【Linux】日志与策略模式、线程池
在了解了线程的基本概念和线程互斥与同步之后,我们可以以此设计一个简单的线程池。【Linux】线程-CSDN博客
【Linux】线程同步与互斥-CSDN博客
线程池也是一种池化技术。提前申请一些线程,等待有任务时就直接让线程去执行,不用再收到任务之后再创建线程。
一.日志设计
以往,我们多线程在向显示器打印信息时,会出现信息混杂的现象。这是因为多线程向显示器打印信息时,显示器是一种临界资源。访问临界资源应该对其进行保护,否则就会出现数据不一致。为了解决该现象,我们可以设计处一个日志类,打印信息时都使用该类,所以,我们得保证该类打印信息是原子的。
1.策略模式
策略模式(Strategy Pattern)是一种行为设计模式,它使你能在运行时改变对象的行为。其主要思想是将算法或行为封装到独立的类中,这些类称为策略类。上下文类(Context)使用策略类来执行特定的算法或行为,而客户端可以根据需要选择不同的策略。
我们可以根据策略模式设计出不同的刷新策略,比如向显示器刷新,或者向指定路径的指定文件刷新。
而策略模式的具体实现方式就是先实现一个策略类,里面包含了一个虚函数,该虚函数是未来要执行的行为或者算法。
然后我们再通过继承的方式具体的实现某一个种策略。
namespace MyLog
{using namespace MutexModule;#define gap "\r\n"// 策略模式——刷新策略// 虚基类class logstrategy{public:~logstrategy() = default;virtual void synclog(const std::string &message) = 0;};// 刷新策略1--->向显示器刷新class consolelogstrategy : public logstrategy{public:~consolelogstrategy() {}void synclog(const std::string &message) override{// 向显示器刷新需要加锁mutexguard lock(_mutex);std::cout << message << gap;}private:Mutex _mutex;};// 刷新策略2--->向指定文件里刷新const std::string defaultPath = "./log";const std::string defaultName = "log.log";class filelogstrategy : public logstrategy{public:filelogstrategy(const std::string &path = defaultPath, const std::string &name = defaultName): _path(path),_file(name){// 指定路径存在,直接返回;不存在,创建路径if (std::filesystem::exists(_path)){return;}try{std::filesystem::create_directories(_path);}catch (const std::filesystem::filesystem_error &e){std::cerr << e.what() << '\n';}}~filelogstrategy() {}void synclog(const std::string &message) override{// 向指定文件里打印, 向指定文件里面打印也得是原子的,得加锁mutexguard lock(_mutex);// 拼接路径+文件名std::string filename = _path + (_path.back() == '/' ? "" : "/") + _file;// 向指定文件里面以追加方式写入std::ofstream out(filename, std::ios::app);out << message << gap;out.close();}private:std::string _path;std::string _file;Mutex _mutex;};
}说明:我们实现了两种刷新策略,向显示器刷新、向指定路径的指定文件刷新。但不论哪种刷新方式,我们都得保证是原子的,即任意时刻只能有一个线程刷新,这样就不会产生数据混杂的情况。所以,这里我们实现原子性的方法是借助互斥锁。
2.日志类
有了刷新策略之后,下一步便是处理日志的具体内容了。这里我们期望打印出来的日志包含以下信息:
[时间][日志等级][进程pid][文件名][行号] - 日志正文
[2025-5-4 10:05:48][INFO][828670][thread.hpp][38]- create newthread-1 success
[2025-5-4 10:05:48][INFO][828670][thread.hpp][38]- create newthread-2 success
[2025-5-4 10:05:48][INFO][828670][thread.hpp][38]- create newthread-3 success
[2025-5-4 10:05:48][INFO][828670][thread.hpp][38]- create newthread-4 success
[2025-5-4 10:05:48][INFO][828670][thread.hpp][38]- create newthread-5 success
对于日志类来说,他首先得有自己的刷新策略,所以日志类包含一个成员那就是刷新策略,并且我们得指定默认的刷新策略:
class logger{public:logger(){// 默认使用显示器刷新策略UseConsoleStrategy();}~logger() {}void UseConsoleStrategy() { _fflush_strategy = std::make_unique<consolelogstrategy>(); }void UseFileLogStrategy() { _fflush_strategy = std::make_unique<filelogstrategy>(); }private:std::unique_ptr<logstrategy> _fflush_strategy;}有了刷新方式之后,我们下一步便是处理日志内容了。这里我们采取内部类的方式,实现日志内容的设计:
// 获取时间std::string GetTime(){// 1.获取当前的时间戳time_t cur_time = time(nullptr);// 2.将时间戳转化为年月日-时分秒struct tm format_time;localtime_r(&cur_time, &format_time);char time_buffer[128] = {0};snprintf(time_buffer, sizeof(time_buffer), "%d-%d-%d %d:%02d:%02d",format_time.tm_year + 1900,format_time.tm_mon + 1,format_time.tm_mday,format_time.tm_hour,format_time.tm_min,format_time.tm_sec);return time_buffer;}// 日志等级enum class loglevel{DEBUG,INFO,WARINING,ERROR,FATAL};// 获取日志等级std::string loglevelToString(loglevel level){switch (level){case loglevel::DEBUG:return "DEBUG";case loglevel::INFO:return "INFO";case loglevel::WARINING:return "WARNING";case loglevel::ERROR:return "ERROR";case loglevel::FATAL:return "FATAL";default:return "UNKNOEN";}} // 内部类// 用来描述日志具体内容class logmessage{public:logmessage(loglevel &level, const std::string &name, int number, logger &logger): _cur_time(GetTime()),_log_level(level),_file(name),_line_number(number),_pid(getpid()),_logger(logger){// 将格式化信息写入ss字符串流中std::stringstream ss;ss << "[" << _cur_time << "]"<< "[" << loglevelToString(_log_level) << "]"<< "[" << _pid << "]"<< "[" << _file << "]"<< "[" << _line_number << "]"<< "- ";// 从字符串中获取字符串_format_info = ss.str();}~logmessage(){// 如果有刷新策略,在对象析构的时候进行刷新if (_logger._fflush_strategy){_logger._fflush_strategy->synclog(_format_info);}}// 日志的主要内容template <typename T>logmessage &operator<<(const T &message){std::stringstream ss;ss << message;_format_info += ss.str();return *this;}private:std::string _cur_time;loglevel _log_level;pid_t _pid;std::string _file;int _line_number;std::string _format_info;logger &_logger;}; // end of logmessage 内部类,用来处理日志的格式化内容以及主要内容有了以上内容,我们的日志类已经基本上实现了,但是我们还得再日志类中实现一个仿函数,该仿函数的返回值是内部类类型,有了内部类类型,我们就可以根据内部重载的<<运算符制作日志消息,最后在该内部类对象析构的时候进行刷新即可。所以我们在返回内部类对象时返回临时对象,并且不要接收,采取匿名的方式,这样它的声明周期就只有1行,该行结束就会自动刷新了。
// logger类内成员public:logmessage operator()(loglevel level, const std::string &file, int line){return logmessage(level, file, line, *this);}为了方便使用,我们直接在命名空间中,定义一个全局的logger对象,使用日志类的时候,直接使用该全局对象。全局对象访问仿函数来实现日志的构成和打印。所以我们的调用方式就变为:
Glogger(loglevel, filename, linenumber) << "xxx" << "xxx" << ...;但是这样还是不太优雅,我们还得手动设置文件名和行号。我们可以使用宏来简化使用。
#define LOG(level) Glogger(level, __FILE__, __LINE__)
#define USE_CONSOLE_STARATEGY Glogger.UseConsoleStrategy()
#define USE_FILE_LOG_STARATRGY Glogger.UseFileLogStrategy()二.线程池
线程池作为一种池化技术,可以提前申请好资源,当数据或者任务到来时,直接去处理,不用在创建线程了。
设计方案:
- 线程池要在创建的时候创建出多个线程,我们用数组将所有的线程管理起来。
- 除了线程外,还得有任务,所以我们还得有一个任务队列。
- 在处理任务时,和添加任务时都得是原子的,所以还得有互斥锁。
- 当任务队列为空时,但线程池还没有结束,所以我们得让所有的线程等待,所以还得有条件变量。
在创建线程池的时候,直接在构造函数创建n个线程即可,因为创建线程需要指定执行的方法,所以我们实现一个handler方法,用来让创建出的线程去执行。
ThreadPool(const int threads = defaultThreadSize):_num(threads), _isRunning(true), _sleepernumber(0){// 创建_num个线程for(int i=0; i<_num; i++){_threads.emplace_back([this](){Handler();});}}而对于handler方法来说,所有的线程都用从任务队列中获取任务,但任务队列作为临界资源,同一时刻只能有一个线程访问,所以我们必须得加锁。
但是还有一个问题,当线程池结束的时候,如果此时还有线程在等待,我们就应该叫醒它们,否则就会导致内存泄漏问题。所以,在判断线程需要等待时,需满足两个条件,线程池没有结束,并且没有任务,才需要等待,否则直接执行后面的代码。
在执行后面的代码时,我们需要判断线程池是否结束,如果结束了,并且没有任务,则直接让线程退出,否则执行完任务,在退出。
