基于BERT类的MRPC语义相似度检测(从0到-1系列)
基于BERT类的MRPC语义相似度检测(从0到-1系列)
介绍
BERT(Bidirectional Encoder Representations from Transformers)是由Google开发的一种预训练模型,它是一种基于Transformer机制的深度双向模型,可以对大规模文本数据进行无监督预训练,然后在各种NLP任务中进行微调。BERT 模型在多项自然语言处理任务上取得了巨大成功,成为了NLP 领域里的一个重要里程碑。
语意相似度检测任务是NLP领域中一项重要的任务,它旨在判断两个文本片段之间的语义相似程度。在这项任务中,我们需要输入两个文本片段,然后输出一个相似度分数,表示这两个文本片段之间的语义相似程度。语义相似度检测任务在很多NLP应用中非常有用,比如信息检索、问答系统、自动摘要等领域。
BERT 在语意相似度检测任务中的应用非常成功,通过将两个文本片段拼接并输入到BERT模型中,可以得到两个文本片段的语义表示,然后通过一些微调层或者特定的输出层进行语义相似度的判断。BERT 模型具有强大的语义表达能力,可以有效地捕捉文本之间的语义信息,因此在语义相似度检测任务中取得了很好的效果。
数据预处理
分析数据基本结构
Quality #1 ID #2 ID #1 String #2 String
1 702876 702977 Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence . Referring to him as only " the witness " , Amrozi accused his brother of deliberately distorting his evidence .
0 2108705 2108831 Yucaipa owned Dominick 's before selling the chain
to Safeway in 1998 for $ 2.5 billion . Yucaipa bought Dominick 's in
1995 for $ 693 million and sold it to Safeway for $ 1.8 billion in
1998 .
数据由五个列组合而成,其中 ID 这一属性对该任务无明显作用,故使用 py 脚本剔除,python脚本如下:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author: bruanlin
# datetime: 2025/4/23 13:44
# software: PyCharm
# project: [Bert-mrpc]-[data_trasform]
""" Code Describe :nothing!!
"""import pandas as pd
from typing import Tuple
import logging
import os
from pathlib import Path# 配置日志记录
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)def load_mrpc_data(file_path: str) -> Tuple[pd.DataFrame, int]:"""加载MRPC数据集"""try:# 显式指定列类型防止自动类型推断错误dtype_spec = {'#1 ID': 'string','#2 ID': 'string','#1 String': 'string','#2 String': 'string','Quality': 'int8'}# 分块读取大文件(适用于Colab内存受限情况)chunks = pd.read_csv(file_path,sep='\t',header=0,dtype=dtype_spec,usecols=['Quality', '#1 String', '#2 String'], # 明确指定需要列chunksize=1000,on_bad_lines='warn' # 跳过格式错误行)df = pd.concat(chunks)except FileNotFoundError:logger.error(f"文件未找到: {file_path}")raiseexcept pd.errors.ParserError as e:logger.error(f"TSV解析错误: {str(e)}")raise# 记录初始行数original_rows = df.shape[0]# 数据清洗df = df.dropna(subset=['#1 String', '#2 String']) # 删除空值行df = df.rename(columns={'Quality': 'label','#1 String': 'sentence1','#2 String': 'sentence2'})# 记录清洗结果cleaned_rows = df.shape[0]logger.info(f"数据清洗完成: 原始行数={original_rows}, 有效行数={cleaned_rows}, "f"丢弃行数={original_rows - cleaned_rows}")return df.reset_index(drop=True), (original_rows - cleaned_rows)def save_processed_data(df: pd.DataFrame,output_dir = "processed_data",file_name = "mrpc_processed",formats ='tsv') -> None:"""保存数据"""# 创建输出目录Path(output_dir).mkdir(parents=True, exist_ok=True)# 确保列顺序正确df = df[['label', 'sentence1', 'sentence2']]# 保存不同格式try:full_path = os.path.join(output_dir, f"{file_name}.{formats}")if formats == 'tsv':# TSV格式(默认格式)df.to_csv(full_path,sep='\t',index=False,header=True, # 根据需求调整quoting=3, # 与原始数据一致escapechar='\\')elif formats == 'csv':# CSV格式(带列名)df.to_csv(full_path,index=False,quotechar='"',escapechar='\\')else:raise ValueError(f"不支持的格式: {formats}")print(f"成功保存 {full_path} ({os.path.getsize(full_path) / 1024:.1f}KB)")except Exception as e:print(f"保存 {formats} 格式失败: {str(e)}")# 使用示例
if __name__ == "__main__":try:train_df, train_dropped = load_mrpc_data("DATASET/MRPC/train.tsv")dev_df, dev_dropped = load_mrpc_data("DATASET/MRPC/dev.tsv")# 展示样本结构print("\n训练集样例:")print(train_df[['label', 'sentence1', 'sentence2']].head(3))# 数据分布分析print("\n标签分布:")print(train_df['label'].value_counts(normalize=True))# 保存数据try:# 保存训练集数据save_processed_data(train_df,"./DATASET/train_processed","train_processed_mrpc","tsv")save_processed_data(dev_df,"./DATASET/dev_processed","dev_processed_mrpc","tsv")except Exception as e:logger.error(f"保存数据失败: {e}")except Exception as e:logger.error("数据加载失败,请检查文件路径和格式")剔除后的实验数据如下:
