第二章-科学计算库NumPy
第二章-科学计算库NumPy
Numpy 作为高性能科学计算和数据分析的基础包,是其他重要数据分析工具的基础, 掌握 NumPy 的功能及其用法, 将有助于后续其他数据分析工具的学习.
2.1 认识 NumPy 数组对象
NumPy 中最重要的一个特点就是其 N 维数组对象, 即 ndarray(别名 array) 对象, 该对象具有矢量算术能力和复杂的广播能力, 可以执行一些科学计算. 不同于 Python 标准库, ndarray 对象拥有对高维数组的处理能力, 这也是数值计算中缺一不可的重要特性.
ndarray 对象中定义了一些重要的属性, 具体如下.
| 属性 | 具体说明 |
|---|---|
| ndarray.ndim | 维度个数,也就是数组轴的个数, 比如一维, 二维, 三维等 |
| ndarray.shape | 数组的维度, 这是一个整数的元组, 表示每个维度上数组的大小. 例如, 一个 n 行 m 列的数组, 它的 shape 属性为 (n,m) |
| ndarray.size | 数组元素的总个数, 等于 shape 属性中元组元素的乘积 |
| ndarray.dtype | 描述数组中元素类型的对象, 既可以使用标准的 Python 类型创建或指定, 也可以使用 NumPy 特有的数据类型来指定, 比如 numpy.int32, numpy.float64等 |
| ndarray.itemsize | 数组中每个元素的字节大小. 例如, 元素类型为 float64的数组有 8(64/8) 个字节, 这相当于 ndarray.dtype.itemsize |
值得一提的是, ndarray 对象中存储元素的类型必须是相同的.
具体代码如下.
import numpy as np # 导入 numpy 工具包
data = np.arange(12).reshape(3,4) # 创建一个 3 行 4 列的数据
data
array([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]])
type(data)
numpy.ndarray
data.ndim # 数组维度的个数, 输出结果 2, 表示二维数组
2
data.shape # 数组的维度, 输出结果(3,4), 表示 3 行 4 列
(3, 4)
data.size # 数组元素的个数, 输出结果 12, 表示总共有 12 个元素
12
data.dtype # 数组元素的类型, 输出结果是 dtype('int64')# 表示元素类型都是 int64
dtype('int32')
2.2 创建 NumPy 数组
创建 ndarray 对象的方式有若干种, 其中最简单的方式就是使用 array() 函数, 在调用该函数时传入一个 Python 现有的类型即可, 比如列表, 元组. 例如, 通过 array() 函数分别创建一个一维数组和二维数组, 具体代码如下.
import numpy as np
data1 = np.array([1,2,3]) # 创建一个一维数组
data1
array([1, 2, 3])
data2 = np.array([[1,2,3],[4,5,6]]) # 创建一个二维数组
data2
array([[1, 2, 3],[4, 5, 6]])
除了可以使用 array() 函数创建 ndarray 对象外, 还有其他创建数组的方式, 具体分为以下几种:
- 通过 zeros() 函数创建元素值都是 0 的数组, 示例代码如下.
np.zeros((3,4))
array([[0., 0., 0., 0.],[0., 0., 0., 0.],[0., 0., 0., 0.]])
- 通过调用 ones() 函数创建元素值都是 1 的数组, 示例代码如下.
np_ones = np.ones((3,4))
np_ones
#np_ones.dtype # dtype('float64')
array([[1., 1., 1., 1.],[1., 1., 1., 1.],[1., 1., 1., 1.]])
- 通过 empty() 函数创建一个新的数组, 该数组只分配了内存空间, 它里面填充的元素都是随机的, 且数据类型默认为 float64, 示例代码如下
np.empty((5,2))
array([[6.23042070e-307, 4.67296746e-307],[1.69121096e-306, 1.05695507e-307],[1.89146896e-307, 7.56571288e-307],[3.11525958e-307, 1.24610723e-306],[1.29061142e-306, 5.53353523e-322]])
- 通过 arange() 函数可以创建一个等差数组, 它的功能类似于 range(), 只不过 arange() 函数的返回结果是数组, 而不是列表, 示例代码如下.
np.arange(1,20,5) # 从 1 到 20, 步差为 5
array([ 1, 6, 11, 16])
读者可能注意到, 有些数组元素的后面会跟着一个小数点, 而有些元素后面没有, 比如 1 和 1., 产生这种现象, 主要是因为元素的数据类型不同所导致的.
值得一提的是, 在创建 ndarray 对象时, 我们可以显式的声明数组元素的类型, 示例代码如下.
np.array([1,2,3,4],float)
array([1., 2., 3., 4.])
np.ones((2,3),dtype='float64')
array([[1., 1., 1.],[1., 1., 1.]])
关于 ndarray 对象数据的更多介绍, 将在下面进行讲解.
2.3 ndarray 对象的数据结构
2.3.1 查看数据结构
如前面所述, 通过 “ndarray.dtype” 可以创建一个表示数据类型的对象. 要想获取数据类型的名称, 则需要访问 name 属性进行获取, 示例代码如下.
data_one = np.array([[1,2,3],[4,5,6]])
data_one.dtype.name
'int32'
注意:在默认情况下, 64 位 Windows 系统输出的结果为 int32, 64 位 Linux 或 MacOS 系统输出结果为 int64, 当然也可以通过 dtype 来指定数据类型的长度.
上述代码中, 使用 dtype 属性查看 data_one 对象的类型, 输出的结果为 int32. 从数据类型的命名方式上可以看出, Numpy 的数据类型是有一个类型名(如 int, float)和元素位长的数字组成.
如果在创建数组时, 没有显式的指明数据的类型, 可以根据列表或元组中的元素类型推导出来. 默认情况下, 通过 zeros(), ones(), empty() 函数创建的数组中的数据类型为 float64.
以下是 Numpy 中常用的数据类型.
| 数据类型 | 含义 |
|---|---|
| bool | 布尔类型, 值为 True 或 False |
| int8, uint8 | 有符号和无符号的 8 位整数 |
| int16, uint16 | 有符号和无符号的 16 位整数 |
| int32, uint32 | 有符号和无符号的 32 位整数 |
| int64, uint64 | 有符号和无符号的 64 位整数 |
| float16 | 半精度浮点数(16位) |
| float32 | 半精度浮点数(32位) |
| float64 | 半精度浮点数(64位) |
| complex64 | 复数, 分别用两个 32 位浮点数表示实部和虚部 |
| complex128 | 复数, 分别用两个 64 位浮点数表示实部和虚部 |
| object | Python对象 |
| string_ | 固定长度的字符串类型 |
| unicode | 固定长度的 unicode 类型 |
每一个 Numpy 内置的数据类型都有一个特征码, 它能唯一的标识一种数据类型, NumPy 内置特征码如下.
| 特征码 | 含义 |
|---|---|
| b | 布尔型 |
| i | 有符号整型 |
| u | 无符号整型 |
| f | 浮点型 |
| c | 复数类型 |
| O | Python 对象 |
| S,a | 字节字符串 |
| U | unicode 字符串 |
| V | 原始数据 |
2.3.2 转换数据类型
ndarray 对象的数据类型可以通过 astype() 方法进行转换, 示例代码如下.
data = np.array([[1,2,3],[4,5,6]])
print(data.dtype)
data
int32array([[1, 2, 3],[4, 5, 6]])
float_data = data.astype(np.float64) # 转换数据类型为 float64
print(float_data.dtype)
float_data
float64array([[1., 2., 3.],[4., 5., 6.]])
上述示例中, 将数据类型 int64 转换为 float64, 即整型转换为浮点型. 若希望将数据的类型由浮点型转换为整型, 则需要将小数点后面的部分截掉(不会四舍五入), 具体示例代码如下.
float_data = np.array([1.2,2.3,3.5])
float_data
array([1.2, 2.3, 3.5])
int_data = float_data.astype(np.int64) # 不会四舍五入
int_data
array([1, 2, 3], dtype=int64)
如果数组中的元素是字符串类型的, 且字符串中的每个字符都是数字,也可以使用 astype() 方法将字符串转换为数值类型, 具体示例如下.
str_data = np.array(['1','2','3'])
int_data = str_data.astype(np.int64)
int_data
array([1, 2, 3], dtype=int64)
2.4 数组运算
