#基础Machine Learning 算法(上)
机器学习算法的分类
机器学习算法大致可以分为三类:
-
监督学习算法 (Supervised Algorithms):在监督学习训练过程中,可以由训练数据集学到或建立一个模式(函数 / learning model),并依此模式推测新的实例。该算法要求特定的输入/输出,首先需要决定使用哪种数据作为范例。例如,文字识别应用中一个手写的字符,或一行手写文字。主要算法包括神经网络、支持向量机、最近邻居法、朴素贝叶斯法、决策树等。
-
无监督学习算法 (Unsupervised Algorithms):这类算法没有特定的目标输出,算法将数据集分为不同的组。
-
强化学习算法 (Reinforcement Algorithms):强化学习普适性强,主要基于决策进行训练,算法根据输出结果(决策)的成功或错误来训练自己,通过大量经验训练优化后的算法将能够给出较好的预测。类似有机体在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。在运筹学和控制论的语境下,强化学习被称作“近似动态规划”(approximate dynamic programming,ADP)。
-
特点 监督学习 无监督学习 数据特性 数据带有标签或期望输出 数据无标签 学习目标 学习输入输出映射关系,用于预测未知数据的输出(如分类或回归) 发现数据的内在结构和模式(如聚类、降维等) 学习过程 利用标记数据进行训练,模型通过比较预测输出和真实标签来调整参数 无标记数据,模型直接分析数据特征,发现模式和结构 常见算法 分类算法:决策树、支持向量机、朴素贝叶斯等;回归算法:线性回归、岭回归等 聚类算法:k - 均值、层次聚类等;降维算法:主成分分析(PCA)、线性判别分析(LDA)等 应用场景 分类任务:垃圾邮件识别、图像分类等;回归任务:房价预测、股票价格预测等 聚类任务:客户细分、文档聚类等;降维任务:数据可视化、特征工程等
监督学习算法
- 线性回归算法(Linear Regression):用于回归任务,通过拟合一条直线或超平面来预测连续值。
- 支持向量机算法(Support Vector Machine, SVM):用于分类任务,通过找到一个超平面来最大化不同类别之间的间隔。
- 最近邻居/k-近邻算法(K-Nearest Neighbors, KNN):用于分类和回归任务,通过查找训练集中最近的邻居来预测新样本的标签。
- 逻辑回归算法(Logistic Regression):用于分类任务,通过 logistic 函数将线性回归的输出映射到概率值。
- 决策树算法(Decision Tree):用于分类和回归任务,通过构建树形结构来进行决策。
- 随机森林算法(Random Forest):用于分类和回归任务,是一种集成学习方法,通过构建多个决策树并综合它们的结果来进行预测。
- 朴素贝叶斯算法(Naive Bayes):用于分类任务,基于贝叶斯定理,并假设特征之间相互独立。
无监督学习算法
- k-平均算法(K-Means):用于聚类任务,将数据集划分为 k 个簇,每个簇由其均值表示。
- 降维算法(Dimensional Reduction):包括主成分分析(PCA)、t-SNE 等,用于减少数据的特征维度,常用于数据可视化和特征工程。
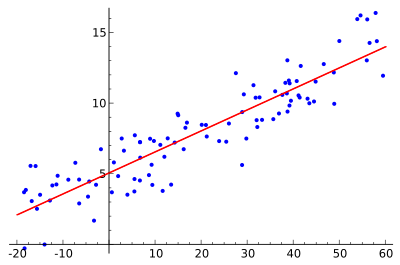
1. 线性回归算法 Linear Regression
回归分析(Regression Analysis)是统计学的数据分析方法,目的在于了解两个或多个变量间是否相关、相关方向与强度,并建立数学模型以便观察特定变量来预测其它变量的变化情况。
线性回归算法(Linear Regression)的建模过程就是使用数据点来寻找最佳拟合线。公式,y = mx + c,其中 y 是因变量,x 是自变量,利用给定的数据集求 m 和 c 的值。
线性回归又分为两种类型,即 简单线性回归(simple linear regression),只有 1 个自变量;*多变量回归(multiple regression),至少两组以上自变量。
公式
线性回归的公式通常表示为:
y = m ⋅ x + c \ y = m \cdot x + c \ y=m⋅x+c
其中:
- ( y ) 是因变量(我们想要预测的值)。
- ( x ) 是自变量(用于预测 ( y ) 的值)。
- ( m ) 是斜率,表示 ( x ) 变化一个单位时 ( y ) 的变化量。
- ( c ) 是截距,表示当 ( x = 0 ) 时 ( y ) 的值。
在多变量线性回归中,公式可以扩展为:
y = m 1 ⋅ x 1 + m 2 ⋅ x 2 + … + m n ⋅ x n + c \ y = m_1 \cdot x_1 + m_2 \cdot x_2 + \ldots + m_n \cdot x_n + c \ y=m1⋅x1+m2⋅x2+…+mn⋅xn+c
其中
x 1 , x 2 , … , x n \ x_1, x_2, \ldots, x_n \ x1,x2,…,xn
是多个自变量,
