【数据结构】励志大厂版·初阶(复习+刷题)排序

![]()
前引:本篇作为初阶结尾的最后一篇—排序,将先介绍八种常用的排序方法,然后开始刷题,小编会详细注释每句代码的作用,不会出现看不懂的情况,这点大家放心,既是写给大家同时也是写给自己的!已经迫不及待想看看Hoare大佬的排序了!各种分组分组排序的思想如何在题目中得到体现?突破口在哪!~~以下排序实现我们最优先实现单趟,再实现整体!由易到难!
【注:本文仅仅是作为复习使用,完整的思维讲解可打开小编主页,有详细教程讲解哦!】
目录
稳定排序与不稳定排序有哪些
直接插入排序
实现思路:
复杂度:
希尔排序
实现思路:
代码优化:
复杂度:
堆排序
实现思路:
复杂度:
冒泡排序
实现思路:
代码优化:
复杂度:
选择排序
实现思路:
复杂度:
Hoare排序
实现思路:
复杂度:
快排(双指针)
实现思路:
复杂度:
归并排序
实现思路:
复杂度:
排序OJ题(1)
排序OJ(2)
排序OJ(3)
排序OJ(4)
排序OJ(5)
稳定排序与不稳定排序有哪些
稳定:冒泡排序、直接插入排序、归并排序
不稳定: 快速排序、堆排序、选择排序、希尔排序
直接插入排序
实现思路:
从第一个元素开始,默认第一个元素是有序的,将其之后的元素与前面的进行依次比较, 根据条件进行移动、插入
单趟实现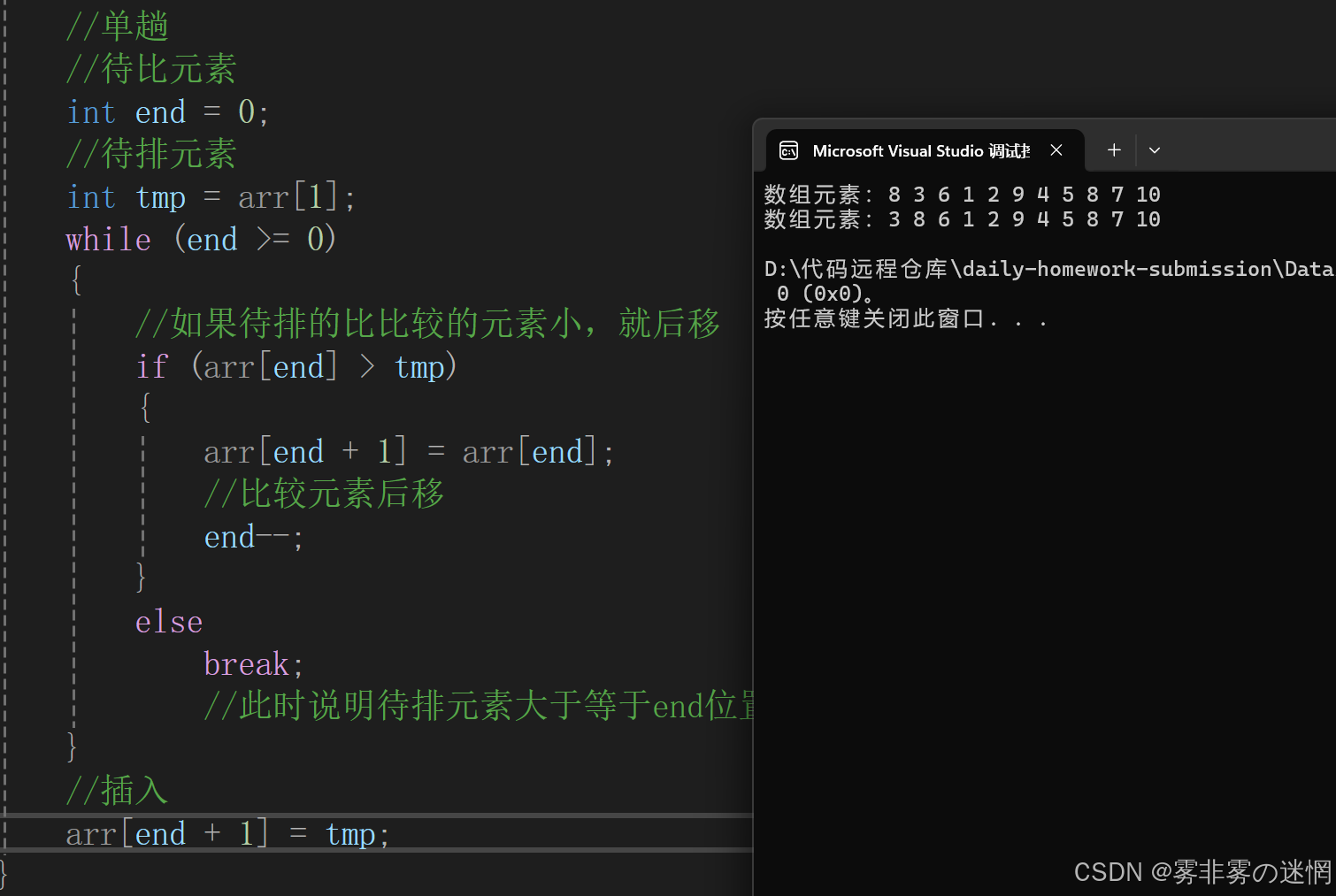
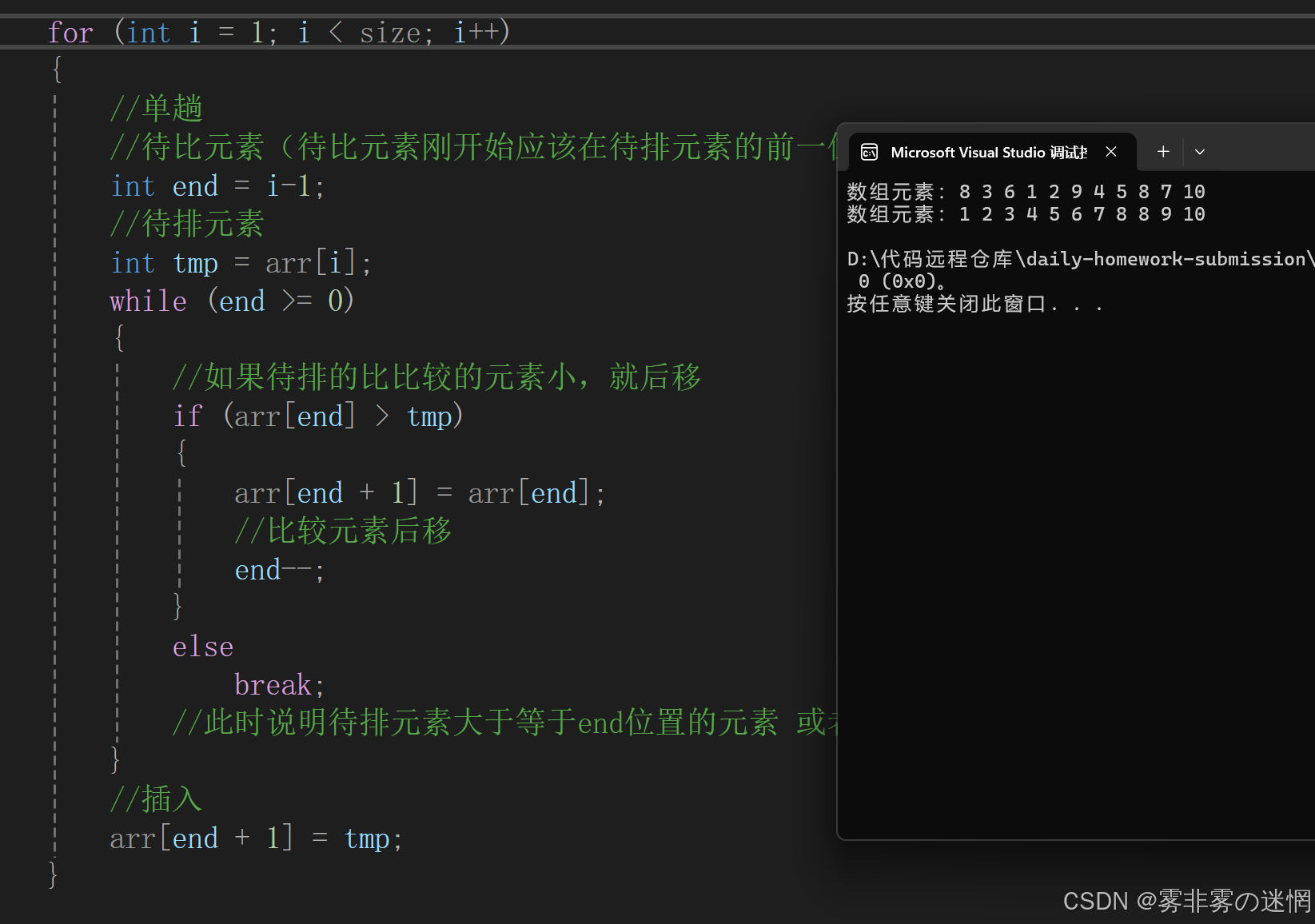
整体实现
//直接插入排序
void Direct(int* arr, int size)
{//断言assert(arr);for (int i = 1; i < size; i++){//单趟//待比元素(待比元素刚开始应该在待排元素的前一位)int end = i-1;//待排元素int tmp = arr[i];while (end >= 0){//如果待排的比比较的元素小,就后移if (arr[end] > tmp){arr[end + 1] = arr[end];//比较元素后移end--;}elsebreak;//此时说明待排元素大于等于end位置的元素 或者 已经到数组末尾}//插入arr[end + 1] = tmp;}
}复杂度:
时间复杂度最坏:O(N^2) 空间复杂度:O(1)
希尔排序
实现思路:
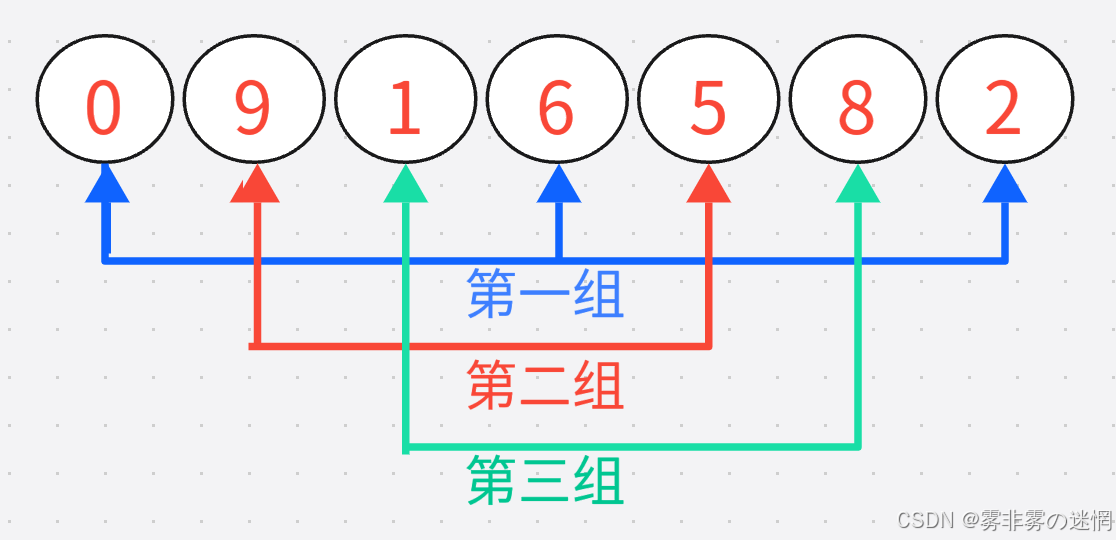
希尔排序是在直接插入排序上的优化,从大概有序到整体有序,避免了最坏情况。将一个数组分组,保证每组间隔一致,将每组进行直接插入排序,再整体实现直接插入排序
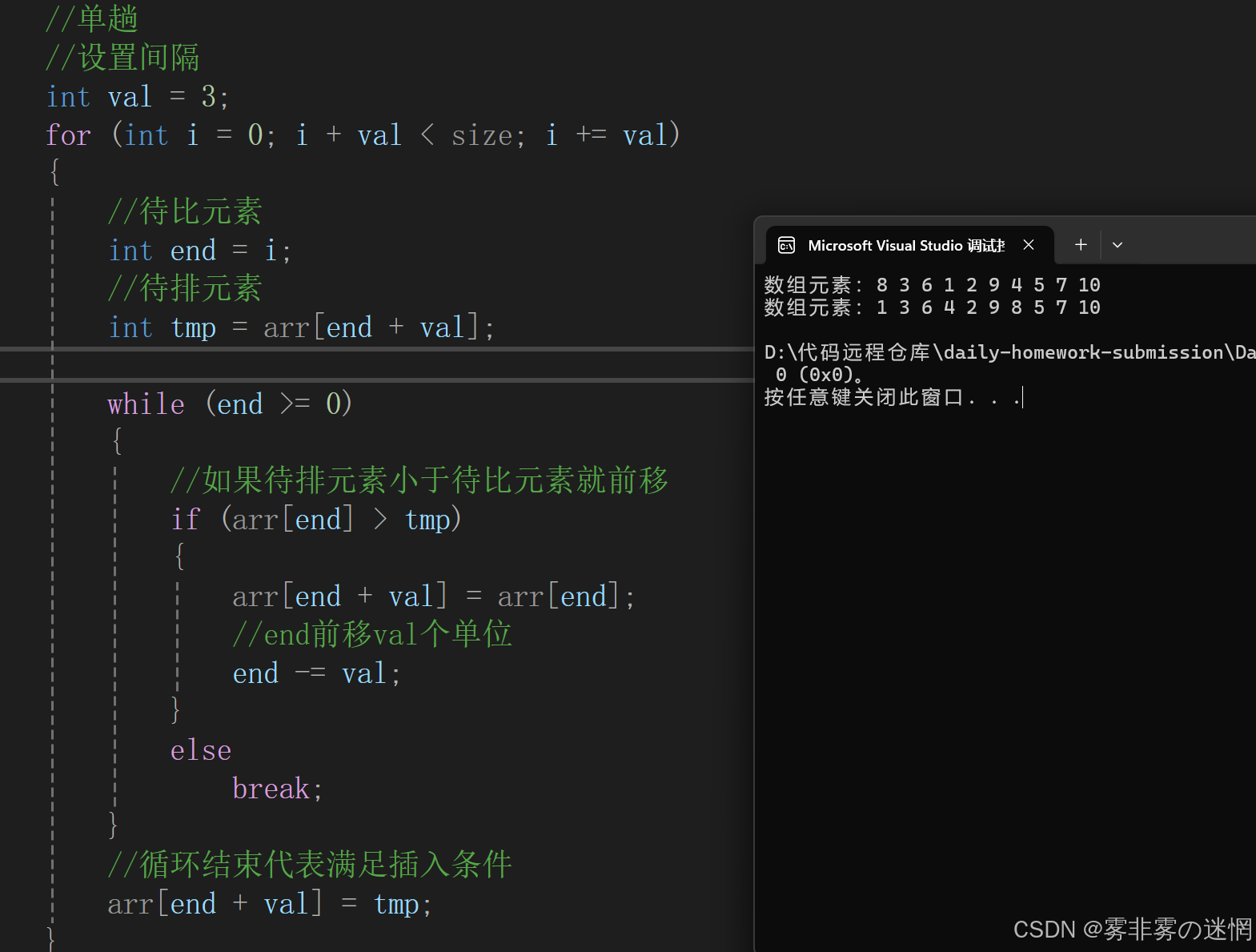
单趟实现(注意待排元素不越界)
整体实现达到大概有序
再进行一趟直接插入排序达到整体有序
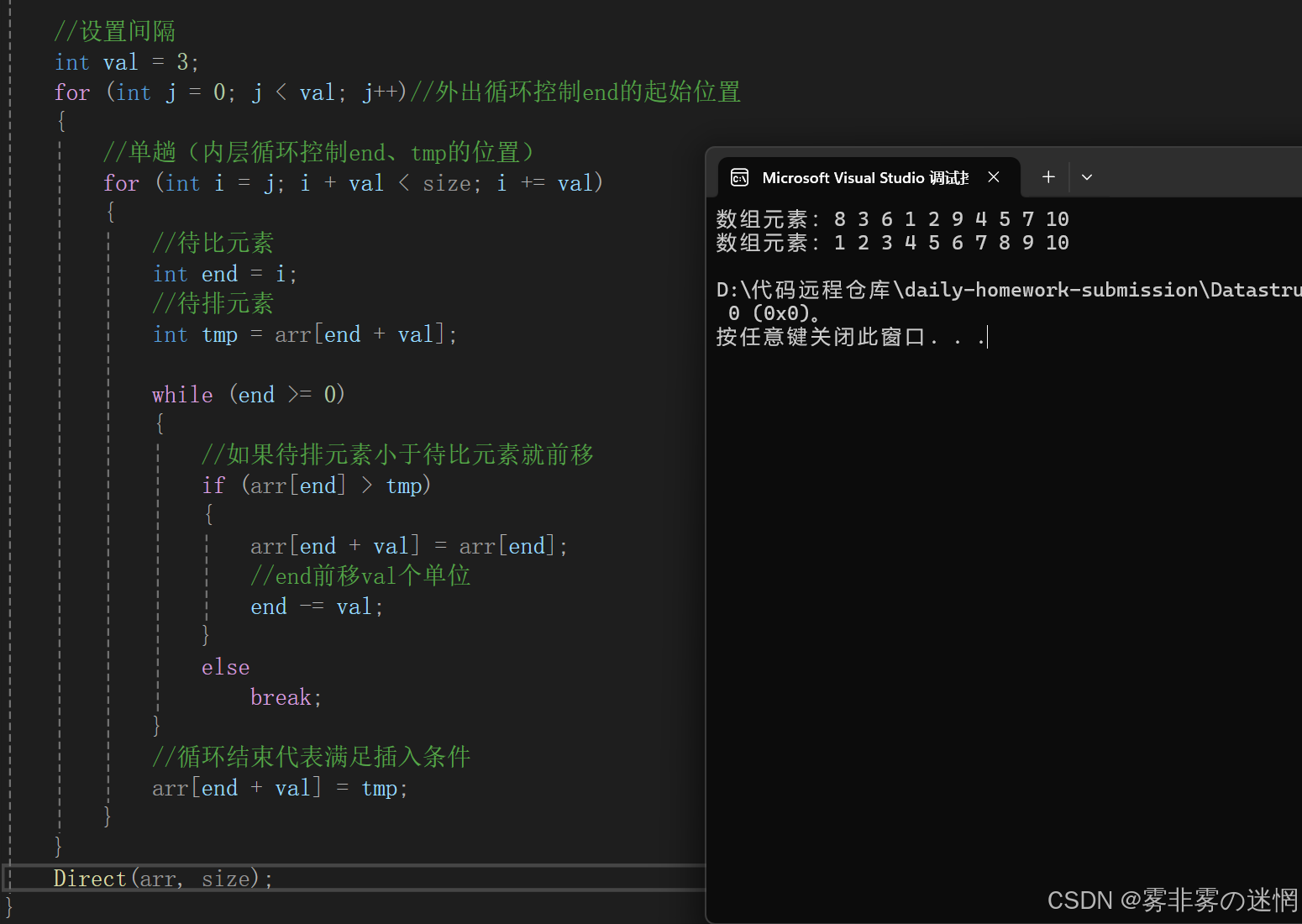
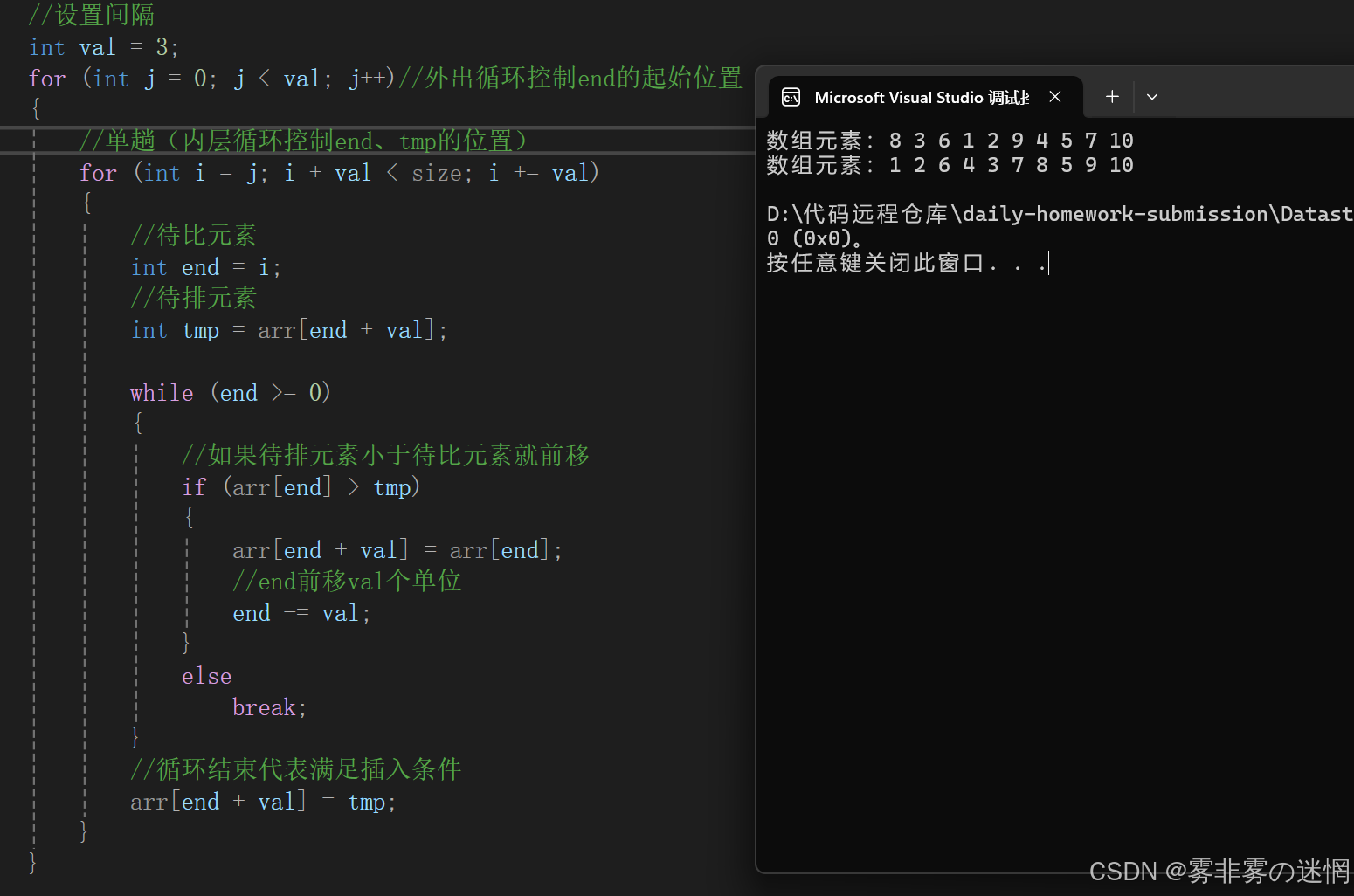
//希尔排序
void Shell(int* arr, int size)
{//断言assert(arr);//设置间隔int val = 3;for (int j = 0; j < val; j++)//外出循环控制end的起始位置{//单趟(内层循环控制end、tmp的位置)for (int i = j; i + val < size; i += val){//待比元素int end = i;//待排元素int tmp = arr[end + val];while (end >= 0){//如果待排元素小于待比元素就前移if (arr[end] > tmp){arr[end + val] = arr[end];//end前移val个单位end -= val;}elsebreak;}//循环结束代表满足插入条件arr[end + val] = tmp;}}Direct(arr, size);
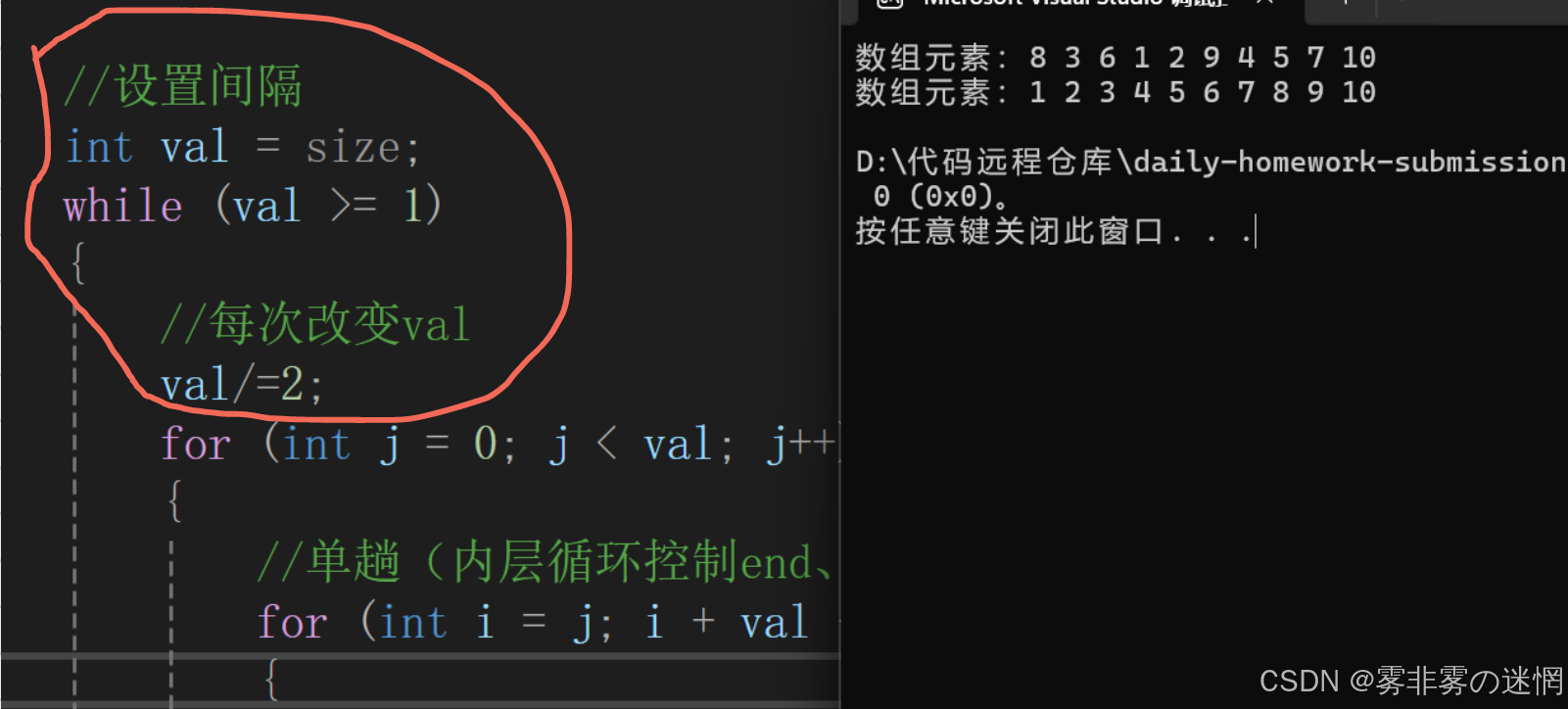
}代码优化:
假如有一万个数据,那么间隔val就太短了不适合,我们可以让间隔为每次的二分之一,根据长度选择间隔。最后间隔会达到1,同时也就不用去再接入直接插入排序的接口了
复杂度:
优化之前时间复杂度最坏情况:O(N^2)
优化之后明显感觉更效率:外层*内层O(logN)* O(N)
空间复杂度:O(1)
堆排序
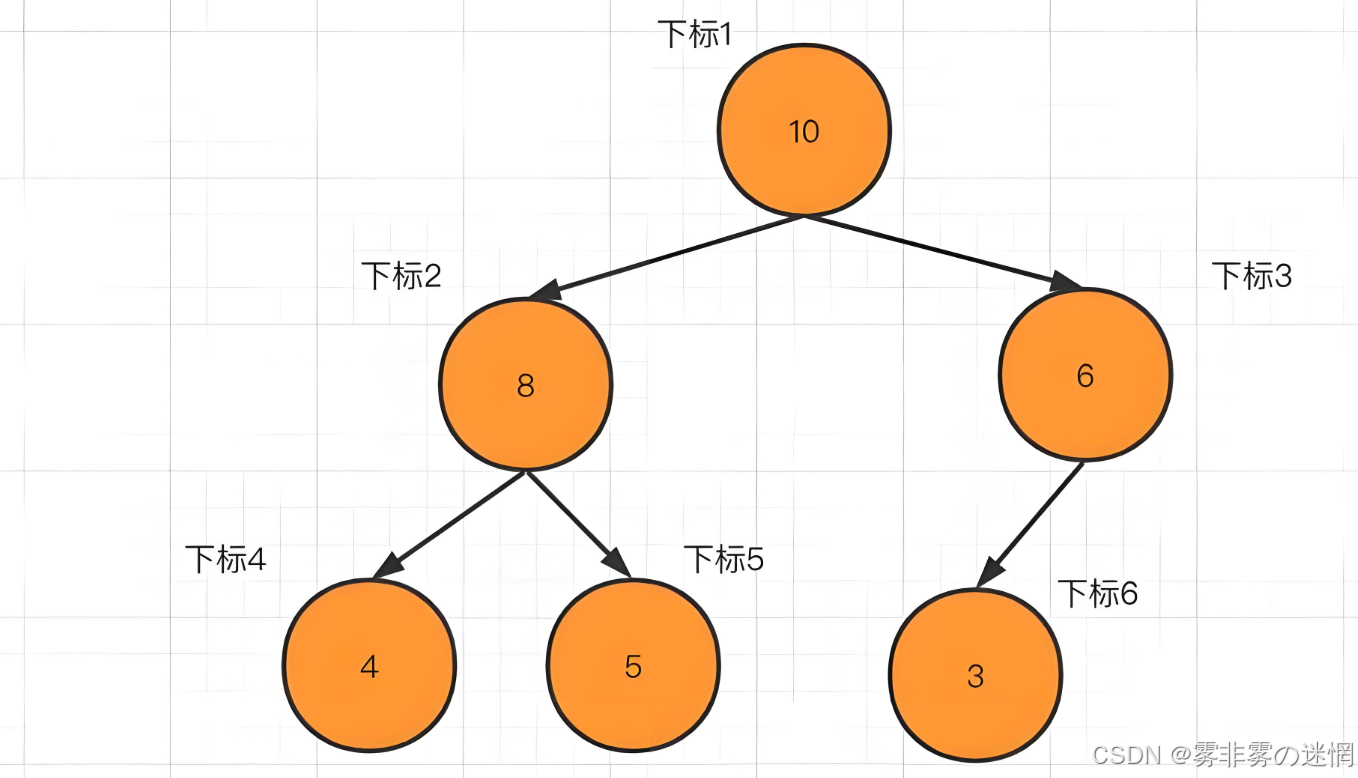

