【Hive入门】Hive性能调优:小文件问题与动态分区合并策略详解
目录
引言
1 Hive小文件问题概述
1.1 什么是小文件问题
1.2 小文件产生的原因
2 Hive小文件合并机制
2.1 hive.merge.smallfiles参数详解
2.2 小文件合并流程
2.3 合并策略选择
3 动态分区与小文件问题
3.1 动态分区原理
3.2 动态分区合并策略
3.3 动态分区合并流程
4 高级调优技巧
4.1 基于存储格式的优化
4.2 定时合并策略
4.3 写入时优化
5 案例分析
5.1 日志分析案例
5.2 数据仓库ETL案例
6 监控与评估
6.1 小文件检测方法
6.2 性能评估指标
7 总结
7.1 Hive小文件处理
7.2 参数推荐配置
引言
在大数据领域,Apache Hive作为构建在Hadoop之上的数据仓库工具,被广泛应用于数据ETL、分析和报表生成等场景。然而,随着数据量的增长和业务复杂度的提升,Hive性能问题逐渐显现,其中小文件问题尤为突出。本文将深入探讨Hive中的小文件问题及其解决方案,特别是通过参数hive.merge.smallfiles进行小文件合并和动态分区合并的技术细节。
1 Hive小文件问题概述
1.1 什么是小文件问题
小文件问题指的是在Hadoop分布式文件系统(HDFS)中存储了大量远小于HDFS块大小(通常为128MB或256MB)的文件。这些小文件会导致:
- NameNode内存压力:HDFS中每个文件、目录和块都会在NameNode内存中占用约150字节的空间
- MapReduce效率低下:每个小文件都会启动一个Map任务,造成任务调度开销远大于实际数据处理时间
- 查询性能下降:Hive查询需要打开和处理大量文件,增加了I/O开销
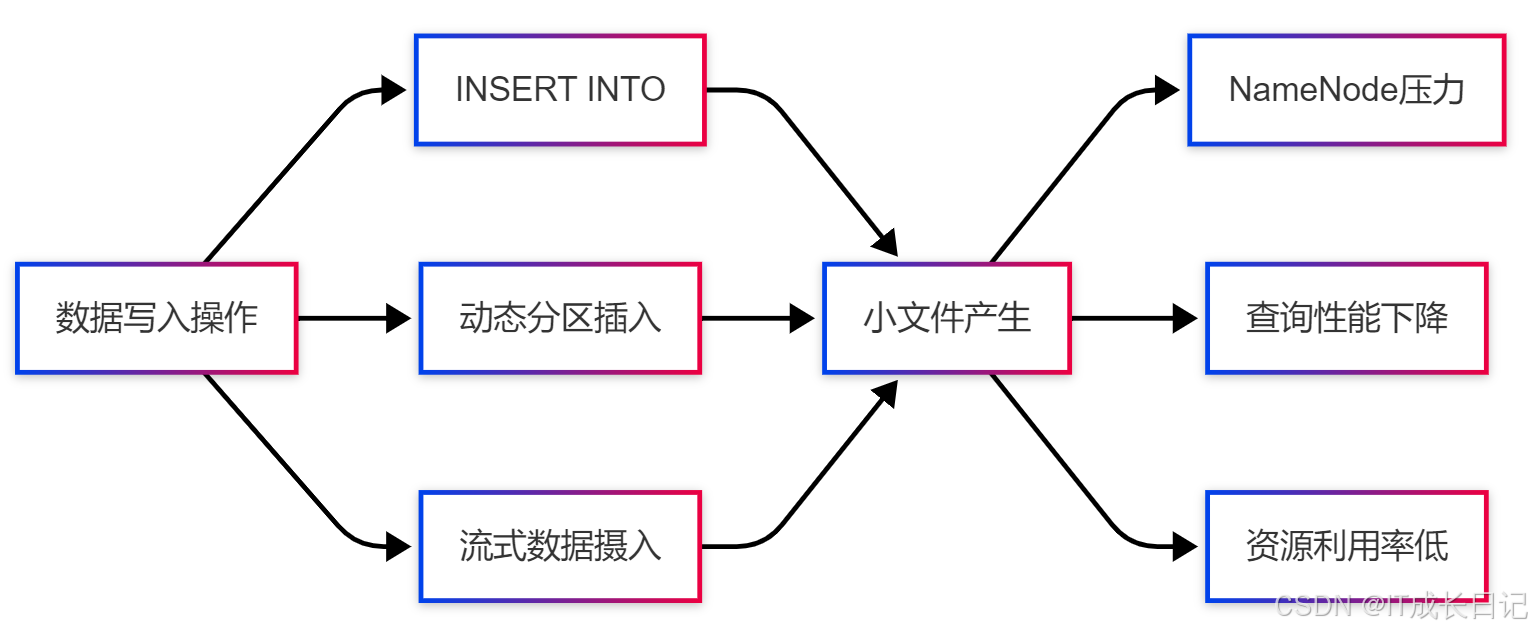
1.2 小文件产生的原因
在Hive中,小文件通常由以下操作产生:
- 频繁执行INSERT语句:特别是INSERT INTO和动态分区插入
- 动态分区:当分区字段基数(cardinality)很高时,会产生大量小文件
- 流式数据摄入:如Flume、Kafka等实时写入小批量数据
- 过度分区:分区粒度过细导致每个分区数据量很小
2 Hive小文件合并机制
2.1 hive.merge.smallfiles参数详解
Hive提供了hive.merge.smallfiles参数来控制小文件合并行为:
-- 开启小文件合并
SET hive.merge.mapfiles = true; -- 合并Map-only作业输出的小文件
SET hive.merge.mapredfiles = true; -- 合并MapReduce作业输出的小文件
SET hive.merge.smallfiles.avgsize = 16000000; -- 平均文件大小小于该值会触发合并
SET hive.merge.size.per.task = 256000000; -- 合并后每个文件的目标大小参数解释:
- hive.merge.mapfiles:控制是否合并Map-only任务输出的文件,默认false
- hive.merge.mapredfiles:控制是否合并MapReduce任务输出的文件,默认false
- hive.merge.smallfiles.avgsize:当输出文件的平均大小小于此值时,启动合并流程,默认16MB
- hive.merge.size.per.task:合并操作后每个文件的目标大小,默认256MB
2.2 小文件合并流程