m 1 , m 2 , … , m n \ m_1, m_2, \ldots, m_n \ m1,m2,…,mn
是对应的系数。
例子
假设有如下数据集,描述了房屋面积(平方米)与房价(万元)之间的关系:
| 房屋面积(( x )) | 房价(( y )) |
|---|---|
| 50 | 60 |
| 70 | 80 |
| 90 | 100 |
| 110 | 120 |
| 130 | 140 |
我们想找到一条直线来描述房屋面积和房价之间的关系,以便预测新房屋的房价。
简单线性回归
在这个例子中,我们只有一个自变量(房屋面积),因此使用简单线性回归。
-
计算平均值:
-
x ˉ = 50 + 70 + 90 + 110 + 130 5 = 90 \ \bar{x} = \frac{50 + 70 + 90 + 110 + 130}{5} = 90 \ xˉ=550+70+90+110+130=90
-
b a r y = 60 + 80 + 100 + 120 + 140 5 = 100 \\bar{y} = \frac{60 + 80 + 100 + 120 + 140}{5} = 100 \ bary=560+80+100+120+140=100
-
-
计算斜率(( m )):
m = ∑ i = 1 n ( x i − x ˉ ) ( y i − y ˉ ) ∑ i = 1 n ( x i − x ˉ ) 2 \ m = \frac{\sum_{i=1}^{n} (x_i - \bar{x})(y_i - \bar{y})}{\sum_{i=1}^{n} (x_i - \bar{x})^2} \ m=∑i=1n(xi−xˉ)2∑i=1n(xi−xˉ)(yi−yˉ)
代入数据:
m = ( 50 − 90 ) ( 60 − 100 ) + ( 70 − 90 ) ( 80 − 100 ) + ( 90 − 90 ) ( 100 − 100 ) + ( 110 − 90 ) ( 120 − 100 ) + ( 130 − 90 ) ( 140 − 100 ) ( 50 − 90 ) 2 + ( 70 − 90 ) 2 + ( 90 − 90 ) 2 + ( 110 − 90 ) 2 + ( 130 − 90 ) 2 \ m = \frac{(50-90)(60-100) + (70-90)(80-100) + (90-90)(100-100) + (110-90)(120-100) + (130-90)(140-100)}{(50-90)^2 + (70-90)^2 + (90-90)^2 + (110-90)^2 + (130-90)^2} \ m=(50−90)2+(70−90)2+(90−90)2+(110−90)2+(130−90)2(50−90)(60−100)+(70−90)(80−100)+(90−90)(100−100)+(110−90)(120−100)+(130−90)(140−100)
计算分子和分母:-
分子:
( − 40 ) ( − 40 ) + ( − 20 ) ( − 20 ) + ( 0 ) ( 0 ) + ( 20 ) ( 20 ) + ( 40 ) ( 40 ) = 1600 + 400 + 0 + 400 + 1600 = 4000 \ (-40)(-40) + (-20)(-20) + (0)(0) + (20)(20) + (40)(40) = 1600 + 400 + 0 + 400 + 1600 = 4000 \ (−40)(−40)+(−20)(−20)+(0)(0)+(20)(20)+(40)(40)=1600+400+0+400+1600=4000 -
分母:
KaTeX parse error: Can't use function '\(' in math mode at position 2: \̲(̲-40)^2 + (-20)^… -
斜率:
m = 4000 4000 = 1 \ m = \frac{4000}{4000} = 1 \ m=40004000=1
-
-
计算截距(( c )):
c = y ˉ − m ⋅ x ˉ = 100 − 1 ⋅ 90 = 10 \ c = \bar{y} - m \cdot \bar{x} = 100 - 1 \cdot 90 = 10 \ c=yˉ−m⋅xˉ=100−1⋅90=10 -
回归方程:
y = 1 ⋅ x + 10 \ y = 1 \cdot x + 10 \ y=1⋅x+10
预测
现在,我们可以使用这个方程来预测新房屋的房价。例如,如果房屋面积是 100 平方米,预测的房价为:
y = 1 ⋅ 100 + 10 = 110 万元 \ y = 1 \cdot 100 + 10 = 110 \text{ 万元} \ y=1⋅100+10=110 万元
多变量线性回归
如果数据集中包含多个自变量,例如房屋面积和房间数量,我们使用多变量线性回归:
| 房屋面积(( x_1 )) | 房间数量(( x_2 )) | 房价(( y )) |
|---|---|---|
| 50 | 2 | 60 |
| 70 | 3 | 80 |
| 90 | 4 | 100 |
