Python的简单练习
两数的最大公约数
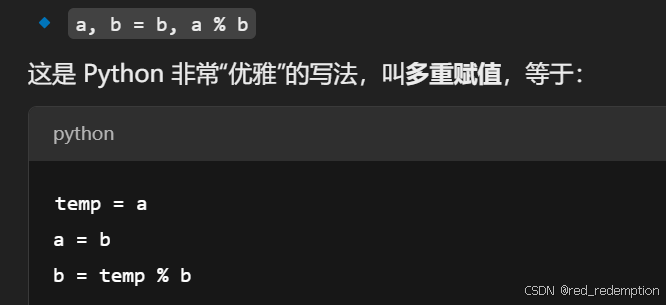
def gcd(a, b):while b != 0:a, b = b, a % breturn a# 示例
a = 36
b = 60
print(f"{a} 和 {b} 的最大公约数是: {gcd(a, b)}")while b != 0:
-
while:是 Python 的 循环语句,意思是“当...的时候一直重复做某事”。 -
b != 0:表示“只要 b 不等于 0”,就继续执行下面的代码。
对角线相连的菱形
n = int(input("请输入菱形的边长:"))# 上半部分(含中间行)
for i in range(n):for j in range(2 * n - 1):if j == n - 1 - i or j == n - 1 + i:print("*", end="")else:print(" ", end="")print()# 下半部分(不含中间行)
for i in range(n - 2, -1, -1):for j in range(2 * n - 1):if j == n - 1 - i or j == n - 1 + i:print("*", end="")else:print(" ", end="")print()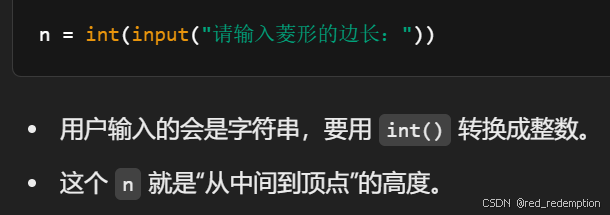
if j == n - 1 - i or j == n - 1 + i
print()直接换行
杨辉三角
def generate_yanghui_triangle(n):triangle = [] # 存储整个三角形for i in range(n):row = [1] * (i + 1) # 每一行最开始全是 1# 从第二个元素到倒数第二个元素开始计算for j in range(1, i):row[j] = triangle[i - 1][j - 1] + triangle[i - 1][j]triangle.append(row)return triangle# 显示杨辉三角
def print_triangle(triangle):n = len(triangle)for i, row in enumerate(triangle):print(" " * (n - i), end="") # 打印前导空格对齐for num in row:print(f"{num} ", end="")print()# 示例
rows = int(input("请输入杨辉三角的行数:"))
triangle = generate_yanghui_triangle(rows)
print_triangle(triangle)
triangle 实际上是一个:列表的列表
[
[1],
[1, 1],
[1, 2, 1],
[1, 3, 3, 1],
...
]
Python 不会主动去判断变量类型,也不要求变量的结构一定一致
只是遍历 triangle 这个变量。只要这个变量“像个列表”,能被遍历就行
len(triangle) 是获取 triangle 的行数
for i, row in enumerate(triangle):一边遍历列表,一边记录当前的“行号” i 和当前的“行内容” row
print(" " * (n - i), end="")让数字靠近中轴线
def func():
print("hello")
这个会报错,因为没有缩进。
def func():
print("hello", end="") # 不换行
print("world")
这个没问题,虽然不换行,但语法结构没错,因为语句都在 def 下面、缩进对齐。
统计不同字符(字母、数字、空格、其他字符)的个数
text = input("请输入一段文本:")letters = 0
digits = 0
spaces = 0
others = 0for ch in text:if ch.isalpha(): # 字母letters += 1elif ch.isdigit(): # 数字digits += 1elif ch.isspace(): # 空格spaces += 1else: # 其他字符others += 1print(f"字母: {letters} 个")
print(f"数字: {digits} 个")
print(f"空格: {spaces} 个")
print(f"其他字符: {others} 个")
检查字符串包含
text = "Life is short.I use python"if "python" in text:new_text = text.replace("python", "Python")print("替换后的字符串:", new_text)
else:print("原字符串:", text)
随机生成六位验证码
random模块
---randint(0,9)可生成一个0-9之间的随机整数
---random.choice()从参数中选择一个
string模块
---string.ascii_letters可得到所有字母
---string.digits可得到所有数字
import random
import stringdef generate_code(length=6):chars = string.ascii_letters + string.digits # 所有字母 + 数字code = ''.join(random.choice(chars) for _ in range(length))return code# 示例
print("生成的验证码是:", generate_code())random.choice(chars) for _ in range(length), 生成器表达式(generator expression)
''.join(...) 会把生成器里的字符连成一个字符串
code = ''
for _ in range(6):
code += random.choice(chars)也可以但是 .join() + 生成器写法更快、更优雅。
进度条
进度条一般以图形的方式显示已完成任务量和未完成任务量,并以动态文字的方式显示任务的完成度。要求编写程序实现文本进度条功能。
import timedef progress_bar(total=30):for i in range(total + 1):percent = int((i / total) * 100)bar = '#' * i + '-' * (total - i)print(f"\r[{bar}] {percent}%", end="")time.sleep(0.1) # 模拟加载过程print("\n任务完成!")# 示例
progress_bar()
total 表示 进度条的总长度,
i / total → 得到当前进度(比如 0.5),* 100 → 换算成百分比
\r → 回到行首,刷新当前行,end="" 避免换行,sleep() 控制速度
过滤敏感词
编写代码,实现具有过滤敏感词功能的程序。
def filter_sensitive(text, sensitive_words):for word in sensitive_words:if word in text:text = text.replace(word, "*" * len(word))return text# 示例
sensitive_list = ["暴力", "不健康", "sb", "傻瓜"]
user_input = input("请输入一段话:")filtered = filter_sensitive(user_input, sensitive_list)
print("过滤后的结果:", filtered)
将字符串的每一个字符放入列表中
text = "hello"
char_list = list(text)
print(char_list)

