高并发内存池(五):性能测试与性能优化
前言
在前几期的实现中,我们完成了tcmalloc基础的内存管理功能,但还存在两个关键问题:
-
未处理超过256KB的大内存申请。
-
前期测试覆盖不足,导致多线程场景下隐藏了一些bug。
本文将修复这些问题,并实现三个目标:
-
增加大块内存分配逻辑
-
替换系统自带的malloc
-
通过性能测试定位优化瓶颈
目录
一、功能完善
1.大内存块需求
1.1.申请
1.2.释放
2.优化释放
3.测试
二、脱离malloc
1.定长内存池替代new
三、Bug修复
四、性能测试
Debug
性能分析
五、性能优化
测试结果
Debug模式
Release模式
六、源码
一、功能完善
1.大内存块需求
1.1.申请
在ThreadCache中我们最大只能申请到256KB的内存,要申请大于256KB的内存,就要添加新的逻辑,不能到自由链表桶中申请。
怎么解决呢?很简单,既然在ThreadCache层解决不了,那么直接去PageCache的桶中获取Span就行,因为我们以8KB为一页,256KB也就是32页。只要在32页到128页内的空间申请都到PageCache桶中申请。
代码实现:在ConcurrentAlloc函数中添加一个size>256KB的分支,让它到PageCache中申请Span,注意这个过程需要进行内存对齐和加锁。内存对齐:因为现在是以页为单位申请,所以需要以1页为对齐数对齐。需要添加RoundUp函数逻辑,如下:
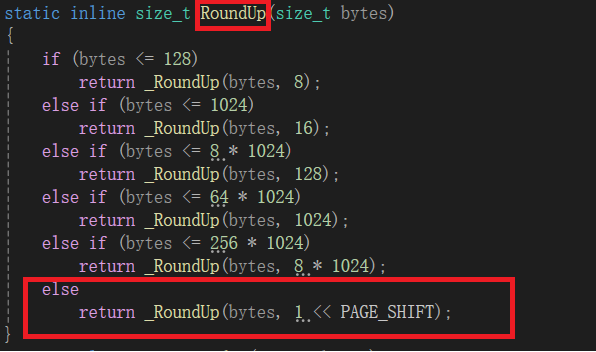
这里看上去8*1024和1<<PAGE_SHIFT(即1<<13)是一样的,但事实上8*1024字节是固定的,PAGE_SHIFT是根据需求改变的。
ConcurrentAlloc中添加的部分:
static void* ConcurrentAlloc(size_t size)
{if (size > MAX_BYTES){PAGE_ID bytes = SizeClass::RoundUp(size);PageCache::GetInstance()->_pageMtx.lock();Span* span = PageCache::GetInstance()->NewSpan(bytes >> PAGE_SHIFT);PageCache::GetInstance()->_pageMtx.unlock();void* ptr = (void*)(span->_pageId << PAGE_SHIFT);return ptr;}else{//正常逻辑//......}
}对于小于128页的内存申请NewSpan无需修改,如果用户需求是>128页呢?此时PageCache桶就无法满足,我们直接向系统申请即可,并且使用Span结构统一管理。如下NewSpan中添加的部分:
Span* PageCache::NewSpan(size_t k)
{assert(k > 0);if (k > NPAGES - 1){Span* kSpan = new Span;void* ptr = SystemAlloc(k);kSpan->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;kSpan->_n = k;_idSpanMap[kSpan->_pageId] = kSpan;return kSpan;}//......
}1.2.释放
大内存块不能被挂在ThreadCache桶中,需要单独写释放逻辑。即直接放到PageCache桶中。代码实现:在ConcurrentFree中添加size>256KB的分支,调用ReleaseSpanToPageCache,并且在此期间进行上锁。如下,添加的部分:
static void ConcurrentFree(void* ptr,size_t size)
{Span* span = PageCache::GetInstance()->MapObjectToSpan(ptr);if (size > MAX_BYTES){PageCache::GetInstance()->_pageMtx.lock();PageCache::GetInstance()->ReleaseSpanToPageCache(span);PageCache::GetInstance()->_pageMtx.unlock();}else{//正常逻辑//......}
}同样的对于小于128页的内存释放ReleaseSpanToPageCache无需修改,如果释放的内存是>128页呢?此时无法挂到PageCache桶中,我们直接让系统释放即可,并且删除Span结构。如下ReleaseSpanToPageCache中添加的部分:
void PageCache::ReleaseSpanToPageCache(Span* span)
{if (span->_n > NPAGES - 1){void* ptr = (void*)(span->_pageId << PAGE_SHIFT);SystemFree(ptr);delete span;return;}//......
