大连理工大学选修课——机器学习笔记(6):决策树
决策树
决策树概述
决策树——非参数机器学习方法
参数方法:
参数估计是定义在整个空间的模型
所有训练数据参与估算
所有的检验输入都用相同的模型和参数
非参数方法:
非参数估计采用局部模型
输入空间被分裂为一系列可以用距离度量的局部空间
每个输入只使用邻近区域由训练样本计算得到的局部模型
决策树特点
-
采用分治策略
- 简洁高效可并行
- 递归
-
输入空间被描述为一种树形结构
- 层次递归
- 内部结点:决策节点
- 叶子结点:决策结果,可做分类,也可做回归分析
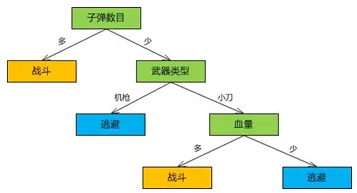
决策树方法简介
→每个结点的决策函数都是定义在d维空间的判别式
-
将空间有效地分为较小区域
-
子结点对父结点确定的区域进一步分裂
-
每个结点的决策函数是一个简单函数
- 不同的函数确定不同的判别式形状和区域形状
→可以快速确定输入的区域
- 对于二值分类,每次决策可以排除一半的实例
- 如果是 k k k个类别,可在 l o g 2 k log_2k log2k次决策后找到答案
→可解释性好
- 可写成容易理解的决策规则
构建决策树
决策树的构建方法
→只采用一个输入维
- 处理离散变量
- 根据属性值的多少确定分支数量
- 如果是连续数值,则离散化处理
- 处理连续变量
- 根据数值确定阈值: f m ( x ) : x j > w m 0 f_m(x):x_j>w_{m0} fm(x):xj>wm0
- 将空间一分为二
→构造一棵决策树
L m = { x ∣ x j > w m 0 } R m = { x ∣ x j ≤ w m 0 } 两个区域相互正交,叶子节点定义输入空间的矩形 L_m=\{x|x_j>w_{m0}\}\\ R_m=\{x|x_j\leq w_{m0}\}\\ 两个区域相互正交,叶子节点定义输入空间的矩形 Lm={x∣xj>wm0}Rm={x∣xj≤wm0}两个区域相互正交,叶子节点定义输入空间的矩形
→单变量决策树:每次分裂只用一个特征
-
根据训练样本构造的决策树,称为树归纳。
-
给定的训练集可以构造很多的编码树,要找到最优树:
- 节点数量
- 决策函数复杂度
- NP完全问题
→通常采用贪心算法
单变量决策树的构建问题
→多特征样本在构建时的特征变量选择
- 不同的变量分裂结果不同
- 离散/连续变量分裂也存在差别
→何时分裂会得到最终结果?
- 没有特征变量时,分裂自然终止
- 如果还存在可用的特征变量,是否继续分裂?
→建立决策树过程中的评价方法
- 熵和定义基于熵的评价指标
- 基尼系数
- 分类误差
ID3算法
输入输出
输入:
- 训练数据集 D D D,包含若干样本,每个样本有 d d d个特征和一个类别标签。
- 特征集 A = { A 1 , A 2 , ⋯ , A d } A=\{ A_1,A_2,\cdots,A_d \} A={A1,A2,⋯,Ad}。
- 目标属性(类别标签) C C C。
输出:一棵决策树。
算法步骤:
-
检查终止条件
满足以下任意条件,停止分裂,返回叶子结点:
- 所有样本属于同一类。
- 无剩余特征可用。
- 样本集为空(极少发生)。
-
选择最优分裂特征
对剩余特征逐个计算信息增益,选择增益最大的特征作为当前结点的分裂特征:
-
计算数据集的熵
E n t r o p y ( D ) = − ∑ k = 1 K p k l o g 2 p k Entropy(D)=-\sum_{k=1}^Kp_k\ log_2\ p_k Entropy(D)=−k=1∑Kpk log2 pk
-
计算特征 A i A_i Ai的信息增益
