吴恩达深度学习作业 RNN模型——字母级语言模型
一. 简单复习一下RNN
RNN
RNN适用于处理序列数据,令是序列的第i个元素,那么
就是一个长度为
的序列,NLP中最常见的元素是单词,对应的序列是句子。
RNN使用同一个神经网络处理序列中的每一个元素。同时,为了表示序列的先后关系,RNN还有表示记忆的隐变量a,它记录了前几个元素的信息。对第t个元素的运算如下:
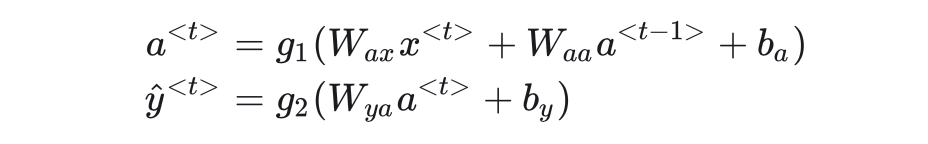
其中,W,b都是线性运算的参数,g是激活函数,隐藏层的激活函数一般用tanh,输出层的激活函数根据实际情况选用。另外a的初始值,
语言模型
语言模型是NLP中的一个基础任务。语言模型是NLP中的一个基础任务。假设我们以单词为基本元素,句子为序列,那么一个语言模型能够输出某句话的出现概率。通过比较不同句子的出现概率,我们能够开发出很多应用。比如在英语里,同音的"apple and pear"比"apple and pair"的出现概率高(更可能是一个合理的句子)。当一个语音识别软件听到这句话时,可以分别写下这两句发音相近的句子,再根据语言模型断定这句话应该写成前者。
规范地说,对于序列,语言模型的输出是
这个柿子也可以写成:
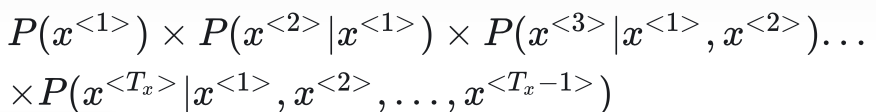
即一句话的出现概率,等于第一个单词出现在句首的概率,乘上第二个单词在第一个单词之后的概率,乘上第三个单词再第一、二个单词之后的概率,这样一直乘下去。
单词级的语言模型需要的数据量比较大,在这个项目中,我们将搭建一个字母级语言模型。即我们以字母为基本元素,单词为序列。语言模型会输出每个单词的概率。比如我们输入"apple"和"appll",语言模型会告诉我们单词"apple"的概率更高,这个单词更可能是一个正确的英文单词。
RNN语言模型
为了计算语言模型的概率,我们可以用RNN分别输出最后把这些概率乘起来。
这个式子,说白了就是i给定前t-1个字母,猜一猜第t个字母最可能是哪个,比如给定了前四个字母"appl",第五个单词构成"apply", "apple"的概率比较大,构成"appll", "appla"的概率较小。
为了让神经网络学会这个概率,我们可以令RNN的输入为<sos> x_1, x_2, ..., x_T,RNN的标签为x_1, x_2, ..., x_T, <eos>(<sos>和<eos>是句子开始和结束的特殊字符,实际实现中可以都用空格' '表示。<sos>也可以粗暴地用全零向量表示),即输入和标签都是同一个单词,只是它们的位置差了一格。模型每次要输出一个softmax的多分类概率,预测给定前几个字母时下一个字母的概率。这样,这个模型就能学习到前面那个条件概率了。
二. 代码细节
参考 https://zhuanlan.zhihu.com/p/558838663
1. 数据集获取:
为了搭建字母级语言模型,我们只需要随便找一个有很多单词的数据集。这里我选择了斯坦福大学的大型电影数据集,它收录了IMDb上的电影评论,正面评论和负面评论各25000条。这个数据集本来是用于情感分类这一比较简单的NLP任务,拿来搭字母级语言模型肯定是没问题的。
这个数据集的文件结构大致如下:
├─test
│ ├─neg
│ │ ├ 0_2.txt
│ │ ├ 1_3.txt
│ │ └ ...
│ └─pos
├─train
│ ├─neg
│ └─pos
└─imdb.vocab其中,imdb.vocab记录了数据集中的所有单词,一行一个。test和train测试集和训练集,它们的neg和pos子文件夹分别记录了负面评论和正面评论。每一条评论都是一句话,存在txt文件里。
代码细节:
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import os
import re#from dldemos.BasicRNN.constant import EMBEDDING_LENGTH, LETTER_LIST, LETTER_MAPdef read_imdb_words(dir = 'data',split='pos',is_train=True,n_files=1000):subdir = 'train' if is_train else 'test'dir = os.path.join(dir,subdir,split)all_str = ''for file in os.listdir(dir):if n_files <= 0:breakwith open(os.path.join(dir, file), 'rb') as f:line = f.read().decode('utf-8')all_str += linen_files -= 1words = re.sub(u'([^\u0020\u0061-\u007a])','',all_str.lower()).split(' ')return wordsdef read_imdb(dir='data', split = 'pos', is_train = True):subdir = 'train' if is_train else 'test'dir = os.path.join(dir, subdir, split)lines = []for file in os.listdir(dir):with open(os.path.join(dir, file), 'rb') as f:line = f.read().decode('utf-8')lines.append(line)return linesdef read_imbd_vocab(dir='data'):fn = os.path.join(dir, 'imdb.vocab')with open(fn, 'rb') as f:word = f.read().decode('utf-8').replace('\n', ' ')print("read_imbd_vocab:",word)# words = re.sub(r'([^\u0020a-z])', '',word.lower().split(' '))# 清理字符串(移除所有非空格和非小写字母的字符)words= re.sub(r'[^ a-z]', '', word.lower())# 按空格分割单词words = words.split(' ')print("read_imbd_vocab:",words)filtered_words = [w for w in words if len(w) > 0]return filtered_wordsvocab = read_imbd_vocab()
print(vocab[0])
print(vocab[1])lines = read_imdb()
print('Length of the files:', len(lines))
print('lines[0]', lines[0])
words = read_imdb_words(n_files=100)print('Length of the words:', len(words))
for i in range(5):print(words[i])read_imbd_vocab最终返回的数据单词如下:
![]()
1)words = re.sub(u'([^\u0020\u0061-\u007a])', '', all_str.lower())
步骤 1:
all_str.lower()
作用:将原字符串
all_str转换为全小写。示例:
"Hello World! 123"→"hello world! 123"步骤 2:
re.sub(u'([^\u0020\u0061-\u007a])', '', ...)
正则表达式模式:
([^\u0020\u0061-\u007a])
\u0020:Unicode 的空格字符(ASCII 32)。
\u0061-\u007a:Unicode 的小写字母范围(a到z,对应 ASCII 97-122)。
[^...]:匹配不包含在括号内的任何字符。整体含义:匹配所有非空格且非小写字母的字符。
替换操作:将这些字符替换为空字符串(即删除它们)。
示例:
"hello world! 123"→"hello world "
(移除了!和123,但末尾可能留下多余空格)import re# 清理字符串(移除所有非空格和非小写字母的字符) cleaned_word = re.sub(r'[^ a-z]', '', word.lower())# 按空格分割单词 words = cleaned_word.split(' ')步骤 3:
split(' ')
作用:按空格分割字符串为单词列表。
潜在问题:连续空格可能导致空字符串(如
"hello world"→["hello", "", "world"])。示例:
"hello world "→["hello", "world", ""]
清理字符串:
转换为全小写。
删除所有非小写字母(
a-z)和非空格()的字符。分割单词:
按空格分割成单词列表(可能包含空字符串)。
2). output = torch.empty_like(word)
这行代码的作用是:
-
torch.empty_like(input)是一个PyTorch函数,它会创建一个新张量(output),满足以下条件:-
形状相同:与输入张量
word的维度(shape)完全一致。 -
数据类型相同:与
word的数据类型(dtype,如float32、int64)相同。 -
设备相同:与
word所在的设备(如CPU或GPU)一致。 -
未初始化内存:新张量的元素值是未定义的(可能是任意随机值,取决于内存的当前状态)。
-
2.数据集读取
RNN的输入不是字母,而是表示字母的向量。最简单的字母表示方式是one-hot编码,每一个字母用一个某一维度为1,其他维度为0的向量表示。比如我有a, b, c三个字母,它们的one-hot编码分别为:
a: [1,0,0]
b: [0,1,0]
c: [0,0,1]
EMBEDDING_LENGTH = 27
LETTER_MAP = {' ': 0}
ENCODING_MAP =[' ']
for i in range(26):LETTER_MAP[chr(ord('a')+i)] =i +1ENCODING_MAP.append(chr(ord('a')+i))
LETTER_LIST = list(LETTER_MAP.keys())print("LETTER_MAP:",LETTER_MAP)
print("ENCODING_MAP:",ENCODING_MAP)
print("LETTER_LIST:",LETTER_LIST)'''
字符生成: chr(ord('a') + i)动态生成每个小写字母:
ord('a')返回a的ASCII码97。
97 + i随i从0到25变化, 得到97到122 (对应ASCII中的a到z)。
chr()将ASCII码转换为字符,得到a, b, ..., z。打印结果更直观:

