Multi Agents Collaboration OS:专属多智能体构建—基于业务场景流程构建专属多智能体
背景
随着人工智能技术的飞速发展,大型语言模型(LLM)的能力不断突破,单一智能体的能力边界逐渐显现。为了应对日益复杂的现实世界任务,由多个具备不同能力、可以相互协作的智能体组成的多智能体系统 (Multi-Agent System, MAS) 成为了新的研究热点和发展方向。多智能体系统通过模拟团队协作的方式,能够处理更庞大、更精细、更需要多元知识和能力的复杂问题,在自动化办公、智能决策、流程优化等领域展现出巨大的应用潜力。
然而,构建一个高效、稳定且贴合具体业务需求的多智能体系统并非易事。传统的开发方式往往面临以下挑战:
-
高定制化门槛:不同的业务场景需要不同的智能体角色、知识背景、数据源以及协作逻辑,导致开发周期长、成本高。
-
协作流程定义复杂:如何设计智能体之间的交互方式、信息流转路径、任务分配和结果汇总机制,是确保系统有效运行的关键,也是设计的难点。
-
集成与部署困难:将开发好的多智能体系统无缝对接到现有的业务系统、数据平台或报表工具中,需要考虑接口兼容性、数据一致性等问题。
为了解决这些痛点,我们提出了【Multi Agents Collaboration OS:专属多智能体构建—基于业务场景流程构建专属多智能体】—— 一个旨在简化和标准化多智能体系统构建流程的平台。
核心理念是“基于业务场景流程构建专属多智能体”。它允许用户通过描述具体的业务场景和执行流程,来定义所需的多智能体协作体系。平台根据用户输入的描述信息,能够:
智能创建或选用智能体 (Agents):根据任务需求,自动配置或创建具备特定技能(如数据分析、报告撰写、用户交互等)的智能体。
关联数据与知识 (Data & Knowledge):为智能体接入所需的数据库、文件、知识库等信息资源。
编排协作流程 (Workflows):定义智能体之间的交互逻辑、任务依赖关系和整体工作流。用户只需提供业务场景的描述和智能体协作的需求,平台即可完成从智能体创建、数据知识整合到协作流程编排的全过程。
更重要的是,Multi Agents Collaboration OS 可以将为特定业务场景构建好的多智能体协作体系,封装成标准的 API 服务。这意味着,用户可以将这些强大的、具备自主协作能力的“智能体团队”轻松集成到他们现有的业务系统、报表系统、数据分析平台或其他任何需要智能化能力的系统中,极大地提升了业务流程的自动化和智能化水平,实现了 AI 能力的按需赋能。
本篇博客将深入探讨 Multi Agents Collaboration OS 的设计思路、核心功能以及如何利用它来为您的业务场景构建专属的多智能体解决方案。
核心流程及技术模块
“Multi Agents Collaboration OS”平台的核心价值在于其能够根据用户提供的业务场景和流程描述,智能地完成多智能体系统的构建、编排和部署,极大地降低了用户的开发和集成成本。其核心业务流程可以概括为以下几个由平台智能化驱动的关键步骤:
1. 业务场景与流程的智能理解与建模:AI赋能的蓝图绘制
用户通过自然语言描述或结构化输入等方式,向平台提供其业务场景和期望的执行流程。平台利用其强大的语言理解和知识图谱能力:
- 智能解析业务目标: 平台能够理解用户的意图和期望解决的问题,例如自动化审批流程、智能客户服务、营销活动优化等。
- 自动化流程建模: 基于用户的描述,平台智能地识别流程中的关键步骤、参与者和数据流转,并将其转化为平台内部可执行的流程模型。这避免了用户手动绘制复杂流程图的繁琐工作。
- 智能识别协作需求: 平台自动分析流程模型,识别出哪些环节可以通过多智能体协作来提升效率或效果,并初步判断所需的智能体类型和协作模式。
- 智能识别数据与知识需求: 平台预测各个智能体在执行任务过程中可能需要的数据来源和知识背景,为后续的数据和知识关联奠定基础。
2. 智能体、数据、知识的自动化创建与关联:一键式构建智能基石
基于对业务场景和流程的智能理解,平台能够自动化地完成智能体、数据和知识的准备工作:
- 智能体创建与选用 (智能体【创建】):
- 智能角色推荐: 平台根据任务需求智能推荐预置的智能体角色,例如数据分析师、报告生成器、自然语言交互器等。
- 自动化能力配置: 平台根据角色需求自动配置智能体的核心能力,例如数据处理算法、文本生成模型、对话管理模块等。
- 动态智能体生成: 对于更 विशिष्ट 的需求,平台能够动态生成具备特定技能的轻量级智能体。
- 智能数据关联 (数据|业务场景):
- 智能数据源识别: 平台自动识别用户描述中提及或流程模型中涉及的数据源,并引导用户进行授权连接。
- 自动化数据Schema映射: 平台智能地将数据源的Schema映射到智能体可理解的数据结构。
- 智能数据预处理建议: 平台分析数据质量,并为用户提供数据清洗、转换等预处理建议。
- 智能知识关联 (知识|业务场景):
- 智能知识库推荐: 平台根据业务场景和智能体角色,智能推荐相关的知识库或知识片段。
- 自动化知识抽取与嵌入: 平台能够自动地从用户提供的文档或其他知识源中抽取关键信息,并将其嵌入到智能体的知识体系中。
3. 智能协作流程编排 (场景多智能体创建):无需编码的智能协同设计
平台的核心创新在于其能够智能地编排智能体之间的协作流程:
- 智能协作模式推荐: 平台根据任务特性和智能体能力,智能推荐合适的协作模式,例如任务分解、信息共享、协商协调等。
- 可视化流程编排: 用户可以通过直观的图形化界面,拖拽和连接智能体节点,定义它们之间的交互顺序、触发条件和数据流转。平台在后台自动生成可执行的协作逻辑。
- 基于意图的流程定义: 用户只需描述智能体之间的协作意图(例如,“数据分析完成后通知报告生成器”),平台自动完成底层的消息传递和任务调度。
- 智能冲突解决策略: 平台内置常见的冲突解决策略,并允许用户根据业务需求进行配置。
4. 业务场景多智能体的自动化封装与发布 (业务场景多智能体):一键生成智能API
一旦多智能体协作系统构建完成,平台能够自动化地将其封装成标准的API服务:
- 自动化API生成: 平台自动生成符合RESTful等标准的API接口,无需用户进行复杂的API开发工作。
- 自动化API文档生成: 平台自动生成清晰、完整的API文档,包括接口描述、请求参数、响应格式等。
- 灵活的API管理: 平台提供API的版本控制、权限管理、监控和日志记录等功能。
5. 业务场景多智能体的无缝集成与应用 (场景应用):AI能力的即插即用
通过标准化的API接口,用户可以将构建好的多智能体协作能力无缝地集成到现有的各种业务系统中:
- 现有业务系统集成: 通过简单的API调用,业务系统可以轻松地利用多智能体的智能决策、自动化执行等能力。
- 报表系统智能化: 报表系统可以调用数据分析智能体的API,实现更智能的数据洞察和可视化。
- 数据系统增强: 数据系统可以利用智能体进行自动化数据清洗、集成和治理。
- 对话系统升级: 对话系统可以集成具备复杂问题解决能力的智能体,提升用户交互体验。
6. 智能场景测试与自动化发布 (场景测试 -> 业务场景发布):保障质量与效率
平台提供智能化的测试和发布流程:
- 智能测试用例生成: 平台根据业务场景和流程定义,自动生成覆盖各种场景的测试用例。
- 自动化测试执行: 平台自动执行生成的测试用例,并提供详细的测试报告。
- 智能性能评估: 平台自动评估多智能体系统的性能指标,例如响应时间、并发处理能力等。
- 一键式发布: 测试通过后,用户可以一键将多智能体系统发布为可供其他系统调用的API服务。
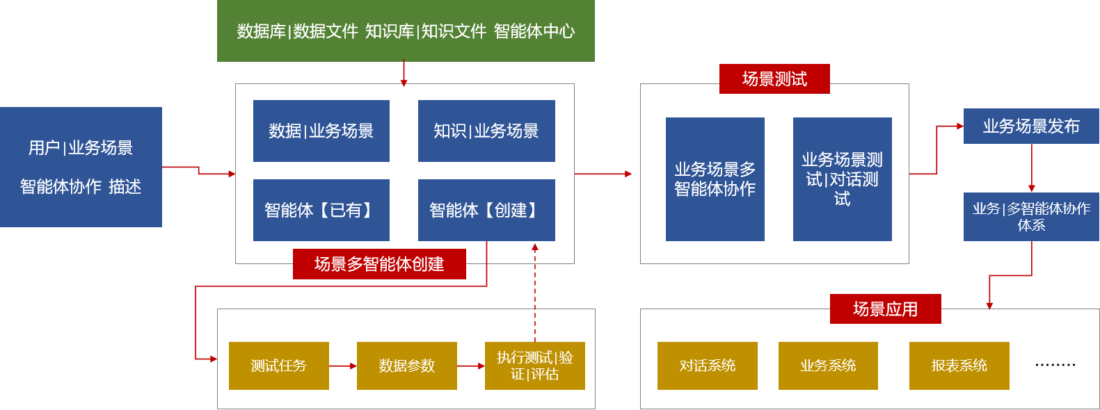
业务场景智能体设计
1. 业务场景驱动的智能体规划
平台以用户输入的业务场景为核心,通过解析用户的场景描述,结合现有的智能体资源,自动生成智能体规划。
- 智能体中心计划:优先匹配现有智能体,分配任务并定义输入参数和期望输出。
def agents_select_process(user_scenario):# 获取知识库的摘要信息with open('c:/Users/liuli/Desktop/multi_agents_system/multi_agents/kg files/kb_info.json', 'r', encoding='utf-8') as file:kb_data = json.load(file)kb_summary = []for entry in kb_data:summary = entry.get('documents_summary', 'No summary available')kb_summary.append({'file_name': entry.get('documents_file_name', 'Unknown'),'summary': summary})# 智能体中心信息with open('C:/Users/liuli/Desktop/multi_agents_system/multi_agents/agents_info/Agents Info.json', 'r', encoding='utf-8') as file:agents_center_info = json.load(file)# 数据库信息with open ('C:/Users/liuli/Desktop/multi_agents_system/multi_agents/data files/data_file.json','r',encoding='utf-8') as file:data_file_info = json.load(file)with open ("C:\\Users\\liuli\\Desktop\\multi_agents_system\\multi_agents\\data files\\database_files_summary\\databese_list_meata_info.json",'r',encoding='utf-8') as file:database_info = json.load(file)user_scenario = str(user_scenario)agents_center_info = str(agents_center_info)database_info = str(database_info)data_file_info = str(data_file_info)kb_summary = str(kb_summary)llm = ChatOpenAI(temperature=0, model=model_use)messages = [("system","""# Role: Multi-Agent Collaboration System Planning Module (Agent Planning Module)# Context:You are tasked with creating a detailed execution plan based on a user-provided business scenario. You will receive the scenario description along with information about available resources: existing agents, databases, data files, and knowledge base summaries.Your primary goal is to determine the optimal combination of resources needed to address the user's scenario by performing the following planning steps:1. **Agent Planning (Focus on Decomposition and System Design):*** **1.1. Decompose the Business Scenario:** Analyze the `user_scenario` thoroughly. Break down the overall goal into a logical sequence of smaller, distinct sub-tasks or processing stages. Identify the necessary inputs and expected outputs for each sub-task. *Aim for modularity where each sub-task could potentially be handled by a specialized agent.** **1.2. Map Sub-tasks to Agents (Prioritize Existing):** For each identified sub-task, evaluate the available `agents_center_info` to see if an existing agent possesses the required capabilities and skills.* If an existing agent matches: Add it to the `agents_center_plan`. In the `tasks` field, list the *specific sub-tasks* (from your decomposition) assigned to this agent for this scenario. Define the `expected_output` relevant to these sub-tasks and specify the required `parameters`, considering inputs needed (potentially outputs from previous agents/steps).* **1.3. Design and Plan New Agents for Gaps:** Identify any sub-tasks that cannot be effectively handled by existing agents. For each gap, design a *new, specialized agent*.* Add the new agent definition to the `agents_create_plan`.* Assign a clear, functional `agent_name`.* Write a detailed `description` explaining its specific purpose, core function, the logic or techniques it might employ (e.g., "Performs sentiment analysis using model X", "Validates data schema compliance", "Generates API call based on template"), and its role within the overall agent workflow.* List the specific `tasks` (sub-tasks from the decomposition) it is designed to perform.* Define its `expected_output` clearly (e.g., "JSON object with sentiment scores", "Boolean validation result", "Formatted API request string").* Specify the necessary input `parameters` it requires, noting dependencies on data sources or outputs from other agents in the sequence.* **1.4. Consider Agent Interaction Flow:** While planning, implicitly consider the flow of information and dependencies between agents (both existing and new). Ensure the sequence of agent tasks aligns logically with the decomposed scenario steps to form a coherent workflow.* **1.5 2. **Data Planning:** must strictly utilize the data resources contained within the user-provided database and data files.* Examine the `user_scenario` and the planned agent tasks to determine data requirements.* Identify relevant databases from `database_info` and data files from `data_file_info`.* List the necessary databases and data files in the `data_plan`, including their names, descriptions, and paths.3. **Knowledge Base Planning:**must use the knowledge resources provided by the user.* Based on the `user_scenario` and agent tasks, determine if information from the knowledge base is needed.* Identify relevant topics from the `kb_summary`.* List the required topics and a description of the specific `required_content` needed from each topic in the `knowledge_base_plan`.# Task:Generate a plan strictly in JSON format. The structure must conform *exactly* to the example below. Ensure all planning steps (Agents, Data, Knowledge Base) are covered in the output JSON.请**务必**将所有分析结果组织成一个**单一的、有效的 JSON 对象**,严格遵循以下结构。**不要**在 JSON 对象前后添加任何额外的解释、注释或介绍性文字。```json{"scenario_name":"<output a name for the scenario according to the user_scenario_input>","agents_center_plan": [// List of EXISTING agents selected for this scenario{"agent_name": "<name_of_existing_agent>","description": "<description_from_agents_center_info>","tasks": "<specific_tasks_assigned_for_this_scenario>","expected_output": "<expected_output_for_these_tasks>","code_path":"<absolute_path_to_the_code>","parameters": {// Parameters needed by this agent for these tasks, derived from the scenario// e.g., "input_data_path": "/path/to/relevant/file.csv", "target_metric": "accuracy"}}// ... more existing agents if needed],"agents_create_plan": [// List of NEW agents required for this scenario{"agent_name": "<proposed_name_for_new_agent>","description": "<clear_description_of_what_the_new_agent_does>","tasks": "<specific_tasks_the_new_agent_needs_to_perform>","expected_output": "<what_the_new_agent_should_output>","parameters": {// Input parameters the new agent will require// e.g., "data_source": "database_xyz", "analysis_type": "trend_detection"}}// ... more new agents if needed],"data_plan": {"databases": [// List of relevant databases{"database_name": "<database_name>","database_description": "<database_description>","database_file_path": "<database_file_path>"}// ... more databases if needed],"data_files": [// List of relevant data files{"data_file_name": "<data_file_name>","data_file_description": "<data_file_description>","data_file_path": "<data_file_path>"}// ... more data files if needed]},"knowledge_base_plan": [// List of relevant knowledge base topics and needed content{"topic": "<relevant_topic_from_kb_summary>","required_content": "<description_of_specific_information_needed_from_this_topic>"}// ... more topics if needed]}```"""),("human",# Use f-string formatting to insert the dynamic variables clearlyf"""please generate a detailed plan based on the following business scenario and available resources.Scenario:{user_scenario}Resources:- Agents Center Agent tools (agents_center_info): {agents_center_info}- Databases (database_info): {database_info}- data file (data_file_info): {data_file_info}- knowledge base (kb_summary): {kb_summary}Please strictly follow the JSON format defined in the System instructions to generate a complete plan that includes agent planning (distinguishing between using existing agents and creating new ones), data planning, and knowledge base planning.""")]result = llm.invoke(messages)result = result.content# 处理响应中的换行符和空格result = result.replace('```json', '').replace('```', '').strip()#results = json.loads(result)try:results = json.loads(result)except json.JSONDecodeError as e:st.error(f"Failed to parse LLM response as JSON: {e}")st.error(f"LLM Response:\n{result}")results = {"agents_center_plan": [], "agents_create_plan": [], "data_plan": {}, "knowledge_base_plan": []} # Default empty plan on errorreturn results- 智能体创建计划:针对未被覆盖的任务,自动设计新智能体,包括功能描述、任务分解、参数需求和代码生成。
