使用Langchain+DeepSeep进行测试相关工作
1.使用BaseChatModel实现自定义DeepSeekLLM
import json
import typing
from typing import Optional, Any, List, Dict, Union, Sequence, Callable, Literalimport requests
from langchain_core.callbacks import CallbackManagerForLLMRun
from langchain_core.language_models.chat_models import BaseChatModel
from langchain_core.messages import HumanMessage, AIMessage, BaseMessage
from langchain_core.messages import SystemMessage
from langchain_core.outputs import ChatResult, ChatGeneration
from langchain_core.prompts import PromptTemplate
from langchain_core.tools import BaseToolfrom config.settings import deepseek_settings
from core.utils.base_utils import BaseUtils
from core.utils.my_logger import loggerclass DeepSeekLLM(BaseChatModel):api_key: str = deepseek_settings.api_keybase_url: str = deepseek_settings.base_urlmodel: str = deepseek_settings.modelmax_tokens: int = deepseek_settings.max_tokenstemperature: float = deepseek_settings.temperaturetimeout: int = deepseek_settings.timeoutstreaming: bool = deepseek_settings.streaming# 对话历史记录(维护多轮上下文)conversation_history: List[BaseMessage] = []# 工具列表tools: List[dict] = []def bind_tools(self, tools: Sequence[Union[typing.Dict[str, Any], type, Callable, BaseTool] # noqa: UP006], *, tool_choice: Optional[Union[str, Literal["any"]]] = None, **kwargs: Any) -> "DeepSeekLLM":"""添加工具,以deepseek形式"""formatted_tools = []for tool in tools:if isinstance(tool, BaseTool):formatted_tool = {"type": "function","function": {"name": tool.name,"description": tool.description,"parameters": tool.args_schema.schema() if tool.args_schema else {}}}formatted_tools.append(formatted_tool)new_instance = self.copy() # 创建新实例避免污染原配置new_instance.tools = formatted_toolsreturn new_instance # 返回自身类型@propertydef _llm_type(self) -> str:"""返回模型标识"""return self.model@propertydef _identifying_params(self):"""返回模型参数"""return {"model_name": self.model,"temperature": self.temperature,"max_tokens": self.max_tokens,"streaming": self.streaming}def _format_message(self, message: BaseMessage) -> Dict:"""将LangChain消息格式转换为DeepSeek API格式"""if isinstance(message, HumanMessage):return {"role": "user", "content": message.content}elif isinstance(message, AIMessage):return {"role": "assistant", "content": message.content}elif isinstance(message, SystemMessage):return {"role": "system", "content": message.content}else:raise ValueError(f"不支持的消息类型: {type(message)}")def _generate(self, messages: list[BaseMessage], stop: Optional[list[str]] = None,run_manager: Optional[CallbackManagerForLLMRun] = None, **kwargs: Any) -> ChatResult:"""实现与DeepSeek交互并返回原始响应结果"""url = f"{self.base_url}/chat/completions"headers = {"Content-Type": "application/json","Authorization": f"Bearer {self.api_key}"}formatted_messages = [self._format_message(m) for m in messages]payload = {"model": self.model,"messages": formatted_messages,"temperature": self.temperature,"max_tokens": self.max_tokens,"stream": self.streaming}# 输出jsonif self.model == "deepseek-chat" and deepseek_settings.json_type:payload["response_format"] = {"type": "json_object"}# 添加工具if self.tools:payload["tools"] = self.toolspayload["tool_choice"] = "auto"response = requests.post(url, headers=headers, json=payload, timeout=self.timeout, stream=self.streaming)if response.status_code != 200:logger.error(f"DeepSeek API请求失败: {response.text}")raise ValueError(f"DeepSeek API请求失败: {response.text}")if self.streaming:return self._handle_streaming_response(response, run_manager)else:return self._handle_normal_response(response)def _handle_normal_response(self, response: requests.Response) -> ChatResult:"""处理非流式响应"""response_data = response.json()message = response_data["choices"][0]["message"]# 获取推理模型的思维链if self.model == "deepseek-reasoner":reasoning_content = message["reasoning_content"]else:reasoning_content = None# 处理工具调用信息tool_calls = message.get("tool_calls", [])formatted_tool_calls = []for tool_call in tool_calls:if "function" in tool_call:function = tool_call["function"]formatted_tool_calls.append({"id": tool_call["id"],"name": function["name"],"args": json.loads(function["arguments"])})# 构造LangChain格式的响应generation = ChatGeneration(message=AIMessage(content=message["content"],response_metadata={"token_usage": response_data.get("usage", {}), # token使用情况"finish_reason": response_data["choices"][0].get("finish_reason"), # 模型输出状态},tool_calls=formatted_tool_calls,reasoning_content=reasoning_content))return ChatResult(generations=[generation])def _handle_streaming_response(self, response: requests.Response,run_manager: CallbackManagerForLLMRun) -> ChatResult:"""处理流式响应"""content_buffer = []reasoning_content_buffer = []finish_reason = ''usage = {}try:for line in response.iter_lines():if line:decoded_line = line.decode('utf-8').strip()if decoded_line.startswith('data:'):event_data = decoded_line[5:].strip()if event_data == '[DONE]':breaktry:data = json.loads(event_data)delta = data.get('choices', [{}])[0].get('delta', {})usage = data.get('usage')content = delta.get('content', '') or ''reasoning_content = delta.get('reasoning_content', '') or ''finish_reason = delta.get('finish_reason', '') or ''# 过滤None和空值if isinstance(content, str) and content:content_buffer.append(content)if run_manager:run_manager.on_llm_new_token(content)if isinstance(reasoning_content, str) and reasoning_content:reasoning_content_buffer.append(reasoning_content)if run_manager:run_manager.on_llm_new_token(reasoning_content)except (json.JSONDecodeError, KeyError, IndexError) as e:logger.warning(f"解析异常事件块: {e}")continueexcept requests.exceptions.ChunkedEncodingError as e:logger.error(f"流式传输中断: {e}")# 空内容兜底处理final_content = ''.join(content_buffer) if content_buffer else "【响应内容为空】"# 构造LangChain格式的响应generation = ChatGeneration(message=AIMessage(content=final_content,response_metadata={"token_usage": usage, # token使用情况"finish_reason": finish_reason # 模型输出状态},reasoning_content=''.join(reasoning_content_buffer)))return ChatResult(generations=[generation])def calculate_api_token_usage(self, response: BaseMessage):"""统计token消耗情况"""token_usage = response.response_metadata.get('token_usage', {})prompt_tokens = token_usage["prompt_tokens"]completion_tokens = token_usage["completion_tokens"]total_tokens = token_usage["total_tokens"]# 记录完整token消耗logger.info(f"Token使用统计 - Prompt: {prompt_tokens} ({prompt_tokens / 1024:.2f}K) | "f"Completion: {completion_tokens} ({completion_tokens / 1024:.2f}K) | "f"Total: {total_tokens} ({total_tokens / 1024:.2f}K)")def call(self,propmt: Union[str, PromptTemplate], # 支持直接字符串或LangChain模板input_variables: Optional[Dict] = None, # 模板变量字典reset_conversation: bool = True # 是否重置对话历史 True:重置 False:不重置) -> Dict:"""与DeepSeek交互"""logger.info(f"llm参数:{self._identifying_params}")# 历史管理:重置或保留上下文if reset_conversation:self.conversation_history = [] # 清空历史记录# 变量默认值处理if input_variables is None:input_variables = {} # 兼容无变量的提示词# 提示词格式化处理if isinstance(propmt, PromptTemplate):# LangChain模板:自动填充变量full_prompt = propmt.format(**input_variables)else:# 普通字符串:检查是否需要变量插值full_prompt = propmt.format(**input_variables) if input_variables else propmt# 构造消息列表(DeepSeek API格式)messages = [HumanMessage(content=full_prompt)]# 注入历史上下文(如果是连续对话)if self.conversation_history:messages = self.conversation_history + messages# 与DeepSeek交互response = self._generate(messages).generations[0].message # 传入完整messages(含历史)if self.model == "deepseek-reasoner":logger.info(f"DeepSeek思维链内容:{response.reasoning_content}")full_response = response.contentlogger.info(f"DeepSeek返回结果: {full_response}")# 统计token使用情况self.calculate_api_token_usage(response)# 更新对话历史(除非当前是独立对话)self.conversation_history.extend([HumanMessage(content=full_prompt),AIMessage(content=full_response)])try:parsed = BaseUtils.parse_deepseek_response(full_response) # 使用自定义解析return parsedexcept ValueError:logger.error("DeepSeek返回内容无法解析为有效JSON")def continue_conversation(self, user_input: str):"""自动多轮对话"""return self.call(user_input, reset_conversation=False)def reset_conversation(self) -> None:"""重置会话"""self.conversation_history = []if __name__ == "__main__":ds = DeepSeekLLM()ds.temperature = 0.7s = ds.call("你好")