Pytorch提供了用于管理数据读取的Dataset类。Dataset一般只会存储数据的信息,而非原始数据,比如存储图片路径,而每次读取时,Dataset才会去实际读取数据。在这个项目里,我们用Data set存储原始的单词数组,实际读取时,每次返回一个one-hot 编码的向量。
实际dataset使用时,要继承这个类,实现_len_和__getitem__方法。前者表示获取数据集的长度,后者表示获取某项数据。
import torch
from torch.utils.data import DataLoader,Datasetclass WordDataset(Dataset):def __init__(self, words, max_length, is_one_hot=True):super().__init__()self.words = wordsself.n_words = len(words)self.max_length = max_lengthself.is_onehot = is_one_hotdef __len__(self):return self.n_wordsdef __getitem__(self, index):word = self.words[index] + ' 'word_length = len(word)#print("word:",word)if self.is_onehot:tensor = torch.zeros(self.max_length, EMBEDDING_LENGTH)for i in range(self.max_length):if i < word_length:tensor[i][LETTER_MAP[word[i]]] = 1else:tensor[i][0] = 1else:tensor = torch.zeros(self.max_length, dtype = torch.long)for i in range(word_length):tensor[i] = LETTER_MAP[word[i]]return tensor构造数据集的参数是
words, max_length, is_onehot。words是单词数组。max_length表示单词的最大长度。在训练时,我们一般要传入一个batch的单词。可是,单词有长有短,我们不可能拿一个动态长度的数组去表示单词。为了统一地表达所有单词,我们可以记录单词的最大长度,把较短的单词填充空字符,直到最大长度。is_onehot表示是不是one-hot编码,我设计的这个数据集既能输出用数字标签表示的单词(比如abc表示成[0, 1, 2]),也能输出one-hoe编码表示的单词(比如abc表示成[[1, 0, 0], [0, 1, 0], [0, 0, 1]])。
在获取数据集时,我们要根据是不是one-hot编码,先准备好一个全是0的输出张量。如果存的是one-hot编码,张量的形状是[MAX_LENGTH, EMBEDDING_LENGTH],第一维是单词的最大长度,第二维是one-hot编码的长度。而如果是普通的标签数组,则张量的形状是[MAX_LENGTH]。准备好张量后,遍历每一个位置,令one-hot编码的对应位为1,或者填入数字标签。
另外,我们用空格表示单词的结束。要在处理前给单词加一个' ',保证哪怕最长的单词也会至少有一个空格。
有了数据集类,结合之前写好的数据集获取函数,可以搭建一个DataLoader。DataLoader是PyTorch提供的数据读取类,它可以方便地从Dataset的子类里读取一个batch的数据,或者以更高级的方式取数据(比如随机取数据)。
def get_dataloader_and_max_langth(limit_length = None, is_one_hot = True, is_vocab = True):if is_vocab:words = read_imbd_vocab()else:words = read_imdb_words(n_files=200)max_length = 0for word in words:max_length = max(max_length, len(word))if limit_length is not None and max_length > limit_length:words = [w for w in words if len(w) <= limit_length]max_length = limit_lengthmax_length +=1dataset = WordDataset(words, max_length, is_one_hot)print("max_length:",max_length)return DataLoader(dataset, batch_size=256), max_length这个函数会先调用之前编写的数据读取API获取单词数组。之后,函数会计算最长的单词长度。这里,我用limit_length过滤了过长的单词。据实验,这个数据集里最长的单词竟然有60多个字母,把短单词填充至60需要浪费大量的计算资源。因此,我设置了limit_length这个参数,不去读取那些过长的单词。
计算完最大长度后,别忘了+1,保证每个单词后面都有一个表示单词结束的空格。
最后,用DataLoader(dataset, batch_size=256)就可以得到一个DataLoader。batch_size就是指定batch size的参数。我们这个神经网络很小,输入数据也很小,可以选一个很大的batch size加速训练。
3.模型预览
class RNN1(nn.Module):def __init__(self, hidden_units = 32):super().__init__()self.hidden_units = hidden_unitsself.linear_a = nn.Linear(self.hidden_units + EMBEDDING_LENGTH, hidden_units)self.linear_y = nn.Linear(hidden_units, EMBEDDING_LENGTH)self.tanh = nn.Tanh()def forward(self, word: torch.Tensor):#word shape: [batch, max_word_length, embedding_length]batch, Tx = word.shape[0:2]#word shape: [max_word_length, batch, embedding_length]word = torch.transpose(word, 0, 1)output = torch.empty_like(word)a = torch.zeros(batch, self.hidden_units)x = torch.zeros(batch, EMBEDDING_LENGTH)for i in range (Tx):next_a = self.tanh(self.linear_a(torch.cat((x,a),1)))hat_y = self.linear_y(next_a)output[i] = hat_yx = word[i]a = next_areturn torch.transpose(output, 0, 1)
我们可以把第一行公式里的两个合并一下,拼接一下。这样,只需要两个线性层就可以描述RNN了。
因此,在初始化函数中,我们定义两个线性层linear_a,linear_y。另外,hidden_units表示隐藏层linear_a的神经元数目。tanh就是普通的tanh函数,它用作第一层的激活函数。
linear_a就是公式的第一行,由于我们把输入x和状态a拼接起来了,这一层的输入通道数是hidden_units + EMBEDDING_LENGTH,输出通道数是hidden_units。第二层linear_y表示公式的第二行。我们希望RNN能预测下一个字母的出现概率,因此这一层的输出通道数是EMBEDDING_LENGTH=27,即字符个数。
在描述模型运行的forward函数中,我们先准备好输出张量,再初始化好隐变量a和第一轮的输入x。根据公式,循环遍历序列的每一个字母,用a, x计算hat_y,并维护每一轮的a, x。最后,所有hat_y拼接成的output就是返回结果。
我们来看一看这个函数的细节。一开始,输入张量word的形状是[batch数,最大单词长度,字符数=27]。我们提前获取好形状信息。
# word shape: [batch, max_word_length, embedding_length]
batch, Tx = word.shape[0:2]
我们循环遍历的其实是单词长度那一维。为了方便理解代码,我们可以把单词长度那一维转置成第一维。根据这个新的形状,我们准备好同形状的输出张量。输出张量output[i][j]表示第j个batch的序列的第i个元素的27个字符预测结果。
4.训练
首先,调用之前编写的函数,准备好dataloader和model。同时,准备好优化器optimizer和损失函数citerion。优化器和损失函数按照常见配置选择即可。
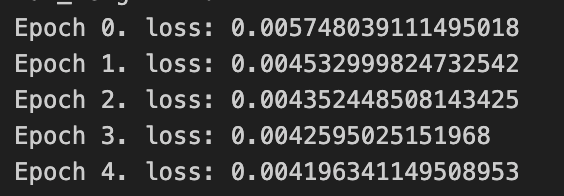
这个语言模型一下就能训练完,做5个epoch就差不多了。每一代训练中, 先调用模型求出hat_y,再调用损失函数citerion,最后反向传播并优化模型参数。
def train_rnn1():data, max_length = get_dataloader_and_max_langth(19)model = RNN1()optimizer = torch.optim.Adam(model.parameters(), lr=0.001)citerion = torch.nn.CrossEntropyLoss()for epoch in range(5):loss_sum = 0dataset_len = len(data.dataset)for y in data:hat_y = model(y)n, Tx, _ = hat_y.shapehat_y = torch.reshape(hat_y,(n*Tx,-1))y = torch.reshape(y, (n* Tx, -1))label_y = torch.argmax(y, 1)loss = citerion(hat_y, label_y)optimizer.zero_grad()loss.backward()torch.nn.utils.clip_grad_norm_(model.parameters(), 0.5)optimizer.step()loss_sum += lossprint(f'Epoch {epoch}. loss: {loss_sum / dataset_len}')torch.save(model.state_dict(), 'rnn1.pth')return model
算损失函数前需要预处理一下数据,交叉熵损失函数默认hat_y的维度是[batch数,类型数],label_y是一个一维整形标签数组。而模型的输出形状是[batch数,最大单词长度,字符数],我们要把前两个维度融合在一起。另外,我们并没有提前准备好label_y,需要调用argmax把one-hot编码转换回标签。
之后就是调用PyTorch的自动求导功能。注意,为了防止RNN梯度过大,我们可以用clip_grad_norm_截取梯度的最大值。
输出:

5. 测试
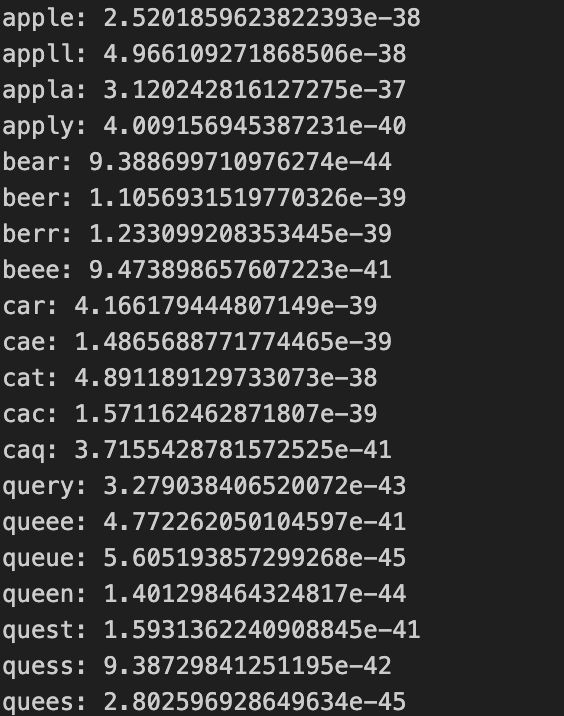
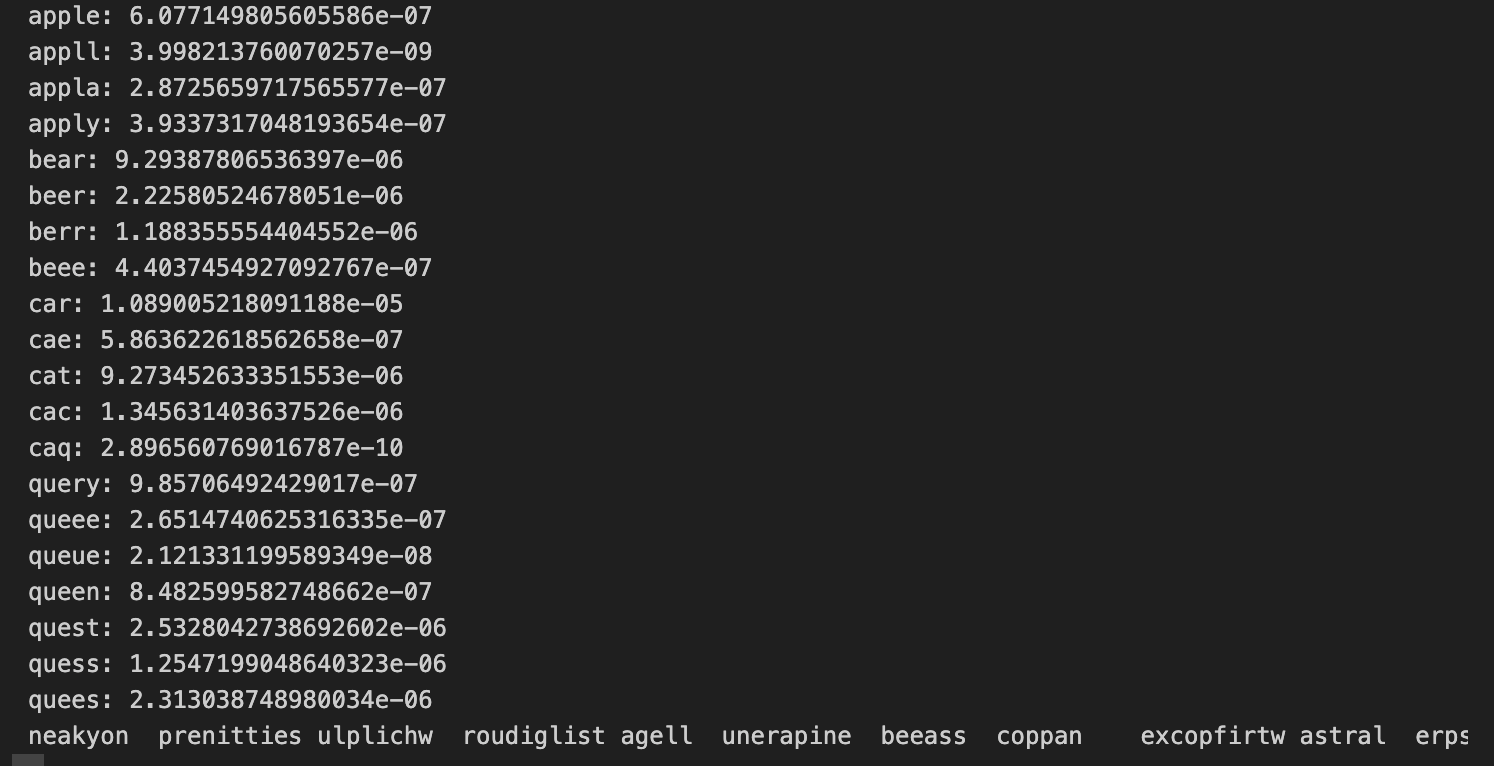
我们可以手动为字母级语言模型写几个测试用例,看看每一个单词的概率是否和期望的一样。我的测试单词列表是:
test_words = ['apple', 'appll', 'appla', 'apply', 'bear', 'beer', 'berr', 'beee', 'car','cae', 'cat', 'cac', 'caq', 'query', 'queee', 'queue', 'queen', 'quest','quess', 'quees'
]几组长度一样,但是最后几个字母不太一样的“单词”。通过观察这些词的概率,我们能够验证语言模型的正确性。理论上来说,英文里的正确单词的概率会更高。
我们的模型只能输出每一个单词的softmax前结果。我们还要为模型另写一个求语言模型概率的函数。
@torch.no_grad()def language_model(self, word: torch.Tensor):# word shape: [batch, max_word_length, embedding_length]batch, Tx = word.shape[0:2]# word shape: [max_word_length, batch, embedding_length]# word_label shape: [max_word_length, batch]word = torch.transpose(word, 0, 1)word_label = torch.argmax(word, 2)# output shape: [batch]output = torch.ones(batch, device=word.device)a = torch.zeros(batch, self.hidden_units, device=word.device)x = torch.zeros(batch, EMBEDDING_LENGTH, device=word.device)for i in range(Tx):next_a = self.tanh(self.linear_a(torch.cat((a, x), 1)))tmp = self.linear_y(next_a)hat_y = F.softmax(tmp, 1)probs = hat_y[torch.arange(batch), word_label[i]]#从hat_y里取出每一个batch里word_label[i]处的概率output *= probsx = word[i]a = next_areturn output@torch.no_grad()def sample_word(self):batch = 1output = ''a = torch.zeros(batch, self.hidden_units)x = torch.zeros(batch, EMBEDDING_LENGTH)for i in range(10):next_a = self.tanh(self.linear_a(torch.cat((a,x),1)))tmp = self.linear_y(next_a)hat_y = F.softmax(tmp, 1)np_prob = hat_y[0].detach().cpu().numpy()letter = np.random.choice(LETTER_LIST, p=np_prob)output += letterif letter == ' ':breakx = torch.zeros(batch, EMBEDDING_LENGTH)x[0][LETTER_MAP[letter]] = 1a = next_areturn output这个函数和forward大致相同。只不过,这次我们的输出output要表示每一个单词的概率。因此,它被初始化成一个全1的向量。
# output shape: [batch]
output = torch.ones(batch, device=word.device)
每轮算完最后一层的输出后,我们手动调用F.softmax得到softmax的概率值。
tmp = self.linear_y(next_a)
hat_y = F.softmax(tmp, 1)
接下来,我们要根据每一个batch当前位置的单词,去hat_y里取出需要的概率。比如第2个batch当前的字母是b,我们就要取出hat_y[2][2]。
第i轮所有batch的字母可以用word_label[i]表示。根据这个信息,我们可以用probs = hat_y[torch.arange(batch), word_label[i]]神奇地从hat_y里取出每一个batch里word_label[i]处的概率。把这个概率乘到output上就算完成了一轮计算。
有了语言模型函数,我们可以测试一下开始那些单词的概率。
