哈希表笔记(二)redis
Redis哈希表实现分析
这份代码是Redis核心数据结构之一的字典(dict)实现,本质上是一个哈希表的实现。Redis的字典结构被广泛用于各种内部数据结构,包括Redis数据库本身和哈希键类型。
核心特点
- 双表设计:每个字典包含两个哈希表,一个用于日常操作,另一个用于rehash操作时使用
- 渐进式rehash:rehash操作不是一次性完成的,而是分散在多次操作中完成,避免阻塞
- 多种哈希算法:提供了三种哈希算法,分别针对整数值、字符串等不同类型的键
- 链地址法解决冲突:使用链表来解决哈希冲突
- 动态扩容和收缩:根据负载因子自动调整哈希表大小
关键数据结构
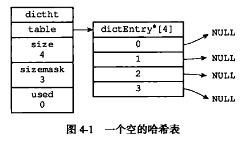
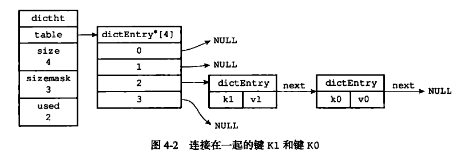
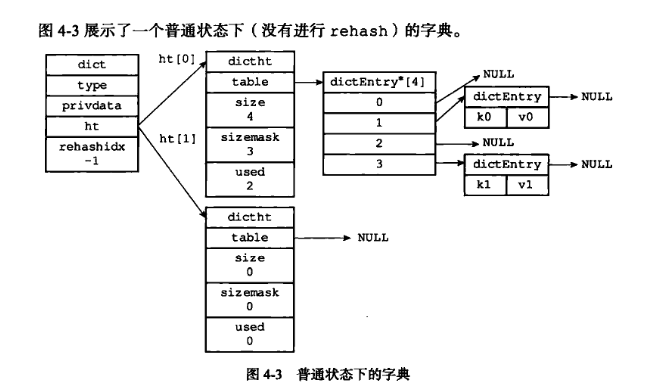
- 解释
假设你有一个指向dictEntry的指针,比如:
dictEntry *entry = /* 已经指向某个节点 */;
那么:
-
访问
keyvoid *k = entry->key; // 如果你知道 key 实际上是个字符串,就可以这样: char *str = (char*)entry->key; printf("key = %s\n", str); -
访问 union 里的
val
你的 union 定义里有一个void *val,另两个是整数型:// 取出 void* 版的值 void *p = entry->v.val;// 如果你想把它当成 64 位无符号整数: uint64_t u = entry->v.u64;// 或者当成 64 位有符号整数: int64_t s = entry->v.s64; -
如果是直接用结构体(非指针)
dictEntry e; // …给 e.key、e.v.val 赋值 … void *k2 = e.key; void *p2 = e.v.val; -
示例:遍历链表并打印
for (dictEntry *e = head; e != NULL; e = e->next) {printf("key ptr = %p, val ptr = %p\n", e->key, e->v.val); }
要点
->用于指针访问成员,.用于结构体变量本身。- 访问 union 中的具体字段就是
entry->v.字段名。 - 根据你存进去的实际类型,记得做对应的类型转换。
// 哈希表节点
typedef struct dictEntry {void *key; // 键union {void *val;uint64_t u64;int64_t s64;double d;} v; // 值struct dictEntry *next; // 指向下一个哈希表节点,形成链表
} dictEntry;// 哈希表
typedef struct dictht {dictEntry **table; // 哈希表数组unsigned long size; // 哈希表大小unsigned long sizemask; // 哈希表大小掩码,用于计算索引值,等于size-1unsigned long used; // 已有节点数量
} dictht;// 字典
typedef struct dict {dictType *type; // 字典类型,保存一组用于操作特定类型键值的函数void *privdata; // 私有数据,保存需要传给特定类型函数的可选参数dictht ht[2]; // 哈希表,包含两个,一个正常使用,一个rehash时使用long rehashidx; // rehash索引,记录rehash进度,-1表示未进行rehashunsigned long iterators;// 安全迭代器数量
} dict;
哈希算法实现
Redis提供了三种哈希算法:
-
Thomas Wang’s 32 bit Mix函数:用于整数哈希
unsigned int dictIntHashFunction(unsigned int key) -
MurmurHash2算法:用于字符串哈希
unsigned int dictGenHashFunction(const void *key, int len) -
基于djb的简化哈希算法:大小写不敏感的字符串哈希
unsigned int dictGenCaseHashFunction(const unsigned char *buf, int len)
渐进式rehash机制
扩容触发时机
Redis哈希表的扩容不是在插入值后立即开始的,而是在满足特定条件时触发:
-
哈希表负载因子达到阈值:
if (d->ht[0].used >= d->ht[0].size &&(dict_can_resize ||d->ht[0].used/d->ht[0].size > dict_force_resize_ratio)) {return dictExpand(d, d->ht[0].used*2); }- 当
used >= size(负载因子≥1)且允许resize时触发扩容 - 即使不允许resize,如果负载因子超过强制阈值(默认为5),也会触发扩容
- 这个检查发生在
_dictExpandIfNeeded函数中,该函数在添加新键值对时会被调用
- 当
-
显式调用
dictResize函数时
扩容初始化过程
扩容开始时会进行以下初始化:
int dictExpand(dict *d, unsigned long size) {dictht n; /* 新哈希表 */unsigned long realsize = _dictNextPower(size);// ...检查条件.../* 分配新哈希表内存并初始化所有指针为NULL */n.size = realsize;n.sizemask = realsize-1;n.table = zcalloc(realsize*sizeof(dictEntry*));n.used = 0;/* 这是第一次初始化? */if (d->ht[0].table == NULL) {d->ht[0] = n;return DICT_OK;}/* 准备第二个哈希表用于渐进式rehashing */d->ht[1] = n;d->rehashidx = 0; // 标记rehash开始return DICT_OK;
}
关键点:
- 创建字典时,两个哈希表(ht[0]和ht[1])都是空的
- 第一次使用时,只初始化ht[0]
- 扩容时,会为ht[1]分配空间,并将rehashidx设为0(表示开始rehash)
扩容过程中的查询操作
当哈希表处于rehash过程中(rehashidx ≥ 0)时,查询操作会同时检查两个表:
dictEntry *dictFind(dict *d, const void *key) {dictEntry *he;unsigned int h, idx, table;// ...检查条件...if (dictIsRehashing(d)) _dictRehashStep(d); // 先执行一步rehashh = dictHashKey(d, key);// 在两个表中查找for (table = 0; table <= 1; table++) {idx = h & d->ht[table].sizemask;he = d->ht[table].table[idx];while(he) {if (key==he->key || dictCompareKeys(d, key, he->key))return he;he = he->next;}// 如果没有在rehash,只检查ht[0]if (!dictIsRehashing(d)) break;}return NULL;
}
关键特点:
- 渐进式rehash: 每次查询操作都会执行一步rehash(调用
_dictRehashStep) - 双表查询: 先查询ht[0],如果在rehash中且没找到,再查询ht[1]
- 混合状态: rehash过程中,数据分布在两个表中:
- 已rehash的桶的数据在ht[1]中
- 未rehash的桶的数据在ht[0]中
渐进式rehash机制
rehash过程不是一次性完成的,而是渐进式进行:
int dictRehash(dict *d, int n) {// ...检查条件...while(n-- && d->ht[0].used != 0) {// ...找到非空桶...// 将这个桶中的所有键从ht[0]移到ht[1]de = d->ht[0].table[d->rehashidx];while(de) {nextde = de->next;// 计算在ht[1]中的新位置h = dictHashKey(d, de->key) & d->ht[1].sizemask;de->next = d->ht[1].table[h];d->ht[1].table[h] = de;d->ht[0].used--;d->ht[1].used++;de = nextde;}d->ht[0].table[d->rehashidx] = NULL;d->rehashidx++; // 移至下一个桶}// 检查是否完成if (d->ht[0].used == 0) {zfree(d->ht[0].table);d->ht[0] = d->ht[1]; // ht[1]变成ht[0]_dictReset(&d->ht[1]); // 重置ht[1]d->rehashidx = -1; // 标记rehash结束return 0;}return 1; // 还有更多要rehash
}
rehash触发点:
- 字典操作时:
_dictRehashStep函数在添加、查找、删除等操作时被调用 - 后台定时任务: Redis会定期调用
dictRehashMilliseconds进行一定时间的rehash - 空闲时间: Redis在空闲时也会进行rehash操作
总结:扩容过程中的查询流程
- 扩容触发:当负载因子达到阈值时,Redis会开始扩容
- 初始状态:创建字典时两个哈希表都是空的,仅在需要时初始化
- 扩容初始化:为ht[1]分配新空间,rehashidx设为0
- 查询过程:
- 每次查询先执行一步rehash操作
- 同时在两个表中查找键
- 先查ht[0]再查ht[1]
- rehash完成:所有键移动完成后,ht[1]变成ht[0],旧的ht[0]被释放,rehashidx重置为-1
rehash触发条件:
- 扩容:当哈希表的负载因子(used/size)大于预设值(默认为1)且允许rehash,或者负载因子超过强制rehash阈值(默认为5)
- 收缩:当负载因子小于预设值(通常为0.1)
主要函数列表
| 函数名 | 功能描述 |
|---|---|
dictCreate | 创建一个新的字典 |
_dictInit | 初始化字典 |
dictResize | 调整哈希表大小到刚好能容纳所有元素 |
dictExpand | 扩展哈希表大小 |
dictRehash | 执行N步渐进式rehash |
dictRehashMilliseconds | 在指定时间内执行rehash |
_dictRehashStep | 执行单步rehash |
dictAdd | 添加键值对 |
dictAddRaw | 添加只有键的节点 |
dictReplace | 替换已有键的值,不存在则添加 |
dictReplaceRaw | 替换版本的dictAddRaw |
dictGenericDelete | 查找并删除键值对的通用函数 |
dictDelete | 删除键值对并释放内存 |
dictDeleteNoFree | 删除键值对但不释放内存 |
_dictClear | 清空整个哈希表 |
dictRelease | 释放字典及其内部结构 |
dictFind | 查找键对应的节点 |
dictFetchValue | 获取键对应的值 |
dictGetIterator | 获取字典迭代器 |
dictGetSafeIterator | 获取安全迭代器 |
dictNext | 获取迭代器的下一个元素 |
dictReleaseIterator | 释放迭代器 |
dictGetRandomKey | 随机获取一个键值对 |
dictGetSomeKeys | 获取多个随机键值对 |
dictScan | 渐进式遍历字典的所有键值对 |
_dictExpandIfNeeded | 根据需要扩展哈希表 |
_dictNextPower | 计算下一个合适的哈希表大小(2的幂) |
_dictKeyIndex | 计算键在哈希表中的索引 |
dictEmpty | 清空字典中的所有键值对 |
dictEnableResize | 允许调整哈希表大小 |
dictDisableResize | 禁止调整哈希表大小 |
dictGetStats | 获取字典统计信息 |