| 110 | 5 | 120 |
| 130 | 6 | 140 |
-
建立模型:
y = m 1 ⋅ x 1 + m 2 ⋅ x 2 + c \ y = m_1 \cdot x_1 + m_2 \cdot x_2 + c \ y=m1⋅x1+m2⋅x2+c -
使用线性回归算法(如梯度下降或最小二乘法)来求解 ( m_1 )、( m_2 ) 和 ( c )。
-
预测:使用求得的参数来预测新房屋的房价。
通过这个简单的例子,可以看出线性回归如何通过拟合数据点来建立预测模型。
2. 支持向量机算法(Support Vector Machine,SVM)
支持向量机(SVM)是一种用于分类任务的监督学习算法。它的基本思想是将数据点映射到高维空间中,并找到一个最优的超平面来分隔不同类别的数据点。这个超平面的选择不仅要正确分类训练数据,还要最大化与最近数据点(支持向量)之间的距离,以提高模型的泛化能力。需要注意的是,支持向量机需要对输入数据进行完全标记,仅直接适用于二分类任务,应用将多类任务需要减少到几个二元问题。
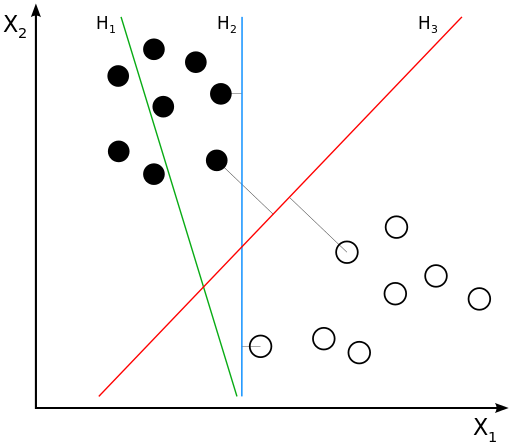
举例说明
假设有如下数据集,描述了两类不同类别的点,用 x 和 y 表示两个特征:
表格
复制
| x | y | 类别 |
|---|---|---|
| 1 | 2 | A |
| 2 | 3 | A |
| 3 | 3 | A |
| 6 | 7 | B |
| 7 | 8 | B |
| 8 | 9 | B |
我们的目标是找到一个超平面来分隔类别 A 和类别 B。
线性可分情况
-
数据可视化:
- 将数据点绘制在二维平面上,类别 A 的点分布在左边,类别 B 的点分布在右边。
-
寻找最优超平面:
-
SVM 会找到一个超平面,使得这个超平面与最近的类别 A 和类别 B 的点之间的距离最大化。
-
假设找到的最优超平面方程为:
w1x+w2y+b=0
-
支持向量是那些离超平面最近的点,例如类别 A 中的点 (3, 3) 和类别 B 中的点 (6, 7)。
-
-
间隔计算:
- 计算支持向量到超平面的距离,并最大化这个距离。
-
分类决策:
- 对于新的数据点,根据其在超平面的哪一侧来判断其类别。
非线性可分情况
假设数据集如下,描述了两类不同类别的点,但这些点在二维空间中无法用一条直线分隔:
表格
复制
| x | y | 类别 |
|---|---|---|
| 1 | 1 | A |
| 2 | 2 | A |
| 3 | 3 | A |
| 2 | 4 | B |
| 3 | 5 | B |
| 4 | 6 | B |
-
数据可视化:
- 将数据点绘制在二维平面上,类别 A 的点分布在左下角,类别 B 的点分布在右上角,但无法用一条直线分隔。
-
核技巧:
-
使用径向基函数核(RBF)将数据映射到高维空间中,使其在高维空间中线性可分。
-
RBF 核函数定义为:
K(x,x′)=exp(−γ∥x−x′∥2)
其中,γ 是核函数的参数,控制映射到高维空间的程度。
-
-
寻找最优超平面:
- 在高维空间中找到一个超平面来分隔数据点。
- 支持向量是那些离超平面最近的点。
-
分类决策:
- 对于新的数据点,将其映射到高维空间后,根据其在超平面的哪一侧来判断其类别。
3. 最近邻居/k-近邻算法 (K-Nearest Neighbors,KNN)
KNN算法是一种基于实例的学习,或者是局部近似和将所有计算推迟到分类之后的惰性学习。用最近的邻居(k)来预测未知数据点。k 值是预测精度的一个关键因素,无论是分类还是回归,衡量邻居的权重都非常有用,较近邻居的权重比较远邻居的权重大。
KNN 算法的缺点是对数据的局部结构非常敏感。计算量大,需要对数据进行规范化处理,使每个数据点都在相同的范围。
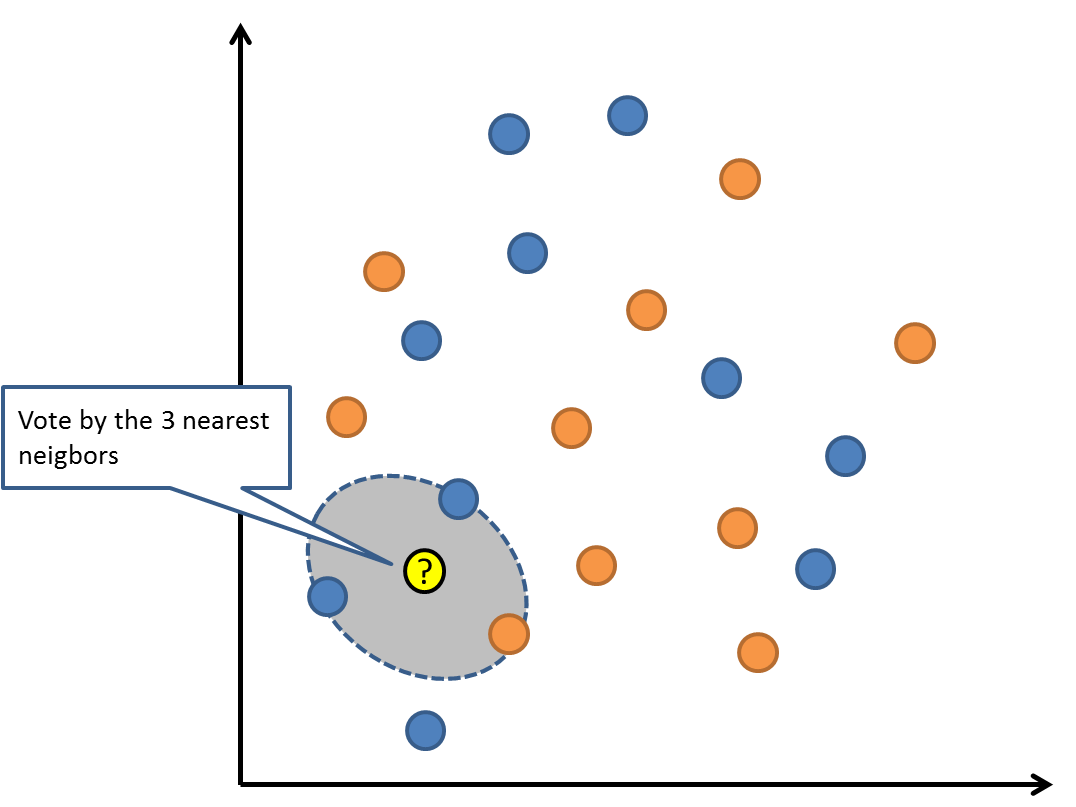
- KNN 也可以用于回归问题。例如,我们有一组房屋,的数据包括房屋的面积、房龄等特征以及房价(目标变量)。当我们想要预测一套新房子的价格时,就找到训练集中与新房子在面积和房龄等方面最相似的 k 个房子,然后取这 k 个房子价格的平均值作为新房子的预测价格。不过,回归问题中的 KNN 实现细节和应用场景相对分类问题有所不同,主要在于输出结果是从连续值中预测而不是分类标签。
4. 逻辑回归算法 Logistic Regression
逻辑回归是一种用于解决二分类问题的监督学习算法(也可以通过一些扩展方法用于多分类)。它的目标是找到一个决策边界,将不同类别的数据点分开。例如,在一个二维平面上,这可能是一条直线或曲线,用于区分两类样本。
逻辑回归算法(Logistic Regression)一般用于需要明确输出的场景,如某些事件的发生(预测是否会发生降雨)。通常,逻辑回归使用某种函数将概率值压缩到某一特定范围。
逻辑回归模型的输出是一个概率值,表示样本属于某个类别的概率。这个概率值通过逻辑函数(也称为 sigmoid 函数)来计算。逻辑函数的数学表达式为:
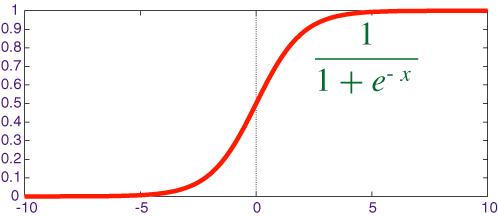
其中 z 是线性组合(如 z=θ0+θ1x1+θ2x2+⋯+θnx**n)。


