加速LLM大模型推理,KV缓存技术详解与PyTorch实现
随着大型语言模型(LLM)规模和复杂度的指数级增长,推理效率已成为人工智能领域亟待解决的关键挑战。当前,GPT-4、Claude 3和Llama 3等大模型虽然表现出强大的理解与生成能力,但其自回归解码过程中的计算冗余问题依然显著制约着实际应用场景中的响应速度和资源利用效率。
键值(KV)缓存技术作为Transformer架构推理优化的核心策略,通过巧妙地存储和复用注意力机制中的中间计算结果,有效解决了自回归生成过程中的重复计算问题。与传统方法相比,该技术不仅能够在不牺牲模型精度的前提下显著降低延迟,更能实现近线性的计算复杂度优化,为大规模模型部署提供了实用解决方案。
本文将从理论基础出发,系统阐述KV缓存的工作原理、技术实现与性能优势。我们将通过PyTorch实现完整演示代码,详细分析缓存机制如何与Transformer架构的自注意力模块协同工作,并通过定量实验展示不同序列长度下的性能提升。此外,文章还将讨论该技术在实际应用中的局限性及未来优化方向,为读者提供全面而深入的技术洞察。
无论是追求极致推理性能的AI工程师,还是对大模型优化技术感兴趣的研究人员,本文的实践导向方法都将帮助你理解并掌握这一关键性能优化技术。
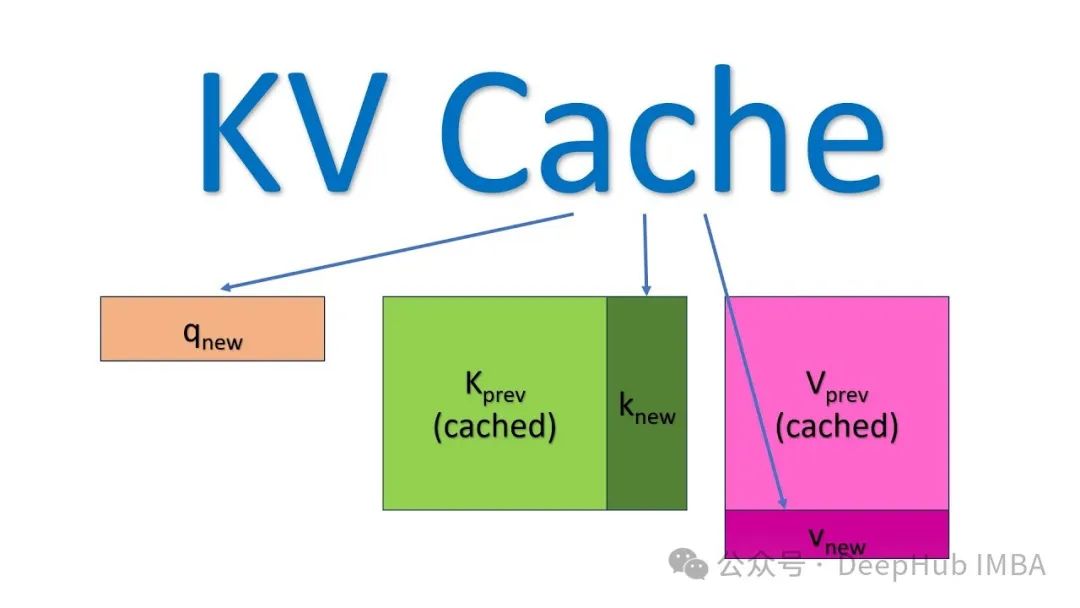
KV缓存是一种优化技术,用于存储注意力机制中已计算的Key和Value张量,这些张量可在后续自回归生成过程中被重复利用,从而有效减少冗余计算,显著提升推理效率。
键值缓存原理
注意力机制基础
# 多头注意力
classMultiHeadAttention(nn.Module):def__init__(self, head_size, num_head):super().__init__()self.sa_head=nn.ModuleList([Head(head_size) for_inrange(num_head)])self.dropout=nn.Dropout(dropout)self.proj=nn.Linear(embed_size, embed_size)defforward(self, x):x=torch.cat([head(x) forheadinself.sa_head], dim=-1)x=self.dropout(self.proj(x))returnx
MultiHeadAttention
类的实现遵循标准的多头注意力模块设计。输入张量形状为(B, T, C),其中B代表批次大小,T表示序列长度(在本实现中最大序列长度为
block_size
),C表示嵌入维度。
多头注意力机制的核心思想是将嵌入空间划分为多个头,每个头独立计算注意力权重。对于嵌入维度C=128且头数量为4的情况,每个头的维度为128/4=32。系统将分别计算这4个大小为32的注意力头,然后将结果拼接成形状为(B, T, 128)的输出张量。
KV缓存的必要性
为理解KV缓存的必要性,首先需要分析注意力机制的计算过程:
classHead(nn.Module):def__init__(self, head_size):super().__init__()self.head_size=head_sizeself.key=nn.Linear(embed_size, head_size, bias=False)self.query=nn.Linear(embed_size, head_size, bias=False)self.value=nn.Linear(embed_size, head_size, bias=False)self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size)))self.dropout=nn.Dropout(dropout)defforward(self, x):B, T, C=x.shapek=self.key(x)q=self.query(x)v=self.value(x)wei=q@k.transpose(2, 1)/self.head_size**0.5wei=wei.masked_fill(self.tril[:T, :T] ==0, float('-inf'))wei=F.softmax(wei, dim=2) # (B , block_size, block_size)wei=self.dropout(wei)out=wei@vreturnout
在注意力头的实现中,系统通过线性变换生成Key、Value和Query,它们的形状均为(B, T, C),其中C为头的大小。
Query与Key进行点积运算,生成形状为(B, T, T)的权重矩阵,表示各token之间的相关性。权重矩阵经过掩码处理转换为下三角矩阵,确保在点积运算过程中每个token仅考虑前面的token(即从1到n),这强制实现了因果关系,使得自回归模型中的token仅使用历史信息预测下一个token。
下图展示了自回归生成在注意力机制中的实现过程:
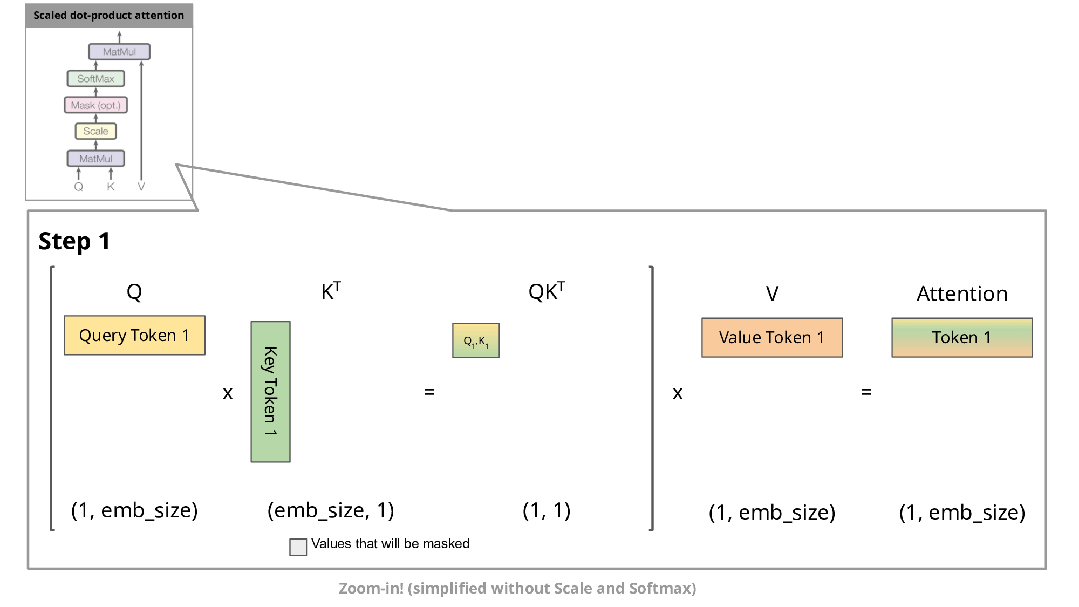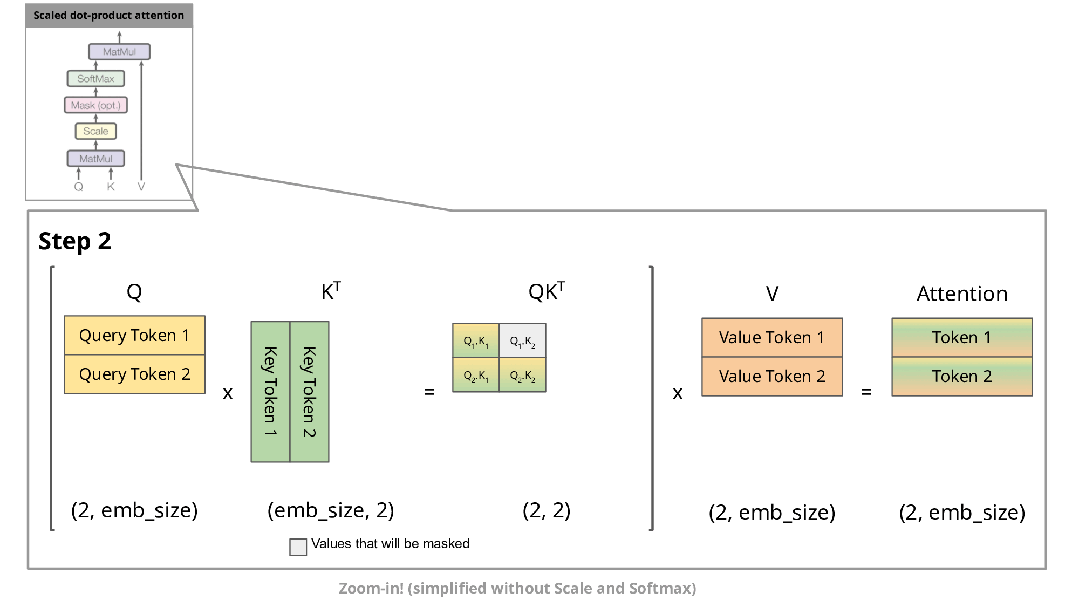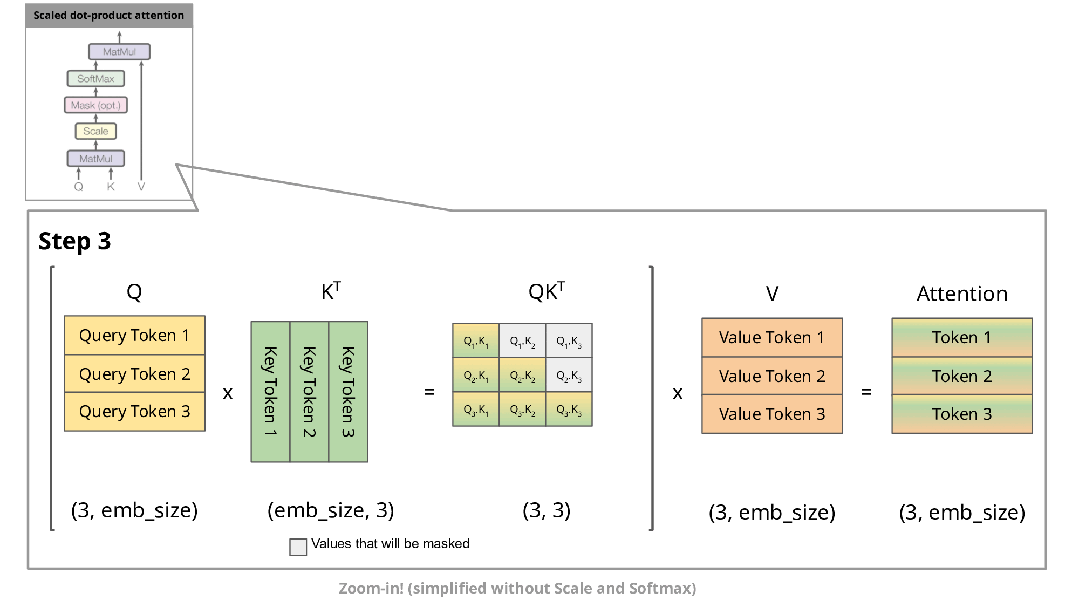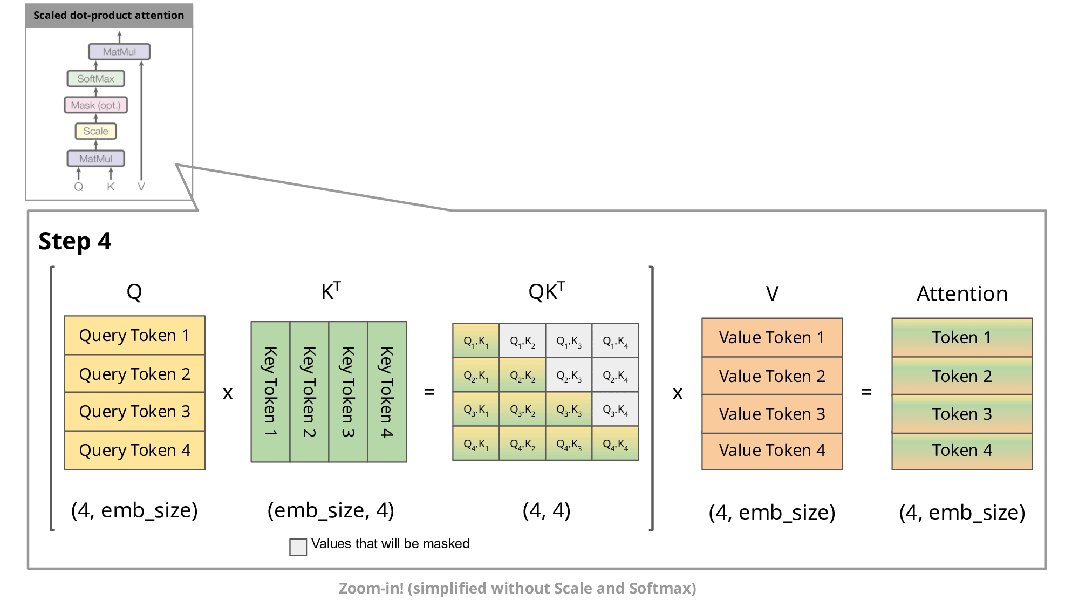
在自回归生成的每个步骤中,系统均需重新计算已经计算过的Key和Value。例如,在第2步中,K1与第1步生成的K1相同。由于在推理阶段模型参数已固定,相同输入将产生相同输出,因此将这些Key和Value存储在缓存中并在后续步骤中复用是更高效的方法。
下图直观展示了KV缓存的工作机制:
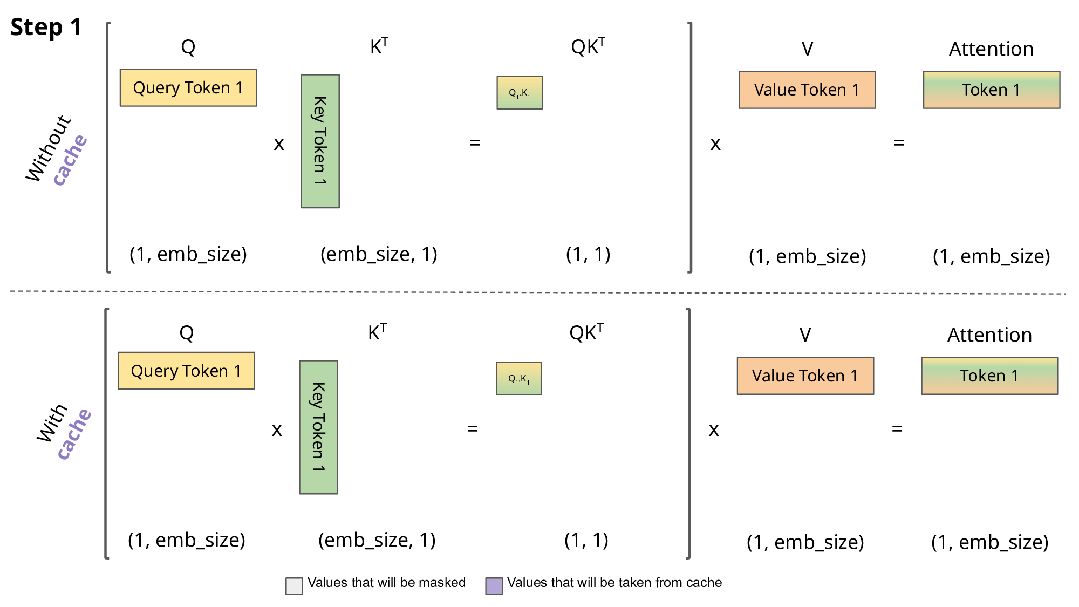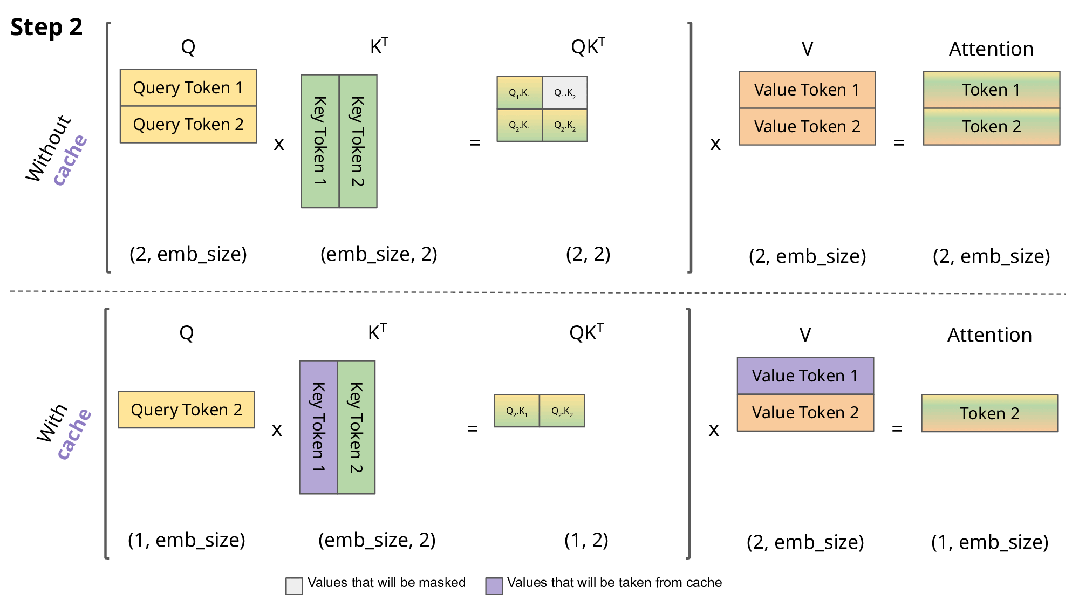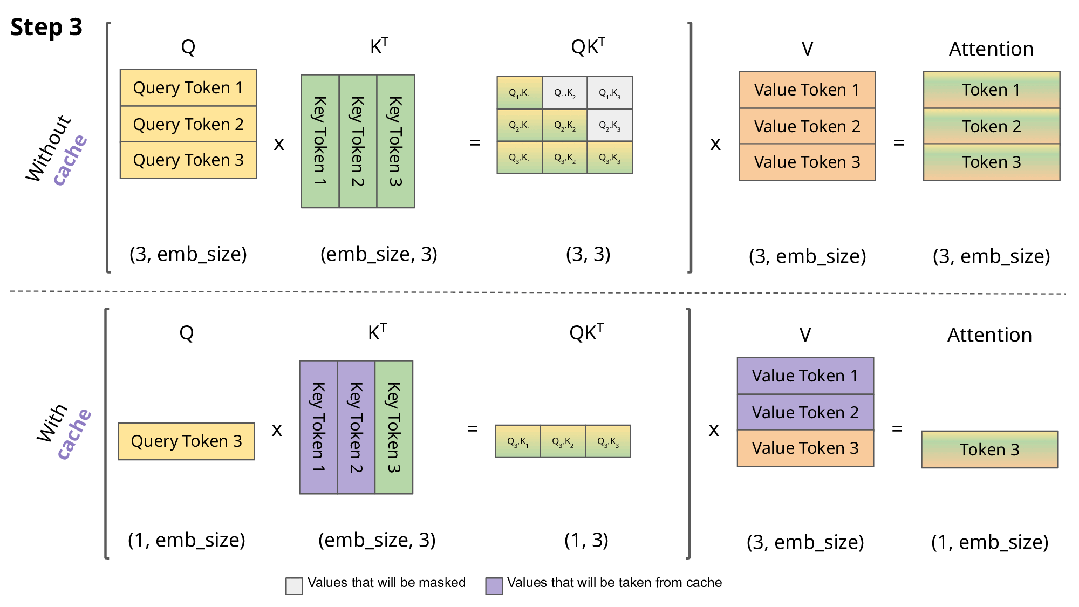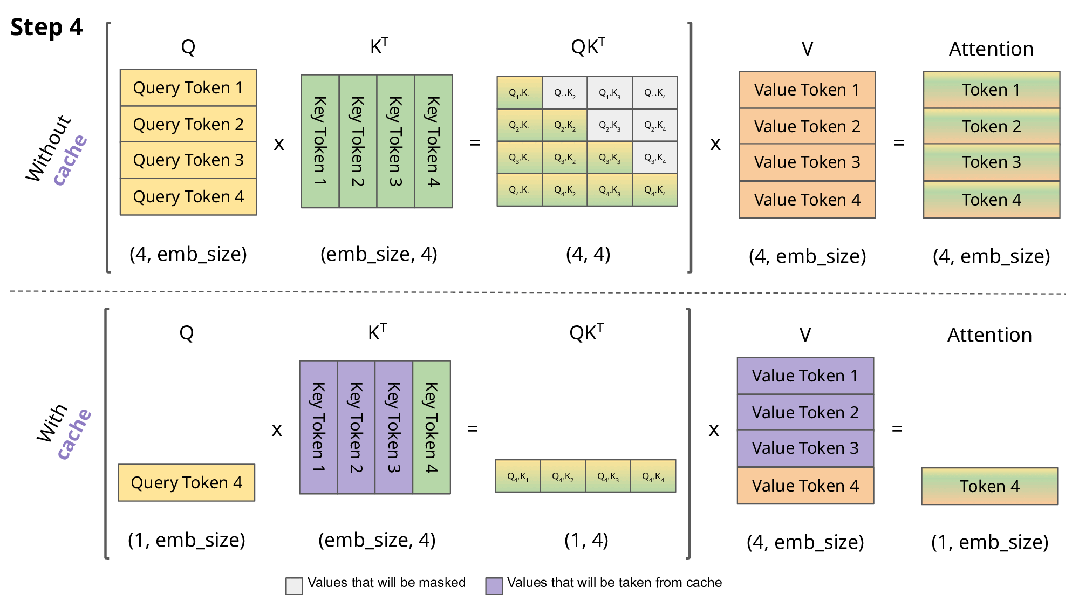
实现KV缓存的主要区别在于:
- 推理时每次仅传入一个新token,而非增量传递所有token
- 由于Key和Value已缓存,无需重复计算历史token的表示
- 无需对权重进行掩码处理,因为每次只处理单个Query token,权重矩阵(QK^T)的维度为(B, 1, T)而非(B, T, T)
缓存机制实现
KV缓存的实现基于形状为(B, T, C)的零张量初始化,其中T为最大处理的token数量(即block_size):
classHead(nn.Module):def__init__(self, head_size):super().__init__()self.head_size=head_sizeself.key=nn.Linear(embed_size, head_size, bias=False)self.query=nn.Linear(embed_size, head_size, bias=False)self.value=nn.Linear(embed_size, head_size, bias=False)self.dropout=nn.Dropout(dropout)self.k_cache=Noneself.v_cache=Noneself.cache_index=0defforward(self, x):B, T, C=x.shape# 形状: B, 1, Ck=self.key(x)q=self.query(x)v=self.value(x)# 如果缓存为空则初始化ifself.k_cacheisNoneorself.v_cacheisNone:# 使用固定大小初始化缓存self.k_cache=torch.zeros(B, block_size, self.head_size, device=x.device)self.v_cache=torch.zeros(B, block_size, self.head_size, device=x.device)self.cache_index=0returnout