I G ( D , A i ) = E n t r o p y ( D ) − ∑ v ∈ V a l u e s ( A i ) ∣ D v ∣ ∣ D ∣ E n t r o p y ( D v ) IG(D,A_i)=Entropy(D)-\sum_{v\in Values(A_i)}\frac{|D_v|}{|D|}Entropy(D_v) IG(D,Ai)=Entropy(D)−v∈Values(Ai)∑∣D∣∣Dv∣Entropy(Dv)
V a l u e s ( A i ) Values(A_i) Values(Ai):特征 A i A_i Ai的所有可能取值。
D v D_v Dv: D D D中 A i = v A_i=v Ai=v的子集。
-
选择信息增益最大的特征
-
A b e s t = a r g m a x I G ( D , A i ) A_{best}=arg\ maxIG(D,A_i) Abest=arg maxIG(D,Ai)
-
按特征值分裂数据集
根据 A b e s t A_{best} Abest的取值,将 D D D划分为若干子集 D v D_v Dv,每个子集对应一个分支。
- ID3算法存在的问题
- 只能处理离散属性
- 更多值属性偏向问题:当一个属性具有大量可能值时,ID3算法倾向于选择该属性进行分裂,即使它可能不是最有信息量的属性。如:ID号可能会被优先选择,因为它的可能值很多。
C4.5算法
- 改进:
- 连续属性的离散化
- 解决多值属性的偏向
-
信息增益计算的标准化
引入增益率,通过特征的固有信息对信息增益进行归一化:
I R ( D , A ) = I ( A , D ) H A ( D ) ( H A ( D ) = − ∑ i = 1 n ∣ D i ∣ D l o g 2 ∣ D i ∣ D ) I_R(D,A)=\frac{I(A,D)}{H_A(D)}\\ (H_A(D)=-\sum_{i=1}^n\frac{|D_i|}{D}log_2\frac{|D_i|}{D}) IR(D,A)=HA(D)I(A,D)(HA(D)=−i=1∑nD∣Di∣log2D∣Di∣)
I R ( D , A ) I_R(D,A) IR(D,A):增益率。
H A ( D ) H_A(D) HA(D):固有信息,衡量特征 A i A_i Ai的取值分布的均匀性。
其中n为特征 A 的类别数, Di为特征 A的第i个取值对应的样本个数,|D| 为样本个数。
-
CART算法
-
特点
- 使用基尼系数选择分裂用的最优特征
- 建立的决策树是二叉树
-
基尼系数的计算
假设有K个类别,第k个类别的概率为pk , 则基尼系数的表达式为:
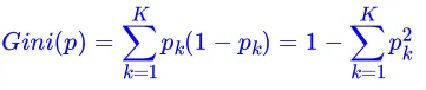
对于二值分类:
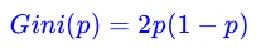
对于样本D,如果根据特征A的某个值a,把D分成D1和D2两部分,则在特征A的条件下,D的基尼系数表达式:
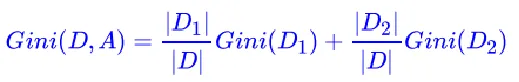
对于个给定的样本D,假设有K个类别,第k个类别的数量|Ck|为,则样本D的基尼系数表达式为:
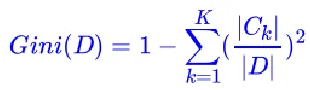
-
连续属性的离散化处理
处理思路与C4.5一样,衡量的标准是基尼系数,连续属性还会参与后续的结点分裂 -
二叉树的实现
找到基尼系数最小的二分结果
例如{A2}和{A1, A3},建立二叉树
后续还有机会对结点{A1, A3}按照特征A进行分裂 -
算法描述
算法输入是训练集D,基尼系数的阈值,样本数量的阈值输出是决策树T
- 对于当前结点的数据集为D,如果样本个数小于阈值或者没有特征,则返回决策子树,当前结点停止递归;
- 计算样本集D的基尼系数,如果基尼系数小于阈值,则返回决策树子树,当前结点停止递归;
- 计算当前结点现有的各个特征的各个特征值对数据集D的基尼系数;
- 在计算出来的各个特征的各个取值对数据集D的基尼系数中,选择基尼系数最小的特征A和对应的取值a。根据这个最优特征和最优值,把数据集分裂成两部分D1和D2,同时建立当前结点的左右结点,左结点的数据集为D1,右结点的数据集为D2;