NumPy 数组不需要遍历循环, 即可对每个元素执行批量的算术运算操作, 这个过程叫做矢量化运算. 不过, 如果两个数组的大小(ndarray.shape)不同, 则它们进行算术运算时会出现广播机制. 除此之外, 数组还支持使用算术运算符与标量进行运算.
2.4.1 矢量化运算
在 NumPy 中, 大小相等的数组之间的任何算术运算都会应用到元素级, 即只用位置相同的元素之间, 所得的运算结果组成一个新的数组. 接下来, 同意一张示意图来描述什么是矢量化运算.
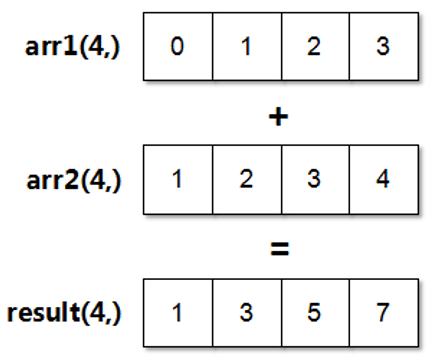
由上述图片可知, 数组 arr1 与 arr2 对齐以后, 会让相同位置的元素相加得到一个新的数组 result. 其中, result 数组中的每个元素为操作数相加的结果, 并且结果的位置跟操作数的位置是相同的.
大小相等的数组之间的算术运算, 示例代码如下.
data1 = np.array([[1,2,3],[4,5,6]])
data2 = np.array([[1,2,3],[4,5,6]])
data1 + data2 # 数组相加
array([[ 2, 4, 6],[ 8, 10, 12]])
data1 * data2 # 数组相乘
array([[ 1, 4, 9],[16, 25, 36]])
data1 - data2 # 数组相减
array([[0, 0, 0],[0, 0, 0]])
data1 / data2 # 数组相除
array([[1., 1., 1.],[1., 1., 1.]])
2.4.2 数组广播
数组在进行矢量化运算时, 要求数组的形状是相等的. 当形状不相等的数组执行算术运算的时候, 就会出现广播机制, 该机制会对数组进行扩展, 使数组的 shape 属性一致, 这样就可以进行矢量化运算了. 示例如下.
arr1 = np.array([[0],[1],[2],[3]])
arr1.shape
(4, 1)
arr2 = np.array([1,2,3])
arr2.shape
(3,)
arr1 + arr2
array([[1, 2, 3],[2, 3, 4],[3, 4, 5],[4, 5, 6]])
上述代码中, 数组 arr1 的 shape 是 (4,1), arr2 的 shape 是 (3,), 这两个数组要是进行相加, 按照广播机制就会对数组 arr1 和 arr2 都进行扩展, 使得数组 arr1 和 arr2 的 shape 都变成 (4,3).
具体数组广播机制实现如图所示.
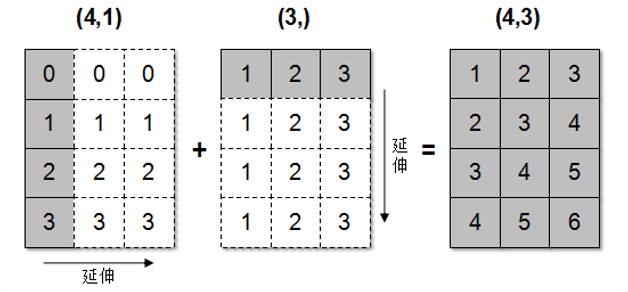
注意: 广播机制实现了对两个或两个以上数组的运算, 即使这些数组的 shape 不是完全相同的, 需要满足如下的条件:
- 数组维度全部相同
- 其中一个数组的某一个维度为 1.
广播机制需要扩展维度小数组, 使得它与维度最大的数组的 shape 值仙童, 以便使用元素级函数或运算符进行运算.
arr3 = np.array([[0,1],[2,3],[4,5],[6,7]])
print(arr3.shape)
arr3
(4, 2)array([[0, 1],[2, 3],[4, 5],[6, 7]])
arr4 = np.array([[1],[2]])
print(arr4.shape)
arr4
(2, 1)array([[1],[2]])
arr3 + arr4 # 相加报错, 两个维度都不相同
---------------------------------------------------------------------------ValueError Traceback (most recent call last)Cell In[52], line 1
----> 1 arr3 + arr4ValueError: operands could not be broadcast together with shapes (4,2) (2,1)
arr5 = np.array([[1,2],[2,3],[3,4]])
print(arr5.shape)
arr5
(3, 2)array([[1, 2],[2, 3],[3, 4]])
arr3 + arr5 # error
# 第一维度:4 和 3 → 不相等且都不为 1 → 无法广播。
# 第二维度:2 和 2 → 相等 → 可以广播。
---------------------------------------------------------------------------ValueError Traceback (most recent call last)Cell In[54], line 1
----> 1 arr3 + arr5ValueError: operands could not be broadcast together with shapes (4,2) (3,2)
2.4.3 数组与标量间的运算
大小相等的数组之间的任何算术运算都会将运算应用到元素级, 同样, 数组与标量的算术运算也会将那个标量值传播给各个元素. 当数组进行相加, 相减, 乘以或除以一个数字时, 这些被称为标量运算. 标量运算会产生一个与数组具有相同数量的行和列的新矩阵, 其原始矩阵的每个元素都被相加, 相减, 乘以或者相除.
数组和标量之间的运算, 示例代码如下.
import numpy as np
data1 = np.array([[1,2,3],[4,5,6]])
data1 + 10
array([[11, 12, 13],[14, 15, 16]])
data1 - 10
array([[-9, -8, -7],[-6, -5, -4]])
data1 * 10
array([[10, 20, 30],[40, 50, 60]])
data1 / 10
array([[0.1, 0.2, 0.3],[0.4, 0.5, 0.6]])
2.5 ndarray 的索引和切片
ndarray 对象支持索引和切片操作, 且提供了比常规 Python 序列更多的索引功能, 除了使用整数进行索引以外, 还可以使用整数数组和布尔数组进行索引.
2.5.1 整数索引和切片的基本使用
ndarray 对象的元素可以通过索引和切片来访问和修改, 就像 Python 内置的容易对象一样, 下面是一个一维数组, 从表面上来看, 该数组使用索引和切片的方式与 Python 列表的功能相差不大, 具体代码如下.
import numpy as np
arr = np.arange(8)
arr
array([0, 1, 2, 3, 4, 5, 6, 7])
arr[5] # 获取索引(下标)为 5 的元素
5
arr[3:5] # 获取索引从 3~5 的元素, 但不包括 5
array([3, 4])
arr[1:6:2] # 获取索引从 1~6 的元素, 步长为 2
array([1, 3, 5])
不过, 对于多维数组, 索引和切片的使用方式与列表就大不一样了. 在二维数组中, 每个索引位置上的元素不再是一个标量了, 而是一个一维数组, 具体代码示例如下.
arr2d = np.array([[1,2,3],[4,5,6],[7,8,9]]) # 创建二维数组
arr2d
array([[1, 2, 3],[4, 5, 6],[7, 8, 9]])
arr2d[1] # 获取索引为 1 的元素
array([4, 5, 6])
此时, 如果我们想通过索引的方式来获取二维数组的单个元素, 就需要通过形如 "arr[x,y]", 以逗号分割的索引来实现. 其中, x 表示行号, y 表示列号. 示例代码如下.
arr2d[0,1] # 获取第 0 行第 1 列的元素
2
下面, 通过一张图来描述数组 arr2d 的索引方式, 如下图所示.
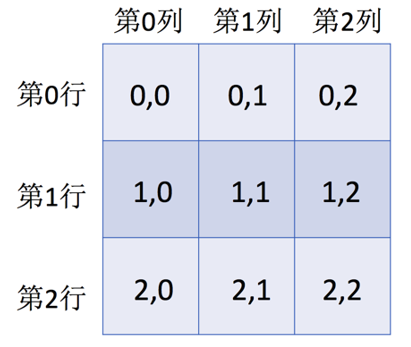
从图中可以看出, arr2d 是一个 3 行 3 列的数组, 如果我们想获取数组的单个元素, 必须同时指定这个元素的行索引和列索引. 例如, 获取索引位置为第 1 行第 1 列的元素, 我们可以通过 arr2d[1,1] 来实现.
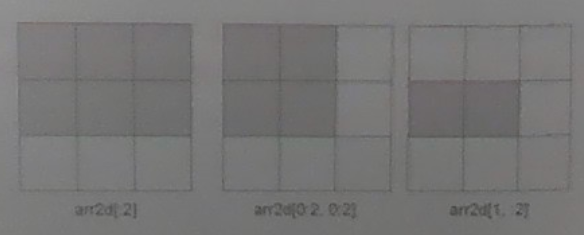
相比一维数组, 多维数组的切片方式花样更多, 多维数组的切片是沿着行或列的方向选取元素的, 我们可以传入一个切片, 也可以传入多个切片, 还可以将切片与整数索引混合使用.
# 多维数组传入一个切片
arr2d[:2]
array([[1, 2, 3],[4, 5, 6]])
# 多维数组传入两个切片
arr2d[0:2,0:2]
array([[1, 2],[4, 5]])
# 切片与整数索引混合使用
arr2d[1,:2]
array([4, 5])
上述多维数组切片操作的相关示意图如下.
2.5.2 花式(数组)索引的基本使用
花式索引是 Numpy 的一个术语, 是指将整数数组或列表作为索引, 然后根据索引数组或索引列表的每个元素作为目标数组的下标再进行取值.
- 当使用一维数组或列表作为索引时, 如果使用索引要操作的目标是一维数组, 则获取的结果是对应下标的元素;
- 如果要操作的目标是一个二维数组, 则获取的结果就是对应下标的一行数据.
例如, 创建一个 4 行 4 列的二维数组, 示例代码如下.
import numpy as np
demo_arr = np.empty((4,4)) # 4 行 4 列的空数组
for i in range(4): # 遍历 4 行demo_arr[i] = np.arange(i,i+4) # 每一行一个数组从 [i ~ i+4)
demo_arr
array([[0., 1., 2., 3.],[1., 2., 3., 4.],[2., 3., 4., 5.],[3., 4., 5., 6.]])
将 [0,2] 作为索引, 分别获取 demo_arr 中索引 0 对应的一行数据以及索引 2 对应的一行数据, 示例代码如下.
demo_arr[[0,2]] # 获取索引为 [0,2] 的元素行
array([[0., 1., 2., 3.],[2., 3., 4., 5.]])
上述操作的相关示意图如下.