}2.优化释放
![]()
如上实现,用户在调用释放内存的接口时是需要手动传入内存大小size,这样很繁琐,而且容易出错。我们希望不需要用户传这个参数也能完成工作。
该如何做?可以从这个方向思考?
- 理清楚这个参数的作用是什么,是否用其他操作可以替代这个效果。
- 有没有其他方式获得size,比如通过传入的ptr。
第1点基本上不用考虑了,因为我们的代码中已经充斥着大量的size的使用,要用其他方式来替代成本太大了。
对于第2点是有可行性的,因为在Span切割时已经确定了一个Span中切割的所有小块内存的大小都是一样的。而在上一期我们已经建立了页号与Span的映射表,一个地址(ptr)除以8KB就能得到它所在的页号,也就能得到它对于的Span。
也就是在Span中记录它切割的内存块大小即可。所以添加成员变量_objSize,在Span分配和切割时进行填写,这里就不展示。
接下来可以把size参数去掉,通过ptr找到Span然后找到_objSize。如下:
static void ConcurrentFree(void* ptr)
{Span* span = PageCache::GetInstance()->MapObjectToSpan(ptr);if (span->_objSize > MAX_BYTES){PageCache::GetInstance()->_pageMtx.lock();PageCache::GetInstance()->ReleaseSpanToPageCache(span);PageCache::GetInstance()->_pageMtx.unlock();}else{assert(pTLSThreadCache);pTLSThreadCache->Deallocate(ptr, span->_objSize);}
}3.测试
测试代码:
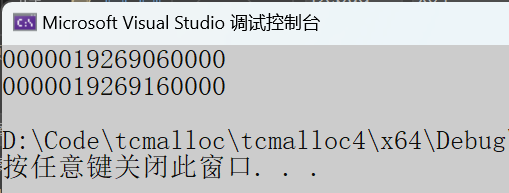
void BigAlloc()
{void* p1 = ConcurrentAlloc(257 * 1024);cout << p1 << endl;ConcurrentFree(p1);void* p2 = ConcurrentAlloc(129 * 8 * 1024);cout << p2 << endl;ConcurrentFree(p2);
}测试结果:
二、脱离malloc
1.定长内存池替代new
在程序中我们还有一些地方使用了malloc,比如申请Span时,申请ThreadCache时。
注:new的底层就是malloc。
我们希望把这些地方也脱离malloc,为什么呢?
-
锁竞争:malloc/free 通常使用全局锁来保证线程安全,在高并发场景下会成为严重瓶颈。
-
系统调用开销:malloc 可能触发 brk/sbrk 或 mmap 系统调用,导致用户态/内核态切换。
-
传统 malloc 难以有效处理高频率小内存分配释放导致的内存碎片。
-
长期运行后可能出现内存足够但无法分配的情况。
-
通用 malloc 需要兼顾各种场景,无法针对特定应用模式优化。
-
高并发场景通常有特定的内存使用模式(如固定大小对象)。
因为Span和ThreadCache都是固定的内存大小,我们可以使用定长内存池来替代。定长内存池的学习可以参考下文:
定长内存池原理及实现-CSDN博客
然后在Common.h中添加头文件,并定义一个模板参数为Span的定长内存池。
#include "ObjectPool.h"
using namespace my_MemoryPool;
struct Span;
static FixedMemoryPool<Span> _spanPool;如果是VS2022可以通过Ctrl+f查找所有的new和delete申请释放的Span,把它们替换成 _spanPool.New()和_spanPool.Delete()。
在ThreadCache的申请中,定义一个模板参数为ThreadCache的定长内存池静态变量。然后替换new。如下:
static void* ConcurrentAlloc(size_t size)
{if (size > MAX_BYTES){//......}else{if (pTLSThreadCache == nullptr){static FixedMemoryPool<ThreadCache> tcPool;pTLSThreadCache = tcPool.New();}return pTLSThreadCache->Allocate(size);}
}三、Bug修复
1.页号到Span的映射
在NewSpan中满足_spanLists[k]不为空的逻辑,我们需要把取到的Span的页与Span映射填写到哈希表中。并且把它_isUse设为true。
对哈希表(_idSpanMap)的查找MapObjectToSpan函数中涉及find,可能被多个线程同时访问出现错误,需要加锁。
2.桶下标计算
static inline int _Index(size_t bytes, size_t align_shift)
