Deformable DETR模型解读(附源码+论文)
Deformable DETR
论文链接:Deformable DETR: Deformable Transformers for End-to-End Object Detection
官方链接:Deformable-DETR(这个需要在linux上运行,所以我是用的是mmdetection里面的Deformable DERT,看了一下源码基本是一致的)
总体流程
Deformable DETR需要前置知识储备——DETR,这个我之前有写过一篇,大家可以先去了解一下,因为DETR里的内容我不会在这里重复讲解。你了解过DETR后,再来看Deformable DETR会发现超级简单,它只是在DETR的基础上做了一些改动,但是效果却会出奇的好,既节约的大量计算,又提高了效果。
ok,言归正传。目标检测想要效果做的好,有一个简单粗暴的方式,输入特征得大。举个例子,你输入100×100的特征数据效果一定比50×50的好。但问题是,这计算量可不是两倍的关系了,DETR的Transformers可是需要每个点与每个点做自注意力和交叉注意力计算。100×100展开成序列长度为1w,每个点又需要与其它1w个点做计算,计算量可是1w×1w,这直接喂给模型这可吃不消。我之前写的DETR里有说过,DETR的训练非常难,8个V100要跑6天才跑完300epoch,这还加大输入特征,简直要显卡老命。
Deformable DETR的作者就想啊,我能不能既增大输入特征,又不增加计算量呢?(既要马儿跑又要马儿不吃草)。做Transformers的时候需要计算每个点与每个点之间的关系,但是真的有那个必要吗?想象一下一张图,图上的每个点正常只与周边的点有羁绊,如果离的很远好像就搭不上什么关系了。按这个思路,那可不可以只计算周边的几个点呢?答案是,yes!并且实验表明,Deformable DETR训练epoch少10倍,就可以达到与DETR相同的效果(比如,Deformable DETR训练30个epoch = DETR训练300个epoch)。而且,由于Deformable DETR的输入特征大,所以它检测小目标的效果也会比DETR好。
那么Deformable DETR具体怎么做呢?看我娓娓道来
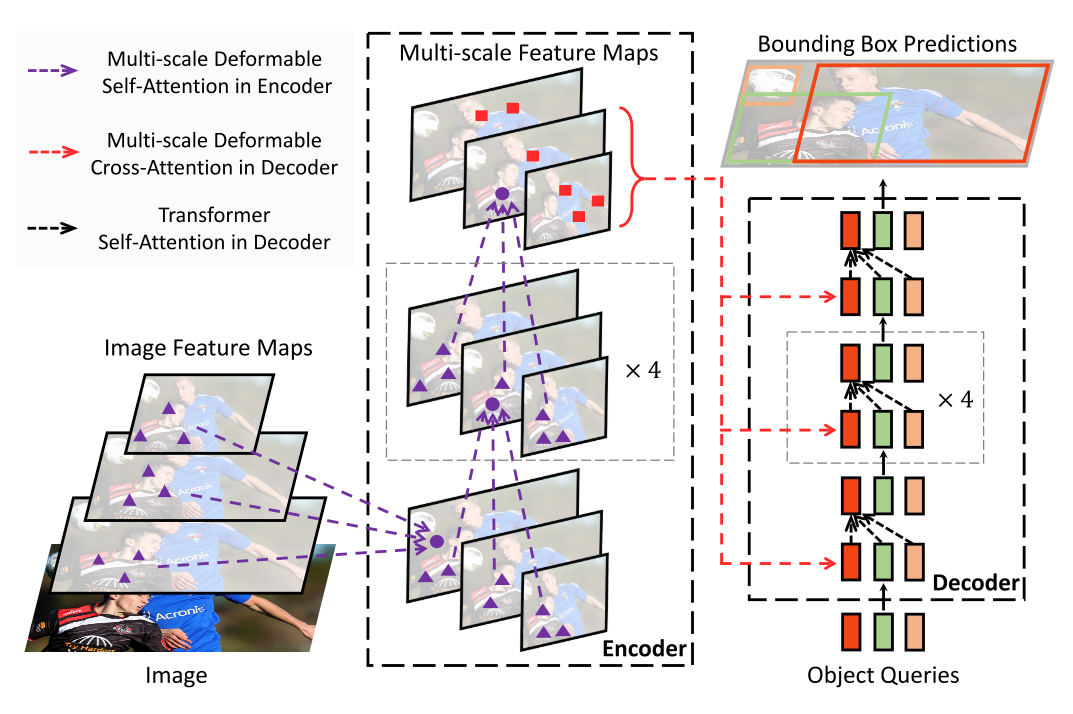
整体流程如下图。首先,一张图像传过来要做的第一件事,就是用backbone提取特征。现在做目标检测流行的事情就是多尺度特征提取,这也是Deformable DETR里的重点之一。比如下图,分别提取了3个层级特征图(代码里是4层)。但这里有个问题,Transform是有位置编码的,但很显然不同层级的每个点在归一化之后位置是一样的,所以还需要加上层级位置编码(在代码里这还是个可学习的参数)。
中间的Encoder就是对3个层级的特征图上每个点进行采样。上面不是说了嘛,跟每个点做Transform计算太费资源了,所以每个点采样几个点做Transform计算。代码里是每个点采样4个点,有小伙伴肯定问,woc?这么少!这能行?!结果告诉你是OK的,而且比跟全部计算的效果还好!那为什么是采样4个,不是2个?8个?16个?… 那就归咎于神经网络的玄学了… 中间的×4意思是注意力机制做了4遍,最后得到每个层级每个点对应的向量,就是每个点对应的特征是什么。
在右边的Decoder里,将encoder的结果做了交叉注意力,然后再做自注意力。在原始的DERT里是每张图绘制100个锚框,这里作者表示不够不够,绘制了300个锚框。
下图详细讲一下Encoder模块,这里为了方便理解这样画的,因为在代码里,特征图经过Transform都是展开成一个序列进行计算的,但是那样画图就有点抽象了,不好理解。这里先输入一张特征图(理论上是序列,这里只是方便理解这么画的),经过一个全连接得到Transform里的Value,这里输出3个head是注意力机制头。
Value有了,那Query呢?在图的上面(这里的Query其实和下面输入的特征图是一个东西,但是这里就画的是序列),也经过一个全连接获得3个采样点的偏移位置(代码里是4个)。这个偏移位置我解释一下,比如你取一个点的坐标是(30,30),这时候你获得它3个采样点的偏移位置分别是(1,1),(1,2),(-2,-1),那么它分别是(31,31),(31,32),(28,29)。
这3个采样点有了,但是感觉可以更优化一下。这3个采样点的重要性一样吗?好像不一定吧。作者给Query又连了一个全连接+Softmax计算了3个采样的权重。这样再给采样点进行加权求和,得到3个头所对应的特征。最后连个全连接层得到输出。
代码
configs
首先到tools/train.py里配置一下参数, 我用的是这个
../configs/deformable_detr/deformable-detr_r50_16xb2-50e_coco.py
运行后大概率会报错,常见的就是路径问题,我这里给个通用的解决方法。
运行train.py后会在路径tools/下生成一个work_dirs/deformable-detr_r50_16xb2-50e_coco/deformable-detr_r50_16xb2-50e_coco.py文件,将deformable-detr_r50_16xb2-50e_coco.py文件改个名字,比如my_deformable-detr_r50_16xb2-50e_coco.py,然后放在自己指定的路径下,比如我会放在configs/deformable_detr/my_deformable-detr_r50_16xb2-50e_coco.py。
这个配置文件里会包含所有的配置,不用自己一个一个找了,然后看一下这个配置文件里的路径。比如train_dataloader里的ann_file、data_root路径有没有问题,搞不懂相对路径的直接用绝对路径替换就行。别的配置基本不用改,如果你看得懂可以自己改一下。我好像是啥也没改,我是根据官方的路径放我的数据集的,所以没改路径好像。
那么既然改了我的config文件,那配置参数也得改一下,改成自己的那个就行。
../configs/deformable_detr/my_deformable-detr_r50_16xb2-50e_coco.py
backbone
首先跳入到mmdet/models/detectors/base_detr.py里DetectionTransformer的方法loss中。
def loss(self, batch_inputs: Tensor,batch_data_samples: SampleList) -> Union[dict, list]:img_feats = self.extract_feat(batch_inputs)head_inputs_dict = self.forward_transformer(img_feats,batch_data_samples)losses = self.bbox_head.loss(**head_inputs_dict, batch_data_samples=batch_data_samples)return losses
self.extract_feat就是基础的提取特征模块,进去看看怎么操作的。这里用的是resnet50(可在配置文件里自己设置)。来到路径mmdet/models/backbones/resnet.py里ResNet下的方法forward。
def forward(self, x):"""Forward function."""if self.deep_stem:x = self.stem(x)else:x = self.conv1(x)x = self.norm1(x)x = self.relu(x)x = self.maxpool(x)outs = []for i, layer_name in enumerate(self.res_layers):res_layer = getattr(self, layer_name)x = res_layer(x)if i in self.out_indices:outs.append(x)return tuple(outs)
resnet模块很简单的,就是基础的conv->BN->relu三件套。for循环里有4个层级,并且后3个层级的结果都会放到out中。最终,outs存放着三个层级的输出{(b,512,h,w),(b,1024,h/2,w/2),(b,2048,h/4,w/4)},分别表示从浅到深的层级特征。(这里的hw并不表示图片的原来尺寸,只是为了方便表示后面层级的输出图片size相对于前面size的比例)
在extract_feat里做完backbone还有一个neck层。
def extract_feat(self, batch_inputs: Tensor) -> Tuple[Tensor]:x = self.backbone(batch_inputs)if self.with_neck:x = self.neck(x)return x
这个neck层并没有什么特殊的,只是对最后一层的输出再多做一层特征提取,进去看一下。在路径mmdet/models/necks/channel_mapper.py下ChannelMapper的方法forward中。
def forward(self, inputs: Tuple[Tensor]) -> Tuple[Tensor]:assert len(inputs) == len(self.convs)outs = [self.convs[i](inputs[i]) for i in range(len(inputs))]if self.extra_convs:for i in range(len(self.extra_convs)):if i == 0:outs.append(self.extra_convs[0](inputs[-1]))else:outs.append(self.extra_convs[i](outs[-1]))return tuple(outs)
可以看到,先对三个输出层的数据先进行了一波conv,它将每层的输出特征图的个数都转为了256。并对最后一层又走了一遍convs模块,最终返回的outs存放了4个层级的输出{(b,256,h,w),(b,256,h/2,w/2),(b,256,h/4,w/4),(b,256,h/8,w/8)}。
=======================================================================
ok,回到最初的位置,现在往下看self.forward_transformer。
transformer
在路径mmdet/models/detectors/base_detr.py下DetectionTransformer的方法forward_transformer。
def forward_transformer(self,img_feats: Tuple[Tensor],batch_data_samples: OptSampleList = None) -> Dict:encoder_inputs_dict, decoder_inputs_dict = self.pre_transformer(img_feats, batch_data_samples)encoder_outputs_dict = self.forward_encoder(**encoder_inputs_dict)tmp_dec_in, head_inputs_dict = self.pre_decoder(**encoder_outputs_dict)decoder_inputs_dict.update(tmp_dec_in)decoder_outputs_dict = self.forward_decoder(**decoder_inputs_dict)head_inputs_dict.update(decoder_outputs_dict)return head_inputs_dict
这波代码基本就是全流程了,这里还画了个图,非常形象,如下。

