MTV-SCA:基于多试向量的正弦余弦算法
3 正弦余弦算法 (SCA)
正弦余弦算法(SCA)是为全局优化而开发的,并受到两个函数,正弦和余弦的启发。与其他基于启发式种群的算法一样,SCA在问题的预设最小值和最大值边界内随机生成候选解。然后,通过应用方程(1)中显示的两个不同的数学表达式来计算更新的解决方案,以实现探索和开发之间的平衡。
X i t + 1 = { X i t + r 1 × sin ( r 2 ) × ∣ r 3 × P i t − X i t ∣ , r 4 < 0.5 X i t + r 1 × cos ( r 2 ) × ∣ r 3 × P i t − X i t ∣ , r 4 ≥ 0.5 (1) X_i^{t+1} = \begin{cases} X_i^t + r_1 \times \sin(r_2) \times |r_3 \times P_i^t - X_i^t|, & r_4 < 0.5 \\ X_i^t + r_1 \times \cos(r_2) \times |r_3 \times P_i^t - X_i^t|, & r_4 \geq 0.5 \end{cases} \tag{1} Xit+1={Xit+r1×sin(r2)×∣r3×Pit−Xit∣,Xit+r1×cos(r2)×∣r3×Pit−Xit∣,r4<0.5r4≥0.5(1)
其中 X i t X_i^t Xit和 P i t P_i^t Pit分别是第t次迭代中第i个解的位置和目标解, r 1 r_1 r1、 r 2 r_2 r2和 r 3 r_3 r3是随机生成的。方程(1)中表达式的选择由随机数 r 4 r_4 r4决定,它在0和1之间遵循均匀分布。
通过使用 r 1 r_1 r1、 r 2 r_2 r2和 r 3 r_3 r3,SCA调节算法如何被探索和使用。参数 r 1 r_1 r1可用于平衡SCA早期和后期阶段的探索和开发。根据此参数,新解将被导向目标或远离目标。为了在算法的后期阶段识别最优解,它首先指导搜索过程在整个搜索空间中寻找解决方案,或者利用目标解的接近性。当 r 1 r_1 r1大于0时,目标解和解之间的距离将增加,而当 r 1 r_1 r1较小时,距离将减少。 r 1 r_1 r1的计算使用方程(2)进行。
r 1 = a − t × a T (2) r_1 = a - t \times \frac{a}{T} \tag{2} r1=a−t×Ta(2)
其中a是一个常数值,t是当前迭代次数,T是最大迭代次数。解与目标解位置的距离由随机参数 r 2 r_2 r2表示。一般来说, r 1 r_1 r1的较大值表示增加的探索,考虑到当前解和目标解之间的较大距离;相反,较小的值表示探索,考虑到较短的距离。参数 r 3 r_3 r3用于展示距离计算在多大程度上受到目标解的影响。
4 提出的多试验向量基于正弦余弦算法 (MTV-SCA)
尽管SCA在解决优化问题时具有简单性和多功能性,但其效率受到限制,给复杂问题的应用带来了重大挑战。SCA在解的准确性方面存在弱点,收敛速度慢,容易陷入局部最优,缺乏探索能力,无法在探索和开发之间保持平衡。这些缺陷源于SCA搜索策略,导致在处理复杂挑战时性能较弱。最佳当前解是SCA位置更新方程中唯一使用的解,用于估计到下一个搜索区域的距离,为SCA提供了有限的探索能力。此外,SCA并未充分利用当前解位置的信息。同时,利用搜索策略和控制参数来解决具有广泛特征的问题。此外,为了在搜索过程的不同阶段获得最佳性能,使用各种替代策略与各种参数值结合是有益的。
本文介绍了一种基于多试验向量的正弦余弦算法(MTV-SCA),其中单SCA的搜索策略通过多试验向量(MTV)方法得到加强。使用MTV方法的优势在于定义各种不同的搜索策略,每种策略都定制为实现不同的目标,以及在整个搜索过程中的合作。此外,提供各种正弦和余弦函数来调整相应搜索策略的参数值。利用这些函数的目的是实现在开发先前发现的良好解决方案和发现先前未访问的搜索空间部分之间的良好平衡。此外,在提出的MTV-SCA中,每个试验向量生产者(TVP)被分配应用于基于MTV方法的获胜者分配策略的特定部分种群。这种方法确保了来自不同子种群的解决方案之间的信息有效共享,最终在种群分配阶段提高了算法的性能。
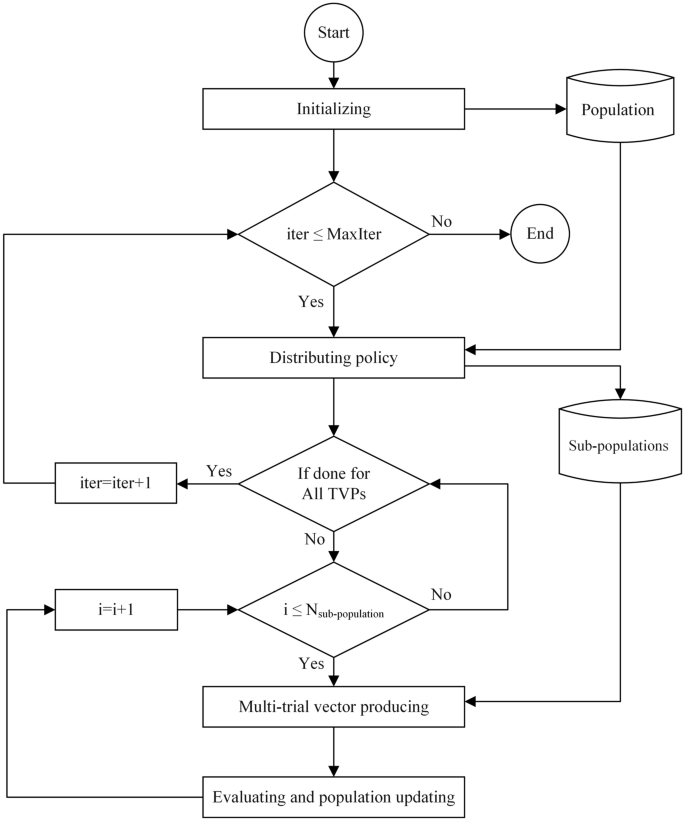
图1展示了MTV-SCA的流程图,包括四个步骤:初始化、分布、多试验向量生产和种群评估。一旦N个解决方案在搜索空间中初始化,每个TVP的子种群大小在每次迭代期间计算。接下来,在多试验向量生产步骤中,通过SCA-TVP或Pool-TVP中的一个或多个策略为每个解决方案生成候选解决方案。在Pool-TVP中,我们设计了四种新的搜索策略,分别命名为S1-TVP、S2-TVP、S3-TVP和S4-TVP,以便对其子种群的解决方案进行有效搜索。此外,S1-TVP旨在实现平衡的探索和开发,并避免陷入局部最优,S2-TVP有效地探索搜索空间,而S3-TVP维持搜索新解决方案与改进当前解决方案之间的平衡状态。此外,S4-TVP旨在平衡搜索空间的探索和开发,并防止过早收敛。此外,每个TVP利用正弦和余弦函数,目的是在开发先前获得的最优解决方案和发现搜索空间中未访问区域之间保持权衡。S1-TVP中使用的Chebyshev方法引入了搜索过程中的随机性和多样性,这可以使算法更有效地探索搜索空间的不同区域。正弦系数提供搜索半径和方向的周期性调整,使算法能够更彻底地搜索并避免陷入局部最优。余弦系数平衡探索和开发,帮助改进解决方案,并专注于搜索空间中前景广阔的区域。然后,在种群评估和更新步骤中,计算候选解决方案的适应度并与之前的值进行比较。作为最后一步,如果候选解决方案的适应度小于解决方案的当前位置,则候选解决方案替换解决方案。否则,解决方案的位置和适应度值保持不变。
初始化:N个解决方案在D维搜索空间中随机初始化,考虑下界(L)和上界(U)边界,使用公式(3)。
