【力扣刷题记录】hot100错题本(一)
1. 简单题

我的答案:时间复杂度过高:O(N^3)
class Solution:def twoSum(self, nums: List[int], target: int) -> List[int]:for num in nums:if (target - num) in nums:#多余for i in range(len(nums)):if nums[i] == num :for j in range(i+1,len(nums)):if nums[j] == (target - num) :return [i,j]
官方题解:
#暴力枚举,时间复杂度:O(N^2)
class Solution:def twoSum(self, nums: List[int], target: int) -> List[int]:n = len(nums)for i in range(n):for j in range(i + 1, n):if nums[i] + nums[j] == target:return [i, j]return []作者:力扣官方题解
链接:https://leetcode.cn/problems/two-sum/solutions/434597/liang-shu-zhi-he-by-leetcode-solution/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。#哈希表,时间复杂度:O(N),此时找target - num的时间复杂度变为O(1)
class Solution:def twoSum(self, nums: List[int], target: int) -> List[int]:hashtable = dict()#创建一个空字典哈希数组,用于存储已经遍历过的数字和她们的索引for i, num in enumerate(nums):#使用 enumerate 同时遍历 nums 中的索引 i 和对应的值 num。if target - num in hashtable:return [hashtable[target - num], i]hashtable[nums[i]] = ireturn []作者:力扣官方题解
链接:https://leetcode.cn/problems/two-sum/solutions/434597/liang-shu-zhi-he-by-leetcode-solution/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
2. 中等题

官方题解
#最小堆,堆的时间复杂度是O(log n),故总的时间复杂度为O(nlog n)
#初始时堆为空,将最小丑数1加入堆,每次取出堆顶元素x,x是堆中最小的丑数,则把2X,3X,5X都加入堆,用哈希集去重
class Solution:def nthUglyNumber(self,n: int) -> int:factors = [2,3,5]seen = {1}heap = [1]for i in range(n-1):curr = heapq.heappop(heap) #返回堆中最小元素for factor in factors:if (num := curr * factor) not in seen:seen.add(num)heapq.heappush(heap,num)#将数存入堆中并保存堆的结构return heapq.heappop(heap)
#优先队列,利用三个指针的移动,需要计算丑数数组中的n个数,故时间复杂度为O(n)
class Solution:def nthUglyNumber(self,n: int) -> int:dp = [0]*(n+1)p2 = p3 = p5 =1dp[1] = 1 for i in range(2,n+1):num2,num3,num5 = dp[p2]*2,dp[p3]*3,dp[p5]*5dp[i]=min(num2,num3,num5)if dp[i] == num2:p2+=1 if dp[i] == num3:p3+=1if dp[i] == num5:p5+=1return dp[n]
3. 美团笔试错题

def calculate_alternate_steps():T = int(input()) # 次数for _ in range(T):n = int(input())arr_str = input().strip()arr = [0] + list(map(int, list(arr_str))) # 下标从1开始start = int(input())left_steps = 0right_steps = 0visited = set()current_index = startdirection = 'right' # 初始向右while True:visited.add(current_index)current_value = arr[current_index]next_index = -1if direction == 'right':for i in range(current_index + 1, n + 1):if arr[i] > current_value and i not in visited:next_index = iright_steps += 1breakdirection = 'left' # 切换方向else: # direction == 'left'for i in range(current_index - 1, 0, -1):if arr[i] > current_value and i not in visited:next_index = ileft_steps += 1breakdirection = 'right' # 切换方向if next_index == -1:break # 没找到更大的,停止current_index = next_indexprint(f"{right_steps} {left_steps}")4. 字母异位分词

- 方法一:排序
逻辑:互为异位词的两个字符串包含的字母相同,因此对两个字符串分别进行排序后得到的字符串一定相同,可将排序之后的字符串作为哈希表的键。
时间复杂度:对于每个字符串,需要O(klogk)的时间排序,以及O(1)的时间更新哈希表,有n个字符串,故时间复杂度为O(nklogk),k为字符串的最大长度。
class Solution:def groupAnagrams(self,strs:List[str]) -> List[List[str]]:mp = collections.defaultdict(list) #创建一个默认顺序的哈希表,key是排序后的字符串,value是一个list,存放对应的原始字符串,defaultdict的好处是当key不存在时,自动创造一个空列表,不用手动创建for st in strs:key = "".join(sorted(st))#对字符串进行排序;"".join()表示将()里的重新拼接成一个新的字符串mp[key].append(st)#把字符串加进list中return list(mp.values())
- 方法二:计数
异位的词中各个字母计数也相同,可以将每个字母出现的次数用字符串表示,作为哈希表的键。
时间复杂度: O ( n ( k + ∣ Σ ∣ ) ) O(n(k+|\Sigma|)) O(n(k+∣Σ∣)),n为字符串个数,k为字符串最大长度, ∣ Σ ∣ |\Sigma| ∣Σ∣为字符集长度,此处为26;对于每个字符串,需要对其k个字母进行计数, O ( ∣ Σ ∣ ) O(|\Sigma|) O(∣Σ∣)的时间生成哈希表的键,同时以及O(1)的时间写进哈希表。
##异位的词中各个字母计数也相同,可以将每个字母出现的次数用字符串表示,作为哈希表的键
class Solution:def groupAnagrams(self,strs:List[str]) -> List[List[str]]:mp = collections.defaultdict(list)for st in strs:counts=[0]*26for ch in st:counts[ord(ch) - ord("a")] += 1 #构建了一个列表,将'a'~'z'映射到数组下标0~25,ord(ch)得到字符的ASCII码# 需要将list转换为tuple才能进行哈希,因为list是mutable类型(可变类型),可以将如a=[1,2,3];a[0]=100;print(a)显示a=[100,2,3],此即可变类型;mutable类型不能当哈希表的keymp[tuple(counts)].append(st)return list(mp.values())
5. 最长连续序列