键值对的基本操作流程
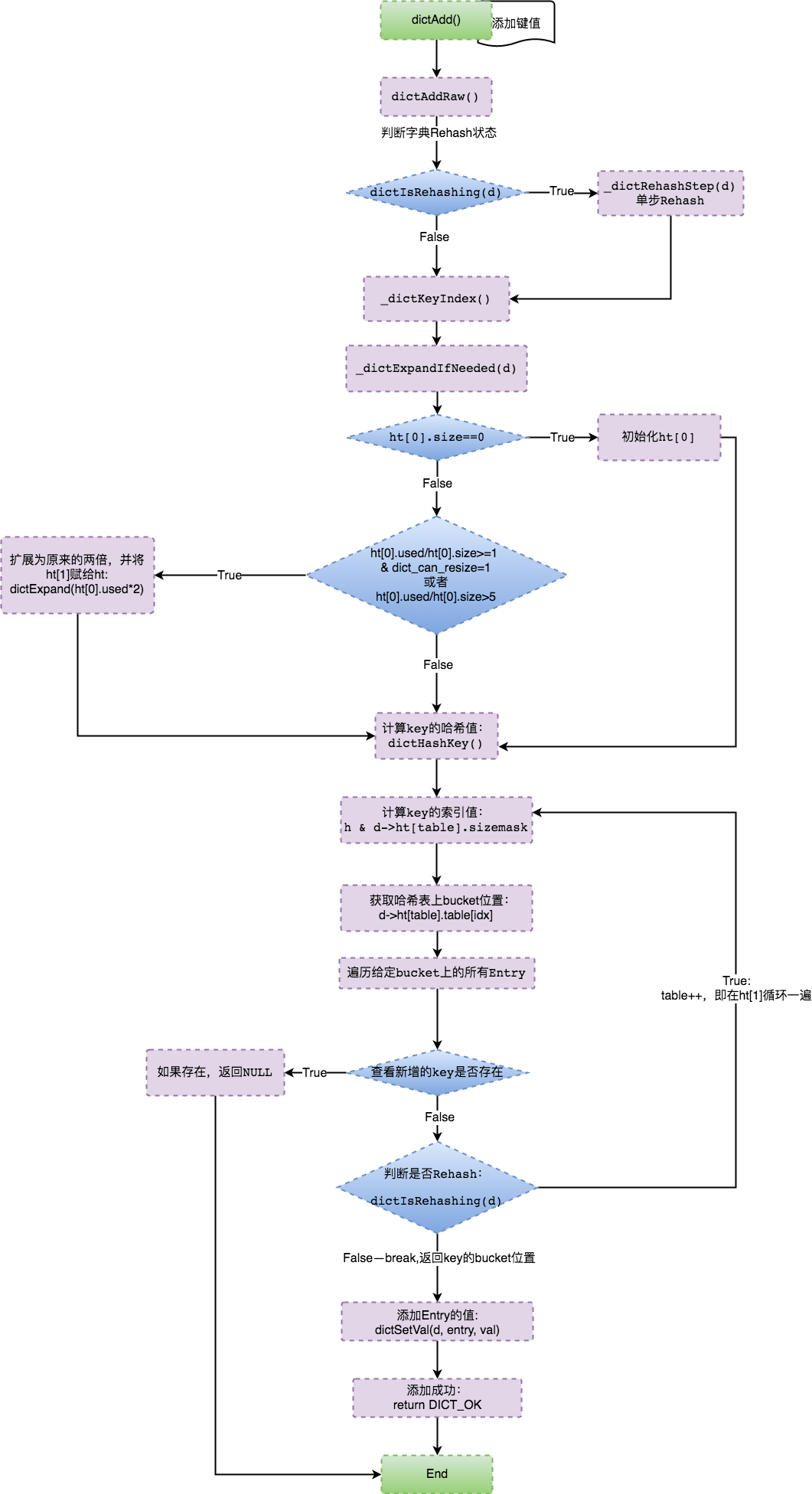
添加键值对
- 检查是否需要扩展哈希表
- 计算键的哈希值
- 定位到哈希表的索引位置
- 创建新节点并插入到链表头部
- 更新哈希表的used计数
查找键值对
- 计算键的哈希值
- 定位到哈希表的索引位置
- 遍历链表查找匹配的键
- 如果正在rehash,需要在两个哈希表中都查找
删除键值对
- 计算键的哈希值
- 定位到哈希表的索引位置
- 遍历链表查找匹配的键
- 从链表中删除节点并更新哈希表计数
- 如果正在rehash,需要在两个哈希表中都查找
负载因子与rehash
Redis定义了两个重要参数来控制rehash行为:
dict_can_resize:是否允许rehash,默认为1dict_force_resize_ratio:强制rehash的负载因子阈值,默认为5
当满足以下条件时会触发rehash:
- 负载因子(used/size) >= 1 且 允许rehash
- 或者 负载因子 > 强制rehash阈值
这确保了哈希表在负载过高时能自动扩容,同时也可以通过设置参数来控制rehash行为,避免在某些特殊情况下(如子进程正在进行持久化)进行rehash操作。
/* Hash Tables 实现** 这个文件实现了内存中的哈希表,支持插入/删除/替换/查找/获取随机元素等操作。* 哈希表会在需要时自动调整大小,使用的是2的幂作为表大小,哈希冲突通过链地址法处理。*/#include "fmacros.h"#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdarg.h>
#include <limits.h>
#include <sys/time.h>
#include <ctype.h>#include "dict.h"
#include "zmalloc.h"
#include "redisassert.h"/* Redis字典结构采用哈希表作为底层实现,每个字典包括两个哈希表,一个用来平常使用,另一个在rehash的时候使用。Redis提供了三种哈希算法,对整数,字符串等类型的键都能较好的处理。Redis的哈希表采用了链地址法来解决哈希冲突。Redis在对字典进行扩容和收缩时,需要对哈希表中的所有键值对rehash到新哈希表里面,但这个rehash操作不是一次性完成的,而是采用渐进式完成,这一措施使得rehash过程不会影响Redis对字典进行增删查改操作的效率。
*//* 通过dictEnableResize()/dictDisableResize()函数可以启用/禁用哈希表的大小调整。* 这对Redis很重要,因为我们使用写时复制机制,当有子进程在执行持久化操作时,我们不希望移动太多内存。* * 注意即使当dict_can_resize设为0时,也不是所有的大小调整都会被阻止:* 如果元素数量与桶数量的比率 > dict_force_resize_ratio,哈希表仍然会扩大。*/
static int dict_can_resize = 1;
// Redis定义了一个负载因子dict_force_resize_ratio,该因子的初始值为5,如果满足一定条件,则需要进行rehash操作
static unsigned int dict_force_resize_ratio = 5;/* -------------------------- 私有函数原型 ---------------------------- */static int _dictExpandIfNeeded(dict *ht);
static unsigned long _dictNextPower(unsigned long size);
static int _dictKeyIndex(dict *ht, const void *key);
static int _dictInit(dict *ht, dictType *type, void *privDataPtr);/* -------------------------- 哈希函数 -------------------------------- */
/* 这部分是redis提供的三种计算哈希值的算法函数- Thomas Wang's 32 bit Mix函数,对一个整数进行哈希,该方法在dictIntHashFunction中实现- 使用MurmurHash2哈希算法对字符串进行哈希,该方法在dictGenHashFunction中实现- 使用基于djb哈希的一种简单的哈希算法,该方法在dictGenCaseHashFunction中实现
*//* Thomas Wang的32位Mix函数 */
unsigned int dictIntHashFunction(unsigned int key)
{key += ~(key << 15);key ^= (key >> 10);key += (key << 3);key ^= (key >> 6);key += ~(key << 11);key ^= (key >> 16);return key;
}static uint32_t dict_hash_function_seed = 5381;void dictSetHashFunctionSeed(uint32_t seed) {dict_hash_function_seed = seed;
}uint32_t dictGetHashFunctionSeed(void) {return dict_hash_function_seed;
}/* MurmurHash2算法,由Austin Appleby设计 */
unsigned int dictGenHashFunction(const void *key, int len) {uint32_t seed = dict_hash_function_seed;const uint32_t m = 0x5bd1e995;const int r = 24;/* 初始化哈希值为一个"随机"值 */uint32_t h = seed ^ len;/* 每次处理4字节数据 */const unsigned char *data = (const unsigned char *)key;while(len >= 4) {uint32_t k = *(uint32_t*)data;k *= m;k ^= k >> r;k *= m;h *= m;h ^= k;data += 4;len -= 4;}/* 处理剩余不足4字节的数据 */switch(len) {case 3: h ^= data[2] << 16;case 2: h ^= data[1] << 8;case 1: h ^= data[0]; h *= m;};/* 对哈希值进行几次最终混合,确保最后几个字节充分混合 */h ^= h >> 13;h *= m;h ^= h >> 15;return (unsigned int)h;
}/* 不区分大小写的哈希函数(基于djb哈希) */
unsigned int dictGenCaseHashFunction(const unsigned char *buf, int len) {unsigned int hash = (unsigned int)dict_hash_function_seed;while (len--)hash = ((hash << 5) + hash) + (tolower(*buf++)); /* hash * 33 + c */return hash;
}/* ----------------------------- API实现 ------------------------- *//* 重置一个已经通过ht_init()初始化的哈希表* 注意:这个函数应该只被ht_destroy()调用 */
// 置空一个哈希表
static void _dictReset(dictht *ht)
{ht->table = NULL;ht->size = 0;ht->sizemask = 0;ht->used = 0;
}/* 创建一个新的哈希表 */
// 创建一个空字典
dict *dictCreate(dictType *type, void *privDataPtr)
{dict *d = zmalloc(sizeof(*d));// 字典初始化_dictInit(d,type,privDataPtr);return d;
}/* 初始化哈希表 */
int _dictInit(dict *d, dictType *type, void *privDataPtr)
{_dictReset(&d->ht[0]);_dictReset(&d->ht[1]);d->type = type; // 设定字典类型d->privdata = privDataPtr;d->rehashidx = -1; // 初始化为-1,未进行rehash操作d->iterators = 0; // 正在使用的迭代器数量return DICT_OK;
}/* 调整表的大小至最小的能容纳所有元素的大小,* 并保持USED/BUCKETS比率接近于 <= 1 */
int dictResize(dict *d)
{int minimal;if (!dict_can_resize || dictIsRehashing(d)) return DICT_ERR;minimal = d->ht[0].used;if (minimal < DICT_HT_INITIAL_SIZE)minimal = DICT_HT_INITIAL_SIZE;return dictExpand(d, minimal);
}/* 扩展或创建哈希表 */
int dictExpand(dict *d, unsigned long size)
{dictht n; /* 新哈希表 */unsigned long realsize = _dictNextPower(size);/* 如果大小小于已有元素数量,则无效 */if (dictIsRehashing(d) || d->ht[0].used > size)return DICT_ERR;/* Rehashing到相同大小的表没有意义 */if (realsize == d->ht[0].size) return DICT_ERR;/* 分配新哈希表内存并初始化所有指针为NULL */n.size = realsize;n.sizemask = realsize-1;n.table = zcalloc(realsize*sizeof(dictEntry*));n.used = 0;/* 这是第一次初始化吗?如果是,那么这不是真正的rehashing* 我们只需设置第一个哈希表使其能接受键 */if (d->ht[0].table == NULL) {d->ht[0] = n;return DICT_OK;}/* 准备第二个哈希表用于渐进式rehashing */d->ht[1] = n;d->rehashidx = 0;return DICT_OK;
}/* 执行N步渐进式rehash操作。如果还有键需要从旧表移到新表,返回1,否则返回0。** 注意一个rehash步骤包括将一个桶(可能有多个键,因为我们使用链地址法)从旧表移到新表,* 但由于哈希表的一部分可能由空位组成,不能保证此函数一定会rehash至少一个桶,* 因为它最多会访问N*10个空桶,否则它的工作量将无限制,函数可能长时间阻塞。 *//* rehash是Redis字典实现的一个重要操作。dict采用链地址法来处理哈希冲突,那么随着数据存放量的增加,必然会造成冲突链表越来越长,
最终会导致字典的查找效率显著下降。这种情况下,就需要对字典进行扩容。另外,当字典中键值对过少时,就需要对字典进行收缩来节省空间,
这些扩容和收缩的过程就采用rehash来实现。通常情况下,字典的键值对数据都存放在ht[0]里面,如果此时需要对字典进行rehash,会进行如下步骤:1. 为ht[1]哈希表分配空间,空间的大小取决于要执行的操作和字典中键值对的个数2. 将保存在ht[0]中的键值对重新计算哈希值和索引,然后存放到ht[1]中。3. 当ht[0]中的数据全部迁移到ht[1]之后,将ht[1]设为ht[0],并为ht[1]新创建一个空白哈希表,为下一次rehash做准备。执行N步渐进式的rehash操作,如果仍存在旧表中的数据迁移到新表,则返回1,反之返回0每一步操作移动一个索引值下的键值对到新表
*/