x i j = L j + ( U j − L j ) × rand ( 0 , 1 ) (3) x_{ij} = L_j + (U_j - L_j) \times \text{rand}(0, 1) \tag{3} xij=Lj+(Uj−Lj)×rand(0,1)(3)
其中 x i j x_{ij} xij是第i个解决方案的第j维的值。第j维的最小值和最大值分别表示为 L j L_j Lj和 U j U_j Uj,而rand是一个在[0,1]范围内均匀分布的随机值。问题的大小和维度分别由N和D表示。N×D矩阵,称为X,用于保存生成的解决方案的位置。适应度函数, f ( X i ( t ) ) f(X_i(t)) f(Xi(t)),用于在种群初始化和每次迭代后确定解决方案 X i X_i Xi的适应度值。
分布:为了确定子种群SC-TVP和Pool-TVP的大小,必须考虑经过n次迭代后改进的解决方案的数量,n是一个特定的迭代次数。改进率ImpRate是改进解决方案的适应度与前n次迭代中总函数评估数的比率。TVP ImpRate由公式(4)确定。
ImpRate S C − T V P = N ImprovedsolutionsbySC-TVP N S C − T V P × N F E s (4) \text{ImpRate}_{SC-TVP} = \frac{N_{\text{ImprovedsolutionsbySC-TVP}}}{N_{SC-TVP} \times N_{FEs}} \tag{4} ImpRateSC−TVP=NSC−TVP×NFEsNImprovedsolutionsbySC-TVP(4)
ImpRate P o o l − T V P = N ImprovedsolutionsbyPool-TVP N P o o l − T V P × N F E s (5) \text{ImpRate}_{Pool-TVP} = \frac{N_{\text{ImprovedsolutionsbyPool-TVP}}}{N_{Pool-TVP} \times N_{FEs}} \tag{5} ImpRatePool−TVP=NPool−TVP×NFEsNImprovedsolutionsbyPool-TVP(5)
其中改进率分别表示为ImpRate S C − T V P _{SC-TVP} SC−TVP和ImpRate P o o l − T V P _{Pool-TVP} Pool−TVP,子种群大小分别表示为 N S C − T V P N_{SC-TVP} NSC−TVP和 N P o o l − T V P N_{Pool-TVP} NPool−TVP,每个TVP在前n次迭代中执行的函数评估数分别表示为 N F E s N_{FEs} NFEs。
MTV-SCA的分布规则如公式(5)所述,考虑到MTV-SCA的分布策略,因此,具有较高ImpRate的子种群具有较大的子种群。
如果 ImpRate S C − T V P > ImpRate P o o l − T V P \text{ImpRate}_{SC-TVP} > \text{ImpRate}_{Pool-TVP} ImpRateSC−TVP>ImpRatePool−TVP 则 N S C − T V P = N Pad-TVP = λ × N N_{SC-TVP} = N_{\text{Pad-TVP}} = \lambda \times N NSC−TVP=NPad-TVP=λ×N
如果 ImpRate S C − T V P < ImpRate P o o l − T V P \text{ImpRate}_{SC-TVP} < \text{ImpRate}_{Pool-TVP} ImpRateSC−TVP<ImpRatePool−TVP 则 N S C − T V P = ( λ × N ) / 2 , N Pool-TVP = ( λ × N ) + ( λ × N ) / 2 N_{SC-TVP} = (\lambda \times N) / 2, N_{\text{Pool-TVP}} = (\lambda \times N) + (\lambda \times N) / 2 NSC−TVP=(λ×N)/2,NPool-TVP=(λ×N)+(λ×N)/2
其中N是解决方案的总数,子种群的大小通过考虑TVP的改进率 N S C − T V P N_{SC-TVP} NSC−TVP和 N P o o l − T V P N_{Pool-TVP} NPool−TVP,以及变异系数λ来考虑。计算子种群XSC和XPool的大小后,创建子种群。
多试验向量生产:搜索策略和参数值对算法解决优化问题的效率有显著影响。然而,问题的单峰性、多峰性、可分性和不可分性意味着各种搜索策略和控制参数值对于各种优化任务是必需的。此外,具有不同控制参数值的多种搜索策略可能优于在解决特定问题时在不同发展阶段使用单一搜索策略。受这些观察的启发,我们为经典SCA提出了一组试验向量生产者和控制参数,以在每次迭代中生成一个活跃的种群。随着迭代的进行, X i X_i Xi的位置由SC-TVP和Pool-TVP的策略分别调整。SC-TVP增强了搜索有希望的搜索空间区域的能力,并在局部区域找到新的解决方案。Pool-TVP在开发、逃离局部最优和实现探索与开发之间平衡方面发挥作用。
首先介绍初步信息,然后全面解释所提出的TVP。在所提出的S1-TVP和S2-TVP中,每个转换矩阵,分别表示为M和M’,用于为每个子种群生成候选试验向量。矩阵M,具有维度N×D,是从D×D的下三角矩阵创建的,其中所有元素都等于1。这个D×D矩阵被复制(N/D)次以形成一个方阵。如果M中还有剩余的行,它们用方阵的第一行填充。然后,对M的行应用随机排列。通过这种方式,通过用M中相应元素的逆替换每个元素获得M’矩阵。
对于每个属于XSC i t _i^t it的解决方案,一个试验向量 V S 2 i t + 1 VS2_i^{t+1} VS2it+1生成如下:
C S C i t + 1 = { X S C i t + r 1 × sin ( r 2 ) × ∣ r 3 × P t − X S C i t ∣ , r 4 < 0.5 X S C i t + r 1 × cos ( r 2 ) × ∣ r 3 × P t − X S C i t ∣ , r 4 ≥ 0.5 (6) CSC_i^{t+1} = \begin{cases} XSC_i^t + r_1 \times \sin(r_2) \times |r_3 \times P^t - XSC_i^t|, & r_4 < 0.5 \\ XSC_i^t + r_1 \times \cos(r_2) \times |r_3 \times P^t - XSC_i^t|, & r_4 \geq 0.5 \end{cases} \tag{6} CSCit+1={XSCit+r1×sin(r2)×∣r3×Pt−XSCit∣,XSCit+r1×cos(r2)×∣r3×Pt−XSCit∣,r4<0.5r4≥0.5(6)
其中CSC i t + 1 _i^{t+1} it+1表示为XSC i t _i^t it生成的候选解决方案, r 1 r_1 r1由公式(2)计算, r 2 r_2 r2、 r 3 r_3 r3和 r 4 r_4 r4是随机数,P t ^t t是第t次迭代中目标解的位置。
池试验向量生产者(Pool-TVP):Pool-TVP是不同试验向量生产者的集合S1-TVP、S2-TVP、S3-TVP和S4-TVP,具有各种正弦和余弦函数作为搜索策略的控制参数。建议的XPool分配给四个TVP涉及每次迭代中解决方案的随机分配。根据Pool的大小,将解决方案分配给TVP,从而创建子种群XS1、XS2、XS3和XS4。试验向量生产者在搜索过程的不同阶段表现出不同的性能特征,同时面对特定问题。提出S1-TVP旨在帮助算法在探索和开发之间保持平衡,避免陷入局部最优。S1-TVP具有最快的收敛速度,并且在解决单峰问题时表现良好。另一方面,S2-TVP在探索搜索空间方面有效,并且收敛速度较慢,具有更高的探索能力。S3-TVP在探索和开发之间取得良好平衡,具有更高的收敛速度,并且适用于解决多峰问题。S4-TVP旨在平衡搜索空间的探索和开发,并提供过早收敛。
S1-TVP:提出S1-TVP的目的是使算法能够在探索和开发之间保持平衡,并避免陷入局部最优。通过考虑种群的最佳解决方案和两个随机选择的解决方案之间的缩放差异来实现这一点。该策略结合了当前最佳位置、随机选择解决方案的差异以及随机生成的候选解决方案,以产生候选解决方案并将其移向潜在更好的解决方案。此外,Chebyshev和随机控制参数在探索和开发之间提供平衡,从而实现更有针对性的搜索搜索空间的最佳区域。
对于每个属于XS1 i t _i^t it的解决方案,一个试验向量 V S 1 i t + 1 VS1_i^{t+1} VS1it+1通过公式(7)计算:
V S 1 i t + 1 = P t + Chebyshev ( t ) × ( X r 1 t − X r 2 t ) + rand × ( X r 3 t − X r 4 t ) (7) VS1_i^{t+1} = P^t + \text{Chebyshev}(t) \times (X_{r1}^t - X_{r2}^t) + \text{rand} \times (X_{r3}^t - X_{r4}^t) \tag{7} VS1it+1=Pt+Chebyshev(t)×(Xr1t−Xr2t)+rand×(Xr3t−Xr4t)(7)
其中P t ^t t是迄今为止的最佳解决方案, X r 1 t X_{r1}^t Xr1t、 X r 2 t X_{r2}^t Xr2t、 X r 3 t X_{r3}^t Xr3t和 X r 4 t X_{r4}^t Xr4t是从当前种群X中随机选择的解决方案。Chebyshev,由公式(13)计算,是一个生成值的函数,这些值在-1和1之间振荡,振荡频率随着迭代次数增加。Chebyshev的使用使算法能够在平坦区域更有效地探索搜索空间,并在崎岖区域采取更小的步骤。
Chebyshev ( t + 1 ) = cos ( t × cos − 1 ( Chebyshev ( t ) ) ) (8) \text{Chebyshev}(t + 1) = \cos(t \times \cos^{-1}(\text{Chebyshev}(t))) \tag{8} Chebyshev(t+1)=cos(t×cos−1(Chebyshev(t)))(8)
该解决方案 X S 1 i t XS1_i^t XS1it的候选试验向量通过公式(9)计算:
C S C i t + 1 = M i × X S 1 i t + 1 + M ‾ i × V S 1 i t + 1 (9) CSC_i^{t+1} = M_i \times XS1_i^{t+1} + \overline{M}_i \times VS1_i^{t+1} \tag{9} CSCit+1=Mi×XS1it+1+Mi×VS1it+1(9)
其中M和 M ‾ i \overline{M}_i Mi是第i个解决方案的相应值, C S C i t + 1 CSC_i^{t+1} CSCit+1是为S1-TVP子种群生成的候选试验向量。
S2-TVP:该策略涉及从种群中随机选择三个个体,并创建一个新的试验向量,通过添加两个个体与第三个个体之间的缩放差异。该策略已被证明在探索搜索空间方面非常有效,特别是在处理复杂和高维优化问题时。突变策略使算法能够移动当前种群并探索搜索空间的新区域。此外,它能够快速有效地探索搜索空间,这意味着它可以在更短的时间内找到好的解决方案,而不是收敛到其他启发式算法。
对于每个属于XS2 i t _i^t it的解决方案,一个试验向量 V S 2 i t + 1 VS2_i^{t+1} VS2it+1生成如下:
V S 2 i t + 1 = X r 1 t + rand × ( X r 2 t − X r 3 t ) (10) VS2_i^{t+1} = X_{r1}^t + \text{rand} \times (X_{r2}^t - X_{r3}^t) \tag{10} VS2it+1=Xr1t+rand×(Xr2t−Xr3t)(10)
其中rand是一个随机生成的数字, X r 1 t X_{r1}^t Xr1t、 X r 2 t X_{r2}^t Xr2t和 X r 3 t X_{r3}^t Xr3t是当前种群X中的随机选择的解决方案。该解决方案 X S 2 i t XS2_i^t XS2it的候选试验向量通过公式(11)计算:
C S 2 i t + 1 = M i × X S 2 i t + 1 + M ‾ i × V S 2 i t + 1 (11) CS2_i^{t+1} = M_i \times XS2_i^{t+1} + \overline{M}_i \times VS2_i^{t+1} \tag{11} CS2it+1=Mi×XS2it+1+Mi×VS2it+1(11)
其中M和 M ‾ i \overline{M}_i Mi是第i个解决方案的相应值, C S 2 i t + 1 CS2_i^{t+1} CS2it+1是为S2-TVP子种群生成的候选试验向量。
S3-TVP:S3-TVP在探索和开发之间取得良好平衡,并具有更高的收敛速度。这是因为它在突变过程中使用当前和随机解决方案。这是因为它在突变过程中使用随机解决方案,这有助于探索搜索空间的不同区域。当前解决方案 X S 3 i t XS3_i^t XS3it在子种群XS3 i t _i^t it中被随机向量 X r 1 t X_{r1}^t Xr1t的方向移动,然后被当前种群中的两个其他随机选择的解决方案 X r 2 t X_{r2}^t Xr2t和 X r 3 t X_{r3}^t Xr3t之间的缩放差异所扰动。该解决方案 X S 3 i t XS3_i^t XS3it的候选试验向量通过公式(12)计算:
C S 3 i t + 1 = X S 3 i t + sinusoidal ( t ) × ( X r 1 t − X S 3 i t ) + rand × ( X r 2 t − X r 3 t ) (12) CS3_i^{t+1} = XS3_i^t + \text{sinusoidal}(t) \times (X_{r1}^t - XS3_i^t) + \text{rand} \times (X_{r2}^t - X_{r3}^t) \tag{12} CS3it+1=XS3it+sinusoidal(t)×(Xr1t−XS3it)+rand×(Xr2t−Xr3t)(12)
其中 C S 3 i t + 1 CS3_i^{t+1} CS3it+1表示为第i个解决方案 X S 3 i t XS3_i^t XS3it提供的候选解决方案, sinusoidal ( t ) \text{sinusoidal}(t) sinusoidal(t)是用于调整搜索半径和方向的系数,由公式(13)计算。
Sinusoidal ( t + 1 ) = C × ( Sinusoidal ( t ) ) 2 × sin ( t × Sinusoidal ( t ) ) (13) \text{Sinusoidal}(t + 1) = C \times (\text{Sinusoidal}(t))^2 \times \sin(t \times \text{Sinusoidal}(t)) \tag{13} Sinusoidal(t+1)=C×(Sinusoidal(t))2×sin(t×Sinusoidal(t))(13)
正弦函数[113]可以通过允许算法更彻底地探索搜索空间来帮助防止过早收敛。通过定期增加搜索半径和更改搜索方向,算法可以避免陷入局部最优,并继续搜索全局最优。
S4-TVP:平衡搜索空间的探索和开发并避免过早收敛的目标是通过该策略维持的。它根据当前位置、两个随机选择的解决方案以及依赖于当前迭代次数和总迭代次数的正弦和余弦函数的组合来更新 X S 4 i t XS4_i^t XS4it的位置。该解决方案 X S 4 i t XS4_i^t XS4it的候选试验向量通过公式(14)计算:
C S 4 i t + 1 = X S 4 i t + ( cos ( t / MaxIter ) ) × sin ( rand × ( t / MaxIter ) ) × ( X r 1 t − X r 2 t ) (14) CS4_i^{t+1} = XS4_i^t + (\cos(t / \text{MaxIter})) \times \sin(\text{rand} \times (t / \text{MaxIter})) \times (X_{r1}^t - X_{r2}^t) \tag{14} CS4it+1=XS4it+(cos(t/MaxIter))×sin(rand×(t/MaxIter))×(Xr1t−Xr2t)(14)
其中t是当前迭代次数,MaxIter是总迭代次数, X r 1 t X_{r1}^t Xr1t和 X r 2 t X_{r2}^t Xr2t是当前种群X中随机选择的解决方案。 cos ( MaxIter ) × sin ( rand × ( t / MaxIter ) ) \cos(\text{MaxIter}) \times \sin(\text{rand} \times (t / \text{MaxIter})) cos(MaxIter)×sin(rand×(t/MaxIter))用于提供控制参数的动态调整,以平衡探索和开发,并避免过早收敛,从而提高所提出TVP的效率。前一部分从0到-1随着Master接近Master变化,允许逐渐减少搜索半径,这有助于细化解决方案并专注于搜索空间中前景广阔的区域。后一部分从控制参数调整中随机选择一个元素。随机值rand在0和1之间均匀分布,为正弦函数生成随机角度。这种随机性有助于避免陷入局部最优,通过探索搜索空间的不同区域。

