【强化学习】强化学习算法 - 多臂老虎机问题
1、环境/问题介绍
- 概述:多臂老虎机问题是指:智能体在有限的试验回合 𝑇 内,从 𝐾 台具有未知奖赏分布的“老虎机”中反复选择一个臂(即拉杆),每次拉杆后获得随机奖励,目标是在累积奖励最大化的同时权衡探索(尝试不同臂以获取更多信息)和利用(选择当前估计最优臂)
你站在赌场前,有三台老虎机(臂 A 、 B 、 C A、B、C A、B、C),它们的中奖概率分别为 ( p A , p B , p C ) ( p_A, p_B, p_C ) (pA,pB,pC),但你并不知道具体数值。你有 100 次拉杆的机会,每次只能选择一台机器并拉动其拉杆,若中奖则获得 1 枚筹码,否则 0。你的目标是在这 100 次尝试中,尽可能多地赢得筹码。
这个例子直观地展示了多臂老虎机问题的核心要素:
- 未知性:每台机器的中奖概率对你未知。
- 试错学习:通过拉杆并观察结果,逐步估计每台机器的回报。
- 探索–利用权衡:需要在尝试新机器(探索)与选择当前估计最优机器(利用)之间取得平衡,以最大化总收益。
2、主要算法
2.1. ε-贪心算法(Epsilon‑Greedy)
1. 算法原理
以概率 ε 随机探索,概率 1 − ε 选择当前估计最高的臂,实现简单的探索–利用平衡。
-
这里的 ϵ (epsilon) 是一个介于 0 和 1 之间的小参数(例如 0.1, 0.05)。它控制着探索的程度:
-
ϵ=0:纯粹的贪婪算法 (Greedy),只利用,不探索。如果初始估计错误,可能永远无法找到最优臂。
-
ϵ=1:纯粹的随机探索,完全不利用过去的经验。
-
0<ϵ<1:在大部分时间利用已知最优选择,但保留一小部分机会去探索其他可能更好的选择。
ϵ-Greedy 保证了即使某个臂的初始估计很差,仍然有一定概率被选中,从而有机会修正其估计值。
-
-
变种: 有时会使用随时间衰减的 ϵ 值(如 ϵ = 1 / t ϵ =1/t ϵ=1/t 或 ϵ = c / log t ϵ =c / \log t ϵ=c/logt),使得算法在早期更多地探索,随着信息积累越来越充分,逐渐转向利用。
2. ε-Greedy 算法实现步骤
假设有 K K K 个臂,总共进行 T T T 次试验。
-
初始化 (Initialization):
- 设置探索概率 ϵ \epsilon ϵ(一个小的正数)。
- 为每个臂 a = 1 , . . . , K a = 1, ..., K a=1,...,K 初始化奖励估计值 Q 0 ( a ) = 0 Q_0(a) = 0 Q0(a)=0。
- 为每个臂 a = 1 , . . . , K a = 1, ..., K a=1,...,K 初始化被选择的次数 N 0 ( a ) = 0 N_0(a) = 0 N0(a)=0。
-
循环执行 (Loop): 对于时间步 t = 1 , 2 , . . . , T t = 1, 2, ..., T t=1,2,...,T:
- 选择动作 (Select Action):
- 生成一个 [0, 1) 范围内的随机数 p p p。
- 如果 p < ϵ p < \epsilon p<ϵ (探索):
从所有 K K K 个臂中等概率随机选择一个臂 A t A_t At。 - 如果 p ≥ ϵ p \ge \epsilon p≥ϵ (利用):
选择当前估计奖励最高的臂 A t = arg max a Q t − 1 ( a ) A_t = \arg\max_{a} Q_{t-1}(a) At=argmaxaQt−1(a)。- 注意: 如果有多个臂具有相同的最高估计值,可以随机选择其中一个,或按编号选择第一个。
- 执行动作并观察奖励 (Execute Action & Observe Reward):
拉动选定的臂 A t A_t At,得到奖励 R t R_t Rt。这个奖励通常是从该臂的未知奖励分布中采样得到的。 - 更新估计值 (Update Estimates):
- 更新被选中臂 A t A_t At 的计数: N t ( A t ) = N t − 1 ( A t ) + 1 N_t(A_t) = N_{t-1}(A_t) + 1 Nt(At)=Nt−1(At)+1。
- 更新被选中臂 A t A_t At 的奖励估计值。常用的方法是增量式样本均值:
Q t ( A t ) = Q t − 1 ( A t ) + 1 N t ( A t ) [ R t − Q t − 1 ( A t ) ] Q_t(A_t) = Q_{t-1}(A_t) + \frac{1}{N_t(A_t)} [R_t - Q_{t-1}(A_t)] Qt(At)=Qt−1(At)+Nt(At)1[Rt−Qt−1(At)]
这等价于:
Q t ( A t ) = 臂 A t 到目前为止获得的总奖励 臂 A t 到目前为止被选择的总次数 Q_t(A_t) = \frac{\text{臂 } A_t \text{ 到目前为止获得的总奖励}}{\text{臂 } A_t \text{ 到目前为止被选择的总次数}} Qt(At)=臂 At 到目前为止被选择的总次数臂 At 到目前为止获得的总奖励 - 对于未被选择的臂 a ≠ A t a \neq A_t a=At,它们的计数和估计值保持不变: N t ( a ) = N t − 1 ( a ) N_t(a) = N_{t-1}(a) Nt(a)=Nt−1(a), Q t ( a ) = Q t − 1 ( a ) Q_t(a) = Q_{t-1}(a) Qt(a)=Qt−1(a)。
- 选择动作 (Select Action):
-
结束 (End): 循环 T T T 次后结束。最终的 Q T ( a ) Q_T(a) QT(a) 值代表了算法对每个臂平均奖励的估计。算法在整个过程中获得的总奖励为 ∑ t = 1 T R t \sum_{t=1}^T R_t ∑t=1TRt。
3. 优缺点
优点:
- 简单性: 概念清晰,易于理解和实现。
- 保证探索: 只要 ϵ > 0 \epsilon > 0 ϵ>0,就能保证持续探索所有臂,避免完全陷入局部最优。
- 理论保证: 在一定条件下(如奖励有界), ϵ \epsilon ϵ-Greedy 算法可以收敛到接近最优的策略。
缺点:
- 探索效率低: 探索时是完全随机的,没有利用已知信息。即使某个臂的估计值已经很低且置信度很高,仍然会以 ϵ K \frac{\epsilon}{K} Kϵ 的概率去探索它。