合并过程详细说明:
- 评估阶段:作业完成后,Hive计算输出文件的平均大小
- 决策阶段:如果平均大小小于阈值,则触发合并流程
- 执行阶段:启动一个额外的MapReduce任务读取所有小文件
- 写入阶段:按照目标大小将数据重新写入新文件
- 清理阶段:合并完成后删除原始小文件
2.3 合并策略选择
- 合并为更大的文件:
SET hive.merge.mapfiles=true;
SET hive.merge.mapredfiles=true;
SET hive.merge.size.per.task=256000000;
SET hive.merge.smallfiles.avgsize=16000000;- 合并为ORC/Parquet的块(针对列式存储):
SET hive.exec.orc.default.block.size=256000000;
SET parquet.block.size=256000000;3 动态分区与小文件问题
3.1 动态分区原理
动态分区允许Hive根据查询结果自动创建分区
- 语法
INSERT INTO TABLE employee_partitioned
PARTITION(dept, country)
SELECT name, salary, dept, country
FROM employee;动态分区优势:
- 简化了多分区写入操作
- 避免了手动指定每个分区
动态分区问题:
- 容易产生大量小文件
- 当分区字段基数高时问题更严重
3.2 动态分区合并策略
针对动态分区的小文件问题,Hive提供了专门的优化参数:
-- 开启动态分区
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;-- 动态分区优化
SET hive.merge.tezfiles=true; -- 在Tez引擎上合并文件
SET hive.merge.sparkfiles=true; -- 在Spark引擎上合并文件
SET hive.exec.insert.into.multilevel.dirs=true; -- 支持多级目录插入3.3 动态分区合并流程

