内存 “舞台” 上,进程如何 “翩翩起舞”?(转)
在数字世界里,计算机的每一次高效运转都离不开内存与进程的默契配合。内存,恰似一座宏大且有序的舞台,为进程提供了施展拳脚的空间。而进程,则如同舞台上的舞者,它们在内存的舞台上,遵循着一套复杂而精妙的规则,灵动地 “翩翩起舞”。
从启动程序的那一刻起,进程便踏上了这片舞台,开始了它与内存的互动之旅。这一过程,关乎计算机系统的高效稳定运行,也与我们日常使用的各类软件、应用的流畅体验紧密相连。接下来,就让我们一同揭开进程在内存舞台上的精彩 “舞步”,探寻它们背后的神秘机制 。
一、内存相关概述
在深入了解进程与内存的关系之前,我们先来认识一下内存这个计算机的关键部件。内存,也被称为内存储器或主存储器,它就像是计算机的 “临时仓库”,在计算机运行程序时扮演着至关重要的角色。
内存是计算机中重要的部件之一,它是与CPU进行沟通的桥梁。计算机中所有程序的运行都是在内存中进行的,因此内存的性能对计算机的影响非常大。内存(Memory)也被称为内存储器,其作用是用于暂时存放CPU中的运算数据,以及与硬盘等外部存储器交换的数据。只要计算机在运行中,CPU就会把需要运算的数据调到内存中进行运算,当运算完成后CPU再将结果传送出来,内存的运行也决定了计算机的稳定运行。
内存又称主存,是CPU能直接寻址的存储空间,由半导体器件制成。内存的特点是存取速率快。内存是电脑中的主要部件,它是相对于外存而言的。我们平常使用的程序,如Windows操作系统、打字软件、游戏软件等,一般都是安装在硬盘等外存上的,但仅此是不能使用其功能的,必须把它们调入内存中运行,才能真正使用其功能,我们平时输入一段文字,或玩一个游戏,其实都是在内存中进行的。就好比在一个书房里,存放书籍的书架和书柜相当于电脑的外存,而我们工作的办公桌就是内存。通常我们把要永久保存的、大量的数据存储在外存上,而把一些临时的或少量的数据和程序放在内存上,当然内存的好坏会直接影响电脑的运行速度。
内存就是暂时存储程序以及数据的地方,比如当我们在使用WPS处理文稿时,当你在键盘上敲入字符时,它就被存入内存中,当你选择存盘时,内存中的数据才会被存入硬(磁)盘。
内存一般采用半导体存储单元,包括随机存储器(RAM),只读存储器(ROM),以及高速缓存(CACHE)。只不过因为RAM是其中最重要的存储器。(synchronous)SDRAM同步动态随机存取存储器:SDRAM为168脚,这是目前PENTIUM及以上机型使用的内存。SDRAM将CPU与RAM通过一个相同的时钟锁在一起,使CPU和RAM能够共享一个时钟周期,以相同的速度同步工作,每一个时钟脉冲的上升沿便开始传递数据,速度比EDO内存提高50%。DDR(DOUBLE DATA RATE)RAM :SDRAM的更新换代产品,他允许在时钟脉冲的上升沿和下降沿传输数据,这样不需要提高时钟的频率就能加倍提高SDRAM的速度。
当我们打开电脑上的某个程序,比如一款图像处理软件,这个程序的代码和运行时所需的数据并不会直接从硬盘读取然后被 CPU 处理。因为硬盘的读取速度相对较慢,如果 CPU 直接从硬盘读取数据,计算机的运行效率会极其低下。这时,内存就发挥了关键的 “中介” 作用。在程序启动时,操作系统会将程序的代码和初始数据从硬盘加载到内存中。内存的读取速度比硬盘快得多,通常是硬盘的几十倍甚至上百倍 ,这使得 CPU 能够快速地从内存中读取指令和数据进行处理,大大提高了计算机的运行速度。在图像处理过程中,当我们对图片进行裁剪、调色等操作时,相关的数据会在内存中被快速地读取和修改,处理结果也会暂时存储在内存中,直到我们保存图像时,数据才会被写入硬盘进行长期存储。内存就像是一个高速运转的中转站,协调着 CPU 与硬盘之间的数据传输,让计算机能够高效地完成各种复杂的任务。
内存的内部是由各种IC电路组成的,它的种类很庞大,但是其主要分为三种存储器:
-
只读存储器(ROM):ROM表示只读存储器(Read Only Memory),在制造ROM的时候,信息(数据或程序)就被存入并永久保存。这些信息只能读出,一般不能写入,即使机器停电,这些数据也不会丢失。ROM一般用于存放计算机的基本程序和数据,如BIOS ROM。其物理外形一般是双列直插式(DIP)的集成块。
-
随机存储器(RAM):随机存储器(Random Access Memory)表示既可以从中读取数据,也可以写入数据。当机器电源关闭时,存于其中的数据就会丢失。我们通常购买或升级的内存条就是用作电脑的内存,内存条(SIMM)就是将RAM集成块集中在一起的一小块电路板,它插在计算机中的内存插槽上,以减少RAM集成块占用的空间。目前市场上常见的内存条有1G/条,2G/条,4G/条等。
-
高速缓冲存储器(Cache):Cache也是我们经常遇到的概念,也就是平常看到的一级缓存(L1 Cache)、二级缓存(L2 Cache)、三级缓存(L3 Cache)这些数据,它位于CPU与内存之间,是一个读写速度比内存更快的存储器。当CPU向内存中写入或读出数据时,这个数据也被存储进高速缓冲存储器中。当CPU再次需要这些数据时,CPU就从高速缓冲存储器读取数据,而不是访问较慢的内存,当然,如需要的数据在Cache中没有,CPU会再去读取内存中的数据。
二、虚拟内存技术
当进程在内存这个 “临时仓库” 中运行时,虚拟内存则是背后的 “魔法”,让进程能够高效地使用内存资源。
2.1为什么需要使用虚拟内存
进程需要使用的代码和数据都放在内存中,比放在外存中要快很多。问题是内存空间太小了,不能满足进程的需求,而且现在都是多进程,情况更加糟糕。所以提出了虚拟内存,使得每个进程用于3G的独立用户内存空间和共享的1G内核内存空间。(每个进程都有自己的页表,才使得3G用户空间的独立)这样进程运行的速度必然很快了。而且虚拟内存机制还解决了内存碎片和内存不连续的问题。为什么可以在有限的物理内存上达到这样的效果呢?
2.2虚拟内存详解
虚拟内存是计算机系统内存管理的一种技术,它就像是给应用程序戴上了一副 “魔法眼镜”,让应用程序以为自己拥有连续可用的内存,即一个连续完整的地址空间 。但实际上,这些内存通常被分隔成多个物理内存碎片,还有部分暂时存储在外部磁盘存储器上。当计算机缺少运行某些程序所需的物理内存时,操作系统就会使用硬盘上的虚拟内存进行替代。这就好比你有一个小书架(物理内存),放不下所有的书(程序数据),于是你在旁边放了一个大箱子(虚拟内存),把暂时不看的书放在箱子里,等需要的时候再拿出来。在 32 位的操作系统中,每个进程可以拥有 4GB 的虚拟内存空间,但实际的物理内存可能远远小于这个数字。
