剑指大规模 AI 可观测,阿里云 Prometheus 2.0 应运而生
作者:曾庆国(悦达)
Prometheus 大家应该非常熟悉,正文开始前,让我们一起来回顾开源 Prometheus 项目的发展史。Prometheus 最初由 SoundCloud 的工程师 Björn Rabehl 和 Julius Volz 于 2012 年开发。当时,SoundCloud 需要一个更高效、灵活的监控系统来替代传统工具(如 Nagios 和 Graphite),以应对快速增长的分布式系统复杂性。2015 年,Prometheus 在 GitHub 上开源,并发布 v0.1.0。紧接着 2016 年随着云原生时代的到来,继 Kubernetes 之后,Prometheus 成为 CNCF 的第二个正式项目,随后在 2018 年成为第二个正式毕业项目。2024 到 2025 年 Prometheus 开源社区发布了 3.X 版本,活力不减当年。Prometheus 项目以灵活简单的数据协议,丰富的生态工具链和云原生项目广泛地默认支持,成为云原生时代监控领域的事实规范。
作为国内最早提供 Prometheus SaaS 化服务的厂商,阿里云 Prometheus 团队一直在跟进开源 Prometheus 的开发进展。目前阿里云 Prometheus 上已经有数万客户在使用,每天写入几十 PB 的流量,广泛应用在云产品监控、Kubernetes 监控、业务监控、AI Infra 监控和 AI 推理监控等场景。形成了阿里云上最大规模的观测指标数据生态。
2024 年开始,整个开源技术社区展现出 ALL IN AI 的趋势,推动着 AI 时代的到来。那么 Prometheus 是否会成为上个时代的产物无法适配 AI 时代的业务诉求呢?我们的答案是否定的。恰恰相反我们看到随着人工智能技术的快速发展,AI 技术栈正经历从单点模型到复杂系统、从单模态到多模态、从静态推理到动态服务化的演进。在这一过程中,AI 系统的复杂性呈指数级增长:
-
模型规模:参数量从百万级跃升至万亿级,训练和推理的资源需求激增,然而算力紧缺是国内短期内难以解决的难题;
-
系统架构:从单机部署转向分布式集群,大模型服务通过 SGLang,VLLM,Ray 等引擎分布式部署。涉及 GPU/TPU 集群、分布式存储、流水线调度等多组件协同;
-
数据流复杂性:基础训练需要训练数据、推理请求、特征工程、模型版本等形成多维度数据流。推理服务结合 MCP 工具链形成了远超过往的复杂分布式系统。
大规模 AI 可观测的挑战
大规模 AI Infra
AI Infra 核心关注 AI 模型训练和推理所依赖的基础算力供给。通常我们谈 AI Infra 主要会包括以下几方面:
(1)硬件设备统一监控
AI Infra 管理一些特有的设备以支撑 AI 计算,当然常规 CPU 算力同样需要,统一监控需要覆盖下述场景。
-
异构硬件管理:GPU、TPU、CPU、FPGA 的混合部署增加了资源分配的复杂性,需要有效的全局监控来提供可靠的基础设施。
-
GPU 健康状态监控:GPU 内存泄漏、温度异常、显存不足等问题可能导致训练中断。
-
网络与存储 IO:模型训练过程通常涉及大量的网络交换和存储数据交换,继而产生了配套的高性能网络、大规模存储等设施,网络与存储 IO 的波动直接影响训练效率。
-
能耗与成本控制:AI 训练的高能耗需实时监控以优化资源利用率。
(2)大规模容器集群
我们观察到,大模型训练集群目前基本采用 Kubernetes 架构。OpenAI 在去年底发生大规模故障,核心就是因为 Kubernetes 集群 API Server 发生雪崩问题。据公开信息,早在 2021 年,OpenAI 训练 GPT-3 的集群规模在 7500+ 个节点(远超社区 5000 节点最大规模限制),使用 Prometheus 收集大量指标数据。 本次故障的诱因就是因为节点上安装的遥测组件导致 API Server 故障继而导致雪崩。在阿里云内部,大规模集群节点超过 1w 节点,数十万的 Pod 数量。对于观测组件的挑战非常大,然而全方面的观测能力是必需。针对大规模容器集群的观测数据(指标、元数据、日志等)采集、计算和存储,特别是针对训练集群,离线任务集群等 Pod 变更非常频繁的情况,常规开源的组件都是无法支撑的。
(3)云上异构产品
云上的用户搭建用于训练或推理服务,通常使用到多种云产品。以阿里云为例,灵骏计算或 ECS 等产品提供算力,网络、存储相关产品提供高性能存储和网络,PAI 提供 AI PaaS 平台产品,百炼等提供模型服务。还有正在快速发展的 AI 网关、FC 计算等。目前阿里云已基本实现核心产品的监控数据以 Prometheus 规范统一供给,以实现异构云产品的统一监控。这种统一大大降低了用户获取和使用异构产品监控数据的门槛。
