基于图像处理的道路监控与路面障碍检测系统设计与实现 (源码+定制+开发) 图像处理 计算机视觉 道路监控系统 视频帧分析 道路安全监控 城市道路管理
博主介绍:
✌我是阿龙,一名专注于Java技术领域的程序员,全网拥有10W+粉丝。作为CSDN特邀作者、博客专家、新星计划导师,我在计算机毕业设计开发方面积累了丰富的经验。同时,我也是掘金、华为云、阿里云、InfoQ等平台的优质作者。通过长期分享和实战指导,我致力于帮助更多学生完成毕业项目和技术提升。技术范围:
我熟悉的技术领域涵盖SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等方面的设计与开发。如果你有任何技术难题,我都乐意与你分享解决方案。主要内容:
我的服务内容包括:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文撰写与辅导、论文降重、长期答辩答疑辅导。我还提供腾讯会议一对一的专业讲解和模拟答辩演练,帮助你全面掌握答辩技巧与代码逻辑。🍅获取源码请在文末联系我🍅
温馨提示:文末有 CSDN 平台官方提供的阿龙联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的阿龙联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的阿龙联系方式的名片!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
目录
YOLO介绍:
数据集介绍:
训练结果展示:
核心代码介绍:
训练模型代码:
项目实现界面:
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!
一、详细操作演示视频
在文章的尾声,您会发现一张电子名片👤,欢迎通过名片上的联系方式与我取得联系,以获取更多关于项目演示的详尽视频内容。视频将帮助您全面理解项目的关键点和操作流程。期待与您的进一步交流!

YOLO介绍:
YOLO 系列模型通过多层特征融合(Feature Fusion)在不同尺度上同时提取语义信息和空间细节,从而提升小目标和复杂场景下的检测精度。以 YOLOv3 为例,先利用主干网络(Darknet-53)在三种不同分辨率的特征图上做预测,然后通过上采样(Upsampling)与浅层特征拼接(Concatenation)实现自上而下的特征融合。YOLOv4/YOLOv5 则进一步引入了特征金字塔网络(FPN)和路径聚合网络(PANet),在自顶向下和自底向上的双向信息流中,加入空间金字塔池化(SPP)等模块,对多尺度特征进行丰富的上下文融合,以兼顾检测速度与精度。
数据集介绍:



训练结果展示:
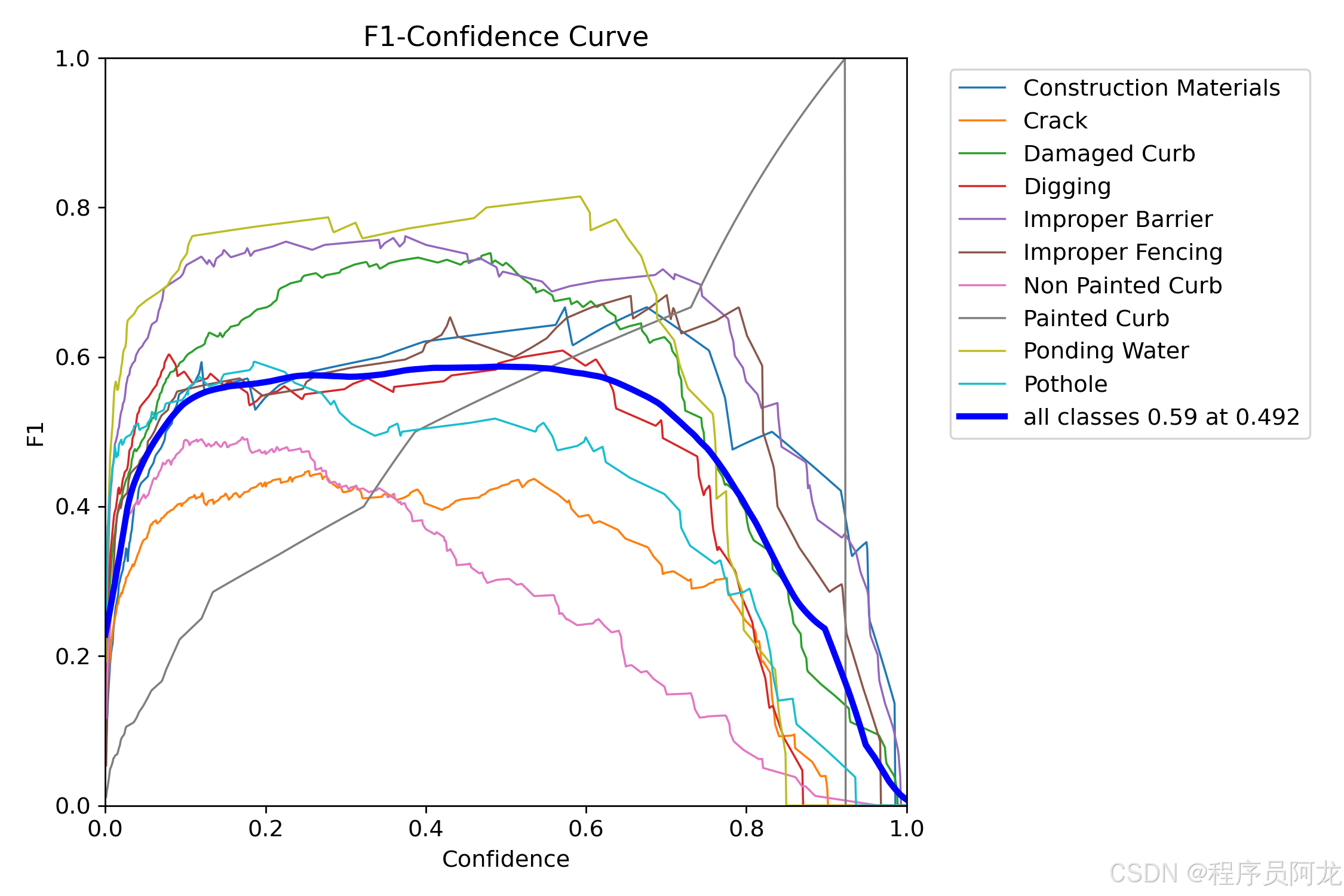
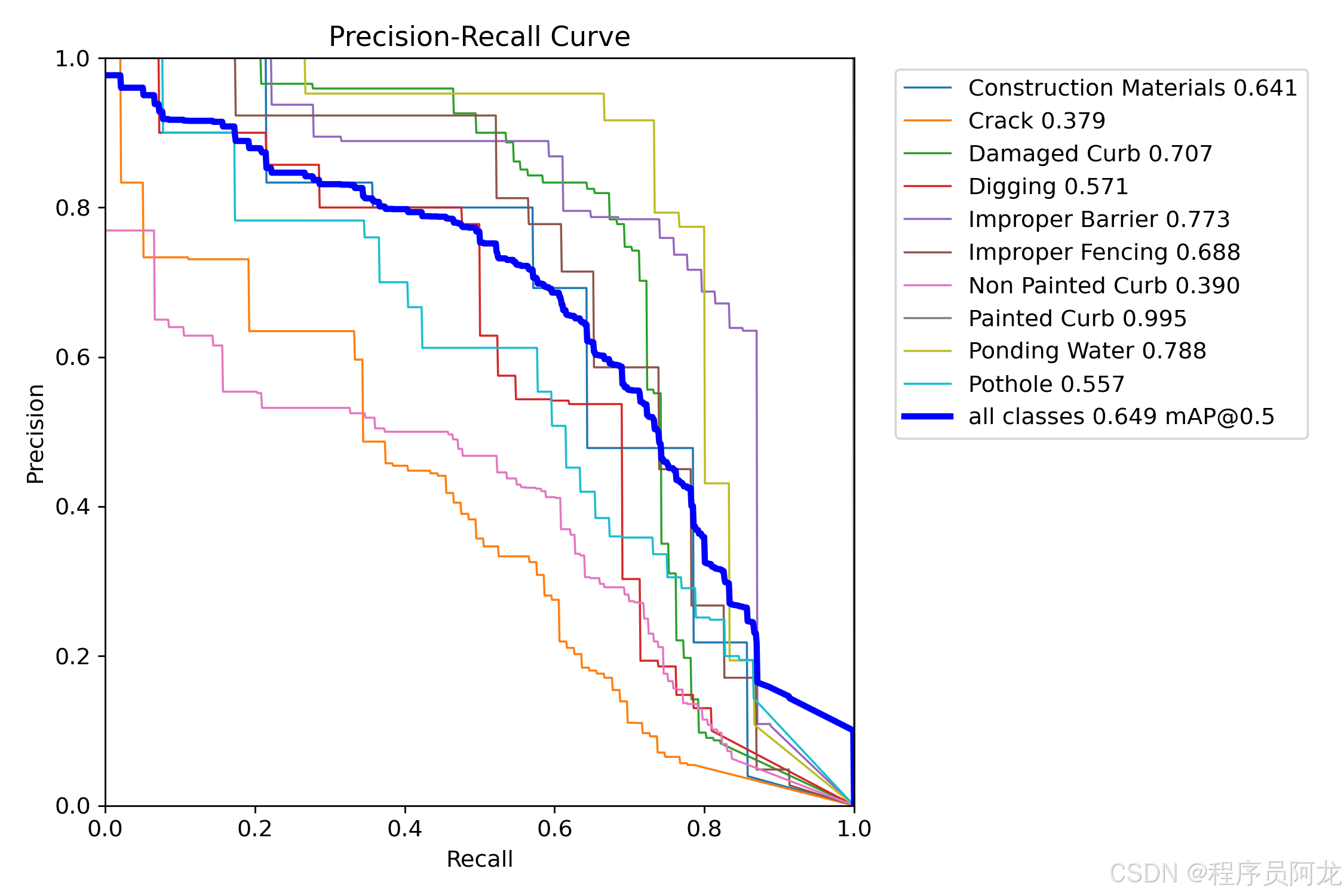