2.创建Converter基类,用于统一处理deepseek相关操作
#!/usr/bin/env python3
# -*- coding:utf-8 -*-from abc import ABC, abstractmethod
from typing import Dict, Anyfrom core.llm.deepseek_client import DeepSeekLLM
from core.utils.my_logger import loggerclass BaseConverter(ABC):def __init__(self, llm_client=None):self.llm = llm_client or DeepSeekLLM()def _validate_response(self, response: Dict) -> bool:"""统一响应校验(所有子类共享)"""required_fields = {"data": list, "has_more": bool}for field, expected_type in required_fields.items():if not isinstance(response.get(field), expected_type):logger.error(f"响应校验失败:缺少必要字段 {field} 或类型不匹配")raise ValueError(f"Invalid response format: missing {field} or wrong type")return Truedef _merge_response(self, existing: Dict, new: Dict) -> Dict:"""统一响应合并(所有子类共享)"""return {"data": existing["data"] + new["data"],"has_more": new.get("has_more", False) # 以新响应的has_more为准}@abstractmethoddef _get_prompt(self, prompt: Any, is_first: bool) -> str:"""抽象方法:子类必须实现提示词生成逻辑"""passdef _call_llm(self, prompt: Any, is_first: bool) -> Dict | str:"""统一LLM调用流程(子类直接调用)"""prompt_text = self._get_prompt(prompt, is_first) # 子类定义的提示词逻辑if is_first:response = self.llm.call(prompt_text) # 调用DeepSeekLLM的单次对话else:response = self.llm.continue_conversation(prompt_text) # 调用多轮对话return response
3.基础工具类
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import json
import os
import re
from pathlib import Pathclass BaseUtils:@staticmethoddef parse_deepseek_response(text: str) -> dict | str:"""将deepseek返回内容转换成json"""# 尝试直接解析为JSONtry:return json.loads(text)except json.JSONDecodeError:pass# 处理```jsonif text.startswith("```json"):first_brace_index = text.find('{')last_brace_index = text.rfind('}')# 提取第一个 '{' 到最后一个 '}' 之间的数据extracted_json_str = text[first_brace_index:last_brace_index + 1]try:# 解析提取的 JSON 字符串parsed_data = json.loads(extracted_json_str)return parsed_dataexcept json.JSONDecodeError:raise ValueError# 处理```pythonif text.startswith("```python"):start_index = text.find('```python')end_index = text.find('```', start_index + len('```python'))if start_index != -1 and end_index != -1:start = start_index + len('```python')return text[start:end_index].strip()raise ValueError@staticmethoddef camel_to_snake(name):# 驼峰转下划线命名name = re.sub(r'(.)([A-Z][a-z]+)', r'\1_\2', name)name = re.sub('([a-z\d])([A-Z])', r'\1_\2', name)return name.lower()@staticmethoddef filepath_to_modulepath(file_path: str, project_root: str) -> str:"""将文件路径转换为Python模块导入路径"""# 转换为Path对象并解析为绝对路径file_path = Path(file_path).resolve()project_root = Path(project_root).resolve()try:# 获取相对于项目根目录的路径relative_path = file_path.relative_to(project_root)except ValueError as e:raise ValueError(f"文件 {file_path} 不在项目根目录 {project_root} 下") from e# 移除.py后缀module_path = relative_path.with_suffix('')# 转换路径分隔符为点(.)module_str = str(module_path).replace(os.sep, '.')# 处理Windows路径可能存在的反斜杠module_str = module_str.replace('\\', '.')# 处理__init__.py文件的情况if module_str.endswith('.__init__'):module_str = module_str[:-9]return module_strif __name__ == "__main__":t = BaseUtils.camel_to_snake("SendCgOrderModel")
4.文件操作工厂
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
"""文档解析并返回Document"""
import os
from abc import ABC, abstractmethodimport pandas as pd
from docx import Document as DocxDocument
from langchain.schema import Documentfrom core.utils.my_logger import loggerclass BaseDocumentParser(ABC):"""所有文档解析器的抽象基类"""@abstractmethoddef parse(self, file_path: str) -> Document:"""解析文档并返回LangChain Document对象"""pass@abstractmethoddef supported_formats(self) -> list:"""返回支持的文档格式扩展名"""passclass WordDocumentParser(BaseDocumentParser):"""读取weord文档"""def __init__(self):self._supported_formats = ['.docx']def parse(self, file_path: str) -> Document:# 优先验证文件存在性if not os.path.exists(file_path):logger.error(f"文件不存在: {file_path}")raise FileNotFoundError(f"文件不存在: {file_path}")# 文件解析(使用上下文管理器确保资源释放)try:doc = DocxDocument(file_path)logger.info(f"成功打开文件: {file_path}")except Exception as e:logger.exception(f"文件解析失败: {file_path} - 错误: {str(e)}")raise Exception(f"无法解析Word文件: {file_path}") from efull_text = []# 提取文档内容try:# 遍历文档中的所有段落和表格(按原始顺序)for element in doc.element.body:if element.tag.endswith('p'): # 段落paragraph = [p for p in doc.paragraphs if p._element is element][0]full_text.append(paragraph.text)elif element.tag.endswith('tbl'): # 表格table = [t for t in doc.tables if t._element is element][0]full_text.append('\n--- 表格开始 ---')for row in table.rows:row_text = [cell.text for cell in row.cells]full_text.append('|'.join(row_text))full_text.append('--- 表格结束 ---\n')except Exception as e:logger.exception(f"内容提取异常: {file_path} - 错误: {str(e)}")raise Exception(f"内容提取失败: {file_path}") from e# 结果拼接与返回result = "".join(full_text) # 用双换行分隔不同内容块logger.debug(f"提取完成,字符数: {len(result)}")return Document(page_content=result, metadata={"source": file_path, "full_size": len(result)})def supported_formats(self) -> list:return self._supported_formatsclass ExcelDocumentParser(BaseDocumentParser):"""读取excel"""def __init__(self):self._supported_formats = ['.xlsx', '.xls']def parse(self, file_path: str) -> Document:if not os.path.exists(file_path):logger.error(f"文件不存在: {file_path}")raise FileNotFoundError(f"文件不存在: {file_path}")try:df = pd.read_excel(file_path)logger.info(f"成功打开文件: {file_path}")full_text = df.to_csv(sep='\t', na_rep='nan')return Document(page_content=full_text, metadata={"source": file_path, "full_size": len(full_text)})except Exception as e:logger.exception(f"文件解析失败: {file_path} - 错误: {str(e)}")raise Exception(f"无法解析Excel文件: {file_path}") from edef supported_formats(self) -> list:return self._supported_formats@staticmethoddef write_to_excel(data, file_path):"""写入excel"""try:df = pd.DataFrame(data)df.to_excel(file_path, index=False)logger.info(f"成功写入Excel文件: {file_path}")except Exception as e:logger.exception(f"写入文件失败: {file_path} - 错误: {str(e)}")raise Exception(f"无法写入Excel文件: {file_path}") from eclass DocumentParserFactory:_parsers = {'.docx': WordDocumentParser(),'.xlsx': ExcelDocumentParser(),'.xls': ExcelDocumentParser()}@classmethoddef get_parser(cls, file_path: str) -> BaseDocumentParser:_, ext = os.path.splitext(file_path)ext = ext.lower()if ext in cls._parsers:return cls._parsers[ext]# 如果没有找到合适地解析器,尝试检查所有解析器支持的类型supported = []for parser in cls._parsers.values():supported.extend(parser.supported_formats())logger.error(f"不支持的文件格式: {ext}. 支持的格式有: {', '.join(set(supported))}")raise ValueError(f"不支持的文件格式: {ext}. 支持的格式有: {', '.join(set(supported))}")@classmethoddef parse_document(cls, file_path: str) -> Document:"""解析文档的便捷方法"""parser = cls.get_parser(file_path)return parser.parse(file_path)if __name__ == "__main__":5.根据需求文档内容生成功能测试用例