label sentence1 sentence2
1 He said the foodservice pie business doesn 't fit the company 's
long-term growth strategy . The foodservice pie business does not fit
our long-term growth strategy .
0 The dollar was at 116.92 yen against the yen , flat on
the session , and at 1.2891 against the Swiss franc , also flat . The
dollar was at 116.78 yen JPY = , virtually flat on the session , and
at 1.2871 against the Swiss franc CHF = , down 0.1 percent .
创建 dataset 和 dataloader
# 参数设置
Max_length = 128
Batch_size = 32
Lr = 2e-5
Epochs = 10
Model_name = 'bert-base-uncased'
train_tsv_path = "/kaggle/input/mrpc-bert/train_processed_mrpc.tsv"
dev_tsv_path = "/kaggle/input/mrpc-bert/dev_processed_mrpc.tsv"
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 加载
def load_mrpc_data(file_path):"""加载并预处理MRPC TSV文件"""try:chunks = pd.read_csv(file_path,sep='\t',header=0,dtype=str,usecols=['label', 'sentence1', 'sentence2'], # 关键修改点chunksize=1000,on_bad_lines='warn')df = pd.concat(chunks)# 类型转换df['label'] = pd.to_numeric(df['label'], errors='coerce').astype('Int8')df = df.dropna().reset_index(drop=True)return dfexcept Exception as e:print(f"Error: {e}")return None # 确保异常时返回明确空值# 创建自定义Dataset
class MRPCDataset(Dataset):def __init__(self, dataframe, tokenizer, max_len):self.data = dataframeself.tokenizer = tokenizerself.max_len = max_lendef __len__(self):return len(self.data)def __getitem__(self, index):# 提取单行数据row = self.data.iloc[index]sentence1 = str(row['sentence1'])sentence2 = str(row['sentence2'])label = int(row['label'])# 分词与编码encoding = self.tokenizer.encode_plus(text=sentence1,text_pair=sentence2,add_special_tokens=True, # 添加[CLS], [SEP]max_length=self.max_len,padding='max_length',truncation=True,return_tensors='pt', # 返回PyTorch Tensorreturn_token_type_ids=True,return_attention_mask=True)return {'input_ids': encoding['input_ids'].flatten(),'attention_mask': encoding['attention_mask'].flatten(),'token_type_ids': encoding['token_type_ids'].flatten(),'label': torch.tensor(label, dtype=torch.long)}# 初始化组件
tokenizer = BertTokenizer.from_pretrained(Model_name,cache_dir="./huggingface_models", # 指定缓存目录mirror='https://mirror.sjtu.edu.cn/huggingface' # 上海交大镜像)
df = load_mrpc_data(train_tsv_path)
dataset = MRPCDataset(df, tokenizer, max_len=Max_length)# 创建DataLoader
dataloader = DataLoader(dataset,batch_size=Batch_size,shuffle=True,num_workers=4, # 多进程加载pin_memory=True # 加速GPU传输
)# 加载验证集
dev_df = load_mrpc_data(dev_tsv_path)
dev_dataset = MRPCDataset(dev_df, tokenizer, Max_length)
dev_dataloader = DataLoader(dev_dataset,batch_size=Batch_size,shuffle=False,num_workers=2
)
训练
训练指标
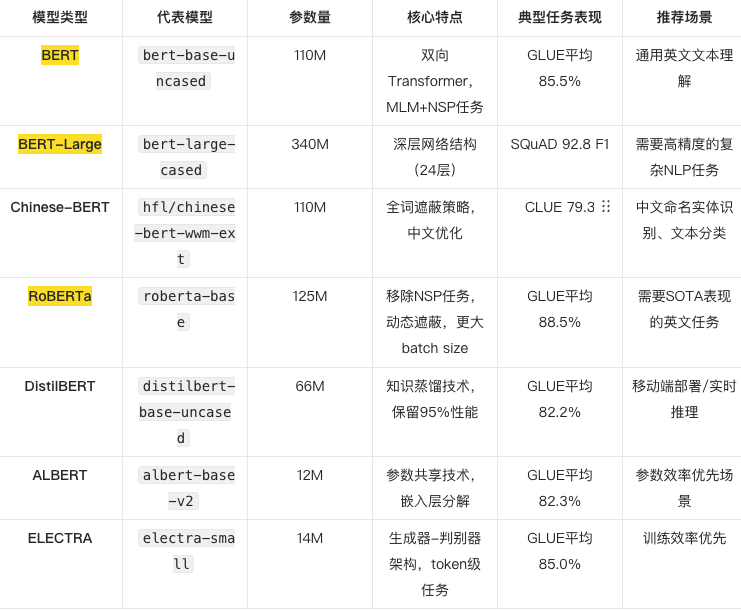
训练平台 kaggle-GPUT4
优化器 Adamw
Max_length 128
Batch_size 32
Lr 2e-5
Epochs 30# ====================创建训练组件===============
model = BertForSequenceClassification.from_pretrained(Model_name,num_labels=2, # 二分类任务force_download=True, # 强制重新下载mirror='https://mirror.sjtu.edu.cn/huggingface',cache_dir="./huggingface_models"
)
model.to(device)# ===============优化器 ==================
# 修改优化器初始化代码
optimizer = AdamW(model.parameters(), lr=Lr, weight_decay=0.01)
total_steps = len(dataloader) * Epochs
scheduler = get_linear_schedule_with_warmup(optimizer,num_warmup_steps=0,num_training_steps=total_steps
)训练函数
