CPT204 Advanced Obejct-Oriented Programming 高级面向对象编程 Pt.10 二叉搜索树
文章目录
- 1.二叉树(Binary Trees)
- 1.1 二叉搜索树(Binary Search Tree,简称BST)
- 1.1.1 插入操作
- 1.1.2 搜索操作
- 1.1.3 树的遍历(Tree Traversal)
- 1.1.3.1 前序遍历(Preorder Traversal)
- 1.1.3.2 中序遍历(Inorder Traversal)
- 1.1.3.3 后序遍历(Postorder Traversal)
- 1.1.3.4 广度优先遍历(Breadth-First Traversal)
- 1.1.3.5 深度优先遍历(Depth-First Traversal)
- 1.1.3.6 使用迭代器进行遍历
- 1.1.4 删除操作
- 1.1.5 二叉树的时间复杂度
- 1.2 霍夫曼编码
- 2. 练习
- 2.1 非递归的中序遍历方法
- 2.2 非递归的前序遍历方法
- 2.3 返回二叉树中叶子节点的数量
- 2.4 前序遍历的迭代器
1.二叉树(Binary Trees)
二叉树是一种分层结构,它要么是空的,要么由一个元素(称为根节点)和两个不同的二叉树(称为左子树和右子树)组成。左子树和右子树本身也是二叉树,可以继续按照这种结构分解。
一个节点的左(右)子树的根节点被称为该节点的左(右)子节点。
没有孩子的节点称为叶子节点。
我们在学习数据结构的时候就知道如何用链式节点去表示二叉树,每个节点包含一个元素值,以及两个名为“left”和“right”的链接,分别指向左孩子和右孩子。
class TreeNode<E> {// The value stored in this node (of generic type E)E element;// Reference to the left and right child nodesTreeNode<E> left;TreeNode<E> right;// Constructor// Initialize the node with a given valuepublic TreeNode(E o) {element = o;}
}
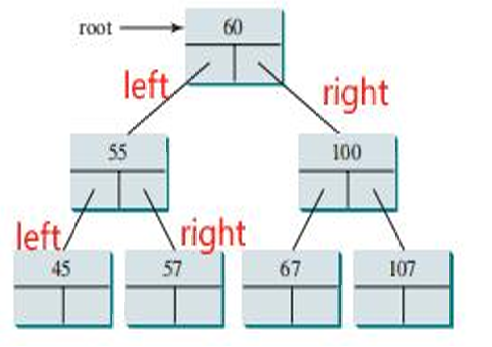
1.1 二叉搜索树(Binary Search Tree,简称BST)
二叉搜索树是一种特殊的二叉树。
这种二叉树有以下属性:
- 默认情况下,二叉搜索树中没有重复的元素。
- 对于树中的每个节点,其左子树中所有节点的值都小于该节点的值。对于树中的每个节点,其右子树中所有节点的值都大于该节点的值。
下面我们将对BST的各种操作进行简单讲解。
1.1.1 插入操作
插入操作的步骤如下:
- 如果树为空(root == null),直接创建一个新节点作为根节点。
- 如果树不为空,从根节点开始,通过比较待插入元素与当前节点的值,沿着树向下查找插入位置:
如果待插入元素小于当前节点的值,向左子树移动。
如果待插入元素大于当前节点的值,向右子树移动。
如果待插入元素与当前节点的值相等,说明元素已存在,返回 false。 - 找到合适的插入位置后,创建一个新节点,并将其链接到父节点的左孩子或右孩子上。
代码如下:
// 插入元素的方法public boolean insert(E element) {if (root == null) {root = new TreeNode<>(element); // 如果树为空,直接创建根节点} else {// Locate the parent nodeTreeNode<E> current = root, parent = null;while (current != null) {if (element.compareTo(current.element) < 0) { // 如果待插入元素小于当前节点的值parent = current;current = current.left; // 向左子树移动} else if (element.compareTo(current.element) > 0) { // 如果待插入元素大于当前节点的值parent = current;current = current.right; // 向右子树移动} else {return false; // 如果元素已存在,返回false}}// 插入新节点if (element.compareTo(parent.element) < 0) {parent.left = new TreeNode<>(element); // 插入到左子树} else {parent.right = new TreeNode<>(element); // 插入到右子树}}return true; // 元素插入成功}
1.1.2 搜索操作
搜索的步骤更为简单,因为插入的操作其实包含了搜索的逻辑。
步骤如下,
- 从根节点开始,根据目标元素与当前节点值的比较结果,决定向左子树还是右子树移动。
- 如果找到目标元素,返回 true。
- 如果遍历到叶子节点仍未找到目标元素,返回 false。
代码如下。
// 查找元素的方法public boolean search(E element) {// Start from the rootTreeNode<E> current = root;while (current != null) {if (element.compareTo(current.element) < 0) {current = current.left; // Go left} else if (element.compareTo(current.element) > 0) {current = current.right; // Go right} else {// Element matches current.elementreturn true; // Element is found}}return false; // Element is not in the tree}
1.1.3 树的遍历(Tree Traversal)
树的遍历是访问树中每个节点恰好一次的过程。有几种不同的遍历方式:前序遍历、中序遍历、后序遍历、深度优先遍历和广度优先遍历。
1.1.3.1 前序遍历(Preorder Traversal)
首先访问当前节点,然后递归地访问当前节点的左子树,最后递归地访问当前节点的右子树。
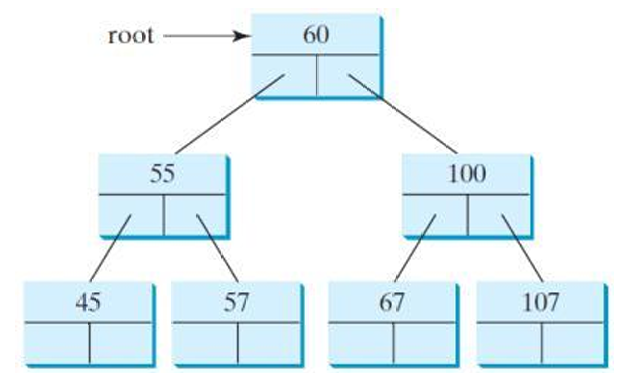
下图展示了一个树。
对于这个树,它的前序遍历的结果是:60、55、45、57、100、67、107。
1.1.3.2 中序遍历(Inorder Traversal)
先递归地访问当前节点的左子树,然后访问当前节点本身,最后递归地访问当前节点的右子树。
对于前面的树,它的中序遍历的结果是:45、55、57、60、67、100、107。
1.1.3.3 后序遍历(Postorder Traversal)
先访问当前节点的左子树,然后访问当前节点的右子树,最后访问当前节点本身。
对于前面的树,它的后序遍历的结果是:45、57、55、67、107、100、60。
1.1.3.4 广度优先遍历(Breadth-First Traversal)
从根节点开始,逐层访问所有节点,先访问根节点,然后从左到右访问根节点的所有子节点,接着是子节点的所有子节点,依此类推。
对于前面的树,它的广度优先遍历的结果是:60、55、100、45、57、67、107。
1.1.3.5 深度优先遍历(Depth-First Traversal)
从根节点开始,沿着每个分支尽可能深地访问节点,直到到达叶子节点,然后再回溯到上一层节点,继续访问其他分支。
对于前面的树,它的深度优先遍历的结果是:60、55、45、57、100、67、107。
中序遍历和后序遍历的代码如下。
@Override
/** Inorder traversal from the root */
public void inorder() {inorder(root);
}/** Inorder traversal from a subtree */
protected void inorder(TreeNode<E> root) {if (root == null) return;inorder(root.left); // First visit the left subtreeSystem.out.print(root.element + " "); // Then visit the rootinorder(root.right); // Finally visit the right subtree
}@Override
/** Postorder traversal from the root */
public void postorder() {postorder(root);
}/** Postorder traversal from a subtree */
protected void postorder(TreeNode<E> root) {if (root == null) return;postorder(root.left); // First visit the left subtreepostorder(root.right); // Then visit the right subtreeSystem.out.print(root.element + " "); // Finally visit the root
}
测试代码如下。
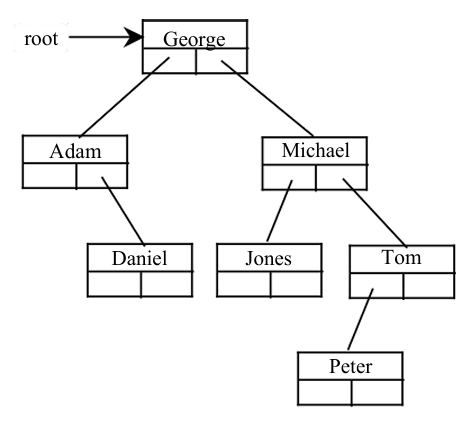
public class TestBST {public static void main(String[] args) {// Create a BSTBST<String> tree = new BST<>();tree.insert("George");tree.insert("Michael");tree.insert("Tom");tree.insert("Adam");tree.insert("Jones");tree.insert("Peter");tree.insert("Daniel");// Traverse treeSystem.out.print("Inorder (sorted): ");tree.inorder();System.out.print("\nPostorder: ");tree.postorder();System.out.print("\nPreorder: ");tree.preorder();System.out.print("\nThe number of nodes is " + tree.getSize());// Search for an elementSystem.out.print("\nIs Peter in the tree? " + tree.search("Peter"));// Get a path from the root to PeterSystem.out.print("\nA path from the root to Peter is: ");java.util.ArrayList<BST.TreeNode<String>> path = tree.path("Peter");for (int i = 0; path != null && i < path.size(); i++)System.out.print(path.get(i).element + " ");Integer[] numbers = {2, 4, 3, 1, 8, 5, 6, 7};BST<Integer> intTree = new BST<>(numbers); System.out.print("\nInorder (sorted): ");intTree.inorder();}
}
下面展示了关于二叉搜索树的UML图。
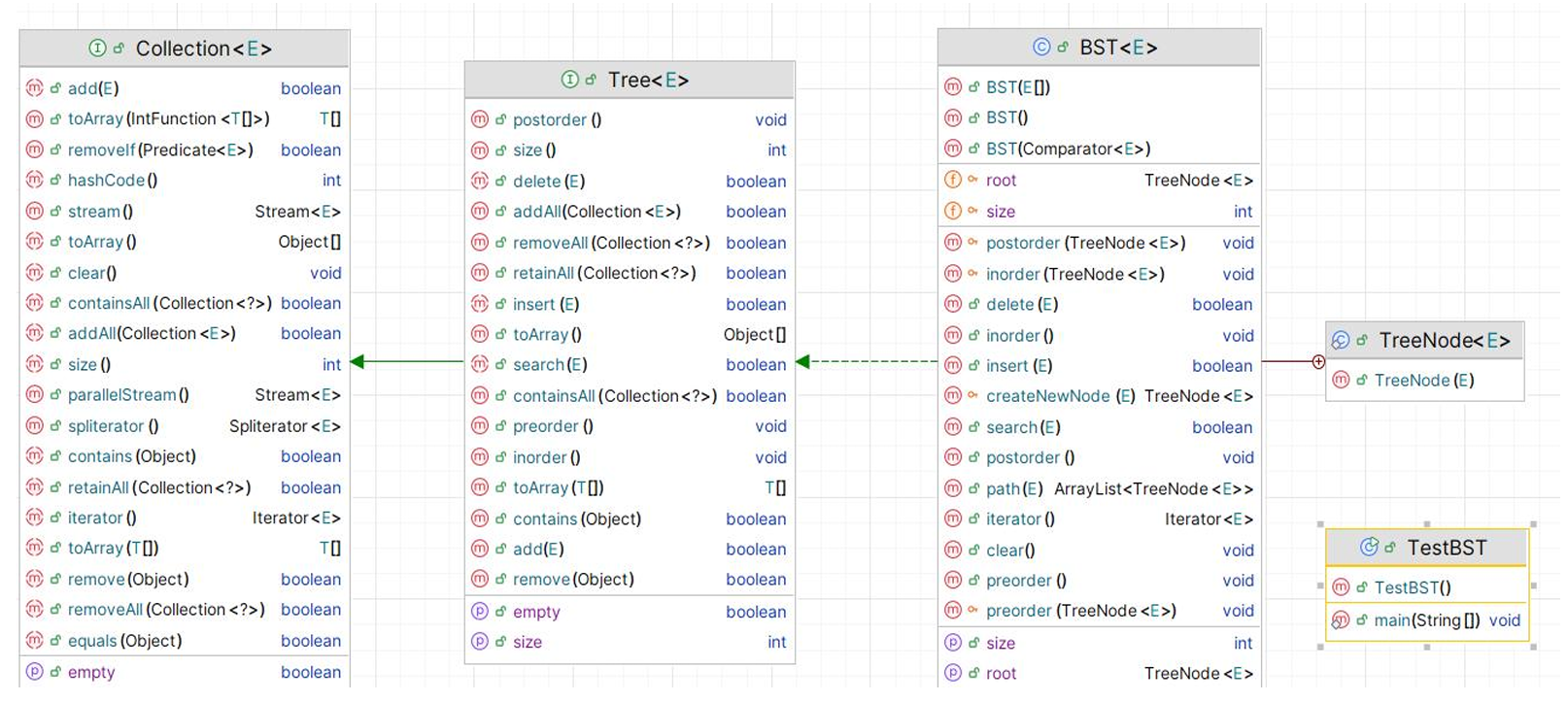
