模型部署——cuda编程入门
CUDA中的线程与线程束
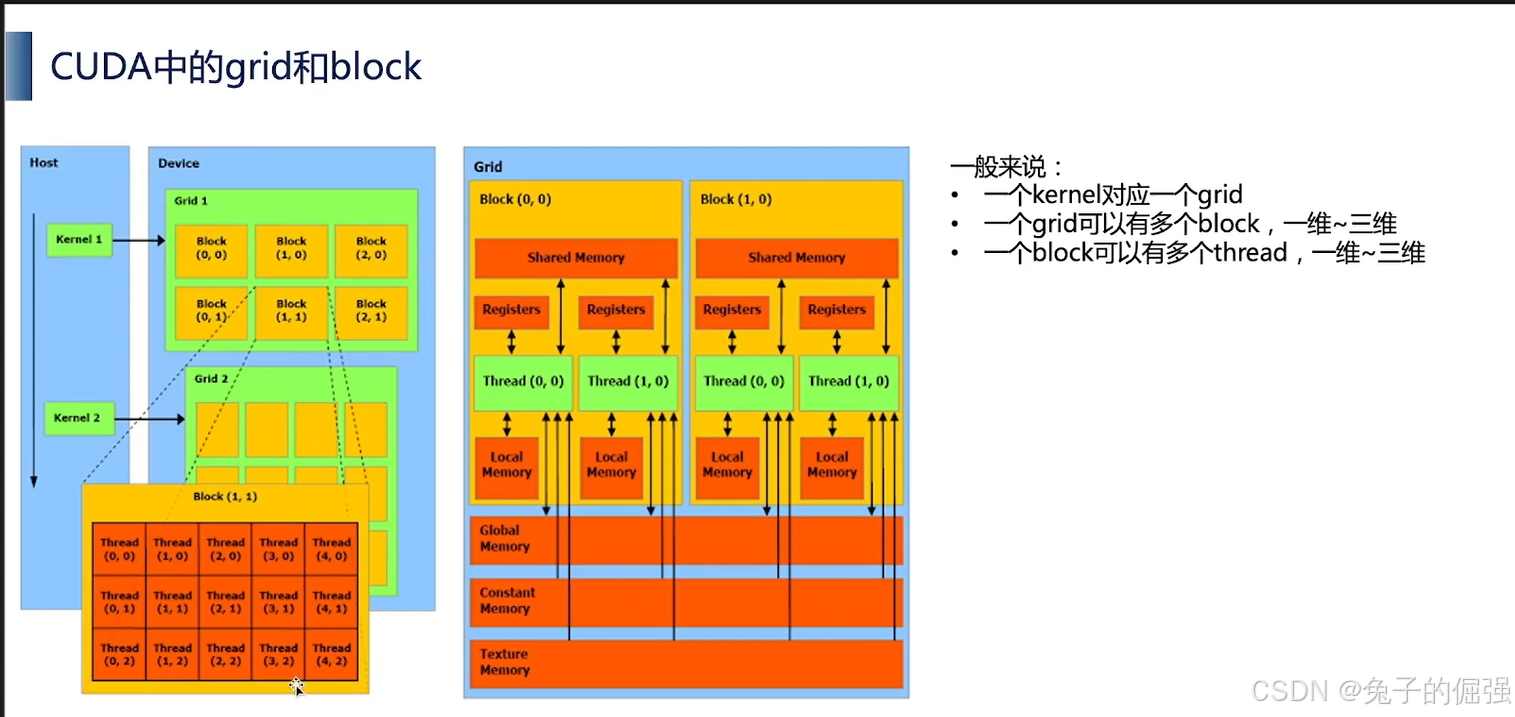
- kernel是在device上线程中并行执行的函数,核函数用__global__符号声明,在调用时需要用<<<grid_size, block_size>>>来指定kernel要执行的线程数量。在CUDA中,每一个线程都要执行核函数,并且每个线程会分配一个唯一的线程号thread ID,这个ID值可以通过核函数的内置变量threadIdx来获得。
- synchronize是同步的意思,有几种synchronize
cudaDeviceSynchronize: CPU与GPU端完成同步,CPU不执行之后的语句,直到这个语句以前的所有cuda操作结束
cudaStreamSynchronize: 跟cudaDeviceSynchronize很像,但是这个是针对某一个stream的。只同步指定的stream中的cpu/gpu操作,其他的不管
cudaThreadSynchronize: 现在已经不被推荐使用的方法
__syncthreads: 线程块内同步 - 核函数编写和调用举例
#include <cuda_runtime.h>
#include <stdio.h>// 核函数
__global__ void print_idx_kernel(){printf("block idx: (%3d, %3d, %3d), thread idx: (%3d, %3d, %3d)\n",blockIdx.z, blockIdx.y, blockIdx.x,threadIdx.z, threadIdx.y, threadIdx.x);
}void print_one_dim(){int inputSize = 8;int blockDim = 4;int gridDim = inputSize / blockDim;dim3 block(blockDim);dim3 grid(gridDim);// 核函数调用print_idx_kernel<<<grid, block>>>();cudaDeviceSynchronize();
}
.cu与.cpp的相互引用及Makefile
编译器:gcc g++ nvcc
举个例子:
nvcc print_index.cu -o app -I /usr/local/cuda/include
获取编译器选项:
g++ --help
nvcc --help
Makefile编写(是否可以使用CMakeLists.txt?)
.cpp中不能直接调用核函数,需要在.cu中提供调用接口
使用CUDA进行MATMUL计算
host端与device端数据传输
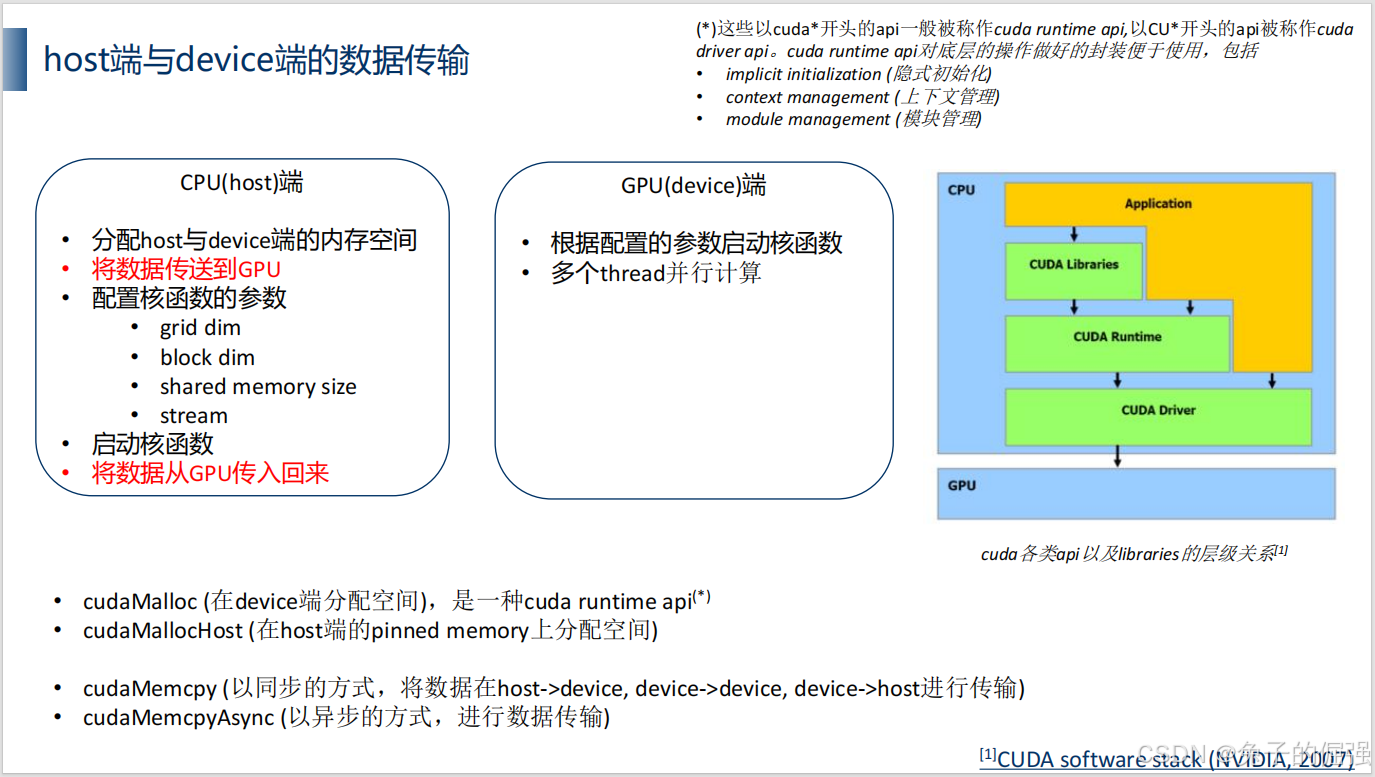
host端与device端数据传输代码实现:
void MatmulOnDevice(float *M_host, float *N_host, float* P_host, int width, int blockSize){/* 设置矩阵大小 */int size = width * width * sizeof(float);/* 分配M, N在GPU上的空间*/float *M_device;float *N_device;cudaMalloc(&M_device, size);cudaMalloc(&N_device, size);/* 分配M, N拷贝到GPU上*/cudaMemcpy(M_device, M_host, size, cudaMemcpyHostToDevice);cudaMemcpy(N_device, N_host, size, cudaMemcpyHostToDevice);/* 分配P在GPU上的空间*/float *P_device;cudaMalloc(&P_device, size);/* 调用kernel来进行matmul计算, 在这个例子中我们用的方案是:将一个矩阵切分成多个blockSize * blockSize的大小 */dim3 dimBlock(blockSize, blockSize);dim3 dimGrid(width / blockSize, width / blockSize);MatmulKernel <<<dimGrid, dimBlock>>> (M_device, N_device, P_device, width);/* 将结果从device拷贝回host*/cudaMemcpy(P_host, P_device, size, cudaMemcpyDeviceToHost);cudaDeviceSynchronize();/* Free */// free与malloc的顺序是反着的cudaFree(P_device);cudaFree(N_device);cudaFree(M_device);
}
cuda core矩阵乘法核函数编写
/* matmul的函数实现*/
__global__ void MatmulKernel(float *M_device, float *N_device, float *P_device, int width){/* 我们设定每一个thread负责P中的一个坐标的matmul所以一共有width * width个thread并行处理P的计算*/// 确定负责计算的结果元素的索引int y = blockIdx.y * blockDim.y + threadIdx.y;int x = blockIdx.x * blockDim.x + threadIdx.x;float P_element = 0;/* 对于每一个P的元素,我们只需要循环遍历width次M和N中的元素就可以了*/for (int k = 0; k < width; k ++){float M_element = M_device[y * width + k];float N_element = N_device[k * width + x];P_element += M_element * N_element;}P_device[y * width + x] = P_element;
}
cuda core 每个线程执行核函数计算一个结果元素
GPU刚开始执行核函数的时候,会存在一个warmup阶段,耗时会比较长
CPU与GPU的浮点运算会存在误差,误差控制在e-4以内是ok的
CUDA中规定,一个block中可以分配的thread的数量最大是1024个线程,如果大于1024会显示配置错误
为什么block size = 1的时候比等于16的时候慢很多?
cuda中的error handler

