AIDC智算中心建设:存储核心技术解析
目录
一、智算中心存储概述
1、存储发展
2、智算存储指导政策
3、智算智能存储必要性
二、智算中心存储架构及特征
1、智算存储中心架构
2、智算存储特征
三、智算中心存储核心技术解析
1、长记忆存储范式为推理提质增效
2、数据编织加强全局数据高效处理
3、超节点存储架构持续支撑扩展法则
4、高性能并行文件系统以存强算
5、全闪存存储技术为数据提速降耗
6、存储内生安全保护企业数据资产
一、智算中心存储概述
1、存储发展
人工智能(Artificial Intelligence)起源于20 世纪五六十年代,历经符号主义、连接主义和行为主义三次浪潮的相互交织发展,如今作为一项新兴的通用技术,正推动着社会生活与各行各业的巨变。随着大模型的爆发式增长和持续迭代,模型参数量从几万跃升至数千亿甚至更大,模型层数从开始的个位数逐步发展到成百上千,原始数据集也达到 PB 级,对以数据存储为代表的多领域产生了根本性的影响。

2024 年 2 月 16 日,OpenAI 再度引领风潮,发布了首款文生视频大模型 Sora,大模型由单模态的 NLP 领域向文生视频等多模态方向迅速演进,标志着 AI 技术正迈向一个全新的高峰。相较于传统的NLP 语言大模型,视频大模型所需的训练数据量极为庞大,原始数据体量相较于 NLP 能达到几百甚至上千 PB 级以上,2025 年2 月,Grok3发布,其多模态能力获得全球瞩目,Grok 3 所用数据量比Grok2增加了 3 倍,通过增加数据量而不是模型参数的方式实现了大模型能力的倍增。这些都对人工智能基础设施的数据存储和处理能力提出了极高的挑战。
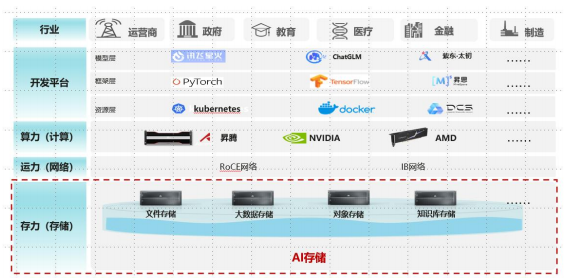
来源:中国信息通信研究院
新型AI存储是指专为人工智能应用和服务设计的数据存储系统,具备超高性能、超大容量、极致安全、数据编织等特征,可以有效支撑海量数据的分析和学习,是AI基础架构不可或缺的组成部分。如上述AI基础架构图,作为大模型的数据载体,新型AI存储与大模型数据归集、预处理、训练、推理等全生命周期流程紧密相关,且逐步成为AI数据全生命周期服务与管理平台的重要组成部分。当今在不同行业和组织内部具备形成多元化数据集的条件下,新型AI存储正在成为数据资源的统一管理平台,并以此为基础构成跨域跨部门的AI数据湖,为数据赋能提供关键的技术支撑。
