MySQL表的增删查改
目录
- 一、MySQL表的增删查改
- 二、Create
- 单行数据+全列插入
- 多行数据 + 指定列插入
- 插入否则更新
- 替换数据
- 三、Retrieve
- SELECT 列
- WHERE 条件
- NULL的查询
- 结果排序
- 筛选分页结果
- 四、Update
- 将孙悟空同学的数学成绩修改为80分
- 将曹孟德同学的数学成绩修改为60分,语文成绩修改为70分
- 将总成绩倒数前三的3位同学的数学成绩加上30分
- 将所有同学的语文成绩修改为原来的2倍
- 五、Delete
- 删除数据
- 删除整张表数据
- 截断表
- 六、插入查询结果
- 七、聚合函数
- 统计班级共有多少同学
- 统计班级收集的QQ号有多少个
- 统计本次考试数学成绩的分数个数
- 统计数学成绩总分
- 统计平均总分
- 返回英语最高分
- 返回70分以上的英语最低分
- 八、分组查询
- 分组查询测试表 —— 雇员信息表
- 显示每个部门的平均工资和最高工资
- 显示每个部门的每种岗位的平均工资和最低工资
- HAVING 条件
一、MySQL表的增删查改
- 表的增删查改简称CRUD:Create(新增),Retrieve(查找),Update(修改),Delete(删除)。
- CRUD的操作对象是对表当中的数据,是典型的DML(Data Manipulation Language)数据操作语言。
二、Create
新增数据
INSERT [INTO] table_name [(column1 [, column2] ...)] VALUES (value_list1) [, (value_list2)] ...;
说明:
- SQL中大写的表示关键字,[ ]中代表的是可选项。
- SQL中的每个value_list都表示插入的一条记录,每个value_list都由若干待插入的列值组成。
- SQL中的column列表,用于指定每个value_list中的各个列值应该插入到表中的哪一列。
创建一个学生表,表当中包含自增长的主键id、学号、姓名和QQ号。
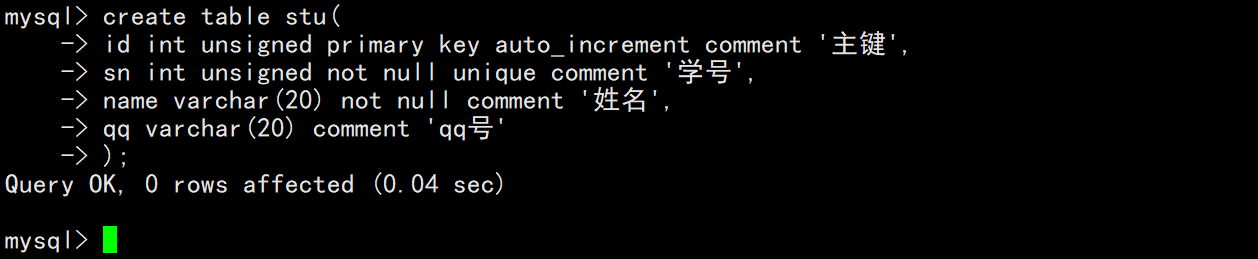
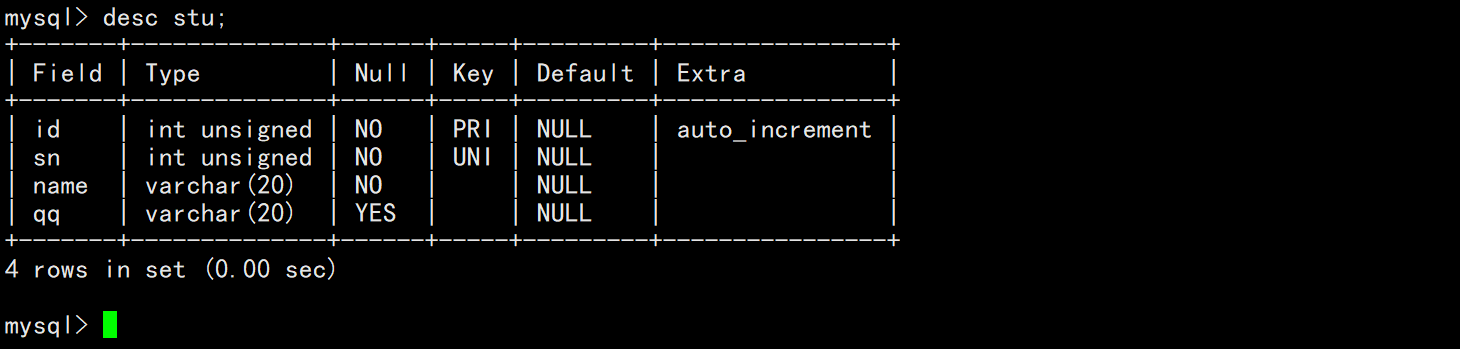
创建完表后,查看表的结构。
单行数据+全列插入
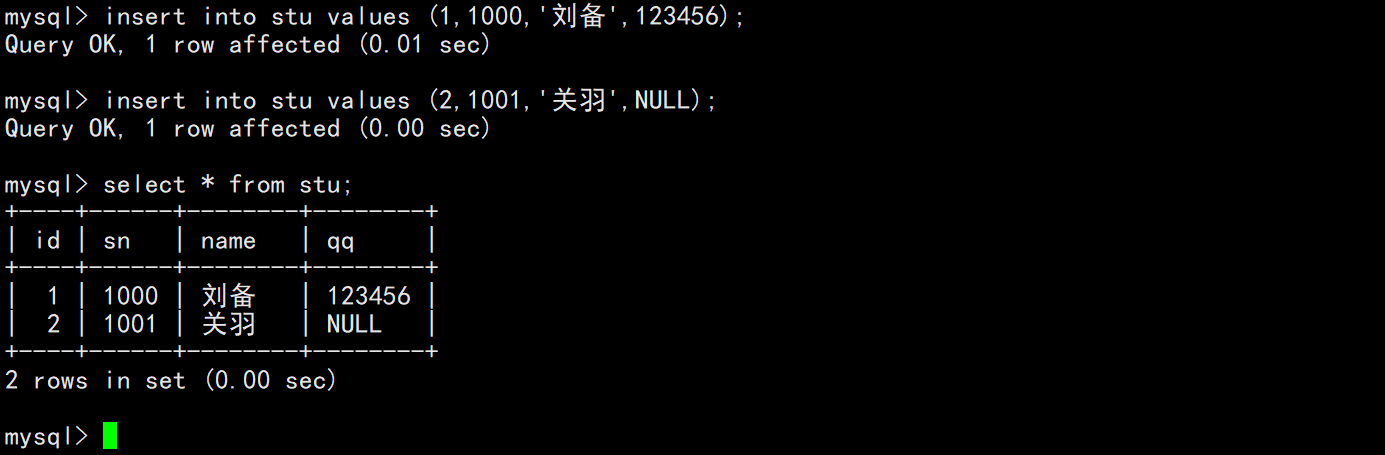
下面使用insert语句向学生表中插入记录,每次向表中插入一条记录,并且插入记录时不指定column列表,表示按照表中默认的列顺序进行全列插入,因此插入的每条记录中的列值需要按表列顺序依次列出。
多行数据 + 指定列插入
使用insert语句也可以一次向表中插入多条记录,插入的多条记录之间使用逗号隔开,并且插入记录时可以只指定某些列进行插入。
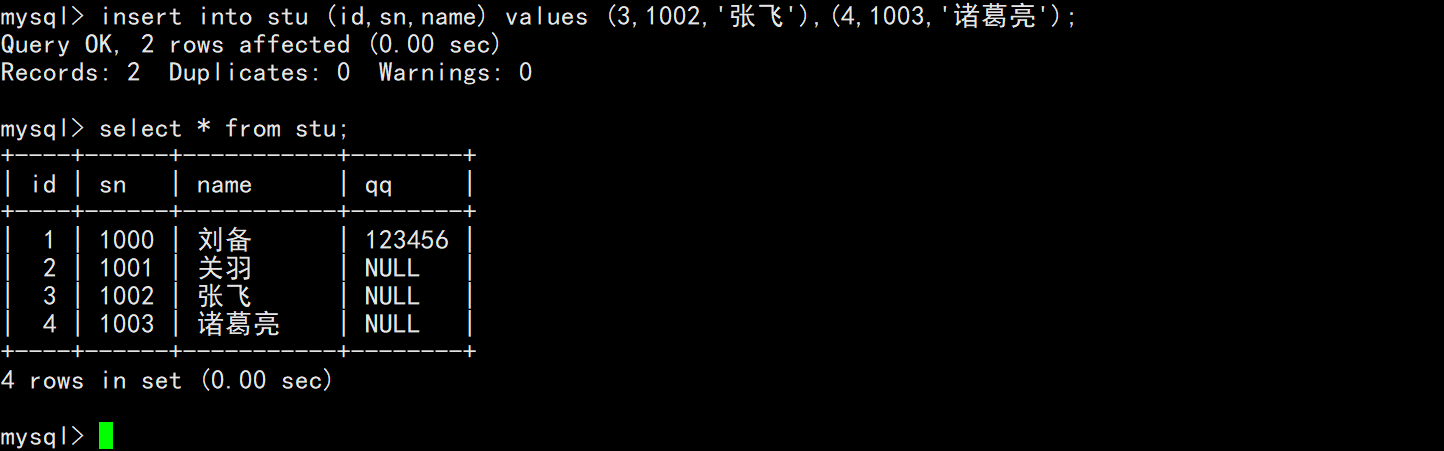
说明: 在插入记录时,只有允许为空的列或自增长字段可以不指定值插入,不允许为空的列必须指定值插入,否则会报错。
插入否则更新

这时可以选择性的进行同步更新操作:
- 如果表中没有冲突数据,则直接插入数据。
- 如果表中有冲突数据,则将表中的数据进行更新。
插入否则更新的SQL如下:
INSERT ... ON DUPLICATE UPDATE column1=value1 [, column2=value2] ...;
说明:
- SQL中大写的表示关键字,[ ]中代表的是可选项。
- SQL中INSERT之后语法与之前的INSERT语句相同。
- UPDATE后面的column=value,表示当插入记录出现冲突时需要更新的列值。
向学生表中插入记录时,如果没有出现主键冲突则直接插入记录,如果出现了主键冲突,则将表中冲突记录的学号和姓名进行更新。
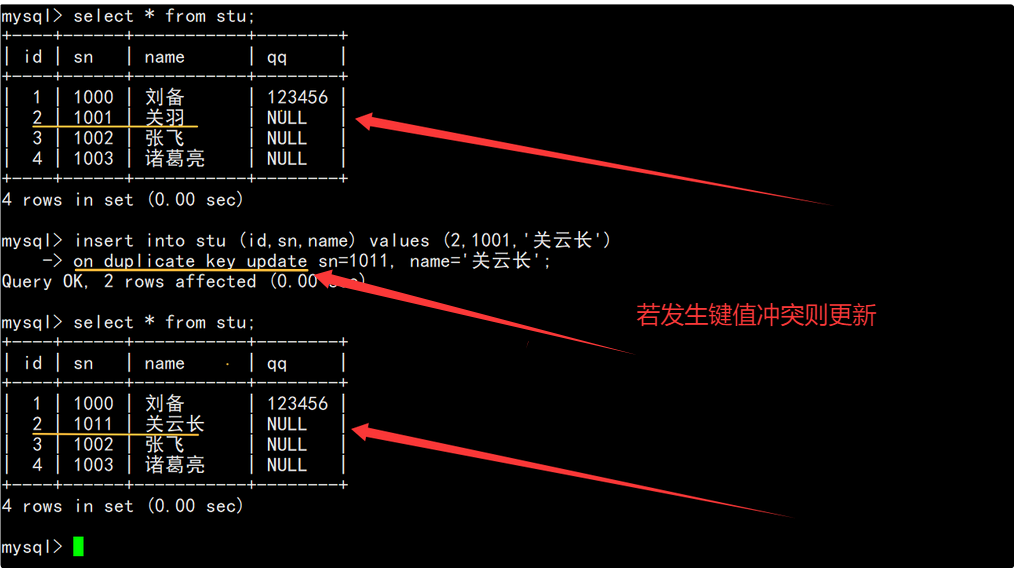
执行插入否则更新的SQL后,可以通过受影响的数据行数来判断本次数据的插入情况:
- 0 row affected:表中有冲突数据,但冲突数据的值和指定更新的值相同。
- 1 row affected:表中没有冲突数据,数据直接被插入。
- 2 row affected:表中有冲突数据,并且数据已经被更新。
替换数据
- 如果表中没有冲突数据,则直接插入数据。
- 如果表中有冲突数据,则先将表中的冲突数据删除,然后再插入数据。
只需要在插入数据时将SQL语句中的INSERT改为REPLACE即可。
若3号不存在则直接插入,否则修改数据。
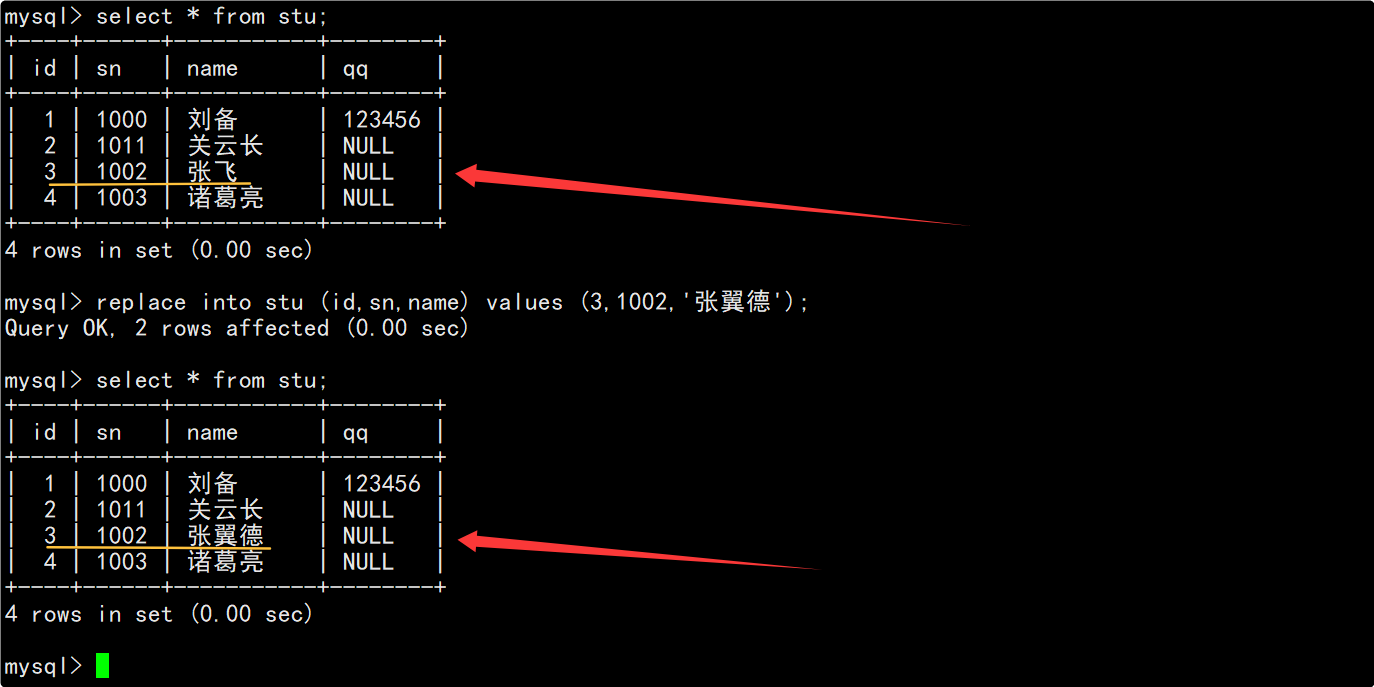
执行替换数据的SQL后,也可以通过受影响的数据行数来判断本次数据的插入情况:
- 1 row affected:表中没有冲突数据,数据直接被插入。
- 2 row affected:表中有冲突数据,冲突数据被删除后重新插入。
三、Retrieve
查找数据
SELECT [DISTINCT] {* | {column1 [, column2] ...}} FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...];
说明:
- SQL中大写的表示关键字,[ ]中代表的是可选项。
- { }中的 | 代表可以选择左侧的语句或右侧的语句。
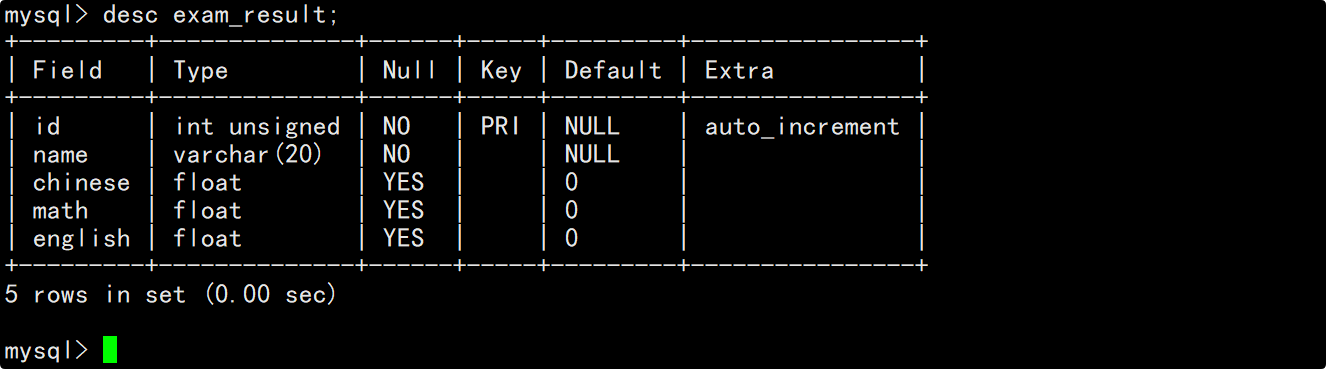
创建一个成绩表,表当中包含自增长的主键id、姓名以及该同学的语文成绩、数学成绩和英语成绩。