获取GPU的硬件信息
利用cuda runtime api打印硬件信息 & LOG
#include <stdio.h>
#include <cuda_runtime.h>
#include <string>#include "utils.hpp"int main(){int count;int index = 0;cudaGetDeviceCount(&count);while (index < count) {cudaSetDevice(index);cudaDeviceProp prop;cudaGetDeviceProperties(&prop, index);LOG("%-40s", "*********************Architecture related**********************");LOG("%-40s%d%s", "Device id: ", index, "");LOG("%-40s%s%s", "Device name: ", prop.name, "");LOG("%-40s%.1f%s", "Device compute capability: ", prop.major + (float)prop.minor / 10, "");LOG("%-40s%.2f%s", "GPU global meory size: ", (float)prop.totalGlobalMem / (1<<30), "GB");LOG("%-40s%.2f%s", "L2 cache size: ", (float)prop.l2CacheSize / (1<<20), "MB");LOG("%-40s%.2f%s", "Shared memory per block: ", (float)prop.sharedMemPerBlock / (1<<10), "KB");LOG("%-40s%.2f%s", "Shared memory per SM: ", (float)prop.sharedMemPerMultiprocessor / (1<<10), "KB");LOG("%-40s%.2f%s", "Device clock rate: ", prop.clockRate*1E-6, "GHz");LOG("%-40s%.2f%s", "Device memory clock rate: ", prop.memoryClockRate*1E-6, "Ghz");LOG("%-40s%d%s", "Number of SM: ", prop.multiProcessorCount, "");LOG("%-40s%d%s", "Warp size: ", prop.warpSize, "");LOG("%-40s", "*********************Parameter related************************");LOG("%-40s%d%s", "Max block numbers: ", prop.maxBlocksPerMultiProcessor, "");LOG("%-40s%d%s", "Max threads per block: ", prop.maxThreadsPerBlock, "");LOG("%-40s%d:%d:%d%s", "Max block dimension size:", prop.maxThreadsDim[0], prop.maxThreadsDim[1], prop.maxThreadsDim[2], "");LOG("%-40s%d:%d:%d%s", "Max grid dimension size: ", prop.maxGridSize[0], prop.maxGridSize[1], prop.maxGridSize[2], "");index ++;printf("\n");}return 0;
}Roofline model(待补充)
Nsight system and Nsight compute
谷歌搜索下载:官网链接
Nsight system
参考链接
安装目录:
ls /usr/local/bin |grep nsys
nsys
nsys-ui启动GUI界面
sudo ./nsys-ui(不加sudo会存在权限问题)
举个例子:
配置可执行文件以及感兴趣内容:
 可视化分析:
可视化分析:
 详细使用手册:官网文档
详细使用手册:官网文档
Nsight compute
查看可安装版本:
sudo apt policy nsight-compute-2022.2.1
安装:
sudo apt install nsight-compute-2022.2.1
查看安装位置:
dpkg -L nsight-compute-2022.2.1
路径:/opt/nvidia/nsight-compute/2022.2.1/
文件:ncu ncu-ui等启动:
sudo ./ncu-ui
举个例子:
基本配置:replay mode: application
 选择感兴趣内容:
选择感兴趣内容:
 launch即可,第一次运行会比较慢,会重复运行很多次。
launch即可,第一次运行会比较慢,会重复运行很多次。
结果:
 不知道为什么roofline model没有正常显示出来,需要查一查?
不知道为什么roofline model没有正常显示出来,需要查一查?
扩展知识
共享内存以及BANK CONFLICT
shared memory
硬件结构
SM(Streaming Multiprocessor)
在CUDA编程模型中,线程被组织成线程块(block),多个线程块组成一个网格(grid)。每个线程块被分配到一个SM中执行,而SM内部的warp调度器会将线程块中的线程分成多个warp进行执行。
当一个warp中的线程需要等待某些操作(例如内存访问)完成时,SM可以切换到另一个warp继续执行,从而提高计算效率。

