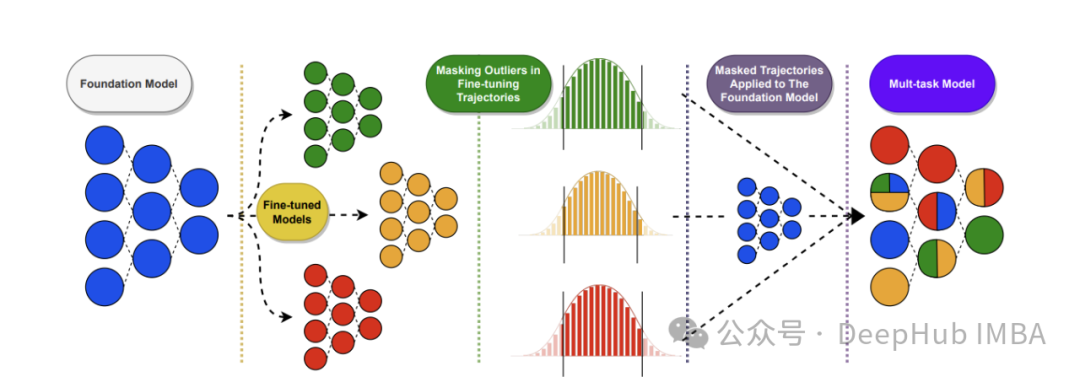
零训练成本优化LLM: 11种LLM权重合并策略原理与MergeKit实战配置
随着大语言模型的快速发展,如何在不消耗大量计算资源的情况下优化模型性能成为业界关注焦点。模型权重合并技术提供了一种零训练成本的高效解决方案,能够智能整合多个专业微调模型的优势,无需额外训练即可显著提升性能表现。本文系统剖析11种前沿权重合并策略的理论基础与数学原理,从简单的线性插值到复杂的几何映射方法,并通过开源工具MergeKit提供详细的实战配置示例。无论您是AI研究人员寻求最优参数组合,企业开发者追求成本效益的模型优化方案,还是对LLM内部机制感兴趣的技术爱好者,本文都将为您提供全面且实用的技术指南,助您在资源受限条件下实现大语言模型的高效优化与融合。
1、线性权重平均:Model Soup
Model Soup技术基于一个简洁而有效的思想:对多个微调模型的权重进行加权平均。该方法的核心假设是,从相同预训练骨干网络(针对相关任务或领域)微调的模型在参数空间中处于"连通"区域,因此它们的线性组合可以产生具有更强泛化能力的模型。
对于一组模型,给定一组非负系数 (α₁, α₂, …, αₙ),且这些系数的总和为 1,合并后的模型可表示为:
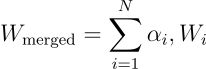
参数配置
- weight (α) — 指定张量的相对权重(若 normalize=False 则为绝对权重)
- normalize — 若设为 true,所有模型的权重贡献将被归一化,这是默认行为
models:- model: meta-llama/Llama-3.1-8B-Instructparameters:weight: 0.5- model: NousResearch/Hermes-3-Llama-3.1-8Bparameters:weight: 0.15- model: deepseek-ai/DeepSeek-R1-Distill-Llama-8Bparameters:weight: 0.35merge_method: lineardtype: float16
2、Spherical Linear Interpolation - SLERP
SLERP 方法在归一化权重向量球面上的大圆弧上执行插值计算。与直线(欧几里得)插值不同,它保留了向量间的角度关系。当权重向量经过归一化处理时,这一特性尤为重要,能够确保插值生成的模型仍然"保持在流形上"。
对于两个权重向量 (a) 和 (b) 以及插值参数 (t∈[0,1]),SLERP 的计算公式为:
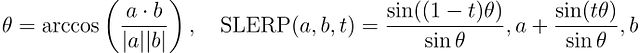
参数配置
- t (插值因子) — 控制在两个模型之间大圆弧上的插值位置
models:- model: deepseek-ai/DeepSeek-R1-Distill-Llama-8Bmerge_method: slerpbase_model: meta-llama/Llama-3.1-8B-Instructparameters:t: 0.5dtype: float16
3、近邻交换 (Nearswap)
Nearswap 技术旨在识别并利用参数空间中两个模型在"接近"(即相似度高)区域的特性进行合并。该方法首先对模型参数(或层)进行分区处理,然后仅对差异值在指定阈值范围内的参数执行"交换"或平均操作。
其实现过程包括:
计算距离:
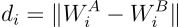
基于阈值 τ 执行参数合并:
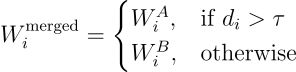
参数配置
- t (相似度阈值) — 定义参数被视为"接近"并符合交换条件的距离阈值
models:- model: meta-llama/Llama-3.1-8B-Instruct- model: deepseek-ai/DeepSeek-R1-Distill-Llama-8Bmerge_method: nearswapbase_model: meta-llama/Llama-3.1-8B-Instructparameters:t: 0.5dtype: float16
4、任务算术 (Task Arithmetic)
任务算术技术基于一个关键见解:模型参数通常会编码与特定任务相关的"方向性信息"。通过减去共同(共享)表示并添加特定于任务的组件,可以构建出能更有效执行复合任务的模型。
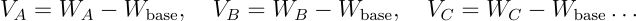
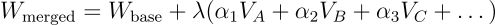
参数配置
- weight (α) — 指定张量的相对权重(若 normalize=False 则为绝对权重)
- normalize — 若设为 true,所有模型的权重贡献将被归一化,这是默认行为
- lambda — 应用于任务向量加权和之后的缩放因子
models:- model: NousResearch/Hermes-3-Llama-3.1-8Bparameters:weight: 0.3- model: deepseek-ai/DeepSeek-R1-Distill-Llama-8Bparameters:weight: 0.7merge_method: task_arithmeticbase_model: meta-llama/Llama-3.1-8B-Instructparameters:lambda: 0.5dtype: float16
5、修剪、选择符号和合并 (TIES-Merging)
TIES-MERGING 算法通过三步处理流程解决了合并多个特定任务模型时的参数干扰问题:修剪、选择符号和不相交合并。该方法旨在创建一个有效整合各个特定任务模型知识的合并模型,同时减轻冲突参数更新的负面影响。
具体实现步骤:
- 对每个任务向量,保留幅度最高的前 k% 参数,并将其余(底部 (100−k)%)置零,形成修剪后的任务向量。
- 对每个参数位置,计算所有修剪后任务向量中正负符号的总幅度,将具有较大总幅度的符号分配给合并模型的符号向量。
- 对每个参数,定义一个包含修剪后任务向量中符号与所选符号一致的任务索引集合,通过求取参数均值计算不相交平均值。
参数配置
- weight (α) — 指定张量的相对权重(若 normalize=False 则为绝对权重)
- normalize — 若设为 true,所有模型的权重贡献将被归一化,这是默认行为
- lambda — 应用于任务向量加权和之后的缩放因子
- density (k) — 与基础模型差异中需保留的权重比例
models:- model: NousResearch/Hermes-3-Llama-3.1-8Bparameters:weight: 0.3- model: deepseek-ai/DeepSeek-R1-Distill-Llama-8Bparameters:weight: 0.7merge_method: tiesbase_model: meta-llama/Llama-3.1-8B-Instructparameters:lambda: 0.5density: 0.7dtype: float16
6、丢弃和重新缩放 (DARE)
DARE(丢弃和重新缩放)算法旨在减少大型语言模型增量参数(从预训练到微调的变化)中的冗余信息。该方法随机将一部分增量参数置零,并将剩余参数按 1/(1-p) 倍重新缩放,其中 p 表示丢弃率,然后将处理后的参数加回预训练参数中。
实现流程:
- 给定预训练模型(权重为 W_PRE)和针对任务 t 微调的模型(权重为 W_SFT_t),计算增量参数 Δ_t。
- 使用伯努利分布,随机将 p 比例的增量参数置零。对 Δ_t 中的每个元素,从 Bernoulli§ 抽取随机变量 m_t。