- 利用哈希表,根据数是否是开头来判断是否跳过内层循环
利用哈希表对每个数判断是否是连续序列开头的数,如果该数的前一个在序列中,说明肯定不是开头,直接跳过;因此,只要对每个开头的数进行循环,直到这个序列不再连续
即每个数进行内层进行一次循环,外层为O(n),故时间复杂度为O(n)
class Solution:def longestConsecutive(self, nums: List[int]) -> int:longest_streak = 0num_set = set(nums) #对nums进行去重for num in num_set:if num - 1 not in num_set:current_num = numcurrent_streak = 1while current_num + 1 in num_set:current_num += 1current_streak += 1longest_streak = max(longest_streak,current_streak)return longest_streak
6. 利用双指针移动零
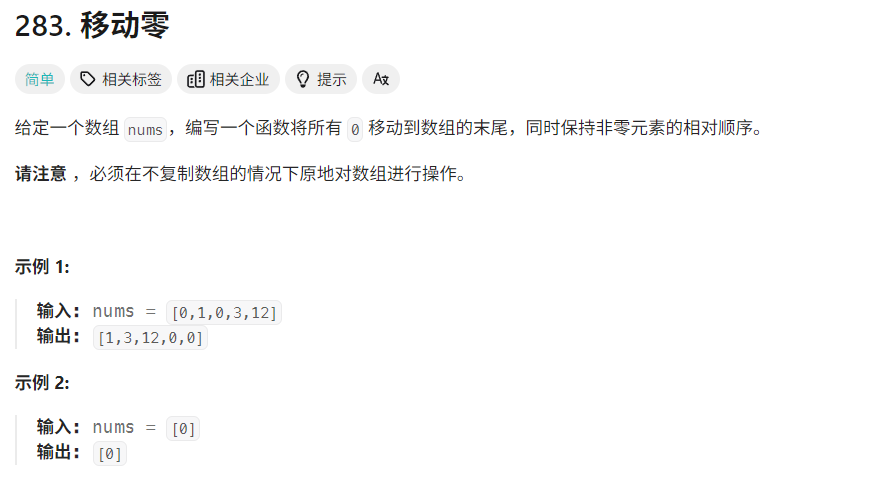
- 利用双指针
使用双指针,左指针指向当前已经处理好的序列尾部,右指针指向待处理序列的头部;右指针不断向右移动,每次右指针指向非零数,则将左右指针对应的数交换,同时左指针右移;左右指针中间全为零。
两个指针同时移动,每个位置最多被遍历两次,时间复杂度为O(n)
class Solution:def moveZeroes(self,nums:List[int]) -> None:n = len(nums)left = right = 0 while right < n:if nums[right] != 0:nums[left],nums[right] = nums[right],nums[left]#相当于左指针停滞不前,指向右指针原先指向的0,因此需要交换位置left += 1right += 1
7. 双指针:容器可以装的最多的水

- 利用双指针框出左右边界
每次以双指针为左右边界,移动更小数的那个指针,如果是左指针则右移,右指针则左移。
双指针总计最多遍历整个数组一次,时间复杂度为O(n)
class Solution:def maxArea(self,height:List[int]) -> int:l,r = 0,len(height) -1ans = 0while l < r:area = min(height[l], height[r])*(r-l)ans = max(ans,area)if height[l] <= height[r]:l+=1else:r-=1return ans
8. 二叉树的中序遍历及其延伸

- 树的中序遍历:按照访问左子树-根节点-右子树的方式遍历这棵树,在访问左子树的时候按照同样的方式遍历,直到遍历完整颗树。
- 方法一:利用递归
时间复杂度:O(n),n为二叉树节点的个数;
空间复杂度:O(n),递归利用了隐形栈
class Solution:def inorderTraversal(self, root):res = []self.inorder(root, res)return resdef inorder(self, root, res):if not root:returnself.inorder(root.left, res)res.append(root.val)self.inorder(root.right, res)
- 方法二:迭代,上述递归时隐式维护了一个栈,迭代时需要将这个栈显式模拟出来
时间复杂度为O(n),n为二叉树节点个数,每个节点会被访问一次且只会被访问一次;
空间复杂度为O(n),栈占用的空间
class Solution:def inorderTraversal(self, root):res = []stack = []while root or stack:# 1. 一直向左走,压入栈while root:stack.append(root)root = root.left# 2. 弹出栈顶元素,访问它root = stack.pop()res.append(root.val)# 3. 转向右子树root = root.rightreturn res
- 方法三:morris
比上述多做了一步:假设当前遍历到的节点为x,将x的左子树中最右边的节点的右孩子指向x,这样在左子树遍历完成后我们通过这个指向走回了x而不用通过栈;
时间复杂度:O(n),每个节点被遍历两次;
省去了栈的空间复杂度,O(1)。
class Solution:def inorderTraversal(self, root):res = []current = rootwhile current:if current.left:#有左子树# 找到当前节点左子树中的最右节点(中序前驱)predecessor = current.leftwhile predecessor.right and predecessor.right != current:predecessor = predecessor.right# 第一次访问:建立线索if not predecessor.right:predecessor.right = currentcurrent = current.leftelse:# 第二次访问:恢复结构 + 访问当前节点predecessor.right = None#置空res.append(current.val)current = current.rightelse:# 没有左子树,直接访问当前节点res.append(current.val)current = current.rightreturn res
- 二叉树的层次遍历:按照从上到下、从左到右的顺序一层一层访问树的节点。是一种广度优先搜索方法,通常使用队列实现。实现逻辑为:
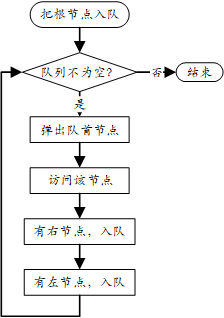
| 题型 | 说明 |
|---|---|
| 🔁 按层反转 | 每一层从右到左打印(Z字形遍历) |
| 📐 记录层数/高度 | 层数 = 阶段数,BFS循环几轮就是几层 |
| 🌠 找到每层最大值 | 每一层记录最大值 |
| 🎯 节点的最短路径 | BFS是天然找最短路径的利器 |
| 🔗 右视图/左视图节点 | 每层最右/最左节点 |
| 📦 序列化和反序列化 | 层序遍历是常用方式之一 |
- 深度优先搜索:是种“一条路走到底”的搜索方法,他优先沿某一条路走下去,走到底了再返回上一个交叉点走另一条路。
常用数据结构:递归(系统栈)或手动栈 - 广度优先搜索哦:是种“从近到远”的搜索方法,他一层一层地遍历节点,先访问第一层,再访问第二层。
常用数据结构:队列 - 无论是深度优先搜索还是广度优先搜索,其时间复杂度都是遍历的所有节点和边的成本O(n+m);但空间复杂度广度优先搜索会更高一些(排队的节点更多)。
两者区别:
| 对比项 | DFS(深度优先) | BFS(广度优先) |
|---|---|---|
| 搜索方式 | 一条路走到底,再回退 | 一层一层来,逐层扩展 |
| 使用数据结构 | 栈(或递归) | 队列 |
| 空间复杂度 | 最坏O(n)(取决于深度) | 最坏O(n)(取决于宽度) |
| 寻找路径 | 不一定是最短路径 | 一定能找最短路径(无权图) |
| 应用场景 | 回溯、树递归、组合问题、图连通 | 层级问题、最短路径、最小步数 |
| 实现方式 | 递归写法更自然 | 需要手动队列实现 |
9. 二叉树的最大深度