这里我会一步一步debug到pre_transformer、forward_encoder、pre_decoder和forward_decoder讲解内容。
首先来到路径mmdet/models/detectors/deformable_detr.py下DeformableDETR的方法pre_transformer中。
def pre_transformer(self,mlvl_feats: Tuple[Tensor],batch_data_samples: OptSampleList = None) -> Tuple[Dict]:batch_size = mlvl_feats[0].size(0)# construct binary masks for the transformer.assert batch_data_samples is not Nonebatch_input_shape = batch_data_samples[0].batch_input_shapeinput_img_h, input_img_w = batch_input_shapeimg_shape_list = [sample.img_shape for sample in batch_data_samples]same_shape_flag = all([s[0] == input_img_h and s[1] == input_img_w for s in img_shape_list])# support torch2onnx without feeding masksif torch.onnx.is_in_onnx_export() or same_shape_flag:...# 不用看else:masks = mlvl_feats[0].new_ones((batch_size, input_img_h, input_img_w))for img_id in range(batch_size):img_h, img_w = img_shape_list[img_id]masks[img_id, :img_h, :img_w] = 0mlvl_masks = []mlvl_pos_embeds = []for feat in mlvl_feats:mlvl_masks.append(F.interpolate(masks[None], size=feat.shape[-2:]).to(torch.bool).squeeze(0))mlvl_pos_embeds.append(self.positional_encoding(mlvl_masks[-1]))feat_flatten = []lvl_pos_embed_flatten = []mask_flatten = []spatial_shapes = []for lvl, (feat, mask, pos_embed) in enumerate(zip(mlvl_feats, mlvl_masks, mlvl_pos_embeds)):batch_size, c, h, w = feat.shapespatial_shape = torch._shape_as_tensor(feat)[2:].to(feat.device)# [bs, c, h_lvl, w_lvl] -> [bs, h_lvl*w_lvl, c]feat = feat.view(batch_size, c, -1).permute(0, 2, 1)pos_embed = pos_embed.view(batch_size, c, -1).permute(0, 2, 1)lvl_pos_embed = pos_embed + self.level_embed[lvl].view(1, 1, -1)# [bs, h_lvl, w_lvl] -> [bs, h_lvl*w_lvl]if mask is not None:mask = mask.flatten(1)feat_flatten.append(feat)lvl_pos_embed_flatten.append(lvl_pos_embed)mask_flatten.append(mask)spatial_shapes.append(spatial_shape)# (bs, num_feat_points, dim)feat_flatten = torch.cat(feat_flatten, 1)lvl_pos_embed_flatten = torch.cat(lvl_pos_embed_flatten, 1)# (bs, num_feat_points), where num_feat_points = sum_lvl(h_lvl*w_lvl)if mask_flatten[0] is not None:mask_flatten = torch.cat(mask_flatten, 1)else:mask_flatten = None# (num_level, 2)spatial_shapes = torch.cat(spatial_shapes).view(-1, 2)level_start_index = torch.cat((spatial_shapes.new_zeros((1,)), # (num_level)spatial_shapes.prod(1).cumsum(0)[:-1]))if mlvl_masks[0] is not None:valid_ratios = torch.stack( # (bs, num_level, 2)[self.get_valid_ratio(m) for m in mlvl_masks], 1)else:valid_ratios = mlvl_feats[0].new_ones(batch_size, len(mlvl_feats),2)encoder_inputs_dict = dict(feat=feat_flatten,feat_mask=mask_flatten,feat_pos=lvl_pos_embed_flatten,spatial_shapes=spatial_shapes,level_start_index=level_start_index,valid_ratios=valid_ratios)decoder_inputs_dict = dict(memory_mask=mask_flatten,spatial_shapes=spatial_shapes,level_start_index=level_start_index,valid_ratios=valid_ratios)return encoder_inputs_dict, decoder_inputs_dict
从名字就可以知道mlvl_feats是多尺度的特征图像,里面包含了四组数据。
我们先获取图像输入的形状input_img_h和input_img_w,但是很显然,每张图片不可能正好就是这个大小。所以我们建立一个mask,它的size为(input_img_h,input_img_w),初始化全为1。然后获取每张图片的实际大小img_h和img_w,将对应区域的mask值设置为 0,表示该区域是有效区域。
现在每张图片的mask有了,但是我们要处理的是mlvl_feats啊,这尺寸对不上啊。所以我们进入一个for循环,将每张图片的mask进行下采样,使其适配mlvl_feats里不同尺寸的特征图大小。mlvl_pos_embeds看名字就知道是加位置编码的。
现在mlvl_feats、mlvl_masks、mlvl_pos_embeds这些格式还是(...,h,w),但是我们要做transformer不能直接对(h,w)图像格式做啊,得拉长为h×w。所以我们进入一个for循环,将所有的数据格式都拉长,顺便调整一下维度,将h×w调到前面去。中间可以看到有一个加法操作,看名字就知道,位置编码pos_embed+层级编码level_embed。可以看一下这个level_embed,如下,可以看到这并不是一个固定值,是一个可以学习的参数。
self.level_embed = nn.Parameter(torch.Tensor(self.num_feature_levels, self.embed_dims))
为了方便后面计算,将四个层级的数据拼在一起。如何区分每个层级的数据呢?因为每个层级的长度是固定的嘛,h×w,所以计算一下每个层级开始的index,存放在level_start_index里。
get_valid_ratio是计算特征图在mask上的有效比例。上面不是说了,输入size是固定的,但是原图size不一定就是输入size,因此做了一个mask,0表示有效区域,1表示无效区域。然后又根据多尺度特征图的size对mask进行缩放。get_valid_ratio通过一个for循环计算mlvl_masks上四个不同尺度的高宽的有效比例。
encoder
路径mmdet/models/layers/transformer/deformable_detr_layers.py下DeformableDetrTransformerEncoder的方法forward里。
def forward(self, query: Tensor, query_pos: Tensor,key_padding_mask: Tensor, spatial_shapes: Tensor,level_start_index: Tensor, valid_ratios: Tensor,**kwargs) -> Tensor:reference_points = self.get_encoder_reference_points(spatial_shapes, valid_ratios, device=query.device)for layer in self.layers:query = layer(query=query,query_pos=query_pos,key_padding_mask=key_padding_mask,spatial_shapes=spatial_shapes,level_start_index=level_start_index,valid_ratios=valid_ratios,reference_points=reference_points,**kwargs)return query
我们现在要做Transformer,而Transformer序列上的token需要根据不同层级的特征图上的点做计算,但是不同层级的特征图的H和W不一样啊,它们的坐标对应关系也不一样。为了方便大家理解,我画了张图,如下。
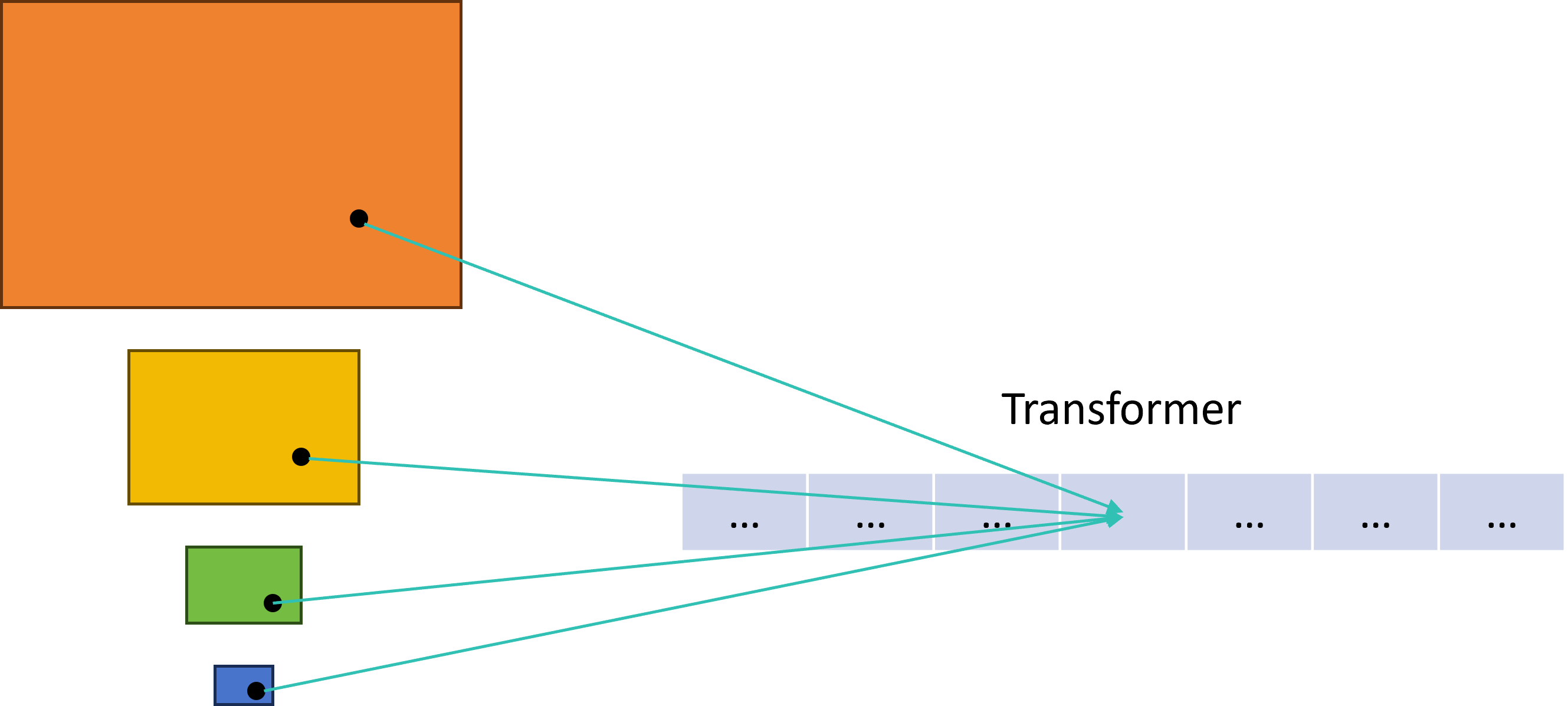
self.get_encoder_reference_points就是来计算特征图中每个位置相对于整个图像的位置(其实就是归一化),然后用这个参考点来计算Transformer序列上的值。来看看它怎么实现的。
def get_encoder_reference_points(spatial_shapes: Tensor, valid_ratios: Tensor,device: Union[torch.device, str]) -> Tensor:reference_points_list = []for lvl, (H, W) in enumerate(spatial_shapes):ref_y, ref_x = torch.meshgrid(torch.linspace(0.5, H - 0.5, H, dtype=torch.float32, device=device),torch.linspace(0.5, W - 0.5, W, dtype=torch.float32, device=device))ref_y = ref_y.reshape(-1)[None] / (valid_ratios[:, None, lvl, 1] * H)ref_x = ref_x.reshape(-1)[None] / (valid_ratios[:, None, lvl, 0] * W)ref = torch.stack((ref_x, ref_y), -1)reference_points_list.append(ref)reference_points = torch.cat(reference_points_list, 1)# [bs, sum(hw), num_level, 2]reference_points = reference_points[:, :, None] * valid_ratios[:, None]return reference_points