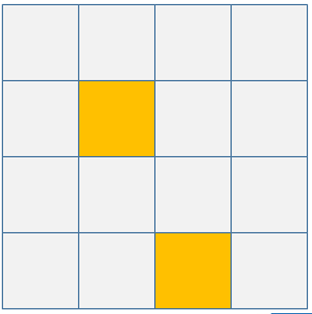
如果使用两个花式索引操作数组时, 即两个列表或数组, 则会将第 1 个作为行索引, 第 2 个作为列索引, 通过二维数组索引的方式, 选取其对应位置的元素, 示例代码如下.
demo_arr[[1,3],[1,2]] # 获取索引为 (1,1) 和 (3,2) 的元素
array([2., 5.])
上述操作的相关示意图如下.
2.5.3 布尔型索引的基本使用
布尔型索引指的是将一个布尔数组作为数组索引, 返回的数据是布尔数组中 True 对应位置的值.
假设现在有一组存储了学生姓名的数组, 以及一组存储了学生各科成绩的数组, 存储学生成绩的数组中, 每一行成绩对应的是一个学生的成绩. 如果我们想筛选某个学生对应的成绩, 可以通过比较运算符, 先产生一个布尔型数组, 然后利用布尔型数组作为索引, 返回布尔值 True 对应位置的数据. 示例代码如下:
# 存储学生姓名的数组
student_name = np.array(["Tom","Lily","Jack","Rose"])
student_name
array(['Tom', 'Lily', 'Jack', 'Rose'], dtype='<U4')
# 存储学生成绩的数组
student_score = np.array([[79,88,80],[89,90,92],[83,78,85],[78,76,80]])
student_score
array([[79, 88, 80],[89, 90, 92],[83, 78, 85],[78, 76, 80]])
# 对 student_name 和字符串 "Jack" 通过运算符产生一个布尔型数组
student_name == "Jack"
array([False, False, True, False])
# 将布尔数组作为索引应用与存储成绩的数组 student_score,
# 返回的数据是 True 值对应的行
student_score[student_name == "Jack"]
array([[83, 78, 85]])
布尔索引的相关示意图如下.
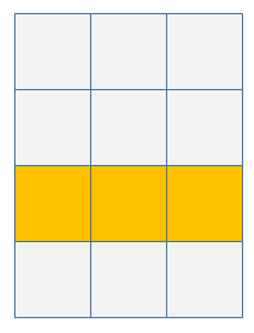
需要注意的是, 布尔型数组的长度必须和被索引的轴长度一致.
此外, 我们还可以将布尔型数组跟切片混合使用, 示例代码如下:
student_score[student_name == "Jack", :1]
array([[83]])
值得一提的是, 使用布尔型索引获取值的时候, 除了可以使用 "==" 运算符, 还可以使用诸如 "!=", "-" 来进行否定, 也可以使用 "&"和"|"等符号来组合多个布尔条件.
2.6 数组的转置和轴对称
数组的转置是指将数组中的每个元素按照一定的规则进行位置变换. NumPy 提供了 transpose() 方法和 T 属性两种实现形式. 其中, 简单的转置可以使用 T 属性, 它其实就是进行轴对换而已. 例如, 现在有个 3 行 4 列的二维数组, 那么使用 T 属性对数组转置后, 形成的是一个 4 行 3 列的新数组, 示例代码如下.
arr = np.arange(12).reshape(3,4)
arr
array([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]])
arr.T # 使用 T 属性对数组进行转置
array([[ 0, 4, 8],[ 1, 5, 9],[ 2, 6, 10],[ 3, 7, 11]])
对于高纬度的数组而言, transpose() 方法需要得到一个由轴编号组成的元组, 才能对这些轴进行转置. 假设现在有个数组 arr, 具体代码如下:
arr = np.arange(16).reshape((2,2,4)) # 2 面 2 行 4 列
arr
array([[[ 0, 1, 2, 3],[ 4, 5, 6, 7]],[[ 8, 9, 10, 11],[12, 13, 14, 15]]])
arr.shape
(2, 2, 4)
上述数组 arr 的 shape 是 (2,2,4), 表示是一个三维数组, 也就是说有三个轴, 每个轴都对应着一个编号, 分别是 0, 1, 2.
如果希望对 arr 进行转置操作, 就需要对它的 shape 中的顺序进行调换. 也就是说, 当使用 transpose() 方法对函数的 shape 进行变换时, 需要以元组的形式传入 shape 的编号, 比如 (1,2,0).如果调用 transpose() 方法时传入 "(0,1,2)" ,则数组的 shape 不会发生任何变化.
下面是 arr 调用 transpose(1,2,0) 的示例, 具体代码如下
arr.transpose(1,2,0) # 使用 transpose() 方法对数组进行转置
array([[[ 0, 8],[ 1, 9],[ 2, 10],[ 3, 11]],[[ 4, 12],[ 5, 13],[ 6, 14],[ 7, 15]]])
转换过程如图:

如果我们不输入任何参数, 直接调用 transpose() 方法, 则其执行的效果就是将数组进行转置, 作用等价于 transpose(2,1,0). 具体结果如下图所示.

在某些情况下, 我们可能只需要转换其中的两个轴, 这时我们可以使用 ndarray 提供的 swapaxes() 方法实现, 该方法需要接收一对轴编号, 示例代码如下.
arr
array([[[ 0, 1, 2, 3],[ 4, 5, 6, 7]],[[ 8, 9, 10, 11],[12, 13, 14, 15]]])
arr.swapaxes(1,0) # 使用 swapaxes 方法插入一对小括号对数组进行转置
array([[[ 0, 1, 2, 3],[ 8, 9, 10, 11]],[[ 4, 5, 6, 7],[12, 13, 14, 15]]])
多学一招: 轴编号
在 NumPy 中维度(dimensions)叫做轴(axes), 轴的个数叫做秩(rank). 例如, 3D 空间中有个点的坐标[1,2,1]是一个秩为 1 的数组, 因为它只有一个轴. 这个轴有 3 个元素, 所以我们说它长度为 3.
在下面的示例中, 数组有 2 个轴, 第一个轴的长度为32, 第二个轴的长度为 3.
np.array([[1,0,0],[0,1,2]])
array([[1, 0, 0],[0, 1, 2]])
2.7 NumPy 通用函数
在 NumPy 中, 提供了诸如 "sin", "cos" 和 "exp" 等常见的数学函数, 这些函数叫做通用函数(ufunc). 通用函数是一种针对 ndarray 中的数据执行元素级运算的函数, 函数返回的是一个新的数组. 通常情况下, 我们将 ufunc 中接受的一个数组参数的函数称为一元通用函数. 而接收两个数组参数的称为二元通用函数. 下面是一些常见的一元和二元通用函数.
| 常见一元的通用函数函数 | 描述 |
|---|---|
| abs, fabs | 计算整数, 浮点数或复数的绝对值 |
| sqrt | 计算各元素的平方根 |
| square | 计算各元素的平方 |
| exp | 计算各元素的指数 e 的 x 次方 |
| log, log10, log2, log1p | 分别为自然对数(底数为e), 底数为 10 的 log, 底数为 2 的log, log(1+x) |
| sign | 计算各元素的正负号: 1(正数), 0(零), -1(负数) |
| ceil | 计算各元素的 ceilling 值, 即大于或者等于该值的最小整数 |
| floor | 计算各元素的 floor 值, 即小于等于该值的最大整数 |
| rint | 将各元素四舍五入到最接近的整数 |
| modf | 将数组的小数和整数部分以两个独立数组的形式返回 |
| isnan | 返回一个表示 “哪些值是 NaN” 的布尔型数组 |
| isfinite, isinf | 分别返回表示 “那些元素是有穷的” 或 “哪些元素是无穷” 的布尔型数组 |
| sin, sinh, cos, cosh, tan, tanh | 普通型和双曲型三角函数 |
| arcos,arccosh,arcsion | 反三角函数 |
| 常见二元通用函数 | 描述 |
|---|---|
| add | 数组对应的元素相加 |
| subtract | 从第一个数组中减去第二个数组中的元素 |
| multiply | 数组元素相乘 |
| divide,floor_divide | 除法或向下整除法(舍去余数) |
| maximum, fmax | 元素级的最大值计算 |
| minimum, fmin | 元素级的最小值计算 |
| mod | 元素级取余 |
| copysign | 将第二个数组中的值的符号赋值给第一个数组中的值 |
| greater,greater_equal,less,less-equal,equal,not_equal,logical_and,logical_or,logical_xor | 执行元素级的比较运算, 最终产生布尔型数组, 相当于运算符 >,>=,<,<=,==,!= |
为了更好理解, 接下来, 通过一些代码来演示上述部分函数的用法. 有关一元通用函数的示例代码如下.
import numpy as np
arr = np.array([4,9,16])
# 计算数组元素的平方根
np.sqrt(arr)
array([2., 3., 4.])
# 计算数组元素的绝对值
np.abs(arr)
array([ 4, 9, 16])
# 计算数组元素的平方
np.square(arr)
array([ 16, 81, 256])
有关二元通用函数的示例代码如下
x = np.array([12,9,13,15])
y = np.array([11,10,4,8])
# 计算两个数组的和
np.add(x,y)
array([23, 19, 17, 23])
# 计算两个数组的乘积
np.multiply(x,y)
array([132, 90, 52, 120])
# 两个数组元素级最大值的比较
np.maximum(x,y)
array([12, 10, 13, 15])
# 执行元素级的比较操作
np.greater(x,y)
array([ True, False, True, True])
2.8 利用 NumPy 数组进行数据处理
NumPy 数组可以将许多数据处理任务转换为简洁的数组表达式, 它处理数据的速度要比内置的 Python 循环快了至少一个数量级, 所以, 我们把数组作为处理数据的首选. 接下来, 本章节将讲解如何利用数组来处理数据, 包括条件逻辑, 统计, 排序, 检索数组元素以及唯一化.
2.8.1 将条件逻辑转为数组运算
NumPy 的 where() 函数是三元表达式 x if condition else y 的矢量化版本.
假设有两个数值类型的数组和一个布尔类型的数组, 具体如下:
import numpy as np
arr_x = np.array([1,5,7])
arr_y = np.array([2,6,8])
arr_con = np.array([True,False,True])
现在提出一个需求, 即当 arr_con 的元素值为 True 时, 从 arr_x 数组中获取一个值, 否则从 arr_y 数组中获取一个值. 使用 where() 函数实现的方式如下所示.
result = np.where(arr_con, arr_x, arr_y)
result
array([1, 6, 7])
2.8.2 数组统计运算
通过 NumPy 库中的相关方法, 我们可以很方便的运用 Python 进行数组的统计汇总, 比如, 计算数组极大值, 极小值以及平均值等. 下面是 NumPy 数组中与统计运算相关的方法.
| 方法 | 描述 |
|---|---|
| sum | 对数组中全部或某个轴向的元素求和 |
| mean | 算术平均值 |
| min | 计算数组中的最小值 |
| max | 计算数组中的最大值 |
| argmin | 表示最小值的索引 |
| argmax | 表示最大值的索引 |
| cumsum | 所有元素的累计和 |
| cumprod | 所有元素的累计乘积 |
需要注意的是, 当使用 ndarray 对象调用 cumsum() 和cumprod() 方法后, 产生的结果是一个由中间结果组成的数组.
下面是一些示例.
arr = np.arange(10)
print(arr)
arr.sum() # 求和
[0 1 2 3 4 5 6 7 8 9]45
arr.mean() # 求平均值
4.5
arr.min() # 求最小值
0
arr.max() # 求最大值
9
arr.argmin() # 最小值的下标
0
arr.argmax() # 最大值的下标
9
arr.cumsum() # 元素的累计和
array([ 0, 1, 3, 6, 10, 15, 21, 28, 36, 45])
arr.cumprod() # 元素的累计乘积
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
2.8.3 数组排序
如果希望对 NumPy 数组中的元素进行排序, 可以通过 sort() 方法实现, 示例代码如下.
arr = np.array([[6,2,7],[3,6,2],[4,3,2]])
arr
array([[6, 2, 7],[3, 6, 2],[4, 3, 2]])
arr.sort()
arr
array([[2, 6, 7],[2, 3, 6],[2, 3, 4]])
从上述代码可以看出, 当调用 sort() 方法后, 数组 arr 中数据按行从小到大进行排序. 需要注意的是, 使用 sort() 方法排序会修改数组本身.
如果希望对任何一个轴上的元素进行排序, 只需要将轴的编号作为 sort() 方法的参数传入即可. 示例代码如下.