创建完表后查看表结构,可以看到表结构。
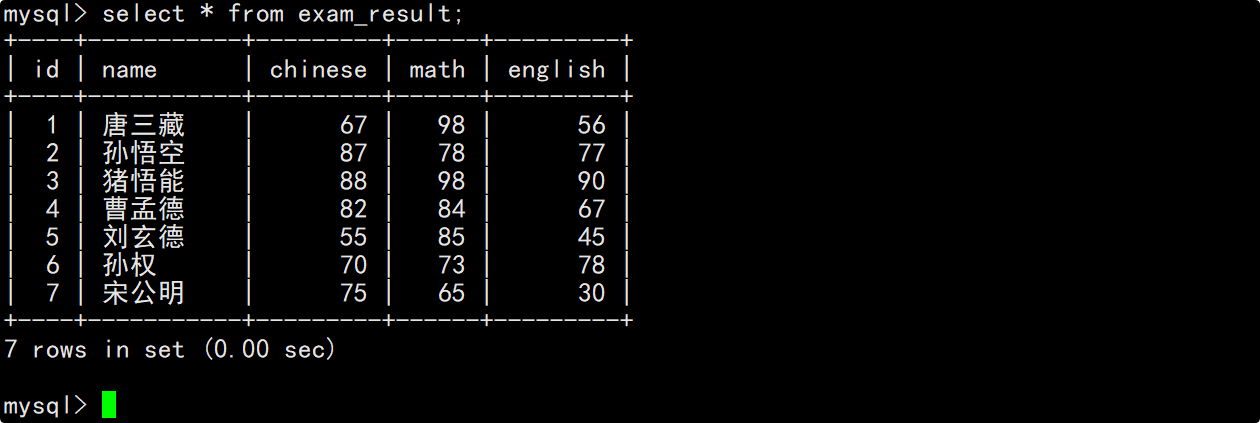
插入一些信息,以供进行查找。

SELECT 列
全列查询
在查询数据时直接用 * 代替column列表,表示进行全列查询,这时将会显示被筛选出来的记录的所有列信息。
说明: 通常情况下不建议使用*进行全列查询,因为被查询到的数据需要通过网络从MySQL服务器传输到本主机,查询的列越多也就意味着需要传输的数据量越大,此外,进行全列查询还可能会影响到索引的使用。
指定列查询
在查询数据时也可以只对指定的列进行查询,这时将需要查询的列在column列表列出即可。
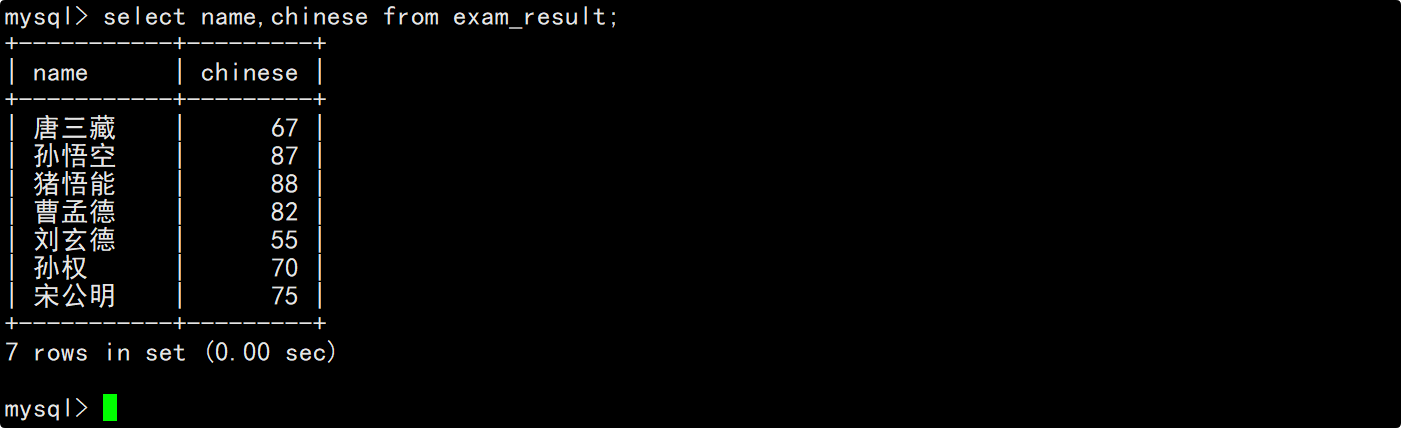
查询字段为表达式
查询数据时,column列表中除了能罗列表中存在的列名外,也可以将表达式罗列到column列表中。
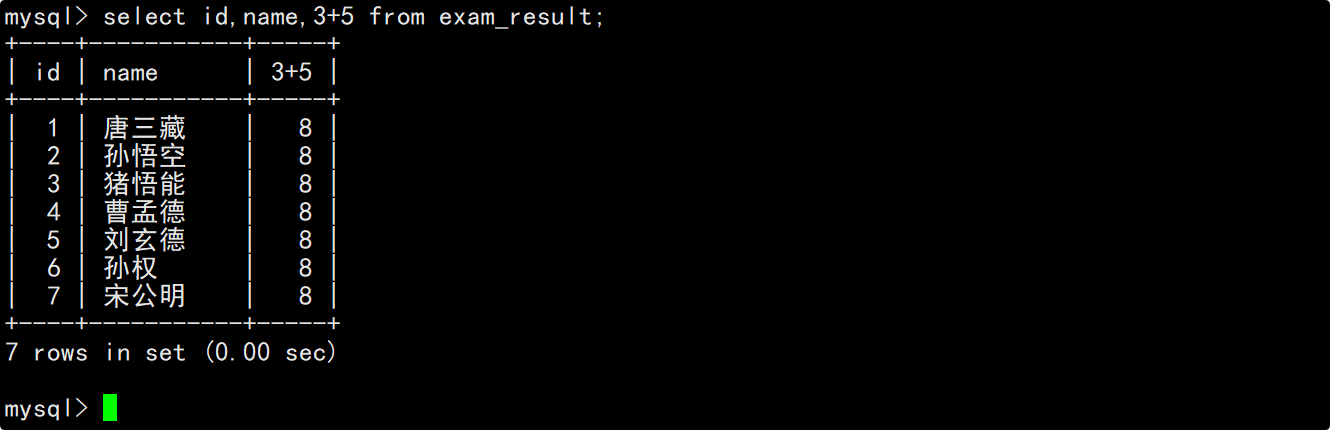
select不仅能够用来查询数据,还可以用来计算某些表达式或执行某些函数。

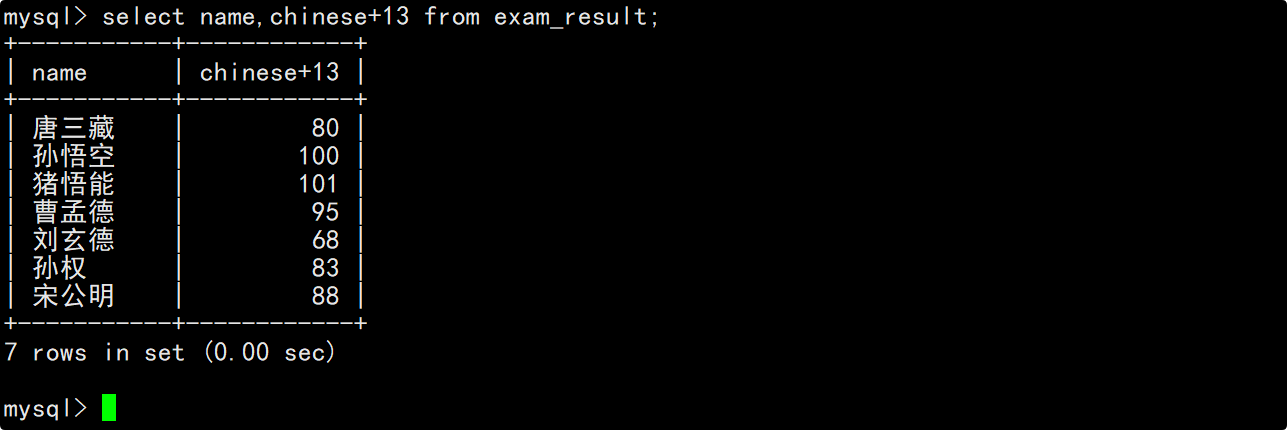
如果我们将表达式罗列到column列表,那么每当一条记录被筛选出来时就会执行这个表达式,然后将表达式的计算结果作为这条记录的一个列值进行显示。
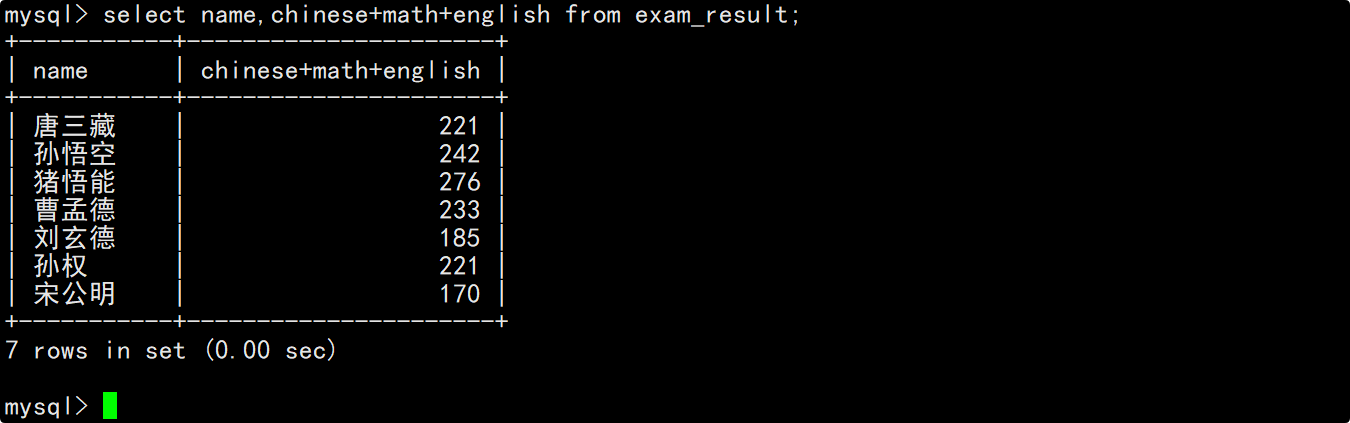
column列表中的表达式可以包含表中已有的字段,这时每当一条记录被筛选出来时,就会将记录中对应的列值提供给表达式进行计算。
column列表中的表达式中也可以包含多个表中已有的字段,这时我们就可以通过表达式计算出更多有意义的数据。
为查询结果指定别名
SELECT column [AS] alias_name [...] FROM table_name;
说明:
- SQL中大写的表示关键字,[ ]中代表的是可选项。
比如查询成绩表中的数据时,将每条记录中的三科成绩相加,然后将计算结果对应的列指定别名为“总分”。
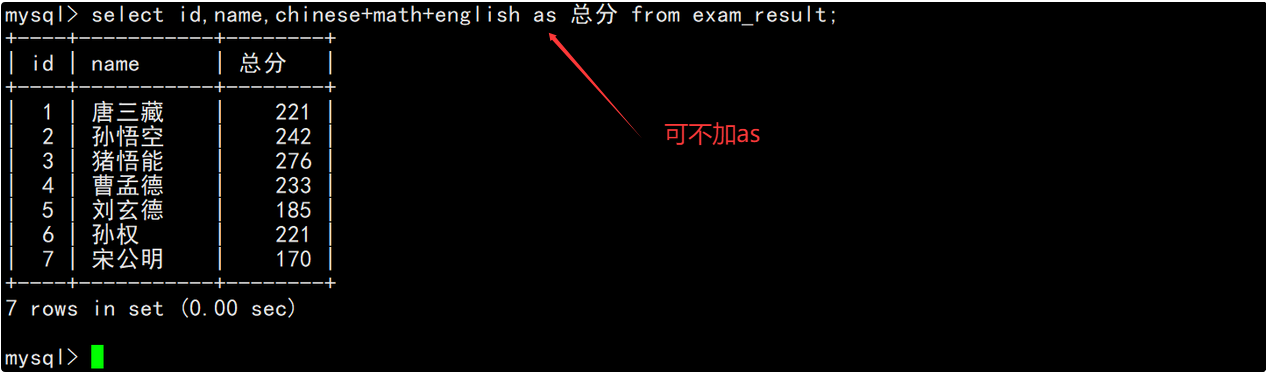
结果去重
查询成绩表时指定查询数学成绩对应的列,可以看到数学成绩中有重复的分数。
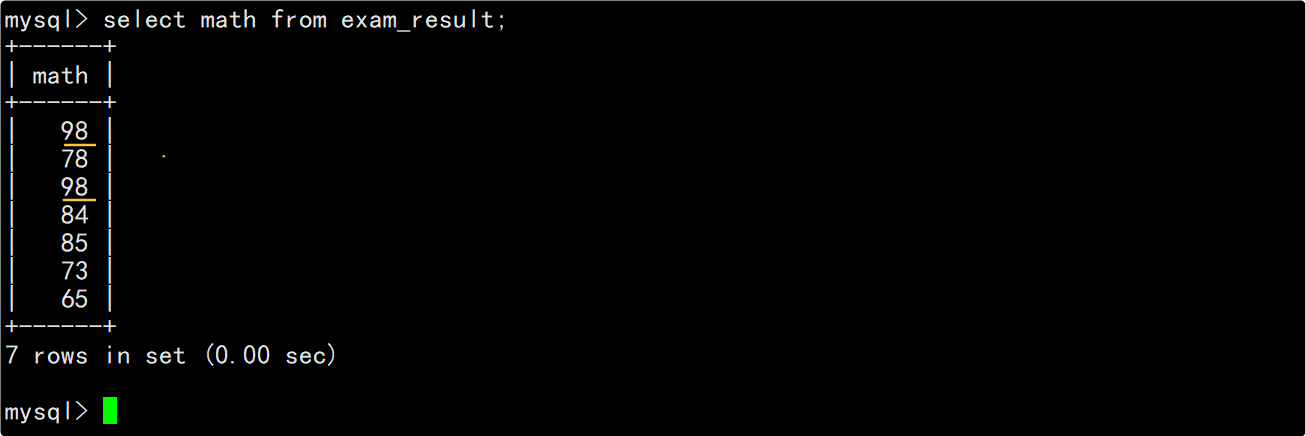
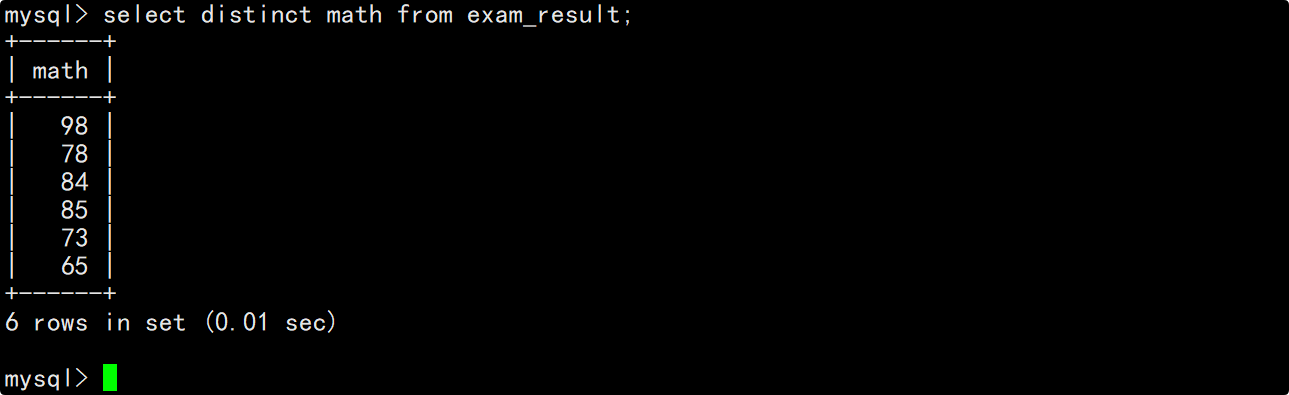
若想要对查询结果进行去重操作,可以在SQL中的select后面带上distinct。
WHERE 条件
添加where子句的区别:
- 如果在查询数据时没有指定where子句,那么会直接将表中所有的记录作为数据源来依次执行select语句。
- 如果在查询数据时指定了where子句,那么在查询数据时会先根据where子句筛选出符合条件的记录,然后将符合条件的记录作为数据源来依次执行select语句。
where子句中可以指明一个或多个筛选条件,各个筛选条件之间用逻辑运算符AND或OR进行关联,下面给出了where子句中常用的比较运算符和逻辑运算符。
比较运算符:
| 运算符 | 说明 |
|---|---|
| >、>=、<、<= | 大于、大于等于、小于、小于等于 |
| = | 等于。NULL不安全,例如NULL=NULL的结果是NULL而不是TRUE(1) |
| <=> | 等于。NULL安全,例如NULL<=>NULL的结果就是TRUE(1) |
| !=、<> | 不等于 |
| BETWEEN a0 AND a1 | 范围匹配。如果a0<=value<=a1,则返回TRUE(1) |
| IN(option1, option2, …) | 如果是IN中的任意一个option,则返回TRUE(1) |
| IS NULL | 如果是NULL,则返回TRUE(1) |
| IS NOT NULL | 如果不是NULL,则返回TRUE(1) |
| LIKE | 模糊匹配。%表示任意多个字符(包括0个),_表示任意一个字符 |
逻辑运算符:
| 运算符 | 说明 |
|---|---|
| AND | 多个条件同时为TRUE(1),则结果为TRUE(1),否则为FALSE(0) |
| OR | 任意一个条件为TRUE(1),则结果为TRUE(1),否则为FALSE(0) |
| NOT | 条件为TRUE(1),则结果为FALSE(0);条件为FALSE(0),则结果为TRUE(1) |
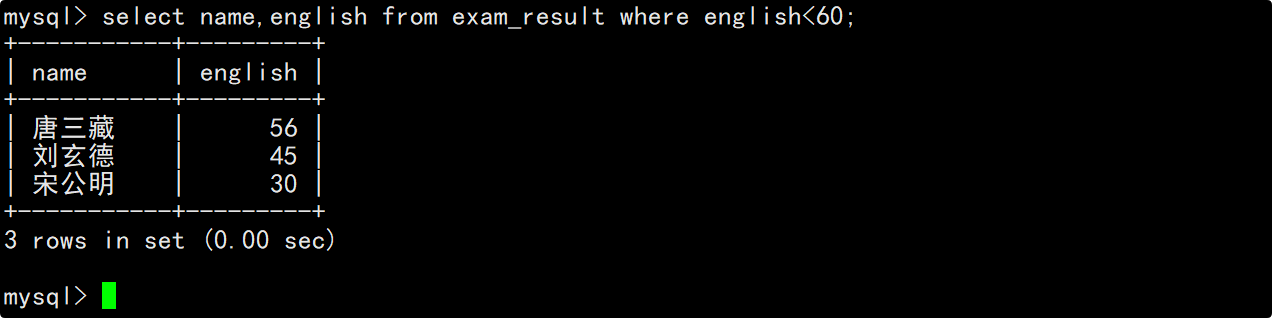
查询英语不及格的同学及其英语成绩
在where子句中指明筛选条件为英语成绩小于60,在select的column列表中指明要查询的列为姓名和英语成绩。
查询语文成绩在80到90分的同学及其语文成绩
在where子句中指明筛选条件为语文成绩大于等于80并且小于等于90,在select的column列表中指明要查询的列为姓名和语文成绩。
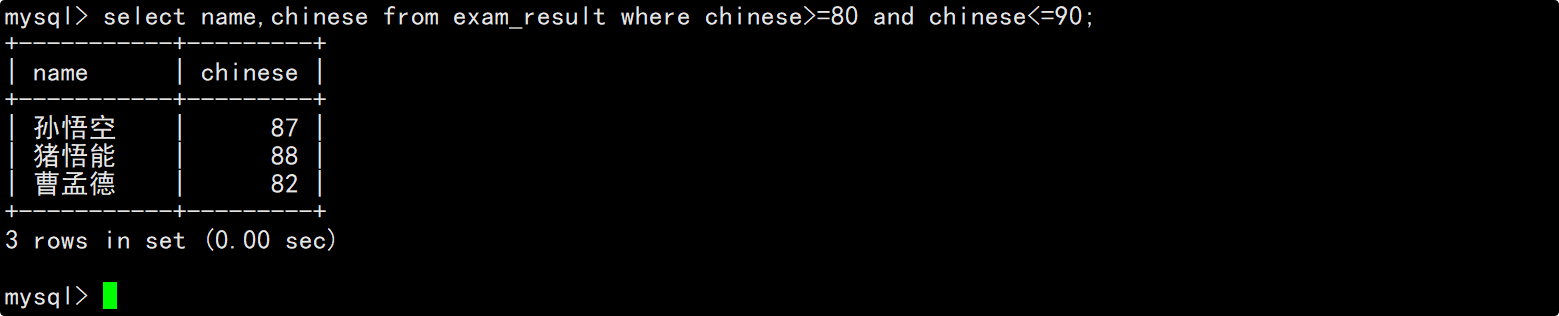
此外,这里也可以使用BETWEEN a0 AND a1来指明语文成绩的的所在区间。
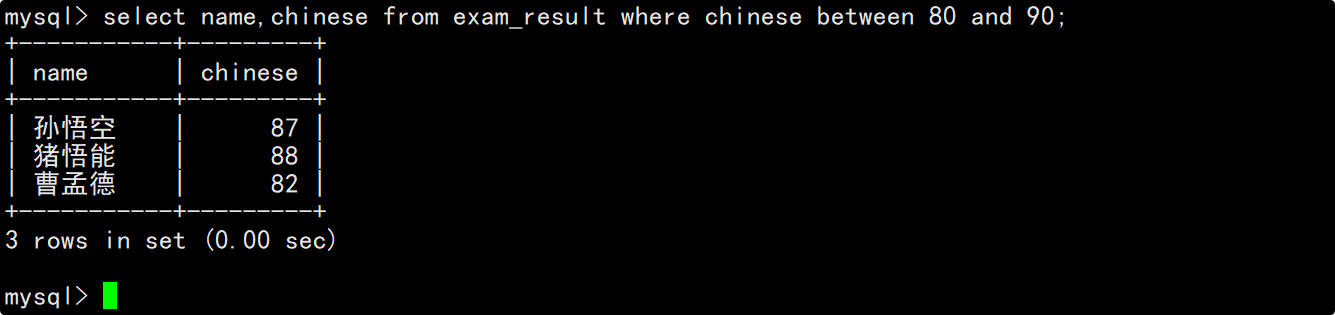
查询数学成绩是58或59或98或99分的同学及其数学成绩
在where子句中指明筛选条件为数学成绩等于58或59或98或99,在select的column列表中指明要查询的列为姓名和数学成绩。