自回归模型在训练时使用固定的上下文长度,即当前token预测下一个token时可回溯的最大token数量。在本实现中,这个上下文长度由
block_size
参数确定,表示缓存的最大token数量,通过缓存索引进行跟踪:
defforward(self, x):B, T, C=x.shape# B, 1, Ck=self.key(x)q=self.query(x)v=self.value(x)# 如果缓存为空则初始化ifself.k_cacheisNoneorself.v_cacheisNone:# 使用固定大小初始化缓存self.k_cache=torch.zeros(B, block_size, self.head_size, device=x.device)self.v_cache=torch.zeros(B, block_size, self.head_size, device=x.device)self.cache_index=0# 原地更新缓存ifself.cache_index+T<=block_size:self.k_cache[:, self.cache_index:self.cache_index+T, :] =kself.v_cache[:, self.cache_index:self.cache_index+T, :] =v# 注意:鉴于我们一次只传递一个token,T将始终为1,因此上面的操作# 等效于直接执行self.k_cache[:, self.cache_index, :] = k# 更新缓存索引self.cache_index=min(self.cache_index+T, block_size)# 注意力点积wei=q@self.k_cache.transpose(2, 1)/self.head_size**0.5wei=F.softmax(wei, dim=2) # (B, block_size, block_size)wei=self.dropout(wei)out=wei@self.v_cachereturnout
从第一个token开始,系统将Key-Value对存入对应的缓存位置,并递增缓存索引直到达到设定的上限:
defforward(self, x):B, T, C=x.shape# B, 1 (T), Ck=self.key(x)q=self.query(x)v=self.value(x)ifself.k_cacheisNoneorself.v_cacheisNone:# 使用固定大小初始化缓存self.k_cache=torch.zeros(B, block_size, self.head_size, device=x.device)self.v_cache=torch.zeros(B, block_size, self.head_size, device=x.device)self.cache_index=0# 原地更新缓存ifself.cache_index+T<=block_size:self.k_cache[:, self.cache_index:self.cache_index+T, :] =kself.v_cache[:, self.cache_index:self.cache_index+T, :] =velse:# 将token向后移动一步shift=self.cache_index+T-block_size# Shift将始终为1self.k_cache[:, :-shift, :] =self.k_cache[:, shift:, :].clone()self.v_cache[:, :-shift, :] =self.v_cache[:, shift:, :].clone()self.k_cache[:, -T:, :] =kself.v_cache[:, -T:, :] =v# 更新缓存索引self.cache_index=min(self.cache_index+T, block_size)wei=q@self.k_cache.transpose(2, 1)/self.head_size**0.5wei=wei.masked_fill(self.tril[:T, :T] ==0, float('-inf'))wei=F.softmax(wei, dim=2) # (B, block_size, block_size)wei=self.dropout(wei)out=wei@self.v_cachereturnout
当缓存索引达到
block_size
时,系统会将所有token向前移动一个位置,为新token腾出空间,并将新token分配到最后一个位置:
# 缓存移动示例
k_cache=torch.zeros(1, 3, 3)
v_cache=torch.zeros(1, 3, 3)steps=3
foriinrange(steps):k_cache[:, i, :] =torch.randint(10, (1, 3))
print("k_cache Before:\n", k_cache)shift=1
k_cache[:, :-shift, :] =k_cache[:, shift:, :].clone()
v_cache[:, :-shift, :] =v_cache[:, shift:, :].clone()
print("k_cache After:\n", k_cache)# 输出 :-
k_cacheBefore:
tensor([[[2., 2., 9.],[3., 6., 4.],[3., 9., 5.]]])k_cacheAfter:
tensor([[[3., 6., 4.],[3., 9., 5.],[3., 9., 5.]]]) # 这个最后的token随后被新的Key Token k_cache[:, -T:, :] = k替换
以上即为KV缓存在注意力机制中的完整实现。接下来我们将分析KV缓存对推理性能的具体影响。
推理性能比较
本节将展示KV缓存优化技术对推理性能的实际影响。以下是实现了KV缓存的GPT模型代码:
# 导入库
importtorch
importtorch.nnasnn
fromtorch.nnimportfunctionalasF
# 读取txt文件(编码解码)/* 从以下地址下载:https://raw.githubusercontent.com/karpathy/char-rnn/master/data/tinyshakespeare/input.txt */
text=open('input.txt', 'r',).read()
vocab=sorted(list(set(text)))
encode=lambdas: [vocab.index(c) forcins]
decode=lambdal: [vocab[c] forcinl]
# 划分训练集和验证集
x=int(0.9*len(text))
text=torch.tensor(encode(text), dtype=torch.long)
train, val=text[:x], text[x:]
# 创建一个get_batch函数以(batch_size, vocab_size(8))的形状从文本中随机加载数据
device='cuda'iftorch.cuda.is_available() else'cpu'