arr = np.array([[6,2,7],[3,6,2],[4,3,2]])
arr
array([[6, 2, 7],[3, 6, 2],[4, 3, 2]])
arr.sort(0)
arr
array([[3, 2, 2],[4, 3, 2],[6, 6, 7]])
理解: arr.sort(0) 的直观操作
- 轴0(行方向):想象你 从上到下垂直移动(处理每一列)。
- 轴1(列方向):想象你 从左到右水平移动(处理每一行)。
当执行 arr.sort(0)(沿轴0排序)时:
- 操作方向:从上到下(垂直方向)。
- 具体行为:对 每一列 独立排序(每一列的数字按升序排列)。
原始数组:
列0 列1 列2↓ ↓ ↓
[6, 2, 7] ← 行0
[3, 6, 2] ← 行1
[4, 3, 2] ← 行2沿轴0(列方向)排序后的结果:
列0排序 ↓ 列1排序 ↓ 列2排序 ↓[3, 2, 2] ← 行0[4, 3, 2] ← 行1[6, 6, 7] ← 行2
关键理解
- 为什么叫「沿行方向处理」?
因为你在处理时,沿着行的方向(上下移动),依次处理每一列的数据(比如先处理列0,再处理列1)。
2.8.4 检索数组元素
在 NumPy 中, all() 函数用于判断整个数组中的元素的值是否完全满足条件, 如果满足条件返回 True, 否则返回 False. any() 函数用于判断整个数组中的元素至少有一个满足条件就返回 True, 否则返回 False.
使用 all() 和 any() 函数检索数组元素的示例代码如下.
arr = np.array([[1,-2,-7],[-3,6,2],[4,3,2]])
arr
array([[ 1, -2, -7],[-3, 6, 2],[ 4, 3, 2]])
np.any(arr>0) # arr 的所有元素是否有一个大于 0
True
np.all(arr>0) # arr 的所有元素是否都大于 0
False
2.8.5 唯一化及其他集合逻辑
针对一维数组, NumPy 提供了 unique() 函数来找出数组中的唯一值, 并返回排序后的结果, 示例代码如下.
arr = np.array([12,11,34,23,12,8,11])
np.unique(arr) # 去重
array([ 8, 11, 12, 23, 34])
除此之外, 还有一个 in1d() 函数用于判断数组中的元素是否在另一个数组中存在, 该函数返回的是一个布尔型的数组, 示例代码如下.
np.in1d(arr,[11,12])
array([ True, True, False, False, True, False, True])
NumPy 提供的有关集合的函数还有很多, 下面是数组集合运算的常见函数.
| 函数 | 描述 |
|---|---|
| unique(x) | 计算 x 中的唯一元素, 并返回有序结果 |
| intersect1d(x,y) | 计算 x 和 y 中的公共元素, 并返回有序结果 |
| union1d(x,y) | 计算 x 和 y 的并集, 并返回有序结果 |
| in1d(x,y) | 得到一个表示"x 的元素是否包含 y"的布尔型数组 |
| setdiff1d(x,y) | 集合的差, 即元素在 x 中且不在 y 中 |
| setxor1d(x,y) | 集合的对称差, 即存在于一个数组中但不同时存在于两个数组中的元素 |
2.9 线性代数模块
线性代数是数学运算中的一个重要工具, 它在图形信号处理, 音频信号处理中起非常重要的作用. numpy.linalg 模块中有一组标准的矩阵分解运算以及诸如逆和行列式之类的东西. 例如, 矩阵相乘, 如果通过 “*” 对两个数组相乘, 得到的是一个元素级的乘积, 而不是一个矩阵点积.
NumPy 中提供了一个用于矩阵乘法的 dot() 方法, 该方法的用法示例如下.
import numpy as np
arr_x = np.array([[1,2,3],[4,5,6]])
arr_y = np.array([[1,2],[3,4],[5,6]])
print(arr_x)
print(arr_y)
arr_x.dot(arr_y) # 等价于 np.dot(arr_x,arr_y)
[[1 2 3][4 5 6]]
[[1 2][3 4][5 6]]array([[22, 28],[49, 64]])
矩阵点积的条件是矩阵A的列数等于矩阵B的行数, 假设 A 为 m✕p 的矩阵, B 为 p✕n 的矩阵, 那么矩阵 A 与 B 的乘积就是一个 m✕n 的矩阵 C, 其中矩阵 C 的第 i 行第 j 列的元素可以表示为:
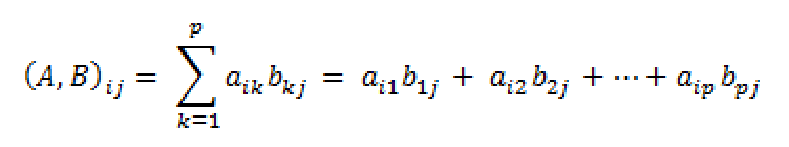
上述矩阵 arr_x 与 arr_y 的乘积如下图所示.
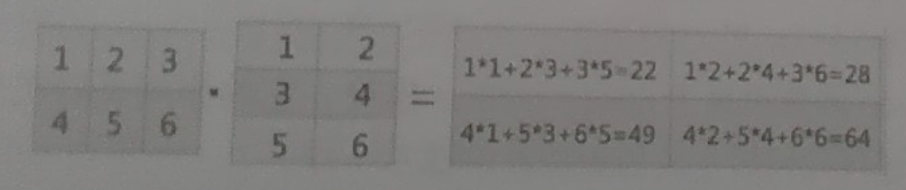
除此之外, linalg 模块中还提供了其他很多有用的函数, 具体如下.
| 函数 | 描述 |
|---|---|
| dot | 矩阵乘法 |
| diag | 以一维数组的形式返回方阵的对角线, 或将一维数组转为方阵 |
| trace | 计算对角线元素和 |
| det | 计算矩阵的行列式 |
| eig | 计算方阵的特征值和特征向量 |
| inv | 计算方阵的逆 |
| qr | 计算 qr 分解 |
| svd | 计算奇异值(SVD) |
| solve | 解线性方程组 Ax=b, 其中 A 是一个方阵 |
| 1stsq | 计算 Ax=b 的最小二乘解 |
2.10 随机数模块
与 Python 的 random 模块相比, NumPy 的 random 模块功能更多, 它增加了一些可以高效生成多种概率分布的样本值的函数. 例如, 通过 NumPy 的 random 模块随机生成了一个 3 行 3 列的数组, 示例代码如下.
import numpy as np
np.random.rand(3,3) # 随机生成一个二维数组
array([[0.15259203, 0.96894671, 0.11222132],[0.49061311, 0.97040608, 0.50455898],[0.04179985, 0.8569699 , 0.8445863 ]])
上述代码中, rand() 函数隶属于 numpy.random 模块, 它的作用是随机生成 N 维浮点数组. 需要注意的是, 每次运行代码后生成的随机数组都不一样.
除此之外, random 模块中还包括了可以生成服从多种概率分布随机数的其他函数. 下面列举了 numpy.random 模块中用于生成大量样本值的函数.
| random 模块的常见函数 | 描述 |
|---|---|
| seed | 生成随机数的种子 |
| rand | 产生均匀分布的样本值 |
| randint | 从给定的上下限范围内随机选取整数 |
| normal | 产生正态分布的样本值 |
| beta | 产生 Beta 分布的样本值 |
| uniform | 产生在 [0,1] 中的均匀分布的样本值 |
在上面的函数中, seed() 函数可以保证生成的随机只具有可预测性, 也就是说产生的随机数相同, 它的语法格式如下:
numpy.random.seed(seed=none)
上述函数中只有一个 seed 参数, 用于指定随机数生成时所用算法开始的整数值. 当调用 seed() 函数时, 如果传递给 seed 参数的值相同, 则每次生成的随机数都是一样的. 如果不传递这个参数值, 则系统会根据时间来自己选择值, 此时每次生成的随机数会因时间差异而不同.
使用 seed() 函数的示例代码如下.
np.random.seed(0) # 生成随机数的种子
np.random.rand(5) # 随机生成包含 5 个元素的浮点数组
array([0.5488135 , 0.71518937, 0.60276338, 0.54488318, 0.4236548 ])
np.random.seed(0)
np.random.rand(5)
array([0.5488135 , 0.71518937, 0.60276338, 0.54488318, 0.4236548 ])
np.random.seed()
np.random.rand(5)
array([0.62979455, 0.48687157, 0.23137517, 0.71878505, 0.93389724])
由此可见, seed() 函数使得随机数具有预见性. 当传递的参数值不同或者不传递参数时, 则该函数的作用跟 rand() 函数相同, 即多次生成随机数且每次生成的随机数都不同.
{% note success flat %}
小结
本章主要针对科学计算哭 NumPy 进行了介绍, 包括 ndarray 数组对象的属性和数据类型, 数组的运算, 索引和切片操作, 数组的转置和轴对称个, NumPy 通用函数, 线性代数模块, 随机数模块, 以及使用数组进行数据处理的相关操作.
{% endnote %}
相关文章:

第二章-科学计算库NumPy
第二章-科学计算库NumPy Numpy 作为高性能科学计算和数据分析的基础包,是其他重要数据分析工具的基础, 掌握 NumPy 的功能及其用法, 将有助于后续其他数据分析工具的学习. 2.1 认识 NumPy 数组对象 NumPy 中最重要的一个特点就是其 N 维数组对象, 即 ndarray(别名 array) 对象…...

3.2goweb框架GORM
GORM 是 Go 语言中功能强大的 ORM(对象关系映射)框架,支持 MySQL、PostgreSQL、SQLite、SQL Server 等主流数据库。以下是 GORM 的核心概念和用法详解: 一、基础入门 1. 安装 go get -u gorm.io/gorm go get -u gorm.io…...

KUKA机器人不同的用户权限详细介绍
对于KUKA机器人,主菜单里有一个“用户组”的登录,不同的用户组对应不同的权限。 一、KUKA示教器正常开机后显示以下界面,对于8.5及以上的系统,增加了快捷登录用户组的符号 ,直接点击即可打开。在 smartHMI 上&…...

AI对IT行业的重塑:挑战与机遇并存的技术革命
一、必要性:AI成为IT行业的基础设施 在云计算、大数据和物联网构成的数字生态中,AI技术已成为IT行业的"水电煤"。以微软Azure为例,其AI云服务支撑着全球超过85%的《财富》500强企业,通过机器学习模型自动优化服务器集群…...

利用IEEE异常机制优化Fortran浮点数计算
利用IEEE异常机制优化Fortran浮点数计算 在Fortran程序中,IEEE浮点异常机制可以帮助你检测和优化浮点数计算,提高数值稳定性和程序健壮性。以下是几种利用IEEE异常机制优化浮点数计算的方法: 1. 启用和检测IEEE异常 现代Fortran࿰…...

构建网页版IPFS去中心化网盘
前言:我把它命名为无限网盘 Unlimited network disks(ULND),可以实现简单的去中心化存储,其实实现起来并不难,还是依靠强大的IPFS,跟着我一步一步做就可以了。 第一步:准备开发环境…...

【solidity基础】一文说清楚合约函数的大小事
在 Solidity 里,函数是合约的关键构成部分,用于执行特定任务或操作的代码块,可以包含逻辑、访问状态变量、进行计算,并且可以接受参数和返回值。 但是solidity 的函数与其他语言不太一样,经常会有同学搞混,这里开一篇文章完整介绍一下 solidity 函数的用法。 1. 函数定…...

用Python构建自动驾驶传感器融合算法:从理论到实践
用Python构建自动驾驶传感器融合算法:从理论到实践 随着自动驾驶技术的飞速发展,传感器在自动驾驶系统中的作用愈发重要。传感器不仅是车辆感知外部环境的“眼睛”,它们提供的信息也是自动驾驶决策系统的基础。然而,单一传感器的感知能力是有限的。为了提升自动驾驶系统的…...

PLC与工业电脑:有什么区别?
随着工业部门的快速发展,自动化已经从奢侈品转变为绝对必需品。世界各地的工业越来越多地采用工业自动化来提高效率、提高精度并最大限度地减少停机时间。这场自动化革命的核心是两项关键技术:可编程逻辑控制器(PLC)和电脑&#x…...

机器学习:在虚拟环境中使用 Jupyter Lab
机器学习:在虚拟环境中使用 Jupyter Lab 第一步:激活虚拟环境 打开终端(CMD/PowerShell)并执行: $cmd #激活虚拟环境 $conda activate D:\conda_envs\mll_env 激活后,终端提示符前会显示环境名称&…...

