【C++】通过红黑树封装map和set
前言:
通过之前的学习,我们已经学会了红黑树和map、set。这次我们要实现自己的map和set,对,使用红黑树进行封装!
当然,红黑树内容这里就不在赘述,我们会复用红黑树的代码,所以先将红黑树头文件代码拷贝过来。当然,也需要创建两个新的头文件,我将它们命名为"mymap.h"和"myset.h"。
这里把红黑树中的前中序遍历删除了,因为用不上。
提前声明,RBTree.h中的方法都是大写的,因为要和map和set类区分,这里map和set是按照STL标准实现的。
一:创建头文件
创建"mymap.h"和"myset.h",并包含"RBTree.h"头文件(这个就是我们之前实现的红黑树头文件,大家随意命名),之后为了方便后续操作,我们将它们都封装到一个bit命名空间中去。
这里set只需要K,一个模板参数;而map需要 K,V两个模板参数。其中的私有成员变量是红黑树。
二:修改模板参数
此时我们面临第一个问题,红黑树在其他类中声明,需要传入模板参数,但是set需要一个模板参数;map需要两个模板参数,我们该怎么想RBTree传入参数呢?
此时我们就需要将RBTree的模板参数修改了,其实C++源代码也是这么干的。
但是在此之前,还有一个问题,我们定义树节点的时候也应该修正。我们先来看看RBTree是如何修改的:
template<class K, class T>
class RBTree
{//......
}它将第二个参数修改为了T。
此时你慌了,WTF!这?这后面的代码不都要修改吗?那map和set又是怎么传入参数的?
因为set只存K,所以可以传入两个K;而map存键值对,我们第一个传入K,第二个传入pair<K, V>即可。
map头文件:
#pragma once
#include"RBTree.h"namespace bit
{template<class K, class V>class map{public:private:RBTree<K, pair<K, V>> _t;};
}
set头文件:
#pragma once
#include"RBTree.h"namespace bit
{template<class K>class set{public:private:RBTree<K, K> _t;};
}当然,树节点里面的也不再是只针对K, V存储了,而是存的T。
//定义树节点
template<class T>
struct RBTreeNode
{//让编译器生成默认构造RBTreeNode() = default;//写一个构造RBTreeNode(const T& data): _data(data){}T _data;RBTreeNode* _left = nullptr;RBTreeNode* _right = nullptr;RBTreeNode* _parent = nullptr; //父节点Colour _col = RED; //默认为红色
};看到这里你可能一头雾水,没事,我们画个图你就懂了:
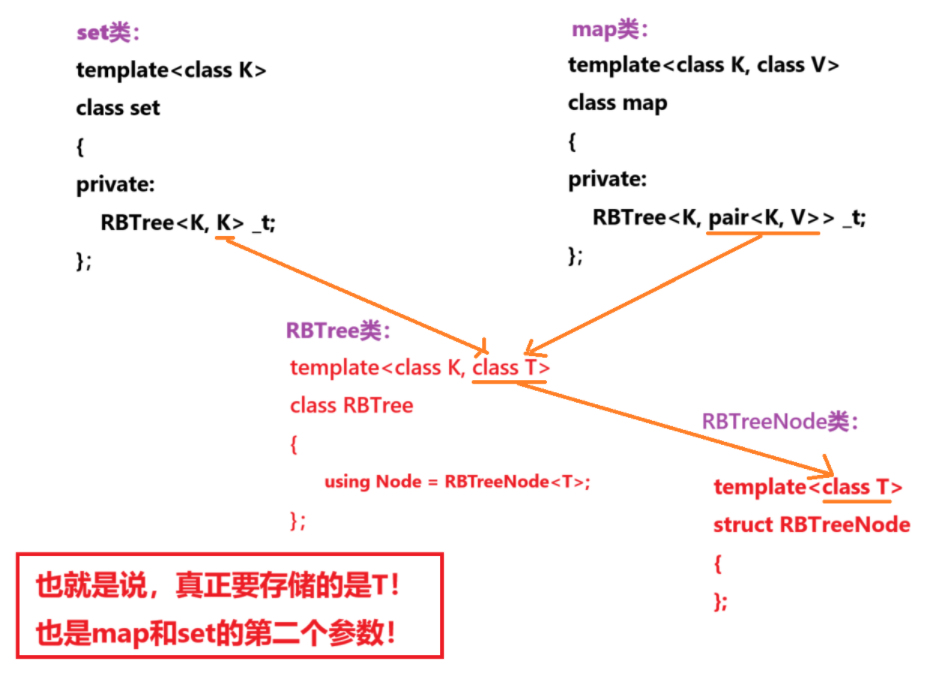
此时你就会想:为啥底层要这样设计?一个参数看起来也可以完成。
对,可以。但是你可曾想过,如果设计为一个参数,是不是每次比较(只和键比较)是不是每次都要再套一层,增加了代码复杂度。而多写一个K作为参数,我们比较的时候就会少些操作,比从pair中提取first更高效。
而且多写一个Key会使查找和比较更加轻松。也更方便解耦。
所以我们每次插入的就不再是pair,而是T类型的data,所以这里修改Insert代码:
//插入
bool Insert(const T& data)
{
}如果是set的insert插入的就是K;map的insert插入的就是pair<K, V>。
三:每个类增加仿函数
此时你兴致勃勃的去修改Insert代码(以下只展示修改部分):
bool Insert(const T& data)
{if (_root == nullptr){Node* newNode = new Node(data); //修改部分_root = newNode;_root->_col = BLACK; //更新根节点 并置为黑色return true;}//... //新建节点cur = new Node(data); //修改部分
}但聪明的你发现,这里的比较会出现问题:
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{if (kv.first > cur->_kv.first){parent = cur;cur = cur->_right;}else if (kv.first < cur->_kv.first){parent = cur;cur = cur->_left;}else{//已经存在该值了 不处理return false;}
}我怎知道到底该比较哪个呢?我又不知道上面传入的到底是set还是map,这可咋办?完犊子了。后面的比较不都歇菜了?
对,你当然不知道,这是由谁传给你你才知道的,也就是谁封装得你,谁知道(就像qsort函数一样)。所以我们应该先让set和map对RBTree这个类传入一个能转换的,之后才能比较。
此时就需要用到仿函数了,大家都知道,仿函数是一个类,里面实质上就是对“()”的重载,所以我们在set和map类中写一个内部类,map的仿函数传入pair<K, V>放回first;set传入K,返回K。
先对map添加仿函数:
template<class K, class V>
class map
{//template<K, V> 此时不需要给内部类加模板参数 因为它知道外部的模板参数struct MapOfK{const K& operator()(const pair<K, V>& kv){return kv.first;}};
public:
private:RBTree<K, pair<K, V>, MapOfK> _t; //传入仿函数
};在对set添加仿函数:
template<class K>
class set
{struct SetOfK{const K& operator()(const K& key){return key;}};public:
private:RBTree<K, K, SetOfK> _t;
};此时注意RBTree的模板参数也需要多一个参数,我们称作:KeyOfT。
//新增模板参数 KeyOfT
template<class K, class T, class KeyOfT>
class RBTree
{//...
};之后我们就可以通过KeyOfT来实现具体比较的是哪个操作对象了,为了方便,因为仿函数是一个类,我们在RBTree类中实例化一个KeyOfT对象命名为kot,只要对T进行比较就转换一下:
template<class K, class T, class KeyOfT>
class RBTree
{
public://对RBTreeNode进行重命名using Node = RBTreeNode<T>;//实例化一个KeyOfT对象KeyOfT kot;//插入bool Insert(const T& data){if (_root == nullptr){Node* newNode = new Node(data);_root = newNode;_root->_col = BLACK; //更新根节点 并置为黑色return true;}Node* parent = nullptr;Node* cur = _root;while (cur){//if (kv.first > cur->_kv.first)if (kot(data) > kot(cur->_data)) //使用kot{parent = cur;cur = cur->_right;}//else if (kv.first < cur->_kv.first)else if (kot(data) < kot(cur->_data)) //使用kot{parent = cur;cur = cur->_left;}else{//已经存在该值了 不处理return false;}}//新建节点cur = new Node(data);//if (kv.first > parent->_kv.first)if (kot(data) > kot(parent->_data)) //使用kot{parent->_right = cur;}else{parent->_left = cur;}cur->_parent = parent; //记得更新父节点//调整树...