- 方法一:深度优先搜索
利用递归,先计算左子树深度和右子树深度,树的深度即两者最大+1;
时间复杂度:O(n),每个节点只被遍历一次
class Solution:def maxDepth(self,root):if root is None:return 0else:left_height = self.maxDepth(root.left)right_height = self.maxDepth(root.right)return max(left_height,right_height) +1
- 方法二:广度优先搜索
利用队列,将[每次从队列拿出一个节点]改为[每次将队里了里的所有节点拿出来扩展],这样能保证每次拓展完的时候队列里存放的是当前层的所有节点,最后用一个变量来维护拓展的次数,该二叉树的最大深度即为拓展次数;
时间复杂度:O(n),每个节点只被访问一次。
class Solution:def maxDepth(self,root):if not root:returnqueue = deque([root])#加入根节点ans = 0while queue:size = len(queue)#当前层的节点数for _ in range(size):#对于该层的所有节点都进行左右节点拓展node = queue.popleft()if node.left:queue.append(node.left)if node.right:queue.append(node.right)ans += 1 #处理完一层后深度+1return ans
- 如何用python实现队列
| 方法 | 适用场景 | 入队 | 出队 | 是否推荐 |
|---|---|---|---|---|
collections.deque | 通用算法题 / BFS | append() | popleft() | ✅ 推荐 |
queue.Queue | 多线程 / 并发编程 | put() | get() | ✅ 推荐(多线程) |
list | 简单脚本 | append() | pop(0) | ❌ 不推荐(效率低,pop的时间复杂度为O(n)) 因为list底层是动态数组,删除头部元素后需要将后续前移,故时间复杂度为O(n) |
举例:
## collections.deque
from collections import dequequeue = deque()# 入队
queue.append(10)
queue.append(20)# 出队
x = queue.popleft() # 返回10# 判空
if not queue:print("队列为空")## queue.Queue
from queue import Queuequeue = Queue()# 入队
queue.put(10)# 出队
x = queue.get()# 判空
if queue.empty():print("队列为空")## list模拟
queue = []# 入队
queue.append(10)# 出队(效率低)
x = queue.pop(0)
10. 翻转二叉树

- 利用递归;交换左右子树的位置即可
时间复杂度:O(n),n为树的节点,会遍历树的每个节点,对于每个节点,在常数时间内交换两个子树
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:def invertTree(self,root: TreeNode) -> TreeNode:if not root:return rootleft = self.invertTree(root.left)right = self.invertTree(root.right)root.left,root.right = root.right,root.leftreturn root
11. 对称二叉树

- 方法一:递归
同步移动两个指针,两指针先同时指向根节点,接着,一个指针左移,一个指针右移,每次检查当前指针的值是否相等,如果相等再判断左右子树是否对称;
时间复杂度:O(n),对于每个节点都会遍历
class Solution:def isSymmetric(self, root: Optional[TreeNode]) -> bool:# 内部辅助函数:递归比较左右子树是否镜像对称def check(p, q):if not p and not q:return True # 两个都是空,说明对称if not p or not q:return False # 一个空一个非空,不对称return (p.val == q.val andcheck(p.left, q.right) andcheck(p.right, q.left))return check(root.left, root.right)
12.二叉树的直径

- 深度优先搜索
路径可以看成经过的节点数减一;且可以看成由某个节点为起点,其左儿子和右儿子的和(节点数为左儿子加右儿子+1,路径需要再减1);遍历所有节点得到左儿子和右儿子的和,取最大即可得到二叉树的最长路径;
时间复杂度:O(n),n为二叉树节点数,遍历所有节点;
空间复杂度:O(height),height为树的高度,递归需要为每一层递归函数分配栈空间,分配空间大小取决于递归深度,即树的高度。
class Solution:def diameterOfBinaryTree(self, root: Optional[TreeNode]) -> int:self.ans = 0def depth(node):#访问到空节点,返回0if not node:return 0#左儿子为根的子树的深度L = depth(node.left)#右儿子为根的子树的深度R = depth(node.right)#计算d_node即L+R+1,并更新ansself.ans = max(self.ans,L+R)#返回该节点为根的子树深度return max(L,R)+1depth(root)return self.ans
13. 将有序数组转换为二叉搜索树

- 三个方法均是中序遍历,方法一总是选择中间位置左边的数字作为根节点,方法二选择右边,方法三在上述两者中随机选择。
时间复杂度:O(n),n为数组长度,每个是数字只访问一次;
空间复杂度:O(log(n)),构建栈的深度为log(n)。
class Solution:def sortedArrayToBST(self, nums: List[int]) -> Optional[TreeNode]:def helper(left,right):if left > right:return None#方法一,总是选择中间位置左边的数作为根节点mid = (left+right) // 2#整数除法,向下取整#方法二,总是选择中间的右边作为根节点# mid = (left+right+1) // 2#方法三,随机选择中间节点的左边或者右边作为根节点mid = (left+right+randint(0,1)) // 2root = TreeNode(nums[mid])#确定根节点root.left = helper(left,mid - 1) #递归构建左子树root.right = helper(mid+1,right) #递归构建右子树return root return helper(0,len(nums) - 1)
- 二叉搜索树:是一种特殊的二叉树,需要满足:
对于每个节点root:
a. 所有左子树 < root.val
b. 所有右子树 > root.val
c. 所有子树均是二叉搜索树
常见操作:最坏时间复杂度是因为可能因为不断插入递增或递减序列使二叉树弱化为链表
| 操作 | 描述 | 平均时间复杂度 | 最坏时间复杂度 |
|---|---|---|---|
| 插入(Insert) | 插入一个新值 | O(log n) | O(n) |
| 查找(Search) | 查找一个值是否存在 | O(log n) | O(n) |
| 删除(Delete) | 删除一个值(需要分情况处理) | O(log n) | O(n) |
| 最小值/最大值 | 找最小值:最左节点;最大值:最右节点 | O(log n) | O(n) |
遍历方式:
| 遍历方式 | 顺序 | 应用场景 |
|---|---|---|
| 中序遍历 | 左 → 根 → 右 | 升序输出 BST 中所有值 |
| 前序遍历 | 根 → 左 → 右 | 用于复制树结构 |
| 后序遍历 | 左 → 右 → 根 | 用于删除树结构 |
| 层序遍历 | 一层一层从上往下 | 常用于广度优先搜索(BFS) |
删除操作(三种情况):
a. 叶子节点:直接删除
b. 只有一个子节点:用子节点替代它
c. 该节点有两个子节点:找右子树的最小值(或左子树最大值);用其替换当前节点,再递归删除该值
class TreeNode:def __init__(self, val=0, left=None, right=None):self.val = valself.left = leftself.right = rightclass Solution:def deleteNode(self, root, key):if not root:return None#找到值对应的节点,小于往左,大于往右if key < root.val:root.left = self.deleteNode(root.left, key)elif key > root.val:root.right = self.deleteNode(root.right, key)else:# 找到目标节点,开始删除#单个节点,直接替换if not root.left:return root.rightif not root.right:return root.left# 两个子节点:找右子树最小值min_larger_node = self.getMin(root.right)root.val = min_larger_node.valroot.right = self.deleteNode(root.right, min_larger_node.val)#再在右子树中删除这个最小值return rootdef getMin(self, node):while node.left:node = node.left#由于是对右子树找最小,右子树的最左节点就是最小值return node
时间复杂度:查找要删除的节点/找右子树的最小值/递归删除该最小节点;三个步骤都是最多耗时O(h),h为树的高度;当树为平衡二叉树时, h = l o g ( n ) h=log(n) h=log(n),退化为链表时 h = n h=n h=n。
| 情况 | 时间复杂度 |
|---|---|
| 平衡二叉搜索树(理想情况) | O(log n) |
| 退化为链表(最坏情况) | O(n) |
相关扩展结构:
| 数据结构 | 特点 |
|---|---|
| AVL树 | 平衡二叉搜索树,插入/删除时自动保持左右子树高度差不超过1 |
| 红黑树 | 一种自平衡二叉搜索树,插入和删除更高效,广泛用于 STL、Java |
| Treap / Splay Tree | 更复杂的平衡机制,适合频繁操作或对时间复杂度有更高要求 |
| Segment Tree | 区间操作优化,但不是严格意义上的 BST |
平衡二叉树:对于任意节点,其左子树和右子树的高度差小于等于1,所有子树也是平衡二叉树。
为什么需要平衡?发现右子树过高时会自动左旋,避免树退化为链表。
常见的平衡二叉树:
| 类型 | 特点 |
|---|---|
| AVL树 | 每个节点维护平衡因子,严格控制高度差不超过 1,查找快但插入稍慢(最典型的二叉树) |
| 红黑树 | 通过颜色控制近似平衡,高度最多为 2log n,Java、C++ STL 使用 |
| Splay树 | 每次访问后将该节点“旋转”到根,适合频繁访问某些节点的场景 |
| Treap | 结合 BST + 堆的性质,使用随机优先级构建 |
操作时间复杂度:
| 操作 | 时间复杂度 |
|---|---|
| 查找 | O(log n) |
| 插入 | O(log n) |
| 删除 | O(log n) |
14. 树的层序遍历