def train_epoch(model, dataloader, optimizer, scheduler, device):model.train()total_loss = 0progress_bar = tqdm(dataloader, desc="Training", leave=False)for batch in progress_bar:optimizer.zero_grad()input_ids = batch['input_ids'].to(device)attention_mask = batch['attention_mask'].to(device)token_type_ids = batch['token_type_ids'].to(device)labels = batch['label'].to(device)outputs = model(input_ids=input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids,labels=labels)loss = outputs.losstotal_loss += loss.item()loss.backward()torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)optimizer.step()scheduler.step()progress_bar.set_postfix({'loss': f"{loss.item():.4f}"})return total_loss / len(dataloader)
验证函数
def evaluate(model, dataloader, device):model.eval()total_loss = 0predictions = []true_labels = []with torch.no_grad():for batch in tqdm(dataloader, desc="Evaluating", leave=False):input_ids = batch['input_ids'].to(device)attention_mask = batch['attention_mask'].to(device)token_type_ids = batch['token_type_ids'].to(device)labels = batch['label'].to(device)outputs = model(input_ids=input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids,labels=labels)loss = outputs.losstotal_loss += loss.item()logits = outputs.logitspreds = torch.argmax(logits, dim=1)predictions.extend(preds.cpu().numpy())true_labels.extend(labels.cpu().numpy())accuracy = accuracy_score(true_labels, predictions)f1 = f1_score(true_labels, predictions)avg_loss = total_loss / len(dataloader)return avg_loss, accuracy, f1if __name__ == "__main__":# 查看第一个batchsample_batch = next(iter(dataloader))print(f"Batch输入尺寸:")print(f"Input IDs: {sample_batch['input_ids'].shape}")print(f"Attention Mask: {sample_batch['attention_mask'].shape}")print(f"Token Type IDs: {sample_batch['token_type_ids'].shape}")print(f"Labels: {sample_batch['label'].shape}")# 输出示例print("\n解码第一个样本:")print(tokenizer.decode(sample_batch['input_ids'][0]))print(f"======== training model ===========")# 主训练循环# 初始化指标存储列表metrics_data = []best_f1 = 0for epoch in range(Epochs):print(f"\nEpoch {epoch + 1}/{Epochs}")print("-" * 40)# 训练阶段train_loss = train_epoch(model, dataloader, optimizer, scheduler, device)print(f"Train Loss: {train_loss:.4f}")# 验证阶段val_loss, val_acc, val_f1 = evaluate(model, dev_dataloader, device)print(f"Val Loss: {val_loss:.4f} | Accuracy: {val_acc:.4f} | F1: {val_f1:.4f}")# 记录指标metrics_data.append({'Epoch': epoch + 1,'Train Loss': round(train_loss, 4),'Val Loss': round(val_loss, 4),'Accuracy': round(val_acc, 4),'F1 Score': round(val_f1, 4)})metrics_df = pd.DataFrame([metrics_data[-1]]) # 只取最新数据if epoch == 0:metrics_df.to_excel("training_metrics.xlsx", index=False)else:with pd.ExcelWriter("training_metrics.xlsx", mode='a', engine='openpyxl',if_sheet_exists='overlay') as writer:metrics_df.to_excel(writer, index=False, header=False, startrow=epoch + 1)# 保存最佳模型if val_f1 > best_f1:best_f1 = val_f1model.save_pretrained("./best_model")tokenizer.save_pretrained("./best_model")print(f"New best model saved with F1: {val_f1:.4f}")print("\nTraining completed!")print(f"Best Validation F1: {best_f1:.4f}")
总体结果与实验总结
采用预训练模型bert-base-uncased,在数据集 MRPC 上测试得到的情况如下:
| Train Loss | 0.0024 |
|---|---|
| Val Loss | 1.6600 |
| Accuracy | 0.8247 |
| Val Loss | 0.8811 |
| F1 | 0.0024 |
| Best Validation F1 | 0.8862 |
分析比对现有方法,形成简单的总结报告,想办法提升性能(不一定要比所有方法都好,接近即可),制作表格,自己方法与其他方法的性能对比。
相似度检测任务的现有方法
模型对比
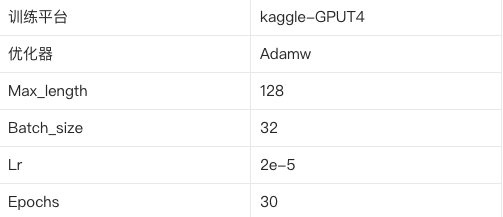
训练结果如下,超参数设置如下
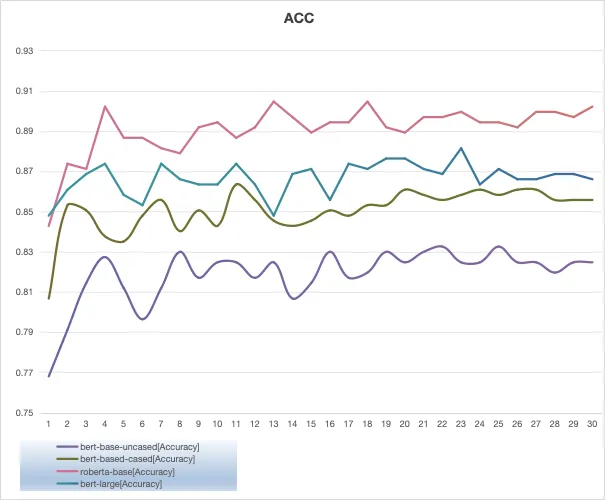
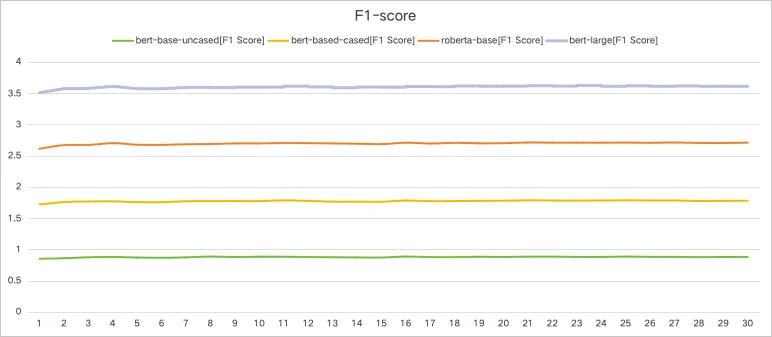
总结对比
优化改进
| 数据 | 数据增强 |
|---|---|
| 训练过程 | AdamW 分层学习率设置 |
| 训练过程 | 超参数搜索 |
| 模型 | 模型集成 |
数据增强