5.决策树算法 Decision Tree
决策树(Decision tree)是一种特殊的树结构,由一个决策图和可能的结果(例如成本和风险)组成,用来辅助决策。机器学习中,决策树是一个预测模型,树中每个节点表示某个对象,而每个分叉路径则代表某个可能的属性值,而每个叶节点则对应从根节点到该叶节点所经历的路径所表示的对象的值。决策树仅有单一输出,通常该算法用于解决分类问题。
一个决策树包含三种类型的节点:
- 决策节点:通常用矩形框来表示
- 机会节点:通常用圆圈来表示
- 终结点:通常用三角形来表示
简单决策树算法案例,确定人群中谁喜欢使用信用卡。考虑人群的年龄和婚姻状况,如果年龄在30岁或是已婚,人们更倾向于选择信用卡,反之则更少。
通过确定合适的属性来定义更多的类别,可以进一步扩展此决策树。在这个例子中,如果一个人结婚了,他超过30岁,他们更有可能拥有信用卡(100% 偏好)。测试数据用于生成决策树。


总结
| 算法名称 | 基本原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 线性回归 | 通过拟合一条直线或多维超平面来预测连续值。 | 简单易懂,计算高效。 | 只能处理线性关系,对异常值敏感。 | 回归任务,如房价预测。 |
| 支持向量机(SVM) | 在高维空间中寻找一个最优超平面来分隔不同类别的数据点。 | 分类效果好,泛化能力强。 | 对参数选择敏感,计算复杂度高。 | 分类任务,尤其是高维数据。 |
| K-近邻(KNN) | 基于最近的邻居来预测未知数据点的类别或值。 | 简单易懂,适用于非线性数据。 | 计算量大,对数据局部结构敏感。 | 分类和回归任务。 |
| 逻辑回归 | 通过逻辑函数将线性回归的输出映射到概率值,用于二分类问题。 | 模型可解释性强。 | 假设特征独立,可能不适用于强相关特征数据。 | 二分类任务,如垃圾邮件识别。 |
| 决策树 | 通过构建树形结构来进行决策,每个节点表示某个属性的测试。 | 模型可解释性强,能处理非线性关系。 | 容易过拟合,对数据波动敏感。 | 分类任务,如客户细分。 |
相关文章:
)
#基础Machine Learning 算法(上)
机器学习算法的分类 机器学习算法大致可以分为三类: 监督学习算法 (Supervised Algorithms):在监督学习训练过程中,可以由训练数据集学到或建立一个模式(函数 / learning model),并依此模式推测新的实例。…...

