【机器学习】朴素贝叶斯
目录
一、朴素贝叶斯的算法原理
1.1 定义
1.2 贝叶斯定理
1.3 条件独立性假设
二、朴素贝叶斯算法的几种常见类型
2.1 高斯朴素贝叶斯 (Gaussian Naive Bayes)
【训练阶段】 - 从数据中学习模型参数
【预测阶段】 - 对新样本 Xnew 进行分类
2. 2 多项式朴素贝叶斯 (Multinomial Naive Bayes)
【训练阶段】 - 学习模型参数
【预测阶段】 - 对新样本 Xnew 进行分类
2.3 伯努利朴素贝叶斯 (Bernoulli Naive Bayes)
【训练阶段】 - 学习模型参数
【预测阶段】 - 对新样本 Xnew 进行分类
三、实例:基于朴素贝叶斯的好瓜预测
任务: 对一个给定的西瓜样本进行二分类(好瓜/坏瓜)
1.训练数据
2.测试数据
3.计算步骤
4.代码实现
四、学习总结
一、朴素贝叶斯的算法原理
1.1 定义
朴素贝叶斯是一种基于 贝叶斯定理 的 概率分类算法。它属于 监督学习 算法的一种,也就是说,它需要一个带有标签(即正确答案)的训练数据集来学习。
它的核心思想是:对于一个未知类别的数据样本,计算该样本 属于各个类别的概率,然后选择 概率最大的那个类别 作为它的预测类别。
1.2 贝叶斯定理
贝叶斯定理描述了在已知某些条件下,一个事件发生的概率。
在分类问题中,我们想知道的是:在看到了某个数据样本的特征(X)之后,这个样本属于某个类别(y)的概率是多少?
这个概率被称为 后验概率 (Posterior Probability),用数学公式表示就是 P(y∣X)。
贝叶斯定理的公式如下:
其中
P(y∣X): 后验概率 (Posterior Probability)
P(X∣y): 似然性 (Likelihood)
- 在 假设样本属于类别 y 的前提下,观察到特征数据 X 的概率。
P(y): 先验概率 (Prior Probability)
- 在 观察到任何特征数据 X 之前,认为样本属于类别 y 的概率。
P(X): 证据 (Evidence)
- 观察到特征 X 的概率。这是一个归一化因子,确保所有类别的后验概率加起来等于1。在分类任务中,对于所有类别,P(X) 的值都是相同的。因此,在比较不同类别的后验概率 P(y∣X) 时,我们 只需要比较分子 P(X∣y)P(y) 的大小即可,可以忽略分母 P(X)。
所以,我们的目标简化为:计算每个类别 y 的 P(X∣y)P(y) 值,哪个类别的这个值最大,就预测样本属于哪个类别。
1.3 条件独立性假设
计算似然性 P(X∣y) 看似简单,但 X 通常包含多个特征 (x1,x2,...,xn)。
直接计算 P(x1,x2,...,xn∣y) 是非常困难的,因为它需要考虑所有特征之间的复杂联合关系,这需要极大的数据集才能准确估计。
为了简化计算,“朴素”贝叶斯算法引入了一个关键的假设:
给定类别 y 的条件下,所有特征 X=(x1,x2,...,xn) 之间是相互条件独立的
这意味着:
二、朴素贝叶斯算法的几种常见类型
朴素贝叶斯算法的核心思想基于 贝叶斯定理 和 特征条件独立性假设 。
不同的朴素贝叶斯变体主要是因为它们对 特征数据的概率分布 P(xi∣y) 做出了不同的假设。
根据特征数据类型的不同,最常见的朴素贝叶斯分类器有以下三种:
- 高斯朴素贝叶斯 (Gaussian Naive Bayes)
- 多项式朴素贝叶斯 (Multinomial Naive Bayes)
- 伯努利朴素贝叶斯 (Bernoulli Naive Bayes)
2.1 高斯朴素贝叶斯 (Gaussian Naive Bayes)
主要用于处理 连续型特征
【训练阶段】 - 从数据中学习模型参数
1.计算先验概率 P(y)
- 统计训练数据中每个类别 y出现了多少次。
- 用每个类别的样本数除以总样本数,得到该类别的先验概率。
- 公式:

2.按类别分组数据
- 将训练数据按照类别标签分开,方便后续计算。
3.计算每个类别下每个特征的均值 μy,i 和标准差 σy,i
对每一个类别 y:
- 对该类别下的每一个连续特征 xi:
- 计算这个特征在 只属于类别 y 的样本 中的 平均值 μy,i
- 计算这个特征在 只属于类别 y 的样本 中的 标准差 σy,i
4.处理零标准差情况
- 如果在某个类别 y 下,某个特征 xi 的所有值都完全相同,那么计算出的标准差 σy,i 会是 0。这在后续计算高斯概率密度时会导致除零错误。
- 解决方法: 检查是否有 σy,i=0 的情况。如果存在,将其替换为一个非常小的正数,或者使用更复杂的方差平滑技术。
5.存储模型参数
- 保存好计算出的所有类别的先验概率 P(y),以及每个类别下每个特征的均值 μy,i 和(处理过的)标准差 σy,i。
【预测阶段】 - 对新样本 Xnew 进行分类
假设新样本 Xnew 包含特征值 (x1,x2,...,xn)
1.为每个可能的类别 y 计算得分
初始化得分: 通常取先验概率的对数: 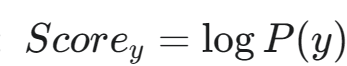
累加特征的对数似然: 对于新样本中的 每一个连续特征 xi:
- 取出训练阶段为类别 y 和特征 i 存储的均值 μy,i 和标准差 σy,i。
- 使用 高斯概率密度函数 (PDF) 公式 计算该特征值 xi 在类别 y 模型下的概率密度:
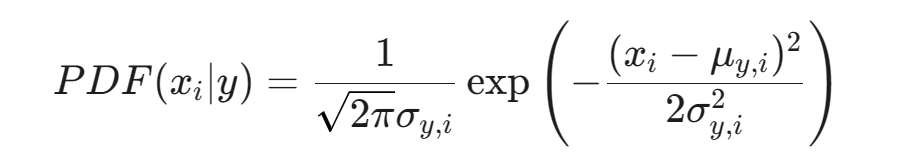
- 将计算得到的 logPDF(xi∣y) 加到对应类别 y 的得分上:
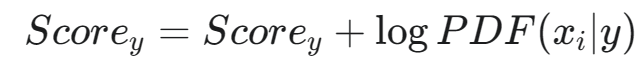
2.比较得分并预测
- 对所有可能的类别 y 都执行完步骤 1 后,比较它们最终的 Score
- 得分最高的那个类别,就是高斯朴素贝叶斯对新样本 Xnew 的预测结果。
2. 2 多项式朴素贝叶斯 (Multinomial Naive Bayes)
特征是离散的,通常表示某件事发生的次数或频率
【训练阶段】 - 学习模型参数
1.计算先验概率 P(y)
- 同高斯朴素贝叶斯
2.按类别分组数据
- 同高斯朴素贝叶斯
3.统计特征计数 Nyi 和总计数 Ny
确定整个数据集的 特征词汇表(所有出现过的不同特征/单词)。
设词汇表大小(或总特征数)为 k。
对每一个类别 y:
- 计算 Ny:该类别下 所有样本 中,所有特征 出现的 总次数 之和。
- 对词汇表中的每一个特征 xi:
- 计算 Nyi:该类别下 所有样本 中,特征 xi 出现的 总次数。
4.选择平滑参数 α
- 通常使用拉普拉斯平滑,即 α=1
5.存储模型参数
保存先验概率 P(y),所有类别的总特征数 Ny,每个类别下每个特征的计数 Nyi,以及词汇表大小 k 和平滑参数 α。
【预测阶段】 - 对新样本 Xnew 进行分类
假设新样本 Xnew 由特征计数 (count(x1),count(x2),...,count(xk)) 表示,其中 count(xi) 是特征 i 在 Xnew 中出现的次数。
1.为每个可能的类别 y 计算得分
初始化得分: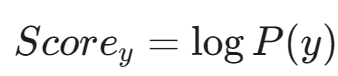