spatial_shapes里存放的是每个层级的H和W,for循环遍历它们。使用 torch.meshgrid生成每个特征图层级的网格坐标,ref_y和ref_x。valid_ratios里存放的是上面计算的垂直和水平方向上的有效比例,用于确保参考点映射到有效区域。最后将它们拼接在一起,然后根据每个层级的有效比例,调整参考点,最终返回reference_points的size为(b,n,4,2),表示4个层级和2个坐标xy。
=======================================================================
回到DeformableDetrTransformerEncoder的方法forward里。现在进入到一个for循环,来看看self.layers的构造。在路径mmdet/models/layers/transformer/detr_layers.py下DetrTransformerEncoderLayer的方法forward里。
def forward(self, query: Tensor, query_pos: Tensor,key_padding_mask: Tensor, **kwargs) -> Tensor:query = self.self_attn(query=query,key=query,value=query,query_pos=query_pos,key_pos=query_pos,key_padding_mask=key_padding_mask,**kwargs)query = self.norms[0](query)query = self.ffn(query)query = self.norms[1](query)return query
首先做了多尺度的自注意力,后面再连个标准化、全连接、标准化,这些就不说了,主要看重点对象self.self_attn。这里可以看到,传入的query、key、value都是query。进去看看怎么个事。这个路径在mmcv的包里,给个相对路径吧,自己的环境路径\Lib\site-packages\mmcv\ops\multi_scale_deform_attn.py下MultiScaleDeformableAttention的方法forward里。
def forward(self,query: torch.Tensor,key: Optional[torch.Tensor] = None,value: Optional[torch.Tensor] = None,identity: Optional[torch.Tensor] = None,query_pos: Optional[torch.Tensor] = None,key_padding_mask: Optional[torch.Tensor] = None,reference_points: Optional[torch.Tensor] = None,spatial_shapes: Optional[torch.Tensor] = None,level_start_index: Optional[torch.Tensor] = None,**kwargs) -> torch.Tensor:if value is None:value = queryif identity is None:identity = queryif query_pos is not None:query = query + query_posif not self.batch_first:# change to (bs, num_query ,embed_dims)query = query.permute(1, 0, 2)value = value.permute(1, 0, 2)bs, num_query, _ = query.shapebs, num_value, _ = value.shapeassert (spatial_shapes[:, 0] * spatial_shapes[:, 1]).sum() == num_valuevalue = self.value_proj(value)if key_padding_mask is not None:value = value.masked_fill(key_padding_mask[..., None], 0.0)value = value.view(bs, num_value, self.num_heads, -1)sampling_offsets = self.sampling_offsets(query).view(bs, num_query, self.num_heads, self.num_levels, self.num_points, 2)attention_weights = self.attention_weights(query).view(bs, num_query, self.num_heads, self.num_levels * self.num_points)attention_weights = attention_weights.softmax(-1)attention_weights = attention_weights.view(bs, num_query,self.num_heads,self.num_levels,self.num_points)if reference_points.shape[-1] == 2:offset_normalizer = torch.stack([spatial_shapes[..., 1], spatial_shapes[..., 0]], -1)sampling_locations = reference_points[:, :, None, :, None, :] \+ sampling_offsets \/ offset_normalizer[None, None, None, :, None, :]elif reference_points.shape[-1] == 4:sampling_locations = reference_points[:, :, None, :, None, :2] \+ sampling_offsets / self.num_points \* reference_points[:, :, None, :, None, 2:] \* 0.5else:raise ValueError(f'Last dim of reference_points must be'f' 2 or 4, but get {reference_points.shape[-1]} instead.')if ((IS_CUDA_AVAILABLE and value.is_cuda)or (IS_MLU_AVAILABLE and value.is_mlu)):output = MultiScaleDeformableAttnFunction.apply(value, spatial_shapes, level_start_index, sampling_locations,attention_weights, self.im2col_step)else:output = multi_scale_deformable_attn_pytorch(value, spatial_shapes, sampling_locations, attention_weights)output = self.output_proj(output)if not self.batch_first:# (num_query, bs ,embed_dims)output = output.permute(1, 0, 2)return self.dropout(output) + identity
identity是为了最后做残差连接的。query加上了位置编码,所以现在query和key、value是有区别的。给value做了一个全连接self.value_proj,毕竟value是通过query初始化来的,但是value并不是query,所以给value连个全连接做初始化(这地方比较神奇,跟传统的qkv的初始化方法不一样)。然后根据之前计算的mask,将无效区域赋值为0 ,不做计算。接着将维度分给8个注意力头。
self.sampling_offsets计算采样偏移,感觉是论文里非常核心的内容,但是做起来却非常简单,就是连了一个全连接。这个全连接的输入256那是固定的,但是输出256是有讲究的。我们需要计算4个层级的特征图,每张特征图上的每个点需要计算出4个偏移位置(采样点),每个偏移位置包括xy,而我们又有8个注意力头,那正好8×4×4×2=256。看一下我们计算出来的sampling_offsets在view后的的size为(b,n,8,4,4,2)。
self.attention_weights计算权重,也是论文核心内容,但也是很简单的操作。这次全连接的输出是128,表示8个注意力头,4个层级上的4个采样点的权重,8×4×4=128。计算出的attention_weights连一个softmax归一化,view后size为(b,n,8,4,4)。
上面两步我都感觉很神奇,仅仅用了query连两个全连接就得到了采样点的偏移位置和采样点的权重,但是论文也没解释为什么这样就可行。
现在我们有4个层级上每个点的4个偏移位置了,那就可以计算出采样点的实际位置了。首先看一下偏移位置信息sampling_offsets,可以看到里面的值都是些(1,0)、(2,0)...这些类型的,一看就是绝对位置的偏移值,所以先给它归一化,offset_normalizer里放的就是每个层级的尺寸。因为reference_points里的值是归一化后的结果,所以这么一加,ok。
现在我们要走一个MultiScaleDeformableAttnFunction,但是这里被封装起来了,看不见源码,所以我去Deformable-DETR/models/ops/functions/ms_deform_attn_func.py找了一下。
def ms_deform_attn_core_pytorch(value, value_spatial_shapes, sampling_locations, attention_weights):# for debug and test only,# need to use cuda version insteadN_, S_, M_, D_ = value.shape_, Lq_, M_, L_, P_, _ = sampling_locations.shapevalue_list = value.split([H_ * W_ for H_, W_ in value_spatial_shapes], dim=1)sampling_grids = 2 * sampling_locations - 1sampling_value_list = []for lid_, (H_, W_) in enumerate(value_spatial_shapes):# N_, H_*W_, M_, D_ -> N_, H_*W_, M_*D_ -> N_, M_*D_, H_*W_ -> N_*M_, D_, H_, W_value_l_ = value_list[lid_].flatten(2).transpose(1, 2).reshape(N_*M_, D_, H_, W_)# N_, Lq_, M_, P_, 2 -> N_, M_, Lq_, P_, 2 -> N_*M_, Lq_, P_, 2sampling_grid_l_ = sampling_grids[:, :, :, lid_].transpose(1, 2).flatten(0, 1)# N_*M_, D_, Lq_, P_sampling_value_l_ = F.grid_sample(value_l_, sampling_grid_l_,mode='bilinear', padding_mode='zeros', align_corners=False)sampling_value_list.append(sampling_value_l_)# (N_, Lq_, M_, L_, P_) -> (N_, M_, Lq_, L_, P_) -> (N_, M_, 1, Lq_, L_*P_)attention_weights = attention_weights.transpose(1, 2).reshape(N_*M_, 1, Lq_, L_*P_)output = (torch.stack(sampling_value_list, dim=-2).flatten(-2) * attention_weights).sum(-1).view(N_, M_*D_, Lq_)return output.transpose(1, 2).contiguous()