当线程拿到任务之后,就可以释放锁了,因为此时该任务已经属于该线程私有的了,如果再持有锁,就得等任务执行完才能获取下一个任务,导致效率底下。
void Handler(){// 获取线程名字char name[128] = { 0 };pthread_getname_np(pthread_self(), name, sizeof(name));// 从任务队列中获取任务while(true){T t;{// 加锁访问任务队列,任意时刻只能有一个线程访问任务队列mutexguard lock(_mutex);// 当线程池终止了,但有可能还有线程再等待,此时已经没有任务,其他的线程都已经被回收了,这些线程会导致内存泄露// 但是如果直接叫醒所有线程,它们不会退出循环,而是继续等待// 所以在进行等待的时候,要判断线程池是否还在运行,如果已经结束,并且任务队列为空,则不需要等待// 一个不满足,就必须等待while(_isRunning && _taskManager.empty()){// 任务队列为空,线程进行等待_sleepernumber++;_cond.Wait(_mutex);_sleepernumber--;}// 当线程池已经终止了&&任务队列为空,就让线程结束if(!_isRunning && _taskManager.empty()){LOG(loglevel::INFO) << name << "退出";break;}// 获取任务t = _taskManager.front();_taskManager.pop();}// 执行任务// 当一个线程加锁拿出任务后,这个任务已经从任务队列中消失了,只属于该线程私有,所以先解锁,再执行,提高效率。t();}}添加任务也会访问临界资源任务队列,所以也得加锁,当然也得保证线程池还在运行,否则就不添加。并且,添加之后,就有任务了,我们判断此时是否有线程再等待,如果有,则唤醒,让其获取任务。
// 向任务队列中新增任务bool emplace(const T& task){// 任意时刻,都只允许只有一个线程插入任务mutexguard lock(_mutex);if(!_isRunning) return false;_taskManager.emplace(task); if(_sleepernumber){WakeUpOne();}return true;}void WakeUpOne(){LOG(loglevel::INFO) << "唤醒一个线程";_cond.signal();}我们还得有接口,让线程池停止。停止运行之后,如果还有任务就继续执行,没有任务了,就让线程退出。但因为有可能还有线程再等待,它们收不到任务了,如果还等待的化,就会导致内存泄露问题,所以,再停止线程池之后,我们需要唤醒所有的线程。
void WakeUpAll(){if(_sleepernumber){LOG(loglevel::INFO) << "唤醒所有线程";_cond.broadcast();}}// 让线程池终止void Stop(){if(!_isRunning) return;_isRunning = false;LOG(loglevel::INFO) << "线程池已经被终止";// 线程池结束就让所有等待的线程苏醒,否则它们不会退出WakeUpAll();}// 回收线程void Join(){if(_isRunning) return;for(auto& thread : _threads){thread.Join();}}有了以上接口,我们的线程池就可以运行起来了。但是,如果在内存中同时存在多个线程池的话,就会导致资源提前被申请,导致后面来的任务申请不到线程了。也有可能线程池很多,但处理的热任务很少,就会导致资源浪费问题。
所以,我们期望,线程池只能被实例化出一份,即内存中只允许有一个线程池。借此,我们来引出,单例模式线程池。
1.单例模式线程池
所谓单例模式,其实就是一个类只能实例化出一个对象。
而实现单例模式有两中方案:饿汉模式和懒汉模式。
- 饿汉模式:在将代码加载到内存中时,就已经初始化了该对象
- 懒汉模式:在代码加载到内存中时,只初始化一个该类对象的指针,并不具体实例化。当真正使用的时候,在进行实例化
在一个类比较大的时候,在加载的时候直接创建对象比较耗时
懒汉模式采用延时创建技术,就可以加快启动进程的时候
在内核中,我们使用malloc申请内存空间,其实就使用了懒汉模式,先给你虚拟地址空间,当你使用该虚拟地址空间的时候,再给你从内存中开辟,并构建映射关系
我们这里采取懒汉模式实现单例:
首先,单例模式只能实例化一个对象,所以我们不应该将构造、拷贝构造,赋值函数等暴露出来。我们在类内定义一个静态的该类对象的指针。因为静态对象是全局的,所以在代码加载到内存中时,他就已经被创建了,但因为我们创建的是指针,所以还没有真正意义上创建对象。
static ThreadPool<T>* _inc; // 未来实例化出的对象
static Mutex _sm; // 用来实现单例模式我们提供一个静态函数,用来初始化静态对象,初始化该静态对象一定得是原子的,要不然如果该函数被多线程同时访问,就有可能创建多个对象。
static ThreadPool<T>* Getinstance(int threadsize = defaultThreadSize){LOG(loglevel::DEBUG) << "获取线程池单例...";if(!_inc){mutexguard lock(_sm); if(!_inc){LOG(loglevel::INFO) << "线程池单例创建....";_inc = new ThreadPool<T>(threadsize);}}return _inc;}我们这里采取双if判断,来提高获取单例的运行效率。如果没有外层的if,每一个线程都得先申请锁,然后再判断,申请锁的时候什么都做不了。就算我们单例创建好了,下一次还得申请锁,在判断。
所以我们额外添加一个if判断,单例还没有创建的时候确实没有变化,但对有已经有了单例来说,就可以让其他线程提前退出,获取到单例。
#ifndef __ThreadPool__HPP__
#define __ThreadPool__HPP__#include <iostream>
#include <queue>
#include "thread.hpp"
#include "log.hpp"
#include "mutex.hpp"
#include "cond.hpp"namespace ThreadPoolModule
