光流法:从传统方法到深度学习方法
1 光流法简介
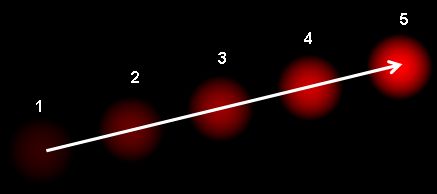
光流(Optical Flow)是指图像中像素灰度值随时间的变化而产生的运动场。 简单来说,它描述了图像中每个像素点的运动速度和方向。 光流法是一种通过分析图像序列中像素灰度值来计算光流的方法。对于图像数据计算出来的光流是一个二维向量场。比如Opencv官方给的示例图,该图中显示了一个连续运动的光点,箭头的方向表示光流的方向,箭头的大小表示光流的大小。有了光流场,我们就可以利用光流场来跟踪图像中的目标物体,就可以进行运动跟踪,目标检测,视频压缩,运动分割,三维重建等。
光流法基于以下基本假设:
- 亮度恒定:就是同一点随着时间的变化,其亮度不会发生改变。
- 小运动假设(Small Motion Assumption): 相邻帧之间的运动是微小的,足以进行线性近似。
假设每两帧画面之间的时间间隔为 Δ t \Delta t Δt,且运动很小,通过泰勒级数展开,有:
I ( x + Δ x , y + Δ y , t + Δ t ) = I ( x , y , t ) + ∂ I ∂ x Δ x + ∂ I ∂ y Δ y + ∂ I ∂ t Δ t + R ( x , y , t ) \begin{aligned} {\displaystyle I(x+\Delta x,y+\Delta y,t+\Delta t)=I(x,y,t)+{\frac {\partial I}{\partial x}}\Delta x+{\frac {\partial I}{\partial y}}\Delta y+{\frac {\partial I}{\partial t}}\Delta t+} R(x,y,t) \end{aligned} I(x+Δx,y+Δy,t+Δt)=I(x,y,t)+∂x∂IΔx+∂y∂IΔy+∂t∂IΔt+R(x,y,t)
其中, I ( x , y , t ) I(x, y, t) I(x,y,t) 表示图像在点 ( x , y ) (x, y) (x,y) 处的灰度值, t t t 表示时间, Δ x \Delta x Δx、 Δ y \Delta y Δy 和 Δ t \Delta t Δt 分别表示水平、垂直和时间上的位移, R ( x , y , t ) R(x, y, t) R(x,y,t) 表示泰勒级数展开的高阶项。根据光流法的基本假设,有:
I ( x + Δ x , y + Δ y , t + Δ t ) = I ( x , y , t ) I(x+\Delta x,y+\Delta y,t+\Delta t)=I(x,y,t) I(x+Δx,y+Δy,t+Δt)=I(x,y,t)
由于泰勒高阶项趋近于0,直接忽略,则有:
∂ I ∂ x Δ x + ∂ I ∂ y Δ y + ∂ I ∂ t Δ t = 0 {\displaystyle {\frac {\partial I}{\partial x}}\Delta x+{\frac {\partial I}{\partial y}}\Delta y+{\frac {\partial I}{\partial t}}\Delta t=0} ∂x∂IΔx+∂y∂IΔy+∂t∂IΔt=0
等价为:
∂ I ∂ x Δ x Δ t + ∂ I ∂ y Δ y Δ t + ∂ I ∂ t Δ t Δ t = 0 {\displaystyle {\frac {\partial I}{\partial x}}{\frac {\Delta x}{\Delta t}}+{\frac {\partial I}{\partial y}}{\frac {\Delta y}{\Delta t}}+{\frac {\partial I}{\partial t}}{\frac {\Delta t}{\Delta t}}=0} ∂x∂IΔtΔx+∂y∂IΔtΔy+∂t∂IΔtΔt=0
其中, Δ t \Delta t Δt 表示时间间隔, Δ x \Delta x Δx 和 Δ y \Delta y Δy 分别表示水平和垂直上的位移。则:
∂ I ∂ x V x + ∂ I ∂ y V y + ∂ I ∂ t = 0 {\displaystyle {\frac {\partial I}{\partial x}}V_{x}+{\frac {\partial I}{\partial y}}V_{y}+{\frac {\partial I}{\partial t}}=0} ∂x∂IVx+∂y∂IVy+∂t∂I=0
其中, V x V_x Vx 和 V y V_y Vy 分别表示光流在水平和垂直方向上的分量。则我们需要求解的问题为:
I x V x + I y V y = − I t {\displaystyle I_{x}V_{x}+I_{y}V_{y}=-I_{t}} IxVx+IyVy=−It
简化为:
∇ I T ⋅ V ⃗ = − I t {\displaystyle \nabla I^{T}\cdot {\vec {V}}=-I_{t}} ∇IT⋅V=−It
2 传统算法
2.1.1 Lucas-Kanade光流法
Lucas-Kanade 方法是一种广泛使用的光流估计微分方法,由 Bruce D. Lucas 和Takeo Kanade开发。该方法假设光流在所考虑像素的局部邻域中基本恒定,并根据最小二乘准则求解该邻域内所有像素的基本光流方程。
LK光流法基于以下假设:
- 小运动假设(Small Motion Assumption): 相邻帧之间的运动是微小的,足以进行线性近似。
- 亮度恒定:就是同一点随着时间的变化,其亮度不会发生改变。
- 空间一致性:场景中相同表面的相邻点具有相似的运动,并且其投影到图像平面上的距离也比较近。一个场景上邻近的点投影到图像上也是邻近点,且邻近点速度一致。
前两个假设是基于泰勒展开的,是所有传统光流法的基础。根据前两个假设,前面已经推导过需要求解:
∇ I T ⋅ V ⃗ = − I t {\displaystyle \nabla I^{T}\cdot {\vec {V}}=-I_{t}} ∇IT⋅V=−It
空间一致性假设(邻域光流相似假设)
针对第三个假设,我们可以假设在一个大小为 w × w w \times w w×w 的窗口内,所有像素点的光流都相同。则有:
I x ( q 1 ) V x + I y ( q 1 ) V y = − I t ( q 1 ) I x ( q 2 ) V x + I y ( q 2 ) V y = − I t ( q 2 ) ⋮ I x ( q n ) V x + I y ( q n ) V y = − I t ( q n ) {\displaystyle {\begin{aligned}I_{x}(q_{1})V_{x}+I_{y}(q_{1})V_{y}&=-I_{t}(q_{1})\\I_{x}(q_{2})V_{x}+I_{y}(q_{2})V_{y}&=-I_{t}(q_{2})\\&\;\ \vdots \\I_{x}(q_{n})V_{x}+I_{y}(q_{n})V_{y}&=-I_{t}(q_{n})\end{aligned}}} Ix(q1)Vx+Iy(q1)VyIx(q2)Vx+Iy(q2)VyIx(qn)Vx+Iy(qn)Vy=−It(q1)=−It(q2) ⋮=−It(qn)
其中, q 1 , q 2 , ⋯ , q n q_{1}, q_{2}, \cdots, q_{n} q1,q2,⋯,qn 表示窗口内的像素点, I x ( q ) I_{x}(q) Ix(q) 和 I y ( q ) I_{y}(q) Iy(q) 表示窗口内像素点的梯度, I t ( q ) I_{t}(q) It(q) 表示窗口内像素点灰度梯度。将该公式表示为矩阵形式为 A v = b {\displaystyle Av=b} Av=b:
A = [ I x ( q 1 ) I y ( q 1 ) I x ( q 2 ) I y ( q 2 ) ⋮ ⋮ I x ( q n ) I y ( q n ) ] v = [ V x V y ] b = [ − I t ( q 1 ) − I t ( q 2 ) ⋮ − I t ( q n ) ] {\displaystyle A={\begin{bmatrix}I_{x}(q_{1})&I_{y}(q_{1})\\[10pt]I_{x}(q_{2})&I_{y}(q_{2})\\[10pt]\vdots &\vdots \\[10pt]I_{x}(q_{n})&I_{y}(q_{n})\end{bmatrix}}\quad \quad \quad v={\begin{bmatrix}V_{x}\\[10pt]V_{y}\end{bmatrix}}\quad \quad \quad b={\begin{bmatrix}-I_{t}(q_{1})\\[10pt]-I_{t}(q_{2})\\[10pt]\vdots \\[10pt]-I_{t}(q_{n})\end{bmatrix}}} A= Ix(q1)Ix(q2)⋮Ix(qn)Iy(q1)Iy(q2)⋮Iy(qn) v= VxVy b= −It(q1)−It(q2)⋮−It(qn)
该系统方程组的数量多于未知数的数量,无法直接求解。因此,我们可以使用最小二乘来求解数值解,得到:
v = ( A T A ) − 1 A T b {\displaystyle v=\left(A^{T}A\right)^{-1}A^{T}b} v=(ATA)−1ATb
其矩阵形式为:
[ V x V y ] = [ ∑ i I x ( q i ) 2 ∑ i I x ( q i ) I y ( q i ) ∑ i I y ( q i ) I x ( q i ) ∑ i I y ( q i ) 2 ] − 1 [ − ∑ i I x ( q i ) I t ( q i ) − ∑ i I y ( q i ) I t ( q i ) ] {\displaystyle {\begin{bmatrix}V_{x}\\[10pt]V_{y}\end{bmatrix}}={\begin{bmatrix}\sum _{i}I_{x}(q_{i})^{2}&\sum _{i}I_{x}(q_{i})I_{y}(q_{i})\\[10pt]\sum _{i}I_{y}(q_{i})I_{x}(q_{i})&\sum _{i}I_{y}(q_{i})^{2}\end{bmatrix}}^{-1}{\begin{bmatrix}-\sum _{i}I_{x}(q_{i})I_{t}(q_{i})\\[10pt]-\sum _{i}I_{y}(q_{i})I_{t}(q_{i})\end{bmatrix}}} VxVy = ∑iIx(qi)2∑iIy(qi)Ix(qi)∑iIx(qi)Iy(qi)∑iIy(qi)2 −1 −∑iIx(qi)It(qi)−∑iIy(qi)It(qi)
为了方程 A T A v = A T b {\displaystyle A^{T}Av=A^{T}b} ATAv=ATb可解, A T A {\displaystyle A^{T}A} ATA应该是可逆的,或者 A T A {\displaystyle A^{T}A} ATA的特征值满足 λ 1 ≥ λ 2 > 0 {\displaystyle \lambda _{1}\geq \lambda _{2}>0} λ1≥λ2>0。为了避免噪音问题,通常 λ 2 {\displaystyle \lambda _{2}} λ2不能太小。另外,如果 λ 1 / λ 2 {\displaystyle \lambda _{1}/\lambda _{2}} λ1/λ2太大,这意味着点
页 p {\displaystyle p} p位于边缘,容易导致多孔径问题(即不同方向的光流观察到的结果一致,而无法确认光流的方向)。因此,为了使该方法正常工作,条件是 λ 1 {\displaystyle \lambda _{1}} λ1和 λ 2 {\displaystyle \lambda _{2}} λ2足够大且具有相似的量级。这个条件也是角点检测的条件。这项观察表明,通过检查单个图像,可以轻松判断哪个像素适合使用 Lucas-Kanade 方法。
算法改进
LK光流假设相同点在相邻帧画面中移动租足够小,但是在实际场景中很多时候光流是很大的,因此需要对LK光流法进行改进。其中一种改进方法就是引入图像金字塔的多尺度处理。使用图像金字塔改进 LK 光流算法的主要思想是:
- 解决大位移问题: 传统的 LK 光流算法基于小运动假设,当图像中存在大位移运动时,算法的精度会下降。 通过使用图像金字塔,可以将大位移运动分解为多个小位移运动,从而提高算法的精度。
- 由粗到精的策略: 首先在金字塔的顶层(低分辨率图像)估计光流,然后在金字塔的下一层(较高分辨率图像)对光流进行细化,以此类推,直到金字塔的底层(原始图像)。 这种由粗到精的策略可以有效地减少计算量,并提高算法的鲁棒性。
基本步骤为:
- 构建图像金字塔: 对连续的两帧图像分别构建图像金字塔。