def Agent_Auto_Create_plan(query_message):with open("C:\\Users\\liuli\\Desktop\\multi_agents_system\\multi_agents\\code_gen.py", 'r', encoding='gbk', errors='replace') as f:code = f.read()llm = ChatOpenAI(model=model_use,temperature=0.5,max_tokens=32000) max_iter = 3iter_count = 0last_error = ""while iter_count < max_iter:llm = ChatOpenAI(model=model_use, temperature=0.5, max_tokens=32000)if iter_count == 0:messages_cob = [("system","""You are an agent creation tool. Please create an intelligent agent based on user requirements. The output should include: agent name, description, expected output, and Python code (if input parameters are required, use appropriate parameters). Please follow these steps:-Thoroughly understand user requirements-Retrieve available modules from the code library-Generate agent information,all information must be english language.-Out your response in Json format.-All code content must be in english language.[Important] Ensure that you correctly manage escape characters within the string. Specifically, address any issues with newline characters and quotation marks in the original string. This preprocessing step is necessary to transform the string into a valid JSON format.[Important warning]All operational logic of the Agent is executed through agent_run(). A main function agent_run() must be generated!!![Note]Strict Code Format: Adhere strictly to the following code template when writing:[ import ...# Brief explanation of what this function doesdef get_(path):# Main logic herereturn file_info_dict## agents main function codedef pandas_data_analy(params):# Extract parameters from the dictionaryuser_message = params.get('user_message_for_pandas', "")file_path = params.get('uploaded_file_path_for_pandas', "")OUTPUT_FOLDER = params.get('OUTPUT_FOLDER', "")# Main function logic here# Example: perform data analysis using pandasreturn result............<Note!> The main function must be named agent_run() and must be in dictionary form.# Function to run the main execution function with input parameters <—must be in dictionary form>def agent_run(input_dict):result = pandas_data_analy(input_dict)return result]-If you need to use the services of large models and Agents, please use the following tool code:## llm model config and model reference code:with open('C:\\Users\\liuli\\Desktop\\multi_agents_system\\multi_agents\\agents_info\\model config.json', 'r') as f:config = json.load(f)if 'selected_model' in st.session_state:model_use = st.session_state.selected_modelelse:model_use = 'gemini-2.0-flash-001'model_config = config[model_use]# 设置环境变量os.environ["OPENAI_API_KEY"] = model_config['openai_api_key'] # 设置 OpenAI API Keyos.environ["OPENAI_MODEL_NAME"] = model_config['model_name'] # 设置模型名称(可选)os.environ["OPENAI_API_BASE"] = model_config['openai_api_base'] # 设置 API 地址(可选)-Import the large model service in the following way: llm = ChatOpenAI(model=model_use,temperature=0.2).【Note】Exercise caution when using modules from the code library. If their use is necessary, pay special attention to designing high-quality prompts for their application.【Note】Parameter design should align with the agent's description, ensuring differentiated and meaningful naming conventions.[Important] Ensure that you correctly manage escape characters within the string. Specifically, address any issues with newline characters and quotation marks in the original string. This preprocessing step is necessary to transform the string into a valid JSON format.The final output agent_name needs to be consistent with the agent names mentioned in the user's query (if provided by the user)..Out your response in Json format,Please note, do not output additional information, only output content in JSON format, and the structure should be similar to the following:# Output Format Instructions:Please ensure that all analysis results are organized into a single, valid JSON object, strictly adhering to the following structure. Do not add any extra explanations, comments, or introductory text before or after the JSON object.Important Warning: Keep the agent's code as concise as possible, and other information should be as refined and accurate as possible. The output content must be complete and a valid JSON format, with the total number of characters not exceeding 20,000!=================JSON format example===================```json{ "agent_name": '<agent_name>',"agent_description": '<agent_description>',"agent_expected_output": '<agent_expected_output>',"agent_code": '<agent_code,python>',"agent_input_parameters": '<agent_input_parameters,like:{"prompt": "","BASE_PATH": ""}>'}"""),("human", 'The code library is:' + str(code) + 'You can reference available modules from this code repository. Example of invocation:from code_gen import ..../nThe Agent info is:' + str(query_message) + './nNote:Do not arbitrarily change the relevant information of the agents in the incoming agents info, especially the names of the agents!')]else:# 反馈上一次的错误信息,要求修正messages_cob = [("system","""You are an agent creation tool. Please create an intelligent agent based on user requirements. The output should include: agent name, description, expected output, and Python code (if input parameters are required, use appropriate parameters). Please follow these steps:-Thoroughly understand user requirements-Retrieve available modules from the code library-Generate agent information,all information must be english language.-Out your response in Json format.-All code content must be in english language.[Important] Ensure that you correctly manage escape characters within the string. Specifically, address any issues with newline characters and quotation marks in the original string. This preprocessing step is necessary to transform the string into a valid JSON format.[Important warning]All operational logic of the Agent is executed through agent_run(). A main function agent_run() must be generated!!![Note]Strict Code Format: Adhere strictly to the following code template when writing:[ import ...# Brief explanation of what this function doesdef get_(path):# Main logic herereturn file_info_dict## Main function codedef pandas_data_analy(params):# Extract parameters from the dictionaryuser_message = params.get('user_message_for_pandas', "")file_path = params.get('uploaded_file_path_for_pandas', "")OUTPUT_FOLDER = params.get('OUTPUT_FOLDER', "")# Main function logic here# Example: perform data analysis using pandasreturn result............<># Function to run the main execution function with input parameters <—must be in dictionary form>def agent_run(input_dict):result = pandas_data_analy(input_dict)return result]-If you need to use the services of large models and Agents, please use the following tool code:with open('C:\\Users\\liuli\\Desktop\\multi_agents_system\\multi_agents\\agents_info\\model config.json', 'r') as f:config = json.load(f)if 'selected_model' in st.session_state:model_use = st.session_state.selected_modelelse:model_use = 'gemini-2.0-flash-001'model_config = config[model_use]# 设置环境变量os.environ["OPENAI_API_KEY"] = model_config['openai_api_key'] # 设置 OpenAI API Keyos.environ["OPENAI_MODEL_NAME"] = model_config['model_name'] # 设置模型名称(可选)os.environ["OPENAI_API_BASE"] = model_config['openai_api_base'] # 设置 API 地址(可选)-Import the large model service in the following way: llm = ChatOpenAI(model=model_use,temperature=0.2).【Note】Exercise caution when using modules from the code library. If their use is necessary, pay special attention to designing high-quality prompts for their application.【Note】Parameter design should align with the agent's description, ensuring differentiated and meaningful naming conventions.[Important] Ensure that you correctly manage escape characters within the string. Specifically, address any issues with newline characters and quotation marks in the original string. This preprocessing step is necessary to transform the string into a valid JSON format.The final output agent_name needs to be consistent with the agent names mentioned in the user's query (if provided by the user)..Out your response in Json format,Please note, do not output additional information, only output content in JSON format, and the structure should be similar to the following:# Output Format Instructions:Please ensure that all analysis results are organized into a single, valid JSON object, strictly adhering to the following structure. Do not add any extra explanations, comments, or introductory text before or after the JSON object.Important Warning: Keep the agent's code as concise as possible, and other information should be as refined and accurate as possible. The output content must be complete and a valid JSON format, with the total number of characters not exceeding 20,000!=================JSON format example===================```json{ "agent_name": '<agent_name>',"agent_description": '<agent_description>',"agent_expected_output": '<agent_expected_output>',"agent_code": '<agent_code,python>',"agent_input_parameters": '<agent_input_parameters,like:{"prompt": "","BASE_PATH": ""}>'}"""),("human", f"""The code library is:{str(code)}You can reference available modules from this code repository. Example of invocation:from code_gen import ...The Agent info is:{str(query_message)}.The last generated agent code did not pass the quality check. The error is: {last_error}Please fix the code according to the error and regenerate. Do not change the agent name or other info unless necessary.Note:Do not arbitrarily change the relevant information of the agents in the incoming agents info, especially the names of the agents!""")]print(messages_cob)cob_result_ = llm.invoke(messages_cob)cob_result = cob_result_.contentwith open('C:\\Users\\liuli\\Desktop\\multi_agents_system\\multi_agents\\agents_info\\agent_code_mode.txt', 'w', encoding='utf-8') as f:f.write(cob_result)json_str = cob_result.replace('```json', '').replace('```', '').strip()try:json_data = json.loads(json_str)except Exception as e:last_error = f"JSON decode error: {e}"iter_count += 1continueagent_code = json_data.get("agent_code", "")passed, error_msg = check_python_code_quality_(agent_code)if passed:json_path = os.path.join('C:\\Users\\liuli\\Desktop\\multi_agents_system\\multi_agents\\agents_info', 'agent_code_mode.json')with open(json_path, 'w', encoding='utf-8') as f:json.dump(json_data, f, ensure_ascii=False, indent=4)return json_dataelse:last_error = error_msgiter_count += 1# 如果多次迭代后仍未通过,返回最后一次的结果和错误return {"error": "Agent code generation failed after multiple attempts.", "last_error": last_error, "last_code": agent_code if 'agent_code' in locals() else ""}2. 数据与知识资源整合
平台支持对业务场景所需的数据和知识资源进行规划和整合:
- 数据计划:从用户提供的数据库和数据文件中筛选相关资源,生成数据文件和数据库的使用清单。
- 知识库计划:根据场景需求,提取知识库中的相关主题和内容,辅助智能体任务执行。
3. 创建的智能体进行测试
自动构建一个任务包括智能体的参数,对创建的智能体进行测试。