核心代码介绍:
import random
import tempfile
import time
import os
import cv2
import numpy as np
import streamlit as st
from QtFusion.path import abs_path
from QtFusion.utils import drawRectBoxfrom log import ResultLogger, LogTable
from model import Web_Detector
from chinese_name_list import Label_list
from ui_style import def_css_hitml
from utils import save_uploaded_file, concat_results, load_default_image, get_camera_names
import tempfile
from PIL import ImageFont, ImageDraw, Image
from datetime import datetimeimport numpy as np
import cv2
from hashlib import md5def calculate_polygon_area(points):# 计算多边形面积的函数return cv2.contourArea(points.astype(np.float32))def draw_with_chinese(img, text, position, font_size):# 假设这是一个自定义函数,用于在图像上绘制中文文本# 具体实现需要根据你的需求进行调整font = cv2.FONT_HERSHEY_SIMPLEXcolor = (255, 255, 255)thickness = 2cv2.putText(img, text, position, font, font_size, color, thickness, cv2.LINE_AA)return imgdef generate_color_based_on_name(name):# 使用哈希函数生成稳定的颜色hash_object = md5(name.encode())hex_color = hash_object.hexdigest()[:6] # 取前6位16进制数r, g, b = int(hex_color[0:2], 16), int(hex_color[2:4], 16), int(hex_color[4:6], 16)return (b, g, r) # OpenCV 使用BGR格式def draw_with_chinese(image, text, position, font_size=20, color=(255, 0, 0)):"""在OpenCV图像上绘制中文文字"""# 将图像从 OpenCV 格式(BGR)转换为 PIL 格式(RGB)image_pil = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))draw = ImageDraw.Draw(image_pil)# 使用指定的字体font = ImageFont.truetype("simsun.ttc", font_size, encoding="unic")draw.text(position, text, font=font, fill=color)# 将图像从 PIL 格式(RGB)转换回 OpenCV 格式(BGR)return cv2.cvtColor(np.array(image_pil), cv2.COLOR_RGB2BGR)def adjust_parameter(image_size, base_size=1000):# 计算自适应参数,基于图片的最大尺寸max_size = max(image_size)return max_size / base_sizedef adjust_parameter(image_size, base_size=1000):max_size = max(image_size)return max_size / base_sizedef draw_detections(image, info, alpha=0.2):name, bbox, conf, cls_id, mask = info['class_name'], info['bbox'], info['score'], info['class_id'], info['mask']adjust_param = adjust_parameter(image.shape[:2])spacing = int(20 * adjust_param)if mask is None:x1, y1, x2, y2 = bboxaim_frame_area = (x2 - x1) * (y2 - y1)cv2.rectangle(image, (x1, y1), (x2, y2), color=(0, 0, 255), thickness=int(5 * adjust_param))image = draw_with_chinese(image, name, (x1, y1 - int(30 * adjust_param)), font_size=int(35 * adjust_param))y_offset = int(50 * adjust_param) # 类别名称上方绘制,其下方留出空间else:mask_points = np.concatenate(mask)aim_frame_area = calculate_polygon_area(mask_points)mask_color = generate_color_based_on_name(name)try:overlay = image.copy()cv2.fillPoly(overlay, [mask_points.astype(np.int32)], mask_color)image = cv2.addWeighted(overlay, 0.3, image, 0.7, 0)cv2.drawContours(image, [mask_points.astype(np.int32)], -1, (0, 0, 255), thickness=int(8 * adjust_param))# 计算面积、周长、圆度area = cv2.contourArea(mask_points.astype(np.int32))perimeter = cv2.arcLength(mask_points.astype(np.int32), True)circularity = 4 * np.pi * area / (perimeter ** 2) if perimeter > 0 else 0# 计算色彩mask = np.zeros(image.shape[:2], dtype=np.uint8)cv2.drawContours(mask, [mask_points.astype(np.int32)], -1, 255, -1)color_points = cv2.findNonZero(mask)selected_points = color_points[np.random.choice(color_points.shape[0], 5, replace=False)]colors = np.mean([image[y, x] for x, y in selected_points[:, 0]], axis=0)color_str = f"({colors[0]:.1f}, {colors[1]:.1f}, {colors[2]:.1f})"# 绘制类别名称x, y = np.min(mask_points, axis=0).astype(int)image = draw_with_chinese(image, name, (x, y - int(30 * adjust_param)), font_size=int(35 * adjust_param))y_offset = int(50 * adjust_param) # 类别名称上方绘制,其下方留出空间# 绘制面积、周长、圆度和色彩值# metrics = [("Area", area), ("Perimeter", perimeter), ("Circularity", circularity), ("Color", color_str)]# for idx, (metric_name, metric_value) in enumerate(metrics):# text = f"{metric_name}: {metric_value}"# image = draw_with_chinese(image, text, (x, y - y_offset - spacing * (idx + 1)),# font_size=int(35 * adjust_param))except Exception as e:print(f"An error occurred: {e}")return image, aim_frame_areadef calculate_polygon_area(points):"""计算多边形的面积,输入应为一个 Nx2 的numpy数组,表示多边形的顶点坐标"""if len(points) < 3: # 多边形至少需要3个顶点return 0return cv2.contourArea(points)def format_time(seconds):# 计算小时、分钟和秒hrs, rem = divmod(seconds, 3600)mins, secs = divmod(rem, 60)# 格式化为字符串return "{:02}:{:02}:{:02}".format(int(hrs), int(mins), int(secs))def save_chinese_image(file_path, image_array):"""保存带有中文路径的图片文件参数:file_path (str): 图片的保存路径,应包含中文字符, 例如 '示例路径/含有中文的文件名.png'image_array (numpy.ndarray): 要保存的 OpenCV 图像(即 numpy 数组)"""try:# 将 OpenCV 图片转换为 Pillow Image 对象image = Image.fromarray(cv2.cvtColor(image_array, cv2.COLOR_BGR2RGB))# 使用 Pillow 保存图片文件image.save(file_path)print(f"成功保存图像到: {file_path}")except Exception as e:print(f"保存图像失败: {str(e)}")class Detection_UI:"""检测系统类。Attributes:model_type (str): 模型类型。conf_threshold (float): 置信度阈值。iou_threshold (float): IOU阈值。selected_camera (str): 选定的摄像头。file_type (str): 文件类型。uploaded_file (FileUploader): 上传的文件。detection_result (str): 检测结果。detection_location (str): 检测位置。detection_confidence (str): 检测置信度。detection_time (str): 检测用时。"""def __init__(self):"""初始化行人跌倒检测系统的参数。"""