{using namespace MyThread;using namespace MutexModule;using namespace MyCond;using namespace MyLog;// 默认使用5个线程的线程池const int defaultThreadSize = 5;template <typename T>class ThreadPool{private:void WakeUpAll(){if(_sleepernumber){LOG(loglevel::INFO) << "唤醒所有线程";_cond.broadcast();}}void WakeUpOne(){LOG(loglevel::INFO) << "唤醒一个线程";_cond.signal();}// 同一时刻,内存中不需要存在多个线程池// 利用单例模式来控制该进程池只能实例化出一个对象:单例模型即一个类只能实例化一个对象// 单例模式有两种实现方式:饿汉模型和懒汉模式// 饿汉模式:在将代码加载到内存中时,就已经初始化了该对象// 懒汉模式:在代码加载到内存中时,只初始化一个该类对象的指针,并不具体实例化。当真正使用的时候,在进行实例化// 在一个类比较大的时候,在加载的时候直接创建对象比较耗时// 懒汉模式采用延时创建技术,就可以加快启动进程的时候// 在内核中,我们使用malloc申请内存空间,其实就使用了懒汉模式,先给你虚拟地址空间,当你使用该虚拟地址空间的时候,再给你从内存中开辟,并构建映射关系// 因为单例模式只能创建一个对象,所以不应该将类的构造,拷贝构造,赋值重载函数公开ThreadPool(const int threads = defaultThreadSize):_num(threads), _isRunning(true), _sleepernumber(0){// 创建_num个线程for(int i=0; i<_num; i++){_threads.emplace_back([this](){Handler();});}}ThreadPool(const ThreadPool& tp) = delete;ThreadPool operator=(const ThreadPool& tp) = delete;public:// 有可能有多个执行流进入该函数,但是只能创建一个对象static ThreadPool<T>* Getinstance(int threadsize = defaultThreadSize){LOG(loglevel::DEBUG) << "获取线程池单例...";if(!_inc){mutexguard lock(_sm); if(!_inc){LOG(loglevel::INFO) << "线程池单例创建....";_inc = new ThreadPool<T>(threadsize);}}return _inc;}~ThreadPool(){}void Handler(){// 获取线程名字char name[128] = { 0 };pthread_getname_np(pthread_self(), name, sizeof(name));// 从任务队列中获取任务while(true){T t;{// 加锁访问任务队列,任意时刻只能有一个线程访问任务队列mutexguard lock(_mutex);// 当线程池终止了,但有可能还有线程再等待,此时已经没有任务,其他的线程都已经被回收了,这些线程会导致内存泄露// 但是如果直接叫醒所有线程,它们不会退出循环,而是继续等待// 所以在进行等待的时候,要判断线程池是否还在运行,如果已经结束,并且任务队列为空,则不需要等待// 一个不满足,就必须等待while(_isRunning && _taskManager.empty()){// 任务队列为空,线程进行等待_sleepernumber++;_cond.Wait(_mutex);_sleepernumber--;}// 当线程池已经终止了&&任务队列为空,就让线程结束if(!_isRunning && _taskManager.empty()){LOG(loglevel::INFO) << name << "退出";break;}// 获取任务t = _taskManager.front();_taskManager.pop();}// 执行任务// 当一个线程加锁拿出任务后,这个任务已经从任务队列中消失了,只属于该线程私有,所以先解锁,再执行,提高效率。t();}}// 让线程池终止void Stop(){if(!_isRunning) return;_isRunning = false;LOG(loglevel::INFO) << "线程池已经被终止";// 线程池结束就让所有等待的线程苏醒,否则它们不会退出WakeUpAll();}// 回收线程void Join(){if(_isRunning) return;for(auto& thread : _threads){thread.Join();}}// 向任务队列中新增任务bool emplace(const T& task){// 任意时刻,都只允许只有一个线程插入任务mutexguard lock(_mutex);if(!_isRunning) return false;_taskManager.emplace(task); if(_sleepernumber){WakeUpOne();}return true;}private:std::vector<Thread> _threads; // 线程池int _num; // 线程个数std::queue<T> _taskManager; // 任务队列Mutex _mutex; // 互斥锁cond _cond; // 信号量bool _isRunning; // 线程池是否运行int _sleepernumber; // 当前等待的线程个数static ThreadPool<T>* _inc; // 未来实例化出的对象static Mutex _sm; // 用来实现单例模式};// 初始化静态成员template <typename T>ThreadPool<T>* ThreadPool<T>::_inc = nullptr;template <typename T>Mutex ThreadPool<T>::_sm;
}#endif三.重入和线程安全
如果函数是可重入的,那么它就是线程安全的。
线程安全不一定是可重入的,而可重入的一定是线程安全的。
四.死锁
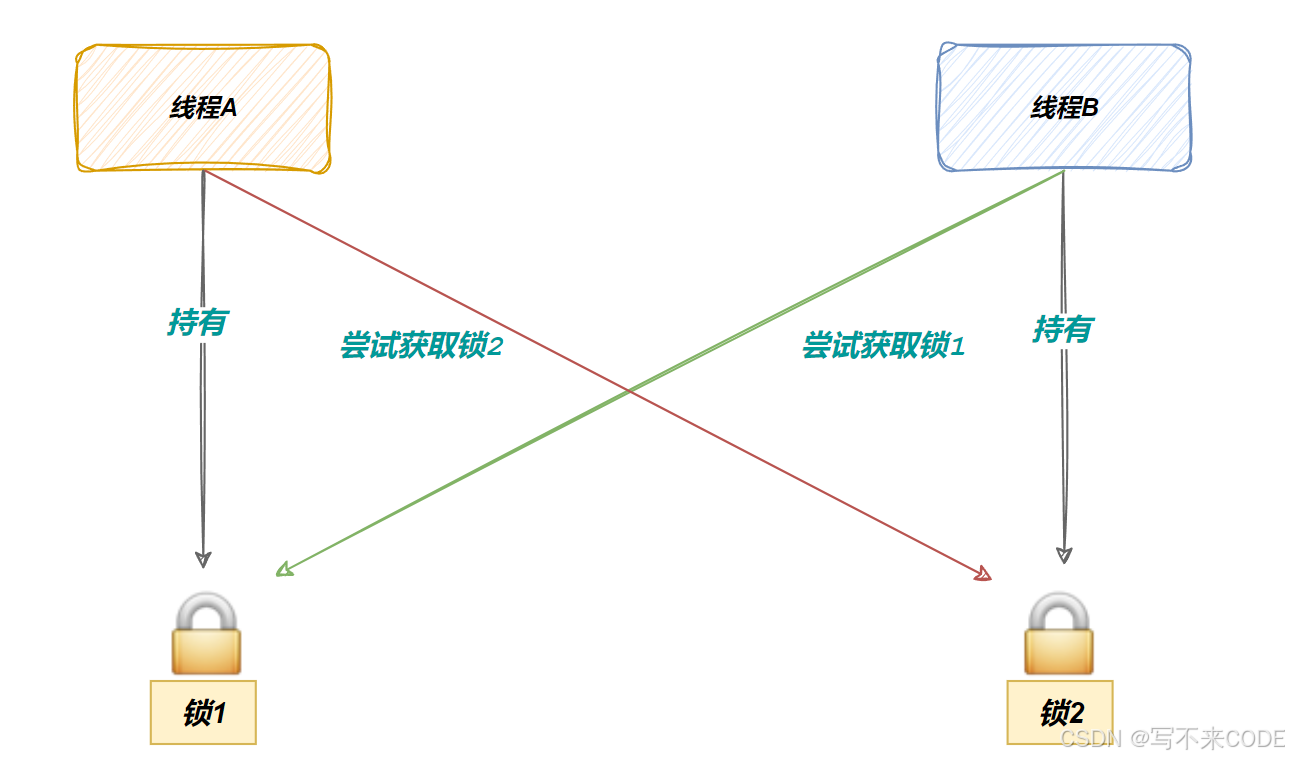
死锁是指一组线程中,都占有自己的资源,同时又向使用对方的资源,这样导致线程互相申请无法推进线程运行的现象就叫做死锁。
简单来说,线程A想要访问的资源必须同时持有锁1和锁2,线程B也一样。但此时线程A持有锁1,线程B持有锁2.而它们又同时访问对方的锁,这样就导致谁都申请不到锁,导致阻塞挂起。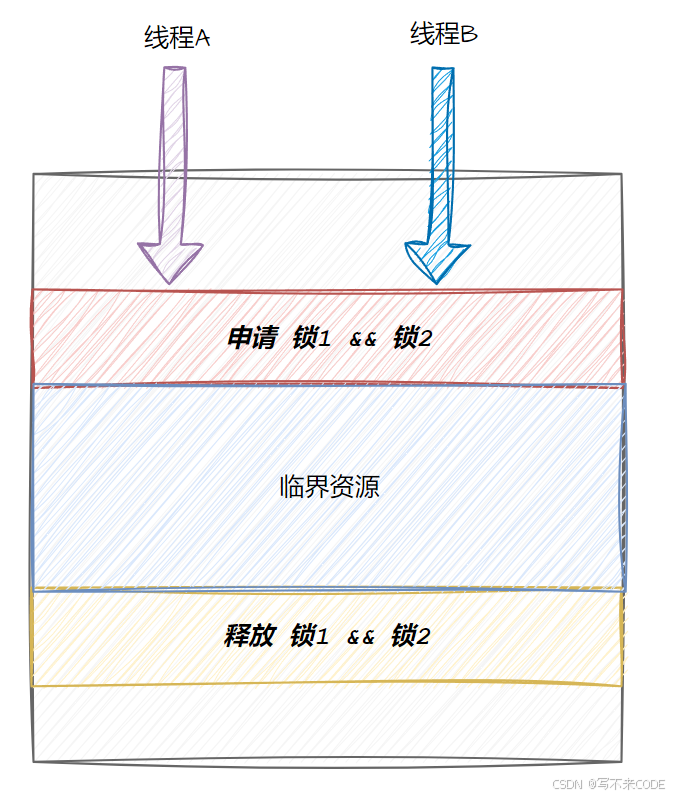