例如:对于程序计数器位数为32位的处理器来说,他的地址发生器所能发出的地址数目为2^32=4G个,于是这个处理器所能访问的最大内存空间就是4G。在计算机技术中,这个值就叫做处理器的寻址空间或寻址能力。
照理说,为了充分利用处理器的寻址空间,就应按照处理器的最大寻址来为其分配系统的内存。如果处理器具有32位程序计数器,那么就应该按照下图的方式,为其配备4G的内存:
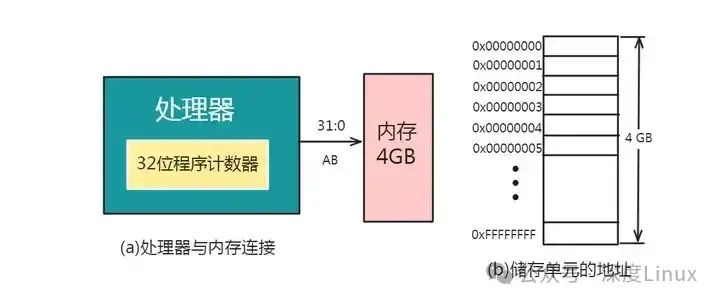
这样,处理器所发出的每一个地址都会有一个真实的物理存储单元与之对应;同时,每一个物理存储单元都有唯一的地址与之对应。这显然是一种最理想的情况。
但遗憾的是,实际上计算机所配置内存的实际空间常常小于处理器的寻址范围,这是就会因处理器的一部分寻址空间没有对应的物理存储单元,从而导致处理器寻址能力的浪费。例如:如下图的系统中,具有32位寻址能力的处理器只配置了256M的内存储器,这就会造成大量的浪费:
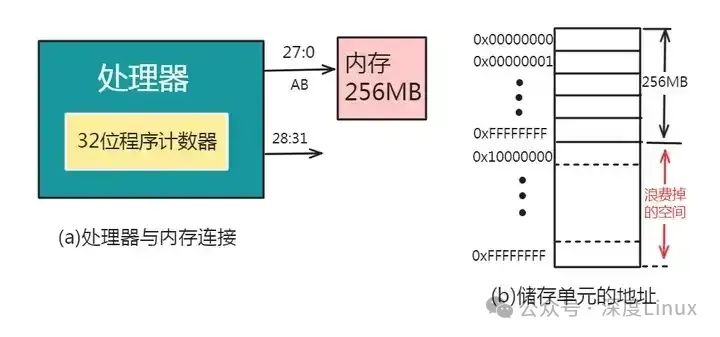
另外,还有一些处理器因外部地址线的根数小于处理器程序计数器的位数,而使地址总线的根数不满足处理器的寻址范围,从而处理器的其余寻址能力也就被浪费了。例如:Intel8086处理器的程序计数器位32位,而处理器芯片的外部地址总线只有20根,所以它所能配置的最大内存为1MB:
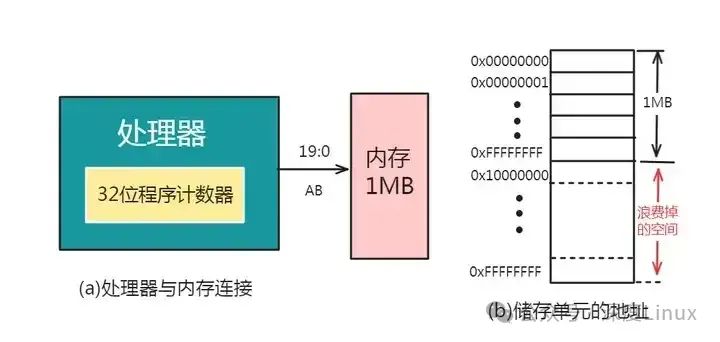
在实际的应用中,如果需要运行的应用程序比较小,所需内存容量小于计算机实际所配置的内存空间,自然不会出什么问题。但是,目前很多的应用程序都比较大,计算机实际所配置的内存空间无法满足。
实践和研究都证明:一个应用程序总是逐段被运行的,而且在一段时间内会稳定运行在某一段程序里。
这也就出现了一个方法:如下图所示,把要运行的那一段程序自辅存复制到内存中来运行,而其他暂时不运行的程序段就让它仍然留在辅存。
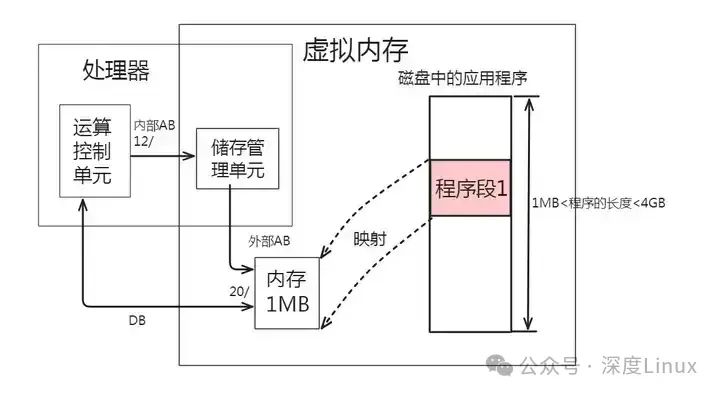
当需要执行另一端尚未在内存的程序段(如程序段2),如下图所示,就可以把内存中程序段1的副本复制回辅存,在内存腾出必要的空间后,再把辅存中的程序段2复制到内存空间来执行即可:
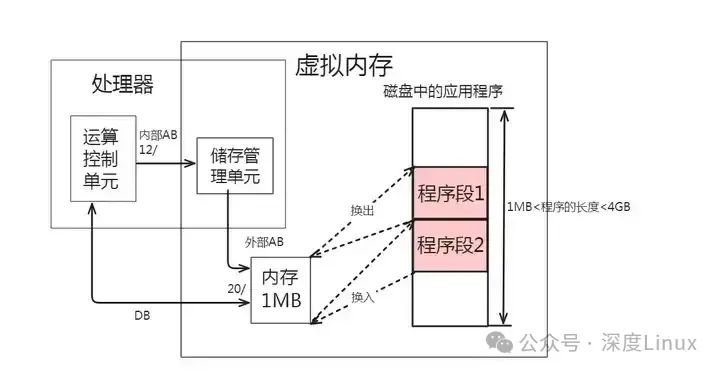
在计算机技术中,把内存中的程序段复制回辅存的做法叫做“换出”,而把辅存中程序段映射到内存的做法叫做“换入”。经过不断有目的的换入和换出,处理器就可以运行一个大于实际物理内存的应用程序了。或者说,处理器似乎是拥有了一个大于实际物理内存的内存空间。于是,这个存储空间叫做虚拟内存空间,而把真正的内存叫做实际物理内存,或简称为物理内存。
那么对于一台真实的计算机来说,它的虚拟内存空间又有多大呢?计算机虚拟内存空间的大小是由程序计数器的寻址能力来决定的。例如:在程序计数器的位数为32的处理器中,它的虚拟内存空间就为4GB。
可见,如果一个系统采用了虚拟内存技术,那么它就存在着两个内存空间:虚拟内存空间和物理内存空间。虚拟内存空间中的地址叫做“虚拟地址”;而实际物理内存空间中的地址叫做“实际物理地址”或“物理地址”。处理器运算器和应用程序设计人员看到的只是虚拟内存空间和虚拟地址,而处理器片外的地址总线看到的只是物理地址空间和物理地址。
由于存在两个内存地址,因此一个应用程序从编写到被执行,需要进行两次映射。第一次是映射到虚拟内存空间,第二次时映射到物理内存空间。在计算机系统中,第两次映射的工作是由硬件和软件共同来完成的。承担这个任务的硬件部分叫做存储管理单元MMU,软件部分就是操作系统的内存管理模块了。
在映射工作中,为了记录程序段占用物理内存的情况,操作系统的内存管理模块需要建立一个表格,该表格以虚拟地址为索引,记录了程序段所占用的物理内存的物理地址。这个虚拟地址/物理地址记录表便是存储管理单元MMU把虚拟地址转化为实际物理地址的依据,记录表与存储管理单元MMU的作用如下图所示:
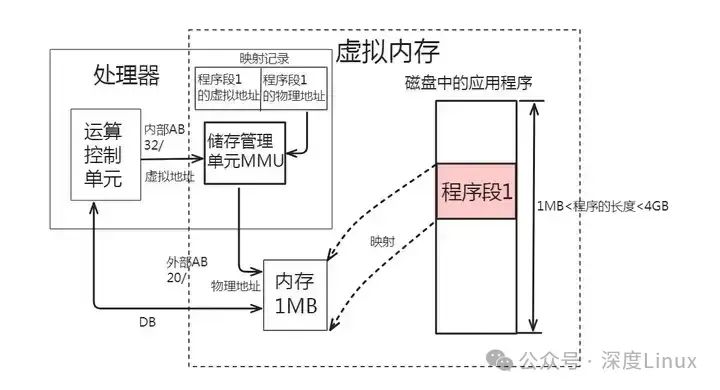
综上所述,虚拟内存技术的实现,是建立在应用程序可以分成段,并且具有“在任何时候正在使用的信息总是所有存储信息的一小部分”的局部特性基础上的。它是通过用辅存空间模拟RAM来实现的一种使机器的作业地址空间大于实际内存的技术。
从处理器运算装置和程序设计人员的角度来看,它面对的是一个用MMU、映射记录表和物理内存封装起来的一个虚拟内存空间,这个存储空间的大小取决于处理器程序计数器的寻址空间。
可见,程序映射表是实现虚拟内存的技术关键,它可给系统带来如下特点:
-
系统中每一个程序各自都有一个大小与处理器寻址空间相等的虚拟内存空间;
-
在一个具体时刻,处理器只能使用其中一个程序的映射记录表,因此它只看到多个程序虚存空间中的一个,这样就保证了各个程序的虚存空间时互不相扰、各自独立的;
-
使用程序映射表可方便地实现物理内存的共享。
2.3虚拟地址空间布局
Linux 内核给每个进程都提供了一个独立的虚拟地址空间,并且这个地址空间是连续的。这样,进程就可以很方便地访问内存,更确切地说是访问虚拟内存。
虚拟地址空间的内部又被分为内核空间和用户空间两部分,不同字长(也就是单个CPU指令可以处理数据的最大长度)的处理器,地址空间的范围也不同。比如最常见的 32 位和 64 位系统,它们的虚拟地址空间,如下所示:
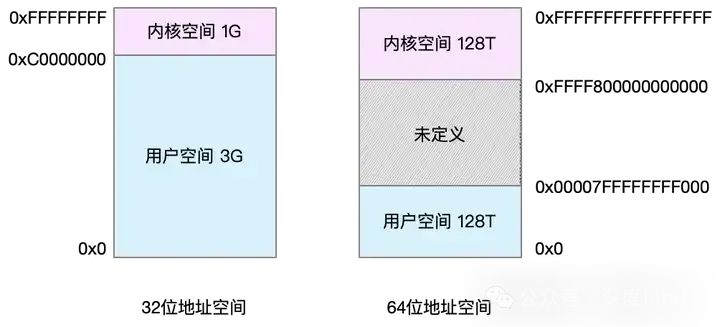
通过这里可以看出,32位系统的内核空间占用 1G,位于最高处,剩下的3G是用户空间。而 64 位系统的内核空间和用户空间都是 128T,分别占据整个内存空间的最高和最低处,剩下的中间部分是未定义的。
进程在用户态时,只能访问用户空间内存;只有进入内核态后,才可以访问内核空间内存。虽然每个进程的地址空间都包含了内核空间,但这些内核空间,其实关联的都是相同的物理内存。这样,进程切换到内核态后,就可以很方便地访问内核空间内存。
既然每个进程都有一个这么大的地址空间,那么所有进程的虚拟内存加起来,自然要比实际的物理内存大得多。所以,并不是所有的虚拟内存都会分配物理内存,只有那些实际使用的虚拟内存才分配物理内存,并且分配后的物理内存,是通过内存映射来管理的;内存映射,其实就是将虚拟内存地址映射到物理内存地址。为了完成内存映射,内核为每个进程都维护了一张页表,记录虚拟地址与物理地址的映射关系,如下图所示:
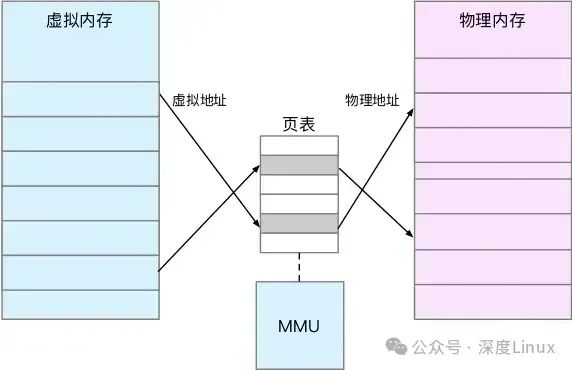
页表实际上存储在 CPU 的内存管理单元 MMU中,这样,正常情况下,处理器就可以直接通过硬件,找出要访问的内存;而当进程访问的虚拟地址在页表中查不到时,系统会产生一个缺页异常,进入内核空间分配物理内存、更新进程页表,最后再返回用户空间,恢复进程的运行。
另外,TLB(Translation Lookaside Buffer,转译后备缓冲器)会影响 CPU 的内存访问性能,TLB 其实就是 MMU 中页表的高速缓存。由于进程的虚拟地址空间是独立的,而 TLB 的访问速度又比 MMU 快得多,所以,通过减少进程的上下文切换,减少TLB的刷新次数,就可以提高TLB 缓存的使用率,进而提高CPU的内存访问性能;不过要注意,MMU 并不以字节为单位来管理内存,而是规定了一个内存映射的最小单位,也就是页,通常是 4 KB大小。这样,每一次内存映射,都需要关联 4 KB 或者 4KB 整数倍的内存空间。
页的大小只有4 KB ,导致的另一个问题就是,整个页表会变得非常大。比方说,仅 32 位系统就需要 100 多万个页表项(4GB/4KB),才可以实现整个地址空间的映射。为了解决页表项过多的问题,Linux 提供了两种机制,也就是多级页表和大页(HugePage)。
多级页表就是把内存分成区块来管理,将原来的映射关系改成区块索引和区块内的偏移。由于虚拟内存空间通常只用了很少一部分,那么,多级页表就只保存这些使用中的区块,这样就可以大大地减少页表的项数。
Linux用的正是四级页表来管理内存页,如下图所示,虚拟地址被分为5个部分,前4个表项用于选择页,而最后一个索引表示页内偏移。
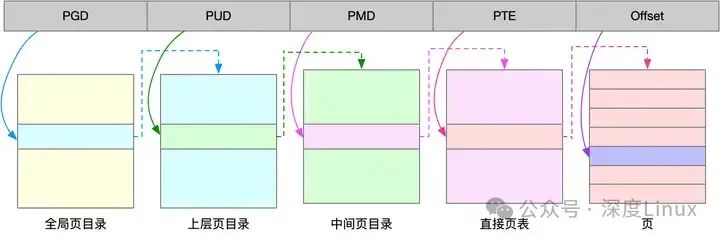
大页,就是比普通页更大的内存块,常见的大小有 2MB 和 1GB。大页通常用在使用大量内存的进程上,比如Oracle、DPDK等。
通过这些机制,在页表的映射下,进程就可以通过虚拟地址来访问物理内存了。
以 Linux 23位系统为例,进程的虚拟地址空间布局从低到高主要包含以下几个部分:
-
LOAD Segments:这部分包含了代码段(.text)、数据段(.data)和 BSS 段等。代码段存储着 CPU 执行的机器指令,它是只读的,防止指令被其他程序修改 。数据段用于存储初始化的全局变量和静态变量,BSS 段则用来存放未初始化的全局变量和静态变量。
-
堆(Heap):堆是用于保存程序运行时动态申请的内存空间的区域,比如使用malloc或new申请的内存空间就来自堆 。堆的地址空间是 “向上增加” 的,即当堆上保存的数据越多,堆的地址就越高。
-
共享库数据:很多进程会共享一些库文件,这些共享库的数据就存储在这里。通过共享库,多个进程可以共享相同的代码和数据,节省内存空间。
-
栈(Stack):栈主要用于保存函数的局部变量(不包括static声明的静态变量,静态变量存放在数据段或 BSS 段)、参数、返回值、函数返回地址以及调用者环境信息(如寄存器值)等 。栈的内存由系统进行管理,在函数完成执行后,系统会自行释放栈区内存,不需要用户手动管理。整个程序的栈区大小可以由用户自行设定,Windows 默认的栈区大小为 1M ,64 位的 Linux 默认栈大小为 10MB。
-
内核数据:这是操作系统内核使用的内存区域,用户进程一般不能直接访问。它包含了内核代码、内核数据结构以及一些系统调用的相关信息。
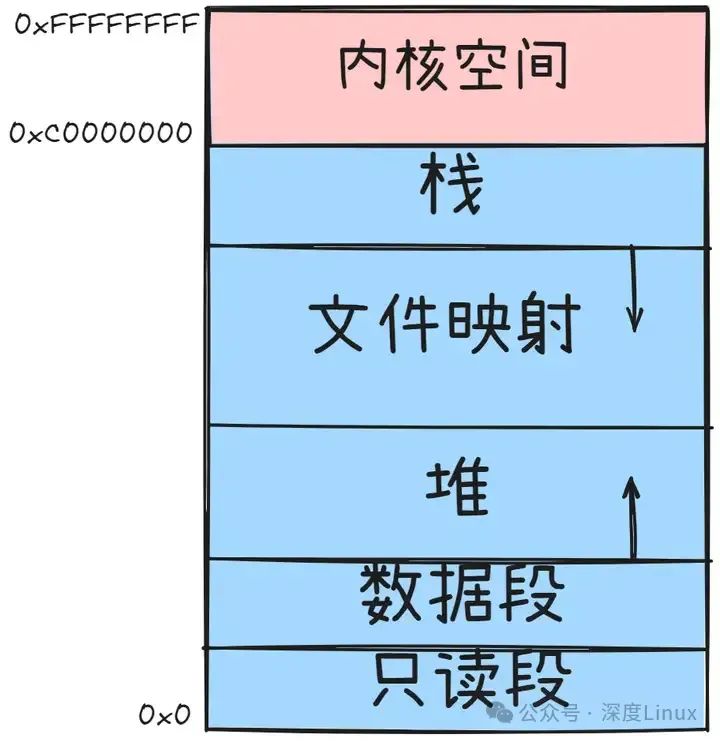
通过这张图可以看到,用户空间内存,从低到高分别是五种不同的内存段:
-
只读段,包括代码和常量等。
-
数据段,包括全局变量等。
-
堆,包括动态分配的内存,从低地址开始向上增长。
-
文件映射段,包括动态库、共享内存等,从高地址开始向下增长。
-
栈,包括局部变量和函数调用的上下文等。栈的大小是固定的,一般是 8 MB。
在这五个内存段中,堆和文件映射段的内存是动态分配的。比如说,使用 C 标准库的 malloc() 或者 mmap() ,就可以分别在堆和文件映射段动态分配内存;其实64位系统的内存分布也类似,只不过内存空间要大得多。
2.3虚拟内存使用方式
进程在启动时,操作系统会为其分配虚拟内存空间,并建立虚拟地址到物理地址的映射关系。在进程运行过程中,当需要访问内存时,CPU 会生成虚拟地址,这个虚拟地址会经过内存管理单元(MMU)的转换,找到对应的物理地址,然后访问物理内存。如果所需的内存页不在物理内存中,就会发生缺页中断,操作系统会从磁盘的虚拟内存中读取相应的内存页到物理内存中,并更新映射关系。
在 Linux 系统中,进程可以通过mmap、sbrk和brk等函数来操作虚拟内存。mmap函数用于将一个文件或者其它对象映射进内存 ,比如将共享库映射到进程的虚拟地址空间中。sbrk和brk函数则用于改变进程数据段的大小,从而实现内存的动态分配和释放。当malloc分配小于 128k 的内存时,会使用brk分配内存,将数据段的最高地址指针往高地址推;当malloc分配大于 128k 的内存时,会使用mmap在堆和栈之间找一块空闲内存分配 。
malloc() 是 C 标准库提供的内存分配函数,对应到系统调用上,有两种实现方式,即 brk() 和 mmap()。
-
对小块内存(小于128K),C 标准库使用 brk() 来分配,也就是通过移动堆顶的位置来分配内存。这些内存释放后并不会立刻归还系统,而是被缓存起来,这样就可以重复使用。
-
而大块内存(大于 128K),则直接使用内存映射 mmap() 来分配,也就是在文件映射段找一块空闲内存分配出去。
这两种方式,自然各有优缺点:
-
brk() 方式的缓存,可以减少缺页异常的发生,提高内存访问效率。不过,由于这些内存没有归还系统,在内存工作繁忙时,频繁的内存分配和释放会造成内存碎片。
-
mmap() 方式分配的内存,会在释放时直接归还系统,所以每次 mmap 都会发生缺页异常。在内存工作繁忙时,频繁的内存分配会导致大量的缺页异常,使内核的管理负担增大。这也是malloc 只对大块内存使用 mmap 的原因。
了解这两种调用方式后,还需要清楚一点,那就是,当这两种调用发生后,其实并没有真正分配内存。这些内存,都只在首次访问时才分配,也就是通过缺页异常进入内核中,再由内核来分配内存。