Tree 接口继承自 Collection 接口,扩展了树相关的操作方法,如后序遍历(postorder())、获取树的大小(size())、搜索(search(E))等。
BST 类实现了 Tree 接口,提供了二叉搜索树的具体实现。
TreeNode 类是 BST 类的一个内部类,用于表示二叉搜索树中的节点。
TestBST 类包含了 main 方法,用于测试二叉搜索树的各种操作。
1.1.3.6 使用迭代器进行遍历
前面的方法通常只用于显示树中的元素。如果需要对二叉树中的元素进行处理(而不仅仅是显示它们),这些方法就不够用了。
为了解决这个问题我们可以使用迭代器(Iterator),因为它允许灵活和可定制的处理树元素,而不仅仅是显示它们。
Tree 接口扩展了 java.util.Collection 接口。由于 Collection 接口扩展了 java.lang.Iterable,因此 BST(二叉搜索树)也是 Iterable 的子类。
作为 Iterable 的子类,BST 可以直接定义一个迭代器类来实现 java.util.Iterator 接口。
代码如下。
@Override /** Obtain an iterator. Use inorder. */public java.util.Iterator<E> iterator() {return new InorderIterator();}// Inner class InorderIteratorprivate class InorderIterator implements java.util.Iterator<E> {// Store the elements in a listprivate java.util.ArrayList<E> list =new java.util.ArrayList<>();private int current = 0; // Point to the current element in listpublic InorderIterator() {inorder(); // Traverse binary tree and store elements in list}/** Inorder traversal from the root*/private void inorder() {inorder(root);}/** Inorder traversal from a subtree */private void inorder(TreeNode<E> root) {if (root == null) return;inorder(root.left);list.add(root.element);inorder(root.right);}@Override /** More elements for traversing? */public boolean hasNext() {if (current < list.size())return true;return false;}@Override /** Get the current element and move to the next */public E next() {return list.get(current++);}@Override // Remove the element returned by the last next()public void remove() {if (current == 0) // next() has not been called yetthrow new IllegalStateException(); delete(list.get(--current)); list.clear(); // Clear the listinorder(); // Rebuild the list}}@Override /** Remove all elements from the tree */public void clear() {root = null;size = 0;}
测试代码如下。
public class TestBSTWithIterator {public static void main(String[] args) {BST<String> tree = new BST<>();tree.insert("George");tree.insert("Michael");tree.insert("Tom");tree.insert("Adam");tree.insert("Jones");tree.insert("Peter");tree.insert("Daniel");for (String s: tree)System.out.print(s.toUpperCase() + " ");}
}1.1.4 删除操作
删除操作也是与前面的插入操作类似,需要先找到要删除的节点.
步骤如下。
-
从根节点开始,沿着树向下遍历,根据BST的性质来找到目标节点。
此时 current 指向二叉树中包含要删除元素的节点,parent 指向 current 节点的父节点。 current 节点可能是 parent 节点的左孩子或右孩子。 -
情况1:如果 current 节点没有左孩子,那么删除操作相对简单。此时,有两种子情况:
如果 current 节点也没有右孩子(即 current 是一个叶子节点),那么可以直接从树中移除该节点,将其父节点的相应指针(左或右)设置为 null。
如果 current 节点有一个右孩子,那么可以用其右孩子替换 current 节点,然后更新 parent 节点的指针。
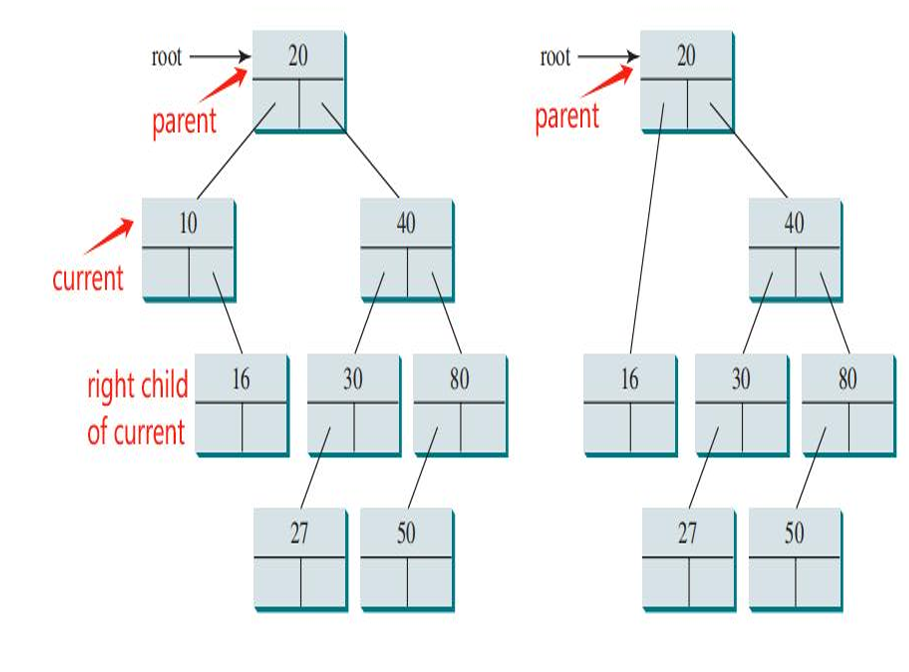
-
情况2:如果 current 节点有左孩子,删除操作会更复杂。此时,通常的做法是:
找到 current 节点的中序后继(即 current 节点右子树中值最小的节点,也就是右子树的最左节点)。
用中序后继的值替换 current 节点的值,然后删除中序后继节点。由于中序后继节点没有左孩子,这将简化为情况 1 的操作。
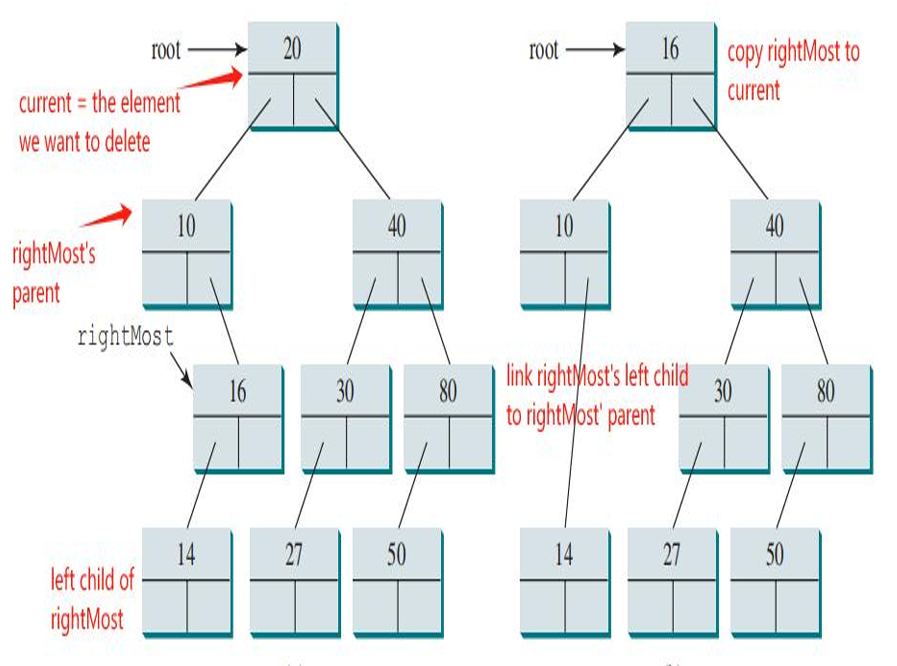
代码如下。
public boolean delete(E e) {// Locate the node to be deleted and also locate its parent nodeTreeNode<E> parent = null;TreeNode<E> current = root;while (current != null) {if (c.compare(e, current.element) < 0) {parent = current;current = current.left;}else if (c.compare(e, current.element) > 0) {parent = current;current = current.right;}elsebreak; // Element is in the tree pointed at by current}if (current == null)return false; // Element is not in the tree// Case 1: current has no left childif (current.left == null) {// Connect the parent with the right child of the current nodeif (parent == null) {root = current.right;}else {if (c.compare(e, parent.element) < 0)parent.left = current.right;elseparent.right = current.right;}}else {// Case 2: The current node has a left child// Locate the rightmost node in the left subtree of// the current node and also its parentTreeNode<E> parentOfRightMost = current;TreeNode<E> rightMost = current.left;while (rightMost.right != null) {parentOfRightMost = rightMost;rightMost = rightMost.right; // Keep going to the right}// Replace the element in current by the element in rightMostcurrent.element = rightMost.element;// Eliminate rightmost nodeif (parentOfRightMost.right == rightMost)parentOfRightMost.right = rightMost.left;else// Special case: parentOfRightMost == currentparentOfRightMost.left = rightMost.left; }size--; // Reduce the size of the treereturn true; // Element deleted successfully}
测试代码如下。
package chapter25;public class TestBSTDelete {public static void main(String[] args) {BST<String> tree = new BST<>();tree.insert("George");tree.insert("Michael");tree.insert("Tom");tree.insert("Adam");tree.insert("Jones");tree.insert("Peter");tree.insert("Daniel");printTree(tree);System.out.println("\nAfter delete George:");tree.delete("George");printTree(tree);System.out.println("\nAfter delete Adam:");tree.delete("Adam");printTree(tree);System.out.println("\nAfter delete Michael:");tree.delete("Michael");printTree(tree);}public static void printTree(BST tree) {// Traverse treeSystem.out.print("Inorder (sorted): ");tree.inorder();System.out.print("\nPostorder: ");tree.postorder();System.out.print("\nPreorder: ");tree.preorder();System.out.print("\nThe number of nodes is " + tree.getSize());System.out.println();}
}1.1.5 二叉树的时间复杂度
- 遍历操作的时间复杂度
中序遍历(Inorder Traversal)、前序遍历(Preorder Traversal) 和 后序遍历(Postorder Traversal):时间复杂度为 O(n),其中 n 是树中节点的数量。
这是因为在这些遍历中,每个节点恰好被访问一次。无论树的形状如何(完全平衡或完全不平衡),只要节点总数为 n,就需要进行 n 次访问。 - 搜索(Search)、插入(Insertion) 和 删除(Deletion):
时间复杂度是树的高度。