value_list里存放了每个层级的尺度大小。sampling_locations的值是归一化后的,所以取值范围是[0,1],sampling_grids将采样范围规划到[-1,1]。
for循环遍历这四个层级。先对value展平、转置和reshape,得到size为(8×b,32,h,w)。同理,对sampling_grids也进行此操作,得到size为(8×b,n,4,2)。F.grid_sample在value里根据给定的sampling_grids采样坐标进行采样,并使用双线性插值进行采样,每个采样点的值将基于其四个邻近像素的值进行加权平均。这个怎么理解呢,你这样想象一下。对于每个查询点query,它需要采样四个点做关系计算,这四个点的位置已知,在sampling_grid_l_里。于是它根据坐标位置在value_l_对应的特征图上找它的特征值(因为value_l_的size是(...,h,w),sampling_grid_l_的size是(...,xy),根据xy坐标在hw尺寸的图上找到对应位置,这个应该能理解吧)。但是它还转个弯,它不直接按xy坐标位置去找对应的特征值,它根据xy周边的4个点进行加权平均计算出该位置的特征值。(这块我理解了好久,因为debug不进去,只能想象)
处理完采样点,采样权重的形状得和采样点一样,所以也转置reshape一下。将采样点堆叠在一起,然后展平与采样权重加权求和,并reshape回原来的size,返回的size为(b,n,256)。
=======================================================================
回到MultiheadAttention的方法forward,下面就很简单了。连个全连接,做个残差连接返回结果。这个过程还要重复好几次,好像做了是6层,做完encoder就可以做decoder了。
Decoder
在路径mmdet/models/detectors/deformable_detr.py下DeformableDETR的方法pre_decoder。
def pre_decoder(self, memory: Tensor, memory_mask: Tensor,spatial_shapes: Tensor) -> Tuple[Dict, Dict]:batch_size, _, c = memory.shapeif self.as_two_stage:...# 没用 不看else:enc_outputs_class, enc_outputs_coord = None, Nonequery_embed = self.query_embedding.weightquery_pos, query = torch.split(query_embed, c, dim=1)query_pos = query_pos.unsqueeze(0).expand(batch_size, -1, -1)query = query.unsqueeze(0).expand(batch_size, -1, -1)reference_points = self.reference_points_fc(query_pos).sigmoid()decoder_inputs_dict = dict(query=query,query_pos=query_pos,memory=memory,reference_points=reference_points)head_inputs_dict = dict(enc_outputs_class=enc_outputs_class,enc_outputs_coord=enc_outputs_coord) if self.training else dict()return decoder_inputs_dict, head_inputs_dict
可以看到query_embed的size为(300,512),原始Dert每次预测100个检测框,这里增加到了300个。这里query_embed的512维切成两块,query和query_pos,两个平分秋色,各拿走256维。给query_pos连了一个全连接层,输出size为(b,300,2),将原本256维转为2维,代表预测每个查询位置的xy坐标。做个sigmoid激活,将输出限制在[0,1],就是归一化坐标。
根据流程,pre_decoder做完之后是forward_decoder。来到路径mmdet/models/detectors/deformable_detr.py下DeformableDETR的方法forward_decoder。
def forward_decoder(self, query: Tensor, query_pos: Tensor, memory: Tensor,memory_mask: Tensor, reference_points: Tensor,spatial_shapes: Tensor, level_start_index: Tensor,valid_ratios: Tensor) -> Dict:inter_states, inter_references = self.decoder(query=query,value=memory,query_pos=query_pos,key_padding_mask=memory_mask, # for cross_attnreference_points=reference_points,spatial_shapes=spatial_shapes,level_start_index=level_start_index,valid_ratios=valid_ratios,reg_branches=self.bbox_head.reg_branchesif self.with_box_refine else None)references = [reference_points, *inter_references]decoder_outputs_dict = dict(hidden_states=inter_states, references=references)return decoder_outputs_dict
首先我们来看一下self.decoder的内容,来到路径mmdet/models/layers/transformer/deformable_detr_layers.py里DeformableDetrTransformerDecoder的方法forward中。
def forward(self,query: Tensor,query_pos: Tensor,value: Tensor,key_padding_mask: Tensor,reference_points: Tensor,spatial_shapes: Tensor,level_start_index: Tensor,valid_ratios: Tensor,reg_branches: Optional[nn.Module] = None,**kwargs) -> Tuple[Tensor]:output = queryintermediate = []intermediate_reference_points = []for layer_id, layer in enumerate(self.layers):if reference_points.shape[-1] == 4:... # 不是 不看else:assert reference_points.shape[-1] == 2reference_points_input = \reference_points[:, :, None] * \valid_ratios[:, None]output = layer(output,query_pos=query_pos,value=value,key_padding_mask=key_padding_mask,spatial_shapes=spatial_shapes,level_start_index=level_start_index,valid_ratios=valid_ratios,reference_points=reference_points_input,**kwargs)if reg_branches is not None:... # Noneif self.return_intermediate:intermediate.append(output)intermediate_reference_points.append(reference_points)if self.return_intermediate:return torch.stack(intermediate), torch.stack(intermediate_reference_points)return output, reference_points
这里一个for循环遍历self.layers,这里的self.layers也是六层,不过东西比encoder多了,它不仅有多尺度的自注意力,还有交叉注意力。这六层每一次的结果都会被保存下来。
reference_points和valid_ratios在对应的宽度和高度上相乘,得到一个新的张量reference_points_input,size为 (b,300,4,2)。每个查询在4个层级下的参考点坐标都会根据该层级的有效区域比例进行调整。比如,如果某个层级的有效区域比率为 0.5,则该层级对应的参考点坐标会缩放到原来的 50% 的范围内。
ok,主要是说这个layer。在路径mmdet/models/layers/transformer/detr_layers.py下DetrTransformerDecoderLayer的方法forward。
def forward(self,query: Tensor,key: Tensor = None,value: Tensor = None,query_pos: Tensor = None,key_pos: Tensor = None,self_attn_mask: Tensor = None,cross_attn_mask: Tensor = None,key_padding_mask: Tensor = None,**kwargs) -> Tensor:query = self.self_attn(query=query,key=query,value=query,query_pos=query_pos,key_pos=query_pos,attn_mask=self_attn_mask,**kwargs)query = self.norms[0](query)query = self.cross_attn(query=query,key=key,value=value,query_pos=query_pos,key_pos=key_pos,attn_mask=cross_attn_mask,key_padding_mask=key_padding_mask,**kwargs)query = self.norms[1](query)query = self.ffn(query)query = self.norms[2](query)return query
首先做个自注意力,在自己的环境路径\Lib\site-packages\mmcv\cnn\bricks\transformer.py下MultiheadAttention的forward。
def forward(self,query,key=None,value=None,identity=None,query_pos=None,key_pos=None,attn_mask=None,key_padding_mask=None,**kwargs):if key is None:key = queryif value is None:value = keyif identity is None:identity = queryif key_pos is None:if query_pos is not None:# use query_pos if key_pos is not availableif query_pos.shape == key.shape:key_pos = query_poselse:warnings.warn(f'position encoding of key is'f'missing in {self.__class__.__name__}.')if query_pos is not None:query = query + query_posif key_pos is not None:key = key + key_posif self.batch_first:query = query.transpose(0, 1)key = key.transpose(0, 1)value = vspose(0, 1)out = self.attn(query=query,key=key,value=value,attn_mask=attn_mask,key_padding_mask=key_padding_mask)[0]if self.batch_first:out = out.transpose(0, 1)return identity + self.dropout_layer(self.proj_drop(out))