【YOLO11改进】改进Conv、颈部网络STFEN、以及引入PIOU用于小目标检测!
改进后的整体网络架构 改进一:RFD模块(Conv) YOLOv11模型的跨步卷积下采样虽然快速聚合了局部特征,并且实现了较高的计算效率,但其固有的信息压缩机制会导致细粒度特征的不可逆丢失。针对特征保留与计算效率的平衡问题,本文采用RFD模块替换跨步卷积下采样模块。RFD模块通…...

算法之上的权力——空域治理的政治哲学
当AI算法成为空域资源分配的核心机制,我们不得不直面一个核心问题:谁拥有算法,谁控制算法,谁审查算法?调度系统表面上是中立技术,实则承载了深刻的价值判断与权力结构。本章提出“算法即治理”命题…...

虚幻引擎作者采访
1万小时编程_哔哩哔哩_bilibili https://www.youtube.com/watch?v477qF6QNSvc 提姆斯温尼是一位传奇性的视频游戏程序员,Epic Games 的创始人兼首席执行官。 该公司开发了虚幻引擎、堡垒之夜、战争机器、虚幻竞技场等许多开创性和有影响力的视频游戏。 他哥哥…...

CodeBlocks25配置wxWidgets3.2
一、下载CodeBlocks 25.03版本 1.去Sourceforge.net Code::Blocks - Browse /Binaries/25.03/Windows at SourceForge.net 下载codeblocks-25.03mingw-nosetup.zip 2.解压到d盘,并把目录改为codeblocks 二、.下载wxWidgets 3.2.8 1. 去Sourceforge.net wxWidg…...

Python 整理3种查看神经网络结构的方法
1. 网络结构代码 import torch import torch.nn as nn# 定义Actor-Critic模型 class ActorCritic(nn.Module):def __init__(self, state_dim, action_dim):super(ActorCritic, self).__init__()self.actor nn.Sequential(# 全连接层,输入维度为 state_dim…...
)
【Bootstrap V4系列】学习入门教程之 组件-卡片(Card)
Bootstrap V4系列 学习入门教程之 组件-卡片(Card) 卡片(Card)一、Example二、Content types 内容类型2.1 Body 主体2.2 Titles, text, and links 标题、文本和链接2.3 Images 图片2.4 List groups 列表组2.5 Kitchen sink 洗涤槽…...

AI Agent开发第50课-机器学习的基础-线性回归如何应用在商业场景中
开篇 虽然我们这个系列主讲AI Agent,但是这个系列是一个喂饭式从0到深入的全AI类计算机教程系列,它主要面向的是培养出一个个AI时代的程序员,不是像外部那种很水的只是做做套壳、聊天、绘图小工具的急功近利式教学。而机器学习是现代AI的基础与基石,一些机器学习、深度学习…...
)
代码随想录第34天:动态规划7(打家劫舍问题:链式、环式、树式房屋)
一、背包问题小结 1.递推公式: 1.问能否能装满背包(或者最多装多少):dp[j] max(dp[j], dp[j - nums[i]] nums[i]) 2.问装满背包有几种方法:dp[j] dp[j - nums[i]] 3.问背包装满最大价值:dp[j] max…...