1.死锁的四个必要条件
- 0x1.互斥条件:一个临界资源只能被一个执行流访问
- 0x2.请求与保持条件:一个执行流因为请求而导致阻塞时,对已有的资源不释放
- 0x3.不剥夺条件:一个执行流已获得的资源,在未使用完前,不可被抢夺
- 0x4.循环等待条件:若干个执行流,采取循环的申请对方的资源,导致了头尾衔接的等待资源关系。
2.避免死锁
死锁产生上面四种条件必须同时具有,所以我们只需要破坏其中的条件即可,死锁就不会成立!!!!
解决方案1:我们可以使用trylock来申请锁,在申请另一个锁时,发现申请失败,就可以释放掉当前的锁,来让其他人获取。
当然还有其他方法来避免死锁,可以自行了解。
以上,便是单例线程池的所有内容!
相关文章:

【Linux】日志与策略模式、线程池
在了解了线程的基本概念和线程互斥与同步之后,我们可以以此设计一个简单的线程池。【Linux】线程-CSDN博客 【Linux】线程同步与互斥-CSDN博客 线程池也是一种池化技术。提前申请一些线程,等待有任务时就直接让线程去执行,不用再收到任务之…...

【神经网络与深度学习】生成模型-单位高斯分布 Generating Models-unit Gaussian distribution
引言 在生成模型的研究与应用中,单位高斯分布(标准正态分布)作为数据采样的基础扮演着至关重要的角色。其数学特性、潜在空间的连续性、灵活性以及通用性,使得生成模型能够高效且稳定地学习和生成样本。本文将详细探讨从单位高斯…...