- 限制最大动态分区数:
SET hive.exec.max.dynamic.partitions=1000;
SET hive.exec.max.dynamic.partitions.pernode=100;- 分区裁剪:在查询前过滤不必要分区
SET hive.optimize.dynamic.partition.prune=true;- 合并层级控制:对于多级分区,可以控制合并粒度
SET hive.merge.level=partition; -- 按分区合并4 高级调优技巧
4.1 基于存储格式的优化
不同存储格式对小文件处理有不同影响:
| 存储格式 | 小文件处理能力 | 合并效率 | 适用场景 |
| TEXT | 差 | 高 | 原始数据 |
| ORC | 中 | 中 | 分析查询 |
| Parquet | 中 | 中 | 分析查询 |
| AVRO | 好 | 低 | 序列化 |
- ORC格式优化示例:
CREATE TABLE optimized_table (...
) STORED AS ORC
TBLPROPERTIES ("orc.compress"="SNAPPY","orc.create.index"="true","orc.stripe.size"="268435456", -- 256MB"orc.block.size"="268435456" -- 256MB
);4.2 定时合并策略
对于无法避免小文件产生的场景,可以设置定时合并任务:
- 使用Hive合并命令:
ALTER TABLE table_name CONCATENATE;- 使用Hadoop Archive(HAR):
hadoop archive -archiveName data.har -p /user/hive/warehouse/table /user/hive/archive- 自定义合并脚本:
# 示例
for partition in partitions:if avg_file_size(partition) < threshold:merge_files(partition, target_size)4.3 写入时优化
在数据写入阶段预防小文件产生:
- 批量插入:减少INSERT操作频率
- 合理设置Reduce数量:
SET mapred.reduce.tasks=适当数量;- 使用CTAS代替INSERT:
CREATE TABLE new_table AS SELECT * FROM source_table;5 案例分析
5.1 日志分析案例
- 场景:每日用户行为日志,按dt(日期)、hour(小时)两级分区
- 问题:每小时一个约5MB的小文件
- 解决方案:
-- 建表时指定合并参数
CREATE TABLE user_behavior (user_id string,action string,...
) PARTITIONED BY (dt string, hour string)
STORED AS ORC
TBLPROPERTIES ("orc.compress"="SNAPPY","hive.merge.mapfiles"="true","hive.merge.smallfiles.avgsize"="64000000", -- 64MB"hive.merge.size.per.task"="256000000" -- 256MB
);-- 插入数据时控制动态分区
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
SET hive.exec.max.dynamic.partitions.pernode=100;INSERT INTO TABLE user_behavior
PARTITION(dt, hour)
SELECT user_id, action, ..., dt, hour
FROM raw_log;5.2 数据仓库ETL案例
- 场景:每日全量同步上游数据库表
- 问题:全表扫描产生大量小文件
- 解决方案:
-- 使用CTAS创建中间表
CREATE TABLE temp_table STORED AS ORC AS
SELECT * FROM source_table;-- 使用DISTRIBUTE BY控制文件分布
SET hive.exec.reducers.bytes.per.reducer=256000000;INSERT OVERWRITE TABLE target_table
SELECT * FROM temp_table
DISTRIBUTE BY FLOOR(RAND()*10); -- 随机分布到10个Reducer-- 定期合并历史分区
ALTER TABLE target_table PARTITION(dt='20230101') CONCATENATE;6 监控与评估
6.1 小文件检测方法
- HDFS命令检查:
hdfs dfs -count -q /user/hive/warehouse/db/table- Hive元数据查询:
SELECT partition_name, file_count, total_size
FROM metastore.PARTITIONS p
JOIN metastore.TBLS t ON p.TBL_ID = t.TBL_ID
WHERE t.TBL_NAME = 'table_name';- 自定义监控脚本:
# 检查分区文件数量和大小分布
for part in partitions:files = list_files(part)if len(files) > threshold:alert_small_files(part)6.2 性能评估指标
| 指标 | 优化前 | 优化后 | 测量方法 |
| 文件数量 | 1000 | 10 | hdfs dfs -count |
| NameNode内存使用 | 高 | 低 | NameNode UI |
| 查询响应时间 | 慢 | 快 | EXPLAIN ANALYZE |
| 任务执行时间 | 长 | 短 | JobHistory |
7 总结
7.1 Hive小文件处理
预防为主:
- 合理设计分区策略
- 控制动态分区数量
- 使用适当Reduce数量
合并为辅:
- 启用hive.merge.smallfiles
- 定期执行合并操作
- 根据存储格式调整参数
监控持续:
- 建立小文件监控告警
- 定期评估合并效果
- 根据业务变化调整策略
7.2 参数推荐配置
-- 通用小文件合并配置
SET hive.merge.mapfiles=true;
SET hive.merge.mapredfiles=true;
SET hive.merge.smallfiles.avgsize=64000000; -- 64MB
SET hive.merge.size.per.task=256000000; -- 256MB-- 动态分区优化配置
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
SET hive.exec.max.dynamic.partitions=2000;
SET hive.exec.max.dynamic.partitions.pernode=100;-- 存储格式优化
SET hive.exec.orc.default.block.size=268435456; -- 256MB
SET parquet.block.size=268435456; -- 256MB通过合理配置这些参数可以显著改善Hive中的小文件问题,提升集群整体性能和查询效率。
相关文章:

【Hive入门】Hive性能调优:小文件问题与动态分区合并策略详解
目录 引言 1 Hive小文件问题概述 1.1 什么是小文件问题 1.2 小文件产生的原因 2 Hive小文件合并机制 2.1 hive.merge.smallfiles参数详解 2.2 小文件合并流程 2.3 合并策略选择 3 动态分区与小文件问题 3.1 动态分区原理 3.2 动态分区合并策略 3.3 动态分区合并流程…...

基于Springboot+Vue3.0的前后端分离的个人旅游足迹可视化平台
文章目录 0、前言1、前端开发1.1 登录注册页面1.2 首页1.3 足迹管理1.3.1 足迹列表1.3.2 添加足迹1.4 个人中心1.4.1 足迹成就1.4.2 个人信息1.4.3 我的计划2、后端开发2.1 用户接口开发2.2 足迹点接口2.3 旅游计划接口3、完整代码资料下载0、前言 项目亮点: 前端用户权限动态…...

安妮推广导航系统开心版多款主题网址推广赚钱软件推广变现一键统计免授权源码Annie
一、源码描述 这是一套推广导航源码(Annie),基于Funadmin框架(ThinkPHP8Layui ),内置多款主题,可以用于网址推广,或者用于软件推广,PC端软件手机端软件,后台…...

单片机-STM32部分:1、STM32介绍
飞书文档https://x509p6c8to.feishu.cn/wiki/CmpZwTgHhiQSHZkvzjdc6c4Yn1g STM32单片机不是一款芯片,而是一个系列的芯片? STM32系列单片机是ST(意法半导体)公司开发的一套32位微控制器基于Arm Cortex()-M处理器,它包…...

PHP-session
PHP中,session(会话)是一种在服务器上存储用户数据的方法,这些数据可以在多个页面请求或访问之间保持。Session提供了一种方式来跟踪用户状态,比如登录信息、购物车内容等。当用户首次访问网站时,服务器会创…...

php artisan resetPass 执行密码重置失败的原因?php artisan resetPass是什么 如何使用?-优雅草卓伊凡
php artisan resetPass 执行密码重置失败的原因?php artisan resetPass是什么 如何使用?-优雅草卓伊凡 可能的原因 命令不存在:如果你没有正确定义这个命令,Laravel 会报错而不是提示”重置密码失败”用户不存在:’a…...

AI大模型-微调和RAG方案选项
在搭建知识库的方向上,有两个落地方案:微调、RAG。两个方案的比对: 方案选型 微调 让大模型(LLM)去学习现有知识(调整大模型的参数,让它学习新的知识),最终生成一个新的…...