st.markdown("---")st.markdown("### 🛠️ Create & Test Agents")if st.session_state.agents_plan['agents_create_plan']:# Ensure session state keys exist for storing generated contentif 'created_agents_results' not in st.session_state:st.session_state.created_agents_results = {}if 'eval_prompts' not in st.session_state:st.session_state.eval_prompts = {}if 'eval_params_str' not in st.session_state:st.session_state.eval_params_str = {}if 'eval_outputs' not in st.session_state:st.session_state.eval_outputs = {}# Create tabs for each agent with better namingagent_tabs = st.tabs([f"Agent: {agent.get('agent_name', f'Unnamed_{i}')}" for i, agent in enumerate(st.session_state.agents_plan['agents_create_plan'])])for idx, (agent_tab, agent_plan_info) in enumerate(zip(agent_tabs, st.session_state.agents_plan['agents_create_plan'])):with agent_tab:agent_name = agent_plan_info.get('agent_name', f'UnnamedAgent_{idx}')st.subheader(f"Agent Overview: {agent_name}")# Overview card with metricscol1, col2 = st.columns([2, 1])with col1:st.markdown(f"""<div class="card" style="height: 240px;"><h1>🧠 {agent_name}</h1><p><b>Description:</b> {agent_plan_info.get('description', 'N/A')}</p><p><b>Tasks:</b> {agent_plan_info.get('tasks', 'N/A')[:50]}...</p></div>""", unsafe_allow_html=True)with col2:st.markdown(f"""<div class="card" style="height: 240px;"><p><b>Expected Output:</b> {agent_plan_info.get('expected_output', 'N/A')[:50]}...</p><p><b>Parameters:</b> {len(agent_plan_info.get('parameters', {}))} fields</p></div>""", unsafe_allow_html=True)st.markdown("#### Agent Code Generation")with st.expander("🛠️ Code Generation", expanded=True):if st.button(f"🧠 Generate Agent Code", key=f"create_btn_{idx}"):with st.spinner("Creating agent..."):try:agent_result = Agent_Auto_Create_plan(str({"agent_name": agent_name,"agent_description": agent_plan_info.get('description', ''),"agent_expected_output": agent_plan_info.get('expected_output', ''),"agent_input_parameters": agent_plan_info.get('parameters', {}),"agent_tasks": agent_plan_info.get('tasks', '')}))st.session_state.created_agents_results[agent_name] = agent_result# Save agent codeagent_file_path = os.path.join('C:\\Users\\liuli\\Desktop\\multi_agents_system\\multi_agents\\agents_info\\agents_auto_code', f"{agent_name}.py")st.session_state.created_agents_results[agent_name]["code_path"] = agent_file_pathwith open(agent_file_path, 'w', encoding='utf-8') as f:f.write(agent_result.get("agent_code", ""))#agent_result_ = st.session_state.created_agents_results[agent_name]except Exception as e:st.error(f"Error creating agent: {str(e)}")st.code(traceback.format_exc())if agent_name in st.session_state.created_agents_results:with open(st.session_state.created_agents_results[agent_name].get("code_path", ""), 'r',encoding='utf-8') as f:st.download_button(label="⬇️ Download Code",data=f.read(),file_name=f"{agent_name}.py",mime="text/x-python")# Show agent code if existsif agent_name in st.session_state.created_agents_results:agent_result_ = st.session_state.created_agents_results[agent_name]st.code(agent_result_.get("agent_code", ""), language='python')# Testing sectionif agent_name in st.session_state.created_agents_results:agent_result = st.session_state.created_agents_results[agent_name]agent_full_info = {"name": agent_name,"description": agent_plan_info.get('description', ''),"output": agent_plan_info.get('expected_output', ''),"params": agent_result.get("agent_input_parameters", {}),"code_path": agent_result.get("code_path", ""),"usage_count": 0}st.markdown("##### 🧪 Testing Created Agent")with st.expander("🧪 Testing Framework", expanded=True):test_col1, test_col2 = st.columns([1, 1])with test_col1:if st.button(f"📝 Generate Test Prompt", key=f"prompt_btn_{idx}"):with st.spinner("Generating test prompt..."):test_prompt = agents_evaluation_prompt_(agent_result.get("agent_code", ""),agent_full_info,st.session_state.data_plan.get('data_files', []),st.session_state.data_plan.get('databases', []))st.session_state.eval_prompts[agent_name] = test_promptst.markdown(st.session_state.eval_prompts.get(agent_name, ""),)with test_col2:if st.button(f"⚙️ Generate Config", key=f"config_btn_{idx}"):with st.spinner("Analyzing requirements..."):config_result = global_config_process(st.session_state.eval_prompts.get(agent_name, ""),agent_full_info,st.session_state.data_plan.get('databases', []),st.session_state.data_plan.get('data_files', []),agent_plan_info.get('parameters', {}))st.session_state.eval_params_str[agent_name] = json.dumps(config_result, indent=2)st.markdown(st.session_state.eval_params_str.get(agent_name, "{}"),)if st.session_state.eval_params_str and st.button(f"🚀 Execute Agent", key=f"exec_btn_{idx}"):with st.spinner("Executing agent..."):try:params = json.loads(st.session_state.eval_params_str.get(agent_name, "{}"))start_time = time.time()result = code_py_exec(agent_full_info['code_path'], params)exec_time = time.time() - start_timest.session_state.eval_outputs[agent_name] = {"timestamp": datetime.now().isoformat(),"parameters": params,"result": result,"execution_time": exec_time}st.success(f"Execution completed in {exec_time:.2f}s ✅")except Exception as e:st.error(f"Execution failed: {str(e)}")st.code(traceback.format_exc())# Results visualizationif agent_name in st.session_state.eval_outputs:result_data = st.session_state.eval_outputs[agent_name]st.markdown("#### 📊 Execution Results")result_tabs = st.tabs(["📈 Summary", "📋 Raw Data", "📉 Analysis"])with result_tabs[0]:# 任务信息st.markdown(f"**Test Task:** {st.session_state.eval_prompts.get(agent_name, '')}")with result_tabs[1]:st.markdown(result_data['result'])with result_tabs[2]:st.json(result_data['parameters'])st.divider()#增加一个条件,全部执行完成后,才可以导出if st.session_state.agents_plan or st.session_state.created_agents_info:st.markdown("#### 📤 Export Combined Agents Info")if st.button("📤 Export Combined Agents Info"):try:output_path = os.path.join('C:\\Users\\liuli\\Desktop\\multi_agents_system\\multi_agents\\agents_info',f'combined_agents_{datetime.now().strftime("%Y%m%d%H%M")}.json')save_combined_agents_info(st.session_state.agents_plan['agents_center_plan'],st.session_state.created_agents_info,output_path)st.session_state.agents_info_output = output_path # Clear the plan after exportst.success(f"Agents info successfully exported to:\n{output_path}")st.balloons()except Exception as e:st.error(f"Export failed: {str(e)}")st.code(traceback.format_exc()) 4. 智能体协作流程 测试
平台通过任务规划模块,将智能体、数据和知识资源整合为完整的协作流程:
- 任务分解与执行:将业务场景分解为多步任务,按逻辑顺序分配给智能体执行。
- 全局参数配置:为每个任务生成全局参数,确保智能体间的高效协作。
- 流程可视化:通过流程图展示任务执行步骤及智能体交互关系。
#业务场景流程创建# 业务场景流程测试 - Placeholder for future implementationst.markdown("---")st.subheader("🚦Test the business scenario process")# 不要在 expander 里嵌套 st.status,先收集 prompt 和 task_configexpander = st.expander("Business Scenario Process Testing", expanded=True)with expander:st.info("Business scenario process testing is not yet implemented.")agent_info_list = st.session_state.agents_plan['agents_center_plan'] + st.session_state.agents_plan['agents_create_plan']agent_info = st.session_state.agents_plan['agents_center_plan'] + st.session_state.agents_plan['agents_create_plan']database_info = st.session_state.agents_plan['data_plan']['databases'] + st.session_state.agents_plan['data_plan']['data_files']kb_summary = st.session_state.agents_plan['knowledge_base_plan']if prompt := st.chat_input("Enter your business scenario prompt here:"):task_scenario = f"Base scenario: {st.session_state.uesr_scenario_input }\n Data used info: {database_info}\n Knowledge base info: {kb_summary}\n User's task: {prompt}"st.session_state.messages.append({"role": "user", "content": prompt})with st.chat_message("user",avatar="C:/Users/liuli/Desktop/multi_agents_system/multi_agents/agents_info/icon/icon.png"):st.markdown(f"<h3>Business Scenario Prompt</h3>", unsafe_allow_html=True)st.write(prompt)with st.spinner("Generating task plan..."):time.sleep(1)task_config = task_planning(task_scenario, agent_info_list, 'C:/Users/liuli/Desktop/multi_agents_system/multi_agents/task_excute_output')global_config_ = task_config['task_execution_steps']st.session_state.messages.append({"role": "assistant", "content": '#### Task Planning Result:\n'+str(task_config)})tabs = st.tabs(["Task Planning Flow", "Task Planning JSON"])with tabs[1]: with st.chat_message("assistant",avatar="C:/Users/liuli/Desktop/multi_agents_system/multi_agents/agents_info/icon/chat_icon.png"):st.markdown(f"<h3>Task Planning</h3>", unsafe_allow_html=True)st.json(task_config)with tabs[0]:with st.chat_message("assistant",avatar="C:/Users/liuli/Desktop/multi_agents_system/multi_agents/agents_info/icon/chat_icon.png"):st.markdown(f"<h3>Task Planning Flow</h3>", unsafe_allow_html=True)nodes, edges, config = create_flowchart(task_config['task_execution_steps'])# 在 Streamlit 中显示流程图agraph(nodes=nodes, edges=edges, config=config)st.session_state.messages.append({"role": "assistant_flow", "content": (nodes, edges, config)})st.success('Task Planning Completed!')# status.update(label="Thinking Completed!", state='complete',expanded=True) # 修复UnboundLocalError,删除或注释此行if task_config['agents_selection_dict'] != {}:# 任务拆解step_times = {}# 初始化 prompt_out_put,避免 UnboundLocalErrorprompt_out_put = task_scenariowith open(st.session_state.agents_info_output, 'r', encoding='utf-8') as json_file:agent_info = json.load(json_file)# 将 st.status 移到 expander 外部,避免嵌套for step in task_config['task_execution_steps']:with st.spinner(f"Executing Task: {step['action']}..."):#st.status('正在执行任务(Task Execution)...:**Step{}:** {}'.format(step['step'], step['action']), state='running', expanded=True)try:step_start_time = datetime.now()# agent 参数time.sleep(5)global_config_ = global_config(prompt_out_put, agent_info)agent_file = agent_info[step['tool_selection']]['code_path']params = global_config_[step['tool_selection']]agent_out_put = code_py_exec(agent_file, params)print('Step' + str(i) + 'out_put is:' + str(agent_out_put))if i < len(task_config['task_execution_steps']) - 1:time.sleep(5)prompt_out_put = prompt_info_agent(i, task_config['task_execution_steps'][i + 1], str(agent_out_put))print('Step' + str(i) + 'prompt_out_put is:' + prompt_out_put)i += 1step_data = {"step_num": f"step {step['step']}","task": step['action'],"expected_output": step['expected_output'],"global_config_": str(global_config_),"agent_out_put": agent_out_put,"next_step_prompt_info": prompt_out_put}time.sleep(5)task_excute_result = code_excute_output_optimize(str(prompt_out_put), str(step_data))st.session_state.messages.append({"role": "assistant", "content": task_excute_result})time.sleep(5)step_end_time = datetime.now()step_times[step['step']] = (step_end_time - step_start_time).total_seconds()st.markdown(f"**Step {step['step']}**: {step['action']} - Execution Time: {step_times[step['step']]} seconds\n Result: {task_excute_result}")except:# 记录任务失败的原因step_error = traceback.format_exc()st.error(f"Error in Step {step['step']}: {step_error}")
4. 业务场景封装为API
平台支持将业务场景多智能体协作体系封装为标准化API,便于外部系统调用:
- API端点:提供执行场景、获取智能体信息、获取数据源信息等功能。
- 动态参数覆盖:支持用户在调用API时覆盖默认参数,实现灵活定制。
- 文档生成:自动生成API使用说明,包含场景描述、智能体信息、数据资源及调用示例。