网络安全自动化:找准边界才能筑牢安全防线
数字时代,企业每天要面对成千上万的网络攻击。面对庞大的服务器群、分散的团队和长期不重启的设备,很多企业开始思考:哪些安全操作适合交给机器自动处理?哪些必须由人工把关?今天我们就用大白话聊聊这件事。 一、这些事…...

ctfshow——web入门361~368
最近练习ssti 当 Web 应用程序使用模板引擎动态生成 HTML 页面或其他类型的输出时,如果用户输入未经过充分验证或转义就被直接嵌入到模板中,就可能发生 SSTI 攻击。攻击者可以利用这个弱点注入恶意模板代码,该代码将在服务器端执行。 常见的…...
)
备忘录模式(Memento Pattern)
🧠 备忘录模式(Memento Pattern) 备忘录模式 是行为型设计模式之一。它通过将对象的状态存储在一个备忘录中,允许对象在不暴露其内部结构的情况下,保存和恢复自己的状态。该模式允许将对象的状态保存到备忘录中&#…...

五一假期作业
sub_process.c #include <stdio.h> // 标准输入输出库 #include <pthread.h> // POSIX线程库 #include <sys/ipc.h> // IPC基础定义(如消息队列/共享内存) #include <sys/msg.h> // 消息队列操作相关…...

Multi Agents Collaboration OS:专属多智能体构建—基于业务场景流程构建专属多智能体
背景 随着人工智能技术的飞速发展,大型语言模型(LLM)的能力不断突破,单一智能体的能力边界逐渐显现。为了应对日益复杂的现实世界任务,由多个具备不同能力、可以相互协作的智能体组成的多智能体系统 (Multi-Agent Sys…...

数据库的二级索引
二级索引 10.1 二级索引作为额外的键 表结构 正如第8章提到的,二级索引本质上是包含主键的额外键值对。每个索引通过B树中的键前缀来区分。 type TableDef struct {// 用户定义的部分Name stringTypes []uint32 // 列类型Cols []string // 列名Indexes …...

湖北理元理律师事务所:债务法律服务的民生价值重构
当前我国居民杠杆率达62.3%(央行2023年数据),债务问题已从经济议题演变为社会议题。湖北理元理律师事务所通过构建覆盖咨询、备案、规划的全链条服务,试图在法律框架内探索债务危机的社会化解决方案。 民生导向的服务设计 1.阶梯…...

DotNetBrowser 3.2.0 版本发布啦!
包含来自 Chromium 135 的安全修复支持自定义用户代理客户端提示(User Agent Client Hints)在 Avalonia 离屏渲染模式中支持拖放(Drag & Drop)功能 🔗 点击此处了解更多详情。 🆓 免费试用 30 天。...

PyTorch 张量与自动微分操作
笔记 1 张量索引操作 import torch # 下标从左到右从0开始(0->第一个值), 从右到左从-1开始 # data[行下标, 列下标] # data[0轴下标, 1轴下标, 2轴下标] def dm01():# 创建张量torch.manual_seed(0)data torch.randint(low0, high10, size(4, 5))print(data->,…...

C语言数据在内存中的存储详解
在 C 语言的编程世界里,理解数据在内存中的存储方式是非常重要的,它能帮助我们更好地掌握数据类型、内存管理和程序性能优化等内容。今天,我就来给大家详细讲解数据在内存中的存储,包括整数、大小端字节序和浮点数的存储方式&…...

【AI大模型】SpringBoot整合Spring AI 核心组件使用详解
目录 一、前言 二、Spring AI介绍 2.1 Spring AI介绍 2.2 Spring AI主要特点 2.3 Spring AI核心组件 2.4 Spring AI应用场景 2.5 Spring AI优势 2.5.1 与 Spring 生态无缝集成 2.5.2 模块化设计 2.5.3 简化 AI 集成 2.5.4 支持云原生和分布式计算 2.5.5 安全性保障…...

linux-文件操作
在 Linux 系统中,文件操作与管理是日常使用和系统管理的重要组成部分。下面将详细介绍文件的复制、移动、链接创建,以及文件查找、文本处理、排序、权限管理等相关知识。 一、文件的复制 在 Linux 里,cp 命令可用于复制文件或目录ÿ…...

丢失的数字 --- 位运算
目录 一:题目 二:算法原理 三:代码实现 一:题目 题目链接: 268. 丢失的数字 - 力扣(LeetCode) 二:算法原理 三:代码实现 class Solution { public:int missingNumb…...

