论文速读《Embodied-R: 基于强化学习激活预训练模型具身空间推理能力》
项目主页:https://embodiedcity.github.io/Embodied-R/
论文链接:https://arxiv.org/pdf/2504.12680
代码链接:https://github.com/EmbodiedCity/Embodied-R.code
0. 简介
具身智能是通用人工智能的重要组成部分。我们希望预训练模型不仅能在信息空间中实现问答、多模态理解,还能像人一样在真实三维空间中基于连续的视觉观测实现感知、思考和动作。这意味着预训练模型在感知基础上,形成对环境的形而上的理解,并结合意图规划自我动作,比如:“总结历史动作轨迹”、“归纳自身与周围对象的空间关系”、"根据导航目标确定下一步的动作"等。
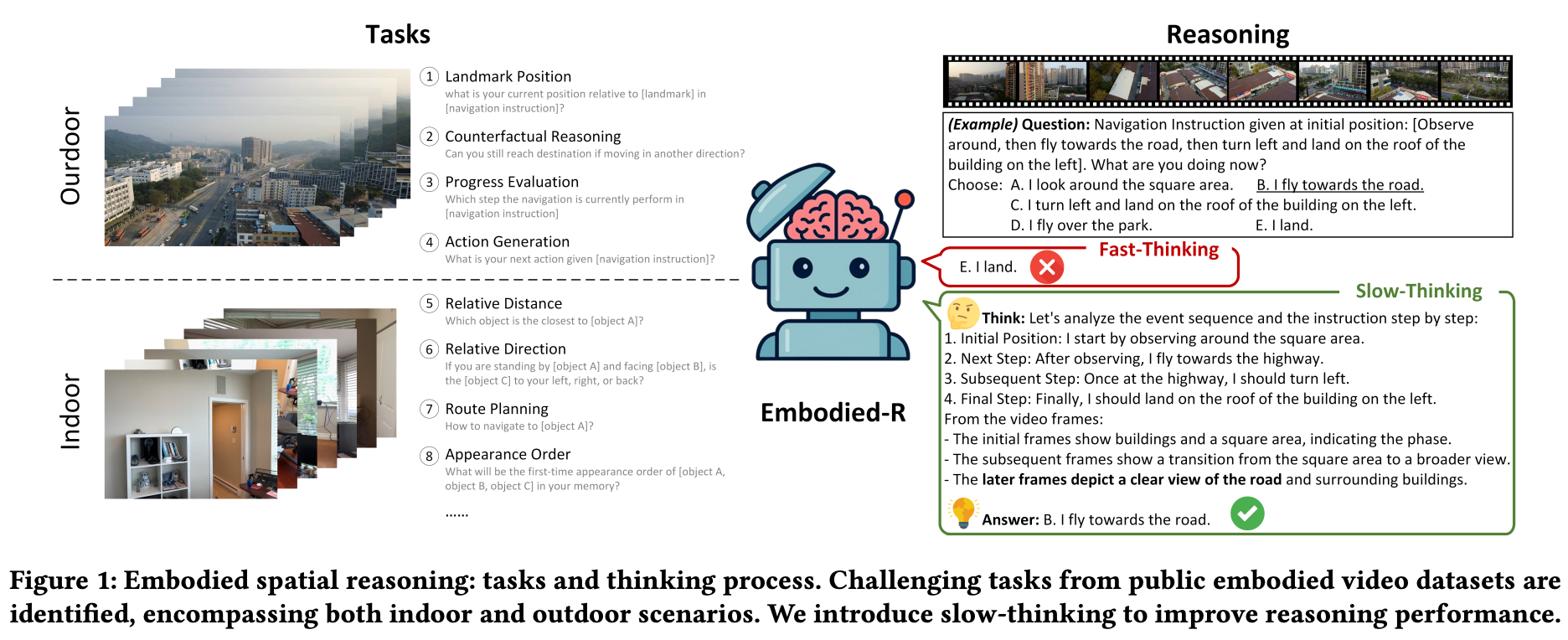
图1:具身空间推理:任务与思维过程。我们从公共的具身视频数据集中识别出具有挑战性的任务,涵盖室内和室外场景。我们引入了慢思考的概念,以提升推理性能。
受OpenAI-o1/o3、DeepSeek-R1等推理模型的启发,本论文提出了首个基于连续视觉感知的具身空间推理框架Embodied-R,通过强化学习(RL, Reinforcement Learning)和大小模型协同,将R1推理训练范式拓宽至具身智能领域。在训练资源受限情况下,只训练其中的小规模参数基座模型,最终表现媲美Gemini-2.5-Pro、OpenAI-o1等SOTA多模态推理模型。