推理 App 架构快速发展
随着 2025 年 DeepSeek 的火爆,大模型推理服务持续火爆,几乎所有的互联网企业、数字化转型企业都已开始搭建企业自己的推理服务。目前我们观察到,常见的 AI 应用架构大概如下:
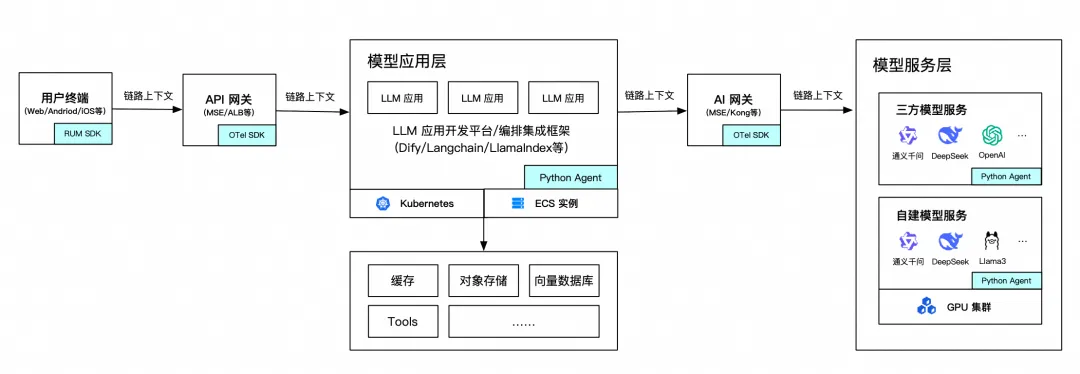
对于这种新型技术架构,监控指标设计非常重要。通过模型服务服务于模型应用的推理性能、成功率、准确率和成本都是需要重点关注的。对于一次推理的端到端全过程以及每个阶段的关键指标我们认为如下:
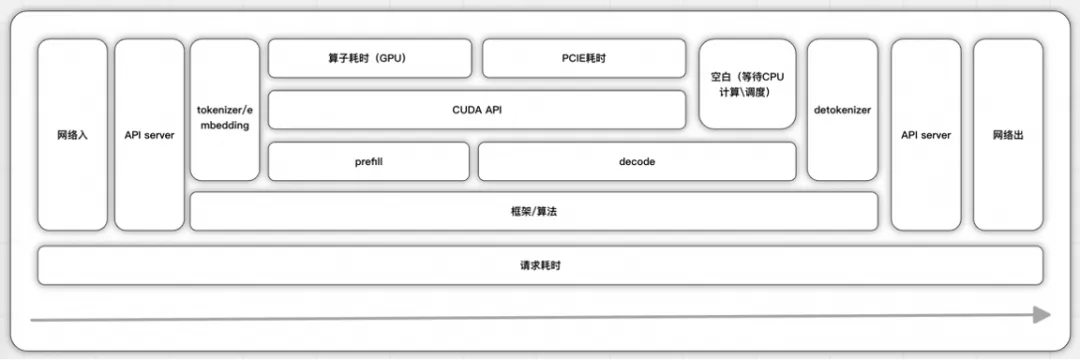
- Time To First Token (TTFT): 首 Token 延迟,即从接收请求到生成第一个 token 的时间,通常要求控制在 2-3 秒内。该指标直接反映 Prefill 阶段的计算效率
- Prefill 是计算密集型,GPU 的利用率较高,所以也需要观测 GPU 的使用率和 KV Cache 的利用率
- Time Per Output Token (TPOT):每个输出 token 的延迟(不含首个 Token),一般需低于 50 毫秒以保证生成流畅性(约每秒 20 个 token)
- MBU:内存带宽利用率,decode 是 IO 密集型,需要把参数和 KV cache 从显存加载到计算单元,这个过程计算能力一般不是瓶颈,显存带宽才是瓶颈,而在多卡集群的情况下,PCIe 卡带宽或者速度更快的 NVlink 带宽有可能成为瓶颈
- throughout:吞吐量,即每秒针对所有请求生成的 token 数。这个和 batchsize 有关,与 ttot 和 tpot 都是有制衡作用,推理性能目标是,最快的首个 token 响应时间、最高的吞吐量和最快的每个输出 token 时间。
- Token 黑洞问题,输入 Token 或输出 Token 循环重复输出,基于 AI 网关识别 Token 黑洞。
推理服务的全面监控对于 AI 应用的稳定运行至关重要。目前,黄金指标体系基本已经形成,新的稳定性问题也在持续出现,通过多模态指标、Trace 和日志数据实现对 AI 应用的观测,我们认为比历史任何时候的需求都更为重要。
MCP Tools 模式的分布式
MCP 定义了模型与工具服务之间的交互协议,这使得模型服务与海量的数字化服务产生了链接。这意味着通用模型服务将托举起一个架构负责的大规模分布式系统。通常对于用户的一个对话需求,背后需要几个甚至几十个 Tools 来完成。其中如果出现性能瓶颈或 Token 黑洞,都会导致整个推理过程不符合预期。因此对于 MCP Tools 本身和上下游的统一监控尤为重要。对于分布式系统的统一监控是 Prometheus 监控体系的核心优势。
多模态可观测数据
Prometheus 社区目前也在与 OpenTelemetry 的融合,推动指标(Metrics)、日志(Logs)、追踪(Tracing)的统一收集与处理。在 AI 可观测场景,完整的洞察方案都是需要结合指标、调用链和日志。以实现快速的故障定位。指标通常用来统计数据、告警、发现问题,调用链负责追逐分布式系统调用,例如 MCP Server 或 Agent2Agent 以定位故障点位或代码行数,日志用以明确具体的故障原因。良好的观测系统依赖业务开发者做好指标定义、和 Trace 埋点。通常需要通过数据计算技术实现多种数据之间的转换,或通过外挂探针技术实现数据精确采集,这些都是可观测方案的核心。
阿里云 Prometheus 2.0 方案
为了应对大规模 AI 可观测的挑战,阿里云 Prometheus 团队总结 1.0 的产品技术在云原生时代大规模落地的经验,重新整合离散的技术,推出了全新的阿里云 Prometheus 2.0 方案。本方案同样全面兼容 Prometheus 社区的协议规范,提供用户全方位的使用体验提升。接下来我从数据采集、存储、计算、查询、数据生态和分析语言、业务系统集成等维度做简要介绍。
数据采集 LoongCollector
团队坚持自研指标采集服务,本次升级进行了全面的重构。将指标采集和服务发现能力全面移植到阿里云开源 LoongCollector,以实现一个支持多模态数据大规模采集的统一组件。目前 LoongCollector 已支持日志、指标、元数据、Profiling 等数据形态。从指标数据看,LoongCollector 架构上区分服务发现模块 LoongOperator 和数据采集 Pipeline Collector。以容器集群数据采集为例,LoongOperator 实现了超 10w+ 的 Target 发现规模和分布式调度,Collector 副本数根据 Target 数量和数据量自动扩容。全面兼容社区 CRD 规范,支持 ServiceMonitor, PodMonitor,Prometheus Rule,PrometheusConfig 等。Collector 部分采用 C++ 实现,在内部使用的场景中,跑出了单核 70 M/s 的性能。同时全面兼容社区 Prometheus Agent,VM Agent 对于指标采集的规范和约定。同等数据规模下,性能较 VM Agent(目前开源实现中性能较好的)内存下降 50%,CPU 下降 20%。在随后的版本计划中,LoongCollector 将发行标准 Kubernetes 集群版、SideCar 版和主机版本,以实现无处不在的数据采集。