种群评估和更新:在每个优化周期之后,计算当前候选解决方案种群的目标函数,并与先前的适应度值进行比较。最优候选解决方案随后被保留用于后续迭代,因为它们被证明是最有效的。这个过程很重要,因为它有助于确保候选解决方案种群保持多样性,同时也改善了整体适应度。通过选择下一代的最佳解决方案,算法能够在探索搜索空间的新区域的同时,也开发已经识别的有前景的区域。
Nadimi-Shahraki, M.H., Taghian, S., Javaheri, D. et al. MTV-SCA: multi-trial vector-based sine cosine algorithm. Cluster Comput 27, 13471–13515 (2024). https://doi.org/10.1007/s10586-024-04602-4
相关文章:

MTV-SCA:基于多试向量的正弦余弦算法
3 正弦余弦算法 (SCA) 正弦余弦算法(SCA)是为全局优化而开发的,并受到两个函数,正弦和余弦的启发。与其他基于启发式种群的算法一样,SCA在问题的预设最小值和最大值边界内随机生成候选解。然后,通过应用方…...

STL之vector容器
vector的介绍 1.vector是可变大小数组的容器 2.像数组一样,采用连续的空间存储,也就意味着可以通过下标去访问,但它的大小可以动态改变 3.每次的插入都要开空间吗?开空间就要意味着先开临时空间,然后在拷贝旧的到新…...