累加特征的对数似然: 对于词汇表中的 每一个特征 xi (从 i=1 到 k):
- 取出训练阶段为类别 y 存储的 Nyi, Ny
- 使用 平滑公式计算条件概率 P(xi∣y):
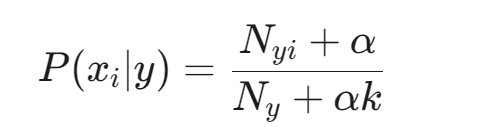
- 获取该特征 xi 在 新样本 Xnew 中的计数 count(xi)。
- 将该特征对得分的贡献(其计数值乘以其对数概率)累加到对应类别 y 的得分上:
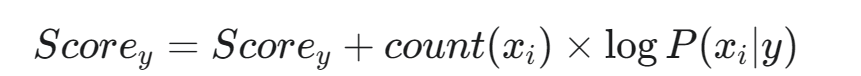
这里体现了出现次数越多的特征,对总得分的影响越大
2.比较得分并预测
- 比较所有类别的最终 Score
- 得分最高的类别即为预测结果。
2.3 伯努利朴素贝叶斯 (Bernoulli Naive Bayes)
特征是二元的(0/1),表示某事物是否存在、发生与否。
【训练阶段】 - 学习模型参数
1.计算先验概率 P(y)
- 同高斯朴素贝叶斯。
2.按类别分组数据
- 同高斯朴素贝叶斯。
3.统计特征出现次数 Ny,xi=1 和类别总数 Ny
确定所有可能的二元特征列表
对每一个类别 y:
- 计算 Ny:属于该类别的 样本总数
对每一个特征 xi:
- 计算 Ny,xi=1:在类别 y 的样本中,特征 xi 出现过(值为1)的样本数量。
4.选择平滑参数 α
- 通常 α=1
5.存储模型参数
- 保存先验概率 P(y),每个类别下每个特征的出现次数 Ny,xi=1,以及每个类别的总样本数 Ny
【预测阶段】 - 对新样本 Xnew 进行分类
假设新样本 Xnew 由二元特征向量 (x1,x2,...,xk) 表示,其中 xi∈{0,1}。
1.为每个可能的类别 y 计算得分
初始化得分: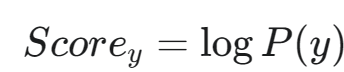
累加特征的对数似然: 对于 每一个特征 xi (从 i=1 到 k):
取出训练阶段为类别 y 存储的 Ny,xi=1 和 Ny
计算特征 i 在类别 y 下出现的概率 P(xi=1∣y):
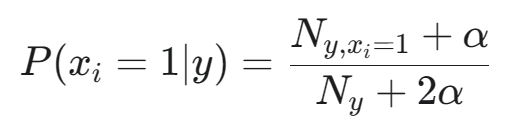
计算特征 i 在类别 y 下不出现的概率 P(xi=0∣y)
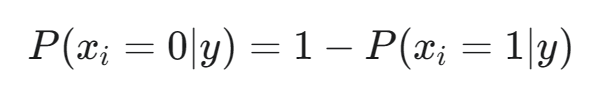
根据新样本 Xnew 中特征 xi 的值,选择对应的概率并累加其对数:
- 如果 Xnew 中 xi=1(特征出现),则
- 如果 Xnew 中 xi=0(特征未出现),则
2.比较得分并预测
- 比较所有类别的最终 Score
- 得分最高的类别即为预测结果
三、实例:基于朴素贝叶斯的好瓜预测
目标是根据一系列已知特征,判断一个西瓜是“好瓜”(标记为“是”)还是“坏瓜”(标记为“否”)。
任务: 对一个给定的西瓜样本进行二分类(好瓜/坏瓜)
1.训练数据
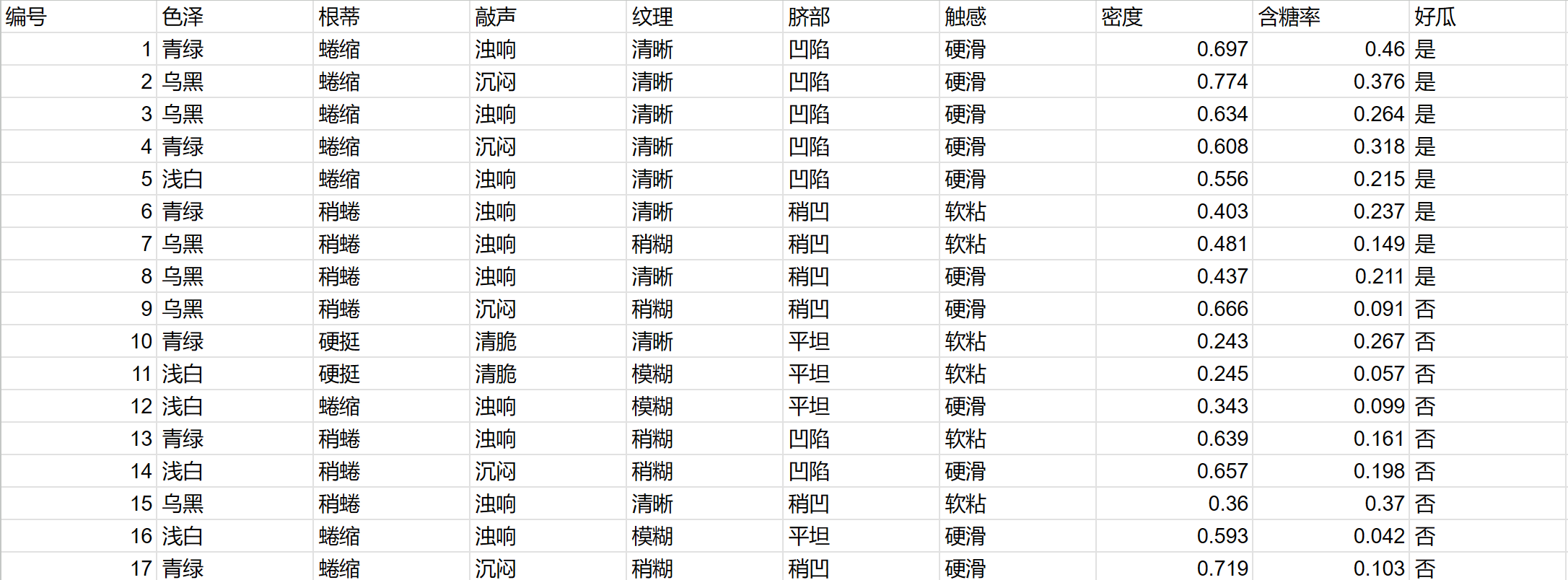
数据集摘要:
- 总样本数: 17
- 好瓜 (是) 数量: 8
- 坏瓜 (否) 数量: 9
2.测试数据
![]()
3.计算步骤
使用拉普拉斯平滑和高斯分布假设,方差使用N作为分母