1. 主要贡献
-
首个基于连续视觉感知的具身空间推理框架:Embodied-R将推理训练范式拓展到具身智能领域,处理第一人称视角下的连续视觉输入。
-
创新的大小模型协同架构:将感知与推理分离,利用大规模VLM进行感知,小规模LM进行推理,实现资源高效的模型训练。
-
有效的奖励机制设计:提出专门针对具身推理的逻辑一致性奖励,解决训练过程中的奖励欺骗问题。
-
显著性能提升:相比商用多模态大模型提升超10%,相比SFT训练模型提升5%以上,在分布外数据集上表现媲美Gemini-2.5-Pro。
2. 相关工作
2.1 大型语言模型推理
近期,增强推理能力已成为大模型技术的关键焦点,在数学和逻辑问题求解等任务上展现出显著性能。随着OpenAI的o1发布,众多研究提出了各种技术方法以实现类似功能,包括:
- 思维链(Chain-of-Thought, CoT):通过中间推理步骤提高复杂问题解决能力
- 蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS):探索多种可能的推理路径
- 知识蒸馏:从强推理能力模型中提取知识
- 监督微调(SFT)或直接偏好优化(DPO):结合拒绝采样改进推理质量
DeepSeek-R1和Kimi K1.5引入了基于规则的奖励结合强化学习培养大型语言模型推理能力涌现的方法,这种强化学习范式引起了极大关注,后续工作成功复现了相关结果。
2.2 基于视觉-语言模型的具身空间推理
具身智能旨在开发利用大型多模态模型作为其"大脑",在三维物理世界中实现感知、导航和操作的智能体。人类视觉-空间感知更类似于连续的RGB观察(如视频流),而非静态图像或点云。具身视频基准测试表明,虽然感知任务相对容易解决,但空间推理任务——如空间关系推断、导航和规划——仍然极具挑战性。现有研究主要关注非具身内容推理,很少关注涉及具身连续视觉输入的场景。
2.3 大小模型协作
现有研究主要关注解决与大模型相关的资源消耗和隐私风险,以及小模型在特定场景中的效率和性能优势。小模型可以协助大模型进行数据选择、提示优化和推理增强。有研究探索了使用小模型检测幻觉和隐私泄露,提高整体系统可靠性。虽然本研究与减少计算资源需求的目标相同,但它强调了大规模VLM在感知和小规模LM在增强具身空间推理方面的互补性角色。
3. 核心算法
们首先定义具身空间推理问题。随后,介绍基于VLM的感知模块和基于LM的推理模块。协作框架如图2所示。
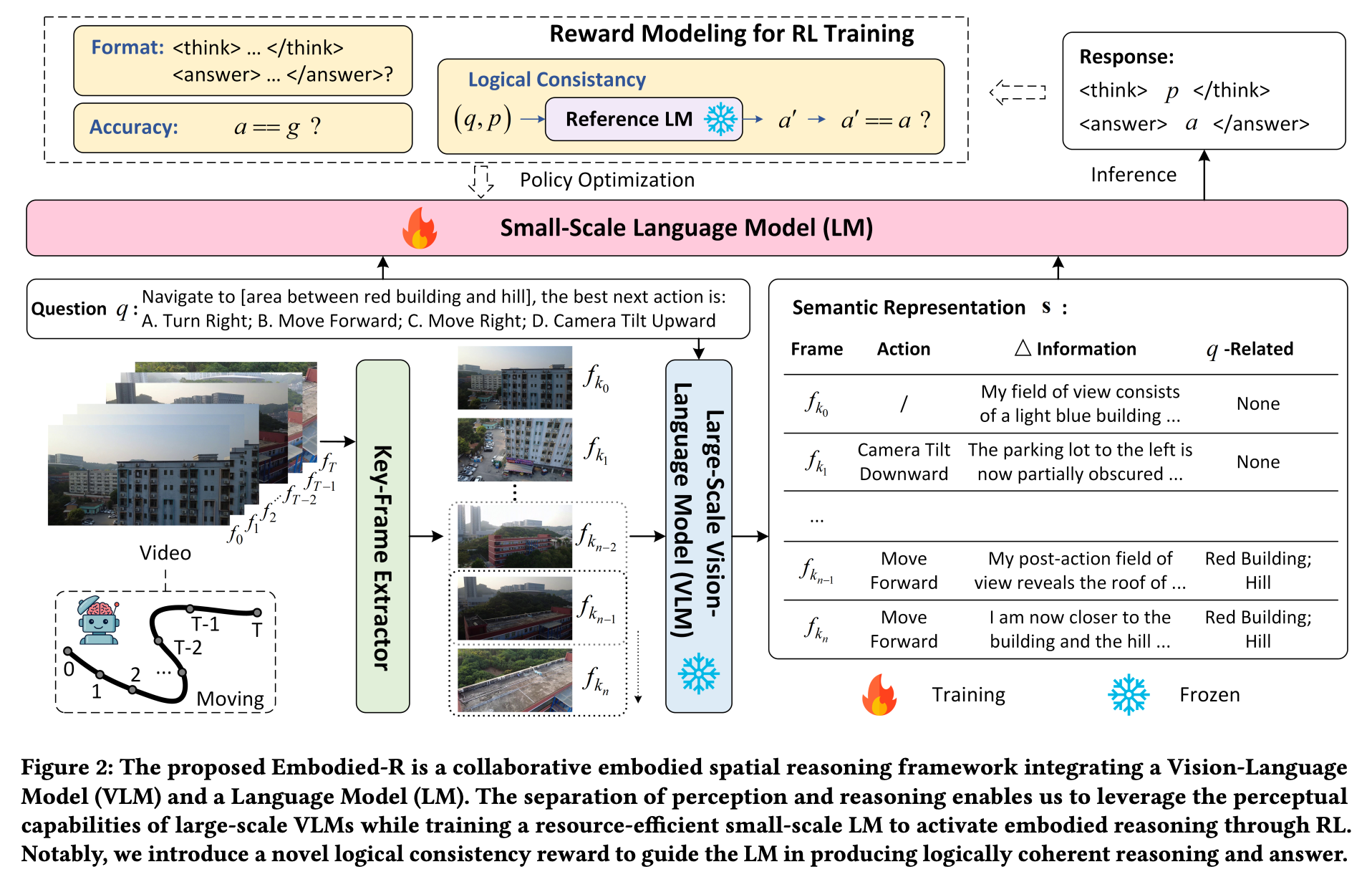
图2:所提出的Embodied-R是一个协作的具身空间推理框架,它集成了视觉-语言模型(VLM)和语言模型(LM)。感知与推理的分离使我们能够利用大规模VLM的感知能力,同时训练一个资源高效的小规模LM,通过强化学习(RL)激活具身推理。值得注意的是,我们引入了一种新颖的逻辑一致性奖励,以引导LM生成逻辑上连贯的推理和答案。
3.1 问题定义
在物理世界中,智能体在空间中移动,生成一系列视频帧(连续视觉观察) f = [ f 0 , f 1 , … , f T ] f = [f_0, f_1, \ldots, f_T] f=[f0,f1,…,fT]。假设空间推理问题表示为 q q q。我们的目标是构建一个模型,以 q q q和 f f f作为输入,输出答案 a a a。如果答案 a a a在语义上与真实答案 g g g一致,则认为是正确的;否则,视为不正确。
3.2 基于大规模VLM的感知
3.2.1 关键帧提取器
随着智能体在空间中连续移动,高采样频率导致连续帧之间存在显著重叠。一方面,VLM依赖环境中静态物体在帧间的变化来推断智能体姿态变化。另一方面,帧间过度重叠会导致VLM和LLM的推理成本增加。针对这一问题,我们设计了一个针对具身视频特性的关键帧提取器,选择既保持重叠又确保帧间信息增益充分的关键帧。
关键帧的提取基于由运动连续性引起的视野重叠。当智能体向前移动时,后一帧的视觉内容预期与前一帧部分重叠;向后移动时情况相反。类似地,在左右旋转时,后一帧应在水平方向与前一帧部分重叠;在上下旋转时,重叠发生在垂直方向。由于视觉观察的采样频率通常远高于智能体的运动速度,帧间通常表现出显著重叠。