实现思路:
利用堆的向上调整、向下调整来存储数据,再利用多次出堆顶元素来完成排序。下面小编用大顶堆、从下标1开始存储来实现堆排序
实现堆:
//建推Heap Heapspace;//初始化
void Perliminary(Heap* Heapspace)
{//初始化变量Heapspace->max = MAX;Heapspace->size = 0;Heapspace->data = (int*)malloc(sizeof(int) * Heapspace->max);if (Heapspace->data == NULL){printf("初始化失败\n");return;}
}
//交换函数
void Exchange(int* p1, int* p2)
{int tmp = *p1;*p1 = *p2;*p2 = tmp;
}
//上浮调整
void Upward(int* data,int child)
{//设置父节点下标int parent = child / 2;while (parent > 0){//如果子节点大于父节点,就交换if (data[child] > data[parent]){Exchange(&data[child], &data[parent]);//更新父节点、子节点child = parent;parent = child / 2;}elsebreak;}
}
//入堆
void Enter(Heap* Heapspace, int data)
{//判断堆是否存满,是则扩容if (Heapspace->size == Heapspace->max){int* pc = (int*)malloc(sizeof(int) * (Heapspace->max) * 2);if (pc == NULL){printf("空间扩容失败\n");return;}//更新堆信息Heapspace->max *= 2;Heapspace->data = pc;}//入堆Heapspace->size++;Heapspace->data[Heapspace->size] = data;//上浮调整Upward(Heapspace->data, Heapspace->size);
}
//打印堆元素
void Printf_Heap(Heap Heapspace, int size)
{printf("堆元素:");for (int i = 1; i <= size; i++){printf("%d ", Heapspace.data[i]);}printf("\n");
}
//下沉调整
void Subsidence(Heap* Heapspace)
{//设置子节点、父节点下标int parent = 1;int child = 2 * parent;//堆尾堆顶交换Exchange(&Heapspace->data[1], &Heapspace->data[Heapspace->size]);//出堆顶元素if (Heapspace->size > 1){Heapspace->size--;}while (parent > 0 && child <= Heapspace->size){//找左右子节点最大值if (child <= Heapspace->size && Heapspace->data[child] < Heapspace->data[child + 1]){child++;}//调整堆顶if (child <= Heapspace->size && Heapspace->data[parent] < Heapspace->data[child]){Exchange(&Heapspace->data[parent], &Heapspace->data[child]);//调整下标parent = child;child = 2 * parent;}elsebreak;}
}堆排序:
利用堆的下沉调整:每次将堆尾元素与堆顶元素交换,然后调整堆以保持大顶堆的性质,多次调整达到排序效果
for (int j = 0; j < size; j++)