- 持续探索: 如果 ϵ \epsilon ϵ 是常数,即使在后期已经对各臂有了较好的估计,算法仍然会以 ϵ \epsilon ϵ 的概率进行不必要的探索,影响最终的总奖励。使用衰减 ϵ \epsilon ϵ 可以缓解这个问题。
- 未考虑不确定性: 选择利用哪个臂时,只看当前的估计值 Q ( a ) Q(a) Q(a),没有考虑这个估计的不确定性。
2.2. UCB (Upper Confidence Bound) 算法
1. UCB (Upper Confidence Bound) 算法
核心思想:对于每个臂(老虎机),不仅要考虑它当前的平均奖励估计值,还要考虑这个估计值的不确定性。一个臂被选择的次数越少,我们对其真实平均奖励的估计就越不确定。UCB 算法会给那些不确定性高(即被选择次数少)的臂一个“奖励加成”,使得它们更有可能被选中。这样,算法倾向于选择那些 潜力高(可能是当前最佳,或者因为尝试次数少而有很大不确定性,可能被低估)的臂。
2. UCB 算法原理
UCB 算法在每个时间步 t t t 选择臂 A t A_t At 时,会计算每个臂 a a a 的一个置信上界分数,然后选择分数最高的那个臂。这个分数由两部分组成:
- 当前平均奖励估计值 (Exploitation Term): Q t − 1 ( a ) Q_{t-1}(a) Qt−1(a),即到时间步 t − 1 t-1 t−1 为止,臂 a a a 的平均观测奖励。这代表了我们当前对该臂价值的最好估计。
- 不确定性加成项 (Exploration Bonus): 一个基于置信区间的项,用于量化估计值的不确定性。常见的形式是 c ln t N t − 1 ( a ) c \sqrt{\frac{\ln t}{N_{t-1}(a)}} cNt−1(a)lnt。
因此,选择规则为:
A t = arg max a [ Q t − 1 ( a ) + c ln t N t − 1 ( a ) ] A_t = \arg\max_{a} \left[ Q_{t-1}(a) + c \sqrt{\frac{\ln t}{N_{t-1}(a)}} \right] At=argamax[Qt−1(a)+cNt−1(a)lnt]
让我们解析这个公式:
- Q t − 1 ( a ) Q_{t-1}(a) Qt−1(a): 臂 a a a 在 t − 1 t-1 t−1 时刻的平均奖励估计。
- N t − 1 ( a ) N_{t-1}(a) Nt−1(a): 臂 a a a 在 t − 1 t-1 t−1 时刻之前被选择的总次数。
- t t t: 当前的总时间步(总拉杆次数)。
- ln t \ln t lnt: 总时间步 t t t 的自然对数。随着时间的推移, t t t 增大, ln t \ln t lnt 也缓慢增大,这保证了即使一个臂的 N ( a ) N(a) N(a) 很大,探索项也不会完全消失,所有臂最终都会被持续探索(尽管频率会降低)。
- c c c: 一个正常数,称为探索参数。它控制着不确定性加成项的权重。 c c c 越大,算法越倾向于探索; c c c 越小,越倾向于利用。理论上 c = 2 c=\sqrt{2} c=2 是一个常用的选择,但在实践中可能需要调整。
工作机制:
- 如果一个臂 a a a 的 N t − 1 ( a ) N_{t-1}(a) Nt−1(a) 很小,那么分母 N t − 1 ( a ) \sqrt{N_{t-1}(a)} Nt−1(a) 就很小,导致不确定性加成项很大。这使得该臂即使 Q t − 1 ( a ) Q_{t-1}(a) Qt−1(a) 不高,也有较高的 UCB 分数,从而被优先选择(探索)。
- 随着一个臂被选择的次数 N ( a ) N(a) N(a) 增加,不确定性项会逐渐减小,UCB 分数将越来越依赖于实际的平均奖励 Q ( a ) Q(a) Q(a)(利用)。
- ln t \ln t lnt 项确保了随着时间的推移,即使是那些表现似乎较差的臂,只要它们的 N ( a ) N(a) N(a) 相对较小,其 UCB 分数也会缓慢增长,保证它们不会被完全放弃。
处理 N ( a ) = 0 N(a)=0 N(a)=0 的情况: 在算法开始时,为了避免分母为零,通常需要先将每个臂都尝试一次。
3. UCB 算法实现步骤
假设有 K K K 个臂,总共进行 T T T 次试验。
-
初始化 (Initialization):
- 设置探索参数 c > 0 c > 0 c>0。
- 为每个臂 a = 1 , . . . , K a = 1, ..., K a=1,...,K 初始化奖励估计值 Q 0 ( a ) = 0 Q_0(a) = 0 Q0(a)=0 (或一个较大的初始值以鼓励早期探索)。
- 为每个臂 a = 1 , . . . , K a = 1, ..., K a=1,...,K 初始化被选择的次数 N 0 ( a ) = 0 N_0(a) = 0 N0(a)=0。
-
初始探索阶段 (Initial Exploration Phase):
- 为了确保每个臂至少被选择一次(避免后续计算 ln t N ( a ) \sqrt{\frac{\ln t}{N(a)}} N(a)lnt 时出现除以零),先将每个臂 a = 1 , . . . , K a = 1, ..., K a=1,...,K 都拉动一次。
- 这通常会占用前 K K K 个时间步( t = 1 t=1 t=1 到 t = K t=K t=K)。对于每个 t = a t=a t=a (其中 a a a 从 1 到 K K K):
- 选择臂 A t = a A_t = a At=a。
- 执行动作,观察奖励 R t R_t Rt。
- 更新 N t ( a ) = 1 N_t(a) = 1 Nt(a)=1。
- 更新 Q t ( a ) = R t Q_t(a) = R_t Qt(a)=Rt。
- (其他臂的 N N N 和 Q Q Q 保持为 0 或初始值)。
-
主循环阶段 (Main Loop): 对于时间步 t = K + 1 , . . . , T t = K+1, ..., T t=K+1,...,T:
- 计算所有臂的 UCB 分数: 对于每个臂 a = 1 , . . . , K a = 1, ..., K a=1,...,K,计算其 UCB 值:
UCB t ( a ) = Q t − 1 ( a ) + c ln t N t − 1 ( a ) \text{UCB}_t(a) = Q_{t-1}(a) + c \sqrt{\frac{\ln t}{N_{t-1}(a)}} UCBt(a)=Qt−1(a)+cNt−1(a)lnt- 注意:此时 N t − 1 ( a ) ≥ 1 N_{t-1}(a) \ge 1 Nt−1(a)≥1 且 t ≥ K + 1 ≥ 2 t \ge K+1 \ge 2 t≥K+1≥2,所以 ln t ≥ ln 2 > 0 \ln t \ge \ln 2 > 0 lnt≥ln2>0。
- 选择动作 (Select Action):
选择具有最高 UCB 分数的臂:
A t = arg max a UCB t ( a ) A_t = \arg\max_{a} \text{UCB}_t(a) At=argamaxUCBt(a)- 如果存在多个臂具有相同的最高分数,可以随机选择其中一个。
- 执行动作并观察奖励 (Execute Action & Observe Reward):
拉动选定的臂 A t A_t At,得到奖励 R t R_t Rt。 - 更新估计值 (Update Estimates):
- 更新被选中臂 A t A_t At 的计数: N t ( A t ) = N t − 1 ( A t ) + 1 N_t(A_t) = N_{t-1}(A_t) + 1 Nt(At)=Nt−1(At)+1。
- 使用增量式样本均值更新被选中臂 A t A_t At 的奖励估计值:
Q t ( A t ) = Q t − 1 ( A t ) + 1 N t ( A t ) [ R t − Q t − 1 ( A t ) ] Q_t(A_t) = Q_{t-1}(A_t) + \frac{1}{N_t(A_t)} [R_t - Q_{t-1}(A_t)] Qt(At)=Qt−1(At)+Nt(At)1[Rt−Qt−1(At)] - 对于未被选择的臂 a ≠ A t a \neq A_t a=At,它们的计数和估计值保持不变: N t ( a ) = N t − 1 ( a ) N_t(a) = N_{t-1}(a) Nt(a)=Nt−1(a), Q t ( a ) = Q t − 1 ( a ) Q_t(a) = Q_{t-1}(a) Qt(a)=Qt−1(a)。
- 计算所有臂的 UCB 分数: 对于每个臂 a = 1 , . . . , K a = 1, ..., K a=1,...,K,计算其 UCB 值:
-
结束 (End): 循环 T T T 次后结束。
4. 优缺点
优点:
- 智能探索: 相较于 ϵ \epsilon ϵ-Greedy 的随机探索,UCB 的探索更有针对性,优先探索那些潜力更大(不确定性高)的臂。
- 无需设置 ϵ \epsilon ϵ: 它不需要像 ϵ \epsilon ϵ-Greedy 那样设定探索概率 ϵ \epsilon ϵ(尽管需要设定探索参数 c c c)。
- 性能优越: 在许多平稳(Stationary)的 MAB 问题中,UCB 及其变种通常比 ϵ \epsilon ϵ-Greedy 表现更好,尤其是在试验次数较多时。
- 良好的理论性质: UCB 算法有很强的理论支持,其累积遗憾(Regret)通常被证明是对数级别的( O ( log T ) O(\log T) O(logT)),这是非常理想的性能。
缺点:
- 需要知道总时间步 t t t: 标准 UCB 公式需要用到总时间步 t t t 的对数 ln t \ln t lnt。
- 对参数 c c c 敏感: 探索参数 c c c 的选择会影响算法性能,可能需要根据具体问题进行调整。
- 对非平稳环境敏感: 标准 UCB 假设臂的奖励分布是固定的(平稳的)。在奖励分布随时间变化的环境(非平稳)中,其性能可能会下降(因为旧的观测数据可能不再准确)。有一些变种(如 D-UCB, SW-UCB)用于处理非平稳环境。
- 计算开销: 每次选择都需要计算所有臂的 UCB 分数,虽然计算量不大,但比 ϵ \epsilon ϵ-Greedy 的贪婪选择略高。
2.3. Thompson Sampling 汤普森采样算法
1. Thompson Sampling 算法简介
核心思想:
- 维护信念分布: 对每个臂 a a a 的未知奖励参数(例如,伯努利臂的成功概率 p a p_a pa)维护一个后验概率分布。这个分布反映了基于已观察到的数据,我们对该参数可能取值的信念。
- 采样: 在每个时间步 t t t,为每个臂 a a a 从其当前的后验分布中抽取一个样本值 θ a \theta_a θa。这个样本可以被看作是该臂在当前信念下的一个“可能”的真实参数值。
- 选择: 选择具有最大采样值 θ a \theta_a θa 的那个臂 A t A_t At。
- 更新信念: 观察所选臂 A t A_t At 的奖励 R t R_t Rt,然后使用贝叶斯定理更新臂 A t A_t At 的后验分布,将新的观测信息融合进去。
这种方法的巧妙之处在于,选择臂的概率自动与其后验分布中“该臂是最优臂”的概率相匹配。
- 如果一个臂的后验分布集中在较高的值(即我们很确定它很好),那么从中采样的值很可能最高,该臂被选中的概率就高(利用)。
- 如果一个臂的后验分布很宽(即我们对它的真实值很不确定),那么即使其均值不是最高,它也有机会采样到一个非常高的值而被选中,从而实现探索。
2. Thompson Sampling 算法原理
在这种情况下,通常使用 Beta 分布 作为成功概率 p a p_a pa 的先验和后验分布,因为 Beta 分布是伯努利似然函数的共轭先验 (Conjugate Prior)。这意味着,如果先验是 Beta 分布,并且观测数据来自伯努利分布,那么后验分布仍然是 Beta 分布,只是参数会更新。
- Beta 分布: Beta ( α , β ) (\alpha, \beta) (α,β) 由两个正参数 α \alpha α 和 β \beta β 定义。其均值为 α α + β \frac{\alpha}{\alpha + \beta} α+βα。 α \alpha α 可以看作是“观测到的成功次数 + 1”, β \beta β 可以看作是“观测到的失败次数 + 1”(这里的“+1”来自一个常见的 Beta(1,1) 均匀先验)。分布的形状由 α \alpha α 和 β \beta β 控制,当 α + β \alpha+\beta α+β 增大时,分布变得更窄,表示不确定性降低。