此外,这里也可以通过IN(58, 59, 98, 99)的方式来判断数学成绩是否符合筛选要求。
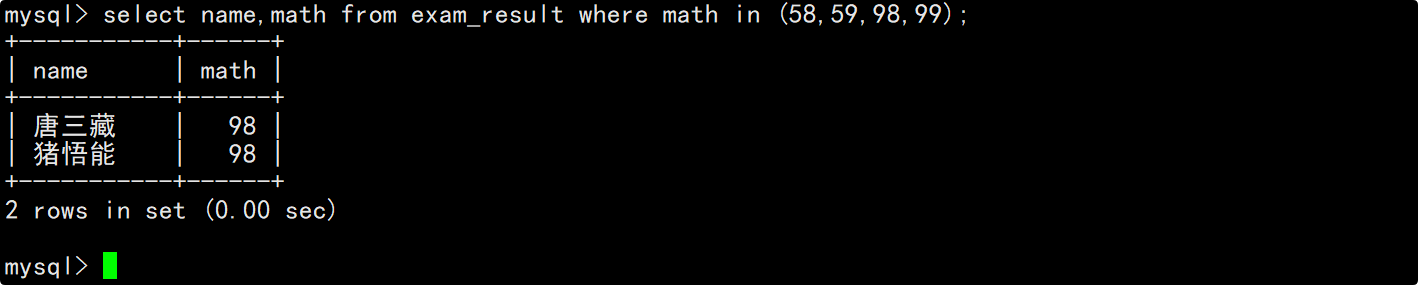
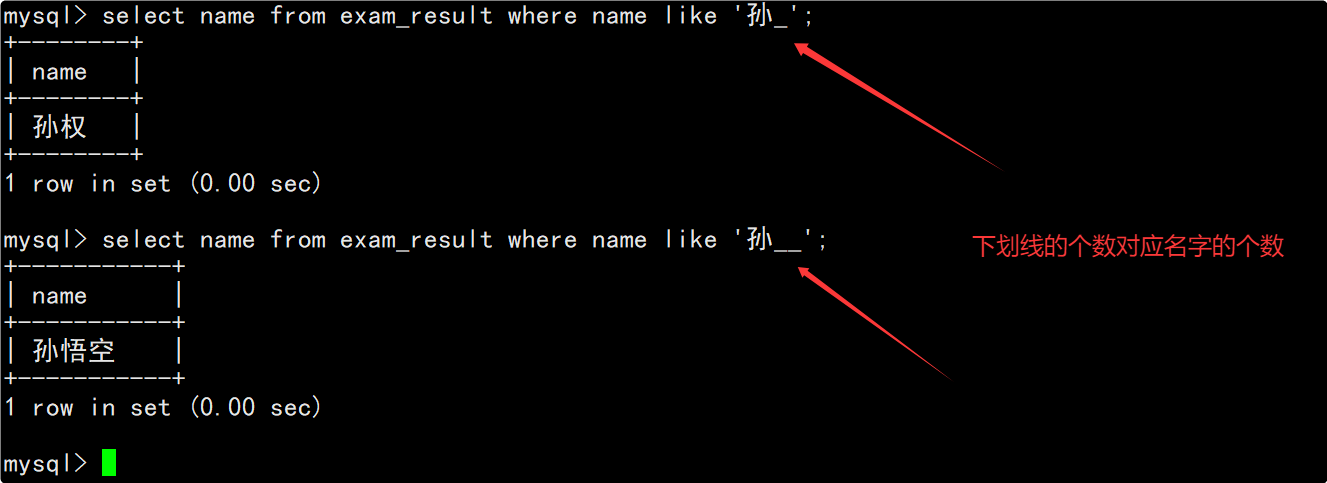
分别查询姓孙的同学和孙某同学
- 查询姓孙的同学
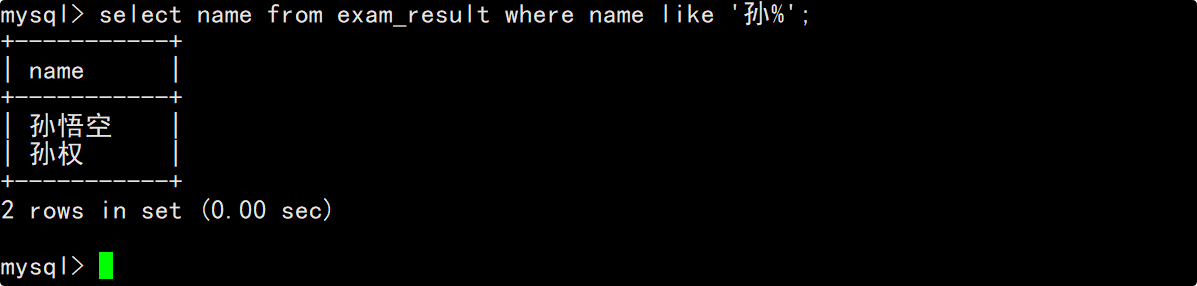
- 查询孙某同学
在where子句中通过模糊匹配来判断当前同学是否为孙某(需要用到_来严格匹配单个字符),在select的column列表中指明要查询的列为姓名。
查询语文成绩高于英语成绩的同学
在where子句中指明筛选条件为语文成绩大于英语成绩,在select的column列表中指明要查询的列为姓名、语文成绩和英语成绩。
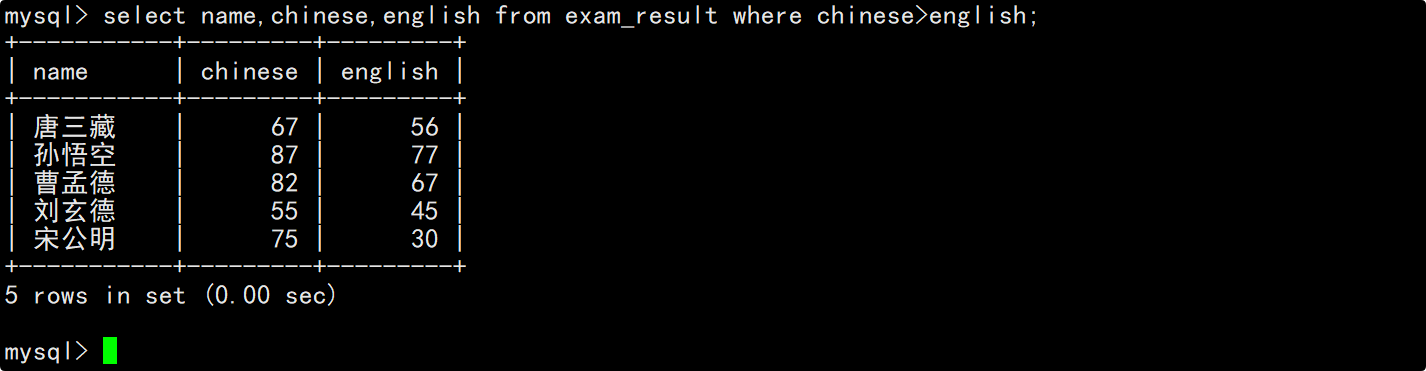
查询总成绩在200分以下的同学
在select的column列表中添加表达式查询,查询的表达式为语文、数学和英语成绩之和,为了方便观察可以将表达式对应的列指定别名为“总分”,在where子句中指明筛选条件为三科成绩之和小于200。

注意: 在where子句中不能使用select中指定的别名:
- 查询数据时是先根据where子句筛选出符合条件的记录。
- 然后再将符合条件的记录作为数据源来依次执行select语句。
也就是说,where子句的执行是先于select语句的,所以在where子句中不能使用别名,如果在where子句中使用别名,那么在查询数据时就会产生报错。

查询语文成绩大于80分并且不姓孙的同学
在where子句中指明筛选条件为语文成绩大于80,并且通过模糊匹配和not来保证该同学不姓孙,在select的column列表中指明要查询的列为姓名和语文成绩。

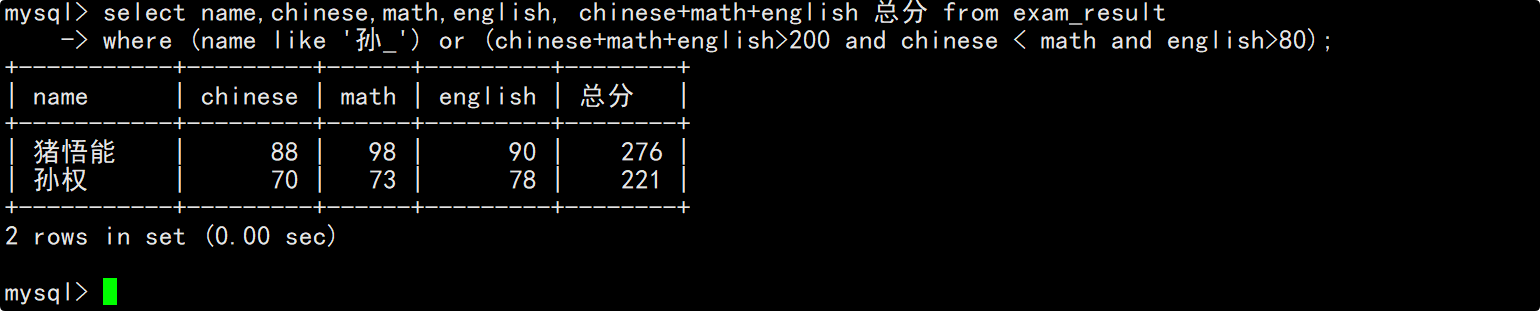
查询孙某同学,否则要求总成绩大于200分并且语文成绩小于数学成绩并且英语成绩大于80分
题目给出条件有两个:1.孙某,需要用到模糊匹配(‘姓%’);2.总分大于200且语文成绩小于数学成绩且英语成绩大于80,需要用到表达式查询和逻辑运算符。
NULL的查询
准备测试表
前面演示新增数据的学生表来演示NULL查询,学生表中的内容。

查询QQ号已知的同学
在where子句中指明筛选条件为QQ号不是NULL,在select的column列表中指明要查询的列为id,姓名和QQ号。

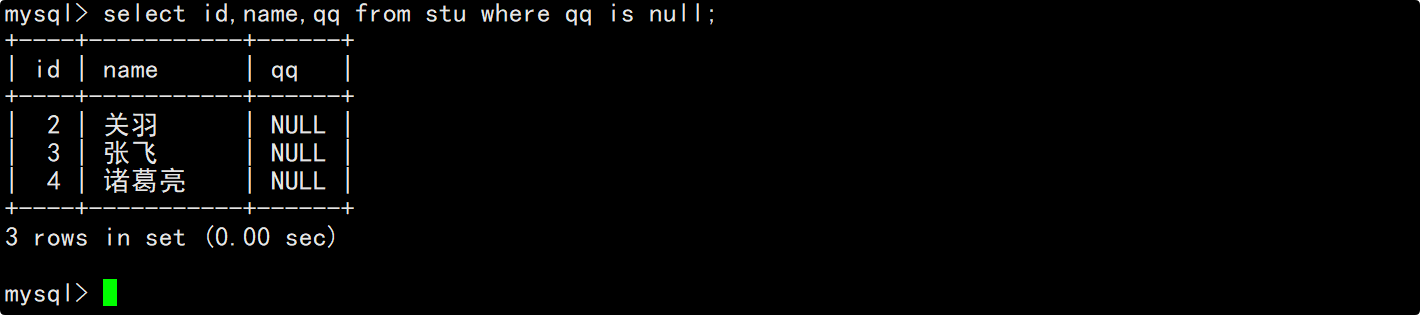
查询QQ号未知的同学
在where子句中指明筛选条件为QQ号为NULL,在select的column列表中指明要查询的列为id,姓名和QQ号。
需要注意的是,在与NULL值作比较的时候应该使用<=>运算符,使用=运算符无法得到正确的查询结果。

因为=运算符是NULL不安全的,使用=运算符将任何值与NULL作比较,得到的结果都是NULL。

但是<=>运算符是NULL安全的,使用<=>运算符将NULL和NULL作比较得到的结果为TRUE(1),将非NULL值与NULL作比较得到的结果为FALSE(0)。

结果排序
SELECT ... FROM table_name [WHERE ...] ORDER BY column [ASC | DESC] [, ...];
说明:
- SQL中大写的表示关键字,[ ]中代表的是可选项。
- ASC和DESC分别代表的是排升序和排降序,默认为ASC。
注意: 如果查询SQL中没有order by子句,那么返回的顺序是未定义的。
查询同学及其数学成绩,按数学成绩升序显示
在select的column列表中指明要查询的列为姓名和数学成绩,在order by子句中指明按照数学成绩进行升序排序。
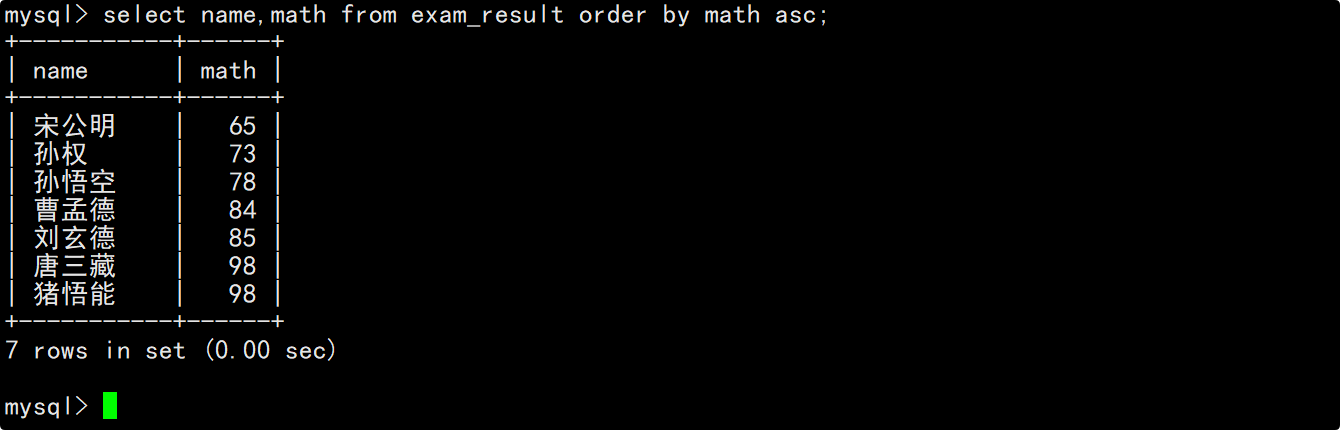
查询同学及其QQ号,按QQ号升序显示
在select的column列表中指明要查询的列为姓名和QQ号,在order by子句中指明按照QQ号进行升序排序。

说明: NULL值视为比任何值都小,因此排升序时出现在最上面。
查询同学的各门成绩,依次按数学降序、英语升序、语文升序显示
在select的column列表中指明要查询的列为姓名、数学成绩、英语成绩和语文成绩,在order by子句中指明依次按照数学成绩排降序、英语成绩排升序和语文成绩排升序。
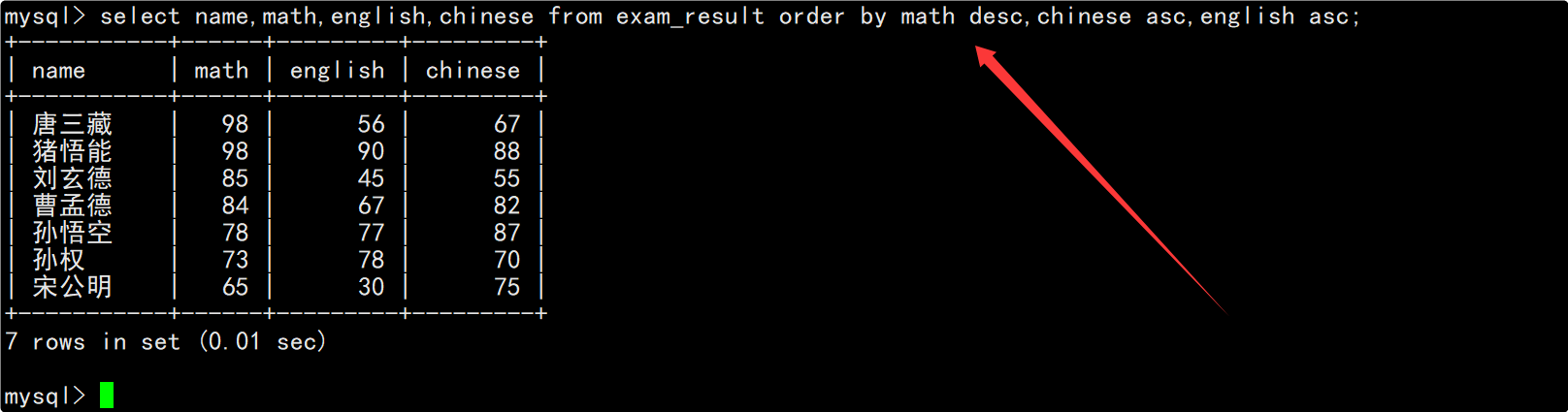
可以看到显示结果是按照数学成绩进行降序排序的,而相同的数学成绩之间则是按照英语成绩进行升序排序的(如果数学成绩相等就按英语升序)。
说明:
- order by子句中可以指明按照多个字段进行排序,每个字段都可以指明按照升序或降序进行排序,各个字段之间使用逗号隔开,排序优先级与书写顺序相同。
- 比如上述SQL中,当两条记录的数学成绩相同时就会按照英语成绩进行排序,如果这两条记录的英语成绩也相同就会继续按照语文成绩进行排序,以此类推。
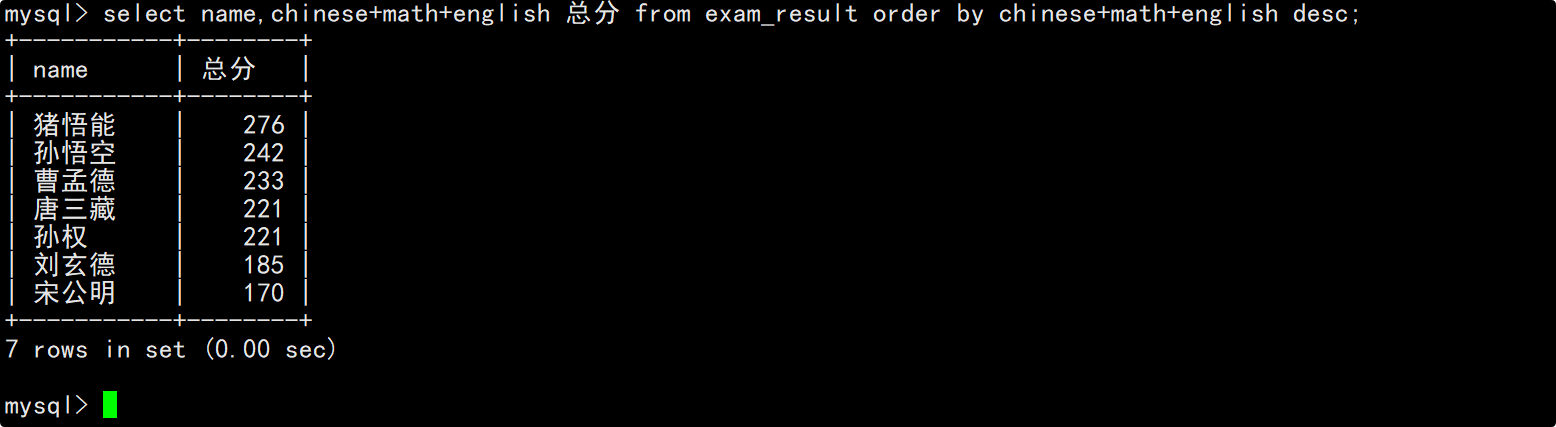
查询同学及其总分,按总分降序显示
在select的column列表中指明要查询的列为姓名和总分(表达式查询),在order by子句中指明按照总分进行降序排序。
查询姓孙的同学或姓曹的同学及其数学成绩,按数学成绩降序显示
题目前半句是描述查询,后半句排序,在排序的时候必须要有数据,因此可以先完成前面的查询动作,然后再根据题目要求进行排序。
筛选分页结果
从第0条记录开始,向后筛选出n条记录:
SELECT ... FROM table_name [WHERE ..] [ORDER BY ...] LIMIT n;
从第s条记录开始,向后筛选出n条记录:
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n;
从第s条记录开始,向后筛选出n条记录:
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;
说明:
- SQL中大写的表示关键字,[ ]中代表的是可选项。
- 查询SQL中各语句的执行顺序为:where、select、order by、limit。
- limit子句在筛选记录时,记录的下标从0开始。
建议: 对未知表进行查询时最好在查询SQL后加上limit 1,避免在查询全表数据时因为表中数据过大而导致数据库卡死。
按id进行分页,每页3条记录,分别显示第1、2、3页
使用成绩表中的数据来演示分页查询,成绩表中的内容如下: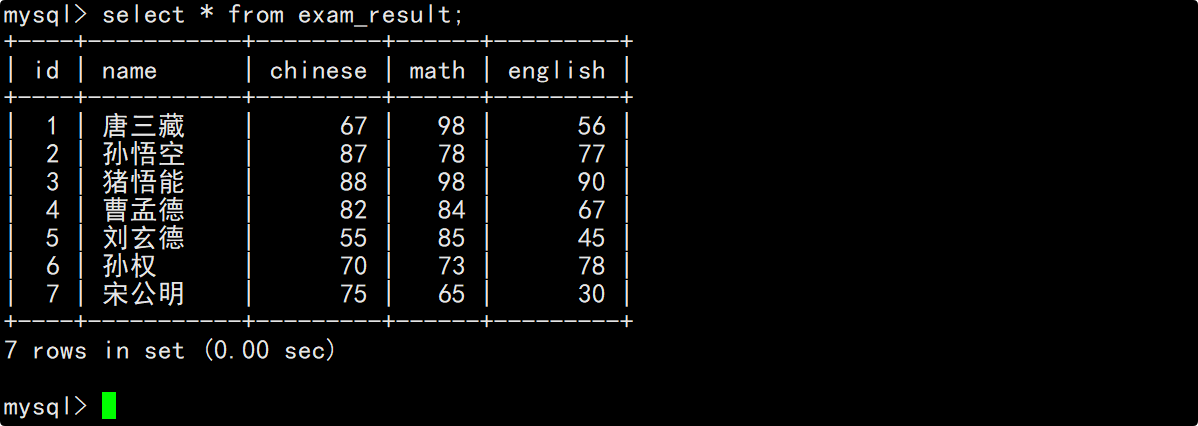
查询第1页记录时在查询全表数据的SQL后,加上limit子句指明从第0条记录开始,向后筛选出3条记录。
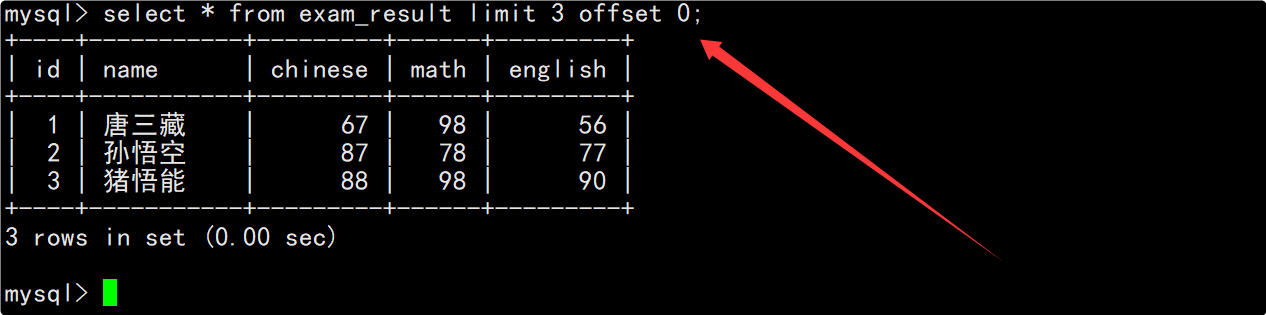
查询第2页记录时在查询全表数据的SQL后,加上limit子句指明从第3条记录开始,向后筛选出3条记录。
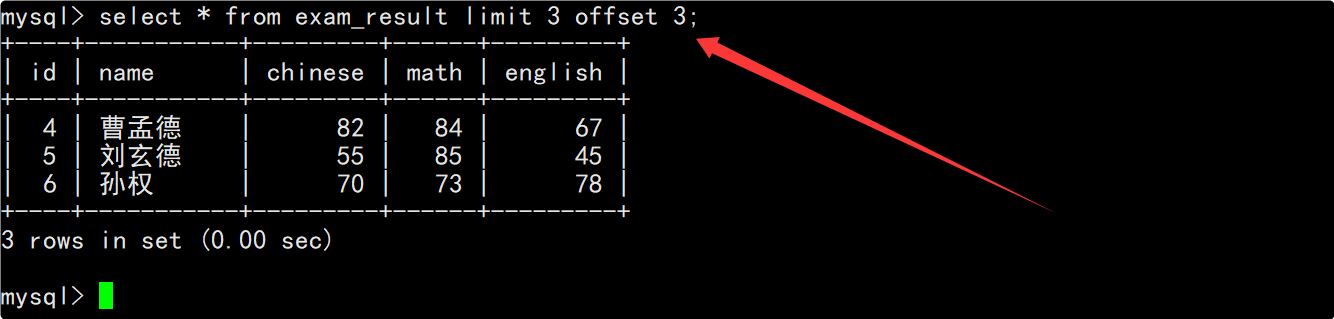
查询第3页记录时在查询全表数据的SQL后,加上limit子句指明从第6条记录开始,向后筛选出3条记录。