核函数编写
#include "cuda_runtime_api.h"
#include "utils.hpp"#define BLOCKSIZE 16/* 使用shared memory把计算一个tile所需要的数据分块存储到访问速度快的memory中
*/
__global__ void MatmulSharedStaticKernel(float *M_device, float *N_device, float *P_device, int width){__shared__ float M_deviceShared[BLOCKSIZE][BLOCKSIZE];__shared__ float N_deviceShared[BLOCKSIZE][BLOCKSIZE];/* 对于x和y, 根据blockID, tile大小和threadID进行索引*/int x = blockIdx.x * blockDim.x + threadIdx.x;int y = blockIdx.y * blockDim.y + threadIdx.y;float P_element = 0.0;int ty = threadIdx.y;int tx = threadIdx.x;/* 对于每一个P的元素,我们只需要循环遍历width / tile_width 次就okay了,这里有点绕,画图理解一下*/for (int m = 0; m < width / BLOCKSIZE; m ++) {M_deviceShared[ty][tx] = M_device[y * width + (m * BLOCKSIZE + tx)];N_deviceShared[ty][tx] = N_device[(m * BLOCKSIZE + ty)* width + x];__syncthreads(); // 上述两句所有thread都会执行,等待所有thread执行完成for (int k = 0; k < BLOCKSIZE; k ++) {P_element += M_deviceShared[ty][k] * N_deviceShared[k][tx];}__syncthreads();}P_device[y * width + x] = P_element;
}__global__ void MatmulSharedDynamicKernel(float *M_device, float *N_device, float *P_device, int width, int blockSize){/* 声明动态共享变量的时候需要加extern,同时需要是一维的 注意这里有个坑, 不能够像这样定义: __shared__ float M_deviceShared[];__shared__ float N_deviceShared[];因为在cuda中定义动态共享变量的话,无论定义多少个他们的地址都是一样的。所以如果想要像上面这样使用的话,需要用两个指针分别指向shared memory的不同位置才行*/extern __shared__ float deviceShared[];int stride = blockSize * blockSize;/* 对于x和y, 根据blockID, tile大小和threadID进行索引*/int x = blockIdx.x * blockSize + threadIdx.x;int y = blockIdx.y * blockSize + threadIdx.y;float P_element = 0.0;int ty = threadIdx.y;int tx = threadIdx.x;/* 对于每一个P的元素,我们只需要循环遍历width / tile_width 次就okay了 */for (int m = 0; m < width / blockSize; m ++) {deviceShared[ty * blockSize + tx] = M_device[y * width + (m * blockSize + tx)];deviceShared[stride + (ty * blockSize + tx)] = N_device[(m * blockSize + ty)* width + x];__syncthreads();for (int k = 0; k < blockSize; k ++) {P_element += deviceShared[ty * blockSize + k] * deviceShared[stride + (k * blockSize + tx)];}__syncthreads();}if (y < width && x < width) {P_device[y * width + x] = P_element;}
}
动态共享内存比静态共享内存速度慢,没有特殊情况下,使用静态共享内存。
cuda event进行时间测算

BANK CONFLICT(存储体冲突)
在shared memory中什么是bank?

什么时候会发生bank conflict

按行存储,按列访问的时候,会发生bank conflict:
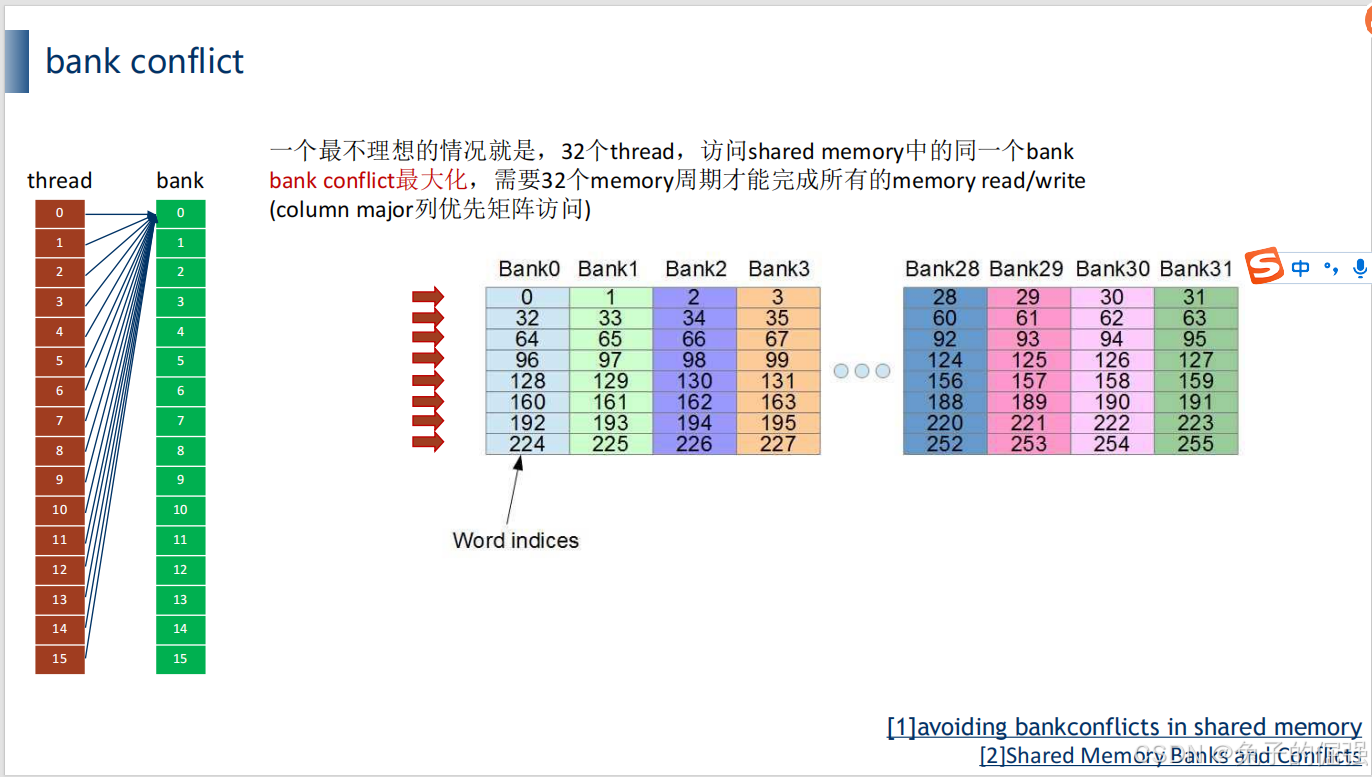
如何减缓bank conflict

代码实现
#include "cuda_runtime_api.h"
#include "utils.hpp"#define BLOCKSIZE 16/* 使用shared memory把计算一个tile所需要的数据分块存储到访问速度快的memory中
*/
__global__ void MatmulSharedStaticConflictPadKernel(float *M_device, float *N_device, float *P_device, int width){/* 添加一个padding,可以防止bank conflict发生,结合图理解一下*/__shared__ float M_deviceShared[BLOCKSIZE][BLOCKSIZE + 1];__shared__ float N_deviceShared[BLOCKSIZE][BLOCKSIZE + 1];/* 对于x和y, 根据blockID, tile大小和threadID进行索引*/int x = blockIdx.x * BLOCKSIZE + threadIdx.x;int y = blockIdx.y * BLOCKSIZE + threadIdx.y;float P_element = 0.0;int ty = threadIdx.y;int tx = threadIdx.x;/* 对于每一个P的元素,我们只需要循环遍历width / tile_width 次就okay了,这里有点绕,画图理解一下*/for (int m = 0; m < width / BLOCKSIZE; m ++) {/* 这里为了实现bank conflict, 把tx与tx的顺序颠倒,同时索引也改变了*/M_deviceShared[tx][ty] = M_device[x * width + (m * BLOCKSIZE + ty)];N_deviceShared[tx][ty] = M_device[(m * BLOCKSIZE + tx)* width + y];__syncthreads();for (int k = 0; k < BLOCKSIZE; k ++) {P_element += M_deviceShared[tx][k] * N_deviceShared[k][ty];}__syncthreads();}/* 列优先 */P_device[x * width + y] = P_element;
}__global__ void MatmulSharedDynamicConflictPadKernel(float *M_device, float *N_device, float *P_device, int width, int blockSize){/* 声明动态共享变量的时候需要加extern,同时需要是一维的 注意这里有个坑, 不能够像这样定义: __shared__ float M_deviceShared[];__shared__ float N_deviceShared[];因为在cuda中定义动态共享变量的话,无论定义多少个他们的地址都是一样的。所以如果想要像上面这样使用的话,需要用两个指针分别指向shared memory的不同位置才行*/extern __shared__ float deviceShared[];int stride = (blockSize + 1) * blockSize;/* 对于x和y, 根据blockID, tile大小和threadID进行索引*/int x = blockIdx.x * blockSize + threadIdx.x;int y = blockIdx.y * blockSize + threadIdx.y;float P_element = 0.0;int ty = threadIdx.y;int tx = threadIdx.x;/* 对于每一个P的元素,我们只需要循环遍历width / tile_width 次就okay了 */for (int m = 0; m < width / blockSize; m ++) {/* 这里为了实现bank conflict, 把tx与tx的顺序颠倒,同时索引也改变了*/deviceShared[tx * (blockSize + 1) + ty] = M_device[x * width + (m * blockSize + ty)];deviceShared[stride + (tx * (blockSize + 1) + ty)] = N_device[(m * blockSize + tx) * width + y];__syncthreads();for (int k = 0; k < blockSize; k ++) {P_element += deviceShared[tx * (blockSize + 1) + k] * deviceShared[stride + (k * (blockSize + 1 ) + ty)];}__syncthreads();}/* 列优先 */P_device[x * width + y] = P_element;
}
STREAM和EVENT
什么是stream