# 初始化类别标签列表和为每个类别随机分配颜色self.cls_name = Label_listself.colors = [[random.randint(0, 255) for _ in range(3)] for _ inrange(len(self.cls_name))]# 设置页面标题self.title = "基于图像处理技术道路监控监测路面障碍设计"self.setup_page() # 初始化页面布局def_css_hitml() # 应用 CSS 样式# 初始化检测相关的配置参数self.model_type = Noneself.conf_threshold = 0.15 # 默认置信度阈值self.iou_threshold = 0.5 # 默认IOU阈值# 初始化相机和文件相关的变量self.selected_camera = Noneself.file_type = Noneself.uploaded_file = Noneself.uploaded_video = Noneself.custom_model_file = None # 自定义的模型文件# 初始化检测结果相关的变量self.detection_result = Noneself.detection_location = Noneself.detection_confidence = Noneself.detection_time = None# 初始化UI显示相关的变量self.display_mode = None # 设置显示模式self.close_flag = None # 控制图像显示结束的标志self.close_placeholder = None # 关闭按钮区域self.image_placeholder = None # 用于显示图像的区域self.image_placeholder_res = None # 图像显示区域self.table_placeholder = None # 表格显示区域self.log_table_placeholder = None # 完整结果表格显示区域self.selectbox_placeholder = None # 下拉框显示区域self.selectbox_target = None # 下拉框选中项self.progress_bar = None # 用于显示的进度条# 初始化FPS和视频时间指针self.FPS = 30self.timenow = 0# 初始化日志数据保存路径self.saved_log_data = abs_path("tempDir/log_table_data.csv", path_type="current")# 如果在 session state 中不存在logTable,创建一个新的LogTable实例if 'logTable' not in st.session_state:st.session_state['logTable'] = LogTable(self.saved_log_data)# 获取或更新可用摄像头列表if 'available_cameras' not in st.session_state:st.session_state['available_cameras'] = get_camera_names()self.available_cameras = st.session_state['available_cameras']# 初始化或获取识别结果的表格self.logTable = st.session_state['logTable']# 加载或创建模型实例if 'model' not in st.session_state:st.session_state['model'] = Web_Detector() # 创建Detector模型实例self.model = st.session_state['model']# 加载训练的模型权重self.model.load_model(model_path=abs_path("weights/yolov8s.pt", path_type="current"))# 为模型中的类别重新分配颜色self.colors = [[random.randint(0, 255) for _ in range(3)] for _ inrange(len(self.model.names))]self.setup_sidebar() # 初始化侧边栏布局def setup_page(self):# 设置页面布局# st.set_page_config(# page_title=self.title,# page_icon="REC",# initial_sidebar_state="expanded"# )# 居中显示标题st.markdown(f'<h1 style="text-align: center;">{self.title}</h1>',unsafe_allow_html=True)def setup_sidebar(self):"""设置 Streamlit 侧边栏。在侧边栏中配置模型设置、摄像头选择以及识别项目设置等选项。"""# 置信度阈值的滑动条self.conf_threshold = float(st.sidebar.slider("置信度设定", min_value=0.0, max_value=1.0, value=0.15))# IOU阈值的滑动条self.iou_threshold = float(st.sidebar.slider("IOU设定", min_value=0.0, max_value=1.0, value=0.25))# 设置侧边栏的模型设置部分st.sidebar.header("模型设置")# 选择模型类型的下拉菜单self.model_type = st.sidebar.selectbox("选择任务类型", ["检测任务","分割任务"])# 选择模型文件类型,可以是默认的或者自定义的model_file_option = st.sidebar.radio("模型设置", ["默认", "指定权重文件"])if model_file_option == "指定权重文件":# 如果选择自定义模型文件,则提供文件上传器model_file = st.sidebar.file_uploader("选择.pt文件", type="pt")# 如果上传了模型文件,则保存并加载该模型if model_file is not None:self.custom_model_file = save_uploaded_file(model_file)self.model.load_model(model_path=self.custom_model_file)self.colors = [[random.randint(0, 255) for _ in range(3)] for _ inrange(len(self.model.names))]elif model_file_option == "默认":if self.model_type == "检测任务":self.model.load_model(model_path=abs_path("./yolo11s.pt", path_type="current"))elif self.model_type == "分割任务":self.model.load_model(model_path=abs_path("./yolo11s-seg.pt", path_type="current"))# 为模型中的类别重新分配颜色self.colors = [[random.randint(0, 255) for _ in range(3)] for _ inrange(len(self.model.names))]# 设置侧边栏的摄像头配置部分st.sidebar.header("摄像头识别设置")# 选择摄像头的下拉菜单self.selected_camera = st.sidebar.selectbox("选择摄像头序号", self.available_cameras)# 设置侧边栏的识别项目设置部分st.sidebar.header("图片视频识别设置")# 选择文件类型的下拉菜单self.file_type = st.sidebar.selectbox("选择文件类型", ["图片文件", "视频文件"])# 根据所选的文件类型,提供对应的文件上传器if self.file_type == "图片文件":self.uploaded_file = st.sidebar.file_uploader("上传图片", type=["jpg", "png", "jpeg"])elif self.file_type == "视频文件":self.uploaded_video = st.sidebar.file_uploader("上传视频文件", type=["mp4"])# 提供相关提示信息,根据所选摄像头和文件类型的不同情况if self.selected_camera == "摄像头检测关闭":if self.file_type == "图片文件":st.sidebar.write("请选择图片并点击'开始运行'按钮,进行图片检测!")if self.file_type == "视频文件":st.sidebar.write("请选择视频并点击'开始运行'按钮,进行视频检测!")else:st.sidebar.write("请点击'开始检测'按钮,启动摄像头检测!")def load_model_file(self):if self.custom_model_file:self.model.load_model(self.custom_model_file)else:pass # 载入def process_camera_or_file(self):"""处理摄像头或文件输入。根据用户选择的输入源(摄像头、图片文件或视频文件),处理并显示检测结果。"""# 如果选择了摄像头输入if self.selected_camera != "摄像头检测关闭":self.logTable.clear_frames() # 清除之前的帧记录# 创建一个结束按钮self.close_flag = self.close_placeholder.button(label="停止")# 使用 OpenCV 捕获摄像头画面if str(self.selected_camera) == '0':camera_id = 0else:camera_id = self.selected_cameracap = cv2.VideoCapture(camera_id)self.uploaded_video = Nonefps = cap.get(cv2.CAP_PROP_FPS)self.FPS = fps# 设置总帧数为1000total_frames = 1000current_frame = 0self.progress_bar.progress(0) # 初始化进度条try:if len(self.selected_camera) < 8:camera_id = int(self.selected_camera)else:camera_id = self.selected_cameracap = cv2.VideoCapture(camera_id)# 获取和帧率fps = cap.get(cv2.CAP_PROP_FPS)self.FPS = fps# 创建进度条self.progress_bar.progress(0)# 创建保存文件的信息camera_savepath = './tempDir/camera'if not os.path.exists(camera_savepath):os.makedirs(camera_savepath)# ret, frame = cap.read()# height, width, layers = frame.shape# size = (width, height)## file_name = abs_path('tempDir/camera.avi', path_type="current")# out = cv2.VideoWriter(file_name, cv2.VideoWriter_fourcc(*'DIVX'), fps, size)while cap.isOpened() and not self.close_flag:ret, frame = cap.read()if ret:# 调节摄像头的分辨率# 设置新的尺寸new_width = 1080new_height = int(new_width * (9 / 16))# 调整图像尺寸frame = cv2.resize(frame, (new_width, new_height))framecopy = frame.copy()image, detInfo, _ = self.frame_process(frame, 'camera')# 保存目标结果图片if detInfo:file_name = abs_path(camera_savepath + '/' + str(current_frame + 1) + '.jpg', path_type="current")save_chinese_image(file_name, image)## # 保存目标结果视频# out.write(image)# 设置新的尺寸new_width = 1080new_height = int(new_width * (9 / 16))# 调整图像尺寸resized_image = cv2.resize(image, (new_width, new_height))resized_frame = cv2.resize(framecopy, (new_width, new_height))if self.display_mode == "叠加显示":self.image_placeholder.image(resized_image, channels="BGR", caption="视频画面")else:self.image_placeholder.image(resized_frame, channels="BGR", caption="原始画面")self.image_placeholder_res.image(resized_image, channels="BGR", caption="识别画面")self.logTable.add_frames(image, detInfo, cv2.resize(frame, (640, 640)))# 更新进度条progress_percentage = int((current_frame / total_frames) * 100)self.progress_bar.progress(progress_percentage)current_frame = (current_frame + 1) % total_frames # 重置进度条else:breakif self.close_flag:self.logTable.save_to_csv()self.logTable.update_table(self.log_table_placeholder)cap.release()# out.release()self.logTable.save_to_csv()self.logTable.update_table(self.log_table_placeholder)cap.release()# out.release()finally:if self.uploaded_video is None:name_in = Noneelse:name_in = self.uploaded_video.nameres = self.logTable.save_frames_file(fps=self.FPS, video_name=name_in)st.write("识别结果文件已经保存:" + self.saved_log_data)if res:st.write(f"结果的目标文件已经保存:{res}")else:# 如果上传了图片文件if self.uploaded_file is not None:self.logTable.clear_frames()self.progress_bar.progress(0)# 显示上传的图片source_img = self.uploaded_file.read()file_bytes = np.asarray(bytearray(source_img), dtype=np.uint8)image_ini = cv2.imdecode(file_bytes, 1)framecopy = image_ini.copy()image, detInfo, select_info = self.frame_process(image_ini, self.uploaded_file.name)save_chinese_image('./tempDir/' + self.uploaded_file.name, image)# self.selectbox_placeholder = st.empty()# self.selectbox_target = self.selectbox_placeholder.selectbox("目标过滤", select_info, key="22113")self.logTable.save_to_csv()self.logTable.update_table(self.log_table_placeholder) # 更新所有结果记录的表格# 设置新的尺寸new_width = 1080new_height = int(new_width * (9 / 16))# 调整图像尺寸resized_image = cv2.resize(image, (new_width, new_height))resized_frame = cv2.resize(framecopy, (new_width, new_height))if self.display_mode == "叠加显示":self.image_placeholder.image(resized_image, channels="BGR", caption="图片显示")else:self.image_placeholder.image(resized_frame, channels="BGR", caption="原始画面")self.image_placeholder_res.image(resized_image, channels="BGR", caption="识别画面")self.logTable.add_frames(image, detInfo, cv2.resize(image_ini, (640, 640)))self.progress_bar.progress(100)# 如果上传了视频文件elif self.uploaded_video is not None:# 处理上传的视频self.logTable.clear_frames()self.close_flag = self.close_placeholder.button(label="停止")video_file = self.uploaded_videotfile = tempfile.NamedTemporaryFile(delete=False, suffix='.mp4')try:tfile.write(video_file.read())tfile.flush()tfile.seek(0) # 确保文件指针回到文件开头cap = cv2.VideoCapture(tfile.name)# 获取视频总帧数和帧率total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))fps = cap.get(cv2.CAP_PROP_FPS)self.FPS = fps# 计算视频总长度(秒)total_length = total_frames / fps if fps > 0 else 0print('视频时长:' + str(total_length)[:4] + 's')# 创建进度条self.progress_bar.progress(0)current_frame = 0# 创建保存文件的信息video_savepath = './tempDir/' + self.uploaded_video.nameif not os.path.exists(video_savepath):os.makedirs(video_savepath)# ret, frame = cap.read()# height, width, layers = frame.shape# size = (width, height)# file_name = abs_path('tempDir/' + self.uploaded_video.name + '.avi', path_type="current")# out = cv2.VideoWriter(file_name, cv2.VideoWriter_fourcc(*'DIVX'), fps, size)while cap.isOpened() and not self.close_flag:ret, frame = cap.read()if ret:framecopy = frame.copy()# 计算当前帧对应的时间(秒)current_time = current_frame / fpsif current_time < total_length:current_frame += 1current_time_str = format_time(current_time)image, detInfo, _ = self.frame_process(frame, self.uploaded_video.name,video_time=current_time_str)# 保存目标结果图片if detInfo:# 将字符串转换为 datetime 对象time_obj = datetime.strptime(current_time_str, "%H:%M:%S")# 将 datetime 对象格式化为所需的字符串格式formatted_time = time_obj.strftime("%H_%M_%S")file_name = abs_path(video_savepath + '/' + formatted_time + '_' + str(current_frame) + '.jpg',path_type="current")save_chinese_image(file_name, image)# # 保存目标结果视频# out.write(image)# 设置新的尺寸new_width = 1080new_height = int(new_width * (9 / 16))# 调整图像尺寸resized_image = cv2.resize(image, (new_width, new_height))resized_frame = cv2.resize(framecopy, (new_width, new_height))if self.display_mode == "叠加显示":self.image_placeholder.image(resized_image, channels="BGR", caption="视频画面")else:self.image_placeholder.image(resized_frame, channels="BGR", caption="原始画面")self.image_placeholder_res.image(resized_image, channels="BGR", caption="识别画面")self.logTable.add_frames(image, detInfo, cv2.resize(frame, (640, 640)))# 更新进度条if total_length > 0:progress_percentage = int(((current_frame + 1) / total_frames) * 100)try:self.progress_bar.progress(progress_percentage)except:passcurrent_frame += 1else:breakif self.close_flag:self.logTable.save_to_csv()self.logTable.update_table(self.log_table_placeholder)cap.release()# out.release()self.logTable.save_to_csv()self.logTable.update_table(self.log_table_placeholder)cap.release()# out.release()finally:if self.uploaded_video is None:name_in = Noneelse:name_in = self.uploaded_video.nameres = self.logTable.save_frames_file(fps=self.FPS, video_name=name_in)st.write("识别结果文件已经保存:" + self.saved_log_data)if res:st.write(f"结果的目标文件已经保存:{res}")tfile.close()# 如果不需要再保留临时文件,可以在处理完后删除print(tfile.name + ' 临时文件可以删除')# os.remove(tfile.name)else:st.warning("请选择摄像头或上传文件。")def toggle_comboBox(self, frame_id):"""处理并显示指定帧的检测结果。Args:frame_id (int): 指定要显示检测结果的帧ID。根据用户选择的帧ID,显示该帧的检测结果和图像。"""# 确保已经保存了检测结果if len(self.logTable.saved_results) > 0:frame = self.logTable.saved_images_ini[-1] # 获取最近一帧的图像image = frame # 将其设为当前图像# 遍历所有保存的检测结果for i, detInfo in enumerate(self.logTable.saved_results):if frame_id != -1:# 如果指定了帧ID,只处理该帧的结果if frame_id != i:continueif len(detInfo) > 0:name, bbox, conf, use_time, cls_id = detInfo # 获取检测信息label = '%s %.0f%%' % (name, conf * 100) # 构造标签文本disp_res = ResultLogger() # 创建结果记录器res = disp_res.concat_results(name, bbox, str(round(conf, 2)), str(use_time)) # 合并结果self.table_placeholder.table(res) # 在表格中显示结果# 如果有保存的初始图像if len(self.logTable.saved_images_ini) > 0:if len(self.colors) < cls_id:self.colors = [[random.randint(0, 255) for _ in range(3)] for _ inrange(cls_id+1)]image = drawRectBox(image, bbox, alpha=0.2, addText=label,color=self.colors[cls_id]) # 绘制检测框和标签# 设置新的尺寸并调整图像尺寸new_width = 1080new_height = int(new_width * (9 / 16))resized_image = cv2.resize(image, (new_width, new_height))resized_frame = cv2.resize(frame, (new_width, new_height))# 根据显示模式显示处理后的图像或原始图像if self.display_mode == "叠加显示":self.image_placeholder.image(resized_image, channels="BGR", caption="识别画面")else:self.image_placeholder.image(resized_frame, channels="BGR", caption="原始画面")self.image_placeholder_res.image(resized_image, channels="BGR", caption="识别画面")def frame_process(self, image, file_name,video_time = None):"""处理并预测单个图像帧的内容。Args:image (numpy.ndarray): 输入的图像。file_name (str): 处理的文件名。Returns:tuple: 处理后的图像,检测信息,选择信息列表。对输入图像进行预处理,使用模型进行预测,并处理预测结果。"""