排序算法详解笔记(二)
归并排序
#include <vector>
#include <iostream>
#include <algorithm> // For std::inplace_merge in optimization// Helper function to merge two sorted subarrays
void merge(std::vector<int>& arr, int left, int mid, int right) {int n1 = mid - left + 1;int n2 = right - mid;// Create temporary arraysstd::vector<int> L(n1);std::vector<int> R(n2);// Copy data to temp arrays L[] and R[]for (int i = 0; i < n1; ++i)L[i] = arr[left + i];for (int j = 0; j < n2; ++j)R[j] = arr[mid + 1 + j];// Merge the temp arrays back into arr[left..right]int i = 0; // Initial index of first subarrayint j = 0; // Initial index of second subarrayint k = left; // Initial index of merged subarraywhile (i < n1 && j < n2) {if (L[i] <= R[j]) {arr[k] = L[i];i++;} else {arr[k] = R[j];j++;}k++;}// Copy the remaining elements of L[], if there are anywhile (i < n1) {arr[k] = L[i];i++;k++;}// Copy the remaining elements of R[], if there are anywhile (j < n2) {arr[k] = R[j];j++;k++;}
}// Main function that sorts arr[left..right] using merge()
void mergeSortRecursive(std::vector<int>& arr, int left, int right) {if (left >= right) { // Base case: single element or empty arrayreturn;}int mid = left + (right - left) / 2; // Avoid potential overflowmergeSortRecursive(arr, left, mid);mergeSortRecursive(arr, mid + 1, right);merge(arr, left, mid, right);
}// Wrapper function
void mergeSort(std::vector<int>& arr) {if (arr.empty()) return;mergeSortRecursive(arr, 0, arr.size() - 1);
}// --- Example Usage ---
// int main() {
// std::vector<int> data = {12, 11, 13, 5, 6, 7};
// mergeSort(data);
// std::cout << "Sorted array: ";
// for (int x : data) std::cout << x << " ";
// std::cout << std::endl; // Output: Sorted array: 5 6 7 11 12 13
// return 0;
// }
缺点
- 空间复杂度高:标准的归并排序需要 O ( n ) O(n) O(n) 的额外空间来存储临时合并数组。
- 对于小数组,递归开销和合并操作的常数因子可能比插入排序等简单算法更大。
优化方案
- 原地归并(In-place Merge):尝试在 O ( 1 ) O(1) O(1) 额外空间内完成合并。C++ 标准库提供了
std::inplace_merge。虽然空间复杂度降低,但时间复杂度可能会增加,且实现复杂。 - 混合排序:对于小于某个阈值(例如 16 或 32 个元素)的小子数组,切换到插入排序,因为插入排序在小数据集上通常更快,且空间开销小。
- 迭代实现(自底向上):避免递归调用栈的开销,通过迭代的方式从小到大合并子数组。
边界问题
- 空数组:需要处理输入为空的情况(如
arr.empty()检查)。 - 单元素数组:递归的基准条件
if (left >= right)正确处理了这种情况,直接返回。 - 索引计算:计算
mid时使用left + (right - left) / 2可以防止left + right可能产生的整数溢出。确保left,mid,right索引在数组范围内。
快速排序
#include <vector>
#include <iostream>
#include <algorithm> // For std::swap, std::partition
#include <random> // For random pivot optimization// Partition function (using Lomuto partition scheme as an example)
int partition(std::vector<int>& arr, int low, int high) {int pivot = arr[high]; // Choose the last element as the pivotint i = (low - 1); // Index of smaller elementfor (int j = low; j <= high - 1; ++j) {// If current element is smaller than or equal to pivotif (arr[j] <= pivot) {i++; // Increment index of smaller elementstd::swap(arr[i], arr[j]);}}std::swap(arr[i + 1], arr[high]); // Place pivot in its correct positionreturn (i + 1); // Return the partition index
}// --- Optimization: Random Pivot ---
int partition_random(std::vector<int>& arr, int low, int high) {// Generate a random index between low and highstd::random_device rd;std::mt19937 gen(rd());std::uniform_int_distribution<> distrib(low, high);int randomIndex = distrib(gen);// Swap the random element with the last elementstd::swap(arr[randomIndex], arr[high]);// Use the standard partition logicreturn partition(arr, low, high);
}// --- Optimization: Three-way partition (for handling duplicates) ---
// Partitions arr[l..r] into three parts: < pivot, == pivot, > pivot
void partition3Way(std::vector<int>& arr, int l, int r, int& i, int& j) {if (r <= l) return;i = l; // arr[l..i-1] < pivotj = r; // arr[j+1..r] > pivotint p = l; // scan pointer arr[i..p-1] == pivotint pivot = arr[l]; // Choose first element as pivotwhile (p <= j) {if (arr[p] < pivot) {std::swap(arr[i++], arr[p++]);} else if (arr[p] > pivot) {std::swap(arr[p], arr[j--]);} else { // arr[p] == pivotp++;}}// Now arr[l..i-1] < v, arr[i..j] == v, arr[j+1..r] > v// 'i' is the start index of the equal part, 'j' is the end index
}// Main recursive function for Quick Sort
void quickSortRecursive(std::vector<int>& arr, int low, int high) {if (low < high) {// Choose a partition scheme:// int pi = partition(arr, low, high); // Standard Lomutoint pi = partition_random(arr, low, high); // Randomized PivotquickSortRecursive(arr, low, pi - 1); // Sort elements before partitionquickSortRecursive(arr, pi + 1, high); // Sort elements after partition// --- Using 3-way partition ---// int i, j;// partition3Way(arr, low, high, i, j);// quickSortRecursive(arr, low, i - 1);// quickSortRecursive(arr, j + 1, high);}
}// Wrapper function
void quickSort(std::vector<int>& arr) {if (arr.empty()) return;quickSortRecursive(arr, 0, arr.size() - 1);
}// --- Example Usage ---
// int main() {
// std::vector<int> data = {10, 7, 8, 9, 1, 5};
// quickSort(data);
// std::cout << "Sorted array: ";
// for (int x : data) std::cout << x << " ";
// std::cout << std::endl; // Output: Sorted array: 1 5 7 8 9 10
// return 0;
// }
缺点
- 最坏情况性能:当 pivot 选择不佳(如每次都选到最大或最小值)时,时间复杂度退化到 O ( n 2 ) O(n^2) O(n2),特别是在输入已排序或反向排序时。
- 递归深度:在最坏情况下,递归深度可达 O ( n ) O(n) O(n),可能导致栈溢出。
- 不稳定排序:相等元素的相对顺序可能改变。
优化方案
- 随机化 Pivot:如
partition_random所示,随机选择 pivot 可以大大降低出现最坏情况的概率,使期望时间复杂度为 O ( n log n ) O(n \log n) O(nlogn)。 - 三数取中(Median-of-Three):选择数组首、中、尾三个元素的中位数作为 pivot,能更好地避免极端 pivot。
- 切换到插入排序:对于小子数组(例如元素少于 10-20 个),递归调用切换到插入排序可以提高效率,因为它在小数据集上常数因子小。
- 三向切分(3-Way Partitioning):如
partition3Way所示,特别适用于处理包含大量重复元素的数组,将数组分为小于、等于、大于 pivot 的三部分,可以显著提高效率。 - 尾递归优化:对两次递归调用中的较大子数组进行递归,较小子数组进行尾递归(或迭代),可以限制栈深度至 O ( log n ) O(\log n) O(logn)。
边界问题
- 空数组或单元素数组:基准条件
if (low < high)处理了这种情况。 - 分区索引:确保分区函数返回的索引
pi是有效的,并且递归调用quickSortRecursive(arr, low, pi - 1)和quickSortRecursive(arr, pi + 1, high)的范围是正确的,避免无限循环或越界。 - 重复元素:标准的 Lomuto 或 Hoare 分区在处理大量重复元素时可能效率不高或导致不平衡分区。三向切分是更好的选择。
堆排序
#include <vector>
#include <iostream>
#include <algorithm> // For std::swap, std::make_heap, std::pop_heap, std::sort_heap// Function to heapify a subtree rooted with node i which is an index in arr[]
// n is size of heap
void heapify(std::vector<int>& arr, int n, int i) {int largest = i; // Initialize largest as rootint left = 2 * i + 1; // left child indexint right = 2 * i + 2; // right child index// If left child is larger than rootif (left < n && arr[left] > arr[largest])largest = left;// If right child is larger than largest so farif (right < n && arr[right] > arr[largest])largest = right;// If largest is not rootif (largest != i) {std::swap(arr[i], arr[largest]);// Recursively heapify the affected sub-treeheapify(arr, n, largest);}
}// Main function to do heap sort