torch.manual_seed(1337)
batch_size=8# 我们将并行处理多少个独立序列?
block_size=1024# 预测的最大上下文长度?
embed_size=256
dropout=0
num_head=4
num_layers=4
defget_batch(split):# 生成一小批输入x和目标y的数据data=trainifsplit=='train'elsevalix=torch.randint(len(data) -block_size, (batch_size,))x=torch.stack([data[i:i+block_size] foriinix])y=torch.stack([data[i+1:i+block_size+1] foriinix])returnx.to(device), y.to(device)
xb, yb=get_batch('train')
# 注意力头
classHead(nn.Module):def__init__(self, head_size):super().__init__()self.head_size=head_sizeself.key=nn.Linear(embed_size, head_size, bias=False)self.query=nn.Linear(embed_size, head_size, bias=False)self.value=nn.Linear(embed_size, head_size, bias=False)self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size)))self.dropout=nn.Dropout(dropout)defforward(self, x):B, T, C=x.shapek=self.key(x)q=self.query(x)v=self.value(x)wei=q@k.transpose(2, 1)/self.head_size**0.5wei=wei.masked_fill(self.tril[:T, :T] ==0, float('-inf'))wei=F.softmax(wei, dim=2) # (B , block_size, block_size)wei=self.dropout(wei)out=wei@vreturnout# 多头注意力
classMultiHeadAttention(nn.Module):def__init__(self, head_size, num_head):super().__init__()self.sa_head=nn.ModuleList([Head(head_size) for_inrange(num_head)])self.dropout=nn.Dropout(dropout)self.proj=nn.Linear(embed_size, embed_size)defforward(self, x):x=torch.cat([head(x) forheadinself.sa_head], dim=-1)x=self.dropout(self.proj(x))returnxclassFeedForward(nn.Module):def__init__(self, embed_size):super().__init__()self.ff=nn.Sequential(nn.Linear(embed_size, 4*embed_size),nn.ReLU(),nn.Linear(4*embed_size, embed_size),nn.Dropout(dropout))defforward(self, x):returnself.ff(x)classBlock(nn.Module):def__init__(self, embed_size, num_head):super().__init__()head_size=embed_size//num_headself.multihead=MultiHeadAttention(head_size, num_head)self.ff=FeedForward(embed_size)self.ll1=nn.LayerNorm(embed_size)self.ll2=nn.LayerNorm(embed_size)defforward(self, x):x=x+self.multihead(self.ll1(x))x=x+self.ff(self.ll2(x))returnx# 超简单的bigram模型
classBigramLanguageModelWithCache(nn.Module):def__init__(self, vocab_size):super().__init__()# 每个token直接从查找表中读取下一个token的logitsself.token_embedding_table=nn.Embedding(vocab_size, embed_size)self.possitional_embedding=nn.Embedding(block_size, embed_size)self.linear=nn.Linear(embed_size, vocab_size)self.block=nn.Sequential(*[Block(embed_size, num_head) for_inrange(num_layers)])self.layer_norm=nn.LayerNorm(embed_size)defforward(self, idx, targets=None):B, T=idx.shape# idx和targets都是(B,T)整数张量logits=self.token_embedding_table(idx) # (B,T,C)ps=self.possitional_embedding(torch.arange(T, device=device))x=logits+ps #(B, T, C)logits=self.block(x) #(B, T, c)logits=self.linear(self.layer_norm(logits)) # 这应该在head_size和Vocab_size之间进行映射iftargetsisNone:loss=Noneelse:B, T, C=logits.shapelogits=logits.view(B*T, C)targets=targets.view(B*T)loss=F.cross_entropy(logits, targets)returnlogits, lossdefgenerate(self, idx, max_new_tokens):# idx是当前上下文中索引的(B, T)数组for_inrange(max_new_tokens):# 获取预测结果logits, loss=self(idx) # logits形状:B, 1, Clogits=logits[:, -1, :] # 变为(B, C)# 应用softmax获取概率probs=F.softmax(logits, dim=-1) # (B, C)# 从分布中采样idx_next=torch.multinomial(probs, num_samples=1).to(device) # (B, 1)# 无需拼接,因为我们一次只传递一个tokenidx=idx_nextreturnidx
generate函数在推理阶段被显式调用,不参与训练过程:
m_kv_cache=BigramLanguageModelWithCache(65).to(device)m_kv_cache.load_state_dict(torch.load("bigram.pth"))
通过执行generate命令可以测量KV缓存对推理性能的影响:
m_kv_cache=BigramLanguageModelWithCache(65).to(device)steps=10000print("".join(decode(m_kv_cache.generate(torch.zeros([1,1], dtype=torch.long).to(device) , max_new_tokens=steps)[0].tolist())))
下图展示了标准模型与KV缓存模型在不同生成步数下的推理时间对比,测试模型的序列长度(block_size)为1024,嵌入维度为256:
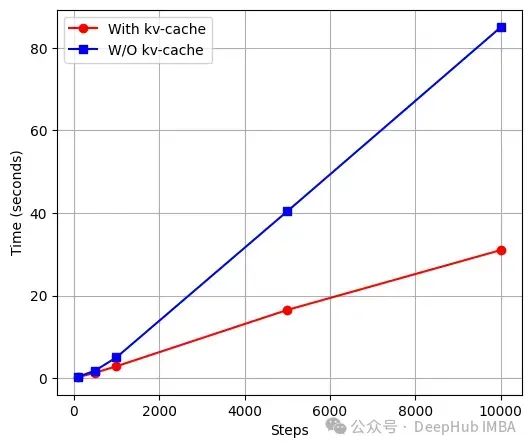
# 数据点steps = [100, 500, 1000, 5000, 10000]kv-cache = [0.2, 1.3, 2.85, 16.5, 31] # 红线w/0 kv-cache = [0.3, 1.8, 5.01, 40.4, 85] # 蓝线
实验结果表明,KV缓存模型在推理性能上总体优于标准模型,但其效率取决于浮点运算次数(FLOPs),而FLOPs会随着序列长度(block_size)和嵌入维度(embed_size)的增加而增加。对于较小的模型配置(如block_size=8, embed_size=64),标准模型可能更高效。由于计算复杂度随模型大小增加,KV缓存的优势在大型模型中更为明显。有关标准Transformer与KV缓存模型的FLOPs计算详情,可参考Rajan的技术文章[2]。
以下是生成的输出示例:
TRUCEMIM-y vit s.PETRO: histe feRil ass:
Whit Cimovecest isthen iduche neesoxlg anouther ankes aswerclin
'swal k s with selon more stoflld noncr id, mcis heis,
A?
TIOink
bupt venonn, d Ce?tey
Ke thiston tiund thorn fethe sutan kiportanou wuth thas tthers, steiellellke, on s hyou trefit.Bwat dotive wother, foru;Anke; ineees ronon irun: heals, I it Heno; gedad n thouc e,on pind ttanof anontoay:Isher!Ase, mesev minds
需要注意的是,生成的文本看似无意义,但这主要是由于计算资源和训练数据的限制,而非KV缓存技术本身的问题。尽管标准模型能生成更接近真实英语的单词,但KV缓存模型仍保留了基本的结构特征,只是输出质量有所降低。
最后,我们使用Hugging Face的预训练GPT-2模型进行了对比测试:
fromtransformersimportAutoModelForCausalLM, AutoTokenizer
importtime# 加载模型和分词器
model_name="gpt2"
model=AutoModelForCausalLM.from_pretrained(model_name)
tokenizer=AutoTokenizer.from_pretrained(model_name)# 文本提示
prompt="Once upon a time"
input_ids=tokenizer(prompt, return_tensors="pt").input_ids# 生成文本并测量时间的函数
defgenerate_text(use_cache):# 生成文本start_time=time.time()output_ids=model.generate(input_ids.to(device), use_cache=use_cache, max_new_tokens=1000)elapsed_time=time.time() -start_time# 解码输出output_text=tokenizer.decode(output_ids[0], skip_special_tokens=True)returnoutput_text, elapsed_time# 不使用KV缓存生成
output_without_cache, time_without_cache=generate_text(use_cache=False)
print("Without KV Cache:")
print(output_without_cache)
print(f"Time taken: {time_without_cache:.2f} seconds\n")# 使用KV缓存生成
output_with_cache, time_with_cache=generate_text(use_cache=True)
print("With KV Cache:")
print(output_with_cache)print(f"Time taken: {time_with_cache:.2f} seconds")
测试结果:
Without KV Cache:Once upon a time, the world was a place of great beauty and great danger. The world was a place of great danger, and the world was a place of great danger. The world was a place of great danger, and the world was a place of great danger. The world was a place of great danger, and the world was a place of great danger.Time taken: 76.70 secondsWith KV Cache:Once upon a time, the world was a place of great beauty and great danger. The world was a place of great danger, and the world was a place of great danger. The world was a place of great danger, and the world was a place of great danger. The world was a place of great danger, and the world was a place of great danger.Time taken: 62.46 seconds
总结
本文详细阐述了KV缓存的工作原理及其在大型语言模型推理优化中的应用,文章不仅从理论层面阐释了KV缓存的工作原理,还提供了完整的PyTorch实现代码,展示了缓存机制与Transformer自注意力模块的协同工作方式。实验结果表明,随着序列长度增加,KV缓存技术的优势愈发明显,在长文本生成场景中能将推理时间降低近60%。这一技术为优化大模型部署提供了一种无需牺牲精度的实用解决方案,为构建更高效的AI应用奠定了基础。
https://avoid.overfit.cn/post/3e49427b9e42440aa0c8d834c1906f2f
作者:Shubh Mishra
相关文章:

加速LLM大模型推理,KV缓存技术详解与PyTorch实现
随着大型语言模型(LLM)规模和复杂度的指数级增长,推理效率已成为人工智能领域亟待解决的关键挑战。当前,GPT-4、Claude 3和Llama 3等大模型虽然表现出强大的理解与生成能力,但其自回归解码过程中的计算冗余问题依然显著制约着实际应用场景中的…...

江西省电价新政发布!微电网源网荷储充一体化平台重塑企业能源格局!
一. 江西省发改委发布发布 4月25日,江西省发改委发布关于公开征求《关于进一步完善分时电价机制有关事项的通知(征求意见稿)》意见的公告。征求意见提出: 江西省:中午3小时谷段电价,电价下浮60%~70% 除1…...

深夜突发:OpenAI紧急修复GPT-4o“献媚”问题
凌晨三点,OpenAI首席执行官Sam Altman发布官方声明,宣布针对GPT-4o的“献媚”问题展开紧急修复。这场突如其来的技术风波,源于近期大量用户对模型行为模式的不满。许多用户发现,当他们向GPT-4o提出类似“你觉得我怎么样”或“如果…...

Webpack 和 Vite 中静态资源动态加载的实现原理与方法详解
静态资源动态加载 需求背景:现在需要加载指定文件夹下的对应图片,需要根据用户选的参数自动加载对应图片 一、前言:模块化开发的演进需求 在现代前端工程中,随着SPA应用复杂度的提升,静态资源动态加载已成为优化首屏性…...