- 对左右的子结点递归的调用1-4步,生成决策树。
-
特殊处理
CART的叶子结点的不纯性不一定降到最低:叶子结点中的样本可能会属于多个类
在用CART树做预测时,选择训练样本所占比例最大的类别作为预测结果
或者在构建决策树时,将叶子结点的类别标签选择为比例最大的训练样本类别 -
建立回归树
- ID3和C4.5只建立分类树
这一点限制了两个算法的使用范围 - CART的长处除了计算量小以外,还有该算法既可以做分类又可以做回归
- CART的回归树和分类树大同小异
回归的输出是连续的
设置为到达该结点所有样本实例输出的均值
分裂属性选择的衡量标准是分类误差
- ID3和C4.5只建立分类树
-
均方误差度量
定义二值化的指示函数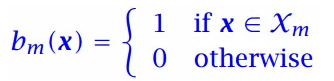
结点m的预测输出:
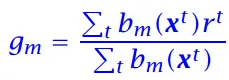
结点m的误差:
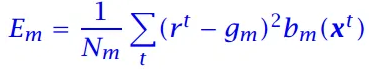
-
分裂的操作
如果结点m的误差太大,不能接受(根据预设的阈值判断),需要对结点进行分裂
在众多选的分裂结果中选择诸分支误差和最小的,每次递归的分裂都是得到二分的结果
对于结点m的分支 j: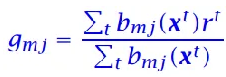
分裂后的总误差:
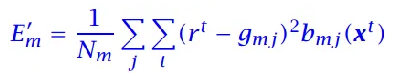
-
误差阈值
-
调节模型复杂程度的超参数
-
图片为误差阈值降低后树的变化
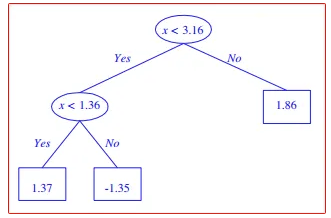
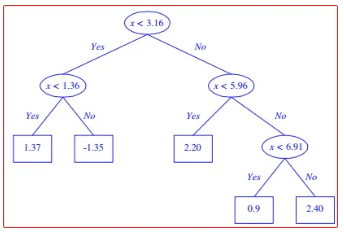
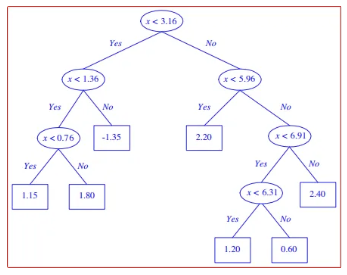
过拟合
-
过拟合问题:不要期望把结点的不纯性降到最低,小于某个阈值即可
剪枝
- 先剪枝
到达一个结点的实例数小于训练集的某个百分比(设个阈值,例如5%),然后就停止该结点的进一步分裂。速度快,但效果不是很理想。
- 后剪枝
先让树完全增长至零训练误差或者结点不纯性降到最低,然后剪掉导致过拟合的子树。
后剪枝是全局搜索,效果更好,但会很慢。
几种量化结点纯度的指标对比
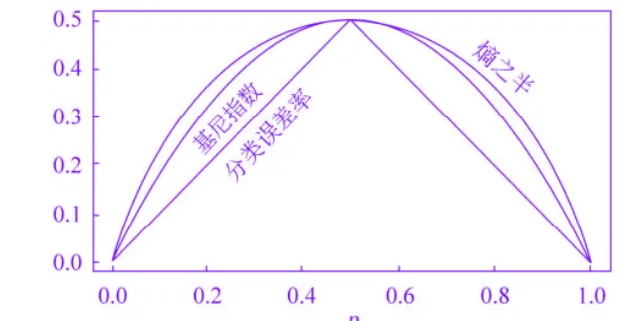
基尼系数是熵的一个很好的近似
熵与信息增益
熵的概念
——熵度量了事物的不确定性
-
越不确定的事物,熵越大
-
随机事件X的熵定义:
H ( X ) = − ∑ i = 1 n p i l o g p i H(X)=-\sum_{i=1}^np_ilogp_i H(X)=−i=1∑npilogpi
-
联合熵:
H ( X , Y ) = − ∑ p ( x i , y i ) l o g p ( x i , y i ) H(X,Y)=-\sum p(x_i,y_i)logp(x_i,y_i) H(X,Y)=−∑p(xi,yi)logp(xi,yi)
- 条件熵
H ( X ∣ Y ) = − ∑ p ( x i , y i ) l o g p ( x i ∣ y i ) = ∑ p ( y j ) H ( X ∣ y j ) H(X|Y)=-\sum p(x_i,y_i)logp(x_i|y_i)=\sum p(y_j)H(X|y_j) H(X∣Y)=−∑p(xi,yi)logp(xi∣yi)=∑p(yj)H(X∣yj)
信息增益
- 信息增益也称为互信息
- 定义如下:
I ( X , Y ) = H ( X ) − H ( X ∣ Y ) I(X,Y)=H(X)-H(X|Y) I(X,Y)=H(X)−H(X∣Y)
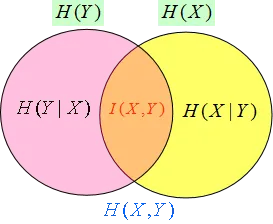
计算实例:



树结点度量指标
→度量结点的不纯性
-
用熵描述结点m的不纯性
I m = H ( C ) = − ∑ i = 1 K p m i l o g p m i I_m=H(C)=-\sum_{i=1}^Kp_m^ilogp_m^i Im=H(C)=−i=1∑Kpmilogpmi
p m i p_m^i pmi表示第 i i i类样本所占比例
如果结点不需要分裂(到达结点m的所有实例只属于一个类别C,没有不确定性),则不纯性 I m = 0 I_m=0 Im=0,即 H ( C ) − 0 H(C)-0 H(C)−0。
-
子结点不纯性的计算
假设父节点 m m m的离散属性有n个取值,即有n个输出
- 连续属性有两个输出 ( n = 2 ) (n=2) (n=2),有如下统计:
∑ j = 1 n N m j = N m \sum_{j=1}^nN_{mj}=N_m j=1∑nNmj=Nm
N m j N_{mj} Nmj个实例中有 N m j i N_{mj}^i Nmji个属于类 C i C_i Ci
∑ i = 1 K N m j i = N m j ∑ i = 1 n N m j i = N m i \sum_{i=1}^K N_{mj}^i = N_{mj}\qquad \sum_{i=1}^n N_{mj}^i=N_m^i i=1∑KNmji=Nmji=1∑nNmji=Nmi
p ^ ( C i ∣ x , m , j ) = p m l i = N m j i N m j \hat p(C_i|x,m,j)=p_{ml}^i=\frac{N_{mj}^i}{N_{mj}} p^(Ci∣x,m,j)=pmli=NmjNmji
n个子结点的总不纯度为:
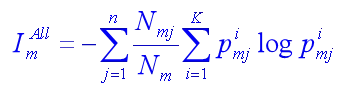
分裂选用的特征
- 每次分裂需要选择特定的属性进行
-
选择的策略:
-
能使不纯度下降最大的属性:
I m − I m A H I_m-I_m^{AH} Im−ImAH
-
能使信息增益最大的属性
两个随机变量之间的统计依赖性或信息共享程度
衡量已知一个变量的信息后,另一个变量的不确定性减少的程度
I ( X m , C m j ) = H ( X m ) − H ( X m ∣ C m j ) I(X_m, C_{mj})=H(X_m)-H(X_m|C_{mj}) I(Xm,Cmj)=H(Xm)−H(Xm∣Cmj)
-
-
连续属性的处理
- 通常,构建决策树时只考虑使用离散属性
- 而连续属性需要转换成只有两个取值的离散属性
- 可以选择使用所可能取值的平均值/均值作为阈值。
决策树C4.5算法的处理
设样本的连续属性有m个不同取值,将所有取值排序,取所有相邻的两个值,计算他们的均值,从而得到 m − 1 m-1 m−1个均值,将它们作为候选阈值。测试用每个阈值分裂二值结果的互信息,选择能带来最大互信息的均值作为最后的阈值进行二值分裂。
使用决策树
-
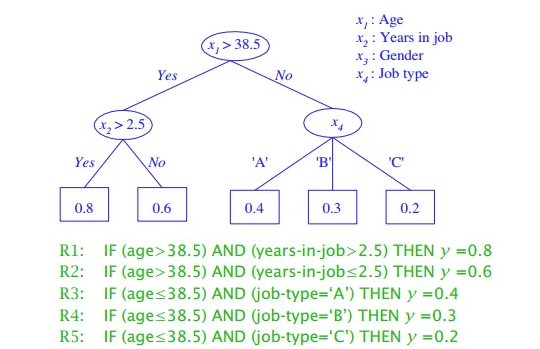
决策树的每一条从根到叶子的路径:对应的条件的合取(AND)。
-
对于分类树,可能有过个叶子被标记为相同的类:多个路径对应的条件用析取(OR)。
-
各个路径可以用IF-THEN规则表示
几种经典模型的对比
| 算法 | 支持
模型 | 树结构 | 特征选择 | 连续值
处理 | 缺失值
处理 | 剪枝 |
| — | — | — | — | — | — | — |
| ID3 | 分类 | 多叉树 | 信息增益 | 不支持 | 不支持 | 不支持 |
| C4.5 | 分类 | 多叉树 | 信息增益比 | 支持 | 支持 | 支持 |
| CART | 分类,
回归 | 二叉树 | 基尼系数,
均方差 | 支持 | 支持 | 支持 |
决策树模型评价
- 优点
1)简单直观,生成的决策树很直观
2)基本不需要预处理,不需要提前归一化
3)相比于神经网络之类的黑盒分类模型,决策树在逻辑上
可以得到很好的解释
4)可以交叉验证的剪枝来选择模型,从而提高泛化能力
5)对于异常点的容错能力好,健壮性高。
- 缺点
- 决策树算法非常容易过拟合,导致泛化能力不强
- 通常把决策树用作基准模型(baseline)
- 或作为集成学习的弱学习模型
- 决策树会因为样本发生一点点的改动,就会导致树
结构的剧烈改变 - 寻找最优的决策树是一个NP难的问题,我们一般是
通过启发式方法,容易陷入局部最优。
总结
- 每个类可能存在对各分支对应的多个解释和描述
- 这些不同的解释可能会在空间中不相交
- 不必考虑各个区域(特征子空间)上的分布信息
- 直接对分离类实例的判别式进行编码
- 属于基于判别式的(discriminant-based)方法
- 更多地应用于分类
相关文章:
:决策树)
大连理工大学选修课——机器学习笔记(6):决策树
决策树 决策树概述 决策树——非参数机器学习方法 参数方法: 参数估计是定义在整个空间的模型 所有训练数据参与估算 所有的检验输入都用相同的模型和参数 非参数方法: 非参数估计采用局部模型 输入空间被分裂为一系列可以用距离度量的局部空间…...