{return ((bytes + (1 << align_shift) - 1) >> align_shift) - 1;
}我们讲过以上计算出来的只是这个对齐后的字节数 对于相应 对齐数 在数组上起始位置的相对位置,还需要加上前面对齐占用的数组元素个数才能得到正确的下标。而忽略了需要给_Index传的也是相对位置,如下:
static inline size_t Index(size_t bytes)
{assert(bytes <= MAX_BYTES);static int group_array[4] = { 16, 56, 56, 56 };if (bytes <= 128)return _Index(bytes, 3);else if (bytes <= 1024)return _Index(bytes - 128, 4) + group_array[0];else if (bytes <= 8 * 1024)return _Index(bytes - 1024, 7) + group_array[0] + group_array[1];else if (bytes <= 64 * 1024)return _Index(bytes - 8 * 1024, 10) + group_array[0] + group_array[1] + group_array[2];else if (bytes <= 256 * 1024)return _Index(bytes - 64 * 1024, 13) + group_array[0] + group_array[1] + group_array[2] + group_array[3];else{assert(false);return -1;}
}FetchRangeObj函数中计算桶下标写成了SizeClass::RoundUp(size); 正确的应该是:
//计算Span链表桶下标
size_t index = SizeClass::Index(size); 3.SpanList[页数]
有很多地方需要加SpanList[页数]都写成了SpanList,可以通过Ctrl+f查找并修改。
4.Span切割
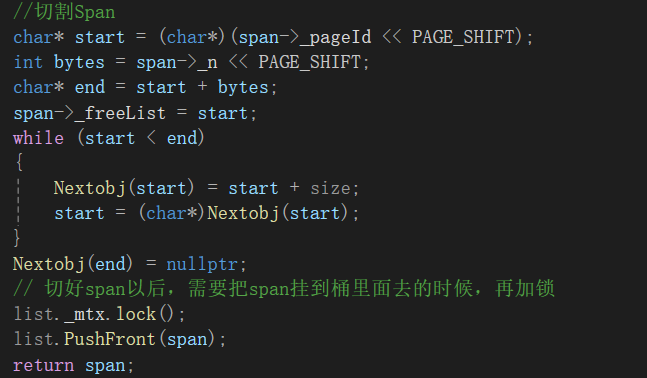
如上写法,因为end已经是结尾的最后一个字符了,虽然这里Nextobj(end)是合法的,但只用了一个字节,而我们再次访问空间的时候用的是4/8字节,就检测不到nullptr,被误认为是开好的空间,从而出现非法访问。
解决方法:添加一个中间变量,如下:
char* start = (char*)((PAGE_ID)span->_pageId << PAGE_SHIFT);
size_t bytes = span->_n << PAGE_SHIFT;
char* end = start + bytes;
span->_freeList = start;
char* tmp = start;
start += size;
while (start < end)
{Nextobj(tmp) = start;tmp = (char*)Nextobj(tmp);start += size;
}
Nextobj(tmp) = nullptr;
span->_objSize = size;
// 切好span以后,需要把span挂到桶里面去的时候,再加锁
list._mtx.lock();
list.PushFront(span);
return span;四、性能测试
主要是与malloc做对比,这里这样设计,每轮申请和释放ntimes次,nworks个线程,执行rounds轮,然后计算它们要花费的时间。以下给出测试代码,不过这里大家大可不必纠结代码,我们直接来看结果。
性能测试代码:
#include"ConcurrentAlloc.h"
#include<cstdio>
// ntimes 一轮申请和释放内存的次数
// rounds 轮次
void BenchmarkMalloc(size_t ntimes, size_t nworks, size_t rounds)
{std::vector<std::thread> vthread(nworks);std::atomic<size_t> malloc_costtime = 0;std::atomic<size_t> free_costtime = 0;for (size_t k = 0; k < nworks; ++k){vthread[k] = std::thread([&, k]() {std::vector<void*> v;v.reserve(ntimes);for (size_t j = 0; j < rounds; ++j){size_t begin1 = clock();for (size_t i = 0; i < ntimes; i++){v.push_back(malloc(16));//v.push_back(malloc((16 + i) % 8192 + 1));}size_t end1 = clock();size_t begin2 = clock();for (size_t i = 0; i < ntimes; i++)free(v[i]);size_t end2 = clock();v.clear();malloc_costtime += (end1 - begin1);free_costtime += (end2 - begin2);}});}for (auto& t : vthread){t.join();}printf("%zu个线程并发执行%zu轮次,每轮次malloc %zu次: 花费:%.2f ms\n",nworks, rounds, ntimes, (double)malloc_costtime);printf("%zu个线程并发执行%zu轮次,每轮次free %zu次: 花费:%.2f ms\n",nworks, rounds, ntimes, (double)free_costtime);printf("%zu个线程并发malloc&free %zu次,总计花费:%.2f ms\n",nworks, nworks * rounds * ntimes, (double)(malloc_costtime + free_costtime));
}
// 单轮次申请释放次数 线程数 轮次
void BenchmarkConcurrentMalloc(size_t ntimes, size_t nworks, size_t rounds)
{std::vector<std::thread> vthread(nworks);std::atomic<size_t> malloc_costtime = 0;std::atomic<size_t> free_costtime = 0;for (size_t k = 0; k < nworks; ++k){vthread[k] = std::thread([&]() {std::vector<void*> v;v.reserve(ntimes);for (size_t j = 0; j < rounds; ++j){size_t begin1 = clock();for (size_t i = 0; i < ntimes; i++){v.push_back(ConcurrentAlloc(16));//v.push_back(ConcurrentAlloc((16 + i) % 8192 + 1));}size_t end1 = clock();size_t begin2 = clock();for (size_t i = 0; i < ntimes; i++){ConcurrentFree(v[i]);}size_t end2 = clock();v.clear();malloc_costtime += (end1 - begin1);free_costtime += (end2 - begin2);}});}for (auto& t : vthread)t.join();printf("%zu个线程并发执行%zu轮次,每轮次concurrent alloc %zu次: 花费:%.2f ms\n",nworks, rounds, ntimes, (double)malloc_costtime);printf("%zu个线程并发执行%zu轮次,每轮次concurrent dealloc %zu次: 花费:%.2f ms\n",nworks, rounds, ntimes, (double)free_costtime);printf("%zu个线程并发concurrent alloc&dealloc %zu次,总计花费:%.2f ms\n",nworks, nworks * rounds * ntimes, (double)(malloc_costtime + free_costtime));
}
int main()
{size_t n = 10000;cout << "==========================================================" << endl;BenchmarkConcurrentMalloc(n, 4, 10);cout << endl << endl;BenchmarkMalloc(n, 4, 10);cout << "==========================================================" << endl;return 0;
}Debug
固定内存:
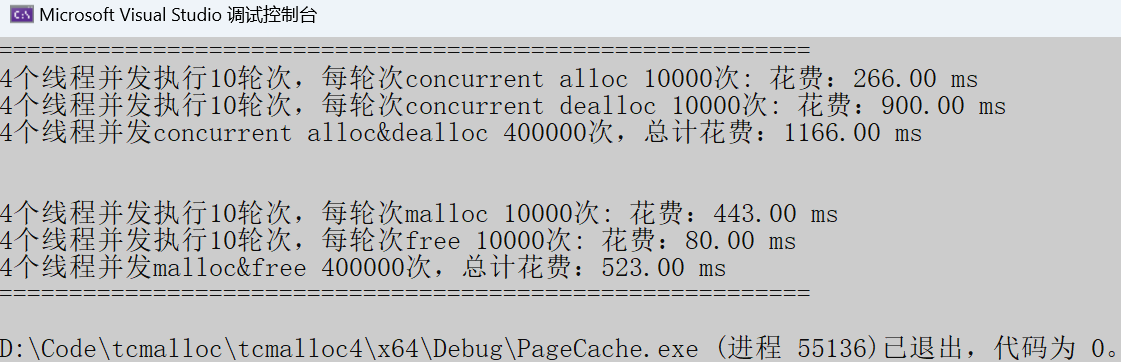
- 申请内存:tcmalloc快于malloc两倍左右。
- 释放内存:tcmalloc整整慢了malloc十倍多。
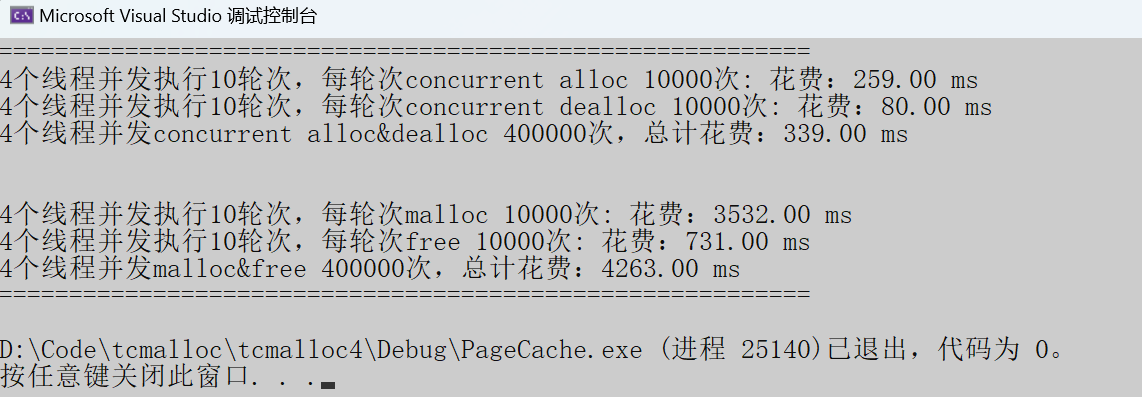
随机内存:
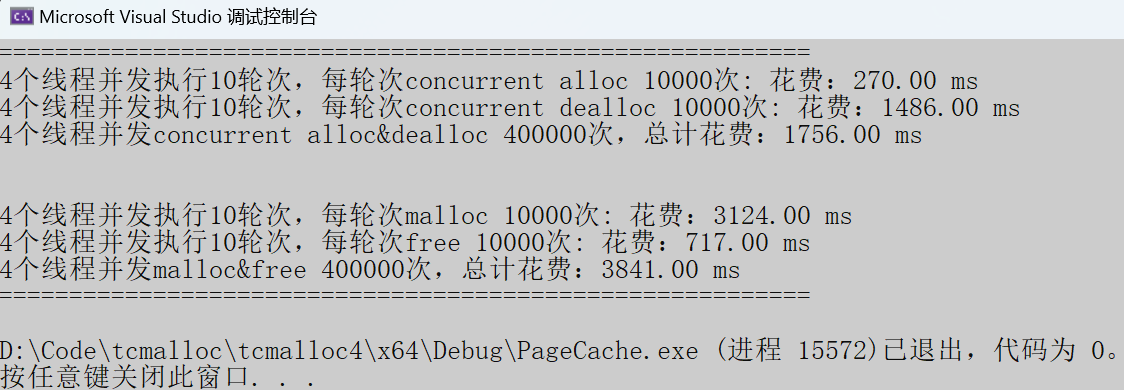
- 申请内存:tcmalloc快于malloc十倍多。
- 释放内存:tcmalloc慢了malloc两倍多。
我们观察发现,tcmalloc总在释放的过程慢于malloc,要突破性能瓶颈我们就需要对tcmalloc的释放过程做优化。
性能分析
这里做性能分析主要是找到哪个函数消耗的时间长,然后针对性的进行修改。