大规模时序存储
阿里云 Prometheus 1.0 的时序存储独立建设,与日志、Trace 等数据形态互通性不佳。随着 AI 时代到来以及全栈可观测需求的发展。我们越发认为可观测数据的采集和存储需要统一,生态数据处理能力应该互通。因此在 2.0 版本中,我们将时序存储底层与阿里云日志、Trace 等数据存储形态实现统一。这种统一体现在网关统一,存储层统一,计算和查询技术栈一致。在此基础上,自研全新的时序数据引擎,在内存实时压缩、文件压缩、自适应 Block、多数据类型、支持数据更新等技术上实现突破。在查询计算引擎上,为了充分发挥 CPU 多核、指令加速能力,以及对计算、内存资源的精细化控制。相对于社区目前主流的 Go 语言实现的 Prometheus 计算引擎,我们使用 C++ 来开发新的 Prometheus 计算引擎。新的引擎对于计算流程上及实现上进行了全面改造,实现了更高的性能、稳定性和 QoS 控制。此外在 PromQL 的兼容性测试中,Prometheus C++ 计算引擎与开源的兼容度为 100%。
在线上一些典型的查询场景,目前 Prometheus 2.0 和 VictoriaMetrics 的查询延迟如下:
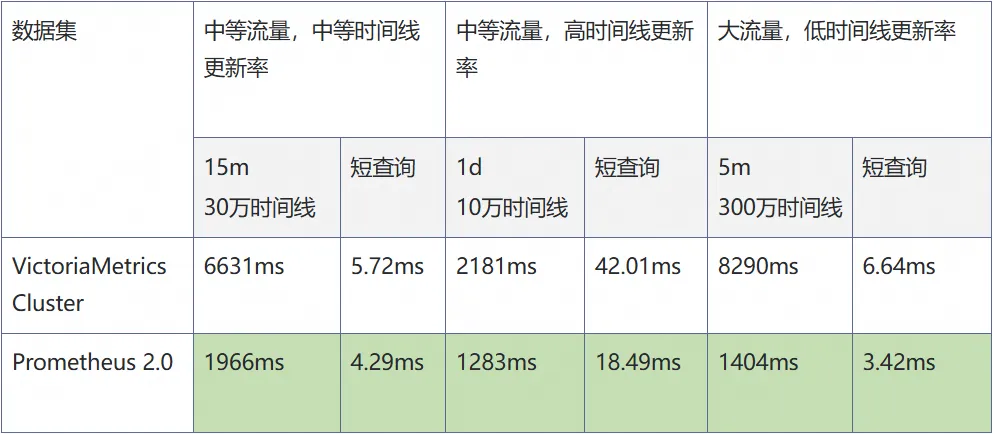
从测试结果可以看出,阿里云 Prometheus 2.0 的查询性能对比 VictoriaMetrics 在各个场景下全面领先。
预聚合计算(RecordingRule 与 ScheduleSQL)
对于指标相关的预聚合计算的考虑,我们认为除了 Metric2Metric 以外,Log2Metric,Metric2Others 在 AI 全栈观测中应用广泛。Prometheus 社区在 2018 年就引入 RecordingRule 规范和实现。提供以 PromQL 语法框架下的 Metric2Metric 计算。这种能力在阿里云 Prometheus 1.0 版本中同样提供,服务了数千的用户,运行了数万的计算任务。但我们认为该功能没有达到 Stable 状态。1.0 主要继承了社区的实现,从任务调度上出现较多的调度不均、失效等问题,运维成本较高。
在 2.0 版本中,我们基于在日志服务中广泛使用的调度和计算引擎,重写了 RecordingRule 实现。从调度上解决了调度不均、调度失效、调度性能不足的问题,实现更大规模的指标数据预聚合计算。计算上基于全新的时序引擎,以实现高性能的数据加载和计算。这种计算能力将广泛用于云产品监控,容器监控等场景。通过预计算来解决 PromQL 复杂,容器指标理解门槛高,查询计算成本高等问题。
只有 RecordingRule,我们认为是不够的。我们经常收到用户需求,能不能用类似 SQL 的语法来进行指标计算,因为业务开发者对于 PromQL 的掌握是有门槛的。另外,由于 Prometheus PromQL 的限制,对于涉及多值或更多算子的需求是难以满足的。由于我们将指标存储与阿里云日志存储实现统一,天然集成了日志领域的 ScheduleSQL 计算能力。这是一种类 SQL 的语法,可以实现对指标数据多样化的分析。同样 ScheduleSQL 作用于常规日志数据时,可以直接从日志计算出统计指标存入 Prometheus。全面打通了数据格式间的孤岛。
查询聚合 View
聊完采集、存储和计算,来到数据查询阶段。阿里云 Prometheus 2.0 除了提供标准的单实例 Query、RemoteRead 接口以外,针对统一监控的查询场景提供查询时聚合 View 的产品能力。在 1.0 版本中该功能已经推出并得到广泛使用,它支持跨区域、跨账号的统一查询多个 Prometheus 实例。 这里利用到算子下推、数据自动路由等技术实现数据查询加速。
在 2.0 版本中,得益于底层存储的融合,聚合计算进一步加强。查询引擎升级为通用聚合引擎,底层支持聚合指标存储、日志存储和事件存储,结合 SPL 可以实现异构数据的统一分析。另外在跨区域数据查询上优化了网络链路,性能得到显著提升。
云上指标数据生态