分层学习率
def create_model(model_name, num_labels=2):"""创建带分层参数的模型"""model = AutoModelForSequenceClassification.from_pretrained(model_name,num_labels=num_labels)# 参数分组no_decay = ["bias", "LayerNorm.weight"]optimizer_grouped_parameters = [{"params": [p for n, p in model.named_parameters()if "embeddings" in n and not any(nd in n for nd in no_decay)],"lr": config['lr'] * 0.1,"weight_decay": 0.0},{"params": [p for n, p in model.named_parameters()if "classifier" in n],"lr": config['lr'] * 10,"weight_decay": 0.01}]return model, optimizer_grouped_parameters
● 分层逻辑
○ 排除动态学习率
■ Bias参数:偏移量不需要正则化(过大的L2惩罚会降低模型灵活性)
■ LayerNorm参数:标准化层权重已自带缩放机制,额外正则化可能破坏分布
○ 词嵌入层的学习率设置:“lr”: config[‘lr’] * 0.1,“weight_decay”: 0.0
○ 分类器学习率设置: “lr”: config[‘lr’] * 10,“weight_decay”: 0.01
超参数搜索
def objective(trial):"""Optuna超参数优化目标函数"""# 超参数建议范围config.update({'lr': trial.suggest_float('lr', 1e-6, 5e-5, log=True),'batch_size': trial.suggest_categorical('batch_size', [16, 32, 64]),'aug_prob': trial.suggest_float('aug_prob', 0.1, 0.3)})# 初始化模型集合models = []optimizers = []schedulers = []for model_name in config['model_names']:model, params = create_model(model_name)model.to(device)optimizer = AdamW(params)scheduler = get_linear_schedule_with_warmup(optimizer,num_warmup_steps=100,num_training_steps=len(train_loader) * config['epochs'])models.append(model)optimizers.append(optimizer)schedulers.append(scheduler)# 训练循环best_f1 = 0for epoch in range(config['epochs']):for model, optimizer, scheduler in zip(models, optimizers, schedulers):train_epoch(model, train_loader, optimizer, scheduler, device)metrics = evaluate_ensemble(models, dev_loader, device)trial.report(metrics['f1'], epoch)if metrics['f1'] > best_f1:best_f1 = metrics['f1']if trial.should_prune():raise optuna.TrialPruned()return best_f1模型集成评估
"model_names": ['bert-base-uncased','roberta-base','google/electra-small-discriminator'],
"ensemble_weights": [0.4, 0.3, 0.3]def evaluate_ensemble(models, dataloader, device):"""集成模型评估"""all_logits = []true_labels = []for model in models:model.eval()model_logits = []with torch.no_grad():for batch in tqdm(dataloader):inputs = {k: v.to(device) for k, v in batch.items() if k != 'label'}outputs = model(**inputs)model_logits.append(outputs.logits.cpu().numpy())if len(true_labels) == 0:true_labels.extend(batch['label'].cpu().numpy())all_logits.append(np.concatenate(model_logits))# 加权集成weighted_logits = np.zeros_like(all_logits[0])for i, weight in enumerate(config['ensemble_weights']):weighted_logits += all_logits[i] * weightpredictions = np.argmax(weighted_logits, axis=1)return {'accuracy': accuracy_score(true_labels, predictions),'f1': f1_score(true_labels, predictions)}
相关文章:
)
基于BERT类的MRPC语义相似度检测(从0到-1系列)
基于BERT类的MRPC语义相似度检测(从0到-1系列) 介绍 BERT(Bidirectional Encoder Representations from Transformers)是由Google开发的一种预训练模型,它是一种基于Transformer机制的深度双向模型,可以对…...