{//下沉调整Subsidence(&Heapspace);
}
复杂度:
时间复杂度为O(N logN),空间复杂度为O(1)
冒泡排序
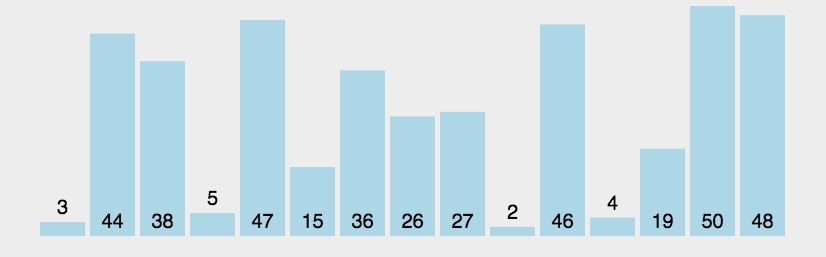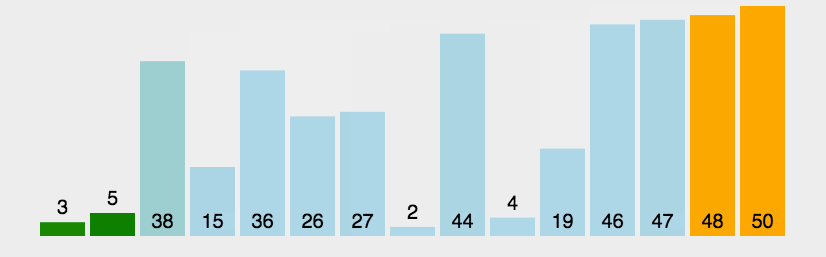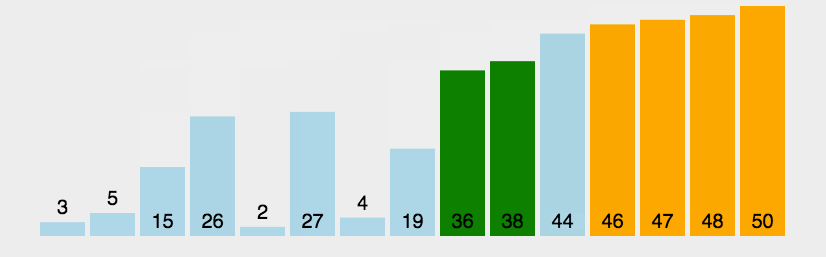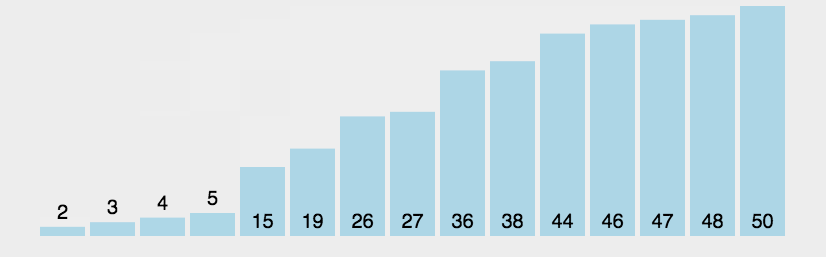
实现思路:
从第一个元素开始,与之后的所有元素进行比较,较大则交换位置,直至排完所有元素
单趟实现: 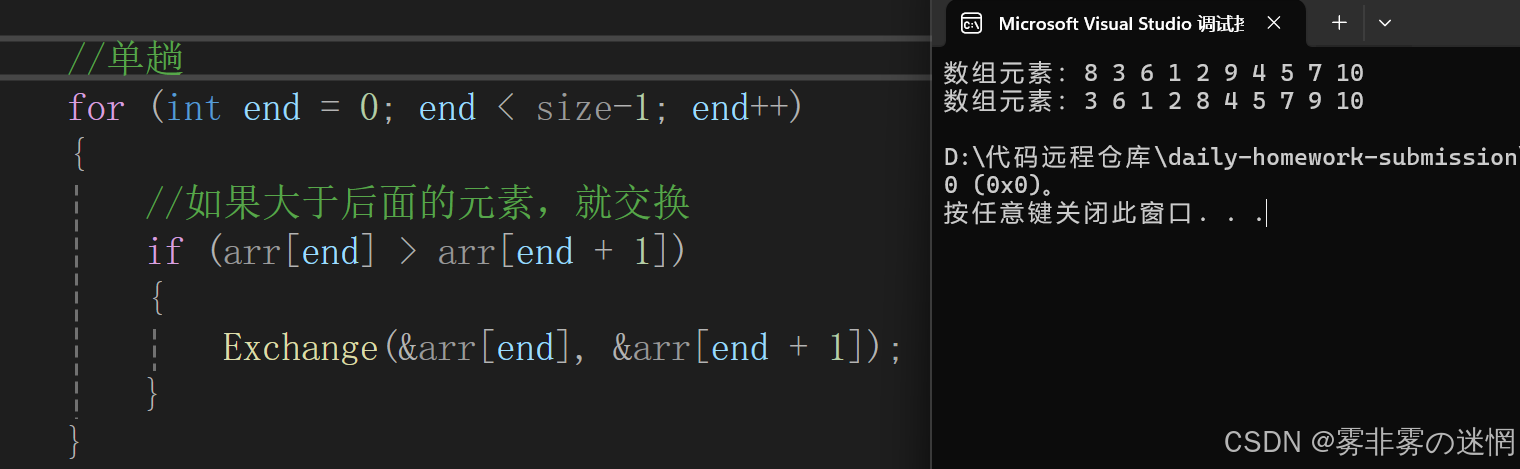
整体实现:
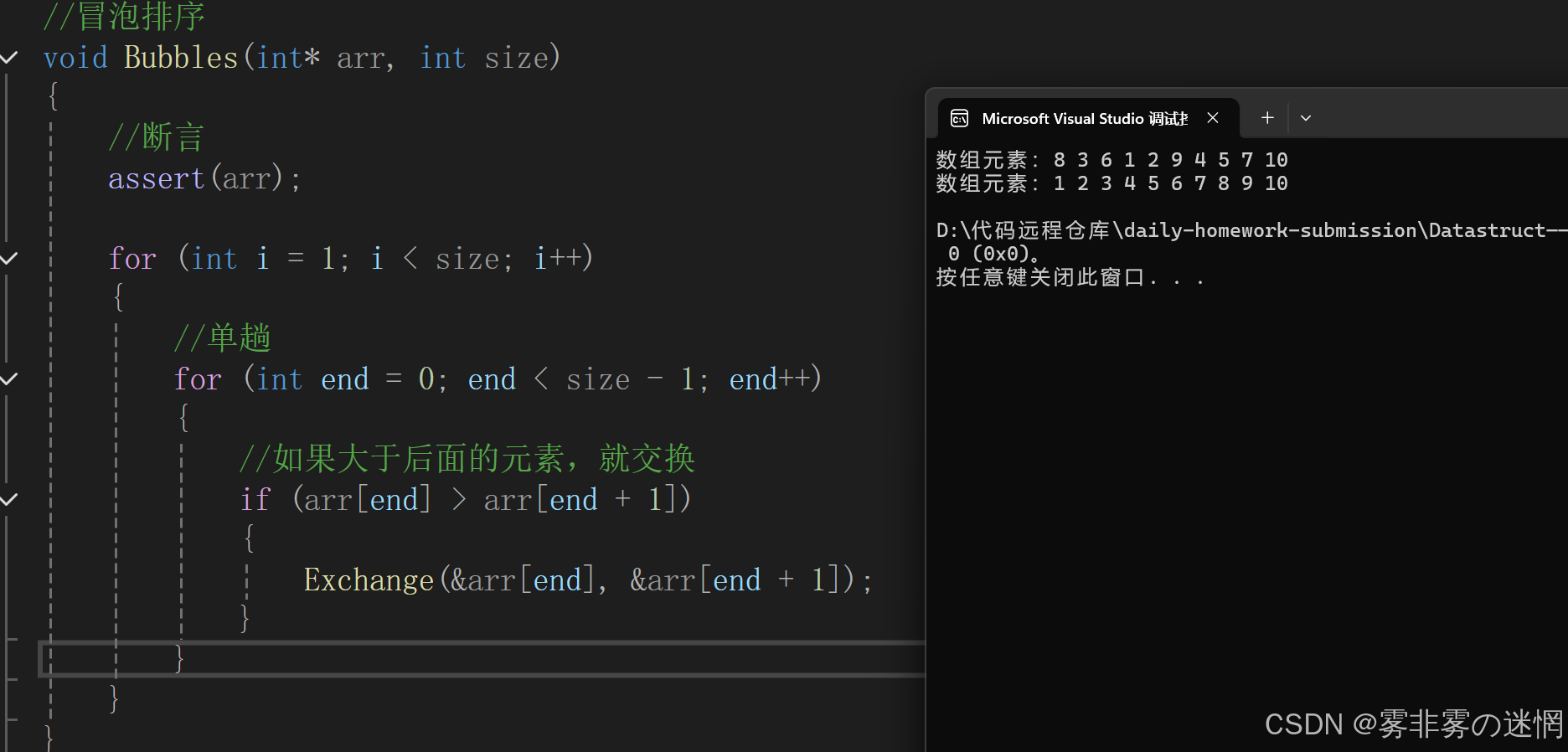
//冒泡排序
void Bubbles(int* arr, int size)
{//断言assert(arr);for (int i = 1; i < size; i++){//单趟for (int end = 0; end < size - 1; end++){//如果大于后面的元素,就交换if (arr[end] > arr[end + 1]){Exchange(&arr[end], &arr[end + 1]);}}}
}代码优化:
如果经过单趟,没有任何排序过程,说明整体都是有序的,可以直接结束循环
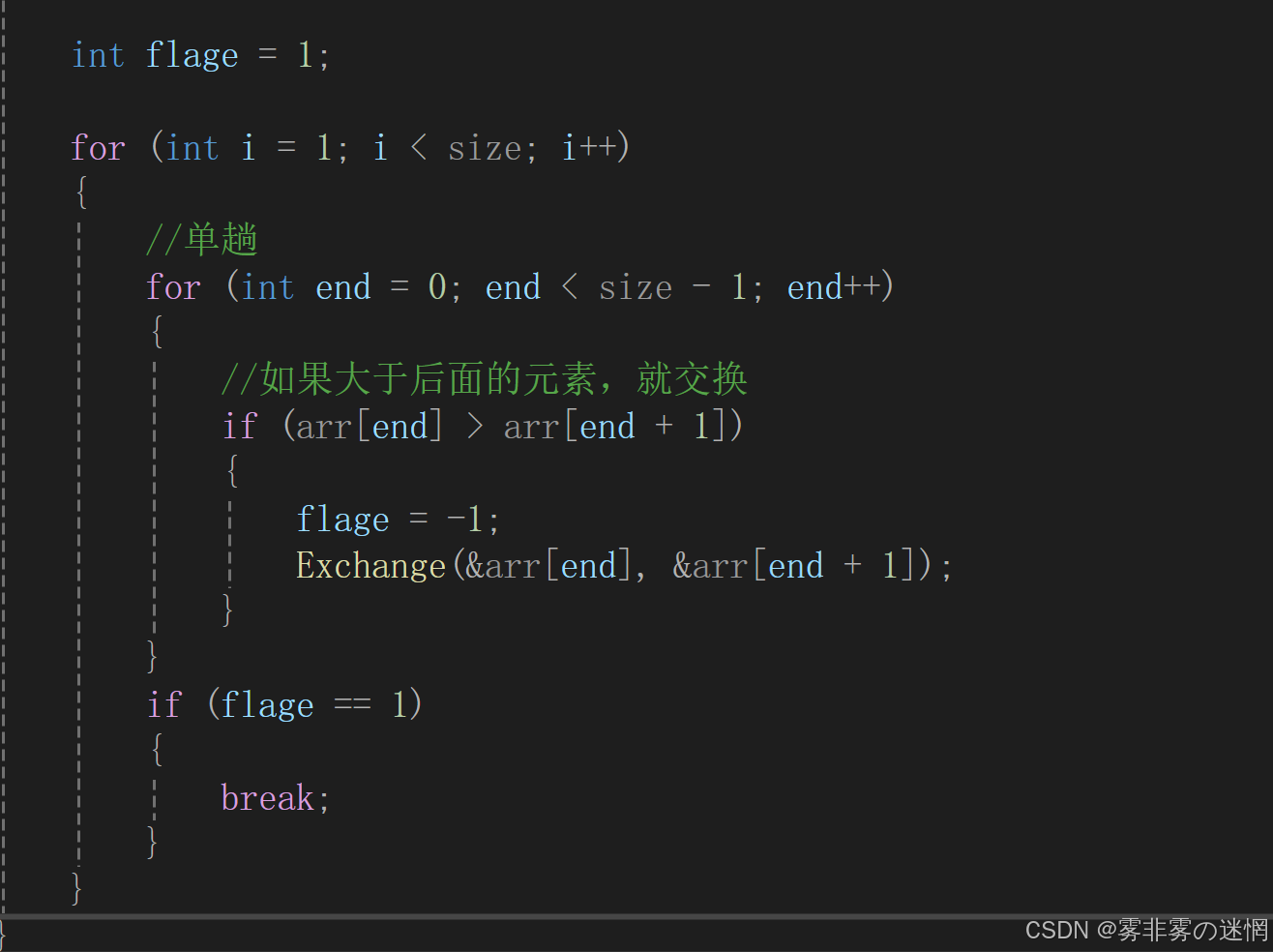
复杂度:
时间复杂度:O(N^2),空间复杂度:O(1)
选择排序
实现思路:
开始整个数组都是无序的额,找整个无序组中的最小值,与有序部分的末尾进行交换,一直重复
单趟实现:
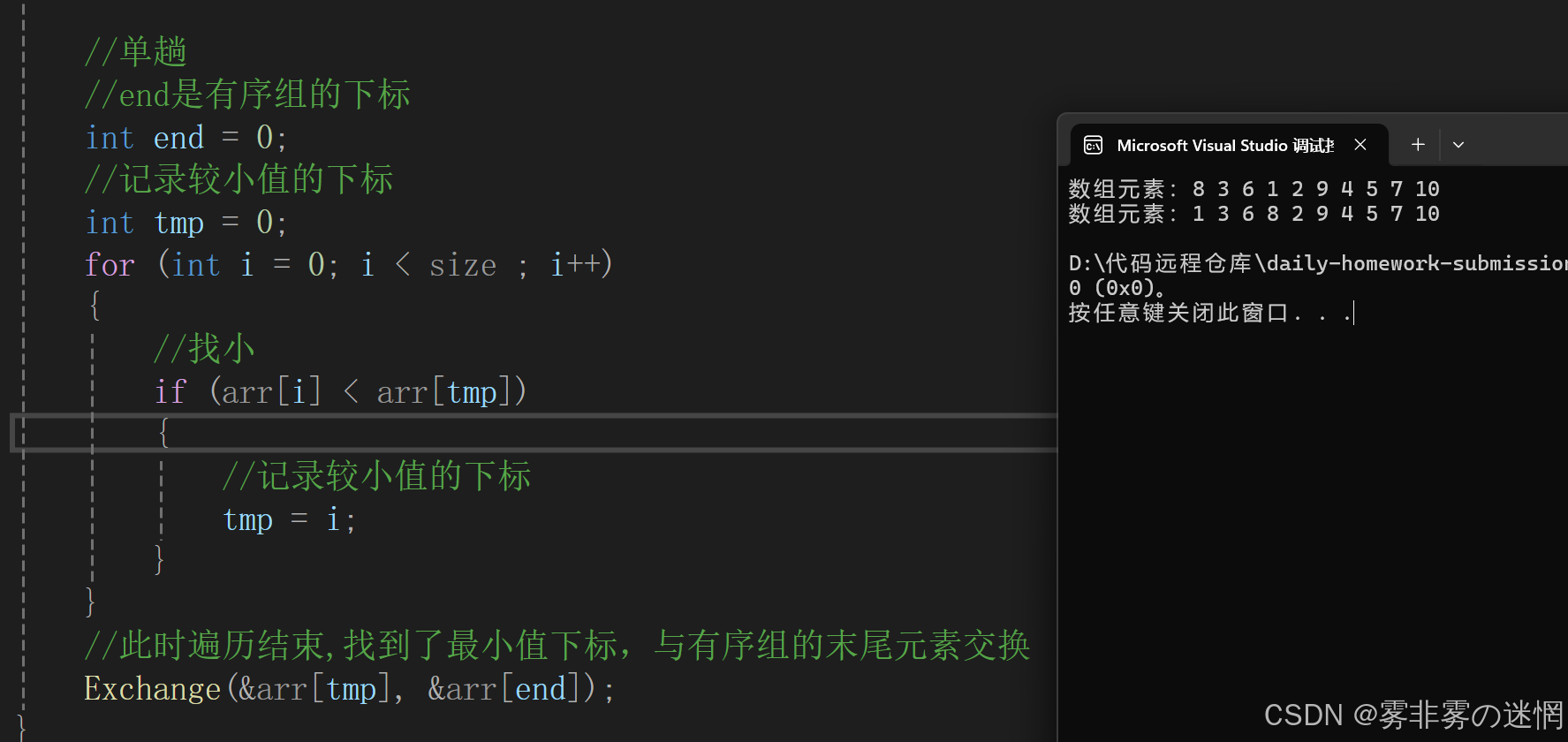
整体实现:
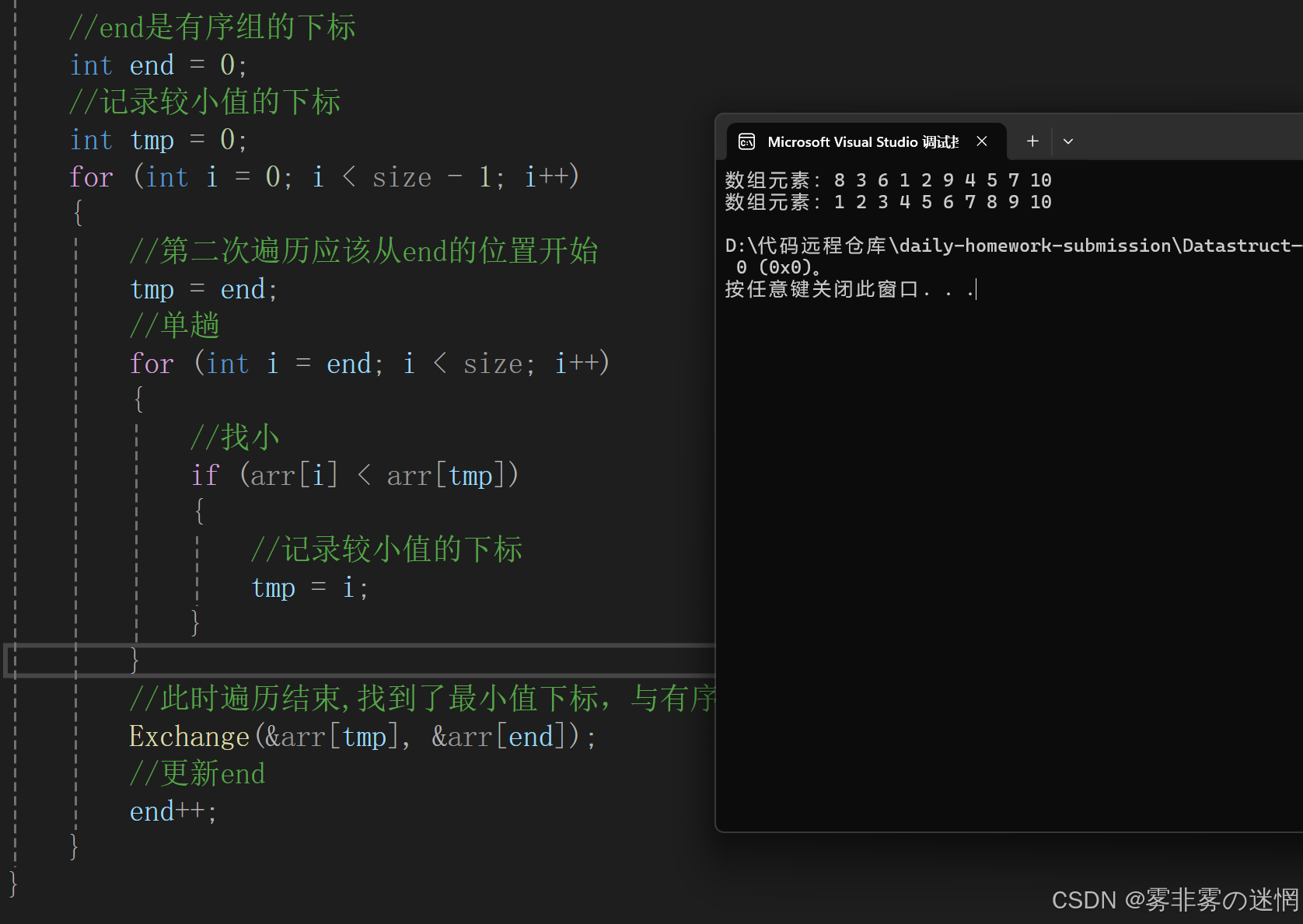
//选择排序
void Select(int* arr, int size)
{//断言assert(arr);//end是有序组的下标int end = 0;//记录较小值的下标int tmp = 0;for (int i = 0; i < size - 1; i++){//第二次遍历应该从end的位置开始tmp = end;//单趟for (int i = end; i < size; i++){//找小if (arr[i] < arr[tmp]){//记录较小值的下标tmp = i;}}//此时遍历结束,找到了最小值下标,与有序组的末尾元素交换Exchange(&arr[tmp], &arr[end]);//更新endend++;}
}复杂度:
时间复杂度:O(N^2),空间复杂度:O(1)
Hoare排序
实现思路:
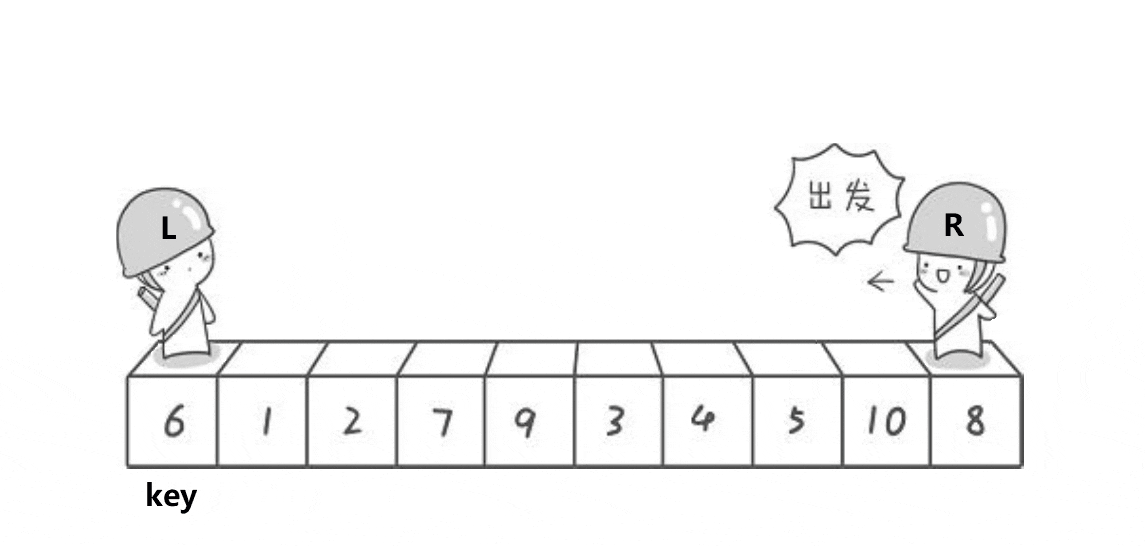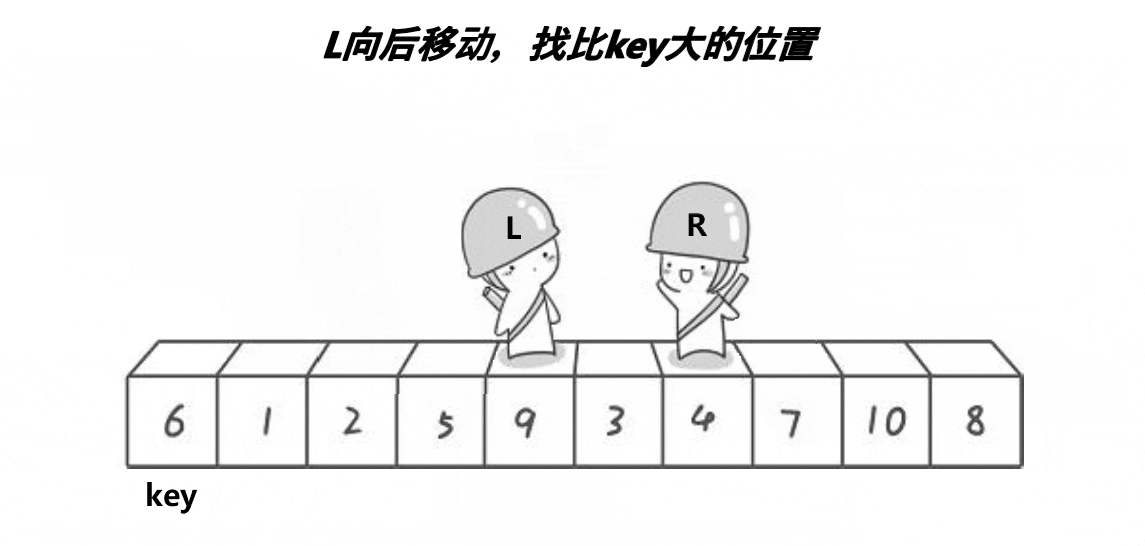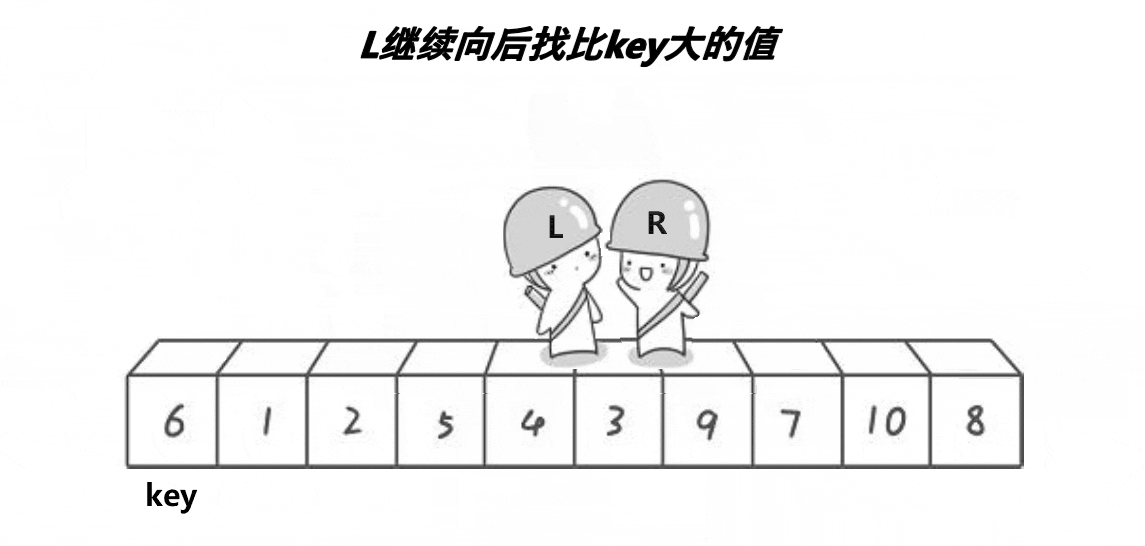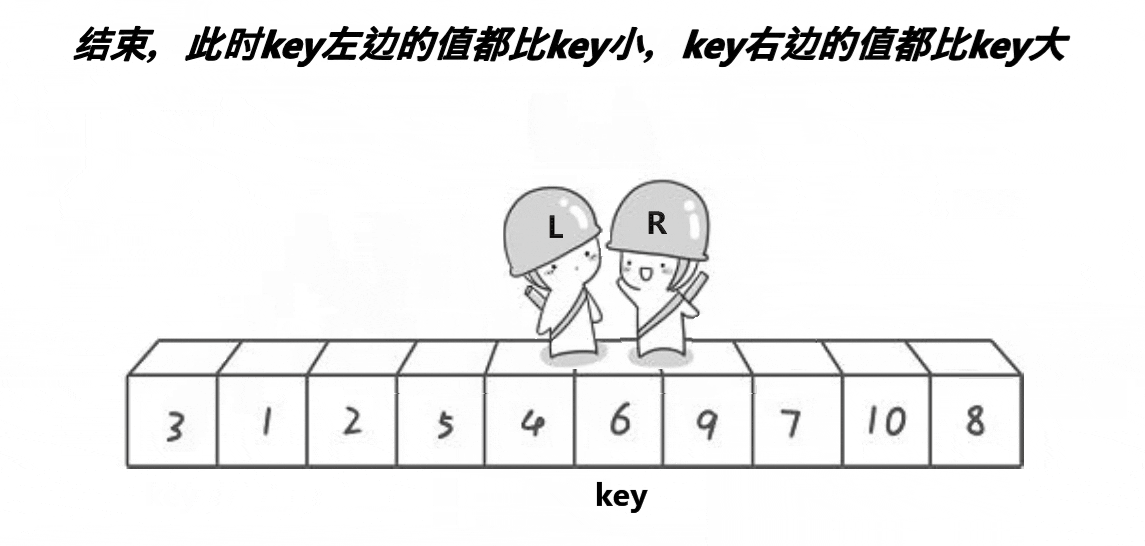
通过两个指针的移动,左边找大,右边找小,目的是让大的去到右边,小的去到左边,二者相遇再与 key 位置交换。记得 key 在哪边,对面的指针先动。否则会出现下面这个情况:
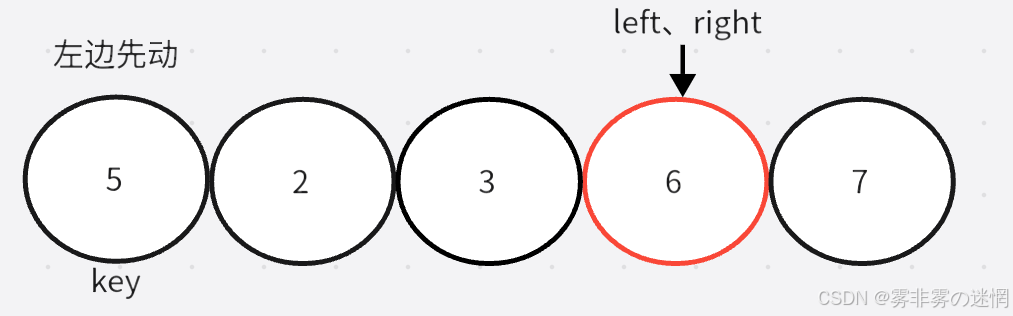
当两个指针发生交换时,左边指针会因为找到大的停下,右边再与左边的相遇,那么这个元素较大;如果右边先走,那么交换之后,右边找到的一定是小的,相遇时也能保证是小的
单趟实现:
左边找大,右边找小,相遇则交换 key 的位置元素
整体实现:
此时需要更新 key 的位置到二者相遇的位置,然后就将数组分为了两组,分别递归,例如:
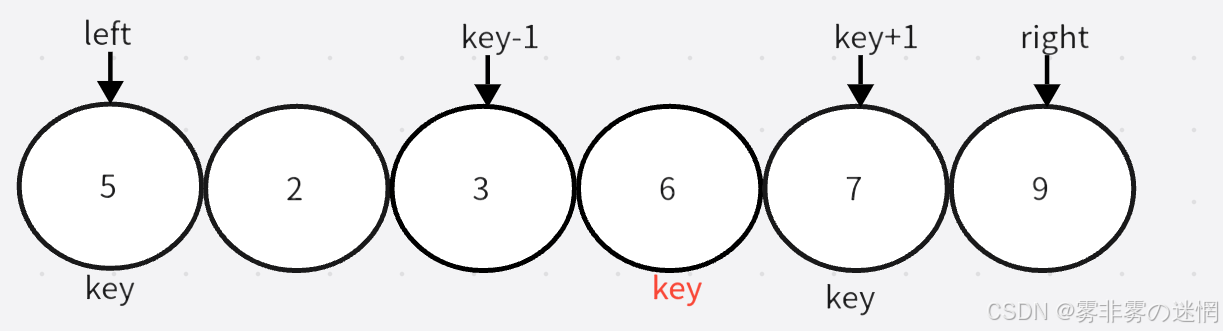
记录的原因以及递归的过程:
如果不记录left、right,那么递归右区间时,right会随着左递归不断变化,导致无法递归右区间