列表去重
li_one = [1, 2, 1, 2, 3, 5, 4, 3, 5, 7, 4, 7, 8]# 使用集合去重,再转回列表(注意顺序会改变)
li_one_unique = list(set(li_one))print("去重后的列表:", li_one_unique)set(li_one):
-
set是 Python 中的集合类型,它的特点是:-
不允许重复元素
-
元素无序
-
list(...):
-
因为集合类型
set不是列表,如果你想继续像操作列表那样使用它(比如排序、索引等),就需要转回列表类型。 -
所以用
list(set(li_one))就把“去重后的集合”变成了一个新列表。
由于集合 set 是无序的,所以转换之后的新列表 li_one_unique 的元素顺序通常会和原来 li_one 中的顺序不一致。
列表合并降序排列
li_num1 = [5, 5, 2, 7]
li_num2 = [3, 6]# 合并
merged_list = li_num1 + li_num2# 降序排序
sorted_desc = sorted(merged_list, reverse=True)print("合并后并降序排序的列表:", sorted_desc)
sorted() 是 Python 的一个内置函数,用于对任何可迭代对象进行排序(比如列表、元组、集合等)。
返回的是一个新的已排序列表,不会修改原来的 merged_list。
-
reverse是sorted()的一个可选参数。 -
当你设置
reverse=True时,表示按照降序来排列元素。 -
如果是默认的
reverse=False,就是升序排列。
8名教师随机分配办公室
import random# 老师名单
teachers = ['孙老师', '吴老师', '王老师', '钱老师', '李老师', '周老师', '赵老师', '郑老师']# 办公室,初始化为空列表
offices = [[], [], []]# 打乱老师顺序(确保分配随机性)
random.shuffle(teachers)# 分配老师:前3个给办公室1,接着3个给办公室2,剩下2个给办公室3
offices[0] = teachers[:3]
offices[1] = teachers[3:6]
offices[2] = teachers[6:]# 打印分配结果
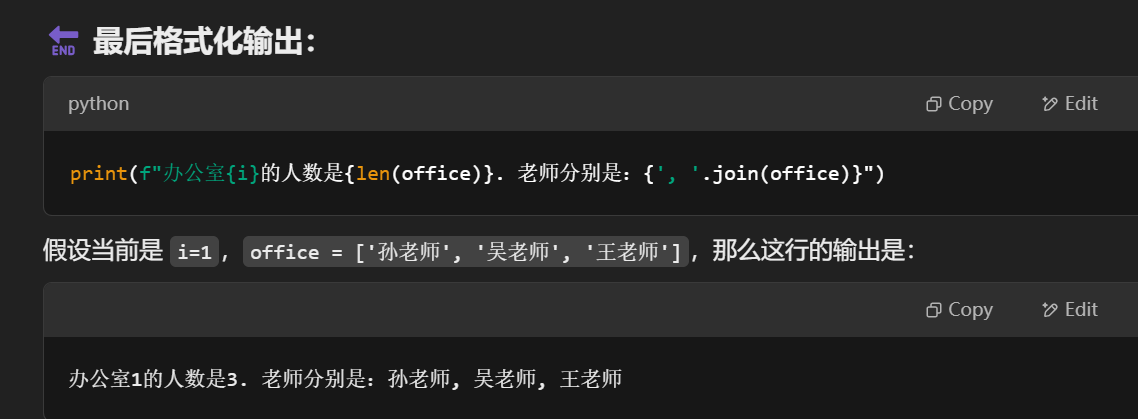
for i, office in enumerate(offices, 1):print(f"办公室{i}的人数是{len(office)}. 老师分别是:{', '.join(office)}")
enumerate(offices, 1) 会遍历每一个办公室列表,并同时给它一个“编号”:
| 第一次循环 | i = 1, office = ['孙老师', '吴老师', '王老师'] |
|---|---|
| 第二次循环 | i = 2, office = ['钱老师', '李老师', '周老师'] |
| 第三次循环 | i = 3, office = ['赵老师', '郑老师'] |
enumerate(..., 1) 的 1 是指定从1开始编号(默认是从0开始的)。
len(office) 就是这个办公室里老师的数量
join() 是一个字符串方法,用来把一个列表里的字符串连接成一个字符串,中间用逗号隔开。
office = ['孙老师', '吴老师', '王老师']
', '.join(office) → '孙老师, 吴老师, 王老师'
十大歌手评选
votes = {} # 用于记录每个歌手的得票数print("请输入你要投票的歌手名字(输入 'end' 结束):")while True:name = input("投票给:")if name.lower() == 'end':breakvotes[name] = votes.get(name, 0) + 1# 排序输出:按票数从高到低
sorted_votes = sorted(votes.items(), key=lambda x: x[1], reverse=True)print("\n投票结果:")
for singer, count in sorted_votes:print(f"{singer}: {count}票")
votes[name] = votes.get(name, 0) + 1
作用:每投一次票,票数加1。
这行是给歌手(或候选人)计票用的。
-
votes是一个字典,记录每个人的票数:
例如:{'张三': 2, '李四': 3} -
votes.get(name, 0)的意思是:-
去字典里找名字为
name的那个人的票数; -
如果还没出现过(字典里没有这个名字),就返回
0; -
相当于默认票数是0。
-
-
然后
+1:当前票数加一。 -
最终更新写入字典:
-
如果是新的人,就新加进去;
-
如果已经有了,就在原来的基础上加1。
-
sorted_votes = sorted(votes.items(), key=lambda x: x[1], reverse=True)
作用:把投票结果按票数从高到低排序。
-
votes.items():把字典转换成一个列表,每一项是(名字, 票数)这样的元组:{'张三': 3, '李四': 1}.items() → [('张三', 3), ('李四', 1)] -
sorted(..., key=lambda x: x[1]):
排序的时候按照元组的第2个元素(也就是票数)来比较。lambda x: x[1]是匿名函数,意思是“拿到每个(名字, 票数)元组的票数”。 -
reverse=True:表示降序排列(票数多的排前面)。
分类统计字符个数
编写程序,用户输入一个字符串,以回车结束,利用字典统计其中字母和数字出现的次数(回车符代表结束)。
输入格式是一个以回车结束的字符串,例如输入abc1ab,输出{'a': 2, 'b': 2, 'c': 1, '1': 1}。
text = input("请输入一个字符串(回车结束):")
counter = {}for char in text:if char.isalnum(): # 判断是否是字母或数字counter[char] = counter.get(char, 0) + 1print(counter)
计票机制(类歌手)
candidates = ['张三', '李四', '王五']