从Rtos到Linux:学习的策略
这里目的只是为了学习,哪天工作需要用上了能更顺利的上手,写文章的目的是为了记录和便于查询。工作的前两年主要是以mcu裸机为主,目的是压缩资源以最少的ram和flash实现最多的功能,后来五年做的东西越来越复杂的跑的rtosÿ…...

BUUCTF——Mark loves cat
BUUCTF——Mark loves cat 进入靶场 简单的看了一下功能点 扫一下目录吧 扫目录发现一个.git 下一下源码看看 找到个flag.php和index.php <?php$flag file_get_contents(/flag);再看看index.php(代码有点长,所以只留了后面有用的) &…...

C/C++滑动窗口算法深度解析与实战指南
C/C滑动窗口算法深度解析与实战指南 引言 滑动窗口算法是解决数组/字符串连续子序列问题的利器,通过动态调整窗口边界,将暴力解法的O(n)时间复杂度优化至O(n)。本文将系统讲解滑动窗口的核心原理、C/C实现技巧及经典应用场景,助您掌握这一高…...
)
Webug4.0靶场通关笔记15- 第19关文件上传(畸形文件)
目录 第19关 文件上传(畸形文件) 1.打开靶场 2.源码分析 (1)客户端源码 (2)服务器源码 3.渗透实战 (1)构造脚本 (2)双写绕过 (3)访问脚本 本文通过《…...

黑马点评大总结
8.2.1 短信登录 首先是用户提交手机号,后端将生成的验证码以及用户信息存入session中,用户登录时进行拦截并从session中拿出来信息校验,并把用户信息存入ThreadLocal中session共享问题:每个tomcat有自己的一份session,…...

LeetCode:返回倒数第k个结点
1、题目描述 实现一种算法,找出单向链表中倒数第 k 个节点。返回该节点的值。 注意:本题相对原题稍作改动 示例: 输入: 1->2->3->4->5 和 k 2 输出: 4 说明: 给定的 k 保证是有效的。 2、…...

zotero pdf中英翻译插件使用
最近发现一个pdf中英翻译的神器zotero-pdf2zh,按照官方安装教程走一遍的时候,发现一些流程不清楚的问题, 此文就是整理一些安装需要的文件以及遇到的问题: 相关文件下载地址 Zotero 是一款免费的、开源的文献管理工具࿰…...

Java后端程序员学习前端之CSS
什么是css Cascading Style Sheet 层叠级联样式表 表现 (美化网页) 字体,颜色,边距,高度,宽度,背景图片,网页定位,网页浮动.. 发展史 CSS1.0 CSS2.0 DIV(块)CSS,HTML与CSS结构分离…...

MySQL——数据库基础操作
学习MySQL之前,要先配置好相关环境与软件下载,怎么就不展开了:找找网上对应环境下的教程即可 目录 数据库与MySQL 案例使用 MySQL架构 SQL指令分类 储存引擎 库操作 创建数据库 编码集与校验规则 校验规则的影响 删除数据库 数…...

[低代码 + AI] 明道云与 Dify 的三种融合实践方式详解
随着低代码平台和大语言模型工具的不断发展,将企业数据与智能交互能力融合,成为提高办公效率与自动化水平的关键一步。明道云作为一款成熟的低代码平台,Dify 则是一个支持自定义工作流的开源 LLM 应用框架。两者结合,可以实现灵活、高效的智能化业务处理。 本文将详解明道…...

湖北理元理律师事务所:规模化债事服务的探索与实践
在个人债务问题日益普遍化的当下,如何通过合法、系统化的服务帮助债务人化解危机,成为法律服务业的重要课题。湖北理元理律师事务所作为经国家司法局批准设立的债事服务机构,其构建的“法律技术金融”服务模式,为债务优化领域提供…...

MySQL JOIN详解:掌握数据关联的核心技能
一、为什么需要JOIN? 在关系型数据库中,数据通常被拆分到不同的表中以提高存储效率。当我们需要从多个表中组合数据时,JOIN操作就成为了最关键的技能。通过本文,您将全面掌握MySQL中7种JOIN操作,并学会如何在实际场景中…...

深入浅出数据库规范化的三大范式
数据库的“成长之路”:从1NF到3NF的规范化进化 在数据库的世界里,关系模式就像一个“孩子”,需要一步步学习“规矩”,才能健康成长。今天,我们就来聊聊数据库的规范化历程——从第一范式(1NF)出…...
:SaaS与移动应用商业模式的关键要点剖析)
精益数据分析(39/126):SaaS与移动应用商业模式的关键要点剖析
精益数据分析(39/126):SaaS与移动应用商业模式的关键要点剖析 在创业和数据分析的探索之旅中,每一次深入研究不同的商业模式都是一次宝贵的学习机会。今天,依旧怀揣着与大家共同进步的期望,深入解读《精益…...
)
【PostgreSQL数据分析实战:从数据清洗到可视化全流程】4.3 数据脱敏与安全(模糊处理/掩码技术)
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 PostgreSQL数据脱敏实战:从模糊处理到动态掩码的全流程解析4.3 数据脱敏与安全:模糊处理与掩码技术深度实践4.3.1 数据脱敏的核心技术体系4.3.1.1 技…...