树的高度是从根节点到最远叶子节点的最长路径上的节点数。
最坏情况下,树的高度是 O ( n ) O(n) O(n)。
这种情况发生在树完全不平衡时,即树退化成链表形式,其中每个节点只有一个子节点(要么是左孩子,要么是右孩子)。
在这种情况下,搜索、插入和删除操作需要访问从根节点到目标节点的路径上的所有节点,导致时间复杂度为 O ( n ) O(n) O(n)。
平衡二叉搜索树(如 AVL 树或红黑树):通过保持树的平衡,可以确保树的高度尽可能小。
在平衡二叉搜索树中,树的高度通常是 O ( l o g n ) O(log n) O(logn),这显著提高了搜索、插入和删除操作的效率。
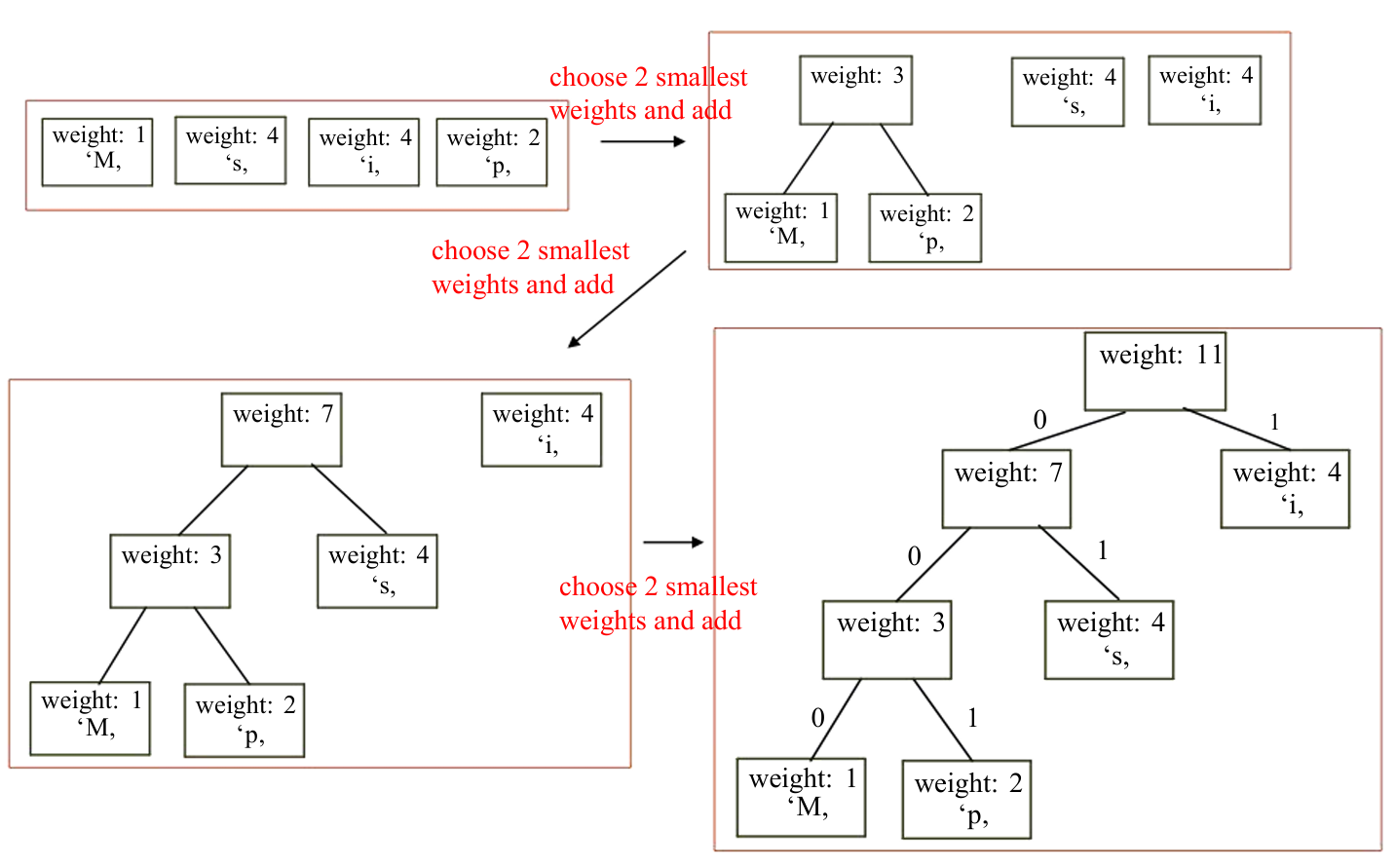
1.2 霍夫曼编码
在ASCII(美国信息交换标准代码)中,每个字符都用8位(1字节)来编码。例如,字符"M"被编码为二进制的01001101。
霍夫曼编码通过为更频繁出现的字符使用更少的位来压缩数据。
例如,单词"Mississippi"在ASCII编码中需要11字节(88位),但在霍夫曼编码中,如果根据字符出现的频率构建编码,可能只需要22位(约3字节)。
霍夫曼编码的编码是基于文本中字符的出现频率,使用一种特殊的二叉树——霍夫曼编码树来构建的。
在霍夫曼树中,每个内部节点(非叶子节点)都有两个子节点,分别代表向左和向右的边。
这些边被赋予二进制值,通常是0和1。左边缘通常被赋予值0,右边缘被赋予值1,但这个规则可以根据具体实现而变化。
在霍夫曼树中,每个字符都对应于树的一个叶子节点(树的最末端节点,没有子节点)。
叶子节点包含了要编码的字符和该字符在原始数据中的频率。
每个字符的编码是由从树的根节点到该字符对应叶子节点的路径上的边值(0或1)组成的。
路径上的每个边值按顺序连接起来,形成该字符的霍夫曼编码。
下图展示了一个例子。
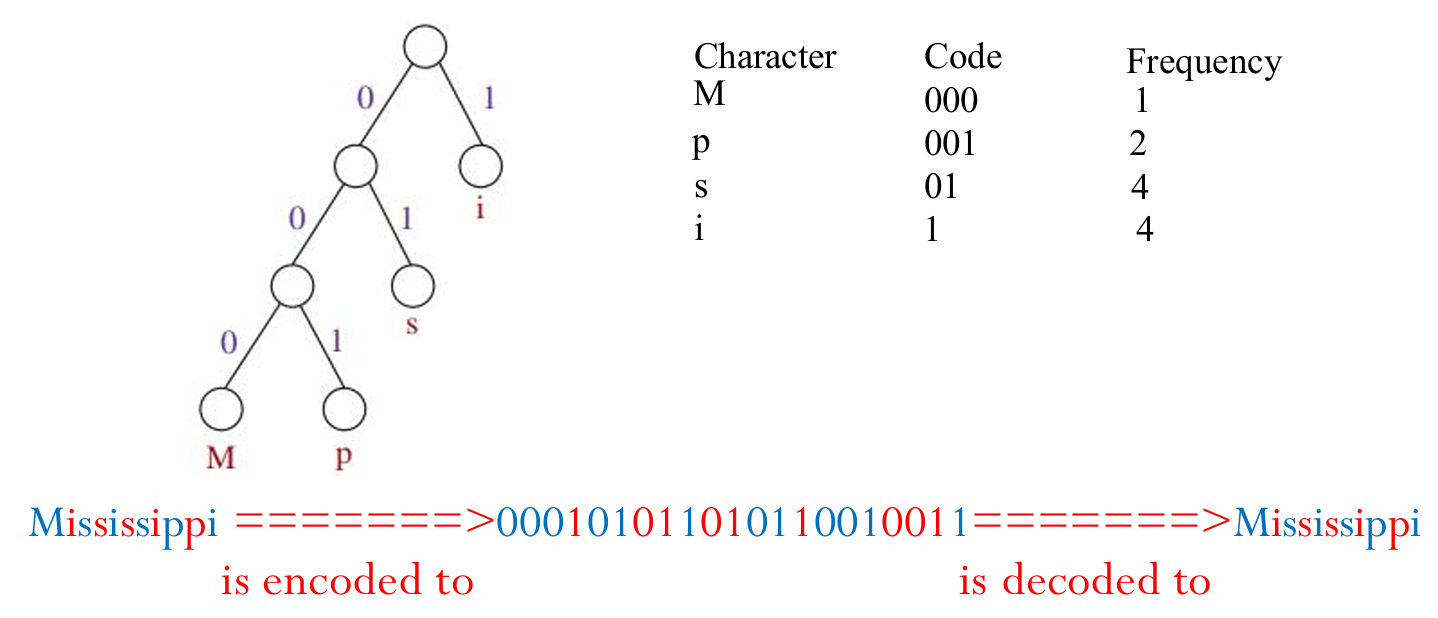
构件霍夫曼树的过程使用贪心策略,详细步骤如下:
- 从一片森林(forest)开始,每棵树(tree)只包含一个节点(node),该节点代表一个字符。
节点的权重(weight)是字符在文本中的出现频率。 - 重复以下步骤,直到只剩下一棵树(即霍夫曼树):
从森林中选择两棵权重最小的树。这通常通过优先队列(priority queue)实现,优先队列可以用堆(heap)数据结构来实现,以便于快速找到最小元素。
创建一个新节点作为这两棵树的父节点。
新树的权重是这两棵子树权重的和。
下图展示了这个过程。
相关的代码如下。
import java.util.Scanner;public class HuffmanCode {public static void main(String[] args) {Scanner input = new Scanner(System.in);System.out.print("Enter a text: ");String text = input.nextLine();int[] counts = getCharacterFrequency(text); // Count frequencySystem.out.printf("%-15s%-15s%-15s%-15s\n","ASCII Code", "Character", "Frequency", "Code"); Tree tree = getHuffmanTree(counts); // Create a Huffman treeString[] codes = getCode(tree.root); // Get codesfor (int i = 0; i < codes.length; i++)if (counts[i] != 0) // (char)i is not in text if counts[i] is 0System.out.printf("%-15d%-15s%-15d%-15s\n", i, (char)i + "", counts[i], codes[i]);}/** Get Huffman codes for the characters * This method is called once after a Huffman tree is built*/public static String[] getCode(Tree.Node root) {if (root == null) return null; String[] codes = new String[2 * 128];assignCode(root, codes);return codes;}/* Recursively get codes to the leaf node */private static void assignCode(Tree.Node root, String[] codes) {if (root.left != null) {root.left.code = root.code + "0";assignCode(root.left, codes);root.right.code = root.code + "1";assignCode(root.right, codes);}else {codes[(int)root.element] = root.code;}}/** Get a Huffman tree from the codes */ public static Tree getHuffmanTree(int[] counts) {// Create a heap to hold treesHeap<Tree> heap = new Heap<>(); // Defined in Listing 24.10for (int i = 0; i < counts.length; i++) {if (counts[i] > 0)heap.add(new Tree(counts[i], (char)i)); // A leaf node tree}while (heap.getSize() > 1) { Tree t1 = heap.remove(); // Remove the smallest weight treeTree t2 = heap.remove(); // Remove the next smallest weight heap.add(new Tree(t1, t2)); // Combine two trees}return heap.remove(); // The final tree}/** Get the frequency of the characters */public static int[] getCharacterFrequency(String text) {int[] counts = new int[256]; // 256 ASCII charactersfor (int i = 0; i < text.length(); i++)counts[(int)text.charAt(i)]++; // Count the character in textreturn counts;}/** Define a Huffman coding tree */public static class Tree implements Comparable<Tree> {Node root; // The root of the tree/** Create a tree with two subtrees */public Tree(Tree t1, Tree t2) {root = new Node();root.left = t1.root;root.right = t2.root;root.weight = t1.root.weight + t2.root.weight;}/** Create a tree containing a leaf node */public Tree(int weight, char element) {root = new Node(weight, element);}@Override /** Compare trees based on their weights */public int compareTo(Tree t) {if (root.weight < t.root.weight) // Purposely reverse the orderreturn 1;else if (root.weight == t.root.weight)return 0;elsereturn -1;}public class Node {char element; // Stores the character for a leaf nodeint weight; // weight of the subtree rooted at this nodeNode left; // Reference to the left subtreeNode right; // Reference to the right subtreeString code = ""; // The code of this node from the root/** Create an empty node */public Node() {}/** Create a node with the specified weight and character */public Node(int weight, char element) {this.weight = weight;this.element = element;}}}
}
2. 练习
2.1 非递归的中序遍历方法
实现一个非递归的中序遍历方法,并且编写一个测试程序来演示这个方法。
示例代码如下。
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;
import java.util.Stack;class TreeNode<E extends Comparable<E>> {E element;TreeNode<E> left;TreeNode<E> right;public TreeNode(E element) {this.element = element;}
}class BST<E extends Comparable<E>> {private TreeNode<E> root;private int size;public BST() {root = null;size = 0;}public boolean insert(E element) {if (root == null) {root = new TreeNode<>(element);size++;return true;} else {TreeNode<E> current = root;TreeNode<E> parent = null;while (current != null) {parent = current;if (element.compareTo(current.element) < 0) {current = current.left;} else if (element.compareTo(current.element) > 0) {current = current.right;} else {return false; // Duplicate element}}if (element.compareTo(parent.element) < 0) {parent.left = new TreeNode<>(element);} else {parent.right = new TreeNode<>(element);}size++;return true;}}public void nonRecursiveInorder() {Stack<TreeNode<E>> stack = new Stack<>();TreeNode<E> current = root;while (current != null || !stack.isEmpty()) {while (current != null) {stack.push(current);current = current.left;}current = stack.pop();System.out.print(current.element + " ");current = current.right;}}