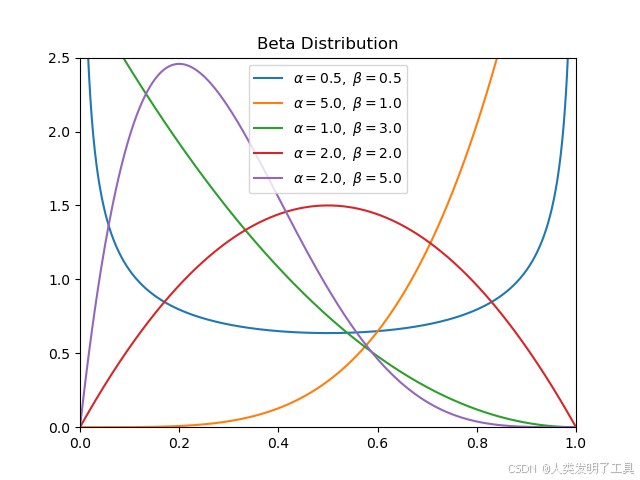
算法流程中的关键步骤:
- 初始化: 为每个臂 a a a 设置 Beta 分布的初始参数,通常为 α a = 1 , β a = 1 \alpha_a = 1, \beta_a = 1 αa=1,βa=1。这对应于一个 Beta(1, 1) 分布,即 [0, 1] 上的均匀分布,表示在没有任何观测数据之前,我们认为 p a p_a pa 在 [0, 1] 区间内取任何值的可能性都相同。
- 采样: 在每个时间步 t t t,为每个臂 a a a 从其当前的后验分布 Beta ( α a , β a ) (\alpha_a, \beta_a) (αa,βa) 中独立抽取一个随机样本 θ a \theta_a θa。
- 选择: 选择使得 θ a \theta_a θa 最大的臂 A t = arg max a θ a A_t = \arg\max_a \theta_a At=argmaxaθa。
- 更新: 假设选择了臂 A t A_t At 并观察到奖励 R t ∈ { 0 , 1 } R_t \in \{0, 1\} Rt∈{0,1} :
- 每个臂 a a a 的奖励是 0 (失败) 或 1 (成功)
- 如果 R t = 1 R_t = 1 Rt=1 (成功),则更新臂 A t A_t At 的参数: α A t ← α A t + 1 \alpha_{A_t} \leftarrow \alpha_{A_t} + 1 αAt←αAt+1。
- 如果 R t = 0 R_t = 0 Rt=0 (失败),则更新臂 A t A_t At 的参数: β A t ← β A t + 1 \beta_{A_t} \leftarrow \beta_{A_t} + 1 βAt←βAt+1。
- 未被选择的臂的参数保持不变。
随着观测数据的增加,每个臂的 Beta 分布会变得越来越集中(方差减小),反映了我们对其真实成功概率 p a p_a pa 的信念越来越确定。
3. Thompson Sampling 算法实现步骤
假设有 K K K 个臂,总共进行 T T T 次试验。
-
初始化 (Initialization):
- 对于每个臂 a = 1 , . . . , K a = 1, ..., K a=1,...,K:
- 设置 Beta 分布参数 α a = 1 \alpha_a = 1 αa=1。
- 设置 Beta 分布参数 β a = 1 \beta_a = 1 βa=1。
- 对于每个臂 a = 1 , . . . , K a = 1, ..., K a=1,...,K:
-
循环执行 (Loop): 对于时间步 t = 1 , 2 , . . . , T t = 1, 2, ..., T t=1,2,...,T:
- 采样阶段 (Sampling Phase):
- 对于每个臂 a = 1 , . . . , K a = 1, ..., K a=1,...,K:
- 从 Beta 分布 Beta ( α a , β a ) (\alpha_a, \beta_a) (αa,βa) 中抽取一个随机样本 θ a \theta_a θa。
- (这需要一个能够从 Beta 分布生成随机数的函数库,例如 Python 的
numpy.random.beta)。
- 对于每个臂 a = 1 , . . . , K a = 1, ..., K a=1,...,K:
- 选择动作 (Select Action):
- 找到使得样本值 θ a \theta_a θa 最大的臂:
A t = arg max a ∈ { 1 , . . . , K } θ a A_t = \arg\max_{a \in \{1, ..., K\}} \theta_a At=arga∈{1,...,K}maxθa - 如果存在多个臂具有相同的最大样本值,可以随机选择其中一个。
- 找到使得样本值 θ a \theta_a θa 最大的臂:
- 执行动作并观察奖励 (Execute Action & Observe Reward):
- 拉动选定的臂 A t A_t At,得到奖励 R t ∈ { 0 , 1 } R_t \in \{0, 1\} Rt∈{0,1}。
- 更新后验分布 (Update Posterior):
- 如果 R t = 1 R_t = 1 Rt=1:
α A t ← α A t + 1 \alpha_{A_t} \leftarrow \alpha_{A_t} + 1 αAt←αAt+1 - 如果 R t = 0 R_t = 0 Rt=0:
β A t ← β A t + 1 \beta_{A_t} \leftarrow \beta_{A_t} + 1 βAt←βAt+1
- 如果 R t = 1 R_t = 1 Rt=1:
- 采样阶段 (Sampling Phase):
-
结束 (End): 循环 T T T 次后结束。
4. 优缺点
优点:
- 性能优异: 在实践中,Thompson Sampling 通常表现非常好,经常优于或至少媲美 UCB 算法,尤其是在累积奖励方面。
- 概念优雅且自然: 基于贝叶斯推理,提供了一种原则性的方式来处理不确定性并通过概率匹配来平衡探索与利用。
- 易于扩展: 可以相对容易地适应不同的奖励模型(如高斯奖励,只需将 Beta-Bernoulli 更新替换为 Normal-Normal 或 Normal-Inverse-Gamma 更新)。
- 无需手动调整探索参数: 不像 ϵ \epsilon ϵ-Greedy 的 ϵ \epsilon ϵ 或 UCB 的 c c c 需要仔细调整(虽然先验选择也可能影响性能,但通常对标准先验如 Beta(1,1) 较为鲁棒)。
- 良好的理论性质: 具有较好的理论累积遗憾界。
缺点:
- 需要指定先验: 作为贝叶斯方法,需要为参数选择一个先验分布。虽然通常有标准选择(如 Beta(1,1)),但在某些情况下先验的选择可能影响早期性能。
- 计算成本: 需要在每个时间步从后验分布中采样。对于 Beta 分布,采样通常很快,但对于更复杂的模型,采样可能比 UCB 的直接计算更耗时。
- 实现略复杂: 相较于 ϵ \epsilon ϵ-Greedy,需要理解贝叶斯更新规则并使用能进行分布采样的库。
相关文章:

【强化学习】强化学习算法 - 多臂老虎机问题
1、环境/问题介绍 概述:多臂老虎机问题是指:智能体在有限的试验回合 𝑇 内,从 𝐾 台具有未知奖赏分布的“老虎机”中反复选择一个臂(即拉杆),每次拉杆后获得随机奖励,目…...

Spring MVC Controller 方法的返回类型有哪些?
Spring MVC Controller 方法的返回类型非常灵活,可以根据不同的需求返回多种类型的值。Spring MVC 会根据返回值的类型和相关的注解来决定如何处理响应。 以下是一些常见的 Controller 方法返回类型: String: 最常见的类型之一,用于返回逻辑…...

Diamond iO:实用 iO 的第一缕曙光
1. 引言 当前以太坊基金会PSE的Machina iO团队宣布,其已经成功实现了 Diamond iO: A Straightforward Construction of Indistinguishability Obfuscation from Lattices —— 其在2025年2月提出的、结构简单的不可区分混淆(iO)构造…...

Spring MVC中跨域问题处理
在Spring MVC中处理跨域问题可以通过以下几种方式实现,确保前后端能够正常通信: 方法一:使用 CrossOrigin 注解 适用于局部控制跨域配置,直接在Controller或方法上添加注解。 示例代码: RestController CrossOrigin…...
Python爬虫数据存储技巧:二进制格式(Pickle/Parquet)性能优化实战)
Python爬虫(20)Python爬虫数据存储技巧:二进制格式(Pickle/Parquet)性能优化实战
目录 背景介绍一、二进制存储的核心优势二、Python Pickle:轻量级对象序列化1. 基本介绍2. 代码示例3. 性能与局限性 三、Apache Parquet:列式存储的工业级方案1. 基本介绍2. 代码示例(使用PyArrow库)3. 核心优势 四、性能对比与选…...
什么是MCP?)
MCP系列(一)什么是MCP?
一、MCP 是什么:从 USB-C 到 AI 的「万能接口」哲学 MCP(Model Context Protocol,模型上下文协议) 是Anthropic于2024年11月推出的AI跨系统交互标准,专为解决LLM(大语言模型)的「数字失语症」—…...