# image = cv2.resize(image, (640, 640)) # 调整图像大小以适应模型pre_img = self.model.preprocess(image) # 对图像进行预处理# 更新模型参数params = {'conf': self.conf_threshold, 'iou': self.iou_threshold}self.model.set_param(params)t1 = time.time()pred = self.model.predict(pre_img) # 使用模型进行预测t2 = time.time()use_time = t2 - t1 # 计算单张图片推理时间aim_area = 0 #计算目标面积det = pred[0] # 获取预测结果# 初始化检测信息和选择信息列表detInfo = []select_info = ["全部目标"]# 如果有有效的检测结果if det is not None and len(det):det_info = self.model.postprocess(pred) # 后处理预测结果if len(det_info):disp_res = ResultLogger()res = Nonecnt = 0# 遍历检测到的对象for info in det_info:name, bbox, conf, cls_id, mask = info['class_name'], info['bbox'], info['score'], info['class_id'], info['mask']# 绘制检测框、标签和面积信息image,aim_frame_area = draw_detections(image, info, alpha=0.5)# image = drawRectBox(image, bbox, alpha=0.2, addText=label, color=self.colors[cls_id])res = disp_res.concat_results(name, bbox, str(int(aim_frame_area)),video_time if video_time is not None else str(round(use_time, 2)))# 添加日志条目self.logTable.add_log_entry(file_name, name, bbox, int(aim_frame_area), video_time if video_time is not None else str(round(use_time, 2)))# 记录检测信息detInfo.append([name, bbox, int(aim_frame_area), video_time if video_time is not None else str(round(use_time, 2)), cls_id])# 添加到选择信息列表select_info.append(name + "-" + str(cnt))cnt += 1# 在表格中显示检测结果self.table_placeholder.table(res)return image, detInfo, select_infodef frame_table_process(self, frame, caption):# 显示画面并更新结果self.image_placeholder.image(frame, channels="BGR", caption=caption)# 更新检测结果detection_result = "None"detection_location = "[0, 0, 0, 0]"detection_confidence = str(random.random())detection_time = "0.00s"# 使用 display_detection_results 函数显示结果res = concat_results(detection_result, detection_location, detection_confidence, detection_time)self.table_placeholder.table(res)# 添加适当的延迟cv2.waitKey(1)def setupMainWindow(self):""" 运行检测系统。 """# st.title(self.title) # 显示系统标题st.write("--------")st.write("———————————————————————————————————————————Vision-Studio————————————————————————————————————————————")st.write("--------")# 插入一条分割线# 创建列布局,将表格移到最右侧col1, col2, col3 = st.columns([4, 1, 2])# 在第一列设置显示模式的选择with col1:self.display_mode = st.radio("单/双画面显示设置", ["叠加显示", "对比显示"])# 根据显示模式创建用于显示视频画面的空容器if self.display_mode == "叠加显示":self.image_placeholder = st.empty()if not self.logTable.saved_images_ini:self.image_placeholder.image(load_default_image(), caption="原始画面")else:# "双画面显示"self.image_placeholder = st.empty()self.image_placeholder_res = st.empty()if not self.logTable.saved_images_ini:self.image_placeholder.image(load_default_image(), caption="原始画面")self.image_placeholder_res.image(load_default_image(), caption="识别画面")# 显示用的进度条self.progress_bar = st.progress(0)# 创建一个空的结果表格res = concat_results("None", "[0, 0, 0, 0]", "0.00", "0.00s")# 在最右侧列设置识别结果表格的显示with col3:self.table_placeholder = st.empty() # 调整到最右侧显示self.table_placeholder.table(res)# 创建一个导出结果的按钮st.write("---------------------")if st.button("导出结果"):self.logTable.save_to_csv()if self.uploaded_video is None:name_in = Noneelse:name_in = self.uploaded_video.nameres = self.logTable.save_frames_file(fps=self.FPS, video_name=name_in)st.write("识别结果文件已经保存:" + self.saved_log_data)if res:st.write(f"结果的目标文件已经保存:{res}")self.logTable.clear_data()# 显示所有结果记录的空白表格self.log_table_placeholder = st.empty()self.logTable.update_table(self.log_table_placeholder)# 在第五列设置一个空的停止按钮占位符with col2:st.write("")self.close_placeholder = st.empty()# 在第二列处理目标过滤# with col2:# self.selectbox_placeholder = st.empty()# detected_targets = ["全部目标"] # 初始化目标列表## 遍历并显示检测结果# for i, info in enumerate(self.logTable.saved_results):# name, bbox, conf, use_time, cls_id = info# detected_targets.append(name + "-" + str(i))# self.selectbox_target = self.selectbox_placeholder.selectbox("目标过滤", detected_targets)## 处理目标过滤的选择# for i, info in enumerate(self.logTable.saved_results):# name, bbox, conf, use_time, cls_id = info# if self.selectbox_target == name + "-" + str(i):# self.toggle_comboBox(i)# elif self.selectbox_target == "全部目标":# self.toggle_comboBox(-1)with col2:st.write("")run_button = st.button("开始检测")if run_button:self.process_camera_or_file() # 运行摄像头或文件处理else:# 如果没有保存的图像,则显示默认图像if not self.logTable.saved_images_ini:self.image_placeholder.image(load_default_image(), caption="原始画面")if self.display_mode == "对比显示":self.image_placeholder_res.image(load_default_image(), caption="识别画面")# 实例化并运行应用
if __name__ == "__main__":app = Detection_UI()app.setupMainWindow()
训练模型代码:
import osimport torch
import yaml
from ultralytics import YOLO # 导入YOLO模型
from QtFusion.path import abs_path
device = "0" if torch.cuda.is_available() else "cpu"if __name__ == '__main__': # 确保该模块被直接运行时才执行以下代码workers = 1batch = 2data_name = "data"data_path = abs_path(f'datasets/{data_name}/{data_name}.yaml', path_type='current') # 数据集的yaml的绝对路径unix_style_path = data_path.replace(os.sep, '/')# 获取目录路径directory_path = os.path.dirname(unix_style_path)# 读取YAML文件,保持原有顺序with open(data_path, 'r') as file:data = yaml.load(file, Loader=yaml.FullLoader)# 修改path项if 'path' in data:data['path'] = directory_path# 将修改后的数据写回YAML文件with open(data_path, 'w') as file:yaml.safe_dump(data, file, sort_keys=False)if 'train' in data and 'val' in data and 'test' in data:data['train'] = directory_path + '/train'data['val'] = directory_path + '/val'data['test'] = directory_path + '/test'# 将修改后的数据写回YAML文件with open(data_path, 'w') as file:yaml.safe_dump(data, file, sort_keys=False)# 注意!不同模型大小不同,对设备等要求不同,如果要求较高的模型【报错】则换其他模型测试即可model = YOLO(model='./ultralytics/cfg/models/v11/yolo11.yaml', task='detect').load('./yolo11s.pt') # 加载预训练的YOLOv11模型# model = YOLO(model=r'F:\last\codeseg\200+种YOLOv11检测分割算法改进源码配置文件大全\改进YOLOv11检测模型配置文件\yolo11-DBB.yaml', task='detect').load('./yolo11s.pt') # yolo11-efficientViT.yaml、yolo11-ADown.yaml、...results2 = model.train( # 开始训练模型data=data_path, # 指定训练数据的配置文件路径device=device, # 自动选择进行训练workers=workers, # 指定使用2个工作进程加载数据imgsz=640, # 指定输入图像的大小为640x640epochs=200, # 指定训练100个epochbatch=batch, # 指定每个批次的大小为8name='train_v8_' + data_name # 指定训练任务的名称)