int dictRehash(dict *d, int n) {int empty_visits = n*10; /* 最大允许访问的空桶值,也就是该索引下没有键值对 */if (!dictIsRehashing(d)) return 0;while(n-- && d->ht[0].used != 0) {dictEntry *de, *nextde;/* 注意rehashidx不能溢出,因为我们确定还有元素,因为ht[0].used != 0 */// rehashidx不能大于哈希表的大小assert(d->ht[0].size > (unsigned long)d->rehashidx);while(d->ht[0].table[d->rehashidx] == NULL) {d->rehashidx++;if (--empty_visits == 0) return 1;}// 获取需要rehash的索引值下的链表de = d->ht[0].table[d->rehashidx];/* 将这个桶中的所有键从旧哈希表移动到新哈希表 */// 将该索引下的键值对全部转移到新表while(de) {unsigned int h;nextde = de->next; // 保存链表后一个节点/* 获取在新哈希表中的索引 */// 获取当前节点的键在新哈希表ht[1]中的索引h = dictHashKey(d, de->key) & d->ht[1].sizemask;de->next = d->ht[1].table[h];d->ht[1].table[h] = de;d->ht[0].used--;d->ht[1].used++;de = nextde;}d->ht[0].table[d->rehashidx] = NULL;d->rehashidx++;}/* 检查我们是否已经rehash了整个表... */// 检查是否整个表都迁移完成if (d->ht[0].used == 0) {// 释放ht[0]zfree(d->ht[0].table);// 将ht[1]转移到ht[0]d->ht[0] = d->ht[1];// 重置ht[1]为空哈希表_dictReset(&d->ht[1]);// 完成rehash,-1代表没有进行rehash操作d->rehashidx = -1;return 0;}/* 还有更多要rehash... */// 如果没有完成则返回1return 1;
}// 获取当前的时间戳(以毫秒为单位)
long long timeInMilliseconds(void) {struct timeval tv;gettimeofday(&tv,NULL);return (((long long)tv.tv_sec)*1000)+(tv.tv_usec/1000);
}/* 在ms毫秒到ms+1毫秒之间的时间内进行rehash */
// rehash操作每次执行ms时间就退出
int dictRehashMilliseconds(dict *d, int ms) {long long start = timeInMilliseconds();int rehashes = 0;while(dictRehash(d,100)) { // 每次执行100步rehashes += 100;if (timeInMilliseconds()-start > ms) break; // 如果时间超过指定时间ms就退出}return rehashes;
}/* 此函数仅执行一步rehash,且仅当没有安全迭代器绑定到我们的哈希表时。* 当我们在rehash过程中有迭代器时,不能修改两个哈希表,否则某些元素可能会被遗漏或重复。** 这个函数被字典中的常见查找或更新操作调用,以便在字典被主动使用时自动从H1迁移到H2。 */
// 在执行查询和更新操作时,如果符合rehash条件就会触发一次rehash操作,每次执行一步
static void _dictRehashStep(dict *d) {if (d->iterators == 0) dictRehash(d,1);
}/* 添加一个元素到目标哈希表 */
// 向指定哈希表中添加一个元素
int dictAdd(dict *d, void *key, void *val)
{// 往字典中添加一个只有key的键值对dictEntry *entry = dictAddRaw(d,key);if (!entry) return DICT_ERR;// 为添加的只有key键值对设定值dictSetVal(d, entry, val);return DICT_OK;
}/* 低级添加函数。此函数添加条目但不设置值,而是将dictEntry结构返回给用户,* 用户将确保按照自己的意愿填充值字段。** 此函数也直接暴露给用户API,主要用于在哈希值中存储非指针,例如:** entry = dictAddRaw(dict,mykey);* if (entry != NULL) dictSetSignedIntegerVal(entry,1000);** 返回值:** 如果键已存在,返回NULL。* 如果添加了键,返回哈希条目供调用者操作。*/
// 添加只有key的键值对,如果成功则返回该键值对,反之则返回空
dictEntry *dictAddRaw(dict *d, void *key)
{int index;dictEntry *entry;dictht *ht;// 如果正在进行rehash操作,则先执行rehash操作if (dictIsRehashing(d)) _dictRehashStep(d);/* 获取新元素的索引,如果元素已存在则返回-1 */// 获取新键值对的索引值,如果key存在则返回-1if ((index = _dictKeyIndex(d, key)) == -1)return NULL;/* 分配内存并存储新条目* 将元素插入到链表顶部,假设在数据库系统中,最近添加的条目更可能被频繁访问。 */// 如果正在进行rehash则添加到ht[1],反之则添加到ht[0]ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];// 申请内存,存储新键值对entry = zmalloc(sizeof(*entry));// 使用开链法(哈希桶)来处理哈希冲突entry->next = ht->table[index];ht->table[index] = entry;ht->used++;/* 设置哈希条目字段 */// 设定entry的键,如果有自定义的复制键函数,则调用,否则直接赋值dictSetKey(d, entry, key);return entry;
}/* 添加一个元素,如果键已存在则丢弃旧值* 如果从头开始添加键,返回1,如果已经存在具有此类键的元素,* dictReplace()只执行值更新操作,则返回0。 */
// 这里是另一种添加键值对的方式,如果存在就替换旧的键值对
int dictReplace(dict *d, void *key, void *val)
{dictEntry *entry, auxentry;/* 尝试添加元素。如果键不存在,dictAdd将成功 */// 直接调用dictAdd函数,如果添加成功就表示没有存在相同的keyif (dictAdd(d, key, val) == DICT_OK)return 1;/* 如果已存在,获取条目 */// 如果键已存在,则找到这个键值对entry = dictFind(d, key);/* 设置新值并释放旧值。注意,按这个顺序做很重要,* 因为值可能与以前的值完全相同。在这种情况下,考虑引用计数,* 你想要增加(设置),然后减少(释放),而不是相反 */// 然后用新的value来替换旧valueauxentry = *entry;dictSetVal(d, entry, val);dictFreeVal(d, &auxentry);return 0;
}/* dictReplaceRaw()只是dictAddRaw()的一个版本,它总是返回指定键的哈希条目,* 即使键已经存在且不能添加(在这种情况下,返回已存在键的条目)。** 有关更多信息,请参见dictAddRaw()。 */
dictEntry *dictReplaceRaw(dict *d, void *key) {dictEntry *entry = dictFind(d,key);return entry ? entry : dictAddRaw(d,key);
}/* 查找并删除元素 */
// 查找并删除指定键对应的键值对
static int dictGenericDelete(dict *d, const void *key, int nofree)
{unsigned int h, idx;dictEntry *he, *prevHe;int table;// 字典为空if (d->ht[0].size == 0) return DICT_ERR; /* d->ht[0].table is NULL */// 如果正在进行rehash,则触发一次rehash操作if (dictIsRehashing(d)) _dictRehashStep(d);// 计算哈希值h = dictHashKey(d, key);for (table = 0; table <= 1; table++) {// 根据size掩码计算索引值idx = h & d->ht[table].sizemask;he = d->ht[table].table[idx];prevHe = NULL;// 执行在链表中删除某个节点的操作while(he) {if (key==he->key || dictCompareKeys(d, key, he->key)) {/* 从链表中解链该元素 */if (prevHe)// 如果有前置元素,前置元素指向要删除的元素的下一个元素prevHe->next = he->next;else// 头节点的话,索引位置指向要删除的元素的下一个元素d->ht[table].table[idx] = he->next;if (!nofree) {// 释放键和值dictFreeKey(d, he);dictFreeVal(d, he);}zfree(he);d->ht[table].used--;return DICT_OK;}prevHe = he;he = he->next;}// 如果没有进行rehash操作,则没必要对ht[1]进行查找if (!dictIsRehashing(d)) break;}return DICT_ERR; /* 未找到 */
}// 删除该键值对,并释放键和值
int dictDelete(dict *ht, const void *key) {return dictGenericDelete(ht,key,0);
}// 删除该键值对,不释放键和值
int dictDeleteNoFree(dict *ht, const void *key) {return dictGenericDelete(ht,key,1);
}/* 销毁整个字典 */
// 清除整个字典
int _dictClear(dict *d, dictht *ht, void(callback)(void *)) {unsigned long i;/* 释放所有元素 */// 清除和释放所有元素for (i = 0; i < ht->size && ht->used > 0; i++) {dictEntry *he, *nextHe;if (callback && (i & 65535) == 0) callback(d->privdata);if ((he = ht->table[i]) == NULL) continue;while(he) { // 循环删除整个单链表nextHe = he->next;dictFreeKey(d, he); // 释放键dictFreeVal(d, he); // 释放值zfree(he); // 释放键值对结构ht->used--;he = nextHe;}}/* 释放表和分配的缓存结构 */// 释放哈希表并重新分配空的哈希表作为缓存结构zfree(ht->table);/* 重新初始化表 */// 重置哈希表_dictReset(ht);return DICT_OK; /* 永不失败 */
}/* 清除并释放哈希表 */
// 删除和释放整个字典结构
void dictRelease(dict *d)
{_dictClear(d,&d->ht[0],NULL); // 清除哈希表ht[0]_dictClear(d,&d->ht[1],NULL); // 清除哈希表ht[1]zfree(d); // 释放字典
}// 根据键查找键值对
dictEntry *dictFind(dict *d, const void *key)