具体而言,我们使用透视变换来模拟帧间的几何关系。假设 f t f_t ft是一个关键帧,要确定 f t + 1 f_{t+1} ft+1是否也应被视为关键帧,我们使用Oriented FAST和Rotated BRIEF (ORB)算法计算 f t f_t ft和 f t + 1 f_{t+1} ft+1的关键点和描述符。接着,应用暴力匹配器等特征匹配算法匹配两帧间的描述符,并使用随机样本一致性(RANSAC)算法估计单应性矩阵。然后计算两帧间的重叠率。如果重叠率低于预定义阈值,表明帧间存在显著视觉变化,标记 f t + 1 f_{t+1} ft+1为关键帧。否则,算法继续计算 f t f_t ft和 f t + 2 f_{t+2} ft+2之间的重叠率。此过程持续进行,直到识别出新的关键帧,该关键帧随后成为后续帧的参考。考虑视点变化的影响,旋转(水平和垂直)会导致更大的视野变化,在这些运动过程中会记录更多帧。如果提取的关键帧索引表示为 f ′ = [ f k 0 , f k 1 , … , f k n ] f' = [f_{k_0}, f_{k_1}, \ldots, f_{k_n}] f′=[fk0,fk1,…,fkn],则关键帧提取过程可总结为:
f ′ = K-Extractor ( f ) f' = \text{K-Extractor}(f) f′=K-Extractor(f)
3.2.2 具身语义表示
由于感知能力与模型大小呈正相关,我们使用大规模VLM处理视觉输入以确保高质量感知。每个关键帧的差异信息会被顺序描述。这种方法提供两个关键优势:
- 顺序和动态处理更符合具身场景的特性,其中视觉观察随时间持续生成。在每个时刻,模型应该将历史语义表示与最新视觉观察整合,快速更新空间感知的语义理解。
- 它有助于通过避免同时处理所有帧时出现的输入token限制来处理长视频。
具体来说,对于第一帧,VLM识别场景中存在的物体、它们的属性和空间位置。对于后续帧,将前一帧和当前帧输入VLM以提取关键语义表示 s k j s_{k_j} skj:
s k j ∼ ψ θ ( s ∣ f k j − 1 , f k j ; q ) , j = 1 , 2 , . . . , n s_{k_j} \sim \psi_\theta(s|f_{k_{j-1}}, f_{k_j};q), j = 1, 2, ..., n skj∼ψθ(s∣fkj−1,fkj;q),j=1,2,...,n
其中 s k j s_{k_j} skj包含三个项目:
- 动作:根据连续帧间视觉观察的变化推断智能体的动作。
- △信息:确定智能体与已知物体之间空间关系的变化,以及识别视野中是否出现新物体。
- 与 q q q相关的内容:检测与推理任务相关的物体或信息是否出现在最新视野中。
通过这种方式,我们可以从关键帧 f ′ f' f′中提取空间语义表示 s = [ s k 0 , s k 1 , . . . , s k n ] s = [s_{k_0}, s_{k_1}, ..., s_{k_n}] s=[sk0,sk1,...,skn]。
3.3 基于小规模LM的推理
给定语义感知,我们可以训练一个训练友好的小规模语言模型,能够执行具身空间推理。假设小规模LM表示为 π θ \pi_\theta πθ,模型推断的响应 o o o可表示为: o ∼ π θ ( o ∣ q , s ) o \sim \pi_\theta(o | q, s) o∼πθ(o∣q,s)。
我们的训练目标是确保模型遵循"思考-回答"范式,其中思考过程逻辑严密,答案正确。我们遵循DeepSeek-R1-Zero并采用计算效率高的RL训练策略——分组相对策略优化(Group Relative Policy Optimization, GRPO)。除了基于规则的格式和准确性奖励外,我们还提出了针对具身推理任务量身定制的新型推理过程奖励,以缓解奖励欺骗并增强推理过程与最终答案之间的逻辑一致性。
3.3.1 分组相对策略优化
对于给定的查询 q q q和语义标注 s s s,GRPO使用参考策略 π ref \pi_{\text{ref}} πref生成一组输出 { o 1 , o 2 , … , o G } \{o_1, o_2, \ldots, o_G\} {o1,o2,…,oG}。参考策略通常指未经GRPO训练的原始模型。然后通过优化以下目标更新策略模型 π θ \pi_\theta πθ:
J ( θ ) = E ( q , s ) ∼ D , { o i } i = 1 G ∼ π old ( o ∣ q , s ) [ 1 G ∑ i = 1 G ( min ( π θ ( o i ∣ q , s ) π old ( o i ∣ q , s ) A i , clip ( π θ ( o i ∣ q , s ) π old ( o i ∣ q , s ) , 1 − ϵ , 1 + ϵ ) A i ) − β D KL ( π θ ∥ π ref ) ) ] J(\theta) = \mathbb{E}_{(q,s)\sim D,\{o_i\}^G_{i=1}\sim\pi_{\text{old}}(o|q,s)}\left[\frac{1}{G}\sum^{G}_{i=1}\left(\min\left(\frac{\pi_\theta(o_i|q, s)}{\pi_{\text{old}}(o_i|q, s)}A_i, \text{clip}\left(\frac{\pi_\theta(o_i|q, s)}{\pi_{\text{old}}(o_i|q, s)}, 1 - \epsilon, 1 + \epsilon\right)A_i\right) - \beta D_{\text{KL}}(\pi_\theta \parallel \pi_{\text{ref}})\right)\right] J(θ)=E(q,s)∼D,{oi}i=1G∼πold(o∣q,s)[G1i=1∑G(min(πold(oi∣q,s)πθ(oi∣q,s)Ai,clip(πold(oi∣q,s)πθ(oi∣q,s),1−ϵ,1+ϵ)Ai)−βDKL(πθ∥πref))]
其中 ϵ \epsilon ϵ和 β \beta β是超参数, D KL ( π θ ∥ π ref ) D_{\text{KL}}(\pi_\theta \parallel \pi_{\text{ref}}) DKL(πθ∥πref)是KL散度惩罚: D KL ( π θ ∥ π ref ) = π ref ( r i ∣ q , s ) log π ref ( r i ∣ q , s ) π θ ( r i ∣ q , s ) − 1 D_{\text{KL}}(\pi_\theta \parallel \pi_{\text{ref}}) = \pi_{\text{ref}}(r_i|q, s) \log \frac{\pi_{\text{ref}}(r_i|q,s)}{\pi_\theta(r_i|q,s)} - 1 DKL(πθ∥πref)=πref(ri∣q,s)logπθ(ri∣q,s)πref(ri∣q,s)−1。 A i A_i Ai表示与输出 o i o_i oi对应的优势,从对应的 { r 1 , r 2 , … , r G } \{r_1, r_2, \ldots, r_G\} {r1,r2,…,rG}计算: A i = r i − mean ( { r 1 , r 2 , . . . , r G } ) std ( { r 1 , r 2 , . . . , r G } ) A_i = \frac{r_i - \text{mean}(\{r_1,r_2,...,r_G\})}{\text{std}(\{r_1,r_2,...,r_G\})} Ai=std({r1,r2,...,rG})ri−mean({r1,r2,...,rG})。
3.3.2 奖励建模
奖励建模是RL算法的关键组件,因为其设计引导模型优化方向。我们提出三种奖励类型:格式奖励、准确性奖励和逻辑一致性奖励。这些奖励分别设计用于引导模型学习"思考-回答"推理模式、准确的具身空间推理和推理与答案之间的逻辑一致性。
格式奖励:我们的目标是让模型首先生成具身推理过程 p i p_i pi,然后给出最终答案 a i a_i ai。推理过程和答案分别封装在<think></think>和<answer></answer>标签中:
请扮演一个智能体的角色。给定一个问题和一系列帧,你应首先思考推理过程,然后提供最终答案。推理过程和答案分别封装在<think>和<answer></answer>标签中,如:<think>此处为推理过程</think><answer>此处为答案</answer>。
确保你的答案与思考过程一致且直接从中推导出,保持两部分之间的逻辑连贯性。这些帧代表你从过去到现在的自我中心观察。问题: q q q。视频: f ′ f' f′。助手:
应用正则表达式评估 o i o_i oi是否满足指定要求,从而生成格式奖励 r i ′ r'_i ri′:
r i ′ = { 1 , 如果格式正确 ; 0 , 如果格式不正确 . r'_i = \begin{cases} 1, & \text{如果格式正确}; \\ 0, & \text{如果格式不正确}. \end{cases} ri′={1,0,如果格式正确;如果格式不正确.
准确性奖励:准确性奖励模型 r i ′ ′ r''_i ri′′评估答案 a i a_i ai是否在语义上与真实答案 g g g一致。例如,多项选择题通常具有精确且唯一的答案,当响应遵循指定格式时容易提取。
r i ′ ′ = { 1 , a i = g ; 0 , a i ≠ g . r''_i = \begin{cases} 1, & a_i = g; \\ 0, & a_i \neq g. \end{cases} ri′′={1,0,ai=g;ai=g.
逻辑一致性奖励:当仅使用格式奖励和准确性奖励时,我们一致观察到欺骗行为。具体而言,对于可能答案有限的空间推理任务(如物体相对于智能体身体的相对位置),出现了错误推理过程 p i p_i pi导致正确答案 a i a_i ai的情况,这被错误地分配了正奖励。随着此类案例积累,模型响应的逻辑一致性恶化。为解决这一问题,我们引入了一个简单而有效的过程奖励。我们的目标是确保逻辑一致性的下限,使得 π θ \pi_\theta πθ的推理能力不应低于参考模型 π ref \pi_{\text{ref}} πref。因此,当模型的答案正确时( a i = g a_i = g ai=g),我们将问题 q q q和推理过程 p i p_i pi输入参考模型而不提供视频帧,得到一个答案:
a i ′ ∼ π ref ( a ∣ q , p i ) a'_i \sim \pi_{\text{ref}}(a|q, p_i) ai′∼πref(a∣q,pi)
如果 a i ′ a'_i ai′与 a i a_i ai一致,表明推理过程可以逻辑地导致答案;否则,反映了推理过程与答案之间的逻辑不一致。
r i ′ ′ ′ = { 1 , a i = a i ′ = g ; 0 , 其他情况 . r'''_i = \begin{cases} 1, & a_i = a'_i = g; \\ 0, & \text{其他情况}. \end{cases} ri′′′={1,0,ai=ai′=g;其他情况.
总奖励:总奖励是上述三种奖励的线性组合:
r i = ω 1 r i ′ + ω 2 r i ′ ′ + ω 3 r i ′ ′ ′ r_i = \omega_1 r'_i + \omega_2 r''_i + \omega_3 r'''_i ri=ω1ri′+ω2ri′′+ω3ri′′′
4. 实验
4.1 实验设置
研究主要关注三维物理空间运动中的推理问题,选用两个主要数据集:
- UrbanVideo-Bench:无人机航拍的室外数据
- VSI-Bench:室内第一人称导航数据
从每个数据集中选取四种任务类型,具有长推理链和低准确率特点。Embodied-R的基座模型为:
- VLM:Qwen2.5-VL-72B-Instruct
- LLM:Qwen2.5-3B-Instruct
4.2 实验结果
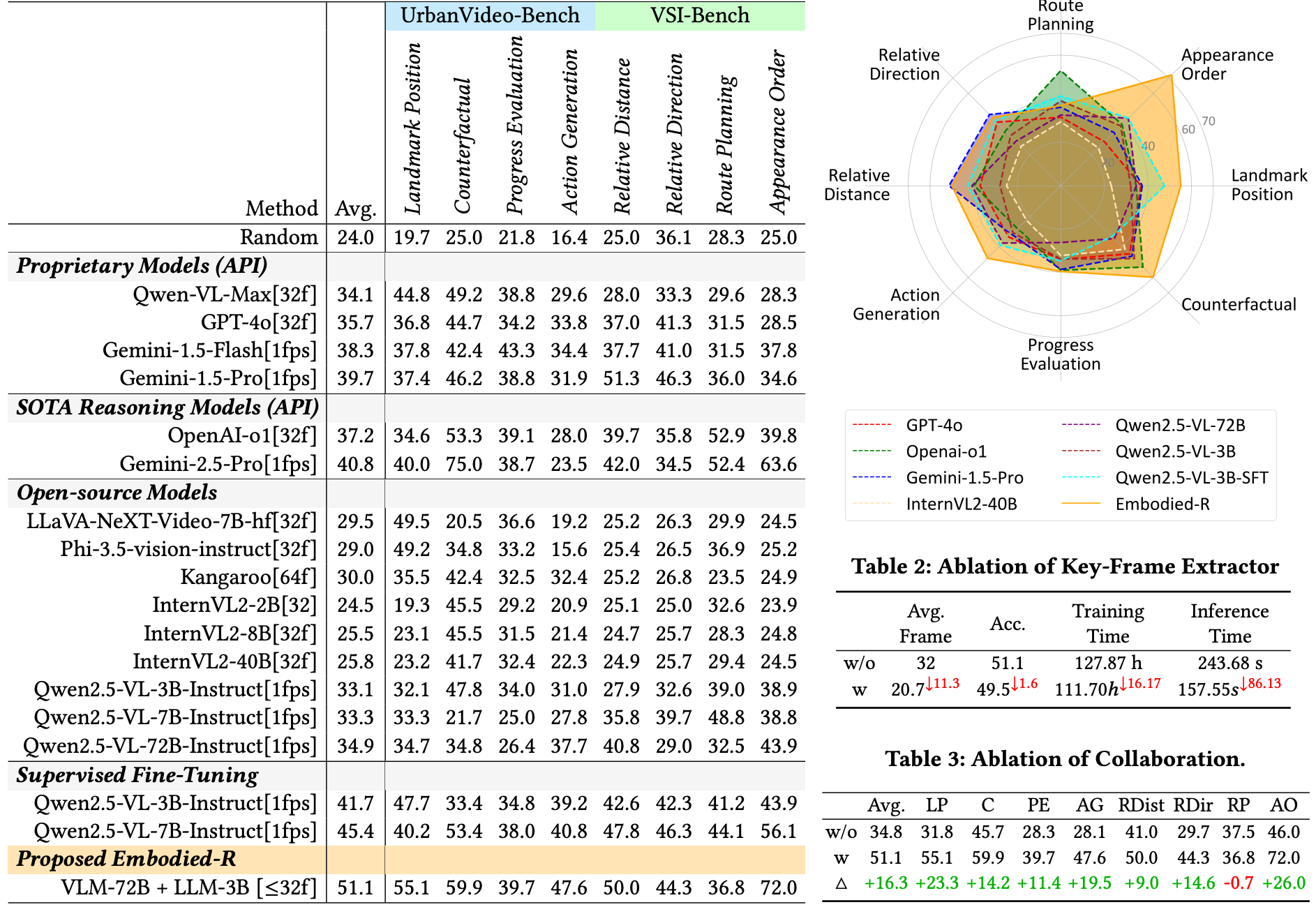
- Embodied-R的推理增强模型在性能上显著优于现有模型
- 相比商用多模态大模型提升超10%
- 相比SFT训练模型提升5%以上
5. 结论与思考
-
推理能力、Aha Moment与回答长度的关系:
- 在具身空间推理任务中,简洁推理模式可能比冗长的推理过程更有效
- LM训练趋于最优文本输出分布,不一定需要长文本推理
-
直接对VLMs进行RL训练的效果:
- 尝试对Qwen2.5-VL-3B-Instruct模型直接RL训练,相似参数和时间下表现远逊于LM
- VLM感知能力有限,制约推理提升
-
奖励设计的重要性:
- 仅使用准确率和格式奖励会导致模型产生奖励欺骗行为
- 逻辑一致性奖励能显著提升推理与答案的一致性,将逻辑一致输出比例从46.01%提升至99.43%
-
RL与SFT训练模型的泛化能力:
- 在分布外数据集测试中,RL训练模型普遍表现更好
- Embodied-R在EgoSchema数据集表现媲美Gemini-2.5-Pro
- RL可能是比SFT更具泛化能力的训练方式
相关文章:

论文速读《Embodied-R: 基于强化学习激活预训练模型具身空间推理能力》
项目主页:https://embodiedcity.github.io/Embodied-R/ 论文链接:https://arxiv.org/pdf/2504.12680 代码链接:https://github.com/EmbodiedCity/Embodied-R.code 0. 简介 具身智能是通用人工智能的重要组成部分。我们希望预训练模型不仅能在…...

VMware Fusion安装win11 arm;使用Mac远程连接到Win
目录 背景步骤1. 安装Fusion2. 下载Win113. 安装Win113.1 初始步骤3.2 进入安装 4. 安装Windows APP 背景 最近国补太火热了,让Macbook来到6000这个价位。实在没忍住,最后入手了一台M3芯片的Macbook Air(jd6799)。 既然运维出身&…...

【ARM】DS-试用授权离线激活
1、 文档目标 解决客户无法在公司网络管控下进行ARM DS 试用激活,记录解决方案。 2、 问题场景 客户在ARM DS激活时无法连接到ARM认证网址,客户公司网络管理无法开放全部网络权限,只能针对特定网址和网络端口可以开放或客户公司开发环境无法…...

泰迪杯特等奖案例学习资料:基于卷积神经网络与集成学习的网络问政平台留言文本挖掘与分析
(第八届“泰迪杯”数据挖掘挑战赛A题特等奖案例深度解析) 一、案例背景与核心挑战 1.1 应用场景与行业痛点 随着“互联网+政务”的推进,网络问政平台成为政府与民众沟通的重要渠道。某市问政平台日均接收留言超5000条,涉及民生、环保、交通等20余类诉求。然而,传统人工…...

基于 ReentrantReadWriteLock 实现高效并发控制
在多线程 Java 应用中,管理共享资源的访问是确保数据一致性和避免竞争条件的关键挑战。在某些场景中,多个线程需要频繁读取共享数据,而只有一个线程偶尔需要更新数据。例如,在一个网页投票系统中,大量用户可能同时查看投票结果(读操作),而投票更新(写操作)则相对较少…...
:2025年企业AI转型的催化剂)
代理式AI(Agentic AI):2025年企业AI转型的催化剂
李升伟 摘译 步入2025:代理式AI开启企业智能化转型新纪元 随着2025年临近,企业已不再纠结"是否采用人工智能",而是迫切追问"如何加速AI进化"。传统AI系统在敏捷性、扩展性和自主性上的局限日益显现,新一代技…...

MySQL中MVCC指什么?
简要回答: MVCC(multi version concurrency control)即多版本并发控制,为了确保多线程下数据的安全,可以通过undo log和ReadView来实现不同的事务隔离级别。 对于已提交读和可重复读隔离级别的事务来说,M…...

购物数据分析
这是一个关于电商双11美妆数据分析的项目页面,包含版本记录、运行代码提示、评论等功能模块的相关描述。,会涉及数据处理、可视化、统计分析等代码逻辑,用于处理美妆电商双11相关数据,如销售数据统计、消费者行为分析等 。 数据源…...

基于GA遗传优化的不同规模城市TSP问题求解算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.本算法原理 5.完整程序 1.程序功能描述 旅行商问题(Traveling Salesman Problem,TSP)是一个经典的组合优化问题,旨在找到一个旅行商在访问多个城市后回到起…...

Nginx 安全防护与 HTTPS 部署
目录 一. 核心安全配置 1. 隐藏版本号 2. 限制危险请求方法 3. 请求限制(CC 攻击防御) 4. 防盗链 二. 高级防护 1. 动态黑名单 2. nginx https 配置 2.1 https 概念 2.1.1 https 为什么不安全 2.1.2 安全通信的四大原则 2.1.3 HTTPS 通信原理…...
)
隐私计算框架FATE二次开发心得整理(工业场景实践)
文章目录 版本介绍隐私计算介绍前言FATE架构总体架构FateBoard架构前端架构后端架构 FateClient架构创建DAG方式DAG生成任务管理python SDK方式 FateFlow架构Eggroll架构FATE算法架构Cpn层FATE ML层 组件新增流程新增组件流程新增算法流程 版本介绍 WeBank的FATE开源版本 2.2.…...
)
MySQL性能调优探秘:我的实战笔记 (上篇:从EXPLAIN到SQL重写)
哈喽,各位技术伙伴们!👋 最近我一头扎进了 MySQL 性能调优的奇妙世界,感觉就像打开了新世界的大门!从一脸懵懂到现在能看懂 EXPLAIN 的“天书”,还能对 SQL “指点江山”,这个过程充满了“啊哈&…...

第15章 Python数据类型详解之分解理解:基础数据类型常见易错点和性能优化篇
文章目录 @[toc]第15章 Python数据类型详解之分解理解:基础数据类型常见易错点和性能优化一、常见易错点剖析1. 整数(`int`)2. 浮点数(`float`)3. 布尔(`bool`)4. 字符串(`str`)5. 字节(`bytes`)与字节数组(`bytearray`)二、性能优化策略1. 整数运算优化2. 浮点数…...

20250506联想Lenovo笔记本电脑的USB鼠标失效之后在WIN10下的关机的方法【触摸板被禁用】
20250506联想Lenovo笔记本电脑的USB鼠标失效之后在WIN10下的关机的方法【触摸板被禁用】 2025/5/6 20:35 缘起:在调试的时候,USB鼠标突然失效了。 由于USB转TTL电平的串口CH340经常插拔【可能接口接触不良了,插拔测试一下是不是串口坏掉了】。…...

【Hive入门】Hive安全管理与权限控制:审计日志全解析,构建完善的操作追踪体系
目录 引言 1 Hive审计日志概述 1.1 审计日志的核心价值 1.2 Hive审计日志类型 2 HiveServer2操作日志配置 2.1 基础配置方案 2.2 日志格式解析 2.3 日志轮转配置 3 Metastore审计配置 3.1 Metastore审计启用 3.2 审计事件类型 4 高级审计方案 4.1 与Apache Ranger…...

某团小程序mtgsig,_token 生成逻辑分析
前言 本文章中所有内容仅供学习交流,抓包内容、敏感网址、数据接口均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关,若有侵权,请联系我立即删除! 太久不更新 重新找回号 …...

C#问题 加载格式不正确解决方法
出现上面问题 解决办法:C#问题 改成x86 不要选择anycpu...