在做性能分析时要保证是在debug下,并把向malloc申请内存的部分注释掉。然后做如下操作:
右键项目打开属性,然后做如下配置:
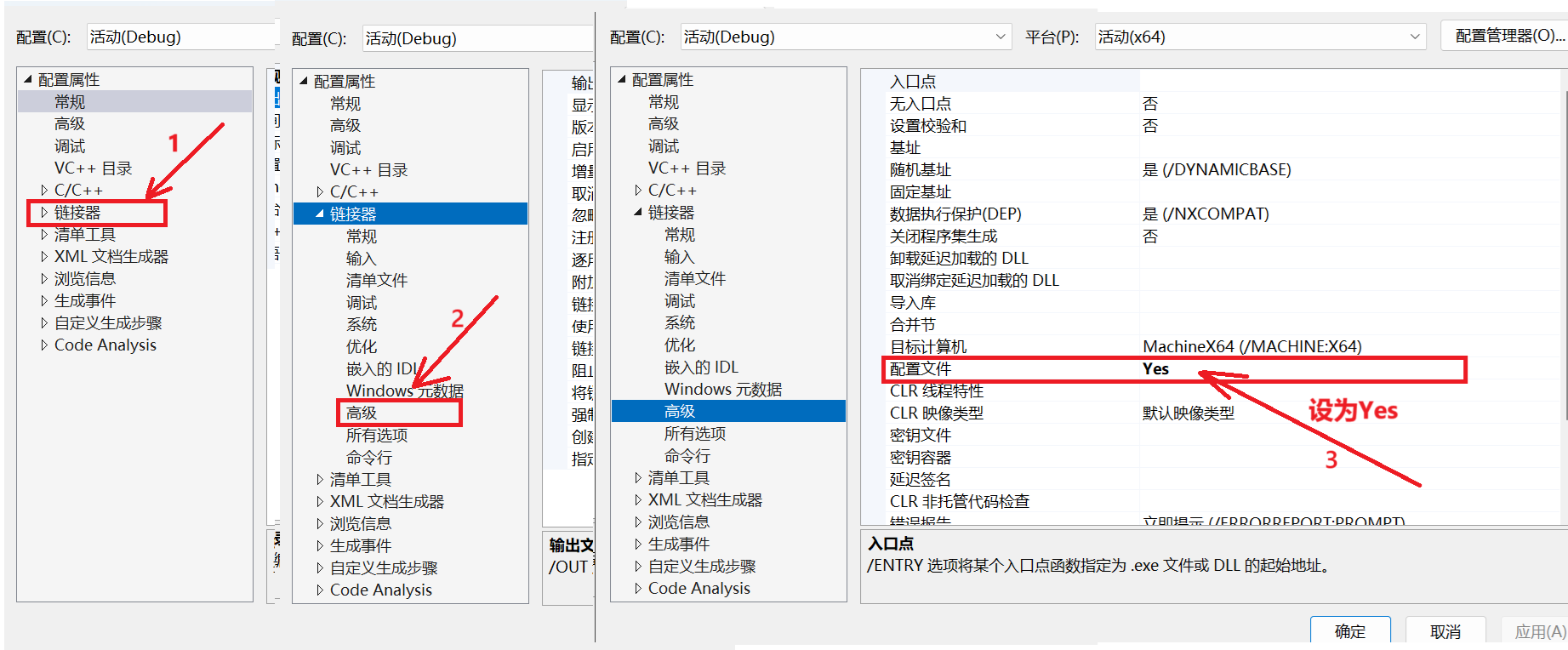
打开调试性能探查器
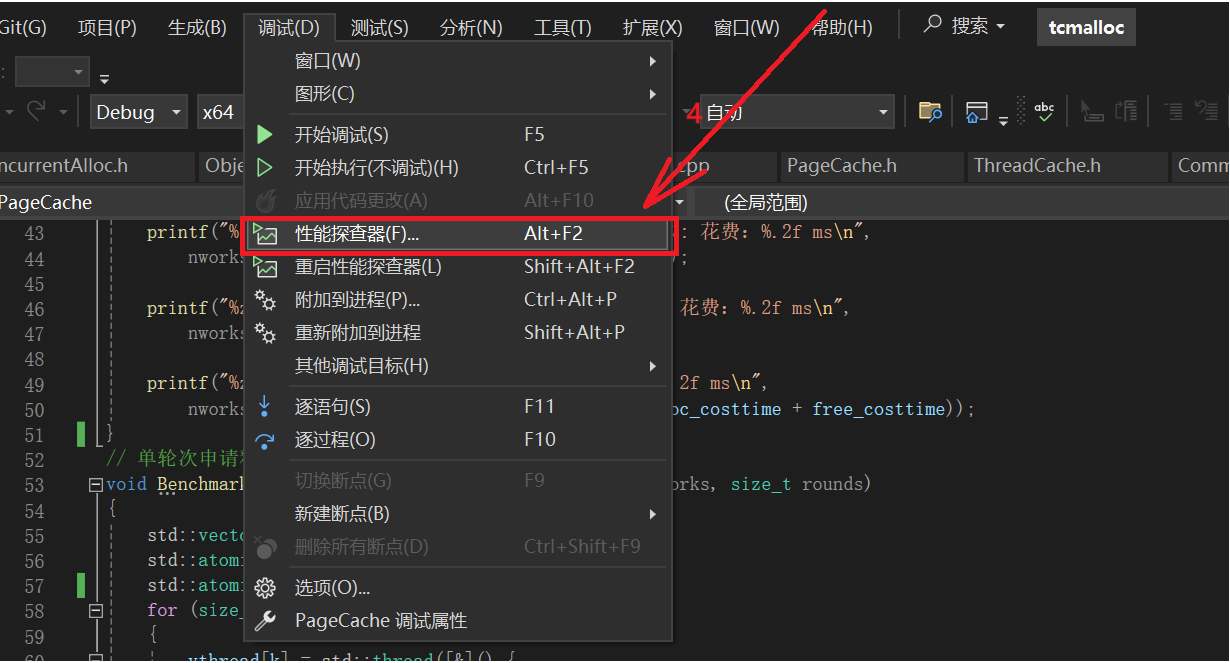
打开检测
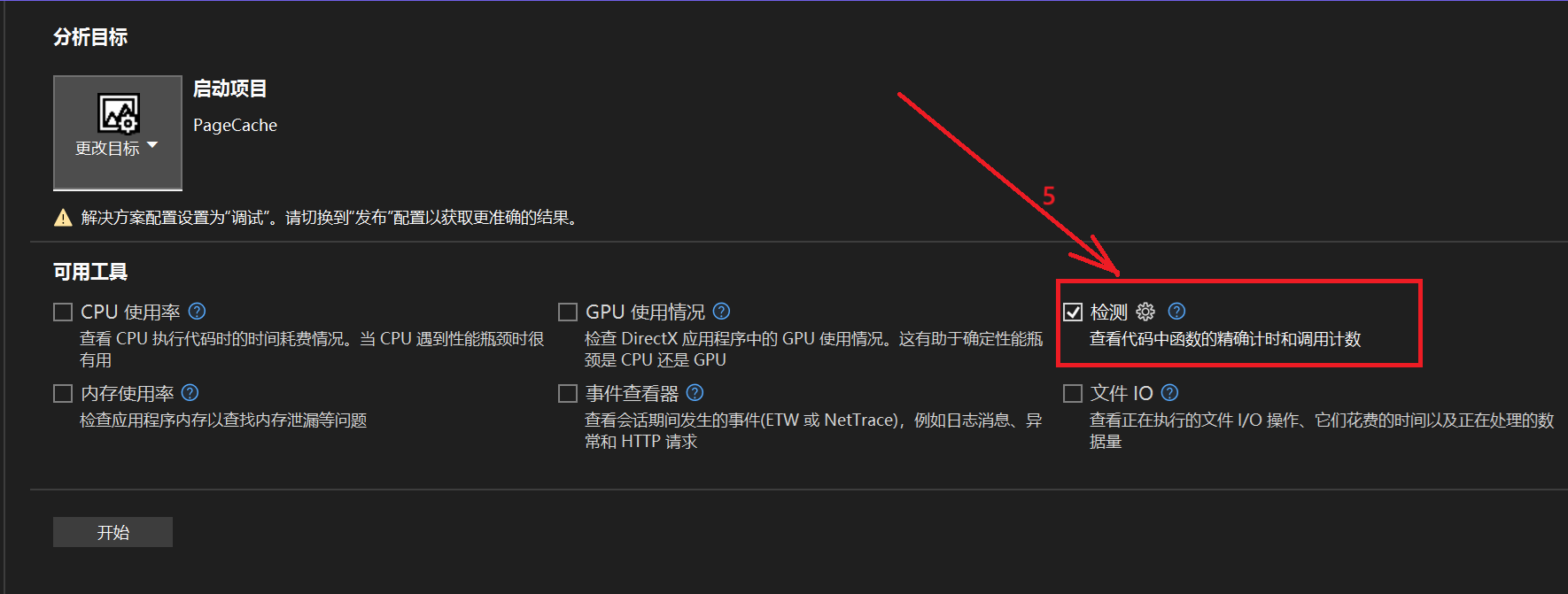
打开详细信息
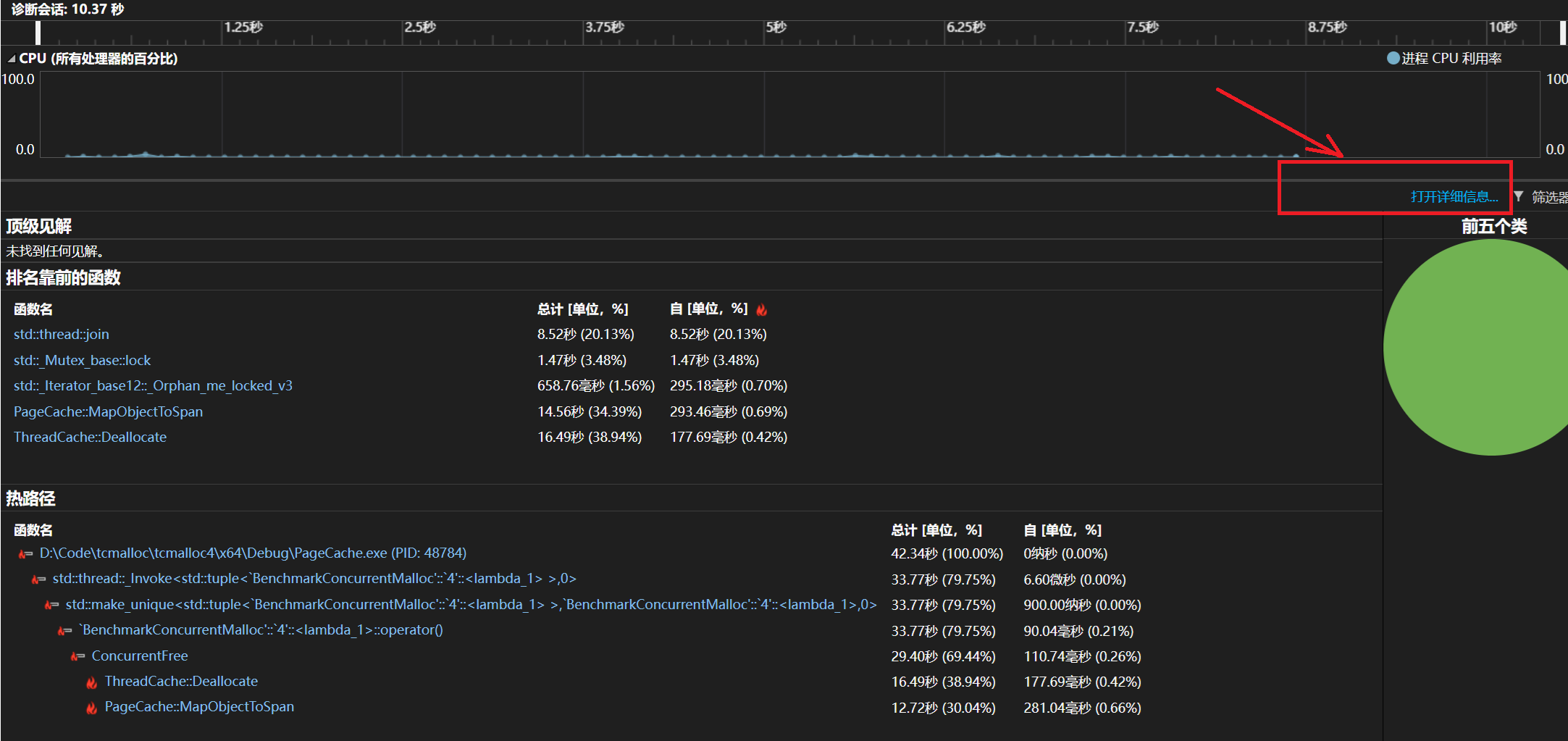
打开火焰图
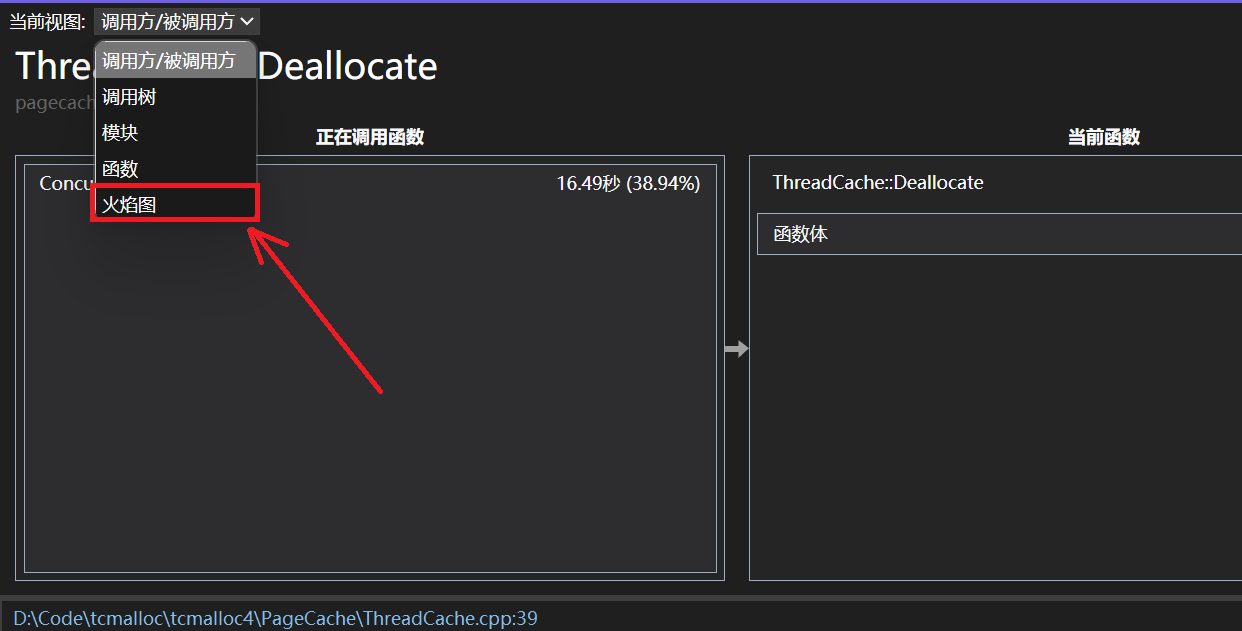
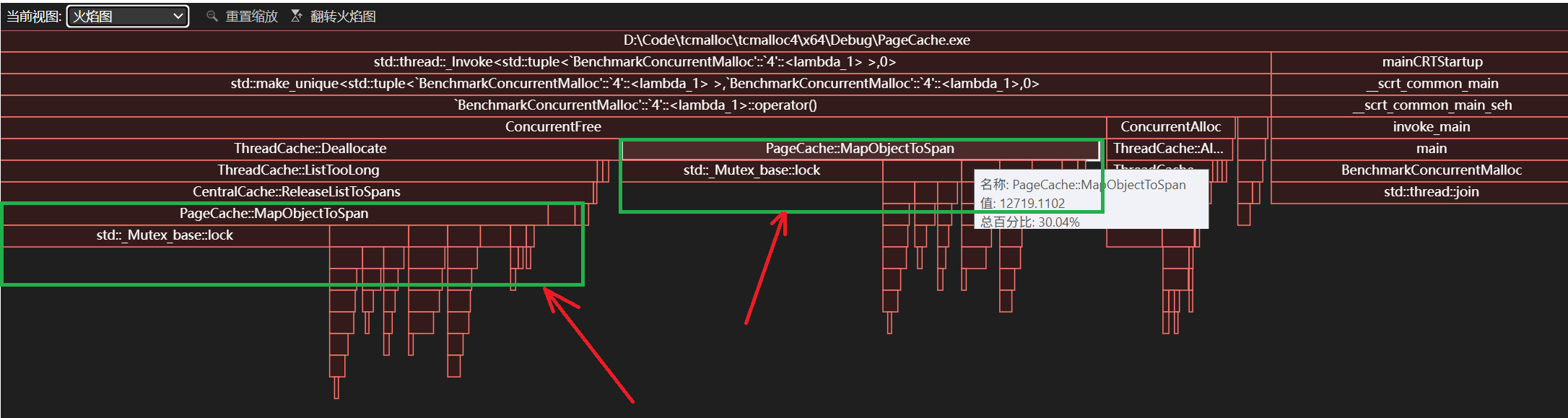
我们可以观察到几乎60%以上的时间消耗都是来自函数MapObjectToSpan,而主要是来自内部锁竞争的消耗。在map中查找越慢,锁竞争越激烈。
接下来我们对MapObjectToSpan进行替代。
五、性能优化
MapObjectToSpan是用来查找页号与Span的映射关系的,使用哈希桶unordered_map,STL中并未对数据结构并发访问问题进行处理,不是原子的。所以在find()查找过程会出问题,需要加锁来保护临界资源。
这里我们考虑换一种结构,使用基数树,基数树是一种通过压缩公共前缀路径优化存储的前缀树结构,支持高效的前缀匹配和键值查询。
这里我们设定三棵基数树,分别是一层,两层,三层。
只有一层的基数树本质就是数组(直接定址法的哈希表),页号到Span的映射,如下:
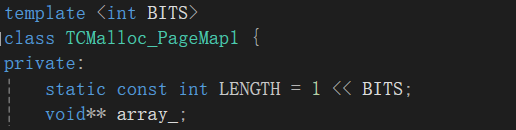
template <int BITS>
class TCMalloc_PageMap1 {
private:static const int LENGTH = 1 << BITS;void** array_;
public:typedef uintptr_t Number;//构造函数,给数组开空间explicit TCMalloc_PageMap1() {size_t size = sizeof(void*) << BITS;size_t alignSize = SizeClass::_RoundUp(size, 1 << PAGE_SHIFT);array_ = (void**)SystemAlloc(alignSize >> PAGE_SHIFT);memset(array_, 0, sizeof(void*) << BITS);}//通过页号得到Spanvoid* get(Number k) const {if ((k >> BITS) > 0) {return NULL;}return array_[k];}//添加页号与Span的映射void set(Number k, void* v) {array_[k] = v;}
};
BITS给的是32-PAGE_SHIFT(32位下)或64-PAGE_SHIFT(64位下),表示存储页号的位数。
比如32位机器下8KB为一页,需要(2^32)/(2^13)=2^19个页号,即2^(32-PAGE_SHIFT)。
如果内存比较大,就需要开辟更大的数组,又因为很难一次性开出。所以把它拆除多块。即2层或3层
对于两层这样设定:
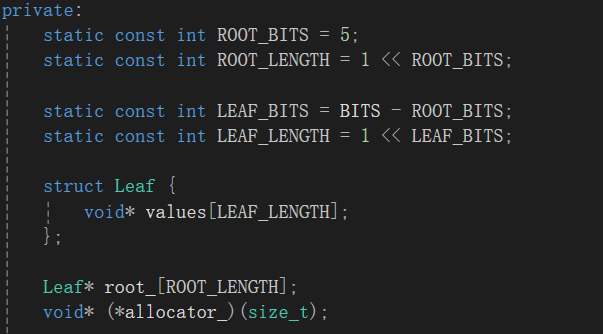
以32位为例,如上需要19位空间来储存页号,对于第一层给5位,也就是2^5=32个空间。然后把后14位给第二层。合计开辟(2^5)*(2^14)。与一层基数树开辟的空间相同。
拿到传来的页号,它是4字节的即32位,用前5位去匹配第一层并找到第二层的映射表,再用后面的位去匹配映射表找到对应的Span。
三层基数树的设定同理,不做讲解。
注意对于64位机器,(2^64)/(2^13)=2^53个页,要一次性开辟这么大的空间几乎是不可能的,所以必须使用三层,相当于把空间拆成小块开辟。而且等需要用到时再开辟,要不然会造成很多浪费。
以32位机器为例,把原来unordered_map结构改为TCMalloc_PageMap1,如下:
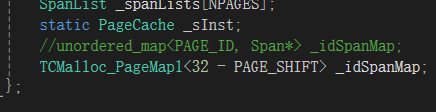
然后用Ctrl+f找到所有使用_idSpanMap的地方,进行修改。
再次进行性能测试查看火焰图:
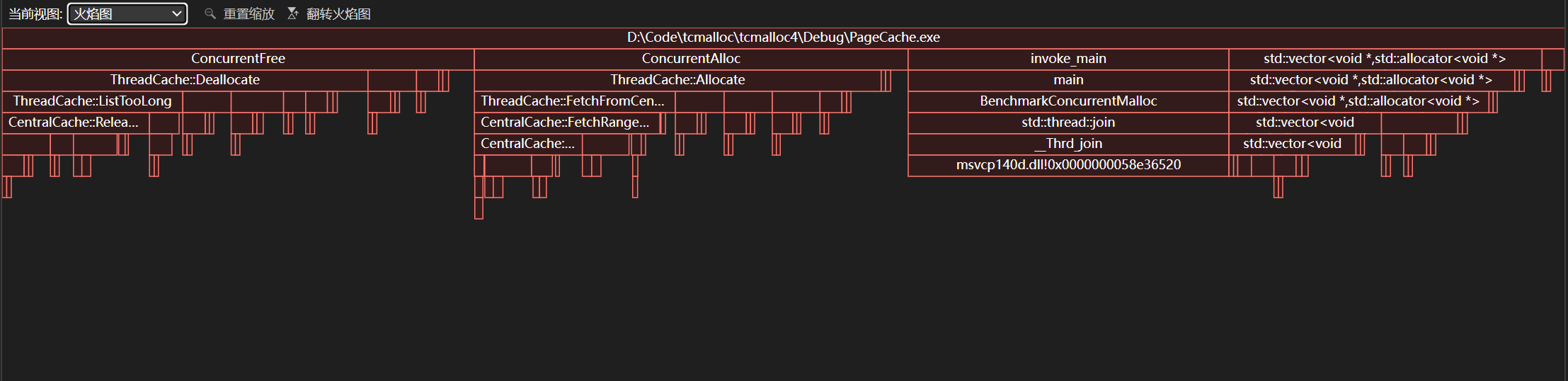
它们的时间消耗的是差不多的,没有针对性的优化意义不是很大。
测试结果
Debug模式
固定内存申请
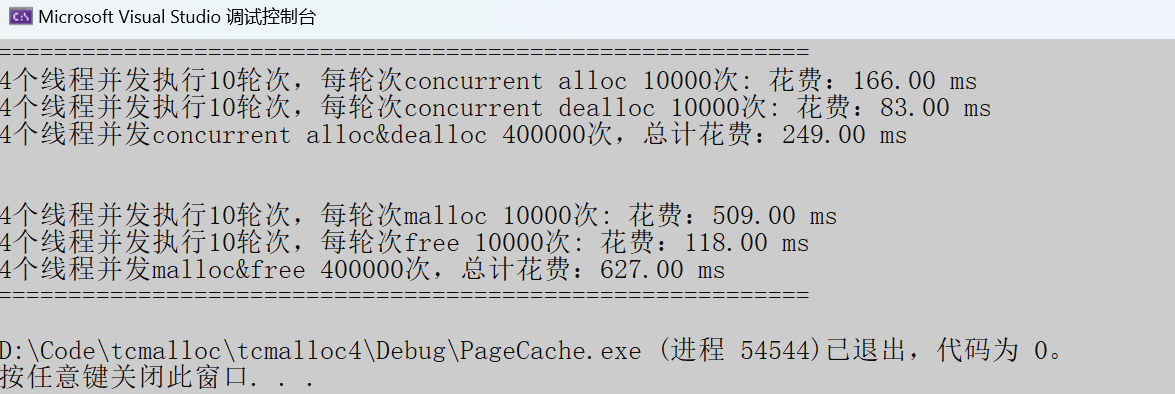
随机内存申请:
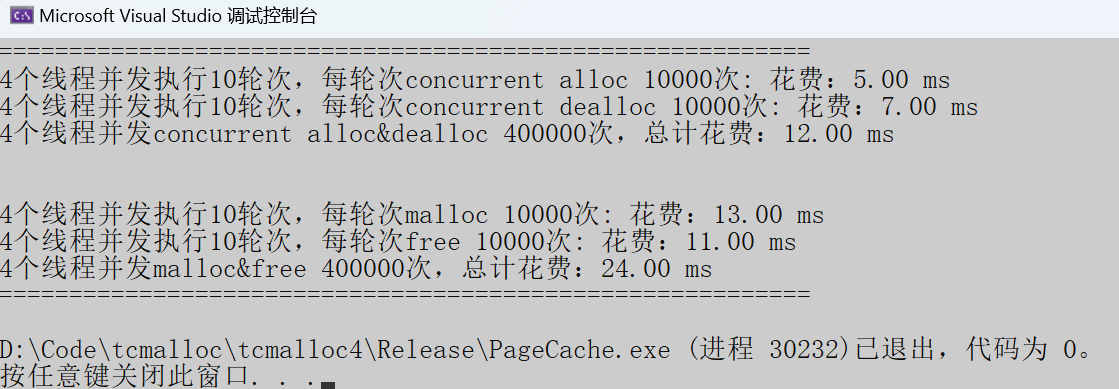
Release模式
固定内存申请:
随机内存申请:
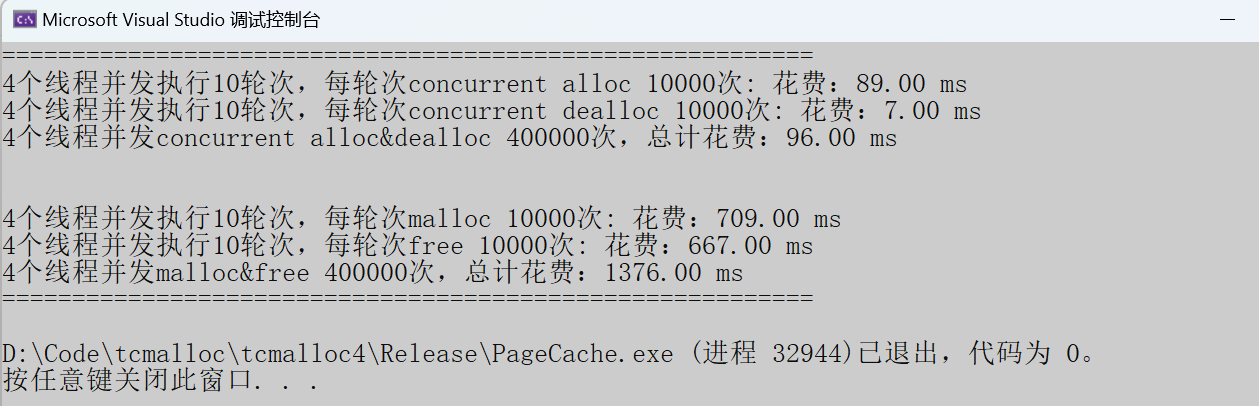
当下 tcmalloc 的性能堪称一骑绝尘,对 malloc 形成了直接碾压,优势一目了然!
非常感谢您能耐心读完这篇文章。倘若您从中有所收获,还望多多支持呀!