现代前端工具链深度解析:从包管理到构建工具的完整指南
前言 在当今快速发展的前端生态中,高效的工具链已经成为开发者的必备利器。一个优秀的前端工具链可以显著提升开发效率、优化项目性能并改善团队协作体验。本文将深入探讨现代前端开发中最核心的两大工具类别:包管理工具(npm/yarn)和构建工具(Webpack/V…...

[C语言]猜数字游戏
文章目录 一、游戏思路揭秘二、随机数生成大法1、初探随机数:rand函数的魔力2、随机数种子:时间的魔法3、抓住时间的精髓:time函数 三、完善程序四、游戏成果1、游戏效果2、源代码 一、游戏思路揭秘 猜数字游戏,这个听起来就让人…...

【Linux】g++安装教程
Linux上安装g教程 实现c语言在Linux上编译运行 1. 更新软件包列表 打开终端,先更新软件包列表以确保获取最新版本信息: sudo apt update2. 安装 build-essential 工具包 build-essential 包含 g、gcc、make 和其他编译所需的工具: sudo…...
)
MQTT - Android MQTT 编码实战(MQTT 客户端创建、MQTT 客户端事件、MQTT 客户端连接配置、MQTT 客户端主题)
Android MQTT 编码实战 1、Settting 在项目级 build.gradle 目录下导入 MQTT 客户端依赖 implementation org.eclipse.paho:org.eclipse.paho.mqttv5.client:1.2.5 implementation org.eclipse.paho:org.eclipse.paho.android.service:1.1.1AndroidManifest.xml,…...

Redis分布式锁使用以及对接支付宝,paypal,strip跨境支付
本章重点在于如何使用redis的分布式锁来锁定库存。减少超卖,同时也对接了支付宝,paypal,strip跨境支付 第一步先建立一个商品表 CREATE TABLE sys_product (id bigint(20) NOT NULL AUTO_INCREMENT COMMENT 主键,code varchar(60) DEFAUL…...
)
沙箱逃逸(Python沙盒逃逸深度解析)
沙箱逃逸(Python沙盒逃逸深度解析) 一、沙盒逃逸的核心目标 执行系统命令 通过调用os.system、subprocess.Popen等函数执行Shell命令,例如读取文件或反弹Shell。 文件操作 读取敏感文件(如/etc/passwd)、写入后门文件…...

k8s-Pod生命周期
初始化容器 初始化容器是在pod的主容器启动之前要运行的容器,主要是做一些主容器的前置工作,它具有两大特征: 1. 初始化容器必须运行完成直至结束,若某初始化容器运行失败,那么kubernetes需要重启它直到成功完成 2. 初…...

基于Springboot + vue实现的中医院问诊系统
项目描述 本系统包含管理员、医生、用户三个角色。 管理员角色: 用户管理:管理系统中所有用户的信息,包括添加、删除和修改用户。 配置管理:管理系统配置参数,如上传图片的路径等。 权限管理:分配和管理…...

computed计算值为什么还可以依赖另外一个computed计算值?
在 Vue(或类似的响应式框架)中,computed 计算属性之所以可以依赖另一个 computed 属性,是因为: ✅ 本质上 computed 是响应式依赖的“派生值” 每个 computed 本质上就是一个 基于其他响应式数据计算出来的值。 当你在…...

近期实践总结
一、计算机二级考试到底教会了我们什么? 1、概况 根据本人复习、考试的经验,不难发现里面的试题或多或少有些死板(甚至可以说落后于时代),当今时代已经不是二十年前什么都需要手搓的时代了,引擎、集成类软…...

Arduion 第一天,变量的详细解析
Arduino变量详解与嵌入式开发扩展 一、变量基础篇 1.1 变量声明与初始化 <ARDUINO>int ledPin 13; // 声明并初始化float sensorValue; // 先声明后赋值unsigned long startTime; // 无符号长整型void setup() {sensorValue analogRead(A0) *…...