整体来说,Linux 使用伙伴系统来管理内存分配。这些内存在MMU中以页为单位进行管理,伙伴系统也一样,以页为单位来管理内存,并且会通过相邻页的合并,减少内存碎片化(比如brk方式造成的内存碎片);在用户空间,malloc 通过 brk() 分配的内存,在释放时并不立即归还系统,而是缓存起来重复利用;在内核空间,Linux 则通过 slab 分配器来管理小内存。可以把slab 看成构建在伙伴系统上的一个缓存,主要作用就是分配并释放内核中的小对象。
对内存来说,如果只分配而不释放,就会造成内存泄漏,甚至会耗尽系统内存。所以,在应用程序用完内存后,还需要调用 free() 或 unmap(),来释放这些不用的内存。
当然,系统也不会任由某个进程用完所有内存。在发现内存紧张时,系统就会通过一系列机制来回收内存,比如下面这三种方式:
-
回收缓存,比如使用 LRU(Least Recently Used)算法,回收最近使用最少的内存页面;
-
回收不常访问的内存,把不常用的内存通过交换分区直接写到磁盘中;
-
杀死进程,内存紧张时系统还会通过 OOM(Out of Memory),直接杀掉占用大量内存的进程。
其中,第二种方式回收不常访问的内存时,会用到交换分区(以下简称 Swap)。Swap 其实就是把一块磁盘空间当成内存来用。它可以把进程暂时不用的数据存储到磁盘中(这个过程称为换出),当进程访问这些内存时,再从磁盘读取这些数据到内存中(这个过程称为换入)。
所以,可以发现,Swap 把系统的可用内存变大了。不过要注意,通常只在内存不足时,才会发生 Swap 交换。并且由于磁盘读写的速度远比内存慢,Swap 会导致严重的内存性能问题。
第三种方式提到的 OOM(Out of Memory),其实是内核的一种保护机制。它监控进程的内存使用情况,并且使用 oom_score 为每个进程的内存使用情况进行评分:
-
一个进程消耗的内存越大,oom_score 就越大;
-
一个进程运行占用的 CPU 越多,oom_score 就越小。
这样,进程的 oom_score 越大,代表消耗的内存越多,也就越容易被 OOM 杀死,从而可以更好保护系统。
当然,为了实际工作的需要,管理员可以通过 /proc 文件系统,手动设置进程的 oom_adj ,从而调整进程的 oom_score;oom_adj 的范围是 [-17, 15],数值越大,表示进程越容易被 OOM 杀死;数值越小,表示进程越不容易被 OOM 杀死,其中 -17 表示禁止OOM。
比如用下面的命令,就可以把 sshd 进程的 oom_adj 调小为 -16,这样, sshd 进程就不容易被 OOM 杀死。
1 echo -16 > /proc/$(pidof sshd)/oom_adj三、进程与内存的交互舞步
3.1进程启动时的内存加载
当我们启动一个进程时,操作系统就像是一个忙碌的 “搬运工”,开始了一系列复杂而有序的内存加载工作。以 Windows系统为例,当我们双击一个.exe 可执行文件时,操作系统首先会读取该文件的头部信息,这个头部信息就像是一个 “导航图”,包含了程序运行所需的各种关键信息,如程序的入口点、依赖的动态链接库(DLL)等。
操作系统会为进程分配虚拟内存空间,这个空间就像是一个 “虚拟舞台”,进程将在上面进行各种操作 。然后,操作系统会根据可执行文件头部的信息,将程序的主要代码段和初始化数据加载到虚拟内存的相应位置。这些代码段和数据是程序启动和运行的基础,就像是一场演出的核心演员和基本道具。在加载代码段时,CPU 会读取其中的指令,开始执行程序的初始化工作,比如初始化全局变量、设置程序的运行环境等。
对于依赖的动态链接库,操作系统会在内存中查找是否已经加载了这些库。如果已经加载,就直接将库的地址映射到进程的虚拟地址空间中,让进程可以共享这些库的代码和数据 ,就像多个进程可以共用同一个舞台道具;如果没有加载,操作系统会从磁盘中读取相应的动态链接库文件,并将其加载到内存中,然后再进行地址映射。动态链接库的使用可以节省内存空间,提高程序的可维护性和可扩展性 。许多应用程序都会依赖于系统提供的一些通用的动态链接库,如 Windows 系统中的 Kernel32.dll,它提供了许多基本的操作系统功能调用。
3.2运行时内存分配
在进程运行过程中,常常需要动态分配内存来存储一些临时数据。以 C 语言中的malloc函数为例,它是进程运行时动态内存分配的一个典型工具。当我们调用malloc函数时,它会向操作系统申请一定大小的内存空间。
在 32 位的 Linux 系统中,malloc的内存分配机制如下:当请求的内存小于 128KB 时,malloc会使用brk系统调用,通过移动堆顶指针来分配内存 。假设堆顶指针初始指向地址 0x1000,我们调用malloc(100)申请 100 字节的内存,malloc会将堆顶指针移动到 0x1064(假设系统内存对齐为 8 字节,100 字节向上取整为 104 字节,加上一些元数据,假设为 8 字节,共 112 字节,即 0x70,所以堆顶指针移动到 0x1000 + 0x70 = 0x1070),并返回 0x1008 这个地址给用户程序,用户程序就可以使用这块内存来存储数据。
当请求的内存大于等于 128KB 时,malloc会使用mmap系统调用,在堆和栈之间的内存区域中找一块合适的空闲内存进行分配 。mmap会在虚拟地址空间中创建一个新的映射,将磁盘上的文件或者匿名内存区域映射到进程的虚拟地址空间中。这样,进程就可以像访问普通内存一样访问这个映射区域。
在动态内存分配过程中,虚拟内存的写时复制(Copy - on - Write,COW)策略发挥了重要作用。当一个进程通过fork系统调用创建子进程时,子进程会共享父进程的内存页面。在子进程或父进程没有对这些共享页面进行写操作之前,它们实际上共享的是相同的物理内存页面 ,只有当其中一个进程试图对共享页面进行写操作时,操作系统才会为写操作的进程复制一份物理内存页面,使得父子进程拥有各自独立的物理内存页面,这样可以节省内存资源,提高系统的效率。
如果进程访问的内存页面不在物理内存中,就会发生缺页中断。操作系统会根据页表信息,从磁盘的虚拟内存中找到对应的页面,并将其加载到物理内存中 。然后,操作系统会更新页表,将虚拟地址与新加载的物理内存页面建立映射关系,使得进程能够继续访问该内存页面。
3.3内存回收与管理