通讯协议开发实战:从零到一打造企业级通信解决方案
简介 从工业控制到物联网,掌握主流通信协议开发是构建现代智能系统的核心能力。本文将通过深入分析CAN FD和MQTT两种关键协议的原理、特性及应用场景,结合TypeScript和Node.js技术栈,设计一个完整的实时运动控制系统开发案例。从协议解析到数据转换,再到系统集成,全程提供…...
)
《MATLAB实战训练营:从入门到工业级应用》工程实用篇-自动驾驶初体验:车道线检测算法实战(MATLAB2016b版)
《MATLAB实战训练营:从入门到工业级应用》工程实用篇-🚗 自动驾驶初体验:车道线检测算法实战(MATLAB2016b版) 大家好!今天我要带大家一起探索自动驾驶中一个非常基础但又至关重要的技术——车道线检测。我…...
?)
【网络】什么是串口链路(Serial Link)?
在路由器上,串口链路(Serial Link)就是指路由器之间通过串行接口(serial interface)和串行电缆(通常是V.35、RS-232或同步串行线路)直接点对点相连的那一段连线。它和我们平常在局域网里用的以太…...

为了结合后端而学习前端的学习日志——【黑洞光标特效】
前端设计专栏 今天给大家带来一个超酷的前端特效——黑洞光标!让你的鼠标变成一个会吞噬光粒子的迷你黑洞,点击时还会喷射出绿色能量粒子!🌠 🚀 效果预览 想象一下:你的鼠标变成一个旋转的黑洞࿰…...

set autotrace报错
报错: SQL> set autotrace traceonly SP2-0618: Cannot find the Session Identifier. Check PLUSTRACE role is enabled SP2-0611: Error enabling STATISTICS report原因分析: 根据上面的错误提示“SP2-0618: Cannot find the Session Identifie…...

算法每日一题 | 入门-顺序结构-大象喝水
大象喝水 题目描述 一只大象口渴了,要喝 20 升水才能解渴,但现在只有一个深 h 厘米,底面半径为 r 厘米的小圆桶 (h 和 r 都是整数)。问大象至少要喝多少桶水才会解渴。 这里我们近似地取圆周率 π 3.14 \pi3.14 π…...

n8n 构建一个 ReAct AI Agent 示例
n8n 构建一个 ReAct AI Agent 示例 0. 引言1. 详细步骤创建一个 "When Executed by Another Workflow"创建一个 "Edit Fields (Set)"再创建一个 "Edit Fields (Set)"创建一个 HTTP Request创建一个 If 节点在 true 分支创建一个 "Edit Fiel…...
)
Scartch038(四季变换)
知识回顾 1.了解和简单使用音乐和视频侦测模块 2.使用克隆体做出波纹特效 3.取色器妙用侦测背景颜色 前言 我国幅员辽阔,不同地方的四季会有不同的美丽景色,这节课我带你使用程序做一个体现北方四季变化的程序 之前的程序基本都是好玩的,这节课做一个能够赏心悦目的程序。…...

【Linux】SELinux 的基本操作与防火墙的管理
目录 一、SELinux的管理 1.1 Linux 系统的安全机制 1.2 SELinux 的概述 1.3 SELinux 的配置 1.3.1 查看 SELinux 的工作方式 1.3.2 设置 SELinux 的工作方式 1.3.2.1 基于配置文件修改(推荐方式) 1.3.2.2 基于命令方式修改 二、防火墙管理 2.1 防…...

【React Hooks原理 - useCallback、useMemo】
useMemo用于缓存计算结果,它只在依赖项发生变化时重新计算 原理: 依赖项检查:useMemo接收2个参数,一个“创建”函数和一个依赖项数组。依赖项数组中的值在每次渲染时都会被比较,以决定是否需要重新计算 缓存机制&am…...

一格一格“翻地毯”找单词——用深度优先搜索搞定单词搜索
一格一格“翻地毯”找单词——用深度优先搜索搞定单词搜索 一、引子:别看题简单,实则套路深 说起“单词搜索”这个题目,初学者第一眼可能会说:“哦不就是个查字母吗?”其实,真没这么简单。 LeetCode 上那…...

深入了解 OpenIddict:实现 OAuth 2.0 和 OpenID Connect 协议的 .NET 库
在现代 Web 开发中,身份验证和授权是安全性的重要组成部分。随着对安全性的要求不断增加,OAuth 2.0 和 OpenID Connect(OIDC)协议已经成为许多应用程序的标准身份验证方式。而 OpenIddict,作为一个用于实现 OAuth 2.0 …...

学习黑客 TCP/IP
一句话总结:把 TCP/IP 看成大型多人在线游戏的“世界引擎”:链路层是地基,互联网层是道路,运输层是交通系统,应用层是景点与商店;协议们则是各种交通工具与技能(TCP 稳重的长途客车,…...

【沐风老师】3DMAX按元素UV修改器插件教程
3DMAX按元素UV修改器UV By Element是一个脚本化的修改器插件。对于需要创建随机化纹理效果的用户而言,3DMAX的UV By Element修改器无疑是一款高效工具,它将以伪随机量偏移、旋转和/或缩放每个元素的UV坐标。 【版本要求】 3dMax 2016及以上 【安装方法】…...

Jetpack Compose 边距终极指南:Margin 和 Padding 的正确处理方式
Jetpack Compose 边距终极指南:Margin 和 Padding 的正确处理方式 在 Android 开发中,Jetpack Compose 彻底改变了 UI 构建方式,但许多开发者对如何处理边距(Margin/Padding)感到困惑。本文将深入解析 Compose 的边距…...

Go语言--语法基础4--基本数据类型--类型转换
Go 是一种强类型的语言,所以如果在赋值的时候两边类型不一致会报错。一个类型的值可以被转换成另一种类型的值。由于 Go 语言不存在隐式类型转换,因此所有的类型转换都必须显式的声明。 强制类型转换语法 使用 type (a) 这种形式来进行强制类型转换&am…...
 LineEdit、QTextEdit)
【C++ Qt】输入类控件(上) LineEdit、QTextEdit
每日激励:“不设限和自我肯定的心态:I can do all things。 — Stephen Curry” 绪论: 本次分享聚焦 Qt 框架里常用的输入框组件,重点讲解 QLineEdit(单行输入框)和 QTextEdit(多行输入框&…...
)
【c++深入系列】:万字详解vector(附模拟实现的vector源码)
🔥 本文专栏:c 🌸作者主页:努力努力再努力wz 💪 今日博客励志语录: 种子破土时从不问‘会不会有光’,它只管生长 ★★★ 本文前置知识: 模版 1.什么是vector 那么想必大家都学过顺…...
,CLOCK)
OpenHarmony平台驱动开发(二),CLOCK
OpenHarmony平台驱动开发(二) CLOCK 概述 功能简介 CLOCK,时钟是系统各个部件运行的基础,以CPU时钟举例,CPU 时钟是指 CPU 内部的时钟发生器,它以频率的形式工作,用来同步和控制 CPU 内部的各…...