- 将保留的非零增量参数按因子 1/(1−p) 进行重新缩放,以补偿丢弃值造成的影响。
- 最后,将重新缩放的增量参数 Δ̂_t 加回预训练权重 W_PRE,得到 DARE 适应后的权重 W_DARE_t。
DARE 技术可以与 TIES 的符号共识算法结合使用 (dare_ties),也可以独立使用 (dare_linear)。
参数配置 (dare_ties)
- weight (α) — 指定张量的相对权重(若 normalize=False 则为绝对权重)
- normalize — 若设为 true,所有模型的权重贡献将被归一化,这是默认行为
- lambda — 应用于任务向量加权和之后的缩放因子
- density (k) — 与基础模型差异中需保留的权重比例
models:- model: NousResearch/Hermes-3-Llama-3.1-8Bparameters:weight: 0.3- model: deepseek-ai/DeepSeek-R1-Distill-Llama-8Bparameters:weight: 0.7merge_method: dare_tiesbase_model: meta-llama/Llama-3.1-8B-Instructparameters:lambda: 0.5density: 0.7dtype: float16
参数配置 (dare_linear)
- weight (α) — 指定张量的相对权重(若 normalize=False 则为绝对权重)
- normalize — 若设为 true,所有模型的权重贡献将被归一化,这是默认行为
- lambda — 应用于任务向量加权和之后的缩放因子
models:- model: NousResearch/Hermes-3-Llama-3.1-8Bparameters:weight: 0.3- model: deepseek-ai/DeepSeek-R1-Distill-Llama-8Bparameters:weight: 0.7merge_method: dare_linearbase_model: meta-llama/Llama-3.1-8B-Instructparameters:lambda: 0.5dtype: float16
7、Model Breadcrumbs
Model Breadcrumbs是任务算术的扩展技术,它通过丢弃与基础模型差异中既小又极大的部分来优化合并效果。该算法可以与 TIES 的符号共识算法结合使用 (breadcrumbs_ties),也可以独立使用 (breadcrumbs)。
实现过程包括四个主要步骤:
- 任务向量创建:对于每个针对特定任务微调的模型,计算其权重与原始预训练基础模型权重之间的差异,构成任务向量。
- 异常值和可忽略扰动移除:定义两个百分比阈值,β(左尾)和 γ(右尾)。在每层排序权重中屏蔽(置零)底部 β% 和顶部 (100-γ)% 的权重,以消除大异常值和可忽略扰动。
- 组合任务向量:通过求和聚合所有任务的屏蔽任务向量。
- 缩放与整合:将聚合后的任务向量按强度参数 (α) 缩放,然后添加至原始预训练模型的权重中。
参数配置
- weight (α) — 指定张量的相对权重(若 normalize=False 则为绝对权重)
- normalize — 若设为 true,所有模型的权重贡献将被归一化,这是默认行为
- lambda — 应用于任务向量加权和之后的缩放因子
- density — 与基础模型差异中需保留的权重比例
- gamma — 要移除的最大幅度差异的比例
注意:gamma 参数对应论文中描述的参数 β,而 density 表示稀疏化张量的最终密度(通过 density = 1−γ−β 与 γ 和 β 相关)。
models:- model: NousResearch/Hermes-3-Llama-3.1-8Bparameters:weight: 0.3- model: deepseek-ai/DeepSeek-R1-Distill-Llama-8Bparameters:weight: 0.7merge_method: breadcrumbsbase_model: meta-llama/Llama-3.1-8B-Instructparameters:lambda: 0.5density: 0.9gamma: 0.01dtype: float16
models:- model: NousResearch/Hermes-3-Llama-3.1-8Bparameters:weight: 0.3- model: deepseek-ai/DeepSeek-R1-Distill-Llama-8Bparameters:weight: 0.7merge_method: breadcrumbs_tiesbase_model: meta-llama/Llama-3.1-8B-Instructparameters:lambda: 0.5density: 0.9gamma: 0.01dtype: float16
8、Model Stock
Model Stock算法提供了一种经济高效的权重合并方法,旨在通过使用预训练模型作为锚点和少量微调模型来近似权重分布的中心 (μ),从而提高模型性能。该技术利用权重向量的几何特性,特别是各向量间的角度关系,来确定最佳合并比例。
主要实现步骤:
- 平面定义:使用预训练模型的权重向量 (w0) 和两个微调模型的权重向量 (w1 和 w2) 定义一个平面,该平面构成了合并权重的搜索空间。
- 垂足计算:算法寻找该平面上最接近权重分布中心 (μ) 的点 (wH),即 μ 到该平面的垂足。
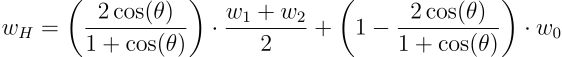
其中:
-
θ 表示两个微调模型权重向量(w1 和 w2)之间的角度
-
wH 表示合并后的权重向量
-
w0 表示预训练模型的权重向量
-
(w1 + w2)/2 表示两个微调权重向量的平均值,对应原文中的 w12
-
插值比例计算:插值比例 t = 2 * cos(θ) / (1 + cos(θ)) 决定了平均微调权重与预训练权重对合并权重的贡献比例。该比例仅取决于角度 θ,角度越小,对预训练模型的依赖性越低。
-
扩展到 N 个微调模型:
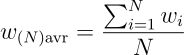
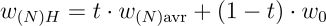
其中 t = N * cos(θ) / (1 + (N−1) * cos(θ)),θ 表示预训练模型与 N 个微调模型之间的角度,w(N)H 表示合并后的权重向量。
参数配置
- filter_wise:若设为 true,权重计算将按行而非按张量进行(不推荐)
models:- model: NousResearch/Hermes-3-Llama-3.1-8B- model: deepseek-ai/DeepSeek-R1-Distill-Llama-8Bmerge_method: model_stockbase_model: meta-llama/Llama-3.1-8B-Instructdtype: float16
9、归一化球面线性插值 (NuSLERP)
NuSLERP 通过在执行插值前显式归一化权重向量,对标准 SLERP 方法进行了改进。当模型使用不同缩放系数进行训练时(例如,由于自适应归一化层),这种"归一化"版本尤为有用,可避免插值过程中混合不兼容的尺度问题。
参数配置
- weight:指定张量的相对权重
- nuslerp_flatten:设为 false 可执行逐行/逐列插值,而非将张量作为整体向量处理
- nuslerp_row_wise:对行向量而非列向量应用 SLERP 算法