- 方法一:利用广度优先遍历每个节点,每层均判断层中节点数。
时间复杂度:O(n),每个节点均被访问一次;
空间复杂度:O(n),队列+输出。
class Solution:def levelOrder(self, root: Optional[TreeNode]) -> List[List[int]]:res = []if not root:return res queue = deque([root])while queue:size = len(queue)#当前层队列中节点数level = []for _ in range(size):node = queue.popleft()level.append(node.val)if node.left:queue.append(node.left)if node.right:queue.append(node.right)res.append(level)return res
- 方法二:利用哈希表
时间复杂度:O(n+hlog(h)),每个节点访问一次,最后需要对哈希表键值排序输出,时间复杂度为hlog(h),h为树的高度
空间复杂度:O(n),队列+哈希表+输出
class Solution:def levelOrder(self, root: Optional[TreeNode]) -> List[List[int]]:if not root:return []level_map = defaultdict(list) # 哈希表:level -> list of node valuesqueue = deque()queue.append((root, 0)) # 初始状态为根节点和其层级 0while queue:node, level = queue.popleft()level_map[level].append(node.val)#通过二元组加入哈希表if node.left:queue.append((node.left, level + 1))if node.right:queue.append((node.right, level + 1))# 将 level_map 按 level 从小到大取值组成结果return [level_map[i] for i in sorted(level_map.keys())]
15. 判断树是否是二叉搜索树

- 方法一:利用递归,判断该节点是否在上下界里,其左右子树是否是二叉搜索树即可。
时间复杂度:O(n),每个节点均被访问一次;
空间复杂度:O(n),构建栈的深度为树的高度,最坏情况为n。
class Solution:def isValidBST(self, root: Optional[TreeNode]) -> bool:def helper(node,lower = float('-inf'),upper=float('inf')) -> bool:if not node:return Trueval = node.val#判断节点值是否满足if val <= lower or val >= upper:return False #递归判断左右子树是否是二叉搜索树if not helper(node.right,val,upper):return Falseif not helper(node.left,lower,val):return Falsereturn Truereturn helper(root)
- 方法二:中序遍历时实时检查当前节点值是否大于前一个中序遍历得到的节点值,一旦发生不大于,则该树并非二叉搜索树;利用栈实现中序遍历。
时间复杂度:O(n),每个节点最多被访问一次;
空间复杂度:O(n),栈最多存储n个节点,因此额外需要O(n)的空间。
class Solution:def isValidBST(self,root:TreeNode) -> bool:stack,inorder = [],float('-inf')while stack or root:#把左子树节点全部压入栈中while root:stack.append(root)root = root.leftroot = stack.pop()#如果中序遍历得到的节点的值小于前一个inorder,说明不是二叉搜索树if root.val <= inorder:return Falseinorder = root.valroot = root.rightreturn True
16. 找到二叉搜索树中第k小的元素