除了技术全面升级以外,阿里云 Prometheus 的核心竞争力是提供了全面的云产品监控数据生态。截止目前,已经超过 80% 的核心云产品底层采用 Prometheus 技术栈采集、存储和计算监控数据。我们通过 Prometheus 标准协议向用户提供最为及时、完善的云产品监控指标,一举从过去分钟级的指标数据提升到秒级。这非常有利于全面上云的用户建立全栈监控。
目前,阿里云 Prometheus 为用户提供灵骏计算、PAI、百炼、AI 网关、 FC 等 AI 全技术栈产品的完整监控数据。
智能分析语言 PromQL 与 SPL
PromQL 是 Prometheus 开源项目带来的指标查询语言。PromQL 通过标签驱动、直观语法、强大运算能力和生态集成,成为现代可观测性指标工具链的核心。它不仅简化了时间序列数据的查询与分析,还通过与 Prometheus 生态的深度整合,为系统监控、性能调优和故障排查提供了高效、灵活的解决方案。无论是开发人员调试微服务,还是运维团队管理云原生环境,PromQL 都是不可或缺的利器。
阿里云 Prometheus 2.0 查询引擎实现了 PromQL 的 100% 社区兼容性,并提供了额外的扩展算子。这使得用户可以无缝转移社区成果到阿里云 Prometheus 服务,没有迁移成本。
对于更高级的数据计算,例如数据富化(增加标签),多模数据联合计算等需求,数据关联查询等需求,我们即将提供一种新的计算形式 SPL。它是一种 Pipeline 模式的数据计算编排,SPL 提供了大量的算子和多路数据提取能力,可以直接作用于数据流处理。用户可以基于 SPL 实现指标数据的实时加工处理。也可以用于与 AI 系统的集成来实现标准的数据提取。指标数据不是可观测的唯一,与日志、Trace、Entity 等数据实现关联分析是故障洞察最为有效的手段。 SPL 为实现该能力提供支撑。
业务分析-大数据生态集成
指标数据除了用于稳定性监控,服务运维人员以外,已经有大量的用户将 Prometheus 技术栈用于业务分析服务于业务和运营。用户通过在业务代码中植入 SDK 来埋点业务指标,通过阿里云 Prometheus 服务提供的可靠采集、存储服务管理数据,最后通过 Grafana 来可视化分析。除此之外,我们还有其他手段来与业务数据打通吗?通常业务系统的离线业务分析会采用大数据技术栈,例如 Flink、Kafka 等。对此,阿里云 Prometheus 服务借助底层统一能力,支持用户通过 Kafka 或 Flink RemoteWrite Sink 等模式,将时序数据从其他数据分析平台写入阿里云 Prometheus。也可以通过数据订阅消费、数据投递等渠道将数据写入大数据分析体系,实现了良好的数据互通性。
新版本的实现从去年开始在阿里云内部投产,截止目前 Prometheus 2.0 已在内部 AI 系统的可观测中全面落地:
- 单集群规模:常规模式下支持 5K+ 集群节点(10w+ Targets)的采集规模、提供 1 GB/s 的数据采集能力;针对部分超大规模集群,仅需禁用部分通用功能后实现可靠的数据采集。
- 成本优势:某超大规模推荐系统客户将监控成本降低 40%,同时查询性能提升 2 倍;
- AI 专用场景:为百炼、通义千问等大模型提供从训练资源利用率到推理 SLA 的全链路监控。
阿里云 Prometheus 2.0 服务正在整合到阿里云云监控平台,通过阿里云云监控控制台对客提供服务。存量 v1 Prometheus 实例我们会逐步后台迁移到新版本。
为了为你提供更为标准的云上服务, 阿里云 Prometheus 2.0 服务的 OpenAPI 体系进行了升级迁移,后续你可以从云监控 2.0 的 API 体系(cms-20240330)中获取到。需要基于 OpenAPI 进行集成的用户需要做出对应的 API 变更,我们在此表达歉意。如果您对本文介绍到的某些特性有兴趣,欢迎通过用户群、工单等形式与我们交流。
结语: AI 观测的未来已来
阿里云 Prometheus 2.0 通过存储、计算、智能分析、生态的全面升级,重新定义了面对超大规模 AI 系统的商业化 Prometheus 方案。其核心价值不仅在于技术指标的突破,更在于实现了可观测数据生态从云上“基础设施层”延伸到“业务模型层”的全覆盖,为 AI 工程化落地提供了不可或缺的观测工具。随着 AI 技术向实时性、大规模化演进,阿里云 Prometheus 2.0 或将成为企业构建下一代 AI 系统的基础设施基石。阿里云 Prometheus 2.0 是阿里云可观测产品族的一员,在不久的将来我们将全面发布云监控 2.0 产品,以提供更为全面的智能观测技术和产品栈。
在此,谨代表阿里云 Prometheus 团队全体开发者,感谢多年以来数万用户的支持和需求反馈,是你们推动了阿里云 Prometheus 服务的持续成长。我们继续努力,为您提供最为可靠的可观测基础数据服务。
相关文章:

剑指大规模 AI 可观测,阿里云 Prometheus 2.0 应运而生
作者:曾庆国(悦达) Prometheus 大家应该非常熟悉,正文开始前,让我们一起来回顾开源 Prometheus 项目的发展史。Prometheus 最初由 SoundCloud 的工程师 Bjrn Rabehl 和 Julius Volz 于 2012 年开发。当时,…...

阿里云2核2g安装nexus
阿里云2核2g安装nexus # 安装 JDK 1.8 sudo yum install -y java-1.8.0-openjdk-devel# 验证安装 java -version创建运行用户 cd /opt sudo wget https://download.sonatype.com/nexus/3/latest-unix.tar.gz sudo tar -xzf latest-unix.tar.gz sudo mv nexus-3* nexussudo us…...

eFish-SBC-RK3576工控板USB HOST接口USB3.0测试操作指南
本小节特指丝印号为J8的USB HOST接口,本开发板只有两个USB3.0接口,无USB2.0 这里接U盘测试。 在不接入任何USB外设的情况下,先查看/dev目录下是否存在/dev/sd*设备,执行命令: $ ls /dev/sd* 如下图所示: …...

嵌入式软件学习指南:从入门到进阶
嵌入式软件是物联网(IoT)、汽车电子、智能家居等领域的核心技术之一。它涉及硬件与软件的紧密结合,要求开发者不仅会写代码,还要理解底层硬件的工作原理。本文将带你系统了解嵌入式软件的学习路径、核心知识体系及实用资源推荐。 …...

【论文阅读】Adversarial Training Towards Robust Multimedia Recommender System
Adversarial Training Towards Robust Multimedia Recommender System 题目翻译:面向鲁棒多媒体推荐系统的对抗训练 论文链接:点这里 标签:多媒体推荐、对抗训练、推荐系统鲁棒性 摘要 随着多媒体内容在网络上的普及,迫切需要开…...

转换算子和行动算子的区别
转换算子会从一个已经存在的数据集 (RDD)中生成一个新的数据集 (RDD),比如map就是一个转换算子,它通过映射关系从一个RDD生成了一个新的RDD。 行动算子 (actions): 行动算子在进行数据集计算后会给driver程序返回一个值。 转换算子和行动算子最大的区别࿱…...

Selenium的driver.get_url 和 手动输入网址, 并点击的操作,有什么不同?
我在搞爬取的时候,发现有些网站直接用driver.get(url) 跳转到目标特定的网址的时候,会被强制跳转到其他的网址上,但是如果是自己手动,在网址栏那里输入网址,并点回车,却能完成跳转。 这是在使用 Selenium …...