models:- model: deepseek-ai/DeepSeek-R1-Distill-Llama-8Bparameters:weight: 0.5- model: NousResearch/Hermes-3-Llama-3.1-8Bparameters:weight: 0.5merge_method: nuslerpbase_model: meta-llama/Llama-3.1-8B-Instructdtype: float16
10、通过幅度采样进行丢弃和重新缩放 (DELLA)
DELLA 方法可以与 TIES 的符号选择步骤结合使用 (della),也可以独立使用 (della_linear)。该方法包含以下核心步骤:
丢弃 (Drop):采用基于幅度的创新修剪方法 MAGPRUNE:
- 根据神经网络中每个节点增量参数的幅度(绝对值)进行排序
- 为每个参数分配一个与其幅度成反比的丢弃概率 (Pd),幅度较大的参数被丢弃的概率较低,由超参数 ∆ 控制概率步长
- 超参数 ‘p’ 控制平均丢弃概率,‘ϵ’ 影响最小丢弃概率 (pmin = p−ϵ/2)
- 根据分配的概率随机丢弃增量参数,丢弃的参数被置零
- 将剩余(未丢弃)的增量参数重新缩放 1/(1−pi),其中 pi 是第 i 个参数的丢弃概率,以补偿丢弃参数的影响,确保模型输出嵌入得以保留
选择 (Elect):通过计算所有专家对应增量参数之和的符号,确定每个参数位置的主导方向,仅选择与主导方向符号相同的增量参数。
融合 (Fuse):计算每个位置选定增量参数的平均值。
获取合并模型:将融合后的增量参数(按因子 λ 缩放)添加到基础模型的参数中。
参数配置
- weight (α) — 指定张量的相对权重(若 normalize=False 则为绝对权重)
- normalize — 若设为 true,所有模型的权重贡献将被归一化,这是默认行为
- lambda — 应用于任务向量加权和之后的缩放因子
- density — 与基础模型差异中要保留的权重比例
- epsilon — 基于幅度的丢弃概率的最大变化范围。分配的丢弃概率将在 density−epsilon 到 density+epsilon 的范围内变化(选择 density 和 epsilon 值时,请确保概率范围在 0 到 1 之内)
models:- model: NousResearch/Hermes-3-Llama-3.1-8Bparameters:weight: 0.3- model: deepseek-ai/DeepSeek-R1-Distill-Llama-8Bparameters:weight: 0.7merge_method: dellabase_model: meta-llama/Llama-3.1-8B-Instructparameters:lambda: 0.5density: 0.7epsilon: 0.01dtype: float16
models:- model: NousResearch/Hermes-3-Llama-3.1-8Bparameters:weight: 0.3- model: deepseek-ai/DeepSeek-R1-Distill-Llama-8Bparameters:weight: 0.7merge_method: della_linearbase_model: meta-llama/Llama-3.1-8B-Instructparameters:lambda: 0.5density: 0.7epsilon: 0.01dtype: float16
11、选择、计算和擦除 (SCE)
SCE(选择、计算、擦除)是一种用于合并多个目标 LLM 的技术,这些 LLM 共享相同的架构和规模,但已使用来自不同源 LLM 的知识分别进行了微调。该方法作用于"融合向量",即表示枢轴 LLM 和每个目标 LLM 在成对知识融合阶段后的权重差异。
实现过程包含以下四个步骤:
- 对于融合向量集中的每个参数矩阵,选择在不同目标 LLM 之间具有最高方差的前 k% 元素。
- 对于每个参数矩阵,计算每个目标 LLM 的合并系数,即其对应过滤融合向量中所选元素的平方和,并按该矩阵所有目标 LLM 的总平方和进行归一化。
- 对于过滤融合向量中的每个参数,对所有目标 LLM 的值求和。如果给定参数的和为正(或负),则将该参数的所有负(或正)值置零,以消除冲突的更新方向。
- SCE 处理后,最终合并 LLM 的参数矩阵通过任务算术方法计算得出。
参数配置
- weight (α) — 指定张量的相对权重(若 normalize=False 则为绝对权重)
- normalize — 若设为 true,所有模型的权重贡献将被归一化,这是默认行为
- lambda — 应用于任务向量加权和之后的缩放因子
- select_topk — 要保留的增量参数中具有最高方差的元素比例
models:- model: NousResearch/Hermes-3-Llama-3.1-8Bparameters:weight: 0.3- model: deepseek-ai/DeepSeek-R1-Distill-Llama-8Bparameters:weight: 0.7merge_method: scebase_model: meta-llama/Llama-3.1-8B-Instructparameters:lambda: 0.5select_topk: 0.7dtype: float16
总结
本文系统介绍了11种先进的LLM权重合并策略,从简单的线性权重平均到复杂的几何映射方法,全面揭示了如何在零训练成本下优化大语言模型性能。这些方法各具特色:Model Soup通过简单加权平均实现模型融合;SLERP保持角度关系确保插值质量;任务算术聚焦方向性信息;TIES-Merging通过修剪减轻参数干扰;Model Stock利用几何特性寻找最佳合并比例;而SCE则专注于消除冲突更新方向。MergeKit工具让这些先进算法变得触手可及,通过简明的YAML配置即可实现复杂的权重融合。在算力资源受限、无法进行完整微调的情况下,权重合并技术为研究人员和开发者提供了一种经济高效的方案,让模型优化更加灵活高效,为LLM生态系统的发展提供了新的可能性。
引用
- Model Soups: Averaging Weights of Multiple Fine-Tuned Models Improves Accuracy Without Retraining 2203.05482
- Editing Models with Task Arithmetic 2212.04089
- TIES-Merging: Resolving Interference When Merging Models 2306.01708
- Language Models are Super Mario: Absorbing Abilities from Homologous Models as a Free Lunch 2311.03099
- Model Breadcrumbs: Scaling Multi-Task Model Merging with Sparse Masks 2312.06795
- Model Stock: All we need is just a few fine-tuned models 2403.19522
- DELLA-Merging: Reducing Interference in Model Merging through Magnitude-Based Sampling 2406.11617
- FuseChat: Knowledge Fusion of Chat Models 2408.07990
https://avoid.overfit.cn/post/161535f4639f41809589f36b57b16bc7
相关文章:

零训练成本优化LLM: 11种LLM权重合并策略原理与MergeKit实战配置
随着大语言模型的快速发展,如何在不消耗大量计算资源的情况下优化模型性能成为业界关注焦点。模型权重合并技术提供了一种零训练成本的高效解决方案,能够智能整合多个专业微调模型的优势,无需额外训练即可显著提升性能表现。本文系统剖析11种…...
)
基于tabula对pdf中多个excel进行识别并转换成word中的优化(五)
优化地方:处理合并的单元格内容。 1、修改为stream"complex" 2、增加换行符f"{table_data[i - 1][j]}\n{table_data[i][j]}".strip() 一、pdf中excel样例 二、完整代码 import tabula import numpy as np from docx import Document from docx…...

QT中的网络编程
Qt中的网络编程是通过封装操作系统的API进行实现的 C标准库中,并没有提供网络编程的封装接口 进行网络编程时本质是在编写应用层代码,需要传输层提供支持 传输层最核心的协议为UDP/TCP 使用Qt网络编程的API时,需要在.pro文件中添加network模块…...

0.5 像素边框实现
0.5 像素边框怎么实现 文章目录 0.5 像素边框怎么实现方法 1:使用 transform: scale() 缩放(推荐)方法 2:直接使用 0.5px 边框(部分浏览器支持)方法 3:使用 box-shadow 模拟边框方法 4ÿ…...