votes = dict.fromkeys(candidates, 0)print("候选人有:", ', '.join(candidates))
print("请输入投票人名(输入 'end' 结束):")while True:name = input("投票给:")if name.lower() == 'end':breakif name in votes:votes[name] += 1else:print("无效候选人,票数不计。")# 输出最终结果
sorted_votes = sorted(votes.items(), key=lambda x: x[1], reverse=True)print("\n计票结果:")
for person, count in sorted_votes:print(f"{person}: {count}票")
votes = dict.fromkeys(candidates, 0)
作用:根据候选人列表创建一个初始“投票字典”,每个人的票数都设为 0。
candidates = ['张三', '李四', '王五']
votes = dict.fromkeys(candidates, 0) # 得到
votes = {'张三': 0, '李四': 0, '王五': 0}
name.lower()
作用:把用户输入的名字全部转成小写,通常用于不区分大小写的匹配判断。
sorted_votes = sorted(votes.items(), key=lambda x: x[1], reverse=True)
这就是你前面问过的:
-
按照**票数(x[1])**进行排序;
-
reverse=True表示 降序(票数多的排在前面); -
结果是一个列表,元素是元组
(名字, 票数)。
斗地主发牌看牌
(要求看牌时排序展示)
import random # 导入随机模块,用于洗牌# 定义花色(suits)和点数(ranks)
suits = ['♠', '♥', '♣', '♦'] # 黑桃、红桃、梅花、方块
ranks = ['3', '4', '5', '6', '7', '8', '9', '10', 'J', 'Q', 'K', 'A', '2'] # 常规牌面# 生成一副完整的扑克牌(不包括大小王的52张 + 小王 + 大王)
deck = [s + r for r in ranks for s in suits] + ['小王', '大王']# 洗牌:打乱deck中的顺序
random.shuffle(deck)# 创建三个玩家的牌堆 + 1个底牌堆
player1 = []
player2 = []
player3 = []
bottom = []# 发牌(共54张,前51张发给三位玩家,最后3张作为底牌)
for i in range(len(deck)):if i < 51:if i % 3 == 0:player1.append(deck[i]) # 玩家1每隔3张拿一张elif i % 3 == 1:player2.append(deck[i]) # 玩家2每隔3张拿一张else:player3.append(deck[i]) # 玩家3每隔3张拿一张else:bottom.append(deck[i]) # 剩下3张作为底牌# 定义一个排序函数:将玩家手牌按点数大小排序
def sort_cards(cards):# 创建一个牌面优先级映射(数字越大表示牌越大)order = {r: i for i, r in enumerate(ranks)} # 3最小,2最大(不含王)order.update({'小王': 13.5, '大王': 14}) # 王的等级高于所有普通牌# 自定义排序函数:提取每张牌的“点数”部分用于比较def card_key(card):if card in ['小王', '大王']:return order[card] # 王直接用其键值return order[card[1:]] # 从第2位开始取(排除花色)# 返回按牌面大小排序后的牌列表return sorted(cards, key=card_key)# 输出发牌结果,并按点数顺序展示每位玩家的手牌
print("\n=== 发牌结果 ===")
print("玩家1:", sort_cards(player1))
print("玩家2:", sort_cards(player2))
print("玩家3:", sort_cards(player3))
print("底牌:", sort_cards(bottom))
deck = [s + r for r in ranks for s in suits]
是花色在前,点数在后的生成方式,比如 ♠3, ♥3, ♣3, ♦3, ♠4, ...
如果你想让点数排在前(比如 3♠),只需调换一下顺序。
for i in range(len(deck)):
deck = ['♠3', '♥4', ..., '小王', '大王']
相对于for i in range(54): # i 依次是 0, 1, 2, ..., 53
-
i < 51:表示前 51 张是正常发给玩家的; -
i >= 51:表示最后 3 张是底牌。
然后再通过 i % 3 来轮流分给 3 个玩家。
order = {r: i for i, r in enumerate(ranks)}
这行用的是字典推导式,将点数与大小关系建立起来。
enumerate(ranks) 会返回每个点数及其位置编号:
ranks = ['3', '4', '5', ..., '2']
→ [('3', 0), ('4', 1), ..., ('2', 12)]所以构造出的字典是:
order = {'3': 0, '4': 1, '5': 2, '6': 3, '7': 4,'8': 5, '9': 6, '10': 7, 'J': 8, 'Q': 9,'K': 10, 'A': 11, '2': 12
}order.update({'小王': 13.5, '大王': 14})
这行的意思是:往 order 字典中再加两个键值对:比“2”还大,用来确保在排序时,“王”排到最上面。
def card_key(card):
if card in ['小王', '大王']:
return order[card]
return order[card[1:]]
return sorted(cards, key=card_key)