Android学习总结之jetpack组件间的联系
在传统安卓开发中,UI 组件(Activity/Fragment)常面临三个核心问题: 生命周期混乱:手动管理 UI 与数据的绑定 / 解绑,易导致内存泄漏(如 Activity 销毁后回调仍在触发)。数据断层&am…...

linux的信号量初识
Linux下的信号量(Semaphore)深度解析 在多线程或多进程并发编程的领域中,确保对共享资源的安全访问和协调不同执行单元的同步至关重要。信号量(Semaphore)作为经典的同步原语之一,在 Linux 系统中扮演着核心角色。本文将深入探讨…...

【安装指南】Centos7 在 Docker 上安装 RabbitMQ4.0.x
目录 前置知识:RabbitMQ 的介绍 一、单机安装 RabbitMQ 4.0.7版本 1.1 在线拉取镜像 二、延迟插件的安装 2.1 安装延迟插件 步骤一:下载延迟插件 步骤二:将延迟插件放到插件目录 步骤三:启动延迟插件 步骤四:重启 RabbitMQ 服务 步骤五:验收成果 步骤六:手动…...

Android和iOS测试的区别有哪些?
作为移动端测试工程师,Android 和 iOS 的测试差异直接影响测试策略设计。本文从测试环境、工具链、兼容性、发布流程等维度全面解析,并附实战建议。 1. 测试环境差异 维度AndroidiOS设备碎片化高(厂商/分辨率/系统版本多样)低(仅苹果设备,版本集中)系统开放性开放(可Ro…...

spring中的@PostConstruct注解详解
基本概念 PostConstruct 是 Java EE 规范的一部分,后来也被纳入到 Spring 框架中。它是一个标记注解,用于指示一个方法应该在依赖注入完成后被自动调用。 主要特点 生命周期回调:PostConstruct 标记的方法会在对象初始化完成、依赖注入完成…...

大模型开发学习笔记
文章目录 大模型基础大模型的使用大模型训练的阶段大模型的特点及分类大模型的工作流程分词化(tokenization)与词表映射 大模型的应用 进阶agent的组成和概念planning规划子任务分解ReAct框架 memory记忆Tools工具\工具集的使用langchain认知框架ReAct框架plan-and-Execute计划…...
【android Framework 探究】pixel 5 内核编译
相关文章: 【android Framework 探究】android 13 aosp编译全记录 【android Framework 探究】android 13 aosp 全记录 - 烧录 一,环境 主机 -> Ubuntu 18.04.6 LTS 内存 -> 16GB 手机 -> pixel 5 代号redfin。kernel代号redbull 二…...
)
PowerBI实现点击空白处隐藏弹窗(详细教程)
PowerBI点击空白处隐藏弹窗 第五届PowerBI可视化大赛中亚军作品:金融企业智慧经营分析看板 有个功能挺好玩的:点击空白处隐藏弹窗,gif动图如下: 我们以一个案例分享下实现步骤: 第一步, 先添加一个显示按钮ÿ…...

【git】获取特定分支和所有分支
1 特定分支 1.1 克隆指定分支(默认只下载该分支) git clone -b <分支名> --single-branch <仓库URL> 示例(克隆 某一个 分支): git clone -b xxxxxx --single-branch xxxxxxx -b :指定分支…...

Windows配置grpc
Windows配置grpc 方法一1. 使用git下载grph下载速度慢可以使用国内镜像1.1 更新子模块 2. 使用Cmake进行编译2.1 GUI编译2.2 命令行直接编译 3. 使用Visual Studio 生成解决方法 方法二1. 安装 vcpkg3.配置vckg的环境变量2. 使用 vcpkg 安装 gRPC3. 安装 Protobuf4. 配置 CMake…...

【学习笔记】深入理解Java虚拟机学习笔记——第2章 Java内存区域与内存溢出异常
第2章 Java内存区域与内存溢出异常 2.1 概述 略 2.2 运行时数据区域 2.2.1 程序计数器 线程私有,记录执行的字节码位置 2.2.2 Java 虚拟机栈 线程私有,存储一个一个的栈帧,通过栈帧的出入栈来控制方法执行。 -栈帧:对应一个…...
(文末有下载方式))
数字智慧方案6189丨智慧应急综合解决方案(46页PPT)(文末有下载方式)
资料解读:智慧应急综合解决方案 详细资料请看本解读文章的最后内容。 在当前社会环境下,应急管理的重要性愈发凸显。国务院发布的《“十四五” 国家应急体系规划》以及 “十四五” 智慧应急专项规划,明确了应急管理体系建设的方向和重点&…...

解决 3D Gaussian Splatting 中 SIBR 可视化组件报错 uv_mesh.vert 缺失问题【2025最新版!】
一、📌 引言 在使用 3D Gaussian Splatting(3DGS)进行三维重建和可视化的过程,SIBR_gaussianViewer_app 是一款官方推荐的本地可视化工具,允许我们在 GPU 上实时浏览重建结果。然而,许多用户在启动该工具时…...

见多识广4:Buffer与Cache,神经网络加速器的Buffer
目录 前言传统意义上的Buffer与Cache一言以蔽之定义与主要功能BufferCache 数据存储策略二者对比 神经网络加速器的bufferInput BufferWeight BufferOutput Buffer与传统buffer的核心区别总结 前言 知识主要由Qwen和Kimi提供,我主要做笔记。 参考文献: …...
的工作原理)
微服务中组件扫描(ComponentScan)的工作原理
微服务中组件扫描(ComponentScan)的工作原理 你的问题涉及到Spring框架中ComponentScan的工作原理以及Maven依赖管理的影响。我来解释为什么能够扫描到common模块的bean而扫描不到其他模块的bean。 根本原因 关键在于**类路径(Classpath)**的包含情况: Maven依赖…...

C++之类和对象基础
⾯向对象三⼤特性:封装、继承、多态 类和对象 一.类的定义1. 类的定义格式2.类域 二.实例化1.对象2.对象的大小 三.this指针 在 C 的世界里,类和对象构成了面向对象编程(Object-Oriented Programming,OOP)的核心框架&…...

【DIY小记】新手小白超频遇到黑屏问题解决分享
最近玩FPS游戏的时候,发现以前一顿操作超频之后的电脑,有一定概率会出问题。具体表现比如一种是,电脑显示器直接黑屏,所有键盘交互没有响应,只能直接重启电脑,还有一种是偶现卡顿,直接死机或者卡…...