【Vagrant+VirtualBox创建自动化虚拟环境】Ansible测试Playbook
文章目录 Vagrant安装vagrant安装 VirtualBox如何使用 Ansible安装AnsiblePlaybook测试创建hosts文件创建setup.yml文件 Vagrant Vagrant是一个基于Ruby的工具,用于创建和部署虚拟化开发环境。它使用Oracle的开源VirtualBox虚拟化系统,使用 Chef创建自动…...

“连接世界的桥梁:深入理解计算机网络应用层”
一、引言 当你浏览网页、发送邮件、聊天或观看视频时,这一切都离不开计算机网络中的应用层(Application Layer)。 应用层是网络协议栈的最顶层,直接为用户的各种应用程序提供服务。它为用户进程之间建立通信桥梁,屏蔽了…...

Vulkan与OpenGL的对比
传统图形API与现代图形API 传统图形API指的是OpenGL/DirectX11这类简单易用、驱动托管严重的图形接口;而现代图形API则指的是Vulkan/Metal/DirectX12这类使用复杂、暴露更多底层硬件功能来显式控制的弱驱动设计的图形接口。 现代图形API与传统图形API相比ÿ…...

海外社交App的Web3革命:去中心化社交与Token经济实战指南
一、Web3社交的核心组件:从身份到经济的重构 去中心化身份(DID)技术栈:Ceramic IDX协议构建链上身份图谱代码示例:javascript// 创建DID const ceramic new CeramicClient() const did new DID({ provider: cerami…...

凯撒密码算法的实现
在密码学里,凯撒密码(也叫恺撒密码、移位密码、恺撒代码或者恺撒移位)是一种简单且广为人知的加密技术。它属于替换密码的一种,在这种加密方式中,明文中的每个字母都会被替换成字母表中往后移动固定位数的字母。例如&a…...