MySQL 第一讲---基础篇 安装
前言: 在当今数据驱动的时代,掌握数据库技术已成为开发者必备的核心技能。作为全球最受欢迎的开源关系型数据库,MySQL承载着淘宝双十一每秒50万次的交易请求,支撑着Facebook百亿级的数据存储,更是无数互联网企业的数据…...

【JavaScript-Day 1】从零开始:全面了解 JavaScript 是什么、为什么学以及它与 Java 的区别
Langchain系列文章目录 01-玩转LangChain:从模型调用到Prompt模板与输出解析的完整指南 02-玩转 LangChain Memory 模块:四种记忆类型详解及应用场景全覆盖 03-全面掌握 LangChain:从核心链条构建到动态任务分配的实战指南 04-玩转 LangChai…...

C++ 复习
VS 修改 C 语言标准 右键项目-属性 输入输出 //引用头文件,用<>包裹起来的一般是系统提供的写好的代码 编译器会在专门的系统路径中去进行查找 #include <iostream> //自己写的代码文件一般都用""包裹起来 编译器会在当前文件所在的目录中査…...
(文末有下载方式))
数字智慧方案5877丨智慧交通项目方案(122页PPT)(文末有下载方式)
篇幅所限,本文只提供部分资料内容,完整资料请看下面链接 https://download.csdn.net/download/2301_78256053/89575494 资料解读:智慧交通项目方案 详细资料请看本解读文章的最后内容。 智慧交通项目方案是一个全面的设计框架,…...

如何封装一个线程安全、可复用的 HBase 查询模板
目录 一、前言:原生 HBase 查询的痛点 (一)连接管理混乱,容易造成资源泄露 (二)查询逻辑重复,缺乏统一的模板 (三)多线程/高并发下的线程安全性隐患 (四…...
)
VLM Qwen2.5VL GRPO训练微调 EasyR1 多机多卡训练(2)
在之前博客进行了简单的训练尝试:https://www.dong-blog.fun/post/2060 在本博客,将会深入进行多机多卡训练,以及调整训练奖励函数。 之前构建了镜像: docker build . -t kevinchina/deeplearning:r1 FROM hiyouga/verl:ngc-th2.6.0-cu126-vllm0.8.4-flashinfer0.2.2-cx…...

基于建造者模式的信号量与理解建造者模式
信号量是什么? AI解释:信号量(Semaphore)是操作系统中用于 进程同步与互斥 的经典工具,由荷兰计算机科学家 Edsger Dijkstra 在 1965 年提出。它本质上是一个 非负整数变量,通过原子操作(P 操作…...
)
笔试专题(十四)
文章目录 mari和shiny题解代码 体操队形题解代码 二叉树中的最大路径和题解代码 mari和shiny 题目链接 题解 1. 可以用多状态的线性dp 2. 细节处理:使用long long 存储个数 3. 空间优化:只需要考虑等于’s’,‘sh’,shy’的情况…...

2025年五一数学建模A题【支路车流量推测】原创论文讲解
大家好呀,从发布赛题一直到现在,总算完成了2025年五一数学建模A题【支路车流量推测】完整的成品论文。 给大家看一下目录吧: 摘 要: 一、问题重述 二.问题分析 2.1问题一 2.2问题二 2.3问题三 2.4问题四 2.5 …...

Linux系统:进程程序替换以及相关exec接口
本节重点 理解进程替换的相关概念与原理掌握相关程序替换接口程序替换与进程创建的区别程序替换的注意事项 一、概念与原理 进程程序替换是操作系统中实现多任务和资源复用的关键机制,允许进程在运行时动态加载并执行新程序。 1.1 定义 进程程序替换是指用新程…...

STM32复盘总结——芯片简介
1、stm32介绍 STM32是ST公司基于ARM Cortex-M内核开发的32位微控制器 STM32常应用在嵌入式领域,如智能车、无人机、机器人、无线通信、物联网、工业控制、娱乐电子产品等 STM32功能强大、性能优异、片上资源丰富、功耗低,是一款经典的嵌入式微控制器 目…...