}对,后面的调整不会和data比较,无需修改,修改的部分只有这么点。
之后就是修改Find函数了:
bool Find(const K& key)
{Node* cur = _root;while (cur){//if (key > cur->_kv.first)if (kot(data) > kot(cur->_data)) //kot替换{cur = cur->_right;}else if (kot(data) < kot(cur->_data)) //kot替换{cur = cur->_left;}else{return true;}}return false;
}之后不要忘记在set和map中添加对应的insert方法,本质也就是调用红黑树的Insert方法。
map中insert方法:
bool insert(const pair<K, V>& kv)
{return _t.Insert(kv);
}set中insert方法:
bool insert(const K& key)
{return _t.Insert(key);
}这时候不要着急,我们要调试一下代码了。这里给出test.cpp代码:
#include"myset.h"
#include"mymap.h"namespace bit
{void test_set(){set<int> s;int a[] = { 17, 18, 23, 34, 27, 15, 9, 6, 8, 5, 25 };for (auto e : a){cout << e << endl;s.insert(e);}}void test_map(){map<int, int> m;int a[] = { 17, 18, 23, 34, 27, 15, 9, 6, 8, 5, 25 };for (auto e : a){cout << e << endl;m.insert({ e, e });}}
}int main()
{//bit::test_set();bit::test_map();return 0;
}小编这里没有问题,相信大家也是这样(哈哈)。
四:实现迭代器
上面其实都不算很难,本篇最难的是迭代器的实现,这是本篇的核心知识。
我们知道迭代器的本质就是指针,难道说我们直接在红黑树中定义一个名为iterator的节点指针,之后再实现其他方法吗?但是大家都用过迭代器,这里以list举例,一般用法为(当然你可能会说我一般是使用范围for,但是我们一般想控制具体一点会使用如下方法):
int main()
{list<int> l = { 1, 2, 3 };list<int>::iterator it = l.begin();while (it != l.end()){cout << *it << " ";++it;}return 0;
}我们对it做了解引用,可以发现它就是指针,而且可以++。这里我们想对map和set也实现迭代器该怎么办呢?对了,还是对红黑树实现迭代器,而map和set调用红黑树迭代器。
这里我们如何对红黑树实现迭代器呢?在里面定义指针之后实现类似的方法吗?
不,这样做并不好,我们要将其解耦,也就是说,再定义一个类来专门实现迭代器。
问题接踵而至,这个模板参数该是什么呢?既然是一个指针,指针里存放的是树节点,所以T即可。里面的成员变量就是RBTreeNode的指针。为了方便操作,我们将其声明为结构体。
//定义迭代器
template<class T>
struct RBTreeIterator
{//或者使用 typedef RBTreeNode<T> Node; 看个人习惯using Node = RBTreeNode<T>;//为了减少代码量 重命名RBTreeIteratorusing Self = RBTreeIterator;Node* _node = nullptr;
};这里我们迭代器的模型就构建好了,之后我们就要实现++、!=、*、->、--等运算符的重载了。
但是现行暂停,我们思考一下,我们平时是这样赋值迭代器的:
//拿刚才的list举例 l 是list对象
list<int>::iterator it = l.begin();这就说明begin是一个方法,并且在list中已经被定义了。所以这里我们先在红黑树中定义这个begin方法。我们知道,begin返回的就是这个数据结构中第一个数据的位置,此时我们数据结构是红黑树,它的第一个节点位置在哪里?
中序遍历的第一个位置,也就是最小节点;但是我们要用中序递归方式找吗?仔细思考发现它也是树中最左边的节点,这个就很好找,所以我们现在RBTree中将RBTreeIterator重命名为Iterator,之后实现Begin方法。
template<class K, class T, class KeyOfT>
class RBTree
{
public://对RBTreeNode进行重命名using Node = RBTreeNode<T>;//重命名RBTreeIterator 为 Iteratortypedef RBTreeIterator<T> Iterator;//实现Begin方法Iterator Begin(){//找最左边节点Node* leftMost = _root;while (leftMost->_left){leftMost = leftMost->_left;}//返回的是迭代器 需要调用其构造方法return Iterator(leftMost);}//...
};而对于End方法,也非常简单,我们知道是最后一个节点的下一个位置,其实也就是空指针,所以我们补充End方法。
Iterator End()
{return Iterator(nullptr);
}tips:为了将其和set、map区分,这里使用大写来定义该方法。
返回的类型当然是迭代器类型,因为我们一会还有对这个迭代器进行++等操作。但是我们刚才在迭代器中没有写构造方法,所以补充上去:
//定义迭代器
template<class T>
struct RBTreeIterator
{//或者使用 typedef RBTreeNode<T> Node; 看个人习惯using Node = RBTreeNode<T>;//为了减少代码量 重命名RBTreeIteratorusing Self = RBTreeIterator;//构造方法RBTreeIterator(Node* node): _node(node){}Node* _node = nullptr;
};五:实现迭代器运算符的重载
1.++运算符重载
我们是中序遍历,下一个节点时什么?先来考虑最简单的情况,就是当前遍历节点就是中间节点,下一个节点就应该是右子树的最左边节点:
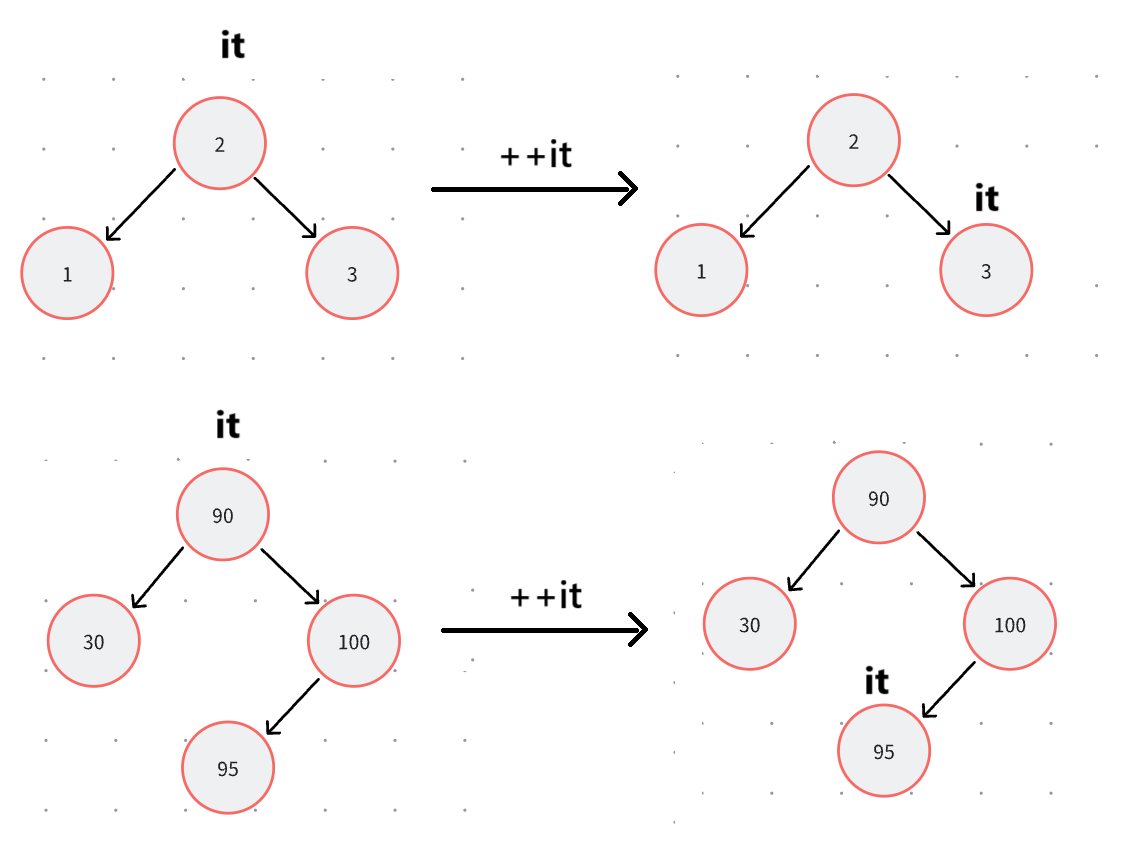
对,上面的情况就这么简单。但是如果右子树为空呢?下图我们只关心如何++,不关心是否为红黑树。
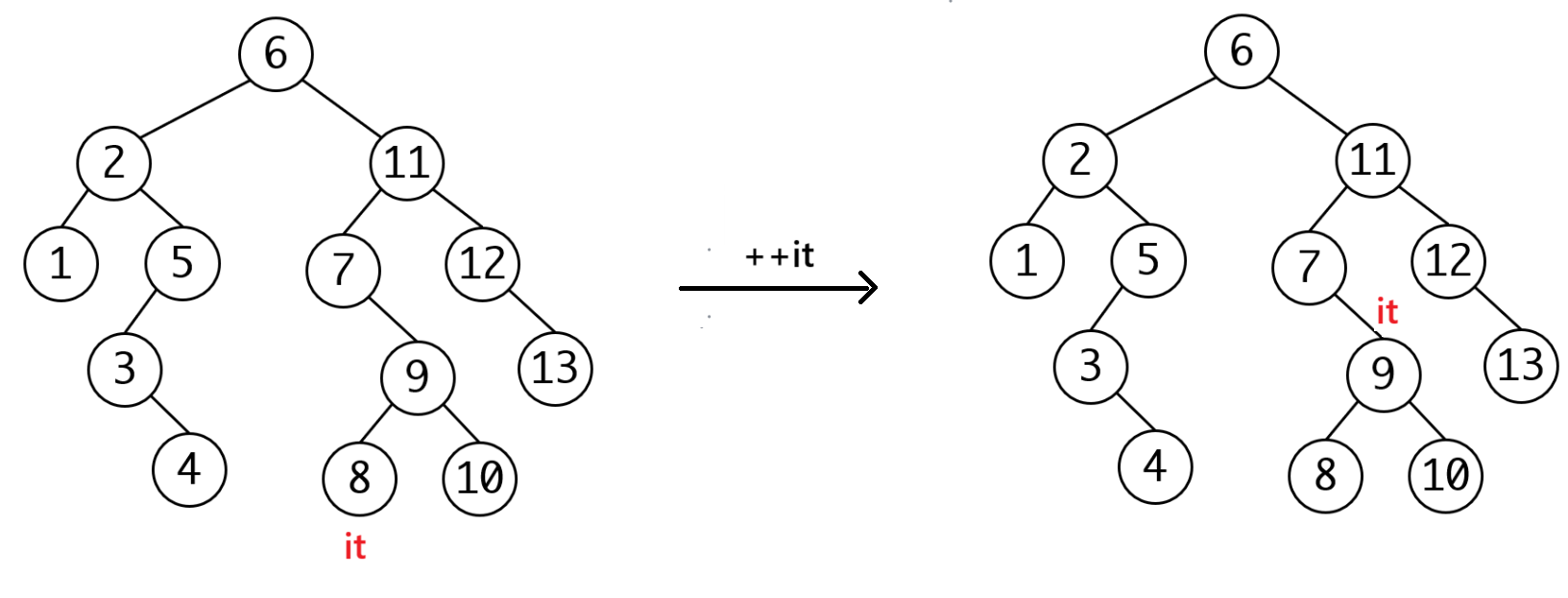
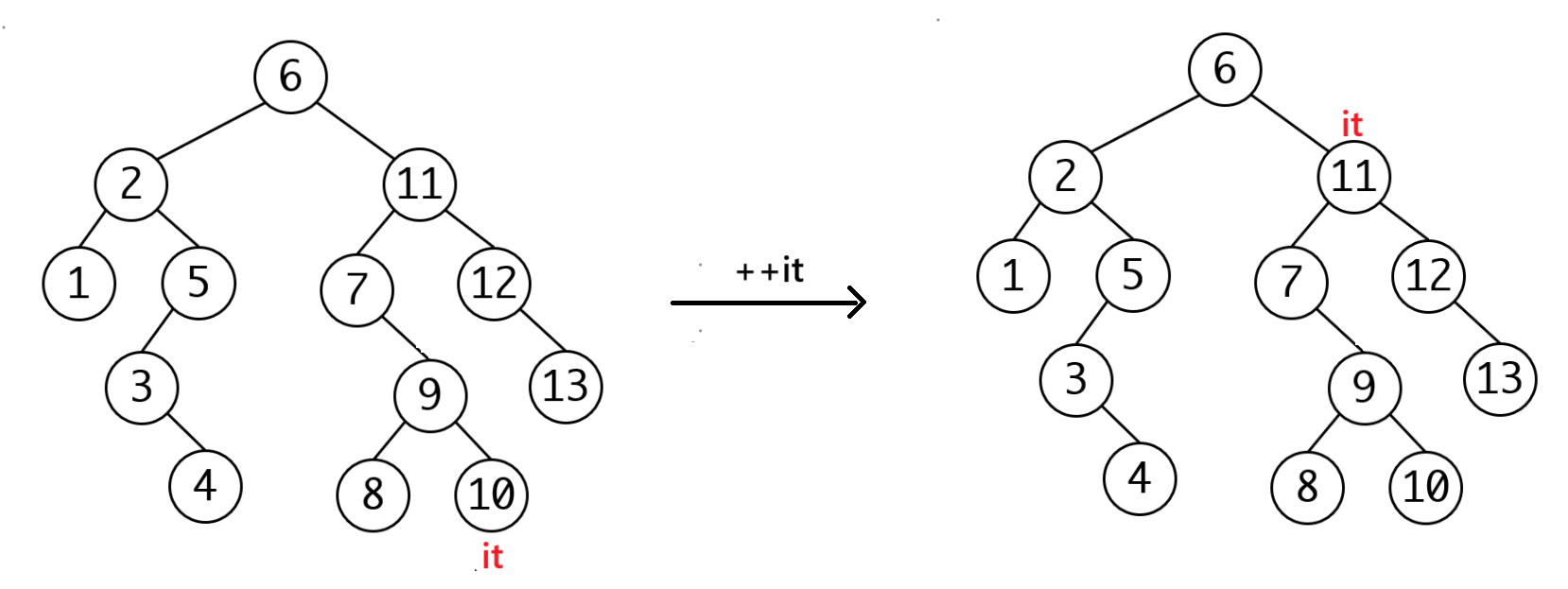
可以发现这其实是一个循环,假设当前it处于cur位置,我们定义一个parent节点(也就是parent = cur->_parent),之后当cur为parent->_left时跳出循环。当然要考虑parent为空的情况。
Self& operator++()
{if (_node->_right){//此时右子树不为空 找右子树最左边节点_node = _node->_right;while (_node->_left){_node = _node->_left;}}else{//右子树为空Node* cur = _node;Node* parent = cur->_parent;//parent可能为空while (parent && cur != parent->_left){cur = parent;parent = cur->_parent;}_node = parent; //记得更改_node 赋值为parent}return *this;
}2.==和!=运算符重载
bool operator!=(const Self& s)
{return _node != s._node;
}bool operator==(const Self& s)