2、智算存储指导政策
国外较早布局人工智能战略,AI存储逐步成为战略关键技术竞争力的重要体现。
-
欧盟委员会在2020年2月发布《人工智能白皮书》,确保对计算和数据基础设施的访问安全,同时提出改善数据访问和管理是根本。
-
英国政府在2021年9月发布《国家人工智能战略》,AI系统中的数据基础和使用将提高专业人工智能、软件和数据技术的能力,并支持关键的新型数据基础设施的发展。
-
美国国防部在2023年11月的《数据、分析和人工智能采用战略》中,提出推进数据、分析和人工智能生态系统,同时改善基础数据管理,为美国人工智能发展和相关国家安全战略制定提供依据。
国内目前对数据存储的产业布局主要在于通用存储。
-
2023年11月,《关于加快场景创新以人工智能高水平应用促进经济高质量发展的指导意见》中提出加强人工智能场景创新要素供给。推动场景算力设施开放,集聚人工智能场景数据资源。
-
2021年12月,中央网信办在《“十四五”国家信息化规划》中提出加强数据收集、汇聚、存储、流通、应用等全生命周期的安全管理,建立健全相关技术保障措施。
-
2020年7月,国家标准化管理委员会等五部门在《国家新一代人工智能标准体系建设指南》中提出规范人工智能研发及应用等过程涉及到的数据存储、处理、分析等大数据相关支撑技术要素,包括大数据系统产品、数据共享开放、数据管理机制、数据治理等标准。
3、智算智能存储必要性
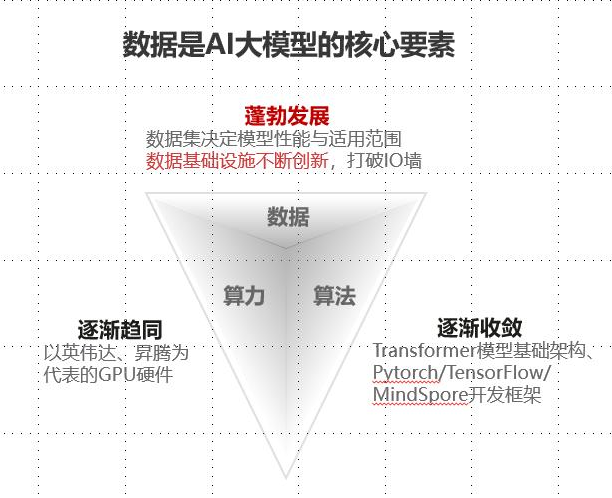
数据决定人工智能高度。
大模型三要素是数据、算力和算法。随着AI技术快速成熟,各企业所使用的算力已逐渐趋同;各企业采用的算法也同样逐渐收敛,大多依托Transformer模型基础架构和以Pytorch、TensorFlow等为代表的开发框架;因此真正体现大模型差异性的要素是数据。
根据公开数据显示,Meta开发的LLaMA3拥有700亿参数和15TB训练数据,而OpenAI的GPT-3.5拥有 1750 亿参数和 570GB 训练数据,尽管 LLaMA3 在参数规模上还不到GPT-3.5的一半,但其表现能力在大部分基准上均超过后者。不难看出,除了模型参数规模以外,训练数据的体量对提升大模型的效果具有显著作用。