【强化学习】强化学习算法 - 多臂老虎机问题
1、环境/问题介绍 概述:多臂老虎机问题是指:智能体在有限的试验回合 𝑇 内,从 𝐾 台具有未知奖赏分布的“老虎机”中反复选择一个臂(即拉杆),每次拉杆后获得随机奖励,目…...

Spring MVC Controller 方法的返回类型有哪些?
Spring MVC Controller 方法的返回类型非常灵活,可以根据不同的需求返回多种类型的值。Spring MVC 会根据返回值的类型和相关的注解来决定如何处理响应。 以下是一些常见的 Controller 方法返回类型: String: 最常见的类型之一,用于返回逻辑…...

Diamond iO:实用 iO 的第一缕曙光
1. 引言 当前以太坊基金会PSE的Machina iO团队宣布,其已经成功实现了 Diamond iO: A Straightforward Construction of Indistinguishability Obfuscation from Lattices —— 其在2025年2月提出的、结构简单的不可区分混淆(iO)构造…...

Spring MVC中跨域问题处理
在Spring MVC中处理跨域问题可以通过以下几种方式实现,确保前后端能够正常通信: 方法一:使用 CrossOrigin 注解 适用于局部控制跨域配置,直接在Controller或方法上添加注解。 示例代码: RestController CrossOrigin…...
Python爬虫数据存储技巧:二进制格式(Pickle/Parquet)性能优化实战)
Python爬虫(20)Python爬虫数据存储技巧:二进制格式(Pickle/Parquet)性能优化实战
目录 背景介绍一、二进制存储的核心优势二、Python Pickle:轻量级对象序列化1. 基本介绍2. 代码示例3. 性能与局限性 三、Apache Parquet:列式存储的工业级方案1. 基本介绍2. 代码示例(使用PyArrow库)3. 核心优势 四、性能对比与选…...
什么是MCP?)
MCP系列(一)什么是MCP?
一、MCP 是什么:从 USB-C 到 AI 的「万能接口」哲学 MCP(Model Context Protocol,模型上下文协议) 是Anthropic于2024年11月推出的AI跨系统交互标准,专为解决LLM(大语言模型)的「数字失语症」—…...

使用Java NIO 实现一个socket通信框架
使用Java NIO(非阻塞I/O)实现一个Socket通信框架,可以让你构建高性能的网络应用。NIO提供了Channel、Buffer和Selector等核心组件,支持非阻塞模式下的网络编程。下面是一个简单的例子,展示了如何使用Java NIO创建一个基本的服务器端和客户端进行Socket通信。 1.服务器端 …...

Web前端技术栈:从入门到进阶都需要学什么内容
概述 Web前端技术栈:从入门到进阶都需要学什么内容。 1. jQuery:经典高效的DOM操作利器 作为早期前端开发的“瑞士军刀”,jQuery通过简洁的语法和链式调用大幅简化了DOM操作与事件处理。其核心模块如选择器引擎、动画效果和Ajax交互至今仍值…...

Kepware 连接Modbus TCP/IP
Modbus TCP modbus tcp 是modbus协议的一个变种,基于TCP/IP协议栈在以太网上进行通信。Modbus TCP采用客户端-服务器(Master-Slave)的通信模型。客户端发起请求,服务器响应请求。一个网络中可以有多个客户端和服务器,…...

PyCharm连接WSL2搭建的Python开发环境
目录 一、开启WSL2服务 二、安装Ubuntu 三、安装Anaconda 四、构建Tensorflow_gpu环境 五、PyCharm连接到WSL2环境 使用 PyCharm 连接 WSL2 搭建 Python 开发环境的主要目的是结合 Windows 的易用性和 Linux 的开发优势,提升开发效率和体验。以下是具体原因和优…...

JVM中类加载过程是什么?
引言 在Java程序运行过程中,类的加载是至关重要的环节,它直接关系到程序的执行效率和安全性。类加载不仅仅是简单地将.class文件读取到内存中,而是经历了加载、连接(包含验证、准备和解析)以及初始化等多个复杂步骤&a…...

JVM中对象的存储
引言 在 Java 虚拟机中,对象的内存布局是一个非常基础且重要的概念。每个 Java 对象在内存中都由三个主要部分构成:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)。…...
:UGC商业模式的指标剖析与运营策略)
精益数据分析(48/126):UGC商业模式的指标剖析与运营策略
精益数据分析(48/126):UGC商业模式的指标剖析与运营策略 在创业和数据分析的学习之旅中,探索不同商业模式的运营奥秘是我们不断前行的动力。今天,依旧怀揣着和大家共同进步的期望,深入研读《精益数据分析》…...

SpringBoot优雅参数检查
SpringBoot优雅参数检查 在 Spring Boot 中,参数验证通常基于 JSR-380(Bean Validation 2.0)规范,结合 javax.validation(或 jakarta.validation)和 Hibernate Validator 实现。以下是常用的验证注解及其意…...
PMSM驱动控制学习---分流电阻采样及重构)
(九)PMSM驱动控制学习---分流电阻采样及重构
在电机控制当中,无论是我们的控制或者电机工作情况的检测,都十分依赖于电机三相电流的值, 所以相电流采样再在FOC控制中是一个特别关键的环节。 在前几篇中我们介绍了逆变电路的相关内容,所以在此基础上我们接着说道电流采样。目前…...