安装深度环境anaconda+cuda+cudnn+pycharm+qt+MVS
下载anaconda,链接:link 默认电脑有显卡驱动,没有的话直接进NVIDIA官网:https://www.nvidia.cn/geforce/drivers/ 下载。 下载cuda 链接:https://developer.nvidia.com/cuda-toolkit-archive 下载cudnn安装包,链接:https://developer.nvidia.com/rdp/cudnn-archive 备注:…...

泰迪杯特等奖案例学习资料:基于多模态特征融合的图像文本检索系统设计
(第十二届泰迪杯数据挖掘挑战赛B题特等奖案例解析) 一、案例背景与核心挑战 1.1 应用场景与行业痛点 随着智能终端与社交媒体的普及,图像与文本数据呈现爆炸式增长,跨模态检索需求日益迫切。传统方法面临以下问题: 语义鸿沟:图像与文本的异构特征分布差异显著,导致跨模…...

进程与线程:05 内核级线程实现
内核级线程代码实现概述 这节课我们要讲内核级线程到底是怎么做出来的,实际上就是要深入探讨内核级线程的代码实现。 在前两节课中,我们学习了用户级线程和内核级线程是如何进行切换的,以及实现切换的核心要点。那两节课讲述的内容…...

Laravel 12 实现 API 登录令牌认证
Laravel 12 实现 API 登录令牌认证 在 Laravel 12 中实现基于令牌(Token)的 API 认证,可以使用 Laravel Sanctum 或 Laravel Passport。以下是两种方式的实现方法: 方法一:使用 Laravel Sanctum (轻量级 API 认证) 1. 安装 Sanctum compo…...
)
【Git】万字详解 Git 的原理与使用(上)
🥰🥰🥰来都来了,不妨点个关注叭! 👉博客主页:欢迎各位大佬!👈 文章目录 1. 初识 Git1.1 Git 是什么?1.2 为什么要有 Git 2. 安装 Git2.1 Linux-Ubuntu 安装 Git2.2 Windo…...

Python高级爬虫之JS逆向+安卓逆向1.7节: 面向对象
目录 引言: 1.7.1 先理解面向过程 1.7.2 再理解面向对象 1.7.3 面向对象的三大特征 1.7.4 类属性,类方法,静态方法 1.7.5 构造函数,对象属性,对象方法 1.7.6 爬虫接单实现了雪糕自由 引言: 大神薯条老师的高级爬虫+安卓逆向教程: 这套爬虫教程会系统讲解爬虫的初…...
)
SpringBoot基础(原理、项目搭建、yaml)
SpringBoot:javaweb的一个框架,基于Spring开发,SpringBoot本身并不提供Spring框架的核心特性以及扩展功能,只是用于快速、敏捷的开发新一代基于Spring框架的应用程序,它与Spring框架紧密结合用于提升Spring开发者体验的…...

MTV-SCA:基于多试向量的正弦余弦算法
3 正弦余弦算法 (SCA) 正弦余弦算法(SCA)是为全局优化而开发的,并受到两个函数,正弦和余弦的启发。与其他基于启发式种群的算法一样,SCA在问题的预设最小值和最大值边界内随机生成候选解。然后,通过应用方…...

STL之vector容器
vector的介绍 1.vector是可变大小数组的容器 2.像数组一样,采用连续的空间存储,也就意味着可以通过下标去访问,但它的大小可以动态改变 3.每次的插入都要开空间吗?开空间就要意味着先开临时空间,然后在拷贝旧的到新…...

Android学习总结之jetpack组件间的联系
在传统安卓开发中,UI 组件(Activity/Fragment)常面临三个核心问题: 生命周期混乱:手动管理 UI 与数据的绑定 / 解绑,易导致内存泄漏(如 Activity 销毁后回调仍在触发)。数据断层&am…...

linux的信号量初识
Linux下的信号量(Semaphore)深度解析 在多线程或多进程并发编程的领域中,确保对共享资源的安全访问和协调不同执行单元的同步至关重要。信号量(Semaphore)作为经典的同步原语之一,在 Linux 系统中扮演着核心角色。本文将深入探讨…...