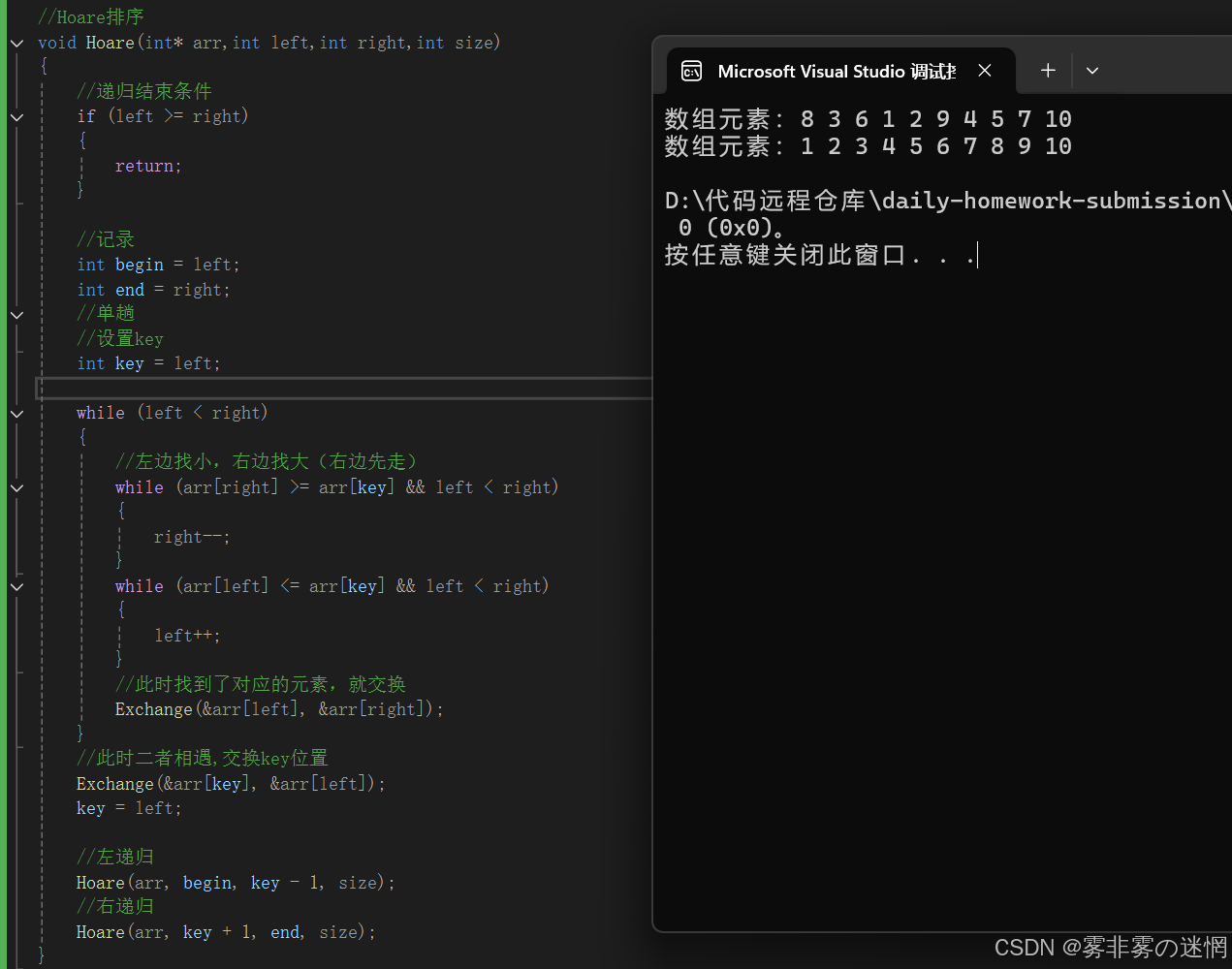
//Hoare排序
void Hoare(int* arr,int left,int right,int size)
{//递归结束条件if (left >= right){return;}//记录int begin = left;int end = right;//单趟//设置keyint key = left;while (left < right){//左边找小,右边找大(右边先走)while (arr[right] >= arr[key] && left < right){right--;}while (arr[left] <= arr[key] && left < right){left++;}//此时找到了对应的元素,就交换Exchange(&arr[left], &arr[right]);}//此时二者相遇,交换key位置Exchange(&arr[key], &arr[left]);key = left;//左递归Hoare(arr, begin, key - 1, size);//右递归Hoare(arr, key + 1, end, size);
}复杂度:
时间复杂度:O(N logN),空间复杂度:O(1)
快排(双指针)
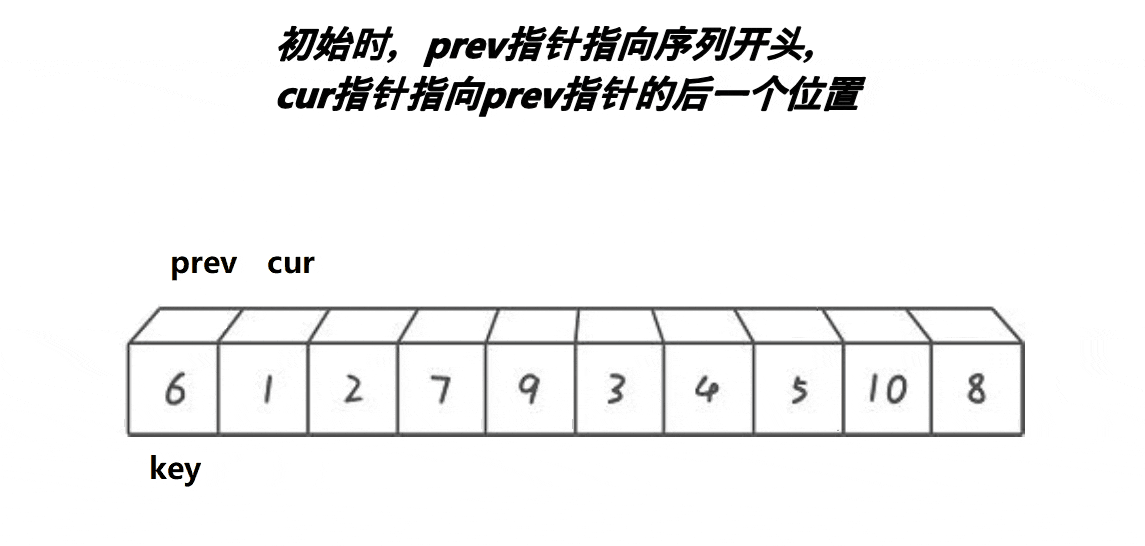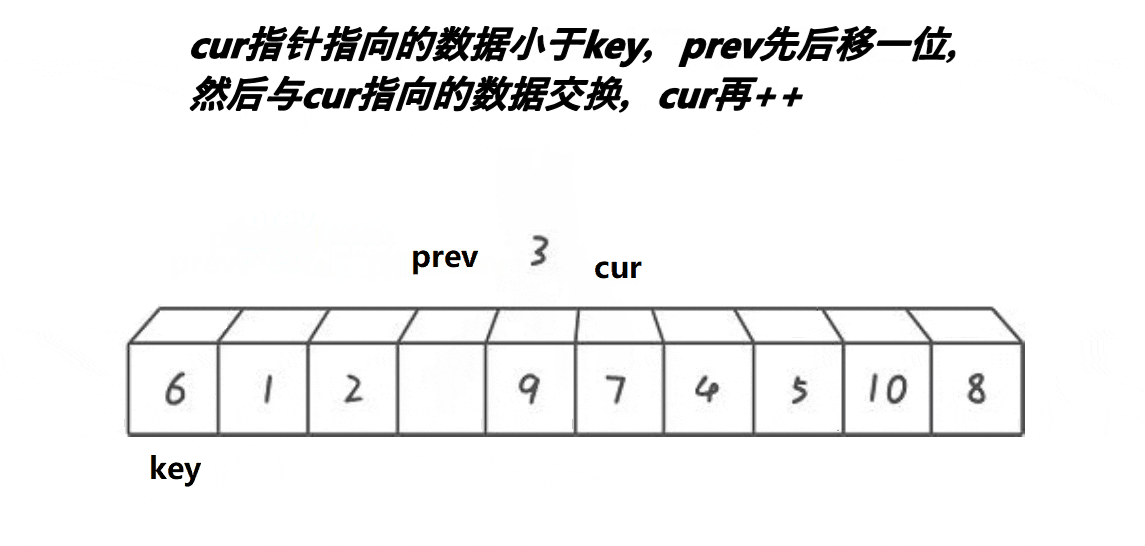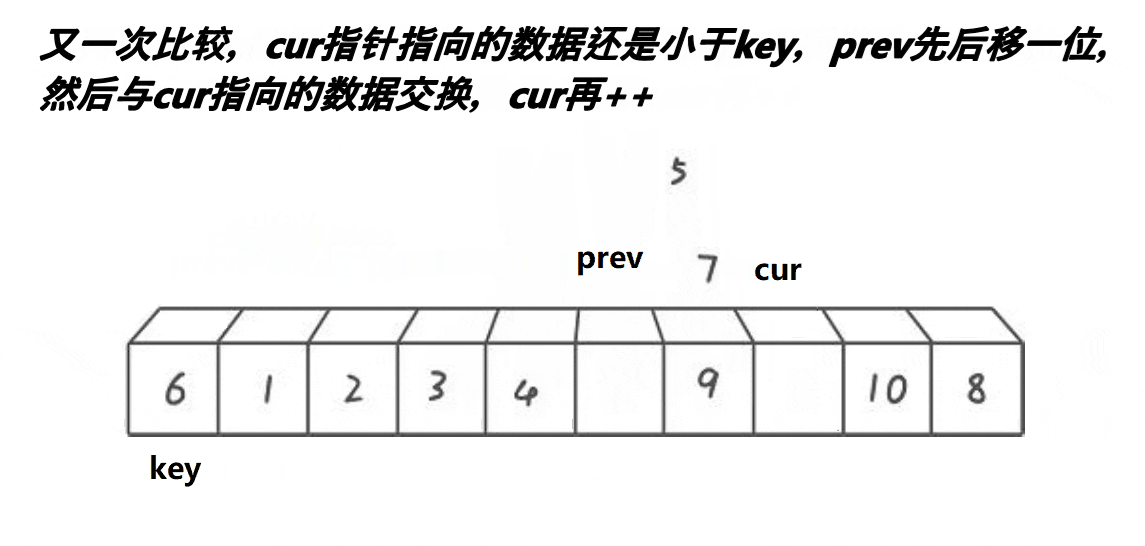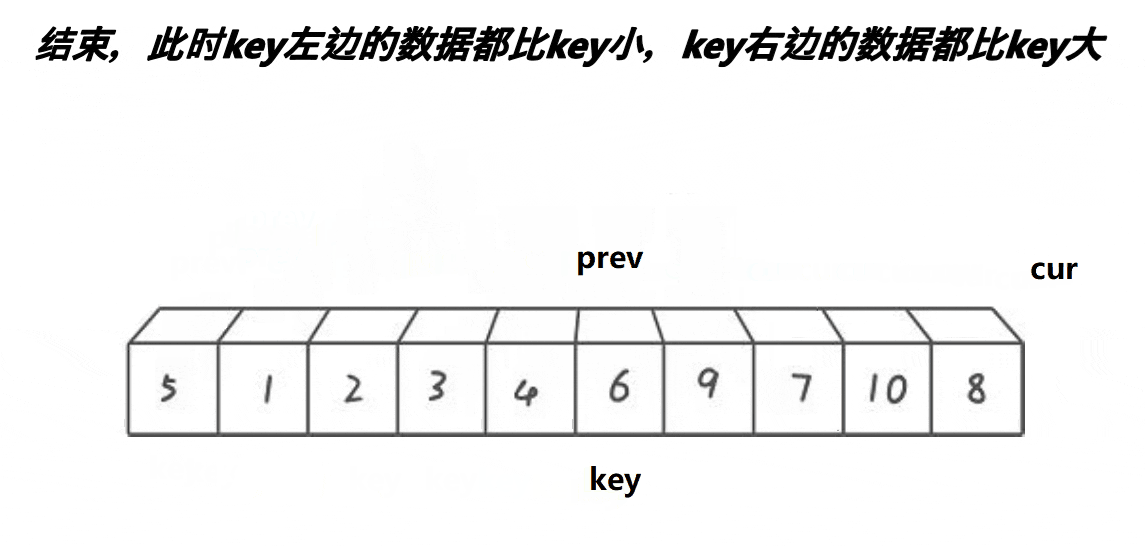
实现思路:
单趟: 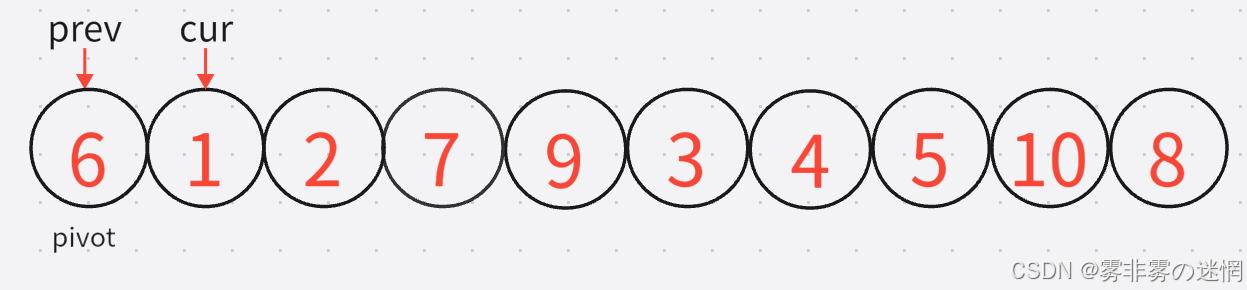
开始时有两个指针 prev 与 cur ,分别找大找小,随后进行交换。注意交换完之后,cur需要移动,否则一直进不了循环(单趟是排完一个数字)
整体实现:
现在我们划分了基准值,分别递归左、右区间,注意记录部分值,原因和Hoare排序一样
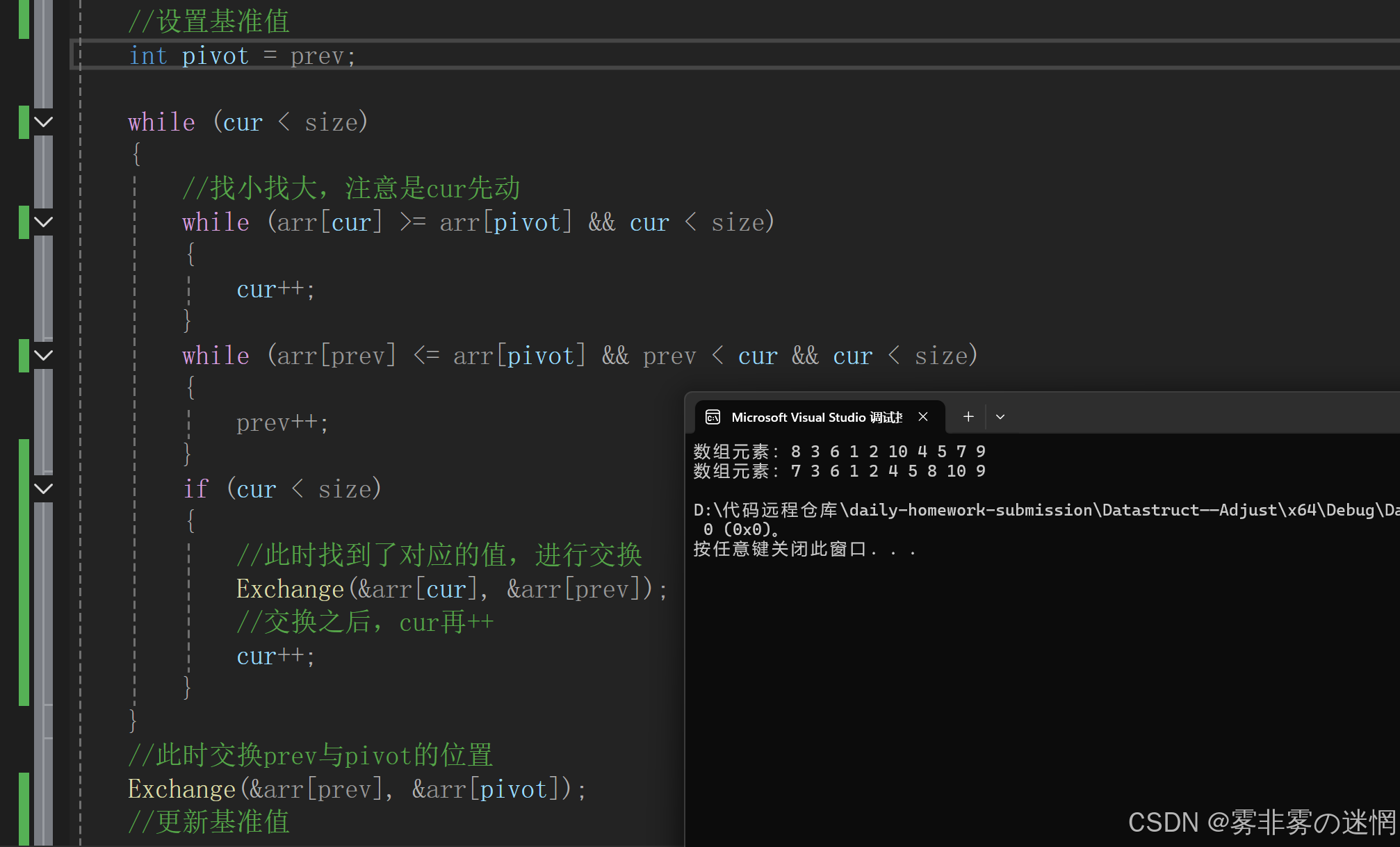
//快排(双指针)
void Snap_shot(int* arr, int size,int prev)