mysql-窗口函数一
目录 一、感受一下分组与窗口函数的区别 二、滑动窗口(子窗口)大小的确认 2.1 分组函数下order by使用 2.2 窗口子句 2.3 执行流程 三、函数使用 窗口函数需要mysql的版本大于等于8才行,可以先检查一下自己的mysql版本是多少 select ve…...

HashMap,高效 哈希
java HashMap 有独特的设计。 哈希表数组的每个位置是一个哈希桶,里面由链表或红黑树实现。(> 8 或 < 6 的变化时,避免频繁切换) 容量(capacity): 哈希表中桶(bucket…...

PyTorch入门------训练图像分类器
前言 1. 操作步骤 2. 数据集 一、公共部分 1.加载并归一化 CIFAR10 2.定义卷积神经网络 二、训练、保存模型参数部分 train_and_save.py 3.定义损失函数和优化器 4.训练网络(使用 CPU 或者 GPU) 5.保存训练好的模型参数 三、加载模型参数、模型推理部分 load_and_infer.py 6…...

DeepSeek V3 架构创新:大规模MoE与辅助损失移除
DeepSeek 团队推出的全新 DeepSeek V3 模型版本,相比之前的 V2 版本,V3 的参数量从两千多亿一跃攀升到 6710 亿,近乎实现了参数规模的三倍增长。如此宏大的模型规模并不只是简单地堆砌参数,而是建立在稀疏混合专家(Mixture-of-Experts,MoE)结构之上。得益于 MoE 的稀疏激…...

MCP 多工具协作链路设计:打造真正的智能工作流
目录 [TOC] 🚀 MCP 多工具协作链路设计:打造真正的智能工作流 🌟 多工具协作链核心思想 🛠️ 设计示例:智能文档分析系统 📑 1. MCP Server 定义多工具 list_txt_files.py read_file_content.py su…...

某修改版软件,已突破限制!
聊一聊 现在很多输入法都带有广告。 用着用着,不是提示升级就是弹出资讯。 特别是忙的时候,很影响心情。 今天给大家分享一款干净的输入法软件。 希望能你喜欢。 软件介绍 Q拼音输入法 工具我们下载后,进行安装。 双击打开,…...

透视Linux内核:深度剖析Socket机制的本质
在Linux操作系统构建的网络世界里,Socket 宛如纵横交错的交通枢纽,承担着不同应用程序间数据往来的重任。无论是日常浏览网页时,浏览器与 Web 服务器间信息的快速交互;还是畅玩网络游戏过程中,玩家操作指令与游戏服务器…...

PostgreSQL数据表操作SQL
数据表操作 创建表 CREATE TABLE t_test(id SERIAL PRIMARY KEY,name varchar(30),birthday date);修改表名 ALTER TABLE t_test RENAME TO t_test1;添加列 ALTER TABLE t_test1 ADD COLUMN score numeric(5,2);删除列 ALTER TABLE t_test1 DROP COLUMN score;修改数据类型 AL…...

