学习与规划的融合Dyna-Q:python从零实现
🧠 向所有学习者致敬!
“学习不是装满一桶水,而是点燃一把火。” —— 叶芝
我的博客主页: https://lizheng.blog.csdn.net
🌐 欢迎点击加入AI人工智能社区!
🚀 让我们一起努力,共创AI未来! 🚀
引言:基于模型的强化学习
强化学习算法大致可以分为无模型和基于模型的方法。
- 无模型强化学习:像 Q-Learning、DQN、REINFORCE、A2C、PPO 这样的算法,都是通过与环境的试错交互直接学习。它们学习价值函数或策略时,并没有显式地构建环境动态(转移和奖励)的表示。
- 基于模型的强化学习:算法会学习一个环境的模型(近似转移函数 P ( s ′ ∣ s , a ) P(s'|s,a) P(s′∣s,a) 和奖励函数 R ( s , a , s ′ ) R(s,a,s') R(s,a,s′)),基于经验进行学习。然后可以利用这个学到的模型进行规划——在模型中模拟交互,从而在不需要额外真实世界交互的情况下改进价值函数或策略。
Dyna-Q 是一个将无模型学习和基于模型的规划相结合的经典例子。
Dyna-Q 是什么?
Dyna-Q 是 Richard Sutton 提出的一种架构,它将直接强化学习(从真实经验中学习)与规划(从由学到的模型生成的模拟经验中学习)结合起来。它通过交替进行真实世界中的行动、从真实经验中学习(更新价值/策略和模型),以及使用学到的模型进行多次规划步骤来运行。
直接强化学习与规划
- 直接强化学习:代理在真实环境状态 s t s_t st 中采取行动 a t a_t at,观察到下一个状态 s t + 1 s_{t+1} st+1 和奖励 r t r_t rt。这个真实转换 ( s t , a t , r t , s t + 1 ) (s_t, a_t, r_t, s_{t+1}) (st,at,rt,st+1) 用于使用标准的无模型算法(例如 Q-Learning)更新代理的价值函数(例如,Q 表)。
- 模型学习:同样的真实转换 ( s t , a t , r t , s t + 1 ) (s_t, a_t, r_t, s_{t+1}) (st,at,rt,st+1) 也用于更新代理对环境的内部模型。在表格情况下,这通常意味着存储观察到的结果:模型 ( s t , a t ) → ( r t , s t + 1 ) (s_t, a_t) \rightarrow (r_t, s_{t+1}) (st,at)→(rt,st+1)。
- 规划:代理使用 模拟 经验进行 k k k 次额外的更新。在每个规划步骤中,它:
- 随机选择一个它之前经历过的状态 s s s 和行动 a a a。
- 咨询它的学到的模型,预测结果奖励 r r r 和下一个状态 s ′ s' s′: ( r , s ′ ) = 模型 ( s , a ) (r, s') = \text{模型}(s, a) (r,s′)=模型(s,a)。
- 使用这个模拟转换 ( s , a , r , s ′ ) (s, a, r, s') (s,a,r,s′) 应用相同的直接强化学习更新规则(例如,Q-Learning)来更新价值函数。
Dyna 架构
“Dyna”这个名字反映了这种动态的相互作用:真实经验直接改进模型和价值函数/策略,而模型则允许通过模拟进行规划步骤,间接通过模拟进一步改进价值函数/策略。
为什么选择 Dyna-Q?模型的价值
像 Dyna-Q 这样的基于模型的方法提供了显著的优势,主要在于样本效率:
- 数据效率:真实世界的交互可能代价高昂或速度缓慢。通过学习模型,代理可以从一次真实转换中生成许多模拟转换。这些模拟经验允许对价值函数或策略进行比仅使用直接强化学习更多的更新,从而实现更快的学习,减少真实世界的交互次数。
- 聚焦更新:规划步骤可以潜在地专注于状态-行动空间的重要部分,或者通过模拟轨迹更快地传播价值信息。
- 适应性:如果环境发生变化,模型可以被更新,从而允许规划过程快速调整策略(尽管基本的 Dyna-Q 更简单地通过 Dyna-Q+ 来解决这个问题)。
主要代价是需要学习和存储模型,以及规划步骤的计算开销。学到的策略的质量也取决于学到的模型的准确性。
Dyna-Q 的应用场景和方式
Dyna-Q 是一个基础且极具说明性的例子,适用于:
- 表格强化学习问题:具有离散状态和行动的环境,其中 Q 表和简单模型可以有效学习(例如,网格世界、简单迷宫)。
- 需要高样本效率的场景:当真实环境交互成本较高时。
- 教育目的:清晰地展示了将模型学习和规划相结合的概念。
尽管基本的 Dyna-Q 使用表格 Q-Learning 和简单的确定性模型,但 Dyna 架构可以扩展:
- 使用函数近似(神经网络)对价值函数/策略和模型进行学习(例如,Dyna-DQN)。
- 学习概率模型。
- 使用更复杂的规划算法(例如,蒙特卡洛树搜索)与学到的模型结合。
Dyna-Q 的数学基础
Dyna-Q 主要依赖于其底层组件的数学原理:用于直接强化学习和模型更新的 Q-Learning,以及在规划期间应用的 Q-Learning 更新规则。
Q-Learning 回顾(直接强化学习部分)
代理维护一个行动价值函数 Q ( s , a ) Q(s, a) Q(s,a),表示从状态 s s s 开始,采取行动 a a a,并按照当前策略继续下去的预期回报。对于一个 真实 转换 ( s t , a t , r t , s t + 1 ) (s_t, a_t, r_t, s_{t+1}) (st,at,rt,st+1),Q 值使用 TD 误差进行更新:
Q ( s t , a t ) ← Q ( s t , a t ) + α [ r t + γ max a ′ Q ( s t + 1 , a ′ ) − Q ( s t , a t ) ] Q(s_t, a_t) \leftarrow Q(s_t, a_t) + \alpha \left[ r_t + \gamma \max_{a'} Q(s_{t+1}, a') - Q(s_t, a_t) \right] Q(st,at)←Q(st,at)+α[rt+γa′maxQ(st+1,a′)−Q(st,at)]
其中 α \alpha α 是学习率, γ \gamma γ 是折扣因子。
模型学习(表格情况)
模型 模型 ( s , a ) \text{模型}(s, a) 模型(s,a) 存储在状态 s s s 中采取行动 a a a 的观察结果。对于确定性环境,在观察到 ( s t , a t , r t , s t + 1 ) (s_t, a_t, r_t, s_{t+1}) (st,at,rt,st+1) 后,模型更新为:
模型 ( s t , a t ) ← ( r t , s t + 1 ) \text{模型}(s_t, a_t) \leftarrow (r_t, s_{t+1}) 模型(st,at)←(rt,st+1)
这通常存储在一个字典或哈希映射中,其中键是 ( 状态 , 行动 ) (\text{状态}, \text{行动}) (状态,行动) 对。
规划(模拟经验更新)
在每个规划步骤中,代理:
- 从之前观察到的对中选择一个状态-行动对 ( s p , a p ) (s_p, a_p) (sp,ap)。
- 从模型中检索模拟结果: ( r p , s p ′ ) = 模型 ( s p , a p ) (r_p, s'_p) = \text{模型}(s_p, a_p) (rp,sp′)=模型(sp,ap)。
- 使用这个 模拟 转换对 Q ( s p , a p ) Q(s_p, a_p) Q(sp,ap) 应用 Q-Learning 更新:
Q ( s p , a p ) ← Q ( s p , a p ) + α [ r p + γ max a ′ Q ( s p ′ , a ′ ) − Q ( s p , a p ) ] Q(s_p, a_p) \leftarrow Q(s_p, a_p) + \alpha \left[ r_p + \gamma \max_{a'} Q(s'_p, a') - Q(s_p, a_p) \right] Q(sp,ap)←Q(sp,ap)+α[rp+γa′maxQ(sp′,a′)−Q(sp,ap)]
这允许基于学到的模型传播价值信息,而无需与真实环境交互。
Dyna-Q 的逐步解释
- 初始化:Q 表 Q ( s , a ) Q(s, a) Q(s,a)(例如,初始化为零),模型 模型 ( s , a ) \text{模型}(s, a) 模型(s,a)(为空)。超参数 α , γ , ϵ \alpha, \gamma, \epsilon α,γ,ϵ,规划步骤 k k k。
- 每个剧集循环:
a. 从环境中获取初始状态 s s s。
b. 每个剧集步骤循环:
i. 使用基于 Q Q Q 的策略(例如, ϵ \epsilon ϵ-贪婪)从状态 s s s 中选择行动 a a a。
ii. 采取行动 a a a,观察真实奖励 r r r 和下一个状态 s ′ s' s′。
iii. 直接强化学习更新:使用真实转换 ( s , a , r , s ′ ) (s, a, r, s') (s,a,r,s′) 通过 Q-Learning 规则更新 Q ( s , a ) Q(s, a) Q(s,a)。
iv. 模型更新:存储观察到的转换: 模型 ( s , a ) ← ( r , s ′ ) \text{模型}(s, a) \leftarrow (r, s') 模型(s,a)←(r,s′)。如果需要采样,将 ( s , a ) (s,a) (s,a) 添加到观察到的对列表中。
v. 规划:重复 k k k 次:
1. 从 之前观察到的 对中随机采样一个状态 s p s_p sp 和行动 a p a_p ap。
2. 从模型中获取模拟结果: ( r p , s p ′ ) = 模型 ( s p , a p ) (r_p, s'_p) = \text{模型}(s_p, a_p) (rp,sp′)=模型(sp,ap)。
3. 使用 ( s p , a p , r p , s p ′ ) (s_p, a_p, r_p, s'_p) (sp,ap,rp,sp′) 对 Q ( s p , a p ) Q(s_p, a_p) Q(sp,ap) 应用 Q-Learning 更新。
vi. 更新状态: s ← s ′ s \leftarrow s' s←s′。
vii. 如果 s ′ s' s′ 是终止状态,则退出剧集步骤循环。 - 重复:直到收敛或达到最大剧集数。
Dyna-Q 的关键组成部分
行动价值函数(Q 表)
- 存储在每个状态下采取每个行动的估计价值。
- 在表格情况下,通常是一个字典或多维数组。
- 通过直接强化学习和规划步骤进行更新。
环境模型(学到的)
- 存储学到的动态(转移和奖励)。
- 在表格 Dyna-Q 中,通常是一个字典,将 ( 状态 , 行动 ) (\text{状态}, \text{行动}) (状态,行动) 元组映射到 ( 奖励 , 下一个状态 ) (\text{奖励}, \text{下一个状态}) (奖励,下一个状态) 元组。
- 仅从真实环境交互中更新。
直接强化学习更新
- 基于在环境中实际经历的转换更新 Q 表(例如,Q-Learning)。
规划更新(基于模型)
- 基于通过查询学到的模型生成的模拟转换更新 Q 表。