计算后验概率


比较结果
计算出的 "好瓜=是" 的得分 (0.02177) 远大于 "好瓜=否" 的得分 (0.000036)
结论
根据朴素贝叶斯分类器的计算结果,对于测试样本 "测1"(特征为 青绿, 蜷缩, 浊响, 清晰, 凹陷, 硬滑, 密度=0.697, 含糖率=0.460),预测结果为 是 (好瓜)。
4.代码实现
import pandas as pd
import math# 1. 数据准备
data = {'色泽': ['青绿', '乌黑', '乌黑', '青绿', '浅白', '青绿', '乌黑', '乌黑', '乌黑', '青绿', '浅白', '浅白', '青绿', '浅白', '乌黑', '浅白', '青绿'],'根蒂': ['蜷缩', '蜷缩', '蜷缩', '蜷缩', '蜷缩', '稍蜷', '稍蜷', '稍蜷', '稍蜷', '硬挺', '硬挺', '蜷缩', '稍蜷', '稍蜷', '稍蜷', '蜷缩', '蜷缩'],'敲声': ['浊响', '沉闷', '浊响', '沉闷', '浊响', '浊响', '浊响', '浊响', '沉闷', '清脆', '清脆', '浊响', '浊响', '沉闷', '浊响', '浊响', '沉闷'],'纹理': ['清晰', '清晰', '清晰', '清晰', '清晰', '清晰', '稍糊', '清晰', '稍糊', '清晰', '模糊', '模糊', '稍糊', '稍糊', '清晰', '模糊', '稍糊'],'脐部': ['凹陷', '凹陷', '凹陷', '凹陷', '凹陷', '稍凹', '稍凹', '稍凹', '稍凹', '平坦', '平坦', '平坦', '凹陷', '凹陷', '稍凹', '平坦', '稍凹'],'触感': ['硬滑', '硬滑', '硬滑', '硬滑', '硬滑', '软粘', '软粘', '硬滑', '硬滑', '软粘', '软粘', '硬滑', '软粘', '硬滑', '软粘', '硬滑', '硬滑'],'密度': [0.697, 0.774, 0.634, 0.608, 0.556, 0.403, 0.481, 0.437, 0.666, 0.243, 0.245, 0.343, 0.639, 0.657, 0.360, 0.593, 0.719],'含糖率': [0.460, 0.376, 0.264, 0.318, 0.215, 0.237, 0.149, 0.211, 0.091, 0.267, 0.057, 0.099, 0.161, 0.198, 0.370, 0.042, 0.103],'好瓜': ['是', '是', '是', '是', '是', '是', '是', '是', '否', '否', '否', '否', '否', '否', '否', '否', '否']
}
df = pd.DataFrame(data)# 定义离散和连续特征列名
discrete_cols = ['色泽', '根蒂', '敲声', '纹理', '脐部', '触感']
continuous_cols = ['密度', '含糖率']
target_col = '好瓜'# 2. 训练模型
# 计算先验概率 P(y)
prior_prob = df[target_col].value_counts(normalize=True).to_dict()# 计算离散特征的条件概率 P(xi|y) - 使用拉普拉斯平滑
cond_prob_discrete = {}
for feature in discrete_cols:cond_prob_discrete[feature] = {}# 获取该特征的所有可能取值possible_values = df[feature].unique()k = len(possible_values) for value in possible_values:cond_prob_discrete[feature][value] = {}for class_label in df[target_col].unique():# 获取目标类别的数据子集class_subset = df[df[target_col] == class_label]# 计算分子:(类别为y且特征为x的数量 + 1)count_feature_class = class_subset[class_subset[feature] == value].shape[0] + 1# 计算分母:(类别为y的数量 + k)count_class = class_subset.shape[0] + kcond_prob_discrete[feature][value][class_label] = count_feature_class / count_class# 计算连续特征的均值和标准差,按类别分组
mean_std_continuous = {}
for feature in continuous_cols:mean_std_continuous[feature] = {}for class_label in df[target_col].unique():class_subset = df[df[target_col] == class_label]# 计算均值和标准差 (使用 N-1 作为分母,即样本标准差)mean = class_subset[feature].mean()std = class_subset[feature].std()# 防止标准差为0 (如果某类下某个连续特征值都一样)if std == 0:std = 1e-6 mean_std_continuous[feature][class_label] = {'mean': mean, 'std': std}# 高斯概率密度函数
def gaussian_pdf(x, mean, std):exponent = math.exp(-((x - mean) ** 2 / (2 * std ** 2)))return (1 / (math.sqrt(2 * math.pi) * std)) * exponent# 3. 预测函数 (Prediction Function)
def predict_watermelon(test_data):scores = {}# 遍历每个类别 ('是', '否')for class_label in prior_prob.keys():# 初始化得分为该类别的先验概率 P(y)score = math.log(prior_prob[class_label])# 计算离散特征的条件概率连乘 (对数形式下为连加)for feature in discrete_cols:value = test_data[feature]if value in cond_prob_discrete[feature]:score += math.log(cond_prob_discrete[feature][value][class_label])else:score += math.log(1e-9) # 计算连续特征的高斯概率密度连乘 (对数形式下为连加)for feature in continuous_cols:x = test_data[feature]stats = mean_std_continuous[feature][class_label]pdf = gaussian_pdf(x, stats['mean'], stats['std'])if pdf > 0:score += math.log(pdf)else:score += math.log(1e-9)scores[class_label] = score# 返回得分最高的类别prediction = max(scores, key=scores.get)return prediction, scores# 4. 进行预测
test_sample = {'色泽': '青绿','根蒂': '蜷缩','敲声': '浊响','纹理': '清晰','脐部': '凹陷','触感': '硬滑','密度': 0.697,'含糖率': 0.460
}# 调用预测函数
prediction, scores = predict_watermelon(test_sample)print(f"\n测试样本: {test_sample}")
print(f"预测结果: {prediction}")
print(f"各类别的对数得分: {scores}")四、学习总结
通过学习,我清晰了整个朴素贝叶斯算法的运作流程:从训练数据中学习先验概率 P(y) 和所有特征的条件概率(或相关统计量)P(xi∣y),到预测阶段将这些概率(通常是以对数形式来保证数值稳定性)组合起来,计算出每个类别的最终得分,最后基于得分比较做出分类决策。
朴素贝叶斯算法的优点在于简单高效、对小数据集表现良好、对噪声鲁棒,适合快速建模场景(如西瓜预测和垃圾邮件分类)。但其缺点也很明显:特征独立性假设不现实、对数据分布敏感、分类能力有限。针对这些缺点,可通过特征工程、分布变换或模型改进提升性能。
相关文章:

【机器学习】朴素贝叶斯
目录 一、朴素贝叶斯的算法原理 1.1 定义 1.2 贝叶斯定理 1.3 条件独立性假设 二、朴素贝叶斯算法的几种常见类型 2.1 高斯朴素贝叶斯 (Gaussian Naive Bayes) 【训练阶段】 - 从数据中学习模型参数 【预测阶段】 - 对新样本 Xnew 进行分类 2. 2 多项式朴素贝叶斯 (…...

服务器硬件老化导致性能下降的排查与优化
随着企业数字化转型的深入,服务器作为IT基础设施的核心载体,其稳定性与性能直接影响业务连续性。然而,硬件老化导致的性能衰减问题普遍存在且易被忽视。本报告通过系统性分析服务器硬件老化现象,提出多维度排查方法与优化方案&…...

学习记录:DAY19
Docker 部署与项目需求分析 前言 人总是本能地恐惧未知,令生活陷入到经验主义的循环之中。但我们终将面对。今天的目标是把 Docker 部署学完,然后对项目进行需求分析。 日程 下午 4:30:Docker 部署项目部分学完了,做下笔记。晚…...

机器学习中的数据转换:关键步骤与最佳实践
机器学习中的数据转换:关键步骤与最佳实践 摘要 :在机器学习领域,数据是模型的核心,而数据的转换是构建高效、准确模型的关键步骤之一。本文深入探讨了机器学习中数据转换的重要性、常见的数据类型及其转换方法,以及在…...

【C++教程】三目运算符
C的三目运算符(条件运算符)是一种简洁的条件表达式工具,其形式为 条件 ? 表达式1 : 表达式2。以下是对其用法的详细总结: 1. 基本用法 条件判断:若条件为真,返回表达式1的值;否则返回表达式2…...

鼠标获取坐标 vs 相机获取坐标
Cesium鼠标点击获取坐标 vs 相机视角获取坐标 鼠标点击获取坐标流程图 #mermaid-svg-WwyCUbcFQekWG97C {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-WwyCUbcFQekWG97C .error-icon{fill:#552222;}#mermaid-svg-W…...

HarmonyOS SDK助力鸿蒙版今日水印相机,真实地址防护再升级
今日水印相机是一款真实记录"工作"和"生活"的水印拍照APP。作为专业的可信影像服务平台,今日水印相机依托时间、地点、身份三重数字水印技术,为企业和个人提供考勤打卡、外勤巡检、生活美好时刻记录等场景的可信存证服务。 面对虚拟…...

数组滑动窗口单调栈单调队列trick集【leetcode hot100 c++速查!!!】
文章目录 栈经典模版题-括号最小栈字符串解码每日温度柱状图的最大矩形 堆数组中的第k个最大元素前k个高频元素数据流中的中位数 数组最大子数组和合并区间轮转数组除自身以外数组的乘积 我们尝试将这三类问题放在一个专题中进行讨论,是因为它们有很多公共的部分。 …...