我们之前建立了一个排序规则 order,用于表示每张牌的大小关系:
order = {'3': 0, '4': 1, ..., '2': 12,'小王': 13.5, '大王': 14
}
现在你有一手牌,比如:
cards = ['♠3', '♦A', '小王', '♥10', '♣2']
def card_key(card): 定义一个排序时的“取键函数”。
在 Python 的 sorted(..., key=...) 中,我们可以自定义用什么“值”来排序 —— 这里我们自定义的函数名是 card_key。
if card in ['小王', '大王']: return order[card]
- 如果这张牌是 `'小王'` 或 `'大王'`,那就直接返回 `order` 中对应的数值(13.5 或 14)用于排序。
-
如果不是王,那就说明是正常的扑克牌,比如
'♠3'、'♥10'等。 -
card[1:]表示从索引1开始切取,也就是去掉前面的花色符号,只保留点数:
| 原始牌 | card[1:] | 排序用值 (order[card[1:]]) |
|---|---|---|
'♠3' | '3' | 0 |
'♦A' | 'A' | 11 |
'♥10' | '10' | 7 |
这样我们就可以用这些数值去比较牌的大小了。
return sorted(cards, key=card_key)
-
sorted(...)是 Python 内置的排序函数,会返回一个新的列表。 -
key=card_key指定了“按照什么规则排序”,也就是我们自定义的card_key函数。 -
这样就能确保牌是按照
order字典定义的大小顺序排列的。
为什么要用 card[1:] 而不是正则或者其他方式提取点数?
点数部分可能是 '10'、'J'、'Q',所以不能只取一个字符,要用切片取后面所有字符 → card[1:]。
编写函数完成角谷猜想
模拟和验证一个著名数学问题——角谷猜想(也叫冰雹猜想,英文叫 Hailstone conjecture 或 Collatz Conjecture)。
对于任意一个正整数 n,重复以下操作:
-
如果 n 是偶数:把 n 变成 n / 2
-
如果 n 是奇数:把 n 变成 3n + 1
重复这个过程,最终总会变成 1
def hailstone_sequence(n):steps = [n] # 记录整个序列(从 n 开始)while n != 1: # 不断重复直到 n 变成 1if n % 2 == 0:n = n // 2 # 偶数除以2else:n = n * 3 + 1 # 奇数乘3加1steps.append(n) # 每次结果加入列表return steps # 返回完整路径饮品自动售货机
def vending_machine():menu = {'1': ('可乐', 3),'2': ('绿茶', 2.5),'3': ('矿泉水', 2)}print("欢迎使用自动售货机:")for k, v in menu.items():print(f"{k}: {v[0]} - ¥{v[1]}")choice = input("请输入你要购买的饮品编号:")if choice not in menu:print("无效选择")returndrink, price = menu[choice]money = float(input(f"请投币(需要 ¥{price}):"))if money >= price:change = money - priceprint(f"你购买了 {drink},找零 ¥{change:.2f}")else:print("金额不足,交易取消")# 示例调用
vending_machine()
学生管理系统
students = []def add_student(name, age):students.append({'name': name, 'age': age})print(f"添加成功:{name}, 年龄{age}")def show_students():print("当前学生列表:")for s in students:print(f"{s['name']}({s['age']}岁)")# 示例
add_student('小明', 18)
add_student('小红', 17)
show_students()
两个数的最大公约数与最小公倍数
def gcd(a, b):while b:a, b = b, a % breturn adef lcm(a, b):return a * b // gcd(a, b)# 示例
print("最大公约数:", gcd(24, 36))
print("最小公倍数:", lcm(24, 36))登录验证(次数限制)
def login_system():attempts = 0while attempts < 5:username = input("用户名:")password = input("密码:")if username == 'admin' and password == 'admin123':print("登录成功")returnelse:attempts += 1print(f"请重新登录(还剩 {5 - attempts} 次)")print("账户已被锁定,请联系管理员解锁")login_system()
登录验证装饰器 + 系统操作函数
# 模拟登录状态
login_status = {"logged_in": False}# 登录验证装饰器
def require_login(func):def wrapper(*args, **kwargs):if not login_status["logged_in"]:username = input("用户名:")password = input("密码:")if username == "admin" and password == "admin123":login_status["logged_in"] = Trueprint("✅ 登录成功")else:print("❌ 登录失败,无法操作")returnreturn func(*args, **kwargs)return wrapper# 系统功能函数
@require_login
def add_data():print("数据添加成功")@require_login
def delete_data():print("数据删除成功")@require_login