此外数据的质量同样重要,大模型需要规范性、完整性、时效性的高质量数据支撑。对于基础大模型,其数据质量主要基于厂商从公开渠道所获取数据的整体质量。而对于行业大模型的训练及细分场景推理应用,模型效果取决于行业专属的私域数据的质量,其中包含了企业原有数据和行业知识库等。
AI 存储逐步成为大模型的关键基础设施。
AI 存储是大模型数据收集、预处理、训练、推理的关键一环,决定了能保存利用的数据容量、训练及推理的数据存取效率、基础设施可用度以及数据安全。
-
一是 AI 存储与大模型数据处理效率紧密相关,AI 存储直接影响数据访问速度,从而影响大模型训练和推理速度。
-
二是 AI 存储是模型规模和数据量激增时平衡成本的重要因素。模型参数增大会伴随训练数据集规模的指数级增长,从而大幅增加数据储存成本。
-
三是大模型行业落地需要依托 AI 存储来加速数据在各环节的自动流转,保护数据安全,并形成统一的数据管理。面对大模型带来的大量数据处理和工程化工作,也需要结合 AI 存储中的相关技术一并解决。
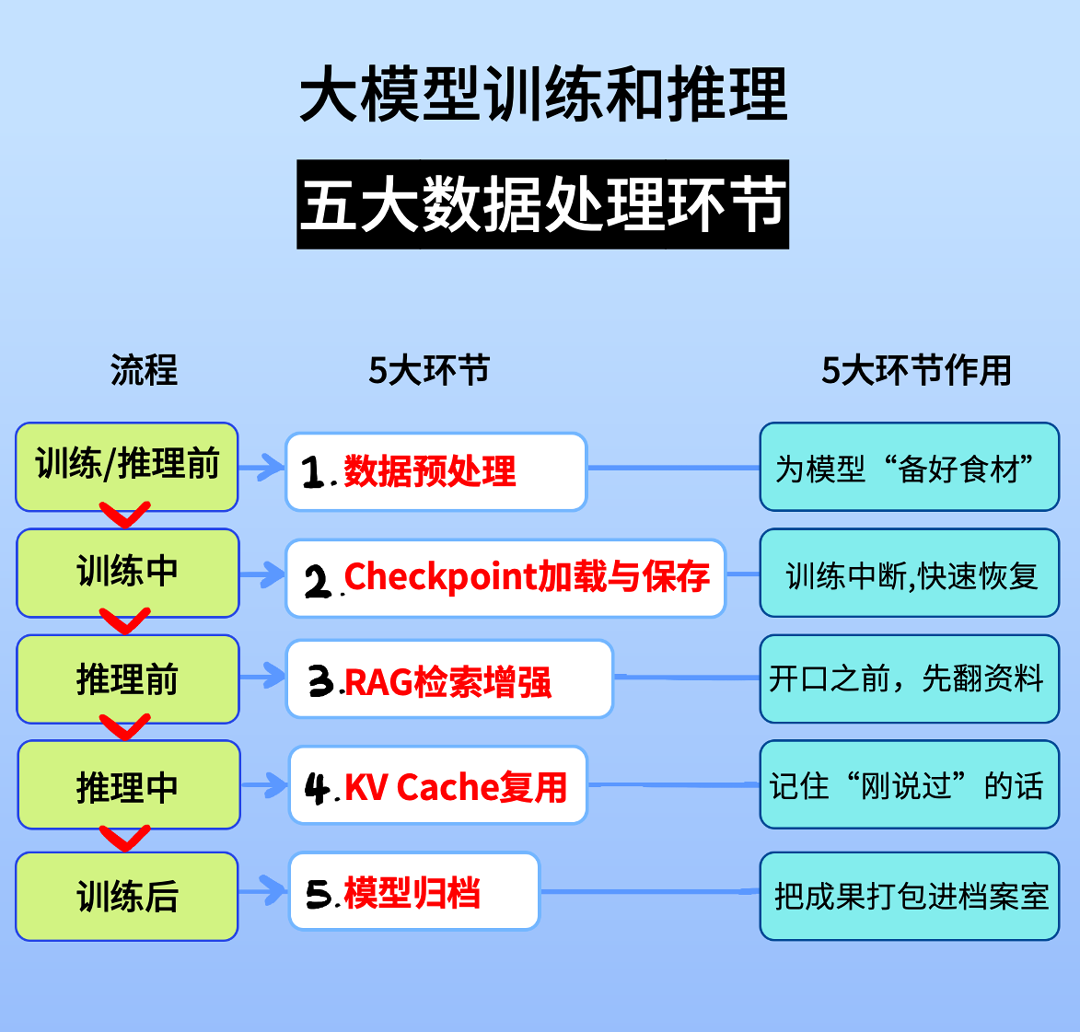
这五个环节,是计算与存储高度耦合的过程,也被称为:半计算半存储型任务。
存储万万不能拖后腿,否则GPU再强都白搭。
二、智算中心存储架构及特征
1、智算存储中心架构
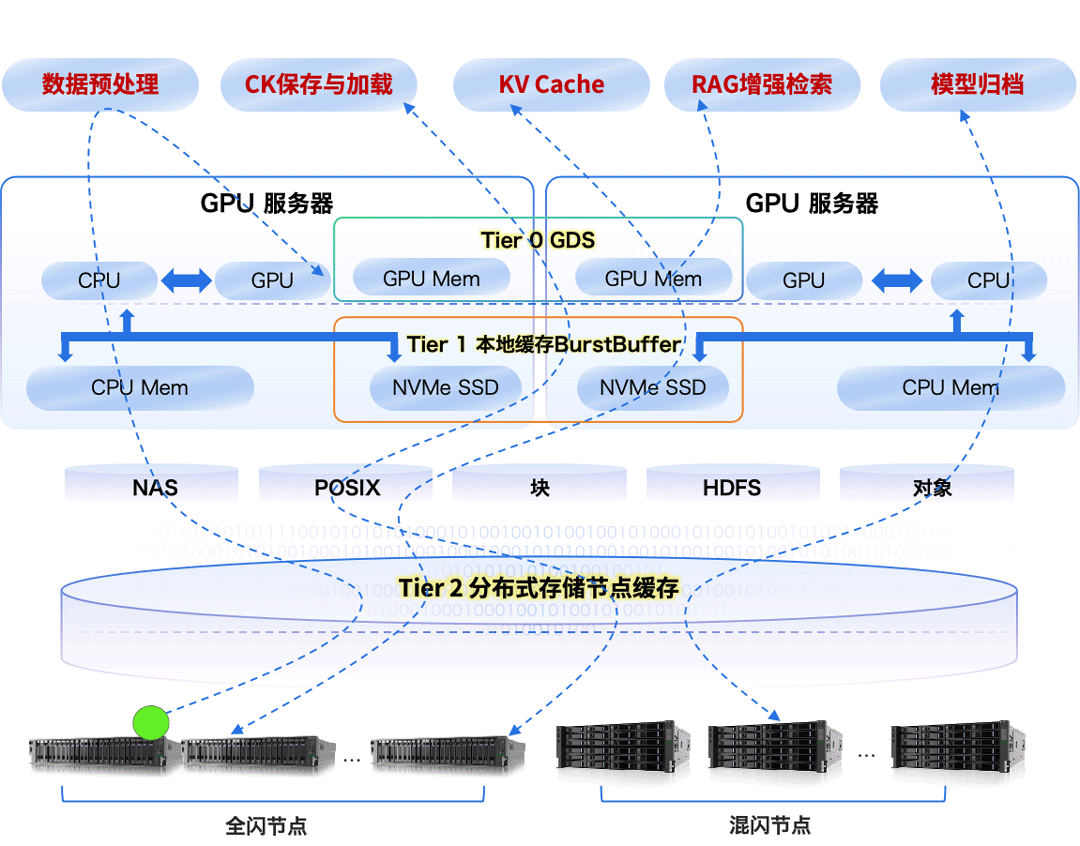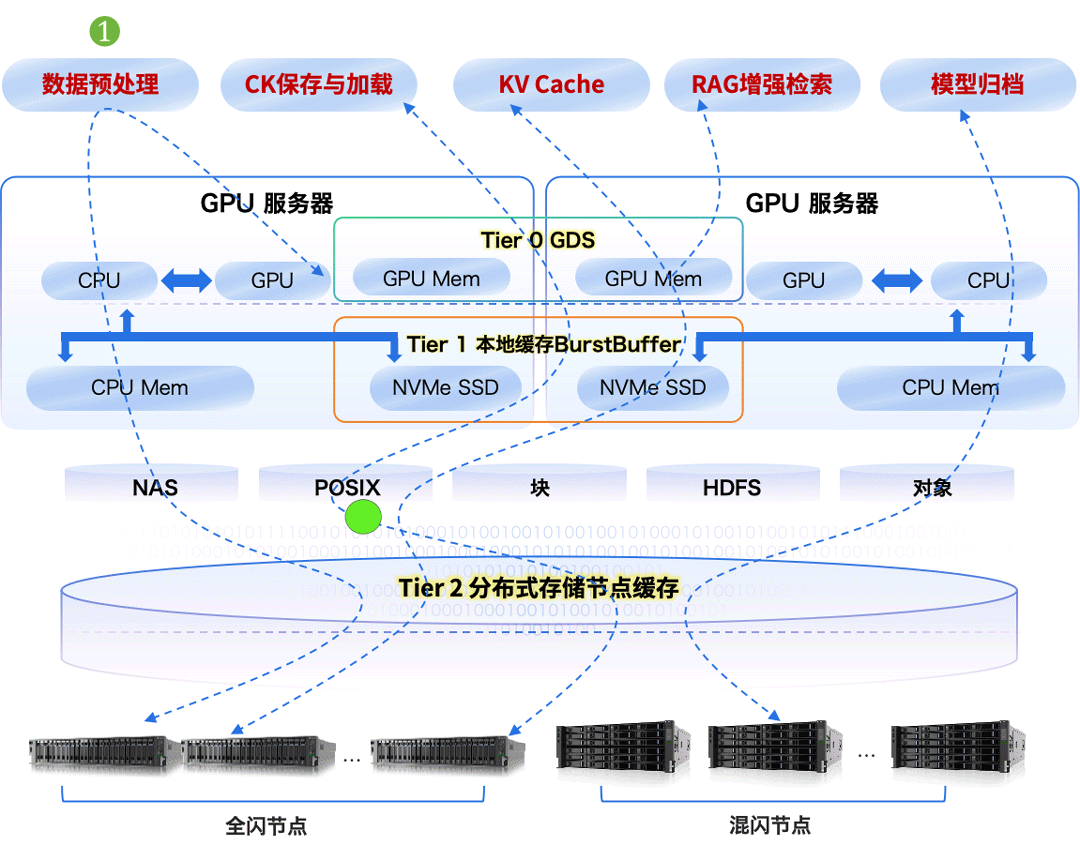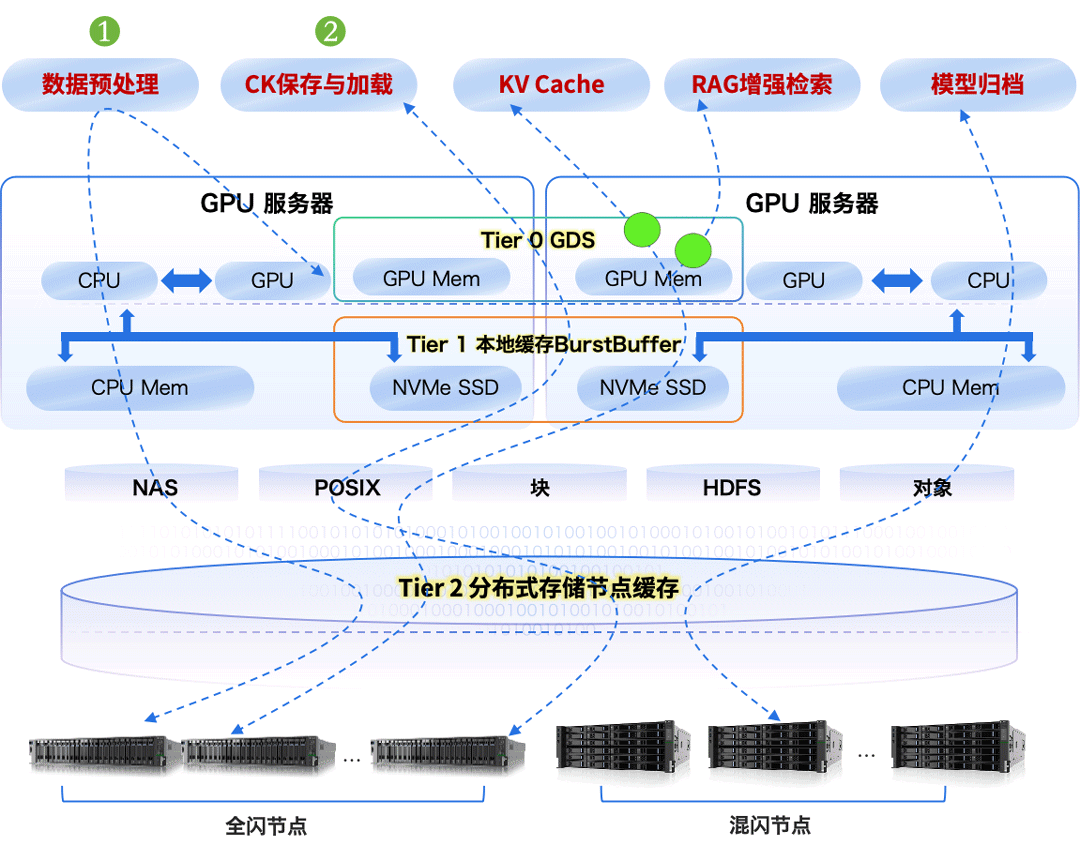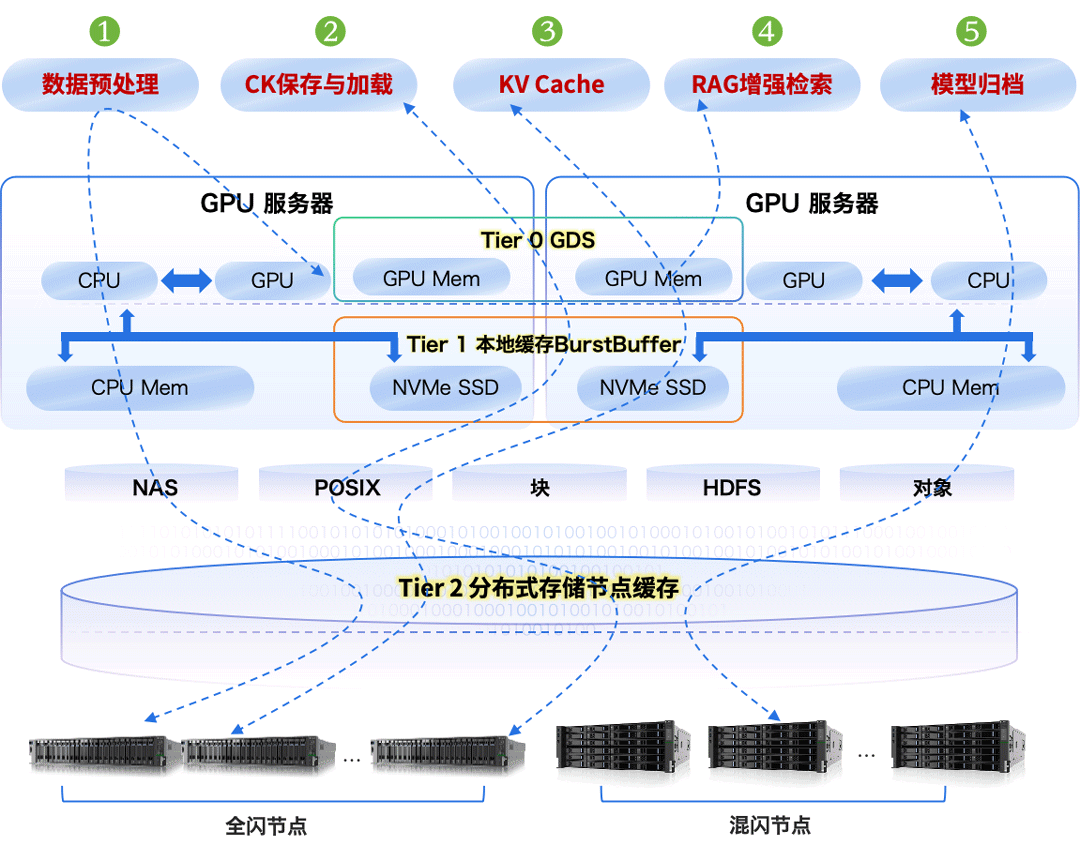
以数据为中心,统一存储基座,融合多元异构算力的新 AI 技术架构,已逐步成为人工智能计算中心的主流架构。多种异构算力紧密围绕在统一的数据底座,改变了过去“数据跟着算力跑”的算力烟囱工作模式,朝着“算力围着数据转”的新模式演进,如下图所示。作为数据载体,数据存储已成为构建大模型的关键基础设施之一。