void heapSort(std::vector<int>& arr) {int n = arr.size();if (n <= 1) return; // Handle empty or single-element array// Build heap (rearrange array) - O(n)// Start from the last non-leaf node and heapify downfor (int i = n / 2 - 1; i >= 0; i--)heapify(arr, n, i);// One by one extract an element from heap - O(n log n)for (int i = n - 1; i > 0; i--) {// Move current root (max element) to endstd::swap(arr[0], arr[i]);// call max heapify on the reduced heap// The size of the heap decreases by 1 in each iterationheapify(arr, i, 0);}
}// --- Alternative using C++ Standard Library ---
void heapSortSTL(std::vector<int>& arr) {if (arr.size() <= 1) return;// Build a max heapstd::make_heap(arr.begin(), arr.end());// Repeatedly extract the max element (moves it to the end)// and restores heap property on the remaining range.std::sort_heap(arr.begin(), arr.end());
}// --- Example Usage ---
// int main() {
// std::vector<int> data = {12, 11, 13, 5, 6, 7};
// // heapSort(data); // Using custom implementation
// heapSortSTL(data); // Using STL
// std::cout << "Sorted array: ";
// for (int x : data) std::cout << x << " ";
// std::cout << std::endl; // Output: Sorted array: 5 6 7 11 12 13
// return 0;
// }
缺点
-
常数因子较大:虽然最坏、平均和最好时间复杂度都是 O ( n log n ) O(n \log n) O(nlogn),但实际运行中的比较和交换次数可能比快速排序(平均情况)多,常数因子更大。
-
不稳定排序:不保证相等元素的原始相对顺序。
-
缓存不友好:堆的操作(特别是
heapify)涉及跳跃式的内存访问(访问父节点和子节点),这可能导致缓存未命中率较高,尤其是在大数据集上。
优化方案
-
使用 C++ STL:
std::make_heap,std::pop_heap,std::sort_heap通常经过高度优化,可能比手动实现更快。 -
底层优化
heapify:可以通过减少比较次数或优化交换逻辑来微调heapify函数,但这通常收益有限。 -
d 叉堆(d-ary heap):使用 d > 2 的堆可以减少堆的高度(变为 log d n \log_d n logdn),可能改善缓存性能,但会增加每个节点的孩子数量,使得
heapify中的比较次数增多。需要权衡。
边界问题
-
空数组或单元素数组:需要显式检查并直接返回,因为
n / 2 - 1对于空数组或单元素数组会是负数或无效索引。 -
索引计算:确保子节点索引
2 * i + 1和2 * i + 2不会越界(left < n和right < n检查)。 -
Heapify 范围:在排序阶段,调用
heapify(arr, i, 0)时,第二个参数i表示当前堆的大小,必须正确传递,否则会访问已排序部分的元素。
内存访问问题
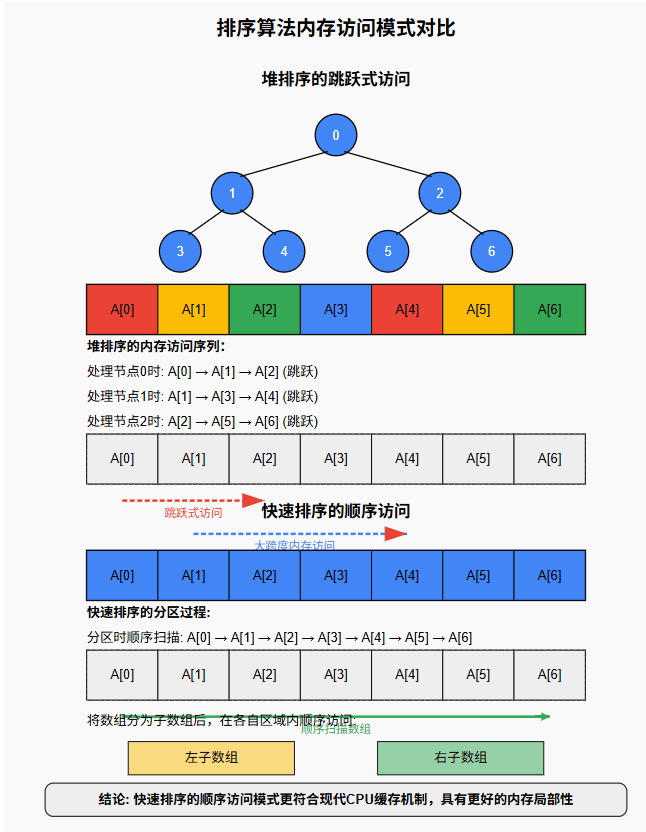
快速排序的内存局部性优势
-
顺序访问模式:
- 快速排序在分区过程中主要是从左到右顺序扫描数组
- 这种顺序访问模式更符合现代计算机的缓存预取机制
-
分治策略的局部性:
- 快速排序将数组分割成子数组后,在每个子数组内完成所有操作
- 这意味着数据访问集中在一个较小的内存区域,提高了缓存命中率
-
内存引用距离小:
- 在处理一个分区时,快速排序操作的元素通常彼此相邻或相距不远
- 这与堆排序中父子节点间的大跨度跳跃形成鲜明对比
堆排序的内存局部性劣势
-
跳跃式访问:
- 堆排序基于完全二叉树,父节点i的子节点在2i+1和2i+2
- 这种访问模式导致大范围的内存跳跃
-
缓存未命中率高:
- 当处理大型数组时,堆的不同层级间的元素可能相距很远
- 这会导致频繁的缓存未命中,增加内存访问延迟
-
访问模式不可预测:
- 堆排序中的元素交换和堆调整涉及的位置不容易被硬件预测
- 这降低了预取机制的效率
性能影响
尽管堆排序和快速排序都具有O(n log n)的平均时间复杂度,但在实际应用中:
-
快速排序通常更快:
- 对于相同规模的随机数据,快速排序常常比堆排序快2-3倍
- 这主要是因为更好的内存局部性和更简单的内部循环
-
随着数据规模增大,差距可能更显著:
- 当数据无法完全装入CPU缓存时,内存局部性的影响变得更为重要
- 在这种情况下,快速排序的优势更加明显
代码示例对比
如果我们比较快速排序和堆排序的核心操作:
// 快速排序的分区操作 - 顺序访问
int partition(int arr[], int low, int high) {int pivot = arr[high];int i = low - 1;for (int j = low; j < high; j++) { // 顺序扫描if (arr[j] <= pivot) {i++;swap(arr[i], arr[j]);}}swap(arr[i + 1], arr[high]);return i + 1;
}// 堆排序的堆调整操作 - 跳跃访问
void heapify(int arr[], int n, int i) {int largest = i;int left = 2 * i + 1; // 跳跃访问int right = 2 * i + 2; // 跳跃访问if (left < n && arr[left] > arr[largest])largest = left;if (right < n && arr[right] > arr[largest])largest = right;if (largest != i) {swap(arr[i], arr[largest]);heapify(arr, n, largest); // 递归可能导致更大的跳跃}
}
实际应用考量
-
标准库实现选择:
- 许多语言的标准库排序实现选择快速排序或其变体,而非堆排序
- 例如,C++的
std::sort通常是快速排序的一种变体
-
适用场景区别:
- 堆排序在需要稳定的O(n log n)性能时有优势(最坏情况也是O(n log n))
- 快速排序在平均情况下更快,但存在O(n²)最坏情况的风险
尾递归
什么是尾递归(Tail Recursion)?
尾递归是一种特殊的递归形式。当一个函数的最后一个动作是调用自身(递归调用),并且该调用的返回值直接被当前函数返回,没有任何后续计算或操作时,这个调用就称为尾递归调用。这个函数就是尾递归函数。
关键特征:
-
递归调用是函数的最后一步。
-
递归调用的结果直接返回,不参与任何其他计算。
示例:
非尾递归(计算阶乘):
int factorial_non_tail(int n) {if (n <= 1) {return 1;} else {// *** 不是尾递归 ***// 递归调用 factorial_non_tail(n - 1) 后,// 还需要执行乘法 n * ... 操作return n * factorial_non_tail(n - 1);}
}
在 n * factorial_non_tail(n - 1) 中,递归调用 factorial_non_tail(n - 1) 返回后,还需要将结果与 n 相乘,所以这不是尾递归。
尾递归(计算阶乘,使用辅助函数):
// 辅助函数,带有累加器 accumulator
int factorial_tail_helper(int n, int accumulator) {if (n <= 1) {return accumulator; // 基本情况:返回累加结果} else {// *** 是尾递归 ***// 递归调用是最后一步,其返回值直接被返回return factorial_tail_helper(n - 1, n * accumulator);}
}// 主函数
int factorial_tail(int n) {return factorial_tail_helper(n, 1); // 初始累加器为 1
}
在 factorial_tail_helper 中,factorial_tail_helper(n - 1, n * accumulator) 是函数的最后一个操作,它的返回值被直接返回。
尾递归优化(Tail Call Optimization - TCO)
尾递归的主要优势在于编译器可以对其进行尾递归优化 (TCO)。
- 原理:由于尾递归调用的结果直接返回,当前函数的调用帧(call frame,包含局部变量、返回地址等信息)在进行尾递归调用之前就不再需要了。编译器可以复用当前的栈帧,而不是创建新的栈帧。
- 效果:优化后的尾递归函数在执行时,其行为类似于迭代(循环)。它不会消耗额外的栈空间,避免了普通递归可能导致的栈溢出问题(Stack Overflow)。
- 转换:编译器(如果支持并启用 TCO)会将尾递归调用转换为一个简单的**跳转(goto)**指令,跳转回函数开头,并更新函数参数。
示例(尾递归阶乘优化后的伪代码):
factorial_tail_helper(n, accumulator):
start:if (n <= 1) {return accumulator;} else {// 更新参数accumulator = n * accumulator;n = n - 1;// 跳转回函数开头,而不是创建新栈帧goto start;}
这实际上等价于一个循环:
int factorial_iterative(int n) {int accumulator = 1;while (n > 1) {accumulator *= n;n--;}return accumulator;
}
优点:
- 避免栈溢出:对于深度递归,可以像迭代一样运行,不受调用栈深度限制。
- 效率提升:减少了函数调用和返回的开销(创建和销毁栈帧)。
限制和注意事项:
- 编译器支持:TCO 是一种优化,不是 C++ 标准强制要求的。GCC、Clang 等主流编译器在开启优化选项(如
-O2,-O3)时通常会执行 TCO。但 Visual Studio (MSVC) 对 C++ 的 TCO 支持有限(尤其是在 x64 架构下)。 - 必须是严格的尾调用:如上所述,递归调用必须是函数的最后一步,且结果直接返回。任何后续操作(如
+ 1,* n)都会阻止 TCO。 - 调试困难:优化后的代码可能没有清晰的调用栈信息,使得调试递归逻辑变得困难。
在实践中,虽然尾递归是一个优雅的概念,但在 C++ 中依赖 TCO 需要谨慎,要了解目标编译器的行为。如果担心栈溢出或追求极致性能,显式地将递归转换为迭代通常是更可靠的方法。
模拟递归栈
系统栈的作用
栈帧的组成
每次函数调用都会在系统栈上创建一个新的栈帧,包含:
- 局部变量
- 返回地址
- 参数值
- 函数执行的上下文信息
栈的LIFO特性
栈遵循"后进先出"(Last-In-First-Out)原则,这与递归的执行顺序直接相关。
递归的栈模拟过程
递归转换为栈操作
显式栈的创建
使用数据结构(如数组或链表)模拟系统栈的行为。
递归状态的保存
将递归函数的状态信息封装为对象或结构体压入栈中。
#include <iostream>
#include <vector>
#include <stack>
#include <string>// 用于展示栈帧的结构体
struct StackFrame {int left;int right;std::string function;int depth;
};// 打印当前栈的状态
void printStack(const std::stack<StackFrame>& stackCopy, const std::string& title) {std::cout << "\n===== " << title << " =====" << std::endl;std::cout << "栈底";std::stack<StackFrame> tempStack = stackCopy;std::vector<StackFrame> frames;while (!tempStack.empty()) {frames.push_back(tempStack.top());tempStack.pop();}for (int i = frames.size() - 1; i >= 0; i--) {std::cout << " <- [" << frames[i].function << "(" << frames[i].left << "," << frames[i].right << ") 深度:" << frames[i].depth << "]";}std::cout << " <- 栈顶" << std::endl;std::cout << "栈深度: " << frames.size() << std::endl;
}// 模拟快速排序的递归栈
void simulateQuicksortStack(int arraySize) {std::cout << "\n\n模拟快速排序递归栈 (数组大小: " << arraySize << ")" << std::endl;std::stack<StackFrame> recursionStack;int maxDepth = 0;// 初始调用recursionStack.push({0, arraySize - 1, "quicksort", 1});maxDepth = 1;printStack(recursionStack, "初始状态");// 模拟递归过程while (!recursionStack.empty()) {StackFrame current = recursionStack.top();recursionStack.pop();// 基本情况if (current.left >= current.right) {printStack(recursionStack, "处理基本情况后");continue;}// 假设我们选择中间元素作为pivot并完成分区int mid = (current.left + current.right) / 2;// 模拟最坏情况:极度不平衡的分区(如已排序数组)// 右侧分区 - 会先处理 (栈是LIFO)recursionStack.push({mid + 1, current.right, "quicksort", current.depth + 1});// 左侧分区recursionStack.push({current.left, mid, "quicksort", current.depth + 1});if (current.depth + 1 > maxDepth) {maxDepth = current.depth + 1;}printStack(recursionStack, "分区后");}std::cout << "\n快速排序最大栈深度: " << maxDepth << std::endl;std::cout << "最坏情况下空间复杂度: O(n),平均情况: O(log n)" << std::endl;