半监督学习与强化学习的结合:新兴的智能训练模式
📌 友情提示: 本文内容由银河易创AI(https://ai.eaigx.com)创作平台的gpt-4o-mini模型生成,旨在提供技术参考与灵感启发。文中观点或代码示例需结合实际情况验证,建议读者通过官方文档或实践进一步确认其准…...
)
C++ 可调用实体 (详解 一站式)
目录 可调用实体 函数对象 函数指针 成员函数指针 空指针的使用(了解) 可调用实体 讲到调用这个词,我们首先能够想到普通函数和函数指针,在学习了类与对象的基础知识后,还增加了成员函数,那么它们都被…...

架构师与高级工程师:职业差异与进阶之路
“学而不思则罔,思而不学则殆。”——孔子 解释:该名言强调了学习和思考的结合,对应文章中工程师若想晋升为架构师,不能仅满足于对工具的学习,还要深入探究事物本质,培养深度思考能力,体现了思…...

声纹监测技术在新能源汽车的应用场景解析
新能源汽车声纹监测技术可应用于多个场景,以下是详细解析: 故障诊断 电机系统故障检测:新能源汽车的电机在运行过程中会发出特定的声音。通过声纹监测技术,采集电机运行时的声音信号并进行分析,能够及时发现电机轴承磨…...

About why docker application mode taskmanager not down in time
Tips: docker flink application mode 当任务完成或者jobmanager cancel,则taskmanager会因为flink集群机制继续保留监听等待jobmanager发送任务命令,当超过大约6 mins,taskmanager便会自动exited退出。...
)
2025-4-27-C++ 学习 数组(2)
数组 2025-4-27-C 学习 数组(2)P2550 [AHOI2001] 彩票摇奖题目描述输入格式输出格式输入输出样例 #1输入 #1输出 #1 说明/提示题解代码 P2615 [NOIP 2015 提高组] 神奇的幻方题目背景题目描述输入格式输出格式输入输出样例 #1输入 #1输出 #1 输入输出样例…...

timerfd定时器时间轮定时器
目录 一、timerfd定时器 二、timerfd定时器代码演示 三、时间轮定时器 一、timerfd定时器 timerfd是一种通过文件描述符管理定时器的机制 #include <sys/timerfd.h> int timerfd_create(int clockid, int flags); 作用:创建定时器的文件描述符 返回值&…...

什么是数据中心代理IP?有哪些用途?
在海外代理IP的选择中,数据中心代理IP是一个热门选项。这些代理服务器为用户分配了非ISP(互联网服务提供商)提供的IP地址,而是由第三方云服务提供商所提供的,通常位于数据中心内的服务器上,由托管和云公司所…...

机器学习分类模型性能评估:应对类别不平衡的策略与指标
在机器学习的世界里,模型们就像一群努力破案的侦探,而数据就是它们的“犯罪现场”。今天,咱们的主角——一个自命不凡的分类模型,接到了一个看似简单的任务:揪出那些患有罕见疾病的患者。这听起来是不是很容易…...

论文导读 - 基于边缘计算、集成学习与传感器集群的便携式电子鼻系统
基于边缘计算、集成学习与传感器集群的便携式电子鼻系统 原论文地址:https://www.sciencedirect.com/science/article/abs/pii/S0925400522015684 引用此论文(GB/T 7714-2015): WANG T, WU Y, ZHANG Y, et al. Portable electr…...

Molex莫仕连接器:增强高级驾驶辅助系统,打造更安全的汽车
随着对先进、高耗电量的系统的需求日益增长,电气化进程不断加速,汽车行业正处于一个十字路口。现代汽车面临着关键挑战,即满足不断增长的电力需求,特别是高级驾驶辅助系统(ADAS)等关键技术的需求。 由于现今的汽车比以往需要更多的…...
)
[密码学实战]SDF之密钥管理类函数(二)
[密码学实战]SDF之密钥管理类函数(二) 一、标准解读:GM/T 0018-2023核心要求 1.1 SDF接口定位 安全边界:硬件密码设备与应用系统间的标准交互层 功能范畴: #mermaid-svg-af5D1B1iHx3K8vSU {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16…...

多实例情况下,实例名较长dbca失败
dbca创建数据库,但是失败,提示ORA-01158 看来千锤百炼的dbca脚本还是菜,直觉上讲不应该mount上,看一下Action 本地已存在多个实例且名称前缀类似,下一步应该分析dbca日志和实例的alert.log 改为 一个简短的实例名就…...

模电——PN结
一、铺垫 这篇文章将会吊打一切、只会从电子、电场力的角度来阐述PN结为啥会形成、和变薄、变厚;不再考虑空穴这种东西;——提出空穴的人,真不是东西 我敢打赌,全网,我的说法不一定对,但是绝对是唯一可以…...

c++11 : 特殊类设计
目录 一 设计一个类:只能在堆上创建对象 二 设计一个类:只能在栈上创建对象 三 设计一个类:不能被拷贝 四 设计一个类:不能被继承 五 设计一个类: 只能创建一个对象(单例模式) 六 饿汉和懒汉模式的对比 一 设计一个类…...