2、智算存储特征
新型人工智能存储(面向 AI 的存储系统)具备极致性能、数据安全、大模型数据范式、高扩展性、数据编织和绿色节能 6 大关键特征。

-
极致的性能密度可以加速数据供给,缩短训练数据的归集与预处理、CheckPoint 数据的保存以及断点续训等造成的算力等待,提升 AI 全流程效率;
-
支持向量、张量、KV Cache 等大模型数据范式,能显著加速数据的融合检索,更好的支持推理应用;
-
AI 存储 99.9999%的可靠性提升 AI 基础设施的持续服务时间,防勒索和存储加密进一步保障数据安全;
-
跨域跨集群的 AI 数据湖支撑异构计算,近存计算的扩展;
-
数据编织提供全局数据可视、可管,实现数据流动效率的倍数提升,并通过数据版本管理和数据血缘管理,保证数据质量不被破坏;
-
绿色的AI存储,可降低每TB 数据的能耗和占用空间。
构建先进的 AI 存储,要从存储介质、系统、架构、数据编织、数据范式和数据安全等多方面发力,协同提升大模型数据存储能力,智算存储结构分层架构如下图所示。

三、智算中心存储核心技术解析
1、长记忆存储范式为推理提质增效
长记忆存储通过多级 KV Cache 助力大模型推理成本降低,用户体验增强。长记忆存储是专业记录大模型思考结果的存储,作为内存的扩展,以分级的方式实现月级、年级、乃至“终身”的记忆能力, 让大模型推理具备慢思考能力,如下图所示。
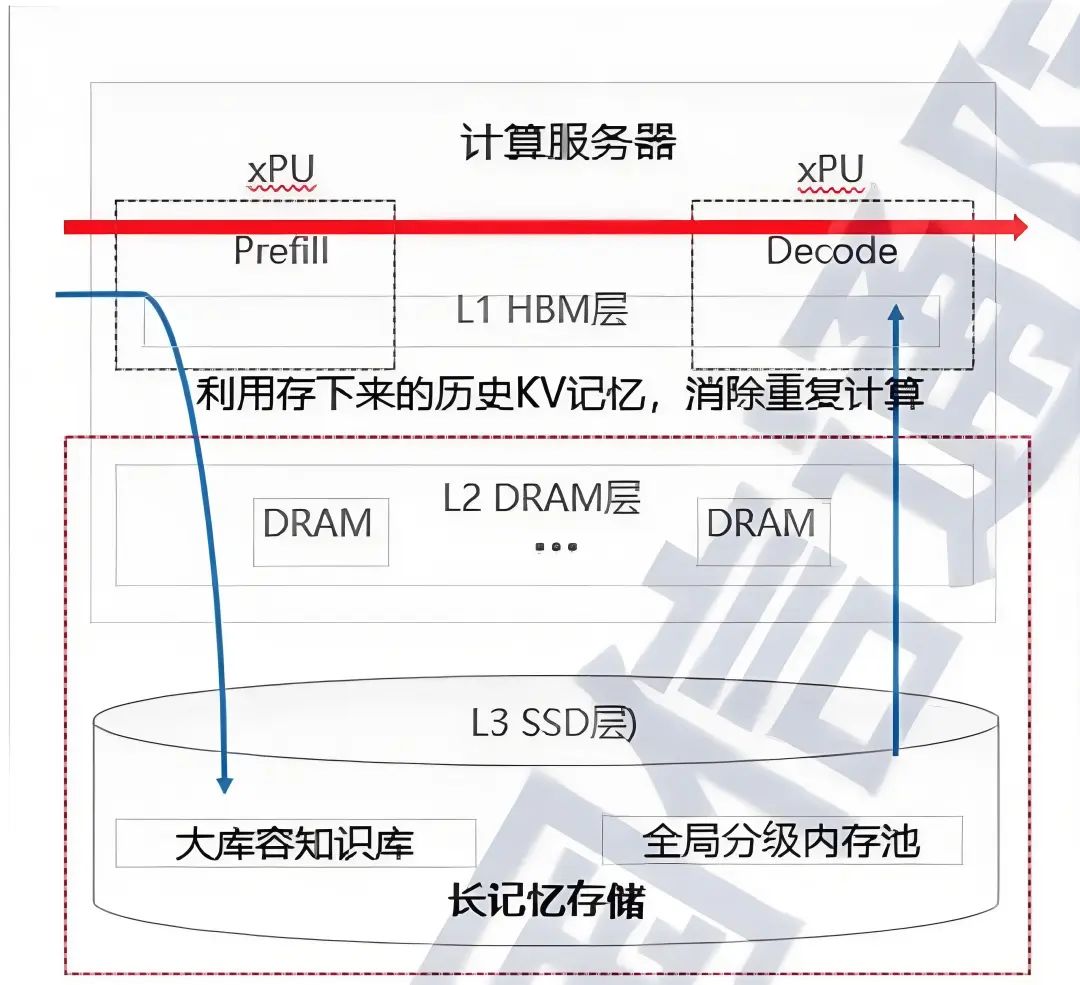
来源:中国信息通信研究院
-
一方面,大模型推理过程中需处理长序列以获取准确的上下文信息、生成高质量输出,模型的计算成本和内存需求通常随序列长度的增加而显著增加,通过 KV Cache 缓存机制,可以有效降低模型长序列推理的内存占用和计算开销,实现有限硬件条件下的高效推理。
-
另一方面,基于高性能长记忆存储技术构建的多级 KV Cache 缓存机制,可以保证 KV Cache 具备随时在线和全局池化共享能力,配合以查代算算法,实现从持久化的KV Cache“长记忆”中调取前期已执行过的计算结果,减少推理过程中的重复计算。根据企业实践,利用该技术可实现推理吞吐提速超50%,显著降低推理的端到端成本,提升大模型行业应用的长序列场景体验。
近数据向量知识库提高大模型检索效率,减少输出幻觉。近数据向量知识库基于快速知识生成、大库容高召回率与多模融合检索关键能力,可实现百亿知识库秒级检索。通过分布式合并建图技术,实现近数建库,根据企业实践,知识生成从月级降至天级,建库时长缩短5 倍,实现知识实时更新。同时利用存储侧容灾备份特性组合,可提供数据库高可用保障,消除单点故障引发重新建库的巨大开销。
2、数据编织加强全局数据高效处理
数据编织成为跨域跨集群数据归集、流动和处理的强大助力,通过数据版本管理和数据血缘管理,保证数据质量不下降。