- 在每个真实步骤后执行 k k k 次。
探索与利用
- 通过基于 Q 表的策略在真实交互中处理(例如, ϵ \epsilon ϵ-贪婪)。
- 规划步骤通常直接使用学到的 Q 值进行更新(在模型内利用当前价值估计)。
规划步骤数量( k k k)
- 一个关键的超参数,控制规划与直接交互的相对量。 k = 0 k=0 k=0 恢复为无模型的 Q-Learning。较大的 k k k 会增加计算成本,但如果模型准确,则可以显著加快学习速度。
超参数
- 学习率 ( α \alpha α),折扣因子 ( γ \gamma γ),探索率 ( ϵ \epsilon ϵ)。
- 规划步骤数量 ( k k k)。
实际示例:自定义网格世界
为什么选择网格世界来展示 Dyna-Q?
网格世界非常适合展示 Dyna-Q,因为:
- 离散状态/行动:适合 Dyna-Q 所使用的 Q 函数和模型的表格表示。
- 简单性:动态过程易于理解和学习,可以专注于 Dyna-Q 机制本身。
- 确定性(可选):确定性版本可以让模型快速变得完全准确,清楚地展示规划的好处。这里我们使用确定性版本。
- 可视化:Q 值、模型和策略可以轻松可视化。
环境描述:(与之前相同,使用元组状态)
- 网格大小:10x10。
- 状态:代理的 ( 行 , 列 ) (\text{行}, \text{列}) (行,列) 元组。
- 行动:4 个离散值(0:上,1:下,2:左,3:右)。
- 起点:(0, 0),终点:(9, 9)。
- 奖励:+10(终点),-1(墙壁),-0.1(步进)。
- 终止条件:到达终点或达到最大步数。
设置环境
导入必要的库。我们只需要基本的 Python 数据结构和 numpy/matplotlib。
# 导入必要的库
import numpy as np
import matplotlib.pyplot as plt
import random
from collections import defaultdict # 适用于 Q 表和模型
from typing import Tuple, Dict, Any, List, DefaultDict# 设置随机种子以确保可重复性
seed = 42
random.seed(seed)
np.random.seed(seed)%matplotlib inline
创建自定义环境
使用 GridEnvironmentTabular 类,稍作修改以直接返回状态元组,适用于表格方法。
class GridEnvironmentTabular:"""返回状态元组的网格世界,适用于表格方法。奖励:+10(终点),-1(墙壁),-0.1(步进)。"""def __init__(self, rows: int = 10, cols: int = 10) -> None:self.rows: int = rowsself.cols: int = colsself.start_state: Tuple[int, int] = (0, 0)self.goal_state: Tuple[int, int] = (rows - 1, cols - 1)self.state: Tuple[int, int] = self.start_stateself.action_dim: int = 4self.action_map: Dict[int, Tuple[int, int]] = {0: (-1, 0), 1: (1, 0), 2: (0, -1), 3: (0, 1)}def reset(self) -> Tuple[int, int]:""" 重置环境,返回状态元组。 """self.state = self.start_statereturn self.statedef step(self, action: int) -> Tuple[Tuple[int, int], float, bool]:"""执行一步,返回 (下一个状态元组, 奖励, 是否完成)。"""if self.state == self.goal_state:return self.state, 0.0, Truedr, dc = self.action_map[action]current_row, current_col = self.statenext_row, next_col = current_row + dr, current_col + dcreward: float = -0.1if not (0 <= next_row < self.rows and 0 <= next_col < self.cols):next_row, next_col = current_row, current_col # 保持原位reward = -1.0self.state = (next_row, next_col)next_state_tuple = self.statedone: bool = (self.state == self.goal_state)if done:reward = 10.0return next_state_tuple, reward, donedef get_action_space_size(self) -> int:return self.action_dim
实例化并测试环境。
custom_env_tabular = GridEnvironmentTabular(rows=10, cols=10)
n_actions_tabular = custom_env_tabular.get_action_space_size()print(f"表格网格环境:")
print(f"大小:{custom_env_tabular.rows}x{custom_env_tabular.cols}")
print(f"行动维度:{n_actions_tabular}")
start_state_tuple = custom_env_tabular.reset()
print(f"起始状态:{start_state_tuple}")
next_s, r, d = custom_env_tabular.step(3) # 向右移动
print(f"步骤结果(行动=右):下一个状态={next_s},奖励={r},完成={d}")
表格网格环境:
大小:10x10
行动维度:4
起始状态:(0, 0)
步骤结果(行动=右):下一个状态=(0, 1),奖励=-0.1,完成=False
实现 Dyna-Q 算法
我们将使用函数实现 Dyna-Q,或者为了结构化,可以选择将其放在一个代理类中。
表示 Q 表和模型
defaultdict 非常适合 Q 表(未访问的状态-行动对返回 0)和模型。
# 初始化 Q 表和模型
# Q 表:将 (状态元组, 行动) 映射到 Q 值
Q_table: DefaultDict[Tuple[Tuple[int, int], int], float] = defaultdict(float)# 模型:将 (状态元组, 行动) 映射到 (奖励, 下一个状态元组)
Model: Dict[Tuple[Tuple[int, int], int], Tuple[float, Tuple[int, int]]] = {}# 跟踪观察到的状态-行动对,以便规划采样
Observed_State_Actions: List[Tuple[Tuple[int, int], int]] = []
行动选择( ϵ \epsilon ϵ-贪婪)
基于 Q 表的标准 ϵ \epsilon ϵ-贪婪选择。
def choose_action_epsilon_greedy(state: Tuple[int, int], q_table: DefaultDict[Tuple[Tuple[int, int], int], float], epsilon: float, n_actions: int) -> int:"""根据 Q 表使用 $\epsilon$-贪婪策略选择行动。参数:- state (Tuple[int, int]): 当前状态元组。- q_table (DefaultDict): 当前 Q 值估计。- epsilon (float): 选择随机行动的概率。- n_actions (int): 可能行动的总数。返回:- int: 选择的行动索引。"""if random.random() < epsilon:# 探索:选择一个随机行动return random.randrange(n_actions)else:# 利用:根据 Q 值选择最佳行动q_values = [q_table[(state, a)] for a in range(n_actions)]max_q = max(q_values)# 处理平局情况,随机选择最佳行动之一best_actions = [a for a, q in enumerate(q_values) if q == max_q]return random.choice(best_actions)
直接强化学习更新(Q-Learning)
对 Q 表执行 Q-Learning 更新。
def q_learning_update(q_table: DefaultDict[Tuple[Tuple[int, int], int], float],state: Tuple[int, int],action: int,reward: float,next_state: Tuple[int, int],alpha: float,gamma: float,n_actions: int,is_done: bool) -> None:"""执行单次 Q-Learning 更新步骤。参数:- q_table: 要更新的 Q 表。- state, action, reward, next_state, is_done: 转换元素。- alpha: 学习率。- gamma: 折扣因子。- n_actions: 行动数量。"""# 获取当前 Q 值current_q = q_table[(state, action)]# 获取下一个状态的最大 Q 值(目标)if is_done:target_q = 0.0 # 如果剧集结束,则没有未来奖励else:next_q_values = [q_table[(next_state, a)] for a in range(n_actions)]max_next_q = max(next_q_values) if next_q_values else 0.0target_q = max_next_q# 计算 TD 目标和 TD 误差td_target = reward + gamma * target_qtd_error = td_target - current_q# 更新 Q 值new_q = current_q + alpha * td_errorq_table[(state, action)] = new_q
模型更新
使用观察到的转换更新学到的模型。