当进程结束运行或者内存不足时,操作系统就会进行内存回收工作,以释放内存空间供其他进程使用。当一个进程结束时,操作系统会回收该进程所占用的所有虚拟内存空间,并将这些空间标记为空闲 。操作系统会检查进程使用的堆内存、栈内存以及其他动态分配的内存区域,将这些内存归还给内存管理系统,就像是一场演出结束后,工作人员会将舞台上的道具和设备清理干净,为下一场演出做准备。
在内存不足的情况下,操作系统会采用内存置换算法来决定哪些内存页面可以被暂时置换到磁盘上,以腾出物理内存空间。常见的内存置换算法有最近最少使用(LRU,Least Recently Used)算法 。LRU 算法的核心思想是,如果一个内存页面在最近一段时间内没有被访问过,那么它在未来被访问的可能性也较小,因此可以将其置换出去。操作系统会维护一个内存页面的访问时间记录,当需要置换页面时,选择访问时间最早的页面进行置换。假设内存中有三个页面 A、B、C,它们的访问时间依次为 10:00、10:10、10:20,当内存不足需要置换页面时,LRU 算法会选择页面 A 进行置换,因为它是最久没有被访问的页面。
除了 LRU 算法,还有先进先出(FIFO,First In First Out)算法,它是将最早进入内存的页面置换出去;时钟(Clock)算法,它是 LRU 算法的一种近似实现,通过一个循环链表和一个访问位来模拟 LRU 算法的行为 。这些算法各有优缺点,操作系统会根据具体的应用场景和系统需求选择合适的算法,以确保系统的内存管理高效、稳定。
四、内存管理的底层奥秘
4.1MMU与地址映射
在进程使用内存的过程中,内存管理单元(MMU,Memory Management Unit)扮演着至关重要的角色,它就像是一个精准的 “翻译官”,负责将进程的虚拟地址动态翻译为物理地址 。
当 CPU 需要访问内存中的数据时,它会首先产生一个虚拟地址。这个虚拟地址会被发送到 MMU。MMU 内部包含了一个高速缓存,即转换后备缓冲器(TLB,Translation Lookaside Buffer),以及与进程相关的页表 。TLB 中存储了近期使用过的虚拟地址到物理地址的映射关系,就像是一个常用词汇的快速翻译手册。当 MMU 接收到虚拟地址后,会首先在 TLB 中查找对应的映射关系。如果在 TLB 中命中,MMU 可以快速地获取到对应的物理地址,从而大大提高了地址转换的速度 。
如果在TLB中没有命中,MMU就需要通过进程的页表来查找映射关系。页表是一个存储虚拟地址与物理地址映射关系的数据结构,它就像是一本完整的翻译词典 。MMU会根据虚拟地址中的页号,在页表中查找对应的物理页框号。找到物理页框号后,再结合虚拟地址中的页内偏移量,就可以计算出最终的物理地址。在 32 位的系统中,如果页面大小为4KB,那么虚拟地址可以被划分为20位的页号和12位的页内偏移量 。假设虚拟地址为 0x00401000,其中 0x0040 是页号,0x1000 是页内偏移量。MMU 通过页号 0x0040 在页表中查找对应的物理页框号,假设找到的物理页框号为 0x0080,那么最终的物理地址就是 0x00801000(0x0080 << 12 | 0x1000)。
4.2页表与多级页表
进程的页表是管理虚拟地址与物理地址映射关系的关键数据结构。它就像是一个精心编排的 “映射目录”,每个表项都记录了一个虚拟页到物理页框的映射关系 。在简单的分页系统中,页表可能是一个线性的数组,数组的索引是虚拟页号,数组的值是对应的物理页框号 。
然而,对于32位甚至64 位的地址空间来说,如果采用简单的线性页表,会占用大量的内存空间。在 32 位系统中,若页面大小为4KB,进程的虚拟地址空间为4GB,那么页表将包含 1M 个页表项(4GB / 4KB = 1M) 。假设每个页表项占用 4 个字节,那么仅页表就会占用4MB 的连续内存空间,这对于内存资源来说是一种巨大的浪费。
为了解决这个问题,现代操作系统通常采用多级页表。以二级页表为例,它将虚拟地址空间进一步划分。在 32 位系统中,可能将 20 位的页号再划分为 10 位的外层页号和 10 位的内层页号 。外层页表的每个表项指向一个内层页表,内层页表的表项才真正记录虚拟页到物理页框的映射关系 。这样,只有当外层页表中对应的表项被访问时,才会加载相应的内层页表,大大减少了内存的占用 。假设外层页号为 0x001,内层页号为 0x002,通过外层页表找到对应的内层页表,再在内层页表中通过内层页号 0x002 找到物理页框号,从而实现虚拟地址到物理地址的转换。
多级页表不仅减少了内存占用,还支持离散存储。由于页表可以离散地存储在物理内存中,不再需要连续的内存空间来存放整个页表,提高了内存的使用效率和灵活性 。
4.3缓存机制与局部性原理
为了进一步提高内存访问的速度,计算机系统引入了多种缓存机制,其中 CPU 缓存、Cache 和 TLB 表起着关键作用,它们的工作原理都基于局部性原理。
局部性原理包括时间局部性和空间局部性。时间局部性是指如果一个数据项被访问,那么在不久的将来它很可能再次被访问 。在一个循环结构中,循环变量和循环体内频繁使用的数据会被多次访问,这就体现了时间局部性。空间局部性是指如果一个数据项被访问,那么与它相邻的数据项很可能也会被访问 。当我们访问一个数组时,通常会按照顺序依次访问数组中的元素,这就利用了空间局部性。
CPU 缓存(Cache)是位于 CPU 和主存之间的高速存储部件,它利用了局部性原理来提高内存访问命中率。当 CPU 需要访问内存数据时,首先会在 Cache 中查找 。如果在 Cache 中命中,CPU 可以快速地获取数据,因为 Cache 的访问速度比主存快得多,通常可以达到主存访问速度的几十倍甚至上百倍 。如果在 Cache 中没有命中,才会访问主存,并将主存中的数据块加载到 Cache 中,以便后续访问。
TLB 表作为 MMU 中的高速缓存,同样利用了局部性原理。它缓存了近期使用过的虚拟地址到物理地址的映射关系 。当 MMU 接收到虚拟地址时,先在 TLB 中查找映射关系,如果命中,就可以快速完成地址转换,避免了通过页表进行查找的开销 。由于TLB的访问速度极快,几乎与 CPU 的速度同步,所以 TLB 的命中率对于地址转换的效率至关重要 。
相关文章:
)
内存 “舞台” 上,进程如何 “翩翩起舞”?(转)
在数字世界里,计算机的每一次高效运转都离不开内存与进程的默契配合。内存,恰似一座宏大且有序的舞台,为进程提供了施展拳脚的空间。而进程,则如同舞台上的舞者,它们在内存的舞台上,遵循着一套复杂而精妙的…...