数据编织是通过构建统一的数据视图,实现跨域跨集群数据的整合和调度,从而使得数据能够被快速地发现和访问,保障全局数据可视可管。随着数据量的爆炸性增长,海量数据往往分散在不同的数据中心,形成所谓的“数据孤岛”,这不仅阻碍了数据的流通和共享,也降低了数据的利用效率。
-
数据编织一方面能将来自多个源头的价值数据快速归集和流动,使数据高效的从源端移动到训练和推理环境的 AI 存储上来,并通过数据版本管理和数据血缘管理,保证数据质量不被破坏,满足权限、安全等方面的各类数据使用规则,提升海量复杂数据的管理效率,直接减少 AI 训练推理端到端周期。
-
另一方面也能实现 AI 训练数据集的按需筛选。通过数据画像,凭借数据的时空信息、数据的标签, 以简化数据的分级分类管理,做到按场景化的数据治理,满足大模型的场景化要求。
AI 全流程业务加速需要数据易共享、高性能、易扩展的统一数据底座。
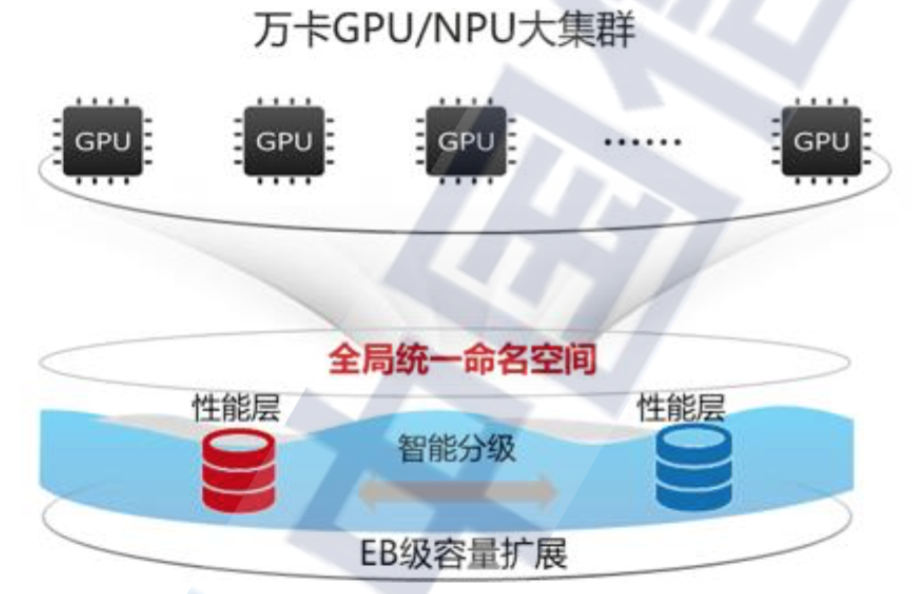
如上图所示,统一数据底座是指对内兼容 AI 全流程工具链所需的多种存储协议,并保证各协议的语义无损,对外呈现统一的命名空间,方便用户管理和访问数据,能够实现数据全生命周期管理。传统解决方案由于需要在不同系统间来回拷贝数据,会严重影响数据处理效率,浪费存储空间,增加运维难度。统一数据管理能够具备高效的数据流转能力,可以在不同阶段实现数据的零拷贝和格式的零转换,实现 AI 各阶段协同业务的无缝对接,减少等待时间。
-
首先,可以指定数据首次写入时的放置策略,例如在数据获取阶段,新获取的数据需要在短时间内处理的,可以直接放置到高性能层;而新获取的数据在短时间内无需处理的或用来长期归档的数据,则可以直接写入容量层;
-
其次,可以设置丰富的数据分级流动策略,例如可以设置访问频度与时间相结合的流动策略,也可以设置容量水位触发的流动策略;
-
再者,根据用户制定的分级策略,数据能够在高性能层和大容量层之间自动分级流动,数据分级迁移过程对业务应用完全透明;
-
最后, 对于已经分级到容量层的数据,用户可以通过命令或 API 对指定的数据集配置预热策略,来加速任务的启动速度。
3、超节点存储架构持续支撑扩展法则
大模型时代,AI 存储架构从传统的层次化、主从服务器架构, 向全对等、全直通的超节点架构转变。
超节点存储能够构建全对等、全直通的架构,实现“DC as a Computer”。存储与计算之间高并行数据直通,通过开放的协议标准,既支持 Scale-up 扩展容量,也支持Scale-out 扩展性能的超节点架构。
-
一方面在宏观上存算分离,计算、存储资源独立部署,通过高通量数据总线互联,统一内存语义访问数据,实现计算、存储资源解耦灵活调度,资源利用率最大化。目前, 模型训练仍然需要通过 CPU 去访问内存,但由于 CPU 的发展逐步放缓,导致内存的带宽和容量成为瓶颈。以 CXL(Compute Express Link) 为代表的高速互联总线,将系统中的计算、存储、内存等资源彻底解构,各自形成统一的共享资源池,让 GPU 可以直接通过 CXL 总线以更快的速度访问内存与存储,从而极大提升大模型的数据加载及流转 效率,实现以数据为中心的超节点架构。
-
另一方面在微观上存算一体, 通过近数据处理,减少数据非必要移动,在数据产生的边缘、数据流动的网络中、数据存储系统中布置专用数据处理算力,算网存融合提升数据处理效率。大模型训练与应用阶段对数据处理效率有极高要求,在传统的数据处理流程中,数据需要在存储介质和处理器之间频繁移动,这不仅耗时而且效率较低。通过近存计算将数据预处理功能卸载到存储设备中,从而减少数据搬运的开销,提高数据处理的速度和效率。基于超节点存储能力,AI 存储能够支撑超十万卡算力集群,为人工智能的持续发展提供动力。
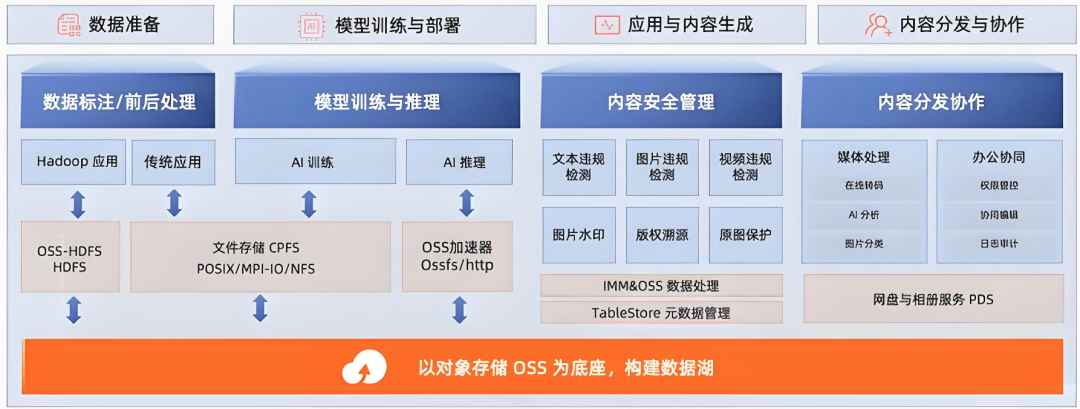
4、高性能并行文件系统以存强算
大模型需要 AI 存储具备高性能并行文件系统以提高数据存取效率,并提供加速卡直通存储技术实现数据直达。
并行文件系统是指支持数据并行读写的高性能文件系统,被广泛使用于需要高算力与高数据量的应用。随着大模型的发展,需要 AI 存储具备高并发、高带宽、 高 IOPS 的并行文件系统,以提高 GPU/NPU 的训练推理效率。AI 存储并行文件系统需具备以下四大能力:
-
高性能。百 PB/s 级带宽 和亿级 IOPS 支持能力,可实现超万卡集群数据调度简化、供给无瓶颈,保障规模扩展场景下的系统性能。每U大于 50GB/s 带宽、百万IOPS 和 PB 级容量,可实现数据存储与处理的高密度,提升大模型使用效率,降低成本。
-
高可靠。通过多路径、全交换、全互联等设计,确保存储系统的高可用性达到
99.9999%,可以实现软硬件故障的自动切换。
-
高扩展。能够支持 EB 级的数据量,且性能随节点数增加而线性增加。
-
加速卡直通存储技术。利用基于总线 P2P的底层传输协议机制,使数据路径无需再经过 CPU,实现加速卡的HBM 和存储设备间数据一跳直达,消除 CPU 处理瓶颈,极大的提升了数据从存储到加速卡的传输效率,在检查点状态数据保存、训练数据加载以及 KV Cache 加速等场景发挥重要作用。
5、全闪存存储技术为数据提速降耗
高性能低能耗的大模型数据存储与处理需要 AI 存储走向全闪存。
存储介质是指用于存储数据的载体,是数据存储的基础。闪存存储是新一代存储介质,相比传统的机械硬盘,在性能、能耗、容量密度等方面有巨大优势,已经成为了业界的共识。闪存存储比机械硬盘时延小 100 倍左右,每秒数据读写次数大1000 倍以上,空间占用节省 50%。 随着闪存介质堆叠层数与颗粒类型方面的突破,其成本也在持续走低,成为处理大模型数据的理想选择。数据读写性能的大幅提升,将减少计算、网络等资源的等待,加速大模型的部署与应用。
根据行业测算, 以 GPT-3 采用 100PFlops 算力下,当存储的读写性能提升 30%,将优化计算侧 30%的利用率,训练周期将从 48 天降低至 36 天,整体训练 时间缩短 32%。使用闪存存储相比机械硬盘能减少能耗 70%。尤其是高密存储节点密度能达到传统存储服务器的 2.6 倍以上,结合存算分离架构,相对使用通用型服务器,减少了存储节点 CPU、内存及配套交换机, 同等容量下带来能耗节约 10%~30%,显著降低大模型数据的存储能耗。数据算法和数据融合技术正在大幅度提高存储能效。
-
数据融合: 随着数据融合技术的成熟,一套存储系统能够同时提供文件、对象等多协议访问能力,通过多协议融合互通能力,一份数据无须协议转换就能够被多种协议同时访问,减少数据搬迁和重复存储,提升 35%的数据处理能效。
-
数据算法:数据压缩,数据重删正在向无损化,场景化演进,随着应用语义压缩/重删技术的发展,有望从根本上解决非结构化数据的存储效率问题,从而进一步提升数据能效。
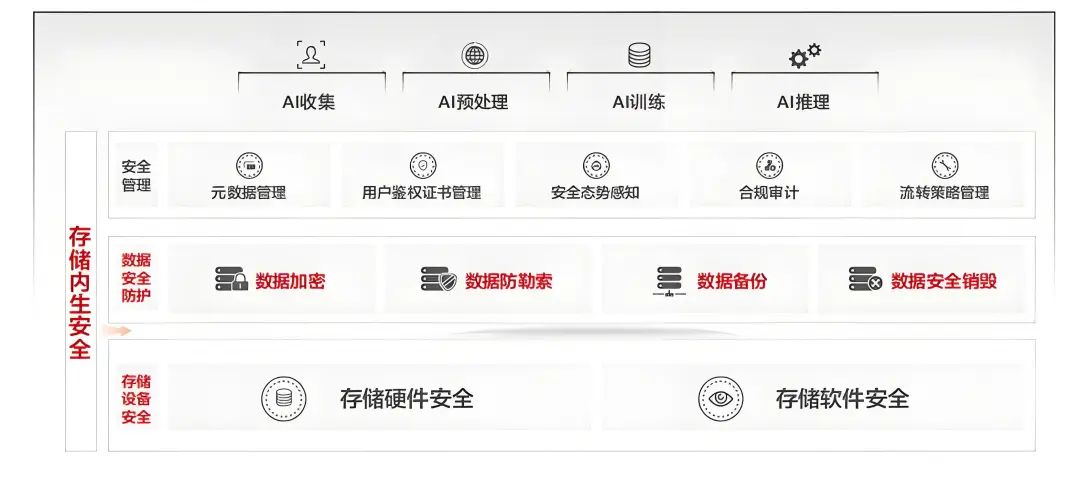
6、存储内生安全保护企业数据资产
存储内生安全是构建大模型系统数据安全防护的最后一道防线。
存储内生安全强调在 AI 存储系统中内置安全机制,以保障数据的机密性、完整性和可用性。相比于传统的外部安全措施,存储内生安全具有更高的灵活性和可控性,能够更好地适应不断变化的安全威胁。在大模型的应用中,存储内生安全通过将安全功能融入到 AI 存储系统中实现对数据的保护。这种方式可以避免将敏感信息暴露在外部网络中,从而降低数据被攻击的风险。同时,存储内生安全还能够提供灵活的安全管理策略,根据不同用户的需求进行定制化的安全设置,提高数据的安全性和合规性。
-
从硬件角度,存储内生安全主要包括构建关键硬件自主能力、硬件三防(防侧信道、防故障注入、防物理攻击)和可信启动等技术。
-
从软件算法角度,重点解决开源软件的风险治理。
-
从数据安全防护角度,AI 存储会围绕数据采集、传输、存储、 处理、共享和销毁全生命周期提供安全防护能力。
-
其一是围绕数据全生命周期,提供端到端加密能力,包括数据传输加密,落盘加密等,提升数据流动和数据储存的安全,并在数据生命周期结束时提供数据安全销毁能力;
-
其二是针对数据完整性、真实性和可用性提供安全快照、本地备份、异地备份、双活容灾等数据容灾与备份能力,结合企业数据分类分级可实施符合政策法规要求的数据保护措施;
-
其三是针对勒索病毒攻击提供网络+存储协同防勒索的能力,实现事前防御勒索病毒攻击、事中进行勒索病毒检测、事后保障数据可恢复。勒索病毒隐蔽性极强、变种频繁,往往使用零日漏洞、钓鱼邮件等方式入侵, 单靠杀毒软件防不胜防;
-
网络防火墙等设备以进不来为防范目标,可拦截 90%左右勒索病毒,而 AI 存储作为数据的最终载体,可以在第一时间感知勒索软件对数据的修改行为,通过侦测分析、安全副本、及时恢复,确保病毒进不来、改不了,数据可恢复。
往期推荐
AIDC智算中心建设:资源池化核心技术解析-CSDN博客
AIDC智算中心建设:计算力核心技术解析-CSDN博客
一文解读DeepSeek在保险业的应用_deepseek 保险行业应用-CSDN博客
一文解读DeepSeek在银行业的应用_deepseek在银行的应用-CSDN博客
欢迎 点赞👍 | 收藏⭐ | 评论✍ | 关注🤗
相关文章:

AIDC智算中心建设:存储核心技术解析
目录 一、智算中心存储概述 1、存储发展 2、智算存储指导政策 3、智算智能存储必要性 二、智算中心存储架构及特征 1、智算存储中心架构 2、智算存储特征 三、智算中心存储核心技术解析 1、长记忆存储范式为推理提质增效 2、数据编织加强全局数据高效处理 3、超节点…...
)
第11次:用户注册(完整版)
第一步:定义用户模型类 class User(AbstractUser):mobile models.CharField(max_length11, uniqueTrue, verbose_name手机号)class Meta:db_table tb_userverbose_name 用户verbose_name_plural verbose_namedef __str__(self):return self.username第二步&…...

论文速读《Embodied-R: 基于强化学习激活预训练模型具身空间推理能力》
项目主页:https://embodiedcity.github.io/Embodied-R/ 论文链接:https://arxiv.org/pdf/2504.12680 代码链接:https://github.com/EmbodiedCity/Embodied-R.code 0. 简介 具身智能是通用人工智能的重要组成部分。我们希望预训练模型不仅能在…...

VMware Fusion安装win11 arm;使用Mac远程连接到Win
目录 背景步骤1. 安装Fusion2. 下载Win113. 安装Win113.1 初始步骤3.2 进入安装 4. 安装Windows APP 背景 最近国补太火热了,让Macbook来到6000这个价位。实在没忍住,最后入手了一台M3芯片的Macbook Air(jd6799)。 既然运维出身&…...

【ARM】DS-试用授权离线激活
1、 文档目标 解决客户无法在公司网络管控下进行ARM DS 试用激活,记录解决方案。 2、 问题场景 客户在ARM DS激活时无法连接到ARM认证网址,客户公司网络管理无法开放全部网络权限,只能针对特定网址和网络端口可以开放或客户公司开发环境无法…...

泰迪杯特等奖案例学习资料:基于卷积神经网络与集成学习的网络问政平台留言文本挖掘与分析
(第八届“泰迪杯”数据挖掘挑战赛A题特等奖案例深度解析) 一、案例背景与核心挑战 1.1 应用场景与行业痛点 随着“互联网+政务”的推进,网络问政平台成为政府与民众沟通的重要渠道。某市问政平台日均接收留言超5000条,涉及民生、环保、交通等20余类诉求。然而,传统人工…...