【每日八股】复习 MySQL Day3:锁
文章目录 昨日内容复习MySQL 使用 B 树作为索引的优势是什么?索引有哪几种?什么是最左匹配原则?索引区分度?联合索引如何排序?使用索引有哪些缺陷?什么时候需要建立索引,什么时候不需要…...

2025年KBS新算法 SCI1区TOP:长颖燕麦优化算法AOO,深度解析+性能实测
目录 1.摘要2.算法原理3.结果展示4.参考文献5.文章&代码获取 1.摘要 本文提出了一种新颖的元启发式算法——长颖燕麦优化算法(AOO),该算法灵感来自动画燕麦在环境中的自然行为。AOO模拟了长颖燕麦的三种独特行为:(i) 通过自然…...

1.4 点云数据获取方式——结构光相机
图1-4-1结构光相机 结构光相机作为获取三维点云数据的关键设备,其工作原理基于主动式测量技术。通过投射已知图案,如条纹、点阵、格雷码等,至物体表面,这些图案会因物体表面的高度变化而发生变形。与此同时,利用相机从特定...

2025.4.29总结
工作:最近手头活变得多起来了,毕竟要测两个版本,有时候觉得很奇怪,活少的时候,又想让别人多分点活,活多的时候,又会有些许不自然。这种反差往往伴随着项目的节奏,伴随着两个极端。所…...

初探RAG
源码 核心工作流程 读取文件的内容将内容保存在向量数据库检索向量数据库用户的问题用户问题 上下文【向量数据】 > LLM 读取文件内容【pdf为例】 from pdfminer.high_level import extract_pages from pdfminer.layout import LTTextContainerclass PDFFileLoader():d…...
技术全景图:从文本到图像的革命)
AIGC(生成式AI)技术全景图:从文本到图像的革命
AIGC(生成式AI)技术全景图:从文本到图像的革命 前言 生成式人工智能(AIGC)正以惊人的速度重塑数字内容的生产方式。从GPT系列模型的文本生成,到Stable Diffusion的图像创作,再到Sora的视频合成…...

通信协议:数字世界的隐形语言——从基础认知到工程实践-优雅草卓伊凡
通信协议:数字世界的隐形语言——从基础认知到工程实践-优雅草卓伊凡 一、理解通信协议:数字世界的”隐形语法” 1.1 通信协议的不可见性与现实存在 通信协议如同空气中的无线电波,虽然看不见摸不着,却实实在在支撑着现代数字世…...

RPC复习
RPC复习 RPC (远程过程调用) 全面解析一、RPC 定义与核心作用1. 什么是RPC?2. 核心作用 二、主流RPC框架对比三、RPC适用场景四、RPC的缺陷五、RPC vs REST vs GraphQL六、Java实现案例:使用Dubbo框架案例描述1. 环境准备2. 定义服务接口3. 服务提供方实…...

Express 文件上传不迷路:req.files 一次性讲明白
前言 在开发后台接口的江湖中,文件上传堪称“隐藏副本”,难度不大但坑点极多。本来只想优雅接收一张图片,结果 undefined、报错、路径错乱轮番登场,逼得人想重拾卖烤红薯的梦想。别慌,本文将用轻松幽默的方式,深入拆解 req.files.file 的每个属性,从前端表单到后台处理…...

Leetcode 3530. Maximum Profit from Valid Topological Order in DAG
Leetcode 3530. Maximum Profit from Valid Topological Order in DAG 1. 解题思路2. 代码实现 题目链接:3530. Maximum Profit from Valid Topological Order in DAG 1. 解题思路 这一题的整体思路就是一个动态规划的思路,我们只需要在当前可以访问的…...

Mysql中索引的知识
Mysql中的索引的定义和种类 核心概念:索引是什么? 想象一下你有一本很厚的书,你想找到其中关于某个特定主题的内容。你有两种方法: 从头到尾翻阅整本书:这就像数据库中的全表扫描 (Full Table Scan)。如果书很长&…...

VSCode Verilog编辑仿真环境搭建
VSCode Verilog环境搭建 下载Iverilog安装Iverilog验证安装VS Code安装插件 下载Iverilog 官网下载Iverilog 安装Iverilog 一定要勾选这两项 建议勾选这两项 验证安装 运行Windows PowerShell输入命令:iverilog输入命令:Get-Command gtkwave …...

linux修改环境变量
添加环境变量注意事项。 vim ~/.bashrc 添加环境变量时,需要source ~/.bashrc后才能有效。同时只对当前shell窗口有效,当打开另外的shell窗口时,需要重新source才能起效。 1.修改bashrc文件后 2.source后打开另一个shell窗口则无效ÿ…...