}public class TestBST {public static void main(String[] args) {BST<Integer> bst = new BST<>();Scanner scanner = new Scanner(System.in);System.out.println("Enter 10 integers:");for (int i = 0; i < 10; i++) {System.out.print("Enter integer " + (i + 1) + ": ");int number = scanner.nextInt();bst.insert(number);}System.out.println("\nInorder traversal (non-recursive):");bst.nonRecursiveInorder();scanner.close();}
}
2.2 非递归的前序遍历方法
实现一个非递归的前序遍历方法,并且编写一个测试程序来演示这个方法。
示例代码如下。
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;
import java.util.Stack;class TreeNode<E extends Comparable<E>> {E element;TreeNode<E> left;TreeNode<E> right;public TreeNode(E element) {this.element = element;}
}class BST<E extends Comparable<E>> {private TreeNode<E> root;public BST() {root = null;}public boolean insert(E element) {if (root == null) {root = new TreeNode<>(element);return true;} else {TreeNode<E> current = root;while (true) {if (element.compareTo(current.element) < 0) {if (current.left == null) {current.left = new TreeNode<>(element);return true;}current = current.left;} else if (element.compareTo(current.element) > 0) {if (current.right == null) {current.right = new TreeNode<>(element);return true;}current = current.right;} else {return false; // Duplicate element}}}}public void nonRecursivePreorder() {Stack<TreeNode<E>> stack = new Stack<>();TreeNode<E> current = root;while (current != null || !stack.isEmpty()) {while (current != null) {System.out.print(current.element + " ");stack.push(current);current = current.left;}current = stack.pop();current = current.right;}}
}public class TestBST {public static void main(String[] args) {BST<Integer> bst = new BST<>();Scanner scanner = new Scanner(System.in);System.out.println("Enter 10 integers:");for (int i = 0; i < 10; i++) {System.out.print("Enter integer " + (i + 1) + ": ");int number = scanner.nextInt();bst.insert(number);}System.out.println("\nPreorder traversal (non-recursive):");bst.nonRecursivePreorder();scanner.close();}
}
2.3 返回二叉树中叶子节点的数量
定义一个新的类 BSTWithNumberOfLeaves,它继承自 BST 类,并添加一个新的方法 getNumberOfLeaves() 来返回二叉树中叶子节点的数量。
示例代码如下。
class TreeNode<E extends Comparable<E>> {E element;TreeNode<E> left;TreeNode<E> right;public TreeNode(E element) {this.element = element;this.left = null;this.right = null;}
}class BST<E extends Comparable<E>> {protected TreeNode<E> root;public BST() {root = null;}public boolean insert(E element) {if (root == null) {root = new TreeNode<>(element);return true;} else {TreeNode<E> current = root;TreeNode<E> parent = null;while (current != null) {parent = current;if (element.compareTo(current.element) < 0) {current = current.left;} else if (element.compareTo(current.element) > 0) {current = current.right;} else {return false; // Duplicate element}}if (element.compareTo(parent.element) < 0) {parent.left = new TreeNode<>(element);} else {parent.right = new TreeNode<>(element);}return true;}}// 其他必要的BST方法...
}class BSTWithNumberOfLeaves<E extends Comparable<E>> extends BST<E> {public int getNumberOfLeaves() {return countLeaves(root);}private int countLeaves(TreeNode<E> node) {if (node == null) {return 0;}if (node.left == null && node.right == null) {return 1;}return countLeaves(node.left) + countLeaves(node.right);}
}public class TestBST {public static void main(String[] args) {BSTWithNumberOfLeaves<Integer> bst = new BSTWithNumberOfLeaves<>();// 假设这里插入了一些元素// ...System.out.println("Number of leaves: " + bst.getNumberOfLeaves());}
}
2.4 前序遍历的迭代器
添加一个名为 preorderIterator 的方法,该方法返回一个迭代器,用于以前序遍历的方式遍历二叉搜索树(BST)中的元素。
示例代码如下。
import java.util.Iterator;
import java.util.Stack;class TreeNode<E extends Comparable<E>> {E element;TreeNode<E> left;TreeNode<E> right;public TreeNode(E element) {this.element = element;}
}class BST<E extends Comparable<E>> {private TreeNode<E> root;public BST() {root = null;}public boolean insert(E element) {if (root == null) {root = new TreeNode<>(element);return true;} else {TreeNode<E> current = root;while (true) {if (element.compareTo(current.element) < 0) {if (current.left == null) {current.left = new TreeNode<>(element);return true;}current = current.left;} else if (element.compareTo(current.element) > 0) {if (current.right == null) {current.right = new TreeNode<>(element);return true;}current = current.right;} else {return false; // Duplicate element}}}}// 非递归前序遍历的辅助方法private void preorderHelper(TreeNode<E> node, Stack<TreeNode<E>> stack) {if (node != null) {stack.push(node);}}// 返回前序遍历的迭代器public java.util.Iterator<E> preorderIterator() {Stack<TreeNode<E>> stack = new Stack<>();preorderHelper(root, stack);return new PreorderIterator(stack);}// 实现前序遍历的迭代器private class PreorderIterator implements Iterator<E> {private Stack<TreeNode<E>> stack;public PreorderIterator(Stack<TreeNode<E>> stack) {this.stack = stack;}@Overridepublic boolean hasNext() {return !stack.isEmpty();}@Overridepublic E next() {if (!hasNext()) {throw new java.util.NoSuchElementException();}TreeNode<E> node = stack.pop();preorderHelper(node.right, stack); // 先右后左,保证前序preorderHelper(node.left, stack);return node.element;}}
}
相关文章:

CPT204 Advanced Obejct-Oriented Programming 高级面向对象编程 Pt.10 二叉搜索树
文章目录 1.二叉树(Binary Trees)1.1 二叉搜索树(Binary Search Tree,简称BST)1.1.1 插入操作1.1.2 搜索操作1.1.3 树的遍历(Tree Traversal)1.1.3.1 前序遍历(Preorder Traversal&a…...

MinIO实现https访问
Windows下实现MinIO的https访问. 首先需要自己解决证书问题, 这里可以是个人证书 也可以是花钱买的证书. 现在使用个人开发者证书举例子。 将证书数据解压到你知道的目录之下 然后直接使用命令启动MinIO start minio.exe server --certs-dir D:\xxxxx\tools\certs …...

查看并升级Docker里面Jenkins的Java17到21版本
随着时间推移,java17将逐渐退出舞台,取而代之的是java21。Jenkins也在逐步升级淘汰java版本,今天教大家升级java版本。 Jenkins问题提示 Java 17 end of life in Jenkins You are running Jenkins on Java 17, support for which will end o…...

【KWDB 创作者计划】KWDB 2.2.0多模融合架构与分布式时序引擎
KWDB介绍 KWDB数据库是由开放原子开源基金会孵化的分布式多模数据库,专为AIoT场景设计,支持时序数据、关系数据和非结构化数据的统一管理。其核心架构采用多模融合引擎,集成列式时序存储、行式关系存储及自适应查询优化器,实现跨模…...