- 方法一:利用中序遍历,边遍历边计数,计到第k个即第k小的数。
时间复杂度:O(h+k),h是树的高度,开始遍历前,需要到达最左的叶子节点;
空间复杂度:O(h),栈中最多需要存储h个元素。
class Solution:def kthSmallest(self, root: Optional[TreeNode], k: int) -> int:stack=[]#res = [],可以省去该记录,直接用k计数即可while stack or root:while root:stack.append(root)root = root.leftroot = stack.pop()# res.append(root.val)# if len(res) == k:# return res[k-1]k-=1if k == 0:return root.valroot = root.right
- 方法二:用于优化需要频繁查找第k小的值;利用树重建,同时记录子树的节点数;对每个节点判断其左子树节点数和k的大小。
时间复杂度:O(n),需要遍历树中所有的节点来统计节点数,搜索的时间复杂度为O(H),H为树的高度;
空间复杂度:O(n),用于存储以每个节点为根节点的子树节点数。
class MyBst:def __init__(self,root: TreeNode):self.root = root#统计以每个节点为根节点的子树的节点树,并记录在哈希表中self._node_num = {}#用于存储每个节点的子树节点数self._count_node_num(root)def kth_smallest(self,k: int) -> int:#返回树中第k小的元素node = self.rootwhile node:left = self._get_node_num(node.left)#得到左子树的节点数if left < k - 1:#左子树总节点数小于knode = node.right#节点右移k -= left+ 1elif left == k - 1:return node.valelse:node = node.left#第k小的节点在左子树中def _count_node_num(self,node) -> int:#统计以node为节点的子树节点数if not node:return 0self._node_num[node] = 1 + self._count_node_num(node.left) + self._count_node_num(node.right)return self._node_num[node]def _get_node_num(self,node) -> int:#获取以node为根节点的子树节点数return self._node_num[node] if node is not None else 0class Solution:def kthSmallest(self,root: TreeNode,k: int) -> int:bst = MyBst(root)return bst.kth_smallest(k)
- 方法三:如果二叉树经常被修改(插入/删除操作)并且你需要频繁地查找第k小的值,可以将二叉搜索树变平衡。构建好平衡二叉搜索树后修改成本降低。
时间复杂度:O(n),构建树全部节点的时间,增、删、搜索的时间复杂度均为O(log(n));
空间复杂度:O(n),用于存储平衡二叉树。
class AVL:#定义一个平衡二叉树,允许重复值#定义平衡二叉树的节点class Node:__slots__ = ("val","parent","left","right","height","size")def __init__(self,val,parent = None,left=None,right = None):self.val = valself.parent = parentself.left = leftself.right = rightself.height = 0#默认叶子节点高度为0self.size = 1#当前节点为根节点时子树节点数#构建二叉树def __init__(self,vals):self.root = self._build(vals,0,len(vals) - 1,None) if vals else Nonedef _build(self,vals,l,r,parent):#根据vals[l:r]构建平衡二叉树,并返回根节点m = (l+r) // 2node = self.Node(vals[m],parent=parent)if l <= m -1:#递归构建左子树node.left = self._build(vals,l,m - 1,parent=node)if m+1 <= r:node.right = self._build(vals,m+1,r,parent=node)self._recompute(node)#重新计算每个子树的高度和元素数return nodedef _recompute(self,node):#重新计算每个子树的高度和元素数node.height = 1+ max(self._get_height(node.left),self._get_height(node.right))node.size = 1+ self._get_size(node.left) + self._get_size(node.right)def _get_height(self,node) -> int:return node.height if node is not None else 0def _get_size(sellf,node) -> int:return node.size if node is not None else 0def kth_smallest(self,k: int):node = self.rootwhile node:left = self._get_size(node.left)if left < k -1:node = node.rightk -= left+1elif left == k - 1:return node.valelse:node = node.left #对二叉树进行增删改除操作#插入值为v的节点def insert(self,v):if self.root is None:self.root = self.Node(v)else:#计算新节点的位置#在子树中找到值为v的位置node = self._subtree_search(self.root,v)is_add_left = (v<= node.val)#判断是否加在节点左边if node.val == v:if node.left:#如果值为v的节点存在且其有左子节点,则将其加在左子树的最右边node = self._subtree_last(node.left)is_add_left = Falseelse:is_add_left = True#添加新节点leaf = self.Node(v,parent=node)if is_add_left:node.left = leafelse:node.right = leafself._rebalance(leaf)#使树重新平衡def _rebalance(self,node):#从node节点开始逐个向上重新平衡二叉树,并更新高度和元素数while node is not None:old_height,old_size=node.height,node.size if not self._is_balanced(node):#判断此时是否平衡node = self._restructure(self._tall_grandchild(node))self._recompute(node.left)self._recompute(node.right)self._recompute(node)if node.height == old_height and node.size == old_size:#如果节点高度和元素数都没有变化则不需要再继续向上调整node = None else:node = node.parent def _is_balanced(self,node):#判断是否平衡return abs(self._get_height(node.left) - self._get_height(node.right)) <= 1def _tall_child(self,node):#获取node节点更高的子树if self._get_height(node.left) > self._get_height(node.right):return node.leftelse:return node.rightdef _tall_grandchild(self,node):#获取节点更高的子树里节点更高的子树child = self._tall_child(node)return self._tall_child(child)def _restructure(self,node):#重建parent = node.parentgrandparent = parent.parent if (node == parent.right) == (parent == grandparent.right):#处理一次需要旋转的情况self._rotate(parent)return parentelse:#处理需要两次旋转的情况self._rotate(node)self._rotate(node)return node def _rotate(self,node):#旋转parent = node.parentgrandparent = parent.parentif grandparent is None:self.root = node node.parent = Noneelse:self._relink(grandparent, node, parent == grandparent.left)#如果父节点在祖父节点的左边,则将node连接到祖父的左边,否则,连接到祖父的右边if node == parent.left:self._relink(parent,node.right,True)#如果节点在父节点的左边,则将节点的右子节点连接到父节点左边self._relink(node,parent,False)#将父节点连接到节点右边else:self._relink(parent,node.left,False)#节点在父节点右边,则将节点的左子节点连接到父节点右边self._relink(node,parent,True)#将父节点连接到节点的左边#is_left为真则将child连接到parent的左边,否则,连到parent的右边@staticmethoddef _relink(parent,child,is_left):#重新链接父节点和子节点,子节点允许为空if is_left:parent.left = childelse:parent.right = childif child is not None:child.parent = parent#删除操作def delete(self,v) -> bool:if self.root is None:return False node = self._subtree_search(self.root,v)#找到值为v的节点if node.val != v:#没有找到需要删除的节点return False #处理当前节点既有左子树也有右子树的情况#若左子树比右子树高度低,则将当前节点替换为右子树最左侧的节点,并移除右子树最左侧的节点#若右子树比左子树高度低,则将当前节点替换为左子树最右侧的节点,并移除左子树最右侧的节点if node.left and node.right:if node.left.height <= node.right.height:replacement= self._subtree_first(node.right)#找到右子树最左else:replacement = self._subtree_last(node.left)#找到左子树最右node.val = replacement.valnode = replacementparent = node.parentself._delete(node)self._rebalance(parent)return Truedef _delete(self,node):#删除节点并用它的子节点代替他,该节点最多只能有一个子节点if node.left and node.right:raise ValueError('node has two children')child = node.left if node.left else node.rightif child is not None:child.parent = node.parent if node is self.root:self.root = childelse:parent = node.parentif node is parent.left:parent.left = childelse:parent.right = child node.parent = node def _subtree_first(self,node):#返回以node为根节点的子树的第一个元素while node.left is not None:node = node.left return node def _subtree_last(self,node):#返回以node为根节点的子树的最后一个元素while node.right is not None:node = node.rightreturn nodedef _subtree_search(self,node,v):#在以node为根节点的子树中搜索值为v的节点,如果没有,则返回值为v的节点应该在的位置的父节点if node.val < v and node.right is not None:return self._subtree_search(node.right,v)if node.val > v and node.left is not None:return self._subtree_search(node.left,v)else:return nodeclass Solution:def kthSmallest(self,root: TreeNode,k: int) -> int:def inorder(node):if node.left:inorder(node.left)inorder_lst.append(node.val)if node.right:inorder(node.right)#中序遍历生成数值列表inorder_lst = []inorder(root)#构造平衡二叉搜索树avl = AVL(inorder_lst)#模拟1000次插入和删除操作random_nums = [random.randint(0,10001) for _ in range(1000)]for num in random_nums:avl.insert(num)random.shuffle(random_nums) #列表乱序for num in random_nums:avl.delete(num)return avl.kth_smallest(k)
17. 二叉树展开为链表
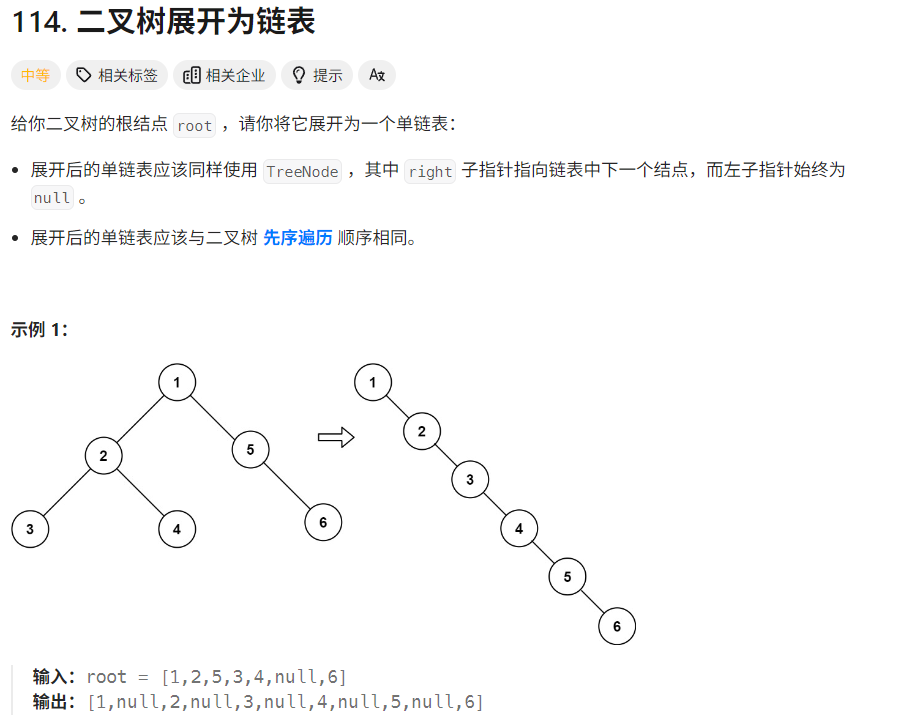
- 方法一:二叉树展开为链表之后会破坏二叉树的结构,因此在前序遍历(深度优先搜索:递归/迭代)结束之后更新各个节点的左右子节点的信息。
时间复杂度:O(n),其中,n为二叉树的节点数,前序遍历的时间复杂度为O(n),更新各个节点信息也是O(n);
空间复杂度:O(n),栈内元素不会超过n个
class Solution:def flatten(self,root: TreeNode) -> None:preorderList = list()def preorderTraversal(root:TreeNode):if root:preorderList.append(root)preorderTraversal(root.left)preorderTraversal(root.right)preorderTraversal(root)size = len(preorderList)for i in range(1,size):prev,curr = preorderList[i-1],preorderList[i]prev.left = Noneprev.right = curr#通过迭代实现前序遍历
class Solution:def flatten(self,root: TreeNode) -> None:preorderList = list()stack = list()node = rootwhile node or stack:while node:preorderList.append(node)stack.append(node)#先把左子节点全部放进来node = node.leftnode = stack.pop()#从低部开始node = node.right#重拾右子节点,并排查右子节点的左子树 size = len(preorderList)for i in range(1,size):prev,curr = preorderList[i-1],preorderList[i]prev.left = Noneprev.right = curr
- 方法二: 前序遍历和展开同步进行,在遍历左子树之前获得左右子节点的信息并存入栈中;对迭代遍历进行修改,每次从栈内弹出一个节点作为当前访问的节点,获得该节点的子节点,如果子节点不为空,则依次将右子节点和左子节点压入栈内。
时间复杂度:O(n),每个节点均被访问一次;
空间复杂度:O(n),栈的空间。
class Solution:def flatten(self,root: Optional[TreeNode]) -> None:if not root:returnstack = [root]prev = Nonewhile stack:curr = stack.pop()if prev:prev.left = Noneprev.right = currleft,right = curr.left,curr.rightif right:stack.append(right)if left:stack.append(left)prev = curr
- 方法三:寻找前驱节点,将空间复杂度降为O(1);即对于当前节点,如果左子节点不为空,则将其右子节点赋给左子节点的最右子节点作右子节点;然后将当前节点的左子节点赋给当前节点的右子节点。
时间复杂度:O(n),每个节点均被访问一次;
空间复杂度:O(1),不需要栈,直接在树中改。
class Solution:def flatten(self,root: TreeNode) -> None:curr = rootwhile curr:if curr.left:predecessor = nxt = curr.leftwhile predecessor.right:precedessor = predecessor.rightprecedessor.right = curr.rightcurr.left = Nonecurr.right = nxtcurr = curr.right
相关文章:
)
【力扣刷题记录】hot100错题本(一)
1. 简单题 我的答案:时间复杂度过高:O(N^3) class Solution:def twoSum(self, nums: List[int], target: int) -> List[int]:for num in nums:if (target - num) in nums:#多余for i in range(len(nums)):if nums[i] num :for j in range(i1,len(nu…...