5.1提示词模板
from langchain_core.prompts import PromptTemplateDEMAND_TO_TESTCASE_PROMPT = PromptTemplate(input_variables=["demand_text"],template="""
作为顶级[物流系统,网络货运,供应链]测试专家,请根据需求生成高密度的功能测试用例集,严格遵循以下规则:
---------------------
需求内容{demand_text}
---------------------
1. 用例结构:必须包含[用例编号|模块|功能点|用例名称|前置条件|测试步骤|预期结果],采用紧凑JSON格式2. 用例生成逻辑:a) 功能点解析:- 模块:匹配核心业务模块(如注册/抢单/取单/调度/装车/收货/支付)- 功能:提取包含操作动词的条目(如新增/修改/删除/筛选/停用/生效/提交/排序/导入/提交/批量/终止/撤销/刷新)- 业务规则:识别带业务规则,流程控制校验的描述(如金额校验/空值校验/逻辑校验/业务规则/唯一性校验/流程/角色权限/关联性校验/风控)b) 用例设计:- 用例设计方法:等价类划分法/边界值分析法/决策表法/正交试验法/场景法/状态转换法/因果图法- 用例设计场景:正常场景/异常场景/边界场景/流程场景/权限场景- 字段类校验合并为:空值+最大值+非法格式先提取需求中的模块,再细分模块下的功能及业务需求和校验规则,然后使用用例设计中方法和场景来生成测试用例3. 数据格式规范:- 除了测试步骤必须"换行符"分隔,其他采用最小化JSON结构(去除换行/缩进)- 用例编号规则:CSYL+用例序号(3位) (例:CSYL001,CSYL002)4. 质量控制:- 每个用例必须对应需求文档中的具体条目,生成足够多的测试用例- 相同校验类型合并用例(如多个字段超长合并验证)5. 输出要求:
{{"data": [{{"用例编号":"CLXZ001","模块":"司机注册","功能点":"身份验证","用例名称":"身份证OCR识别失败","前置条件":"未安装OCR插件","测试步骤":"1.上传模糊照片\n2.提交验证","预期结果":"提示'请上传清晰身份证照片'"}},{{"用例编号":"CLXZ002","模块":"司机注册","功能点":"身份验证","用例名称":"驾驶证过期验证","前置条件":"驾驶证过期","测试步骤":"1.上传过期证件\2.提交","预期结果":"提示'驾驶证已过期'"}}],"has_more":true
}}- 必须返回严格符合以上结构的JSON对象- 模块使用最末级模块名- 只有当真达到token限制无法继续时,才将has_more设为true,用来触发继续对话请生成高密度测试用例(紧凑JSON格式),无需其他解释"""
)我是负责物流系统的测试,所以我的提示词是跟物流系统相关的。
5.2功能实现
# core/llm/doc_to_model_converter.py
import osfrom core.llm.deepseek_client import DeepSeekLLM
from core.llm.document_parser import DocumentParserFactory
from core.llm.document_parser import ExcelDocumentParser
from core.llm.prompt_templates import DEMAND_TO_TESTCASE_PROMPT
from core.utils.base_converter import BaseConverter
from getcwd import get_cwd"""根据需求描述生成功能测试用例"""class DemandToTestCaseConverter(BaseConverter):def __init__(self, llm_client=None):if llm_client is None:llm = DeepSeekLLM()llm.temperature = 0.9llm.model = "deepseek-reasoner"super().__init__(llm_client=llm)else:super().__init__(llm_client=llm_client)def _get_prompt(self, demand_text: str, is_first: bool) -> str:return (DEMAND_TO_TESTCASE_PROMPT.format(demand_text=demand_text)if is_first else "请按照要求继续输出剩余测试用例")def convert(self, doc_path: str, max_rounds: int = 5, file_name=None) -> dict:demand_text = DocumentParserFactory.parse_document(doc_path).page_contentfull_result = {"data": [], "has_more": True}# 生成测试用例for _ in range(max_rounds):if not full_result["has_more"]:breakresponse = self._call_llm(demand_text, is_first=not full_result["data"])self._validate_response(response)full_result = self._merge_response(full_result, response)# 保存到excelif file_name:data = full_result["data"]file_dir = os.path.join(get_cwd(), 'data', 'testcases')file_path = os.path.join(file_dir, f"{file_name}.xlsx")ExcelDocumentParser().write_to_excel(data, file_path)return full_resultif __name__ == "__main__":te = DemandToTestCaseConverter()
实现功能,传入word需求文档路径,会读取word文档内容,然后通过提示词模板组装成用户输入传递给deepseek,然后将deepseek返回的测试用例写入excel
6.根据操作步骤生成ui测试脚本
6.1提示词模板
from langchain_core.prompts import PromptTemplateDEMAND_TO_UI_AUTOMATION_PROMPT = PromptTemplate(input_variables=["url", "test_case", "html", "path"],template="""
作为UI自动化测试专家,请根据以下要素生成符合生产级质量标准的Playwright测试脚本:测试需求:
{test_case}目标URL:
{url}页面元素特征(可能截断):
{html_content}截图存储路径:
{path}代码规范要求:
1. 使用Playwright同步API,严格遵循上下文管理器模式
2. 资源管理:- 使用with语句管理browser和context生命周期- 分层清理资源:page -> context -> browser- 禁止在finally块中重复关闭资源
3. 错误处理:- 使用try/except捕获具体异常类型- 确保异常情况下仍能正确释放资源
4. 验证机制:- 必须使用pytest的assert进行结果验证- 禁止使用自定义状态变量判断结果
5. 执行跟踪:- 每个关键步骤后添加截图(使用唯一递增文件名)- 添加必要的等待机制(networkidle状态)
6. 框架集成:- 符合pytest测试用例结构- 包含必要的pytest依赖声明- 支持直接通过pytest命令运行请生成可直接执行的完整Python3代码,无需其他解释。
"""
)6.2功能实现
# core/llm/demand_to_ui_automation.py
import os
import subprocess
import sys
import tempfilefrom playwright.sync_api import sync_playwrightfrom core.llm.deepseek_client import DeepSeekLLM
from core.llm.prompt_templates import DEMAND_TO_UI_AUTOMATION_PROMPT
from core.utils.base_converter import BaseConverter
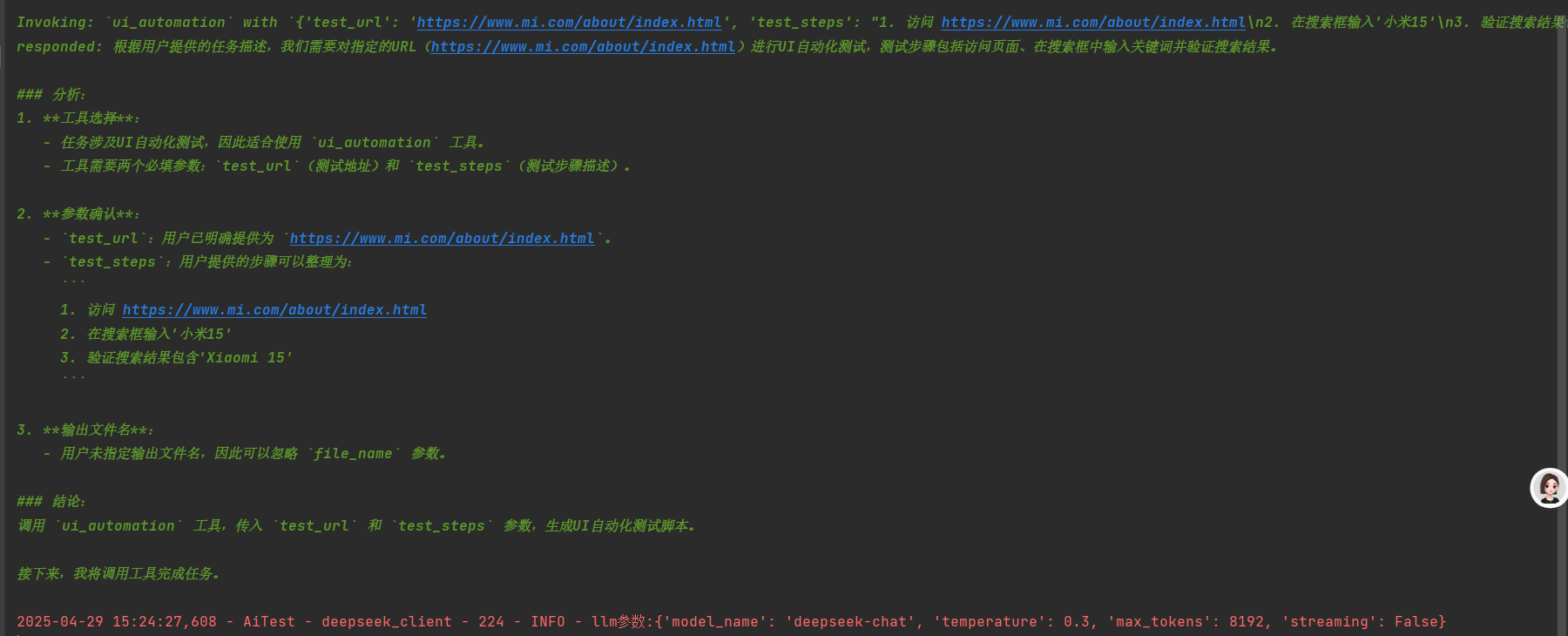
from getcwd import get_cwd"""根据需求描述生成 UI 自动化测试代码"""class DemandToUIAutomationConverter(BaseConverter):def __init__(self, llm_client=None):if llm_client is None:llm = DeepSeekLLM()llm.temperature = 0.3super().__init__(llm_client=llm)else:super().__init__(llm_client=llm_client)def fetch_html_content(self, url: str):"""获取目标url的html代码"""max_html_length = 30000with sync_playwright() as p:browser = p.chromium.launch()page = browser.new_page()page.goto(url)page_content = page.content()if len(page_content) > max_html_length:html_content = page_content[:max_html_length] + "... [truncated for length]"return html_contentdef execute_test(self, code: str) -> dict:"""将传入的 Python 代码写入临时文件并运行,返回运行结果"""try:tmp = tempfile.NamedTemporaryFile(suffix=".py", delete=False)tmp.write(code.encode())tmp.close()result = subprocess.run([sys.executable, tmp.name],capture_output=True,timeout=300)os.remove(tmp.name)return {'stdout': result.stdout.decode('utf-8'),'stderr': result.stderr.decode('utf-8'),'returncode': result.returncode}except Exception as e:return {'stdout': '','stderr': f"执行过程中出现错误: {str(e)}",'returncode': -1}def _get_prompt(self, demand_dict: dict, is_first: bool) -> str:"""组装提示词"""prompt_dict = demand_dicturl = prompt_dict.get("url")html_content = self.fetch_html_content(url)prompt_dict["html_content"] = html_contentprompt_dict["path"] = os.path.join(get_cwd(), "data", "ui_automation")return (DEMAND_TO_UI_AUTOMATION_PROMPT.format(**prompt_dict)if is_first else "请按照要求继续输出剩余 UI 自动化测试代码")def convert(self, prompt_dict: dict, file_name=None):response = self._call_llm(prompt_dict, is_first=True)result = self.execute_test(response)# 保存到文件if file_name:file_dir = os.path.join(get_cwd(), 'data', 'ui_automation')os.makedirs(file_dir, exist_ok=True)file_path = os.path.join(file_dir, f"{file_name}.py")with open(file_path, 'w', encoding='utf-8') as f:for code in response:f.write(code)return resultif __name__ == "__main__":converter = DemandToUIAutomationConverter()test_dict = {"url": "https://www.mi.com/about/index.html","test_case": "1. 访问 https://www.mi.com/about/index.html 2. 在搜索框输入'小米15' 3. 验证搜索结果包含'Xiaomi 15'"}converter.convert(test_dict, file_name="xiaomi_ui_automation")
获取被测目前url的html代码,同时将url,测试步骤,html代码传递给deepseek,然后将deepseek返回的ui测试脚本写入临时.py文件执行,可选择保存脚本
import os
import time
import pytest
from playwright.sync_api import sync_playwrightSCREENSHOT_DIR = r"C:\PycharmProjects\AiTest\data\ui_automation"