}// 归并排序中的合并操作(简化版)
void merge(std::vector<int>& arr, int left, int mid, int right) {// 实际合并操作(简化表示)std::cout << " 合并区间 [" << left << "," << mid << "] 和 [" << (mid + 1) << "," << right << "]" << std::endl;
}// 模拟归并排序的递归栈
void simulateMergesortStack(int arraySize) {std::cout << "\n\n模拟归并排序递归栈 (数组大小: " << arraySize << ")" << std::endl;std::stack<StackFrame> recursionStack;std::vector<int> dummyArray(arraySize, 0); // 用于merge演示int maxDepth = 0;// 初始调用recursionStack.push({0, arraySize - 1, "mergesort", 1});maxDepth = 1;printStack(recursionStack, "初始状态");// 模拟递归过程while (!recursionStack.empty()) {StackFrame current = recursionStack.top();recursionStack.pop();// 基本情况if (current.left >= current.right) {printStack(recursionStack, "处理基本情况后");continue;}int mid = (current.left + current.right) / 2;// 注意:归并排序与快排不同,需要先处理完所有分割,再执行合并// 这意味着栈帧包含了"待合并"的信息// 合并操作(在子问题解决后)StackFrame mergeFrame = {current.left, current.right, "merge", current.depth};mergeFrame.depth = current.depth;// 右侧分区StackFrame rightFrame = {mid + 1, current.right, "mergesort", current.depth + 1};// 左侧分区StackFrame leftFrame = {current.left, mid, "mergesort", current.depth + 1};// 注意入栈顺序:先合并,再右子数组,最后左子数组(这样左子数组会先处理)recursionStack.push(mergeFrame);recursionStack.push(rightFrame);recursionStack.push(leftFrame);if (current.depth + 1 > maxDepth) {maxDepth = current.depth + 1;}printStack(recursionStack, "分割后");}std::cout << "\n归并排序最大栈深度: " << maxDepth << std::endl;std::cout << "空间复杂度: O(log n) 用于递归栈,额外O(n)用于合并操作" << std::endl;
}// 模拟迭代式归并排序
void simulateIterativeMergesort(int arraySize) {std::cout << "\n\n模拟迭代式归并排序 (数组大小: " << arraySize << ")" << std::endl;std::vector<int> dummyArray(arraySize, 0); // 用于merge演示// 自底向上归并for (int size = 1; size < arraySize; size *= 2) {std::cout << "\n合并大小为 " << size << " 的子数组:" << std::endl;for (int left = 0; left < arraySize - size; left += 2 * size) {int mid = left + size - 1;int right = std::min(left + 2 * size - 1, arraySize - 1);merge(dummyArray, left, mid, right);}}std::cout << "\n迭代式归并排序使用O(1)栈空间和O(n)辅助数组空间" << std::endl;
}int main() {// 模拟一个小数组用于演示int smallSize = 8;simulateQuicksortStack(smallSize);simulateMergesortStack(smallSize);simulateIterativeMergesort(smallSize);// 模拟一个较大的数组(仅显示栈深度)int largeSize = 1000000000; // 10亿元素std::cout << "\n\n===== 大数据集分析 =====" << std::endl;std::cout << "数组大小: " << largeSize << " 元素" << std::endl;std::cout << "快速排序最坏情况栈深度: " << largeSize << " (如果数组已排序)" << std::endl;std::cout << "快速排序平均情况栈深度: 约 " << static_cast<int>(log2(largeSize)) << std::endl;std::cout << "归并排序栈深度: 约 " << static_cast<int>(log2(largeSize)) << std::endl;std::cout << "如果每个栈帧使用100字节,最大栈空间需求: " << static_cast<int>(log2(largeSize)) * 100 << " 字节(约 " << (static_cast<int>(log2(largeSize)) * 100) / 1024 << " KB)" << std::endl;return 0;
}
附录
测试代码
#include <iostream>
#include <vector>
#include <algorithm>
#include <random>
#include <chrono>
#include <iomanip>
#include <functional>using namespace std;
using namespace std::chrono;// ================ 归并排序及其优化 ================// 标准归并排序的合并操作 - 需要额外空间
void merge(vector<int>& arr, int left, int mid, int right) {int n1 = mid - left + 1;int n2 = right - mid;// 创建临时数组vector<int> L(n1), R(n2);// 复制数据到临时数组for (int i = 0; i < n1; i++)L[i] = arr[left + i];for (int j = 0; j < n2; j++)R[j] = arr[mid + 1 + j];// 合并临时数组int i = 0, j = 0, k = left;while (i < n1 && j < n2) {if (L[i] <= R[j]) {arr[k] = L[i];i++;} else {arr[k] = R[j];j++;}k++;}// 复制剩余元素while (i < n1) {arr[k] = L[i];i++;k++;}while (j < n2) {arr[k] = R[j];j++;k++;}
}// 标准归并排序
void mergeSort(vector<int>& arr, int left, int right) {// 边界条件处理:空数组或单元素数组if (left >= right) return;int mid = left + (right - left) / 2;mergeSort(arr, left, mid);mergeSort(arr, mid + 1, right);merge(arr, left, mid, right);
}// 优化1:小数组使用插入排序
void insertionSort(vector<int>& arr, int left, int right) {for (int i = left + 1; i <= right; i++) {int key = arr[i];int j = i - 1;while (j >= left && arr[j] > key) {arr[j + 1] = arr[j];j--;}arr[j + 1] = key;}
}// 优化2:混合归并排序(小数组使用插入排序)
void hybridMergeSort(vector<int>& arr, int left, int right, int threshold = 10) {if (right - left <= threshold) {insertionSort(arr, left, right);return;}int mid = left + (right - left) / 2;hybridMergeSort(arr, left, mid, threshold);hybridMergeSort(arr, mid + 1, right, threshold);merge(arr, left, mid, right);
}// 优化3:原地归并排序(减少空间使用,但增加时间复杂度)
void mergeInPlace(vector<int>& arr, int start, int mid, int end) {int start2 = mid + 1;// 如果已经有序if (arr[mid] <= arr[start2]) {return;}// 合并两个有序子数组while (start <= mid && start2 <= end) {// 如果第一个子数组的元素小于或等于第二个子数组的元素if (arr[start] <= arr[start2]) {start++;} else {int value = arr[start2];int index = start2;// 将第二个子数组的元素移动到正确位置while (index != start) {arr[index] = arr[index - 1];index--;}arr[start] = value;// 更新位置start++;mid++;start2++;}}
}void mergeSortInPlace(vector<int>& arr, int left, int right) {if (left < right) {int mid = left + (right - left) / 2;mergeSortInPlace(arr, left, mid);mergeSortInPlace(arr, mid + 1, right);mergeInPlace(arr, left, mid, right);}
}// ================ 快速排序及其优化 ================// 标准分区函数
int partition(vector<int>& arr, int low, int high) {// 使用最后一个元素作为pivotint pivot = arr[high];int i = low - 1;for (int j = low; j < high; j++) {if (arr[j] <= pivot) {i++;swap(arr[i], arr[j]);}}swap(arr[i + 1], arr[high]);return i + 1;
}// 标准快速排序
void quickSort(vector<int>& arr, int low, int high) {// 边界条件处理if (low >= high) return;int pi = partition(arr, low, high);quickSort(arr, low, pi - 1);quickSort(arr, pi + 1, high);
}// 优化1:三数取中选择pivot
int medianOfThree(vector<int>& arr, int low, int high) {int mid = low + (high - low) / 2;// 对三个元素排序if (arr[low] > arr[mid])swap(arr[low], arr[mid]);if (arr[low] > arr[high])swap(arr[low], arr[high]);if (arr[mid] > arr[high])swap(arr[mid], arr[high]);// 将中值放到倒数第二个位置swap(arr[mid], arr[high - 1]);return arr[high - 1];
}int partitionMedian(vector<int>& arr, int low, int high) {// 使用三数取中法选择pivotint pivot = medianOfThree(arr, low, high);int i = low;int j = high - 1;while (true) {while (arr[++i] < pivot);while (arr[--j] > pivot);if (i >= j)break;swap(arr[i], arr[j]);}// 将pivot放回正确位置swap(arr[i], arr[high - 1]);return i;
}// 优化2:混合快速排序(小数组使用插入排序)
void hybridQuickSort(vector<int>& arr, int low, int high, int threshold = 10) {if (high - low <= threshold) {insertionSort(arr, low, high);return;}int pi = partitionMedian(arr, low, high);hybridQuickSort(arr, low, pi - 1, threshold);hybridQuickSort(arr, pi + 1, high, threshold);
}// 优化3:随机化选择pivot