def update_data():print("数据更新成功")# 测试
add_data() # 第一次需登录
delete_data() # 已登录,无需再输密码
什么是 @require_login?
Python 的一个语法糖,叫做:函数装饰器(Decorator)
它的作用是:在不修改原函数代码的情况下,为函数增加额外的功能。
@require_login
def add_data():
print("数据添加成功")
等价于:add_data = require_login(add_data)
也就是说,add_data 这个函数被 require_login 装饰后,变成了它返回的 wrapper 函数。
把装饰器 给函数套了个“壳子”:
@xxx 本质上就是:把当前函数交给 xxx() 来加工
def require_login(func):def wrapper(*args, **kwargs):# 做登录验证return func(*args, **kwargs) # 如果验证通过,再运行原函数return wrapper
这段代码的意思其实是:
✨“我定义了一个叫
require_login的函数工厂,它接受一个函数func,然后给它包一层登录验证功能,最后返回这个‘增强后的函数’。”✨
第一级函数:require_login(func)
这是 你定义的装饰器函数本体。它接收另一个函数作为参数——就是你想“加功能”的那个函数(比如 add_data())。
它的作用就是返回一个新函数:wrapper。
第二级函数:wrapper(*args, **kwargs)
这是你创建的“壳函数”,负责:
-
先判断登录状态
-
如果未登录就提示并要求输入用户名密码
-
如果登录成功,再执行原函数
func(...)
它就像是在你真正的
add_data()、delete_data()等函数 外面套的一层保护壳。
为什么要返回 wrapper 而不是直接运行它?
因为你希望是“以后再用的时候”才执行验证,不是定义的时候就立即执行。
@require_login
def add_data():
...
这时只是把 add_data 换成了新的 wrapper 函数(它内部包含了登录判断 + 原始 add_data),还没有真正执行它。
这段代码是典型的:
“高阶函数 + 闭包结构”
-
高阶函数:函数接收函数作为参数,或返回函数
-
闭包:
wrapper()内部访问了func,形成了“带记忆”的函数
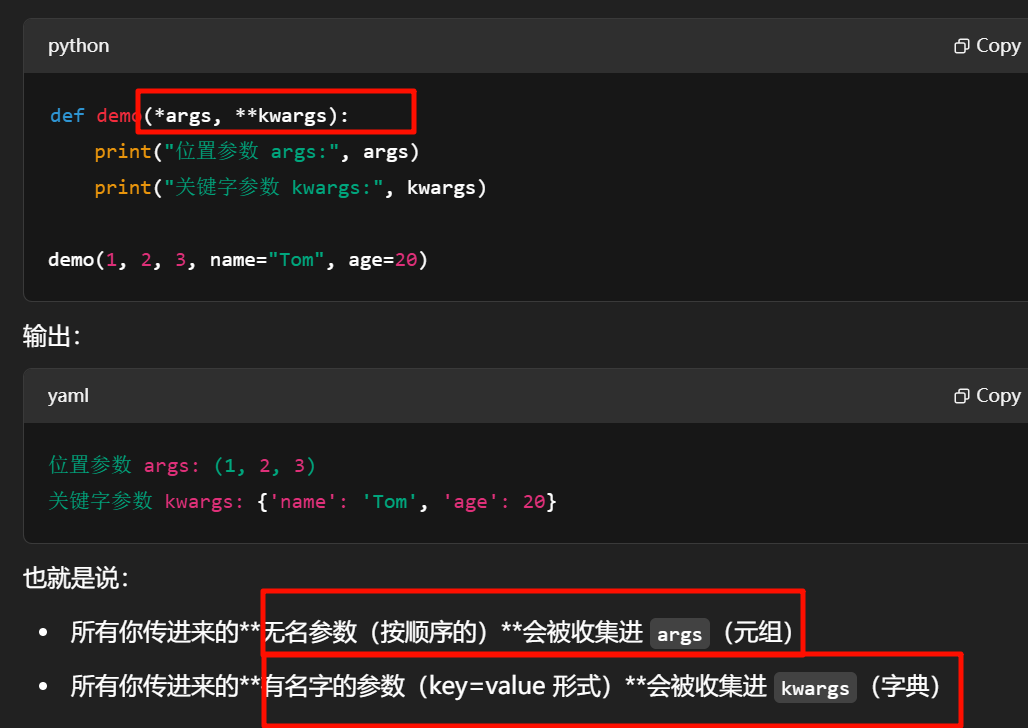
| 写法 | 意义 |
|---|---|
*args | 接收任意数量的位置参数(变成一个元组) |
**kwargs | 接收任意数量的关键字参数(变成一个字典) |
| 用法场景 | 原因 |
|---|---|
| 写装饰器 | 你不知道被包装的函数参数数量和类型 |
| 写通用函数 | 比如日志函数、统计函数,参数可变 |
| 接收动态传参 | 比如配置字典、自动调用接口 |
递归求和函数 f(n)
def f(n):if n == 1:return 1return n + f(n - 1)# 示例
print(f(10)) # 输出 55
找出所有既是回文数又是素数的 3 位数
def is_palindrome(n):return str(n) == str(n)[::-1]def is_prime(n):if n < 2:return Falsefor i in range(2, int(n**0.5) + 1):if n % i == 0:return Falsereturn Truedef find_palindromic_primes():result = []for n in range(100, 1000):if is_palindrome(n) and is_prime(n):result.append(n)return resultprint(find_palindromic_primes())
for i in range(2, int(n**0.5) + 1):if n % i == 0:return False从
2到√n(包含)逐一检查是否能整除n,如果能整除,就不是素数。
**是根号
-
在 Python 中,
**表示 幂运算(power) -
所以
n**0.5就等于n 的 0.5 次方 -
而
n 的 0.5 次方,数学上就是√n
确保从 2 检查到 3,完整覆盖了素数判断所需范围。
range(2, 3+1) → [2, 3)
range(start, end) 的含义:
| 参数 | 含义 |
|---|---|
start | 起始值(包含) |
end | 终止值(不包含) |
模拟轮盘抽奖函数
import randomdef spin_wheel():r = random.random() # 生成 [0.0, 1.0) 的浮点数if 0 <= r < 0.08:return "🎉 恭喜你抽中一等奖!"elif 0.08 <= r < 0.3:return "🎊 恭喜你抽中二等奖!"else:return "✨ 抽中三等奖,继续加油!"# 测试多次抽奖
for _ in range(5):print(spin_wheel())
保存到你运行脚本时所在的目录下,文件名是你传入的那个 json_path。
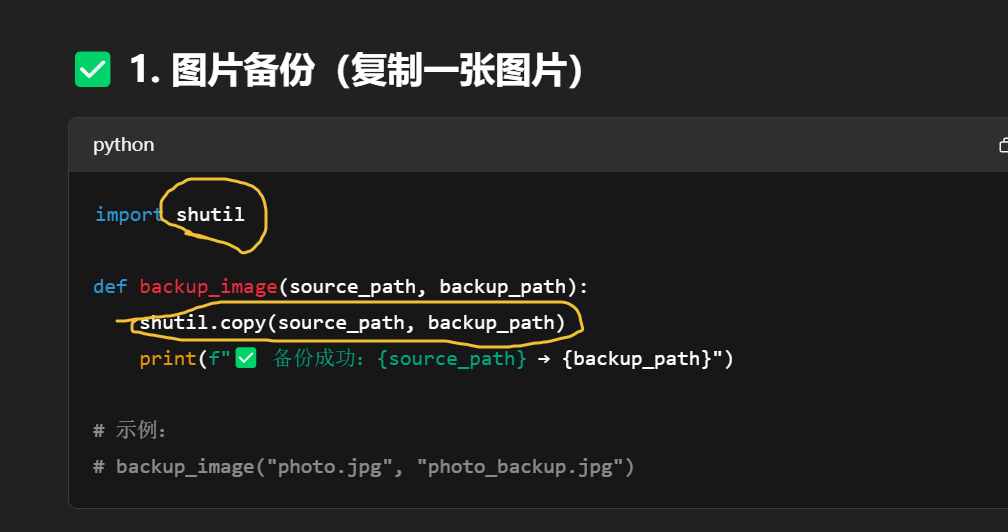
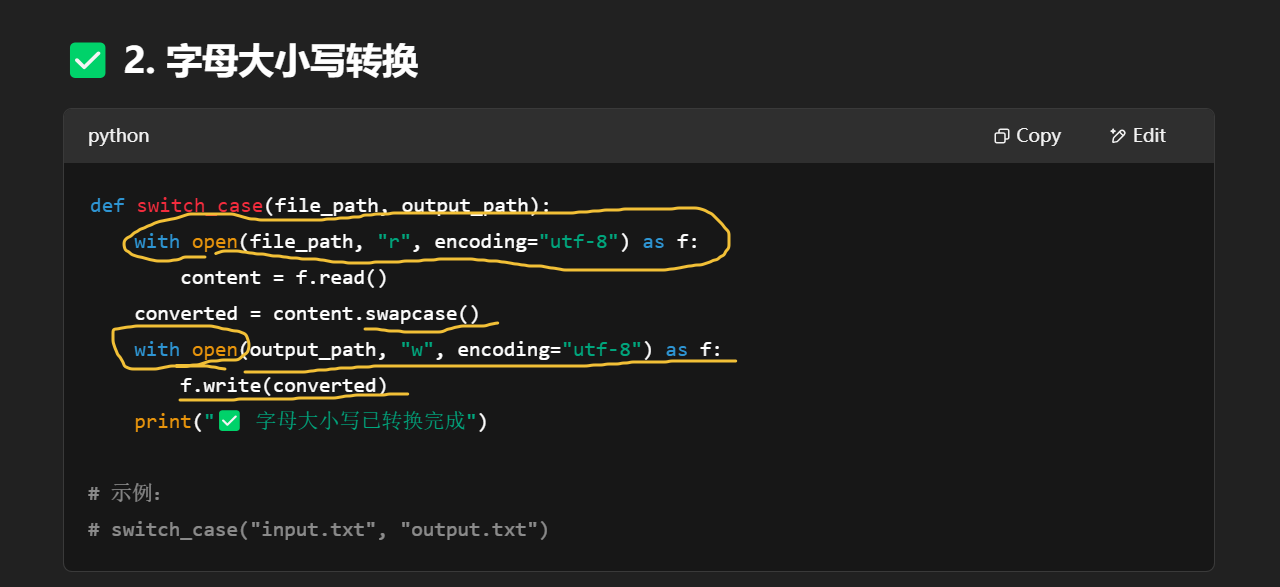
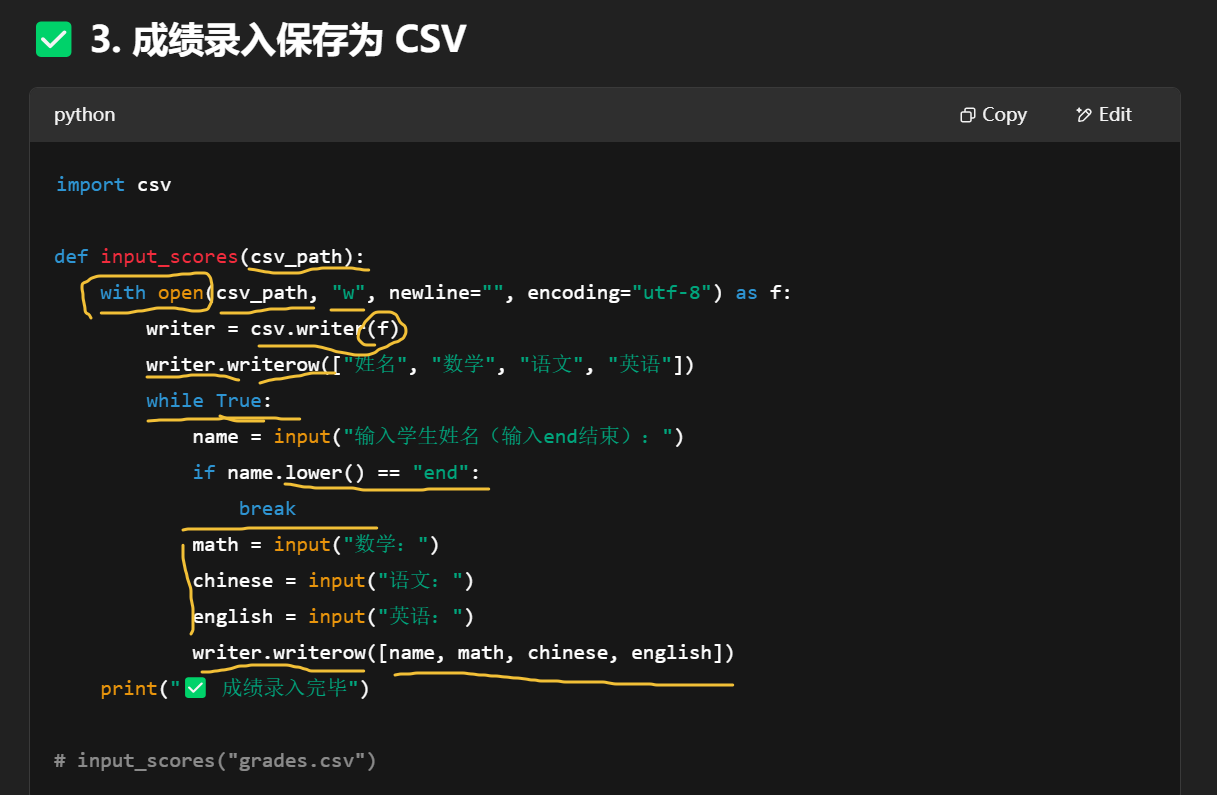
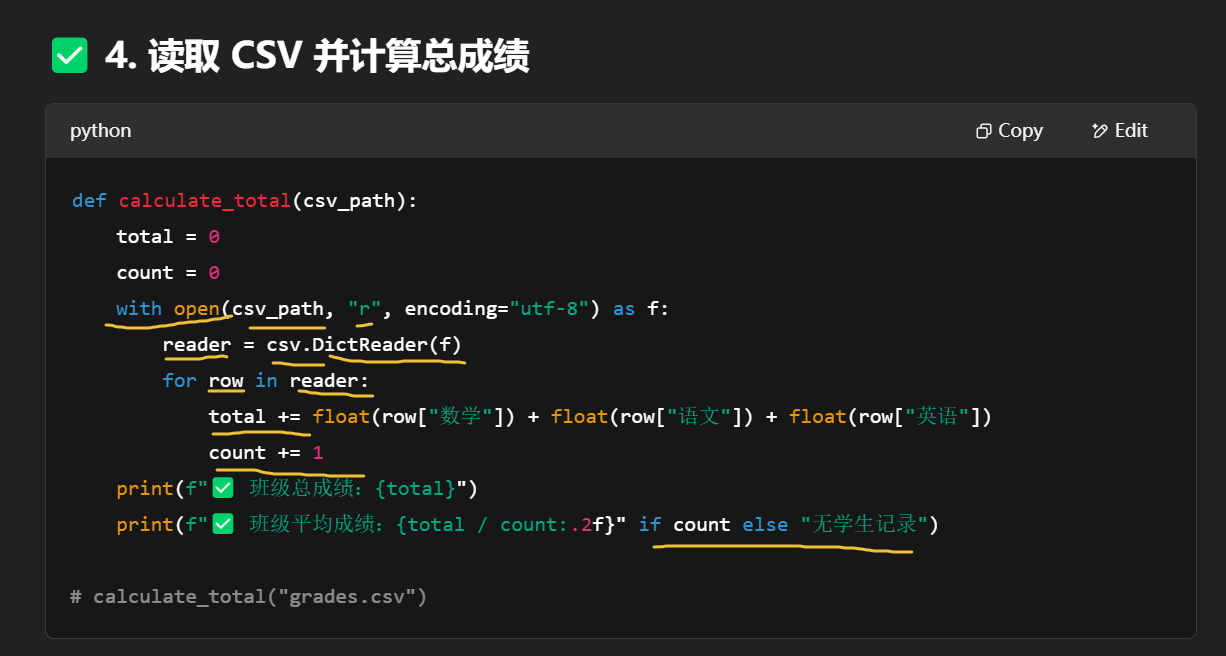
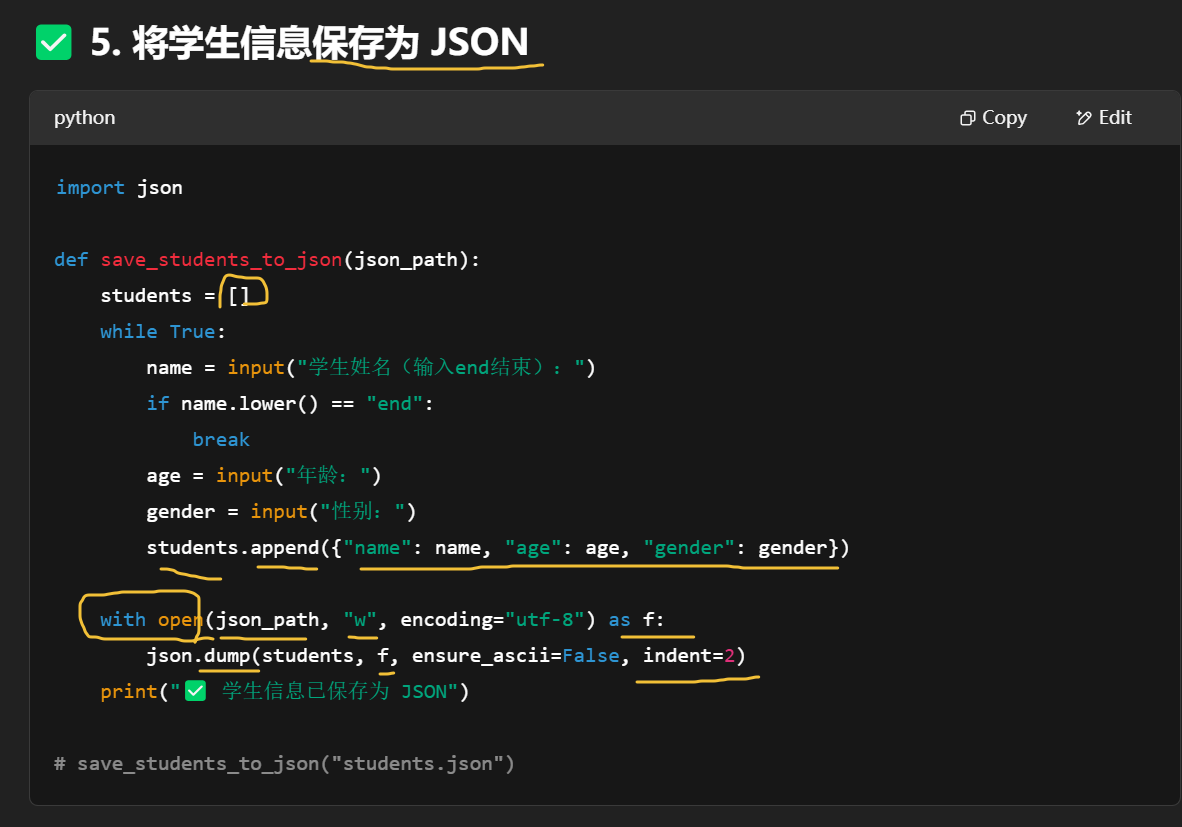
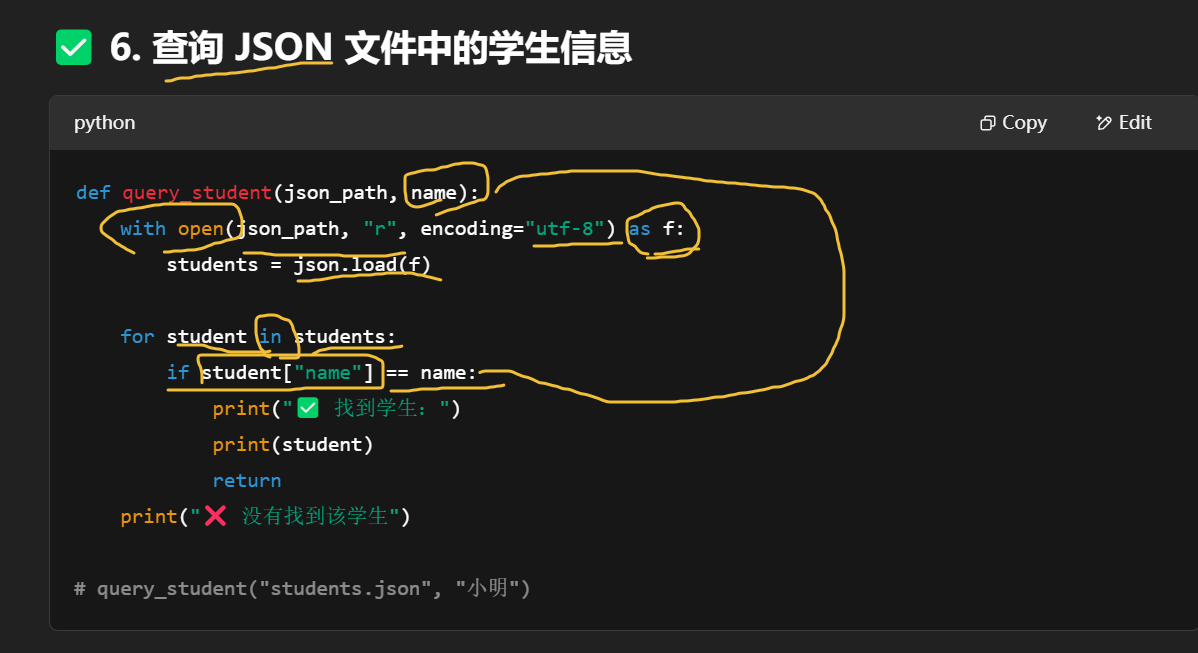
| 技能类型 | 涉及模块/函数 |
|---|---|
| 文件复制 | shutil.copy() |
| 字符操作 | .swapcase() |
| 文件读写 | open(..., "r/w") |
| CSV 写入/读取 | csv.writer / csv.DictReader |
| JSON 存取 | json.dump() / json.load() |
| 条件循环与判断 | while、if |
相关文章:

Python的简单练习
两数的最大公约数 def gcd(a, b):while b ! 0:a, b b, a % breturn a# 示例 a 36 b 60 print(f"{a} 和 {b} 的最大公约数是: {gcd(a, b)}") while b ! 0: while:是 Python 的 循环语句,意思是“当...的时候一直重复做某事”。 b ! 0&am…...

ipvsadm,是一个什么工具?
1. ipvsadm 是什么? ipvsadm(IP Virtual Server Administration)是 Linux 内核中 IPVS(IP Virtual Server) 模块的管理工具,用于配置和监控内核级的负载均衡规则。它是 Kubernetes 中 kube-proxy 在 IPVS …...
:阅读与注释单选框这个类型的按钮 QRadioButton,及各种属性验证,)
QT6 源(72):阅读与注释单选框这个类型的按钮 QRadioButton,及各种属性验证,
(1)按钮间的互斥: (2)源码来自于头文件 qradiobutton . h : #ifndef QRADIOBUTTON_H #define QRADIOBUTTON_H#include <QtWidgets/qtwidgetsglobal.h> #include <QtWidgets/qabstractbutton.h>…...
)
Qt 中实现观察者模式(Observer Pattern)
在 Qt 中实现**观察者模式(Observer Pattern)通常利用其内置的信号与槽(Signals & Slots)**机制,这是最符合 Qt 设计哲学的方式。以下是详细实现方法和关键点: —### 1. 观察者模式的核心思想- Subject(被观察者):维护一个观察者列表,在状态变化时通知观察者。- …...