os.makedirs(SCREENSHOT_DIR, exist_ok=True)def take_screenshot(page, step_name):timestamp = int(time.time() * 1000)screenshot_path = os.path.join(SCREENSHOT_DIR, f"{timestamp}_{step_name}.png")page.screenshot(path=screenshot_path)def test_xiaomi_search():with sync_playwright() as playwright:browser = playwright.chromium.launch(headless=False)context = browser.new_context()page = context.new_page()try:# Step 1: Navigate to target URLpage.goto("https://www.mi.com/about/index.html", wait_until="networkidle")take_screenshot(page, "navigate_to_homepage")# Step 2: Input search keywordsearch_input = page.locator("input[type='search']")search_input.fill("小米15")take_screenshot(page, "input_search_keyword")# Press Enter to submit searchsearch_input.press("Enter")page.wait_for_load_state("networkidle")take_screenshot(page, "submit_search")# Step 3: Verify search resultsresults_locator = page.locator("text=Xiaomi 15")assert results_locator.count() > 0, "Search results did not contain 'Xiaomi 15'"take_screenshot(page, "verify_results")except Exception as e:take_screenshot(page, f"error_{str(e)}")raisefinally:page.close()context.close()browser.close()if __name__ == "__main__":pytest.main(["-v", __file__])
返回脚本及截图
7.根据接口文档生成接口测试用例
7.1根据接口文档生成pydantic模型代码
7.1.1提示词模板
from langchain_core.prompts import PromptTemplate
# 生成pydantic模型代码
DOCX_TO_PYDANTIC_PROMPT = PromptTemplate(input_variables=["doc_text"],template="""
请根据提供的接口文档内容,生成符合Pydantic v2规范的请求模型。具体要求如下:1. 模型规范要求:- 所有模型类名以Model结尾- 使用Python类型注解和Field进行字段定义- 嵌套字段使用嵌套模型表示- 枚举值使用Literal或Enum表示- 文档存在接口地址时,使用接口最后一个单词当做主模型的名称2. 字段校验规则:- 必填性:仅当文档明确标注"必填"时才使用`...`表示必填,否则设为可选字段(Optional+默认值None)- 字符串长度:仅当文档明确提供长度限制时才添加min_length/max_length- 数字范围:仅当文档明确提供取值范围时才添加ge/le等范围限制- 日期时间:优先使用datetime类型,若文档指定格式则通过pattern校验- 特殊格式:仅当文档明确要求格式(如邮箱、手机号)时才添加pattern正则校验- 可选字段:统一使用Optional并设置默认值None3. 模型配置要求:- 只对每个接口的主模型添加model_config配置类,配置如下```model_config = ConfigDict(json_schema_extra={{"api_metadata": {{"path": "文档中的接口路径(未提供则留空)", # 使用测试地址,从域名或端口号后的/开始截取"method": "post/get(未提供则留空)","interface_name": "接口名称(未提供则留空)","raw": "json/form/urlencoded(默认json)" #}},"demand": [], # 存放文档中提到的特殊业务规则"examples": [ # 必须包含一个完整示例{{"field1": "value1", "field2": 100}}]}})```- 若文档未提供示例,生成一个符合字段类型的合理示例。4. 其他要求:- 每个接口模型代码都会存放在单独的.py文件中,所以不要抽象公共基类,即使有重复字段也完整定义- 示例数据应尽量接近真实业务场景- 字段描述应简洁清晰,对文档未明确的信息需注明(如"文档未明确长度限制")5. 输入文档说明:- 文档内容将通过{doc_text}变量传递- 文档可能包含多个接口定义,请为每个接口创建独立模型- 如文档格式不规范,请根据上下文合理推断6. 输出要求:- 必须返回严格符合以下结构的JSON对象的python3代码:{{"data": [{{"model_name": "主模型1名称", # 以Model结尾"code": "完整Python代码"}},{{"model_name": "主模型2名称","code": "完整Python代码"}},// 尽可能多地添加更多完整模型条目...],"has_more": false // 只有当真无法继续输出时才设为true}}- 必须遵守以下输出规则:1) 每次响应必须尽可能返回文档中所有能处理的接口模型2) 只有当真达到token限制无法继续时,才将has_more设为true3) 正常情况下应该一次性输出所有接口模型,has_more保持false4) 禁止人为拆分输出,必须让系统自动判断token限制7. 性能优化:- 优先保证代码准确性,尤其是导入模块,其次才是注释完整性- 示例数据可以适当简化以减少token占用- 字段描述可精简(如"文档未明确"可简写为"待确认")请根据以上要求,为提供的接口文档生成Pydantic模型代码,并且已json格式返回,无需其他解释。
"""
)7.1.2功能实现
#!/usr/bin/env python3
# -*- coding:utf-8 -*-from langchain_core.runnables import RunnableLambdafrom core.llm.deepseek_client import DeepSeekLLM
from core.llm.document_parser import DocumentParserFactory
from core.llm.prompt_templates import DOCX_TO_PYDANTIC_PROMPT
from core.utils.base_converter import BaseConverter
from core.utils.model_utils import ModelUtils
from core.utils.my_logger import logger"""根据word文档内容生成pydantic模型代码"""class DocToPydanticConverter(BaseConverter):def __init__(self, temperature=None):temperature = temperature or 0.7self.llm = DeepSeekLLM(temperature=temperature)super().__init__()def _get_prompt(self, doc_text: str, is_first: bool) -> str:"""组装提示词"""return (DOCX_TO_PYDANTIC_PROMPT.format(doc_text=doc_text)if is_firstelse "请继续输出剩余模型代码")def convert(self, doc_path: str, max_rounds: int = 5) -> list:"""根据word文档内容生成pydantic模型代码"""doc_text = DocumentParserFactory.parse_document(doc_path).page_contentfull_result = {"data": [], "has_more": True}for _ in range(max_rounds):if not full_result["has_more"]:breakresponse = self._call_llm(doc_text, is_first=not full_result["data"])self._validate_response(response)full_result = self._merge_response(full_result, response)metadata_list = []for model in full_result["data"]:metadata_list.append(ModelUtils.save_interface_models(model["code"], model["model_name"]))logger.info(f"metadata_list:{metadata_list}")return metadata_listdef as_runnable(self):"""转换为LangChain Runnable"""return RunnableLambda(lambda doc_path: self.convert(doc_path))if __name__ == "__main__":test_convert = DocToPydanticConverter()
convert()方法会根据word接口文档内容生成pydantic模型代码,同时会把模型代码在/core/models目录下生成对应.文件,同时会在/core/models/_meta目录下生成带有原信息的json文件,用来动态加载生成的pydantic模型类,需要注意word文档中需要添加接口所有必填参数的正确示例,同时应该带有明确的测试地址,请求方法以及请求编码方式。同时会返回带有元信息的列表用于动态加载生成的pydantic类
7.2根据pydantic模型类生成接口测试用例
7.2.1提示词模板
from langchain_core.prompts import PromptTemplate# pydantic模型代码生成接口测试用例
PYDANTIC_TO_TESTCASE_PROMPT = PromptTemplate(input_variables=["pydantic_info"],template="""
请根据提供的Pydantic v2模型信息生成详细的接口测试用例。其中要求如下:1. 严格基于提供的模型信息生成接口测试用例,生成的测试用例应该包含以下信息:接口名称 接口地址 接口方法 请求体编码格式 用例名称 请求参数 预期结果2. 测试类型及要求(必须为每个字段生成所有相关测试用例):- 必填校验:* 为每个必填字段生成一条缺失该字段的测试用例* 必须覆盖所有必填字段(包括嵌套模型中的必填字段)* 用例名称格式:"缺失必填字段-[字段名]"- 数据类型校验:* 为每个字段生成类型错误测试用例* 必须覆盖所有字段的数据类型校验* 用例名称格式:"数据类型错误-[字段名]"- 边界值校验:* 只对个数值类型字段(int,float)生成边界值用例,无需对字符串型进行生成* 用例名称格式:"边界值校验-[字段名]-[类型]"- 枚举校验:* 为每个枚举类型字段生成所有有效值和至少一个无效值测试用例* 用例名称格式:"枚举校验-[字段名]-有效值/[无效值]"- 功能测试:* 基于model_config中的examples生成1-2个正常场景用例- 异常测试:* 生成1-2个多个字段同时错误的异常组合场景3. 请求参数生成规则:- 如果存在嵌套模型,测试用例的请求参数必须以主模型来生成- 对于必填/数据类型/边界测试:* 除了被测试字段外,其他必填字段应该都是有值且正确的- 请求参数中的值:* 必须是具体的值,不能包含任何代码表达式或函数调用* 正确的值可参考model_config中examples的示例参数的值- 边界值测试规则:* 数值类型:- 最小值:生成等于最小值-1和最小值- 最大值:生成等于最大值和最大值+14. 输入内容说明:- pydantic模型将通过{pydantic_info}变量传递- 输入内容应该是一个字典,具体格式如示例:{{"model_name":"模型名称1","model_json_schema":"模型的JSON Schema","model_config":"模型的配置信息"}}5. 最终的输出格式必须是以下JSON格式的测试用例,不要包含任何解释或额外内容:
{{"data": [{{"interface_name": "model_config中interface_name的值","path": "model_config中path的值","method": "model_config中method的值","raw": "model_config中raw的值","case_name": "具体明确的用例名称(按上述命名规则)","request_body":"具体的请求参数","expected_results": "具体的预期结果"}}// 必须为每个字段的所有测试类型生成独立用例],"has_more": false, // 只有当真无法继续输出时才设为true"number": "实际生成的用例总数(自动计算)"
}}- 必须遵守以下输出规则:1) 每次响应返回最多15条测试用例,超过15条并且还有测试用例未输出,将has_more设置true2) 只有当真达到token限制无法继续时,才将has_more设为true3) 正常情况下应该一次性输出所有接口测试用例,has_more保持false4) 禁止人为拆分输出,必须让系统自动判断token限制6. 特别注意:- 必须为每个字段生成完整的测试用例集合(包括必填、类型、边界值等所有相关测试)- 测试用例必须覆盖模型中所有字段的所有测试场景- 每个字段的每种测试类型都应生成独立用例,不得合并- 用例数量(number)必须准确反映实际生成的用例总数- 用例名称必须严格遵循指定的命名格式请根据以上要求,为提供的Pydantic模型生成完整的接口测试用例,只返回json格式内容,无需其他解释。
"""
)
7.2.2功能实现
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
from typing import Type, Listfrom langchain_core.runnables import RunnableLambda
from pydantic import BaseModelfrom core.database.mysql_testcase import add_multiple_test_cases, query_test_cases_by_interface_name, \delete_test_cases_by_interface_name
from core.llm.deepseek_client import DeepSeekLLM
from core.llm.prompt_templates import PYDANTIC_TO_TESTCASE_PROMPT
from core.utils.base_converter import BaseConverter