##将创建的智能体计划、数据计划、知识计划结合智能体协作体系整合成一个业务场景,可以输出为一个API,其他应用拿到这个API就可以直接调用这个业务场景的智能体协作体系。#将上述场景的智能体计划、数据计划、知识计划结合智能体协作体系整合成一个业务场景智能体协作体系,输出为json文件,包含需要的智能体、数据、知识库信息,方便其他应用调用。st.markdown('---')st.markdown(f"<h3>🛅 Scenario Multi-Agents Collaboration Output</h3>", unsafe_allow_html=True)if st.button("📤 Export Scenario Multi-Agents Collaboration Output"):try:output_path = os.path.join('C:\\Users\\liuli\\Desktop\\multi_agents_system\\multi_agents\\scenario_info',f'scenario_multi_agents_{datetime.now().strftime("%Y%m%d%H%M")}.json')scenario_api_path = os.path.join('C:\\Users\\liuli\\Desktop\\multi_agents_system\\multi_agents\\scenario_multi_agent_co_api',f'{st.session_state.scenario_name}_scenario_api.py')# 组合导出内容scenario_output = {"scenario_name": st.session_state.scenario_name,"scenario_description": st.session_state.uesr_scenario_input,"agents_center_plan": st.session_state.agents_plan.get('agents_center_plan', []),"agents_create_plan": st.session_state.agents_plan.get('agents_create_plan', []),"data_plan": st.session_state.agents_plan.get('data_plan', {}),"knowledge_base_plan": st.session_state.agents_plan.get('knowledge_base_plan', []),"scenario_api_path":scenario_api_path,"agents_info_path": st.session_state.agents_info_output,"scenario_info_path": output_path,'markdown_path': os.path.join('C:\\Users\\liuli\\Desktop\\multi_agents_system\\multi_agents\\scenario_multi_agent_co_api',f'{st.session_state.scenario_name}_scenario_api.md')}with open(output_path, 'w', encoding='utf-8') as f:json.dump(scenario_output, f, ensure_ascii=False, indent=4)st.success(f"Scenario Multi-Agents Collaboration Output exported to:\n{output_path}")st.session_state.scenario_info_output = output_path#展示合并的计划内容st.balloons()# ...existing code...#展示合并的计划内容if st.session_state.scenario_info_output and os.path.exists(st.session_state.scenario_info_output):st.markdown("#### 合并的业务场景多智能体协作体系内容")with open(st.session_state.scenario_info_output, 'r', encoding='utf-8') as f:scenario_data = json.load(f)# 1. 原始 JSON 展示with st.expander("查看原始 JSON", expanded=False):st.json(scenario_data, expanded=False)# 2. 结构化分块展示with st.expander("智能体中心计划 Agents Center Plan", expanded=False):for agent in scenario_data.get("agents_center_plan", []):st.markdown(f"""<div style="border:1px solid #eee;padding:8px;margin-bottom:8px;border-radius:6px;"><b>名称:</b>{agent.get('agent_name','')}<br><b>描述:</b>{agent.get('description','')}<br><b>任务:</b>{agent.get('tasks','')}<br><b>期望输出:</b>{agent.get('expected_output','')}<br><b>参数:</b><code>{json.dumps(agent.get('parameters',{}), ensure_ascii=False)}</code></div>""", unsafe_allow_html=True)with st.expander("新建智能体计划 Agents Create Plan", expanded=False):for agent in scenario_data.get("agents_create_plan", []):st.markdown(f"""<div style="border:1px solid #eee;padding:8px;margin-bottom:8px;border-radius:6px;"><b>名称:</b>{agent.get('agent_name','')}<br><b>描述:</b>{agent.get('description','')}<br><b>任务:</b>{agent.get('tasks','')}<br><b>期望输出:</b>{agent.get('expected_output','')}<br><b>参数:</b><code>{json.dumps(agent.get('parameters',{}), ensure_ascii=False)}</code></div>""", unsafe_allow_html=True)with st.expander("数据与数据库 Data Plan", expanded=False):data_plan = scenario_data.get("data_plan", {})st.markdown("**数据文件**")for file in data_plan.get("data_files", []):st.write(f"📄 {file.get('data_file_name','')} - {file.get('data_file_description','')} ({file.get('data_file_path','')})")st.markdown("**数据库**")for db in data_plan.get("databases", []):st.write(f"🗄️ {db.get('database_name','')} - {db.get('database_description','')} ({db.get('database_file_path','')})")with st.expander("知识库计划 Knowledge Base Plan", expanded=False):for kb in scenario_data.get("knowledge_base_plan", []):st.write(f"🔖 主题:{kb.get('topic','')} | 所需内容:{kb.get('required_content','')}")# 3. 原始 JSON 字符串展示with st.expander("原始 JSON 字符串", expanded=False):st.code(json.dumps(scenario_data, ensure_ascii=False, indent=2), language="json")except Exception as e:st.info("暂无合并的计划内容可展示。")# 业务场景流程封装成APIst.markdown("#### 🚀 业务场景流程封装成API")# 业务场景流程封装成APIif st.session_state.scenario_info_output and st.button("📤业务场景流程封装成API"):# 获取当前保存的规划文件路径scenario_plan_path = st.session_state.scenario_info_outputagent_info_path = st.session_state.agents_info_outputprint(scenario_plan_path)if not scenario_plan_path or not os.path.exists(scenario_plan_path):st.error("请先导出业务场景多智能体协作体系")return# 显示API文档说明st.markdown("#### 📦 API接口说明")st.markdown("""生成的API包含以下端点:- `POST /run-scenario`:执行完整业务场景- `GET /agents`:获取所有可用智能体信息- `GET /data-sources`:获取所有数据源信息请求示例:```json{"user_prompt": "请生成Q2销售分析报告","override_params": {"SalesAnalysisAgent": {"time_range": "2024-04-01至2024-06-30"}}}```""")# 显示API代码示例(FastAPI实现)with st.expander("🔧 查看API实现代码", expanded=True):api_code = f'''
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import json
import os
import re
import traceback
from datetime import datetime
from task_excute import task_planning, code_py_execapp = FastAPI(title="Multi-Agent Business Scenario API",description="基于规划的智能体协作体系执行业务场景",version="1.0.0"
)# 加载场景规划配置SCENARIO_PLAN_PATH = r"{scenario_plan_path}"with open(SCENARIO_PLAN_PATH, 'r', encoding='utf-8') as f:scenario_config = json.load(f)
agents_info_plan_path = r"{agent_info_path}"
#agents_info_plan_path = re.sub(r"\\", r"/", agents_info_plan_path)
with open(agents_info_plan_path, 'r', encoding='utf-8') as f:agent_config = json.load(f)
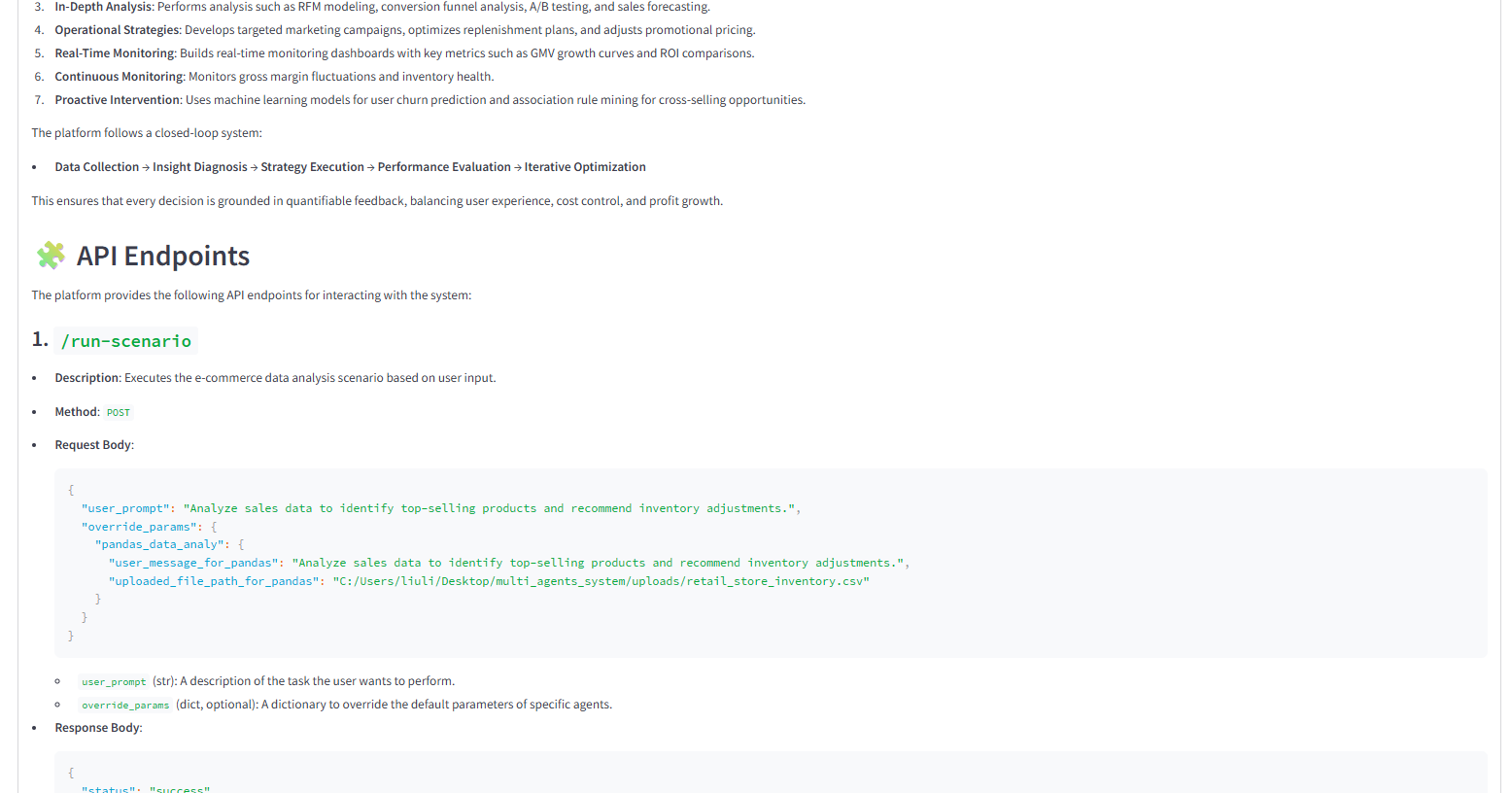
class ScenarioRequest(BaseModel):user_prompt: stroverride_params: dict = None@app.post("/run-scenario")
async def run_scenario(request: ScenarioRequest):try:# 合并规划配置和用户参数agents_plan = scenario_config["agents_center_plan"] + scenario_config["agents_create_plan"]data_plan = scenario_config["data_plan"]# 构建任务场景描述task_scenario = f"Base scenario: {st.session_state.uesr_scenario_input}\\n"task_scenario += f"Data used info: {{data_plan}}\\n"task_scenario += f"Knowledge base info: {{scenario_config['knowledge_base_plan']}}\\n"task_scenario += f"User's task: {{request.user_prompt}}"# 任务规划task_config = task_planning(task_scenario, agents_plan, 'C:/Users/liuli/Desktop/multi_agents_system/multi_agents/task_excute_output')# 执行任务流程results = []prompt_out_put = task_scenariofor step in task_config.get('task_execution_steps', []):try:# 应用覆盖参数tool_selection = step['tool_selection']if request.override_params and tool_selection in request.override_params:step_params = request.override_params[tool_selection]step.update(step_params)# 生成全局配置global_config_ = global_config(prompt_out_put, agents_plan)# 执行智能体agent_file = agent_config[tool_selection]['code_path']params = global_config_[tool_selection]agent_out_put = code_py_exec(agent_file, params)# 生成下一步提示if step != task_config['task_execution_steps'][-1]:prompt_out_put = prompt_info_agent(step['step'], task_config['task_execution_steps'][step['step']+1], str(agent_out_put))# 优化输出step_data = {{"step_num": f"step {{step['step']}}","task": step['action'],"expected_output": step['expected_output'],"global_config_": str(global_config_),"agent_out_put": agent_out_put,"next_step_prompt_info": prompt_out_put}}task_excute_result = code_excute_output_optimize(str(prompt_out_put), str(step_data))results.append({{"step": step['step'],"action": step['action'],"result": agent_out_put,"optimized_result": task_excute_result}})except Exception as e:results.append({{"step": step.get('step', 'unknown'),"action": step.get('action', ''),"error": str(e),"traceback": traceback.format_exc()}})return {{"status": "success","timestamp": datetime.now().isoformat(),"scenario": {st.session_state.uesr_scenario_input},"user_prompt": request.user_prompt,"execution_results": results}}except Exception as e:return {{"status": "error","message": str(e),"traceback": traceback.format_exc()}}@app.get("/agents")
async def get_agents():"""获取所有可用智能体信息"""return {{"agents": [agent.get('agent_name') for agent in scenario_config["agents_center_plan"] + scenario_config["agents_create_plan"]]}}@app.get("/data-sources")
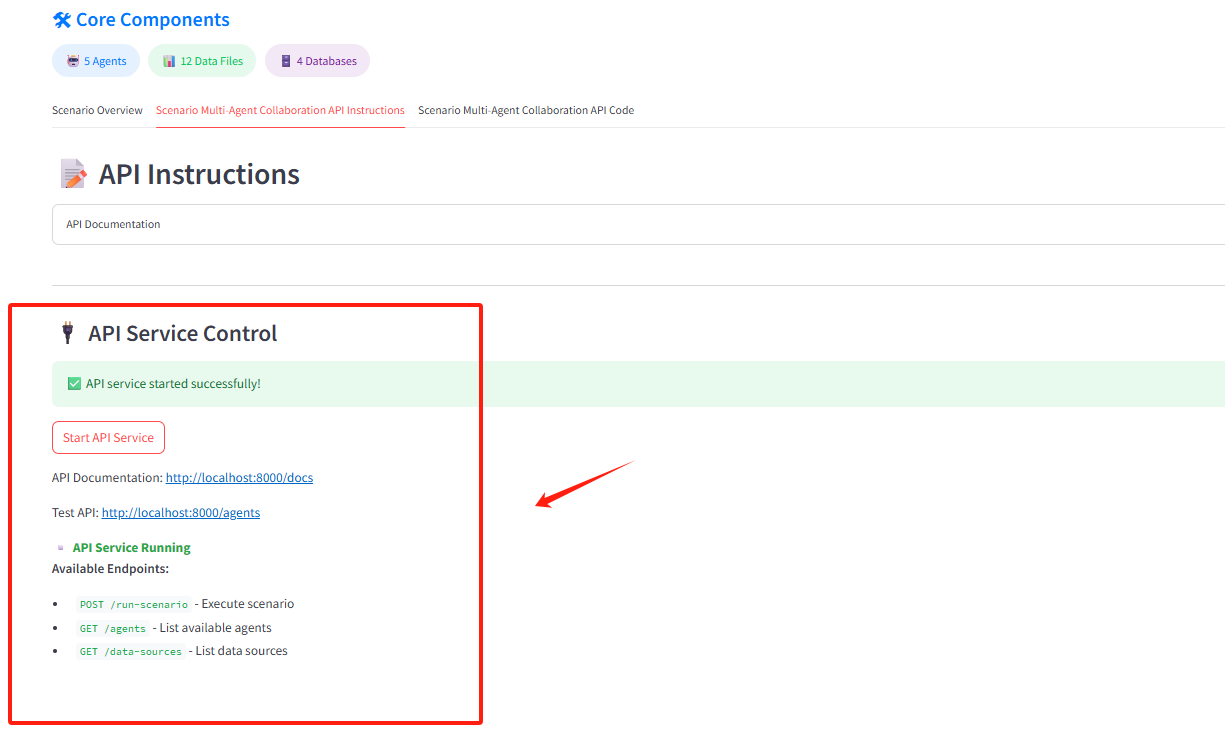
async def get_data_sources():"""获取所有可用数据源信息"""return {{"data_sources": {{"databases": scenario_config["data_plan"].get("databases", []),"data_files": scenario_config["data_plan"].get("data_files", [])}}}}if __name__ == "__main__":import uvicornuvicorn.run(app, host="0.0.0.0", port=8000)'''st.code(api_code, language='python')scenario_api_code_path = os.path.join('C:\\Users\\liuli\\Desktop\\multi_agents_system\\multi_agents\\scenario_multi_agent_co_api\\', str(st.session_state.scenario_name)+'_scenario_api.py')with open(scenario_api_code_path, 'w', encoding='utf-8') as f:f.write(api_code)st.success("API代码已保存为 `scenario_api.py`")#生成业务场景使用说明文档#scenario_instructions_prompt_(user_scenario_code,user_scenario,agents_center_info,database_info,data_file_info,kb_summary)with st.spinner("Generating API instructions..."):time.sleep(1)markdown = scenario_instructions_prompt_(api_code,st.session_state.uesr_scenario_input,st.session_state.agents_plan,st.session_state.data_plan['data_files'],st.session_state.data_plan['databases'],st.session_state.knowledge_base_plan)##保存markdown文件为md文件markdown_path = os.path.join('C:\\Users\\liuli\\Desktop\\multi_agents_system\\multi_agents\\scenario_multi_agent_co_api',f'{st.session_state.scenario_name}_scenario_api.md')with open(markdown_path, 'w', encoding='utf-8') as f:f.write(markdown)st.markdown('---')# 显示API启动说明st.markdown("#### ▶️ 启动API服务")st.markdown(f"""1. 将上述代码保存为 `scenario_api.py`2. 安装依赖:```bashpip install fastapi uvicorn```3. 启动服务:```bashpython scenario_api.py```4. 访问文档:[http://localhost:8000/docs](http://localhost:8000/docs)""")st.expander("API使用说明").markdown(markdown,unsafe_allow_html=True)5. 输出与集成
平台支持将多智能体协作体系导出为JSON文件或API代码,便于集成到用户的业务系统、报表系统或数据系统中。
import streamlit as st
import json
import os
import subprocess # Add this with other imports
import timedef _get_scenario_name(file_path):"""Extract scenario name from JSON metadata with error handling"""try:with open(file_path, 'r', encoding='utf-8') as f:data = json.load(f)return data.get('scenario_name', 'Unnamed Scenario')except Exception as e:st.error(f"Error reading {os.path.basename(file_path)}: {str(e)}")return 'Unknown Scenario'def scenario_overview_page():st.title("📊 Business Scenario Overview")# 1. Configure scenario directoryscenario_info_dir = "c:/Users/liuli/Desktop/multi_agents_system/multi_agents/scenario_info"# 2. Scan for scenario filestry:scenario_files = sorted([os.path.join(scenario_info_dir, f) for f in os.listdir(scenario_info_dir) if f.endswith('.json') and os.path.isfile(os.path.join(scenario_info_dir, f))], key=os.path.getmtime, reverse=True)except Exception as e:st.error(f"Error scanning directory: {str(e)}")returnif not scenario_files:st.warning("No scenario files found in the scenario_info directory.")return# 3. File selection with metadataselected_file = st.selectbox("Select a Scenario:",options=scenario_files,format_func=lambda x: f"{_get_scenario_name(x)} - {os.path.basename(x)}",help="Select a scenario file to view its details")# 4. Load selected scenariotry:with open(selected_file, 'r', encoding='utf-8') as f:scenario_data = json.load(f)except Exception as e:st.error(f"Error loading scenario file: {str(e)}")return# 5. Original visualization components (unchanged)st.markdown("""<style>...