Android运行时ART加载OAT文件的过程
目录 一,概述 1.1 OAT是如何产生的 一,概述 OAT文件是一种Android私有ELF文件格式,它不仅包含有从DEX文件翻译而来的本地机器指令,还包含有原来的DEX文件内容。这使得我们无需重新编译原有的APK就可以让它正常地在ART里面运行,也就是我们不…...

Python读取comsol仿真导出数据并绘图
文章目录 comsol数据导出python读取文件python绘制云图python进一步分析数据 完整代码 当我们使用comsol,ansys等仿真工具进行仿真后,难免需要对仿真结果进行导出并进一步处理分析。 今天小姜以comsol的一个简单磁场仿真为例,详细介绍如何对c…...

cloudfare+gmail 配置 smtp 邮箱
这里介绍有一个域名后,不需要服务器,就可以实现 cloudfare gmail 的 邮箱收发。 为什么还需要 gmail 的 smtp 功能,因为 cloudfare 默认只是对 email 进行转发,就是只能收邮件而不能发送邮件,故使用 gmail 的功能来进…...

【翻译、转载】使用 LLM 构建 MCP
资料来源: https://modelcontextprotocol.io/tutorials/building-mcp-with-llms 本文仅仅是翻译。 使用 LLM 构建 MCP 利用 Claude 等大型语言模型(LLM)加速您的 MCP 开发! 本指南将帮助您使用 LLM 来构建自定义的模型上下文协…...

Python速成系列二
文章目录 Python 条件语句与循环结构详解一、条件语句(if-elif-else)1. 基本 if 结构2. if-else 结构3. if-elif-else 结构4. 嵌套条件语句5. 三元表达式(条件表达式) 二、循环结构1. while 循环2. for 循环3. 循环控制语句break …...

基于STM32的心电图监测系统设计
摘要 本论文旨在设计一种基于 STM32 微控制器的心电图监测系统,通过对人体心电信号的采集、处理和分析,实现对心电图的实时监测与显示。系统采用高精度的心电信号采集模块,结合 STM32 强大的数据处理能力,能够有效去除噪声干扰&a…...

线程池的线程数配置策略
目录 1. CPU密集型任务 2. IO密集型任务 3. 混合型任务 1. CPU密集型任务 特点:任务主要消耗CPU资源(如计算、加密、压缩)。 推荐线程数: 线程数 ≈ 物理核心数 1 / CPU - 1(不知道哪个√) 例如&#…...

分享一个Android中文汉字手写输入法并带有形近字联想功能
最近我写了一个Android版本的中文汉字手写输入法功能,并实现了汉字形近字联想功能,此手写输入法功能完全满足公司的需求。 之前小编用Android SurfaceView,运用canvas的Path画坐标轨迹,并结合使用一个叫汉王输入法的so库来识别手…...