医疗人工智能大模型中的关键能力:【中期训练】mid-training
引言 医疗人工智能(AI)领域的快速发展正在重塑医疗保健的未来。从辅助诊断到个性化治疗方案,AI技术已经显示出改变医疗实践的巨大潜力。然而,在将AI技术应用于医疗场景时,我们面临着独特的挑战。医疗数据的复杂性、决策的高风险性以及对可解释性的严格要求,都使得医疗AI…...
)
Unity垃圾回收(GC)
1.GC的作用:定期释放不再使用的内存空间。 注:C不支持GC,需要手动管理内存,使用new()申请内存空间,使用完后通过delete()释放掉,但可能出现忘记释放或者指针…...

什么是跨域,如何解决跨域问题
什么是跨域,如何解决跨域问题 一、什么是跨域 跨域是指浏览器出于安全考虑,限制网页脚本访问不同源(协议、域名、端口)的资源。两个URL的协议、域名或端口任意一个不相同时,就属于不同源,浏览器会阻止脚本…...

JVM的双亲委派模型
引言 Java类加载机制中的双亲委派模型通过层层委托保证了核心类加载器与应用类加载器之间的职责分离和加载安全性,但其单向的委托关系也带来了一些局限性。尤其是在核心类库需要访问或实例化由应用类加载器加载的类时,双亲委派模型无法满足需求…...
的调用)
ARCGIS PRO DSK 选择坐标系控件(CoordinateSystemsControl )的调用
在WPF窗体上使用 xml:加入空间命名引用 xmlns:mapping"clr-namespace:ArcGIS.Desktop.Mapping.Controls;assemblyArcGIS.Desktop.Mapping" 在控件区域加入: <mapping:CoordinateSystemsControl x:Name"CoordinateSystemsControl&q…...

一个电平转换电路导致MCU/FPGA通讯波形失真的原因分析
文章目录 前言一、问题描述二、原因分析三、 仿真分析四、 尝试的解决方案总结前言 一、问题描述 一个电平转换电路,800kHz的通讯速率上不去,波形失真,需要分析具体原因。输出波形如下,1码(占空比75%)低于5V,0码(占空比25%)低于4V。,严重失真。 电平转换电路很简单,M…...

不同OS版本中的同一yum源yum list差异排查思路
问题描述: qemu-guest-agent二进制rpm包的yum仓库源和yum源仓库配置文件path_to_yum_conf, 通过yum list --available -c path_to_yum_conf 查询时,不同的OS版本出现了不同的结果 anolis-8无法识别 centos8可以识别 说明: 1 测试…...

Android Studio开发安卓app 设置开机自启
Android Studio开发安卓app 设置开机自启 AndroidManifest.xml增加配置 增加的配置已标记 AndroidManifest.xml完整配置 <?xml version="1.0" encoding="utf-8"?> <manifest xmlns:android="http://schemas.android.com/apk/res/androi…...

全文索引数据库Elasticsearch底层Lucene
Lucene 全文检索的心,天才的想法。 一个高效的,可扩展的,全文检索库。全部用 Java 实现,无须配置。仅支持纯文本文件的索引(Indexing)和搜索(Search)。不负责由其他格式的文件抽取纯文本文件,或从网络中抓取文件的过程…...

互联网大厂Java求职面试:分布式系统中向量数据库与AI应用的融合探索
互联网大厂Java求职面试:分布式系统中向量数据库与AI应用的融合探索 面试开场:技术总监与郑薪苦的“较量” 技术总监(以下简称T):郑薪苦先生,请简单介绍一下你在分布式系统设计方面的经验。 郑薪苦&…...

游戏引擎学习第262天:绘制多帧性能分析图
回顾并为今天设定阶段 事情开始录制了,大家好,欢迎来到游戏直播节目。我们正在直播完成游戏的开发工作,目前我们正在做性能分析器,它现在已经非常酷了。我们只是在清理一些界面问题,但它能做的事情真的很厉害。我觉得…...

1、RocketMQ 核心架构拆解
1. 为什么要使用消息队列? 消息队列(MQ)是分布式系统中不可或缺的中间件,主要解决系统间的解耦、异步和削峰填谷问题。 解耦:生产者和消费者通过消息队列通信,彼此无需直接依赖,极大提升系统灵…...

探索 C++ 语言标准演进:从 C++23 到 C++26 的飞跃
引言 C 作为一门历史悠久且广泛应用的编程语言,其每一次标准的演进都备受开发者关注。从早期的 C98 到如今的 C23,再到令人期待的 C26,每一个版本都为开发者带来了新的特性和改进,推动着软件开发的不断进步。本文将深入探讨 C23 …...