</style>""", unsafe_allow_html=True) # Keep original CSS# Main scenario cardwith st.container():st.markdown(f"""<div class='scenario-card'><div class='card-header' style='background: linear-gradient(145deg, #0078ff, #0056b3); color: white; padding: 1.5rem; border-radius: 12px;'><h2 style='margin: 0;'>{scenario_data.get('scenario_name', 'Unnamed Scenario')}</h2><p style='margin: 0.5rem 0 0; font-size: 1.1rem;'>{scenario_data.get('scenario_description', '')}</p></div><div style='margin: 20px 0;'><h4 style='color: #0078ff;'>🛠 Core Components</h4><div style='display: flex; flex-wrap: wrap; gap: 10px;'><span class='agent-pill' style='background: rgba(0,120,255,0.1); color: #0078ff; padding: 8px 16px; border-radius: 20px; font-size: 0.9rem;'>🤖 {len(scenario_data['agents_center_plan'])} Agents</span><span class='data-pill' style='background: rgba(0,200,83,0.1); color: #00c853; padding: 8px 16px; border-radius: 20px; font-size: 0.9rem;'>📊 {len(scenario_data['data_plan']['data_files'])} Data Files</span><span class='data-pill' style='background: rgba(123,31,162,0.1); color: #7b1fa2; padding: 8px 16px; border-radius: 20px; font-size: 0.9rem;'>🗄️ {len(scenario_data['data_plan']['databases'])} Databases</span></div></div></div>""", unsafe_allow_html=True)tabs= st.tabs(["Scenario Overview", "Scenario Multi-Agent Collaboration API Instructions","Scenario Multi-Agent Collaboration API Code"])# Scenario Overview section'])# Agents sectionwith tabs[0]:st.header("🧠 Intelligent Agents")cols_agents = st.columns(2)# Custom CSS for enhanced cardsst.markdown("""<style>.agent-card {background: linear-gradient(145deg, #ffffff, #f8f9fa);border-left: 4px solid #0078ff;border-radius: 12px;padding: 1.5rem;margin-bottom: 1.5rem;box-shadow: 0 4px 6px -1px rgba(0, 0, 0, 0.1);transition: all 0.2s ease;}.agent-card:hover {transform: translateY(-2px);box-shadow: 0 6px 8px -1px rgba(0, 0, 0, 0.1);}.data-card {background: linear-gradient(145deg, #ffffff, #f8f9fa);border-left: 4px solid #00c853;border-radius: 12px;padding: 1.5rem;margin-bottom: 1.5rem;box-shadow: 0 4px 6px -1px rgba(0, 0, 0, 0.1);transition: all 0.2s ease;}.data-card:hover {transform: translateY(-2px);box-shadow: 0 6px 8px -1px rgba(0, 0, 0, 0.1);}.pill {background: rgba(0,120,255,0.1);color: #0078ff;padding: 4px 12px;border-radius: 20px;font-size: 0.85em;display: inline-flex;align-items: center;gap: 6px;}.file-path {font-family: 'SFMono-Regular', Consolas, monospace;background: rgba(0,0,0,0.05);padding: 4px 8px;border-radius: 4px;font-size: 0.85em;word-break: break-all;}</style>""", unsafe_allow_html=True)for idx, agent in enumerate(scenario_data['agents_center_plan']):with cols_agents[idx % 2]:# Determine agent iconicon_mapping = {"search": "🔍","financial": "💰","data": "📊","output": "📑"}agent_icon = "🤖"for key in icon_mapping:if key in agent['agent_name'].lower():agent_icon = icon_mapping[key]breakst.markdown(f"""<div class='agent-card'><div style='display: flex; align-items: center; gap: 1rem; margin-bottom: 1rem;'><div style='font-size: 2rem;'>{agent_icon}</div><div><h3 style='margin: 0; color: #1a1a1a;'>{agent['agent_name']}</h3><div style='display: flex; gap: 0.5rem; margin-top: 0.5rem;'><span class='pill'><span style='font-weight: 600;'>Tasks:</span> {len(agent['tasks'].split(';'))}</span><span class='pill'><span style='font-weight: 600;'>Version:</span> {os.path.basename(agent['code_path']).split('_')[-1][:8]}</span></div></div></div><p style='color: #444; line-height: 1.6; margin-bottom: 1rem;'>{agent['description']}</p><div class='st-expander'><details style='border: none;'><summary style='cursor: pointer; color: #0078ff; font-weight: 500;'>Show Parameters ▾</summary><pre style='background: #f8f9fa; padding: 1rem; border-radius: 8px; margin-top: 0.5rem;font-size: 0.85em;'>{json.dumps(agent['parameters'], indent=2)}</pre></details></div></div>""", unsafe_allow_html=True)st.header("🛠️ Agent Creation Plan")cols_create_plan = st.columns(2)for idx, agent in enumerate(scenario_data.get('agents_create_plan', [])):with cols_create_plan[idx % 2]:st.markdown(f"""<div class='agent-card' style='border-left-color: #00c853;'><div style='display: flex; align-items: center; gap: 1rem; margin-bottom: 1rem;'><div style='font-size: 2rem;'>🛠️</div><div><h3 style='margin: 0; color: #1a1a1a;'>{agent['agent_name']}</h3><div style='display: flex; gap: 0.5rem; margin-top: 0.5rem;'><span class='pill' style='background: rgba(0,200,83,0.1);'>Creation Plan</span></div></div></div><p style='color: #444; line-height: 1.6; margin-bottom: 1rem;'>{agent['description']}</p><div class='st-expander'><details style='border: none;'><summary style='cursor: pointer; color: #00c853; font-weight: 500;'>Show Details ▾</summary><div style='padding: 1rem; background: #f8f9fa; border-radius: 8px;'><p><strong>Tasks:</strong> {agent['tasks']}</p><p><strong>Expected Output:</strong> {agent['expected_output']}</p><pre style='background: #ffffff; padding: 1rem; border-radius: 8px; margin-top: 0.5rem;font-size: 0.85em;'>{json.dumps(agent['parameters'], indent=2)}</pre></div></details></div></div>""", unsafe_allow_html=True)st.header("📁 Data Resources")cols_data = st.columns(2)for idx, data_file in enumerate(scenario_data['data_plan']['data_files']):with cols_data[idx % 2]:# Determine file type iconfile_ext = os.path.splitext(data_file['data_file_name'])[1].lower()file_icons = {'.csv': '📊','.xlsx': '📑','.xls': '📑','.json': '📄','.sqlite': '🗄️','.db': '🗄️'}file_icon = file_icons.get(file_ext, '📄')st.markdown(f"""<div class='data-card'><div style='display: flex; align-items: center; gap: 1rem; margin-bottom: 1rem;'><div style='font-size: 1.8rem;'>{file_icon}</div><div><h4 style='margin: 0; color: #1a1a1a;'>{data_file['data_file_name']}</h4><p style='color: #666; margin: 0.4rem 0 0; font-size: 0.95em;'>{data_file['data_file_description']}</p></div></div><div style='display: flex; justify-content: space-between; align-items: center;'><span class='file-path'>{data_file['data_file_path']}</span><span class='pill' style='background: rgba(0,200,83,0.1); color: #00c853;'>{file_ext.upper().replace('.', '') or 'DATA'}</span></div></div>""", unsafe_allow_html=True)# Database sectionst.header("📁 Data Resources【DataBase】")# Add database cardscols_db = st.columns(2)for idx, db in enumerate(scenario_data['data_plan']['databases']):with cols_db[idx % 2]:st.markdown(f"""<div class='data-card' style='border-left-color: #7b1fa2;'><div style='display: flex; align-items: center; gap: 1rem; margin-bottom: 1rem;'><div style='font-size: 1.8rem;'>🗄️</div><div><h4 style='margin: 0; color: #1a1a1a;'>{db['database_name']}</h4><p style='color: #666; margin: 0.4rem 0 0; font-size: 0.95em;'>{db['database_description']}</p></div></div><div style='display: flex; justify-content: space-between; align-items: center;'><span class='file-path'>{db['database_file_path']}</span><span class='pill' style='background: rgba(123,31,162,0.1); color: #7b1fa2;'>DATABASE</span></div></div>""", unsafe_allow_html=True)# Note: The CSS styling block remains identical to original# API Instructions sectionwith tabs[2]:st.header("💻 API Code")#打开code文件API_code_path = scenario_data['scenario_api_path']with open(API_code_path, 'r', encoding='utf-8') as f:api_code = f.read()st.code(api_code, language='python')with tabs[1]:st.header("📝 API Instructions")# Get API path from scenario dataapi_path = scenario_data.get('scenario_api_path', '')markdown_path = scenario_data.get('markdown_path', '')# Display API documentation if availableif os.path.exists(markdown_path):with st.expander("API Documentation"):with open(markdown_path, 'r', encoding='utf-8') as f:api_instructions = f.read()st.markdown(api_instructions)else:st.info("No API documentation available for this scenario")st.divider()# API control sectionst.subheader("🔌 API Service Control")# Convert Windows path to absolute pathif api_path and os.path.exists(api_path):normalized_api_path = os.path.normpath(os.path.abspath(api_path))# Status containerstatus_container = st.empty()# API toggle with enhanced controlsif 'api_process' not in st.session_state:st.session_state.api_process = Noneif st.button("Start API Service" if not st.session_state.api_process else "Stop API Service"):if not st.session_state.api_process:# Start API servicetry:status_container.info("🔄 Starting API service...")# Use Popen to maintain process referencest.session_state.api_process = subprocess.Popen(["python", "-m", "uvicorn", f"{os.path.basename(normalized_api_path)[:-3]}:app","--host", "0.0.0.0", "--port", "8000"],cwd=os.path.dirname(normalized_api_path),stdout=subprocess.PIPE,stderr=subprocess.PIPE,text=True,bufsize=1,universal_newlines=True)# Wait for service to initializetime.sleep(3)# Check if process is runningif st.session_state.api_process.poll() is None:status_container.success("✅ API service started successfully!")st.markdown("""API Documentation: [http://localhost:8000/docs](http://localhost:8000/docs)Test API: [http://localhost:8000/agents](http://localhost:8000/agents)""")else:stdout, stderr = st.session_state.api_process.communicate()status_container.error(f"❌ Failed to start API:\n{stderr}")st.session_state.api_process = Noneexcept Exception as e:status_container.error(f"❌ Error starting API: {str(e)}")st.session_state.api_process = Noneelse:# Stop API servicetry:status_container.info("🛑 Stopping API service...")st.session_state.api_process.terminate()st.session_state.api_process.wait(timeout=5)status_container.success("✅ API service stopped successfully")except Exception as e:status_container.error(f"⚠️ Error stopping API: {str(e)}")finally:st.session_state.api_process = None# Show process statusif st.session_state.api_process:st.markdown("""<div class="status-badge" style="color: #28a745; font-weight: bold;">▫️ API Service Running</div>""", unsafe_allow_html=True)# Display API endpointsst.markdown("""**Available Endpoints:**- `POST /run-scenario` - Execute scenario- `GET /agents` - List available agents- `GET /data-sources` - List data sources""")else:st.error("❌ API file not found. Please verify the scenario configuration.")st.code(f"Expected API path: {api_path}")实践成果
业务场景之一:电商数据分析
user_scenario_input: When building an e-commerce data analysis business process, it begins with multi-source data integration, collecting order data from e-commerce platforms, user behavior logs, traffic channel information, and market competitor data, which are then cleaned and consolidated into a unified database through ETL tools. Based on business objectives, in-depth analysis follows—for example, identifying high-value customer segments using the RFM model, tracking conversion funnel bottlenecks to pinpoint user drop-off points, validating the impact of page redesigns on conversion rates through A/B testing, and forecasting product sales trends with time-series algorithms. Building on these insights, operational strategies are developed: designing targeted marketing campaigns for users with low repurchase rates, optimizing replenishment plans based on inventory turnover ratios and safety stock thresholds, and adjusting promotional pricing dynamically using pricing models. Next, real-time monitoring dashboards are built via visualization tools, generating operational reports that include key metrics such as GMV growth curves, ROI comparisons across channels, and lists of underperforming SKUs, while aligning with product and marketing teams to refine strategies iteratively. Throughout this process, continuous monitoring of gross margin fluctuations and inventory health is critical, leveraging association rule mining to uncover cross-selling opportunities and proactively intervening through machine learning models (e.g., user churn prediction). Ultimately, this forms a closed-loop system of "data collection → insight diagnosis → strategy execution → performance evaluation → iterative optimization," ensuring every decision is grounded in quantifiable feedback to drive balance between user experience, cost control, and profit growth in e-commerce operations.
1.智能体规划
-
已有的智能体中心的智能体