Java大厂面试:Java技术栈中的核心知识点
Java技术栈中的核心知识点 第一轮提问:基础概念与原理 技术总监:郑薪苦,你对JVM内存模型了解多少?能简单说说吗?郑薪苦:嗯……我记得JVM有堆、栈、方法区这些区域,堆是存放对象的地方…...
闪屏)
硬件加速模式Chrome(Edge)闪屏
Chrome开启“硬件加速模式”后,打开浏览器会闪屏或看视频会闪屏,如果电脑只有集显,直接将这个硬件加速关了吧,没啥必要开着 解决方法 让浏览器使用独立显卡 在Windows左下角搜索 图形设置 ,将浏览器添加进去&#…...

【ArcGIS微课1000例】0145:如何按照自定义形状裁剪数据框?
文章目录 一、添加数据二、绘制形状三、裁剪格网和经纬网一、添加数据 打开软件,添加配套实验数据包中0145.rar中的影像数据,如下图所示: 二、绘制形状 1. 在数据视图中,使用绘图 工具条上的新建圆工具 可创建一个椭圆,使其包含要在该数据框中显示的数据范围。 修改椭圆…...

深入了解Linux系统—— 环境变量
命令行参数 我们知道,我们使用的指令它本质上也是一个程序,我们要执行这个指令,输入指令名然后回车即可执行;但是对于指令带选项,又是如何实现的呢? 问题:main函数有没有参数? 在我…...

软考-软件设计师中级备考 12、软件工程
一、软件工程概述 定义:软件工程是一门研究用工程化方法构建和维护有效的、实用的和高质量软件的学科。它涉及到软件的开发、测试、维护、管理等多个方面,旨在运用一系列科学方法和技术手段,提高软件的质量和开发效率,降低软件开…...

FreeSwitch Windows安装
下载 FreeSwitch 官网下载地址https://files.freeswitch.org/windows/ 根据自己的系统选择不同的版本,如下图 官网下载可能比较慢,请使用下方下载 FreeSWITCH-1.10.12-Release-x64.msi https://download.csdn.net/download/a670941001/90752912 2、…...

南京优质的公司有哪些?
南京有许多优质的公司,以下是一些有代表性的: 制造业 • 南京钢铁集团有限公司 :作为国家战略布局的 18 家重点钢企之一,是中国特大型钢铁联合企业,1993 年 12 月进行公司制改革,2010 年 9 月实现整体上市…...

Spring AI 实战:第十一章、Spring AI Agent之知行合一
引言:智能体的知行辩证法 “知为行之始,行为知之成”,王阳明的哲学智慧在AI时代焕发光彩。智能体(LLM Agent)的进化之路,正是"认知-决策-执行"这一闭环的完美诠释: 知明理:融合大语言模型的推理能力与知识图谱的结构化认知行致用:基于ReAct模式的动态工具调…...

LeetCode 1128 等价多米诺骨牌对的数量 题解
今天的每日一题,我的思路还是硬做,不如评论区通过状压写的简单,但是答题思路加算法实现是没有问题的,且时间复杂度也是可以通过的,毕竟全是o(n) 那么我就来说一下我的思路,根据dominoes[i] [a, b] 与 domi…...

管理配置信息和敏感信息
管理配置信息和敏感信息 文章目录 管理配置信息和敏感信息[toc]一、什么是ConfigMap和Secret二、使用ConfigMap为Tomcat提供配置文件三、使用Secret为MongDB提供配置文件 一、什么是ConfigMap和Secret 在 Kubernetes 中,ConfigMap 和 Secret 是两种用于管理配置数据…...

Rust与C/C++互操作实战指南
目录 1.前言2.动态库调用2.1 动态加载2.2 静态加载3.代码调用4.静态库调用1.前言 本文原文为:Rust与C/C++互操作实战指南 由于rust诞生时间太短,目前生态不够完善,因此大量的功能库都需要依赖于C、C++语言的历史积累。 而本文将要介绍的便是如何实现rust与c乃至c++之间实…...

word批量转pdf工具
word批量转pdf工具 图片 说到了办公,怎能不提PDF转换哦? 这是一款一键就可以批量word转换为PDF的小工具,简直是VB界的一股清流。 图片 操作简单到不行,只要把需要转换的word文件和这个工具放在同一个文件夹里,双击…...
排序)
【数据结构】励志大厂版·初阶(复习+刷题)排序
前引:本篇作为初阶结尾的最后一篇—排序,将先介绍八种常用的排序方法,然后开始刷题,小编会详细注释每句代码的作用,不会出现看不懂的情况,这点大家放心,既是写给大家同时也是写给自己的…...

Git推送大文件导致提交回退的完整解决记录
问题背景 在向Gitee推送代码时,因单文件超过平台限制(100MB),推送被拒绝: > git push origin master:master remote: File [6322bc3f1becedcade87b5d1ea7fddbdd95e6959] size 178.312MB, exceeds quota 100MB rem…...

游戏引擎学习第257天:处理一些 Win32 相关的问题
设定今天的工作计划 今天我们本来是打算继续开发性能分析器(Profiler),但在此之前,我们认为有一些问题应该先清理一下。虽然这类事情不是我们最关心的核心内容,但我们觉得现在是时候处理一下了,特别是为了…...