SMMU相关知识
1. 使用smmu的作用 支持具有DMA能力设备的虚拟化实现解决32位系统访问超过4G空间的地址解决系统动态分配大块连续内存 2. 为什么需要使用2级页表 SMMU(系统内存管理单元)采用二级页表架构的核心原因可归结为地址空间管理效率、内存资源优化以及虚拟化…...
)
2025年数字创意设计与图像处理国际会议 (DCDIP 2025)
2025 International Conference on Digital Creative Design and Image Processing 【一】、大会信息 会议简称:DCDIP 2025 大会地点:中国济南 收录检索:提交Ei Compendex,CPCI,CNKI,Google Scholar等 【二…...

39.RocketMQ高性能核心原理与源码架构剖析
1. 源码环境搭建 1.1 主要功能模块 RocketMQ的官方Git仓库地址:GitHub - apache/rocketmq: Apache RocketMQ is a cloud native messaging and streaming platform, making it simple to build event-driven applications. RocketMQ的官方网站上下载指定版…...

SVTAV1 编码函数 svt_aom_is_pic_skipped
一 函数解释 1.1 svt_aom_is_pic_skipped函数的作用是判断当前图片是否可以跳过编码处理。 具体分析如下 函数逻辑 参数说明:函数接收一个指向图片父控制集的指针PictureParentControlSet *pcs, 通过这个指针可以获取与图片相关的各种信息,用于判断是否跳…...

C++负载均衡远程调用学习之基础TCP服务
目录 1.LARS课程模块介绍 2.LARS的功能演示机场景作用 3.LARS的reactor框架的组成部分 4.Lars_reactor的项目目录构建 5.Lars_tcp_server的基础服务开发 6.Lars_tcp_server的accept实现 7.LarsV0.1总结 1.LARS课程模块介绍 2.LARS的功能演示机场景作用 # Lars系统开发 …...

WebRtc09:网络基础P2P/STUN/TURN/ICE
网络传输基本知识 NATSTUN(Session Traversal Utilities for NAT)TURNICE NAT 产生的原因 IPV4地址不够出于网络安全的原因 NAT种类 完全锥型NAT(Full Cone NAT)地址限制型NAT(Address Restricted Cone NAT)端口限制型NAT(Port Restricted Cone NAT…...