OpenAI最新发布的GPT-4.1系列模型,性能体验如何?
简单来说,这次GPT-4.1的核心思路就是:更实用、更懂开发者、更便宜!OpenAI这次没搞太多花里胡哨的概念,而是实实在在地提升了大家最关心的几个点:写代码、听指令、处理超长文本,而且知识库也更新到了2024年6月。 写代码。要说这次GPT-4.1最亮眼的地方,可能就是写代码这块…...
(含模型、可运行代码、数据))
2025五一数学建模C题完整分析论文(共36页)(含模型、可运行代码、数据)
2025年五一数学建模C题完整分析论文 摘要 一、问题分析 二、问题重述 三、模型假设 四、符号定义 五、 模型建立与求解 5.1问题1 5.1.1问题1思路分析 5.1.2问题1模型建立 5.1.3问题1代码 5.1.4问题1求解结果 5.2问题2 5.2.1问题2思路分析 5.2.2问题…...

Vue2基础速成
一、准备工作 首先下载vue2的JavaScript库,并且命名为vue.min.js 下载链接:https://cdn.jsdelivr.net/npm/vue2(若链接失效可去vue官网寻找) CTRLS即可下载保存 文件目录结构 二、使用操作原生DOM与使用VUE操作DOM的便捷性比较…...

Java大厂硬核面试:Flink流处理容错、Pomelo JVM调优、MyBatis二级缓存穿透防护与Kubernetes服务网格实战解析
第二幕:系统架构设计 面试官:设计一个处理10万QPS的秒杀系统需要的技术方案和技术选型 xbhog:采用基础架构: 存储层:Redis限流分布式锁服务层:Sentinel流量控制消息层:RocketMQ事务消息保证最…...

Python实现简易博客系统
下面我将介绍如何使用Python实现一个简易的博客系统,包含前后端完整功能。这个系统将使用Flask作为Web框架,SQLite作为数据库,并包含用户认证、文章发布、评论等基本功能。 1. 系统架构设计 技术栈选择 后端:Flask (Python Web框架)数据库:SQLite (轻量…...

【T型三电平仿真】SPWM调制
自然采样法和规则采样法的特点和计算 https://blog.csdn.net/u010632165/article/details/110889621 单极性和双极性的单双体现在什么地方 单极性和双极性的单双是指载波三角波的极性 为什么simulink进行电路仿真时,都需要放置一个powergui模块 任何使用SimPow…...
 [DLC 解锁] [Steam] [Windows SteamOS macOS])
Astral Ascent 星界战士(星座上升) [DLC 解锁] [Steam] [Windows SteamOS macOS]
Astral Ascent 星界战士(星座上升) [DLC 解锁] [Steam] [Windows & SteamOS & macOS] 需要有游戏正版基础本体,安装路径不能带有中文,或其它非常规拉丁字符; DLC 版本 至最新全部 DLC 后续可能无法及时更新文章…...
)
Ubuntu20.04如何优雅的安装ROS 1(胎教级教程)
1、USTC的源: sudo sh -c . /etc/lsb-release && echo "deb http://mirrors.ustc.edu.cn/ros/ubuntu/ lsb_release -cs main" > /etc/apt/sources.list.d/ros-latest.list2、设置的ROS源添加密钥: sudo apt-key adv --keyserver …...

terraform生成随机密码
在 Terraform 中生成安全随机密码可以通过 random_password 资源实现,以下是完整实现方案及安全实践: 基础实现 (生成随机密码) terraform {required_providers {random {source "hashicorp/random"version "~> 3.5.1" # 使…...

一个linux系统电脑,一个windows电脑,怎么实现某一个文件夹共享
下载Samba linux主机名字不能超过15个字符 sudo dnf install samba samba-client -y 创建共享文件夹 sudo mkdir /shared 配置文件 vim /etc/samba/smb.conf [shared] path /shared available yes valid users linux电脑用户 read only no browsable yes p…...
:网络安全等级保护介绍)
等保系列(一):网络安全等级保护介绍
一、基本概念 网络安全等级保护(以下简称:等保)是根据《中华人民共和国网络安全法》及配套规定(如《信息安全技术 网络安全等级保护基本要求》等)建立的系统性安全防护机制,要求网络运营者根据信息系统的重…...
)
【专题五】位运算(2)
📝前言说明: 本专栏主要记录本人的基础算法学习以及LeetCode刷题记录,按专题划分每题主要记录:(1)本人解法 本人屎山代码;(2)优质解法 优质代码;ÿ…...