Chrome的插件扩展程序安装目录是什么?在哪个文件夹?
目录 前提 直接复制到浏览器中打开 Mac下Chrome extension 安装路径 最近换了mac pro用起来虽然方便,但是对常用的一些使用方法还是不熟悉。这不为了找到mac上chrome插件的安装路径在哪里,花费了不少时间。我想应用有不少像小编一样刚刚使用mac的小白…...

C++23中的std::forward_like:完美转发的增强
文章目录 一、背景与动机(一)完美转发的局限性(二)std::forward_like的提出 二、std::forward_like的设计与实现(一)基本语法(二)实现原理(三)与std::forward…...

AI与软件测试的未来:如何利用智能自动化改变测试流程
用工作流生成测试用例和自动化测试脚本! 随着人工智能(AI)技术的迅猛发展,软件测试作为软件开发生命周期中的关键环节,正在经历一场前所未有的变革。传统的测试方法已经无法满足现代快速迭代和持续交付的需求ÿ…...

React Native 动态切换主题
React Native 动态切换主题 创建主题配置和上下文创建主题化高阶组件主应用组件主屏幕组件(类组件形式) 创建主题配置和上下文 // ThemeContext.jsimport React, { Component, createContext } from react;import { Appearance, AsyncStorage } from rea…...

得物 小程序 6宫格 分析
声明 本文章中所有内容仅供学习交流使用,不用于其他任何目的,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关! 逆向过程 部分python代码 if result …...

PocketFlow一个最小的Agent框架
1、背景 PocketFlow 2、使用 python 的版本需要python3.10 在cookbook中有如何使用的说明,如图所示 在tuils.py中修改代码 def call_llm(messages):# client OpenAI(api_keyos.environ.get("OPENAI_API_KEY", "your-api-key"))client Op…...

Objective-C Block 底层原理深度解析
Objective-C Block 底层原理深度解析 1. Block 是什么? 1.1 Block 的本质 Block 是 Objective-C 中的特殊对象,实现了匿名函数的功能 通过 isa 指针继承自 NSObject,可以响应(如 copy、retain、release)等内存管理方…...

AlDente Pro for Mac电脑 充电限制保护工具 安装教程【简单,轻松上手】
AlDente Pro for Mac电脑 充电限制保护工具 安装教程【简单,轻松上手】 AlDente Pro for Mac,是一款充电限制保护工具,是可以限制最大充电百分比来保护电池的工具。锂离子和聚合物电池(如 MacBook 中的电池)在40&…...

Linux systemd 从理论到实践:现代系统管理的核心工具
文章目录 引言:为什么需要 systemd?第一部分:systemd 核心理论1.1 systemd 的设计哲学1.2 核心组件1.3 单元文件(Unit File)结构 第二部分:实战操作指南2.1 基础命令2.2 服务管理高级操作2.3 日志管理&…...

分享一个移动端项目模板:React-Umi4-mobile
分享一个移动端项目模板:React-Umi4-mobile 大家好,今天想和大家分享一个我最近做的移动端项目模板 React-Umi4-mobile。 模板的主要内容 这个模板主要包括: 基于 Umi 4 框架使用了 antd-mobile 组件库配置了 px 自动转 vw(基…...
)
Tailwind CSS 响应式设计解析(含示例)
本文内容: Tailwindcss V4 中如何使用响应式设计功能,包括默认断点、自定义断点、断点范围控制以及容器查询的各种技巧,帮助你在不离开 HTML 的前提下优雅构建响应式页面。 🌟 默认断点用法(移动优先) Tail…...

ElasticSearch入门
1 elasticsearch概述 1.1 elasticsearch 简介 官网: https://www.elastic.co/ ElasticSearch是一个基于 Lucene 的搜索服务器,基于RESTful web接口。Elasticsearch是用Java开发的,开源的企业级搜索引擎。 Elastic官方宣布Elasticsearch进入Version 8…...

强化学习之基于无模型的算法之时序差分法
2、时序差分法(TD) 核心思想 TD 方法通过 引导值估计来学习最优策略。它利用当前的估计值和下一个时间步的信息来更新价值函数, 这种方法被称为“引导”(bootstrapping)。而不需要像蒙特卡罗方法那样等待一个完整的 episode 结束才进行更新&…...
:连接异常)
【网络原理】TCP异常处理(二):连接异常
目录 一. 由进程崩溃引起的连接断开 二. 由关机引起的连接断开 三. 由断电引起的连接断开 四. 由网线断开引起的连接断开 一. 由进程崩溃引起的连接断开 在一般情况下,进程无论是正常结束,还是异常崩溃,都会触发回收文件资源,…...
)
[stm32] 4-1 USART(1)
文章目录 前言4-1 USARTUSART简介什么是USART?USART名字的含义?如何使用USART? USART的工作原理什么是串并转换?为什么要进行串并转换?移位寄存器串并行转换电路 USART寄存器组和完整框图 前言 本笔记内容,为本人依据…...