说明: 如果从表中筛选出的记录不足n个,则筛选出几个就显示几个。
四、Update
修改数据
UPDATE table_name SET column1=expr1 [, column2=expr2] ... [WHERE ...] [ORDER BY ...] [LIMIT ...];
说明:
- SQL中大写的表示关键字,[ ]中代表的是可选项。
- SQL中的column=expr,表示将记录中列名为column的值修改为expr。
- 在修改数据之前需要先找到待修改的记录,update语句中的where、order by和limit就是用来定位数据的。
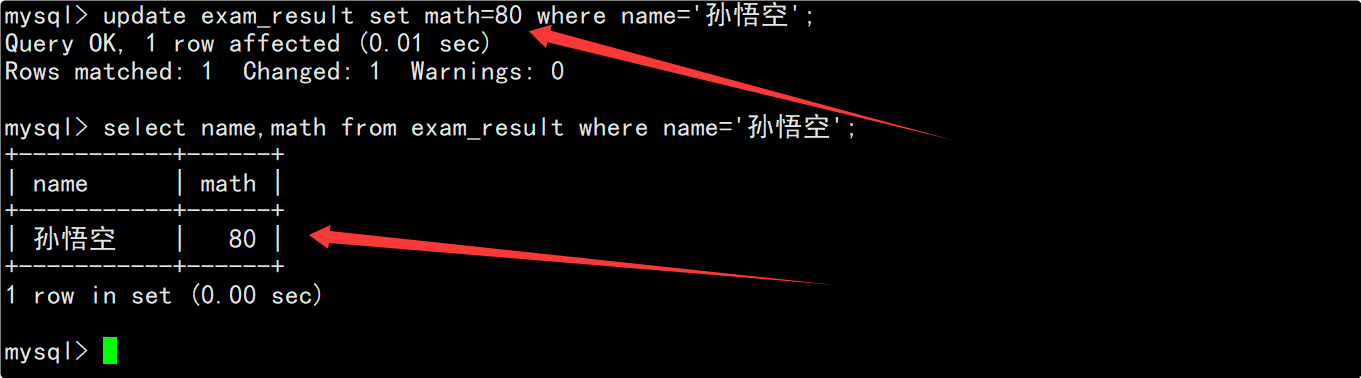
将孙悟空同学的数学成绩修改为80分
在修改数据之前,先查看孙悟空同学当前的数学成绩。

在update语句中指明要将筛选出来的记录的数学成绩改为80分,并在修改后再次查看数据确保数据成功被修改。
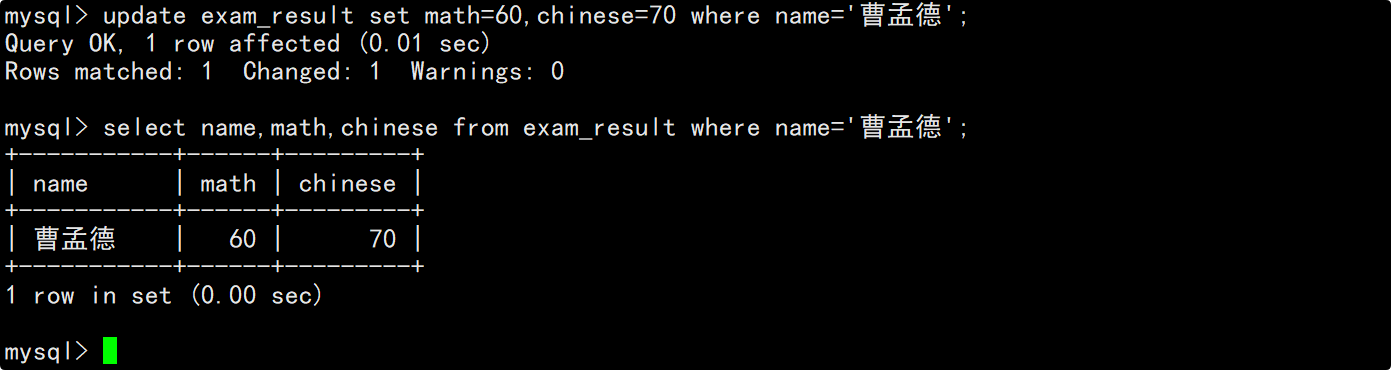
将曹孟德同学的数学成绩修改为60分,语文成绩修改为70分
在修改数据之前,先查看曹孟德同学当前的数学成绩和语文成绩。
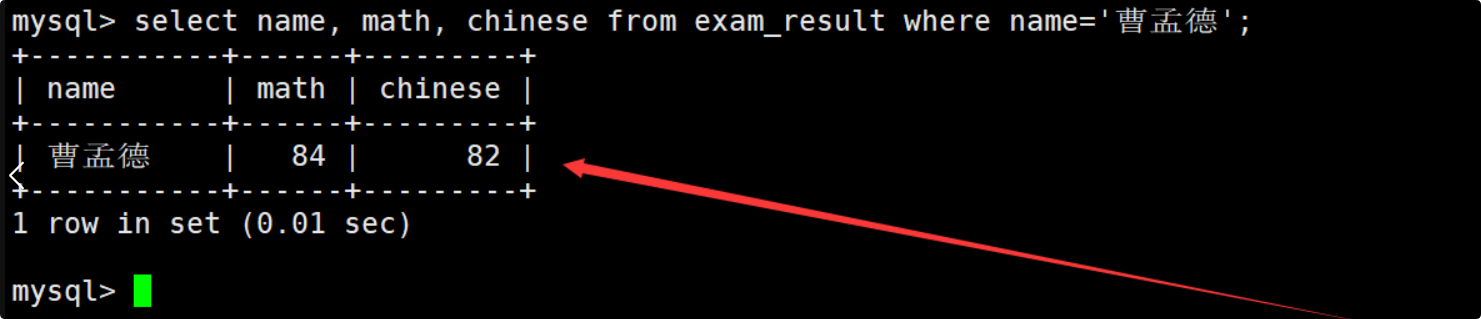
在update语句中指明要将筛选出来的记录的数学成绩改为60分,语文成绩改为70分,并在修改后再次查看数据确保数据成功被修改。
将总成绩倒数前三的3位同学的数学成绩加上30分
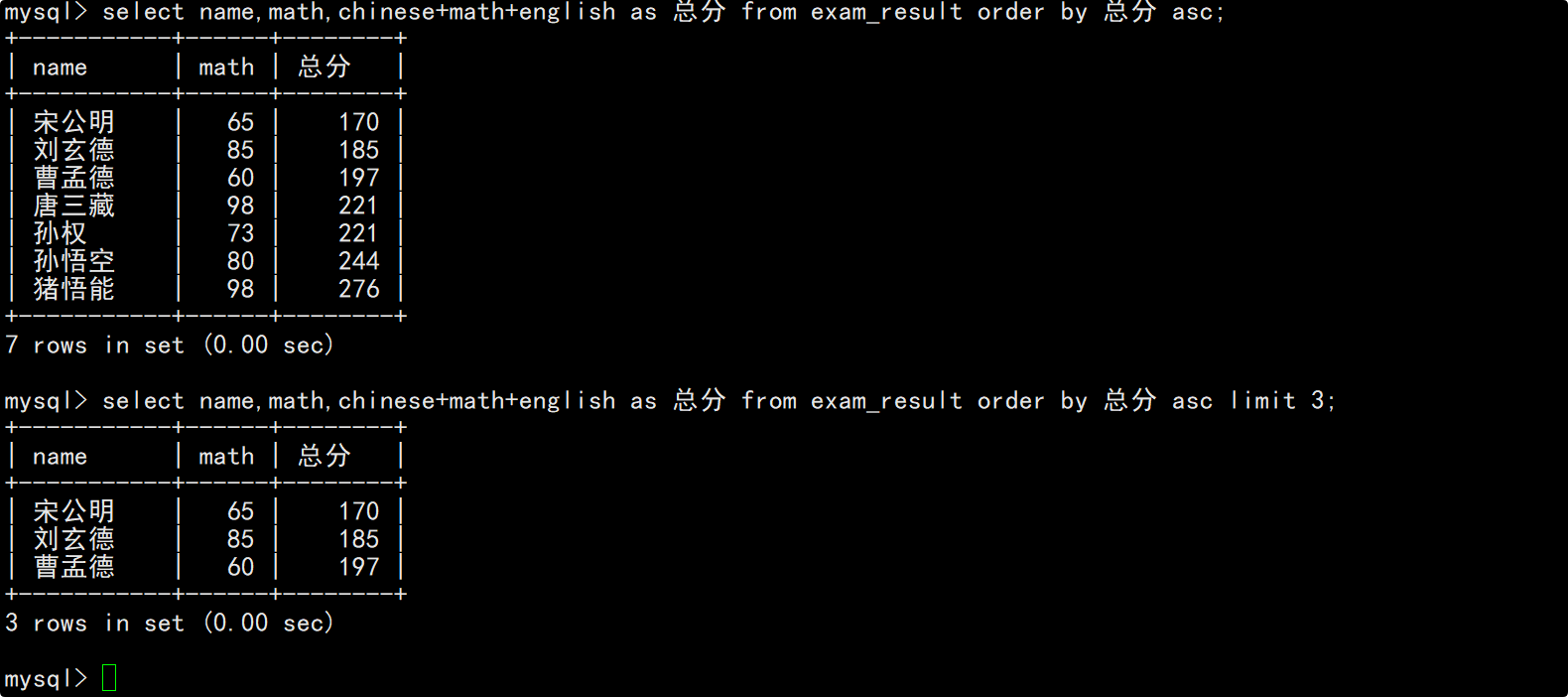
在update语句中指明要将筛选出来的记录的数学成绩加上30分,并在修改后再次查看数据确保数据成功被修改。
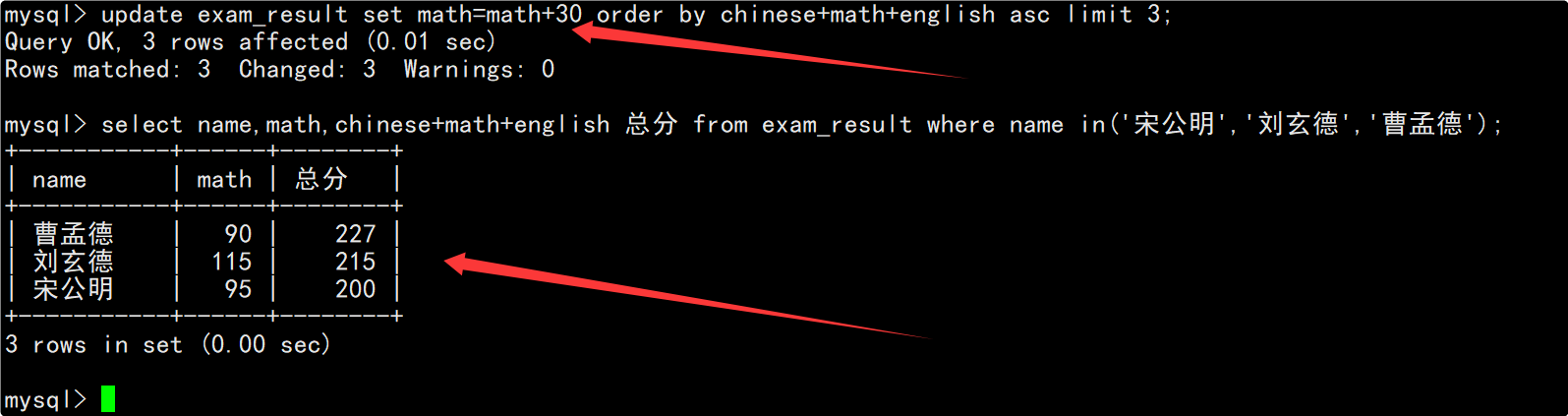
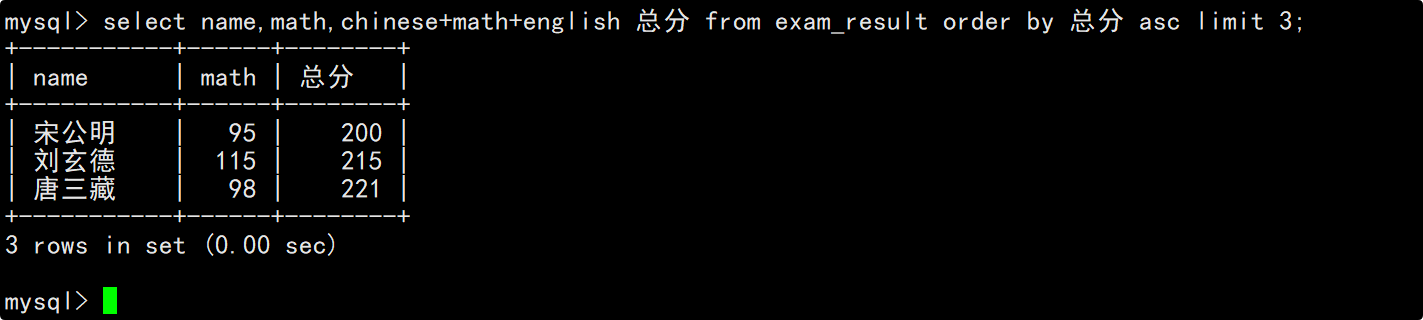
要注意的是,MySQL中不支持+=这种复合赋值运算符,此外,这里在查看更新后的数据时不能查看总成绩倒数前三的3位同学,因为之前总成绩倒数前三的3位同学,数学成绩加上30分后可能就不再是倒数前三了。
将所有同学的语文成绩修改为原来的2倍
在修改数据之前,先查看所有同学的语文成绩。
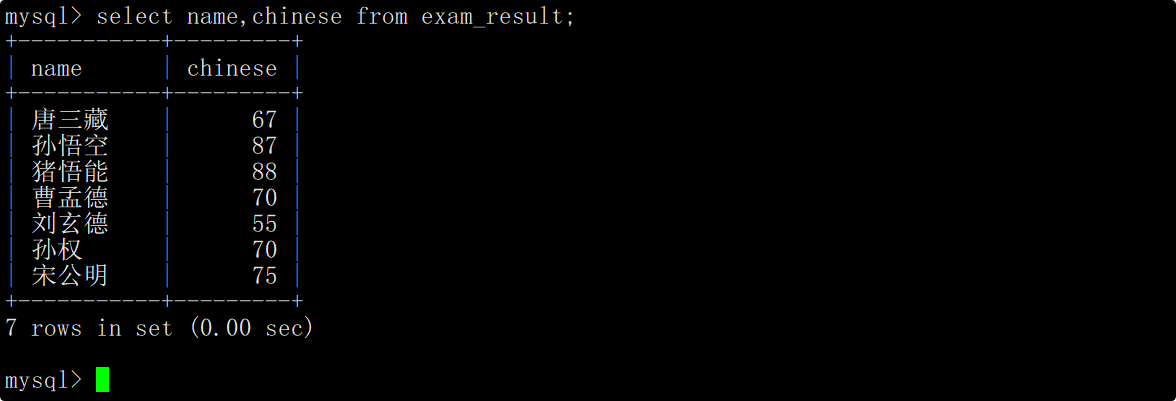
在update语句中指明要将筛选出来的记录的语文成绩变为原来的2倍,并在修改后再次查看数据确保数据成功被修改。
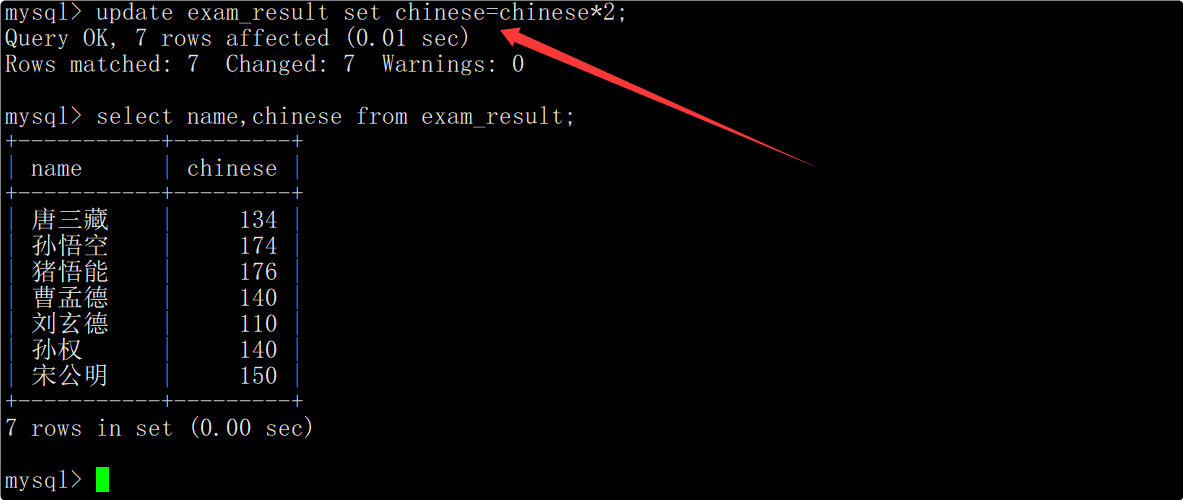
注意: 更新全表的语句慎用!
五、Delete
删除数据
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...];
说明一下:
- SQL中大写的表示关键字,[ ]中代表的是可选项。
- 在删除数据之前需要先找到待删除的记录,delete语句中的where、order by和limit就是用来定位数据的。
删除孙悟空同学的考试成绩
在删除数据之前,先查看孙悟空同学的相关信息,然后在delete语句中指明删除孙悟空对应的记录,并在删除后再次查看数据确保数据成功被删除。
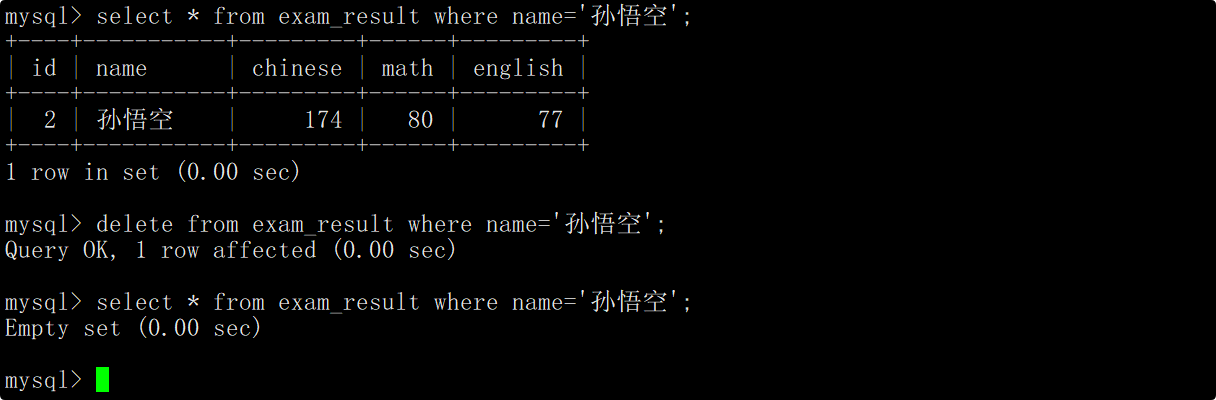
删除整张表数据
创建一张测试表,表中包含一个自增长的主键id和姓名。
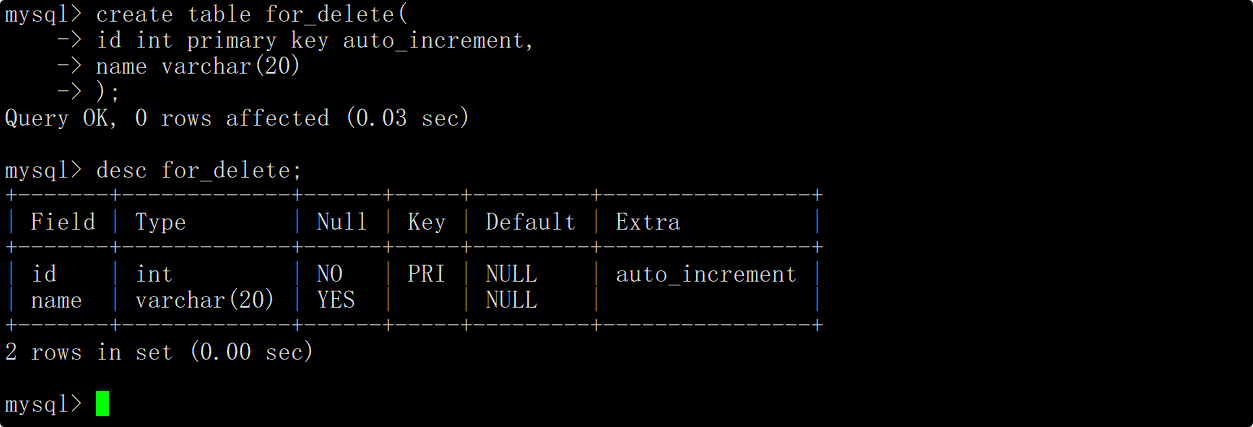
向表中插入一些测试数据用于删除。
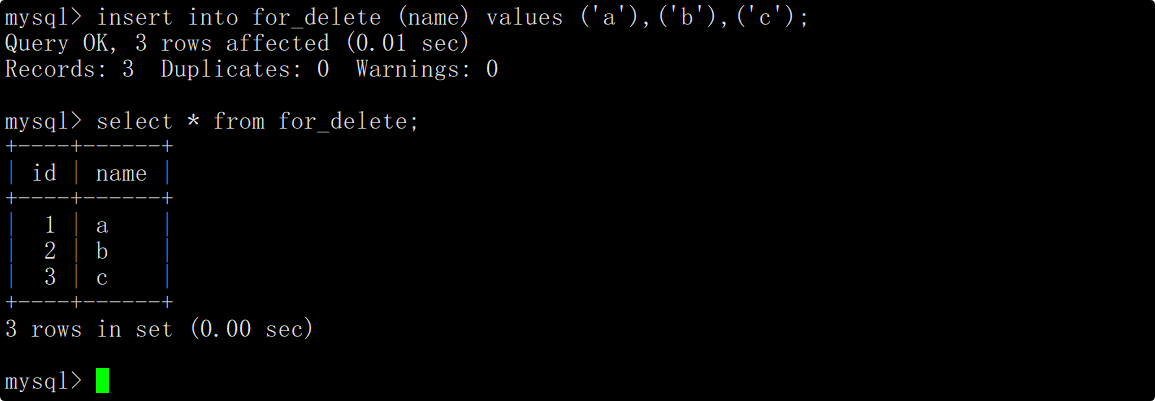
在delete语句中只指明要删除数据的表名,而不通过where、order by和limit指明筛选条件,这时将会删除整张表的数据。