- 初始化光流: 在金字塔的顶层,将光流初始化为零。
- 由粗到精的光流估计: 从金字塔的顶层开始,逐层向下进行光流估计和细化:
- 光流估计: 在当前层,使用 LK 光流算法估计光流。
- 光流上采样: 将当前层的光流上采样到下一层,作为下一层光流的初始值。
- 图像扭曲 (Warping): 使用当前层的光流对下一帧图像进行扭曲,使得两帧图像更加对齐。
- 光流细化: 在下一层,使用 LK 光流算法对光流进行细化。
- 重复步骤 3,直到金字塔的底层。
实践
import cv2
import numpy as npdef visualize_lk_optical_flow(video_path):"""使用金字塔 LK 光流算法预览视频的光流场。Args:video_path (str): 视频文件的路径。"""cap = cv2.VideoCapture(video_path)if not cap.isOpened():print(f"无法打开视频文件: {video_path}")returnret, old_frame = cap.read()if not ret:print("无法读取视频的第一帧。")returnold_gray = cv2.cvtColor(old_frame, cv2.COLOR_BGR2GRAY)# Shi-Tomasi 角点检测参数feature_params = dict(maxCorners=100,qualityLevel=0.3,minDistance=7,blockSize=7)# LK 光流参数lk_params = dict(winSize=(15, 15),maxLevel=2,criteria=(cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 0.03))# 创建随机颜色用于绘制轨迹color = np.random.randint(0, 255, (100, 3))# 检测 Shi-Tomasi 角点p0 = cv2.goodFeaturesToTrack(old_gray, mask=None, **feature_params)# 确保 p0 的数据类型和形状正确if p0 is not None:p0 = np.float32(p0)# 创建一个 mask 用于绘制光流轨迹mask = np.zeros_like(old_frame)while True:ret, frame = cap.read()if not ret:breakframe_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)# 计算光流if p0 is not None: # 确保有角点可以跟踪p1, st, err = cv2.calcOpticalFlowPyrLK(old_gray, frame_gray, p0, None, **lk_params)# 选择好的跟踪点if p1 is not None:good_new = p1[st == 1]good_old = p0[st == 1]# 绘制轨迹for i, (new, old) in enumerate(zip(good_new, good_old)):a, b = new.ravel()c, d = old.ravel()mask = cv2.line(mask, (int(a), int(b)), (int(c), int(d)), color[i].tolist(), 2)frame = cv2.circle(frame, (int(a), int(b)), 5, color[i].tolist(), -1)img = cv2.add(frame, mask)cv2.imshow('LK 光流', img)k = cv2.waitKey(30) & 0xffif k == 27:break# 更新前一帧和跟踪点old_gray = frame_gray.copy()p0 = good_new.reshape(-1, 1, 2)else:# 如果没有跟踪点,重新检测角点p0 = cv2.goodFeaturesToTrack(old_gray, mask=None, **feature_params)if p0 is not None:p0 = np.float32(p0)mask = np.zeros_like(old_frame) # 清空 maskcap.release()cv2.destroyAllWindows()if __name__ == "__main__":video_path = "B:/Code/TestForLearn/Src/PyTest/ImageProcess/videos/3.mp4" # 替换为你的视频文件路径visualize_lk_optical_flow(video_path)

2.1.2 Farneback光流法
Farneback光流法不同于LK光流法,其是基于特征点的稠密光流法,其基于图像金字塔和多尺度处理。 稠密光流意味着它为图像中的每个像素都计算一个运动矢量。 Farneback 算法特别之处在于它使用多项式展开来近似图像的局部邻域,从而估计运动。
Farneback 算法的核心思想是使用二次多项式来近似每个像素的局部邻域的亮度分布。 对于图像中的每个像素 (x, y),其邻域的亮度值 I(x, y) 可以用以下二次多项式表示:
I ( x , y ) ≈ x T ∗ A ∗ x + b T ∗ x + c I(x, y) ≈ x^T * A * x + b^T * x + c I(x,y)≈xT∗A∗x+bT∗x+c
- x = [ x , y ] T x = [x, y]^T x=[x,y]T是像素坐标的向量。
- A A A 是一个 2x2 的矩阵,表示二次项系数。
- b b b 是一个 2x1 的向量,表示一次项系数。
- c c c 是一个标量,表示常数项。
算法通过最小二乘法,在每个像素的局部邻域内,拟合这个二次多项式。 这就得到了每个像素的 A A A、 b b b 和 c c c。假设在时间 t t t 和 t + d t t + dt t+dt 的两个相邻帧中,同一个像素的亮度保持不变(亮度恒定假设)。 那么,对于时间 t t t 的像素 ( x , y ) (x, y) (x,y) 和时间 t + d t t + dt t+dt 的像素 ( x + d x , y + d y ) (x + dx, y + dy) (x+dx,y+dy),有:
I ( x , y , t ) = I ( x + d x , y + d y , t + d t ) I(x, y, t) = I(x + dx, y + dy, t + dt) I(x,y,t)=I(x+dx,y+dy,t+dt)
将这个假设应用到多项式展开中,并进行一系列数学推导(涉及泰勒展开和线性化),可以得到一个线性方程组,用于求解像素的运动矢量 ( d x , d y ) (dx, dy) (dx,dy)。 这个线性方程组可以表示为:
[ A 1 + A 2 ] ∗ d = − 0.5 ∗ ( b 1 − b 2 ) [A_1 + A_2] * d = -0.5 * (b_1 - b_2) [A1+A2]∗d=−0.5∗(b1−b2)
其中:
- A 1 A_1 A1 和 b 1 b_1 b1 是时间 t t t 的帧中像素 ( x , y ) (x, y) (x,y) 的多项式系数。
- A 2 A_2 A2 和 b 2 b_2 b2 是时间 t + d t t + dt t+dt 的帧中像素 ( x , y ) (x, y) (x,y) 的多项式系数。
- d = [ d x , d y ] T d = [dx, dy]^T d=[dx,dy]T 是运动矢量。
通过求解这个线性方程组,可以得到每个像素的运动矢量 ( d x , d y ) (dx, dy) (dx,dy),即光流。
实践
import cv2
import numpy as npdef visualize_farneback_optical_flow_to_mp4(video_path, output_mp4_path):"""使用 Farneback 光流算法预览视频的光流场,并将结果保存为 MP4 视频文件。Args:video_path (str): 视频文件的路径。output_mp4_path (str): 输出 MP4 文件的路径。"""cap = cv2.VideoCapture(video_path)if not cap.isOpened():print(f"无法打开视频文件: {video_path}")returnret, frame = cap.read()if not ret:print("无法读取视频的第一帧。")returnheight, width = frame.shape[:2]fps = cap.get(cv2.CAP_PROP_FPS)# 定义 VideoWriter 对象fourcc = cv2.VideoWriter_fourcc(*'mp4v') # 或使用 'XVID'out = cv2.VideoWriter(output_mp4_path, fourcc, fps, (width, height))prvs = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)hsv = np.zeros_like(frame)hsv[..., 1] = 255while True:ret, frame = cap.read()if not ret:breaknext = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)flow = cv2.calcOpticalFlowFarneback(prvs, next, None, 0.5, 3, 15, 3, 5, 1.2, 0)mag, ang = cv2.cartToPolar(flow[..., 0], flow[..., 1])hsv[..., 0] = ang * 180 / np.pi / 2hsv[..., 2] = cv2.normalize(mag, None, 0, 255, cv2.NORM_MINMAX)bgr = cv2.cvtColor(hsv, cv2.COLOR_HSV2BGR)out.write(bgr) # 写入帧到视频文件cv2.imshow('Farneback 光流', bgr)k = cv2.waitKey(30) & 0xffif k == 27:breakelif k == ord('s'):cv2.imwrite('opticalfb.png', frame)cv2.imwrite('opticalhsv.png', bgr)prvs = nextcap.release()out.release()cv2.destroyAllWindows()print(f"光流 MP4 已保存到: {output_mp4_path}")if __name__ == "__main__":video_path = "Src/PyTest/ImageProcess/videos/3.mp4" # 替换为你的视频文件路径output_mp4_path = "Src/PyTest/ImageProcess/videos/farneback_optical_flow.mp4" # 替换为你想保存 MP4 的路径visualize_farneback_optical_flow_to_mp4(video_path, output_mp4_path)
2.1.3 Horn光流法
Horn-Schunck 算法是一种全局光流估计方法,它试图在整个图像范围内最小化一个能量函数,以获得平滑且符合亮度恒定假设的光流场。 与局部方法(如 Lucas-Kanade)不同,Horn-Schunck 算法考虑了整个图像的全局信息,因此对噪声和光照变化具有更强的鲁棒性。
Horn算法假设整个图像的光流都是平滑的。因此,它会尽量减少光流的扭曲,并优先选择那些更平滑的解。该流被表述为一个全局能量函数,然后寻求最小化。对于二维图像流,该函数如下:
E = ∬ [ ( I x u + I y v + I t ) 2 + α 2 ( ∥ ∇ u ∥ 2 + ∥ ∇ v ∥ 2 ) ] d x d y {\displaystyle E=\iint \left[(I_{x}u+I_{y}v+I_{t})^{2}+\alpha ^{2}(\lVert \nabla u\rVert ^{2}+\lVert \nabla v\rVert ^{2})\right]{{\rm {d}}x{\rm {d}}y}} E=∬[(Ixu+Iyv+It)2+α2(∥∇u∥2+∥∇v∥2)]dxdy
- I x I_x Ix和 I y I_y Iy是图像的梯度。
- I t I_t It是时间导数。
- u u u和 v v v是光流场的分量。
- α \alpha α是平滑项的权重。
该函数可以通过求解相关的多维欧拉-拉格朗日方程来最小化。这些方程是:
∂ E ∂ u − ∂ ∂ x ∂ E ∂ u x − ∂ ∂ y ∂ E ∂ u y = 0 ∂ E ∂ v − ∂ ∂ x ∂ E ∂ v x − ∂ ∂ y ∂ E ∂ v y = 0 \begin{aligned} {\displaystyle {\frac {\partial E}{\partial u}}-{\frac {\partial }{\partial x}}{\frac {\partial E}{\partial u_{x}}}-{\frac {\partial }{\partial y}}{\frac {\partial E}{\partial u_{y}}}=0} \\ {\displaystyle {\frac {\partial E}{\partial v}}-{\frac {\partial }{\partial x}}{\frac {\partial E}{\partial v_{x}}}-{\frac {\partial }{\partial y}}{\frac {\partial E}{\partial v_{y}}}=0} \end{aligned} ∂u∂E−∂x∂∂ux∂E−∂y∂∂uy∂E=0∂v∂E−∂x∂∂vx∂E−∂y∂∂vy∂E=0
L {\displaystyle L} L是能量表达式的被积函数,得出
I x ( I x u + I y v + I t ) − α 2 Δ u = 0 I y ( I x u + I y v + I t ) − α 2 Δ v = 0 \begin{aligned} {\displaystyle I_{x}(I_{x}u+I_{y}v+I_{t})-\alpha ^{2}\Delta u=0}\\ {\displaystyle I_{y}(I_{x}u+I_{y}v+I_{t})-\alpha ^{2}\Delta v=0} \end{aligned} Ix(Ixu+Iyv+It)−α2Δu=0Iy(Ixu+Iyv+It)−α2Δv=0
在实践中,拉普拉斯算子可以用有限差分进行数值近似,可以写成 Δ u ( x , y ) = ( u ‾ ( x , y ) − u ( x , y ) ) {\displaystyle \Delta u(x,y)=({\overline {u}}(x,y)-u(x,y))} Δu(x,y)=(u(x,y)−u(x,y)), u ‾ ( x , y ) {\displaystyle {\overline {u}}(x,y)} u(x,y)是加权平均值 u {\displaystyle u} u在$位置 ( x , y ) (x,y) (x,y) 处像素周围的邻域内计算。使用这个符号,上述方程组可以写成
( I x 2 + α 2 ) u + I x I y v = α 2 u ‾ − I x I t I x I y u + ( I y 2 + α 2 ) v = α 2 v ‾ − I y I t \begin{aligned} {\displaystyle (I_{x}^{2}+\alpha ^{2})u+I_{x}I_{y}v=\alpha ^{2}{\overline {u}}-I_{x}I_{t}}\\ {\displaystyle I_{x}I_{y}u+(I_{y}^{2}+\alpha ^{2})v=\alpha ^{2}{\overline {v}}-I_{y}I_{t}} \end{aligned} (Ix2+α2)u+IxIyv=α2u−IxItIxIyu+(Iy2+α2)v=α2v−IyIt
这是线性的 u {\displaystyle u} u和 v {\displaystyle v} v并且可以针对图像中的每个像素进行求解。然而,由于解依赖于流场的相邻值,因此在更新相邻值后必须重复求解。以下迭代方案是利用克莱姆规则推导出来的:
u k + 1 = u ‾ k − I x ( I x u ‾ k + I y v ‾ k + I t ) α 2 + I x 2 + I y 2 v k + 1 = v ‾ k − I y ( I x u ‾ k + I y v ‾ k + I t ) α 2 + I x 2 + I y 2 \begin{aligned} {\displaystyle u^{k+1}={\overline {u}}^{k}-{\frac {I_{x}(I_{x}{\overline {u}}^{k}+I_{y}{\overline {v}}^{k}+I_{t})}{\alpha ^{2}+I_{x}^{2}+I_{y}^{2}}}}\\ {\displaystyle v^{k+1}={\overline {v}}^{k}-{\frac {I_{y}(I_{x}{\overline {u}}^{k}+I_{y}{\overline {v}}^{k}+I_{t})}{\alpha ^{2}+I_{x}^{2}+I_{y}^{2}}}} \end{aligned} uk+1=uk−α2+Ix2+Iy2Ix(Ixuk+Iyvk+It)vk+1=vk−α2+Ix2+Iy2Iy(Ixuk+Iyvk+It)
u ‾ k {\displaystyle {\overline {u}}^{k}} uk和 v ‾ k {\displaystyle {\overline {v}}^{k}} vk是 u {\displaystyle u} u和 v {\displaystyle v} v的平均值。
实践
import cv2
import numpy as np
from scipy.ndimage.filters import convolve as filter2
import os
from argparse import ArgumentParser"""
see readme for running instructions
"""def show_image(name, image):if image is None:returncv2.imshow(name, image)cv2.waitKey(0)cv2.destroyAllWindows()#compute magnitude in each 8 pixels. return magnitude average