int randomizedPartition(vector<int>& arr, int low, int high) {// 随机选择pivotint random = low + rand() % (high - low + 1);swap(arr[random], arr[high]);return partition(arr, low, high);
}void randomizedQuickSort(vector<int>& arr, int low, int high) {if (low < high) {int pi = randomizedPartition(arr, low, high);randomizedQuickSort(arr, low, pi - 1);randomizedQuickSort(arr, pi + 1, high);}
}// 优化4:三向分区处理重复元素
void threeWayQuickSort(vector<int>& arr, int low, int high) {if (low >= high) return;// 随机选择pivotint random = low + rand() % (high - low + 1);swap(arr[random], arr[low]);int pivot = arr[low];int lt = low; // 小于pivot的元素右边界int gt = high; // 大于pivot的元素左边界int i = low + 1; // 当前处理的元素while (i <= gt) {if (arr[i] < pivot) {swap(arr[lt], arr[i]);lt++;i++;} else if (arr[i] > pivot) {swap(arr[i], arr[gt]);gt--;} else {i++;}}// 递归处理小于和大于pivot的部分threeWayQuickSort(arr, low, lt - 1);threeWayQuickSort(arr, gt + 1, high);
}// ================ 堆排序及其优化 ================// 堆调整函数
void heapify(vector<int>& arr, int n, int i) {int largest = i;int left = 2 * i + 1;int right = 2 * i + 2;if (left < n && arr[left] > arr[largest])largest = left;if (right < n && arr[right] > arr[largest])largest = right;if (largest != i) {swap(arr[i], arr[largest]);heapify(arr, n, largest);}
}// 标准堆排序
void heapSort(vector<int>& arr) {int n = arr.size();// 构建最大堆for (int i = n / 2 - 1; i >= 0; i--)heapify(arr, n, i);// 逐个提取元素for (int i = n - 1; i > 0; i--) {swap(arr[0], arr[i]);heapify(arr, i, 0);}
}// 优化1:非递归堆调整
void heapifyIterative(vector<int>& arr, int n, int i) {int largest = i;int index = i;while (true) {int left = 2 * index + 1;int right = 2 * index + 2;if (left < n && arr[left] > arr[largest])largest = left;if (right < n && arr[right] > arr[largest])largest = right;if (largest == index)break;swap(arr[index], arr[largest]);index = largest;}
}// 优化2:自底向上构建堆(更高效)
void buildHeapBottomUp(vector<int>& arr) {int n = arr.size();// 从最后一个非叶节点开始向上调整for (int i = n / 2 - 1; i >= 0; i--)heapifyIterative(arr, n, i);
}void optimizedHeapSort(vector<int>& arr) {int n = arr.size();// 使用自底向上的方法构建堆buildHeapBottomUp(arr);// 逐个提取元素for (int i = n - 1; i > 0; i--) {swap(arr[0], arr[i]);heapifyIterative(arr, i, 0);}
}// ================ 内存访问模式演示 ================// 测量不同算法的缓存行为
void analyzeCacheBehavior() {const int SIZE = 1000000; // 大数组以突显缓存效果vector<int> data(SIZE);// 填充随机数据random_device rd;mt19937 gen(rd());uniform_int_distribution<> dis(1, SIZE);for (int i = 0; i < SIZE; i++) {data[i] = dis(gen);}cout << "内存访问模式分析 (大数组大小: " << SIZE << ")" << endl;cout << "------------------------------------------------" << endl;// 测量排序算法的执行时间vector<pair<string, function<void(vector<int>&)>>> sortingAlgorithms = {{"归并排序", [](vector<int>& arr) { mergeSort(arr, 0, arr.size() - 1); }},{"快速排序", [](vector<int>& arr) { quickSort(arr, 0, arr.size() - 1); }},{"堆排序", heapSort},{"优化归并排序", [](vector<int>& arr) { hybridMergeSort(arr, 0, arr.size() - 1); }},{"优化快速排序", [](vector<int>& arr) { hybridQuickSort(arr, 0, arr.size() - 1); }},{"三向快速排序", [](vector<int>& arr) { threeWayQuickSort(arr, 0, arr.size() - 1); }},{"优化堆排序", optimizedHeapSort}};for (const auto& algorithm : sortingAlgorithms) {vector<int> testData = data; // 复制原始数据auto start = high_resolution_clock::now();algorithm.second(testData);auto end = high_resolution_clock::now();duration<double, milli> time_ms = end - start;cout << setw(15) << algorithm.first << ": " << fixed << setprecision(2) << time_ms.count() << " ms" << endl;}// 分析不同数据分布对内存访问的影响cout << "\n不同数据分布的影响:" << endl;cout << "------------------------------------------------" << endl;// 创建不同分布的数据vector<pair<string, vector<int>>> distributions;// 随机分布distributions.push_back({"随机数据", data});// 已排序数据vector<int> sortedData = data;sort(sortedData.begin(), sortedData.end());distributions.push_back({"已排序数据", sortedData});// 逆序数据vector<int> reversedData = sortedData;reverse(reversedData.begin(), reversedData.end());distributions.push_back({"逆序数据", reversedData});// 大量重复数据vector<int> duplicateData(SIZE);uniform_int_distribution<> limitedDis(1, SIZE / 100);for (int i = 0; i < SIZE; i++) {duplicateData[i] = limitedDis(gen);}distributions.push_back({"重复数据", duplicateData});// 测试快速排序和堆排序在不同数据分布下的性能for (const auto& dist : distributions) {cout << "\n" << dist.first << ":" << endl;// 测试快速排序vector<int> testData = dist.second;auto start = high_resolution_clock::now();hybridQuickSort(testData, 0, testData.size() - 1);auto end = high_resolution_clock::now();duration<double, milli> quickTime = end - start;// 测试堆排序testData = dist.second;start = high_resolution_clock::now();optimizedHeapSort(testData);end = high_resolution_clock::now();duration<double, milli> heapTime = end - start;cout << setw(15) << "快速排序" << ": " << fixed << setprecision(2) << quickTime.count() << " ms" << endl;cout << setw(15) << "堆排序" << ": " << fixed << setprecision(2) << heapTime.count() << " ms" << endl;}
}// ================ 主函数和测试 ================// 验证排序算法是否正确
bool isSorted(const vector<int>& arr) {for (size_t i = 1; i < arr.size(); i++) {if (arr[i] < arr[i-1]) return false;}return true;
}// 测试排序算法的正确性
void testSortingCorrectness() {const int SIZE = 1000;vector<int> data(SIZE);// 填充随机数据random_device rd;mt19937 gen(rd());uniform_int_distribution<> dis(1, SIZE);for (int i = 0; i < SIZE; i++) {data[i] = dis(gen);}// 测试所有排序算法vector<pair<string, function<void(vector<int>&)>>> sortingAlgorithms = {{"归并排序", [](vector<int>& arr) { mergeSort(arr, 0, arr.size() - 1); }},{"原地归并排序", [](vector<int>& arr) { mergeSortInPlace(arr, 0, arr.size() - 1); }},{"混合归并排序", [](vector<int>& arr) { hybridMergeSort(arr, 0, arr.size() - 1); }},{"快速排序", [](vector<int>& arr) { quickSort(arr, 0, arr.size() - 1); }},{"优化快速排序", [](vector<int>& arr) { hybridQuickSort(arr, 0, arr.size() - 1); }},{"随机化快速排序", [](vector<int>& arr) { randomizedQuickSort(arr, 0, arr.size() - 1); }},{"三向快速排序", [](vector<int>& arr) { threeWayQuickSort(arr, 0, arr.size() - 1); }},{"堆排序", heapSort},{"优化堆排序", optimizedHeapSort}};cout << "排序算法正确性验证" << endl;cout << "------------------------------------------------" << endl;for (const auto& algorithm : sortingAlgorithms) {vector<int> testData = data; // 复制原始数据algorithm.second(testData);bool correct = isSorted(testData);cout << setw(15) << algorithm.first << ": " << (correct ? "正确" : "错误") << endl;}
}int main() {// 设置随机种子srand(time(nullptr));cout << "排序算法分析与优化" << endl;cout << "================================================" << endl;// 测试排序算法的正确性testSortingCorrectness();cout << "\n======================\n" << endl;// 分析内存访问模式analyzeCacheBehavior();return 0;
}
相关文章:
)
排序算法详解笔记(二)
归并排序 #include <vector> #include <iostream> #include <algorithm> // For std::inplace_merge in optimization// Helper function to merge two sorted subarrays void merge(std::vector<int>& arr, int left, int mid, int right) {int …...