from core.utils.model_utils import ModelUtils"""根据pydantic模型代码生成接口测试用例"""class PydanticToTestCaseConverter(BaseConverter):def __init__(self, llm_client=None):if llm_client is None:llm = DeepSeekLLM()llm.temperature = 0.7super().__init__(llm_client=llm)else:super().__init__(llm_client=llm_client)def _get_prompt(self, pydantic_info: dict, is_first: bool) -> str:return (PYDANTIC_TO_TESTCASE_PROMPT.format(pydantic_info=pydantic_info)if is_first else "请继续按照之前的要求输出剩余测试用例")def _metadata_class(self, metadata: dict) -> Type[BaseModel]:"""通过metadata文件动态加载pydantic类"""model_class = ModelUtils.load_from_meta(metadata["meta_path"])return model_classdef _parse_pydantic_class_schema(self, model_class: Type[BaseModel]) -> dict:"""返回pydantic类的模型信息和配置信息"""model_info = {"model_name": model_class.__name__,"model_json_schema": model_class.model_json_schema(),"model_config": model_class.model_config}return model_infodef pydantic_to_testcase(self, metadata: dict | Type[BaseModel], max_rounds: int = 10) -> str:"""pydantic模型生成接口测试用例"""full_result = {"data": [], "has_more": True}model_info = {}interface_name = ''# 动态加载pydantic类if isinstance(metadata, dict):model_class = self._metadata_class(metadata)# 获取pydantic模型信息和配置信息model_info = self._parse_pydantic_class_schema(model_class)interface_name = model_class.model_config["json_schema_extra"]["api_metadata"]["interface_name"]elif issubclass(metadata, BaseModel):model_info = self._parse_pydantic_class_schema(metadata)interface_name = metadata.model_config["json_schema_extra"]["api_metadata"]["interface_name"]for _ in range(max_rounds):if not full_result["has_more"]:breakresponse = self._call_llm(model_info, is_first=not full_result["data"])self._validate_response(response)full_result = self._merge_response(full_result, response)data = full_result["data"]# 根据interface_name查询接口测试用例是否存在test_cases = query_test_cases_by_interface_name(interface_name)# 如果存在删除测试用例if len(test_cases) > 0:delete_test_cases_by_interface_name(interface_name)# 新增测试用例add_multiple_test_cases(data)return interface_namedef convert(self, metadata_list: list | List[Type[BaseModel]]) -> list:interface_name_list = []for metadata in metadata_list:interface_name = self.pydantic_to_testcase(metadata)interface_name_list.append(interface_name)return interface_name_listdef as_runnable(self):"""转换为LangChain Runnable"""return RunnableLambda(lambda metadata_list: self.convert(metadata_list))if __name__ == "__main__":test_convert = PydanticToTestCaseConverter()model_list = [{"model_name": "NewDZZToutWeightModel", "module_path": "core.models.new_dzz_tout_weight_model","file_path": "C:\\PycharmProjects\\AiTest\\core\\models\\new_dzz_tout_weight_model.py","meta_path": "C:\\PycharmProjects\\AiTest\\core\\models\\_meta\\new_dzz_tout_weight_model.json"},{"model_name": "NewDZZTgoodsSendModel", "module_path": "core.models.new_dzz_tgoods_send_model","file_path": "C:\\PycharmProjects\\AiTest\\core\\models\\new_dzz_tgoods_send_model.py","meta_path": "C:\\PycharmProjects\\AiTest\\core\\models\\_meta\\new_dzz_tgoods_send_model.json"}]test_convert.convert(model_list)
convert()方法支持传入原信息数组和类数组用与静态导入类和动态加载类。根据传入的信息获取pydantic的模型信息和配置信息,传入提示词模板后组装成用户输入传递给deepseek,deepseek会生成接口测试用例,这些用例将带有能够进行接口测试的所有信息。会返回一个接口名称数组
7.2.3数据库操作
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import json
from typing import List, Typefrom sqlalchemy import create_engine, Column, Integer, String, Text
from sqlalchemy.orm import declarative_base
from sqlalchemy.orm import sessionmaker# 创建数据库引擎,需要根据实际情况修改数据库连接信息
# 格式:mysql+pymysql://用户名:密码@主机:端口/数据库名
from core.utils.my_logger import loggerengine = create_engine('mysql+pymysql://test:123456@localhost:3306/interface')# 创建基类
Base = declarative_base()# 定义测试用例模型
class TestCase(Base):__tablename__ = 'test_cases'case_id = Column(Integer, primary_key=True, autoincrement=True)interface_name = Column(String(255))request_path = Column(String(255))request_method = Column(String(10))raw = Column(String(10))case_name = Column(String(255))request_params = Column(Text)expected_result = Column(Text)actual_result = Column(Text)def __repr__(self):return f"<TestCase(id={self.case_id}, case_name='{self.case_name}')>"# 创建表
Base.metadata.create_all(engine)# 创建会话
Session = sessionmaker(bind=engine)
session = Session()# 添加多个测试用例
def add_multiple_test_cases(test_cases):for case in test_cases:request_params = case['request_body']if isinstance(request_params, dict):request_params = json.dumps(request_params)new_case = TestCase(interface_name=case['interface_name'],request_path=case['path'],request_method=case['method'],raw=case['raw'],case_name=case['case_name'],request_params=request_params,expected_result=case['expected_results'])session.add(new_case)session.commit()# 查询所有测试用例
def query_all_test_cases() -> list[Type[TestCase]]:cases = session.query(TestCase).all()return cases# 查询指定 interface_name 的测试用例
def query_test_cases_by_interface_name(interface_name) -> List[TestCase]:cases = session.query(TestCase).filter(TestCase.interface_name == interface_name).all()return cases# 更新测试用例的实际结果
def update_actual_result(case_id, actual_result):case = session.query(TestCase).filter_by(case_id=case_id).first()if case:case.actual_result = actual_resultsession.commit()else:logger.error(f"Test case with id {case_id} not found.")# 根据 interface_name 删除测试用例
def delete_test_cases_by_interface_name(interface_name):try:cases = session.query(TestCase).filter(TestCase.interface_name == interface_name).all()for case in cases:session.delete(case)session.commit()logger.info(f"Successfully deleted all test cases with interface_name: {interface_name}")except Exception as e:session.rollback()logger.error(f"Error deleting test cases: {e}")# 关闭会话
session.close()if __name__ == "__main__":# 定义多个测试用例数据test_cases_list = []# 添加多个测试用例add_multiple_test_cases(test_cases_list)# 查询所有测试用例query_all_test_cases()
用于保存接口测试用例和执行结果
7.2.4执行测试
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import json
import time
from urllib import parseimport requests
from langchain_core.runnables import RunnableLambdafrom core.database.mysql_testcase import query_test_cases_by_interface_name, update_actual_result
from core.utils.my_logger import loggerclass BaseRequests:test_url = ""def get_test_url(self, url):return self.test_url + urldef request_setup(self, data, raw: str):request_headers = {}request_body = dataif raw == "json":request_headers['Content-Type'] = "application/json"# request_body = json.loads(data)if raw == "urlencoded":request_headers['Content-Type'] = "application/x-www-form-urlencoded"request_body = parse.urlencode(data)return request_body, request_headersdef post(self, url, data=None, raw: str = None, timeout=10, ):"""post请求"""logger.info(f"请求地址:{url}")request_body, request_headers = self.request_setup(data, raw)logger.info(f"请求参数:{request_body}")logger.info(f"请求头: {json.dumps(request_headers, ensure_ascii=False)}")try:response = requests.post(url, data=request_body, timeout=timeout)logger.info(f"请求响应码:{response.status_code}")logger.info(f"响应内容 (Text): {response.text} \n")return response.textexcept requests.exceptions.Timeout:logger.error(f"请求超时 (URL: {url}, Timeout: {timeout}s)")raise ValueErrorexcept requests.exceptions.ConnectionError:logger.error(f"连接失败 (URL: {url})")raise ValueErrorexcept requests.exceptions.RequestException as e:logger.error(f"请求异常 (URL: {url}, Error: {str(e)})")raise ValueErrordef run_test(self, case_name_list: list):for case_name in case_name_list:test_case_list = query_test_cases_by_interface_name(case_name)for test_case in test_case_list:url = self.get_test_url(test_case.request_path)raw = test_case.rawpayload = test_case.request_paramsif test_case.request_method == "post":response = self.post(url, payload, raw)update_actual_result(test_case.case_id, response)time.sleep(4)def as_runnable(self):"""转换为LangChain Runnable"""return RunnableLambda(lambda case_name_list: self.run_test(case_name_list))if __name__ == "__main__":使用run_test传入需执行的接口名称数组即可进行接口测试,目前只完成了post示例