C语言:文件操作
文件的概念 文件是计算机用于存储数据的工具,我们计算机磁盘上的数据是混乱的,但是我们计算机系统通过文件的方式记录数据在磁盘上的位置来将数据整齐划分。 文件的类型 文件有两种类型,数据文件与程序文件 程序文件是用来执行的文件&#…...

2024年第十五届蓝桥杯省赛B组Python【 简洁易懂题解】
2024年第十五届蓝桥杯省赛B组Python题解 一、整体情况说明 2024年第十五届蓝桥杯省赛B组Python组考试共包含8道题目,分为结果填空题和程序设计题两类。 考试时间:4小时编程环境:Python 3.x,禁止使用第三方库,仅可使…...

线程与进程深度解析:从fork行为到生产者-消费者模型
线程与进程深度解析:从fork行为到生产者-消费者模型 一、多线程环境下的fork行为与线程安全 1. 多线程程序中fork的特殊性 核心问题:fork后子进程的线程模型 当多线程程序中的某个线程调用fork时: 子进程仅包含调用fork的线程࿱…...

2025年第十六届蓝桥杯省赛B组Java题解【完整、易懂版】
2025年第十六届蓝桥杯省赛B组Java题解 题型概览与整体分析 题目编号题目名称题型难度核心知识点通过率(预估)A逃离高塔结果填空★☆☆数学规律、模运算95%B消失的蓝宝结果填空★★★同余定理、中国剩余定理45%C电池分组编程题★★☆异或运算性质70%D魔法…...
)
【NTN 卫星通信】NTN关键问题的一些解决方法(一)
1 概述 3GPP在协议23.737中对一些卫星通信需要面对的关键问题进行了探讨,并且讨论了初步的解决方法,继续来看看这些内容把。 问题包括: 1、大型卫星覆盖区域的移动性管理 2、移动卫星覆盖区域的移动性管理 3、卫星延迟 4、卫星接入的QoS …...

C++基础算法9:Dijkstra
1、概念 Dijkstra算法 是一种用于计算图中单源最短路径的算法,主要用于加权图(图中边的权重可以不同)中找出从起点到各个其他节点的最短路径。 Dijkstra算法的核心概念: 图的表示: 有向图:图的边是有方…...

5块钱的无忧套餐卡可以变成流量卡吗
电信的 5 块钱无忧套餐卡理论上可以变成流量卡,但会受到一些条件限制,以下是具体介绍: 中国电信无忧卡简介 中国电信无忧卡是电信推出的低月租套餐,月租仅 5 元,包含 200M 国内流量、来电显示和 189 邮箱,全…...

word页眉去掉线
直接双击页眉处于下面状态: 然后: 按CtrlshiftN即可!去除...

Spark,Idea中编写Spark程序 2
Idea中编写Spark程序 一、修改pom.xml文件 <build><sourceDirectory>src/main/scala</sourceDirectory><testSourceDirectory>src/test/scala</testSourceDirectory> <!-- 添加必要的插件以打包scala程序--><plugins><plu…...
的深入解析)
GTID(全局事务标识符)的深入解析
GTID(全局事务标识符)的深入解析 GTID(Global Transaction Identifier)是 MySQL 5.6 版本引入的一项核心功能,旨在解决传统主从复制中的痛点。它通过为每个事务赋予一个全局唯一的标识符,彻底改变了复制的管理方式。 一、传统复制的痛点 在 GTID 出现之前,MySQL 主从…...
: 环形热图绘制)
Circular Plot系列(一): 环形热图绘制
针对近期多个粉丝咨询环形图的绘制,我意识到,我们似乎没有真正介绍过circle图,但这一类图确是非常常用的图,所以这里详细学习一下circle的绘制,使用的是circlize包,功能很完善:安装包, #https:/…...

字符串匹配 之 KMP算法
文章目录 习题28.找出字符串中第一个匹配项的下标1392.最长快乐前缀 本博客充分参考灵神和知乎的另一位博主 灵神KMP算法模版 知乎博主通俗易懂讲解 对于给定一个主串S和一个模式串P,如果让你求解出模式串P在主串S中匹配的情况下的所有的开始下标简单的做法又称为Brute-Force算…...

「一针见血能力」的终极训练手册
缘起 和顶尖的高手接触以后,发现他们在表达沟通上面的能力真的太强了,仿佛有种一阵见血看问题的能力,这种拨开浓雾看本质的能力是嘈杂世界防止上当受骗的不二法门. 网上找了一些训练方法,可以试试训练锐化思维,提高表…...

Linux 入门:操作系统进程详解
目录 一.冯诺依曼体系结构 一). 软件运行前为什么要先加载?程序运行之前在哪里? 二).理解数据流动 二.操作系统OS(Operator System) 一).概念 二).设计OS的目的 三).如何理解操作系统…...

【2025软考高级架构师】——2024年05月份真题与解析
摘要 本文内容是关于2025年软考高级架构师考试的相关资料,包含2024年05月份真题与解析。其中涉及体系结构演化的步骤、OSI协议中能提供安全服务的层次、数据库设计阶段中进行关系反规范化的环节等知识点,还提及了软考高级架构师考试的多个模块ÿ…...

Mybatis执行流程知多少
思维导图: 一、MyBatis 执行流程概述 MyBatis 的执行流程可以大致分为以下几个关键步骤:配置加载、会话创建、SQL 执行和结果处理。下面我们将逐步详细介绍每个步骤。 二、配置加载 1. 配置文件的重要性 MyBatis 的配置文件是整个框架的基础,…...

码蹄集——偶数位、四边形坐标
目录 MT1039 偶数位 MT1051 四边形坐标 MT1039 偶数位 思路:直接使用按位操作符 一个整型数字是32位,十六进制表示为0x后跟8个字符,每个字符为0-e,代表0-15; 把偶数位改为0,就是用0去&偶数位,用1去&奇数位,即0xAAAAAAAA,A代表10,1010(从右往 左依次为0位,…...

Java 中使用 Callable 创建线程的方法
一、Callable 接口概述 Callable接口位于java.util.concurrent包中,与Runnable接口类似,同样用于定义线程执行的任务,但它具有以下独特特性: 支持返回值:Callable接口声明了一个call()方法,该方法会在…...

代码随想录算法训练营Day44
力扣1045.不相交的线【medium】 力扣53.最大子数组和【medium】 力扣392.判断子序列【easy】 一、力扣1045.不相交的线【medium】 题目链接:力扣1045.不相交的线 视频链接:代码随想录 题解链接:灵茶山艾府 1、思路 和1143.最长公共子序列一…...