虚幻引擎 IK Retargeter 编辑器界面解析
我来为您详细解释这段关于虚幻引擎IK Retargeter编辑器界面的文本,它描述了动画重定向系统的核心组件和工作原理。 Retarget Phases (重定向阶段) 这部分介绍了动画重定向过程中的三个关键计算阶段,每个阶段都可以单独启用或禁用,这对于调试…...

uc系统中常用命令、标准C库函数和系统调用
目录 一、常用命令 env echo $name 键值 export name unset name gcc -c xxx.c ar 命令 ar -r libxxx.a xxx1.o xxx2.o gcc -c -fpic xxx.c gcc -shared -fpic xxx1.c xxx2.c -o libxxx.so kill [-信号] PID kill -l 软链接:ln -s xxx yyy 硬链接&…...

OpenHarmony - 驱动使用指南,HDF驱动开发流程
OpenHarmony - HDF驱动开发流程 概述 HDF(Hardware Driver Foundation)驱动框架,为驱动开发者提供驱动框架能力,包括驱动加载、驱动服务管理、驱动消息机制和配置管理。并以组件化驱动模型作为核心设计思路,让驱动开发…...

C++负载均衡远程调用学习之UDP SERVER功能
目录 1.LARSV0.9-配置功能 2.LARSV0.10-upd-server的实现 3.LARSV0.10-udp-client的实现 1.LARSV0.9-配置功能 2.LARSV0.10-upd-server的实现 3.LARSV0.10-udp-client的实现...

word交叉引用图片、表格——只引用编号的处理方法
交叉引用图片/表格 在“引用”选项卡上的“题注”组中,单击“插入题注”。勾选【从题注中排除标签】。在文中插入题注。 【注 意】 这时候插入的题注只有编号项了。然后手动打上标签【TABLE】,并在标签和编号项之间加上【样式分隔符,AltCt…...

平台介绍-开放API接口-鉴权
平台的理念是一个组织内部只建一套系统。但是现实情况是,组织内部已经建立了很多系统,是不能一次性替代的,只能先搭起平台,然后逐步开始替换。这样就不可避免的存在其他系统和平台进行交互的问题。 平台为此设计了开放API接口。其…...
)
【Bootstrap V4系列】 学习入门教程之 组件-警告框(Alert)
Bootstrap V4 学习入门教程之 组件-警告框(Alert) 警告框(Alert)一、示例二、链接的颜色三、添加其它内容四、关闭警告框 通过 JavaScript 触发行为触发器本组件所暴露的事件 警告框(Alert) 通过精炼且灵活…...
;)
【服务器通信-socket】——int socket(int domain, int type, int protocol);
#include <sys/types.h> #include <sys/socket.h> int socket(int domain, int type, int protocol); domain: AF_INET 这是大多数用来产生socket的协议,使用TCP或UDP来传输,用IPv4的地址 AF_INET6 与上面类似,不过是来用IPv6的地…...
题解)
洛谷P1014(Cantor 表[NOIP 1999 普及组])题解
题目大意:求Cantor表(按照Z字形排列(如第一项是1/1,然后是1/2,2/1,3/1,2/2))的第N项。 那么,我们需要找出Cantor表的排列规律。根据题目中的Z字形描述&#x…...

【愚公系列】《Manus极简入门》012-自我认知顾问:“内在探索向导”
🌟【技术大咖愚公搬代码:全栈专家的成长之路,你关注的宝藏博主在这里!】🌟 📣开发者圈持续输出高质量干货的"愚公精神"践行者——全网百万开发者都在追更的顶级技术博主! …...

密码学_加密
目录 密码学 01 密码基础进制与计量 02 加解密基操 替换 移位 编码 编码 置换 移位 加解密强度 03 对称加密算法(私钥) 工作过程 缺陷 对称加密算法列举? DES DES算法架构 DES分组加密公式 DES中ECB-CBC两种加密方式 3DES 由于DES密钥太短…...

w317汽车维修预约服务系统设计与实现
🙊作者简介:多年一线开发工作经验,原创团队,分享技术代码帮助学生学习,独立完成自己的网站项目。 代码可以查看文章末尾⬇️联系方式获取,记得注明来意哦~🌹赠送计算机毕业设计600个选题excel文…...

云盘系统设计
需求背景 网盘面向大量C端用户 1000w用户 DAU 20% 每天10次 QPS: 1000w * 0.2 * 10 / 100k 500 峰值估计:500 * 5 2500 功能需求 支持上传,下载,多端共同在线编辑,数据冲突处理 非功能需求 1.latency 20s左右 2.可用性与…...

西电雨课堂《知识产权法》课后作业答案
目录 第 1 章 1.1 课后作业 1.2 课后作业 第 2 章 2.1 课后作业 2.2 课后作业 2.3 课后作业 2.4 课后作业 2.5 课后作业 2.6 课后作业 2.7 课后作业 2.8 课后作业 2.9 课后作业 2.10 课后作业 第 3 章 3.1 课后作业 3.2 课后作业 3.3 课后作业 3…...

通信协议记录仪-产品规格书
以下是为 通信协议记录仪(ProtoLogger Pro) 的详细产品规格书,覆盖 技术细节、场景需求、竞品差异化,确保可作为产品开发、市场营销及竞品分析的核心依据。 通信协议记录仪产品规格书 产品名称:ProtoLogger Pro(中文名称:蹲守…...