{return _node == s._node;
}3.实现->和*运算符重载
这个也能简单,解引用返回存储类型的引用;->返回类型的地址,也就是指针。
T& operator*()
{return _node->_data;
}T* operator->()
{return &_node->_data;
}到这里先暂停,我们要测试一下代码了,所以去set和map中实现迭代器。
这里先完善set中的迭代器并测试set是否正确。所以在set中添加代码:
typedef RBTree<K, K, SetOfK>::Iterator iterator;//实现begin
iterator begin()
{return _t.Begin();
}//实现end
iterator end()
{return _t.End();
}之后测试代码中测试范围for:
namespace bit
{void test_set(){set<int> s;int a[] = { 17, 18, 23, 34, 27, 15, 9, 6, 8, 5, 25 };for (auto e : a){cout << e << endl;s.insert(e);}for (auto e : s){cout << e << " ";}}
}int main()
{bit::test_set();//bit::test_map();return 0;
}我们避免程序直接崩溃,可以现重新生成解决方案,发现程序崩溃……哈哈,这里确实有一个坑。当我们在一个类中声明其他类时,编译器不知道这个类是静态成员还是类型,所以用typename明确指出这是一个类型。
当然还有另外一个解释:因为此时没有实例化RBTree 不知道是什么类型,编译无法通过。所以加上typename在编译的时候确定类型。
补充(来自AI):
核心机制:
模板的二次编译机制:
模板会经历 第一次语法检查(看到模板定义时)和 第二次实例化检查(具体调用时)。
在第一次检查时,编译器并不知道
T::NestedType是什么(因为T尚未确定),所以需要typename明确告诉编译器:"这是一个类型,你先别报错,等实例化时再确认"。
typename的本质作用:
不是让编译器"先不填充类型",而是解决 语法歧义。
在没有
typename时,T::NestedType可能被误认为是静态成员变量(例如T::value),导致语法解析错误。typename强制声明这是一个类型。
所以此时我们在set中定义迭代器时加上typename即可通过编译:
typedef typename RBTree<K, K, SetOfK>::Iterator iterator;此时运行代码输出结果为:
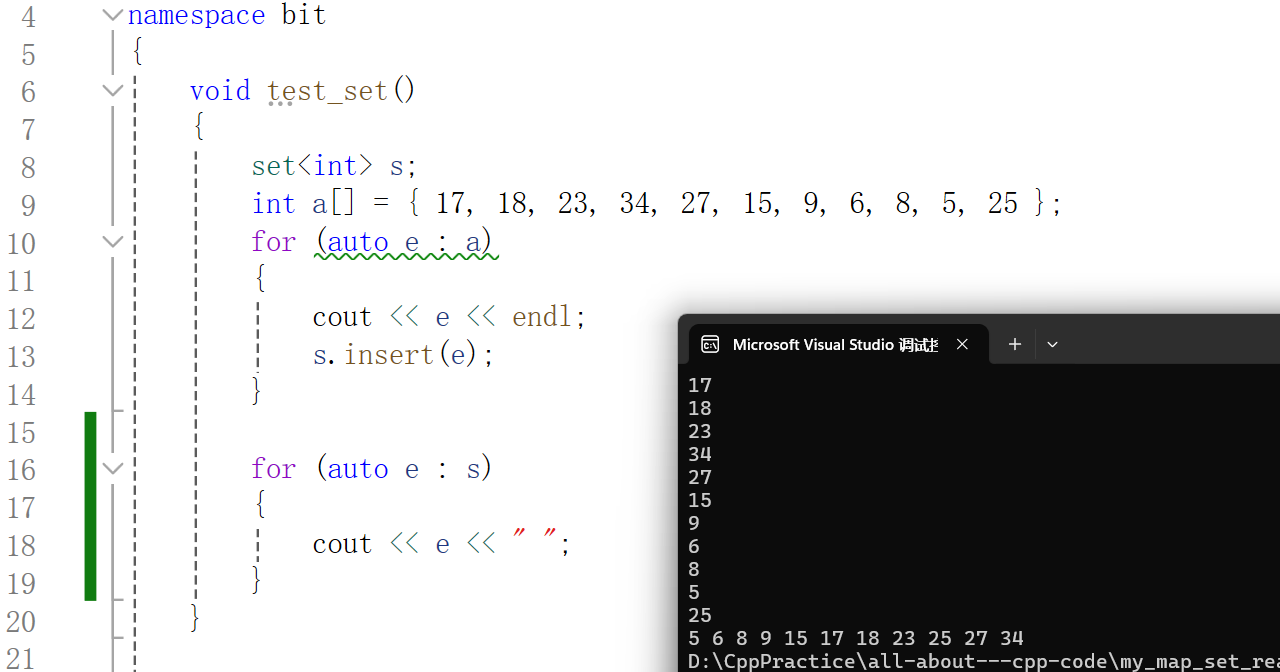
之后就是map的迭代器这里不再赘述。
4.--运算符重载
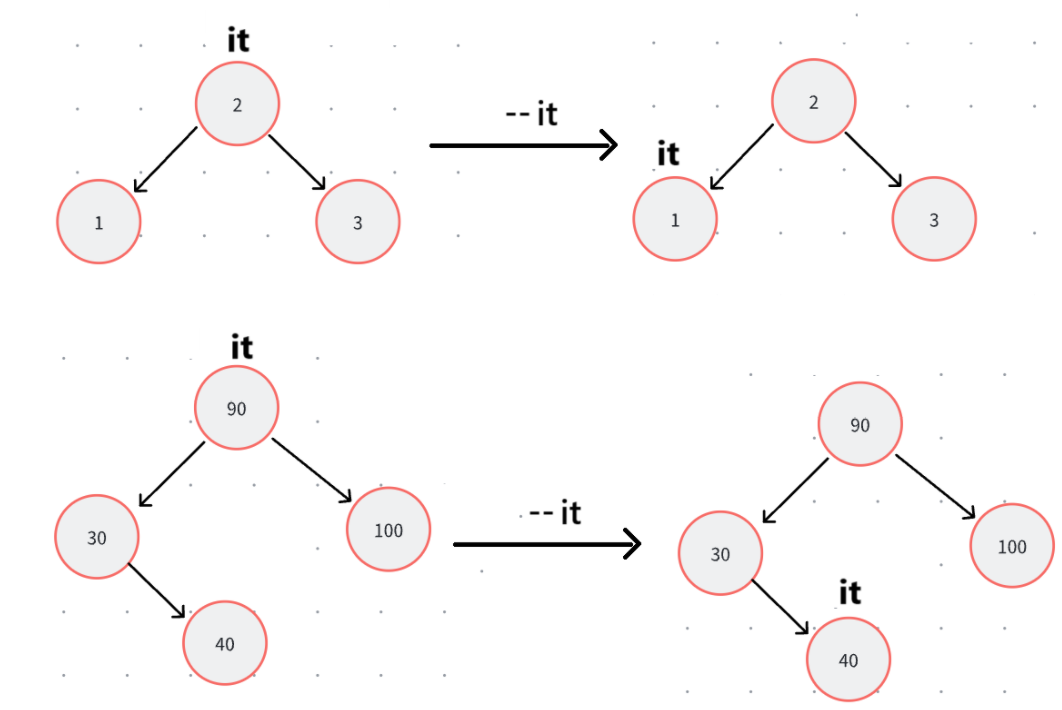
这里我们给自己上上强度,多加一个--运算符重载,说白了就是和++哪里镜像的。但是最开始传入的是End,所以我们要先找最右边节点,也就是判断是否为空,之后赋值。
其他情况,我们先看是否有左子树,有左子树就是左子树最右节点:
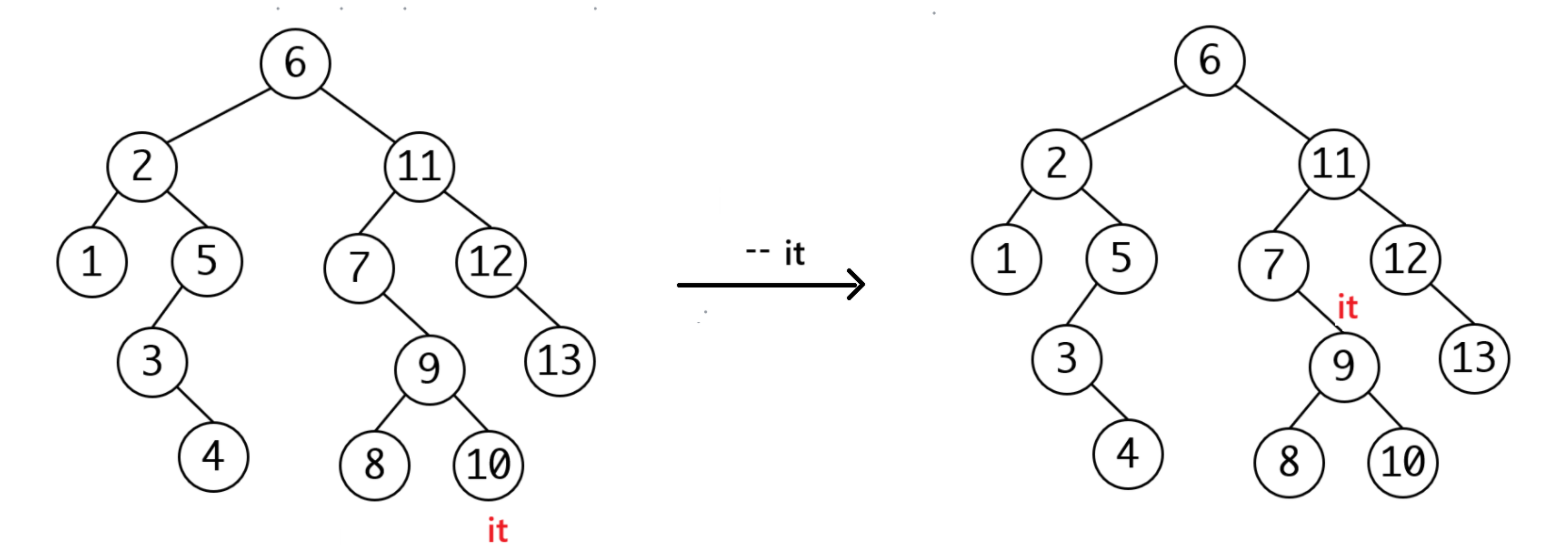
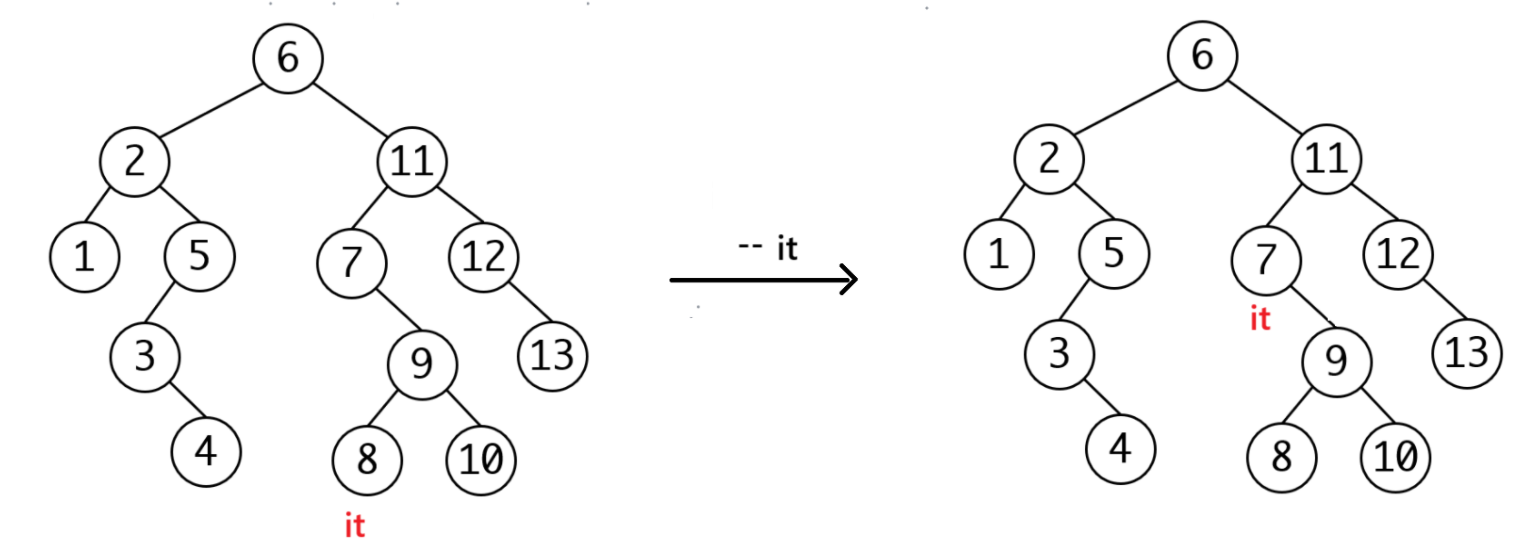
当没有左子树的时候,和++一样,找第一个cur == parent->_right:
OK,当你开始写--的时候,第一步判空,此时新的问题出现了,我们要找树的根节点,但是我们不知道树的根节点!(没想到吧,我们又要修改参数了,呜呜~~我都要哭了……啊啊啊!)
此时我们应该怎么解决?也就是对RBTreeIterator多增加一个参数,也就是要记录根节点。
//定义迭代器
template<class T>
struct RBTreeIterator
{//...//多定义一个成员 专门记录根节点Node* _root = nullptr;
};所以此时RBTreeIterator的构造方法也要修改。
//定义迭代器
template<class T>
struct RBTreeIterator
{//构造方法 //向构造方法多增加root赋值RBTreeIterator(Node* node, Node* root): _node(node), _root(root){}//...//多定义一个成员 专门记录根节点Node* _root = nullptr;
};那么之前在红黑树中的Begin和End都需要多传入_root参数。
//实现Begin方法
Iterator Begin()
{//找最左边节点Node* leftMost = _root;while (leftMost->_left){leftMost = leftMost->_left;}//返回的是迭代器 需要调用其构造方法return Iterator(leftMost, _root);
}Iterator End()
{return Iterator(nullptr, _root);
}此时我们就可以拿到根节点了,同时也可以开始完善--运算符重载了。根据之前的图像,可以写出以下代码:
Self& operator--()
{if (_node == nullptr){//找最右边节点Node* rightMost = _root;while (rightMost->_right){rightMost = rightMost->_right;}_node = rightMost;}else if (_node->_left) //此时有左子树{//找左子树最右节点Node* rightMost = _node->_left;while (rightMost->_right){rightMost = rightMost->_right;}_node = rightMost;}else{//此时没有右子树Node* cur = _node;Node* parent = cur->_parent; //此时要找第一个cur == parent->_right 且parent存在while (parent && cur != parent->_right){cur = parent;parent = cur->_parent;}_node = parent;}return *this;
}之后我们还拿set来做实验,这次我们倒序遍历,但是注意应该先--it迭代器,因为最开始指向空。
void test_set()
{set<int> s;int a[] = { 17, 18, 23, 34, 27, 15, 9, 6, 8, 5, 25 };for (auto e : a){//cout << e << endl;s.insert(e);}for (auto e : s){cout << e << " ";}cout << endl;//倒着遍历set<int>::iterator it = s.end();while (it != s.begin()){//最开始是 nullptr 所以先----it;cout << *it << " ";}cout << endl;
}测试结果:
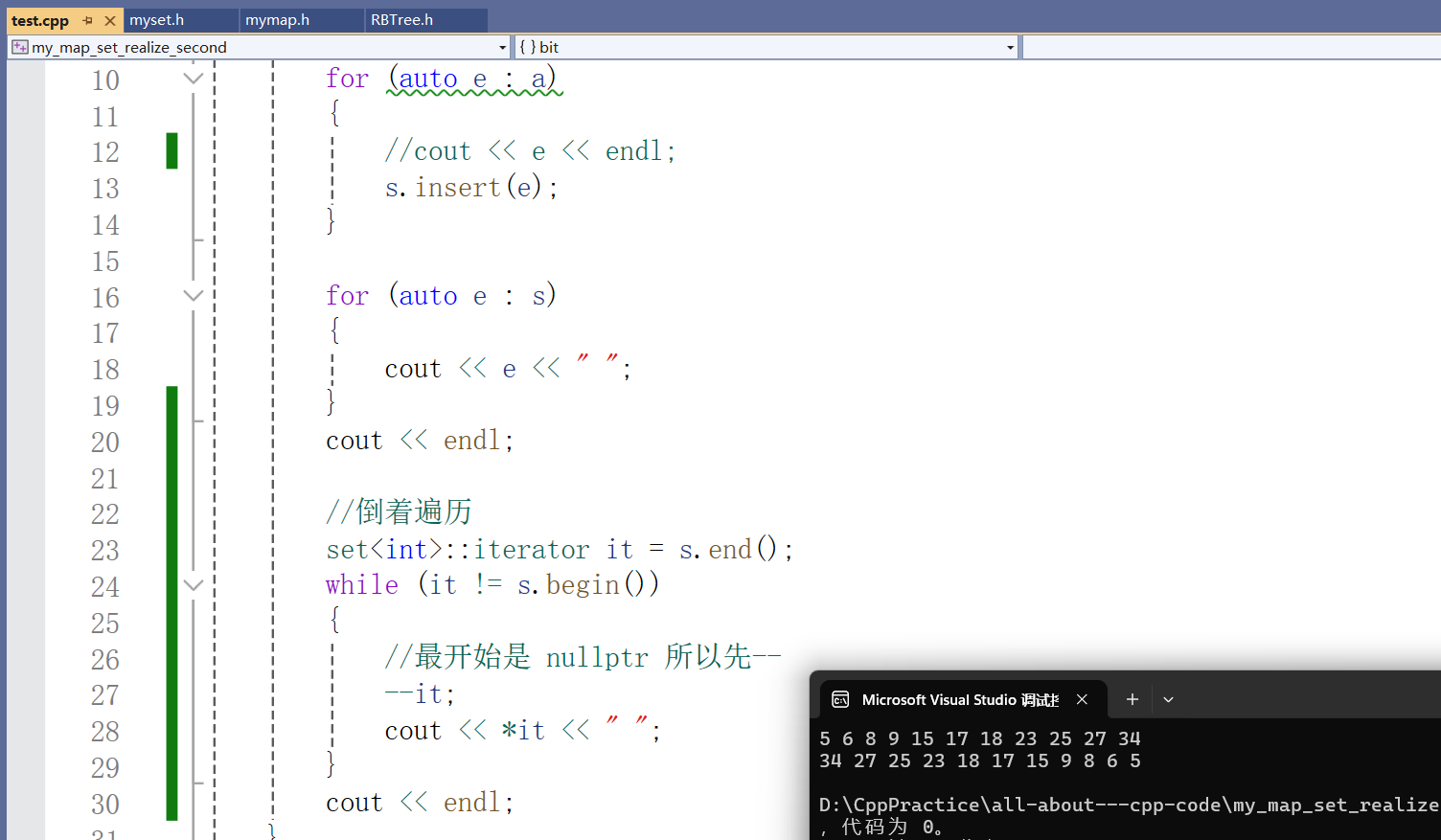
此时我们就几乎实现了所有关于迭代器的基本操作。
六:实现包括const版本的迭代器
注意我上面说的是迭代器基本操作,但是我们知道,底层还存在const_iterator。我们上面实现的迭代器是可以通过解引用来改变里面指向的内容的。但是底层有const_iterator是不允许修改其指向的内容的。
这里我们先区分 int* const 和 const int* 的区别。
- int* const : 指的是指针不能修改,指向的值可以修改。
- const int* : 指的是指针可以修改,指向的值不能修改。
所以 const_iterator 本质上就是 const int*。
这时聪明的你想到了,那么我们在写一个ConstRBTreeIterator类,把里面的模板参数都写成const类型可不可以呢?当然可以,比如:
template<class T>
struct ConstRBTreeIterator
{//... 与RBTreeIterator代码全部相同//唯一不同的是 * -> 的重载const T& operator*(){return _node->_data;}const T* operator->(){return &_node->_data;}