算法笔记.kruskal算法求最小生成树
题目:(来源:AcWing) 给定一个 n 个点 m 条边的无向图,图中可能存在重边和自环,边权可能为负数。 求最小生成树的树边权重之和,如果最小生成树不存在则输出 impossible。 给定一张边带权的无向…...

量子算法调试:Grover算法搜索空间压缩过程可视化方案
一、Grover算法核心原理回顾 Grover算法通过以下两步迭代实现搜索空间压缩: Oracle操作(相位翻转) 标记目标状态: Uω∣x⟩={−∣x⟩x=ω∣x⟩x≠ωUω∣x⟩={−∣x⟩∣x⟩x=ωx=ω 扩散操作(振幅放大) 执行反转平均操作: D=2∣s⟩⟨s∣−ID=2∣s⟩⟨s∣−I 其…...

零基础搭建AI作曲工具:基于Magenta/TensorFlow的交互式音乐生成系统
引言:当AI遇见莫扎特 “音乐是流动的建筑”,当人工智能开始理解音符间的数学规律,音乐创作正经历着前所未有的范式变革。本文将手把手教你构建一套智能作曲系统,不仅能够生成古典钢琴小品,还能实现巴洛克与爵士风格的…...

springboot项目文件上传到服务器本机,返回访问地址
文件上传到服务器本机,然后给出访问地址: 具体如下: 1、添加必要的工具类依赖 <!-- 文件上传工具类 --><dependency><groupId>commons-fileupload</groupId><artifactId>commons-fileupload</artifactId>…...

mysql community 8.0.23升级到8.0.42再到8.4.5
近日生产服务器准备正式试运行,数据进入客户的专有网络,于是甲方派了人过来测漏洞,结果扫出一大堆。其间关于mysql的漏洞300多个,吓死人。给出的补丁地址,打开来看,全部是英文,可能是一些什么测…...

ubuntu安装docker,conda,tmux,btop,nvitop
在 Ubuntu 上安装 Docker Engine (使用华为云源) 1. 更新系统软件包 sudo apt update sudo apt upgrade -y2. 安装必要的依赖包 sudo apt install -y \ca-certificates \curl \gnupg \lsb-release \git \vim \wget3. 添加 Docker 的 GPG 密钥 (来自华为云镜像) # 创建用于存…...

大模型在肝硬化腹水风险预测及临床方案制定中的应用研究
目录 一、引言 1.1 研究背景与意义 1.2 研究目的与创新点 1.3 研究方法与数据来源 二、肝硬化及大模型相关理论基础 2.1 肝硬化概述 2.2 大模型技术原理 2.3 大模型在医疗领域的应用现状 三、大模型预测肝硬化腹水术前风险 3.1 术前风险因素分析 3.2 大模型预测术前…...

孙宇晨将出席迪拜Token2049 与特朗普次子共话加密未来
据官方消息,波场TRON创始人孙宇晨将出席5月1日在迪拜举办的Token2049峰会上,并与特朗普次子埃里克特朗普(Eric Trump)进行一场备受瞩目的炉边对话,出席对话的人士还包括特朗普家族支持的去中心化金融项目WLFI(World Liberty Financial)的联合创始人Zach Witkoff。这场对话不仅彰…...
)
深入理解同源策略与跨域资源共享(CORS)
深入理解同源策略与跨域资源共享(CORS) 前言 在当今的 Web 开发中,跨域资源请求已成为常见需求。然而,浏览器的同源策略(Same-Origin Policy)作为最基础的安全机制,限制了不同源之间的资源交互…...

Vue 生命周期钩子总结
Vue 生命周期钩子总结 Vue 组件的生命周期钩子允许在组件不同阶段执行自定义逻辑。以下是各阶段的钩子函数及其用途、触发时机和注意事项: 1. 生命周期阶段概览 Vue 组件的生命周期分为四个主要阶段: 创建(Creation)࿱…...

【解决方案】Linux解决CUDA安装过程中GCC版本不兼容
Linux解决CUDA安装过程中GCC版本不兼容 目录 问题描述 解决方法 安装后配置 问题描述 Linux环境下安装 CUDA 时,运行sudo sh cuda_10.2.89_440.33.01_linux.run命令出现 “Failed to verify gcc version.” 的报错,提示 GCC 版本不兼容,查…...

网络准入控制系统推荐:2025年构建企业网络安全的第一道防线
随着信息技术的飞速发展,企业网络环境日益复杂,阳途网络准入控制系统作为一种先进的网络安全解决方案,其核心是确保网络接入的安全性。 一、网络准入控制系统的基本原理与功能 网络准入控制以“只有合法的用户、安全的终端才可以接入网络”为…...

AI Agent
李宏毅:从零开始搞懂 AI Agent - 知乎台大李宏毅2025 AI Agent新课来了! - 知乎读懂AI Agent:基于大模型的人工智能代理 - 知乎 1.什么是AI Agent 一个基于大模型的 AI Agent 系统可以拆分为大模型、规划、记忆与工具使用四个组 件部分。AI A…...