K-means
K均值算法(K-means)聚类 【关键词】K个种子,均值 一、K-means算法原理 聚类的概念:一种无监督的学习,事先不知道类别,自动将相似的对象归到同一个簇中。 K-Means算法是一种聚类分析(cluster…...

凌晨三点的数据库崩溃现场
我是小明,一个在创业公司打杂的全栈开发者。上周四凌晨三点,老板突然在群里甩来一句:"明天早会需要用户行为分析报表,重点看 Q1 新注册用户的付费转化率。"我揉着眼睛打开电脑,对着三个屏幕发愣 —— 左边是…...
高频面题全面整理(★2025年5月最新版★))
【大模型面试】大模型(LLMs)高频面题全面整理(★2025年5月最新版★)
【大模型面试】大模型(LLMs)高频面题全面整理(★2025年5月最新版★) 🌟 嗨,你好,我是 青松 ! 🌈 自小刺头深草里,而今渐觉出蓬蒿。 本笔记适合大模型初学者和…...
)
C++入门基础(上)
一. C发展历史 C的起源可以追溯到1979年,当时Bjarne Stroustrup(本贾尼斯特劳斯特卢普,这个翻译的名字不同的地方可能有差异)在贝尔实验室从事计算机科学和软件工程的研究工作。面对项目中复杂的软件开发任务,特别是模拟和操作系统的开发工作…...

Nacos源码—4.Nacos集群高可用分析四
大纲 6.CAP原则与Raft协议 7.Nacos实现的Raft协议是如何写入数据的 8.Nacos实现的Raft协议是如何选举Leader节点的 9.Nacos实现的Raft协议是如何同步数据的 10.Nacos如何实现Raft协议的简版总结 8.Nacos实现的Raft协议是如何选举Leader节点的 (1)初始化RaftCore实例时会开…...

互联网大厂Java求职面试:AI与云原生下的系统设计挑战-3
互联网大厂Java求职面试:AI与云原生下的系统设计挑战-3 第一轮提问:从电商场景切入,聚焦分布式事务与库存一致性 面试官(严肃):郑薪苦,你最近在做电商系统的促销活动,如何处理分布…...
)
【KWDB创作者计划】_通过一篇文章了解什么是 KWDB(KaiwuDB)
文章目录 📋 前言🎯 关于 KaiwuDB 组成🎯 KaiwuDB 核心架构和功能图🧩 KaiwuDB 2.0 版本核心特性🧩 KaiwuDB Lite 版本介绍 🎯 KaiwuDB 产品优势🎯 KaiwuDB 应用场景🧩 典型应用场景…...

双系统电脑中如何把ubuntu装进外接移动固态硬盘
电脑:win11 ubuntu22.04 实体机 虚拟机:VMware17 镜像文件:ubuntu-22.04.4-desktop-amd64.iso 或者 ubuntu20.4的镜像 外接固态硬盘1个 一、首先win11中安装vmware17 具体安装方法,网上很多教程 二、磁盘分区 1.在笔…...

Flink + Kafka 构建实时指标体系的实战方法论
本文聚焦于如何利用 Flink 与 Kafka 构建一套灵活、可扩展的实时指标体系,特别适用于用户行为分析、营销漏斗转化、业务实时看板等场景。 一、为什么要构建实时指标体系? 在数字化运营趋势下,分钟级指标反馈能力变得尤为重要: ✅ 营销投放实时监控 CTR / CVR ✅ 业务增长实…...

RLOO:将多次其他回答的平均reward作为baseline
RLOO:将多次其他回答的平均reward作为baseline TL; DR:基于 REINFROCE 算法,对于同一 prompt 在线采样 k k k 次,取除自己外的其他 k − 1 k-1 k−1 条回答的平均 reward 作为 baseline。 从 PPO 到 REINFORCE 众所周知&…...

在 Laravel 12 中实现 WebSocket 通信时进行身份验证
在 Laravel 12 中实现 WebSocket 通信时,若需在身份验证失败后主动断开客户端连接,需结合 频道认证机制 和 服务端主动断连操作。以下是具体实现步骤: 一、身份验证流程设计 WebSocket 连接的身份验证通常通过 私有频道(Private …...
Transformer 与 LSTM 在时序回归中的实践与优化
🧠 深度学习混合模型:Transformer 与 LSTM 在时序回归中的实践与优化 在处理多特征输入、多目标输出的时序回归任务时,结合 Transformer 和 LSTM 的混合模型已成为一种有效的解决方案。Transformer 擅长捕捉长距离依赖关系,而 LS…...

Java注解
注解的底层原理: 注解的本质是一种继承自Annotation类的特殊接口,也被称为声明式接口,编译后会转换为一个继承自Anotation的接口,并生成相应的字节码文件。 注解的具体实现类是Java运行时生成的动态代理对象(接口本身…...

Linux USB Gadget | 框架 / 复合设备实践 / Configfs 配置
注:本文为“Linux USB Gadget ”相关文章合辑。 图片清晰度受引文原图所限。 略作重排,未整理去重。 如有内容异常,请看原文 Linux USB Gadget 框架概述 2018-04-11 haoxing990 本文记录我在公司 Gadget 相关的驱动开发开发过程中的感悟。…...

Spring Boot之MCP Client开发全介绍
Spring AI MCP(模型上下文协议,Model Context Protocol)客户端启动器为 Spring Boot 应用程序中的 MCP 客户端功能提供了自动配置支持。它支持同步和异步两种客户端实现方式,并提供了多种传输选项。 MCP 客户端启动器提供以下功能: 多客户端实例管理 支持管理多个客户端实…...

nnUNet V2修改网络——暴力替换网络为Swin-Unet
更换前,要用nnUNet V2跑通所用数据集,证明nnUNet V2、数据集、运行环境等没有问题 阅读nnU-Net V2 的 U-Net结构,初步了解要修改的网络,知己知彼,修改起来才能游刃有余。 Swin-Unet是一种基于纯Transformer的U型编码器-解码器架构,专为医学图像分割任务设计。传统方法主…...