8.使用chain组件实现从需求文档到接口测试用例执行
#!/usr/bin/env python3
# -*- coding:utf-8 -*-from langchain_core.runnables import RunnablePassthroughfrom core.utils.base_requests import BaseRequests
from scripts.doc_to_pydantic import DocToPydanticConverter
from scripts.pydantic_to_testcase import PydanticToTestCaseConverterchain = (RunnablePassthrough()| DocToPydanticConverter().as_runnable()| PydanticToTestCaseConverter().as_runnable()| BaseRequests().as_runnable()
)if __name__ == "__main__":doc_path = "//data/高义新大宗接口文档.docx"result = chain.invoke(doc_path)
使用chain创建调用链,将上一步的输出当做下一步的输入,传入word接口文档地址即可完成
接口文档 -> pydantic模型代码 -> 接口测试用例 ->执行接口测试用例
9.使用agent整合所有功能入口
9.1提示词模板
from langchain_core.prompts import PromptTemplateAGENT_PROMPT = PromptTemplate(input_variables=["input", "agent_scratchpad"],template="""你是一个智能助手,旨在帮助用户处理与测试相关的任务。你可以使用以下工具来完成任务:工具说明:
1. doc_to_testcase:当用户提供需求文档路径时使用,参数 doc_path (必填)
2. ui_automation:需要测试URL和步骤时使用,参数 test_url 和 test_steps
3. metadata_to_testcase:处理Pydantic元数据时使用
4. doc_to_pydantic:处理接口文档生成模型时使用当前任务:{input}已调用的工具和结果:{agent_scratchpad}请先仔细分析用户的问题,然后决定使用哪个工具。在调用工具之前,确保你清楚地了解每个工具的用途和参数要求。在调用工具之前先进行一些推理和分析并输出。
"""
)
9.2功能实现
from typing import Optionalfrom langchain.agents import create_openai_tools_agent, AgentExecutor
from langchain_core.tools import StructuredTool
from pydantic import BaseModel, Fieldfrom core.llm.deepseek_client import DeepSeekLLM
from core.llm.prompt_templates import AGENT_PROMPT
from scripts.demand_to_testcase import DemandToTestCaseConverter
from scripts.demand_to_ui_automation import DemandToUIAutomationConverter
from scripts.doc_to_pydantic import DocToPydanticConverter
from scripts.pydantic_to_testcase import PydanticToTestCaseConverterclass TestAIAgent:def __init__(self):self.llm = DeepSeekLLM()self.tools = self._init_tools()bound_llm = self.llm.bind_tools(self.tools)self.agent = AgentExecutor(agent=create_openai_tools_agent(bound_llm, self.tools, prompt=AGENT_PROMPT),tools=self.tools,verbose=True)def _init_tools(self):"""初始化所有工具"""return [self._create_doc_to_testcase_tool(),self._create_ui_automation_tool(),self._create_metadata_to_testcase_tool(),self._create_doc_to_pydantic_tool()]# 以下是工具定义class DocTestInput(BaseModel):doc_path: str = Field(..., description="需求文档的路径")file_name: Optional[str] = Field(default=None,description="(可选)输出文件名,未指定时不传")class UIAutomationInput(BaseModel):test_url: str = Field(..., description="测试的URL地址")test_steps: str = Field(..., description="测试步骤描述")file_name: Optional[str] = Field(default=None,description="(可选)输出文件名,未指定时不传")class DocPydanticInput(BaseModel):doc_path: str = Field(..., description="需求文档的路径")class MetadataInput(BaseModel):metadata: list = Field(..., description="存放Pydantic模型的元信息数组")def _create_doc_to_testcase_tool(self):def convert_doc_to_testcase(doc_path: str, file_name: str = None):return DemandToTestCaseConverter().convert(doc_path, file_name=file_name)return StructuredTool.from_function(func=convert_doc_to_testcase,name="doc_to_testcase",description="根据需求文档生成功能测试用例",args_schema=self.DocTestInput)def _create_ui_automation_tool(self):def convert_ui_automation(test_url: str, test_steps: str, file_name: str = None):prompt_dict = {"url": test_url,"test_case": test_steps}return DemandToUIAutomationConverter().convert(prompt_dict, file_name=file_name)return StructuredTool.from_function(func=convert_ui_automation,name="ui_automation",description="生成UI自动化测试脚本",args_schema=self.UIAutomationInput)def _create_metadata_to_testcase_tool(self):def convert_metadata_to_testcase(metadata: dict):return PydanticToTestCaseConverter().convert([metadata])return StructuredTool.from_function(func=convert_metadata_to_testcase,name="metadata_to_testcase",description="根据Pydantic元数据生成接口测试用例",args_schema=self.MetadataInput)def _create_doc_to_pydantic_tool(self):def convert_doc_to_pydantic(doc_path: str):return DocToPydanticConverter().convert(doc_path)return StructuredTool.from_function(func=convert_doc_to_pydantic,name="doc_to_pydantic",description="根据接口文档生成Pydantic模型",args_schema=self.DocPydanticInput)def process_request(self, user_input: str) -> str:"""统一处理入口"""return self.agent.invoke({"input": user_input})["output"]if __name__ == "__main__":agent = TestAIAgent()# 示例1: 生成功能测试用例result1 = agent.process_request("根据文档中内容生成功能测试用例 文档路径:")# 示例2: 生成UI测试脚本'''result2 = agent.process_request("""测试地址:"https://www.mi.com/about/index.html"测试步骤"1. 访问 https://www.mi.com/about/index.html 2. 在搜索框输入'小米15' 3. 验证搜索结果包含'Xiaomi 15""")# 示例3: 生成接口测试用例result3 = agent.process_request("""根据元信息生成接口测试用例:[{"model_name": "NewDZZTgoodsSendModel", "module_path": "core.models.new_dzz_tgoods_send_model", "file_path": "C:\\PycharmProjects\\DocTestAI\\core\\models\\new_dzz_tgoods_send_model.py", "meta_path": "C:\\PycharmProjects\\DocTestAI\\core\\models\\_meta\\new_dzz_tgoods_send_model.json"}]""")# 示例4: 生成Pydantic模型result4 = agent.process_request("根据文档生成Pydantic模型 文档路径:")'''
使用agent整合上述功能的入口,根据用户输入和工具列表,由deepseek判断调用哪个工具并执行
相关文章:

使用Langchain+DeepSeep进行测试相关工作
1.使用BaseChatModel实现自定义DeepSeekLLM import json import typing from typing import Optional, Any, List, Dict, Union, Sequence, Callable, Literalimport requests from langchain_core.callbacks import CallbackManagerForLLMRun from langchain_core.language_m…...

Java练习6
一.题目 数字加密与解密 需求: 某系统的数字密码(大于 0),比如 1983,采用加密方式进行传输。 规则如下: 先得到每位数,然后每位数都加上 5,再对 10 求余,最后将所有数字反转,得到一…...

二叉树知识点
1、树形结构 1.1概念 二叉树属于树形结构,所以先了解树形结构之后,再学习二叉树。 树形结构是一种非线性的数据结,是由n个有限节点组成的一个具有层次关系的集合,其形状就像一棵到这的树,跟朝上,叶子朝下…...

neo4j暴露公网ip接口——给大模型联通知识图谱
特别鸣谢 我的领导,我的脑子,我的学习能力,感动了 1. 搭建知识图谱数据库(见上一章博客) 这里不加赘述了,请参考上一篇博客搭建 2. FastApi包装接口 这里注意:NEO4J_URI不得写http:,只能写…...

在阿里云实例上部署通义千问QwQ-32B推理模型
通义千问QwQ-32B是阿里云开源的320亿参数推理模型,通过大规模强化学习在数学推理、编程及通用任务中实现性能突破,支持消费级显卡本地部署,兼顾高效推理与低资源消耗。 本文将介绍如何利用vLLM作为通义千问QwQ-32B模型的推理框架,在一台阿里云GPU实例上构建通义千问QwQ-32…...

GEE进行Theil-Sen Median斜率估计和Mann-Kendall检验
介绍一下Theil-Sen Median斜率估计和Mann-Kendall趋势分析,这两种方法经常结合使用,前者用于估计趋势的斜率,后者用于检验趋势的显著性。如多年NPP或者NDVI的趋势分析。 主要介绍使用GEE实现这一内容的代码方法,若使用python&…...

WSL2下Docker desktop的Cadvisor容器监控
由于WSL2的Docker存放是在Linux的docker-desktop目录下,需要从这里面挂载到WSL2里的/var/lib/docker,并且正确挂载启动,才能使 Cadvisor 识别到docker容器并且监控资源。 首先需要在WSL2终端进行挂载操作: sudo mount -t drvfs \…...
)
深度学习---pytorch搭建深度学习模型(附带图片五分类实例)
一、PyTorch搭建深度学习模型流程 1. 环境准备 安装PyTorch及相关库: pip install torch torchvision numpy matplotlib2. 数据准备 数据集加载:使用内置数据集(如CIFAR-10)或自定义数据集。数据预处理:包括归一化…...

基于 STM32 的智慧图书馆智能控制系统设计与实现
一、系统架构概述 智慧图书馆智能控制系统集成环境调控、安全监控、借阅管理与信息推送功能,通过 STM32 主控芯片联动传感器、执行器及云平台,实现图书馆智能化管理。系统架构分为感知层(传感器)、控制层(STM32 主控)、执行层(继电器 / 显示屏)及云端层(数据交互),…...

4. python3基本数据类型
Python3 中有六个标准的数据类型: Number(数字) String(字符串) List(列表) Tuple(元组) Set(集合) Dictionary(字典) Pyt…...

什么是缓冲区溢出?NGINX是如何防止缓冲区溢出攻击的?
大家好,我是锋哥。今天分享关于【什么是缓冲区溢出?NGINX是如何防止缓冲区溢出攻击的?】面试题。希望对大家有帮助; 什么是缓冲区溢出?NGINX是如何防止缓冲区溢出攻击的? 缓冲区溢出是指程序试图向一个固定…...

4.27搭建用户界面
更新 router下面的index.js添加新的children 先区分一下views文件夹下的不同vue文件: Home.vue是绘制home页面的所有的表格。 Main.vue是架构头部和左侧目录的框架的。 研究一下这个routes对象,就可以发现重定向redirect的奥妙所在,我们先把…...
)
常用回环检测算法对比(SLAM)
回环检测本质上是一种数据相似性检测算法,原理是通过识别机器人是否回到历史位置,建立位姿约束以优化全局地图,纠正长期的里程计漂移实现全局地图的一致性,简单讲就是识别场景中的重复特征以修正累积误差。 1. 概述 算法类别原理特点优势劣势词袋模型特征聚类为单词,TF-I…...

《从线性到二维:CSS Grid与Flex的布局范式革命与差异解析》
在前端开发的广袤宇宙中,CSS布局技术宛如闪耀的星辰,不断革新与演进,为构建绚丽多彩的网页世界提供了坚实的支撑。其中,CSS Grid布局与Flex布局作为两颗璀璨的明星,以其独特的魅力和强大的功能,深受开发者们…...

理解 EKS CloudWatch Pod CPU Utilization 指标:与 `kubectl top` 及节点 CPU 的关系
在使用 AWS EKS 时,CloudWatch Container Insights 提供了丰富的容器级别监控指标,帮助我们深入了解应用的运行状态。如下截图中的 ContainerInsights pod_cpu_utilization 指标就是一个非常重要的维度。本文将详细解释这个指标的含义,并将其…...

解读JetBrains ToolBox以及Windows环境AppData的那点事
AppData 顾名思义应用程序数据,指的就是程序运行实例数据。用于存储应用程序的自定义设置和缓存数据。这些数据不仅包括程序个性化的配置,还涵盖了在应用程序运行过程中产生的临时文件和日志信息。 本身它是一个隐藏文件夹,位于每个用户的个人…...

Elasticsearch:ES|QL lookup JOIN 介绍 - 8.18/9.0
警告:此功能在 8.18/9.0 中刚推出。此功能处于技术预览阶段,未来版本可能会更改或删除。Elastic 会努力修复任何问题,但技术预览中的功能不受正式 正式发布功能支持 SLA 的约束。 ES|QL LOOKUP JOIN 处理命令将你的 ES|QL 查询结果表中的数据…...

基于开闭原则优化数据库查询语句拼接方法
背景 在开发实践中,曾有同事在实现新功能时,因直接修改一段数据库查询条件拼接方法的代码逻辑,导致生产环境出现故障。 具体来看,该方法通过在函数内部直接编写条件判断语句实现查询拼接,尽管从面向对象设计的开闭原…...

无人机航拍牛只检测数据集VOC+YOLO格式906张1类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):906 标注数量(xml文件个数):906 标注数量(txt文件个数):906 标注…...
)
【LeetCode 560】和为K的子数组(前缀和+哈希)
题面: 思路: 看到连续非空序列之和,容易想到前缀和计算差分, n u m s nums nums 区间 [ j , i ] [j,i] [j,i] 的和即为: s u m ( i , j ) p r e [ i ] − p r e [ j − 1 ] sum(i, j) pre[i] - pre[j-1] sum(i,j)…...

手术中评估帕金森患者手部运动的无接触式系统
南开大学韩建达教授研究团队提出一种针对帕金森病手术治疗的评估系统,可在手术中对患者手部运动进行实时监测,实现无接触式运动特征提取,并结合可视化数据分析辅助临床决策。相关研究论文“A non-contact system for intraoperative quantita…...

服务器主动发送响应?聊天模块如何实现?
一、背景知识 当我们在某聊天界面中发送一个消息时,如A给B发送了一个消息,而B马上就收到,仔细思考会发现以下问题 : 1. A给服务器发送请求,但服务器却给B发送了响应 2.B没有向服务器发送请求,却收到了…...

服务器远程超出最大连接数的解决方案是什么?
以下是为您撰写的关于服务器远程连接超限问题的解决方案论文,包含技术原理分析、解决策略和实际应用案例: 服务器远程连接超限问题分析与多维解决方案研究 摘要 随着数字化转型进程加速,服务器远程连接过载问题已成为企业IT运维领域的重大挑…...
工业核心板硬件说明书)
【资料分享】全志T536(异构多核ARMCortex-A55+玄铁E907 RISC-V)工业核心板硬件说明书
前 言 本文为创龙科技SOM-TLT536工业核心板硬件说明书,主要提供SOM-TLT536工业核心板的产品功能特点、技术参数、引脚定义等内容,以及为用户提供相关电路设计指导。 为便于阅读,下表对文档出现的部分术语进行解释;对于广泛认同释义的术语,在此不做注释。...

Missashe考研日记-day30
Missashe考研日记-day30 0 写在前面 日记也是写到第30篇了哈哈,满月了,虽然过了不止30天中间有断更,但还是表扬一下自己坚持下来了。:) 1 专业课408 学习时间:2h30min学习内容: 今天有其他事…...