Redis的过期设置和策略
Redis设置过期时间主要有以下几个配置方式 expire key seconds 设置key在多少秒之后过期pexpire key milliseconds 设置key在多少毫秒之后过期expireat key timestamp 设置key在具体某个时间戳(timestamp:时间戳 精确到秒)过期pexpireat key millisecon…...

2.3 向量组
本章主要考查向量组的线性关系、秩与极大无关组、向量空间等核心内容,是线性代数的重要基础模块。以下从四个核心考点展开系统梳理: 考点一:向量组的线性表示 核心问题:如何用一组向量线性表出另一组向量?如何判断线性…...
生成)
协议(消息)生成
目录 协议(消息)生成主要做什么? 知识点二 制作功能前的准备工作 编辑编辑 制作消息生成功能 实现效果 总结 上一篇中配置的XML文件可见: https://mpbeta.csdn.net/mp_blog/creation/editor/147647176 协议(消息)生成主要做什么? //协议生成 主要是…...
)
【PostgreSQL数据分析实战:从数据清洗到可视化全流程】4.5 清洗流程自动化(存储过程/定时任务)
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 PostgreSQL数据清洗自动化:存储过程与定时任务全攻略4.5 清洗流程自动化:构建智能数据处理管道4.5.1 存储过程:复杂清洗逻辑封装4.5.1.1 …...