基于 ReentrantReadWriteLock 实现高效并发控制
在多线程 Java 应用中,管理共享资源的访问是确保数据一致性和避免竞争条件的关键挑战。在某些场景中,多个线程需要频繁读取共享数据,而只有一个线程偶尔需要更新数据。例如,在一个网页投票系统中,大量用户可能同时查看投票结果(读操作),而投票更新(写操作)则相对较少…...
:2025年企业AI转型的催化剂)
代理式AI(Agentic AI):2025年企业AI转型的催化剂
李升伟 摘译 步入2025:代理式AI开启企业智能化转型新纪元 随着2025年临近,企业已不再纠结"是否采用人工智能",而是迫切追问"如何加速AI进化"。传统AI系统在敏捷性、扩展性和自主性上的局限日益显现,新一代技…...

MySQL中MVCC指什么?
简要回答: MVCC(multi version concurrency control)即多版本并发控制,为了确保多线程下数据的安全,可以通过undo log和ReadView来实现不同的事务隔离级别。 对于已提交读和可重复读隔离级别的事务来说,M…...

购物数据分析
这是一个关于电商双11美妆数据分析的项目页面,包含版本记录、运行代码提示、评论等功能模块的相关描述。,会涉及数据处理、可视化、统计分析等代码逻辑,用于处理美妆电商双11相关数据,如销售数据统计、消费者行为分析等 。 数据源…...

基于GA遗传优化的不同规模城市TSP问题求解算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.本算法原理 5.完整程序 1.程序功能描述 旅行商问题(Traveling Salesman Problem,TSP)是一个经典的组合优化问题,旨在找到一个旅行商在访问多个城市后回到起…...

Nginx 安全防护与 HTTPS 部署
目录 一. 核心安全配置 1. 隐藏版本号 2. 限制危险请求方法 3. 请求限制(CC 攻击防御) 4. 防盗链 二. 高级防护 1. 动态黑名单 2. nginx https 配置 2.1 https 概念 2.1.1 https 为什么不安全 2.1.2 安全通信的四大原则 2.1.3 HTTPS 通信原理…...
)
隐私计算框架FATE二次开发心得整理(工业场景实践)
文章目录 版本介绍隐私计算介绍前言FATE架构总体架构FateBoard架构前端架构后端架构 FateClient架构创建DAG方式DAG生成任务管理python SDK方式 FateFlow架构Eggroll架构FATE算法架构Cpn层FATE ML层 组件新增流程新增组件流程新增算法流程 版本介绍 WeBank的FATE开源版本 2.2.…...
)
MySQL性能调优探秘:我的实战笔记 (上篇:从EXPLAIN到SQL重写)
哈喽,各位技术伙伴们!👋 最近我一头扎进了 MySQL 性能调优的奇妙世界,感觉就像打开了新世界的大门!从一脸懵懂到现在能看懂 EXPLAIN 的“天书”,还能对 SQL “指点江山”,这个过程充满了“啊哈&…...

第15章 Python数据类型详解之分解理解:基础数据类型常见易错点和性能优化篇
文章目录 @[toc]第15章 Python数据类型详解之分解理解:基础数据类型常见易错点和性能优化一、常见易错点剖析1. 整数(`int`)2. 浮点数(`float`)3. 布尔(`bool`)4. 字符串(`str`)5. 字节(`bytes`)与字节数组(`bytearray`)二、性能优化策略1. 整数运算优化2. 浮点数…...

20250506联想Lenovo笔记本电脑的USB鼠标失效之后在WIN10下的关机的方法【触摸板被禁用】
20250506联想Lenovo笔记本电脑的USB鼠标失效之后在WIN10下的关机的方法【触摸板被禁用】 2025/5/6 20:35 缘起:在调试的时候,USB鼠标突然失效了。 由于USB转TTL电平的串口CH340经常插拔【可能接口接触不良了,插拔测试一下是不是串口坏掉了】。…...

【Hive入门】Hive安全管理与权限控制:审计日志全解析,构建完善的操作追踪体系
目录 引言 1 Hive审计日志概述 1.1 审计日志的核心价值 1.2 Hive审计日志类型 2 HiveServer2操作日志配置 2.1 基础配置方案 2.2 日志格式解析 2.3 日志轮转配置 3 Metastore审计配置 3.1 Metastore审计启用 3.2 审计事件类型 4 高级审计方案 4.1 与Apache Ranger…...

某团小程序mtgsig,_token 生成逻辑分析
前言 本文章中所有内容仅供学习交流,抓包内容、敏感网址、数据接口均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关,若有侵权,请联系我立即删除! 太久不更新 重新找回号 …...

C#问题 加载格式不正确解决方法
出现上面问题 解决办法:C#问题 改成x86 不要选择anycpu...

K-means
K均值算法(K-means)聚类 【关键词】K个种子,均值 一、K-means算法原理 聚类的概念:一种无监督的学习,事先不知道类别,自动将相似的对象归到同一个簇中。 K-Means算法是一种聚类分析(cluster…...

凌晨三点的数据库崩溃现场
我是小明,一个在创业公司打杂的全栈开发者。上周四凌晨三点,老板突然在群里甩来一句:"明天早会需要用户行为分析报表,重点看 Q1 新注册用户的付费转化率。"我揉着眼睛打开电脑,对着三个屏幕发愣 —— 左边是…...
高频面题全面整理(★2025年5月最新版★))
【大模型面试】大模型(LLMs)高频面题全面整理(★2025年5月最新版★)
【大模型面试】大模型(LLMs)高频面题全面整理(★2025年5月最新版★) 🌟 嗨,你好,我是 青松 ! 🌈 自小刺头深草里,而今渐觉出蓬蒿。 本笔记适合大模型初学者和…...
)
C++入门基础(上)
一. C发展历史 C的起源可以追溯到1979年,当时Bjarne Stroustrup(本贾尼斯特劳斯特卢普,这个翻译的名字不同的地方可能有差异)在贝尔实验室从事计算机科学和软件工程的研究工作。面对项目中复杂的软件开发任务,特别是模拟和操作系统的开发工作…...

Nacos源码—4.Nacos集群高可用分析四
大纲 6.CAP原则与Raft协议 7.Nacos实现的Raft协议是如何写入数据的 8.Nacos实现的Raft协议是如何选举Leader节点的 9.Nacos实现的Raft协议是如何同步数据的 10.Nacos如何实现Raft协议的简版总结 8.Nacos实现的Raft协议是如何选举Leader节点的 (1)初始化RaftCore实例时会开…...

互联网大厂Java求职面试:AI与云原生下的系统设计挑战-3
互联网大厂Java求职面试:AI与云原生下的系统设计挑战-3 第一轮提问:从电商场景切入,聚焦分布式事务与库存一致性 面试官(严肃):郑薪苦,你最近在做电商系统的促销活动,如何处理分布…...
)
【KWDB创作者计划】_通过一篇文章了解什么是 KWDB(KaiwuDB)
文章目录 📋 前言🎯 关于 KaiwuDB 组成🎯 KaiwuDB 核心架构和功能图🧩 KaiwuDB 2.0 版本核心特性🧩 KaiwuDB Lite 版本介绍 🎯 KaiwuDB 产品优势🎯 KaiwuDB 应用场景🧩 典型应用场景…...

双系统电脑中如何把ubuntu装进外接移动固态硬盘
电脑:win11 ubuntu22.04 实体机 虚拟机:VMware17 镜像文件:ubuntu-22.04.4-desktop-amd64.iso 或者 ubuntu20.4的镜像 外接固态硬盘1个 一、首先win11中安装vmware17 具体安装方法,网上很多教程 二、磁盘分区 1.在笔…...

Flink + Kafka 构建实时指标体系的实战方法论
本文聚焦于如何利用 Flink 与 Kafka 构建一套灵活、可扩展的实时指标体系,特别适用于用户行为分析、营销漏斗转化、业务实时看板等场景。 一、为什么要构建实时指标体系? 在数字化运营趋势下,分钟级指标反馈能力变得尤为重要: ✅ 营销投放实时监控 CTR / CVR ✅ 业务增长实…...