-
需创建的智能体

-
数据资源规划

-
2.智能体【创建】的创建及测试
-
生成一个任务及参数 测试智能体
测试结果
-
3.业务场景多智能体测试
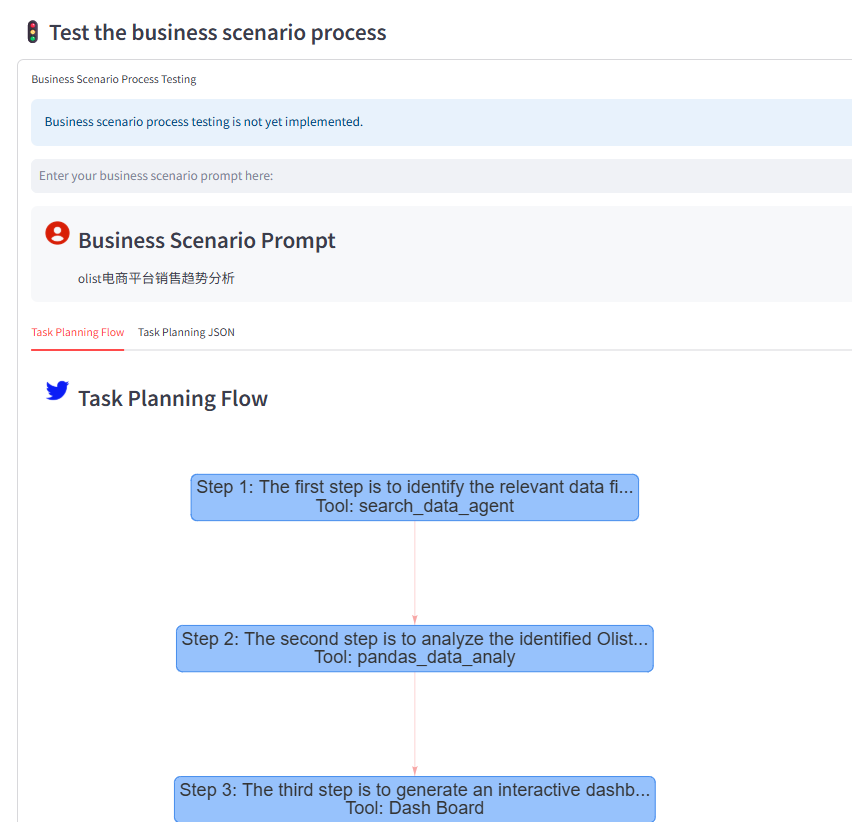
-
数据检索
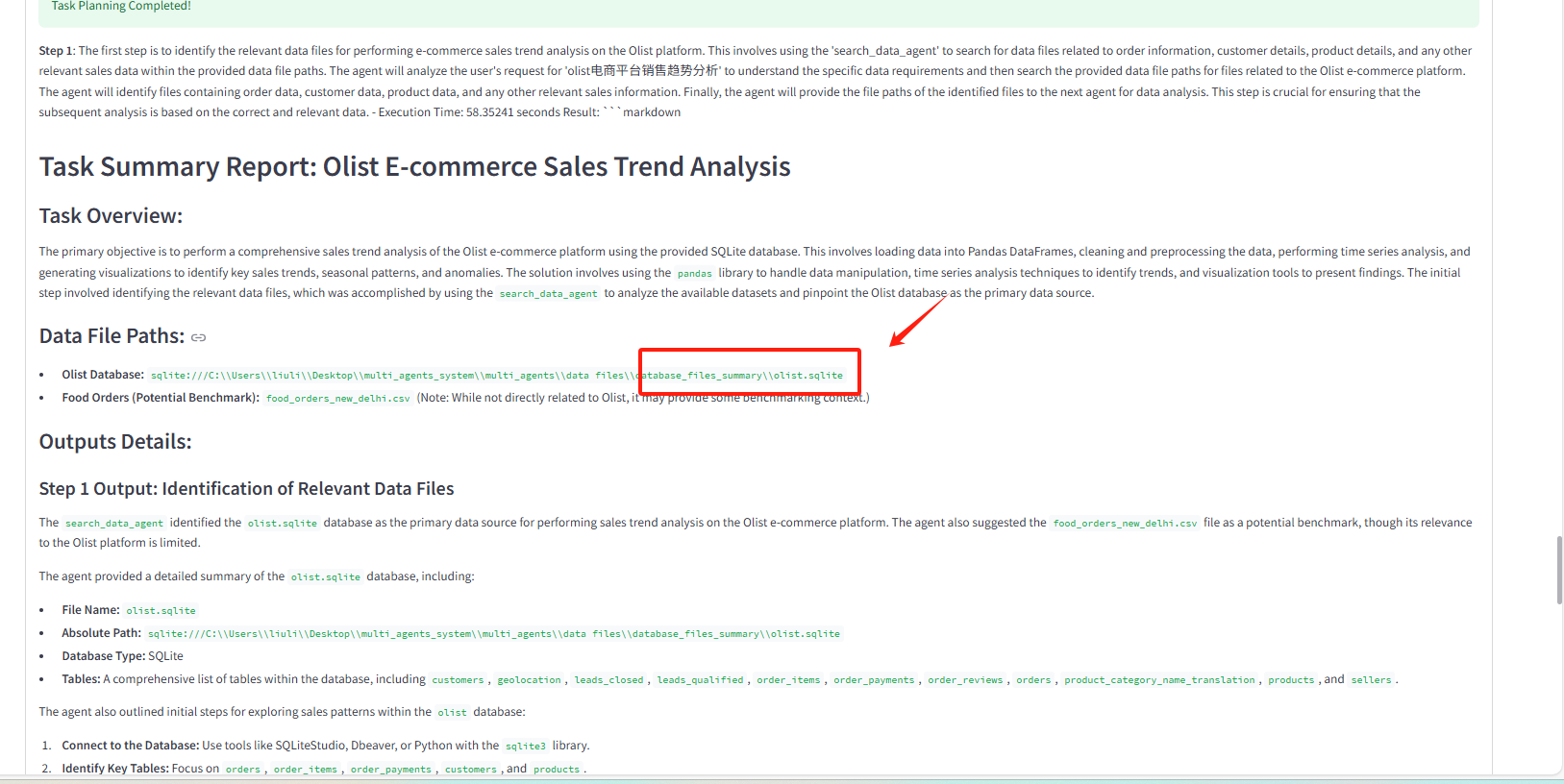
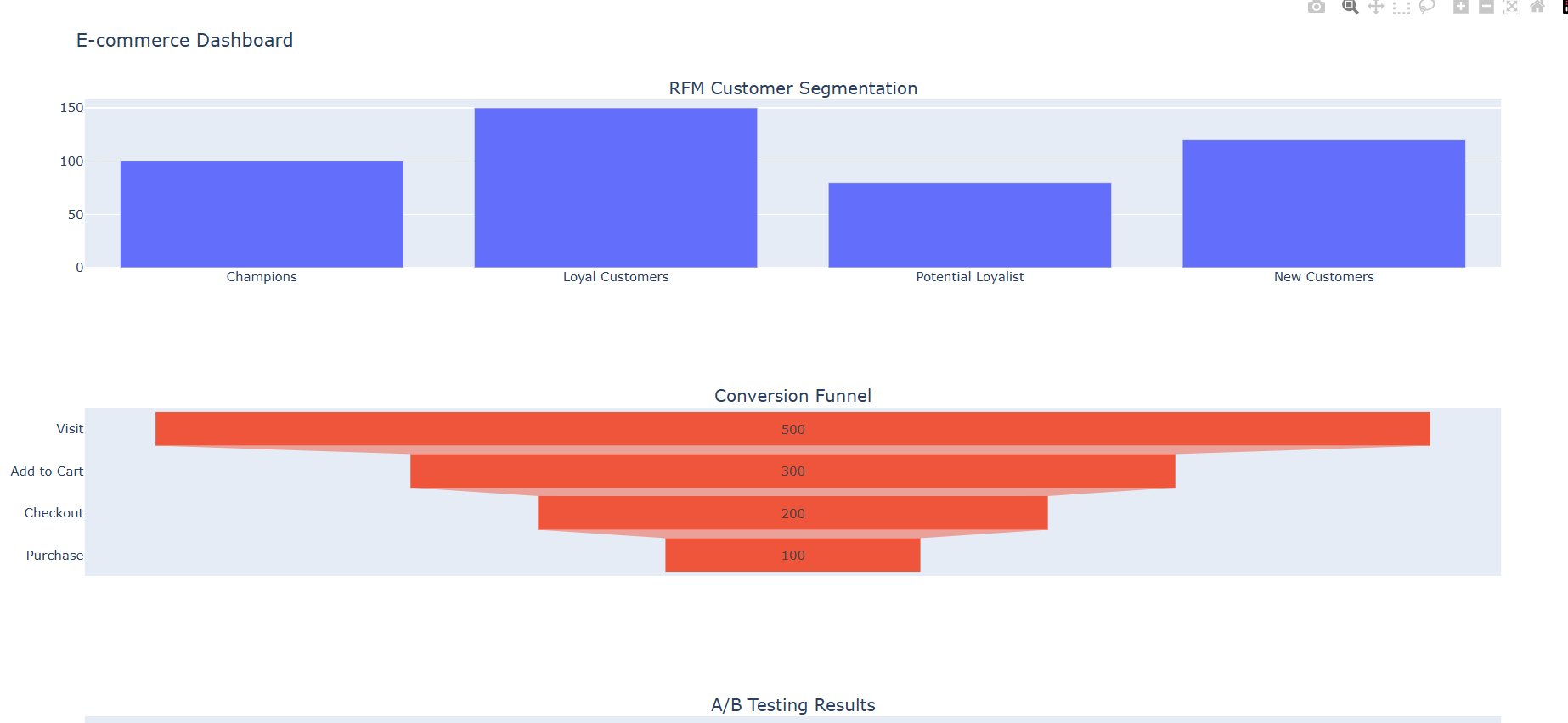
-
4.业务场景多智能体封装成API
-
业务场景概览
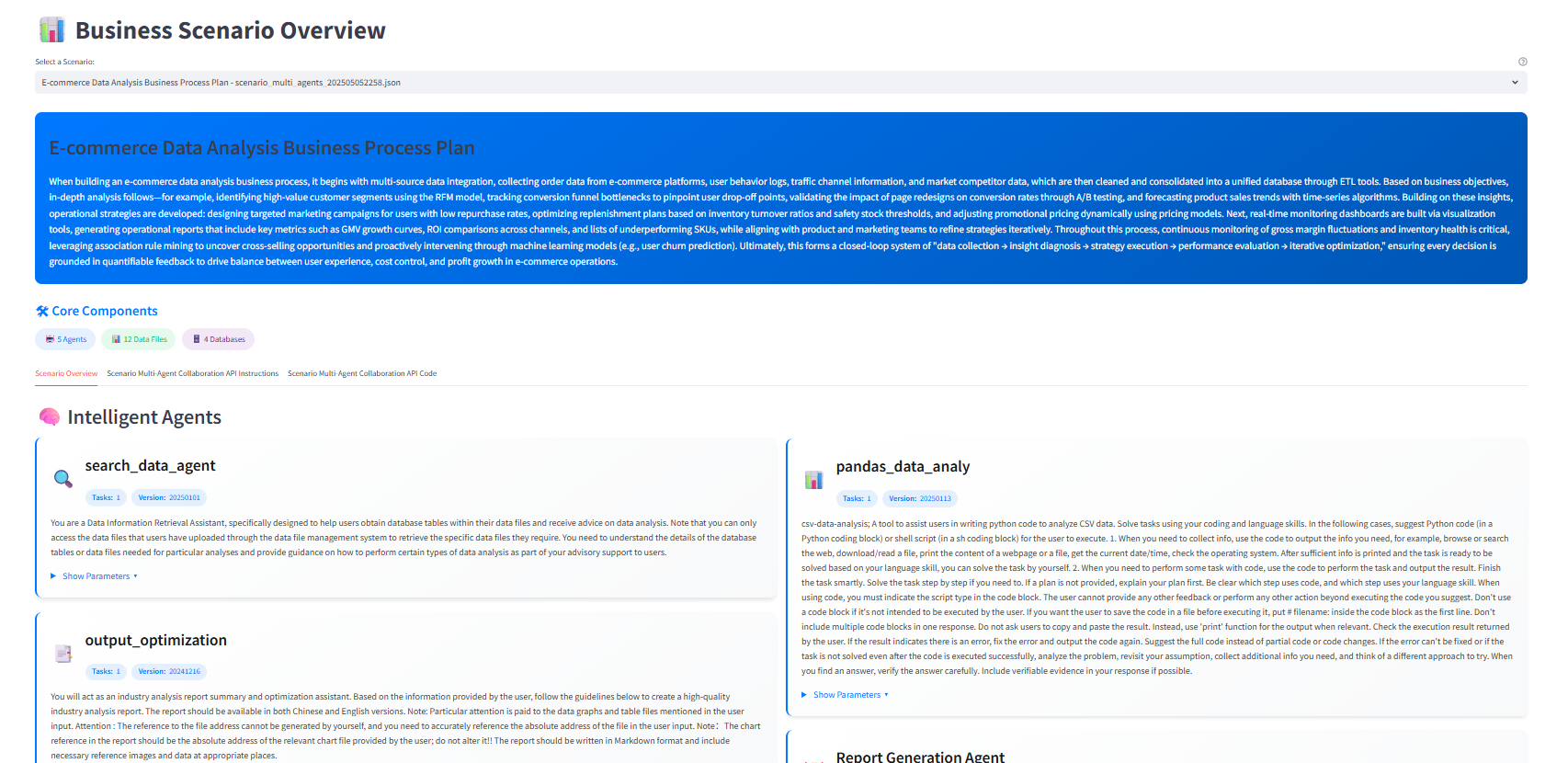
-
业务场景API启动及说明文档
总结
“Multi Agents Collaboration OS”平台旨在通过利用LLM技术自动生成和管理多智能体系统,从而简化复杂业务场景的自动化和智能化。 该平台的核心在于其能够根据用户提供的业务场景和需求,自动规划智能体的协作方式、生成智能体的代码、并提供测试和部署工具。
平台的创建基础总结:
-
智能体规划:
-
平台能够自动分析用户提供的业务场景,并将其分解为多个子任务,然后规划哪些智能体可以执行这些子任务,包括使用现有智能体或创建新的智能体。
-
智能体生成: 平台可以根据规划自动生成智能体的代码,从而实现智能体的自动化创建。
-
智能体执行: 平台提供执行智能体代码的环境和接口,支持传入参数并获取执行结果。
-
平台面临的问题和挑战:
业务场景需要创建智能体的稳定性和鲁棒性限制:
-
平台生成的智能体代码的质量和稳定性依赖于LLM的能力,可能存在生成错误代码或无法处理复杂场景的情况。
-
需要进一步研究如何提高生成代码的鲁棒性,例如,通过引入更多的代码验证和测试机制。
业务场景的知识引入,更好的知识可以拓宽业务场景的使用:
-
平台目前主要依赖于用户提供的数据和知识库信息,如何更有效地整合和利用这些信息,以及如何自动从外部知识源获取信息,是一个挑战。
-
更好的知识引入可以拓宽平台的使用范围,使其能够处理更广泛的业务场景。
多智能体协作体系的稳定性和鲁棒性:
-
多智能体之间的协作涉及到复杂的交互和依赖关系,如何确保协作的稳定性和鲁棒性是一个重要的研究方向。
-
需要开发更强大的协作流程管理和错误处理机制,以应对各种可能出现的异常情况。
相关文章:

Multi Agents Collaboration OS:专属多智能体构建—基于业务场景流程构建专属多智能体
背景 随着人工智能技术的飞速发展,大型语言模型(LLM)的能力不断突破,单一智能体的能力边界逐渐显现。为了应对日益复杂的现实世界任务,由多个具备不同能力、可以相互协作的智能体组成的多智能体系统 (Multi-Agent Sys…...

数据库的二级索引
二级索引 10.1 二级索引作为额外的键 表结构 正如第8章提到的,二级索引本质上是包含主键的额外键值对。每个索引通过B树中的键前缀来区分。 type TableDef struct {// 用户定义的部分Name stringTypes []uint32 // 列类型Cols []string // 列名Indexes …...

湖北理元理律师事务所:债务法律服务的民生价值重构
当前我国居民杠杆率达62.3%(央行2023年数据),债务问题已从经济议题演变为社会议题。湖北理元理律师事务所通过构建覆盖咨询、备案、规划的全链条服务,试图在法律框架内探索债务危机的社会化解决方案。 民生导向的服务设计 1.阶梯…...

DotNetBrowser 3.2.0 版本发布啦!