{dictEntry *he;unsigned int h, idx, table;// 如果 ht[0] 和 ht[1] 表内都没有键值对,返回NULLif (d->ht[0].used + d->ht[1].used == 0) return NULL; /* 字典为空 */// 如果正在进行rehash,则执行rehash操作if (dictIsRehashing(d)) _dictRehashStep(d);// 计算哈希值h = dictHashKey(d, key);// 在两个表中查找对应的键值对for (table = 0; table <= 1; table++) {// 根据掩码来计算索引值idx = h & d->ht[table].sizemask;// 得到该索引值下的存放的键值对链表he = d->ht[table].table[idx];while(he) {// 如果找到该key直接返回if (key==he->key || dictCompareKeys(d, key, he->key))return he;// 找下一个he = he->next;}// 如果没有进行rehash,则直接返回if (!dictIsRehashing(d)) return NULL;}return NULL;
}// 用来返回给定键的值,底层实现还是调用dictFind函数
void *dictFetchValue(dict *d, const void *key) {dictEntry *he;he = dictFind(d,key);return he ? dictGetVal(he) : NULL;
}/* 指纹是一个64位数字,表示字典在给定时间的状态,它只是几个字典属性的异或结果* 当初始化不安全迭代器时,我们获取字典指纹,并在释放迭代器时再次检查指纹。* 如果两个指纹不同,则意味着迭代器的用户在迭代过程中对字典执行了禁止的操作。 */
long long dictFingerprint(dict *d) {long long integers[6], hash = 0;int j;integers[0] = (long) d->ht[0].table;integers[1] = d->ht[0].size;integers[2] = d->ht[0].used;integers[3] = (long) d->ht[1].table;integers[4] = d->ht[1].size;integers[5] = d->ht[1].used;/* 我们通过将每个后续整数与前一个和的整数哈希相加来哈希N个整数。基本上:** Result = hash(hash(hash(int1)+int2)+int3) ...** 这样,不同顺序的相同整数集合(可能)会哈希为不同的数字。 */for (j = 0; j < 6; j++) {hash += integers[j];/* 对于哈希步骤,我们使用Tomas Wang的64位整数哈希。 */hash = (~hash) + (hash << 21); // hash = (hash << 21) - hash - 1;hash = hash ^ (hash >> 24);hash = (hash + (hash << 3)) + (hash << 8); // hash * 265hash = hash ^ (hash >> 14);hash = (hash + (hash << 2)) + (hash << 4); // hash * 21hash = hash ^ (hash >> 28);hash = hash + (hash << 31);}return hash;
}// 获取字典的迭代器
dictIterator *dictGetIterator(dict *d)
{dictIterator *iter = zmalloc(sizeof(*iter));iter->d = d;iter->table = 0;iter->index = -1;iter->safe = 0;iter->entry = NULL;iter->nextEntry = NULL;return iter;
}// 获取安全的字典迭代器
dictIterator *dictGetSafeIterator(dict *d) {dictIterator *i = dictGetIterator(d);i->safe = 1;return i;
}// 获取迭代器的下一个元素
dictEntry *dictNext(dictIterator *iter)
{while (1) {if (iter->entry == NULL) {dictht *ht = &iter->d->ht[iter->table];if (iter->index == -1 && iter->table == 0) {if (iter->safe)iter->d->iterators++;elseiter->fingerprint = dictFingerprint(iter->d);}iter->index++;if (iter->index >= (long) ht->size) {if (dictIsRehashing(iter->d) && iter->table == 0) {iter->table++;iter->index = 0;ht = &iter->d->ht[1];} else {break;}}iter->entry = ht->table[iter->index];} else {iter->entry = iter->nextEntry;}if (iter->entry) {/* 我们需要在这里保存'next',迭代器用户可能会删除我们返回的条目 */iter->nextEntry = iter->entry->next;return iter->entry;}}return NULL;
}// 释放迭代器
void dictReleaseIterator(dictIterator *iter)
{if (!(iter->index == -1 && iter->table == 0)) {if (iter->safe)iter->d->iterators--;elseassert(iter->fingerprint == dictFingerprint(iter->d));}zfree(iter);
}/* 从哈希表中返回一个随机条目。对实现随机算法很有用 */
// 用于从字典中随机返回一个键值对
dictEntry *dictGetRandomKey(dict *d)
{dictEntry *he, *orighe;unsigned int h;int listlen, listele;// 哈希表为空,直接返回NULLif (dictSize(d) == 0) return NULL;// 如果正在进行rehash,则执行一次rehash操作if (dictIsRehashing(d)) _dictRehashStep(d);// 随机返回一个键的具体操作是:// 先随机选取一个索引值,然后在该索引值// 对应的键值对链表中随机选取一个键值对返回if (dictIsRehashing(d)) {do {/* 我们确信在从0到rehashidx-1的索引中没有元素 */// 如果正在进行rehash,则需要考虑两个哈希表中的数据h = d->rehashidx + (random() % (d->ht[0].size +d->ht[1].size -d->rehashidx));he = (h >= d->ht[0].size) ? d->ht[1].table[h - d->ht[0].size] :d->ht[0].table[h];} while(he == NULL);} else {do {h = random() & d->ht[0].sizemask;he = d->ht[0].table[h];} while(he == NULL);}/* 现在我们找到了一个非空桶,但它是一个链表,我们需要从链表中获取一个随机元素。* 唯一明智的方法是计数元素并选择一个随机索引。 */// 到这里,就随机选取了一个非空的键值对链表// 然后随机从这个拥有相同索引值的链表中随机选取一个键值对listlen = 0;orighe = he;while(he) {he = he->next;listlen++;}listele = random() % listlen;he = orighe;while(listele--) he = he->next;return he;
}/* 这个函数对字典进行采样,从随机位置返回几个键。** 它不保证返回'count'中指定的所有键,* 也不保证返回非重复元素,但它会尽力做到这两点。** 返回的哈希表条目的指针存储在'des'中,* 'des'指向一个dictEntry指针数组。数组必须有空间至少存放'count'个元素,* 这就是我们传递给函数的参数,告诉我们需要多少个随机元素。** 函数返回存储到'des'中的项目数量,可能少于'count',* 如果哈希表内部的元素少于'count',或者在合理的步数内没有找到足够的元素。** 注意,当你需要返回项目的良好分布时,这个函数不适合,* 只有当你需要"采样"给定数量的连续元素来运行某种算法或产生统计数据时才适合。* 然而,该函数在产生N个元素时比dictGetRandomKey()快得多。 */
unsigned int dictGetSomeKeys(dict *d, dictEntry **des, unsigned int count) {unsigned long j; /* 内部哈希表id,0或1 */unsigned long tables; /* 1或2个表? */unsigned long stored = 0, maxsizemask;unsigned long maxsteps;if (dictSize(d) < count) count = dictSize(d);maxsteps = count*10;/* 尝试执行与'count'成比例的rehashing工作 */for (j = 0; j < count; j++) {if (dictIsRehashing(d))_dictRehashStep(d);elsebreak;}tables = dictIsRehashing(d) ? 2 : 1;maxsizemask = d->ht[0].sizemask;if (tables > 1 && maxsizemask < d->ht[1].sizemask)maxsizemask = d->ht[1].sizemask;/* 在较大的表内选择一个随机点 */unsigned long i = random() & maxsizemask;unsigned long emptylen = 0; /* 目前连续的空条目 */while(stored < count && maxsteps--) {for (j = 0; j < tables; j++) {/* dict.c rehashing的不变量:在rehashing期间已经访问过的ht[0]索引之前,* 没有填充的桶,所以我们可以跳过ht[0]的0到idx-1之间的索引 */if (tables == 2 && j == 0 && i < (unsigned long) d->rehashidx) {/* 此外,如果我们当前在第二个表中超出范围,* 在当前rehashing索引之前的两个表中都不会有元素,所以如果可能的话我们跳过* (这在从大表到小表时发生) */if (i >= d->ht[1].size) i = d->rehashidx;continue;}if (i >= d->ht[j].size) continue; /* 超出此表范围 */dictEntry *he = d->ht[j].table[i];/* 计算连续的空桶,如果它们达到'count'(最少5个),则跳到其他位置 */if (he == NULL) {emptylen++;if (emptylen >= 5 && emptylen > count) {i = random() & maxsizemask;emptylen = 0;}} else {emptylen = 0;while (he) {/* 收集迭代时发现的非空桶中的所有元素 */*des = he;des++;he = he->next;stored++;if (stored == count) return stored;}}}i = (i+1) & maxsizemask;}return stored;
}/* 位翻转函数。算法来自:* http://graphics.stanford.edu/~seander/bithacks.html#ReverseParallel */
static unsigned long rev(unsigned long v) {unsigned long s = 8 * sizeof(v); // 位大小;必须是2的幂unsigned long mask = ~0;while ((s >>= 1) > 0) {mask ^= (mask << s);v = ((v >> s) & mask) | ((v << s) & ~mask);}return v;