很简单,这里的query、key和value一开始都是query。query和key的位置编码都是上面平分秋色的query_pos。加上位置编码后做自注意力,这里的self.attn是nn模块里的东西很简单,就是300个兄弟自己先做个自注意力。最后做个残差连接返回。
=======================================================================
回到DetrTransformerDecoderLayer的方法forward。下面走了个标准化,ok,来到交叉注意力。可以看的这里的query还是decoder的300个打工仔,value则是encoder的输出,这里就有了一个跨越了,不是自己和自己人计算了。来看看怎么做的,在自环境路径\Lib\site-packages\mmcv\ops\multi_scale_deform_attn.py下MultiScaleDeformableAttention的方法forward。是不是很眼熟,这块和上面encoder计算自注意力走的一样的forward,只不过上次query和value初始都是query,而这次的value可不是query了,这里不重复讲代码了。
=======================================================================
回到DeformableDetrTransformerDecoder的方法forward中。self.layers有6层,同样的事情会做6遍,intermediate和intermediate_reference_points存放中间的结果。最终回到DeformableDETR的forward_decoder,这些数据会打包好存放在decoder_outputs_dict里返回。
Loss
mmdet/models/dense_heads/deformable_detr_head.py里DeformableDETRHead的方法loss。
def loss(self, hidden_states: Tensor, references: List[Tensor],enc_outputs_class: Tensor, enc_outputs_coord: Tensor,batch_data_samples: SampleList) -> dict:batch_gt_instances = []batch_img_metas = []for data_sample in batch_data_samples:batch_img_metas.append(data_sample.metainfo)batch_gt_instances.append(data_sample.gt_instances)outs = self(hidden_states, references)loss_inputs = outs + (enc_outputs_class, enc_outputs_coord,batch_gt_instances, batch_img_metas)losses = self.loss_by_feat(*loss_inputs)return losses
从上面打包好的decoder_outputs_dict里拆出hidden_states和references。hidden_states存放的是刚刚6层预测的300个锚框特征数据,每个锚框数据的特征维度为256,size为(6,b,300,256)。references存放的是每一层预测出来的300个锚框xy坐标,每个list的size为(b,300,2)。看一下self是如何处理这两个数据的,来到路径mmdet/models/layers/transformer/deformable_detr_layers.py里DeformableDETRHead下的方法forward中。
def forward(self, hidden_states: Tensor,references: List[Tensor]) -> Tuple[Tensor, Tensor]:all_layers_outputs_classes = []all_layers_outputs_coords = []for layer_id in range(hidden_states.shape[0]):reference = inverse_sigmoid(references[layer_id])# NOTE The last reference will not be used.hidden_state = hidden_states[layer_id]outputs_class = self.cls_branches[layer_id](hidden_state)tmp_reg_preds = self.reg_branches[layer_id](hidden_state)if reference.shape[-1] == 4:tmp_reg_preds += reference # 不看else:assert reference.shape[-1] == 2tmp_reg_preds[..., :2] += referenceoutputs_coord = tmp_reg_preds.sigmoid()all_layers_outputs_classes.append(outputs_class)all_layers_outputs_coords.append(outputs_coord)all_layers_outputs_classes = torch.stack(all_layers_outputs_classes)all_layers_outputs_coords = torch.stack(all_layers_outputs_coords)return all_layers_outputs_classes, all_layers_outputs_coords
for循环遍历6层数据,获取每层对应的hidden_state和reference。hidden_state会走两个分支,分类和回归。self.cls_branches是用于分类的,输出80个类别的概率;self.reg_branches是用于回归的,得到锚框的四个坐标值xywh。这里我们不是two_stage,所以只有xy的数据,加上reference,获得偏移位置。最后将坐标映射回 [0,1] 区间,存放在对应列表中,返回。
计算损失的方法跟DETR差不多,求预测框与真实框大小和位置的差异。来到路径mmdet/models/task_modules/assigners/hungarian_assigner.py里HungarianAssigner的方法assign。
def assign(self,pred_instances: InstanceData,gt_instances: InstanceData,img_meta: Optional[dict] = None,**kwargs) -> AssignResult:assert isinstance(gt_instances.labels, Tensor)num_gts, num_preds = len(gt_instances), len(pred_instances)gt_labels = gt_instances.labelsdevice = gt_labels.device# 1. assign -1 by defaultassigned_gt_inds = torch.full((num_preds,),-1,dtype=torch.long,device=device)assigned_labels = torch.full((num_preds,),-1,dtype=torch.long,device=device)if num_gts == 0 or num_preds == 0:# 不看# 2. compute weighted costcost_list = []for match_cost in self.match_costs:cost = match_cost(pred_instances=pred_instances,gt_instances=gt_instances,img_meta=img_meta)cost_list.append(cost)cost = torch.stack(cost_list).sum(dim=0)# 3. do Hungarian matching on CPU using linear_sum_assignmentcost = cost.detach().cpu()if linear_sum_assignment is None:raise ImportError('Please run "pip install scipy" ''to install scipy first.')matched_row_inds, matched_col_inds = linear_sum_assignment(cost)matched_row_inds = torch.from_numpy(matched_row_inds).to(device)matched_col_inds = torch.from_numpy(matched_col_inds).to(device)# 4. assign backgrounds and foregrounds# assign all indices to backgrounds firstassigned_gt_inds[:] = 0# assign foregrounds based on matching resultsassigned_gt_inds[matched_row_inds] = matched_col_inds + 1assigned_labels[matched_row_inds] = gt_labels[matched_col_inds]return AssignResult(num_gts=num_gts,gt_inds=assigned_gt_inds,max_overlaps=None,labels=assigned_labels)
gt_instances存放的是真实锚框的数据,包括锚框的位置和类别。pred_instances存放的是预测出来的300个锚框的信息。assigned_gt_inds和assigned_labels存放的是预测的300个框哪些框与真实框匹配的信息,后面详细说,这里先要初始化,全部赋值为-1。
self.match_costs存放的是配置文件里面定义的损失函数,分别是FocalLossCost、BBoxL1Cost和IoUCost。for循环会分别计算预测框与真实框的锚框的分类损失、xywh损失和iou损失。比如真实框有15个,那这300个预测框会分别和这15的真实框做损失计算。linear_sum_assignment是调用scipy包的,用来计算出这300个预测框匹配上的15个框。matched_row_inds存放的是300个预测框对应的id,matched_col_inds存放的是15个真实框对应的id。比如matched_row_inds的值为[8,18,...],matched_col_inds的值为[7,0,...],这就表示第8个预测框对应第7个真实框,以此类推。
ok,这里看到了刚刚初始化的assigned_gt_inds和assigned_labels,assigned_gt_inds和assigned_labels的size都是300。assigned_gt_inds将与真实框匹配的预测框赋值为真实框的id,assigned_labels复制为对应类别标签。
主要内容大概就这些…
相关文章:
)
Deformable DETR模型解读(附源码+论文)
Deformable DETR 论文链接:Deformable DETR: Deformable Transformers for End-to-End Object Detection 官方链接:Deformable-DETR(这个需要在linux上运行,所以我是用的是mmdetection里面的Deformable DERT,看了一下源码基本是…...