再向表中插入一些数据,在插入数据时不指明自增长字段的值,插入数据对应的自增长id值是在之前的基础上继续增长的。
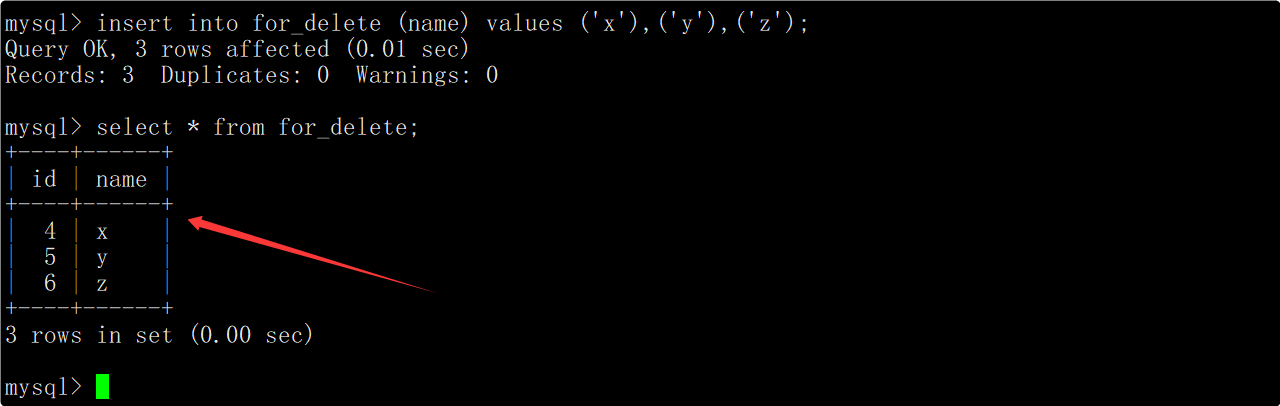
查看创建表时的相关信息时可以看到,有一个AUTO_INCREMENT=n的字段,该字段表示下一次插入数据时自增长字段的值应该为n。
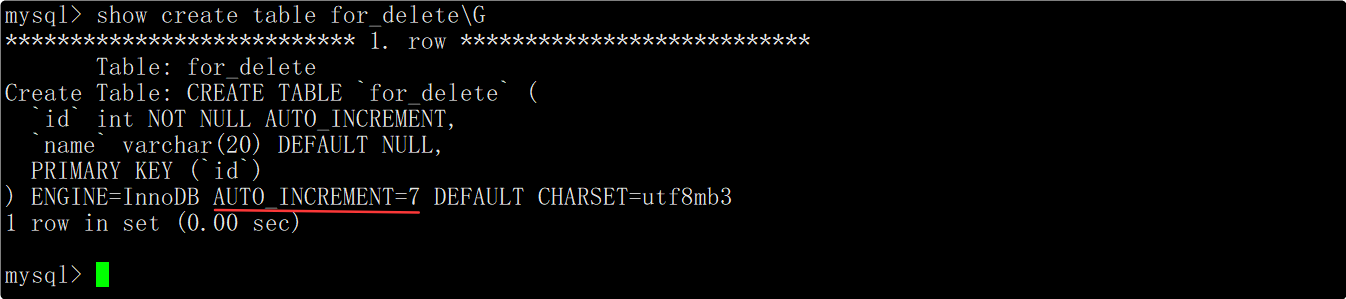
当通过delete语句删除整表数据时,不会重置AUTO_INCREMENT=n字段,因此删除整表数据后插入数据对应的自增长id值会在原来的基础上继续增长。
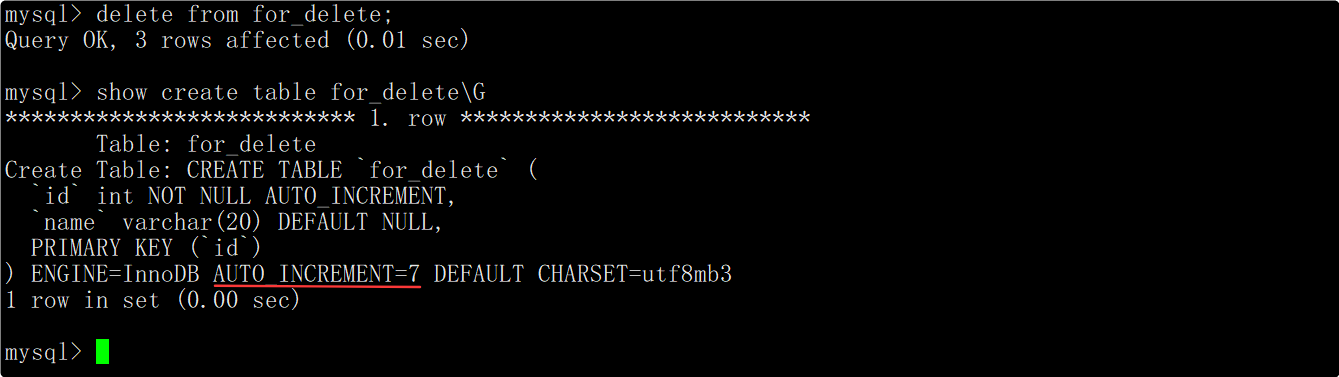
注意: 删除整表操作要慎用!
截断表
截断表的SQL如下:
TRUNCATE [TABLE] table_name;
说明一下:
- SQL中大写的表示关键字,[ ]中代表的是可选项。
- truncate只能对整表操作,不能像delete一样针对部分数据操作。
- truncate实际上不对数据操作,所以比delete更快。
- truncate在删除数据时不经过真正的事务,所以无法回滚。
- truncate会重置AUTO_INCREMENT=n字段。
创建一张测试表,表中包含一个自增长的主键id和姓名。
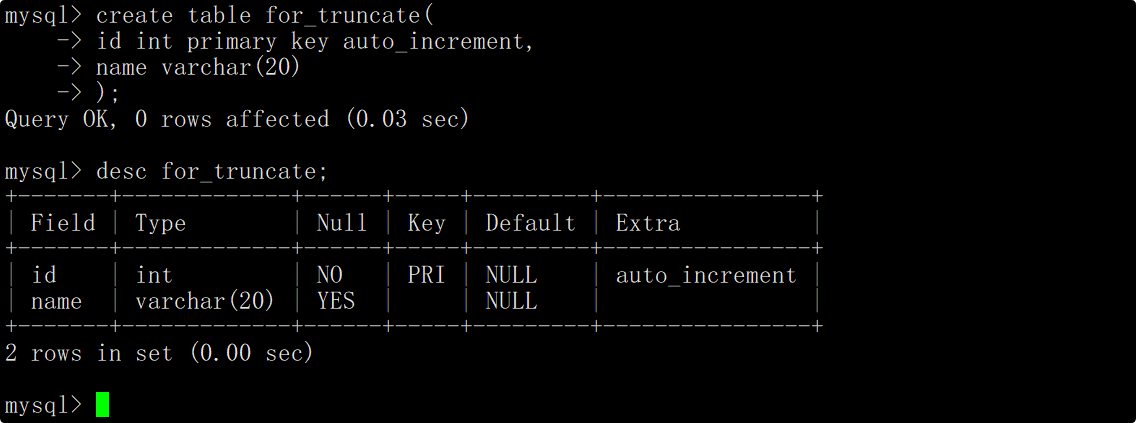
向表中插入一些测试数据用于删除。
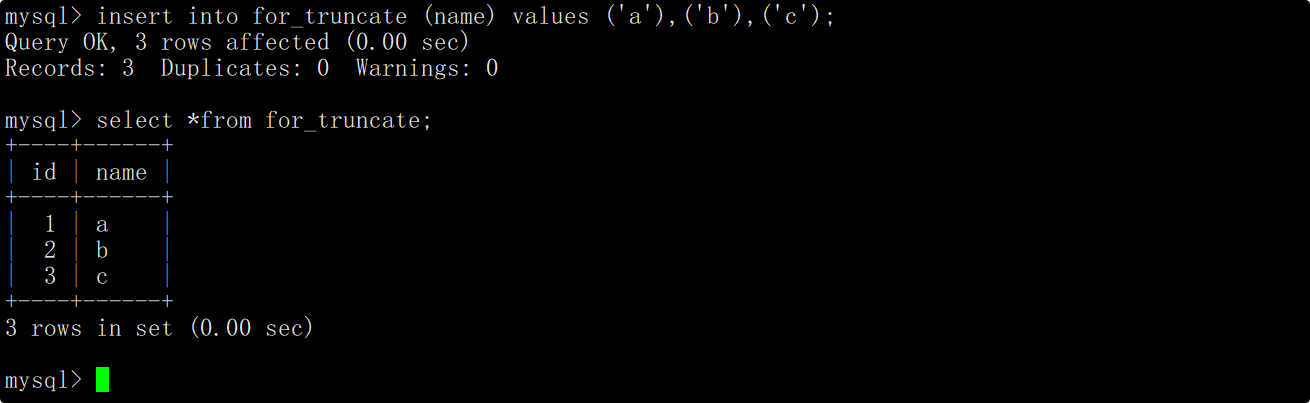
在truncate语句中只指明要删除数据的表名,这时便会删除整张表的数据,但由于truncate实际不对数据操作,因此执行truncate语句后看到影响行数为0。