参考下述链接,理解cuda编程的一些基础概念:
理解CUDA中的thread,block,grid和warp
cuda stream的使用
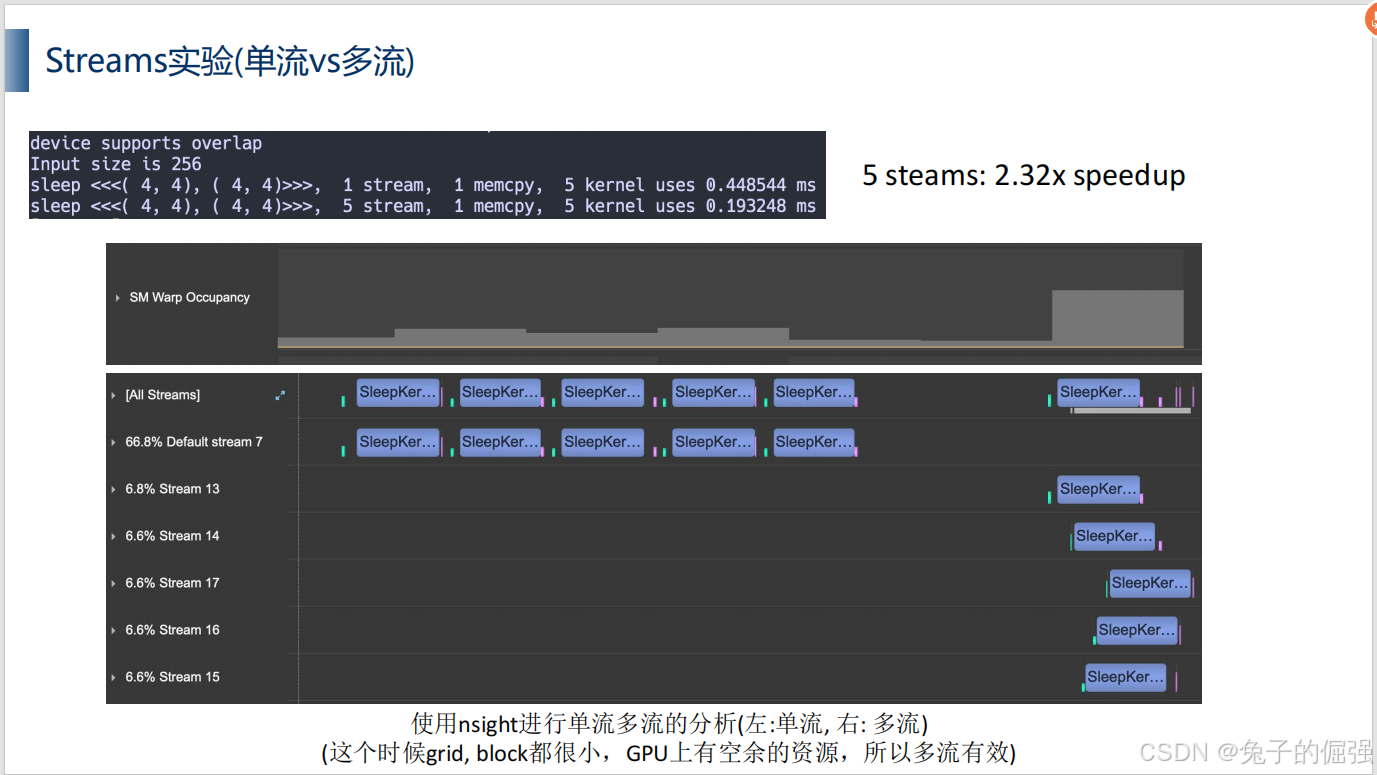
多流编程实现
单流:
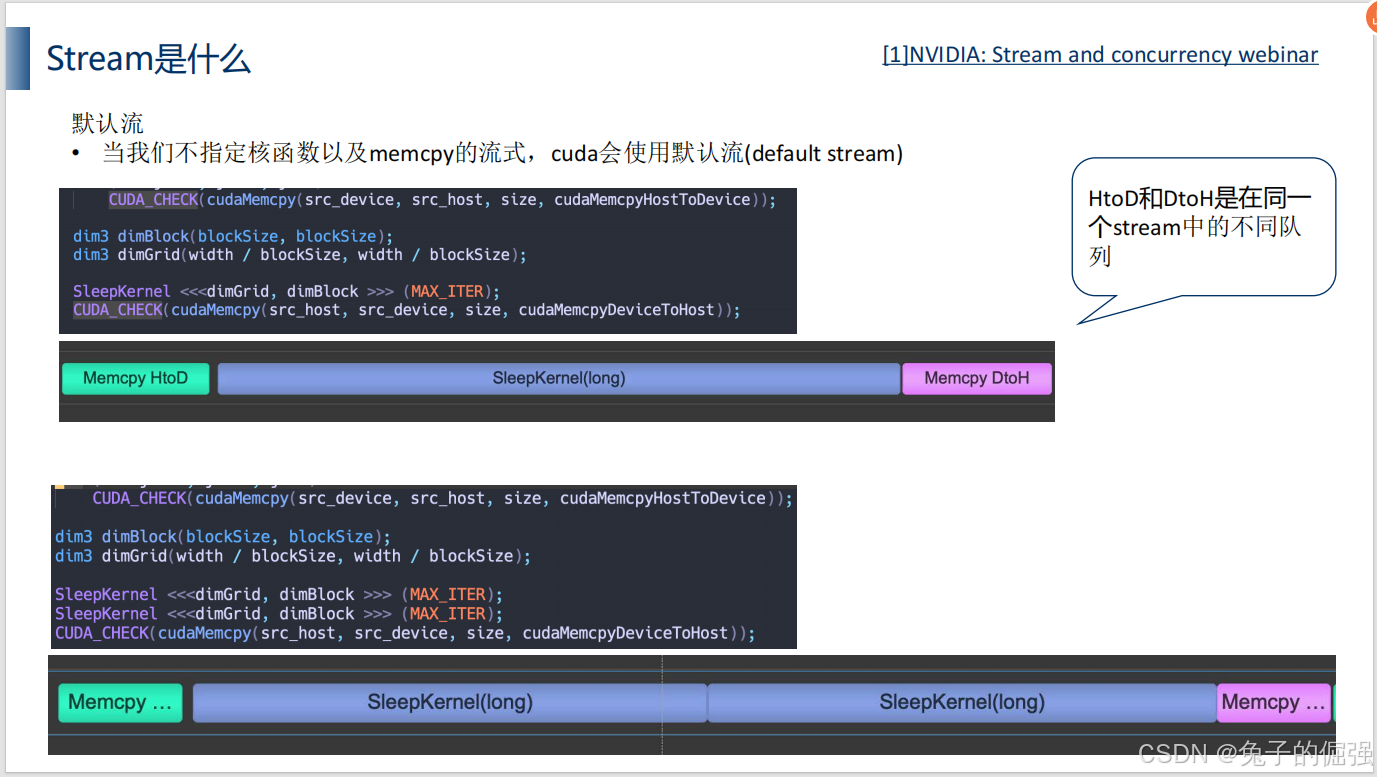