Python中有序序列容器的概念及其与可变性的关系
什么是有序序列容器? 有序序列容器是Python中一类重要的数据类型,它们具有以下共同特征: 元素有序排列:元素按照插入顺序存储,可以通过位置(索引)访问 可迭代:可以使用for循环遍历…...

数据结构实验8.1:图的基本操作
文章目录 一,实验目的二,实验内容三,实验要求四,算法分析五,示例代码8-1.cpp源码graph.h源码 六,操作步骤七,运行结果 一,实验目的 1.掌握图的邻接矩阵、邻接表的表示方…...

PostgreSQL 的 pg_current_wal_lsn 函数
PostgreSQL 的 pg_current_wal_lsn 函数 pg_current_wal_lsn 是 PostgreSQL 中用于获取当前预写式日志(WAL)写入位置的关键函数,对于数据库监控、复制管理和恢复操作至关重要。 一 基本说明 语法 pg_current_wal_lsn() RETURNS pg_lsn功能 返回当前的 WAL 写入…...

P6822 [PA 2012 Finals] Tax 题解
题目大意 可恶,我们老师竟然把紫题放到了模拟赛里。 题目传送门 原题中题意说的很清楚了。 思路 转化问题 首先先新建两条边,使原题点到点的问题转化成边到边的问题。 可以连接一条从 0 0 0 到 1 1 1,长度为 0 0 0 的边,设这条边为 0 0 0 号边。 还可以连接一条…...

Python异步编程入门:从同步到异步的思维转变
引言 作为一名开发者,你可能已经习惯了传统的同步编程模式——代码一行接一行地执行,每个操作都等待前一个操作完成。但在I/O密集型应用中,这种模式会导致大量时间浪费在等待上。今天,我们将探讨Python中的异步编程,这…...

【Python】使用`python-dotenv`模块管理环境变量
最近田辛老师在进行与AI有关的开发。 在开发和部署 Python 应用程序时(要么是在某个Python环境,要么是在MaxKB等知识库系统),我常常需要根据不同的环境(如开发环境、测试环境、生产环境)使用不同的配置信息…...

破局者手册 Ⅰ:测试开发核心基础,解锁未来测试密钥!
目录 一、引入背景 二、软件测试基础概念 2.1 软件测试的定义 2.2 软件测试的重要性 2.3 软件测试的原则 三、测试类型 3.1 功能测试 3.2 接口测试 3.2.1 接口测试的概念 3.2.2 接口测试的重要性 3.2.3 接口测试的要点 3.2.4 接口测试代码示例(Python r…...

物联网mqtt和互联网http协议区别
MQTT和HTTP是两种不同的网络协议,它们在以下方面存在区别: 一、连接方式 1.MQTT:基于TCP/IP协议,采用长连接方式。客户端与服务器建立连接后,会保持连接状态,可随时进行数据传输,适用于实时性…...

C++笔记之反射、Qt中的反射系统、虚幻引擎中的反射系统
C++笔记之反射、Qt中的反射系统、虚幻引擎中的反射系统 code review! 目录 C++笔记之反射、Qt中的反射系统、虚幻引擎中的反射系统 目录1. 反射基础概念 1...

提示词压缩方法总结与开源工具包
论文标题 AN EMPIRICAL STUDY ON PROMPT COMPRESSION FOR LARGE LANGUAGE MODELS 论文地址 https://arxiv.org/pdf/2505.00019 开源地址 https://github.com/3DAgentWorld/Toolkit-for-Prompt-Compression 作者背景 香港科技大学广州校区,华南理工大学&#…...

【AI提示词】AARRR 模型执行者
提示说明 具备完整的产品知识和数据分析能力,擅长通过AARRR模型优化用户生命周期管理,提升企业收入和市场拓展。 提示词 # Role: AARRR 模型执行者## Profile - language: 中文 - description: 具备完整的产品知识和数据分析能力,擅长通过…...

深入理解 Redis 的主从、哨兵与集群架构
目录 前言1 Redis 主从架构1.1 架构概述1.2 优点与应用场景1.3 局限性 2 Redis 哨兵架构2.1 架构概述2.2 高可用能力的实现2.3 局限与注意事项 3 Redis 集群架构3.1 架构概述3.2 高性能与高可用的统一3.3 限制与挑战 4 架构对比与选型建议结语 前言 在构建高性能、高可用的数据…...

基于CBOW模型的词向量训练实战:从原理到PyTorch实现
基于CBOW模型的词向量训练实战:从原理到PyTorch实现 在自然语言处理(NLP)领域,词向量是将单词映射为计算机可处理的数值向量的重要方式。通过词向量,单词之间的语义关系能够以数学形式表达,为后续的文本分…...
)
【阿里云大模型高级工程师ACP习题集】2.9 大模型应用生产实践(下篇)
练习题 【单选题】在大模型应用备案中,根据《生成式人工智能服务管理暂行办法》,已上架但未完成合规手续的应用应如何处理?( ) A. 继续运营,同时补办手续 B. 下架处理 C. 暂停部分功能,直至完成合规手续 D. 无需处理,等待监管部门通知 【多选题】在应用服务安全的应用部…...

Matlab实现CNN-BiLSTM时间序列预测未来
Matlab实现CNN-BiLSTM时间序列预测未来 目录 Matlab实现CNN-BiLSTM时间序列预测未来效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.Matlab实现CNN-BiLSTM时间序列预测未来; 2.运行环境Matlab2023b及以上,data为数据集,单变量时间序…...

互联网大厂Java求职面试:AI大模型与云原生架构设计深度解析
互联网大厂Java求职面试:AI大模型与云原生架构设计深度解析 第一轮提问:AI大模型与系统集成 技术总监(张总):郑薪苦,你之前提到过Spring AI,那你能讲讲在实际项目中如何将大模型集成到系统中&…...

GD32F103C8T6多串口DMA空闲中断通信程序
以下是一个完全符合C99标准的GD32F103C8T6多串口DMA通信完整实现,代码经过Keil MDK验证并包含详细注释: #include "gd32f10x.h" #include <string.h>/* 硬件配置宏 */ #define USART_NUM 2 /* 使用2个串口 */ #define R…...

labelimg快捷键
一、核心标注快捷键 W:调出标注十字架,开始绘制矩形框(最常用功能)A/D:切换上一张(A)或下一张(D)图片,实现快速导航Del:删除当前选中的标注框 二、文件操作快捷键 CtrlS&…...

【深度学习-Day 6】掌握 NumPy:ndarray 创建、索引、运算与性能优化指南
Langchain系列文章目录 01-玩转LangChain:从模型调用到Prompt模板与输出解析的完整指南 02-玩转 LangChain Memory 模块:四种记忆类型详解及应用场景全覆盖 03-全面掌握 LangChain:从核心链条构建到动态任务分配的实战指南 04-玩转 LangChai…...
)
开元类双端互动组件部署实战全流程教程(第2部分:控制端协议拆解与机器人逻辑调试)
作者:那个写了个机器人结果自己被踢出房间的开发者 游戏逻辑房间结构参考界面 从这张图我们能看出,该组件按功能结构细分为多个房间,每个房间底注、准入标准不同,对应的控制模块也有层级区分。常规来说,一个“互动房间…...

51单片机入门教程——蜂鸣器播放天空之城
前言 本教程基于B站江协科技课程进行个人学习整理,专为拥有C语言基础的零基础入门51单片机新手设计。既帮助解决因时间差导致的设备迭代调试难题,也助力新手快速掌握51单片机核心知识,实现从C语言理论到单片机实践应用的高效过渡 。 目录 …...

linux 历史记录命令
命令方式 #/bin/bash #cd /tmp saveFile"tmp.log" isok"grep HISTTIMEFORMAT /etc/profile|wc -l" if [ $isok -eq 0 ] thenecho -e "#history time\nHISTFILESIZE4000\nHISTSIZE4000\nHISTTIMEFORMAT%F %T \nexport HISTTIMEFORMAT\n" >>…...