订单系统冷热分离方案:优化性能与降低存储成本
随着时间推移,订单数据不断积累。在电商平台或者服务型应用中,订单数据是核心数据之一。然而,随着数据量的增长,如何高效存储、管理和查询这些数据成为了系统架构设计的重要问题。在大多数情况下,订单数据的处理不仅涉…...

数据结构学习笔记
第 1 章 绪论 【考纲内容】 (一)数据结构的基本概念 (二)算法的基本概念 算法的时间复杂度和空间复杂度 【知识框架】 【复习提示】 本章内容是数据结构概述,并不在考研大纲中。读者可通过对本章的学习,初步…...

读懂 Vue3 路由:从入门到实战
在构建现代化单页应用(SPA)时,Vue3 凭借其简洁高效的特性成为众多开发者的首选。 而 Vue3 路由(Vue Router)则是 Vue3 生态中不可或缺的一部分,它就像是单页应用的 “导航地图”,帮助用户在不同…...

Aws S3上传优化
上传大约 3.4GB 的 JSON 文件,zip算法压缩后约为 395MB,上传至 S3 效率优化,有一些优化方案可以提高上传速率。下面是几种可能的优化方式,包括选择压缩算法、调整上传方式、以及其他可能的方案。 方案 1. 选择更好的压缩算法 压…...
:基于LLM的个性化营销文案)
Python 数据智能实战 (8):基于LLM的个性化营销文案
写在前面 —— 告别群发轰炸,拥抱精准沟通:用 LLM 为你的用户量身定制营销信息 在前面的篇章中,我们学习了如何利用 LLM 增强用户理解(智能分群)、挖掘商品关联(语义购物篮)、提升预测精度(融合文本特征的流失预警)。我们不断地从数据中提取更深层次的洞察。 然而,…...

html:table表格
表格代码示例: <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>Title</title> </head> <body><!-- 标准表格。 --><table border"5"cellspacing&qu…...

2.maven 手动安装 jar包
1.背景 有的时候,maven仓库无法下载,可以手动安装。本文以pentaho-aggdesigner-algorithm-5.1.5-jhyde.jar为例。 2.预先准备 下载文件到本地指定位置。 2.1.安装pom mvn install:install-file \-Dfile/home/wind/tmp/pentaho-aggdesigner-5.1.5-jh…...

C++ unordered_set unordered_map
上篇文章我们讲解了哈希表的实现,这节尝试使用哈希表来封装unordered_set/map 1. unordered_set/map的框架 封装的过程实际上与set/map类似,在unordered_set/map层传递一个仿函数,用于取出key值 由于我们平常使用的都是unordered_set/map&…...

第37课 绘制原理图——放置离页连接符
什么是离页连接符? 前边我们介绍了网络标签(Net Lable),可以让两根导线“隔空相连”,使原理图更加清爽简洁。 但是网络标签的使用也具有一定的局限性,对于两张不同Sheet上的导线,网络标签就不…...
)
< 自用文 Texas style Smoker > 美式德克萨斯烟熏炉 从设计到实现 (第一部分:烹饪室与燃烧室)
原因: 没钱还馋! 但有手艺。 预计目标: 常见的两种偏置式烟熏炉(Offset Smoker) 左边边是标准偏置式(Standard Offset),右边是反向流动式(Reverse Flow Offset&#x…...

【现代深度学习技术】现代循环神经网络03:深度循环神经网络
【作者主页】Francek Chen 【专栏介绍】 ⌈ ⌈ ⌈PyTorch深度学习 ⌋ ⌋ ⌋ 深度学习 (DL, Deep Learning) 特指基于深层神经网络模型和方法的机器学习。它是在统计机器学习、人工神经网络等算法模型基础上,结合当代大数据和大算力的发展而发展出来的。深度学习最重…...

AimRT从入门到精通 - 03Channel发布者和订阅者
刚接触AimRT的小伙伴可能会疑惑,这个Channel和RPC(后面讲的)到底是什么呢? 但是当我们接触了之后,就会发现,其本质类似ROS的Topic通信!(其本质基于发布订阅模型) 接下来…...

MySQL初阶:数据库基础,数据库和表操作,数据库中的数据类型
1.数据库基础 数据库是一个客户端——服务器结构的程序。 服务器是真正的主体,负责保存和管理数据,数据都存储在硬盘上 数据库处理的主要内容是数据的存储,查找,修改,排序,统计等。 关系型数据库&#…...

AI 驱动的智能交通系统:从拥堵到流畅的未来出行
最近研学过程中发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击链接跳转到网站人工智能及编程语言学习教程。读者们可以通过里面的文章详细了解一下人工智能及其编程等教程和学习方法。下面开始对正文内容的…...

Python清空Word段落样式的方法
在 Python 中,你可以使用 python-docx 库来操作 Word 文档,包括清空段落样式。以下是几种清空段落样式的方法: 方法一:直接设置段落样式为"Normal" from docx import Documentdoc Document(your_document.docx) # 打…...

[javaEE]网络编程
目录 socket对tcp ServerSocket ServerSocket 构造方法: ServerSocket 方法: socket 实现回显服务器和客户端 由于我们之前已经写多了socket对udq的实现,所以我们这节,主要将重心放在Tcp之上 socket对tcp ServerS…...