多流:
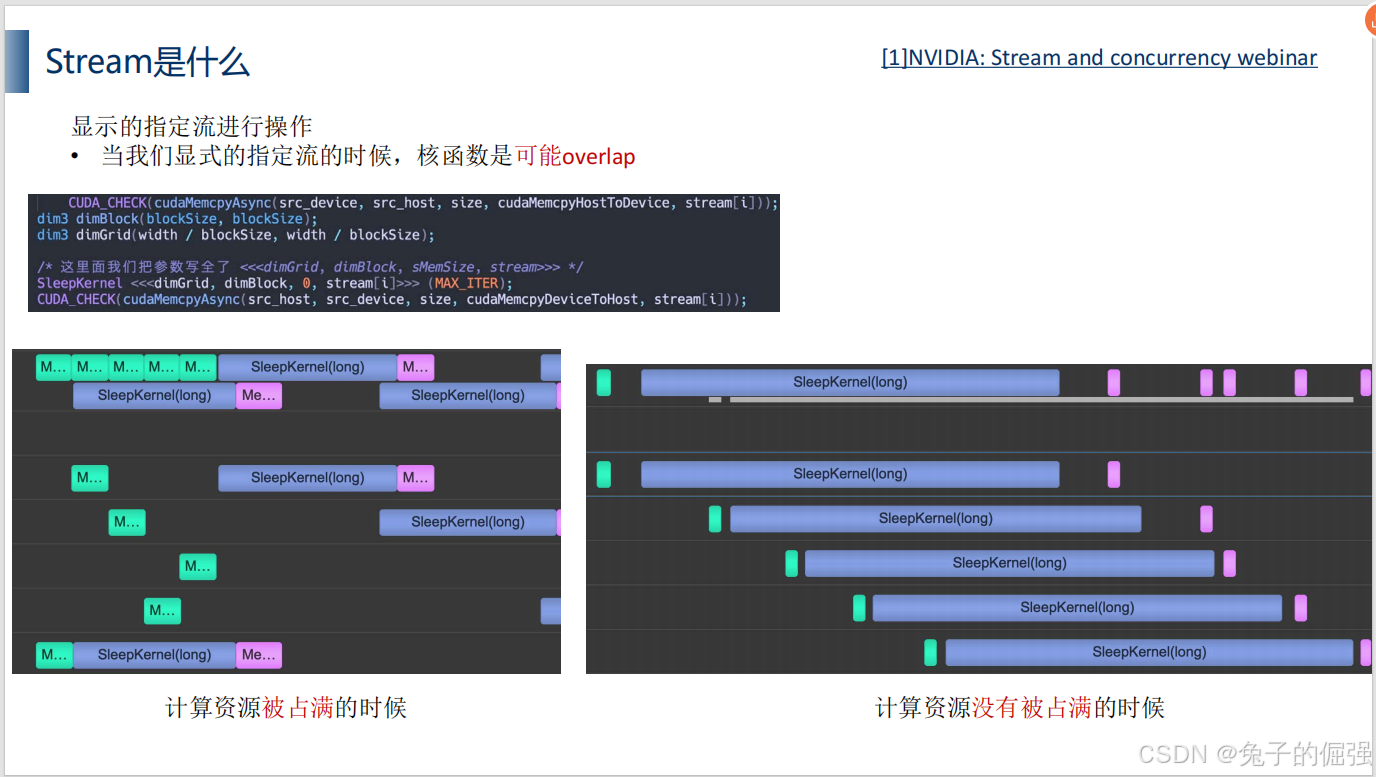
利用nsight systems进行分析:
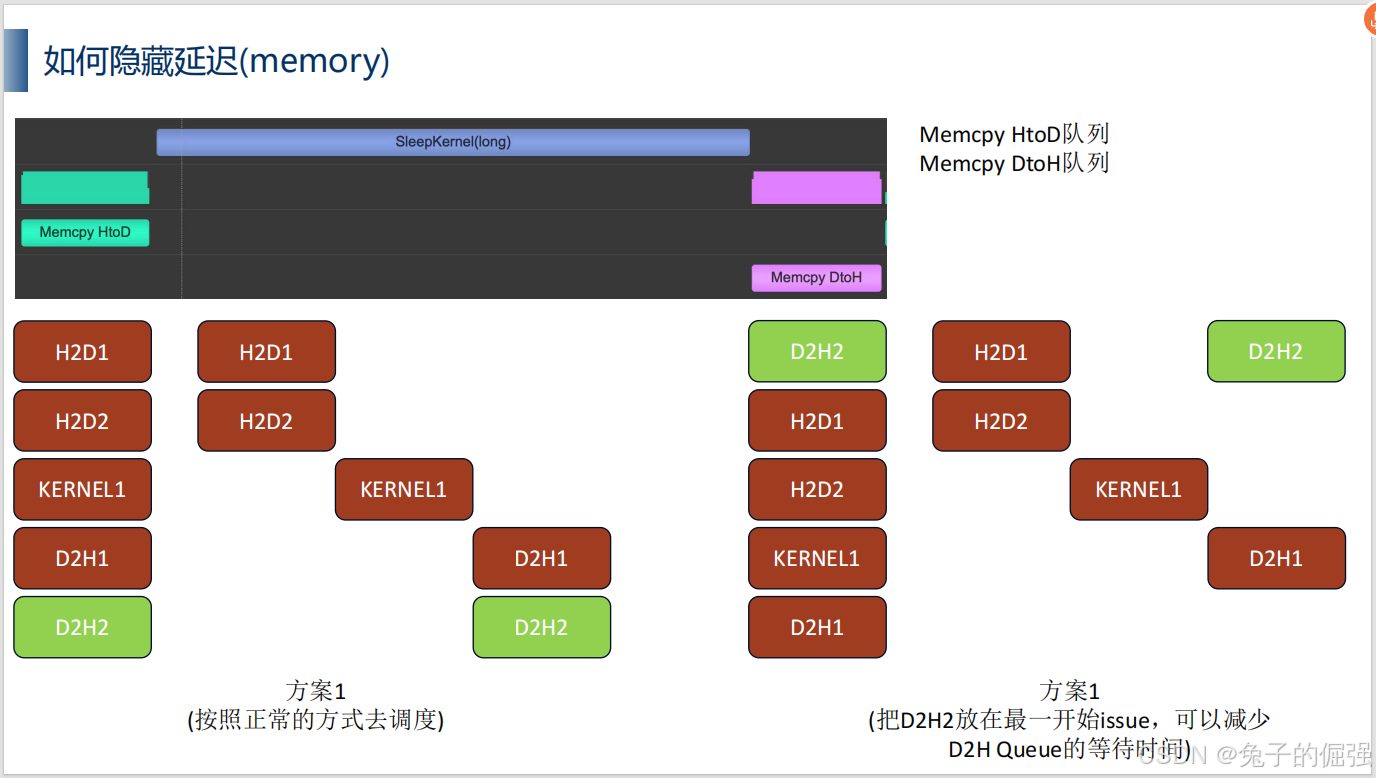
如何利用多流进行隐藏访存和核函数执行延迟的调度
举一个栗子:
使用CUDA进行预处理/后处理
