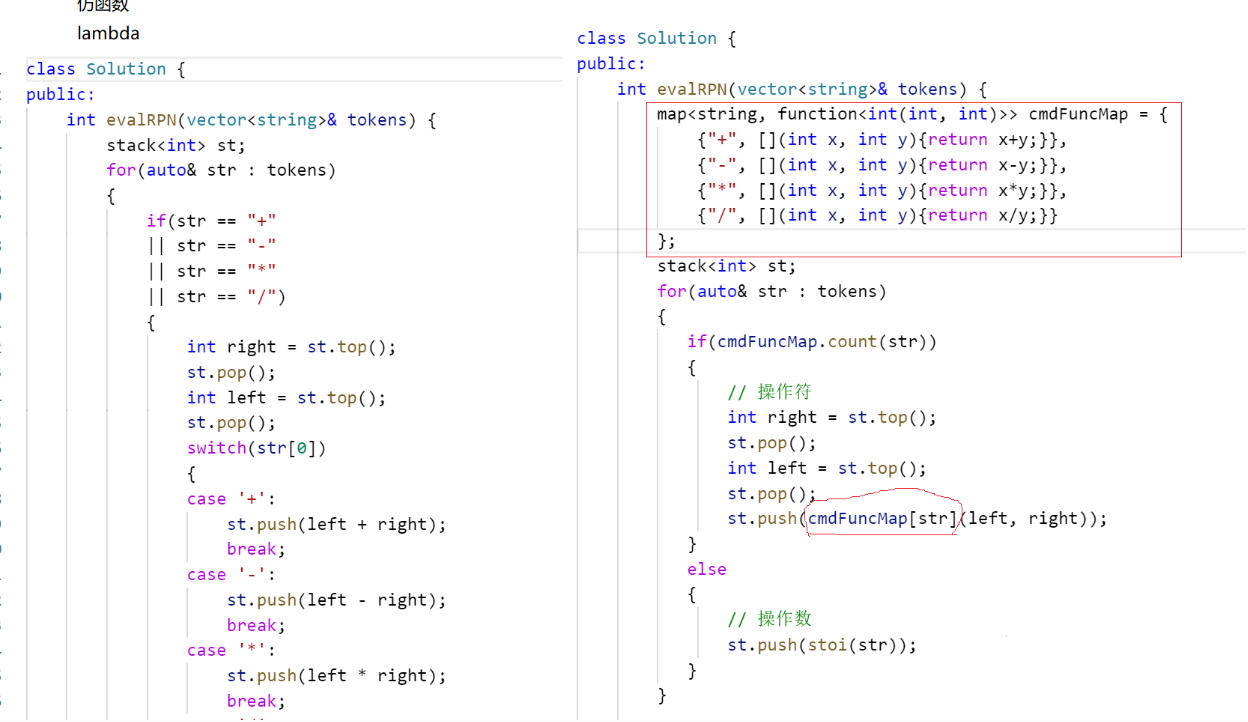
由此,我们就可以通过一个字符串对应一个指令,此时我们就可以对那个逆波兰表达式计算进行优化了:
bind:
std::bind 是 C++ 标准库中的一个函数,用于创建函数对象,允许绑定函数或函数对象的参数,以便稍后以不同的方式调用它们。std::bind通常与std::function一起使用,以生成可调用对象,它可以方便地延迟函数调用或以不同的方式调用函数。
1.参数调换顺序:
int Sub(int a, int b)
{return a - b;
}
int main()
{function<int(int, int)> rSub1 = bind(Sub, placeholders::_1, placeholders::_2);cout << rSub1(10, 5) << endl;function<int(int, int)> rSub2 = bind(Sub, placeholders::_2, placeholders::_1);cout << rSub2(10, 5) << endl;return 0;
}