def sample(model):words =[]for _ in range(20):word = model.sample_word()words.append(word)print(*words)def test_language_model(model, is_onehot=True):data, max_length = get_dataloader_and_max_langth(19)if is_onehot:test_word = words_to_onehot(test_words, max_length)else:test_word = words_to_label_array(test_words, max_length)probs = model.language_model(test_word)for word, prob in zip(test_words, probs):print(f'{word}: {prob}') #rnn1 = train_rnn1()
#rnn1 = RNN1()state_dict = torch.load('rnn1.pth')rnn1.load_state_dict(state_dict)rnn1.eval()# Dropout 层被禁用,BatchNorm 使用全局统计量
test_language_model(rnn1)
sample(rnn1)输出:
采样单词:
语言模型有一个很好玩的应用:我们可以根据语言模型输出的概率分布,采样出下一个单词;输入这一个单词,再采样下一个单词。这样一直采样,直到采样出空格为止。使用这种采样算法,我们能够让模型自动生成单词,甚至是英文里不存在,却看上去很像那么回事的单词。
我们要为模型编写一个新的方法sample_word,采样出一个最大长度为10的单词。这段代码的运行逻辑和之前的forward也很相似。只不过,这一次我们没有输入张量,每一轮的x要靠采样获得。np.random.choice(LETTER_LIST, p=np_prob)可以根据概率分布np_prob对列表LETTER_LIST进行采样。根据每一轮采样出的单词letter,我们重新生成一个x,给one-hot编码的对应位置赋值1。
@torch.no_grad()def sample_word(self):batch = 1output = ''a = torch.zeros(batch, self.hidden_units)x = torch.zeros(batch, EMBEDDING_LENGTH)for i in range(10):next_a = self.tanh(self.linear_a(torch.cat((a,x),1)))tmp = self.linear_y(next_a)hat_y = F.softmax(tmp, 1)np_prob = hat_y[0].detach().cpu().numpy()letter = np.random.choice(LETTER_LIST, p=np_prob)output += letterif letter == ' ':breakx = torch.zeros(batch, EMBEDDING_LENGTH)x[0][LETTER_MAP[letter]] = 1a = next_areturn output使用这个方法,我们可以写一个采样20次的脚本:
def sample(model):words = []for _ in range(20):word = model.sample_word()words.append(word)print(*words)输出:
采样出来的单词几乎不会是英文里的正确单词。不过,这些单词的词缀很符合英文的造词规则,非常好玩。如果为采样函数加一些限制,比如只考虑概率前3的字母,那么算法应该能够采样出更正确的单词。
![]()
三.PyTorch里的RNN函数
刚刚我们手动编写了RNN的实现细节。实际上,PyTorch提供了更高级的函数,我们能够更加轻松地实现RNN。其他部分的代码逻辑都不怎么要改,这里只展示一下要改动的关键部分。
新的模型的主要函数如下:
class RNN2(torch.nn.Module):def __init__(self, hidden_units=64, embeding_dim=64, dropout_rate=0.2):super().__init__()self.drop = nn.Dropout(dropout_rate)self.encoder = nn.Embedding(EMBEDDING_LENGTH, embeding_dim)self.rnn = nn.GRU(embeding_dim, hidden_units, 1, batch_first=True)self.decoder = torch.nn.Linear(hidden_units, EMBEDDING_LENGTH)self.hidden_units = hidden_unitsself.init_weights()def init_weights(self):initrange = 0.1nn.init.uniform_(self.encoder.weight, -initrange, initrange)nn.init.zeros_(self.decoder.bias)nn.init.uniform_(self.decoder.weight, -initrange, initrange)def forward(self, word: torch.Tensor):# word shape: [batch, max_word_length]batch, Tx = word.shape[0:2]first_letter = word.new_zeros(batch, 1)x = torch.cat((first_letter, word[:, 0:-1]), 1)hidden = torch.zeros(1, batch, self.hidden_units, device=word.device)emb = self.drop(self.encoder(x))output, hidden = self.rnn(emb, hidden)y = self.decoder(output.reshape(batch * Tx, -1))return y.reshape(batch, Tx, -1)