工程管理部绩效考核关键指标与项目评估
工程管理部的关键绩效考核指标(KPI)设计旨在全面评估部门在设施设备管理、特种设备保养、维修质量以及业主满意度等方面的工作表现。每个指标都与部门的日常运营紧密相关,直接影响到设施的维护质量和业主的满意度。 本文将深入探讨工程管理部的主要绩效考核指标&am…...

【沉浸式求职学习day29】【信科知识面试题第一部分】【新的模块,值得收藏】
快五一辣,大家什么安排呀哈哈哈~可能五一期间我就不更新啦,时间比较碎片化,要陪重要的人 沉浸式求职学习 理论攻坚-计算机基础知识1.诞生2.发展3.特点4.分类巨型 5.应用计算机辅助: 6.计算机的性能指标7.信息的存储单位 理论攻坚…...

Cliosoft安装
创建安装目录、解压 [rootedatest opt]# mkdir Cliosoft [rootedatest opt]# mv sos_7.05.p9/ Cliosoft/ [rootedatest opt]# cd Cliosoft/ [rootedatest Cliosoft]# cd sos_7.05.p9/ [rootedatest sos_7.05.p9]# tar -xf sos_7.05.p9_linux64.tar 用普通用户eda安装 [rooteda…...

MES管理系统:重构生产任务管理的数智化引擎
在制造业的数字化浪潮中,生产任务管理正从传统的经验驱动转向数据驱动的精细化模式。作为连接计划层与执行层的核心枢纽,MES管理系统通过智能化、动态化的管理手段,将生产任务的接收、分配、执行与优化融入全流程闭环,为企业打造透…...

推荐系统在线离线打分不一致:核心原因与全链路解决方案
目录 一、特征维度:数据处理的「隐形杀手」1.1 特征穿越:训练数据的「上帝视角」1.2 线上线下特征不一致的四大陷阱(1)上线前一致性校验缺失(2)线上特征监控体系缺位(3)特征更新延迟…...

Markdown转WPS office工具pandoc实践笔记
随着DeepSeek、文心一言、讯飞星火等AI工具快速发展,其输出网页内容拷贝到WPS Office过程中,文档编排规整的格式很难快速复制。 注:WPS Office不支持Markdown格式,无法识别式样。 在这里推荐个免费开源工具Pandoc,实现…...
.interrupt();)
记录java线程中断理解,Thread.currentThread().interrupt();
记录java线程中断理解,Thread.currentThread().interrupt(); 一、概述 中断的理解: 1、Java 线程中断,协作式(通过 Thread.interrupt() 触发,需代码显式检查中断状态或调用可中断方法)。 2、操作系统中断…...
)
[零基础]内网ubuntu映射到云服务器上,http访问(frp内网穿透)
阿里云服务器,高校教师可以半价, frp下载地址:https://github.com/fatedier/frp/releases,选amd64, 云服务器开放端口 选择网络与安全–>安全组->管理规则 配置开放端口,7000为支持frp开放的端口&…...

Nginx 核心功能笔记
目录 一、Nginx 简介 二、核心功能详解 三、关键指令解析 四、性能优化要点 五、常见应用场景 一、Nginx 简介 定位 高性能的 HTTP/反向代理服务器,同时支持邮件协议代理(IMAP/POP3/SMTP)。采用 事件驱动、异步非阻塞 架构,…...
)
多地部署Gerrit Replication插件同步异常解决思路及方案(附脚本与CronJob部署)
背景 为了支持多地开发,我司在代码服务器(Gerrit)上使用了Replication插件,进行多地部署同步。 整体结构如下: A地区:主Gerrit服务器B地区:从Gerrit服务器正常的工作流程是: B地区开发者从从服务器拉取代码。B地区开发者向主服务器推送代码。Replication插件保证主从数…...

JAVA--- 关键字static
之前我们学习了JAVA 面向对象的一些基本知识,今天来进阶一下!!! static关键字 static表示静态,是JAVA中的一个修饰符,可以修饰成员方法,成员变量,可用于修饰类的成员(变…...

清华与智谱联合发布TTS模型GLM-4-Voice,支持情绪、语气控制,多语言,实时效果很不错~
项目背景 GLM-4-Voice是由清华大学知识工程组(Tsinghua KEG)和智谱AI(Zhipu AI)联合开发的一个开源端到端语音对话模型,旨在推动语音交互技术的进步,弥合机器与人类自然对话之间的差距。 语音交互的挑战与…...

华为云Astro大屏从iotda影子设备抽取数据做设备运行状态的大屏实施步骤
目录 背景与意义 1. 准备阶段 2. IoTDA 开放影子查询API 3. Astro轻应用创建连接器 4. Astro大屏设计界面 5. 数据绑定与交互逻辑 6. 发布与测试 小结(流程复盘) 背景与意义 随着物联网技术的快速发展,越来越多的设备接入云端&#x…...

Microsoft .NET Framework 3.5 离线安装包 下载
Microsoft. NET Framework 3.5 是支持生成和运行下一代应用程序和XML Web Services 的内部Windows 组件, 对 .NET Framework 2.0 和 3.0 中的许多新功能进行了更新和增补, 且附带了 .NET Framework 2.0 Service Pack 1 和 .NET Framework 3.0 Service…...
的技术演进)
通用人工智能(AGI)的技术演进
通用人工智能(AGI)的技术演进是一个漫长而充满探索的过程,涉及多个领域的技术突破和理念转变。以下是对其演进历程的详细介绍: 早期人工智能探索(20世纪50年代 - 80年代) 符号主义兴起:1950年…...

mac word接入deepseek
网上大多使用Windows版word来接入deepseek,vba文件引入mac后,因底层工具不同,难以直接运行,例如CreateObject("MSXML2.XMLHTTP")无法创建,为此写了一版新的vba,基于mac底层工具来实现。 vba文件点…...

基于大模型的大肠息肉全程管理研究报告
目录 一、引言 1.1 研究背景与意义 1.2 研究目的 二、大模型预测大肠息肉的原理与数据基础 2.1 大模型的技术原理简介 2.2 数据收集与处理 三、术前预测与准备方案 3.1 息肉特征及风险预测 3.2 患者身体状况评估 3.3 术前准备措施 四、术中方案制定与监控 4.1 手术…...

Liunx安装Apache Tomcat
目录 一、了解tomcat 二、下载 三、启动tomcat 四、网页访问tomcat 五、Tomcat修改默认8080端口 六、Tomcat创建项目步骤-实现项目对外访问 一、了解tomcat Apache Tomcat 是一个开源的 Java Servlet 容器 和 Web 服务器,主要用于运行基于 Java 的 Web 应用…...

Java基于MyBatis 实现前端组装查询语句、后端动态执行查询的功能
1. 前端设计 前端逻辑与之前的设计保持一致,依然是将用户输入的查询条件组装成 JSON 格式,并通过 HTTP 请求发送到后端。 示例请求体: {"filters": [{"field": "name","operator": "LIKE",...

RabbitMQ Linux 安装教程详解
RabbitMQ Linux 安装教程详解 在 Linux 系统上安装 RabbitMQ 并确保其稳定运行,对于构建可靠的分布式消息系统至关重要。本文将详细介绍如何在 Linux 系统上安装 RabbitMQ,并提供关键的注意事项,帮助您避免常见的坑点,确保安装过…...

健康养生:拥抱活力生活
在生活节奏日益加快的当下,人们对健康养生的重视程度与日俱增。健康养生并非是一时的跟风之举,而是一种关乎生活品质与生命长度的科学理念和生活方式,其核心在于通过合理的饮食、适度的运动、充足的睡眠以及良好的心态调节,达成身…...

京东商品数据实时采集指南:API 接口调用与数据解析实战
在当今数字化时代,数据已经成为企业决策和市场分析的重要依据。对于电商领域的从业者来说,实时采集京东等平台的商品数据,能够帮助他们了解市场动态、分析竞争对手以及优化自身的产品策略。本文将详细介绍如何通过 API 接口调用实现京东商品数…...

最新字节跳动运维云原生面经分享
继续分享最新的go面经。 今天分享的是组织内部的朋友在字节的go运维工程师岗位的云原生方向的面经,涉及Prometheus、Kubernetes、CI/CD、网络代理、MySQL主从、Redis哨兵、系统调优及基础命令行工具等知识点,问题我都整理在下面了 面经详解 Prometheus …...

AimRT 从零到一:官方示例精讲 —— 六、pb_chn示例.md
pb_chn示例 官方仓库:pb_chn 这个官方示例展示了如何基于 protobuf 协议和 local 后端实现 channel 通信。主要包括四种场景: 基础示例:分别用两个模块(Publisher 和 Subscriber)发布和订阅 protobuf 消息ÿ…...

【Web】如何解决 `npm run dev` 报错 `address already in use 127.0.0.1:9005` 的问题
在开发过程中,我们可能会遇到端口占用的问题,尤其是当多个进程或服务尝试监听同一个端口时。最近在运行 npm run dev 时,我遇到的错误是 address already in use 127.0.0.1:9005,这让我花了些时间才找到问题的根源。本文将总结该问…...