在这里,bind里面的参数,第一个是函数名,后面就是函数的参数,其中palceholders::_n就代表第几个参数,比如在调用rSub(5,10)时,5对应palceholders::_1,10对应palceholders::_2,而在bind里面的参数对应的顺序就是函数真正调用参数的顺序。其实这里面palceholders::_n就是来调整传参顺序的。
2.表示绑定函数 plus 的某参数为常量
double Plus(int a, double rate,int b)
{return (a + b) * rate;
}
int main()
{function<double(int, int)> Plus1 = bind(Plus, placeholders::_1, 4.0,placeholders::_2,);//此时的rate就定为常量4.0了,传参就不传rate参数了cout << Plus1(5, 3) << endl;//等价于cout<<Plus(5,4.0,3)<<endl;}
对于常量,由于设置了常量,那个就不算参数了,因为我们不会传那个参数了。
3.绑定成员函数
当然,std::bind 还支持绑定成员函数和成员函数指针,以及任意可调用对象。你可以在调用时提供实际参数来替换占位符。
class SubType
{
public:static int sub(int a, int b){return a - b;}int ssub(int a, int b, int rate){return (a - b) * rate;}
};int main()
{function<double(int, int)> Sub1 = bind(&SubType::sub, placeholders::_1, placeholders::_2);SubType st;function<double(int, int)> Sub2 = bind(&SubType::ssub, &st, placeholders::_1, placeholders::_2, 3);cout << Sub1(1, 2) << endl;cout << Sub2(1, 2) << endl;function<double(int, int)> Sub3 = bind(&SubType::ssub, SubType(), placeholders::_1, placeholders::_2, 3);cout << Sub3(1, 2) << endl;cout << typeid(Sub3).name() << endl;
}
对于static静态成员函数,我们可以直接调用那个函数,但是对于非静态函数,我们要取函数的地址(这里是特殊处理,要加一个取地址符号,其他情况都不用),由于类要掉非静态函数肯定要一个对象,所以还要传一个对象或者对象的地址才行。
总结
更新不易,辛苦各位小伙伴们动动小手,👍三连走一走💕💕 ~ ~ ~ 你们真的对我很重要!最后,本文仍有许多不足之处,欢迎各位认真读完文章的小伙伴们随时私信交流、批评指正!
专栏订阅:
每日一题
C语言学习
算法
智力题
初阶数据结构
Linux学习
C++学习
更新不易,辛苦各位小伙伴们动动小手,👍三连走一走💕💕 ~ ~ ~ 你们真的对我很重要!最后,本文仍有许多不足之处,欢迎各位认真读完文章的小伙伴们随时私信交流、批评指正!

相关文章:
)
【C++】C++11(上)
🚀write in front🚀 📜所属专栏: C学习 🛰️博客主页:睿睿的博客主页 🛰️代码仓库:🎉VS2022_C语言仓库 🎡您的点赞、关注、收藏、评论,是对我最大…...

工具分享:通过滑块拉取CAN报文信号数值自动发送报文
0. 概述 CAN报文发送工具使用wxpython进行开发,配套Excel模板可以通过修改Excel自定义界面展示的信号名称和信号的属性;同时,工具支持导入现场采集的报文数据自动按照配套Excel模板定义的报文发送周期进行模拟发送。 由于是我好几年前开发的作品,一些开发细节也记得不是很…...

android 折叠屏开发适配全解析:多窗口、铰链处理与响应式布局
安卓适配折叠屏指南 折叠屏设备为安卓开发带来了新的机遇和挑战。以下是适配折叠屏的关键要点: 1. 屏幕连续性检测 // 检查设备是否支持折叠屏特性 private fun isFoldableDevice(context: Context): Boolean {return context.packageManager.hasSystemFeature(&…...

Cloudera CDP 7.1.3 主机异常关机导致元数据丢失,node不能与CM通信
问题描述 plaintext ERROR Could not load post-deployment data from /var/run/cloudera-scm-agent/process/ccdeploy_hadoop-conf_etchadoopconf.cloudera.yarn_-8903374259073700469 IOError: [Errno 2] No such file or directory: /var/run/cloudera-scm-agent/proce…...