大模型如何应对内容安全:原理、挑战与技术路径探讨
随着大语言模型(LLM)技术的广泛应用,从AI写作助手到智能客服、再到生成式内容平台(AIGC),AI 正以前所未有的速度深入人类社会的各个角落。然而,随之而来的内容安全问题也日益凸显:模…...

Flinkcdc 实现 MySQL 写入 Doris
Flinkcdc 实现 MySQL 写入 Doris Flinkcdc 实现 MySQL 写入 Doris 一、环境配置 Doris:3.0.4 JDK 17 MySQL (业务数据库):5.7 MySQL(本地数据库):5.7 Flink:flink-1.19.1 flinkc…...

vim粘贴代码格式错乱 排版错乱 缩进错乱 解决方案
从IDE复制代码, 粘贴到vim打开的文件 出现以下格式错乱解决方案 在使用 Vim 编辑器粘贴代码时,出现格式错乱的问题,通常是因为 Vim 的自动缩进功能与粘贴的代码发生了冲突。Vim 默认会尝试对输入的内容进行自动缩进,这会导致粘贴的代码被错误…...
)
发那科机器人(基本操作、坐标系、I/O通信)
发那科机器人(基本操作、坐标系、I/O通信) 一,机器人基本操作1,坐标系种类2,机器人手动操作一关节运动3,机器人手动操作一直角运动二,坐标系建立1,工具坐标系建立原理及验证方法2,工具坐标系建立步骤3,用户坐标系建立原理及验证方法4,用户坐标系建立步骤三,I/O通信…...

GPU 架构入门笔记
引文位置:https://www.trainy.ai/blog/gpu-utilization-misleading 相关概念是通过 ChatGPT 迅速学习总结而成。 概念: GPU H100 GPU, with 144 SMs 每个 SM(streaming multiprocessors) 的架构: GPU Utilizati…...

centos7使用yum快速安装Docker环境
一、基础环境设置 1:关闭防火墙和内核安全机制 [rootlocalhost ~]# systemctl stop firewalld [rootlocalhost ~]# setenforce 02:配置网络yum源 [rootlocalhost ~]# curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Cento…...
)
解密面试高频题:加权轮询负载均衡算法 (Java 实现)
在分布式系统设计和面试中,负载均衡是一个绕不开的话题。而加权轮询(Weighted Round Robin, WRR)作为一种经典且实用的负载均衡策略,经常出现在笔试题和面试环节中。本文将带你深入理解 WRR 算法的原理,并探讨几种常见…...

Linux中的系统延时任务和定时任务与时间同步服务和构建时间同步服务器
延时任务 在系统中我们的维护工作大多数时在服务器行对闲置时进行 我们需要用延迟任务来解决自动进行的一次性的维护 延迟任务时一次性的,不会重复执行 当延迟任务产生输出后,这些输出会以邮件的形式发送给延迟任务发起者 在RHEL9中默认系统中的所有普通…...

高效运维,智慧监测:COMEM光纤温度测量系统在电力行业中的应用
在电力行业中,变压器的稳定运行对于整个电网的安全很重要。为了确保变压器的健康状态,实时、精确的温度监测成为了不可或缺的一环。COMEM光纤温度测量系统应运而生,为变压器的温度监测提供了创新的解决方案。 变压器温度监测的重要性 变压器在…...

TP5兼容达梦国产数据库
1.首先数据库安装,部署时需配置大小写不敏感 2.安装PHP达梦扩展,一定要是对应版本(兼容操作系统)的扩展,否则会出现各种报错。参考官方文档:https://eco.dameng.com/document/dm/zh-cn/app-dev/php_php_new…...

[leetcode]2302.统计得分小于k的子数组
1.题目 2.事例 3.数据规模 4.思路(滑动窗口) 4.1滑动窗口的定义 滑动窗口是一种在数组、字符串等序列数据结构上进行操作的算法技巧。以下是其定义及相关要素的详细介绍: 定义:滑动窗口可以理解为在一个序列上,用一…...

Linux网络编程:TCP多进程/多线程并发服务器详解
Linux网络编程:TCP多进程/多线程并发服务器详解 TCP并发服务器概述 在Linux网络编程中,TCP服务器主要有三种并发模型: 多进程模型:为每个客户端连接创建新进程多线程模型:为每个客户端连接创建新线程I/O多路复用&am…...

Nacos源码—1.Nacos服务注册发现分析二
大纲 1.客户端如何发起服务注册 发送服务心跳 2.服务端如何处理客户端的服务注册请求 3.注册服务—如何实现高并发支撑上百万服务注册 4.内存注册表—如何处理注册表的高并发读写冲突 2.服务端如何处理客户端的服务注册请求 (1)客户端自动发送服务注册请求梳理 (2)Nacos…...

设备指纹护航电商和金融反欺诈体系建设
众所周知,人的指纹具有唯一性,可以作为人的身份识别标识。对于设备而言,也有可以用于识别的特征。设备指纹是指可以用于唯一标识出某一设备的特征或者独特的设备标识,具有固定性、较难篡改性、唯一性等特质。 设备指纹是金融机构…...