【2025五一数学建模竞赛A题】 支路车流量推测问题|建模过程+完整代码论文全解全析
你是否在寻找数学建模比赛的突破点?数学建模进阶思路! 作为经验丰富的美赛O奖、国赛国一的数学建模团队,我们将为你带来本次数学建模竞赛的全面解析。这个解决方案包不仅包括完整的代码实现,还有详尽的建模过程和解析,…...
——selenium)
案例:自动化获取Web页面小说(没钱修什么仙)——selenium
目录 前言一、目标即结果1. 目标:2. 提前了解网页信息3. 结果 二、逐步分析1 . selenium启动2. 获取所有章节3.打开对应章节链接,获取小说文本4. 内容写入本地文件 三、完整代码四、声名 前言 提示:通过案例掌握selenium语法 涉及技术&#…...
)
硬件工程师面试常见问题(11)
第五十一问:器件手册的翻译题目 要学英语啊,孩子。 第五十二问:二极管三极管常识题 1.二极管的导通电压一般是 0.7V 2.MOS管根据掺杂类型可以分为 NMOS和PMOS 3.晶体三极管在工作时,发射结和集电结均处于正向偏置,该晶体管工作在一饱和态。…...

TTL、LRU、LFU英文全称及释义
以下是 TTL、LRU 和 LFU 的英文全称及其简要解释: 1. TTL 全称:Time To Live(存活时间)含义: 表示数据在缓存或存储中的有效存活时间,过期后自动删除。 Redis 示例:SET key value EX 60&#x…...

本地部署 n8n 中文版
本地部署 n8n 中文版 0. n8n的核心价值1. 本地部署 n8n 中文版2. 访问 n8n 在技术团队寻求高效自动化解决方案的今天,n8n 作为一款安全的工作流自动化平台脱颖而出!它将代码的灵活性与低代码的便捷性深度融合,为开发者提供了独特的工具选择。…...

蓝桥杯比赛
蓝桥杯全国软件和信息技术专业人才大赛是由工业和信息化部人才交流中心主办,国信蓝桥教育科技(北京)股份有限公司承办的计算机类学科竞赛。以下是其相关信息: 参赛对象 具有正式全日制学籍且符合相关科目报名要求的研究生、本科生…...

【Linux】Makefile
Makefile常用用法介绍。 部分图片和经验来源于网络,还有正点原子的Linux驱动开发教程,若有侵权麻烦联系我删除,主要是做笔记的时候忘记写来源了,做完笔记很久才写博客。 专栏目录:记录自己的嵌入式学习之路-CSDN博客 1…...

【工具】Windows批量文件复制教程:用BAT脚本自动化文件管理
一、引言 在日常开发与部署过程中,文件的自动化复制是一个非常常见的需求。无论是在构建过程、自动部署,还是备份任务中,开发者经常需要将某个目录中的 DLL、配置文件、资源文件批量复制到目标位置。相比使用图形界面的复制粘贴操作…...

字节一面:后端开发
前言 这是我字节一面的回忆录,可能有些不全。 由于博主是Java面试Go岗,操作系统和计网问的还是比较多。 个人感觉字节很喜欢追问,博主被追问拷打的找不到北了,总结还是学的太浅了。 面试官给我的建议:再更深挖一些…...

西式烹饪实训室建设路径
在餐饮行业持续变革与教育信息化快速发展的当下,西式烹饪实训室的智能化建设成为提升教学质量、培养适应新时代需求烹饪人才的关键举措。通过引入先进技术,创新教学与管理模式,为学生打造更高效、更具沉浸感的学习环境。凯禾瑞华——实训室建…...

[更新完毕]2025五一杯A题五一杯数学建模思路代码文章教学:支路车流量推测问题
完整内容请看文章最下面的推广群 支路车流量推测问题 摘要 本文针对支路车流量推测问题展开研究,通过建立数学模型解决不同场景下的车流量分析需求。 针对问题一(Y型道路场景),研究两支路汇入主路的车流量推测。通过建立线性增长…...

2025年五一杯C题详细思路分析
C题 社交媒体平台用户分析问题 问题背景 近年来,社交媒体平台打造了多元化的线上交流空间和文化圈,深刻影响着人们社交互动与信息获取。博主基于专业知识或兴趣爱好等创作出高质量内容,吸引并获得用户的关注。用户可以随时通过观看、点赞、…...

攻防世界 dice_game
dice_game dice_game (1) motalymotaly-VMware-Virtual-Platform:~/桌面$ file game game: ELF 64-bit LSB pie executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 2.6.32, BuildID[sha1]254…...

如何进行 JVM 性能调优?
进行 JVM 性能调优是一个系统性的过程,旨在提高 Java 应用程序的响应速度、吞吐量、降低资源消耗(如 CPU 和内存)以及提高稳定性。 以下是一个通用的 JVM 性能调优步骤和常用方法: 第一步:明确目标与建立基线 (Defin…...

艺华直播 5.0 |专注于提供港澳台及央视频道的电视直播应用,加载快,播放流畅
艺华直播是一款专注于提供港澳台及央视频道的电视直播应用。它以加载速度快、播放流畅不卡顿著称,是目前少数能够稳定观看港澳台频道的应用之一。此次分享的版本为测试版,支持4K秒播,带来极致的观看体验。尽管该应用已开始收费,但…...
)
【软件设计师:复习】上午题核心知识点总结(三)
一、编译原理(基础题) 1.编译过程概述(必考) 编译过程分为六个阶段,各阶段核心任务与典型输出如下: 阶段核心任务输入输出关键方法/工具词法分析将字符流转换为标记(Token)流源代码字符串Token序列(如<ID, "x">)正则表达式、有限自动机(DFA/NFA)…...