Arduino项目实战与编程技术详解
一、智能避障小车:超声波传感器与PWM电机控制 1.1 硬件需求与工作原理 智能避障小车的核心在于超声波传感器与电机驱动模块的协同工作。超声波传感器(HC-SR04)通过发射高频声波并接收回波来测量距离,而L298N电机驱动模块则负责控制两个直流电机的转向与速度。 1.1.1 超声…...
)
AI数字人:人类身份与意识的终极思考(10/10)
文章摘要:AI数字人技术正在引发从"像素复刻"到"意识投射"的范式革命,多模态交互、神经辐射场等技术突破推动数字人从工具属性迈向虚拟主体。其发展伴随身份认同危机、伦理困境,促使人类重新思考自我认知与"人之为人…...

【单例模式】简介
目录 概念理解使用场景优缺点实现方式 概念理解 单例模式要保证一个类在整个系统运行期间,无论创建多少次该类的对象,始终只会有一个实例存在。就像操作系统中的任务管理器,无论何时何地调用它,都是同一个任务管理器在工作&#…...

安凯微以创新之芯,赋能万物智能互联新时代
在全球半导体产业步入深度调整期的当下,安凯微用一份“技术浓度”远超“财务数字”的年报,向市场传递出其作为物联网智能硬件核心SoC芯片领军者的战略定力。面对行业短期波动,公司选择以技术纵深突破与生态价值重构为锚点,在逆势中…...

TIME_WAIT状态+UDP概念及模拟实现服务器和客户端收发数据
目录 一、TIME_WAIT状态存在的原因 二、TIME_WAIT状态存在的意义 三、TIME_WAIT状态的作用 四、UDP的基本概念 4.1 概念 4.2 特点 五、模拟实现UDP服务器和客户端收发数据 5.1 服务器udpser 5.2 客户端udpcil 一、TIME_WAIT状态存在的原因 1.可靠的终止TCP连接。 2.…...
:性能测试与性能优化)
高并发内存池(五):性能测试与性能优化
前言 在前几期的实现中,我们完成了tcmalloc基础的内存管理功能,但还存在两个关键问题: 未处理超过256KB的大内存申请。 前期测试覆盖不足,导致多线程场景下隐藏了一些bug。 本文将修复这些问题,并实现三个目标&…...

景联文科技牵头起草的《信息技术 可扩展的生物特征识别数据交换格式 第4部分:指纹图像数据》国家标准正式发布
2025年3月28日,由景联文科技作为第一起草单位主导编制的国家标准GB/T 45284.4-2025 《信息技术 可扩展的生物特征识别数据交换格式 第4部分:指纹图像数据》正式获批发布,将于2025年10月1日开始实施。该标准的制定标志着我国生物特征识别领域标…...

完美解决 mobile-ffmpeg Not overwriting - exiting
在使用ffmpeg库 ,有pcm转换到 aac的过程中报错 mobile-ffmpeg Not overwriting - exiting终于在网上翻到,在output 输出文件的地方加 -y, 重复覆盖的意思,完美解决。...
)
4:QT联合HALCON编程—机器人二次程序抓取开发(九点标定)
判断文件是否存在 //判断文件在不在 int HandEyeCalib::AnsysFileExists(QString FileAddr) {QFile File1(FileAddr);if(!File1.exists()){QMessageBox::warning(this,QString::fromLocal8Bit("提示"),FileAddrQString::fromLocal8Bit("文件不存在"));retu…...

C语言之操作符
目录 1. 操作符的分类 2. 移位操作符 2.1 左移操作符 << 2.2 右移操作符 >> 3. 位操作符 3.1 按位与 & 3.2 按位或 | 3.3 按位异或 ^ 3.4 按位取反 ~ 3.5 例题 3.5.1 按位异或 ^ 拓展公式 3.5.2 不能创建临时变量(第三个变量ÿ…...

【优选算法 | 前缀和】前缀和算法:高效解决区间求和问题的关键
算法相关知识点可以通过点击以下链接进行学习一起加油!双指针滑动窗口二分查找 在本篇文章中,我们将深入解析前缀和算法的原理。从基础概念到实际应用,带你了解如何通过前缀和高效解决数组求和、区间查询等问题。无论你是刚接触算法的新手&am…...

『深夜_MySQL』详解数据库 探索数据库是如何存储的
1. 数据库基础 1.1 什么是数据库 存储数据用文件就可以了,那为什么还要弄个数据库? 一般的文件缺失提供了数据的存储功能,但是文件并没有提供非常好的数据管理能力(用户角度,内容方面) 文件保存数据有以…...

Microsoft Entra ID 免费版管理云资源详解
Microsoft Entra ID(原 Azure AD)免费版为企业提供了基础的身份管理功能,适合小型团队或预算有限的组织。以下从功能解析到实战配置,全面展示如何利用免费版高效管理云资源。 1. 免费版核心功能与限制 1.1 功能概览 功能免费版支持情况基础用户与组管理✔️ 支持创建、删除…...

k8s -hpa
hpa定义弹性自动伸缩 1、横向伸缩,当定义的cpu、mem指标达到hpa值时,会触发pods伸展 2、安装metrics-server 收集pods的cpu。mem信息供hpa参照 安装helm curl -fsSl -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 用helm安装metr…...

Web应用开发指南
一、引言 随着互联网的迅猛发展,Web应用已深度融入日常生活的各个方面。为满足用户对性能、交互与可维护性的日益增长的需求,开发者需要一整套高效、系统化的解决方案。在此背景下,前端框架应运而生。不同于仅提供UI组件的工具库,…...

Vue3 + TypeScript 实现 PC 端鼠标横向拖动滚动
功能说明 拖动功能: 鼠标按下时记录初始位置和滚动位置拖动过程中计算移动距离并更新滚动位置松开鼠标后根据速度实现惯性滚动 滚动控制: 支持鼠标滚轮横向滚动(通过 wheel 事件)自动边界检测防止滚动超出内容…...

MyBatis的SQL映射文件中,`#`和`$`符号的区别
在MyBatis的SQL映射文件中,#和$符号用于处理SQL语句中的参数替换,但它们的工作方式和使用场景有所不同。 #{} 符号 预编译参数:#{} 被用来作为预编译SQL语句的占位符。这意味着MyBatis会将你传入的参数设置为PreparedStatement的参数,从而防止SQL注入攻击,并允许MyBatis对…...
)
Python----卷积神经网络(池化为什么能增强特征)
一、什么是池化 池化(Pooling)是卷积神经网络(CNN)中的一种关键操作,通常位于卷积层之后,用于对特征图(Feature Map)进行下采样(Downsampling)。其核心目的是…...
)
React Native 从零开始完整教程(环境配置 → 国内镜像加速 → 运行项目)
React Native 从零开始完整教程(环境配置 → 国内镜像加速 → 运行项目) 本教程将从 环境配置 开始,到 国内镜像加速,最后成功运行 React Native 项目(Android/iOS),适合新手和遇到网络问题的开…...
)
SNR8016语音模块详解(STM32)
目录 一、介绍 二、传感器原理 1.原理图 2.引脚描述 三、程序设计 main文件 usart.h文件 usart.c文件 四、实验效果 五、资料获取 项目分享 一、介绍 SNR8016语音模块是智纳捷科技生产的一种离线语音识别模块,设计适合用于DIY领域,开放用户设…...
设备初始化)
驱动开发系列54 - Linux Graphics QXL显卡驱动代码分析(一)设备初始化
一:概述 QXL 是QEMU支持的一种虚拟显卡,用于虚拟化环境中的图形加速,旨在提高虚拟机的图形显示和远程桌面的用户体验;QEMU 也称 Quick Emulator,快速仿真器,是一个开源通用的仿真和虚拟化工具,可…...