def update_model(model: Dict[Tuple[Tuple[int, int], int], Tuple[float, Tuple[int, int]]],observed_pairs: List[Tuple[Tuple[int, int], int]],state: Tuple[int, int],action: int,reward: float,next_state: Tuple[int, int]) -> None:"""更新确定性表格模型。参数:- model: 模型字典。- observed_pairs: 跟踪观察到的 (状态, 行动) 对。- state, action, reward, next_state: 转换元素。"""state_action = (state, action)# 存储观察到的结果model[state_action] = (reward, next_state)# 如果尚未存在,则将对添加到观察到的对列表中(用于规划采样)# 使用集合进行高效检查可能更适合大型状态空间,# 但在这里使用列表更简单。if state_action not in observed_pairs:observed_pairs.append(state_action)
规划步骤函数
执行 k k k 次规划更新,使用模型。
def planning_steps(k: int,q_table: DefaultDict[Tuple[Tuple[int, int], int], float],model: Dict[Tuple[Tuple[int, int], int], Tuple[float, Tuple[int, int]]],observed_pairs: List[Tuple[Tuple[int, int], int]],alpha: float,gamma: float,n_actions: int) -> None:"""执行 $k$ 次规划步骤,使用学到的模型。参数:- k: 规划步骤数量。- q_table, model, observed_pairs: 代理的组成部分。- alpha, gamma, n_actions: 超参数。"""if not observed_pairs: # 如果没有观察到任何对,则无法进行规划returnfor _ in range(k):# 从之前观察到的对中随机采样一个状态-行动对state_p, action_p = random.choice(observed_pairs)# 从模型中获取模拟的奖励和下一个状态reward_p, next_state_p = model[(state_p, action_p)]# 使用模拟经验对 Q 表执行 Q-Learning 更新# 注意:模拟的下一个状态可能不是终止状态,因此 is_done 为 False# 在更复杂的模型/环境中,模型可能还会预测终止。q_learning_update(q_table, state_p, action_p, reward_p, next_state_p,alpha, gamma, n_actions, is_done=False)
Dyna-Q 代理类(可选结构)
我们可以将这些组件组合到一个类中,以便更好地组织,类似于用于基于网络的代理的结构。
class DynaQAgent:""" 封装 Dyna-Q 算法的组成部分和逻辑。 """def __init__(self, n_actions: int, alpha: float, gamma: float, epsilon: float, planning_steps: int):self.n_actions: int = n_actionsself.alpha: float = alphaself.gamma: float = gammaself.epsilon: float = epsilonself.k: int = planning_stepsself.q_table: DefaultDict[Tuple[Tuple[int, int], int], float] = defaultdict(float)self.model: Dict[Tuple[Tuple[int, int], int], Tuple[float, Tuple[int, int]]] = {}self.observed_pairs: List[Tuple[Tuple[int, int], int]] = []def choose_action(self, state: Tuple[int, int]) -> int:""" 使用 $\epsilon$-贪婪选择行动。 """return choose_action_epsilon_greedy(state, self.q_table, self.epsilon, self.n_actions)def learn(self, state: Tuple[int, int], action: int, reward: float, next_state: Tuple[int, int], done: bool) -> None:"""执行直接强化学习更新、模型更新和规划步骤。"""# 直接强化学习更新q_learning_update(self.q_table, state, action, reward, next_state, self.alpha, self.gamma, self.n_actions, done)# 模型更新update_model(self.model, self.observed_pairs, state, action, reward, next_state)# 规划planning_steps(self.k, self.q_table, self.model, self.observed_pairs, self.alpha, self.gamma, self.n_actions)def update_epsilon(self, new_epsilon: float) -> None:""" 更新探索率。 """self.epsilon = new_epsilon
运行 Dyna-Q 算法
设置超参数,初始化代理,并运行训练循环。
超参数设置
定义 Dyna-Q 的超参数。
# Dyna-Q 在自定义网格世界中的超参数
ALPHA = 0.1 # 学习率
GAMMA = 0.95 # 折扣因子
EPSILON_START = 1.0 # 初始探索率
EPSILON_END = 0.01 # 最终探索率
EPSILON_DECAY = 0.995 # 每个剧集的 $\epsilon$ 衰减因子
PLANNING_STEPS_K = 50 # 规划步骤数量 $k$NUM_EPISODES_DYNAQ = 500 # 训练剧集数量
MAX_STEPS_PER_EPISODE_DYNAQ = 200 # 每个剧集的最大步数
初始化
初始化环境和 Dyna-Q 代理。
# 实例化环境
env_dynaq = GridEnvironmentTabular(rows=10, cols=10)
n_actions = env_dynaq.get_action_space_size()# 初始化 Dyna-Q 代理
agent = DynaQAgent(n_actions=n_actions,alpha=ALPHA,gamma=GAMMA,epsilon=EPSILON_START,planning_steps=PLANNING_STEPS_K)# 用于绘图的列表
dynaq_episode_rewards = []
dynaq_episode_lengths = []
dynaq_episode_epsilons = []
训练循环
Dyna-Q 训练循环交替执行行动、学习和规划。
print(f"开始 Dyna-Q 训练 ($k={PLANNING_STEPS_K}$)...")# --- Dyna-Q 训练循环 ---
current_epsilon = EPSILON_STARTfor i_episode in range(1, NUM_EPISODES_DYNAQ + 1):state: Tuple[int, int] = env_dynaq.reset()episode_reward: float = 0.0agent.update_epsilon(current_epsilon) # 为代理设置当前 $\epsilon$for t in range(MAX_STEPS_PER_EPISODE_DYNAQ):# 选择行动action: int = agent.choose_action(state)# 与环境交互next_state, reward, done = env_dynaq.step(action)# 学习(直接强化学习、模型更新、规划)agent.learn(state, action, reward, next_state, done)state = next_stateepisode_reward += rewardif done:break# --- 剧集结束 --- dynaq_episode_rewards.append(episode_reward)dynaq_episode_lengths.append(t + 1)dynaq_episode_epsilons.append(current_epsilon)# 衰减 $\epsilon$current_epsilon = max(EPSILON_END, current_epsilon * EPSILON_DECAY)# 打印进度if i_episode % 50 == 0:avg_reward = np.mean(dynaq_episode_rewards[-50:])avg_length = np.mean(dynaq_episode_lengths[-50:])print(f"Epsilon {i_episode}/{NUM_EPISODES_DYNAQ} | 最近 50 个Epsilon的平均奖励:{avg_reward:.2f} | 平均长度:{avg_length:.1f} | $\epsilon$:{current_epsilon:.3f}")print("网格世界训练完成 (Dyna-Q)。")
开始 Dyna-Q 训练 ($k=50$)...
Epsilon 50/500 | 最近 50 个 Epsilon的平均奖励:-15.37 | 平均长度:130.0 | $\epsilon$:0.778
Epsilon 100/500 | 最近 50 个Epsilon的平均奖励:1.82 | 平均长度:51.7 | $\epsilon$:0.606
Epsilon 150/500 | 最近 50 个Epsilon的平均奖励:4.09 | 平均长度:38.3 | $\epsilon$:0.471
Epsilon 200/500 | 最近 50 个Epsilon的平均奖励:5.81 | 平均长度:31.9 | $\epsilon$:0.367
Epsilon 250/500 | 最近 50 个Epsilon的平均奖励:6.50 | 平均长度:28.1 | $\epsilon$:0.286
Epsilon 300/500 | 最近 50 个Epsilon的平均奖励:7.26 | 平均长度:23.2 | $\epsilon$:0.222
Epsilon 350/500 | 最近 50 个Epsilon的平均奖励:7.53 | 平均长度:22.1 | $\epsilon$:0.173