UDP/TCP协议知识及相关机制
一.UDP协议 UDP是一种无连接、不可靠、面向报文、全双工传输层的协议~ 1.无连接 : 知道对端的端口号和IP可以直接传输,不需要建立连接 2..不可靠:没有确认机制,没有重传机制,不知道数据包能否能正确到达对端࿰…...

windows 下 oracle 数据库的备份与还原
1、备份 创建备份出来的文件存放的位置。 创建目录对象,在数据库中创建一个目录对象,该对象指向文件系统中用于存储导出文件的实际目录( sql 命令,可以在 plsql 中执行)。 -- 创建目录对象,\D:\Oracle19c\…...

LeetCode41☞缺失的第一个正数
关联LeetCode题号41 本题特点 数组,哈希表 本题思路 找缺失的最小正数,看举例说明缺失的正数,一种情况是连续的最小的正数,一种是缺失连续但不是最小的正数验证数组内数组是否连续,可以通过 nums[i]1 是否存nums组…...

毕业论文 | 基于STM32的自动烟雾报警系统设计
基于STM32的烟雾报警系统 一、系统设计原理1. **系统架构**2. **工作原理**二、核心公式与算法1. **MQ-2传感器浓度计算**2. **温度传感器数据处理**3. **校准与滤波**三、关键代码实现1. **ADC初始化与数据读取(以MQ-2为例)**2. **报警逻辑与阈值设置**3. **EEPROM存储阈值*…...
)
iOS 性能调优实战:三款工具横向对比实测(含 Instruments、KeyMob、Xlog)
iOS 性能调优实战:三款工具横向对比实测(含 Instruments、KeyMob、Xlog) 在日常 iOS 开发中,性能问题往往是最难排查、最影响体验的部分。无论是 CPU 峰值、内存飙升,还是偶发卡顿、异常崩溃,背后都隐藏着…...

flutter 专题 五十八 关于Flutter提示Your Xcode project requires migration的错误
最近,升级了Flutter后,运行之前的项目报了一个如下的错误: Your Xcode project requires migration. See https://flutter.dev/docs/development/ios-project-migration for details. Error launching application on iPhone 11 Pro.想到之前…...

【c++】【STL】list详解
目录 list的作用list的接口构造函数赋值运算符重载迭代器相关sizeemptyfrontbackassignpush_frontpop_frontpush_backpop_backinserteraseswapresizeclearspliceremoveremove_ifuniquemergesortreverse关系运算符重载(非成员函数) list的模拟实现结点类迭…...

redis 数据类型新手练习系列——List类型
redis 数据类型 Redis 主要支持以下几种数据类型: (1)string(字符串): 基本的数据存储单元,可以存储字符串、整数或者浮点数。 (2)hash(哈希):一个键值对集…...
)
文章记单词 | 第52篇(六级)
一,单词释义 grasp:英 [ɡrɑːsp] 美 [ɡrsp],v. 抓住;紧握;理解;领会;n. 紧握;控制;理解glue:英 [ɡluː] 美 [ɡluː],n. 胶水;胶…...
 / 走迷宫(BFS最短路) / 主持人调度(二)(贪心+优先级队列))
【今日三题】kotori和气球(排列) / 走迷宫(BFS最短路) / 主持人调度(二)(贪心+优先级队列)
⭐️个人主页:小羊 ⭐️所属专栏:每日两三题 很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~ 目录 kotori和气球(排列)走迷宫(BFS最短路)主持人调度(二)(贪心优先级队列) kotori和气球(排列) kotori和…...

Mysql数据库高可用解决方案-Mysql Router
目录 一.MySQL Router介绍 1. 什么是 MySQL Router? 2. MySQL Router 的主要用途 3. MySQL Router 的工作原理 4. MySQL Router 的核心组件 5. MySQL Router 的部署和配置 6. MySQL Router 的优势 7. 注意事项 8. MySQL Router 与其他工具的对比 9. 总结 …...

windows系统 压力测试技术
一、CPU压测模拟 工具:CpuStres v2.0 官网:https://learn.microsoft.com/en-us/sysinternals/downloads/cpustres 功能:是一个工具类,用来模拟在一个进程中启动最多64个线程,且可以独立控制任何一个线程的启动/暂停、…...

汽车免拆诊断案例 | 2015款奔驰C200L车发动机起动延迟
故障现象 一辆2015款奔驰C200L车,搭载274发动机,累计行驶里程约为15.6万km。该车发动机起动延迟,且发动机故障灯异常点亮。 故障诊断 用故障检测仪检测,发动机控制单元中存储有故障代码“P001685 进气凸轮轴(气缸…...

Python AI图像艺术创作:核心技术与实践指南
Python与AI技术的结合为图像艺术创作开辟了全新维度,通过生成对抗网络(GANs)、扩散模型(如Stable Diffusion)和神经风格迁移等技术,创作者可以轻松生成具有高度创意和艺术性的图像作品。 这些技术不仅突破了传统艺术创作的局限性,还大幅降低了专业创作门槛,使艺术创作…...

比亚迪再获国际双奖 以“技术为王”书写中国汽车出海新篇章
近日,全球汽车行业权威奖项“2025世界汽车大奖”(World Car Awards)在纽约国际车展举行颁奖典礼,比亚迪海鸥(BYD SEAGULL/BYD DOLPHIN MINI)摘得“2025世界城市车(World Urban Car)”…...
)
虚幻商城 Quixel 免费资产自动化入库(2025年版)
文章目录 一、背景二、问题讲解1. Quixel 免费资产是否还能一键入库?2. 是不是使用了一键入库功能 Quixel 的所有资产就能入库了?3. 一键入库会入库哪些资产?三、实现效果展示四、实现自动化入库五、常见问题1. 出现401报错2. 出现429报错3. 入库过于缓慢4. 入库 0 个资产一…...

斯坦福RGA软件 老版本和兼容Windows 11版本可选
斯坦福RGA软件 老版本和兼容Windows 11版本可选...

RHCSA Linux 系统 文件系统权限
1. 文件的一般权限 (1)文件权限标识解读 drwxr - xr - x. 12 root root 144 Feb 17 16:51 usr ➤d:文件类型(d 表示目录) ➤rwx:文件所有者权限(读 r,写 w,执行 x&am…...

【补题】Codeforces Global Round 20 D. Cyclic Rotation
题意:偷懒 思路: D. Cyclic Rotation - Yaqu - 博客园 1.有个观察,如果操作过的序列,一定是连续相同的数字,当然这不代表一定操作过了,由于操作过1次后连续就没有意义,可以假设全都操作…...

2025年“深圳杯”数学建模挑战赛C题-分布式能源接入配电网的风险分析
布式能源接入配电网的风险分析 小驴数模 背景知识: 随着我国双碳目标的推进,可再生分布式能源在配电网中的大规模应用不可避免,这对传统配电网运行提出挑战。为了量化分析配电网中接入分布式能源的风险,需要对其进行建模与分析…...