Spark GraphX 机器学习:图计算
引言 在数字化时代,图数据(Graph Data)的价值日益凸显:社交网络中的用户关系、电商平台的商品关联、知识图谱的实体链接……这些以“节点(Vertex)”和“边(Edge)”为核心的非结构化…...

claude 3.7,极为均衡的“全能型战士”大模型,国内直接使用
文章目录 零、前言一、操作指南操作指导 二、小球弹跳三、生成 Mandelbrot set 集四、文本总结能力五、智力推理题六、感受 零、前言 Claude 3.7 Sonnet(下面简称 Claude 3.7)由 Anthropic 发布,“全球首个混合推理模型”的 AI 大模型&#x…...
)
机器学习-入门-决策树(1)
机器学习-入门-决策树(1) 4.1决策树的基本流程 决策树基于“树”结构进行决策 每个“内部结点”对应于某个属性上的“测试”(test)每个分支对应于该测试的一种可能结果(即该属性的某个取值)每个“叶结点”对应于一个“预测结果” 学习过程࿱…...

机器学习实操 第一部分 机器学习基础 第6章 决策树
机器学习实操 第一部分 机器学习基础 第6章 决策树 内容概要 第6章深入介绍了决策树,这是一种功能强大的机器学习算法,能够处理分类、回归以及多输出任务。决策树通过递归地分割数据集来构建模型,具有易于解释和可视化的特点。本章详细讲解…...