Epsilon 400/500 | 最近 50 个Epsilon的平均奖励:7.63 | 平均长度:20.9 | $\epsilon$:0.135
Epsilon 450/500 | 最近 50 个Epsilon的平均奖励:7.75 | 平均长度:20.2 | $\epsilon$:0.105
Epsilon 500/500 | 最近 50 个Epsilon的平均奖励:7.89 | 平均长度:19.7 | $\epsilon$:0.082
网格世界训练完成 (Dyna-Q)。
可视化学习过程
绘制剧集奖励、长度和 ϵ \epsilon ϵ 衰减的图表。
# 绘制 Dyna-Q 在自定义网格世界中的结果
plt.figure(figsize=(18, 4))# 奖励
plt.subplot(1, 3, 1)
plt.plot(dynaq_episode_rewards)
plt.title(f'Dyna-Q ($k={PLANNING_STEPS_K}$):Epsilon奖励')
plt.xlabel('Epsilon')
plt.ylabel('总奖励')
plt.grid(True)
if len(dynaq_episode_rewards) >= 50:rewards_ma_dynaq = np.convolve(dynaq_episode_rewards, np.ones(50)/50, mode='valid')plt.plot(np.arange(len(rewards_ma_dynaq)) + 49, rewards_ma_dynaq, label='50-Epsilon移动平均', color='orange')plt.legend()# 长度
plt.subplot(1, 3, 2)
plt.plot(dynaq_episode_lengths)
plt.title(f'Dyna-Q ($k={PLANNING_STEPS_K}$):剧集长度')
plt.xlabel('Epsilon')
plt.ylabel('步数')
plt.grid(True)
if len(dynaq_episode_lengths) >= 50:lengths_ma_dynaq = np.convolve(dynaq_episode_lengths, np.ones(50)/50, mode='valid')plt.plot(np.arange(len(lengths_ma_dynaq)) + 49, lengths_ma_dynaq, label='50-Epsilon移动平均', color='orange')plt.legend()# $\epsilon$
plt.subplot(1, 3, 3)
plt.plot(dynaq_episode_epsilons)
plt.title('Dyna-Q:$\epsilon$ 衰减')
plt.xlabel('Epsilon')
plt.ylabel('$\epsilon$')
plt.grid(True)plt.tight_layout()
plt.show()
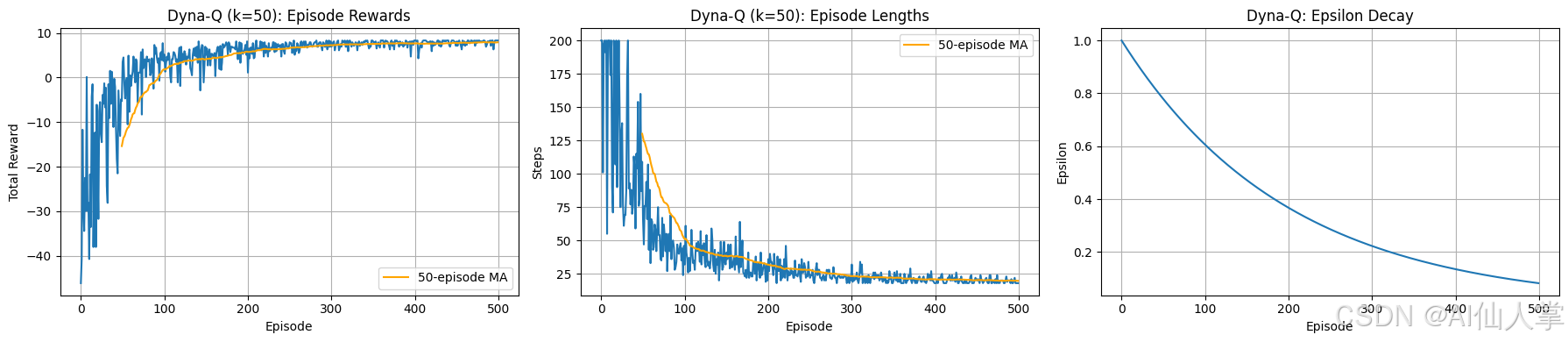
Dyna-Q ( k = 50 k=50 k=50) 学习曲线分析(自定义网格世界):
-
Epsilon奖励:
代理学习效果显著,移动平均值(橙色线)显示出奖励的稳步且显著增长,尤其是在大约第 50 到 200 个’Epsilon’之间,之后趋于稳定并接近最优值(大约 8)。原始奖励(蓝色线)在学习过程中存在一定的波动,但在找到最优策略后稳定下来,表明成功收敛。 -
'Epsilon’长度:
相应地,平均’Epsilon’长度大幅下降。移动平均值显示出明显的下降趋势,在大约第 300 个’Epsilon’时收敛到最优路径长度(大约 18 步)。原始长度最初非常嘈杂,但随着代理学习和探索( ϵ \epsilon ϵ)的减少,逐渐变得更加一致。 -
ϵ \epsilon ϵ 衰减:
控制探索率(选择随机行动的概率)的 ϵ \epsilon ϵ 值,按照指数衰减从 1.0 逐渐降低到接近 0.05 的低值。这种有计划的探索衰减允许代理在初期广泛探索环境,然后逐渐利用其学到的知识(通过真实和模型模拟的经验更新的 Q 值)。衰减率与观察到的学习进度非常匹配。
总体结论:
Dyna-Q( k = 50 k=50 k=50 规划步骤)成功解决了网格世界任务,通过将直接强化学习与基于模型的规划相结合,实现了高效学习。代理学习到了高奖励且高效的路径策略,并稳定收敛。这种有效性得益于计划的探索衰减以及从学到的世界模型中获得的额外更新,可能在某些情况下比纯无模型方法(如基本 Q-Learning)更快地收敛。
分析学到的策略和模型(可选可视化)
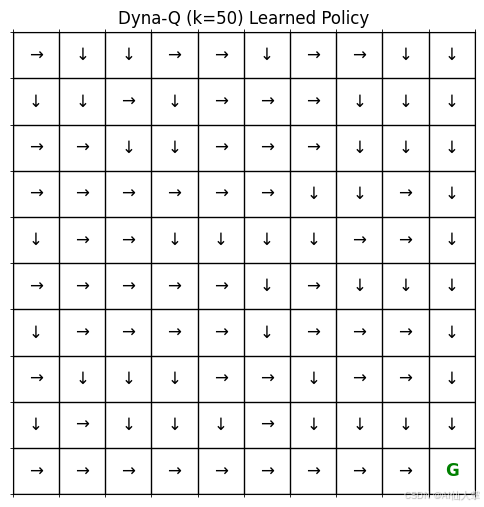
可视化从学到的 Q 表中得出的最终策略。
def plot_tabular_policy_grid(q_table: DefaultDict[Tuple[Tuple[int, int], int], float], env: GridEnvironmentTabular) -> None:"""绘制从表格 Q 表中得出的贪婪策略。"""rows: int = env.rowscols: int = env.colspolicy_grid: np.ndarray = np.empty((rows, cols), dtype=str)action_symbols: Dict[int, str] = {0: '↑', 1: '↓', 2: '←', 3: '→'} fig, ax = plt.subplots(figsize=(cols * 0.6, rows * 0.6))for r in range(rows):for c in range(cols):state_tuple: Tuple[int, int] = (r, c)if state_tuple == env.goal_state:policy_grid[r, c] = 'G'ax.text(c, r, 'G', ha='center', va='center', color='green', fontsize=12, weight='bold')else:q_values = [q_table[(state_tuple, a)] for a in range(env.get_action_space_size())]if not q_values or all(q == 0 for q in q_values): # 如果状态未被访问或所有 Q=0best_action = -1 # 表示尚未学到行动symbol = '.'else:max_q = max(q_values)best_actions = [a for a, q in enumerate(q_values) if q == max_q]best_action = random.choice(best_actions) # 随机打破平局symbol = action_symbols[best_action]policy_grid[r, c] = symbolax.text(c, r, symbol, ha='center', va='center', color='black', fontsize=12)ax.matshow(np.zeros((rows, cols)), cmap='Greys', alpha=0.1)ax.set_xticks(np.arange(-.5, cols, 1), minor=True)ax.set_yticks(np.arange(-.5, rows, 1), minor=True)ax.grid(which='minor', color='black', linestyle='-', linewidth=1)ax.set_xticks([])ax.set_yticks([])ax.set_title(f"Dyna-Q ($k={PLANNING_STEPS_K}$) 学到的策略")plt.show()# 绘制最终策略
print("\n绘制从 Dyna-Q 学到的策略:")
plot_tabular_policy_grid(agent.q_table, env_dynaq)
绘制从 Dyna-Q 学到的策略:
Dyna-Q 的常见挑战与扩展
挑战:模型准确性
- 问题:规划的有效性完全取决于学到的模型的准确性。如果模型质量差(尤其是在随机或复杂环境中),使用它进行规划可能会强化错误的动态,从而导致次优策略。
- 解决方案:
- 充分探索:确保代理充分探索,以体验多样化的转换,从而学习模型。
- 模型不确定性:更高级的方法会跟踪模型的不确定性,并相应地调整规划。
- 概率模型:学习分布 P ( s ′ , r ∣ s , a ) P(s', r | s, a) P(s′,r∣s,a),而不仅仅是单一结果。
- 限制规划:如果怀疑模型不准确,则减少 k k k。
挑战:规划的计算成本
- 问题:每个真实步骤执行 k k k 次更新可能会变得计算成本高昂,尤其是当 k k k 很大或状态空间很大时。
- 解决方案:
- 优化 k k k:选择一个适中的 k k k 值。
- 优先级扫描:一种扩展,其中规划步骤专注于那些值最有可能发生变化的状态(例如,其值刚刚显著变化的状态的前驱),而不是完全随机采样。
挑战:可扩展性(表格限制)
- 问题:基本的表格 Dyna-Q 无法扩展到大型或连续的状态/行动空间。
- 解决方案:
- 函数近似:使用神经网络对 Q 函数(或策略)以及可能的模型进行学习(例如,学习一个动态网络 s t + 1 = f ( s t , a t ) s_{t+1} = f(s_t, a_t) st+1=f(st,at))。这导致了使用函数近似的 Dyna 风格算法(例如,Dyna-DQN、World Models)。
挑战:确定性模型限制
- 问题:简单的模型 模型 ( s , a ) → ( r , s ′ ) \text{模型}(s, a) \rightarrow (r, s') 模型(s,a)→(r,s′) 假设转换是确定性的。它只存储 最后一次 观察到的结果。
- 解决方案:
- 学习频率/概率:在随机环境中存储计数或估计概率 P ( s ′ , r ∣ s , a ) P(s', r | s, a) P(s′,r∣s,a)。
- 更复杂的模型:使用能够表示分布的高斯过程或神经网络。
扩展:Dyna-Q+
- 针对环境动态可能发生变化的情况,它增加了“探索奖励”,以鼓励在最近未访问过的状态中尝试行动,从而更快地发现环境动态的变化。
结论
Dyna-Q 提供了一个清晰且有效的框架,用于将无模型学习与基于模型的规划相结合。通过从真实交互中学习环境模型,并使用它生成模拟经验进行额外更新,与纯无模型方法(如 Q-Learning, k = 0 k=0 k=0)相比,它可以显著提高样本效率。
它的核心优势在于能够多次利用每次真实经验——一次用于直接学习和模型改进,以及通过模拟规划步骤可能进行的多次更新。尽管基本的表格实现存在可扩展性和处理随机性的限制,但底层的 Dyna 架构是一个强大的概念,构成了许多使用函数近似和更复杂规划技术的先进基于模型的强化学习算法的基础。
相关文章:

学习与规划的融合Dyna-Q:python从零实现
🧠 向所有学习者致敬! “学习不是装满一桶水,而是点燃一把火。” —— 叶芝 我的博客主页: https://lizheng.blog.csdn.net 🌐 欢迎点击加入AI人工智能社区! 🚀 让我们一起努力,共创…...
)
电子病历高质量语料库构建方法与架构项目(环境聆听与自动化文档生成篇)
电子病历高质量语料库的构建是一个复杂而系统的工程,涉及数据收集、清洗、标注、验证等多个环节。在项目实施过程中,"环境聆听"和"自动化文档生成"是两个关键支撑要素,前者确保项目能够适应不断变化的技术和业务环境,后者则保障项目过程的可追溯性和知…...

LegalOne:本土与国际视野融合的法律评级,大湾区律师及律师事务所榜单申报启动
在广东这片法律服务发展的热土上,从1979年全国首家法律服务机构诞生,到如今培育出4700家律所与8.7万律师,法律行业始终蓬勃向前。随着粤港澳大湾区建设推进,法律服务市场迈向双向融合的国际化新阶段,众多优秀律所和律师…...

突破传统!TTRL如何开启大模型无监督强化学习新篇章?
在大语言模型(LLMs)蓬勃发展的时代,如何让模型在无明确标签数据下有效学习成为关键难题。本文提出的Test-Time Reinforcement Learning(TTRL)给出了创新解法。它利用多数投票估计奖励,实现LLMs自我进化&…...