}/* dictScan()用于迭代字典的元素。** 迭代的工作方式如下:** 1) 最初你使用游标(v)值0调用函数。* 2) 函数执行迭代的一个步骤,并返回你必须在下一次调用中使用的新游标值。* 3) 当返回的游标为0时,迭代完成。** 函数保证在迭代的开始和结束之间返回字典中存在的所有元素。* 但是,某些元素可能会被返回多次。** 对于返回的每个元素,将使用'privdata'作为第一个参数和字典条目'de'作为第二个参数调用回调参数'fn'。** 工作原理:** 迭代算法由Pieter Noordhuis设计。* 主要思想是从高位开始增加游标。也就是说,不是正常增加游标,* 而是先反转游标的位,然后增加游标,最后再次反转位。** 这种策略是必要的,因为哈希表可能在迭代调用之间调整大小。** dict.c哈希表的大小始终是2的幂,它们使用链接,* 所以元素在给定表中的位置是通过计算Hash(key)和SIZE-1之间的按位AND得到的* (其中SIZE-1总是等价于取Hash(key)和SIZE之间除法的余数的掩码)。** 例如,如果当前哈希表大小为16,掩码为(二进制)1111。* 键在哈希表中的位置将始终是哈希输出的最后四位,依此类推。** 如果表的大小发生变化会怎样?** 如果哈希表增长,元素可以去旧桶的一个倍数中的任何地方:* 例如,假设我们已经用4位游标1100迭代过(掩码为1111,因为哈希表大小=16)。** 如果哈希表调整为64个元素,则新掩码将为111111。* 通过在??1100中替换0或1获得的新桶只能由我们在较小哈希表中扫描桶1100时已经访问过的键定位。** 通过首先迭代高位,由于反转的计数器,如果表大小变大,游标不需要重新启动。* 它将继续使用末尾没有'1100'的游标进行迭代,也没有已经探索过的最后4位的任何其他组合。** 同样,当表大小随时间收缩时,例如从16到8,* 如果已经完全探索了低3位的组合(大小8的掩码是111),* 它将不会再次被访问,因为我们确信我们尝试了,例如,0111和1111(高位的所有变化),* 所以我们不需要再次测试它。** 等等...在rehashing期间你有*两个*表!** 是的,这是真的,但我们总是先迭代较小的表,* 然后我们测试当前游标在较大表中的所有扩展。* 例如,如果当前游标是101,我们也有一个大小为16的较大表,* 我们还在较大表内测试(0)101和(1)101。* 这将问题简化为只有一个表,其中较大的表(如果存在)只是较小表的扩展。** 限制:** 这个迭代器完全无状态,这是一个巨大的优势,包括不使用额外的内存。** 这种设计产生的缺点是:** 1) 我们可能会多次返回元素。然而,这通常在应用级别很容易处理。* 2) 迭代器必须每次调用返回多个元素,因为它需要始终返回给定桶中链接的所有键,* 以及所有扩展,所以我们确信在rehashing过程中不会遗漏移动的键。* 3) 反向游标一开始有些难以理解,但这个注释应该有所帮助。*/
unsigned long dictScan(dict *d,unsigned long v,dictScanFunction *fn,void *privdata)
{dictht *t0, *t1;const dictEntry *de;unsigned long m0, m1;if (dictSize(d) == 0) return 0;if (!dictIsRehashing(d)) {t0 = &(d->ht[0]);m0 = t0->sizemask;/* 发出游标处的条目 */de = t0->table[v & m0];while (de) {fn(privdata, de);de = de->next;}} else {t0 = &d->ht[0];t1 = &d->ht[1];/* 确保t0是较小的表,t1是较大的表 */if (t0->size > t1->size) {t0 = &d->ht[1];t1 = &d->ht[0];}m0 = t0->sizemask;m1 = t1->sizemask;/* 发出游标处的条目 */de = t0->table[v & m0];while (de) {fn(privdata, de);de = de->next;}/* 迭代较大表中的索引,这些索引是较小表中游标指向的索引的扩展 */do {/* 发出游标处的条目 */de = t1->table[v & m1];while (de) {fn(privdata, de);de = de->next;}/* 增加较小掩码未覆盖的位 */v = (((v | m0) + 1) & ~m0) | (v & m0);/* 继续,直到掩码差异覆盖的位为非零 */} while (v & (m0 ^ m1));}/* 设置未掩码位,以便增加反转的游标* 在较小表的掩码位上操作 */v |= ~m0;/* 增加反转的游标 */v = rev(v);v++;v = rev(v);return v;
}/* ------------------------- 私有函数 ------------------------------ *//* 如果需要,扩展哈希表 */
static int _dictExpandIfNeeded(dict *d)
{/* 增量rehashing已经在进行中。返回。 */if (dictIsRehashing(d)) return DICT_OK;/* 如果哈希表为空,将其扩展到初始大小。 */if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);/* 如果我们达到了1:1的比率,并且我们允许调整哈希表大小(全局设置),* 或者我们应该避免它但元素/桶之间的比率超过了"安全"阈值,* 我们调整大小,将桶数量加倍。 */// 哈希表中键值对的数量与哈希表的大小的比大于负载因子if (d->ht[0].used >= d->ht[0].size &&(dict_can_resize ||d->ht[0].used/d->ht[0].size > dict_force_resize_ratio)){return dictExpand(d, d->ht[0].used*2);}return DICT_OK;
}/* 我们的哈希表容量是2的幂 */
static unsigned long _dictNextPower(unsigned long size)
{unsigned long i = DICT_HT_INITIAL_SIZE;if (size >= LONG_MAX) return LONG_MAX;while(1) {if (i >= size)return i;i *= 2;}
}/* 返回可以填充给定'key'的哈希条目的空闲槽的索引。* 如果键已存在,则返回-1。** 注意,如果我们正在rehashing哈希表,* 索引总是在第二个(新)哈希表的上下文中返回。 */
static int _dictKeyIndex(dict *d, const void *key)
{unsigned int h, idx, table;dictEntry *he;/* 如果需要,扩展哈希表 */if (_dictExpandIfNeeded(d) == DICT_ERR)return -1;/* 计算键的哈希值 */h = dictHashKey(d, key);for (table = 0; table <= 1; table++) {idx = h & d->ht[table].sizemask;/* 搜索此槽是否已包含给定键 */he = d->ht[table].table[idx];while(he) {if (key==he->key || dictCompareKeys(d, key, he->key))return -1;he = he->next;}if (!dictIsRehashing(d)) break;}return idx;
}// 清空字典
void dictEmpty(dict *d, void(callback)(void*)) {_dictClear(d,&d->ht[0],callback);_dictClear(d,&d->ht[1],callback);d->rehashidx = -1;d->iterators = 0;
}// 启用rehash
void dictEnableResize(void) {dict_can_resize = 1;
}// 禁用rehash
void dictDisableResize(void) {dict_can_resize = 0;
}/* ------------------------------- 调试 ---------------------------------*/#define DICT_STATS_VECTLEN 50
size_t _dictGetStatsHt(char *buf, size_t bufsize, dictht *ht, int tableid) {unsigned long i, slots = 0, chainlen, maxchainlen = 0;unsigned long totchainlen = 0;unsigned long clvector[DICT_STATS_VECTLEN];size_t l = 0;if (ht->used == 0) {return snprintf(buf,bufsize,"空字典没有可用的统计信息\n");}/* 计算统计信息 */for (i = 0; i < DICT_STATS_VECTLEN; i++) clvector[i] = 0;for (i = 0; i < ht->size; i++) {dictEntry *he;if (ht->table[i] == NULL) {clvector[0]++;continue;}slots++;/* 对于这个槽上的每个哈希条目... */chainlen = 0;he = ht->table[i];while(he) {chainlen++;he = he->next;}clvector[(chainlen < DICT_STATS_VECTLEN) ? chainlen : (DICT_STATS_VECTLEN-1)]++;if (chainlen > maxchainlen) maxchainlen = chainlen;totchainlen += chainlen;}/* 生成人类可读的统计信息 */l += snprintf(buf+l,bufsize-l,"哈希表 %d 统计信息 (%s):\n"" 表大小: %ld\n"" 元素数量: %ld\n"" 不同的槽: %ld\n"" 最大链长: %ld\n"" 平均链长 (计数): %.02f\n"" 平均链长 (计算): %.02f\n"" 链长分布:\n",tableid, (tableid == 0) ? "主哈希表" : "rehashing目标表",ht->size, ht->used, slots, maxchainlen,(float)totchainlen/slots, (float)ht->used/slots);for (i = 0; i < DICT_STATS_VECTLEN-1; i++) {if (clvector[i] == 0) continue;if (l >= bufsize) break;l += snprintf(buf+l,bufsize-l," %s%ld: %ld (%.02f%%)\n",(i == DICT_STATS_VECTLEN-1)?">= ":"",i, clvector[i], ((float)clvector[i]/ht->size)*100);}/* 与snprintf()不同,返回实际写入的字符数 */if (bufsize) buf[bufsize-1] = '\0';return strlen(buf);
}// 获取字典的统计信息
void dictGetStats(char *buf, size_t bufsize, dict *d) {size_t l;char *orig_buf = buf;size_t orig_bufsize = bufsize;l = _dictGetStatsHt(buf,bufsize,&d->ht[0],0);buf += l;bufsize -= l;if (dictIsRehashing(d) && bufsize > 0) {_dictGetStatsHt(buf,bufsize,&d->ht[1],1);}/* 确保末尾有一个NULL终止符 */if (orig_bufsize) orig_buf[orig_bufsize-1] = '\0';
}
参考
1.美团技术博客
2.redis源码
3.redis源码分析
相关文章:
redis)
哈希表笔记(二)redis
Redis哈希表实现分析 这份代码是Redis核心数据结构之一的字典(dict)实现,本质上是一个哈希表的实现。Redis的字典结构被广泛用于各种内部数据结构,包括Redis数据库本身和哈希键类型。 核心特点 双表设计:每个字典包含两个哈希表࿰…...