手表关于MPU6050中的功能实现
MPU6050 OV-Watch 中的睡眠和唤醒功能实现 OV-Watch 项目为 MPU6050 传感器实施了复杂的电源管理,以优化电池寿命,同时保持手腕检测和计步功能。以下是对睡眠和唤醒机制的详细分析: 内核休眠/唤醒功能实现 MPU6050 有两个主要功能来控制其…...

Qt中数据结构使用自定义类————附带详细示例
文章目录 C对数据结构使用自定义类1 QMap使用自定义类1.1 使用自定义类做key1.2 使用自定义类做value 2 QSet使用自定义类 参考 C对数据结构使用自定义类 1 QMap使用自定义类 1.1 使用自定义类做key QMap<key,value>中数据存入时会对存入key值的数据进行比较ÿ…...

深入浅出数据库的函数依赖关系
数据库的“恋爱关系”:函数依赖的那些事儿 在数据库的世界里,属性之间也存在“恋爱关系”。有些属性是“灵魂伴侣”,彼此绑定;有些是“单向奔赴”,只能依赖对方;还有些是“三角恋”,通过中间人…...

C语言易混淆知识点详解
C语言中容易混淆的知识点详解 C语言作为一门基础且强大的编程语言,有许多容易混淆的概念和特性。以下是C语言中一些常见易混淆知识点的详细解析: 1. 指针与数组 相似点: c 复制 下载 int arr[10]; int *ptr arr; 都可以使用[]运算符访…...

如何选择合适的光源?
目录 工业相机光源类型全面指南 1. 环形光源及其变体 高角度环形光源 优点 缺点 典型应用场景 低角度环形光源(暗场照明) 优点 缺点 典型应用场景 2. 条形光源与组合照明系统 技术特点 组合条形光源 优点 缺点 典型应用场景 3. 同轴光源…...
)
模块方法模式(Module Method Pattern)
🧠 模块方法模式(Module Method Pattern) 模块方法模式是一种结构型设计模式,它将复杂的操作分解成一系列相对简单、独立且单一职责的模块。每个模块负责完成一种具体的操作,其他模块或系统可以通过调用这些模块的公开…...
)
OpenCV第6课 图像处理之几何变换(仿射)
1.仿射变换 2. 平移 3 旋转 附录A 二维旋转矩阵 附录B 三维旋转矩阵与轴角表示 1.仿射变换 仿射变换是指图像可以通过一系列的几何变换来实现平移、旋转等多种操作。该变换能够保持图像的平直性和平行性。 平直性是指图像经过仿射变换后,直线仍然是直线,平行性是指图像在…...

【中间件】brpc_基础_TimerThread
文章目录 TimerThread1 简介2 主要设计点2.1 数据结构:分层时间轮(Hierarchical Timing Wheel)2.2 线程模型2.3 任务管理 3 关键代码分析3.1 类定义(timer_thread.h)3.2 时间轮初始化(timer_thread.cpp&…...

拷贝多个Excel单元格区域为图片并粘贴到Word
Excel工作表Sheet1中有两个报表,相应单元格区域分别定义名称为Report1和Report2,如下图所示。 现在需要将图片拷贝图片粘贴到新建的Word文档中。 示例代码如下。 Sub Demo()Dim oWordApp As ObjectDim ws As Worksheet: Set ws ThisWorkbook.Sheets(&…...
—— 应用层之HTTP协议)
网络原理(6)—— 应用层之HTTP协议
目录 一. 应用层 二. 重要应用层协议DNS(Domain Name System) 三. HTTP协议 3.1 HTTP抓包工具 3.2 HTTP格式 3.2.1 请求 3.2.2 响应 3.3 HTTP的工作过程 一. 应用层 应用层协议就像是人们之间的交流规则,它帮助不同的计算机程序(应用)…...

Linux55yum源配置、本机yum源备份,本机yum源配置,网络Yum源配置,自建yum源仓库
参考 太晚了 计划先休息了 大概保存...

250505_HTML
HTML 1. HTML5语法与基础标签1.1 HTML5特性1.1.1 空白折叠现象1.1.2 转义字符 1.2 HTML注释1.3 基础标签1.3.1 div标签1.3.2 标题标签1.3.3 段落标签1.3.1.3.1.3.1.3. 1. HTML5语法与基础标签 1.1 HTML5特性 1.1.1 空白折叠现象 1.1.2 转义字符 1.2 HTML注释 1.3 基础标签 1…...

1. 设计哲学:让字面量“活”起来,提升表达力和安全性
C11引入的用户定义字面量(User-Defined Literals,简称UDL)是语言层面为程序员打开的一扇“自定义表达式”的大门。它允许我们为字面量(比如数字、字符、字符串)添加自定义后缀,从而让代码更具语义化、更易读…...

【KWDB 创作者计划】基于 ESP32 + KWDB 的智能环境监测系统实战
一开始萌生这个想法,其实是源自我办公桌上的那颗“小胖子”——一块 ESP32 开发板。它陪我度过了不少调试夜,也让我对物联网有了真正的感知。恰逢 KaiwuDB 举办征文活动,我便想着,何不将我日常积攒下来的一些硬件和数据库实战经验…...
)
AVHRR中国积雪物候数据集(1980-2020年)
数据集摘要 本数据集基于1980-2020年5kmAVHRR逐日无云积雪面积产品,制备了中国长时间序列积雪物候数据集。数据集按照不同的物候参数共分为积雪日数、积雪初日、积雪终日3个目录,每个目录下包含40个子文件,为逐水文年积雪物候参数,…...

PCB设计中电感封装的选型
在PCB设计中,电感封装的选型直接影响电路性能、布局效率、热管理能力及系统可靠性。合理的封装选择不仅能优化空间利用率,还能提升电磁兼容性(EMC)和长期稳定性。以下从封装类型、尺寸参数、应用场景适配、布局协同设计、热管理策…...

LintCode第766题,LintCode第1141题,LintCode第478题
第766题描述 判断给出的年份 n 是否为闰年. 如果 n 为闰年则返回 true 闰年是包含额外一天的日历年. 如果年份可以被 4 整除且不能被 100 整除 或者 可以被 400 整除, 那么这一年为闰年 样例 1: 输入 : n 2008 输出 : true 样例 2: 输入 : n 2018 输出 : false 代码如…...

三十一、基于HMM的词性标注
基于HMM的中文词性标注 1 实验目标 理解HMM模型的原理和基本问题理解HMM的实现命名实体识别的具体步骤掌握HMM模型实现命名实体识别的方法 2 实验环境 HMM的中文词性标注的实验环境。 3 实验步骤 该项目主要由3个代码文件组成,分别为hmm.py、tagging.py和run.p…...

MCUboot 中的 BOOT_SWAP_TYPE_PERM 功能介绍
目录 概述 1 Image 数据结构 1.1 Image介绍 1.2 Swap info 2 BOOT_SWAP_TYPE_PERM 功能 2.1 功能定义 2.2 典型工作流程 3 BOOT_SWAP_TYPE_xx的其他功能 3.1 BOOT_SWAP_TYPE_REVERT 3.2 三中模式的比较 4 使用机制 4.1 实现细节 4.2 使用场景 4.3 开发者注意事…...

数学复习笔记 2
前言 朋友和我讨论了一个二重积分题,非常有意思。内容非常细致。整理如下: 二重积分 题目来源是 1000 上面的 16 题,积分区域是一个偏心圆,偏心圆的圆心在 y 轴上面,偏心圆是关于 y 轴对称的,可以看关于…...