什么是:云边端一体化架构
什么是云边端一体化架构 文章目录 什么是云边端一体化架构云、边、端云计算边缘计算终端设备 云边端一体化协同云边端一体化架构协同的流程云边端一体化架构协同的应用云边端一体化架构协同的价值云边端一体化架构协同未来发展趋势 云、边、端 云(Cloud)…...

【2025域适应科研日报】
本笔记主要为了记录自己的科研日报,前段时间刚开始想写的初衷也是为了自己的思考不跑偏,但是有几天又没有坚持下来,看到一位学长的文章,发现这种形式还是很有必要的,所以自己也打算坚持记录下来,由于还正在…...

Linux从入门到精通:全面掌握基础命令与高效操作实战指南
引言 Linux 作为开发者、运维工程师及技术爱好者的核心工具,其命令行的高效性与灵活性无可替代。但对于新手而言,复杂的命令与文件结构往往令人困惑。本文基于官方文档与实践经验,系统梳理 Linux 基础命令、文件管理、目录操作、高级技巧 四大…...

如何提升个人的稳定性?
提升自我的稳定性是一个系统性工程,需要从内在认知、情绪管理、行为习惯到外在环境等多个维度进行优化。 以下是一些具体建议,帮助你逐步增强内心的稳定感: 一、内在认知调整 1. 建立清晰的自我认知 通过反思(如写日记、冥想…...
)
电机常用易混淆概念说明(伺服、舵机、多轮)
1. 概述 基础动力需求 :普通电机(如水泵、风扇)。 高精度控制 :优先伺服系统或伺服电机(如数控机床)。 微型化场景 :舵机(如遥控模型)。 移动底盘 :单舵轮成…...

短视频矩阵系统:源码搭建与定制化开发的深度剖析
在短视频行业蓬勃发展的当下,越来越多的企业和个人希望构建自己的短视频矩阵系统。而在搭建过程中,源码搭建和定制化开发是两种常见的选择,它们各有优劣,适用于不同的需求场景。本文将从多个维度深入探讨两者的区别,为…...
)
8.进程概念(四)
一、环境变量 1.基本概念 环境变量(environment variables)⼀般是指在操作系统中用来指定操作系统运行环境的⼀些参数。 如:我们在编写C/C代码的时候,在链接的时候,从来不知道我们的所链接的动态静态库在哪里,但是照样可以链接成…...