六、源码
tcmalloc/Code · 敲上瘾/ConcurrentMemoryPool - 码云 - 开源中国
相关文章:
:性能测试与性能优化)
高并发内存池(五):性能测试与性能优化
前言 在前几期的实现中,我们完成了tcmalloc基础的内存管理功能,但还存在两个关键问题: 未处理超过256KB的大内存申请。 前期测试覆盖不足,导致多线程场景下隐藏了一些bug。 本文将修复这些问题,并实现三个目标&…...

景联文科技牵头起草的《信息技术 可扩展的生物特征识别数据交换格式 第4部分:指纹图像数据》国家标准正式发布
2025年3月28日,由景联文科技作为第一起草单位主导编制的国家标准GB/T 45284.4-2025 《信息技术 可扩展的生物特征识别数据交换格式 第4部分:指纹图像数据》正式获批发布,将于2025年10月1日开始实施。该标准的制定标志着我国生物特征识别领域标…...

完美解决 mobile-ffmpeg Not overwriting - exiting
在使用ffmpeg库 ,有pcm转换到 aac的过程中报错 mobile-ffmpeg Not overwriting - exiting终于在网上翻到,在output 输出文件的地方加 -y, 重复覆盖的意思,完美解决。...
)
4:QT联合HALCON编程—机器人二次程序抓取开发(九点标定)
判断文件是否存在 //判断文件在不在 int HandEyeCalib::AnsysFileExists(QString FileAddr) {QFile File1(FileAddr);if(!File1.exists()){QMessageBox::warning(this,QString::fromLocal8Bit("提示"),FileAddrQString::fromLocal8Bit("文件不存在"));retu…...