再向表中插入一些数据,在插入数据时不指明自增长字段的值,这时会发现插入数据对应的自增长id值是重新从1开始增长的。
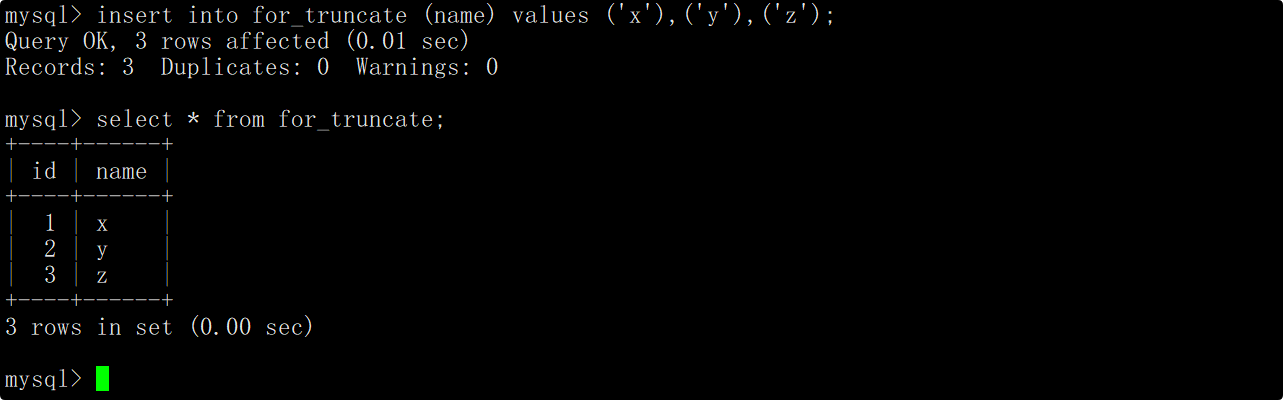
查看创建表时的相关信息时也可以看到,有一个AUTO_INCREMENT=n的字段,该字段表示下一次插入数据时自增长字段的值应该为n。
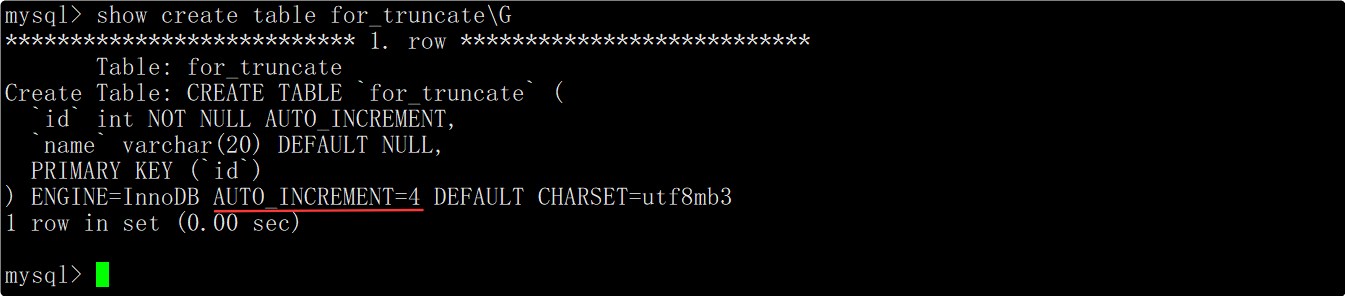
当通过truncate语句删除整表数据时,会重置AUTO_INCREMENT字段,因此截断表后插入数据对应的自增长id值会重新从1开始增长。
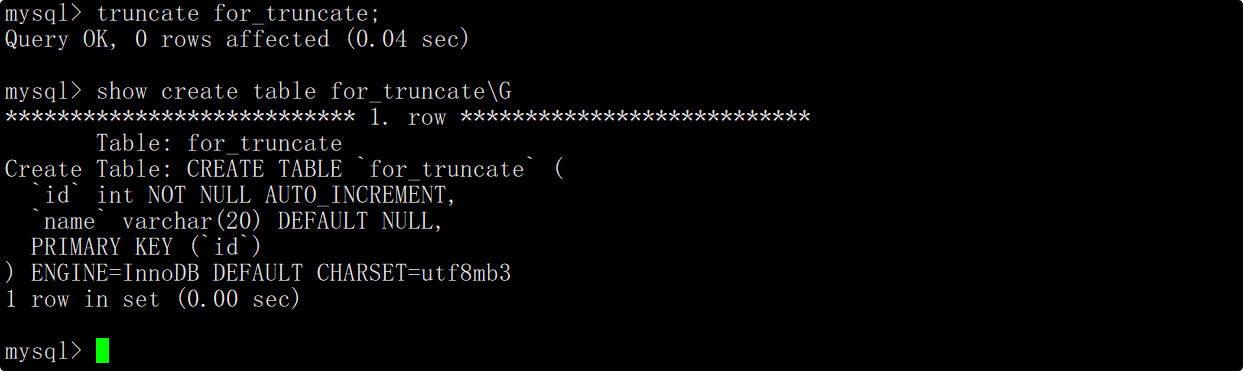
注意: 截断表操作要慎用!
六、插入查询结果
插入查询结果的SQL如下:
INSERT [INTO] table_name [(column1 [, column2] ...)] SELECT ... [WHERE ...] [ORDER BY ...] [LIMIT ...];
说明一下:
- SQL中大写的表示关键字,[ ]中代表的是可选项。
- SQL的作用是将筛选出来的记录插入到指定的表当中。
- SQL中的column,表示将筛选出的记录的各个列插入到表中的哪一列。
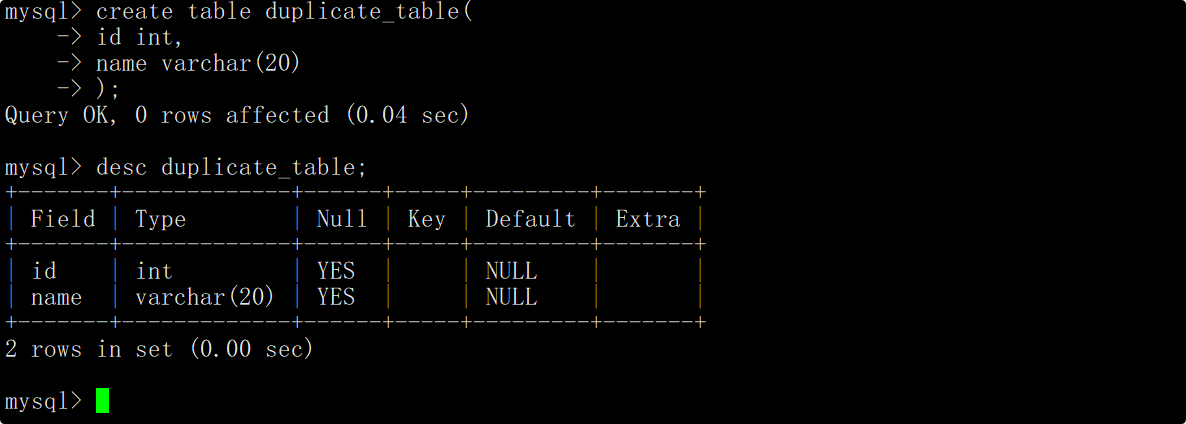
删除表中重复的记录,重复的数据只能有一份
创建一张测试表,表中包含id和姓名。
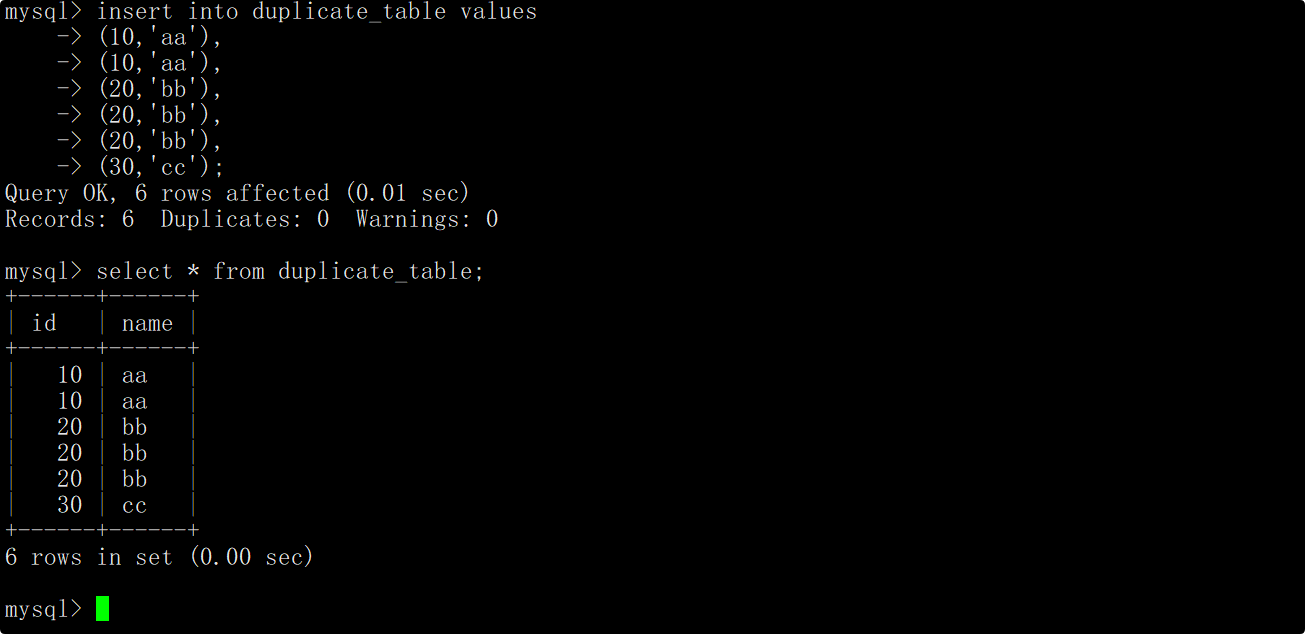
向测试表中插入一些测试数据,数据中存在重复的记录。
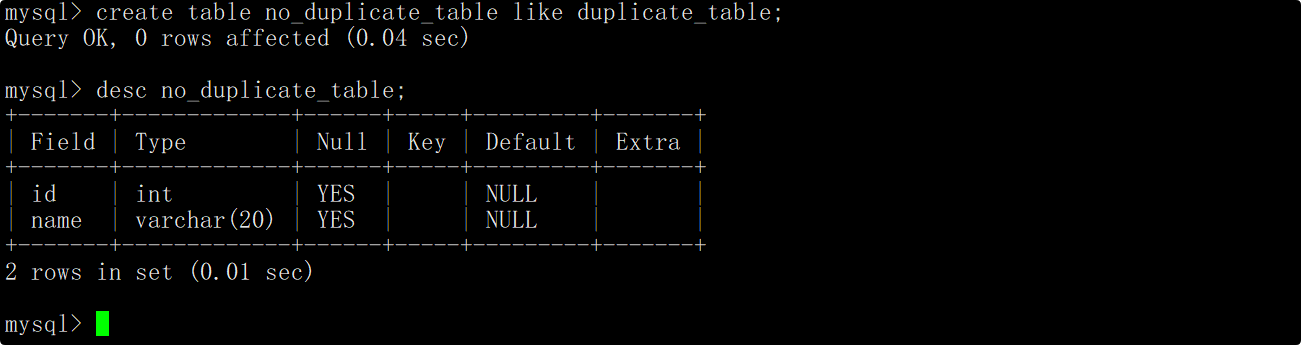
现在要求删除测试表中重复的数据,思路如下:
- 创建一张临时表,该表的结构与测试表的结构相同。
- 以去重的方式查询测试表中的数据,并将查询结果插入到临时表中。
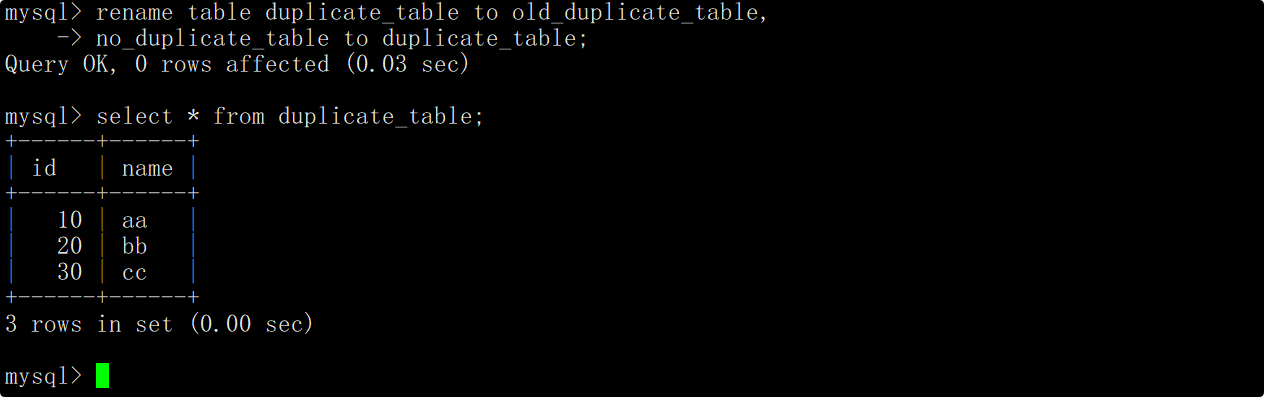
- 将测试表重命名为其他名字,再将临时表重命名为测试表的名字,实现原子去重操作。
由于临时表的结构与测试表相同,因此在创建临时表的时候可以借助like进行创建。如下:
通过插入查询语句将去重查询后的结果插入到临时表中,由于临时表和测试表的结构相同,并且select进行的是全列查询,因此在插入时不用在表名后指明column列表。
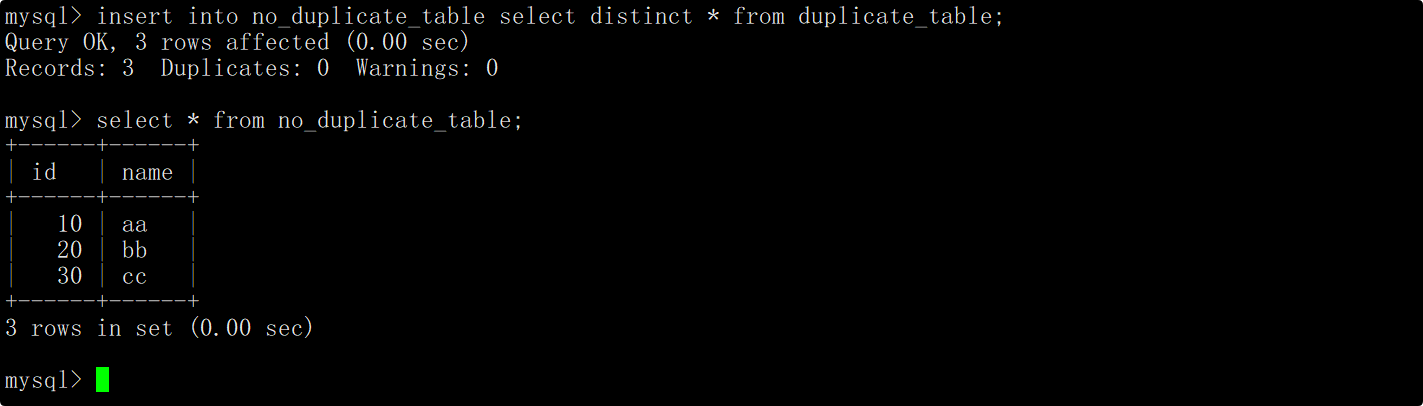
将测试表重命名为其他名字(相当于对去重前的数据进行备份,如果不需要可以直接删除),将临时表重命名为测试表的名字,这时便完成了表中数据的去重操作。
七、聚合函数
聚合函数对一组值执行计算并返回单一的值,常用的聚合函数如下:
| 函数 | 说明 |
|---|---|
| COUNT([DISTINCT] expr) | 返回查询到的数据的数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的最小值,不是数字没有意义 |
聚合函数可以在select语句中使用,此时select每处理一条记录时都会将对应的参数传递给这些聚合函数。
统计班级共有多少同学
准备测试表
使用之前的学生表来进行演示,学生表中的内容如下:
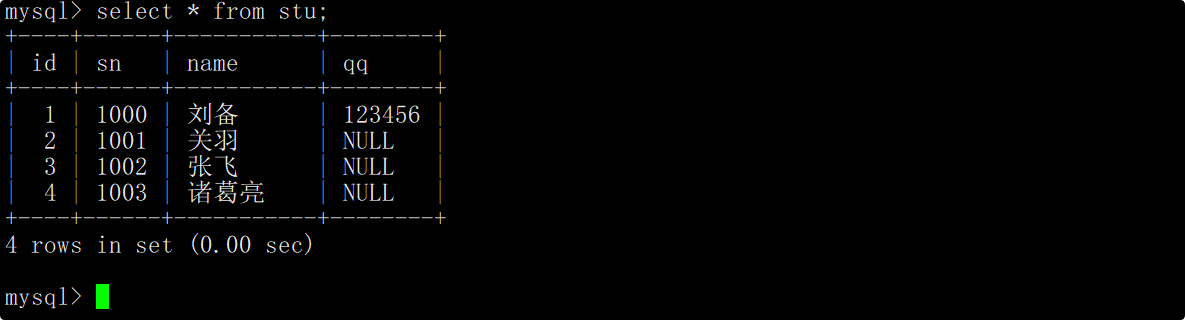
使用*做统计
在select语句中使用count函数,并将*作为参数传递给count函数,这时便能统计出表中的记录条数。
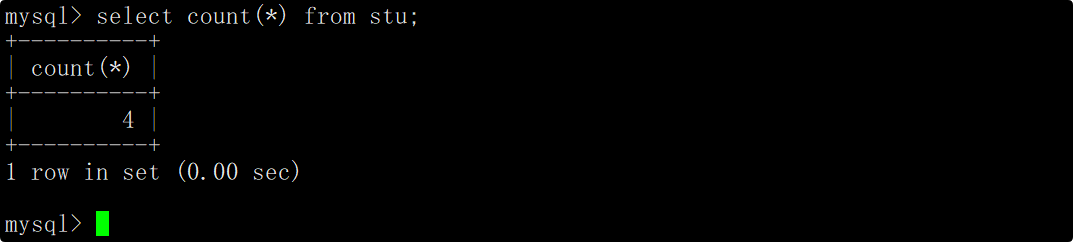
使用表达式做统计
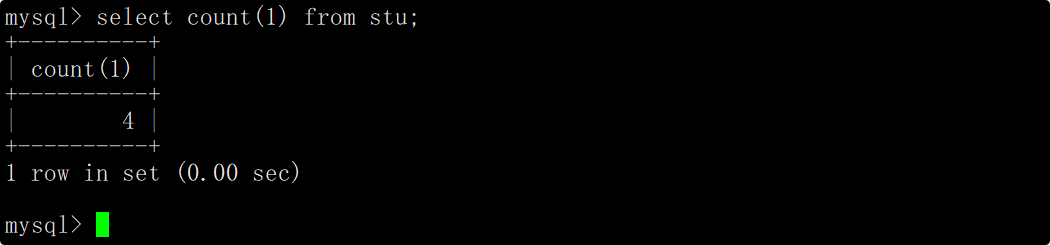
这种写法相当于在查询表中数据时,自行新增了一列列名为特定表达式的列,我们就是在用count函数统计该列中有多少个数据,等价于统计表中有多少条记录。
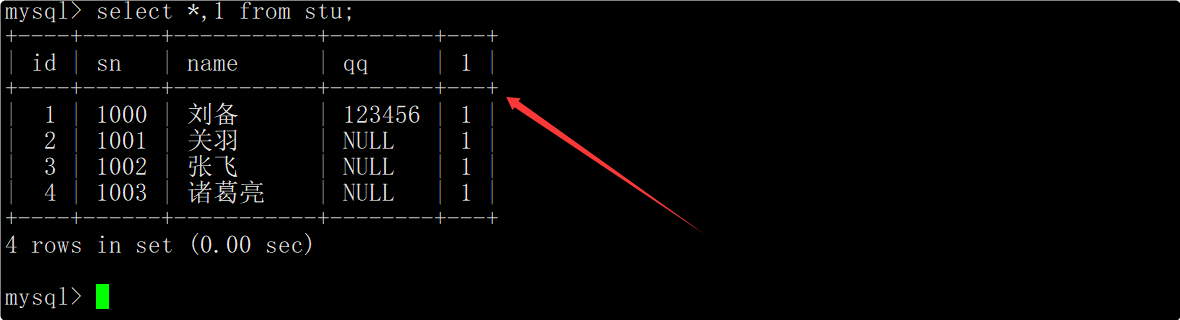
统计班级收集的QQ号有多少个
在select语句中使用count函数统计qq列中数据的个数,这时便能统计出表中QQ号的个数。
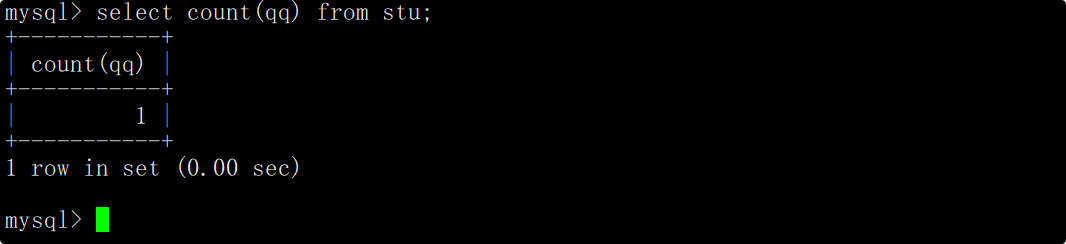
说明一下: 如果count函数的参数是一个确定的列名,那么count函数将会忽略该列中的NULL值。
统计本次考试数学成绩的分数个数
准备测试表
这里用之前的成绩表来进行演示,成绩表中的内容如下:
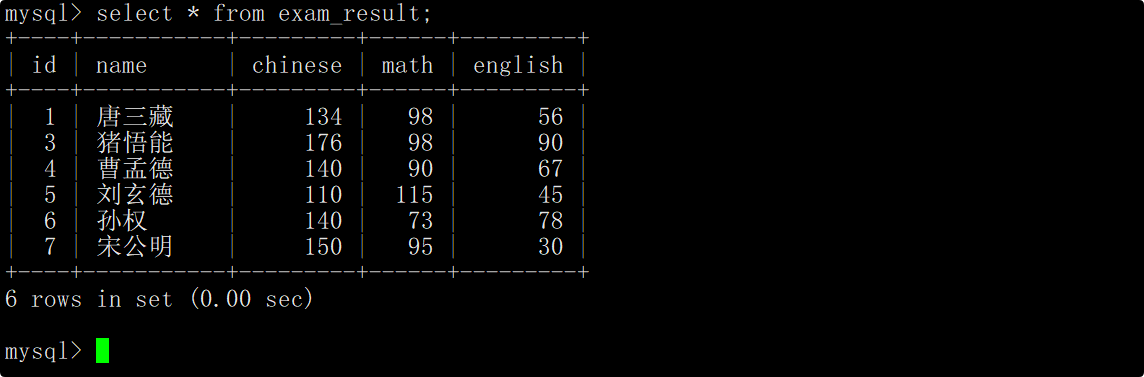
在select语句中使用count函数统计math列中数据的个数,这时便能统计出表中的数学成绩的个数。
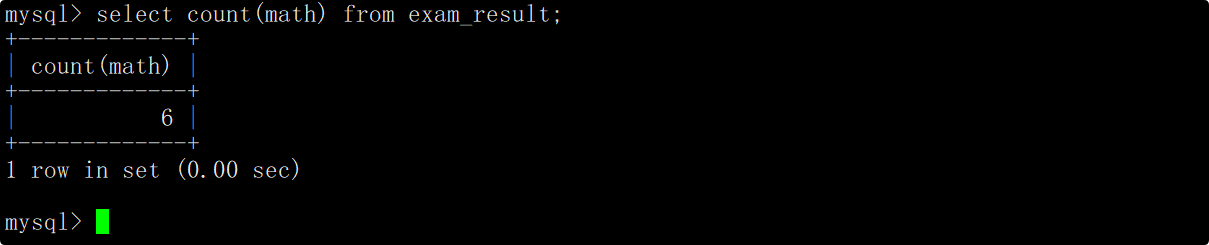
统计本次考试数学成绩的分数个数(去重)
在使用count函数时(包括其他聚合函数),在传递的参数之前加上distinct,这时便能统计出表中数学成绩去重后的个数。

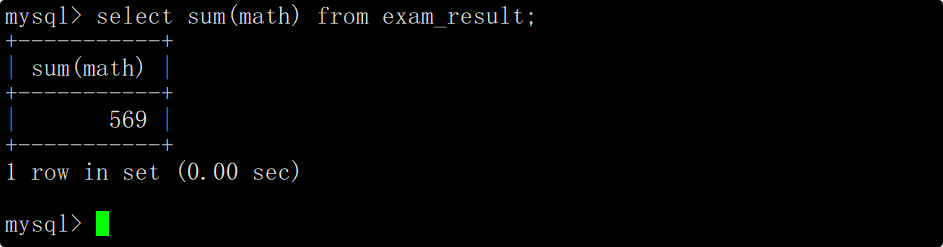
统计数学成绩总分
在select语句中使用sum函数统计math列中数据的总和,这时便能统计出表中的数学成绩的总和。
统计不及格的数学成绩总分
在where子句中指明筛选条件为数学成绩小于60分,在select语句中使用sum函数统计math列中数据的总和。
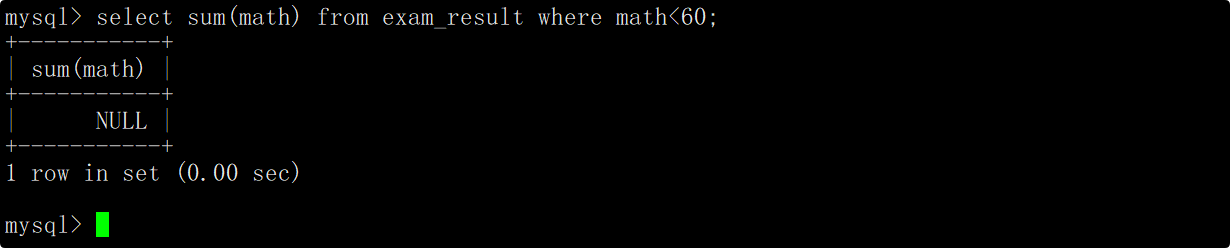
由于当前没有数学不及格的同学,因此求和结果为NULL。
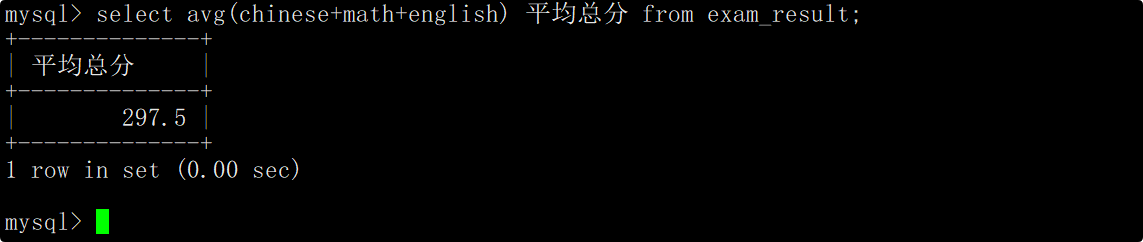
统计平均总分
在select语句中使用avg函数计算总分的平均值。
返回英语最高分
在select语句中使用max函数查询英语成绩最高分。
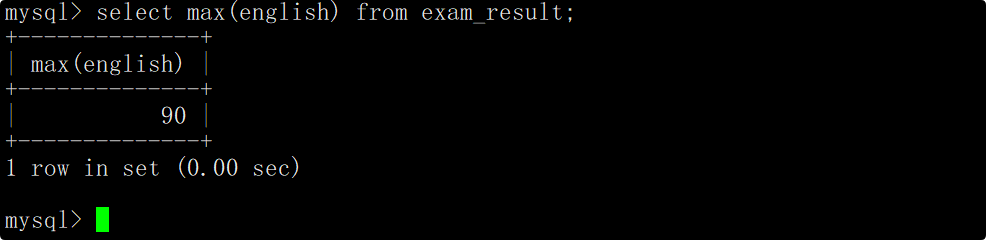
返回70分以上的英语最低分
在where子句中指明筛选条件为英语成绩大于70分,在select语句中使用min函数查询英语成绩最低分。