{//断言assert(arr);int cur = prev + 1;//递归结束条件if (cur >= size){return;}//记录int begin = prev;//设置基准值int pivot = prev;while (cur < size){//找小找大,注意是cur先动while (arr[cur] >= arr[pivot] && cur < size){cur++;}while (arr[prev] <= arr[pivot] && prev < cur && cur < size){prev++;}if (cur < size){//此时找到了对应的值,进行交换Exchange(&arr[cur], &arr[prev]);//交换之后,cur再++cur++;}}//此时交换prev与pivot的位置Exchange(&arr[prev], &arr[pivot]);//更新基准值pivot = prev;//递归左区间(注意此时划分区间需要改变size)Snap_shot(arr, pivot, begin);//递归右区间Snap_shot(arr, size, pivot + 1);
}复杂度:
时间复杂度:O(N logN),空间复杂度:O(1)
归并排序
实现思路:
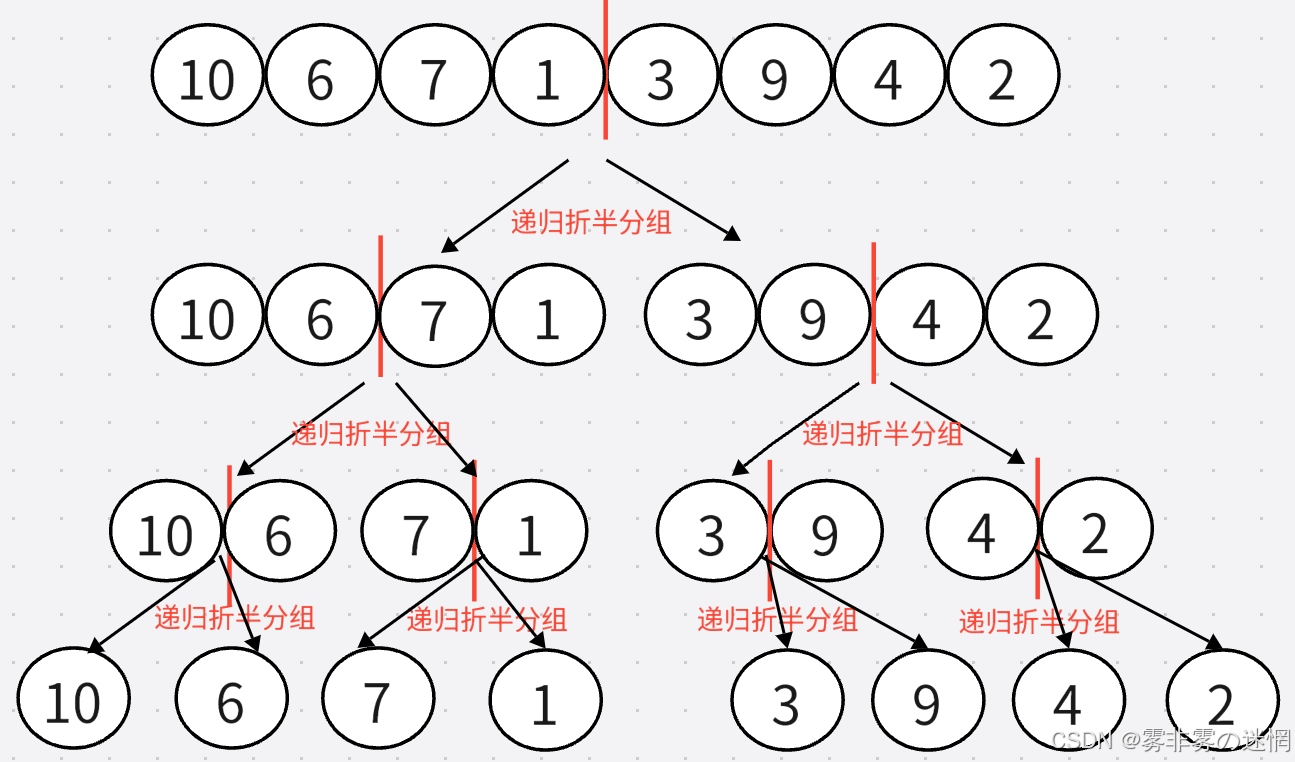
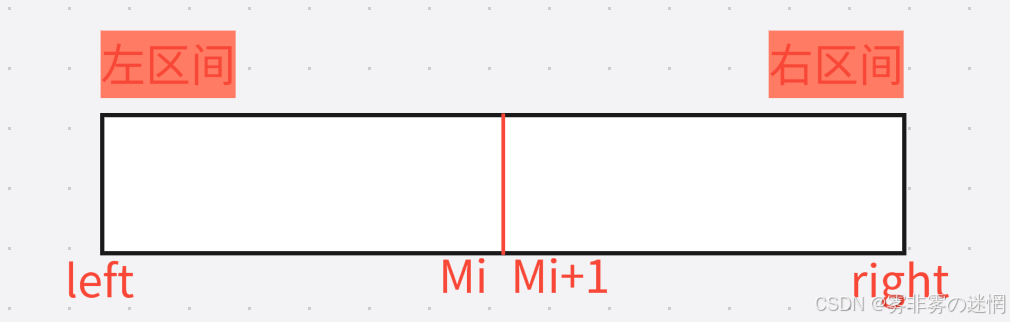
首先咱们看到这是将一个数组每次递归二分,这里通过划分区间并不难,难的是合并时如何排序?
建议一个临时数组,通过每次函数返回的基准值进行划分区间,当划分到左右区间只有一个数据时开始合并,合并时就需要去排序了【由于是复习文章,详细思路可看小编的主页【排序终结篇】】
递归分组:
左区间不断随着Middle分半,右区间会随着左区间传的参数改变left、right来产生,右边同理
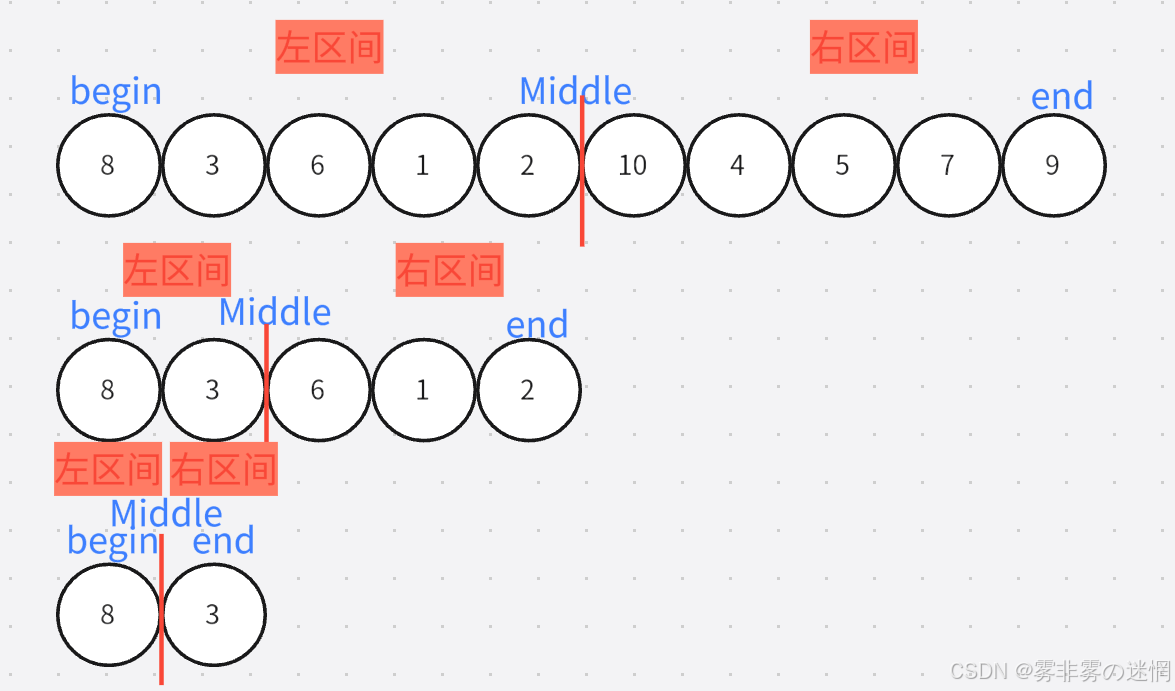
//递归结束条件
if (left >= right)
{return;
}
//划分
int Middle = (left + right) / 2;//递归划分区间
//左区间
Sort(arr, newnode, left, Middle);
//右区间
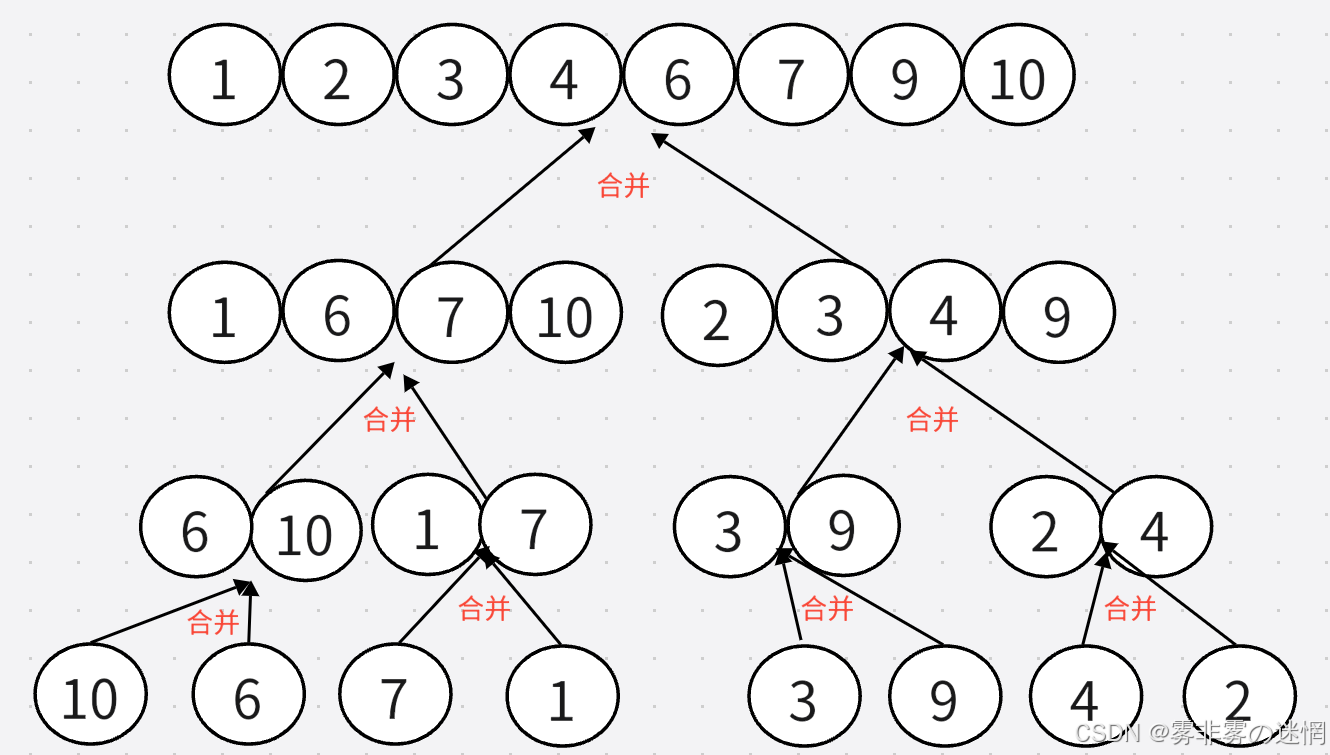
Sort(arr, newnode, Middle + 1, right);归并过程:
此时我们划分了左右区间,分别是
然后我们对这个区间进行排序,排序的结果先放在临时数组,例如:8、3、6、1、2拷贝的例子: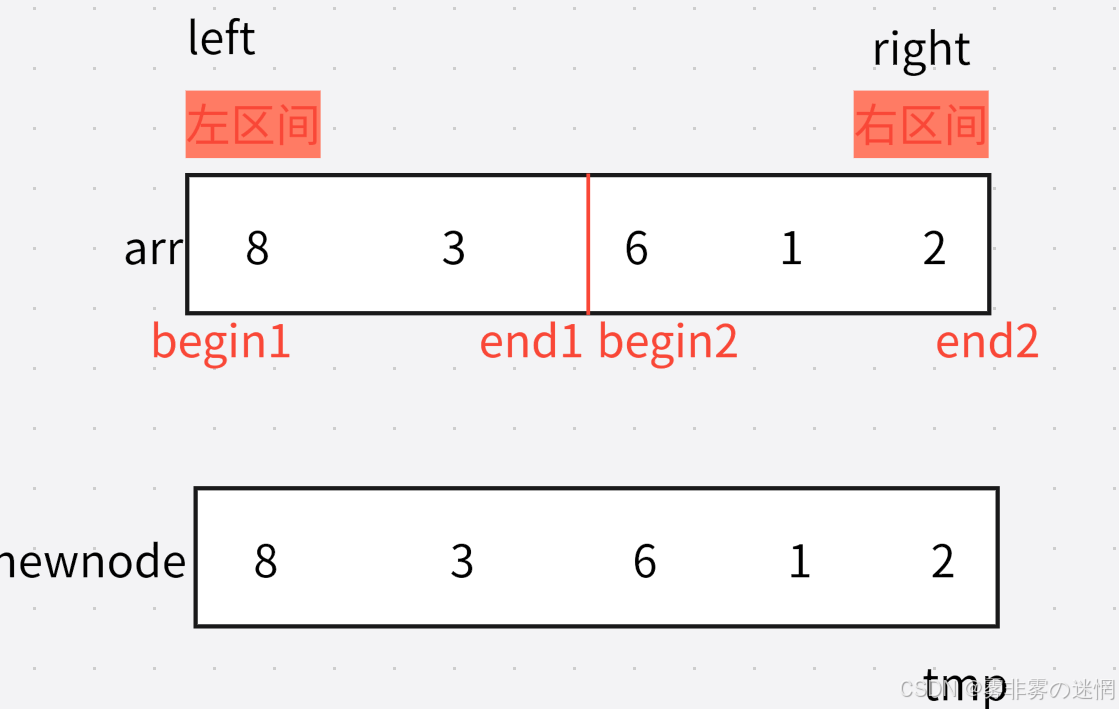
我们可以用memcpy一键拷贝,需要注意它的三个参数:目的地起始位置、源起始位置、字节