超越 DeepSeek-R1,英伟达新模型登顶
近日,英伟达发布全新开源模型系列 Llama-Nemotron,凭借卓越性能引发业界关注,有望重塑开源 AI 格局。 该系列在推理能力上超越 DeepSeek-R1,内存效率与吞吐量显著提升。其创新采用合成数据监督微调与强化学习训练,全方…...

centos8.5.2111 更换阿里云源
使用前提是服务器可以连接互联网 1、备份现有软件配置文件 cd /etc/yum.repos.d/ mkdir backup mv CentOS-* backup/ 2、下载阿里云的软件配置文件 wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-vault-8.5.2111.repo 3、清理并重建…...

阿里云平台与STM32的物联网设计
基于阿里云平台与STM32的物联网设计方案可结合硬件选型、通信协议、云端配置及功能实现等多个维度进行设计。以下是综合多个参考案例的详细设计方案: 一、硬件选型与架构设计 主控芯片选择 STM32系列:推荐使用STM32F103(如STM32F103ZET6、STM…...

ESP32- 开发笔记- 软件开发 6 蓝牙协议栈 1
1 蓝牙 ESP32 是一款支持蓝牙功能的强大微控制器,ESP-IDF (Espressif IoT Development Framework) 提供了完整的蓝牙开发支持。 1.1 蓝牙模式 ESP32 支持两种蓝牙模式,即同时支持经典蓝牙和低功耗蓝牙。 1.1.1 蓝牙经典 (BT/BDR/EDR) 支持传统蓝牙协…...

python爬虫爬取网站图片出现403解决方法【仅供学习使用】
基于CSDN第一篇文章,Python爬虫之入门保姆级教程,学不会我去你家刷厕所。 这篇文章是2021年作者发表的,由于此教程,网站添加了反爬机制,有作者通过添加cookie信息来达到原来的效果,Python爬虫添加Cookies以…...

利用动态数字孪生:Franka Research 3 机械臂在机器人策略评估中的创新实践——基于Real-is-Sim框架的仿真与现实闭环验证
一、前言: 在机器人技术飞速发展的今天,如何高效、准确地评估机器人在现实世界中的操作策略,成为制约机器人技术进一步突破的关键瓶颈。传统方法往往依赖于耗时且成本高昂的真实世界测试,而模拟环境虽能提供便利,却因…...
)
Spark-Core(RDD行动算子)
一、RDD行动算子 行动算子就是会触发action的算子,触发action的含义就是真正的计算数据。 1、reduce 函数签名: def reduce(f: (T, T) > T): T 函数说明:聚集 RDD 中的所有元素,先聚合分区内数据,再聚合分区间…...

spark转换算子
在 Apache Spark 中,转换算子(Transformation)是用于对 RDD(弹性分布式数据集)进行转换操作的函数。这些操作是惰性的,即在调用转换算子时,Spark 并不会立即执行计算,而是记录下转换…...

hadoop的运行模式
(一)Hadoop的运行模式 hadoop一共有如下三种运行方式: 1. 本地运行。数据存储在linux本地,测试偶尔用一下。我们上一节课使用的就是本地运行模式hadoop100。 2. 伪分布式。在一台机器上模拟出 Hadoop 分布式系统的各个组件&#x…...

力扣——25 K个一组翻转链表
目录 1.题目描述: 2.算法分析: 3.代码展示: 1.题目描述: 给你链表的头节点 head ,每 k 个节点一组进行翻转,请你返回修改后的链表。 k 是一个正整数,它的值小于或等于链表的长度。如果节点总…...

React Router Vs Vue Router
文章目录 前言✅ React Router vs Vue Router 对比一览🧩 React Router 的底层原理简述① 路由声明与匹配(基于 JSX)② 历史模式管理③ 响应式状态处理④ 路由渲染机制(Outlet) ✅ 总结:原理是否一样&#…...

Spark中RDD算子的介绍
引言 在大数据处理领域,Apache Spark凭借其高效性和灵活性备受青睐。而弹性分布式数据集(Resilient Distributed Datasets,简称RDD)则是Spark的核心数据结构。RDD算子作为操作RDD的关键工具,掌握它们对于充分发挥Spar…...