产品手册小程序开发制作方案
公司产品手册小程序系统主要是为了解决传统纸质或PDF格式手册更新成本高、周期长,难以及时反映最新产品信息。线下分发效率低,线上分享体验差,不利于品牌推广。传统手册单向传递信息,无法与用户进行互动,企业难以了解用…...

【dify—8】Agent实战——占星师
目录 一、创建Agent应用 二、创建提示词 三、创建变量 四、添加工具 五、发布更新 六、运行 第一部分 安装difydocker教程:【difydocker安装教程】-CSDN博客 第二部分 dock重装教程:【dify—2】docker重装-CSDN博客 第三部分 dify拉取镜像ÿ…...

Redis的键过期删除策略与内存淘汰机制详解
Redis 的键过期删除策略与内存淘汰机制详解 一、键过期删除策略 Redis 通过 定期删除(Active Expire) 和 惰性删除(Lazy Expire) 两种方式结合,管理键的过期清理。 1. 惰性删除(Lazy Expire) …...
)
数据结构——树(中篇)
今日名言: 人生碌碌,竞短论长,却不道枯荣有数,得失难量 上次我们讲了树的相关知识,接下来就进一步了解二叉树吧。本文为个人学习笔记,如有侵权,请 联系删除,如有错误,欢…...

实验三 软件黑盒测试
实验三 软件黑盒测试使用测试界的一个古老例子---三角形问题来进行等价类划分。输入三个整数a、b和c分别作为三角形的三条边,通过程序判断由这三条边构成的三角形类型是等边三角形、等腰三角形、一般三角形或非三角形(不能构成一个三角形)。其中要求输入变量&#x…...