项目实现界面:
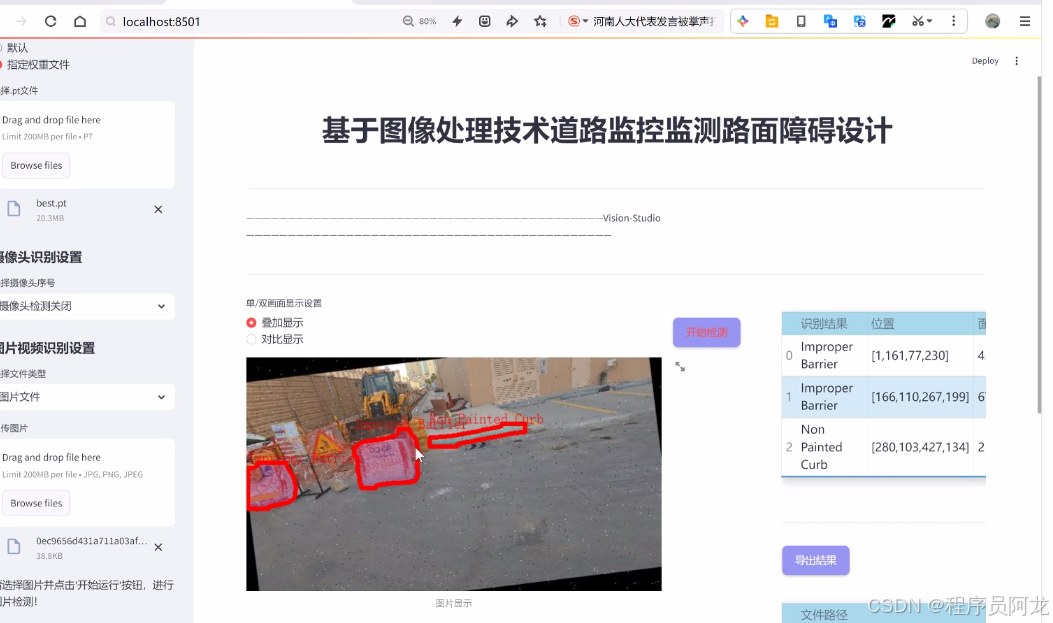

1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

源码获取
文章下方名片联系我即可~
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻
精彩专栏推荐订阅:在下方专栏
相关文章:
 图像处理 计算机视觉 道路监控系统 视频帧分析 道路安全监控 城市道路管理)
基于图像处理的道路监控与路面障碍检测系统设计与实现 (源码+定制+开发) 图像处理 计算机视觉 道路监控系统 视频帧分析 道路安全监控 城市道路管理
博主介绍: ✌我是阿龙,一名专注于Java技术领域的程序员,全网拥有10W粉丝。作为CSDN特邀作者、博客专家、新星计划导师,我在计算机毕业设计开发方面积累了丰富的经验。同时,我也是掘金、华为云、阿里云、InfoQ等平台…...
)
依赖注入详解与案例(前端篇)
依赖注入详解与案例(前端篇) 一、依赖注入核心概念与前端价值 依赖注入(Dependency Injection, DI) 是一种通过外部容器管理组件/类间依赖关系的设计模式,其核心是控制反转(Inversion of Control, IoC&…...

Spark 的 Shuffle 机制:原理与源码详解
Apache Spark 是一个分布式数据处理框架,专为大规模数据分析设计。其核心操作之一是 Shuffle,这是一个关键但复杂的机制,用于在某些操作期间在集群中重新分配数据。理解 Shuffle 需要深入探讨其目的、机制和实现,既包括概念层面&a…...

IdeaVim配置指南
一、什么是 IdeaVim? IdeaVim 是 JetBrains 系列 IDE(如 IntelliJ IDEA, WebStorm, PyCharm 等)中的一个插件,让你在 IDE 里使用 Vim 的按键习惯,大大提升效率。 安装方法: 在 IDE 中打开 设置(Settings) →…...

[监控看板]Grafana+Prometheus+Exporter监控疑难排查
采用GrafanaPrometheusExporter监控MySQL时发现经常数据不即时同步,本示例也是本地搭建采用。 Prometheus面板 1,Detected a time difference of 11h 47m 22.337s between your browser and the server. You may see unexpected time-shifted query res…...

P56-P60 统一委托,关联游戏UI,UI动画,延迟血条
这一部分首先把复杂的每个属性委托全部换成了简洁可复用的委托,之后重新修改了UI蓝图,然后在新增了一个与之前表格关联的动画与血条延迟下降的蓝图 OverlayAuraWidgetController.h // Fill out your copyright notice in the Description page of Project Settings. #pragma …...

智能修复大模型生成的 JSON 字符串:Python 实现与优化
在使用大语言模型(LLM)生成 JSON 格式数据时,常因模型输出不完整、语法错误或格式不规范导致 JSON 解析失败。本文介绍如何通过 json_repair 库实现对 LLM 生成 JSON 字符串的自动修复,并改进原始提取函数以提升容错能力。 一、LLM 生成 JSON 的常见问题 LLM 输出的 JSON …...

【PPT制作利器】DeepSeek + Kimi生成一个初始的PPT文件
如何基于DeepSeek Kimi进行PPT制作 步骤: Step1:基于DeepSeek生成文本,提问 Step2基于生成的文本,用Kimi中PPT助手一键生成PPT 进行PPT渲染-自动渲染 可选择更改模版 生成PPT在桌面 介绍的比较详细,就是这个PPT模版…...

华为设备端口隔离
端口隔离的理论与配置指南 一、端口隔离的理论 基本概念 端口隔离(Port Isolation)是一种在交换机上实现的安全功能,用于限制同一VLAN内指定端口间的二层通信。被隔离的端口之间无法直接通信,但可通过上行端口访问公共资源&#…...

YOLO12改进-C3K2模块改进-引入离散余弦变换DCT 减少噪声提取图像的细节、边缘和纹理等微观特征
离散余弦变换(Discrete Cosine Transform, DCT)由 Nasir Ahmed 于 1974 年提出,最初是为了优化数据压缩。其核心思想是将信号从空间域转换为频率域,从而实现冗余信息的压缩。DCT 在图像和视频处理领域应用广泛,例如 JP…...