Vivo 手机官网交互效果实现解析
在现代网页设计中,流畅的滚动交互和精美的视觉效果是提升用户体验的关键。本文将深入解析 Vivo 手机官网 Demo 中的一个核心交互效果 —— 基于滚轮滚动的内容展示系统。这个系统允许用户通过滚动鼠标滚轮来浏览不同的手机镜头配置信息,同时伴随平滑的过…...

powershell批处理——io校验
powershell批处理——io校验 在刷题时,时常回想,OJ平台是如何校验竞赛队员提交的代码的,OJ平台并不看代码,而是使用“黑盒测试”,用测试数据来验证。对于每题,都事先设定了很多组输入数据(data…...

AI——认知建模工具:ACT-R
ACT-R(Adaptive Control of Thought—Rational)是一种用于模拟人类认知过程的计算架构,广泛应用于心理学、认知科学和人工智能研究。它通过模块化的方式模拟记忆、注意力、学习、决策等认知机制。以下是ACT-R的核心概念、安装方法、基础语法及…...

Docker 容器镜像环境的依赖导出
#工作记录 如果我们想获取 Docker 容器中已有镜像的所有的依赖包信息,包括其他可能的系统依赖,用于在其他环境(如 WSL 或 Windows)中重新搭建相同的运行环境。 以下是完整的步骤: 1. 导出 Python 依赖(r…...

[ubuntu]fatal error: Eigen/Core: No such file or directory
确认是否安装了eigen3sudo apt-get install libeigen3-dev 解决 fatal error: Eigen/Core: No such file or directory 如果已经安装,但当调用 eigen 库时,报错:fatal error: Eigen/Core: No such file or directory 这是因为 eigen 库默认…...
)
《硬件视界》专栏介绍(持续更新ing)
名人说:路漫漫其修远兮,吾将上下而求索。 —— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 ✨ 专栏简介📚 当前专栏目录(持续更新中)&a…...

TypeScript类型挑战-刷题
TypeScript类型挑战 vscode刷题 vscode 插件 热身题 // Test Cases import type { Equal, Expect, NotAny } from "./test-utils";type cases [Expect<NotAny<HelloWorld>>, Expect<Equal<HelloWorld, string>>];// Your Code Here …...
--缓冲流转换流序列化流)
Java后端开发day43--IO流(三)--缓冲流转换流序列化流
(以下内容全部来自上述课程) 缓冲流 1. 字节缓冲流 原理:底层自带了长度为8192的缓冲区提高性能 1.1拷贝文件(一次读写一个字节) //1.创建缓冲流的对象 BufferedInputStream bis new BufferedInputStream(new Fi…...

Nginx性能调优与深度监控
一:Nginx性能调优 1.更改进程数和连接数 (1)进程数 在高并发环境中,需要启动更多的Nginx进程以保证快速响应,用以处理用户的请求,避免造成阻塞。使用psaux命令查看Nginx运行进程的个数。从命令执行结果可…...

【LeetCode】高频 SQL 50题 题解
目录 查询 可回收且低脂的产品 寻找用户推荐人 大的国家 文章浏览 I 无效的推文 连接 使用唯一标识码替换员工ID 产品销售分析 I 进店却未进行过交易的顾客 上升的温度 每台机器的进程平均运行时间 员工奖金 学生们参加各科测试的次数 至少有5名直接下属的经理 …...

基于Qt的app开发第六天
写在前面 博主是一个大一下的计科生,现在正在做C面向对象程序设计的课程设计,具体功能可以看本专栏的第一篇博客。 目前的进度是:配好MySQL驱动->设计完界面->实现各个界面的切换 这一篇博主要初步实现待办板块的功能,即新建…...

剑指大规模 AI 可观测,阿里云 Prometheus 2.0 应运而生
作者:曾庆国(悦达) Prometheus 大家应该非常熟悉,正文开始前,让我们一起来回顾开源 Prometheus 项目的发展史。Prometheus 最初由 SoundCloud 的工程师 Bjrn Rabehl 和 Julius Volz 于 2012 年开发。当时,…...