初始化时,我们用nn.Embedding表示单词的向量。词嵌入(Embedding)是《深度学习专项-RNN》第二门课的内容,我会在下一篇笔记里介绍。这里我们把nn.Embedding看成一种代替one-hot编码的更高级的向量就行。这些向量和线性层参数W一样,是可以被梯度下降优化的。这样,不仅是RNN可以优化,每一个单词的表示方法也可以被优化。
注意,使用nn.Embedding后,输入的张量不再是one-hot编码,而是数字标签。代码中的其他地方也要跟着修改。
nn.GRU可以创建GRU。其第一个参数是输入的维度,第二个参数是隐变量a的维度,第三个参数是层数,这里我们只构建1层RNN,batch_first表示输入张量的格式是[batch, Tx, embedding_length]还是[Tx, batch, embedding_length]。
貌似RNN中常用的正则化是靠dropout实现的。我们要提前准备好dropout层。
def __init__(self, hidden_units=64, embeding_dim=64, dropout_rate=0.2):super().__init__()self.drop = nn.Dropout(dropout_rate)self.encoder = nn.Embedding(EMBEDDING_LENGTH, embeding_dim)self.rnn = nn.GRU(embeding_dim, hidden_units, 1, batch_first=True)self.decoder = torch.nn.Linear(hidden_units, EMBEDDING_LENGTH)self.hidden_units = hidden_unitsself.init_weights()
准备好了计算层后,在forward里只要依次调用它们就行了。其底层原理和我们之前手写的是一样的。其中,self.rnn(emb, hidden)这个调用完成了循环遍历的计算。
由于输入格式改了,令第一轮输入为空字符的操作也更繁琐了一点。我们要先定义一个空字符张量,再把它和输入的第一至倒数第二个元素拼接起来,作为网络的真正输入。
def forward(self, word: torch.Tensor):# word shape: [batch, max_word_length]batch, Tx = word.shape[0:2]first_letter = word.new_zeros(batch, 1)x = torch.cat((first_letter, word[:, 0:-1]), 1)hidden = torch.zeros(1, batch, self.hidden_units, device=word.device)emb = self.drop(self.encoder(x))output, hidden = self.rnn(emb, hidden)y = self.decoder(output.reshape(batch * Tx, -1))return y.reshape(batch, Tx, -1)
PyTorch里的RNN用起来非常灵活。我们不仅能够给它一个序列,一次输出序列的所有结果,还可以只输入一个元素,得到一轮的结果。在采样单词时,我们不得不每次输入一个元素。有关采样的逻辑如下:
@torch.no_grad()
def sample_word(self, device='cuda:0'):batch = 1output = ''hidden = torch.zeros(1, batch, self.hidden_units, device=device)x = torch.zeros(batch, 1, device=device, dtype=torch.long)for _ in range(10):emb = self.drop(self.encoder(x))rnn_output, hidden = self.rnn(emb, hidden)hat_y = self.decoder(rnn_output)hat_y = F.softmax(hat_y, 2)np_prob = hat_y[0, 0].detach().cpu().numpy()letter = np.random.choice(LETTER_LIST, p=np_prob)output += letterif letter == ' ':breakx = torch.zeros(batch, 1, device=device, dtype=torch.long)x[0] = LETTER_MAP[letter]return output
以上就是PyTorch高级RNN组件的使用方法。在使用PyTorch的RNN时,主要的改变就是输入从one-hot向量变成了标签,数据预处理会更加方便一些。另外,PyTorch的RNN会自动完成循环,可以给它输入任意长度的序列。
相关文章:

吴恩达深度学习作业 RNN模型——字母级语言模型
一. 简单复习一下RNN RNN RNN适用于处理序列数据,令是序列的第i个元素,那么就是一个长度为的序列,NLP中最常见的元素是单词,对应的序列是句子。 RNN使用同一个神经网络处理序列中的每一个元素。同时,为了表示序列的…...

数字时代,如何为个人信息与隐私筑牢安全防线?
首席数据官高鹏律师团队编著 在当今数字化时代,个人信息和隐私保护至关重要。我们在享受数字生活带来的便利时,也面临着个人信息泄露、隐私被侵犯的风险。下面将从先进技术和法律途径两个方面,探讨如何严格保护个人信息和隐私。 一、先进技…...

javascript交换值最好三种
代码 1. 位运算(性能高,但只能用于整数) var a15; var b32; console.log(a) //15 console.log(b) //32 a a ^ b; b a ^ b; a a ^ b; console.log(a) //32 console.log(b) //152. 数组结构(性能高,但要ES6) var a15; var b32; console.log(…...

C++-Lambda表达式
目录 1.什么是 Lambda? 2.例子:打印每个元素(和 for_each 一起用) 3.捕获外部变量(Capture) 3.1. 捕获值(拷贝):[] 3.2. 捕获引用:[&] 3.3. 指定捕…...

逻辑回归的多分类实战:以鸢尾花数据集为例
文章目录 引言:从二分类到多分类一、多分类问题无处不在二、One-vs-All策略揭秘1. 核心思想2. 数学表达 三、鸢尾花分类完整实现1. 环境准备2. 数据加载与探索3. 数据预处理4. 模型训练与评估5. 决策边界可视化 四、关键参数解析五、总结 引言:从二分类到…...
)
[面试]SoC验证工程师面试常见问题(一)
SoC验证工程师面试常见问题(一) 摘要:在面试 SoC 验证工程师职位时,面试官通常会重点考察候选人对 SystemVerilog 和 UVM (Universal Verification Methodology) 的掌握程度,因为这两者是现代 IC 验证的核心技能。以下是可能会被问到的常见问题,涵盖 SystemVerilo…...

传统银行服务和 区块链支付无缝融合的一种解决方案
Dragonfly Capital 的合伙人 Alex Pack 曾表示:“DeFi 的目标是重构全球银行体系,并打造开放且无须许可的经营环境。”在 DeFi 的金融世界中,加密资产架构在区块链上,通过各个协议实现资产之间的高效转移和价值的实时流通,如 Metamask 钱包的自托管,Uniswap 的资产交易,…...

大语言模型能力评定探讨
有标准答案的评估(选择题) 评估语言模型能力的基本思路是准备输入和标准答案,比较不同模型对相同输入的输出 由于AI答题有各种各样答案,因此现在是利用选择题考察。 有一个知名的选择题的基准叫做Massive Multitask Language Und…...

解构区块链身份认证:从ID到零知识证明的实战指南
引言 在数字经济高速发展的今天,数字身份已成为个人与数字世界交互的核心凭证。传统中心化身份系统存在数据孤岛、隐私泄露、单点故障等痛点,而区块链技术凭借去中心化、不可篡改、可追溯的特性,为数字身份验证提供了革命性解决方案…...

IntelliJ IDEA 使用教程
文章目录 一、创建项目二、创建模块三、创建包四、创建类五、编写代码六、运行代码注意 一、创建项目 二、创建模块 【File】->【New】->【Module…】 三、创建包 【helloword】->【右击 src】->【New】->【Package】 四、创建类 【helloword】->【s…...

HBM的哪些事
命令操作 这也许是DDR往HBM演进的一些奇淫技巧。 本篇内容属于杂谈,关于HBM的奇淫技巧,随后出专题介绍。...

C++ std::initializer_list 详解
std::initializer_list 是 C11 引入的一个轻量级模板类,用于支持花括号初始化列表({1, 2, 3})的语义。它允许函数或构造函数接受任意长度的同类型初始化列表,是实现统一初始化({} 语法)的核心组件。 1. 基本…...
)
网络原理 - 13(HTTP/HTTPS - 4 - HTTPS)
目录 HTTPS 是什么 不得不的策略 - 应对“运营商劫持” “加密” 是什么 分类 对称加密 非对称加密 HTTPS 工作原理 1)引入对称加密 2) 引入非对称加密 中间人攻击 引入证书 证书的验证过程 完! HTTPS 是什么 HTTPS 也是一个应…...

当MCP撞进云宇宙:多芯片封装如何重构云计算的“芯“未来?
当MCP撞进云宇宙:多芯片封装如何重构云计算的"芯"未来? 2024年3月,AMD发布了震撼业界的MI300A/B芯片——这颗为AI计算而生的"超级芯片",首次在单封装内集成了13个计算芯片(包括3D V-Cache缓存、CDNA3 GPU和Zen4 CPU),用多芯片封装(Multi-Chip Pac…...