SAE极速部署弹性微服务商城——实验记录
SAE极速部署弹性微服务商城 本实验带您体验在SAE上快速部署一个弹性的在线商城微服务应用,使得终端用户可以通过公网访问该商城,并进行压力测试以验证其性能与稳定性。 文章目录 SAE极速部署弹性微服务商城使用SAE部署应用有哪些优势? 对商城…...
)
内存 “舞台” 上,进程如何 “翩翩起舞”?(转)
在数字世界里,计算机的每一次高效运转都离不开内存与进程的默契配合。内存,恰似一座宏大且有序的舞台,为进程提供了施展拳脚的空间。而进程,则如同舞台上的舞者,它们在内存的舞台上,遵循着一套复杂而精妙的…...

产品手册小程序开发制作方案
公司产品手册小程序系统主要是为了解决传统纸质或PDF格式手册更新成本高、周期长,难以及时反映最新产品信息。线下分发效率低,线上分享体验差,不利于品牌推广。传统手册单向传递信息,无法与用户进行互动,企业难以了解用…...

【dify—8】Agent实战——占星师
目录 一、创建Agent应用 二、创建提示词 三、创建变量 四、添加工具 五、发布更新 六、运行 第一部分 安装difydocker教程:【difydocker安装教程】-CSDN博客 第二部分 dock重装教程:【dify—2】docker重装-CSDN博客 第三部分 dify拉取镜像ÿ…...

Redis的键过期删除策略与内存淘汰机制详解
Redis 的键过期删除策略与内存淘汰机制详解 一、键过期删除策略 Redis 通过 定期删除(Active Expire) 和 惰性删除(Lazy Expire) 两种方式结合,管理键的过期清理。 1. 惰性删除(Lazy Expire) …...
)
数据结构——树(中篇)
今日名言: 人生碌碌,竞短论长,却不道枯荣有数,得失难量 上次我们讲了树的相关知识,接下来就进一步了解二叉树吧。本文为个人学习笔记,如有侵权,请 联系删除,如有错误,欢…...

实验三 软件黑盒测试
实验三 软件黑盒测试使用测试界的一个古老例子---三角形问题来进行等价类划分。输入三个整数a、b和c分别作为三角形的三条边,通过程序判断由这三条边构成的三角形类型是等边三角形、等腰三角形、一般三角形或非三角形(不能构成一个三角形)。其中要求输入变量&#x…...

PHP-Cookie
Cookie 是什么? cookie 常用于识别用户。cookie 是一种服务器留在用户计算机上的小文件。每当同一台计算机通过浏览器请求页面时,这台计算机将会发送 cookie。通过 PHP,您能够创建并取回 cookie 的值。 设置Cookie 在PHP中,你可…...
(文末有下载方式))
提升采购管理,打造核心竞争力七步战略采购法详解P94(94页PPT)(文末有下载方式)
资料解读:《提升采购管理,打造核心竞争力 —— 七步战略采购法详解》 详细资料请看本解读文章的最后内容。 在当今竞争激烈的商业环境中,采购管理已成为企业打造核心竞争力的关键环节。这份文件围绕七步战略采购法展开,深入剖析了…...

单片机-89C51部分:13、看门狗
飞书文档https://x509p6c8to.feishu.cn/wiki/LefkwDPU7iUUWBkfKE9cGLvonSh 一、作用 程序发生死循环的时候(跑飞),能够自动复位。 启动看门狗计数器->计数器计数->指定时间内不对计数器赋值(主程序跑飞,无法喂…...

基于MyBatis的银行转账系统开发实战:从环境搭建到动态代理实现
目标: 掌握mybatis在web应用中怎么用 mybatis三大对象的作用域和生命周期 ThreadLocal原理及使用 巩固MVC架构模式 为学习MyBatis的接口代理机制做准备 实现功能: 银行账户转账 使用技术: HTML Servlet MyBatis WEB应用的名称&am…...

纹理采样+光照纹理采样
普通纹理显示 导入纹理 1.将纹理拷贝到项目中 2.配置纹理 纹理显示原理 原始纹理(边长是),如果原始图的边长不是,游戏引擎在运行时,会自动将 纹理的边长补偿为,所以补偿是有损耗的(纹理不一定是…...

408真题笔记
2024 年全国硕士研究生招生考试 计算机科学与技术学科联考 计算机学科专业基础综合 (科目代码:408) 一、单项选择题 第 01~40 小题,每小题 2 分,共 80 分。下列每小题给出的四个选项中,只有一个…...