使用Java NIO 实现一个socket通信框架
使用Java NIO(非阻塞I/O)实现一个Socket通信框架,可以让你构建高性能的网络应用。NIO提供了Channel、Buffer和Selector等核心组件,支持非阻塞模式下的网络编程。下面是一个简单的例子,展示了如何使用Java NIO创建一个基本的服务器端和客户端进行Socket通信。 1.服务器端 …...

Web前端技术栈:从入门到进阶都需要学什么内容
概述 Web前端技术栈:从入门到进阶都需要学什么内容。 1. jQuery:经典高效的DOM操作利器 作为早期前端开发的“瑞士军刀”,jQuery通过简洁的语法和链式调用大幅简化了DOM操作与事件处理。其核心模块如选择器引擎、动画效果和Ajax交互至今仍值…...

Kepware 连接Modbus TCP/IP
Modbus TCP modbus tcp 是modbus协议的一个变种,基于TCP/IP协议栈在以太网上进行通信。Modbus TCP采用客户端-服务器(Master-Slave)的通信模型。客户端发起请求,服务器响应请求。一个网络中可以有多个客户端和服务器,…...

PyCharm连接WSL2搭建的Python开发环境
目录 一、开启WSL2服务 二、安装Ubuntu 三、安装Anaconda 四、构建Tensorflow_gpu环境 五、PyCharm连接到WSL2环境 使用 PyCharm 连接 WSL2 搭建 Python 开发环境的主要目的是结合 Windows 的易用性和 Linux 的开发优势,提升开发效率和体验。以下是具体原因和优…...

JVM中类加载过程是什么?
引言 在Java程序运行过程中,类的加载是至关重要的环节,它直接关系到程序的执行效率和安全性。类加载不仅仅是简单地将.class文件读取到内存中,而是经历了加载、连接(包含验证、准备和解析)以及初始化等多个复杂步骤&a…...

JVM中对象的存储
引言 在 Java 虚拟机中,对象的内存布局是一个非常基础且重要的概念。每个 Java 对象在内存中都由三个主要部分构成:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)。…...
:UGC商业模式的指标剖析与运营策略)
精益数据分析(48/126):UGC商业模式的指标剖析与运营策略
精益数据分析(48/126):UGC商业模式的指标剖析与运营策略 在创业和数据分析的学习之旅中,探索不同商业模式的运营奥秘是我们不断前行的动力。今天,依旧怀揣着和大家共同进步的期望,深入研读《精益数据分析》…...

SpringBoot优雅参数检查
SpringBoot优雅参数检查 在 Spring Boot 中,参数验证通常基于 JSR-380(Bean Validation 2.0)规范,结合 javax.validation(或 jakarta.validation)和 Hibernate Validator 实现。以下是常用的验证注解及其意…...
PMSM驱动控制学习---分流电阻采样及重构)
(九)PMSM驱动控制学习---分流电阻采样及重构
在电机控制当中,无论是我们的控制或者电机工作情况的检测,都十分依赖于电机三相电流的值, 所以相电流采样再在FOC控制中是一个特别关键的环节。 在前几篇中我们介绍了逆变电路的相关内容,所以在此基础上我们接着说道电流采样。目前…...

医疗人工智能大模型中的关键能力:【中期训练】mid-training
引言 医疗人工智能(AI)领域的快速发展正在重塑医疗保健的未来。从辅助诊断到个性化治疗方案,AI技术已经显示出改变医疗实践的巨大潜力。然而,在将AI技术应用于医疗场景时,我们面临着独特的挑战。医疗数据的复杂性、决策的高风险性以及对可解释性的严格要求,都使得医疗AI…...
)
Unity垃圾回收(GC)
1.GC的作用:定期释放不再使用的内存空间。 注:C不支持GC,需要手动管理内存,使用new()申请内存空间,使用完后通过delete()释放掉,但可能出现忘记释放或者指针…...

什么是跨域,如何解决跨域问题
什么是跨域,如何解决跨域问题 一、什么是跨域 跨域是指浏览器出于安全考虑,限制网页脚本访问不同源(协议、域名、端口)的资源。两个URL的协议、域名或端口任意一个不相同时,就属于不同源,浏览器会阻止脚本…...

JVM的双亲委派模型
引言 Java类加载机制中的双亲委派模型通过层层委托保证了核心类加载器与应用类加载器之间的职责分离和加载安全性,但其单向的委托关系也带来了一些局限性。尤其是在核心类库需要访问或实例化由应用类加载器加载的类时,双亲委派模型无法满足需求…...
的调用)
ARCGIS PRO DSK 选择坐标系控件(CoordinateSystemsControl )的调用
在WPF窗体上使用 xml:加入空间命名引用 xmlns:mapping"clr-namespace:ArcGIS.Desktop.Mapping.Controls;assemblyArcGIS.Desktop.Mapping" 在控件区域加入: <mapping:CoordinateSystemsControl x:Name"CoordinateSystemsControl&q…...