阿里云2核2g安装nexus
阿里云2核2g安装nexus # 安装 JDK 1.8 sudo yum install -y java-1.8.0-openjdk-devel# 验证安装 java -version创建运行用户 cd /opt sudo wget https://download.sonatype.com/nexus/3/latest-unix.tar.gz sudo tar -xzf latest-unix.tar.gz sudo mv nexus-3* nexussudo us…...

eFish-SBC-RK3576工控板USB HOST接口USB3.0测试操作指南
本小节特指丝印号为J8的USB HOST接口,本开发板只有两个USB3.0接口,无USB2.0 这里接U盘测试。 在不接入任何USB外设的情况下,先查看/dev目录下是否存在/dev/sd*设备,执行命令: $ ls /dev/sd* 如下图所示: …...

嵌入式软件学习指南:从入门到进阶
嵌入式软件是物联网(IoT)、汽车电子、智能家居等领域的核心技术之一。它涉及硬件与软件的紧密结合,要求开发者不仅会写代码,还要理解底层硬件的工作原理。本文将带你系统了解嵌入式软件的学习路径、核心知识体系及实用资源推荐。 …...

【论文阅读】Adversarial Training Towards Robust Multimedia Recommender System
Adversarial Training Towards Robust Multimedia Recommender System 题目翻译:面向鲁棒多媒体推荐系统的对抗训练 论文链接:点这里 标签:多媒体推荐、对抗训练、推荐系统鲁棒性 摘要 随着多媒体内容在网络上的普及,迫切需要开…...

转换算子和行动算子的区别
转换算子会从一个已经存在的数据集 (RDD)中生成一个新的数据集 (RDD),比如map就是一个转换算子,它通过映射关系从一个RDD生成了一个新的RDD。 行动算子 (actions): 行动算子在进行数据集计算后会给driver程序返回一个值。 转换算子和行动算子最大的区别࿱…...

Selenium的driver.get_url 和 手动输入网址, 并点击的操作,有什么不同?
我在搞爬取的时候,发现有些网站直接用driver.get(url) 跳转到目标特定的网址的时候,会被强制跳转到其他的网址上,但是如果是自己手动,在网址栏那里输入网址,并点回车,却能完成跳转。 这是在使用 Selenium …...

【强化学习】强化学习算法 - 多臂老虎机问题
1、环境/问题介绍 概述:多臂老虎机问题是指:智能体在有限的试验回合 𝑇 内,从 𝐾 台具有未知奖赏分布的“老虎机”中反复选择一个臂(即拉杆),每次拉杆后获得随机奖励,目…...

Spring MVC Controller 方法的返回类型有哪些?
Spring MVC Controller 方法的返回类型非常灵活,可以根据不同的需求返回多种类型的值。Spring MVC 会根据返回值的类型和相关的注解来决定如何处理响应。 以下是一些常见的 Controller 方法返回类型: String: 最常见的类型之一,用于返回逻辑…...

Diamond iO:实用 iO 的第一缕曙光
1. 引言 当前以太坊基金会PSE的Machina iO团队宣布,其已经成功实现了 Diamond iO: A Straightforward Construction of Indistinguishability Obfuscation from Lattices —— 其在2025年2月提出的、结构简单的不可区分混淆(iO)构造…...

Spring MVC中跨域问题处理
在Spring MVC中处理跨域问题可以通过以下几种方式实现,确保前后端能够正常通信: 方法一:使用 CrossOrigin 注解 适用于局部控制跨域配置,直接在Controller或方法上添加注解。 示例代码: RestController CrossOrigin…...
Python爬虫数据存储技巧:二进制格式(Pickle/Parquet)性能优化实战)
Python爬虫(20)Python爬虫数据存储技巧:二进制格式(Pickle/Parquet)性能优化实战
目录 背景介绍一、二进制存储的核心优势二、Python Pickle:轻量级对象序列化1. 基本介绍2. 代码示例3. 性能与局限性 三、Apache Parquet:列式存储的工业级方案1. 基本介绍2. 代码示例(使用PyArrow库)3. 核心优势 四、性能对比与选…...
什么是MCP?)
MCP系列(一)什么是MCP?
一、MCP 是什么:从 USB-C 到 AI 的「万能接口」哲学 MCP(Model Context Protocol,模型上下文协议) 是Anthropic于2024年11月推出的AI跨系统交互标准,专为解决LLM(大语言模型)的「数字失语症」—…...