};不对劲,你发现只有两个运算符重载不一样,难道为了碟醋,包一盘饺子?这太冗余了。
我们知道模板参数可以像函数传参一样使用,既然只有这两个参数不一样,那是否可以考虑当传入的时候就告知应该生成谁。这里一个是引用,一个是指针。所以我们可以修改RBTreeIterator参数,多传入两个参数,一个是T的应用,一个是T的指针,这样我们就可以减少代码量了。
//定义迭代器 引用 指针
template<class T, class Ref, class Ptr>
struct RBTreeIterator
{//修改位置Ref operator*(){return _node->_data;}Ptr operator->(){return &_node->_data;}
};所以说RBTree中传入的模板参数也要修改,并且多定义一个ConstIterator类型:
template<class K, class T, class KeyOfT>
class RBTree
{
public://对RBTreeNode进行重命名using Node = RBTreeNode<T>;//重命名RBTreeIterator 为 Iteratortypedef RBTreeIterator<T, T&, T*> Iterator;typedef RBTreeIterator<T, const T&, const T*> ConstIterator;//...
};这里你会很迷,什么钩八?看图:
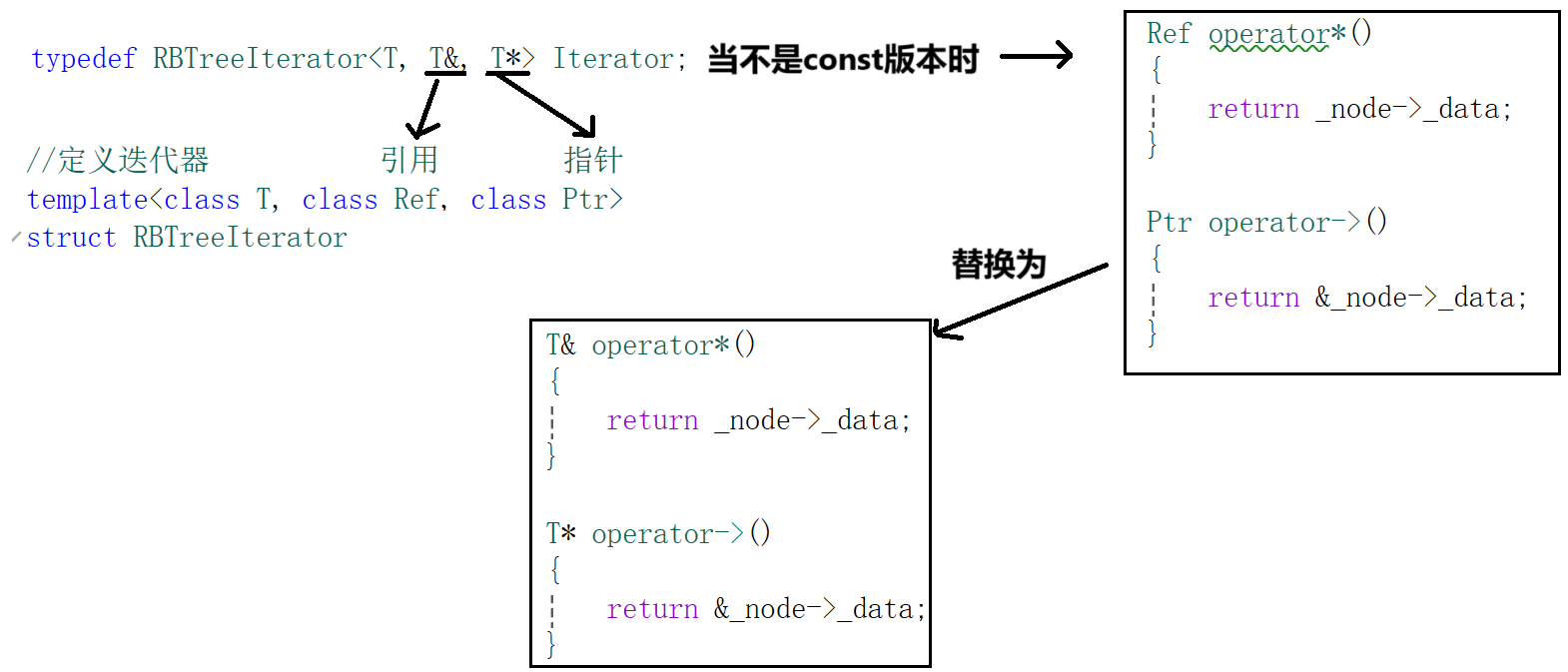
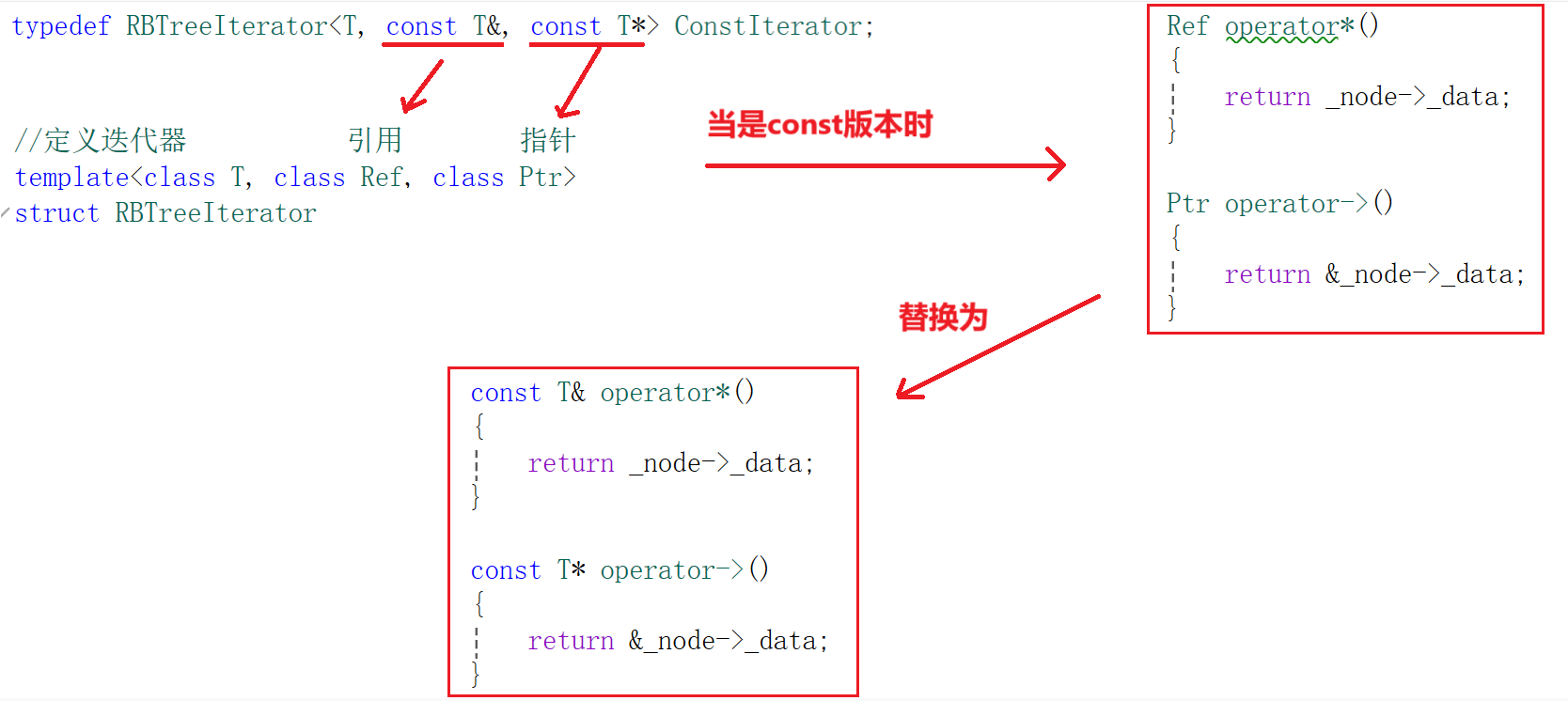
所以我们通过修改传入参数从而实现对const版本和非const版本的操作。此时我们依旧是先实现set中的const_iterator。
template<class K>
class set
{//...
public:typedef typename RBTree<K, K, SetOfK>::Iterator iterator;typedef typename RBTree<K, K, SetOfK>::ConstIterator const_iterator;//实现beginiterator begin(){return _t.Begin();}//实现enditerator end(){return _t.End();}//实现begin const版本const_iterator begin() const{return _t.Begin();}//实现end const版本const_iterator end() const{return _t.End();}//...
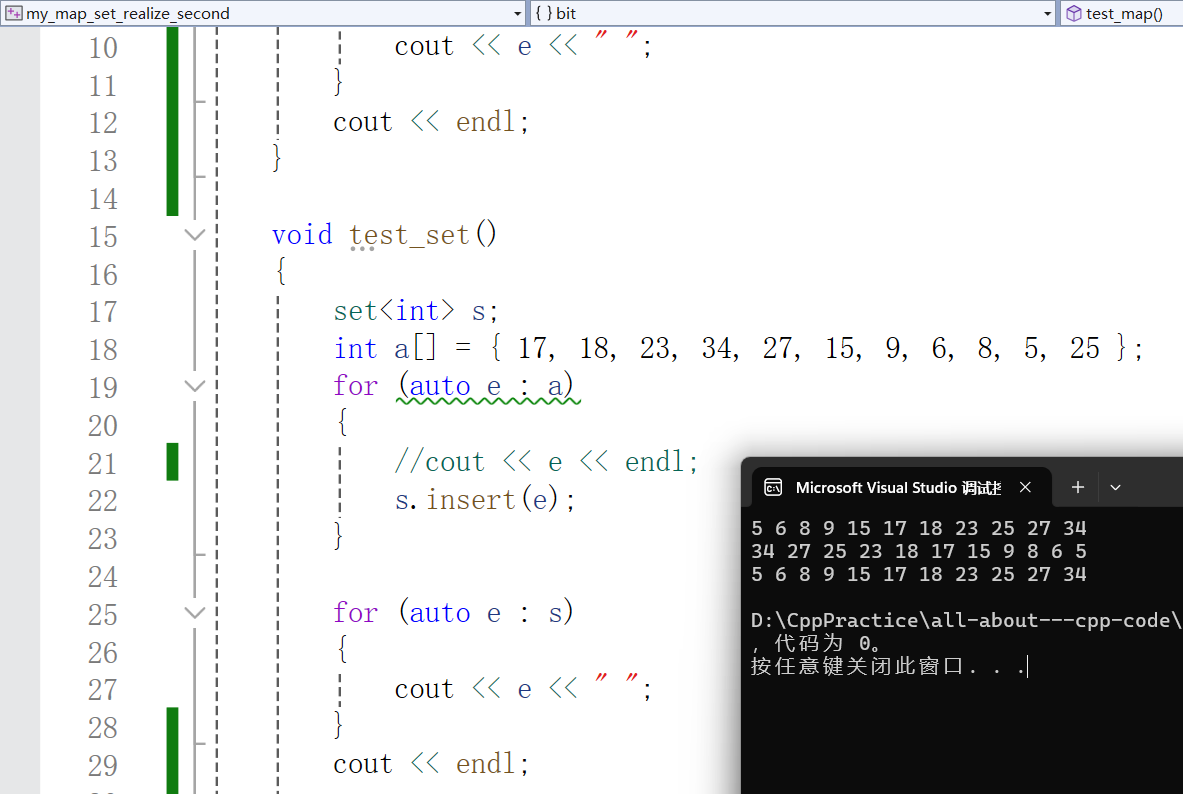
};如何测试呢?我们在bit命名空间中,添加FuncSet函数,它的参数是const set<int>& s即可,这就是常量类型,不可修改。所以如下:
void FuncSet(const set<int>& s)
{for (auto e : s){cout << e << " ";}cout << endl;
}void test_set()
{set<int> s;int a[] = { 17, 18, 23, 34, 27, 15, 9, 6, 8, 5, 25 };for (auto e : a){//cout << e << endl;s.insert(e);}for (auto e : s){cout << e << " ";}cout << endl;//倒着遍历set<int>::iterator it = s.end();while (it != s.begin()){//最开始是 nullptr 所以先----it;cout << *it << " ";}cout << endl;FuncSet(s);
}结果如下:
之后补充map的代码:
template<class K, class V>
class map
{//...
public:typedef typename RBTree<K, pair<K, V>, MapOfK>::Iterator iterator;typedef typename RBTree<K, pair<K, V>, MapOfK>::ConstIterator const_iterator;//实现beginiterator begin(){return _t.Begin();}//实现enditerator end(){return _t.End();}//实现begin const版本const_iterator begin() const{return _t.Begin();}//实现end const版本const_iterator end() const{return _t.End();}//...
};七:修改Insert
之前我们在set和map篇中讲到过,他们的insert方法并不是简单的返回bool。而是一个迭代器,插入节点不存在返回该插入节点的迭代器;存在返回这个位置的迭代器。返回的类型时pair类型(具体细节可以看我的上一篇文章) 。所以我们要修改红色树中的Insert方法。
//插入
pair<Iterator, bool> Insert(const T& data)
{if (_root == nullptr){Node* newNode = new Node(data);_root = newNode;_root->_col = BLACK; //更新根节点 并置为黑色// return true;return make_pair(Iterator(newNode, _root), true);}Node* parent = nullptr;Node* cur = _root;while (cur){//if (kv.first > cur->_kv.first)if (kot(data) > kot(cur->_data)){parent = cur;cur = cur->_right;}//else if (kv.first < cur->_kv.first)else if (kot(data) < kot(cur->_data)){parent = cur;cur = cur->_left;}else{//已经存在该值了 不处理//return false;return make_pair(Iterator(cur, _root), false);}}//新建节点cur = new Node(data);//if (kv.first > parent->_kv.first)if (kot(data) > kot(parent->_data)){parent->_right = cur;}else{parent->_left = cur;}cur->_parent = parent; //记得更新父节点if (parent->_col == BLACK){//return true;return make_pair(Iterator(cur, _root), true);}else{//...}//最后都时 _root->_col = BLACK 即可_root->_col = BLACK;//return true;return make_pair(Iterator(cur, _root), true);
}所以我们也要修改map和set中的insert方法返回值(大家自行修改吧)。
之后再test_map函数中增加以下代码,测试insert函数:
//第一次插入90这个键
cout << "第一次插入90这个键" << endl;
pair<map<int, int>::iterator, bool> p = m.insert({90, 100});
cout << p.first->first << ":" << p.first->second << endl;
cout << p.second << endl;cout << "第二次插入90这个键" << endl;
p = m.insert({ 90, 30 });
cout << p.first->first << ":" << p.first->second << endl;
cout << p.second << endl;运行结果:

八:实现map中[ ]的重载
我们在上一篇讲到了[ ],但是那里没有讲的很清楚,[ ]可以充当insert,也可以查找键对应的值;更可以修改键对应的值,这和它的实现有关,我们先上代码:
V& operator[](const K& key)
{iterator it = insert(make_pair(key, V())).first;return it->second;
}新增test_map1函数:
void test_map1()
{map<std::string, std::string> dict;dict.insert({ "sort", "排序" });dict.insert({ "left", "左边" });dict.insert({ "right", "右边" });dict["left"] = "左边,剩余"; //修改dict["insert"] = "插入"; //插入dict["value"]; //插入 string使用默认构造map<string, string>::iterator it = dict.begin();while (it != dict.end()){cout << it->first << ":" << it->second << endl;++it;}cout << endl;
}运行结果:
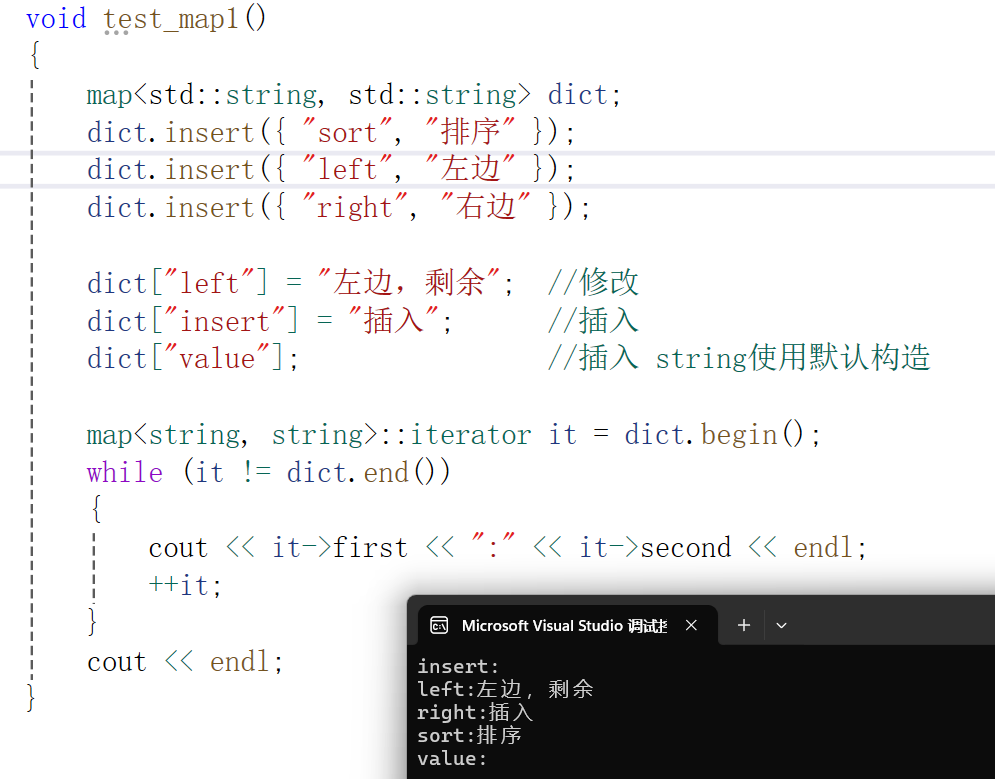
你肯定好奇,为什么能修改对应的值?为什么我们能直接插入。首先我们封装的[ ]里面复用的是insert,我们在insert中传入的参数对应的值是调用的默认构造,之后我们返回的first拿iterator接收,之后通过iterator重载的->拿到对应的值(second),可以看到返回的是引用。以至于在外部使用=可以修改对应的值!