主函数:
//归并排序
void Merge(int* arr,int size)
{assert(arr);//开辟空间int* newnode = (int*)malloc(sizeof(int) * size);if (newnode == NULL){printf("空间开辟失败\n");return;}//将开好的空间传给子函数Sort(arr, newnode, 0, size - 1);
}
子函数(递归、合并函数):
//归并子函数
void Sort(int* arr, int* newnode, int left, int right)
{//递归结束条件if (left >= right){return;}//划分int Middle = (left + right) / 2;//递归划分区间//左区间Sort(arr, newnode, left, Middle);//右区间Sort(arr, newnode, Middle + 1, right);//此时区间划分完毕,进行归并int begin1 = left;int end1 = Middle;int begin2 = Middle + 1;int end2 = right;int tmp = left;while (begin1 <= end1 && begin2 <= end2){if (arr[begin1] < arr[begin2]){//转移到新数组newnode[tmp] = arr[begin1];begin1++;tmp++;}else{newnode[tmp] = arr[begin2];begin2++;tmp++;}}//此时如果有元素未拷贝完,拷贝完剩余部分数据while (begin1 <= end1){newnode[tmp] = arr[begin1];begin1++;tmp++;}while (begin2 <= end2){newnode[tmp] = arr[begin2];begin2++;tmp++;}//拷贝回原数组(注意left、right是下标,所以加一)memcpy(arr+left, newnode+left, sizeof(int) * (right - left + 1));
}
复杂度:
时间复杂度:O(N logN),空间复杂度:O(N)
排序OJ题(1)