Windows服务器提权实战:常见方法、场景与防御指南
在渗透测试中,权限提升(提权)是从低权限账户(如IIS、Apache运行账户)获取系统管理员(如SYSTEM)权限的关键步骤。本文将从实战角度解析Windows服务器提权的常见技术,并结合真…...
 ----顶点指定和基本图元的绘制)
OpenGL-ES 学习(14) ----顶点指定和基本图元的绘制
目录 本节概述顶点的指定常量顶点属性和顶点数组顶点数组顶点属性的定义Shader 中声明顶点属性变量顶点属性的绑定 基本图元绘制基本图元三角形直线绘制图元的API 本节概述 绘制图形的第一步就是指定顶点坐标,可以每个顶点指定,也可以是用于所有顶点的常…...

spring-cloud-alibaba最新版本聚合项目创建
1. 创建聚合项目 修改 pom.xml spring-boot 当前最新版本是 3.4.5 但是 spring-cloud-alibaba 的最新版本是 2023.0.3.2,只适配到 spring-boot 3.2.4 还没有适配到 spring-boot 的 3.4.5 版本。 pom.xml 文件内容如下(可以直接复制): <?xml vers…...

网络分析/
三、网络分析(Network Analysis) 网络分析用于解决路径规划、资源分配等问题,广泛应用于交通规划、物流配送、紧急救援等领域。ArcPy 提供了强大的网络分析工具,如 MakeNetworkDataset、Solve 等。 (一)使用…...

Flutter PIP 插件 ---- 新增PipActivity,Android 11以下支持自动进入PIP Mode
接上文 Flutter PIP 插件 ---- Android 项目地址 PIP, pub.dev也已经同步发布 pip 0.0.3,你的加星和点赞,将是我继续改进最大的动力 开发文档 Add videos using picture-in-picture (PiP)介绍PIP功能从 Android 8.0 (API level 26) 引入&…...

权限提升—Linux提权内核溢出漏洞辅助项目
前言 今天开启Linux提权的篇章,主要是讲一下Linux的内核漏洞提权,利用方式和Windows系统漏洞提权差不多,也是网上的项目扫一下,然后根据漏洞编号去找exp即可。 信息收集 首先要说一下Linux用户的权限划分。 系统用户ÿ…...

超稳定性理论
为了更好的理解后面如何利用超稳定性理论来设计MRACS,本篇先对超稳定性理论做一个介绍。 1、理论介绍 在超稳定性理论中,核心的系统结构如下: 其包含一个线性的前向回路 G ( s ) G(s) G(s)和一个非线性的反馈回路 φ ( v ) \varphi (v) φ…...

治理和管理的区别
治理(Governance)与管理(Management)是两个在组织和社会运行中经常被提及的概念,它们虽然在某些方面有相似之处,但在内涵、范围、主体和目标等方面存在显著的区别。以下是它们的主要区别: 一、…...
(文末有下载方式))
业务流程BPM能力框架体系及华为中兴流程变革案例P83(83页PPT)(文末有下载方式)
资料解读:《业务流程 BPM 能力框架体系及华为中兴流程变革案例》 详细资料请看本解读文章的最后内容。 该文档围绕业务流程管理(BPM)能力框架体系展开,先阐述其定义、驱动因素与能力框架,再详细介绍战略规划、流程治理…...

如何通过日志在本地调试LangChain编写的程序?
LangSmith可以记录LangChain程序对LLM的调用,但它需要登陆LangSmith网站才能看到。有什么办法在本地就能看到详细的信息,以方便调试LangChain编写的程序吗? 使用LangChain提供的set_debug(True) 在Python代码中只需要导入set_debug这个方法…...

UE实用地编插件Physical Layout Tool
免费插件 https://www.fab.com/zh-cn/listings/a7fb6fcf-596f-48e9-83cc-f584aea316b1 可以通过物理模拟批量放置物体 不用再一个个摆放了 装饰环境从未如此简单,您不必再考虑对齐物体。 物理地放置物体,移动它们,在移动或在地图上放置物体…...

传感器的精度,灵敏度等概念介绍
文章目录 🏔️ 海拔高度传感器的四个核心指标1. 🎯 **精度(Accuracy)——“测得的高度准不准”**2. ⚡ **灵敏度(Sensitivity)——“高度微小变化有没有反应”**3. 🔍 **分辨率(Reso…...

前端八股 CSS 1
盒子模型 进行布局时将所有元素表示为一个个盒子box padding margin border content content:盒子内容 待显示的文本和图像 padding:内边距,内容和border之间的空间,不能为负数,受bkc影响 border:边框,…...
Transformer架构的解耦重组现象
技术演进图谱与技术成熟度曲线 (一)架构创新范式迭代 1.1 Transformer架构的解耦重组现象 以2025年Opt模型为例,其通过引入强化学习微调模块实现了传统单层堆叠架构向"感知-推理分离"模式的转型。实验数据显示,该架构…...

【Android】四大组件
目录 1. Activity 2. Service 3. BroadcastReceiver 4. ContentProvider 四大组件各自承担着不同的职责,彼此之间协同工作,共同为用户提供一个流畅的APP体验。 1. Activity 负责展示用户界面,就像App的一个个“页面”,用户通…...
:从理论到实战)
贪心算法精解(Java实现):从理论到实战
一、贪心算法概述 贪心算法(Greedy Algorithm)是一种在每一步选择中都采取当前状态下最优决策的算法策略。它通过局部最优选择来达到全局最优解,具有高效、简洁的特点。 核心特点: 局部最优选择:每一步都做出当前看…...
)
基于BERT类的MRPC语义相似度检测(从0到-1系列)
基于BERT类的MRPC语义相似度检测(从0到-1系列) 介绍 BERT(Bidirectional Encoder Representations from Transformers)是由Google开发的一种预训练模型,它是一种基于Transformer机制的深度双向模型,可以对…...

mysql-窗口函数一
目录 一、感受一下分组与窗口函数的区别 二、滑动窗口(子窗口)大小的确认 2.1 分组函数下order by使用 2.2 窗口子句 2.3 执行流程 三、函数使用 窗口函数需要mysql的版本大于等于8才行,可以先检查一下自己的mysql版本是多少 select ve…...

HashMap,高效 哈希
java HashMap 有独特的设计。 哈希表数组的每个位置是一个哈希桶,里面由链表或红黑树实现。(> 8 或 < 6 的变化时,避免频繁切换) 容量(capacity): 哈希表中桶(bucket…...

PyTorch入门------训练图像分类器
前言 1. 操作步骤 2. 数据集 一、公共部分 1.加载并归一化 CIFAR10 2.定义卷积神经网络 二、训练、保存模型参数部分 train_and_save.py 3.定义损失函数和优化器 4.训练网络(使用 CPU 或者 GPU) 5.保存训练好的模型参数 三、加载模型参数、模型推理部分 load_and_infer.py 6…...