ROBOVERSE:面向可扩展和可泛化机器人学习的统一平台、数据集和基准
25年4月来自UC Berkeley、北大、USC、UMich、UIUC、Stanford、CMU、UCLA 和 北京通用 AI 研究院(BIGAI)的论文“ROBOVERSE: Towards a Unified Platform, Dataset and Benchmark for Scalable and Generalizable Robot Learning”。 数据扩展和标准化评…...
高级用法)
【Bootstrap V4系列】学习入门教程之 组件-轮播(Carousel)高级用法
【Bootstrap V4系列】学习入门教程之 组件-轮播(Carousel)高级用法 轮播(Carousel)高级用法2.5 Crossfade (淡入淡出)2.6 Individual .carousel-item interval (单个轮播项目间隔)2.…...

LangChain4j简介
LangChain4j 是什么? The goal of LangChain4j is to simplify integrating LLMs into Java applications. LangChain4j 的目标是简化将 LLMs 集成到 Java 应用程序中。 提供如下能力: ● 统一的 API: LLM 提供商(如 OpenAI 或 Go…...

Git 撤销已commit但未push的文件
基础知识:HEAD^ 即上个版本, HEAD~2 即上上个版本, 依此类推… 查看commit日志 git log撤销commit,保留git add git reset --soft HEAD^ #【常用于:commit成功,push失败时的代码恢复】保留工作空间改动代码,撤销com…...
)
OC语言学习——面向对象(下)
一、OC的包装类 OC提供了NSValue、NSNumber来封装C语言基本类型(short、int、float等)。 在 Objective-C 中,**包装类(Wrapper Classes)**是用来把基本数据类型(如 int、float、char 等)“包装…...

SafeDrive:大语言模型实现自动驾驶汽车知识驱动和数据驱动的风险-敏感决策——论文阅读
《SafeDrive: Knowledge- and Data-Driven Risk-Sensitive Decision-Making for Autonomous Vehicles with Large Language Models》2024年12月发表,来自USC、U Wisconsin、U Michigan、清华大学和香港大学的论文。 自动驾驶汽车(AV)的最新进…...
Detail-Preserving Latent Diffusion for Stable Shadow Removal论文阅读)
什么是先验?(CVPR25)Detail-Preserving Latent Diffusion for Stable Shadow Removal论文阅读
文章目录 先验(Prior)是什么?1. 先验的数学定义2. 先验在深度生成模型中的角色3. 为什么需要先验?4. 先验的常见类型5. 如何选择或构造先验?6. 小结 先验(Prior)是什么? 在概率统计…...

【论文阅读】Attentive Collaborative Filtering:
Attentive Collaborative Filtering: Multimedia Recommendation with Item- and Component-Level Attention Attentive Collaborative Filtering (ACF)、隐式反馈推荐、注意力机制、贝叶斯个性化排序 标题翻译:注意力协同过滤:基于项目和组件级注意力的…...

如何使用极狐GitLab 软件包仓库功能托管 maven?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 软件包库中的 Maven 包 (BASIC ALL) 在项目的软件包库中发布 Maven 产物。然后,在需要将它们用作依赖项时安装它…...

Notion Windows桌面端快捷键详解
通用导航 这些快捷键帮助用户在 Notion 的界面中快速移动。 打开 Notion:Ctrl T 打开一个新的 Notion 窗口或标签页,方便快速进入工作空间。返回上一页:Ctrl [ 导航回之前查看的页面。前进到下一页:Ctrl ] 跳转到导航历史中的…...

企业智能化第一步:用「Deepseek+自动化」打造企业资源管理的智能中枢
随着Deepseek乃至AI人工智能技术在企业中得到了广泛的关注和使用,多数企业开始了AI探索之旅,迅易科技也不例外,且在不断地实践中强化了AI智能应用创新的强大能力。 为解决企业知识管理碎片化、提高内部工作效率等问题,迅易将目光放…...
)
GoFly企业版框架升级2.6.6版本说明(框架在2025-05-06发布了)
前端框架升级说明: 1.vue版本升级到^3.5.4 把"vue": "^3.2.40",升级到"vue": "^3.5.4",新版插件需要时useTemplateRef,所以框架就对齐进行升级。 2.ArcoDesign升级到2.57.0(目前最新2025-02-10&a…...

LeapVAD:通过认知感知和 Dual-Process 思维实现自动驾驶飞跃——论文阅读
《LeapVAD: A Leap in Autonomous Driving via Cognitive Perception and Dual-Process Thinking》2025年1月发表,来自浙江大学、上海AI实验室、慕尼黑工大、同济大学和中科大的论文。 尽管自动驾驶技术取得了显著进步,但由于推理能力有限,数…...

ps信息显示不全
linux执行ps是默认宽度是受限制的,例如: ps -aux 显示 遇到这种情况,如果显示的信息不是很长可以添加一个w参数来放宽显示宽度 ps -auxw 显示 再添加一个w可以接触宽度限制,有多长就显示多长 ps -auxww 显示...

性能比拼: Redis Streams vs Pub/Sub
本内容是对知名性能评测博主 Anton Putra Redis Streams vs Pub/Sub: Performance 内容的翻译与整理, 有适当删减, 相关指标和结论以原作为准 在这个视频中,我们首先将介绍 Redis Streams 和 Redis Pub/Sub 之间的区别。然后,我们将在 AWS 上运行一个基准…...