快排采用找基准值,划分区间进行递归排序,为分治思想
排序OJ(2)

注意是从后往前比较。
假设此时排序完前7个元素:15、23、38、54、60、72、96 现在将45插入其中
45 VS 96 继续比较直到比到 38, 45>38,停止比较,中间有4个元素加上38一共比较了5次
此题何为从后往前:
例如第一个54已经为有序,现在插入38
38<54,有序组变为 38、54,继续下一个元素,意思是前7个正常排,45采用从后往前排
排序OJ(3)

归并需要额外开辟一个数组作为临时数组
排序OJ(4)

稳定排序的有: 冒泡、直接插入、归并
时间复杂度稳定在O(N^2)的只有直接插入排序
排序OJ(5)

两个指针分别找大找小再交换、最后找大的指针指向的元素与基准值65交换,得到A

【雾非雾】期待与你的下次相遇!
相关文章:
排序)
【数据结构】励志大厂版·初阶(复习+刷题)排序
前引:本篇作为初阶结尾的最后一篇—排序,将先介绍八种常用的排序方法,然后开始刷题,小编会详细注释每句代码的作用,不会出现看不懂的情况,这点大家放心,既是写给大家同时也是写给自己的…...

Git推送大文件导致提交回退的完整解决记录
问题背景 在向Gitee推送代码时,因单文件超过平台限制(100MB),推送被拒绝: > git push origin master:master remote: File [6322bc3f1becedcade87b5d1ea7fddbdd95e6959] size 178.312MB, exceeds quota 100MB rem…...

游戏引擎学习第257天:处理一些 Win32 相关的问题
设定今天的工作计划 今天我们本来是打算继续开发性能分析器(Profiler),但在此之前,我们认为有一些问题应该先清理一下。虽然这类事情不是我们最关心的核心内容,但我们觉得现在是时候处理一下了,特别是为了…...

高性能数据库架构探索:OceanBase 分布式技术深入解析
高性能数据库架构探索:OceanBase 分布式技术深入解析 简介 OceanBase 高性能分布式数据库,解决传统数据库在大规模、高并发场景下的性能瓶颈,通过分布式架构、数据自动分片和强一致性协议,提供高可用性、弹性扩展和出色的性能&am…...
 这里串口的2/0 和 3/0分别都是什么?)
【CISCO】Se2/0, Se3/0:串行口(Serial) 这里串口的2/0 和 3/0分别都是什么?
在 Cisco IOS 设备上,接口名称通常遵循这样一个格式: <类型><槽号>/<端口号>类型(Type):表示接口的物理或逻辑类型,比如 Serial(串行)、FastEthernet、GigabitEt…...

GPU集群训练经验评估框架:运营经理经验分析篇
引言 随着深度学习模型规模的持续增长和复杂度的不断提高,单GPU训练已经难以满足现代AI研究和应用的需求。GPU集群训练作为一种有效的扩展方案,能够显著提升训练效率、处理更大规模的数据集和模型。然而,GPU集群训练涉及到分布式训练框架、集群管理工具、性能优化等多个技术…...

函数多项式拟合
函数多项式拟合 用处 不方便使用math时,可以使用多项式拟合法实现比较高效的数学函数,比如使用avx指令时,O3优化,math中的函数会调用FPU指令集,在指令集切换的过程中代码效率大幅降低,为避免使用math中的…...

【Hive入门】Hive与Spark SQL集成:混合计算实践指南
目录 引言 1 Hive与Spark SQL概述 1.1 Hive简介 1.2 Spark SQL简介 2 Hive与Spark SQL集成架构 2.1 集成原理 2.2 配置集成环境 3 混合计算使用场景 3.1 场景一:Hive表与Spark DataFrame互操作 3.2 场景二:Hive UDF与Spark SQL结合使用 3.3 场…...

TFQMR和BiCGStab方法比较
TFQMR(Transpose-Free Quasi-Minimal Residual)和BiCGStab(Bi-Conjugate Gradient Stabilized)都是用于求解非对称线性方程组的迭代方法,属于Krylov子空间方法的范畴。它们分别是BiCG(双共轭梯度法…...
)
小程序 IView WeappUI组件库(简单增删改查)
IView Weapp 微信小程序UI组件库:https://weapp.iviewui.com/components/card IView Weapp.png 快速上手搭建 快速上手.png iView Weapp 的代码 将源代码下载下来,然后将dict放到自己的项目中去。 iView Weapp 的代码.png 小程序中添加iView Weapp 将di…...

nginx 核心功能 02
目录 1. 正向代理 1.1 编译安装 Nginx 1.2 配置正向代理 2. 反向代理 2.1 配置nginx七层代理 2.2 配置nginx四层代理 3. Nginx 缓存 3.1 缓存功能的核心原理和缓存类型 3.2 代理缓存功能设置 4. Nginx rewrite 和正则 4.1 Nginx正则 4.2 nginx location 4.3 Rewri…...