Vue3源码学习5-不使用 `const enum` 的原因
文章目录 前言✅ 什么是 const enum❌ 为什么 Vue 3 不使用 const enum1. 📦 **影响构建工具兼容性**2. 🔁 **难以做模块间 tree-shaking**3. 🧪 **调试困难**4. 📦 **Vue 是库,不掌控用户配置** ✅ 官方推荐做法&…...

自己部署后端,浏览器显示久久未响应
CIDER地址写错了,应该要写成0.0.0.0/0 。。。。...

【RocketMQ NameServer】- NettyEventExecutor 处理 Netty 事件
文章目录 1. 前言2. NettyEventExecutor 线程3. NettyEvent 是怎么来的4. NettyEventExecutor 线程处理不同事件的逻辑4.1 IDLE\CLOSE\EXCEPTION - onChannelIdle4.2 CONNECT - onChannelConnect 5. 小结 本文章基于 RocketMQ 4.9.3 1. 前言 【RocketMQ】- 源码系列目录 上一…...

JAVA刷题记录: 递归,搜索与回溯
专题一 递归 面试题 08.06. 汉诺塔问题 - 力扣(LeetCode) class Solution {public void hanota(List<Integer> A, List<Integer> B, List<Integer> C) {dfs(A, B, C, A.size());}public void dfs(List<Integer> a, List<In…...
知识点总结归纳)
【进阶】C# 委托(Delegate)知识点总结归纳
1. 委托的基本概念 定义:委托是一种类型安全的函数指针,用于封装方法(静态方法或实例方法)。 核心作用:允许将方法作为参数传递,实现回调机制和事件处理。 类型安全:委托在编译时会检查方法签…...

推理能力:五一模型大放送
--->更多内容,请移步“鲁班秘笈”!!<--- 近日人工智能领域迎来了一波密集的模型发布潮,多家科技巨头和研究机构相继推出了具有突破性特点的AI模型。这些新模型在参数规模、计算效率、多模态能力以及推理能力等方面都展现出…...

数据库=====
创建数据库 1.直接创建数据库 语法:CREATE DATABASE [IF NOT EXISTS] 数据库名 ——[]表示内部内容可省略 2.指定字符集和排序规则方式创建数据库 语法:CREATE DATABASE[IF NOT EXISTS] 数据库名 CHARACTER SET 字符集 COLLATE 排序规则 示例:…...

VITA STANDARDS LIST,VITA 标准清单下载
VITA STANDARDS LIST,VITA 标准清单下载 DesignationTitleAbstractStatusVMEbus Handbook, 4th EditionA users guide to the VME, VME64 and VME64x bus specifications - features over 70 product photos and over 160 circuit diagrams, tables and graphs. The…...

npm pnpm yarn 设置国内镜像
国内镜像 常用的国内镜像: 淘宝镜像 https://registry.npmmirror.com 腾讯云镜像 https://mirrors.cloud.tencent.com/npm/ 华为云镜像 https://repo.huaweicloud.com/repository/npm/ CNPM(阿里系) https://r.cnpmjs.org/ 清华…...

互联网大厂Java面试:从Spring到微服务的技术探讨
场景:互联网大厂Java求职者面试 在一家知名的互联网大厂面试中,面试官王严肃正在面试一位名叫谢飞机的程序员。谢飞机以其独特的幽默感而闻名,但在技术面前,他的能力能否得到认可呢? 第一轮提问:核心技术…...
[machine learning] Transformer - Attention (二)
本文介绍带训练参数的self-attention,即在transformer中使用的self-attention。 首先引入三个可训练的参数矩阵Wq, Wk, Wv,这三个矩阵用来将词向量投射(project)到query, key, value三个向量上。下面我们再定义几个变量: import torch inpu…...
)
Java多语言DApp质押挖矿盗U源码(前端UniApp纯源码+后端Java)
内容: 这款Java多语言DApp质押挖矿盗U源码提供了完整的前端与后端开发框架,适用于区块链应用开发。系统包括: 前端源码(UniApp):采用UniApp开发,跨平台支持iOS、Android及H5。界面简洁…...

如何解决 403 错误:请求被拒绝,无法连接到服务器
解决 403 错误:请求被拒绝,无法连接到服务器 当您在浏览网站或应用时,遇到 403 错误,通常会显示类似的消息: The request could not be satisfied. Request blocked. We can’t connect to the server for this app o…...
协议详解)
CGI(Common Gateway Interface)协议详解
CGI(通用网关接口)是一种标准化的协议,定义了 Web服务器 与 外部程序(如脚本或可执行文件)之间的数据交互方式。它允许服务器动态生成网页内容,而不仅仅是返回静态文件。 1. CGI 的核心作用 动态内容生成&a…...

HybridCLR 详解:Unity 全平台原生 C# 热更新方案
HybridCLR(原 Huatuo)是 Unity 平台革命性的热更新解决方案,它通过扩展 Unity 的 IL2CPP 运行时,实现了基于原生 C# 的完整热更新能力。下面从原理到实践全面解析这一技术。 一、核心原理剖析 1. 技术架构 原始 IL2CPP 流程&am…...

电脑RGB888P转换为JPEG方案 ,K230的RGB888P转换为JPEG方案
K230开发板本身具备将RGB888P转换为JPEG的能力,但需要正确调用硬件或软件接口。以下是具体分析及解决方案: 一、K230原生支持性分析 1. 硬件支持 K230的NPU(神经网络处理器)和图像处理单元(ISP)理论上支持…...

基于SpringBoot+Vue实现的电影推荐平台功能三
一、前言介绍: 1.1 项目摘要 2023年全球流媒体用户突破15亿,用户面临海量内容选择困难,传统推荐方式存在信息过载、推荐精准度低等问题。传统推荐系统存在响应延迟高(平均>2s)。随着互联网的快速发展,…...

NHANES指标推荐:triglyceride levels
文章题目:Association between triglyceride levels and rheumatoid arthritis prevalence in women: a cross-sectional study of NHANES (1999-2018) DOI:10.1186/s12905-025-03645-y 中文标题:女性甘油三酯水平与类风湿性关节炎患病率之间…...

打印Activity的调用者
有时候我们会发现自己应用中的某个Activity被陌名奇妙的打开了,但是不知道是哪里的代码打开的,此时可以打印Activity的调用堆栈,在Activity的onCreate函数中添加如下代码: Arrays.stream(Thread.currentThread().getStackTrace()…...

深入解析 SqlSugar 与泛型封装:实现通用数据访问层
在现代软件开发中,ORM(对象关系映射)框架的使用已经成为不可或缺的部分,SqlSugar 是一款非常流行且强大的 ORM框架。它不仅提供了简单易用的数据库操作,还具备了高效的性能和灵活的配置方式。为了进一步提升数据库操作…...

普通 html 项目引入 tailwindcss
项目根目录安装依赖 npm install -D tailwindcss3 postcss autoprefixer 初始化生成tailwind.config.js npx tailwindcss init 修改tailwind.config.js /** type {import(tailwindcss).Config} */ module.exports {content: ["./index.html"], //根据自己的项目…...
)
Go小技巧易错点100例(二十七)
本期分享: 1. Go语言中的Scan函数 2. debug.Stack()打印堆栈信息 3. Go条件编译 正文: Go语言中的Scan函数 在Go语言中,Scan函数是一个强大的工具,它主要用于从输入源(如标准输入、文件或网络连接)读取…...

单细胞测序数据分析流程的最佳实践
单细胞测试数据分析流程是整个论文数据分析过程中相对固定的部分,有一定的标准流程,以下整理了发表论文的相关内容供简要了解,详细内容可以参照2019年发表的综述:Luecken MD, Theis FJ. Current best practices in single-cell RN…...

Elasticsearch:RAG 和 grounding 的价值
作者:来自 Elastic Toms Mura 了解 RAG、grounding,以及如何通过将 LLM 连接到你的文档来减少幻觉。 更多阅读:Elasticsearch:在 Elastic 中玩转 DeepSeek R1 来实现 RAG 应用 想获得 Elastic 认证吗?查看下一期 Elast…...

经典算法 求解台阶问题
求解台阶问题 题目描述 实现一个算法求解台阶问题。介绍如下: 对于高度为 n 的台阶,从下往上走,每一步的阶数为 1、2 或 3 中的一个。问要走到顶部一共有多少种走法。 输入描述 输入一个数字 N: 1 ≤ N ≤ 35表示台阶的高度 …...