Kotlin Flow流
一 Kotlin Flow 中的 stateIn 和 shareIn 一、简单比喻理解 想象一个水龙头(数据源)和几个水杯(数据接收者): 普通 Flow(冷流):每个水杯来接水时,都要重新打开水龙头从…...
实验(Cisco Packet Tracer)-路由器、交换机的基本配置)
虚拟局域网(VLAN)实验(Cisco Packet Tracer)-路由器、交换机的基本配置
好的,我们来根据你提供的文档,一步步地在 Cisco Packet Tracer 中完成这个跨交换机划分 VLAN 的实验。 实验目标: 配置两台交换机 SW1 和 SW2,划分 VLAN 10 和 VLAN 20,配置 Trunk 链路,并测试同 VLAN 和跨 VLAN 的连…...
)
【论文速递】2025年09周 (Robotics/Embodied AI/LLM)
目录 LLM-Microscope:揭示标点符号在Transformers的上下文中的隐藏作用英文摘要中文摘要 SurveyX:通过大型语言模型实现学术调查自动化英文摘要中文摘要 数学推理的自我奖励校正英文摘要中文摘要 VideoGrain:调整时空关注以进行多元透明视频编…...

自主机器人模拟系统
一、系统概述 本代码实现了一个基于Pygame的2D自主机器人模拟系统,具备以下核心功能: 双模式控制:支持手动控制(WASD键)和自动导航模式(鼠标左键设定目标) 智能路径规划:采用改进型…...

DeepSeek构建非农预测模型:量化关税滞后效应与非线性经济冲击传导
AI分析:非农数据前瞻与关税影响的滞后性 根据AI模型对多维度经济指标的交叉验证,4月非农就业报告或呈现“增速放缓但未失速”的特征。当前市场共识预期为新增就业13.3万人(前值22.8万),失业率维持4.2%,时薪…...
插值表达式、ref、reactive)
前端面经-VUE3篇--vue3基础知识(一)插值表达式、ref、reactive
一、计算属性(computed) 计算属性(Computed Properties)是 Vue 中一种特殊的响应式数据,它能基于已有的响应式数据动态计算出新的数据。 计算属性有以下特性: 自动缓存:只有当它依赖的响应式数据发生变化时ÿ…...

云原生后端架构的优势与最佳实践
📝个人主页🌹:慌ZHANG-CSDN博客 🌹🌹期待您的关注 🌹🌹 在过去的几年里,随着云计算和容器化技术的迅猛发展,云原生架构逐渐成为现代企业和开发团队构建和运维应用系统的首选方式。云原生架构通过高度的自动化、弹性伸缩、微服务化等特点,使得企业能够在不断变化…...

力扣838.推多米诺随笔
“生活就像海洋,只有意志坚强的人,才能到达彼岸。”—— 马克思 题目 n 张多米诺骨牌排成一行,将每张多米诺骨牌垂直竖立。在开始时,同时把一些多米诺骨牌向左或向右推。 每过一秒,倒向左边的多米诺骨牌会推动其左侧…...

aab转apk
一、 android34升级: 1、升级到安卓34(蓝牙、图片) 再蓝牙广播的地方加入Context.RECEIVER_EXPORTED 2、废弃了 BluetoothAdapter#enable() 和 BluetoothAdapter#disable(),需要修改 // 以前的蓝牙操作BluetoothManager bluetoo…...

LeetCode 560. 和为 K 的子数组 | 前缀和与哈希表的巧妙应用
文章目录 方法思路:前缀和 哈希表核心思想关键步骤 代码实现复杂度分析示例解析总结 题目描述 给定一个整数数组 nums 和一个整数 k,请统计并返回该数组中和为 k 的子数组的数量。 子数组是数组中连续的非空元素序列。 示例 输入:nums …...

【Hive入门】Hive性能调优:小文件问题与动态分区合并策略详解
目录 引言 1 Hive小文件问题概述 1.1 什么是小文件问题 1.2 小文件产生的原因 2 Hive小文件合并机制 2.1 hive.merge.smallfiles参数详解 2.2 小文件合并流程 2.3 合并策略选择 3 动态分区与小文件问题 3.1 动态分区原理 3.2 动态分区合并策略 3.3 动态分区合并流程…...

基于Springboot+Vue3.0的前后端分离的个人旅游足迹可视化平台
文章目录 0、前言1、前端开发1.1 登录注册页面1.2 首页1.3 足迹管理1.3.1 足迹列表1.3.2 添加足迹1.4 个人中心1.4.1 足迹成就1.4.2 个人信息1.4.3 我的计划2、后端开发2.1 用户接口开发2.2 足迹点接口2.3 旅游计划接口3、完整代码资料下载0、前言 项目亮点: 前端用户权限动态…...

安妮推广导航系统开心版多款主题网址推广赚钱软件推广变现一键统计免授权源码Annie
一、源码描述 这是一套推广导航源码(Annie),基于Funadmin框架(ThinkPHP8Layui ),内置多款主题,可以用于网址推广,或者用于软件推广,PC端软件手机端软件,后台…...

单片机-STM32部分:1、STM32介绍
飞书文档https://x509p6c8to.feishu.cn/wiki/CmpZwTgHhiQSHZkvzjdc6c4Yn1g STM32单片机不是一款芯片,而是一个系列的芯片? STM32系列单片机是ST(意法半导体)公司开发的一套32位微控制器基于Arm Cortex()-M处理器,它包…...

PHP-session
PHP中,session(会话)是一种在服务器上存储用户数据的方法,这些数据可以在多个页面请求或访问之间保持。Session提供了一种方式来跟踪用户状态,比如登录信息、购物车内容等。当用户首次访问网站时,服务器会创…...

php artisan resetPass 执行密码重置失败的原因?php artisan resetPass是什么 如何使用?-优雅草卓伊凡
php artisan resetPass 执行密码重置失败的原因?php artisan resetPass是什么 如何使用?-优雅草卓伊凡 可能的原因 命令不存在:如果你没有正确定义这个命令,Laravel 会报错而不是提示”重置密码失败”用户不存在:’a…...

AI大模型-微调和RAG方案选项
在搭建知识库的方向上,有两个落地方案:微调、RAG。两个方案的比对: 方案选型 微调 让大模型(LLM)去学习现有知识(调整大模型的参数,让它学习新的知识),最终生成一个新的…...

MySQL 第一讲---基础篇 安装
前言: 在当今数据驱动的时代,掌握数据库技术已成为开发者必备的核心技能。作为全球最受欢迎的开源关系型数据库,MySQL承载着淘宝双十一每秒50万次的交易请求,支撑着Facebook百亿级的数据存储,更是无数互联网企业的数据…...

【JavaScript-Day 1】从零开始:全面了解 JavaScript 是什么、为什么学以及它与 Java 的区别
Langchain系列文章目录 01-玩转LangChain:从模型调用到Prompt模板与输出解析的完整指南 02-玩转 LangChain Memory 模块:四种记忆类型详解及应用场景全覆盖 03-全面掌握 LangChain:从核心链条构建到动态任务分配的实战指南 04-玩转 LangChai…...