LeetCode 102题解 | 二叉树的层序遍历
二叉树的层序遍历 一、题目链接二、题目三、算法原理四、编写代码 一、题目链接 二叉树的层序遍历 二、题目 三、算法原理 本题要求把结果放在不规则的二维数组里,即每一层二叉树的数值放在一行数组中。 回顾之前的层序遍历是借助队列实现的,是不考虑…...

Flink基础整理
文章目录 前言1.Flink系统架构2.编程模型(API层次结构)3.DataSet和DataStream区别4.Flink的批流统一5.Flink的状态后端6.Flink有哪些状态类型7.Flink并行度前言 提示:下面是根据网络或AI整理: 1.Flink系统架构 用户在客户端提交作业(Job)到服务端。服务端为分布式的主从…...

C++23 新特性:为 std::pair 的转发构造函数添加默认实参
文章目录 1\. 背景:std::pair 的转发构造函数2\. C23 的改进:添加默认实参示例代码 3\. 带来的好处3.1 更简洁的代码3.2 提高代码的可维护性3.3 与 std::optional 和 std::variant 的协同 4\. 实现细节示例实现(简化版) 5\. 使用场…...
:图像与媒体资源优化)
JavaScript性能优化实战(9):图像与媒体资源优化
引言 在当今视觉驱动的网络环境中,图像和媒体资源往往占据了网页总下载量的60%-80%,因此对图像和媒体资源进行有效优化已成为前端性能提升的关键领域。尽管网络带宽持续提升,但用户对加载速度的期望也在不断提高,特别是在移动设备和网络条件不稳定的场景下。 本文作为Jav…...
)
施磊老师rpc(四)
文章目录 rpc网络服务简介RpcProvider 的设计目标Eventloop不使用智能指针-弃用RpcProvider类似于集群的服务器provider网络实现**src/include/rpcprovider.h****src/include/mprpcapplication.h****src/rpcprovider.cc** 错误1错误2-重点**本项目的 mprpc 是动态库, muduo..是…...

Java学习手册:MyBatis 框架作用详解
一、MyBatis 简介 MyBatis 是一款优秀的持久层框架,用于简化 JDBC 开发。它通过将 Java 对象与数据库表之间的映射关系进行配置,使得开发者可以使用简单的 SQL 语句和 Java 代码来完成复杂的数据操作。MyBatis 支持自定义 SQL 语句,提供了灵…...
)
【PostgreSQL数据分析实战:从数据清洗到可视化全流程】3.1 数据质量评估指标(完整性/一致性/准确性)
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 数据质量评估核心指标:完整性、一致性、准确性实战解析3.1 数据质量评估指标体系3.1.1 完整性:数据是否存在缺失1.1.1 核心定义与业务影响1.1.2 检测…...
)
分布式系统中的 ActiveMQ:异步解耦与流量削峰(一)
一、引言 在当今数字化时代,分布式系统已成为构建大规模应用的关键架构。随着业务的快速发展和用户量的急剧增长,分布式系统面临着诸多挑战,其中异步通信、系统解耦和流量削峰是亟待解决的重要问题。 以电商系统为例,在秒杀活动中…...
)
【PostgreSQL数据分析实战:从数据清洗到可视化全流程】2.5 事务与锁机制(ACID特性/事务控制语句)
👉 点击关注不迷路 👉 点击关注不迷路 👉 点击关注不迷路 文章大纲 PostgreSQL 事务与锁机制深度解析:ACID 特性与事务控制全流程2.5 事务与锁机制2.5.1 ACID 特性与实现原理2.5.1.1 ACID 核心概念2.5.1.2 MVCC(多版本并发控制)与WAL(预写式日志)协同效应2.5.2 事务…...
*详细教程*)
STM32教程:ADC原理及程序(基于STM32F103C8T6最小系统板标准库开发)*详细教程*
前言: 本文章介绍了STM32微控制器的ADC外设,介绍了ADC的底层原理以及基本结构,介绍了ADC有关的标准库函数,以及如何编写代码实现ADC对电位器电压的读取。 可以根据基本结构图来编写代码 大体流程: 1、开启RCC时钟&am…...

RabbitMQ 深度解析:从核心组件到复杂应用场景
一.RabbitMQ简单介绍 消息队列作为分布式系统中不可或缺的组件,承担着解耦系统组件、保障数据可靠传输、提高系统吞吐量等重要职责。在众多消息队列产品中,RabbitMQ 凭借其可靠性和丰富的特性,在企业级应用中获得了广泛应用。本研究报告将全…...

linux 使用nginx部署ssl证书,将http升级为https
前言 本文基于:操作系统 CentOS Stream 8 使用工具:Xshell8、Xftp8 服务器基础环境: nginx - 请查看 linux 使用nginx部署vue、react项目 所需服务器基础环境,请根据提示进行下载、安装。 1.下载证书 以腾讯云为例ÿ…...

iview 分页改变每页条数时请求两次问题
问题 在iview page分页的时候,修改每页条数时,会发出两次请求。 iview 版本是4.0.0 原因 iview 的分页在调用on-page-size-change之前会调用on-Change。默认会先调用on-Change回到第一页,再调用on-page-size-change改变分页显示数量 此时就会…...

【Hive入门】Hive与Spark SQL深度集成:Metastore与Catalog兼容性全景解析
目录 引言 1 元数据管理体系架构对比 1.1 Hive Metastore架构解析 1.2 Spark Catalog系统设计 2 元数据兼容性深度剖析 2.1 元数据模型映射关系 2.2 元数据同步机制 3 生产环境配置指南 3.1 基础兼容性配置 3.1.1 Spark连接Hive Metastore 3.1.2 多引擎共享配置 3.…...

C#与西门子PLC通信:S7NetPlus和HslCommunication使用指南
西门子S7协议是用来和PLC进行通讯的一个协议,默认端口是102,数据会保存在一个个DB块中,比较经典的用法是一个DB块专门用来读取,一个用来写入。 DB(数据块) {块号}.DBX/DBD/DBW{字节地址}.{位偏移} 1、数据…...

湖北理元理律师事务所:法律科技融合下的债务管理实践
随着债务纠纷数量攀升,如何通过合法途径化解债务风险成为社会焦点。湖北理元理律师事务所作为国家司法局注册的债事服务机构,尝试以“法律技术”重构传统服务模式,为债务人提供系统性解决方案。 专业化服务架构 该律所设立客服、运营、法务…...

Spring Cloud Gateway MVC 基于 Spring Boot 3.4 以 WAR 包形式部署于外部 Tomcat 实战
一、引言 随着微服务架构的广泛应用,Spring Cloud Gateway 作为网关层的核心组件,为服务间的通信与流量管理提供了强大支持。spring-cloud-starter-gateway-mvc 则进一步助力开发者以熟悉的 MVC 模式进行网关开发。同时,将项目以 WAR 包形式…...
LLM论文笔记 27: Looped Transformers for Length Generalization
Arxiv日期:2024.9.25 关键词 长度泛化 transformer结构优化 核心结论 1. RASP-L限制transformer无法处理包含循环的任务的长度泛化 2. Loop Transformer显著提升了长度泛化能力 Input Injection 显著提升了模型的长度泛化性能,尤其在二进制加法等复杂…...

PCIe TLP | 报头 / 包格式 / 地址转换 / 寄存器 / 配置空间类型
注:本文为 “PCIe TLP” 相关文章合辑。 英文引文,机翻未校。 中文引文,未整理去重。 图片清晰度受引文原图所限。 略作重排,如有内容异常,请看原文。 PCIe - TLP Header, Packet Formats, Address Translation, Conf…...

《AI大模型应知应会100篇》第46篇:大模型推理优化技术:量化、剪枝与蒸馏
第46篇:大模型推理优化技术:量化、剪枝与蒸馏 📌 目标读者:人工智能初中级入门者 🧠 核心内容:量化、剪枝、蒸馏三大核心技术详解 实战代码演示 案例部署全流程 💻 实战平台:PyTor…...
)
C++/SDL 进阶游戏开发 —— 双人塔防(代号:村庄保卫战 20)
🎁个人主页:工藤新一 🔍系列专栏:C面向对象(类和对象篇) 🌟心中的天空之城,终会照亮我前方的路 🎉欢迎大家点赞👍评论📝收藏⭐文章 文章目录 三…...

【Python生成器与迭代器】核心原理与实战应用
目录 前言技术背景与价值当前技术痛点解决方案概述目标读者说明一、技术原理剖析核心概念图解核心作用讲解关键技术模块说明技术选型对比二、实战演示环境配置要求核心代码实现案例1:自定义迭代器类案例2:生成器函数案例3:生成器表达式运行结果验证三、性能对比测试方法论量…...
)
2025年最新嵌入式开发STM32单片机详细教程(更新中)
ARM 处理器架构 ARM 处理器从 1984 ARM-1 发展到 2004 ARM-11 之后,放弃数字命名,用 cortex 来命令处理器产品。 Cortex-A系列 主打高性能 手机,平板,智能电视等 Cortex-R系列 主打实时 汽车,工业控…...

neatchat轻量级丝滑的ai模型web客户端
NeatChat 人工智能模型对话web客户端 前言 此项目是nextchat分支,相比原者更加简洁流畅。 部署 docker部署 name: next-chat services:chatgpt-next-web:ports:- 8080:3000environment:- OPENAI_API_KEYsk-xx543Ef3d- BASE_URLhttps://api.ai.com- GOOGLE_API_K…...

学习黑客分析案例
▶️ Day 2 任务 – 「怪物图鉴」实战 选一条最新安全事件(国内外均可,建议 1 年内) 例:CVE-2024-21887 Ivanti VPN RCE 用下列表格框架,3 句话归纳它的“派系”“CIA 受击点”“一句话原理”: 攻击流派…...

sonar-scanner在扫描JAVA项目时为什么需要感知.class文件
1 概述 SonarQube是一个静态代码分析工具,主要用于检查源代码的质量,包括代码重复、潜在漏洞、代码风格问题等。而SonarScanner是SonarQube的客户端工具,负责将代码进行形态分析,并将结果发送到SonarQube服务器。所以,…...
)
AtCoder Beginner Contest 404(ABCDE)
A - Not Found 翻译: 给您一个字符串S,长度在1 到25 之间,由小写英文字母组成。 输出S 中没有出现的一个小写英文字母。 如果有多个这样的字母,可以输出其中任何一个。 思路: 数组记录存在于 s 中的字母。(…...

【言语理解】中心理解题目之结构分析
front:中心理解题目之抓住关键信息 3.1 五种常见对策表达方式 3.1.1 祈使或建议给对策 应该(应) 需要(要) eg:……。对此,媒体要做好自我规约。……。 eg:……。然而,两地仅简单承接…...

DeepSeek-Prover-V2-671B:AI在数学定理证明领域的重大突破
文章目录 什么是DeepSeek-Prover-V2-671B?核心技术亮点1. **超大规模参数与高效推理**2. **超长上下文窗口**3. **强化学习与合成数据** 主要应用场景1. **教育领域**2. **科学研究**3. **工程设计**4. **金融分析** 开源与商业化性能表现总结 2025年4月30日&#x…...

React18组件通信与插槽
1、为DOM组件设置Props 在react中jsx中的标签属性被称为Props DOM组件的类属性,为了防止与js中的class属性冲突改成了className DOM组件的style属性 import image from "./logo.svg"; function App() {const imgStyleObj {width: 200,height: 200,};re…...

第15章 对API的身份验证和授权
第15章 对API的身份验证和授权 在构建RESTful API时,确保只有经过身份验证和授权的用户才能访问特定资源是至关重要的。身份验证是确认用户身份的过程,而授权则是决定用户是否有权访问特定资源的过程。在本章中,我们将详细探讨如何在ASP.NET Core Web API中实现身份验证和授…...

【项目归档】数据抓取+GenAI+数据分析
年后这两个月频繁组织架构变动,所以博客很久没更新。现在暂时算是尘埃落定,趁这段时间整理一下。 入职九个月,自己参与的项目有4个,负责前后端开发,测试,devops(全栈/doge)ÿ…...

如何优化MySQL主从复制的性能?
优化MySQL主从复制的性能需要从硬件、配置、架构设计和运维策略等多方面入手。以下是详细的优化方案: 一、减少主库写入压力 1. 主库优化 二进制日志(binlog)优化: 使用 binlog_formatROW 以获得更高效的复制和更少的数…...

asp.net客户管理系统批量客户信息上传系统客户跟单系统crm
# crm-150708 客户管理系统批量客户信息上传系统客户跟单系统 # 开发背景 本软件是给郑州某企业管理咨询公司开发的客户管理系统软件 # 功能 1、导入客户数据到系统 2、批量将不同的客户分配给不同的业务员跟进 3、可以对客户数据根据紧急程度标记不同的颜色,…...

PCIe | TLP | 报头 / 包格式 / 地址转换 / 配置空间 / 寄存器 / 配置类型
注:本文为 “PCIe - TLP” 相关文章合辑。 英文引文,机翻未校。 中文引文,未整理去重。 图片清晰度受引文原图所限。 略作重排,如有内容异常,请看原文。 PCIe - TLP Header, Packet Formats, Address Translation, Co…...

ip和域名
好的,我来依次回答你的问题: 域名和 IP 地址是什么关系? IP 地址 (Internet Protocol Address):可以想象成互联网上每台设备(比如服务器、电脑、手机)的门牌号码。它是一串数字(例如 IPv4 地址 …...

《解锁GCC版本升级:开启编程新世界大门》
《解锁GCC版本升级:开启编程新世界大门》 一、引言:GCC 版本升级的魔法钥匙 在编程的广阔天地里,GCC(GNU Compiler Collection)宛如一座灯塔,为无数开发者照亮前行的道路。它是一款开源且功能强大的编译器集合,支持 C、C++、Objective - C、Fortran、Ada 等多种编程语言…...

前端跨域问题怎么在后端解决
目录 简单的解决方法: 添加配置类: 为什么会跨域 1. 什么是源 2. URL结构 3. 同源不同源举🌰 同源例子 不同源例子 4. 浏览器为什么需要同源策略 5. 常规前端请求跨域 简单的解决方法: 添加配置类: packag…...

生成式 AI 的工作原理
在科技浪潮汹涌澎湃的当下,生成式 AI 宛如一颗璀璨的新星,照亮了我们探索未知的征程。它不再仅仅是科幻电影中的幻想,而是已经悄然融入我们生活的方方面面,从智能客服的贴心应答,到艺术创作的天马行空,生成式 AI 正以一种前所未有的姿态重塑着世界。然而,你是否曾好奇,…...