高性能数据库架构探索:OceanBase 分布式技术深入解析
高性能数据库架构探索:OceanBase 分布式技术深入解析 简介 OceanBase 高性能分布式数据库,解决传统数据库在大规模、高并发场景下的性能瓶颈,通过分布式架构、数据自动分片和强一致性协议,提供高可用性、弹性扩展和出色的性能&am…...
 这里串口的2/0 和 3/0分别都是什么?)
【CISCO】Se2/0, Se3/0:串行口(Serial) 这里串口的2/0 和 3/0分别都是什么?
在 Cisco IOS 设备上,接口名称通常遵循这样一个格式: <类型><槽号>/<端口号>类型(Type):表示接口的物理或逻辑类型,比如 Serial(串行)、FastEthernet、GigabitEt…...

GPU集群训练经验评估框架:运营经理经验分析篇
引言 随着深度学习模型规模的持续增长和复杂度的不断提高,单GPU训练已经难以满足现代AI研究和应用的需求。GPU集群训练作为一种有效的扩展方案,能够显著提升训练效率、处理更大规模的数据集和模型。然而,GPU集群训练涉及到分布式训练框架、集群管理工具、性能优化等多个技术…...

函数多项式拟合
函数多项式拟合 用处 不方便使用math时,可以使用多项式拟合法实现比较高效的数学函数,比如使用avx指令时,O3优化,math中的函数会调用FPU指令集,在指令集切换的过程中代码效率大幅降低,为避免使用math中的…...

【Hive入门】Hive与Spark SQL集成:混合计算实践指南
目录 引言 1 Hive与Spark SQL概述 1.1 Hive简介 1.2 Spark SQL简介 2 Hive与Spark SQL集成架构 2.1 集成原理 2.2 配置集成环境 3 混合计算使用场景 3.1 场景一:Hive表与Spark DataFrame互操作 3.2 场景二:Hive UDF与Spark SQL结合使用 3.3 场…...

TFQMR和BiCGStab方法比较
TFQMR(Transpose-Free Quasi-Minimal Residual)和BiCGStab(Bi-Conjugate Gradient Stabilized)都是用于求解非对称线性方程组的迭代方法,属于Krylov子空间方法的范畴。它们分别是BiCG(双共轭梯度法…...
)
小程序 IView WeappUI组件库(简单增删改查)
IView Weapp 微信小程序UI组件库:https://weapp.iviewui.com/components/card IView Weapp.png 快速上手搭建 快速上手.png iView Weapp 的代码 将源代码下载下来,然后将dict放到自己的项目中去。 iView Weapp 的代码.png 小程序中添加iView Weapp 将di…...

nginx 核心功能 02
目录 1. 正向代理 1.1 编译安装 Nginx 1.2 配置正向代理 2. 反向代理 2.1 配置nginx七层代理 2.2 配置nginx四层代理 3. Nginx 缓存 3.1 缓存功能的核心原理和缓存类型 3.2 代理缓存功能设置 4. Nginx rewrite 和正则 4.1 Nginx正则 4.2 nginx location 4.3 Rewri…...

LeetCode 102题解 | 二叉树的层序遍历
二叉树的层序遍历 一、题目链接二、题目三、算法原理四、编写代码 一、题目链接 二叉树的层序遍历 二、题目 三、算法原理 本题要求把结果放在不规则的二维数组里,即每一层二叉树的数值放在一行数组中。 回顾之前的层序遍历是借助队列实现的,是不考虑…...

Flink基础整理
文章目录 前言1.Flink系统架构2.编程模型(API层次结构)3.DataSet和DataStream区别4.Flink的批流统一5.Flink的状态后端6.Flink有哪些状态类型7.Flink并行度前言 提示:下面是根据网络或AI整理: 1.Flink系统架构 用户在客户端提交作业(Job)到服务端。服务端为分布式的主从…...

C++23 新特性:为 std::pair 的转发构造函数添加默认实参
文章目录 1\. 背景:std::pair 的转发构造函数2\. C23 的改进:添加默认实参示例代码 3\. 带来的好处3.1 更简洁的代码3.2 提高代码的可维护性3.3 与 std::optional 和 std::variant 的协同 4\. 实现细节示例实现(简化版) 5\. 使用场…...
:图像与媒体资源优化)
JavaScript性能优化实战(9):图像与媒体资源优化
引言 在当今视觉驱动的网络环境中,图像和媒体资源往往占据了网页总下载量的60%-80%,因此对图像和媒体资源进行有效优化已成为前端性能提升的关键领域。尽管网络带宽持续提升,但用户对加载速度的期望也在不断提高,特别是在移动设备和网络条件不稳定的场景下。 本文作为Jav…...
)
施磊老师rpc(四)
文章目录 rpc网络服务简介RpcProvider 的设计目标Eventloop不使用智能指针-弃用RpcProvider类似于集群的服务器provider网络实现**src/include/rpcprovider.h****src/include/mprpcapplication.h****src/rpcprovider.cc** 错误1错误2-重点**本项目的 mprpc 是动态库, muduo..是…...

Java学习手册:MyBatis 框架作用详解
一、MyBatis 简介 MyBatis 是一款优秀的持久层框架,用于简化 JDBC 开发。它通过将 Java 对象与数据库表之间的映射关系进行配置,使得开发者可以使用简单的 SQL 语句和 Java 代码来完成复杂的数据操作。MyBatis 支持自定义 SQL 语句,提供了灵…...