Python实例题:ebay在线拍卖数据分析
目录 Python实例题 题目 实现思路 代码实现 代码解释 read_auction_data 函数: clean_auction_data 函数: exploratory_analysis 函数: visualize_auction_data 函数: 主程序: 运行思路 注意事项 Python实…...
:丢手绢)
算法题(137):丢手绢
审题: 本题需要我们找到距离最远的两个孩子之间的距离,并打印 思路: 方法一:暴力枚举 我们可以找到每个孩子的距离其他孩子的最远距离,然后维护一个maxdis变量得到所有孩子距离其他孩子最远距离的最大值。 而距离分为顺…...

2025年具身智能科技研报
引言 本报告系统梳理了2025年具身智能领域的最新进展,基于国内外权威新闻源与行业研究报告,通过数据可视化与深度分析相结合的方式,呈现该领域多维发展态势。从技术突破层面看,多模态大模型的突破性进展为具身智能注入新动能&…...

TCL科技2025一季度归母净利润10.1亿,半导体显示业务业绩创新高
4月29日,TCL科技(000100)披露2024年年报及2025年一季报。2024全年,TCL科技实现营业收入1648亿元,归母净利润15.6亿元;实现经营现金流净额295亿元,同比增长16.6%。2025年一季度,TCL科…...