游戏引擎学习第255天:构建配置树
为今天的内容设定背景 今天的任务是构建性能分析(profiling)视图。 目前来看,展示性能分析图形本身并不复杂,大部分相关功能在昨天已经实现。图形显示部分应该相对直接,工作量不大。 真正需要解决的问题,是…...

JavaScript性能优化实战之调试与性能检测工具
在进行 JavaScript 性能优化时,了解和使用正确的调试与性能检测工具至关重要。它们能够帮助我们识别性能瓶颈,精确定位问题,并做出有针对性的优化措施。本文将介绍一些常见的调试和性能检测工具,帮助你更好地分析和优化你的 JavaScript 代码。 1️⃣ Chrome DevTools Chro…...
)
C#VisionMaster算子二次开发(非方案版)
前言 在网上VisionMaster的教程通常都是按照方案执行的形式,当然海康官方也是推荐使用整体方案的形式进行开发。但是由于我是做标准设备的,为了适配原有的软件框架和数据结构,就需要将特定需要使用的算子进行二次封装。最直接的好处是&#…...

计算机总线系统入门:理解数据传输的核心
一、总线系统简介:计算机内部的交通网络 在计算机系统中,总线是指连接各个组件的一组共享信号线或传输通道,用于在系统内不同的硬件模块之间传递数据、地址、控制信号等信息。它类似于交通系统中的道路,帮助计算机各个部件&#…...