专题二十一:无线局域网——WLAN
一、WLAN简介 WLAN(Wireless Local Area Network )无线局域网,使用的是 IEEE 802.11 标准系列。 标准版本发布年份最大传输速率频段Wi-Fi代数特点/描述IEEE 802.1119971–2 Mbps2.4 GHzWi-Fi 0最早的无线局域网标准,传输速率低&…...

例数据中关键指标对应的SQL查询模板
以下是针对示例数据中关键指标对应的SQL查询模板,包含MySQL和PostgreSQL两种版本: 1. 订单处理系统指标查询 1.1 订单处理成功率 -- MySQL SELECT DATE_FORMAT(created_at, %Y-%m-%d %H:%i:00) AS time_window,COUNT(*) AS total_orders,SUM(CASE WHE…...

【业务领域】电脑主板芯片电路结构
前言 由前几期视频合集(零基础自学计算机故障排除—7天了解计算机开机过程),讲解了POST的主板软启动过程;有不少网友留言、私信来问各种不开机的故障,但大多网友没能能过我们的这合集视频,很好的理清思路,那这样的情况…...

利用无事务方式插入数据库解决并发插入问题
一、背景 由于项目中同一个网元,可能会被多个不同用户操作,而且操作大部分都是以异步子任务形式进行执行,这样就会带来并发写数据问题,本文通过利用无事务方式插入数据库解决并发插入问题,算是解决问题的一种思路&…...
(文末有下载方式))
数字智慧方案6166丨智慧医养结合大数据平台方案(50页PPT)(文末有下载方式)
数字智慧方案6166丨智慧医养结合大数据平台方案 详细资料请看本解读文章的最后内容。 引言 随着人口老龄化的加剧,智慧医养结合的需求日益迫切。本文将对《数字智慧方案6166丨智慧医养结合大数据平台方案》进行详细解读,探讨如何通过大数据和人工智能…...
(文末有下载方式))
数字智慧方案5974丨智慧农业大数据应用平台综合解决方案(79页PPT)(文末有下载方式)
详细资料请看本解读文章的最后内容。 资料解读:智慧农业大数据应用平台综合解决方案 在当今数字化时代,智慧农业成为农业发展的新趋势,对提升农业生产效率、保障农产品质量、推动农业可持续发展意义重大。这份《智慧农业大数据应用平台综合解…...
)
补题( Convolution, 二维卷积求输出矩阵元素和最大值)
来源:https://codeforces.com/gym/105231/problem/H 题目描述: 一、题目分析 本题涉及深度学习中的二维卷积操作。给定一个nm的二维输入矩阵I和一个kl的核矩阵K ,通过特定公式计算得到(n - k 1)(m - l 1)的输出矩阵O ,要求在…...