【计网】ICMP、IP、Ethernet PDU之间的封装关系
TCP/IP体系结构 应用层RIP、OSPF、FTP运输层TCP、UDP网际层IP、ARP、ICMP网络接口层底层协议(Ethernet) 数据链路层 Ethernet报文格式 6Byte6Byte2Byte46~1500Byte4Byte目的MAC地址源MAC地址类型/长度数据FCS 其中,类型 / 长度值小于 1536…...

JSON 转换为 Word 文档
以下是一个在 Spring Boot 中实现 JSON 转 Word 的示例: 首先,需要在项目中引入相关的依赖,如 json 和 Apache POI 等。在 pom.xml 文件中添加以下内容: <!-- JSON 相关依赖 --> <dependency><groupId>com.fast…...

Kotlin Lambda优化Android事件处理
在 Kotlin 中,Lambda 表达式为 Android 事件处理提供了更加简洁优雅的解决方案。通过合理使用 Lambda,可以显著减少模板代码,提升代码可读性。以下是具体实现方式和应用场景: 一、传统方式 vs Lambda 方式对比 1. 按钮点击事件处…...

Springboot接入Deepseek模型
#实现功能:上下文对话、对话历史、清除会话 #本次提供项目源码压缩包,直接下载解压后导入idea即可正常使用 下载好源码后请在DeepSeek 开放平台中注册账号并充值1块余额,注意充值和API keys,API keys包含了秘钥,获取后复制到项目…...

量子跃迁:破解未来计算的“时空密码”
引言:当量子比特撕裂“摩尔定律”的枷锁 根据德勤《Tech Trends 2025》报告,量子计算机可能在5-20年内成熟,其算力将直接威胁现有加密体系。这不仅是技术的跃迁,更是一场重构数字世界规则的“密码战争”。从谷歌的53量子比特悬铃…...

Spring MVC入门
本内容采用最新SpringBoot3框架版本,视频观看地址:B站视频播放 1. MVC概念 MVC是一种编程思想,它将应用分为模型(Model)、视图(View)、控制器(Controller)三个层次,这三部分以最低的耦合进行协同工作,从而提高应用的可扩展性及可维护性。 模型(Model) 模型层主要…...
TCP和UDP协议、流量控制和拥塞控制、重点协议与端口)
【25软考网工】第五章(6)TCP和UDP协议、流量控制和拥塞控制、重点协议与端口
目录 一、TCP和UDP协议 1. TCP和UDP报文格式 1)TCP传输控制协议 2)UDP用户数据报协议 3)TCP与UDP对比 4)TCP和UDP类比 5)应用案例 例题1#可靠传输服务层 例题2#提供可靠传输功能层 6)TCP报文格式…...

如何修改 JAR 包中的源码
如何修改 JAR 包中的源码 前言一、准备工作二、将 JAR 当作 ZIP 打开并提取三、重写 Java 类方法 A:直接替换已编译的 .class方法 B:运行时类路径优先加载 四、修改 MyBatis(或其他)XML 资源五、重新打包 JAR(命令行&a…...

【Linux网络】应用层协议HTTP
🌈个人主页:秦jh__https://blog.csdn.net/qinjh_?spm1010.2135.3001.5343 🔥 系列专栏:https://blog.csdn.net/qinjh_/category_12891150.html 目录 HTTP 协议 认识 URL urlencode 和 urldecode HTTP 协议请求与响应格式 H…...

高并发架构及场景解决方案
高并发 一、什么是高并发? 高并发是指系统在短时间内能够同时处理大量用户请求或任务的能力,是衡量分布式系统、互联网应用性能的重要指标之一。它的核心目标是确保系统在高负载下仍能稳定、高效运行,同时提供良好的用户体验。 1、高并发系…...

[ linux-系统 ] 常见指令2
1. man 指令 语法:man [选项] 命令 功能:查看联机手册获取帮助。 选项说明-k根据关键字搜索联机帮助。num只在第num章节找。-a显示所有章节的内容。 man是 Unix 和类 Unix 系统中的一个命令,用于查看操作系统和软件的手册页面(ma…...

Spring AI快速入门
一、引入依赖 <dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-model-openai</artifactId> </dependency> <dependencyManagement><dependencies><dependency><groupId>o…...

TCP数据报
三次握手(Three-Way Handshake) 是 TCP 协议中用于建立可靠连接的过程。通过三次握手,客户端和服务器能够确认彼此的存在,并且同步各自的初始序列号,为后续的数据传输做好准备。三次握手确保了双方在正式传输数据前能…...

JS循环-for循环嵌套
打印5行5列星星 效果图 代码: // 打印出5行5列的星星for(i 1 ; i < 5 ; i ) {// 外层控制打印行for(j 1 ; j < 5 ; j ) {// 内层控制每行打印几个document.write(⭐)}document.write(<br>)} 打印侧三角 效果图 代码: for(i 1 ; i &l…...
)
【技术追踪】通过潜在扩散和先验知识增强时空疾病进展模型(MICCAI-2024)
向扩散模型中引入先验知识,实现疾病进展预测,扩散模型开始细节作业了~ 论文:Enhancing Spatiotemporal Disease Progression Models via Latent Diffusion and Prior Knowledge 代码:https://github.com/LemuelPuglisi/BrLP 0、摘…...

Linux/AndroidOS中进程间的通信线程间的同步 - 内存映射
前言 如何使用 mmap()系统调用来创建内存映射。内存映射可用于 IPC 以及其他很多方面。 1 概述 mmap()系统调用在调用进程的虚拟地址空间中创建一个新内存映射。映射分为两种。 文件映射:文件映射将一个文件的一部分直接映射到调用进程的虚拟内存中。一旦一个文…...

单例模式的实现方法
单例模式(Singleton Pattern)是一种常用的软件设计模式,用于确保一个类只有一个实例,并提供一个全局访问点。这种模式在需要控制对资源(如配置对象、线程池、缓存等)的访问时特别有用。 一、单例模…...