C++多线程与锁机制
1. 基本多线程编程 1.1 创建线程 #include <iostream> #include <thread>void thread_function() {std::cout << "Hello from thread!\n"; }int main() {std::thread t(thread_function); // 创建并启动线程t.join(); // 等待线程结束return 0; …...
:自定义传输层开发)
【MCP Node.js SDK 全栈进阶指南】高级篇(4):自定义传输层开发
引言 在MCP(Model Context Protocol)应用开发中,传输层是连接客户端与服务器的关键环节,直接影响应用的性能、可靠性和扩展性。默认的传输方式虽然能满足基本需求,但在复杂场景下,自定义传输层能够为应用提供更高的灵活性和优化空间。本文将深入探讨MCP TypeScript-SDK中…...

当向量数据库与云计算相遇:AI应用全面提速
如果将AI比作一台高速运转的机器引擎,那么数据便是它的燃料。 然而,存储数据的燃料库--传统数据库,在AI时代的效率瓶颈愈发明显,已经无法满足AI对于数据的全新需求。 因此,向量数据库近年来迅速崛起。向量数据库通过…...

【2024-NIPS-版权】Evaluating Copyright Takedown Methods for Language Models
1.背景 目前 LLMs 在训练过程中使用了大量的受版权保护数据,这些数据会导致大模型记忆并生成与训练数据相似的内容,从而引发版权问题。随着版权所有者对模型训练和部署中的版权问题提起诉讼(例如 Tremblay v. OpenAI, Inc. 和 Kadrey v. Met…...

【PyTorch动态计算图原理精讲】从入门到灵活应用
目录 前言技术背景与价值当前技术痛点解决方案概述目标读者说明一、技术原理剖析核心概念图解核心作用讲解关键技术模块说明技术选型对比二、实战演示环境配置要求核心代码实现案例1:基础计算图构建案例2:条件分支动态图案例3:循环结构动态图运行结果验证三、性能对比测试方…...

阿里巴巴Qwen3发布:登顶全球开源模型之巅,混合推理模式重新定义AI效率
今天凌晨,阿里巴巴正式开源了新一代通义千问大模型Qwen3,这一举措不仅标志着国产大模型技术的又一里程碑,更以“混合推理”“极致性能”“超低成本”三大核心优势,刷新了全球开源模型的竞争格局。Qwen3在多项评测中超越DeepSeek-R…...
)
5. 配置舵机ID(具身智能机器人套件)
1. 连接舵机 waveshare驱动器板使用9-12v供电Type-C连接电脑DVG连接一个舵机 2. 使用FT SCServo Debug软件 设置串口设置波特率(默认1000000,100万)打开串口编程界面修改ID 3. 依次修改所有舵机ID 分别使用waveshare驱动板连接舵机&…...

Nacos源码—2.Nacos服务注册发现分析四
大纲 5.服务发现—服务之间的调用请求链路分析 6.服务端如何维护不健康的微服务实例 7.服务下线时涉及的处理 8.服务注册发现总结 7.服务下线时涉及的处理 (1)Nacos客户端服务下线的源码 (2)Nacos服务端处理服务下线的源码 (3)Nacos服务端发送服务变动事件给客户端的源码…...

从Windows开发迁移到信创开发的指南:国产替代背景下的技术路径与实践
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C, C#, Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C、C#等开发语言,熟悉Java常用开…...

从数据到决策:安科瑞EIoT如何让每一度电“清晰可见”?
安科瑞顾强 在能源管理迈向精细化与数字化的今天,安科瑞EIoT能源物联网平台以“数据驱动能源价值”为核心理念,融合物联网、云计算与大数据技术,打通从设备感知到云端决策的全链路闭环,助力工商业企业、园区、物业等场景实现用电…...
)
10.学习笔记-MyBatisPlus(P105-P110)
1.MyBatisPlus入门案例 (1)MyBatisPlus(简称Mp)是基于MyBatis框架基础上开发的增强型工具,目的是简化开发,提高效率。 (2)开发方式:基于MyBatis使用MyBatisPlusÿ…...

LayerSkip: Enabling Early Exit Inference and Self-Speculative Decoding
TL;DR 2024 年 Meta FAIR 提出了 LayerSkip,这是一种端到端的解决方案,用于加速大语言模型(LLMs)的推理过程 Paper name LayerSkip: Enabling Early Exit Inference and Self-Speculative Decoding Paper Reading Note Paper…...

fastapi和flaskapi有什么区别
FastAPI 和 Flask 都是 Python 的 Web 框架,但设计目标和功能特性有显著差异。以下是它们的核心区别: 1. 性能与异步支持 FastAPI 基于 Starlette(高性能异步框架)和 Pydantic(数据校验库)…...