PHP-Cookie
Cookie 是什么? cookie 常用于识别用户。cookie 是一种服务器留在用户计算机上的小文件。每当同一台计算机通过浏览器请求页面时,这台计算机将会发送 cookie。通过 PHP,您能够创建并取回 cookie 的值。 设置Cookie 在PHP中,你可…...
(文末有下载方式))
提升采购管理,打造核心竞争力七步战略采购法详解P94(94页PPT)(文末有下载方式)
资料解读:《提升采购管理,打造核心竞争力 —— 七步战略采购法详解》 详细资料请看本解读文章的最后内容。 在当今竞争激烈的商业环境中,采购管理已成为企业打造核心竞争力的关键环节。这份文件围绕七步战略采购法展开,深入剖析了…...

单片机-89C51部分:13、看门狗
飞书文档https://x509p6c8to.feishu.cn/wiki/LefkwDPU7iUUWBkfKE9cGLvonSh 一、作用 程序发生死循环的时候(跑飞),能够自动复位。 启动看门狗计数器->计数器计数->指定时间内不对计数器赋值(主程序跑飞,无法喂…...

基于MyBatis的银行转账系统开发实战:从环境搭建到动态代理实现
目标: 掌握mybatis在web应用中怎么用 mybatis三大对象的作用域和生命周期 ThreadLocal原理及使用 巩固MVC架构模式 为学习MyBatis的接口代理机制做准备 实现功能: 银行账户转账 使用技术: HTML Servlet MyBatis WEB应用的名称&am…...

纹理采样+光照纹理采样
普通纹理显示 导入纹理 1.将纹理拷贝到项目中 2.配置纹理 纹理显示原理 原始纹理(边长是),如果原始图的边长不是,游戏引擎在运行时,会自动将 纹理的边长补偿为,所以补偿是有损耗的(纹理不一定是…...

408真题笔记
2024 年全国硕士研究生招生考试 计算机科学与技术学科联考 计算机学科专业基础综合 (科目代码:408) 一、单项选择题 第 01~40 小题,每小题 2 分,共 80 分。下列每小题给出的四个选项中,只有一个…...

【Shell 脚本编程】详细指南:第一章 - 基础入门与最佳实践
Shell 脚本编程完全指南:第一章 - 基础入门与最佳实践 引言:Shell 脚本在现代开发中的重要性 Shell 脚本作为 Linux/Unix 系统的核心自动化工具,在 DevOps、系统管理、数据处理等领域扮演着关键角色。本章将系统性地介绍 Shell 脚本的基础知…...

PostgreSQL数据库操作SQL
数据库操作SQL 创建 创建数据库 create database db_test;创建并指定相关参数 with owner : 所有者encoding : 编码connection limit :连接限制 create database db_test1 with owner postgresencoding utf-8connection limit 100;修改 修改数据库名称 renam…...
(下))
RAG工程-基于LangChain 实现 Advanced RAG(预检索-查询优化)(下)
Multi-Query 多路召回 多路召回流程图 多路召回策略利用大语言模型(LLM)对原始查询进行拓展,生成多个与原始查询相关的问题,再将原始查询和生成的所有相关问题一同发送给检索系统进行检索。它适用于用户查询比较宽泛、模糊或者需要…...

VBA数据库解决方案第二十讲:Select From Where条件表达式
《VBA数据库解决方案》教程(版权10090845)是我推出的第二套教程,目前已经是第二版修订了。这套教程定位于中级,是学完字典后的另一个专题讲解。数据库是数据处理的利器,教程中详细介绍了利用ADO连接ACCDB和EXCEL的方法…...

Linux架构篇、第1章_02源码编译安装Apache HTTP Server 最新稳定版本是 2.4.62
Linux_基础篇 欢迎来到Linux的世界,看笔记好好学多敲多打,每个人都是大神! 题目:源码编译安装Apache HTTP Server 最新稳定版本是 2.4.62 版本号: 1.0,0 作者: 老王要学习 日期: 2025.05.01 适用环境: Centos7 文档说明 本文…...

【Machine Learning Q and AI 读书笔记】- 03 小样本学习
Machine Learning Q and AI 中文译名 大模型技术30讲,主要总结了大模型相关的技术要点,结合学术和工程化,对LLM从业者来说,是一份非常好的学习实践技术地图. 本文是Machine Learning Q and AI 读书笔记的第3篇,对应原…...
)
Webug4.0靶场通关笔记08- 第11关万能密码登录(SQL注入漏洞)
目录 第13关 万能密码登录 1.打开靶场 2.源码分析 3.渗透方法1 4.渗透方法2 第13关 万能密码登录 本文通过《webug靶场第13关 万能密码登录》来进行渗透实战。 万能密码是利用 SQL 注入漏洞,构造出能够绕过登录验证的特殊密码字符串。通常,登录验…...

terraform中statefile文件的实现原理及作用
Terraform 的 State 文件(terraform.tfstate)是其基础设施即代码(IaC)机制的核心组件,用于记录和管理云资源的实际状态。以下是其实现原理及核心作用的详细分析: 一、State 文件的实现原理 1. 数据结构与…...

7.0/Q1,GBD数据库最新文章解读
文章题目:Cardiovascular disease s mortality in Brazilian municipalities: estimates from the Global Burden of Disease study, 2000-2018 DOI:10.1016/j.lana.2025.101106 中文标题:巴西城市的心血管疾病死亡率:来自2000-20…...

linux 使用nginx部署next.js项目,并使用pm2守护进程
前言 本文基于:操作系统 CentOS Stream 8 使用工具:Xshell8、Xftp8 服务器基础环境: node - 请查看 linux安装node并全局可用pm2 - 请查看 linux安装pm2并全局可用nginx - 请查看 linux 使用nginx部署vue、react项目 所需服务器基础环境&…...

0基础 | Proteus电路仿真 | 电机使用
目录 电机类型 51单片机对直流电机的控制 基于89C51主控的直流电机控制电路仿真 代码《基于Keil C51》 51单片机对步进电机的控制 控制代码《基于Keil C51》 基于89C51主控的步进电机控制电路仿真 电机类型 直流电机 步进电机 51单片机对直流电机的控制 直流电机&#…...
有何区别?)
人工智能100问☞第14问:人工智能的三大流派(符号主义、联结主义、行为主义)有何区别?
目录 一、通俗解释 二、专业解析 三、权威参考 一、通俗解释 人工智能的三大流派,就像三位不同性格的工程师用各自的方法造机器人: 1、符号主义(逻辑派) 核心:用“教科书式规则”教机器思考。比如教计算机下棋,先写一本《国际象棋必胜法则》,机器…...

油气人工地震资料信号处理中,机器学习和AI应用
在油气人工地震资料信号处理中,机器学习和AI可以应用于多个环节,显著提升数据质量、解释效率和勘探准确性。以下是主要应用场景及对应的开源工具推荐: 1. 数据预处理 应用场景: 噪声压制(如随机噪声、多次波、面波&am…...

Python数据分析课程实验-1
1.1数据分析简介 当今世界对信息技术的依赖程度日渐加深,每天都会产生和存储海量的数据。数据的来源多种多样一自 动检测系统、传感器和科学仪器等。不知你有没有意识到,你每次从银行取钱、买东西、写博客、发微博也会产生新的数据。 什么是数据呢?数据实际上不同于…...

算法--模拟题目
算法–模拟问题 1576. 替换所有的问号 思路:遍历字符串,找到?, 然后遍历字符a 到 z 找到不等于前后字符,替换即可 class Solution { public:string modifyString(string s) {for(int i 0; i < s.size(); i){if(s[i] ?){//替换for(char a a; a < z; a){//当字符不等…...