双线性插值
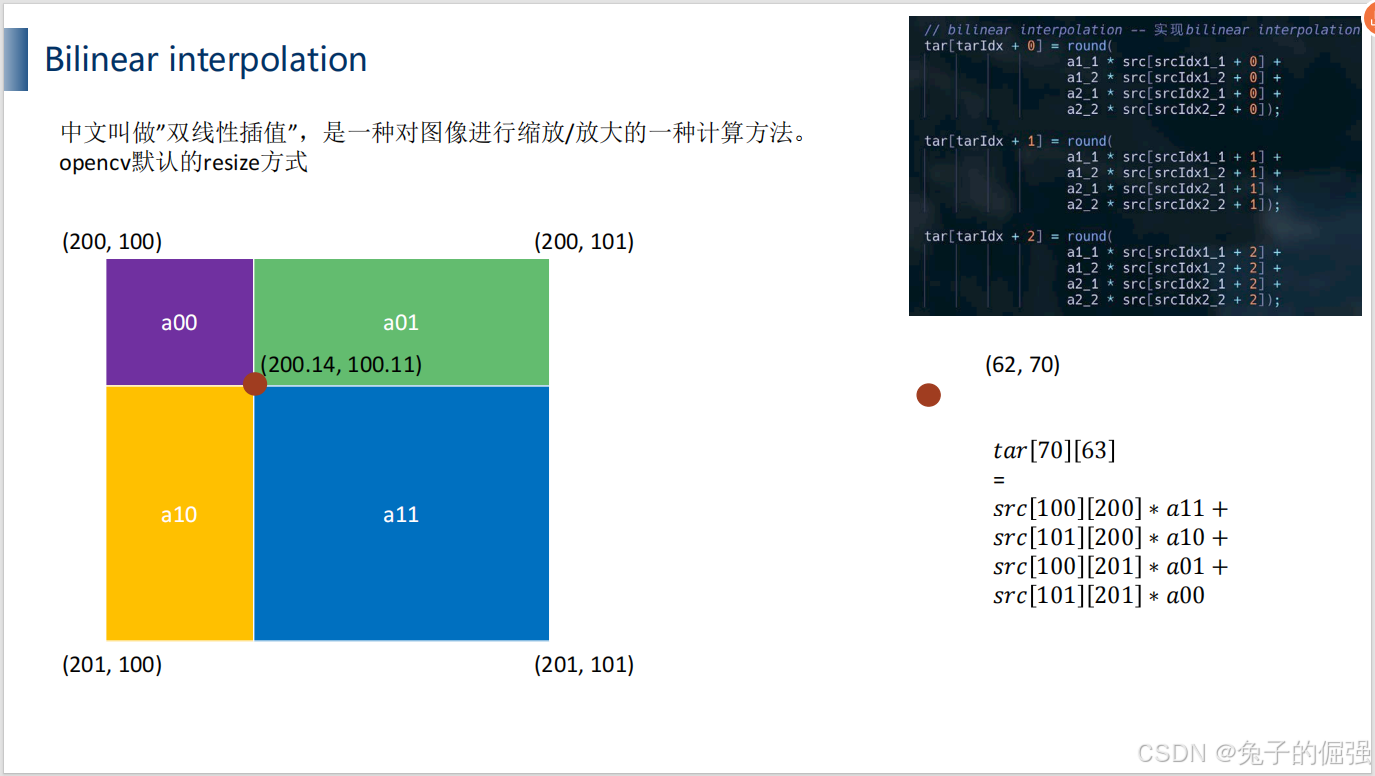
双线性插值的cuda实现
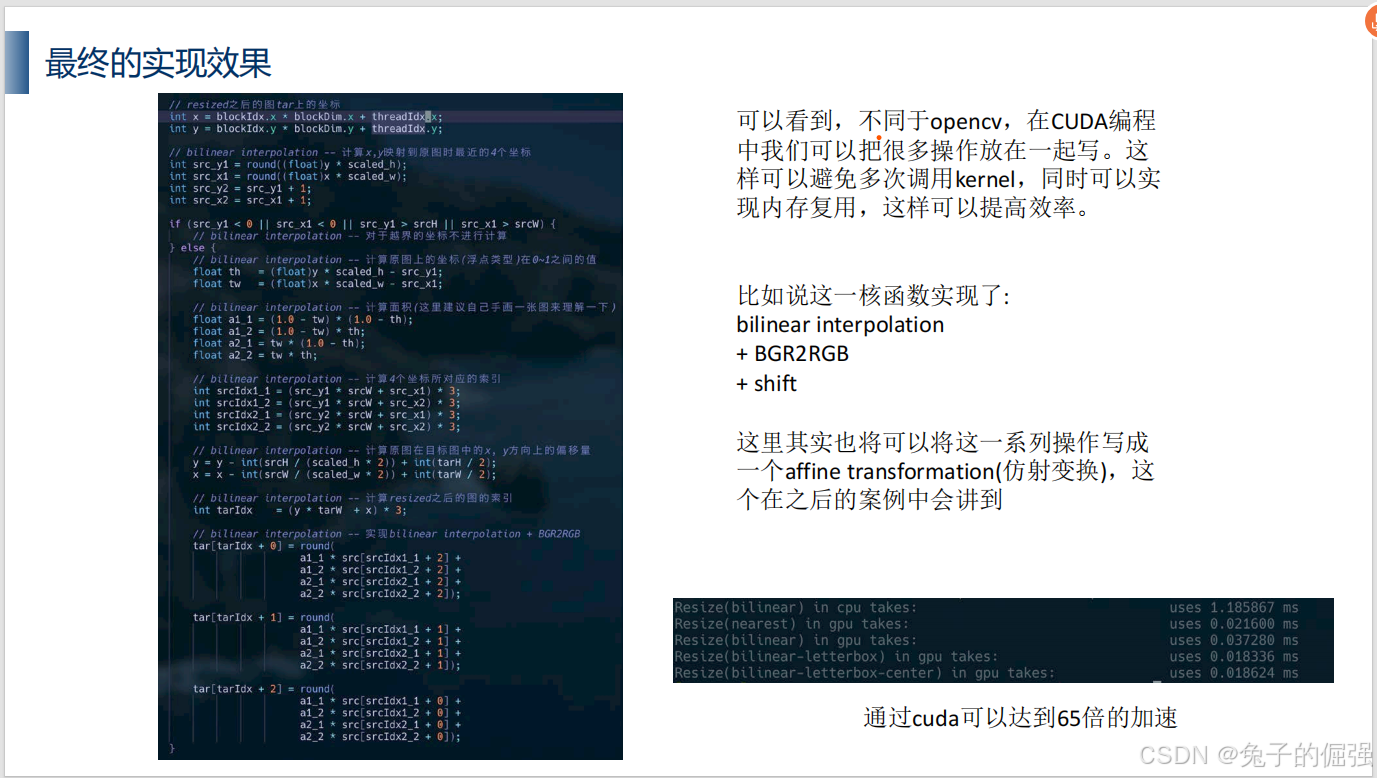
查看图片大小:
identity xx.png
可视化图片:
feh xx.png
相关文章:

模型部署——cuda编程入门
CUDA中的线程与线程束 kernel是在device上线程中并行执行的函数,核函数用__global__符号声明,在调用时需要用<<<grid_size, block_size>>>来指定kernel要执行的线程数量。在CUDA中,每一个线程都要执行核函数,并…...

llfc项目TCP服务器笔记
ChatServer 一个TCP服务器必然会有连接的接收,维持,收发数据等逻辑。那我们就要基于asio完成这个服务的搭建。主服务是这个样子的 #include "LogicSystem.h"#include <csignal>#include <thread>#include <mutex>#include "AsioIOServiceP…...

NPP库中libnppi模块介绍
1. libnppi 模块简介 libnppi 是 NPP 库中专门用于 图像处理 的模块,提供高度优化的 GPU 加速函数,支持: 图像滤波(卷积、形态学操作) 几何变换(旋转、缩放、透视变换) 颜色空间转换…...

从头训练小模型: 3 传统RLHF与DPO的区别
这个步骤我其实是忽略了。如果我的目标是建立一个安全领域的模型,我个人理解这步骤并不太必要。关于人类偏好对齐:在前面的训练步骤中,模型已经具备了基本的对话能力。 此时模型还不知道什么是好的回答,什么是不好的回答。我们希…...

Python-Django系列—视图
一、通用显示视图 以下两个基于类的通用视图旨在显示数据。在许多项目中,它们通常是最常用的视图。 1、DetailView class django.views.generic.detail.DetailView 当该视图执行时,self.object 将包含该视图正在操作的对象。 祖先(MRO&a…...

el-input Vue 3 focus聚焦
https://andi.cn/page/622173.html...
路径问题--剑指offer -珠宝的最大值)
动态规划(5)路径问题--剑指offer -珠宝的最大值
题目: 现有一个记作二维矩阵 frame 的珠宝架,其中 frame[i][j] 为该位置珠宝的价值。拿取珠宝的规则为: 只能从架子的左上角开始拿珠宝每次可以移动到右侧或下侧的相邻位置到达珠宝架子的右下角时,停止拿取 注意࿱…...

ZArchiver正版:高效文件管理,完美解压体验
在使用安卓设备的过程中,文件管理和压缩文件的处理是许多用户常见的需求。无论是解压下载的文件、管理手机存储中的文件,还是进行日常的文件操作,一款功能强大且操作简便的文件管理工具都能极大地提升用户体验。今天,我们要介绍的…...

Netlink在SONiC中的应用
Netlink在SONiC中的应用 Netlink介绍 Netlink 是 Linux 内核态程序与用户空间程序之间进行通信的机制之一,原本是用于传递网络协议栈中的各种控制消息。它采用和套接字(socket)编程接口相同的形式,常用于配置内核网络子系统&…...

ReentrantLock实现公平锁和非公平锁
在 Java 里,公平锁和非公平锁是多线程编程中用于同步的两种锁机制,它们的主要差异在于获取锁的顺序规则。下面是对二者的详细介绍: 公平锁 公平锁遵循 “先来先服务” 原则,也就是线程获取锁的顺序和请求锁的顺序一致。先请求锁…...

【C++】 —— 笔试刷题day_25
一、笨小猴 题目解析 这道题,给定一个字符str,让我们找到这个字符串中出现次数最多字母的出现次数maxn和出现次数最少字母的出现次数minn; 然后判断maxn - minn是否是一个质数,如果是就输出Lucky Word和maxn - minn;如…...

terraform resource创建了5台阿里云ecs,如要使用terraform删除其中一台主机,如何删除?
在 Terraform 中删除阿里云 5 台 ECS 实例中的某一台,具体操作取决于你创建资源时使用的 多实例管理方式(count 或 for_each)。以下是详细解决方案: 方法一:使用 for_each(推荐) 如果创建时使…...

Office 三大组件Excel、Word、Access 里 VBA 区别对比
以下是Excel、Word和Access在VBA中的主要区别对比及详细说明: 核心对象模型 Excel Workbook(工作簿)→ Worksheet(工作表)→ Range(单元格区域) 核心围绕单元格数据处理,如 Cells(1,1).Value = "数据" Word Document(文档)→ Range(文本范围)→ Paragrap…...
:操作系统)
Linux 进程基础(二):操作系统
目录 一、什么是操作系统:用户和电脑之间的「翻译官」🌐 OS 的层状结构🧩 案例解析:双击鼠标的「跨层之旅」 二、操作系统的必要性探究:缺乏操作系统的环境面临的挑战剖析🔑 OS 的「管理者」属性࿱…...

Java高并发处理核心技术详解:从理论到实战
高并发处理能力是衡量系统性能的重要指标。Java作为企业级开发的主力语言,提供了丰富的并发编程工具和框架。 一、Java并发基础 1.1 Java内存模型(JMM) 主内存与工作内存:每个线程拥有独立的工作内存,通过JMM协议与主…...
)
单细胞测序数据分析试验设计赏析(二)
单细胞测序数据分析试验设计赏析(二) 这次的单细胞测序数据分析的试验设计是单细胞测序分析机器学习(with SHAP分析),也是常见的试验设计之一,重点是可以用于筛选鉴定基因调控网络,也可以是构建…...

Docker 服务搭建
💢欢迎来到张翊尘的开源技术站 💥开源如江河,汇聚众志成。代码似星辰,照亮行征程。开源精神长,传承永不忘。携手共前行,未来更辉煌💥 文章目录 Docker 服务搭建在 Ubuntu 上安装 Docker更新软件…...

4电池_基于开关电容的均衡
基于开关电容的均衡系统(Switched-Capacitor Equalization System) 开关电容均衡(Switched-Capacitor Equalization, SCE)是一种广泛应用于 电池组(如锂电池、超级电容组) 的主动均衡技术,通过电…...
 - 波形解析专题P2)
Matlab/Simulink - BLDC直流无刷电机仿真基础教程(七) - 波形解析专题P2
Matlab/Simulink - BLDC直流无刷电机仿真基础教程(七) - 波形解析专题P2 前言一、缺相与相线错接解析二、电源电压波动三、电机感量及磁链变化四、负载突变及堵转五、换相时机不当及换相错误参考链接 前言 本系列文章分享如何使用Matlab的Simulink功能来…...

如何从GitHub上调研优秀的开源项目,并魔改应用于工作中?
在 Go 语言学习中,我们经常会去学习一些优秀的开源项目。但是学完之后,发现很快就忘记了或者学习效果并不好。学习一个开源项目最好的方式就是围绕这个开源项目进行实战。例如,直接魔改这个开源项目并应用于工作中。本文来介绍下如何调用&…...

【Java学习笔记】构造器
构造器(constructor)(又名构造方法) 作用:可以在创建对象时就初始化属性,注意不是创建 基本结构 [修饰符] 方法名(形参列表){方法体; }代码示例 public class 构造器 {public static void m…...
:String 类型全解析)
Redis 数据类型详解(一):String 类型全解析
文章目录 前言一、什么是 Redis 的 String 类型?二、常用命令1.SET2.GET3.MSET4.MGET5.INCR6.INCRBY7.INCRBYFLOAT8.SETNX9.SETEX 三、注意事项总结 前言 提示:这里可以添加本文要记录的大概内容: 在学习 Redis 的过程中,最基础也…...

JAVA---多态
面向对象三大特征:封装、继承、多态 多态 定义:同类型的对象,表现出的不同形态。 它允许不同类的对象通过同一个接口进行调用,并且在运行时根据实际对象类型执行不同的方法。 多态主要通过继承、接口和方法重写来实现。 表现形式…...
+安装kubesphere图形化界面使用和操作)
K8S的使用(部署pod\service)+安装kubesphere图形化界面使用和操作
master节点中通过命令部署一个tomcat 查看tomcat被部署到哪个节点上 在节点3中进行查看 在节点3中进行停止容器,K8S会重新拉起一个服务 如果直接停用节点3(模拟服务器宕机),则K8S会重新在节点2中拉起一个服务 暴露tomcat访…...
)
【Linux系统】第二节—基础指令(2)
hello ~ 好久不见 自己想要的快乐要自己好好争取! 云边有个稻草人-个人主页 Linux—本篇文章所属专栏—欢迎订阅—持续更新中 目录 本节课核心指令知识点总结 本节基本指令详解 07.man 指令 08.cp 指令 09.mv 指令 10.cat 指令 11.more 指令 12.less 指令 …...

Java设计模式: 实战案例解析
Java设计模式: 实战案例解析 在软件开发中,设计模式是一种用来解决特定问题的可复用解决方案。它们是经过实践验证的最佳实践,能够帮助开发人员设计出高质量、易于维护的代码。本文将介绍一些常见的Java设计模式,并通过实战案例解析它们在实际…...

ASP.NET MVC 入门与提高指南九
51. 时空数据处理与 MVC 应用拓展 51.1 时空数据概念 时空数据是指与时间和空间相关的数据,如地理信息系统(GIS)数据、交通流量数据、气象数据等,这些数据随时间和空间变化而变化。 51.2 在 MVC 应用中处理时空数据 地理信息系…...