C语言之操作符
目录 1. 操作符的分类 2. 移位操作符 2.1 左移操作符 << 2.2 右移操作符 >> 3. 位操作符 3.1 按位与 & 3.2 按位或 | 3.3 按位异或 ^ 3.4 按位取反 ~ 3.5 例题 3.5.1 按位异或 ^ 拓展公式 3.5.2 不能创建临时变量(第三个变量ÿ…...

【优选算法 | 前缀和】前缀和算法:高效解决区间求和问题的关键
算法相关知识点可以通过点击以下链接进行学习一起加油!双指针滑动窗口二分查找 在本篇文章中,我们将深入解析前缀和算法的原理。从基础概念到实际应用,带你了解如何通过前缀和高效解决数组求和、区间查询等问题。无论你是刚接触算法的新手&am…...

『深夜_MySQL』详解数据库 探索数据库是如何存储的
1. 数据库基础 1.1 什么是数据库 存储数据用文件就可以了,那为什么还要弄个数据库? 一般的文件缺失提供了数据的存储功能,但是文件并没有提供非常好的数据管理能力(用户角度,内容方面) 文件保存数据有以…...

Microsoft Entra ID 免费版管理云资源详解
Microsoft Entra ID(原 Azure AD)免费版为企业提供了基础的身份管理功能,适合小型团队或预算有限的组织。以下从功能解析到实战配置,全面展示如何利用免费版高效管理云资源。 1. 免费版核心功能与限制 1.1 功能概览 功能免费版支持情况基础用户与组管理✔️ 支持创建、删除…...

k8s -hpa
hpa定义弹性自动伸缩 1、横向伸缩,当定义的cpu、mem指标达到hpa值时,会触发pods伸展 2、安装metrics-server 收集pods的cpu。mem信息供hpa参照 安装helm curl -fsSl -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 用helm安装metr…...

Web应用开发指南
一、引言 随着互联网的迅猛发展,Web应用已深度融入日常生活的各个方面。为满足用户对性能、交互与可维护性的日益增长的需求,开发者需要一整套高效、系统化的解决方案。在此背景下,前端框架应运而生。不同于仅提供UI组件的工具库,…...

Vue3 + TypeScript 实现 PC 端鼠标横向拖动滚动
功能说明 拖动功能: 鼠标按下时记录初始位置和滚动位置拖动过程中计算移动距离并更新滚动位置松开鼠标后根据速度实现惯性滚动 滚动控制: 支持鼠标滚轮横向滚动(通过 wheel 事件)自动边界检测防止滚动超出内容…...

MyBatis的SQL映射文件中,`#`和`$`符号的区别
在MyBatis的SQL映射文件中,#和$符号用于处理SQL语句中的参数替换,但它们的工作方式和使用场景有所不同。 #{} 符号 预编译参数:#{} 被用来作为预编译SQL语句的占位符。这意味着MyBatis会将你传入的参数设置为PreparedStatement的参数,从而防止SQL注入攻击,并允许MyBatis对…...
)
Python----卷积神经网络(池化为什么能增强特征)
一、什么是池化 池化(Pooling)是卷积神经网络(CNN)中的一种关键操作,通常位于卷积层之后,用于对特征图(Feature Map)进行下采样(Downsampling)。其核心目的是…...
)
React Native 从零开始完整教程(环境配置 → 国内镜像加速 → 运行项目)
React Native 从零开始完整教程(环境配置 → 国内镜像加速 → 运行项目) 本教程将从 环境配置 开始,到 国内镜像加速,最后成功运行 React Native 项目(Android/iOS),适合新手和遇到网络问题的开…...
)
SNR8016语音模块详解(STM32)
目录 一、介绍 二、传感器原理 1.原理图 2.引脚描述 三、程序设计 main文件 usart.h文件 usart.c文件 四、实验效果 五、资料获取 项目分享 一、介绍 SNR8016语音模块是智纳捷科技生产的一种离线语音识别模块,设计适合用于DIY领域,开放用户设…...
设备初始化)
驱动开发系列54 - Linux Graphics QXL显卡驱动代码分析(一)设备初始化
一:概述 QXL 是QEMU支持的一种虚拟显卡,用于虚拟化环境中的图形加速,旨在提高虚拟机的图形显示和远程桌面的用户体验;QEMU 也称 Quick Emulator,快速仿真器,是一个开源通用的仿真和虚拟化工具,可…...

通过IP计算分析归属地
在产品中可能存在不同客户端,请求同一个服务端接口的场景。 例如小程序和App或者浏览器中,如果需要对请求的归属地进行分析,前提是需要先获取请求所在的国家或城市,这种定位通常需要主动授权,而用户一般是不愿意提供的…...
)
【网络原理】从零开始深入理解HTTP的报文格式(二)
本篇博客给大家带来的是网络HTTP协议的知识点, 续上篇文章,接着介绍HTTP的报文格式. 🐎文章专栏: JavaEE初阶 🚀若有问题 评论区见 ❤ 欢迎大家点赞 评论 收藏 分享 如果你不知道分享给谁,那就分享给薯条. 你们的支持是我不断创作的动力 . 王子,公主请阅…...
)
【前缀和】二维前缀和(模板题)
DP35 【模板】二维前缀和 DP35 【模板】二维前缀和 给你一个 n 行 m 列的矩阵 A ,下标从 1 开始,接下来有 q 次查询,每次查询输入 4 个参数 x1 , y1 , x2 , y2。 请输出以 (x1, y1) 为左上角,(x2,y2) 为右下角的子矩阵的和。 输入描述: 第一行包含三个整数 …...

【开源工具】Python打造智能IP监控系统:邮件告警+可视化界面+配置持久化
🌐【开源工具】Python打造智能IP监控系统:邮件告警可视化界面配置持久化 🌈 个人主页:创客白泽 - CSDN博客 🔥 系列专栏:🐍《Python开源项目实战》 💡 热爱不止于代码,热…...

kotlin 过滤 filter 函数的作用和使用场景
1. filter 函数的作用 filter 是 Kotlin 集合操作中的一个高阶函数,用于根据指定条件从集合中筛选出符合条件的元素。 作用:遍历集合中的每个元素,并通过给定的 lambda 表达式判断是否保留该元素。返回值:一个新的集合ÿ…...
)
Java泛型(补档)
核心概念 Java 泛型是 Java SE 1.5 引入的一项重要特性,它的核心思想是 参数化类型(Parameterized Types),即通过将数据类型作为参数传递给类、接口或方法,使代码能够灵活地处理多种类型,同时保证类型安全性…...

C语言发展史:从Unix起源到现代标准演进
C语言发展史:从Unix起源到现代标准演进 C语言的诞生与早期发展 C语言的起源可以追溯到上世纪70年代初期,但其真正的萌芽始于1969年的夏天。在计算机发展史上,这是一个具有划时代意义的时刻。 当时,Ken Thompson和Dennis Ritchi…...

nginx 代理时怎么更改 Remote Address 请求头
今天工作中遇到用 localhost 访问网站能访问后台 api,但是用本机IP地址后就拒绝访问,我怀疑是后台获取 Remote Address 然后设置白名单了只能 localhost 访问。 想用 nginx 更改 Remote Address server {listen 8058;server_name localhost;loca…...

解决STM32待机模式无法下载程序问题的深度探讨
在现代嵌入式系统开发中,STM32系列微控制器因其高性能、低功耗和丰富的外设资源而广受欢迎。然而,开发者在使用STM32时可能会遇到一个问题:当微控制器进入待机模式后,无法通过调试接口(如SWD或JTAG)下载程序…...
)
进程、线程、进程间通信Unix Domain Sockets (UDS)
进程、线程、UDS 进程和线程进程间通信Unix Domain Sockets (UDS)UDS的核心适用场景和用途配置UDS的几种主要方式socketpair() 基本配置流程socketpair() 进阶——传递文件描述符 补充socketpair() 函数struct msghdr 结构体struct iovecstruct cmsghdrstruct iovec 、struct m…...

大数据平台与数据仓库的核心差异是什么?
随着数据量呈指数级增长,企业面临着如何有效管理、存储和分析这些数据的挑战。 大数据平台和 数据仓库作为两种主流的数据管理工具,常常让企业在选型时感到困惑,它们之间的界限似乎越来越模糊,功能也有所重叠。本文旨在厘清这两种…...