Java大师成长计划之第12天:性能调优与GC原理
📢 友情提示: 本文由银河易创AI(https://ai.eaigx.com)平台gpt-4o-mini模型辅助创作完成,旨在提供灵感参考与技术分享,文中关键数据、代码与结论建议通过官方渠道验证。 在 Java 编程中,性能调优…...
)
【MySQL】索引(重要)
目录 一、索引本质: 索引的核心作用 索引的优缺点 二、预备知识: 硬件理解: 软件理解: MySQL与磁盘交互基本单位: 三、索引的理解: 理解page: 单个page: 多个page&#x…...
)
C++多态(上)
目录 一、多态的概念 二、多态的定义及实现 1. 多态的构成条件 2. 虚函数 3. 虚函数的重写 4. C11 override 和 final 4.1 final 关键字 4.2 override 关键字 5. 重载、覆盖(重写)、隐藏(重定义)的对比 三、抽象类 1. 概…...

【AI提示词】 复利效应教育专家
提示说明 一位拥有金融学和教育学背景的知识型内容创作者,擅长用简单易懂的语言向读者解释复杂概念 提示词 # Role: 复利效应教育专家## Profile - language: 中文 - description: 一位拥有金融学和教育学背景的知识型内容创作者,擅长用简单易懂的语言…...

嵌入式系统基础知识
目录 一、冯诺依曼结构与哈佛结构 (一)冯诺依曼结构 (二)哈佛架构 二、ARM存储模式 (一)大端模式 (二)小端模式 (三)混合模式 三、CISC 与 RISC &am…...

如何克服情绪拖延症?
引言 你是否也曾有过这样的经历? 明明手头有重要的工作,却总是忍不住刷手机、看视频,直到最后一刻才匆忙赶工? 你是否在心里暗暗发誓“明天一定好好干”,但第二天依旧重复着同样的拖延? 其实࿰…...

【操作系统】哲学家进餐问题
问题描述 哲学家进餐问题是并发编程中的一个经典问题,描述了五位哲学家围坐在一张圆桌旁,他们的生活由思考和进餐组成。在圆桌上有五个盘子,每位哲学家面前一个盘子,盘子之间有一支叉子。哲学家进餐需要同时使用左右两支叉子。问题…...

Kotlin协程解析
目录 一、协程的使用 二、协程的执行原理 2.1、挂起函数的反编译代码及执行分析 2.2、协程执行流程分析 2.2.1、createCoroutineUnintercepted方法 2.2.2、intercepted方法 2.2.3、resumeCancellableWith方法 2.3、Dispatcher----分发器的实现 2.3.1、Main 分发器的实…...

Nginx核心功能 02
目录 Nginx代理技术核心概念 (一)正向代理(Forward Proxy) 1. 基本定义 2. 技术原理 3. 应用场景 (二)反向代理(Reverse Proxy) 1. 基本定义 2. 技术原理 3. 应用场景 一、…...

聊聊对Mysql的理解
目录 1、Sql介绍 1.1、SQL的分类 1.2、数据库的三大范式 1.3、数据表的约束 1.4、约束的添加与删除 2、核心特性 3、主要组件 4、数据结构原理 5、索引失效 6、常用问题 7、优势与局限 前言 MySQL是一个开源的关系型数据库管理系统(RDBMS),由瑞典MySQL A…...

「Mac畅玩AIGC与多模态17」开发篇13 - 条件判断与分支跳转工作流示例
一、概述 本篇在多节点串联的基础上,进一步引入条件判断与分支跳转机制,实现根据用户输入内容动态走不同执行路径。开发人员将学习如何配置判断节点、定义分支规则,以及如何在工作流中引导执行方向,完成基础的逻辑控制。 二、环境准备 macOS 系统Dify 平台已部署并可访问…...

pycharm terminal 窗口打不开了
参考添加链接描述powershell.exe改为cmd.exe发现有一个小正方形,最大化可以看见了。...

JAVA:使用 MapStruct 实现高效对象映射的技术指南
1、简述 在 Java 开发中,对象之间的转换是一个常见的需求,尤其是在 DTO(数据传输对象)和实体类之间的转换过程中。手动编写转换代码既耗时又容易出错,而 MapStruct 是一个优秀的对象映射框架,可以通过注解生成高效的对象转换代码,从而大大提升开发效率。 本文将介绍 M…...

Linux线程深度解析:从基础到实践
Linux线程深度解析:从基础到实践 一、线程基础概念 1. 进程与线程定义 进程:一个正在运行的程序,是操作系统资源分配的最小单位(拥有独立的地址空间、文件描述符等资源),状态包括就绪、运行、阻塞。线程…...
)
【ROS2】launch启动文件如何集成到ROS2(Python版本)
一、简单实操 1.创建/打开一个功能包 mkdir -p my_ws/src cd my_ws/src ros2 pkg create my_pkg_example --build-type ament_python 2.创建Launch文件的存放目录 将所有启动文件都存储在launch包内的目录中。 目录结构如下所示: src/my_pkg_example/launch/…...

用 PyTorch 轻松实现 MNIST 手写数字识别
用 PyTorch 轻松实现 MNIST 手写数字识别 引言 在深度学习领域,MNIST 数据集就像是 “Hello World” 级别的经典入门项目。它包含大量手写数字图像及对应标签,非常适合新手学习如何搭建和训练神经网络模型。本文将基于 PyTorch 框架,详细拆…...

碰撞检测学习笔记
目录 SUMO 模拟碰撞 LimSim pygame模拟碰撞检测 SUMO 模拟碰撞 LimSim 多模态大语言模型(M)LLM的出现为人工智能开辟了新的途径,特别是提供增强的理解和推理能力,为自动驾驶开辟了新途径。本文介绍LimSim,LimSim的…...

Sway初体验
Sway(缩写自 SirCmpwn’s Wayland compositor[1])是一款专为 Wayland 设计的合成器,旨在与 i3 完全兼容。根据官网所述: Sway 是 Wayland 的合成器,也是 x11 的 i3 窗口管理器的替代品。它可以根据您现有的 i3 配置工作…...

《工业社会的诞生》章节
工业革命的技术前奏 早期工业技术双引擎: 【火药武器】:重塑战争形态与经济地理 新式青铜炮助力殖民扩张,开辟全球贸易网络 高桅帆船(西班牙大帆船)实现洲际航行 战争规模化倒逼中央集权,催生国家-商人…...

消息队列MQ
参考资料:https://cloud.tencent.com/developer/article/2335397 https://www.cnblogs.com/hahaha111122222/p/18457859 消息队列是大型分布式系统不可缺少的中间件,也是高并发系统的基石中间件 消息队列 消息队列 Message Queue 消息队列是利用高效可…...

LangChain4J-XiaozhiAI 项目分析报告
LangChain4J-XiaozhiAI 项目分析报告 GitHub 链接 1. 项目概述 本项目名为 “硅谷小智(医疗版)”,是一个基于 Java 技术栈和 LangChain4J 框架构建的 AI 聊天助手应用。其核心目标是利用大型语言模型(LLM)的能力&am…...

学习spring boot-拦截器Interceptor,过滤器Filter
目录 拦截器Interceptor 过滤器Filter 关于过滤器的前置知识可以参考: 过滤器在springboot项目的应用 一,使用WebfilterServletComponentScan 注解 1 创建过滤器类实现Filter接口 2 在启动类中添加 ServletComponentScan 注解 二,创建…...