算法学习时段效能分布
算法学习时段效能分布 晨间时段(06:00-09:00)核心优势最佳任务 午后时段(14:00-17:00)核心优势最佳任务 夜间时段(20:00-23:00)核心优势最佳任务 实证数据支持 晨间时段(06:00-09:00)…...

Linux环境部署iview-admin项目
环境:阿里云服务 系统:CentOS7.X系统 1、下载源码安装包 wget https://nodejs.org/dist/v14.17.3/node-v14.17.3-linux-x64.tar.xz2、解压并放入指定目录 tar -xf node-v14.17.3-linux-x64.tar.xz && mv node-v14.17.3-linux-x64 /usr/local/no…...

在 Ubuntu 系统中,查看已安装程序的方法
在 Ubuntu 系统中,查看已安装程序的方法取决于软件的安装方式(如通过 apt、snap、flatpak 或手动安装)。以下是几种常见方法: 通过 apt 包管理器安装的软件 适用于通过 apt 或 dpkg 安装的 .deb 包。 列出所有已安装的软件包&…...

c++26新功能——Pack indexing
一、模板编程 在模板编程中,有一个问题比较突出,就是对变参模板中参数的控制,比较麻烦。因为是变参,所以想把参数单独拿出来处理,就需要借助一些特殊的技巧,而这种特殊的技巧,往往为大多数开发…...

VSCode通过SSH连接VMware虚拟机
以下是关于VSCode通过SSH连接VMware虚拟机的原理、必要条件及注意事项的说明: 一、连接原理 SSH协议通信:SSH(Secure Shell)是一种加密网络协议,VSCode通过Remote-SSH插件将本地开发环境与虚拟机终端绑定&a…...

7 微调 黑盒蒸馏 突破伦理限制
简介 SecGPT-Distill 是我自己做的一个实验模型, 开源地址: 主要功能是进行模型微调和知识蒸馏而来 这次是运用微调技术,来突破现有模型在处理安全相关问题时的各种限制和约束 代码开源: https://github.com/godzeo/SecGPT-distill-boundless 不回答原理 大部…...

基于51单片机的温湿度控制器proteus仿真
地址: https://pan.baidu.com/s/1cENHPmF0XobqKg_7baZX3Q 提取码:1234 仿真图: 芯片/模块的特点: AT89C52/AT89C51简介: AT89C51 是一款常用的 8 位单片机,由 Atmel 公司(现已被 Microchip 收…...

牛客月赛115 C题-命运之弹 题解
原题链接 https://ac.nowcoder.com/acm/contest/107879/C 题目描述 解题思路 记录每个数字出现的次数。枚举使用「转瞬即逝」的位置,统计后边比当前数字更大的数的数量,进而统计、更新答案。 详细细节见代码,代码里有详细的注释解释。 代…...

视频转GIF
视频转GIF 以下是一个使用 Python 将视频转换为 GIF 的脚本,使用了 imageio 和 opencv-python 库: import cv2 import imageio import numpy as np """将视频转换为GIF图参数:video_path -- 输入视频的路径gif_path -- 输出GIF的路径fp…...

day15 python 复习日
作业: 尝试找到一个kaggle或者其他地方的结构化数据集,用之前的内容完成一个全新的项 目,这样你也是独立完成了一个专属于自己的项目。 要求: 1.有数据地址的提供数据地址,没有地址的上传网盘贴出地址即可。 2.尽可能与…...

性能优化实践:渲染性能优化
性能优化实践:渲染性能优化 在Flutter应用开发中,渲染性能直接影响用户体验。本文将从渲染流程分析入手,深入探讨Flutter渲染性能优化的关键技术和最佳实践。 一、Flutter渲染流程解析 1.1 渲染流水线 Flutter的渲染流水线主要包含以下几…...

【SimSession 】3:中继服务 linux和windows实现及MFC集成实现
实现目标 在 echo 测试程序启动时启动中继服务,并在 echo 程序退出时杀死中继进程。我们可以通过以下方式实现这一目标: linux设计 1 Process Management: 流程管理: Added fork() functionality to create a child process for the relay service添加了 fork()功能,…...

表驱动 FSM 在 STM32 上的高效实现与内存压缩优化——源码、性能与实践
目录 一、引言与背景 二、前提环境与依赖 三、表驱动 FSM 核心原理 四、内存压缩方案详解 4.1 稠密二维表(Dense Table) 4.2 稀疏表压缩(Sparse Table) 4.3 行压缩+Offset 4.4 位域打包(Bit‑Packing)...

windows鼠标按键自定义任意设置
因为用惯了Linux的鼠标中键的复制黏贴,发现windows下有完全可以实现类似自定义功能的软件,推荐一下: X Mouse Button Control。 免费版足够好用。 软件简介: X Mouse Button Control是一款专业的重新映射鼠标按钮的软件工具&…...

常用命令集合
安装Miniconda wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-py310_22.11.1-1-Linux-x86_64.shpython 换清华源 pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple鱼香ros wget http://fishros.com/install -O fishr…...

【图书管理系统】环境介绍、设计数据库和表、配置文件、引入依赖
0. 环境介绍 (1)JDK版本:JDK_8(JDK_1.8) (2)Java语言版本:8 (3)SpringBoot版本:2.6.13 (4)Maven仓库:阿里云 …...

【Linux】日志与策略模式、线程池
在了解了线程的基本概念和线程互斥与同步之后,我们可以以此设计一个简单的线程池。【Linux】线程-CSDN博客 【Linux】线程同步与互斥-CSDN博客 线程池也是一种池化技术。提前申请一些线程,等待有任务时就直接让线程去执行,不用再收到任务之…...

【神经网络与深度学习】生成模型-单位高斯分布 Generating Models-unit Gaussian distribution
引言 在生成模型的研究与应用中,单位高斯分布(标准正态分布)作为数据采样的基础扮演着至关重要的角色。其数学特性、潜在空间的连续性、灵活性以及通用性,使得生成模型能够高效且稳定地学习和生成样本。本文将详细探讨从单位高斯…...

通讯协议开发实战:从零到一打造企业级通信解决方案
简介 从工业控制到物联网,掌握主流通信协议开发是构建现代智能系统的核心能力。本文将通过深入分析CAN FD和MQTT两种关键协议的原理、特性及应用场景,结合TypeScript和Node.js技术栈,设计一个完整的实时运动控制系统开发案例。从协议解析到数据转换,再到系统集成,全程提供…...
)
《MATLAB实战训练营:从入门到工业级应用》工程实用篇-自动驾驶初体验:车道线检测算法实战(MATLAB2016b版)
《MATLAB实战训练营:从入门到工业级应用》工程实用篇-🚗 自动驾驶初体验:车道线检测算法实战(MATLAB2016b版) 大家好!今天我要带大家一起探索自动驾驶中一个非常基础但又至关重要的技术——车道线检测。我…...
?)
【网络】什么是串口链路(Serial Link)?
在路由器上,串口链路(Serial Link)就是指路由器之间通过串行接口(serial interface)和串行电缆(通常是V.35、RS-232或同步串行线路)直接点对点相连的那一段连线。它和我们平常在局域网里用的以太…...

为了结合后端而学习前端的学习日志——【黑洞光标特效】
前端设计专栏 今天给大家带来一个超酷的前端特效——黑洞光标!让你的鼠标变成一个会吞噬光粒子的迷你黑洞,点击时还会喷射出绿色能量粒子!🌠 🚀 效果预览 想象一下:你的鼠标变成一个旋转的黑洞࿰…...

set autotrace报错
报错: SQL> set autotrace traceonly SP2-0618: Cannot find the Session Identifier. Check PLUSTRACE role is enabled SP2-0611: Error enabling STATISTICS report原因分析: 根据上面的错误提示“SP2-0618: Cannot find the Session Identifie…...