阿里云 CentOS YUM 源配置指南
阿里云 CentOS YUM 源配置指南 在使用 CentOS 7 时,由于 CentOS 官方源停止维护等原因,yum install 命令可能会报错 “Cannot find a valid baseurl for repo: centos-sclo-rh/x86_64”。以下是通过更换阿里云源解决该问题的详细步骤。 一、备份原有配…...

阿里云 OpenManus 实战:高效AI协作体系
阿里云 OpenManus 实战:高效AI协作体系 写在最前面初体验:快速部署,开箱即用 真实案例分享:从单体开发到智能良好提示词过程展示第一步:为亚马逊美国站生成商品描述第二步:为eBay全球站生成商品描述结果分析…...

阿里云服务迁移实战: 05-OSS迁移
概述 Bucket 复制分为两种,同区域复制和跨区域复制 同账号复制比较简单,根据提示填写信息即可,本文主要介绍跨账号复制。 同区域复制 授权角色选择 “AliyunOSSRole”, 创建方法见 “跨区域复制”。然后点击确定即可。 跨区域复制 假设我…...

Vue高级特性实战:自定义指令、插槽与路由全解析
一、自定义指令 1.如何自定义指令 ⑴.全局注册语法 通过 Vue.directive 方法注册,语法格式为: Vue.directive(指令名, {// 钩子函数,元素插入父节点时触发(仅保证父节点存在,不一定已插入文档)inserted(…...

Python入门:流程控制练习
本文将介绍Python中流程控制的基础知识,包括条件判断和循环结构,并提供多个实用示例帮助初学者快速掌握这些概念。所有代码都使用基础语法,非常适合Python新手学习。 1. 简单条件判断: 编写一个程序,要求用户输入一个…...

Unity PBR基础知识
PBR原理 基于物理的渲染(Physically Based Rendering,PBR)是指使用基于物理原理和微平面理论建模的着色/光照模型,以及使用从现实中测量的表面参数来准确表示真实世界材质的渲染理念。 PBR基础理念 微平面理论(Micr…...

智慧交警系统架构设计方案
一、引言:智慧交警为何成为城市治理的刚需? 当前,中国城市化进程加速,汽车保有量激增,交通拥堵、事故频发、执法效率不足等问题日益突出。传统交通管理依赖人力巡查与分散系统,已难以应对复杂需求。智慧交…...

NOC科普一
拓扑结构 NoC里Router之间的link链路连接可以定义成不同的结构以改变通信测量和简化片上通信结构。 (a)Ring:环形,每个router都有2个相邻节点,虽然部署和故障排除相对容易,但主要缺点是其通信的距离也即环…...

Linux CentOS 7 安装Apache 部署html页面
*、使用yum包管理器安装Apache。运行以下命令: sudo yum install httpd *、启动Apache服务 sudo systemctl start httpd *、设置Apache服务开机自启 sudo systemctl enable httpd *、验证Apache是否运行 sudo systemctl status httpd 或者,通过浏…...

人工智能在医疗行业的应用和发展前景
人工智能在医疗行业的应用和发展前景 引言 在科技日新月异的今天,人工智能(Artificial Intelligence,AI)已然成为全球最具潜力与影响力的技术之一。医疗行业,作为关乎人类健康与生命的关键领域,正迅速成为人工智能应用的热门阵地。人工智能在医疗领域的应用,不仅为解决…...

vue3+Nest.js项目 部署阿里云
可以先参考之前的vue3express部署的文章 vue3viteexpressmongoDB上线(新手向)_vue3 vite express-CSDN博客 区别在于express和数据库 前端前往上面文章查看 1.nest.js部署 首先,把nest.js中相关的文件打包 除去依赖(node_modules)上传到服…...

phpstudy修改Apache端口号
1. 修改Listen.conf文件 本地phpstudy安装目录: 2.其他问题 ① 修改httpd.conf不起作用 ② 直接通过控制面板配置好像有延迟缓存...

JSON-RPC 2.0 规范中文版——无状态轻量级远程过程调用协议
前言 JSON-RPC是一种简单、轻量且无状态的远程过程调用(RPC)协议,它允许不同系统通过标准化的数据格式进行通信。自2010年由JSON-RPC工作组发布以来,已成为众多应用中实现远程交互的基础协议之一。本规范主要表达了JSON-RPC 2.0版…...

DeepSeek+Dify之七借助API和Trae完成demo
DeepSeek+Dify之六通过API调用工作流 文章目录 背景准备资料1、借助Trae来创建demo2、前后端主要代码3、测试demo4、完整项目背景 在软件开发与项目实践领域,常常需要借助各种工具与技术来快速搭建可运行的示例项目,以验证思路、展示功能或进行技术探索。本文聚焦于借助 Tra…...

C++ 红黑树
上一节我介绍了二叉搜索树家族的AVL树,这里我们来介绍二叉搜索树家族的另一个成员,也是使用最广泛的成员。 1.AVL树与红黑树的区别 平衡性质 AVL 树:是严格的平衡二叉树,要求任意节点的左右子树高度差的绝对值不超过 1ÿ…...

学习海康VisionMaster之线圆测量
一:进一步学习了 今天学习下VisionMaster中的线圆测量:核心就是坐标点到直线的距离量测 1:什么是线圆测量? 工业自动化中很常见的应用尺寸测量,需要量测一个零件的外形尺寸,其中一项如果是需要测量圆心到直…...

Uniapp:置顶
目录 一、出现场景二、效果展示三、具体使用一、出现场景 在项目的开发过程中,我们经常会用到置顶的功能,比如说从页面的最下方滑动到最上面太慢了,这个时候我们就可以使用置顶功能。 二、效果展示 三、具体使用 参数名类型必填说明scrollTopNumber否滚动到页面的目标位置…...

UDP数据报和TCP流套接字编程
文章目录 UDP数据报套接字编程1.DatagramSocket类2.DatagramPacket类3. InetSocketAddress类构建服务端和客户端 TCP流套接字编程1. ServerSocket类2.Socket类构建服务端和客户端 扩展对话形式简易的字典多线程实现线程池实现 UDP数据报套接字编程 1.DatagramSocket类 Datagr…...

某建筑石料用灰岩矿自动化监测
1. 项目简介 某建材有限公司成立于2012年,是一家集矿山开采、石料生产及销售为一体的建筑材料生产企业,拥有两条年产500万吨的环保型精品骨料生产线,各类工程机械 30 多台套,运输车辆50多辆。公司坚持生态优先,以高质…...

C++11 的编译器支持
C11 主要功能特性一览 特性描述提案GCCClangMSVCApple ClangEDG eccpIntel CNvidia HPC C (ex PGI)*Nvidia nvccCrayEmbarcadero C BuilderIBM Open XL C for AIXIBM Open XL C for z/OSIBM XL CSun/Oracle CHP aCCDigital Mars C核心功能右值引用 (T&&)支持移动语义和…...