Hadoop虚拟机中配置hosts
( 一)修改虚拟机的主机名 默认情况下,本机的名称叫:localhost。 我们进入linux系统之后,显示出来的就是[rootlocalhost ~]# 。为了方便后面我们更加便捷地访问这台主机,而不是通过ip地址,我们要…...

a-upload组件实现文件的上传——.pdf,.ppt,.pptx,.doc,.docx,.xls,.xlsx,.txt
实现下面的上传/下载/删除功能:要求支持:【.pdf,.ppt,.pptx,.doc,.docx,.xls,.xlsx,.txt】 分析上面的效果图,分为【上传】按钮和【文件列表】功能: 解决步骤1:上传按钮 直接上代码: <a-uploadmultip…...

QCefView应用和网页的交互
一、demo的主要项目文件 结合QCefView自带的demo代码 main.cpp #include #include <QCefContext.h> #include “MainWindow.h” int main(int argc, char* argv[]) { QApplication a(argc, argv); // build QCefConfig QCefConfig config; config.setUserAgent(“QCef…...

C++,设计模式,【建造者模式】
文章目录 通俗易懂的建造者模式:手把手教你造电脑一、现实中的建造者困境二、建造者模式核心思想三、代码实战:组装电脑1. 产品类 - 电脑2. 抽象建造者 - 装机师傅3. 具体建造者 - 电竞主机版4. 具体建造者 - 办公主机版5. 指挥官 - 装机总控6. 客户端使…...
)
Axure疑难杂症:中继器制作下拉菜单(多级中继器高级交互)
亲爱的小伙伴,在您浏览之前,烦请关注一下,在此深表感谢! Axure产品经理精品视频课已登录CSDN可点击学习https://edu.csdn.net/course/detail/40420 本文视频课程记录于上述地址第五章中继器专题第11节 课程主题:中继器制作下拉菜单 主要内容:创建条件选区、多级中继器…...

科研 | 光子技术为人工智能注入新动力
译《Nature》25.4.9 发表文章《A photonic processing boost for AI》 ▶ 基于人工智能(artificial intelligence, AI)的系统正被越来越广泛地应用于从基因数据解码到自动驾驶的各类任务。但随着AI模型的规模和应用的扩大,性能天花板与能耗壁…...

SQL语句练习 自学SQL网 多表查询
目录 Day 6 用JOINs进行多表联合查询 Day 7 外连接 OUTER JOINs Day 8 外连接 特殊关键字 NULLs Day 6 用JOINs进行多表联合查询 SELECT * FROM Boxoffice INNER JOIN movies ON movies.idboxoffice.Movie_id;SELECT * FROM Boxoffice INNER JOIN moviesON movies.idboxoffi…...

北京亦庄机器人马拉松:人机共跑背后的技术突破与产业启示
2025年4月19日,北京亦庄举办了一场具有里程碑意义的科技赛事——全球首个人形机器人半程马拉松。这场人类与20支机器人战队共同参与的21.0975公里竞速,不仅创造了人形机器人连续运动的最长纪录,更成为中国智能制造领域的综合性技术验证平台。…...
:决策树)
大连理工大学选修课——机器学习笔记(6):决策树
决策树 决策树概述 决策树——非参数机器学习方法 参数方法: 参数估计是定义在整个空间的模型 所有训练数据参与估算 所有的检验输入都用相同的模型和参数 非参数方法: 非参数估计采用局部模型 输入空间被分裂为一系列可以用距离度量的局部空间…...

现代前端工具链深度解析:从包管理到构建工具的完整指南
前言 在当今快速发展的前端生态中,高效的工具链已经成为开发者的必备利器。一个优秀的前端工具链可以显著提升开发效率、优化项目性能并改善团队协作体验。本文将深入探讨现代前端开发中最核心的两大工具类别:包管理工具(npm/yarn)和构建工具(Webpack/V…...

[C语言]猜数字游戏
文章目录 一、游戏思路揭秘二、随机数生成大法1、初探随机数:rand函数的魔力2、随机数种子:时间的魔法3、抓住时间的精髓:time函数 三、完善程序四、游戏成果1、游戏效果2、源代码 一、游戏思路揭秘 猜数字游戏,这个听起来就让人…...

【Linux】g++安装教程
Linux上安装g教程 实现c语言在Linux上编译运行 1. 更新软件包列表 打开终端,先更新软件包列表以确保获取最新版本信息: sudo apt update2. 安装 build-essential 工具包 build-essential 包含 g、gcc、make 和其他编译所需的工具: sudo…...
)
MQTT - Android MQTT 编码实战(MQTT 客户端创建、MQTT 客户端事件、MQTT 客户端连接配置、MQTT 客户端主题)
Android MQTT 编码实战 1、Settting 在项目级 build.gradle 目录下导入 MQTT 客户端依赖 implementation org.eclipse.paho:org.eclipse.paho.mqttv5.client:1.2.5 implementation org.eclipse.paho:org.eclipse.paho.android.service:1.1.1AndroidManifest.xml,…...

Redis分布式锁使用以及对接支付宝,paypal,strip跨境支付
本章重点在于如何使用redis的分布式锁来锁定库存。减少超卖,同时也对接了支付宝,paypal,strip跨境支付 第一步先建立一个商品表 CREATE TABLE sys_product (id bigint(20) NOT NULL AUTO_INCREMENT COMMENT 主键,code varchar(60) DEFAUL…...
)
沙箱逃逸(Python沙盒逃逸深度解析)
沙箱逃逸(Python沙盒逃逸深度解析) 一、沙盒逃逸的核心目标 执行系统命令 通过调用os.system、subprocess.Popen等函数执行Shell命令,例如读取文件或反弹Shell。 文件操作 读取敏感文件(如/etc/passwd)、写入后门文件…...

k8s-Pod生命周期
初始化容器 初始化容器是在pod的主容器启动之前要运行的容器,主要是做一些主容器的前置工作,它具有两大特征: 1. 初始化容器必须运行完成直至结束,若某初始化容器运行失败,那么kubernetes需要重启它直到成功完成 2. 初…...

基于Springboot + vue实现的中医院问诊系统
项目描述 本系统包含管理员、医生、用户三个角色。 管理员角色: 用户管理:管理系统中所有用户的信息,包括添加、删除和修改用户。 配置管理:管理系统配置参数,如上传图片的路径等。 权限管理:分配和管理…...

computed计算值为什么还可以依赖另外一个computed计算值?
在 Vue(或类似的响应式框架)中,computed 计算属性之所以可以依赖另一个 computed 属性,是因为: ✅ 本质上 computed 是响应式依赖的“派生值” 每个 computed 本质上就是一个 基于其他响应式数据计算出来的值。 当你在…...

近期实践总结
一、计算机二级考试到底教会了我们什么? 1、概况 根据本人复习、考试的经验,不难发现里面的试题或多或少有些死板(甚至可以说落后于时代),当今时代已经不是二十年前什么都需要手搓的时代了,引擎、集成类软…...

Arduion 第一天,变量的详细解析
Arduino变量详解与嵌入式开发扩展 一、变量基础篇 1.1 变量声明与初始化 <ARDUINO>int ledPin 13; // 声明并初始化float sensorValue; // 先声明后赋值unsigned long startTime; // 无符号长整型void setup() {sensorValue analogRead(A0) *…...

【每日八股】复习 MySQL Day3:锁
文章目录 昨日内容复习MySQL 使用 B 树作为索引的优势是什么?索引有哪几种?什么是最左匹配原则?索引区分度?联合索引如何排序?使用索引有哪些缺陷?什么时候需要建立索引,什么时候不需要…...

2025年KBS新算法 SCI1区TOP:长颖燕麦优化算法AOO,深度解析+性能实测
目录 1.摘要2.算法原理3.结果展示4.参考文献5.文章&代码获取 1.摘要 本文提出了一种新颖的元启发式算法——长颖燕麦优化算法(AOO),该算法灵感来自动画燕麦在环境中的自然行为。AOO模拟了长颖燕麦的三种独特行为:(i) 通过自然…...

1.4 点云数据获取方式——结构光相机
图1-4-1结构光相机 结构光相机作为获取三维点云数据的关键设备,其工作原理基于主动式测量技术。通过投射已知图案,如条纹、点阵、格雷码等,至物体表面,这些图案会因物体表面的高度变化而发生变形。与此同时,利用相机从特定...