【安装指南】Centos7 在 Docker 上安装 RabbitMQ4.0.x
目录 前置知识:RabbitMQ 的介绍 一、单机安装 RabbitMQ 4.0.7版本 1.1 在线拉取镜像 二、延迟插件的安装 2.1 安装延迟插件 步骤一:下载延迟插件 步骤二:将延迟插件放到插件目录 步骤三:启动延迟插件 步骤四:重启 RabbitMQ 服务 步骤五:验收成果 步骤六:手动…...

Android和iOS测试的区别有哪些?
作为移动端测试工程师,Android 和 iOS 的测试差异直接影响测试策略设计。本文从测试环境、工具链、兼容性、发布流程等维度全面解析,并附实战建议。 1. 测试环境差异 维度AndroidiOS设备碎片化高(厂商/分辨率/系统版本多样)低(仅苹果设备,版本集中)系统开放性开放(可Ro…...

spring中的@PostConstruct注解详解
基本概念 PostConstruct 是 Java EE 规范的一部分,后来也被纳入到 Spring 框架中。它是一个标记注解,用于指示一个方法应该在依赖注入完成后被自动调用。 主要特点 生命周期回调:PostConstruct 标记的方法会在对象初始化完成、依赖注入完成…...

大模型开发学习笔记
文章目录 大模型基础大模型的使用大模型训练的阶段大模型的特点及分类大模型的工作流程分词化(tokenization)与词表映射 大模型的应用 进阶agent的组成和概念planning规划子任务分解ReAct框架 memory记忆Tools工具\工具集的使用langchain认知框架ReAct框架plan-and-Execute计划…...
【android Framework 探究】pixel 5 内核编译
相关文章: 【android Framework 探究】android 13 aosp编译全记录 【android Framework 探究】android 13 aosp 全记录 - 烧录 一,环境 主机 -> Ubuntu 18.04.6 LTS 内存 -> 16GB 手机 -> pixel 5 代号redfin。kernel代号redbull 二…...
)
PowerBI实现点击空白处隐藏弹窗(详细教程)
PowerBI点击空白处隐藏弹窗 第五届PowerBI可视化大赛中亚军作品:金融企业智慧经营分析看板 有个功能挺好玩的:点击空白处隐藏弹窗,gif动图如下: 我们以一个案例分享下实现步骤: 第一步, 先添加一个显示按钮ÿ…...

【git】获取特定分支和所有分支
1 特定分支 1.1 克隆指定分支(默认只下载该分支) git clone -b <分支名> --single-branch <仓库URL> 示例(克隆 某一个 分支): git clone -b xxxxxx --single-branch xxxxxxx -b :指定分支…...

Windows配置grpc
Windows配置grpc 方法一1. 使用git下载grph下载速度慢可以使用国内镜像1.1 更新子模块 2. 使用Cmake进行编译2.1 GUI编译2.2 命令行直接编译 3. 使用Visual Studio 生成解决方法 方法二1. 安装 vcpkg3.配置vckg的环境变量2. 使用 vcpkg 安装 gRPC3. 安装 Protobuf4. 配置 CMake…...

【学习笔记】深入理解Java虚拟机学习笔记——第2章 Java内存区域与内存溢出异常
第2章 Java内存区域与内存溢出异常 2.1 概述 略 2.2 运行时数据区域 2.2.1 程序计数器 线程私有,记录执行的字节码位置 2.2.2 Java 虚拟机栈 线程私有,存储一个一个的栈帧,通过栈帧的出入栈来控制方法执行。 -栈帧:对应一个…...
(文末有下载方式))
数字智慧方案6189丨智慧应急综合解决方案(46页PPT)(文末有下载方式)
资料解读:智慧应急综合解决方案 详细资料请看本解读文章的最后内容。 在当前社会环境下,应急管理的重要性愈发凸显。国务院发布的《“十四五” 国家应急体系规划》以及 “十四五” 智慧应急专项规划,明确了应急管理体系建设的方向和重点&…...