一个电平转换电路导致MCU/FPGA通讯波形失真的原因分析
文章目录 前言一、问题描述二、原因分析三、 仿真分析四、 尝试的解决方案总结前言 一、问题描述 一个电平转换电路,800kHz的通讯速率上不去,波形失真,需要分析具体原因。输出波形如下,1码(占空比75%)低于5V,0码(占空比25%)低于4V。,严重失真。 电平转换电路很简单,M…...

不同OS版本中的同一yum源yum list差异排查思路
问题描述: qemu-guest-agent二进制rpm包的yum仓库源和yum源仓库配置文件path_to_yum_conf, 通过yum list --available -c path_to_yum_conf 查询时,不同的OS版本出现了不同的结果 anolis-8无法识别 centos8可以识别 说明: 1 测试…...

Android Studio开发安卓app 设置开机自启
Android Studio开发安卓app 设置开机自启 AndroidManifest.xml增加配置 增加的配置已标记 AndroidManifest.xml完整配置 <?xml version="1.0" encoding="utf-8"?> <manifest xmlns:android="http://schemas.android.com/apk/res/androi…...

全文索引数据库Elasticsearch底层Lucene
Lucene 全文检索的心,天才的想法。 一个高效的,可扩展的,全文检索库。全部用 Java 实现,无须配置。仅支持纯文本文件的索引(Indexing)和搜索(Search)。不负责由其他格式的文件抽取纯文本文件,或从网络中抓取文件的过程…...

互联网大厂Java求职面试:分布式系统中向量数据库与AI应用的融合探索
互联网大厂Java求职面试:分布式系统中向量数据库与AI应用的融合探索 面试开场:技术总监与郑薪苦的“较量” 技术总监(以下简称T):郑薪苦先生,请简单介绍一下你在分布式系统设计方面的经验。 郑薪苦&…...

游戏引擎学习第262天:绘制多帧性能分析图
回顾并为今天设定阶段 事情开始录制了,大家好,欢迎来到游戏直播节目。我们正在直播完成游戏的开发工作,目前我们正在做性能分析器,它现在已经非常酷了。我们只是在清理一些界面问题,但它能做的事情真的很厉害。我觉得…...

1、RocketMQ 核心架构拆解
1. 为什么要使用消息队列? 消息队列(MQ)是分布式系统中不可或缺的中间件,主要解决系统间的解耦、异步和削峰填谷问题。 解耦:生产者和消费者通过消息队列通信,彼此无需直接依赖,极大提升系统灵…...

探索 C++ 语言标准演进:从 C++23 到 C++26 的飞跃
引言 C 作为一门历史悠久且广泛应用的编程语言,其每一次标准的演进都备受开发者关注。从早期的 C98 到如今的 C23,再到令人期待的 C26,每一个版本都为开发者带来了新的特性和改进,推动着软件开发的不断进步。本文将深入探讨 C23 …...

ROBOVERSE:面向可扩展和可泛化机器人学习的统一平台、数据集和基准
25年4月来自UC Berkeley、北大、USC、UMich、UIUC、Stanford、CMU、UCLA 和 北京通用 AI 研究院(BIGAI)的论文“ROBOVERSE: Towards a Unified Platform, Dataset and Benchmark for Scalable and Generalizable Robot Learning”。 数据扩展和标准化评…...
高级用法)
【Bootstrap V4系列】学习入门教程之 组件-轮播(Carousel)高级用法
【Bootstrap V4系列】学习入门教程之 组件-轮播(Carousel)高级用法 轮播(Carousel)高级用法2.5 Crossfade (淡入淡出)2.6 Individual .carousel-item interval (单个轮播项目间隔)2.…...

LangChain4j简介
LangChain4j 是什么? The goal of LangChain4j is to simplify integrating LLMs into Java applications. LangChain4j 的目标是简化将 LLMs 集成到 Java 应用程序中。 提供如下能力: ● 统一的 API: LLM 提供商(如 OpenAI 或 Go…...

Git 撤销已commit但未push的文件
基础知识:HEAD^ 即上个版本, HEAD~2 即上上个版本, 依此类推… 查看commit日志 git log撤销commit,保留git add git reset --soft HEAD^ #【常用于:commit成功,push失败时的代码恢复】保留工作空间改动代码,撤销com…...
)
OC语言学习——面向对象(下)
一、OC的包装类 OC提供了NSValue、NSNumber来封装C语言基本类型(short、int、float等)。 在 Objective-C 中,**包装类(Wrapper Classes)**是用来把基本数据类型(如 int、float、char 等)“包装…...

SafeDrive:大语言模型实现自动驾驶汽车知识驱动和数据驱动的风险-敏感决策——论文阅读
《SafeDrive: Knowledge- and Data-Driven Risk-Sensitive Decision-Making for Autonomous Vehicles with Large Language Models》2024年12月发表,来自USC、U Wisconsin、U Michigan、清华大学和香港大学的论文。 自动驾驶汽车(AV)的最新进…...
Detail-Preserving Latent Diffusion for Stable Shadow Removal论文阅读)
什么是先验?(CVPR25)Detail-Preserving Latent Diffusion for Stable Shadow Removal论文阅读
文章目录 先验(Prior)是什么?1. 先验的数学定义2. 先验在深度生成模型中的角色3. 为什么需要先验?4. 先验的常见类型5. 如何选择或构造先验?6. 小结 先验(Prior)是什么? 在概率统计…...