20250429 垂直地表发射激光测量偏转可以验证相对性原理吗
垂直地表发射激光测量偏转可以验证相对性原理吗 垂直地表发射激光测量偏转可以在一定条件下用于检验广义相对论中的等效原理和引力对光传播的影响,但要说直接验证整个相对性原理(狭义广义)是不准确的。我们可以逐步分析这个问题:…...

Makefile 在 ARM MCU 开发中的编译与链接参数详解与实践
内容大纲 引言 一、预处理与宏定义 头文件搜索路径:-I 宏定义:-D 二、编译器选项(CFLAGS) 架构与指令集:-mcpu、-mthumb 优化与调试:-Os、-O2、-g 警告与错误:-Wall、-Werror 代码剥离:-ffunction-sections、-fdata-sections 其他常用选项 三、链接器选项(LDFLAGS) 链…...

AimRT 从零到一:官方示例精讲 —— 四、logger示例.md
logger示例 官方仓库:logger 配置文件(configuration_logger.yaml) 依据官方示例项目结构自行编写YAML配置文件: # 基础信息 base_info:project_name: Logger # 项目名称build_mode_tags: ["EXAMPLE", "SIMULATION", "TE…...

mybatis传递多个不同类型的参数到mapper xml文件
在业务中查询某张表时需要设置多个查询条件,并且还要根据id列表进行权限过滤,这时推荐采用Map<String, Object>作为参数进行查询,因为:Object可以设置成不同的类型,比如:List<Integer> ids&…...

信创开发中的数据库详解:国产替代背景下的技术生态与实践指南
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C, C#, Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C、C#等开发语言,熟悉Java常用开…...

【Linux】第十三章 访问Linux文件系统
目录 1. 存储设备是什么?怎么理解分区和格式化? 2. 文件系统是什么? 3. 挂载是什么?挂载点是什么? 4. 怎么理解块设备? 5. 在SATA附加存储中,第一磁盘上的第一个分区和第二磁盘的第二个分区…...

多态与虚函数
在 C 中,virtual 关键字用于实现多态性(Polymorphism),这是面向对象编程(OOPP)的核心特性之一。多态性允许你编写通用的代码,该代码可以操作不同类型的对象,而这些对象可以有不同的内…...

Spring Boot - 配置管理与自动化配置进阶
Spring Boot 的配置管理和自动化配置是其核心特性之一,能够显著提升开发效率和应用灵活性。本文将深入探讨以下内容: 1、配置管理:多环境配置与优先级解析。 2、自动化配置:自定义 Spring Boot Starter 与 spring.factories 扩展…...

第六章 QT基础:7、Qt中多线程的使用
在进行桌面应用程序开发时,假设应用程序需要处理比较复杂的逻辑,如果只有一个线程去处理,就会导致窗口卡顿,无法处理用户的相关操作。 这种情况下,需要使用多线程: 主线程处理窗口事件和控件更新子线程进…...

前端Vue3 + 后端Spring Boot,前端取消请求后端处理逻辑分析
在 Vue3 Spring Boot 的技术栈下,前端取消请求后,后端是否继续执行业务逻辑的答案仍然是 取决于请求处理的阶段 和 Spring Boot 的实现方式。以下是结合具体技术的详细分析: 1. 请求未到达 Spring Boot 场景:前端通过 AbortContr…...

ShaderToy学习笔记 05.3D旋转
1. 3D旋转 1.1. 汇制立方体 由于立方体没有旋转,所以正对着看过去时,看起来是正方形的,所以需要旋转一下,才能看到立方体的样子。 常见几何体的SDF BOX 的SDF为 float sdBox( vec3 p, vec3 b ) {vec3 q abs(p) - b;return len…...

编程日志4.24
栈的链表基础表示结构 #include<iostream> #include<stdexcept> using namespace std; //模板声明,表明Stack类是一个通用的模板,可以用于存储任何类型的元素T template<typename T> //栈的声明 //Stack类的声明,表示一…...

通信设备制造数字化转型中的创新模式与实践探索
在数字化浪潮下,通信设备制造企业积极探索创新模式,推动数字化转型,以提升竞争力和适应市场变化。 在生产模式创新方面,企业引入工业互联网平台,实现设备互联互通与生产过程智能化监控。通过在生产设备上安装传感器&a…...

同一个路由器接口eth0和ppp0什么不同?
答案摘自 百度知道, eth0是以太网接口,是表示以太网连接的物理接口,路由器可能会有不止一个以太网接口,因此可能会eth0,eht1之类的。 ppp0是经以太网接口PPP拨号时创建的链路接口,用以建PPP拨号连接的&am…...

零训练成本优化LLM: 11种LLM权重合并策略原理与MergeKit实战配置
随着大语言模型的快速发展,如何在不消耗大量计算资源的情况下优化模型性能成为业界关注焦点。模型权重合并技术提供了一种零训练成本的高效解决方案,能够智能整合多个专业微调模型的优势,无需额外训练即可显著提升性能表现。本文系统剖析11种…...
)
基于tabula对pdf中多个excel进行识别并转换成word中的优化(五)
优化地方:处理合并的单元格内容。 1、修改为stream"complex" 2、增加换行符f"{table_data[i - 1][j]}\n{table_data[i][j]}".strip() 一、pdf中excel样例 二、完整代码 import tabula import numpy as np from docx import Document from docx…...

QT中的网络编程
Qt中的网络编程是通过封装操作系统的API进行实现的 C标准库中,并没有提供网络编程的封装接口 进行网络编程时本质是在编写应用层代码,需要传输层提供支持 传输层最核心的协议为UDP/TCP 使用Qt网络编程的API时,需要在.pro文件中添加network模块…...

0.5 像素边框实现
0.5 像素边框怎么实现 文章目录 0.5 像素边框怎么实现方法 1:使用 transform: scale() 缩放(推荐)方法 2:直接使用 0.5px 边框(部分浏览器支持)方法 3:使用 box-shadow 模拟边框方法 4ÿ…...

【Vagrant+VirtualBox创建自动化虚拟环境】Ansible测试Playbook
文章目录 Vagrant安装vagrant安装 VirtualBox如何使用 Ansible安装AnsiblePlaybook测试创建hosts文件创建setup.yml文件 Vagrant Vagrant是一个基于Ruby的工具,用于创建和部署虚拟化开发环境。它使用Oracle的开源VirtualBox虚拟化系统,使用 Chef创建自动…...

“连接世界的桥梁:深入理解计算机网络应用层”
一、引言 当你浏览网页、发送邮件、聊天或观看视频时,这一切都离不开计算机网络中的应用层(Application Layer)。 应用层是网络协议栈的最顶层,直接为用户的各种应用程序提供服务。它为用户进程之间建立通信桥梁,屏蔽了…...

Vulkan与OpenGL的对比
传统图形API与现代图形API 传统图形API指的是OpenGL/DirectX11这类简单易用、驱动托管严重的图形接口;而现代图形API则指的是Vulkan/Metal/DirectX12这类使用复杂、暴露更多底层硬件功能来显式控制的弱驱动设计的图形接口。 现代图形API与传统图形API相比ÿ…...