【Linux】Petalinux驱动开发基础
基于Petalinux做Linux驱动开发。 部分图片和经验来源于网络,若有侵权麻烦联系我删除,主要是做笔记的时候忘记写来源了,做完笔记很久才写博客。 专栏目录:记录自己的嵌入式学习之路-CSDN博客 目录 1 一个完整的Linux系统(针对Zynq) 1.1 PS部分 1.2 PL部分(若…...

提升办公效率的PDF转图片实用工具
软件介绍 这款专注于PDF文档处理的工具功能单一但实用,能够将PDF文件内容智能提取并自动拼接成长图,为用户提供便捷的图片化文档处理方案,无需复杂设置即可轻松上手。 简洁直观的用户界面 软件界面设计简洁清爽,没有任何多余…...

动态库与ELF加载
目录 动态库 ELF格式 ELF和后缀的区别 什么是目标文件 ELF文件中的地址--虚拟地址 动静态库和可执行文件 动态库ELF加载 为什么编译时静态库需要指定库?而运行时不需要指定库的,但是动态库需要呢? 总结: 动态库 动态库制作需要的.o文件需要使…...

算法每日一题 | 入门-顺序结构-数字反转
数字反转 题目描述 输入一个不小于 且小于 ,同时包括小数点后一位的一个浮点数,例如 ,要求把这个数字翻转过来,变成 并输出。 输入格式 一行一个浮点数 输出格式 一行一个浮点数 输入输出样例 #1 输入 #1 123.4输出 #1 …...

ROS2学习笔记|实现订阅消息并朗读的详细步骤
本教程将详细介绍如何使用 ROS 2 实现一个节点订阅另一个节点发布的消息,并将接收到的消息通过 espeakng 库进行朗读的完整流程。以下步骤假设你已经安装好了 ROS 2 环境(以 ROS 2 Humble 为例),并熟悉基本的 Linux 操作。 注意&…...

【Hot 100】 146. LRU 缓存
目录 引言LRU 缓存官方解题LRU实现📌 实现步骤分解步骤 1:定义双向链表节点步骤 2:创建伪头尾节点(关键设计)步骤 3:实现链表基础操作操作 1:添加节点到头部操作 2:移除任意节点 步骤…...

web应用开发说明文档
工程目录结构 FACTORY--bin #网络流可执行程序 参考后文1.1部分文字说明webrtc-streamer--deployment #部署相关的配置--mysql #参考1.3 mysql数据库详细说明--conf #存放mysql的配置文件--data #存放pem加密…...

快速搜索与管理PDF文档的专业工具
软件介绍 在处理大量PDF文档时,专业的文档管理工具能显著提升工作效率。这款工具能够帮助用户快速检索PDF内容,并提供了便捷的合并与拆分功能,让复杂的PDF操作变得简单高效。 多文件内容检索能力 不同于传统PDF阅读器的单文件搜索局…...

在GPU集群上使用Megatron-LM进行高效的大规模语言模型训练
摘要 大型语言模型在多个任务中已取得了最先进的准确率。然而,训练这些模型的效率仍然面临挑战,原因有二:a) GPU内存容量有限,即使在多GPU服务器上也无法容纳大型模型;b) 所需的计算操作数量可能导致不现实的训练时间。因此,提出了新的模型并行方法,如张量并行和流水线…...

NocoDB:开源的 Airtable 替代方案
NocoDB:开源的 Airtable 替代方案 什么是 NocoDB?NocoDB 的主要特点丰富的电子表格界面工作流自动化应用商店程序化访问 NocoDB 的应用场景使用 Docker 部署 NocoDB1. 创建数据目录2. 运行 Docker 容器3. 访问 NocoDB 注意事项总结 什么是 NocoDB&#x…...

关于Python:7. Python数据库操作
一、sqlite3(轻量级本地数据库) sqlite3 是 Python 内置的模块,用于操作 SQLite 数据库。 SQLite 是一个轻量级、零配置的关系型数据库系统,整个数据库保存在一个文件中,适合小型项目和本地存储。 SQLite 不需要安装…...

修改ollama.service都可以实现什么?
通过修改 ollama.service 系统服务单元文件,可以实现以下核心配置变更: 一、网络与访问控制 监听地址与端口 通过 Environment="OLLAMA_HOST=0.0.0.0:11434" 修改服务绑定的 IP 和端口: 0.0.0.0 允许所有网络接口访问(默认仅限本地 127.0.0.1)。示例:改为 0.0.…...

k8s笔记——kubebuilder工作流程
kubebuilder工作流程 Kubebuilder 工作流程详解 Kubebuilder 是 Kubernetes 官方推荐的 Operator 开发框架,用于构建基于 Custom Resource Definitions (CRD) 的控制器。以下是其核心工作流程的完整说明: 1. 初始化项目 # 创建项目目录 mkdir my-opera…...

长江学者答辩ppt美化_特聘教授_校企联聘学者_青年长江学者PPT案例模板
WordinPPT / 持续为双一流高校、科研院所、企业等提供PPT制作系统服务。 长江学者特聘教授 “长江学者奖励计划”中的一类,是高层次人才计划的重要组成部分,旨在吸引和培养具有国际领先水平的学科带头人。特聘教授需全职在国内高校工作,是高…...

Vscode/Code-Server 安装中文包——CI/CD
前言 啊好多人问我怎么还不更新,其实本月是已经写了一篇测评的,但是鉴于过于超前会给产品带来不好的影响,所以就没有公开。那么既然这样本月就再更新一篇。 首先 声明 一点,安装中文包的初衷不是看不懂英文,也不是对…...
)
【信息系统项目管理师-论文真题】2012上半年论文详解(包括解题思路和写作要点)
更多内容请见: 备考信息系统项目管理师-专栏介绍和目录 文章目录 试题1:论信息系统工程的风险管理1、写作要点2、解题思路对项目风险的认识和项目风险管理的基本过程、主要方法、工具信息系统项目最主要的风险是什么试题2:论信息系统工程项目可行性研究1、写作要点2、解题思…...

PowerPC架构详解:定义、应用及特点
一、PowerPC架构的定义 PowerPC(Performance Optimization With Enhanced RISC – Performance Computing) 是一种由IBM、摩托罗拉(现NXP)和苹果于1991年联合开发的精简指令集(RISC)处理器架构,…...

IP伪装、代理池与分布式爬虫
一、动态代理IP应用:代理池的获取、选择与使用 代理池技术的核心是通过动态切换IP地址,让爬虫看起来像不同用户在访问网站,从而规避封禁。 (一)代理池的获取途径 1. 免费代理:低成本但高风险 免费代理可…...
)
【Arthas】火焰图优化应用CPU(问题原因:获取调用栈)
优化场景总结归纳 1. 问题背景 现象:在公共搜索功能中,火焰图分析发现 获取Java调用栈(StackTrace) 占用了约 6%的CPU(日常流量下),系统高负载时占比更高。原因: 每次外部API调用时…...
:从组合到排列的全面解析)
回溯算法详解(Java实现):从组合到排列的全面解析
引言 回溯算法是一种强大的算法思想,广泛应用于解决各种组合优化问题。它通过系统性地尝试所有可能的解,并在发现当前路径无法得到解时立即回溯,从而高效地找到问题的解。在本文中,我们将深入探讨回溯算法的核心思想、三要素、通…...
)
【BLE】【nRF Connect】 精讲nRF Connect自动化测试套件(宏录制、XML脚本)
目录 前言 1. nRF Connect自动化测试介绍 1.1. nRF connect宏录制功能介绍 1.2. 电脑端XML方式 1.3 实际应用案例 1.3.1 BLE 稳定性测试 1.3.2 设备固件更新(DFU)测试 1.3.3 批量设备配置 1.4 操作步骤 1.5 注意事项 2. nRF Connect日志记录 2.1. 日志记录功能 …...

springboot war包tomcat中运行报错,启动过滤器异常,一个或多个筛选器启动失败。
错误信息: "level": "ERROR", "thread": "localhost-startStop-1", "class": "o.a.c.c.C.[.[localhost].[/Crmeb-admin]", …...

基于开源AI大模型与AI智能名片S2B2C商城小程序的线上活动执行优化研究
摘要:本文以开源AI大模型、AI智能名片及S2B2C商城小程序为技术载体,探讨线上活动执行阶段的效能提升路径。通过分析某科技展会案例,发现AI智能名片可将参会者信息采集效率提升60%,S2B2C商城小程序的21链动模式使活动裂变传播速度提…...

解决奥壹oelove婚恋原生小程序上架问题,彻底解决解对问题增强版旗舰版通用
现在很多客户还不了解OElove小程序上架流程!因为很多用户对技术无感!随意上架工作都是要靠官方来辅助!这样在在二开性就会失去很多主动权!本人商业用户有全新原生态小程序源码(注意:这是原生非Uniapp&#…...
——类和对象(二))
Java SE(7)——类和对象(二)
1.包(package) 1.1 包的定义 在Java中,包是一种用于组织和管理类,接口和其他包的机制。主要作用是防止命名冲突,并提供一种访问控制机制 1.2 package关键字 package关键字的主要作用是声明当前类在哪个包里面。 当然,用户也可以…...