为什么要学习《金刚经》
《金刚经》作为佛教般若经典的核心,以"缘起性空"为思想根基,通过佛陀与须菩提的对话,揭示了破除执著、见真实相的智慧。 以下从核心要义、精髓段落和现实应用三个维度进行解读: 一、核心思想精髓 1. "凡所有相&am…...
(⭐️⭐️⭐️ 重点章节!!!))
【阿里云大模型高级工程师ACP习题集】2.7 通过微调增强模型能力 (上篇)(⭐️⭐️⭐️ 重点章节!!!)
习题集: 【单选题】在大模型微调中,与提示工程和RAG相比,微调的独特优势在于( ) A. 无需外部工具即可提升模型表现 B. 能让模型学习特定领域知识,提升底层能力 C. 可以更高效地检索知识 D. 能直接提升模型的知识边界,无需训练 【多选题】以下关于机器学习和传统编程的说…...

Docker 容器双网卡访问物理雷达网络教程
作者: 陈梓洋 环境: ubuntu 22.04lts 时间: 2025年4月29日 Docker 容器双网卡访问物理雷达网络教程 这个教程适用于这样的场景:容器保留原有 ROS 通信网络(如 bridge 网络),同时需要访问一个物…...

C++:Lambda表达式
C:Lambda表达式 C中lambda的基本语法1. 捕获列表(Capture List)2. 示例代码示例 1:简单的lambda示例 2:捕获变量示例 3:按引用捕获示例 4:捕获所有变量示例 5:作为函数参数 3. lambd…...

Vim 中替换字符或文本
在 Vim 中替换字符或文本可以使用 替换命令(substitute),其基本语法为: :[range]s/old/new/[flags]1. 基本替换 命令说明:s/foo/bar/替换当前行的第一个 foo 为 bar:s/foo/bar/g替换当前行的 所有 foo 为 bar:%s/foo/bar/g替换 …...

Thinkphp开发自适应职业学生证书查询系统职业资格等级会员证书管理网站
主要功能介绍 1.PHP MYSQL开发,开源,方便二次开发。 2.后台管理界面清新 3.可批量导入导出数据,格式为:JsoN、CSV、 Excel等。 4.自适应手机端,PC端 5.数据修改,添加,删除非常方便,手机上就可以解决 6.可以增加管理员权限等 7.界面可以个性定制开发...
进行语义相似度搜索有什么区别和联系)
OpenAI Embedding 和密集检索(如 BERT/DPR)进行语义相似度搜索有什么区别和联系
OpenAI Embedding 和密集检索(如 BERT/DPR)其实是“同一种思想的不同实现”,它们都属于Dense Retrieval(密集向量检索),只不过使用的模型、部署方式和调用方式不同。 🧠 首先搞清楚:…...

C语言复习笔记--数据在内存中的存储
今天我们来复习一下数据在内存中的存储方式.话不多说进入正题. 整数在内存中的存储 整数的2进制表⽰⽅法有三种,即原码、反码和补码.三种表⽰⽅法均有符号位和数值位两部分,符号位都是⽤0表⽰“正”,⽤1表⽰“负”,⽽数值位最⾼位…...
)
笔试专题(十二)
文章目录 主持人调度题解代码 小红的ABC题解代码 不相邻取数题解代码 空调遥控题解代码 主持人调度 题目链接 题解 1. 排序 2. 先按左端点的大小进行排序,保证时间是连续的,如果后一个点的左端点大于等于前一个点的右端点就是和法的,否则…...
+Leptos(0.7.8)开发桌面应用---后台调用Python Matplotlib绘制图形)
Tauri(2.5.1)+Leptos(0.7.8)开发桌面应用---后台调用Python Matplotlib绘制图形
Rust语言最接近Python Matplotlib绘图库的应该是Plotters,但是试用下来还是没有Matplotlib效果好,所以尝试在Tauri Leptos项目中,后台调用Python Matplotlib绘制图形,并返回给前端Leptos展示。 具体效果如下: 1. 前端…...
:STM32F103加入AFIO控制器)
Qemu-STM32(十七):STM32F103加入AFIO控制器
概述 本文主要描述了在Qemu平台中,如何添加STM32F103的AFIO控制器模拟代码,AFIO是属于GPIO引脚复用配置的功能。 参考资料 STM32F1XX TRM手册,手册编号:RM0008 添加步骤 1、在hw/arm/Kconfig文件中添加STM32F1XX_AFIO&#x…...

刀客doc:小红书商业技术负责人苍响离职
根据大厂日爆的爆料,小红书商业化再度迎来高层人事变动,原商业平台技术负责人苍响(薯名),职级L2,已于本月正式离职,其下属团队现由电商业务负责人接管。 根据刀客doc获得的资料,苍响…...