基于大模型的自然临产阴道分娩全流程预测与方案研究报告
目录 一、引言 1.1 研究背景与目的 1.2 研究意义 1.3 国内外研究现状 二、大模型技术原理与应用概述 2.1 大模型基本原理 2.2 在医疗领域的应用现状 2.3 用于分娩预测的优势 三、术前预测与准备方案 3.1 产妇身体状况评估指标 3.2 大模型预测流程与方法 3.3 基于预…...

用 Tailwind CSS 优化你的 Vue 3 项目! ! !
Vue 3 的响应式魅力 TailwindCSS 的原子级美学 前端开发的舒适巅峰! 在现代前端开发中,组件驱动 原子化 CSS 正在成为新的标准。如果你已经在使用 Vue 3,那不妨试试 Tailwind CSS —— 一个强大的原子化 CSS 框架,它能让你几乎…...

PostgreSQL数据库的array类型
PostgreSQL数据库相比其它数据库,有很多独有的字段类型。 比如array类型,以下表的pay_by_quarter与schedule两个字段便是array类型,即数组类型。 CREATE TABLE sal_emp (name text,pay_by_quarter integer[],schedule t…...

融智学视角集大成范式革命:文理工三类AI与网络大数据的赋能
融智学视角下的“集大成”范式革命:AI与大数据的终极赋能 一、化繁为简的工具革命:AI与大数据的三重解构 信息压缩的数学本质 Kolmogorov复杂度极限突破: K_AI(x)min_p∈P_NN ℓ(p)λ⋅dist(U(p),x) (神经网络程序p的描述长度语…...
)
【2025】Visio 2024安装教程保姆级一键安装教程(附安装包)
前言 大家好!最近很多朋友在问我关于Visio 2024的安装问题,尤其是对于那些需要制作专业流程图和组织结构图的小伙伴来说,这款软件简直是必不可少的办公神器!今天就给大家带来这篇超详细保姆级的Visio 2024安装教程,不…...

C++【继承】
继承 1.继承1.1 继承的概念1.2继承的定义1.2.1定义格式1.2.2继承基类成员访问方式的变化 1.3继承模板 2.基类和派生类之间的转换 1.继承 1.1 继承的概念 继承(inheritance)机制是面向对象程序设计使代码可以复用的最重要的手段,它允许我们在保持原有类特性的基础上…...

理解字、半字与字节 | 从 CPU 架构到编程实践的数据类型解析
注:本文为 “字、半字、字节” 相关文章合辑。 略作重排,未全校。 如有内容异常,请看原文。 理解计算机体系结构中的字、半字与字节 在计算机科学中,理解“字 (Word)”、“半字 (Half-Word)”和“字节 (Byte)”等基本数据单元的…...

VMware搭建ubuntu保姆级教程
目录 VMware Ubuntu 虚拟机配置指南 创建虚拟机 下载 Ubuntu ISO 新建虚拟机 网络配置(双网卡模式) 共享文件夹设置 SSH 远程访问配置 VMware Ubuntu 虚拟机配置指南 创建虚拟机 下载 Ubuntu ISO 【可添加我获取】 官网:Get Ubunt…...

内容社区系统开发文档
1 系统分析 1.1 项目背景 1.2 需求分析 2 系统设计 2.1 系统功能设计 2.2 数据库设计 2.2.1 数据库需求分析 2.2.2 数据库概念结构设计 2.2.3 数据库逻辑结构设计 2.2.4 数据库物理结构设计 2.2.5 数据库视图设计 2.2.6 函数设计 2.2.7 存储过程设计 2.2.8 触发器…...

Ubuntu开放端口
在 Ubuntu 中,我们可以使用 ufw (Uncomplicated Firewall) 来管理防火墙。以下是打开 80 和 8090 端口的步骤: 首先检查防火墙状态 sudo ufw status 如果防火墙没有启用,先启用它: sudo ufw enable 允许 80 端口(…...

PyTorch 与 TensorFlow 中基于自定义层的 DNN 实现对比
深度学习双雄对决:PyTorch vs TensorFlow 自定义层大比拼 目录 深度学习双雄对决:PyTorch vs TensorFlow 自定义层大比拼一、TensorFlow 实现 DNN1. 核心逻辑 二、PyTorch 实现自定义层1. 核心逻辑 三、关键差异对比四、总结 一、TensorFlow 实现 DNN 1…...

质量员考试案例题有哪些常见考点?
质量员考试案例题常见考点如下: 施工质量控制 施工工艺与工序:如混凝土浇筑时的振捣时间、方法,若振捣不充分会导致混凝土出现蜂窝、麻面等质量问题。 施工环境:例如在高温天气下进行砌筑作业,未对砌块进行适当处理或…...
)
Axure疑难杂症:深度理解与认识“事件”“动作”(玩转交互)
亲爱的小伙伴,在您浏览之前,烦请关注一下,在此深表感谢! Axure产品经理精品视频课已登录CSDN可点击学习https://edu.csdn.net/course/detail/40420 课程主题:深度理解与认识“事件”“动作” 主要内容:事件、动作定义、本质、辩证关系、执行顺序 应用场景:原型交互 …...

【AI知识库云研发部署】RAGFlow + DeepSeek
gpu 安装screen:yum install screen 配置ollama: 下载官方安装脚本并执行: curl -fsSL https://ollama.com/install.sh | sh 通过screen后台运行ollama:screen -S ollama 在screen会话中启动服务: export OLLA…...

HTML07:表格标签
表格 基本结构 单元格行列跨行跨列 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>表格学习</title><style>td {text-align: center;vertical-align: middle;}</style> </he…...

【专家库】Kuntal Chowdhury
昆塔尔乔杜里 Kuntal Chowdhury 是 NVIDIA 的 6G 开发者关系经理和技术布道师。他致力于推动与 NVIDIA 平台和工具的开发者和早期采用者生态系统的联系,以促进 6G 研究社区的蓬勃发展。在此之前,他是 BlueFusion, Inc. 的创始人,这是一家创新…...

IAA-Net:一种实孔径扫描雷达迭代自适应角超分辨成像方法——论文阅读
IAA-Net:一种实孔径扫描雷达迭代自适应角超分辨成像方法 1. 论文的研究目标与实际意义1.1 研究目标1.2 实际问题与产业意义2. 论文的创新方法、公式与优势2.1 方法框架与核心步骤2.2 核心公式与推导2.2.1 回波模型与目标函数2.2.2 正则化加权矩阵设计2.2.3 迭代更新公式2.2.4 …...

[论文阅读]MCP Guardian: A Security-First Layer for Safeguarding MCP-Based AI System
MCP Guardian: A Security-First Layer for Safeguarding MCP-Based AI System http://arxiv.org/abs/2504.12757 推出了 MCP Guardian,这是一个框架,通过身份验证、速率限制、日志记录、跟踪和 Web 应用程序防火墙 (WAF) 扫描来…...

提示词工程:通向AGI时代的人机交互艺术
引言:从基础到精通的提示词学习之旅 欢迎来到 "AGI时代核心技能" 系列课程的第二模块——提示词工程。在这个模块中,我们将系统性地探索如何通过精心设计的提示词,释放大型语言模型的全部潜力,实现高效、精…...
-社科数据)
地级市-机器人、人工智能等未来产业水平(2009-2023年)-社科数据
地级市-机器人、人工智能等未来产业水平(2009-2023年)-社科数据https://download.csdn.net/download/paofuluolijiang/90623814 https://download.csdn.net/download/paofuluolijiang/90623814 此数据集统计了2009-2023年全国地级市在机器人、人工智能等…...