PDF24 Tools:涵盖20+种PDF工具,简单高效PDF工具箱,支持一键编辑/转换/合并
一、软件介绍 PDF 24 Tools是一款由德国公司开发的PDF编辑工具,拥有18年的历史,并且一直免费使用,这在同类软件中非常难得。 早在许久之前,我就推荐过这款工具的免费网页版,但由于网页使用起来可能不太方便且速度较慢…...
 : Fisk‘s proof)
12.多边形的三角剖分 (Triangulation) : Fisk‘s proof
目录 1.Fisks proof Trangulation Coloring Domination Pigeon-Hold Principle Generation 2.Orthogonal Polygons (正交多边形) Necessity of floor(n4) Sufficiency by convex Quadrilateralization Generalization 1.Fisks proof Trangulation 引入内对角线&…...

数据库基本概念:数据库的定义、特点、分类、组成、作用
一:数据库相关概念 1.1 定义 (1)数据库:存储数据的仓库 (2)数据库管理系统:模拟和管理数据库的大型软件 (3)SQL:操作关系型数据库的编程语言,定义…...

PostgreSQL 数据库下载和安装
官网: PostgreSQL: Downloads 推荐下载网站:EDB downloads postgresql 我选了 postgresql-15.12-1-windows-x64.exe 鼠标双击,开始安装: 安装路径: Installation Directory: D:\Program Files\PostgreSQL\15 Serv…...

【c++】【STL】queue详解
目录 queue的作用什么是容器适配器queue的接口构造函数emptysizefrontback queue类的实现 queue的作用 queue是stl库提供的一种容器适配器,也就是我们数据结构中学到的队列,是非常常用的数据结构,特点是遵循LILO(last in last ou…...

循环插入数据库行
文章目录 循环插入数据库行 循环插入数据库行 -- 声明变量 DECLARE i INT 201;-- 开始循环 WHILE i < 200 BEGIN-- 插入数据INSERT INTO T_AGVPOS (POS) VALUES (i);SET i i 1; END;...

QMK机械键盘固件开发指南:从源码到实践
QMK机械键盘固件开发指南:从源码到实践 前言 QMK(Quantum Mechanical Keyboard)是一款开源的键盘固件,支持众多自定义键盘的功能配置。通过QMK,您可以完全掌控键盘的每一个按键,实现复杂的宏指令、多层按…...
Unity SpriteMask(精灵遮罩)
🏆 个人愚见,没事写写笔记 🏆《博客内容》:Unity3D开发内容 🏆🎉欢迎 👍点赞✍评论⭐收藏 🔎SpriteMask:精灵遮罩 💡作用就是对精灵图片产生遮罩,…...

AdaBoost算法详解:原理、实现与应用指南
AdaBoost算法详解:原理、实现与应用指南 1. 引言 在机器学习领域,AdaBoost(Adaptive Boosting) 是最早提出的集成学习(Ensemble Learning)**算法之一,由Yoav Freund和Robert Schapire于1995年…...

Flink流式计算核心:DataStream API与时间语义深度解析
本文将围绕Flink最核心的DataStream API展开,结合其独特的时间语义体系,深入解析Flink如何实现对无界流数据的精准控制,并通过真实业务场景案例演示其工程实践方法。 一、DataStream API:Flink处理无界流的“中枢神经” Flink的A…...

C# 方法的结构与执行详解
在编程世界里,方法是一块具有名称的代码,它就像是一个功能盒子,我们可以使用方法的名称从别的地方执行其中的代码,还能把数据传入方法并接收数据输出。方法是类的函数成员,主要由方法头和方法体两个部分构成。 方法头…...

《AI大模型应知应会100篇》第41篇:多轮对话设计:构建高效的交互式应用
第41篇:多轮对话设计:构建高效的交互式应用 摘要 在银行客服机器人突然准确回答出用户第7次追问的信用卡额度规则时,在医疗问诊系统记住患者既往病史的瞬间,多轮对话技术正在创造令人惊叹的交互体验。本文将以工业级案例为经&am…...

【Day 14】HarmonyOS分布式数据库实战
一、分布式数据库基础 1. 核心概念速记表 术语解释示例场景分布式数据库数据自动同步到同账号设备手机添加商品→平板立即显示KV数据模型键值对存储(类似JSON){"cart_item1": {"name":"牛奶","price":10}}数据…...

terraform 删除资源前先校验资源是否存在关联资源
Terraform 删除资源前校验关联资源的解决方案 在使用 Terraform 进行资源删除操作时,确实存在直接删除可能影响关联资源的风险。以下是几种在删除前校验关联资源的方法: 1. 使用 Terraform Data Sources 进行预检查 在删除主资源前,可以通…...

如何免费使用 DeepSeek-Prover-V2?
近日,Deepseek 发布了一个新模型,这是一个在数学推理方面表现卓越的模型,即 DeepSeek Prover V2。 DeepSeek-Prover-V2 是一个专门使用 Lean 4 证明助手进行形式化定理证明的高级语言模型。 简单来说, DeepSeek-Prover-V2 旨在支持数学家和计算机科学家创建和验证形式化证…...

dify+ollama+知识库 部署
这篇文章的前提是已经部署了deepseek和ollama deepseek和ollama安装 代码、配置 本地电脑如果是Windows的话,需要安装Git # 拉取Dify代码 git clone https://github.com/langgenius/dify.git复制配置 进入dify\docker目录 复制.env.example到.env 复制.middlewa…...
)
补题:K - Magic Tree (Gym - 105231K)
来源:问题 - K - Codeforceshttps://codeforces.com/gym/105231/problem/K 题目描述: 一、题目分析 本题给定一个2行m列的网格,从(1, 1)格子开始进行深度优先搜索,每个格子可到达至少一个边相邻的格子且不重复访问,…...
)
文章记单词 | 第58篇(六级)
一,单词释义 naive:英 [naɪˈiːv , nɑːˈiːv] 美 [naɪˈiːv , nɑːˈiːv],形容词,意为 “天真的;幼稚的;轻信的;易受骗的;无经验的;率真的;质朴的”…...

红利底波是什么意思?
红利低波是一种结合了红利策略和低波策略的投资策略,主要选取股息率高且波动率低的股票进行投资,具有 “高收益低风险” 的特点,适合大多数投资者的权益资产配置。以下是具体介绍: 策略构成要素 红利策略 :关注股息率…...

缓存:缓解读库压力的高效方案与应用实践
在软件开发和系统设计中,使用缓存来缓解读库压力是一种常见且有效的优化策略,以下是具体的介绍: 一、缓存的基本概念 缓存是一种临时数据存储区域,它存储了经常访问的数据副本。当应用程序需要访问数据时,首先会检查…...

17. LangChain流式响应与实时交互:打造“类ChatGPT“体验
引言:从"等待加载"到"即时对话"的革命 2025年某在线教育平台的AI助教引入流式交互后,学生平均对话轮次提升3.2倍,完课率提高47%。本文将基于LangChain的异步流式架构,揭秘如何实现毫秒级响应的自然对话体验。…...

仿腾讯会议——服务器结构讲解
总功能 1、数据库类 1、进入mysql 2、查看当前数据库 2、线程池 3、网络类 阻塞和非阻塞是通过套接字来实现的,所以不能发送和接收的阻塞状态不同...

【笔记】深度学习模型训练的 GPU 内存优化之旅③:内存交换篇
开设此专题,目的一是梳理文献,目的二是分享知识。因为笔者读研期间的研究方向是单卡上的显存优化,所以最初思考的专题名称是“显存突围:深度学习模型训练的 GPU 内存优化之旅”,英文缩写是 “MLSys_GPU_Memory_Opt”。…...