DeepSeek V3 架构创新:大规模MoE与辅助损失移除
DeepSeek 团队推出的全新 DeepSeek V3 模型版本,相比之前的 V2 版本,V3 的参数量从两千多亿一跃攀升到 6710 亿,近乎实现了参数规模的三倍增长。如此宏大的模型规模并不只是简单地堆砌参数,而是建立在稀疏混合专家(Mixture-of-Experts,MoE)结构之上。得益于 MoE 的稀疏激…...

MCP 多工具协作链路设计:打造真正的智能工作流
目录 [TOC] 🚀 MCP 多工具协作链路设计:打造真正的智能工作流 🌟 多工具协作链核心思想 🛠️ 设计示例:智能文档分析系统 📑 1. MCP Server 定义多工具 list_txt_files.py read_file_content.py su…...

某修改版软件,已突破限制!
聊一聊 现在很多输入法都带有广告。 用着用着,不是提示升级就是弹出资讯。 特别是忙的时候,很影响心情。 今天给大家分享一款干净的输入法软件。 希望能你喜欢。 软件介绍 Q拼音输入法 工具我们下载后,进行安装。 双击打开,…...

透视Linux内核:深度剖析Socket机制的本质
在Linux操作系统构建的网络世界里,Socket 宛如纵横交错的交通枢纽,承担着不同应用程序间数据往来的重任。无论是日常浏览网页时,浏览器与 Web 服务器间信息的快速交互;还是畅玩网络游戏过程中,玩家操作指令与游戏服务器…...

PostgreSQL数据表操作SQL
数据表操作 创建表 CREATE TABLE t_test(id SERIAL PRIMARY KEY,name varchar(30),birthday date);修改表名 ALTER TABLE t_test RENAME TO t_test1;添加列 ALTER TABLE t_test1 ADD COLUMN score numeric(5,2);删除列 ALTER TABLE t_test1 DROP COLUMN score;修改数据类型 AL…...

OpenAI最新发布的GPT-4.1系列模型,性能体验如何?
简单来说,这次GPT-4.1的核心思路就是:更实用、更懂开发者、更便宜!OpenAI这次没搞太多花里胡哨的概念,而是实实在在地提升了大家最关心的几个点:写代码、听指令、处理超长文本,而且知识库也更新到了2024年6月。 写代码。要说这次GPT-4.1最亮眼的地方,可能就是写代码这块…...
(含模型、可运行代码、数据))
2025五一数学建模C题完整分析论文(共36页)(含模型、可运行代码、数据)
2025年五一数学建模C题完整分析论文 摘要 一、问题分析 二、问题重述 三、模型假设 四、符号定义 五、 模型建立与求解 5.1问题1 5.1.1问题1思路分析 5.1.2问题1模型建立 5.1.3问题1代码 5.1.4问题1求解结果 5.2问题2 5.2.1问题2思路分析 5.2.2问题…...

Vue2基础速成
一、准备工作 首先下载vue2的JavaScript库,并且命名为vue.min.js 下载链接:https://cdn.jsdelivr.net/npm/vue2(若链接失效可去vue官网寻找) CTRLS即可下载保存 文件目录结构 二、使用操作原生DOM与使用VUE操作DOM的便捷性比较…...

Java大厂硬核面试:Flink流处理容错、Pomelo JVM调优、MyBatis二级缓存穿透防护与Kubernetes服务网格实战解析
第二幕:系统架构设计 面试官:设计一个处理10万QPS的秒杀系统需要的技术方案和技术选型 xbhog:采用基础架构: 存储层:Redis限流分布式锁服务层:Sentinel流量控制消息层:RocketMQ事务消息保证最…...

Python实现简易博客系统
下面我将介绍如何使用Python实现一个简易的博客系统,包含前后端完整功能。这个系统将使用Flask作为Web框架,SQLite作为数据库,并包含用户认证、文章发布、评论等基本功能。 1. 系统架构设计 技术栈选择 后端:Flask (Python Web框架)数据库:SQLite (轻量…...

【T型三电平仿真】SPWM调制
自然采样法和规则采样法的特点和计算 https://blog.csdn.net/u010632165/article/details/110889621 单极性和双极性的单双体现在什么地方 单极性和双极性的单双是指载波三角波的极性 为什么simulink进行电路仿真时,都需要放置一个powergui模块 任何使用SimPow…...
 [DLC 解锁] [Steam] [Windows SteamOS macOS])
Astral Ascent 星界战士(星座上升) [DLC 解锁] [Steam] [Windows SteamOS macOS]
Astral Ascent 星界战士(星座上升) [DLC 解锁] [Steam] [Windows & SteamOS & macOS] 需要有游戏正版基础本体,安装路径不能带有中文,或其它非常规拉丁字符; DLC 版本 至最新全部 DLC 后续可能无法及时更新文章…...
)
Ubuntu20.04如何优雅的安装ROS 1(胎教级教程)
1、USTC的源: sudo sh -c . /etc/lsb-release && echo "deb http://mirrors.ustc.edu.cn/ros/ubuntu/ lsb_release -cs main" > /etc/apt/sources.list.d/ros-latest.list2、设置的ROS源添加密钥: sudo apt-key adv --keyserver …...

terraform生成随机密码
在 Terraform 中生成安全随机密码可以通过 random_password 资源实现,以下是完整实现方案及安全实践: 基础实现 (生成随机密码) terraform {required_providers {random {source "hashicorp/random"version "~> 3.5.1" # 使…...

一个linux系统电脑,一个windows电脑,怎么实现某一个文件夹共享
下载Samba linux主机名字不能超过15个字符 sudo dnf install samba samba-client -y 创建共享文件夹 sudo mkdir /shared 配置文件 vim /etc/samba/smb.conf [shared] path /shared available yes valid users linux电脑用户 read only no browsable yes p…...
:网络安全等级保护介绍)
等保系列(一):网络安全等级保护介绍
一、基本概念 网络安全等级保护(以下简称:等保)是根据《中华人民共和国网络安全法》及配套规定(如《信息安全技术 网络安全等级保护基本要求》等)建立的系统性安全防护机制,要求网络运营者根据信息系统的重…...
)
【专题五】位运算(2)
📝前言说明: 本专栏主要记录本人的基础算法学习以及LeetCode刷题记录,按专题划分每题主要记录:(1)本人解法 本人屎山代码;(2)优质解法 优质代码;ÿ…...

【2025五一数学建模竞赛A题】 支路车流量推测问题|建模过程+完整代码论文全解全析
你是否在寻找数学建模比赛的突破点?数学建模进阶思路! 作为经验丰富的美赛O奖、国赛国一的数学建模团队,我们将为你带来本次数学建模竞赛的全面解析。这个解决方案包不仅包括完整的代码实现,还有详尽的建模过程和解析,…...
——selenium)
案例:自动化获取Web页面小说(没钱修什么仙)——selenium
目录 前言一、目标即结果1. 目标:2. 提前了解网页信息3. 结果 二、逐步分析1 . selenium启动2. 获取所有章节3.打开对应章节链接,获取小说文本4. 内容写入本地文件 三、完整代码四、声名 前言 提示:通过案例掌握selenium语法 涉及技术&#…...