nginx面试题
nginx 返回状态码413 Nginx 状态码 413 表示“请求实体过大”(Request Entity Too Large),意味着客户端发送的请求体大小超过了服务器允许的限制。 解决方法 修改 Nginx 配置文件: 找到 Nginx 配置文件,通常位于 /etc…...

flink rocksdb状态说明
文章目录 1.默认情况2.flink中的状态3.RocksDB4.对比情况5.使用6.RocksDB架构7.参考文章8.总结提示:以下主要考虑flink 状态永久存储 rocksdb情况,做一些简单说明 1.默认情况 当flink使用rocksdb存储状态时。无论是永久存储还是临时存储都可能会落盘写文件(如果没有配置存储…...

Linux | WEB服务器的部署及优化
一. web服务的常用知识 1.1 www www(World Wide Web):即为万维网,常被称为“全球信息广播”。它是一种基于超文本和HTTP协议,能够将文字、图形、影像以及声音等多媒体信息,通过超链接的方式组织在一起&…...

Nginx正反向代理与正则表达式
目录 一:正向代理 1.编译安装nginx 2.配置正向代理 二:反向代理 1.配置nginx七层代理 2.配置nginx四层代理 三:nginx 缓存 1.缓存功能的核心原理和缓存类型 2.代理缓存功能设置 四:nginx rewrite 和正则表达式 1.Nginx…...

字节:LLM自动化证明工程基准
📖标题:APE-Bench I: Towards File-level Automated Proof Engineering of Formal Math Libraries 🌐来源:arXiv, 2504.19110 🌟摘要 🔸大型语言模型(LLM)的最新进展在形式定理证明…...

豆包多轮对话优化策略:上下文理解与记忆,意图识别,对话管理
豆包多轮对话优化策略:上下文理解与记忆,意图识别,对话管理 上下文理解与记忆:我会分析每一轮用户输入的文本内容,理解其中的语义、意图和关键信息,并将这些信息与之前轮次的对话内容相结合,形成对整个对话上下文的理解和记忆。例如,在一个关于旅游规划的对话中,用户先…...

ADK 第四篇 Runner 执行器
智能体执行器 Runner,负责完成一次用户需求的响应,是ADK中真正让Agent运行起来的引擎,其核心功能和Agents SDK中的Runner类似,具体作用如下: 会话管理:自动读取/写入 SessionService,维护历史信…...

yolo 用roboflow标注的数据集本地训练 kaggle训练 comet使用 训练笔记5
本地训练 8gb内存,机械硬盘用了4分钟训练完了 ........... model torch.hub.load(path/to/yolov5, custom, path./runs/train/exp10/weights/best.pt, sourcelocal) 连不上github kaggel训练 传kaggle了 # Train YOLOv5s on COCO128 for 3 epochs !python train…...

chili3d笔记11 连接yolo python http.server 跨域请求 flask
from ultralytics import YOLO from flask import Flask, request, jsonify from flask_cors import CORS import base64 from io import BytesIO from PIL import Image import json# 加载模型 model YOLO(./yolo_detect/best.pt)app Flask(__name__) CORS(app) # 启用跨域…...

安全为上,在系统威胁建模中使用量化分析
*注:Open FAIR™ 知识体系是一种开放和独立的信息风险分析方法。它为理解、分析和度量信息风险提供了分类和方法。Open FAIR作为领先的风险分析方法论,已得到越来越多的大型组织认可。 在数字化风险与日俱增的今天,企业安全决策正面临双重挑战…...

STA中的multi_cycle 和false_path详细讨论
特殊路径:跨时钟域下的exception_path:分为多种情况优先 1、不同clk_domain ,但频率相同 create_clock -name CLKM -period 10 -waveform {0 5} [get_ports CLKM] create_clock -name CLKP -period 10 -waveform {0 5} [get_ports CLKP] set_multicycl…...

Vite 的工作流程
Vite 的工作流程基于其创新的 “预构建 按需加载” 机制,通过利用现代浏览器对原生 ES 模块的支持,显著提升了开发效率和构建速度。以下是其核心工作流程的详细分析: 一、开发环境工作流程 1. 启动开发服务器 冷启动:通过 npm …...

NGINX 的 ngx_http_auth_jwt_module模块
一、模块概述 ngx_http_auth_jwt_module 模块用于通过验证请求中提供的 JWT 来进行客户端授权。此模块支持 JSON Web 签名(JWS)、JSON Web 加密(JWE)以及嵌套 JWT(Nested JWT),使其成为一种灵活…...