八、分组查询
分组查询的SQL如下:
SELECT column1 [, column2], ... FROM table_name [WHERE ...] GROUP BY column [, ...] [order by ...] [LIMIT ...];
说明一下:
- SQL中大写的表示关键字,[ ]中代表的是可选项。
- 查询SQL中各语句的执行顺序为:where、group by、select、order by、limit。
- group by后面的列名,表示按照指定列进行分组查询。
分组查询测试表 —— 雇员信息表
雇员信息表内容
雇员信息表中包含三张表,分别是员工表(emp)、部门表(dept)和工资等级表(salgrade)。
员工表(emp)中包含如下字段:
- 雇员编号(empno)。
- 雇员姓名(ename)。
- 雇员职位(job)。
- 雇员领导编号(mgr)。
- 雇佣时间(hiredate)。
- 工资月薪(sal)。
- 奖金(comm)。
- 部门编号(deptno)。
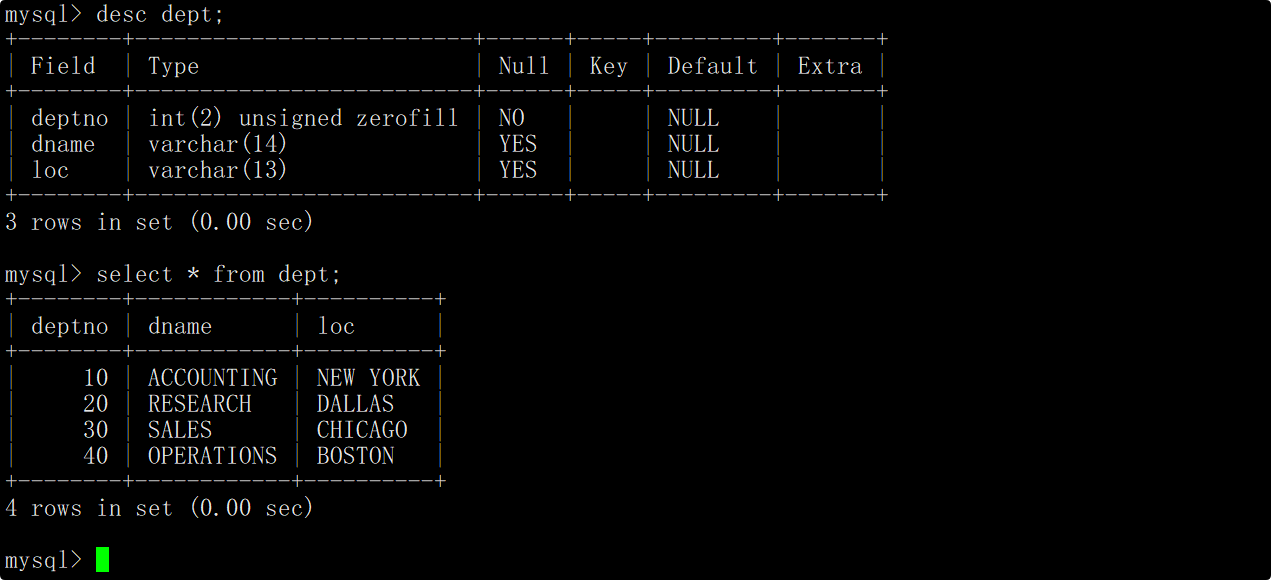
部门表(dept)中包含如下字段:
- 部门编号(deptno)。
- 部门名称(dname)。
- 部门所在地点(loc)。
工资等级表(salgrade)中包含如下字段:
- 等级(grade)。
- 此等级最低工资(losal)。
- 此等级最高工资(hisal)。
雇员信息表SQL
DROP database IF EXISTS `scott`;
CREATE database IF NOT EXISTS `scott` DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;USE `scott`;DROP TABLE IF EXISTS `dept`;
CREATE TABLE `dept` (`deptno` int(2) unsigned zerofill NOT NULL COMMENT '部门编号',`dname` varchar(14) DEFAULT NULL COMMENT '部门名称',`loc` varchar(13) DEFAULT NULL COMMENT '部门所在地点'
);DROP TABLE IF EXISTS `emp`;
CREATE TABLE `emp` (`empno` int(6) unsigned zerofill NOT NULL COMMENT '雇员编号',`ename` varchar(10) DEFAULT NULL COMMENT '雇员姓名',`job` varchar(9) DEFAULT NULL COMMENT '雇员职位',`mgr` int(4) unsigned zerofill DEFAULT NULL COMMENT '雇员领导编号',`hiredate` datetime DEFAULT NULL COMMENT '雇佣时间',`sal` decimal(7,2) DEFAULT NULL COMMENT '工资月薪',`comm` decimal(7,2) DEFAULT NULL COMMENT '奖金',`deptno` int(2) unsigned zerofill DEFAULT NULL COMMENT '部门编号'
);DROP TABLE IF EXISTS `salgrade`;
CREATE TABLE `salgrade` (`grade` int(11) DEFAULT NULL COMMENT '等级',`losal` int(11) DEFAULT NULL COMMENT '此等级最低工资',`hisal` int(11) DEFAULT NULL COMMENT '此等级最高工资'
);insert into dept (deptno, dname, loc)
values (10, 'ACCOUNTING', 'NEW YORK');
insert into dept (deptno, dname, loc)
values (20, 'RESEARCH', 'DALLAS');
insert into dept (deptno, dname, loc)
values (30, 'SALES', 'CHICAGO');
insert into dept (deptno, dname, loc)
values (40, 'OPERATIONS', 'BOSTON');insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7369, 'SMITH', 'CLERK', 7902, '1980-12-17', 800, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7499, 'ALLEN', 'SALESMAN', 7698, '1981-02-20', 1600, 300, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7521, 'WARD', 'SALESMAN', 7698, '1981-02-22', 1250, 500, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7566, 'JONES', 'MANAGER', 7839, '1981-04-02', 2975, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7654, 'MARTIN', 'SALESMAN', 7698, '1981-09-28', 1250, 1400, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7698, 'BLAKE', 'MANAGER', 7839, '1981-05-01', 2850, null, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7782, 'CLARK', 'MANAGER', 7839, '1981-06-09', 2450, null, 10);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7788, 'SCOTT', 'ANALYST', 7566, '1987-04-19', 3000, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7839, 'KING', 'PRESIDENT', null, '1981-11-17', 5000, null, 10);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7844, 'TURNER', 'SALESMAN', 7698,'1981-09-08', 1500, 0, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7876, 'ADAMS', 'CLERK', 7788, '1987-05-23', 1100, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7900, 'JAMES', 'CLERK', 7698, '1981-12-03', 950, null, 30);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7902, 'FORD', 'ANALYST', 7566, '1981-12-03', 3000, null, 20);insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7934, 'MILLER', 'CLERK', 7782, '1982-01-23', 1300, null, 10);insert into salgrade (grade, losal, hisal) values (1, 700, 1200);
insert into salgrade (grade, losal, hisal) values (2, 1201, 1400);
insert into salgrade (grade, losal, hisal) values (3, 1401, 2000);
insert into salgrade (grade, losal, hisal) values (4, 2001, 3000);
insert into salgrade (grade, losal, hisal) values (5, 3001, 9999);
上述SQL中创建了一个名为scott的数据库,在该数据库中分别创建了部门表(dept)、员工表(emp)和工资等级表(salgrade),并分别向三张表中插入了一些数据用于查询。
将上述SQL保存到文件中,然后在MySQL中使用source命令依次执行文件中的SQL。
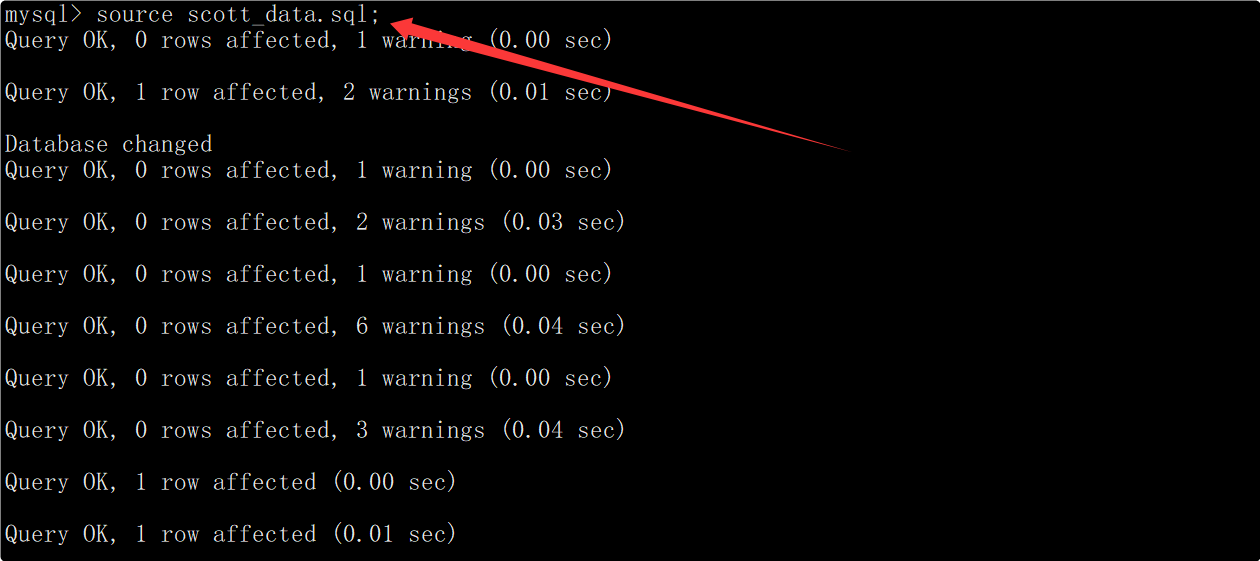
执行完文件中的SQL后查看数据库,就能看到多了一个名为scott的数据库。
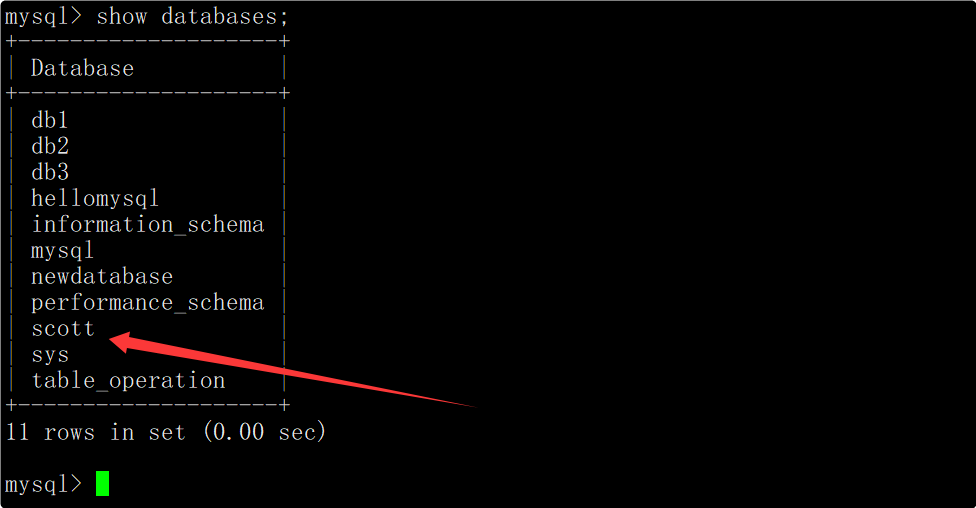
进入该数据库,在该数据库中就可以看到雇员信息表中的三张表。

其中部门表(dept)的表结构和表中的内容如下:
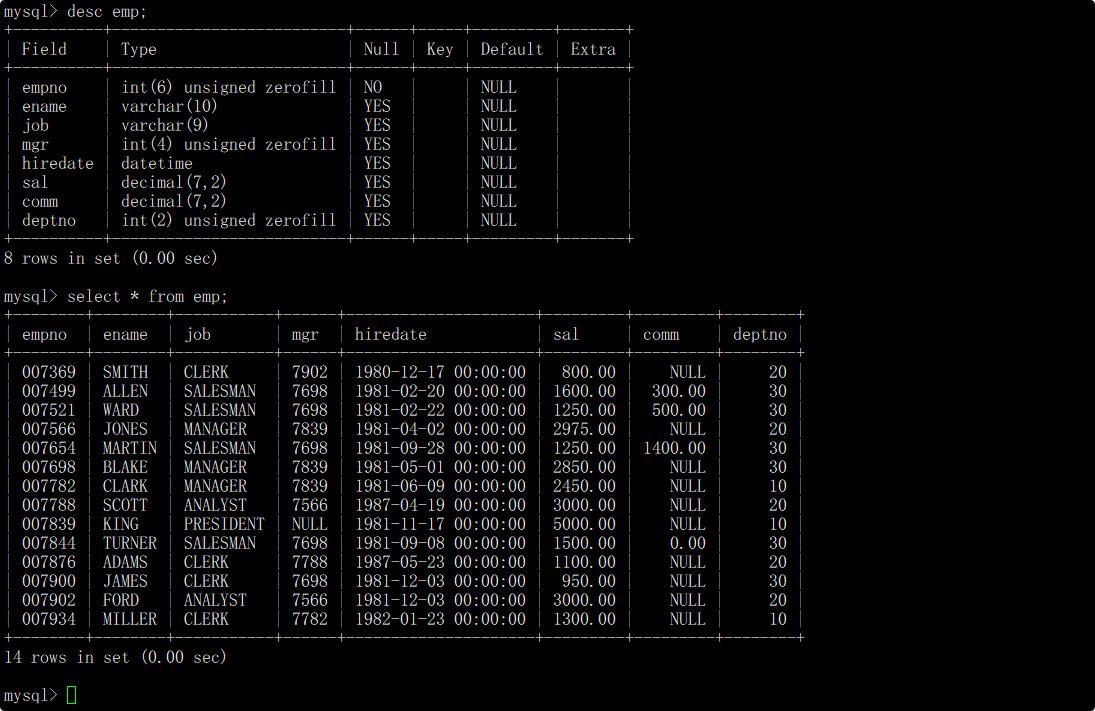
员工表(emp)的表结构和表中的内容如下:
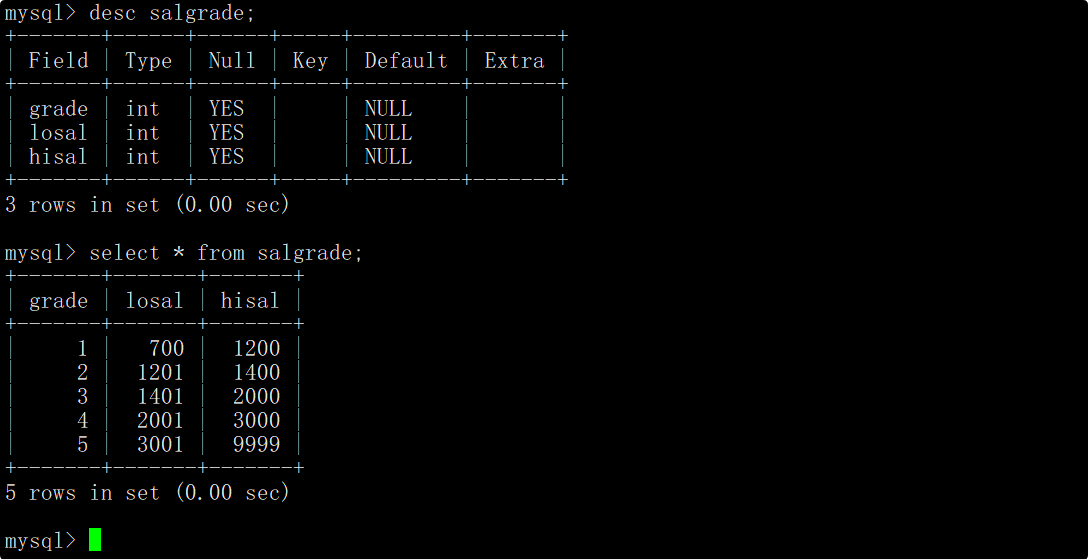
工资等级表(salgrade)的表结构和表中的内容如下:
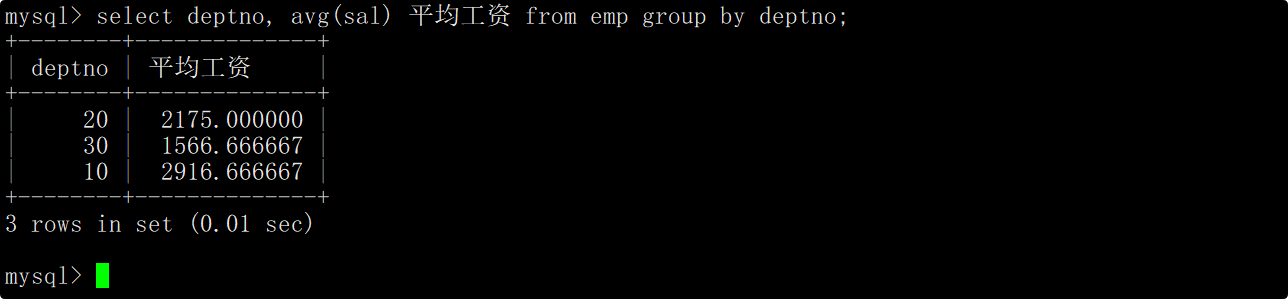
显示每个部门的平均工资和最高工资
在group by子句中指明按照部门号进行分组,在select语句中使用avg函数和max函数,分别查询每个部门的平均工资和最高工资。
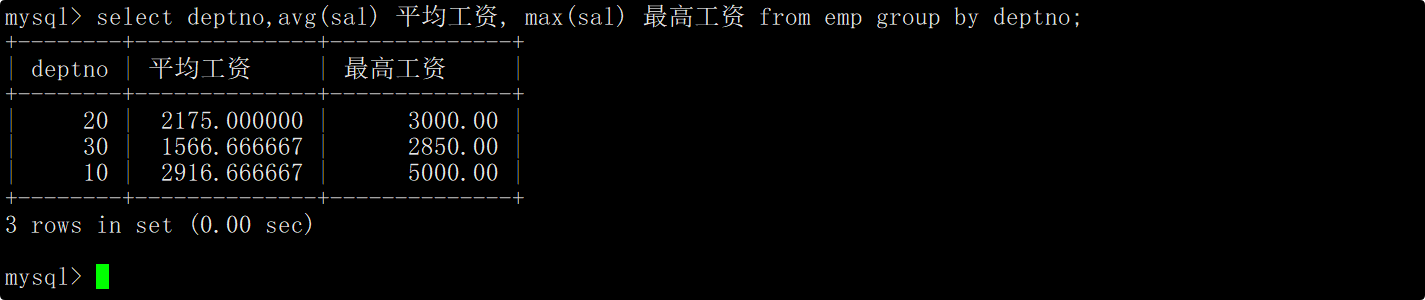
上述SQL会先将表中的数据按照部门号进行分组,然后各自在组内做聚合查询得到每个组的平均工资和最高工资。
显示每个部门的每种岗位的平均工资和最低工资
在group by子句中指明依次按照部门号和岗位进行分组,在select语句中使用avg函数和min函数,分别查询每个部门的每种岗位的平均工资和最低工资。
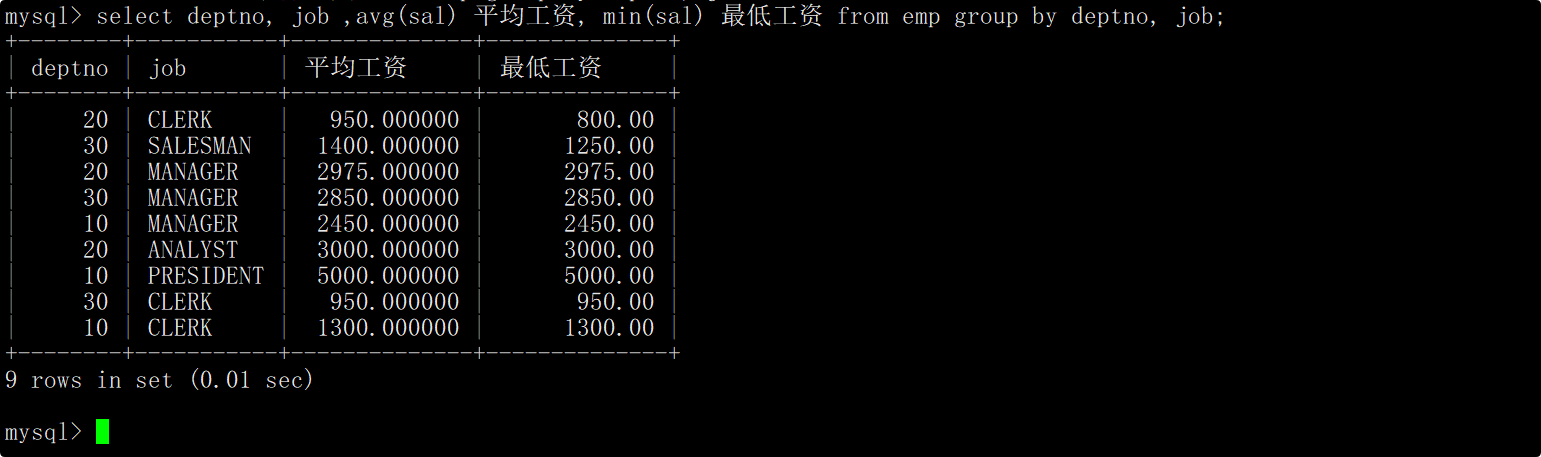
说明一下:
- group by子句中可以指明按照多个字段进行分组,各个字段之间使用逗号隔开,分组优先级与书写顺序相同。
- 比如上述SQL中,当两条记录的部门号相同时,将会继续按照岗位进行分组。
HAVING 条件
SELECT ... FROM table_name [WHERE ...] [GROUP BY ...] [HAVING ...] [order by ...] [LIMIT ...];
说明一下:
- SQL中大写的表示关键字,[ ]中代表的是可选项。
- SQL中各语句的执行顺序为:where、group by、select、having、order by、limit。
- having子句中可以指明一个或多个筛选条件。
having子句和where子句的区别
- where子句放在表名后面,而having子句必须搭配group by子句使用,放在group by子句的后面。
- where子句是对整表的数据进行筛选,having子句是对分组后的数据进行筛选。
- where子句中不能使用聚合函数和别名,而having子句中可以使用聚合函数和别名。
SQL中各语句的执行顺序
查询数据时,SQL中各语句的执行顺序如下:
- 根据where子句筛选出符合条件的记录。
- 根据group by子句对数据进行分组。
- 将分组后的数据依次执行select语句。
- 根据having子句对分组后的数据进行进一步筛选。
- 根据order by子句对数据进行排序。
- 根据limit子句筛选若干条记录进行显示。
显示平均工资低于2000的部门和它的平均工资
- 先统计每个部门的平均工资。
- 然后通过having子句筛选出平均工资低于2000的部门。
统计每个部门的平均工资
在group by子句中指明按照部门号进行分组,在select语句中使用avg函数查询每个部门的平均工资。
显示平均工资低于2000的部门和它的平均工资
在上述SQL的基础上,在having子句中指明筛选条件为平均工资小于2000。