解决 3D Gaussian Splatting 中 SIBR 可视化组件报错 uv_mesh.vert 缺失问题【2025最新版!】
一、📌 引言 在使用 3D Gaussian Splatting(3DGS)进行三维重建和可视化的过程,SIBR_gaussianViewer_app 是一款官方推荐的本地可视化工具,允许我们在 GPU 上实时浏览重建结果。然而,许多用户在启动该工具时…...

见多识广4:Buffer与Cache,神经网络加速器的Buffer
目录 前言传统意义上的Buffer与Cache一言以蔽之定义与主要功能BufferCache 数据存储策略二者对比 神经网络加速器的bufferInput BufferWeight BufferOutput Buffer与传统buffer的核心区别总结 前言 知识主要由Qwen和Kimi提供,我主要做笔记。 参考文献: …...
的工作原理)
微服务中组件扫描(ComponentScan)的工作原理
微服务中组件扫描(ComponentScan)的工作原理 你的问题涉及到Spring框架中ComponentScan的工作原理以及Maven依赖管理的影响。我来解释为什么能够扫描到common模块的bean而扫描不到其他模块的bean。 根本原因 关键在于**类路径(Classpath)**的包含情况: Maven依赖…...

C++之类和对象基础
⾯向对象三⼤特性:封装、继承、多态 类和对象 一.类的定义1. 类的定义格式2.类域 二.实例化1.对象2.对象的大小 三.this指针 在 C 的世界里,类和对象构成了面向对象编程(Object-Oriented Programming,OOP)的核心框架&…...

【DIY小记】新手小白超频遇到黑屏问题解决分享
最近玩FPS游戏的时候,发现以前一顿操作超频之后的电脑,有一定概率会出问题。具体表现比如一种是,电脑显示器直接黑屏,所有键盘交互没有响应,只能直接重启电脑,还有一种是偶现卡顿,直接死机或者卡…...

虚幻引擎 IK Retargeter 编辑器界面解析
我来为您详细解释这段关于虚幻引擎IK Retargeter编辑器界面的文本,它描述了动画重定向系统的核心组件和工作原理。 Retarget Phases (重定向阶段) 这部分介绍了动画重定向过程中的三个关键计算阶段,每个阶段都可以单独启用或禁用,这对于调试…...

uc系统中常用命令、标准C库函数和系统调用
目录 一、常用命令 env echo $name 键值 export name unset name gcc -c xxx.c ar 命令 ar -r libxxx.a xxx1.o xxx2.o gcc -c -fpic xxx.c gcc -shared -fpic xxx1.c xxx2.c -o libxxx.so kill [-信号] PID kill -l 软链接:ln -s xxx yyy 硬链接&…...

OpenHarmony - 驱动使用指南,HDF驱动开发流程
OpenHarmony - HDF驱动开发流程 概述 HDF(Hardware Driver Foundation)驱动框架,为驱动开发者提供驱动框架能力,包括驱动加载、驱动服务管理、驱动消息机制和配置管理。并以组件化驱动模型作为核心设计思路,让驱动开发…...

C++负载均衡远程调用学习之UDP SERVER功能
目录 1.LARSV0.9-配置功能 2.LARSV0.10-upd-server的实现 3.LARSV0.10-udp-client的实现 1.LARSV0.9-配置功能 2.LARSV0.10-upd-server的实现 3.LARSV0.10-udp-client的实现...

word交叉引用图片、表格——只引用编号的处理方法
交叉引用图片/表格 在“引用”选项卡上的“题注”组中,单击“插入题注”。勾选【从题注中排除标签】。在文中插入题注。 【注 意】 这时候插入的题注只有编号项了。然后手动打上标签【TABLE】,并在标签和编号项之间加上【样式分隔符,AltCt…...

平台介绍-开放API接口-鉴权
平台的理念是一个组织内部只建一套系统。但是现实情况是,组织内部已经建立了很多系统,是不能一次性替代的,只能先搭起平台,然后逐步开始替换。这样就不可避免的存在其他系统和平台进行交互的问题。 平台为此设计了开放API接口。其…...