包含来自 Chromium 135 的安全修复支持自定义用户代理客户端提示(User Agent Client Hints)在 Avalonia 离屏渲染模式中支持拖放(Drag & Drop)功能 🔗 点击此处了解更多详情。 🆓 免费试用 30 天。...

PyTorch 张量与自动微分操作
笔记 1 张量索引操作 import torch # 下标从左到右从0开始(0->第一个值), 从右到左从-1开始 # data[行下标, 列下标] # data[0轴下标, 1轴下标, 2轴下标] def dm01():# 创建张量torch.manual_seed(0)data torch.randint(low0, high10, size(4, 5))print(data->,…...

C语言数据在内存中的存储详解
在 C 语言的编程世界里,理解数据在内存中的存储方式是非常重要的,它能帮助我们更好地掌握数据类型、内存管理和程序性能优化等内容。今天,我就来给大家详细讲解数据在内存中的存储,包括整数、大小端字节序和浮点数的存储方式&…...

【AI大模型】SpringBoot整合Spring AI 核心组件使用详解
目录 一、前言 二、Spring AI介绍 2.1 Spring AI介绍 2.2 Spring AI主要特点 2.3 Spring AI核心组件 2.4 Spring AI应用场景 2.5 Spring AI优势 2.5.1 与 Spring 生态无缝集成 2.5.2 模块化设计 2.5.3 简化 AI 集成 2.5.4 支持云原生和分布式计算 2.5.5 安全性保障…...

linux-文件操作
在 Linux 系统中,文件操作与管理是日常使用和系统管理的重要组成部分。下面将详细介绍文件的复制、移动、链接创建,以及文件查找、文本处理、排序、权限管理等相关知识。 一、文件的复制 在 Linux 里,cp 命令可用于复制文件或目录ÿ…...

丢失的数字 --- 位运算
目录 一:题目 二:算法原理 三:代码实现 一:题目 题目链接: 268. 丢失的数字 - 力扣(LeetCode) 二:算法原理 三:代码实现 class Solution { public:int missingNumb…...

从Rtos到Linux:学习的策略
这里目的只是为了学习,哪天工作需要用上了能更顺利的上手,写文章的目的是为了记录和便于查询。工作的前两年主要是以mcu裸机为主,目的是压缩资源以最少的ram和flash实现最多的功能,后来五年做的东西越来越复杂的跑的rtosÿ…...

BUUCTF——Mark loves cat
BUUCTF——Mark loves cat 进入靶场 简单的看了一下功能点 扫一下目录吧 扫目录发现一个.git 下一下源码看看 找到个flag.php和index.php <?php$flag file_get_contents(/flag);再看看index.php(代码有点长,所以只留了后面有用的) &…...

C/C++滑动窗口算法深度解析与实战指南
C/C滑动窗口算法深度解析与实战指南 引言 滑动窗口算法是解决数组/字符串连续子序列问题的利器,通过动态调整窗口边界,将暴力解法的O(n)时间复杂度优化至O(n)。本文将系统讲解滑动窗口的核心原理、C/C实现技巧及经典应用场景,助您掌握这一高…...
)
Webug4.0靶场通关笔记15- 第19关文件上传(畸形文件)
目录 第19关 文件上传(畸形文件) 1.打开靶场 2.源码分析 (1)客户端源码 (2)服务器源码 3.渗透实战 (1)构造脚本 (2)双写绕过 (3)访问脚本 本文通过《…...