Python 装饰器优化策略模式:电商促销折扣的优雅解法
问题背景:促销策略的重复陷阱 在电商促销系统中,我们曾面临这样的痛点: promos [fidelity_promo, bulk_item_promo, large_order_promo] # 6.1节原始方案 def best_promo(order):return max(promo(order) for promo in promos)当新增new…...

redis延时队列详细介绍
Redis延时队列是一种利用Redis数据结构的功能来实现延时任务调度的方法。在Redis中,常用的数据结构包括List(列表)和Sorted Set(有序集合)。延时队列通常是通过有序集合来实现的。 具体实现步骤如下: 将延…...

PHP 开发工程师如何借助 DeepSeek 提升工作效率
在当今数字化时代,PHP 开发工程师面临着不断提高工作效率和应对复杂项目需求的挑战。DeepSeek 作为一款先进的人工智能工具,为 PHP 开发工程师提供了一系列强大的功能,能够显著助力其日常工作。从代码生成与优化,到文档撰写和知识…...

Vibe Coding 新时代:AI 辅助编程完全指南
第一章:什么是 Vibe Coding?AI 编程的新范式 在传统编程的世界里,程序员需要掌握语法、算法和框架,一行一行地编写代码。但随着人工智能的快速发展,一种全新的编程方式正在兴起——这就是 Vibe Coding(氛围编程)。 Vibe Coding 的定义 Vibe Coding 是由 AI 研究者 An…...

Oracle RAC ‘Metrics Global Cache Blocks Lost‘告警解决处理
1. 引言: 前段时间鄙人检查处理过Oracle RAC Metrics Global Cache Blocks Lost’告警,在此总结分享下针对该报警的原因分析及处理办法。 2. 具体事件 通过排查发现造成该告警的原因是共享存储控制器损坏导致的。由于发生已经有段时间了,没…...

Go语言入门基础:协程
第21章 协程 目录 21.1 启动Go协程 协程的概念与特点启动协程的方法及示例协程执行顺序的控制 21.2 通道 通道类型及表示方式21.2.1 实例化通道21.2.2 数据缓冲21.2.3 单向通道21.2.4 通道与select语句 21.3 互斥锁 协程并发访问的逻辑问题互斥锁的使用示例 21.4 WaitGroup类…...

Servlet+tomcat
serverlet 定义:是一个接口,定义了java类被浏览器(tomcat识别)的规则 所以我们需要自定义一个类,实现severlet接口复写方法 通过配置类实现路径和servlet的对应关系 执行原理 当用户在浏览器输入路径,会…...

中间件和组件
文章目录 1. 前言2. 中间件介绍3. 组件介绍4. 区别对比5. 简单类比6. 总结 中间件和组件 1. 前言 中间件和组件是软件开发中两个重要的概念,但它们的定位和作用完全不同。中间件解决的事通信、跨系统、安全等问题,组件是解决具体业务模块,提高…...

piccolo-large-zh-v2 和 bge-m3哪个效果好?
环境: piccolo-large-zh-v2 bge-m3 问题描述: piccolo-large-zh-v2 和 bge-m3哪个效果好? 解决方案: 比较Piccolo-large-zh-v2(商汤)与BGE-M3(智源)的效果时,需结合…...

《告别试错式开发:TDD的精准质量锻造术》
深度解锁TDD:应用开发的创新密钥 在应用开发的复杂版图中,如何雕琢出高质量、高可靠性的应用,始终是开发者们不懈探索的核心命题。测试驱动开发(TDD),作为一种颠覆性的开发理念与方法,正逐渐成…...
案例:构建简单的区块链——密码学基础)
哈希函数详解(SHA-2系列、SHA-3系列、SM3国密)案例:构建简单的区块链——密码学基础
文章目录 一、密码哈希函数概述1.1 哈希函数的基本概念1.2 哈希函数在数据安全中的应用 二、SHA-2系列算法详解2.1 SHA-2的起源与发展2.2 SHA-256技术细节与实现2.3 SHA-384和SHA-512的特点2.4 SHA-2系列算法的安全性评估 三、SHA-3系列算法详解3.1 SHA-3的起源与设计理念3.2 K…...

CUDA输出“hello world”
在我们学习任何一门编程语言的时候, 无疑当我们真正用其输出“hello world”的时候, 我们已经成功入门, 接下来要做的就是从入门到放弃了😆 接下来我们通过对比C和CUDA来学习CUDA的运行逻辑: C中的hello worldCUDA中的hello world文本编辑器编写源代码, 比如vscod…...
)
计算机视觉与深度学习 | 视觉里程计算法综述(传统+深度)
视觉里程计算法综述 1. 算法分类与原理1.1 传统几何方法1.2 深度学习方法2. 关键公式与模型2.1 本征矩阵分解2.2 深度学习模型架构3. 代码实现与开源项目3.1 传统方法实现3.2 深度学习方法实现4. 挑战与未来方向总结传统视觉里程计算法综述1. 算法分类与核心原理1.1 特征点法1.…...

c++ 函数参数传递
C 中的值传递和地址传递 在 C 中,函数参数传递主要有两种方式:值传递和地址传递(指针传递和引用传递都属于地址传递的变体)。 1. 值传递 特点 函数接收的是实参的副本对形参的修改不会影响原始变量适用于小型数据(…...

计算机视觉与深度学习 | 什么是图像金字塔?
图像金字塔详解 图像金字塔 图像金字塔详解1. **定义**2. **原理与公式****2.1 高斯金字塔****2.2 拉普拉斯金字塔**3. **代码示例****3.1 使用OpenCV实现****3.2 手动实现高斯模糊与降采样**4. **应用场景**5. **关键点总结**1. 定义 图像金字塔是一种多尺度图像表示方法,将…...
---自定义advisor扩展+结构化json输出)
AI超级智能体教程(五)---自定义advisor扩展+结构化json输出
文章目录 1.自定义拦截器1.2自定义Advisor1.2打断点调试过程1.3Re-reading Advisor自定义实现 2.恋爱报告开发--json结构化输出2.1原理介绍2.1代码实现2.3编写测试用例2.4结构化输出效果 1.自定义拦截器 1.2自定义Advisor spring里面的这个默认的是SimpleloggerAdvisor&#…...
)
ActiveMQ 集群搭建与高可用方案设计(一)
一、引言 在当今分布式系统盛行的时代,消息中间件扮演着至关重要的角色,而 ActiveMQ 作为一款开源的、功能强大的消息中间件,在众多项目中得到了广泛应用。它支持多种消息传输协议,如 JMS、AMQP、MQTT 等 ,能够方便地实…...

MySQL数据操作全攻略:DML增删改与DQL高级查询实战指南
知识点4【MySQL的DDL】 DDL:主要管理数据库、表、列等操作。 库→表(二维)→列(一维) 数据表的第一行是 列名称 数据库是由一张或多张表组成 我们先学习在数据库中创建数据表 0、常见的数据类型: 1、…...

RabbitMQ 中的六大工作模式介绍与使用
文章目录 简单队列(Simple Queue)模式配置类定义消费者定义发送消息测试消费 工作队列(Work Queues)模式配置类定义消费者定义发送消息测试消费负载均衡调优 发布/订阅(Publish/Subscribe)模式配置类定义消…...

一种基于重建前检测的实孔径雷达实时角超分辨方法——论文阅读
一种基于重建前检测的实孔径雷达实时角超分辨方法 1. 专利的研究目标与实际问题意义2. 专利提出的新方法、模型与公式2.1 重建前检测(DBR)与数据裁剪2.1.1 回波模型与检测准则2.1.2 数据裁剪效果2.2 数据自适应迭代更新2.2.1 代价函数与迭代公式2.2.2 矩阵递归更新2.3 正则化…...