使用Java NIO 实现一个socket通信框架
使用Java NIO(非阻塞I/O)实现一个Socket通信框架,可以让你构建高性能的网络应用。NIO提供了Channel、Buffer和Selector等核心组件,支持非阻塞模式下的网络编程。下面是一个简单的例子,展示了如何使用Java NIO创建一个基本的服务器端和客户端进行Socket通信。 1.服务器端 …...

Web前端技术栈:从入门到进阶都需要学什么内容
概述 Web前端技术栈:从入门到进阶都需要学什么内容。 1. jQuery:经典高效的DOM操作利器 作为早期前端开发的“瑞士军刀”,jQuery通过简洁的语法和链式调用大幅简化了DOM操作与事件处理。其核心模块如选择器引擎、动画效果和Ajax交互至今仍值…...

Kepware 连接Modbus TCP/IP
Modbus TCP modbus tcp 是modbus协议的一个变种,基于TCP/IP协议栈在以太网上进行通信。Modbus TCP采用客户端-服务器(Master-Slave)的通信模型。客户端发起请求,服务器响应请求。一个网络中可以有多个客户端和服务器,…...

PyCharm连接WSL2搭建的Python开发环境
目录 一、开启WSL2服务 二、安装Ubuntu 三、安装Anaconda 四、构建Tensorflow_gpu环境 五、PyCharm连接到WSL2环境 使用 PyCharm 连接 WSL2 搭建 Python 开发环境的主要目的是结合 Windows 的易用性和 Linux 的开发优势,提升开发效率和体验。以下是具体原因和优…...

JVM中类加载过程是什么?
引言 在Java程序运行过程中,类的加载是至关重要的环节,它直接关系到程序的执行效率和安全性。类加载不仅仅是简单地将.class文件读取到内存中,而是经历了加载、连接(包含验证、准备和解析)以及初始化等多个复杂步骤&a…...

JVM中对象的存储
引言 在 Java 虚拟机中,对象的内存布局是一个非常基础且重要的概念。每个 Java 对象在内存中都由三个主要部分构成:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)。…...
:UGC商业模式的指标剖析与运营策略)
精益数据分析(48/126):UGC商业模式的指标剖析与运营策略
精益数据分析(48/126):UGC商业模式的指标剖析与运营策略 在创业和数据分析的学习之旅中,探索不同商业模式的运营奥秘是我们不断前行的动力。今天,依旧怀揣着和大家共同进步的期望,深入研读《精益数据分析》…...

SpringBoot优雅参数检查
SpringBoot优雅参数检查 在 Spring Boot 中,参数验证通常基于 JSR-380(Bean Validation 2.0)规范,结合 javax.validation(或 jakarta.validation)和 Hibernate Validator 实现。以下是常用的验证注解及其意…...
PMSM驱动控制学习---分流电阻采样及重构)
(九)PMSM驱动控制学习---分流电阻采样及重构
在电机控制当中,无论是我们的控制或者电机工作情况的检测,都十分依赖于电机三相电流的值, 所以相电流采样再在FOC控制中是一个特别关键的环节。 在前几篇中我们介绍了逆变电路的相关内容,所以在此基础上我们接着说道电流采样。目前…...

医疗人工智能大模型中的关键能力:【中期训练】mid-training
引言 医疗人工智能(AI)领域的快速发展正在重塑医疗保健的未来。从辅助诊断到个性化治疗方案,AI技术已经显示出改变医疗实践的巨大潜力。然而,在将AI技术应用于医疗场景时,我们面临着独特的挑战。医疗数据的复杂性、决策的高风险性以及对可解释性的严格要求,都使得医疗AI…...