【论文阅读】Attentive Collaborative Filtering:
Attentive Collaborative Filtering: Multimedia Recommendation with Item- and Component-Level Attention Attentive Collaborative Filtering (ACF)、隐式反馈推荐、注意力机制、贝叶斯个性化排序 标题翻译:注意力协同过滤:基于项目和组件级注意力的…...

如何使用极狐GitLab 软件包仓库功能托管 maven?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 软件包库中的 Maven 包 (BASIC ALL) 在项目的软件包库中发布 Maven 产物。然后,在需要将它们用作依赖项时安装它…...

Notion Windows桌面端快捷键详解
通用导航 这些快捷键帮助用户在 Notion 的界面中快速移动。 打开 Notion:Ctrl T 打开一个新的 Notion 窗口或标签页,方便快速进入工作空间。返回上一页:Ctrl [ 导航回之前查看的页面。前进到下一页:Ctrl ] 跳转到导航历史中的…...

企业智能化第一步:用「Deepseek+自动化」打造企业资源管理的智能中枢
随着Deepseek乃至AI人工智能技术在企业中得到了广泛的关注和使用,多数企业开始了AI探索之旅,迅易科技也不例外,且在不断地实践中强化了AI智能应用创新的强大能力。 为解决企业知识管理碎片化、提高内部工作效率等问题,迅易将目光放…...
)
GoFly企业版框架升级2.6.6版本说明(框架在2025-05-06发布了)
前端框架升级说明: 1.vue版本升级到^3.5.4 把"vue": "^3.2.40",升级到"vue": "^3.5.4",新版插件需要时useTemplateRef,所以框架就对齐进行升级。 2.ArcoDesign升级到2.57.0(目前最新2025-02-10&a…...

LeapVAD:通过认知感知和 Dual-Process 思维实现自动驾驶飞跃——论文阅读
《LeapVAD: A Leap in Autonomous Driving via Cognitive Perception and Dual-Process Thinking》2025年1月发表,来自浙江大学、上海AI实验室、慕尼黑工大、同济大学和中科大的论文。 尽管自动驾驶技术取得了显著进步,但由于推理能力有限,数…...

ps信息显示不全
linux执行ps是默认宽度是受限制的,例如: ps -aux 显示 遇到这种情况,如果显示的信息不是很长可以添加一个w参数来放宽显示宽度 ps -auxw 显示 再添加一个w可以接触宽度限制,有多长就显示多长 ps -auxww 显示...

性能比拼: Redis Streams vs Pub/Sub
本内容是对知名性能评测博主 Anton Putra Redis Streams vs Pub/Sub: Performance 内容的翻译与整理, 有适当删减, 相关指标和结论以原作为准 在这个视频中,我们首先将介绍 Redis Streams 和 Redis Pub/Sub 之间的区别。然后,我们将在 AWS 上运行一个基准…...

实践004-Gitlab CICD部署应用
文章目录 Gitlab CICD部署应用部署设计集成Kubernetes后端Java项目部署创建gitlab部署项目创建部署文件创建流水线提交流水线 前端Web项目部署创建gitlab部署项目创建部署文件创建流水线提交流水线 Gitlab CICD部署应用 部署设计 对于前后端服务都基于 Kubernetes 进行部署&a…...

二叉树与优先级队列
1.树 树是由n个数据构成的非线性结构,它是根朝上,叶朝下。 注意:树形结构之中,子树之间不能连接,不然就不构成树形结构 1.子树之间没有交集 2.除了根节点以外,每一个节点有且只有一个父亲节点 3.一个n个…...

如何使用极狐GitLab 软件包仓库功能托管 npm?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 软件包库中的 npm 包 (BASIC ALL) npm 是 JavaScript 和 Node.js 的默认包管理器。开发者使用 npm 共享和重用代码ÿ…...

uniapp自定义底部导航栏h5有效果小程序无效的解决方案
在使用 uni-app 开发跨端应用时,常见问题之一是自定义底部导航栏(tabbar)在H5端有效,但在小程序端无效。这是因为小程序端的页面结构和生命周期与H5有差异,且小程序端的原生tabbar有更高的优先级,覆盖了自定…...
)
开发搭载阿里云平台的物联网APP(支持数据接收与发送)
一、开发环境准备 工具安装 HBuilderX:下载并安装最新版(支持Vue.js和uni-app框架)阿里云IoT SDK:使用JavaScript版SDK(如aliyun-iot-mqtt或mqtt.js)插件安装:HBuilderX插件市场搜索安装mqtt相关…...

Flowchart 流程图的基本用法
以下是 Flowchart 流程图 的基本用法整理,涵盖核心概念、符号含义、绘制步骤及注意事项,助你高效表达流程逻辑: 一、流程图的核心作用 可视化流程:将复杂步骤转化为直观图形,便于理解和分析。梳理逻辑:明确…...

Excel模版下载文件导入
工作中经常遇到Excel模板下载,然后填好后再导入的情况,简单记录下,方便下次使用 Excel模版下载(返回Base64) 模板文件存放位置 import java.util.Base64; import org.apache.commons.io.IOUtils; import org.sprin…...