聊一聊接口测试如何处理鉴权
目录 一、常见鉴权方式及测试方法 1. Basic Auth 2. Token 鉴权 3. OAuth 2.0 4. JWT (JSON Web Token) 5. API Key 6. HMAC 签名 7.Session-Cookie 认证 二、接口测试中的鉴权实践 1. 工具示例(Postman) 2. 代码示例(Python Requ…...

第 2.3 节: 基于 Python 的关节空间与任务空间控制
在机器人控制领域,我们通常关心两个主要的“空间”:关节空间(Joint Space)和任务空间(Task Space,也常称为操作空间 Operational Space)。关节空间描述了机器人各关节的角度或位置集合ÿ…...

[更新完毕]2025东三省A题深圳杯A题数学建模挑战赛数模思路代码文章教学:热弹性物理参数估计
完整内容请看文章最下面的推广群 热弹性物理参数估计 摘要 随着现代电子设备向高性能、微型化方向发展,芯片封装结构面临着日益严峻的热机械可靠性挑战。BGA(球栅阵列)和QFN(四方扁平无引脚)作为两种主流封装形式&am…...

【大模型面试每日一题】Day 5:GQA vs MHA效率对比
【大模型面试每日一题】Day 5:GQA vs MHA效率对比 📌 题目重现 🌟🌟 面试官:最近一些研究(如LLaMA、Mixtral)采用Grouped-Query Attention(GQA)代替传统的Multi-Head A…...

【c语言】字符函数和字符串函数
目录 1.函数介绍 1.1 strlen 1.2 strcpy 1.3 strcat 1.4 strcmp 1.5 strncpy 1.6 strncat 1.7 strncmp 1.8 strstr 1.9 strtok 1.10 strerror 1.11 memcpy 1.12 memmove 1.13 memset 编辑 1.14 memcmp C语言中对字符和字符串的处理很是频繁,但是C语言本身是没有…...
和 Claude 在 Node.js 中构建聊天应用程序)
使用 MCP(模型上下文协议)和 Claude 在 Node.js 中构建聊天应用程序
大家好,这里是架构资源栈!点击上方关注,添加“星标”,一起学习大厂前沿架构! 使用 Node.js 中的 MCP(模型上下文协议)构建聊天应用程序 我最近开发了一个简单的聊天应用程序,允许 …...

B站Michale_ee——ESP32_IDF SDK——FreeRTOS_2 队列
一、通过队列传递三种类型数据(整型、结构体、指针) 1.队列简介 FreeRTOS中的队列本质就是一个先入先出的缓冲区(FIFO,First Input First Output) 2.API简介 (1)创建队列的API (…...

小米MiMo:7B模型逆袭AI大模型战场的技术密码
小米MiMo:7B模型逆袭AI大模型战场的技术密码 在大模型竞争愈发激烈的2025年4月30日,小米以一款名为 MiMo-7B 的开源模型强势突围,在数学推理与代码能力评测中表现亮眼,不仅与规模更大的模型正面对抗,甚至超越了 OpenA…...

Java关键字解析
Java关键字是编程语言中具有特殊含义的保留字,不能用作标识符(如变量名、类名等)。Java共有50多个关键字(不同版本略有差异),下面我将分类详细介绍这些关键字及其使用方式。 一、数据类型相关关键字 1. 基…...

YOLOv8模型训练过程
一,conda环境的创建就略过了 先进行库工具安装 pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple 二,在github上下载好模型,先预测一把 yolo predict modelyolov8n.pt sourceultralytics/assets/bus.jpg 如果无…...
)
1996-2022年全国31省ZF干预度数据/财政干预度数据(含原始数据+计算过程+结果)
1996-2022年全国31省ZF干预度数据/财政干预度数据(含原始数据计算过程结果) 1、时间:1996-2022年 2、来源:国家统计局和各省年鉴 3、指标:地方财政一般预算支出、地区生产总值(GDP)、ZF干预度…...

STM32移植U8G2
STM32 移植 U8G2 u8g2 (Universal 8bit Graphics Library version2 的缩写)是用于嵌入式设备的单色图形库,可以在单色屏幕中绘制 GUI。u8g2 内部附带了例如 SSD13xx,ST7xx 等很多 OLED,LCD 驱动。内置多种不同大小和风…...

26.电流信号的强抗干扰能力运用
电流信号强抗干扰能力运用 1. 电流型信号与电压型信号的传输抗干扰能力差异2. 电流型信号电路示例 1. 电流型信号与电压型信号的传输抗干扰能力差异 现场干扰以电场干扰为主,电压较高但是能量(电流I)较低。如果以能量信号作为传输媒介&#x…...

【 Node.js】 Node.js安装
下载 下载 | Node.js 中文网https://nodejs.cn/download/ 安装 双击安装包 点击Next 勾选使用许可协议,点击Next 选择安装位置 点击Next 点击Next 点击Install 点击Finish 完成安装 添加环境变量 编辑【系统变量】下的变量【Path】添加Node.js的安装路径--如果…...

经典算法 青蛙跳杯子
青蛙跳杯子 题目描述 桌子上有n行m列的杯子,每个杯子与相邻杯子之间的距离为1,已知青蛙的跳跃半径为d,青蛙现在在第一行第一列的杯子上,它跳到最后一行最后一列的杯子上,最少需要跳几次? 输入描述 输入…...

C语言-函数的递归和迭代
以下是我初学C语言的笔记记录,欢迎在评论区补充留言 一,函数的递归 大致有这么几个问题【我看完这堂课后,自己总结的几个问题】 * 问题 1,什么是函数的递归, 2,它是干什么用的,3,有什么条件吗…...

Linux安装部署Postgresql数据库
联网安装方案 Linux能在线安装依赖组件的前提下,可以快速安装部署PG数据库,安装过程使用root管理员帐号: 首先,使用如下命令自动下载Postgresql组件: # 在openEuler、Fedora或CentOS 8上,你可能会使用&a…...