在 JMeter 中使用 BeanShell 获取 HTTP 请求体中的 JSON 数据
在 JMeter 中,您可以使用 BeanShell 处理器来获取 HTTP 请求体中的 JSON 数据。以下是几种方法: 方法一:使用前置处理器获取请求体 如果您需要在发送请求前访问请求体: 添加一个 BeanShell PreProcessor 到您的 HTTP 请求采样器…...

Go 1.25为什么要废除核心类型
关于核心类型为什么要1.25里要移除,作者Robert在博客Goodbye core types - Hello Go as we know and love it!里给了详细耐心的解答。 背景:Go 1.18 引入了泛型(generics),带来了类型参数…...

flask中的Response 如何使用?
在 Flask 中,Response 对象用于生成 HTTP 响应并返回给客户端。以下是其常见用法及示例: 1. 直接返回字符串或 HTML 视图函数返回的字符串会被自动包装为 Response 对象,默认状态码为 200,内容类型为 text/html: app…...

基于SpringAI实现简易聊天对话
简介 本文旨在记录学习和实践 Spring AI Alibaba 提供的 ChatClient 组件的过程。ChatClient 是 Spring AI 中用于与大语言模型(LLM)进行交互的高级 API,它通过流畅(Fluent)的编程接口,极大地简化了构建聊天…...

STM32单片机入门学习——第49节: [15-2] 读写内部FLASH读取芯片ID
写这个文章是用来学习的,记录一下我的学习过程。希望我能一直坚持下去,我只是一个小白,只是想好好学习,我知道这会很难,但我还是想去做! 本文写于:2025.04.29 STM32开发板学习——第49节: [15-2] 读写内部FLASH&读取芯片ID 前言开发板说…...

第14讲:科研图表的导出与排版艺术——高质量 PDF、TIFF 输出与投稿规范全攻略!
目录 📘 前言:导出,不只是“保存”! 🎯 一、你需要掌握的导出目标 🖼️ 二、TIFF / PNG 导出规范(适用于投稿) 🧲 三、PDF 矢量图导出(排版首选) 🧩 四、强烈推荐组合:showtext + Cairo 🧷 五、多个图的组合导出技巧 🧪 六、特殊投稿需求处理 �…...
)
SRIO IP调试问题记录(ready信号不拉高情况)
问题:调试过程中遇到有时写入数据后数据不发送,并且ready信号在写入一定数据后一直拉低的情况(偶发,不是每次必然出现)。buf空间设置为16时,写入15包数据,写完第16包包头后,ready信号…...
)
使用DDR4控制器实现多通道数据读写(十)
一、本章概述 本章节对目前单通道的读写功能进项测试,主要验证读写的数据是否正确,并观察该工程可以存储的最大容量。通过空满信号进行读写测试,根据ila抓取fifo和ddr4全部满的时刻,可以观察到最大容量。再通过debug逻辑可以测试读…...

从 BERT 到 GPT:Encoder 的 “全局视野” 如何喂饱 Decoder 的 “逐词纠结”
当 Encoder 学会 “左顾右盼”:Decoder 如何凭 “单向记忆” 生成丝滑文本? 目录 当 Encoder 学会 “左顾右盼”:Decoder 如何凭 “单向记忆” 生成丝滑文本?引言一、Encoder vs Decoder:核心功能与基础架构对比1.1 本…...

探寻软件稳定性的奥秘
在软件开发的广袤领域中,软件的稳定性宛如基石,支撑着整个软件系统的运行与发展。《发布!软件的设计与部署》这本书的第一部分,对软件稳定性进行了深入且全面的剖析,为软件开发人员、架构师以及相关从业者们提供了极具…...

Reverse-WP记录9
前言 之前写的,一直没发,留个记录吧,万一哪天记录掉了起码在csdn有个念想 1.easyre1 32位无壳elf文件 shiftF12进入字符串,发现一串数字,双击进入 进入main函数 int __cdecl main(int argc, const char **argv, const…...

日常开发小Tips:后端返回带颜色的字段给前端
一般来说,展示给用户的字体格式,都是由前端控制,展现给用户; 但是当要表示某些字段的数据为异常数据,或者将一些关键信息以不同颜色的形式呈现给用户时,而前端又不好判断,那么就可以由后端来控…...

partition_pdf 和chunk_by_title 的区别
from unstructured.partition.pdf import partition_pdf from unstructured.chunking.title import chunk_by_titlepartition_pdf 和 chunk_by_title 初看有点像,都在"分块",但是它们的本质完全不一样。 先看它们核心区别 partition_pdfchun…...