CC52.【C++ Cont】滑动窗口
目录 1.题目 2.分析 方法1:暴力枚举 方法2:暴力枚举的优化:"同向双指针",也称滑动窗口 前置知识 核心操作 例子解释 代码 提交结果 1.题目 LCR 008. 长度最小的子数组 给定一个含有 n 个正整数的数组和一个正整数 target 。 找出该数组中满足其和 ≥ target…...

linux中由于编译选项-D_OS64BIT导致的核心已转储问题
linux中由于编译选项-D_OS64BIT导致的核心已转储问题排查解决: 原因: a.so b.so a.so使用b.so 程序1 程序2 使用a.so 程序1运行正常,程序2启动后提示核心已转储。 程序1和程序2运行的代码都一致,只执行创建xApplication app&…...

Ubuntu搭建 Nginx以及Keepalived 实现 主备
目录 前言1. 基本知识2. Keepalived3. 脚本配置4. Nginx前言 🤟 找工作,来万码优才:👉 #小程序://万码优才/r6rqmzDaXpYkJZF 爬虫神器,无代码爬取,就来:bright.cn Java基本知识: java框架 零基础从入门到精通的学习路线 附开源项目面经等(超全)【Java项目】实战CRU…...

Knife4j 接口文档添加登录验证流程分析
Knife4j 接口文档添加登录验证流程是非常必要的,否则接口文档一旦暴露到外面是很危险的,今天我们详细分析一下。在1.9.6的版本时,作者把swagger-bootstrap-ui项目重命名为Knife4j,今天分析2.0.6版本。 1、pom.xml文件引入 <pa…...

C++之string
string 是C中常见的一个用于处理和操作字符串的类。一直有用它来存储字符串,今天来介绍介绍一下它的定义和一些基本用法吧。 1、头文件 #include <string>2、定义和初始化 #include <iostream> #include <string> using namespace std;int main…...

【含文档+PPT+源码】基于SSM的电影数据挖掘与分析可视化系统设计与实现
项目介绍 本课程演示的是一款基于SSM的电影数据挖掘与分析可视化系统设计与实现,主要针对计算机相关专业的正在做毕设的学生与需要项目实战练习的 Java 学习者。 1.包含:项目源码、项目文档、数据库脚本、软件工具等所有资料 2.带你从零开始部署运行本…...

DeepSeek提示词技巧
以下是使用Deepseek等AI工具时提升效果的提示词模式总结,涵盖核心规律、应用场景及效果对比: 规律一:结构化提示(解决模糊性问题) 问题:开放式问题导致回答笼统 模式:角色任务约束输出格式 例子…...
第 4 版全章节核心考点解析(第4版课程精华版))
软考高项(信息系统项目管理师)第 4 版全章节核心考点解析(第4版课程精华版)
一、核心输入输出速记体系(力扬老师独家口诀) (一)规划阶段万能输入(4 要素) 口诀:章程计划,组织事业 ✅ 精准对应(ITTO 核心输入): 章程&#…...

【linux网络】网络基础概念
1. 初始协议 1.1 OSI 七层模型 OSI(Open System Interconnection,开放系统互连)七层网络模型称为开放式系统互联参考模型,是一个逻辑上的定义和规范; 把网络从逻辑上分为了 7 层. 每一层都有相关、相对应的物理设备&a…...

【PyTorch动态计算图实战解析】从原理到高效开发
目录 前言技术背景与价值当前技术痛点解决方案概述目标读者说明一、技术原理剖析核心概念图解核心作用讲解关键技术模块说明技术选型对比二、实战演示环境配置要求核心代码实现案例1:梯度计算可视化案例2:动态控制流案例3:自定义反向传播运行结果验证三、性能对比测试方法论…...
:常见位运算操作总结)
【专题五】位运算(1):常见位运算操作总结
📝前言说明: 本专栏主要记录本人的基础算法学习以及LeetCode刷题记录,按专题划分每题主要记录:(1)本人解法 本人屎山代码;(2)优质解法 优质代码;ÿ…...

react-native-vector-icons打包报错并且提示:copyReactNativeVectorIconFonts相关信息
使用react-native-vector-icons,打包时会报: FAILURE: Build failed with an exception. * What went wrong: Some problems were found with the configuration of task :app:copyReactNativeVec torIconFonts (type Copy).- Gradle detected a proble…...

【Sqlalchemy Model转换成Pydantic Model示例】
【Sqlalchemy Model转换成Pydantic Model示例】 由于Sqlalchemy和Pydantic的模型字段类型可能有差异, 所以需要一个通用的装换类 def sqlalchemy_to_pydantic_v2(sqlalchemy_model, pydantic_model):"""通用函数,将 SQLAlchemy 模型实例转换为 Pyd…...