相关文章:

MySQL表的增删查改
目录 一、MySQL表的增删查改二、Create单行数据全列插入多行数据 指定列插入插入否则更新替换数据 三、RetrieveSELECT 列WHERE 条件NULL的查询结果排序筛选分页结果 四、Update将孙悟空同学的数学成绩修改为80分将曹孟德同学的数学成绩修改为60分,语文成绩修改为7…...
)
Android第六次面试总结之Java设计模式(二)
一、适配器模式(Adapter Pattern) 1. ListView vs RecyclerView 的 Adapter 核心区别?为什么 RecyclerView 需要 ViewHolder? 解答: 核心区别: 特性ListView.Adapter(如 ArrayAdapter…...

QuecPython+腾讯云:快速连接腾讯云l0T平台
该模块提供腾讯 IoT 平台物联网套件客户端功能,目前的产品节点类型仅支持“设备”,设备认证方式支持“一机一密”和“动态注册认证”。 BC25PA系列不支持该功能。 初始化腾讯 IoT 平台 TXyun TXyun(productID, devicename, devicePsk, ProductSecret)配置腾讯 IoT…...

说下RabbitMQ的整体架构
RabbitMQ 是一个基于 AMQP(Advanced Message Queuing Protocol) 协议的开源消息中间件,RabbitMQ的整体架构围绕消息的生产、路由、存储和消费设计,旨在实现高效、可靠的消息传递,它由多个核心组件协同工作。 核心组件 …...

Qt Creator 网络编程----Socket客户端服务端
1、在Qt项目中的.pro中添加 network模块,用于Socket网络编程使用 QT network 2、相关Tcp网络通信协议头文件 #include <QtNetwork/QTcpServer> #include <QtNetwork/QTcpSocket> #include <QtNetwork/QHostAddress> 3、Qt socket运行实…...

《深度学习实践教程》[吴微] ch-5 3/5层全连接神经网络
一、练习课本上3层全连接神经网络识别手写数字。 答案代码: import torch from torch import nn, optim from torch.autograd import Variable from torch.utils.data import DataLoader from torchvision import datasets, transforms# 定义一些超参数 batch_size…...

OrcaFex11.5
OrcaFlex 11.5是一款专业的海洋工程动态分析软件 由英国Orcina公司开发 主要用于模拟和分析海洋结构物在复杂海洋环境中的动态响应 该软件广泛应用于海上油气开发 海上风电 海洋可再生能源等领域 OrcaFlex 11.5具有强大的建模和仿真能力 支持多种海洋结构物的模拟 包括船舶 …...

MUX-vlan
MUX-VLAN 理论环节 1. 定义与核心作用 Principal VLAN(主VLAN) 是 MUX VLAN(Multiplex VLAN)架构的核心组件,充当公共资源的访问枢纽,实现以下核心功能: 资源共享:允许所有从VLAN…...

vue3中解决 return‘ inside ‘finally‘ block报错的问题
vue3中解决 return’ inside ‘finally’ block报错的问题 这个错误信息通常表明你在使用Vue 3框架时,在finally块中不正确地使用了return语句。在JavaScript中,finally块是保证执行的最后一个代码块,用于释放资源或执行清理操作,…...

TestStand API 简介
TestStand API 简介 在自动化测试领域,TestStand 凭借其灵活的架构和强大的功能,成为众多开发者的首选工具。而 TestStand API(Application Programming Interface,应用程序编程接口)则是打开 TestStand 强大功能的 “…...

vue2+element实现Table表格嵌套输入框、选择器、日期选择器、表单弹出窗组件的行内编辑功能
vue2element实现Table表格嵌套输入框、选择器、日期选择器、表单弹出窗组件的行内编辑功能 文章目录 vue2element实现Table表格嵌套输入框、选择器、日期选择器、表单弹出窗组件的行内编辑功能前言一、准备工作二、行内编辑1.嵌入Input文本输入框1.1遇到问题1.文本框内容修改失…...

【Docker系列】使用格式化输出与排序技巧
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

针对面试-redis篇
1. 缓存穿透 什么是缓存穿透? 缓存穿透就是有人查询一个不存在的数据,数据库查询不到数据也不会直接写入缓存,就会导致每次请求都查数据库。 解决方案一:缓存空数据 当数据库中不存在该数据时,直接把查到的空数据给…...

HTML8:媒体元素
视频和音频 视频元素 video 音频 audio <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>媒体元素学习</title> </head> <body> <!--音频和视频 src:资源路径 controls:控制条…...

把其他conda的env复制到自己电脑的conda上
把其他conda的env复制到自己电脑的conda上 一 拷贝 将要拷贝的env环境拷贝到自己电脑的放置env环境的文件夹中 二 添加配置 找到.conda文件夹下的environments.txt文件,添加配置 三 测试 查看环境是否拷贝成功 激活环境 自此就拷贝成功了!&am…...

抖音热门视频评论数追踪爬虫获取
自动追踪抖音账号收藏夹视频的评论数变化 功能: 1、自动追踪特定抖音账号收藏夹视频热度变化,评论增速超过x,自动通知到钉钉或飞书 2、最新最先进的js逆向算法,无封号风险 3、支持私有化定制 4、可同时追踪500-5w个视频的热度…...

Hive优化秘籍:大数据处理加速之道
目录 一、认识 Hive 性能瓶颈 二、优化从基础开始:查询语句 2.1 列与分区裁剪 2.2 谓词下推 2.3 合理使用排序 三、解决数据倾斜难题 3.1 数据倾斜原因剖析 3.2 针对性优化策略 四、优化 join 操作 4.1 MapJoin 的应用 4.2 大表 join 优化技巧 五、调整 …...
和葡萄酒质量预测(线性回归))
机器学习例题——预测facebook签到位置(K近邻算法)和葡萄酒质量预测(线性回归)
一、预测facebook签到位置 代码展示: import pandas as pd from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier from sklearn.model_selection import…...

10B扩散文生图模型F-Lite技术报告速读
F Lite 技术报告解析 一、研究背景与目标 F Lite 是一个开源的 100 亿参数文本到图像的扩散变换器(DiT)模型。该研究的目标是探索在中等数据规模和计算资源条件下,大规模扩散模型的性能边界。F Lite 基于 Freepik 内部数据集训练࿰…...

源码分析之Leaflet中Marker
概述 Marker类用于创建一个标记点对象,可以用于在地图上添加标记点。Marker类继承自Layer类,提供了一些方法用于创建标记点对象。 源码分析 源码实现 Marker类实现如下: export var Marker Layer.extend({options: {icon: new IconDefault(), // 默认图标实例…...

从0开始学习大模型--Day2--大模型的工作流程以及初始Agent
大模型的工作流程 分词化(Tokenization)与词表映射 分词化(Tokenization)是自然语言处理(NLP)中的重要概念,它是将段落和句子分割成更小的分词(token)的过程。 将一个…...

P48-56 应用游戏标签
这一段课主要是把每种道具的游戏Tag进行了整理与应用 AuraAbilitySystemComponentBase.h // Fill out your copyright notice in the Description page of Project Settings. #pragma once #include "CoreMinimal.h" #include "AbilitySystemComponent.h"…...

4.29 tag的完整实现和登录页面的初步搭建
解释了v-for中每个属性的作用: 打印当前route的信息:(里面会有path的信息)当前的路由信息吧! handleMenu() 菜单选择!点击左侧菜单的栏目就会显示在Home.vue的tag上 这个方法的作用是让Home.vue上出现对应的…...

【Vue.js】 插槽通信——具名插槽通信
目录 前景基本语法命名规则默认内容使用建议 具体实例父组件 index.vue子组件 Category.vue 效果 前景 下面的父子组件代码仍然在Vue.js演练平台直接运行 基本语法 在子组件中定义插槽 <!-- Category.vue --> <slot name"插槽名称">默认内容</slo…...

从设备交付到并网调试:CET中电技术分布式光伏全流程管控方案详解
四月的最后一个工作日,当分布式光伏电站并网指示灯依次亮起的瞬间,CET中电技术与客户共同交出了一份满意的答卷。面对430政策窗口期的考验,我们凭借可靠的技术和高效的团队协作,在系统调试与并网对接的每个步骤都展现出过硬能力&a…...
深入了解AVFoundation-采集:录制视频功能的实现)
(十)深入了解AVFoundation-采集:录制视频功能的实现
引言 在前文章中,我们深入探讨了如何通过 AVCaptureSession 配置 iOS 中的捕捉输入及输出。并通过使用 AVCaptureDeviceInput 和 AVCapturePhotoOutput,我们实现了基础的照片捕获功能,并配置了 PHPreviewView 来显示实时预览。 在本篇中&am…...

数据分析汇报七步法:用结构化思维驱动决策
在当今数据驱动的商业环境中,高效的数据汇报不仅是信息传递的工具,更是撬动决策的杠杆。基于您提供的五张核心图示,我们提炼出一套「七步汇报框架」,将复杂的数据分析转化为清晰的行动指南。这套方法论通过「现状-诊断-预见…...

推荐两本集成电路制作书籍
本书共分19章,涵盖先进集成电路工艺的发展史,集成电路制造流程、介电薄膜、金属化、光刻、刻蚀、表面清洁与湿法刻蚀、掺杂、化学机械平坦化,器件参数与工艺相关性,DFM(Design for Manufacturing)ÿ…...
)
认识Grafana及其面板(Panel)
Grafana简介 Grafana 是一款开源的数据可视化与监控平台,以其强大的数据展示能力、灵活的插件生态和广泛的兼容性,成为企业监控、IT运维、DevOps、物联网(IoT)和业务分析等领域的核心工具。 数据源(Data Source) 对于Grafana而言,Promethe…...

FlinkCDC采集MySQL8.4报错
报错日志 原因: MySQL8.4版本中弃用show MASTER STATUS语法 改为:SHOW BINARY LOG STATUS 解决方案: 1、降MySQL版本 2、修改源码...

Webview通信系统学习指南
Webview通信系统学习指南 一、定义与核心概念 1. 什么是Webview? 定义:Webview是移动端(Android/iOS)内置的轻量级浏览器组件,用于在原生应用中嵌入网页内容。作用:实现H5页面与原生应用的深度交互&…...

人工智能如何革新数据可视化领域?探索未来趋势
在当今数字化时代,数据如同汹涌浪潮般不断涌现。据国际数据公司(IDC)预测,全球每年产生的数据量将从 2018 年的 33ZB 增长到 2025 年的 175ZB。面对如此海量的数据,如何有效理解和利用这些数据成为了关键问题。数据可视…...

探索Hello Robot开源移动操作机器人Stretch 3的新技术亮点与市场定位
Hello Robot 推出的 Stretch 3 机器人凭借其前沿技术和多功能性在众多产品中占据优势。Stretch 3 机器人采用开源设计,为开发者提供了灵活的定制空间,能够满足各种不同的需求。其配备的灵活手腕组件和 Intel Realsense D405 摄像头,显著增强了…...

机器人系统设置
机器人系统设置 机器人系统设置与操作指南 1. 系统设置基础功能 偏好设置 控制柜名称修改:通过文本框输入新名称并确认主题切换:支持橙色/蓝色主题(需重启生效) 语言与日期 系统语言/键盘语言设置时间格式:支持系统时…...

C/C++ 扩展智能提示太慢或无法解析项目
问题 C/C 扩展不解析项目,导致源码中的变量、函数都为灰色状态,无法进行跳转。 有时候 log 会报如下错误: Attempting to get defaults from C compiler in "compilerPath" property: D:/Development/Tools/mingw64/bin/gcc.exe…...

通过Kubernetes 外部 DNS控制器来自动管理Azure DNS 和 AKS
前言: 将应用程序及其服务部署到 Kubernetes 集群后,一个问题浮现:如何使用自定义域名访问它?一个简单的解决方案是创建一条 A 记录,将域名指向服务 IP 地址。这可以手动完成,但随着服务数量的增加&#x…...

Elasticsearch知识汇总之ElasticSearch监控方案
八 ElasticSearch监控方案 8.1 ElasticSearch监控指标 监控指标为磐基生产项指标,以下‘监控项名称’‘指标名称 ‘使用的公式‘都已详细说明,图表如下: 监控项名称 指标英文名称 使用的公式 elasticsearch集群健康状态 Elastic_Cluster…...

【能力比对】K8S数据平台VS数据平台
🔥🔥 AllData大数据产品是可定义数据中台,以数据平台为底座,以数据中台为桥梁,以机器学习平台为中层框架,以大模型应用为上游产品,提供全链路数字化解决方案。 ✨AllData数据中台官方平台&…...

AutoDL+SSH在vscode中远程使用GPU训练深度学习模型
注册AutoDL账号 AutoDL官网:AutoDL 注册登录之后,如果你是学生,一定要进行学生认证,可以省钱。 认证之后,打开算力市场, 进行GPU选择 根据自己需要的环境选择版本 ,选好之后创建并开机 这里注…...

【C语言干货】野指针
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、什么是野指针?二、野指针的三大成因 1.指针未初始化2.指针越界访问2.指针指向已释放的内存 前言 提示:以下是本篇文章正文内容&…...
(2)等等)
QT生成保存 Excel 文件的默认路径,导出的文件后缀自动加(1)(2)等等
//生成保存 Excel 文件的默认路径 QString MainWidget::getDefaultFilePath() const { QString basePath pathEdit->text(); if (basePath.isEmpty() || !QDir(basePath).exists()) { basePath QStandardPaths::writableLocation(QStandardPaths::DocumentsLocation); } r…...

React Native【详解】搭建开发环境,创建项目,启动项目
下载安装 node https://nodejs.cn/download/ 查看 npx 版本 npx -v若无 npx 则安装 npm install -g npx创建项目 npx create-expo-applatestRN_demo 为自定义的项目名称 下载安装 Python 2.7 下载安装 JAVA JDK https://www.oracle.com/java/technologies/downloads/#jdk24-…...

AIDC智算中心建设:存储核心技术解析
目录 一、智算中心存储概述 1、存储发展 2、智算存储指导政策 3、智算智能存储必要性 二、智算中心存储架构及特征 1、智算存储中心架构 2、智算存储特征 三、智算中心存储核心技术解析 1、长记忆存储范式为推理提质增效 2、数据编织加强全局数据高效处理 3、超节点…...
)
第11次:用户注册(完整版)
第一步:定义用户模型类 class User(AbstractUser):mobile models.CharField(max_length11, uniqueTrue, verbose_name手机号)class Meta:db_table tb_userverbose_name 用户verbose_name_plural verbose_namedef __str__(self):return self.username第二步&…...

论文速读《Embodied-R: 基于强化学习激活预训练模型具身空间推理能力》
项目主页:https://embodiedcity.github.io/Embodied-R/ 论文链接:https://arxiv.org/pdf/2504.12680 代码链接:https://github.com/EmbodiedCity/Embodied-R.code 0. 简介 具身智能是通用人工智能的重要组成部分。我们希望预训练模型不仅能在…...

VMware Fusion安装win11 arm;使用Mac远程连接到Win
目录 背景步骤1. 安装Fusion2. 下载Win113. 安装Win113.1 初始步骤3.2 进入安装 4. 安装Windows APP 背景 最近国补太火热了,让Macbook来到6000这个价位。实在没忍住,最后入手了一台M3芯片的Macbook Air(jd6799)。 既然运维出身&…...

【ARM】DS-试用授权离线激活
1、 文档目标 解决客户无法在公司网络管控下进行ARM DS 试用激活,记录解决方案。 2、 问题场景 客户在ARM DS激活时无法连接到ARM认证网址,客户公司网络管理无法开放全部网络权限,只能针对特定网址和网络端口可以开放或客户公司开发环境无法…...

泰迪杯特等奖案例学习资料:基于卷积神经网络与集成学习的网络问政平台留言文本挖掘与分析
(第八届“泰迪杯”数据挖掘挑战赛A题特等奖案例深度解析) 一、案例背景与核心挑战 1.1 应用场景与行业痛点 随着“互联网+政务”的推进,网络问政平台成为政府与民众沟通的重要渠道。某市问政平台日均接收留言超5000条,涉及民生、环保、交通等20余类诉求。然而,传统人工…...

基于 ReentrantReadWriteLock 实现高效并发控制
在多线程 Java 应用中,管理共享资源的访问是确保数据一致性和避免竞争条件的关键挑战。在某些场景中,多个线程需要频繁读取共享数据,而只有一个线程偶尔需要更新数据。例如,在一个网页投票系统中,大量用户可能同时查看投票结果(读操作),而投票更新(写操作)则相对较少…...
:2025年企业AI转型的催化剂)
代理式AI(Agentic AI):2025年企业AI转型的催化剂
李升伟 摘译 步入2025:代理式AI开启企业智能化转型新纪元 随着2025年临近,企业已不再纠结"是否采用人工智能",而是迫切追问"如何加速AI进化"。传统AI系统在敏捷性、扩展性和自主性上的局限日益显现,新一代技…...