C++ 复习
VS 修改 C 语言标准 右键项目-属性 输入输出 //引用头文件,用<>包裹起来的一般是系统提供的写好的代码 编译器会在专门的系统路径中去进行查找 #include <iostream> //自己写的代码文件一般都用""包裹起来 编译器会在当前文件所在的目录中査…...
(文末有下载方式))
数字智慧方案5877丨智慧交通项目方案(122页PPT)(文末有下载方式)
篇幅所限,本文只提供部分资料内容,完整资料请看下面链接 https://download.csdn.net/download/2301_78256053/89575494 资料解读:智慧交通项目方案 详细资料请看本解读文章的最后内容。 智慧交通项目方案是一个全面的设计框架,…...

如何封装一个线程安全、可复用的 HBase 查询模板
目录 一、前言:原生 HBase 查询的痛点 (一)连接管理混乱,容易造成资源泄露 (二)查询逻辑重复,缺乏统一的模板 (三)多线程/高并发下的线程安全性隐患 (四…...
)
VLM Qwen2.5VL GRPO训练微调 EasyR1 多机多卡训练(2)
在之前博客进行了简单的训练尝试:https://www.dong-blog.fun/post/2060 在本博客,将会深入进行多机多卡训练,以及调整训练奖励函数。 之前构建了镜像: docker build . -t kevinchina/deeplearning:r1 FROM hiyouga/verl:ngc-th2.6.0-cu126-vllm0.8.4-flashinfer0.2.2-cx…...

基于建造者模式的信号量与理解建造者模式
信号量是什么? AI解释:信号量(Semaphore)是操作系统中用于 进程同步与互斥 的经典工具,由荷兰计算机科学家 Edsger Dijkstra 在 1965 年提出。它本质上是一个 非负整数变量,通过原子操作(P 操作…...
)
笔试专题(十四)
文章目录 mari和shiny题解代码 体操队形题解代码 二叉树中的最大路径和题解代码 mari和shiny 题目链接 题解 1. 可以用多状态的线性dp 2. 细节处理:使用long long 存储个数 3. 空间优化:只需要考虑等于’s’,‘sh’,shy’的情况…...

2025年五一数学建模A题【支路车流量推测】原创论文讲解
大家好呀,从发布赛题一直到现在,总算完成了2025年五一数学建模A题【支路车流量推测】完整的成品论文。 给大家看一下目录吧: 摘 要: 一、问题重述 二.问题分析 2.1问题一 2.2问题二 2.3问题三 2.4问题四 2.5 …...

Linux系统:进程程序替换以及相关exec接口
本节重点 理解进程替换的相关概念与原理掌握相关程序替换接口程序替换与进程创建的区别程序替换的注意事项 一、概念与原理 进程程序替换是操作系统中实现多任务和资源复用的关键机制,允许进程在运行时动态加载并执行新程序。 1.1 定义 进程程序替换是指用新程…...

STM32复盘总结——芯片简介
1、stm32介绍 STM32是ST公司基于ARM Cortex-M内核开发的32位微控制器 STM32常应用在嵌入式领域,如智能车、无人机、机器人、无线通信、物联网、工业控制、娱乐电子产品等 STM32功能强大、性能优异、片上资源丰富、功耗低,是一款经典的嵌入式微控制器 目…...

安装深度环境anaconda+cuda+cudnn+pycharm+qt+MVS
下载anaconda,链接:link 默认电脑有显卡驱动,没有的话直接进NVIDIA官网:https://www.nvidia.cn/geforce/drivers/ 下载。 下载cuda 链接:https://developer.nvidia.com/cuda-toolkit-archive 下载cudnn安装包,链接:https://developer.nvidia.com/rdp/cudnn-archive 备注:…...

泰迪杯特等奖案例学习资料:基于多模态特征融合的图像文本检索系统设计
(第十二届泰迪杯数据挖掘挑战赛B题特等奖案例解析) 一、案例背景与核心挑战 1.1 应用场景与行业痛点 随着智能终端与社交媒体的普及,图像与文本数据呈现爆炸式增长,跨模态检索需求日益迫切。传统方法面临以下问题: 语义鸿沟:图像与文本的异构特征分布差异显著,导致跨模…...

进程与线程:05 内核级线程实现
内核级线程代码实现概述 这节课我们要讲内核级线程到底是怎么做出来的,实际上就是要深入探讨内核级线程的代码实现。 在前两节课中,我们学习了用户级线程和内核级线程是如何进行切换的,以及实现切换的核心要点。那两节课讲述的内容…...

Laravel 12 实现 API 登录令牌认证
Laravel 12 实现 API 登录令牌认证 在 Laravel 12 中实现基于令牌(Token)的 API 认证,可以使用 Laravel Sanctum 或 Laravel Passport。以下是两种方式的实现方法: 方法一:使用 Laravel Sanctum (轻量级 API 认证) 1. 安装 Sanctum compo…...
)
【Git】万字详解 Git 的原理与使用(上)
🥰🥰🥰来都来了,不妨点个关注叭! 👉博客主页:欢迎各位大佬!👈 文章目录 1. 初识 Git1.1 Git 是什么?1.2 为什么要有 Git 2. 安装 Git2.1 Linux-Ubuntu 安装 Git2.2 Windo…...

Python高级爬虫之JS逆向+安卓逆向1.7节: 面向对象
目录 引言: 1.7.1 先理解面向过程 1.7.2 再理解面向对象 1.7.3 面向对象的三大特征 1.7.4 类属性,类方法,静态方法 1.7.5 构造函数,对象属性,对象方法 1.7.6 爬虫接单实现了雪糕自由 引言: 大神薯条老师的高级爬虫+安卓逆向教程: 这套爬虫教程会系统讲解爬虫的初…...
)
SpringBoot基础(原理、项目搭建、yaml)
SpringBoot:javaweb的一个框架,基于Spring开发,SpringBoot本身并不提供Spring框架的核心特性以及扩展功能,只是用于快速、敏捷的开发新一代基于Spring框架的应用程序,它与Spring框架紧密结合用于提升Spring开发者体验的…...

MTV-SCA:基于多试向量的正弦余弦算法
3 正弦余弦算法 (SCA) 正弦余弦算法(SCA)是为全局优化而开发的,并受到两个函数,正弦和余弦的启发。与其他基于启发式种群的算法一样,SCA在问题的预设最小值和最大值边界内随机生成候选解。然后,通过应用方…...