学习与规划的融合Dyna-Q:python从零实现
🧠 向所有学习者致敬! “学习不是装满一桶水,而是点燃一把火。” —— 叶芝 我的博客主页: https://lizheng.blog.csdn.net 🌐 欢迎点击加入AI人工智能社区! 🚀 让我们一起努力,共创…...
)
电子病历高质量语料库构建方法与架构项目(环境聆听与自动化文档生成篇)
电子病历高质量语料库的构建是一个复杂而系统的工程,涉及数据收集、清洗、标注、验证等多个环节。在项目实施过程中,"环境聆听"和"自动化文档生成"是两个关键支撑要素,前者确保项目能够适应不断变化的技术和业务环境,后者则保障项目过程的可追溯性和知…...

LegalOne:本土与国际视野融合的法律评级,大湾区律师及律师事务所榜单申报启动
在广东这片法律服务发展的热土上,从1979年全国首家法律服务机构诞生,到如今培育出4700家律所与8.7万律师,法律行业始终蓬勃向前。随着粤港澳大湾区建设推进,法律服务市场迈向双向融合的国际化新阶段,众多优秀律所和律师…...

突破传统!TTRL如何开启大模型无监督强化学习新篇章?
在大语言模型(LLMs)蓬勃发展的时代,如何让模型在无明确标签数据下有效学习成为关键难题。本文提出的Test-Time Reinforcement Learning(TTRL)给出了创新解法。它利用多数投票估计奖励,实现LLMs自我进化&…...

什么是:云边端一体化架构
什么是云边端一体化架构 文章目录 什么是云边端一体化架构云、边、端云计算边缘计算终端设备 云边端一体化协同云边端一体化架构协同的流程云边端一体化架构协同的应用云边端一体化架构协同的价值云边端一体化架构协同未来发展趋势 云、边、端 云(Cloud)…...

【2025域适应科研日报】
本笔记主要为了记录自己的科研日报,前段时间刚开始想写的初衷也是为了自己的思考不跑偏,但是有几天又没有坚持下来,看到一位学长的文章,发现这种形式还是很有必要的,所以自己也打算坚持记录下来,由于还正在…...

Linux从入门到精通:全面掌握基础命令与高效操作实战指南
引言 Linux 作为开发者、运维工程师及技术爱好者的核心工具,其命令行的高效性与灵活性无可替代。但对于新手而言,复杂的命令与文件结构往往令人困惑。本文基于官方文档与实践经验,系统梳理 Linux 基础命令、文件管理、目录操作、高级技巧 四大…...

如何提升个人的稳定性?
提升自我的稳定性是一个系统性工程,需要从内在认知、情绪管理、行为习惯到外在环境等多个维度进行优化。 以下是一些具体建议,帮助你逐步增强内心的稳定感: 一、内在认知调整 1. 建立清晰的自我认知 通过反思(如写日记、冥想…...
)
电机常用易混淆概念说明(伺服、舵机、多轮)
1. 概述 基础动力需求 :普通电机(如水泵、风扇)。 高精度控制 :优先伺服系统或伺服电机(如数控机床)。 微型化场景 :舵机(如遥控模型)。 移动底盘 :单舵轮成…...

短视频矩阵系统:源码搭建与定制化开发的深度剖析
在短视频行业蓬勃发展的当下,越来越多的企业和个人希望构建自己的短视频矩阵系统。而在搭建过程中,源码搭建和定制化开发是两种常见的选择,它们各有优劣,适用于不同的需求场景。本文将从多个维度深入探讨两者的区别,为…...
)
8.进程概念(四)
一、环境变量 1.基本概念 环境变量(environment variables)⼀般是指在操作系统中用来指定操作系统运行环境的⼀些参数。 如:我们在编写C/C代码的时候,在链接的时候,从来不知道我们的所链接的动态静态库在哪里,但是照样可以链接成…...

Windows服务器提权实战:常见方法、场景与防御指南
在渗透测试中,权限提升(提权)是从低权限账户(如IIS、Apache运行账户)获取系统管理员(如SYSTEM)权限的关键步骤。本文将从实战角度解析Windows服务器提权的常见技术,并结合真…...
 ----顶点指定和基本图元的绘制)
OpenGL-ES 学习(14) ----顶点指定和基本图元的绘制
目录 本节概述顶点的指定常量顶点属性和顶点数组顶点数组顶点属性的定义Shader 中声明顶点属性变量顶点属性的绑定 基本图元绘制基本图元三角形直线绘制图元的API 本节概述 绘制图形的第一步就是指定顶点坐标,可以每个顶点指定,也可以是用于所有顶点的常…...

spring-cloud-alibaba最新版本聚合项目创建
1. 创建聚合项目 修改 pom.xml spring-boot 当前最新版本是 3.4.5 但是 spring-cloud-alibaba 的最新版本是 2023.0.3.2,只适配到 spring-boot 3.2.4 还没有适配到 spring-boot 的 3.4.5 版本。 pom.xml 文件内容如下(可以直接复制): <?xml vers…...

网络分析/
三、网络分析(Network Analysis) 网络分析用于解决路径规划、资源分配等问题,广泛应用于交通规划、物流配送、紧急救援等领域。ArcPy 提供了强大的网络分析工具,如 MakeNetworkDataset、Solve 等。 (一)使用…...

Flutter PIP 插件 ---- 新增PipActivity,Android 11以下支持自动进入PIP Mode
接上文 Flutter PIP 插件 ---- Android 项目地址 PIP, pub.dev也已经同步发布 pip 0.0.3,你的加星和点赞,将是我继续改进最大的动力 开发文档 Add videos using picture-in-picture (PiP)介绍PIP功能从 Android 8.0 (API level 26) 引入&…...

权限提升—Linux提权内核溢出漏洞辅助项目
前言 今天开启Linux提权的篇章,主要是讲一下Linux的内核漏洞提权,利用方式和Windows系统漏洞提权差不多,也是网上的项目扫一下,然后根据漏洞编号去找exp即可。 信息收集 首先要说一下Linux用户的权限划分。 系统用户ÿ…...

超稳定性理论
为了更好的理解后面如何利用超稳定性理论来设计MRACS,本篇先对超稳定性理论做一个介绍。 1、理论介绍 在超稳定性理论中,核心的系统结构如下: 其包含一个线性的前向回路 G ( s ) G(s) G(s)和一个非线性的反馈回路 φ ( v ) \varphi (v) φ…...

治理和管理的区别
治理(Governance)与管理(Management)是两个在组织和社会运行中经常被提及的概念,它们虽然在某些方面有相似之处,但在内涵、范围、主体和目标等方面存在显著的区别。以下是它们的主要区别: 一、…...
(文末有下载方式))
业务流程BPM能力框架体系及华为中兴流程变革案例P83(83页PPT)(文末有下载方式)
资料解读:《业务流程 BPM 能力框架体系及华为中兴流程变革案例》 详细资料请看本解读文章的最后内容。 该文档围绕业务流程管理(BPM)能力框架体系展开,先阐述其定义、驱动因素与能力框架,再详细介绍战略规划、流程治理…...

如何通过日志在本地调试LangChain编写的程序?
LangSmith可以记录LangChain程序对LLM的调用,但它需要登陆LangSmith网站才能看到。有什么办法在本地就能看到详细的信息,以方便调试LangChain编写的程序吗? 使用LangChain提供的set_debug(True) 在Python代码中只需要导入set_debug这个方法…...

UE实用地编插件Physical Layout Tool
免费插件 https://www.fab.com/zh-cn/listings/a7fb6fcf-596f-48e9-83cc-f584aea316b1 可以通过物理模拟批量放置物体 不用再一个个摆放了 装饰环境从未如此简单,您不必再考虑对齐物体。 物理地放置物体,移动它们,在移动或在地图上放置物体…...

传感器的精度,灵敏度等概念介绍
文章目录 🏔️ 海拔高度传感器的四个核心指标1. 🎯 **精度(Accuracy)——“测得的高度准不准”**2. ⚡ **灵敏度(Sensitivity)——“高度微小变化有没有反应”**3. 🔍 **分辨率(Reso…...

前端八股 CSS 1
盒子模型 进行布局时将所有元素表示为一个个盒子box padding margin border content content:盒子内容 待显示的文本和图像 padding:内边距,内容和border之间的空间,不能为负数,受bkc影响 border:边框,…...
Transformer架构的解耦重组现象
技术演进图谱与技术成熟度曲线 (一)架构创新范式迭代 1.1 Transformer架构的解耦重组现象 以2025年Opt模型为例,其通过引入强化学习微调模块实现了传统单层堆叠架构向"感知-推理分离"模式的转型。实验数据显示,该架构…...