微调 LLaMA 2:定制大型语言模型的分步指南
微调 LLaMA 2:定制大型语言模型的分步指南 深入了解如何运用新技术在 Google Colab 平台上对 Llama-2 进行微调操作,从而有效克服内存与计算方面的限制,让开源大型语言模型变得更加易于获取和使用。自从 Meta 发布了 LLaMA 的首个版本后&…...
)
react-11使用vscode开发react相关扩展插件(相关的快捷生成)
1.快速搭建react组件模板 2.相关搭建命令 2.1 导入导出 前缀方法imp→import moduleName from moduleimn→import moduleimd→import { destructuredModule } from moduleime→import * as alias from moduleima→import { originalName as aliasName} from moduleexp→expo…...
:数理统计)
人工智能数学基础(六):数理统计
数理统计是人工智能中数据处理和分析的核心工具,它通过收集、分析数据来推断总体特征和规律。本文将系统介绍数理统计的基本概念和方法,并结合 Python 实例,帮助读者更好地理解和应用这些知识。资源绑定附上完整资源供读者参考学习࿰…...

组网技术知识点
1.port-isloate enable命令用于实现两个接口之间的二层数据隔离,三层数据互通。 2.交换机最多支持4096个VLAN,编号为1-4094 3.display bfd session all:查看BFD会话状态是否UP 4.RJ45通过双绞线连接以太网; AUI端口࿱…...

常用电机类型及其特点对比
1. 直流电机 直流电机里边固定有环状永磁体,电流通过转子上的线圈产生安培力,当转子上的线圈与磁场平行时,再继续转受到的磁场方向将改变,因此此时转子末端的电刷跟转换片交替接触,从而线圈上的电流方向也改变&#x…...

SVTAV1源码-set_all_ref_frame_type
set_all_ref_frame_type函数的主要作用是为当前图像设置所有可能用到的参考帧类型,并将这些参考帧类型存储到一个数组中,同时记录总共有多少个参考帧类型,以下是该函数的各部分解释: 初始化和准备 MvReferenceFrame rf[2]; *tot_r…...

Can‘t create thread to handle bootstrap
MySQL在docker里面启动失败 关键性报错Cant create thread to handle bootstrap rootubuntu:/data# docker logs 6835ec900d8c 2025-04-30 23:29:4308:00 [Note] [Entrypoint]: Entrypoint script for MySQL Server 8.0.42-1.el9 started. 2025-04-30 23:29:4308:00 [Note] […...

用Power shell脚本批量发布rdl文件到SQL Server Reporting Service
本文用于介绍如何用Power shell脚本批量发布rdl文件到SQL Server Reporting Service. 用户可根据自己的需要创建类似Publish_All_SSRS.ps1的脚本。 目录 1. 目录结构 2. 创建Base_PublishSSRS.ps1 3. 创建Publish_All_SSRS.ps1 4.注意事项 1. 目录结构 目录结构ÿ…...

2025-03 机器人等级考试四级理论真题 4级
1 2025年蛇年春晚,节目《秧BOT》机器人舞蹈表演节目点燃了全国观众的热情,请问参加节目表演的机器人是由哪家公司研发?( ) A.大疆 B.华为 C.优必选 D.宇树科技 【参考答…...
)
12.SpringDoc OpenAPI 功能介绍(用于生成API接口文档)
12.SpringDoc OpenAPI 功能介绍(用于生成API接口文档) SpringDoc OpenAPI 是一个基于 OpenAPI 3.0/3.1 规范的工具,用于为 Spring Boot 应用生成 API 文档。它是 springfox(Swagger 2.x)的现代替代方案,完全支持 Spring Boot 3.x…...

Java 实用时间工具类:DateUtils 与 DurationFormatUtils
前言 在 Java 项目中,处理日期时间相关的操作极为常见。Apache Commons Lang 提供了两个非常实用的时间工具类:DateUtils 和 DurationFormatUtils,它们分别负责简化日期处理和格式化时间间隔,帮助开发者更高效地进行时间操作。 一…...

Unity3D仿星露谷物语开发40之割草动画
1、目标 当Player选择Scythe后,鼠标悬浮在草上,会显示绿色光标。鼠标左击,会触发割草的动画。 2、优化Settings.cs脚本 添加以下两行代码: // Reaping(收割) public const int maxCollidersToTestPerRe…...

量化交易之数学与统计学基础2.4——线性代数与矩阵运算 | 矩阵分解
量化交易之数学与统计学基础2.4——线性代数与矩阵运算 | 矩阵分解 第二部分:线性代数与矩阵运算 第4节:矩阵分解:奇异值分解(SVD)在数据压缩和风险分解的应用 一、奇异值分解(SVD)基础…...

ES使用之查询方式
文章目录 ES中的数据查询返回字段含义track_total_hits 精准匹配(term)单值匹配多值匹配 全文检索(match)range查询高级查询布尔查询 ES中的数据查询 返回字段含义 track_total_hits track_total_hits是 Elasticsearch 中用于 控制匹配文档总数统计行为 的关键参数。就算…...

力扣-数组-41缺失的第一个正数
思路 关键有两点 原地哈希 把1-len的数分别映射到下标为0 - len-1的地方中 交换后,接着查看下标i被交换过来的数,直到他到了该到的位置或者超出范围 使用while,把不满足映射关系的点一直交换,直到下标指向的位置符合要求 代…...

Nginx — http、server、location模块下配置相同策略优先级问题
一、配置优先级简述 在 Nginx 中,http、server、location 模块下配置相同策略时是存在优先级的,一般遵循 “范围越小,优先级越高” 的原则,下面为你详细介绍: 1. 配置继承关系 http 块:作为全局配置块&…...

管家婆易指开单如何设置零售开单
一,零售设置 1,登录管理员账号-基本信息--职员信息-新建职员及其属于哪个门店。 2,系统维护-系统管理-用户配置-系统配置-切换为“触摸屏模式或者普通零售模式” 3,用户及权限设置-给该员工开通零售及开单等相关的权限 4ÿ…...
:原理、应用与实战)
深入浅出循环神经网络(RNN):原理、应用与实战
1、引言 在深度学习领域,循环神经网络(Recurrent Neural Network, RNN)是一种专门用于处理**序列数据**的神经网络架构。与传统的前馈神经网络不同,RNN 具有**记忆能力**,能够捕捉数据中的时间依赖性,广泛应…...

【Java】打印运行环境中某个类引用的jar版本路径
背景 正式环境出现jar版本不匹配问题,不知道正式环境用的哪个jar版本。通过一下可以打印出类调用的jar // 获取 POIFSFileSystem 类的加载器并打印其来源路径 ClassLoader classloaderPOIFS org.apache.poi.poifs.filesystem.POIFSFileSystem.class.getClassLoade…...

【效率提升】Vibe Coding时代如何正确使用输入法:自定义短语实现Prompt快捷输入
AI时代的效率神器:用搜狗拼音自定义短语实现Prompt快捷输入 在日益依赖AI工具的今天,我们经常需要输入各种复杂的prompt来指导AI完成特定任务。有些同学完全忽视了这一层工作的意义,实际上不同质量的prompt对模型的表现影响是巨大的。&#…...