总结:
这一篇内容其实很难,这里算法是基础,语言比算法还要难。大家不要眼高手低,实现了才知道有多难,多有成就感。最初小编实现的时候全是BUG,这个比红黑树好一点,算法的BUG可能一找要找半个小时,而这个也全是BUG,找得快,但是多。多敲两边你会发现你的C++代码能力突飞猛进,这一章包含了很多基础语法和C++特性,大家不要偷懒!
相关文章:

【C++】通过红黑树封装map和set
前言: 通过之前的学习,我们已经学会了红黑树和map、set。这次我们要实现自己的map和set,对,使用红黑树进行封装! 当然,红黑树内容这里就不在赘述,我们会复用红黑树的代码,所以先将…...

【Java IO流】字节输入流FileInputStream、字节输出流FileOutputStream
目录 0.前言 1.FileInputStream 1.1 概述 1.2 构造方法 1.3 成员方法 1.4 FileInputStream读取文件案例演示 2.FileOutputStream 2.1 概述 2.2 构造方法 2.3 成员方法 2.4 写入文本文件案例演示 3.FileInputStream FileOutputStream拷贝文件 0.前言 本文讲解的是…...

信息收集新利器:SSearch Chrome 插件来了
SSearch 下载地址 SSearch 😣用途 每次谷歌语法搜索时还得自己写,我想省事一点,弄了一个插件,先加了几个常用的语法,点击后会跳转到对应搜索页面,也可以直接在搜索框微调 后续也会加些其他语法 &#…...