RLOO:将多次其他回答的平均reward作为baseline
RLOO:将多次其他回答的平均reward作为baseline TL; DR:基于 REINFROCE 算法,对于同一 prompt 在线采样 k k k 次,取除自己外的其他 k − 1 k-1 k−1 条回答的平均 reward 作为 baseline。 从 PPO 到 REINFORCE 众所周知&…...

在 Laravel 12 中实现 WebSocket 通信时进行身份验证
在 Laravel 12 中实现 WebSocket 通信时,若需在身份验证失败后主动断开客户端连接,需结合 频道认证机制 和 服务端主动断连操作。以下是具体实现步骤: 一、身份验证流程设计 WebSocket 连接的身份验证通常通过 私有频道(Private …...
Transformer 与 LSTM 在时序回归中的实践与优化
🧠 深度学习混合模型:Transformer 与 LSTM 在时序回归中的实践与优化 在处理多特征输入、多目标输出的时序回归任务时,结合 Transformer 和 LSTM 的混合模型已成为一种有效的解决方案。Transformer 擅长捕捉长距离依赖关系,而 LS…...

Java注解
注解的底层原理: 注解的本质是一种继承自Annotation类的特殊接口,也被称为声明式接口,编译后会转换为一个继承自Anotation的接口,并生成相应的字节码文件。 注解的具体实现类是Java运行时生成的动态代理对象(接口本身…...

Linux USB Gadget | 框架 / 复合设备实践 / Configfs 配置
注:本文为“Linux USB Gadget ”相关文章合辑。 图片清晰度受引文原图所限。 略作重排,未整理去重。 如有内容异常,请看原文 Linux USB Gadget 框架概述 2018-04-11 haoxing990 本文记录我在公司 Gadget 相关的驱动开发开发过程中的感悟。…...

Spring Boot之MCP Client开发全介绍
Spring AI MCP(模型上下文协议,Model Context Protocol)客户端启动器为 Spring Boot 应用程序中的 MCP 客户端功能提供了自动配置支持。它支持同步和异步两种客户端实现方式,并提供了多种传输选项。 MCP 客户端启动器提供以下功能: 多客户端实例管理 支持管理多个客户端实…...

nnUNet V2修改网络——暴力替换网络为Swin-Unet
更换前,要用nnUNet V2跑通所用数据集,证明nnUNet V2、数据集、运行环境等没有问题 阅读nnU-Net V2 的 U-Net结构,初步了解要修改的网络,知己知彼,修改起来才能游刃有余。 Swin-Unet是一种基于纯Transformer的U型编码器-解码器架构,专为医学图像分割任务设计。传统方法主…...

【计网】ICMP、IP、Ethernet PDU之间的封装关系
TCP/IP体系结构 应用层RIP、OSPF、FTP运输层TCP、UDP网际层IP、ARP、ICMP网络接口层底层协议(Ethernet) 数据链路层 Ethernet报文格式 6Byte6Byte2Byte46~1500Byte4Byte目的MAC地址源MAC地址类型/长度数据FCS 其中,类型 / 长度值小于 1536…...

JSON 转换为 Word 文档
以下是一个在 Spring Boot 中实现 JSON 转 Word 的示例: 首先,需要在项目中引入相关的依赖,如 json 和 Apache POI 等。在 pom.xml 文件中添加以下内容: <!-- JSON 相关依赖 --> <dependency><groupId>com.fast…...

Kotlin Lambda优化Android事件处理
在 Kotlin 中,Lambda 表达式为 Android 事件处理提供了更加简洁优雅的解决方案。通过合理使用 Lambda,可以显著减少模板代码,提升代码可读性。以下是具体实现方式和应用场景: 一、传统方式 vs Lambda 方式对比 1. 按钮点击事件处…...

Springboot接入Deepseek模型
#实现功能:上下文对话、对话历史、清除会话 #本次提供项目源码压缩包,直接下载解压后导入idea即可正常使用 下载好源码后请在DeepSeek 开放平台中注册账号并充值1块余额,注意充值和API keys,API keys包含了秘钥,获取后复制到项目…...

量子跃迁:破解未来计算的“时空密码”
引言:当量子比特撕裂“摩尔定律”的枷锁 根据德勤《Tech Trends 2025》报告,量子计算机可能在5-20年内成熟,其算力将直接威胁现有加密体系。这不仅是技术的跃迁,更是一场重构数字世界规则的“密码战争”。从谷歌的53量子比特悬铃…...

Spring MVC入门
本内容采用最新SpringBoot3框架版本,视频观看地址:B站视频播放 1. MVC概念 MVC是一种编程思想,它将应用分为模型(Model)、视图(View)、控制器(Controller)三个层次,这三部分以最低的耦合进行协同工作,从而提高应用的可扩展性及可维护性。 模型(Model) 模型层主要…...
TCP和UDP协议、流量控制和拥塞控制、重点协议与端口)
【25软考网工】第五章(6)TCP和UDP协议、流量控制和拥塞控制、重点协议与端口
目录 一、TCP和UDP协议 1. TCP和UDP报文格式 1)TCP传输控制协议 2)UDP用户数据报协议 3)TCP与UDP对比 4)TCP和UDP类比 5)应用案例 例题1#可靠传输服务层 例题2#提供可靠传输功能层 6)TCP报文格式…...

如何修改 JAR 包中的源码
如何修改 JAR 包中的源码 前言一、准备工作二、将 JAR 当作 ZIP 打开并提取三、重写 Java 类方法 A:直接替换已编译的 .class方法 B:运行时类路径优先加载 四、修改 MyBatis(或其他)XML 资源五、重新打包 JAR(命令行&a…...

【Linux网络】应用层协议HTTP
🌈个人主页:秦jh__https://blog.csdn.net/qinjh_?spm1010.2135.3001.5343 🔥 系列专栏:https://blog.csdn.net/qinjh_/category_12891150.html 目录 HTTP 协议 认识 URL urlencode 和 urldecode HTTP 协议请求与响应格式 H…...

高并发架构及场景解决方案
高并发 一、什么是高并发? 高并发是指系统在短时间内能够同时处理大量用户请求或任务的能力,是衡量分布式系统、互联网应用性能的重要指标之一。它的核心目标是确保系统在高负载下仍能稳定、高效运行,同时提供良好的用户体验。 1、高并发系…...

[ linux-系统 ] 常见指令2
1. man 指令 语法:man [选项] 命令 功能:查看联机手册获取帮助。 选项说明-k根据关键字搜索联机帮助。num只在第num章节找。-a显示所有章节的内容。 man是 Unix 和类 Unix 系统中的一个命令,用于查看操作系统和软件的手册页面(ma…...

Spring AI快速入门
一、引入依赖 <dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-model-openai</artifactId> </dependency> <dependencyManagement><dependencies><dependency><groupId>o…...

TCP数据报
三次握手(Three-Way Handshake) 是 TCP 协议中用于建立可靠连接的过程。通过三次握手,客户端和服务器能够确认彼此的存在,并且同步各自的初始序列号,为后续的数据传输做好准备。三次握手确保了双方在正式传输数据前能…...

JS循环-for循环嵌套
打印5行5列星星 效果图 代码: // 打印出5行5列的星星for(i 1 ; i < 5 ; i ) {// 外层控制打印行for(j 1 ; j < 5 ; j ) {// 内层控制每行打印几个document.write(⭐)}document.write(<br>)} 打印侧三角 效果图 代码: for(i 1 ; i &l…...
)
【技术追踪】通过潜在扩散和先验知识增强时空疾病进展模型(MICCAI-2024)
向扩散模型中引入先验知识,实现疾病进展预测,扩散模型开始细节作业了~ 论文:Enhancing Spatiotemporal Disease Progression Models via Latent Diffusion and Prior Knowledge 代码:https://github.com/LemuelPuglisi/BrLP 0、摘…...