通过IP计算分析归属地
在产品中可能存在不同客户端,请求同一个服务端接口的场景。 例如小程序和App或者浏览器中,如果需要对请求的归属地进行分析,前提是需要先获取请求所在的国家或城市,这种定位通常需要主动授权,而用户一般是不愿意提供的…...
)
【网络原理】从零开始深入理解HTTP的报文格式(二)
本篇博客给大家带来的是网络HTTP协议的知识点, 续上篇文章,接着介绍HTTP的报文格式. 🐎文章专栏: JavaEE初阶 🚀若有问题 评论区见 ❤ 欢迎大家点赞 评论 收藏 分享 如果你不知道分享给谁,那就分享给薯条. 你们的支持是我不断创作的动力 . 王子,公主请阅…...
)
【前缀和】二维前缀和(模板题)
DP35 【模板】二维前缀和 DP35 【模板】二维前缀和 给你一个 n 行 m 列的矩阵 A ,下标从 1 开始,接下来有 q 次查询,每次查询输入 4 个参数 x1 , y1 , x2 , y2。 请输出以 (x1, y1) 为左上角,(x2,y2) 为右下角的子矩阵的和。 输入描述: 第一行包含三个整数 …...

【开源工具】Python打造智能IP监控系统:邮件告警+可视化界面+配置持久化
🌐【开源工具】Python打造智能IP监控系统:邮件告警可视化界面配置持久化 🌈 个人主页:创客白泽 - CSDN博客 🔥 系列专栏:🐍《Python开源项目实战》 💡 热爱不止于代码,热…...

kotlin 过滤 filter 函数的作用和使用场景
1. filter 函数的作用 filter 是 Kotlin 集合操作中的一个高阶函数,用于根据指定条件从集合中筛选出符合条件的元素。 作用:遍历集合中的每个元素,并通过给定的 lambda 表达式判断是否保留该元素。返回值:一个新的集合ÿ…...
)
Java泛型(补档)
核心概念 Java 泛型是 Java SE 1.5 引入的一项重要特性,它的核心思想是 参数化类型(Parameterized Types),即通过将数据类型作为参数传递给类、接口或方法,使代码能够灵活地处理多种类型,同时保证类型安全性…...

C语言发展史:从Unix起源到现代标准演进
C语言发展史:从Unix起源到现代标准演进 C语言的诞生与早期发展 C语言的起源可以追溯到上世纪70年代初期,但其真正的萌芽始于1969年的夏天。在计算机发展史上,这是一个具有划时代意义的时刻。 当时,Ken Thompson和Dennis Ritchi…...

nginx 代理时怎么更改 Remote Address 请求头
今天工作中遇到用 localhost 访问网站能访问后台 api,但是用本机IP地址后就拒绝访问,我怀疑是后台获取 Remote Address 然后设置白名单了只能 localhost 访问。 想用 nginx 更改 Remote Address server {listen 8058;server_name localhost;loca…...

解决STM32待机模式无法下载程序问题的深度探讨
在现代嵌入式系统开发中,STM32系列微控制器因其高性能、低功耗和丰富的外设资源而广受欢迎。然而,开发者在使用STM32时可能会遇到一个问题:当微控制器进入待机模式后,无法通过调试接口(如SWD或JTAG)下载程序…...
)
进程、线程、进程间通信Unix Domain Sockets (UDS)
进程、线程、UDS 进程和线程进程间通信Unix Domain Sockets (UDS)UDS的核心适用场景和用途配置UDS的几种主要方式socketpair() 基本配置流程socketpair() 进阶——传递文件描述符 补充socketpair() 函数struct msghdr 结构体struct iovecstruct cmsghdrstruct iovec 、struct m…...

大数据平台与数据仓库的核心差异是什么?
随着数据量呈指数级增长,企业面临着如何有效管理、存储和分析这些数据的挑战。 大数据平台和 数据仓库作为两种主流的数据管理工具,常常让企业在选型时感到困惑,它们之间的界限似乎越来越模糊,功能也有所重叠。本文旨在厘清这两种…...

Hadoop虚拟机中配置hosts
( 一)修改虚拟机的主机名 默认情况下,本机的名称叫:localhost。 我们进入linux系统之后,显示出来的就是[rootlocalhost ~]# 。为了方便后面我们更加便捷地访问这台主机,而不是通过ip地址,我们要…...

a-upload组件实现文件的上传——.pdf,.ppt,.pptx,.doc,.docx,.xls,.xlsx,.txt
实现下面的上传/下载/删除功能:要求支持:【.pdf,.ppt,.pptx,.doc,.docx,.xls,.xlsx,.txt】 分析上面的效果图,分为【上传】按钮和【文件列表】功能: 解决步骤1:上传按钮 直接上代码: <a-uploadmultip…...

QCefView应用和网页的交互
一、demo的主要项目文件 结合QCefView自带的demo代码 main.cpp #include #include <QCefContext.h> #include “MainWindow.h” int main(int argc, char* argv[]) { QApplication a(argc, argv); // build QCefConfig QCefConfig config; config.setUserAgent(“QCef…...

C++,设计模式,【建造者模式】
文章目录 通俗易懂的建造者模式:手把手教你造电脑一、现实中的建造者困境二、建造者模式核心思想三、代码实战:组装电脑1. 产品类 - 电脑2. 抽象建造者 - 装机师傅3. 具体建造者 - 电竞主机版4. 具体建造者 - 办公主机版5. 指挥官 - 装机总控6. 客户端使…...
)
Axure疑难杂症:中继器制作下拉菜单(多级中继器高级交互)
亲爱的小伙伴,在您浏览之前,烦请关注一下,在此深表感谢! Axure产品经理精品视频课已登录CSDN可点击学习https://edu.csdn.net/course/detail/40420 本文视频课程记录于上述地址第五章中继器专题第11节 课程主题:中继器制作下拉菜单 主要内容:创建条件选区、多级中继器…...

科研 | 光子技术为人工智能注入新动力
译《Nature》25.4.9 发表文章《A photonic processing boost for AI》 ▶ 基于人工智能(artificial intelligence, AI)的系统正被越来越广泛地应用于从基因数据解码到自动驾驶的各类任务。但随着AI模型的规模和应用的扩大,性能天花板与能耗壁…...

SQL语句练习 自学SQL网 多表查询
目录 Day 6 用JOINs进行多表联合查询 Day 7 外连接 OUTER JOINs Day 8 外连接 特殊关键字 NULLs Day 6 用JOINs进行多表联合查询 SELECT * FROM Boxoffice INNER JOIN movies ON movies.idboxoffice.Movie_id;SELECT * FROM Boxoffice INNER JOIN moviesON movies.idboxoffi…...

北京亦庄机器人马拉松:人机共跑背后的技术突破与产业启示
2025年4月19日,北京亦庄举办了一场具有里程碑意义的科技赛事——全球首个人形机器人半程马拉松。这场人类与20支机器人战队共同参与的21.0975公里竞速,不仅创造了人形机器人连续运动的最长纪录,更成为中国智能制造领域的综合性技术验证平台。…...