神经网络中之多类别分类:从基础到高级应用
神经网络中之多类别分类:从基础到高级应用 摘要 在机器学习领域,多类别分类是解决复杂问题的关键技术之一。本文深入探讨了神经网络在多类别分类中的应用,从基础的二元分类扩展到一对多和一对一分类方法。我们详细介绍了 softmax 函数的原理…...

破解工业3D可视化困局,HOOPS Visualize助力高效跨平台协作与交互!
一、当前3D可视化面临的痛点 (1)性能瓶颈 现有的许多3D可视化工具在处理大型复杂模型时往往力不从心。例如在航空航天、汽车制造等高端制造业,动辄涉及数以亿计的三角面片和海量的纹理细节。这些超大规模的模型在渲染时常常出现卡顿、延迟&…...

感知器准则感知器神经元模型——等价
不同的东西,很多刊物有误。但两者等价。 感知器神经元模型的误差反馈学习 y y y:期望值 y ^ \hat{y} y^:实际输出值 权重更新公式为: w i ← w i η ( y − y ^ ) x i w_i \leftarrow w_i \eta(y - \hat{y})x_i wi←wi…...

Qt学习Day0:Qt简介
0. 关于Qt Qt是C的实践课,之前在C中学习的语法可以有具体的应用场景。Qt的代码量很大,不要死记硬背,学会查询文档的能力更加重要。 建议提升一下相关单词的储备量: 1. Qt是什么? Qt是一个基于C语言的图形用户界面&a…...
原型模式(Prototype Pattern))
JAVA设计模式——(十二)原型模式(Prototype Pattern)
JAVA设计模式——(十二)原型模式(Prototype Pattern) 介绍理解实现Email类测试 应用 介绍 用原型实例指定创建对象的种类,并且通过复制原型已有的对象用于创建新的对象。 理解 原型实例便是我们需要复制的类的实例&…...

C++命名空间
什么是命名空间 命名空间是一种用来避免命名冲突的机制,它可以将一段代码的名称隔离开,使其与其他代码的名称不冲突 简单来说,就是编译器检测到相同的名称的函数,变量,或者其他的相同名称的东西,也许会有疑问,怎么能出现相同的名称的变量呢.这就是C引入的…...

Hello Robot 推出Stretch 3移动操作机器人 提升开源与可用性
Stretch 3机器人是Hello Robot推出的新一代移动操作机器人,专注于提升开源开发与实际应用能力。它结合了先进的设计理念和工程技术,旨在为家庭任务和辅助技术提供智能化解决方案。通过优化硬件性能和软件兼容性,这款机器人不仅增强了灵活性&a…...

[Linux_69] 数据链路层 | Mac帧格式 | 局域网转发 | MTU MSS
目录 0.引入 1.以太网帧格式 2.重谈局域网转发的原理(基于协议) 小结 3.认识MTU 3.1MTU对IP协议的影响 3.2MTU对UDP协议的影响 3.3MTU对于TCP协议的影响 0.引入 在去年的这篇文章中,我们有对网络进行过一个概述[Linux#47][网络] 网络协议 | TCP/IP模型 | 以…...

I2C总线驱动开发:MPU6050应用
引言 I2C(Inter-Integrated Circuit)总线作为嵌入式系统中广泛使用的通信协议,在传感器、外设控制等领域扮演着重要角色。本文将深入探讨I2C总线的工作原理、Exynos4412平台裸机驱动实现、Linux内核中的I2C子系统架构,并以MPU605…...

15.命令模式:思考与解读
原文地址:命令模式:思考与解读 更多内容请关注:深入思考与解读设计模式 引言 在软件开发中,尤其是当系统涉及多个请求、操作或任务时,你是否遇到过这样的情况:每个操作都有自己的执行逻辑,且这些操作可能…...
)
2025年软件工程与数据挖掘国际会议(SEDM 2025)
2025 International Conference on Software Engineering and Data Mining 一、大会信息 会议简称:SEDM 2025 大会地点:中国太原 收录检索:提交Ei Compendex,CPCI,CNKI,Google Scholar等 二、会议简介 2025年软件开发与数据挖掘国际会议于…...

博客系统测试报告
文章目录 目录1. 项目背景2. 项目简介3. 测试工具4. 测试用例5. 功能测试6. 性能测试7. 弱网测试8. 自动化测试9. bug简述10. 测试结论 目录 项目背景项目简介测试工具测试用例功能测试性能测试弱网测试自动化测试bug简述测试结论 1. 项目背景 为了将平时自己写的笔记、知识…...

window 显示驱动开发-线程同步和 TDR
下图显示了 Windows 显示驱动程序模型 (WDDM) 中显示微型端口驱动程序的线程同步的工作原理 如果发生硬件超时,则会启动 超时检测和恢复 (TDR) 进程。 GPU 计划程序调用驱动程序的 DxgkDdiResetFromTimeout 函数,这将重置 GPU。 DxgkDdiResetFromTimeou…...

GEC6818蜂鸣器驱动开发
相关知识:Linux设备驱动开发 insmod 编译好的.ko文件后再运行beep_app.c编译完成的可执行文件即可使板子蜂鸣。 beep_drv.c: #include <linux/module.h> //包含了加载模块时需要使用的大量符号和函数声明 #include <linux/kernel.h> //包含了printk内…...
)
WPF MVVM入门系列教程(五、命令和用户输入)
🧭 WPF MVVM入门系列教程 一、MVVM模式介绍二、依赖属性三、数据绑定四、ViewModel五、命令和用户输入六、ViewModel案例演示 WPF中的命令模型 在WPF中,我们可以使用事件来响应鼠标和键盘动作。 但使用事件会具备一定的局限性,例如&#x…...

基于Jetson Nano与PyTorch的无人机实时目标跟踪系统搭建指南
引言:边缘计算赋能智能监控 在AIoT时代,将深度学习模型部署到嵌入式设备已成为行业刚需。本文将手把手指导读者在NVIDIA Jetson Nano(4GB版本)开发板上,构建基于YOLOv5SORT算法的实时目标跟踪系统,集成无人…...
)
创建简易个人关系图谱(Neo4j )
1. 启动 Neo4j 并进入 Neo4j Browser 确保 Neo4j 已启动,访问: http://localhost:7474/2. 创建人物节点(Person) (1) 创建 Alice CREATE (alice:Person {name: "Alice", age: 28, gender: "Female"}) RETUR…...
 服务器恶意软件分析及防御)
JavaScript 到命令和控制 (C2) 服务器恶意软件分析及防御
攻击始于一个经过混淆的JavaScript文件,该文件从开源服务中获取编码字符串以执行PowerShell脚本。然后,该脚本从一个IP地址和一个URL缩短器下载一个JPG图像和一个文本文件,这两个文件都包含使用隐写术嵌入的恶意MZ DOS可执行文件。这些有效载荷一旦执行,就会部署Stealer恶意…...
:[macOS 64bit App开发]: 如何自动打开“安全性与隐私“控制面板?)
[原创](现代Delphi 12指南):[macOS 64bit App开发]: 如何自动打开“安全性与隐私“控制面板?
[作者] 常用网名: 猪头三 出生日期: 1981.XX.XX 企鹅交流: 643439947 个人网站: 80x86汇编小站 编程生涯: 2001年~至今[共24年] 职业生涯: 22年 开发语言: C/C++、80x86ASM、Object Pascal、Objective-C、C#、R、Python、PHP、Perl、 开发工具: Visual Studio、Delphi、XCode、…...

springboot微服务连接nacos超时
问题现象 java应用启动失败,查看日志,发现是连接Nacos超时,获取不到配置,导致dubbo注册失败,错误日志如下: 2025-05-01 14:50:08.973 ERROR [TW-172.29.245.61-9063-3] [com.alibaba.nacos.common.utils.…...