黑马点评大总结
8.2.1 短信登录 首先是用户提交手机号,后端将生成的验证码以及用户信息存入session中,用户登录时进行拦截并从session中拿出来信息校验,并把用户信息存入ThreadLocal中session共享问题:每个tomcat有自己的一份session,…...

LeetCode:返回倒数第k个结点
1、题目描述 实现一种算法,找出单向链表中倒数第 k 个节点。返回该节点的值。 注意:本题相对原题稍作改动 示例: 输入: 1->2->3->4->5 和 k 2 输出: 4 说明: 给定的 k 保证是有效的。 2、…...

zotero pdf中英翻译插件使用
最近发现一个pdf中英翻译的神器zotero-pdf2zh,按照官方安装教程走一遍的时候,发现一些流程不清楚的问题, 此文就是整理一些安装需要的文件以及遇到的问题: 相关文件下载地址 Zotero 是一款免费的、开源的文献管理工具࿰…...

Java后端程序员学习前端之CSS
什么是css Cascading Style Sheet 层叠级联样式表 表现 (美化网页) 字体,颜色,边距,高度,宽度,背景图片,网页定位,网页浮动.. 发展史 CSS1.0 CSS2.0 DIV(块)CSS,HTML与CSS结构分离…...

MySQL——数据库基础操作
学习MySQL之前,要先配置好相关环境与软件下载,怎么就不展开了:找找网上对应环境下的教程即可 目录 数据库与MySQL 案例使用 MySQL架构 SQL指令分类 储存引擎 库操作 创建数据库 编码集与校验规则 校验规则的影响 删除数据库 数…...

[低代码 + AI] 明道云与 Dify 的三种融合实践方式详解
随着低代码平台和大语言模型工具的不断发展,将企业数据与智能交互能力融合,成为提高办公效率与自动化水平的关键一步。明道云作为一款成熟的低代码平台,Dify 则是一个支持自定义工作流的开源 LLM 应用框架。两者结合,可以实现灵活、高效的智能化业务处理。 本文将详解明道…...

湖北理元理律师事务所:规模化债事服务的探索与实践
在个人债务问题日益普遍化的当下,如何通过合法、系统化的服务帮助债务人化解危机,成为法律服务业的重要课题。湖北理元理律师事务所作为经国家司法局批准设立的债事服务机构,其构建的“法律技术金融”服务模式,为债务优化领域提供…...

MySQL JOIN详解:掌握数据关联的核心技能
一、为什么需要JOIN? 在关系型数据库中,数据通常被拆分到不同的表中以提高存储效率。当我们需要从多个表中组合数据时,JOIN操作就成为了最关键的技能。通过本文,您将全面掌握MySQL中7种JOIN操作,并学会如何在实际场景中…...

深入浅出数据库规范化的三大范式
数据库的“成长之路”:从1NF到3NF的规范化进化 在数据库的世界里,关系模式就像一个“孩子”,需要一步步学习“规矩”,才能健康成长。今天,我们就来聊聊数据库的规范化历程——从第一范式(1NF)出…...
:SaaS与移动应用商业模式的关键要点剖析)
精益数据分析(39/126):SaaS与移动应用商业模式的关键要点剖析
精益数据分析(39/126):SaaS与移动应用商业模式的关键要点剖析 在创业和数据分析的探索之旅中,每一次深入研究不同的商业模式都是一次宝贵的学习机会。今天,依旧怀揣着与大家共同进步的期望,深入解读《精益…...
)
【PostgreSQL数据分析实战:从数据清洗到可视化全流程】4.3 数据脱敏与安全(模糊处理/掩码技术)
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 PostgreSQL数据脱敏实战:从模糊处理到动态掩码的全流程解析4.3 数据脱敏与安全:模糊处理与掩码技术深度实践4.3.1 数据脱敏的核心技术体系4.3.1.1 技…...

nginx面试题
nginx 返回状态码413 Nginx 状态码 413 表示“请求实体过大”(Request Entity Too Large),意味着客户端发送的请求体大小超过了服务器允许的限制。 解决方法 修改 Nginx 配置文件: 找到 Nginx 配置文件,通常位于 /etc…...

flink rocksdb状态说明
文章目录 1.默认情况2.flink中的状态3.RocksDB4.对比情况5.使用6.RocksDB架构7.参考文章8.总结提示:以下主要考虑flink 状态永久存储 rocksdb情况,做一些简单说明 1.默认情况 当flink使用rocksdb存储状态时。无论是永久存储还是临时存储都可能会落盘写文件(如果没有配置存储…...

Linux | WEB服务器的部署及优化
一. web服务的常用知识 1.1 www www(World Wide Web):即为万维网,常被称为“全球信息广播”。它是一种基于超文本和HTTP协议,能够将文字、图形、影像以及声音等多媒体信息,通过超链接的方式组织在一起&…...

Nginx正反向代理与正则表达式
目录 一:正向代理 1.编译安装nginx 2.配置正向代理 二:反向代理 1.配置nginx七层代理 2.配置nginx四层代理 三:nginx 缓存 1.缓存功能的核心原理和缓存类型 2.代理缓存功能设置 四:nginx rewrite 和正则表达式 1.Nginx…...

字节:LLM自动化证明工程基准
📖标题:APE-Bench I: Towards File-level Automated Proof Engineering of Formal Math Libraries 🌐来源:arXiv, 2504.19110 🌟摘要 🔸大型语言模型(LLM)的最新进展在形式定理证明…...

豆包多轮对话优化策略:上下文理解与记忆,意图识别,对话管理
豆包多轮对话优化策略:上下文理解与记忆,意图识别,对话管理 上下文理解与记忆:我会分析每一轮用户输入的文本内容,理解其中的语义、意图和关键信息,并将这些信息与之前轮次的对话内容相结合,形成对整个对话上下文的理解和记忆。例如,在一个关于旅游规划的对话中,用户先…...

ADK 第四篇 Runner 执行器
智能体执行器 Runner,负责完成一次用户需求的响应,是ADK中真正让Agent运行起来的引擎,其核心功能和Agents SDK中的Runner类似,具体作用如下: 会话管理:自动读取/写入 SessionService,维护历史信…...

yolo 用roboflow标注的数据集本地训练 kaggle训练 comet使用 训练笔记5
本地训练 8gb内存,机械硬盘用了4分钟训练完了 ........... model torch.hub.load(path/to/yolov5, custom, path./runs/train/exp10/weights/best.pt, sourcelocal) 连不上github kaggel训练 传kaggle了 # Train YOLOv5s on COCO128 for 3 epochs !python train…...

chili3d笔记11 连接yolo python http.server 跨域请求 flask
from ultralytics import YOLO from flask import Flask, request, jsonify from flask_cors import CORS import base64 from io import BytesIO from PIL import Image import json# 加载模型 model YOLO(./yolo_detect/best.pt)app Flask(__name__) CORS(app) # 启用跨域…...

安全为上,在系统威胁建模中使用量化分析
*注:Open FAIR™ 知识体系是一种开放和独立的信息风险分析方法。它为理解、分析和度量信息风险提供了分类和方法。Open FAIR作为领先的风险分析方法论,已得到越来越多的大型组织认可。 在数字化风险与日俱增的今天,企业安全决策正面临双重挑战…...

STA中的multi_cycle 和false_path详细讨论
特殊路径:跨时钟域下的exception_path:分为多种情况优先 1、不同clk_domain ,但频率相同 create_clock -name CLKM -period 10 -waveform {0 5} [get_ports CLKM] create_clock -name CLKP -period 10 -waveform {0 5} [get_ports CLKP] set_multicycl…...

Vite 的工作流程
Vite 的工作流程基于其创新的 “预构建 按需加载” 机制,通过利用现代浏览器对原生 ES 模块的支持,显著提升了开发效率和构建速度。以下是其核心工作流程的详细分析: 一、开发环境工作流程 1. 启动开发服务器 冷启动:通过 npm …...

NGINX 的 ngx_http_auth_jwt_module模块
一、模块概述 ngx_http_auth_jwt_module 模块用于通过验证请求中提供的 JWT 来进行客户端授权。此模块支持 JSON Web 签名(JWS)、JSON Web 加密(JWE)以及嵌套 JWT(Nested JWT),使其成为一种灵活…...
【Game】Powerful——Transformation Card(10)
文章目录 1 级卡片2 级卡片3 级卡片4 级卡片5 级卡片6 级卡片7 级卡片8 级卡片8.1、神兽8.2、珍兽 9、其他9.1、5 级变身卡9.2、8 级变身卡 10、PK 汇总物理 11、卡片合成 1 级卡片 千变万化等级要求:1 级 金钱龟,防御30⬆ 大耳兔,速度15⬆…...
)
【算法学习】递归、搜索与回溯算法(一)
算法学习: https://blog.csdn.net/2301_80220607/category_12922080.html?spm1001.2014.3001.5482 前言: 这个专题与前面的相比是比较有难度的,但是在平时刷题时出现的概率还是非常高的,下面还是按照之前的逻辑来理清一下这几道…...

发行基础:上传版本注意事项
1、steam的规则是上传,提审,随时可更新。 2、基本流程:根据app id以及depot id,上传本地游戏文件到服务器,把分支版本设置为默认,发布。 试玩版与正式版的app id与depot id是相互独立的。 3、理论上开发者…...

智算中心建设方案和前景分析
智算中心建设方案和前景分析 一、智算中心的概念与重要性 1.1 定义与内涵 智算中心,即智能计算中心,是基于最新人工智能理论,采用领先的人工智能计算架构,专门为人工智能应用提供所需的算力服务、数据服务和算法服务的新型基础…...

亚马逊卖家复刻案例:用社群分层策略实现海外用户月均消费3.2次
近年来,随着跨境电商市场的快速发展,全球消费模式经历深刻变革。尤其是在美国、欧洲等成熟市场,中小卖家面对高度市场集中和运营成本上升的双重压力,纷纷寻求以更精细化的用户运营来提高客户复购率,增加单用户价值。20…...

小刚说C语言刷题—1038编程求解数学中的分段函数
1.题目描述 编程求解数学中的分段函数。 …………x1 (当 x>0 )。 yf(x)…0 (当 x0 )。 ………x−1 (当 x<0 )。 上面描述的意思是: 当x>0 时 yx1 ; 当 x0 时 y0 ; 当 x<0 时 yx−1 。 输入 输入一行,只有一个整数x(−30000≤x≤30…...

kotlin 03flow-stateFlow和sharedFlow企业中使用
一 stateFlow和sharedFlow企业中使用 在企业级 Kotlin 项目中,StateFlow 和 SharedFlow 是 状态管理 与 事件分发 的核心工具,尤其在 MVVM 架构中扮演着极为关键的角色。 ✅ 企业中如何使用 StateFlow 和 SharedFlow 场景工具示例UI 状态同步ÿ…...
的起源、原理、发展、改进和应用(附代码))
【机器学习|学习笔记】决策树Decision Tree(DT)的起源、原理、发展、改进和应用(附代码)
【机器学习|学习笔记】决策树Decision Tree(DT)的起源、原理、发展、改进和应用(附代码) 【机器学习|学习笔记】决策树Decision Tree(DT)的起源、原理、发展、改进和应用(附代码) 文…...

Kotlin-空值和空类型
变量除了能引用一个具体的值之外,还有一种特殊的值,那就是 null, 它代表空值, 也就是不引用任何对象 在Kotlin中, 对空值的处理是非常严格的,正常情况下,我们的变量是不能直接赋值为 null 的,否则无法编译通过, 这直接在编译阶段就避免了空指针问题 Kotlin中所有的类型默认都是…...

Java 企业级开发设计模式全解析
Java 企业级开发设计模式全解析 在 Java 企业级开发的复杂领域中,设计模式如同精湛的工匠工具,能够帮助开发者构建高效、可维护、灵活且健壮的软件系统。它们是无数开发者在长期实践中总结出的解决常见问题的最佳方案,掌握这些模式对于提升开…...

高并发内存池
文章目录 前言一、项目介绍二、内存池介绍1.池化技术2.内存池3.malloc视角下内存的管理 三、定长内存池3.1 设计思路3.2 数据结构 四、高并发内存池整体框架设计4.1 thread cachethreadcache哈希桶映射对齐规则threadcache TLS无锁访问 4.2 central cachecentral cache结构设计…...

常用对称加密算法的Python实现及详解
文章目录 **常用对称加密算法的Python实现及详解****1. 对称加密概述****1.1 对称加密的基本原理****1.2 对称加密的分类****1.3 对称加密的应用** **2. DES(Data Encryption Standard)****2.1 算法原理****2.2 Python实现****2.3 安全性分析** **3. 3DE…...

ByteArrayInputStream 类详解
ByteArrayInputStream 类详解 ByteArrayInputStream 是 Java 中用于从字节数组读取数据的输入流,位于 java.io 包。它允许将内存中的字节数组当作输入流来读取,是处理内存数据的常用工具。 1. 核心特性 内存数据源:从字节数组(b…...