【AI面试准备】AI误判案例知识库优化方案
面试题:建立内部知识库:收集AI误判案例训练领域专属模型。 在回答关于“建立内部知识库收集AI误判案例训练领域专属模型”的面试问题时,建议从以下结构化框架展开,既能体现专业性,又能展现解决问题的系统性和实际落地…...
——AXI 接口MIG 使用(1))
从零开始讲DDR(8)——AXI 接口MIG 使用(1)
一、前言 在之前的系列文章中,我们已经讨论过了MIG ip的接口内容,配置方式和modelsim独立仿真相关的内容,因此,本文对于之前已经讨论过的相关内容只做简单描述,着重介绍AXI 接口MIG使用上与普通ui接口的不同之处。感兴…...
)
字符和编码(python)
位数:英文字符使用 1 个字节表示,中文字符通常使用 3 个字节。示例:汉字 “汉” 的 UTF-8 编码是 \xE6\xB1\x89。优点:兼容 ASCII,广泛用于网络传输和文件存储。 Python 中的字符串类型 在 Python 中,字…...

【STM32】定时器输入捕获
STM32 定时器输入捕获功能笔记 一、什么是输入捕获(Input Capture) 输入捕获是利用定时器的输入通道,在检测到信号电平变化(如上升沿或下降沿)时,立即将当前计数器的值捕获并保存到捕获寄存器(…...

spring-ai集成langfuse
1、pom文件 <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.org/POM/4.…...

SALOME源码分析: ParaVis
本文分析SALOME中ParaVis模块。 注1:限于研究水平,分析难免不当,欢迎批评指正。注2:文章内容会不定期更新。 一、核心组件 二、关键流程 三、FAQs 网络资料 SALOME Scientific visualisationPARAVIS Module - Architecture …...

Ubuntu 安装 MySQL8
在 Ubuntu 下安装 MySQL 服务,推荐使用 apt install 官方的 APT 仓库安装方式,这种方式最安全、最稳定、能自动处理依赖关系,也支持后续升级。不推荐在官网手动下载 .deb 包的方式。 配置 Ubuntu 服务器 1. 确认 Ubuntu 系统版本 使用如下命…...

MATLAB图像加密案例
下面是一个使用 MATLAB 编写的简单图像块置乱加密/解密程序,主要利用了函数来组织代码。 这个程序通过将图像分割成小块,然后根据一个密钥(用于随机数生成器种子)打乱这些块的顺序来实现加密。解密过程则使用相同的密钥恢复原始块顺序。 核心思想: 分块: 将图像划分为 …...
)
同构字符串(简单)
新建两个哈希表,构建s到t中的字母的映射以及t到s中的字母的映射。 class Solution {public boolean isIsomorphic(String s, String t) {Map<Character,Character> s2tnew HashMap<Character,Character>();Map<Character,Character> t2snew Hash…...

红米Note9 4G版拆开后盖操作细节
先把sim卡槽整个拔出 然后如下图做试,4个箭头的位置塞塑料片或者指甲插入,弄开,然后从图中右侧抠开(左侧不行,有排线连着后面手机主板) 如果不按照这种办法,会把后盖很多地方抠烂...

Qt通过QXlsx库文件写入到excl文件,读取excl文件
第一:下载QXlsx库文件 https://download.csdn.net/download/qq_32663053/90739425 第二:在Qt项目中引入QXlsx库,需要把QXlsx库文件放在项目文件夹下 第三:将tableview中的数据存入到excl文件 代码: void MainWindow…...

ESP32 在Platform Arduino平台驱动外部PSAM,进行内存管理
一,基本介绍 本文中主要介绍ESP32、ESP32S3系列单片机,基于Vscode Platform Arduino和Arduino框架下如何使用外部PSAM,以及必要的API调用函数进行内存分配和管理。 使用前提是开发板有外部PSRAM。 二,平台配置 2.1 Arduino平台 …...

【AI论文】WebThinker:赋予大型推理模型深度研究能力
摘要:大型推理模型(LRMs),如OpenAI-o1和DeepSeek-R1,展示了令人印象深刻的长期推理能力。 然而,他们对静态内部知识的依赖限制了他们在复杂的知识密集型任务上的表现,并阻碍了他们生成需要综合各…...

Python爬虫基础总结
Python爬虫基础总结 一、爬虫概述 1.1 什么是爬虫 网络爬虫(Web Crawler)是一种自动浏览万维网的程序或脚本,它按照一定的规则,自动抓取互联网上的信息并存储到本地数据库中。 1.2 爬虫工作流程 URL管理器࿱…...
)
如何构建跨平台可复用的业务逻辑层(Web、App、小程序)
从传统的Web应用到移动端的App,再到近年来快速崛起的小程序,用户的触点变得异常分散且多样化。这种多端并存的现状一方面为企业提供了更广阔的市场机会,另一方面也对开发团队提出了更高的要求:如何在不同平台间实现高效开发、降低…...
用websocket显示大模型的流式输出)
本地大模型编程实战(32)用websocket显示大模型的流式输出
在与 LLM(大语言模型) 对话时,如果每次都等 LLM 处理完毕再返回给客户端,会显得比较卡顿,不友好。如何能够像主流的AI平台那样:可以一点一点吐出字符呢? 本文将模仿后端流式输出文字,前端一块一块的显示文字…...

MySQL数据库上篇
#作者:允砸儿 #日期:乙巳青蛇年 四月初五 笔者好久没有更新。今天来写一下MySQL数据库的内容还是老样子分为上中下三篇来写,话不多说咱们直接进入正题。 什么是数据库 数据库是统一管理的、长期储存在计算机内非仍、有组织的相关数据集合…...

Webug4.0靶场通关笔记13- 第22关越权修改密码
目录 第22关 越权修改密码 1.打开靶场 2.源码分析 3.越权修改密码 (1)获取渗透账号 (2)越权修改aaaaa账号的密码 (3)修改aaaaa用户密码渗透成功 (4)水平越权修改mooyuan账号…...

Python 基于 lstm,cnn 算法的网络舆情可视化系统
大家好,我是Python徐师兄,一个有着7年大厂经验的程序员,也是一名热衷于分享干货的技术爱好者。平时我在 CSDN、掘金、华为云、阿里云和 InfoQ 等平台分享我的心得体会。 🍅文末获取源码联系🍅 2025年最全的计算机软件毕…...