伊甸园之东: 农业革命与暴力的复杂性
农业革命的开始 农业革命是人类历史上的第一次重大经济和社会变革,标志着人们从狩猎采集转向农耕。 该变革虽然进展缓慢,却彻底改变了人类的生活方式和社会结构。狩猎采集社会的特征 狩猎采集者生活在小规模、低密度的部落中,依赖于不稳定的自…...
)
MCP多智能体消息传递机制(Message Passing Between Agents)
目录 🚀 MCP多智能体消息传递机制(Message Passing Between Agents) 🌟 为什么要引入消息传递机制? 🏗️ 核心设计:Agent间消息传递模型 🛠️ 1. 定义标准消息格式 Ὦ…...
)
Deformable DETR模型解读(附源码+论文)
Deformable DETR 论文链接:Deformable DETR: Deformable Transformers for End-to-End Object Detection 官方链接:Deformable-DETR(这个需要在linux上运行,所以我是用的是mmdetection里面的Deformable DERT,看了一下源码基本是…...

游戏引擎学习第255天:构建配置树
为今天的内容设定背景 今天的任务是构建性能分析(profiling)视图。 目前来看,展示性能分析图形本身并不复杂,大部分相关功能在昨天已经实现。图形显示部分应该相对直接,工作量不大。 真正需要解决的问题,是…...

JavaScript性能优化实战之调试与性能检测工具
在进行 JavaScript 性能优化时,了解和使用正确的调试与性能检测工具至关重要。它们能够帮助我们识别性能瓶颈,精确定位问题,并做出有针对性的优化措施。本文将介绍一些常见的调试和性能检测工具,帮助你更好地分析和优化你的 JavaScript 代码。 1️⃣ Chrome DevTools Chro…...
)
C#VisionMaster算子二次开发(非方案版)
前言 在网上VisionMaster的教程通常都是按照方案执行的形式,当然海康官方也是推荐使用整体方案的形式进行开发。但是由于我是做标准设备的,为了适配原有的软件框架和数据结构,就需要将特定需要使用的算子进行二次封装。最直接的好处是&#…...

计算机总线系统入门:理解数据传输的核心
一、总线系统简介:计算机内部的交通网络 在计算机系统中,总线是指连接各个组件的一组共享信号线或传输通道,用于在系统内不同的硬件模块之间传递数据、地址、控制信号等信息。它类似于交通系统中的道路,帮助计算机各个部件&#…...

【Linux】Petalinux驱动开发基础
基于Petalinux做Linux驱动开发。 部分图片和经验来源于网络,若有侵权麻烦联系我删除,主要是做笔记的时候忘记写来源了,做完笔记很久才写博客。 专栏目录:记录自己的嵌入式学习之路-CSDN博客 目录 1 一个完整的Linux系统(针对Zynq) 1.1 PS部分 1.2 PL部分(若…...

提升办公效率的PDF转图片实用工具
软件介绍 这款专注于PDF文档处理的工具功能单一但实用,能够将PDF文件内容智能提取并自动拼接成长图,为用户提供便捷的图片化文档处理方案,无需复杂设置即可轻松上手。 简洁直观的用户界面 软件界面设计简洁清爽,没有任何多余…...

动态库与ELF加载
目录 动态库 ELF格式 ELF和后缀的区别 什么是目标文件 ELF文件中的地址--虚拟地址 动静态库和可执行文件 动态库ELF加载 为什么编译时静态库需要指定库?而运行时不需要指定库的,但是动态库需要呢? 总结: 动态库 动态库制作需要的.o文件需要使…...

算法每日一题 | 入门-顺序结构-数字反转
数字反转 题目描述 输入一个不小于 且小于 ,同时包括小数点后一位的一个浮点数,例如 ,要求把这个数字翻转过来,变成 并输出。 输入格式 一行一个浮点数 输出格式 一行一个浮点数 输入输出样例 #1 输入 #1 123.4输出 #1 …...

ROS2学习笔记|实现订阅消息并朗读的详细步骤
本教程将详细介绍如何使用 ROS 2 实现一个节点订阅另一个节点发布的消息,并将接收到的消息通过 espeakng 库进行朗读的完整流程。以下步骤假设你已经安装好了 ROS 2 环境(以 ROS 2 Humble 为例),并熟悉基本的 Linux 操作。 注意&…...

【Hot 100】 146. LRU 缓存
目录 引言LRU 缓存官方解题LRU实现📌 实现步骤分解步骤 1:定义双向链表节点步骤 2:创建伪头尾节点(关键设计)步骤 3:实现链表基础操作操作 1:添加节点到头部操作 2:移除任意节点 步骤…...

web应用开发说明文档
工程目录结构 FACTORY--bin #网络流可执行程序 参考后文1.1部分文字说明webrtc-streamer--deployment #部署相关的配置--mysql #参考1.3 mysql数据库详细说明--conf #存放mysql的配置文件--data #存放pem加密…...

快速搜索与管理PDF文档的专业工具
软件介绍 在处理大量PDF文档时,专业的文档管理工具能显著提升工作效率。这款工具能够帮助用户快速检索PDF内容,并提供了便捷的合并与拆分功能,让复杂的PDF操作变得简单高效。 多文件内容检索能力 不同于传统PDF阅读器的单文件搜索局…...

在GPU集群上使用Megatron-LM进行高效的大规模语言模型训练
摘要 大型语言模型在多个任务中已取得了最先进的准确率。然而,训练这些模型的效率仍然面临挑战,原因有二:a) GPU内存容量有限,即使在多GPU服务器上也无法容纳大型模型;b) 所需的计算操作数量可能导致不现实的训练时间。因此,提出了新的模型并行方法,如张量并行和流水线…...

NocoDB:开源的 Airtable 替代方案
NocoDB:开源的 Airtable 替代方案 什么是 NocoDB?NocoDB 的主要特点丰富的电子表格界面工作流自动化应用商店程序化访问 NocoDB 的应用场景使用 Docker 部署 NocoDB1. 创建数据目录2. 运行 Docker 容器3. 访问 NocoDB 注意事项总结 什么是 NocoDB&#x…...

关于Python:7. Python数据库操作
一、sqlite3(轻量级本地数据库) sqlite3 是 Python 内置的模块,用于操作 SQLite 数据库。 SQLite 是一个轻量级、零配置的关系型数据库系统,整个数据库保存在一个文件中,适合小型项目和本地存储。 SQLite 不需要安装…...

修改ollama.service都可以实现什么?
通过修改 ollama.service 系统服务单元文件,可以实现以下核心配置变更: 一、网络与访问控制 监听地址与端口 通过 Environment="OLLAMA_HOST=0.0.0.0:11434" 修改服务绑定的 IP 和端口: 0.0.0.0 允许所有网络接口访问(默认仅限本地 127.0.0.1)。示例:改为 0.0.…...

k8s笔记——kubebuilder工作流程
kubebuilder工作流程 Kubebuilder 工作流程详解 Kubebuilder 是 Kubernetes 官方推荐的 Operator 开发框架,用于构建基于 Custom Resource Definitions (CRD) 的控制器。以下是其核心工作流程的完整说明: 1. 初始化项目 # 创建项目目录 mkdir my-opera…...

长江学者答辩ppt美化_特聘教授_校企联聘学者_青年长江学者PPT案例模板
WordinPPT / 持续为双一流高校、科研院所、企业等提供PPT制作系统服务。 长江学者特聘教授 “长江学者奖励计划”中的一类,是高层次人才计划的重要组成部分,旨在吸引和培养具有国际领先水平的学科带头人。特聘教授需全职在国内高校工作,是高…...