【免费】2007-2021年上市公司对外投资数据
2007-2021年上市公司对外投资数据 1、时间:2007-2021年 2、指标:股票代码、统计截止日期、货币编码、货币类型、投资事件类型编码、投资事件类型、报告期末投资金额总计、占报告期对外投资总额的比例(%) 3、范围:上市公司 4、来源&#x…...
:uniq)
每天学一个 Linux 命令(33):uniq
每天学一个 Linux 命令(33):uniq 命令简介 uniq 是 Linux 系统中一个非常实用的文本处理命令,全称为 “unique”。它主要用于从已排序的文本文件中检测、过滤或统计重复的行。该命令通常与 sort 命令配合使用,是 Shell 脚本编程和日常文本处理中的常用工具之一。 命令语…...

WebRtc11:SDP详解
SDP规范 会话层(全局)媒体层(局部) 会话层 会话的名称和目的会话的存活时间会话中包含多个媒体信息 SDP媒体信息 媒体格式传输协议传输IP和端口媒体负载类型 SDP格式 由多个< type > < value > 组成一个会话级…...

51单片机驱动 矩阵键盘
连接方式为8-1顺序连接P1端口P10-P17,代码返回键值 0-15. // 矩阵键盘扫描 uchar key_scan(void) {u8 key_value 255;u8 row, col;// 设置P1.0-P1.3为输出,P1.4-P1.7为输入P1 0xF0; // 1111 0000if((P1 & 0xF0) ! 0xF0) { // 有按键按下delay_m…...

解决The‘InnoDB’feature is disabled; you need MySQL built with ‘InnoDB’ to have it
出现如下语句:The ‘InnoDB feature is disabled; you need MySQL built with ‘InnoDB to have it working; 是mysql配置文件禁掉了这个选项! 关闭mysql数据库 在mysql的安装目录中找到my.ini文件 找到skip-innodb,在前面加上#号…...
)
大模型压缩技术详解(2025最新进展)
在2025年的AI技术格局中,像DeepSeek这样的顶尖模型开源已成为现实。那是否存在一种可行路径,让企业能够使用专注于自身领域的强力AI模型,同时大幅降低部署成本,仅需一张普通的4090显卡?本文将深入探讨两种主流的模型压…...

第 5 篇:红黑树:工程实践中的平衡大师
上一篇我们探讨了为何有序表需要“平衡”机制来保证 O(log N) 的稳定性能。现在,我们要认识一位在实际工程中应用最广泛、久经考验的“平衡大师”——红黑树 (Red-Black Tree)。 如果你用过 Java 的 TreeMap 或 TreeSet,或者 C STL 中的 map 或 s…...

spring-- 事务失效原因及多线程事务失效解决方案
事务失效原因 类的自调用:直接调用本类的方法,没有通过代理对象来调用方法,代理对象内部的事务拦截器不会拦截到这次行为。则不可能开启事务 使用私有方法:因为spring的事务管理是基于AOP实现的,AOP代理无法拦截目标对…...

MLPerf基准测试工具链定制开发指南:构建领域特异性评估指标的实践方法
引言:基准测试的领域适配困局 MLPerf作为机器学习性能评估的"黄金标准",其通用基准集在实际科研中常面临领域适配鸿沟:医疗影像任务的Dice系数缺失、NLP场景的困惑度指标偏差等问题普遍存在。本文通过逆向工程MLPerf v3.1工具…...

深度理解linux系统—— 进程切换和调度
前言: 了解了进程的状态和进程的优先级,我们现在来看进程是如何被CPU调度执行的。 在单CPU的系统在,程序是并发执行的;也就是说在一段时间呢,进程是轮番执行的; 这也是说一个进程在运行时不会一直占用CPU直…...

【凑修电脑的小记录】vscode打不开
想把vscode的数据和环境从c盘移到d盘 大概操作和这篇里差不多 修改『Visual Studio Code(VS Code)』插件默认安装路径的方法 - 且行且思 - 博客园 在原地址保留了个指向新地址的链接文件。 重新安装vscode后双击 管理员身份运行均无法打开࿰…...
(含模型、可运行代码、数据))
2025五一数学建模竞赛A题完整分析论文(共45页)(含模型、可运行代码、数据)
2025年五一数学建模竞赛A题完整分析论文 摘 要 一、问题分析 二、问题重述 三、模型假设 四、符号定义 五、 模型建立与求解 5.1问题1 5.1.1问题1思路分析 5.1.2问题1模型建立 5.1.3问题1参考代码 5.1.4问题1求解结果 5.2问题2 5.2.1问题2思路分析 …...
从0搭建Transformer
0. 架构总览: 1. 位置编码模块: import torch import torch.nn as nn import mathclass PositonalEncoding(nn.Module):def __init__ (self, d_model, dropout, max_len5000):super(PositionalEncoding, self).__init__()self.dropout nn.Dropout(pdrop…...

生物化学笔记:神经生物学概论07 躯体感受器 传入方式 自主神经系统
功能各异的躯体感受器 解释张力: 形形色色的传入方式 脑中的“倒立小人” 自主神经系统...

滑动窗口leetcode 209和76
一、leetcode 209. 长度最小的子数组 代码: class Solution { public:int minSubArrayLen(int target, vector<int>& nums) {int n nums.size();int left 0;int sum 0;int res 100001;for(int right 0;right <n;right){sum nums[right];while(s…...

FPGA:介绍几款高速ADC及其接口形式
本文介绍了几款采样率至少为500Msps的高速ADC芯片,并详细介绍ADC与FPGA之间的常见接口形式,以及FPGA如何正确读取高速ADC的输出数据。以下内容基于当前的高速ADC技术趋势和常见的工程实践。 一、推荐的高速ADC芯片(采样率≥500Msps࿰…...

未使用连接池或配置不当的性能陷阱与优化实践
目录 前言一、传统连接管理的性能缺陷与风险1. 未使用连接池的致命代价2. 连接池配置不当的典型表现 二、高性能连接池选型与核心参数优化1. HikariCP:零开销连接池的标杆2. Druid:功能完备的国产连接池 三、连接池性能调优的黄金法则1. 科学设定最大连接…...
)
亚马逊云服务器性能深度优化方案(2025版)
亚马逊云服务器性能深度优化方案(2025版) 一、计算架构全面升级 1. 新一代AI算力引擎 • Trn2 UltraServer实例:搭载64颗第二代Trainium芯片,单节点FP8算力达83.2 PFlops,支持千亿参数大模型训练,训…...

【IPMV】图像处理与机器视觉:Lec9 Laplace Blending 拉普拉斯混合
【IPMV】图像处理与机器视觉 本系列为2025年同济大学自动化专业**图像处理与机器视觉**课程笔记 Lecturer: Rui Fan、Yanchao Dong Lec0 Course Description Lec3 Perspective Transformation Lec7 Image Filtering Lec8 Image Pyramid Lec9 Laplace Blending 持续更新中 …...

【东枫电子】AMD / Xilinx Alveo™ UL3422 加速器
AMD / Xilinx Alveo™ UL3422 加速器 AMD / Xilinx Alveo™ UL3422 加速器提供超低延迟网络和灵活应变的硬件,支持纳秒级交易策略。AMD Virtex™ UltraScale™ VU2P FPGA 为 AMD / Xilinx Alveo UL3422 加速器提供强大的支持。该加速器采用延迟优化的收发器技术&am…...

Linux架构篇、第一章_03安装部署nginx
Linux_基础篇 欢迎来到Linux的世界,看笔记好好学多敲多打,每个人都是大神! 题目:安装部署nginx 版本号: 1.0,0 作者: 老王要学习 日期: 2025.05.02 适用环境: Centos7 文档说明 本文档聚焦于 CentOS 7 环境下 Nginx 的安装部…...

Semantic Kernel 快速入门
文章目录 Semantic Kernel 快速入门一、什么是 Semantic Kernel?1.1 核心特性 二、安装和配置2.1 安装 .NET SDK2.2 创建新的 .NET 项目2.3 安装 Semantic Kernel 三、快速入门3.1 导入依赖包3.2 添加 AI 服务3.3 添加企业服务3.4 生成内核并检索服务3.5 添加插件创…...
)
MySQL进阶(一)
一、存储引擎 1. MySQL体系结构 连接层: 最上层是一些客户端和链接服务,主要完成一些类似于连接处理、授权认证、及相关的安全方案。服务器也会为安全接入的每个客户端验证它所具有的操作权限 服务层: 第二层架构主要完成大多数的核心服务…...

ThreadLocal理解
1.thread是线程,threadLocal是对象? 在 Java 中: Thread 是线程类,其实例代表线程:Thread 类用于创建和管理线程,每个线程都是 Thread 类的一个实例,用于执行具体的任务,例如&…...
PyTorch、Flash-Attn、Transformers与Triton技术全景解析+环境包
PyTorch、Flash-Attn、Transformers与Triton技术全景解析 包好难找 这里是下载链接 添加链接描述 摘要 本文系统性地介绍了深度学习领域的四大关键技术框架:PyTorch、Flash-Attn、Hugging Face Transformers和Triton,分别从核心特性、技术优势、应用场…...

mindyolo填坑
1、按照gitee上的文档跑预测代码,跑不通 更改: 将predict.py复制到跟目录。如果是cpu(本地测试比较常见),那么正确的命令行是: python predict.py --device_targetCPU --config ./configs/yolov7/yolov7.…...
迭代版)
【C++】平衡二叉树(AVL树)迭代版
目录 前言: 一:判断一棵树是否为平衡二叉树 二:明确思路 1.为什么使用平衡二叉树 2.旋转 2.1 左旋 2.2 右旋 3.冲突节点 4.平衡因子 5.双旋 5.1 左右双旋(LR) 5.2 右左双旋(RL) 6.平衡因子的更新 7.冲突节点问题补充 三&…...

双链表详解
一、双向链表介绍 二、实现双向链表 1.定义双向链表的结构 2.双向链表的初始化 3.双向链表的尾插 4.双向链表的头插 5.双向链表的打印 6.双向链表的尾删 7.双向链表的头删 8.查找指定位置的数据 9.在指定位置之后插入数据 10.删除指定位置的数据 11.链表的销毁 三、…...