def get_magnitude(u, v):scale = 3sum = 0.0counter = 0.0for i in range(0, u.shape[0], 8):for j in range(0, u.shape[1],8):counter += 1dy = v[i,j] * scaledx = u[i,j] * scalemagnitude = (dx**2 + dy**2)**0.5sum += magnitudemag_avg = sum / counterreturn mag_avgdef visualize_optical_flow(u, v, img):h, w = img.shape[:2]hsv = np.zeros((h, w, 3), dtype=np.uint8)magnitude, angle = cv2.cartToPolar(u, v)hsv[..., 0] = angle * 180 / np.pi / 2hsv[..., 1] = 255hsv[..., 2] = cv2.normalize(magnitude, None, 0, 255, cv2.NORM_MINMAX)bgr = cv2.cvtColor(hsv, cv2.COLOR_HSV2BGR)return bgr#compute derivatives of the image intensity values along the x, y, time
def get_derivatives(img1, img2):#derivative masksx_kernel = np.array([[-1, 1], [-1, 1]]) * 0.25y_kernel = np.array([[-1, -1], [1, 1]]) * 0.25t_kernel = np.ones((2, 2)) * 0.25fx = filter2(img1,x_kernel) + filter2(img2,x_kernel)fy = filter2(img1, y_kernel) + filter2(img2, y_kernel)ft = filter2(img1, -t_kernel) + filter2(img2, t_kernel)return [fx,fy, ft]#input: images name, smoothing parameter, tolerance
#output: images variations (flow vectors u, v)
#calculates u,v vectors and draw quiver
def computeHS(beforeImg, afterImg, alpha, delta):beforeImg = beforeImg.astype(float)afterImg = afterImg.astype(float)#removing noisebeforeImg = cv2.GaussianBlur(beforeImg, (5, 5), 0)afterImg = cv2.GaussianBlur(afterImg, (5, 5), 0)# set up initial valuesu = np.zeros((beforeImg.shape[0], beforeImg.shape[1]))v = np.zeros((beforeImg.shape[0], beforeImg.shape[1]))fx, fy, ft = get_derivatives(beforeImg, afterImg)avg_kernel = np.array([[1 / 12, 1 / 6, 1 / 12],[1 / 6, 0, 1 / 6],[1 / 12, 1 / 6, 1 / 12]], float)iter_counter = 0while True:iter_counter += 1u_avg = filter2(u, avg_kernel)v_avg = filter2(v, avg_kernel)p = fx * u_avg + fy * v_avg + ftd = 4 * alpha**2 + fx**2 + fy**2prev = uu = u_avg - fx * (p / d)v = v_avg - fy * (p / d)diff = np.linalg.norm(u - prev, 2)#converges check (at most 300 iterations)if diff < delta or iter_counter > 300:# print("iteration number: ", iter_counter)breakreturn [u, v]if __name__ == '__main__':# Input and output video pathsinput_video_path = "Src/PyTest/ImageProcess/videos/3.mp4" # 替换为你的视频文件路径output_video_path = "Src/PyTest/ImageProcess/videos/horn_schunck.mp4" # 替换为你想保存 MP4 的路径# Read the input videocap = cv2.VideoCapture(input_video_path)if not cap.isOpened():print(f"Error opening video stream or file: {input_video_path}")exit()# Get video propertiesframe_width = int(cap.get(3))frame_height = int(cap.get(4))frame_rate = cap.get(cv2.CAP_PROP_FPS)# Define the codec and create VideoWriter objectfourcc = cv2.VideoWriter_fourcc(*'mp4v')out = cv2.VideoWriter(output_video_path, fourcc, frame_rate, (frame_width, frame_height))# Read the first frameret, frame1 = cap.read()if not ret:print("Failed to read the first frame!")exit()prev_gray = cv2.cvtColor(frame1, cv2.COLOR_BGR2GRAY)# Process the video frame by framewhile(True):ret, frame2 = cap.read()if not ret:break# Convert to grayscalegray = cv2.cvtColor(frame2, cv2.COLOR_BGR2GRAY)# Compute Horn-Schunck optical flowalpha = 15delta = 10**-1u, v = computeHS(prev_gray, gray, alpha, delta)# Visualize the optical flowflow_vis = visualize_optical_flow(u, v, prev_gray)# Write the frame to the output videoout.write(flow_vis)# Display the resulting frame#cv2.imshow('Horn-Schunck Optical Flow', flow_vis)#if cv2.waitKey(1) & 0xFF == ord('q'):# break# Update the previous frameprev_gray = gray# Release video capture and writer objectscap.release()out.release()# Destroy all the windowscv2.destroyAllWindows()print(f"Video saved to {output_video_path}")
3 深度学习算法
深度学习相关的光流算法有很多,这里只简单介绍FlowNet。
3.1 FlowNet
FlowNet 是一个开创性的工作,它首次展示了使用卷积神经网络 (CNN) 直接学习光流估计的可行性。 在此之前,光流估计主要依赖于传统的优化方法,这些方法计算量大,速度慢。 FlowNet 的出现为光流估计领域带来了新的思路,并为后续的深度学习光流算法奠定了基础。
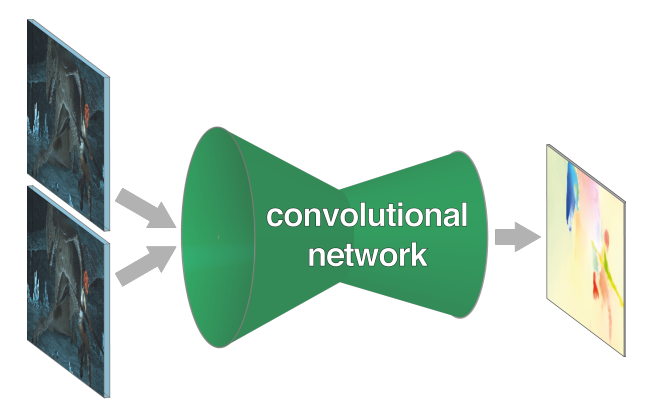
FlowNet 的核心思想是利用 CNN 强大的特征提取和学习能力,直接从图像数据中学习光流的模式。 通过大量的训练数据,CNN 可以学习到图像特征与光流之间的映射关系,从而实现快速且相对准确的光流估计。FlowNet 包含两个主要的变体:FlowNetS (Simple) 和 FlowNetC (Correlation)。
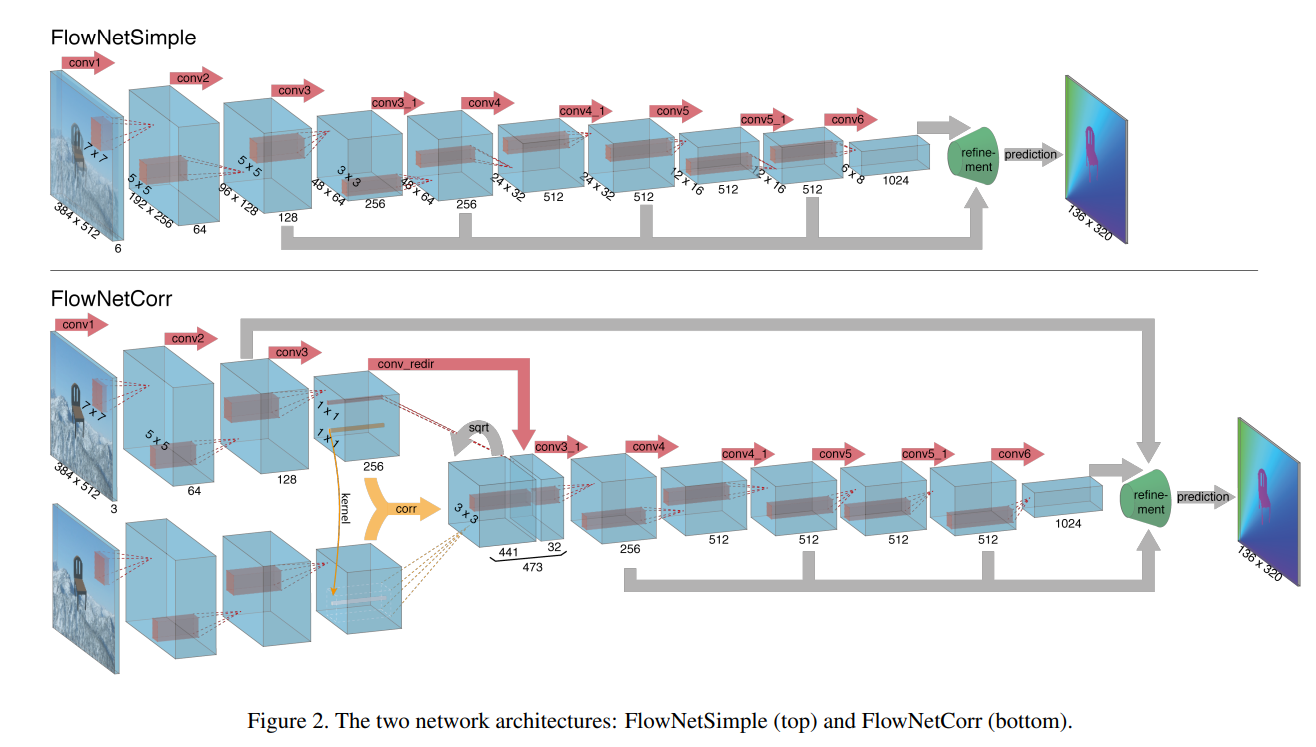
- FlowNetS (Simple):
- 输入: 将两张连续的图像 (I1, I2) 简单地堆叠在一起,形成一个 6 通道的输入。
- 网络结构: 一个标准的 CNN 结构,包含卷积层、池化层和全连接层。
- 输出: 光流场 (u, v),其中 u 和 v 分别表示水平和垂直方向上的运动矢量。
- 特点: 结构简单,易于实现,但精度相对较低。
- FlowNetC (Correlation):
- 输入: 两张连续的图像 (I1, I2) 分别经过一个 CNN 提取特征。
- 相关层 (Correlation Layer): 将两组特征进行相关性计算,得到一个相关性图 (correlation map)。 相关性图表示了 I1 中每个像素与 I2 中所有像素之间的相似度。
- 网络结构: 将相关性图与 I1 的特征图连接在一起,输入到一个 CNN 中。
- 输出: 光流场 (u, v)。
- 特点: 通过相关性计算,可以更好地匹配对应点,从而提高精度。
FlowNet 使用监督学习的方式进行训练,目标是最小化预测的光流场与真实光流场之间的误差。 常用的损失函数包括 L1 损失、L2 损失以及 EPE (End-Point Error)。EPE 是光流估计中最常用的评估指标之一,它衡量的是预测光流矢量与真实光流矢量之间的欧氏距离。 对于每个像素 (x, y),EPE 定义为:
E P E ( x , y ) = ∣ ∣ ( u p r e d ( x , y ) , v p r e d ( x , y ) ) − ( u g t ( x , y ) , v g t ( x , y ) ) ∣ ∣ 2 EPE(x, y) = || (u_{pred}(x, y), v_{pred}(x, y)) - (u_{gt}(x, y), v_{gt}(x, y)) ||_2 EPE(x,y)=∣∣(upred(x,y),vpred(x,y))−(ugt(x,y),vgt(x,y))∣∣2
其中, u p r e d ( x , y ) u_{pred}(x, y) upred(x,y) 和 v p r e d ( x , y ) v_{pred}(x, y) vpred(x,y) 是预测的光流场, u g t ( x , y ) u_{gt}(x, y) ugt(x,y) 和 v g t ( x , y ) v_{gt}(x, y) vgt(x,y) 是真实的光流场。
L1 损失是 EPE 的一种变体,它使用 L1 范数来衡量光流矢量之间的差异:
L 1 ( x , y ) = ∣ ∣ ( u p r e d ( x , y ) , v p r e d ( x , y ) ) − ( u g t ( x , y ) , v g t ( x , y ) ) ∣ ∣ 1 L1(x, y) = || (u_{pred}(x, y), v_{pred}(x, y)) - (u_{gt}(x, y), v_{gt}(x, y)) ||_1 L1(x,y)=∣∣(upred(x,y),vpred(x,y))−(ugt(x,y),vgt(x,y))∣∣1
L2 损失是 EPE 的另一种变体,它使用 L2 范数来衡量光流矢量之间的差异:
L 2 ( x , y ) = ∣ ∣ ( u p r e d ( x , y ) , v p r e d ( x , y ) ) − ( u g t ( x , y ) , v g t ( x , y ) ) ∣ ∣ 2 L2(x, y) = || (u_{pred}(x, y), v_{pred}(x, y)) - (u_{gt}(x, y), v_{gt}(x, y)) ||_2 L2(x,y)=∣∣(upred(x,y),vpred(x,y))−(ugt(x,y),vgt(x,y))∣∣2

FlowNet的优缺点:
- 优点:
- 速度快: 相对于传统的优化方法,FlowNet 的速度非常快,可以实现实时的光流估计。
- 端到端学习: FlowNet 可以直接从图像数据中学习光流,无需手动设计特征。
- 开创性: FlowNet 开创了深度学习光流估计的先河,为后续的研究奠定了基础。
- 缺点:
- 精度较低: 相对于传统的优化方法,FlowNet 的精度较低。
- 依赖于训练数据: FlowNet 的性能 сильно зависит от качества и количества обучающих данных。
- 泛化能力有限: FlowNet 在训练数据之外的场景中表现可能不佳。
4 总结
| 算法 | 原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| LK | 局部恒定性,小运动假设 | 计算简单,速度快,易于实现 | 对噪声敏感,对大位移估计差,容易受光照变化影响,依赖梯度信息 | 小运动场景,光照变化不大的场景,需要快速计算的场景 |
| Farnebäck | 多项式展开 | 对噪声具有一定的鲁棒性,可以处理一定程度的大位移 | 计算复杂度较高,对参数比较敏感 | 运动幅度较大的场景,需要较高精度的场景 |
| Horn-Schunck | 全局平滑性约束 | 可以生成平滑的光流场,对噪声具有一定的鲁棒性 | 计算复杂度高,速度慢,容易过度平滑,对光照变化敏感 | 需要平滑光流场的场景,对精度要求较高的场景 |
| 深度学习算法 | CNN 学习图像特征与光流之间的映射关系 | 速度快,精度高,可以处理复杂的场景 (遮挡、光照变化、运动模糊) | 需要大量的训练数据,对训练数据的质量要求高,泛化能力可能有限,计算资源消耗较大 | 需要高精度和高速度的场景,复杂的场景,例如自动驾驶、机器人和视频分析 |
5 参考文献
- Wiki-光流法
- 光流法–Lucas Kanade算法
- 计算机视觉的基本原理——光流法
- 光流法(optical flow methods)
- Wiki-Lucas-Kanade
- vSLAMNet(三)-光流法-LK光流法
- 经典光流算法 Farneback 原理与源码解析
- Horn–Schunck Optical Flow with a Multi-Scale Strategy
- 【回归本源】光流 - 传统算法
- FlowNet: Learning Optical Flow with Convolutional Networks
相关文章:

光流法:从传统方法到深度学习方法
1 光流法简介 光流(Optical Flow)是指图像中像素灰度值随时间的变化而产生的运动场。 简单来说,它描述了图像中每个像素点的运动速度和方向。 光流法是一种通过分析图像序列中像素灰度值来计算光流的方法。对于图像数据计算出来的光流是一个二…...

如何选择合适的RFID手持终端设备?
一、明确核心需求,锁定关键参数 选购RFID手持终端的首要任务是明确应用场景的核心需求。若用于仓储物流或零售盘点,推荐选择上海岳冉超高频RFID手持终端设备,支持1-20米远距离批量读取;若用于医疗耗材或图书管理,岳冉高…...

Axios 传参与 Spring Boot 接收参数完全指南
Axios 传参与 Spring Boot 接收参数完全指南 本文详细说明前端 Axios 传参与后端 Spring Boot 接收参数的各类场景,包括 GET/POST/PUT/DELETE 请求、路径参数/查询参数/请求体参数 的传递方式,以及如何接收 List、Map 等复杂类型。通过代码示例和对比表…...

NdrpPointerUnmarshallInternal函数分析之pStubMsg--pAllocAllNodesContext的由来
第一部分: // // Check if this is an allocate all nodes pointer AND that were // not already in an allocate all nodes context. // if ( ALLOCATE_ALL_NODES(pFormat[1]) && ! pStubMsg->pAllocAllNodesContext …...

人脑、深思考大模型与其他大模型的区别科普
文章目录 大模型的基本概念与特点深思考大模型的独特之处深思考大模型与其他大模型的对比架构与技术训练数据应用场景提示词编写 大模型给出答案的方式:基于概率还是真的会分析问题?人脑的思考过程基本单位与网络大脑结构与功能分区信息处理流程思维模式…...

Unity-粒子系统:萤火虫粒子特效效果及参数
萤火虫特效由两部分组成。萤火虫粒子底色粒子面片。萤火虫的旋转飞动主要由 Noise参数和Color over Lifetime模块控制。 贴图:中间实周边虚的圆,可随意自行制作 Shader:Universal Render Pipeline/2D/Sprite-Lit-Default 以下是粒子详细参…...

Java垃圾收集器与内存分配策略深度解析
在 Java 与 C 的世界里,内存动态分配与垃圾收集技术仿佛筑起了一道高墙。墙外的人渴望进入,享受自动内存管理的便利;而墙内的人却试图突破,追求更高的性能与控制力。今天,就让我们深入探讨 Java 的垃圾收集器与内存分配…...

优化MySQL性能:主从复制与读写分离实践指南
目录 一、知识介绍 1.MySQL主从复制原理 2.MySQL读写分离原理 二、资源清单 三、案例实施 1.修改主机名 2.搭建MySQL主从复制 3.搭建MySQL读写分离 一、知识介绍 1.MySQL主从复制原理 MySQL支持的复制类型 基于语句的复制基于行的复制混合模型复制 工作过程 主&#…...

Foupk3systemX5OS系统产品设备
Foupk3systemX5OS TXW8(基于Foupk3systemX5OS系统19.62正式版开发的智能移动设备由Foupk3systemX5OS系统与FOUPK3云服务平台共同自主研发) Foupk3systemX5OS TX6(Foupk3systemX5OS TX6基于Foupk3systemX5OS系统19.60正式版开发的智能平板设备…...

【计网】认识跨域,及其在go中通过注册CORS中间件解决跨域方案,go-zero、gin
一、跨域(CORS)是什么? 跨域,指的是浏览器出于安全限制,前端页面在访问不同源(协议、域名、端口任一不同)的后端接口时,会被浏览器拦截。 比如: 前端地址后端接口地址是…...

关于 【Spring Boot Configuration Annotation Processor 未配置问题】 的详细分析、解决方案及代码示例
以下是关于 Spring Boot Configuration Annotation Processor 未配置问题 的详细分析、解决方案及代码示例: 1. 问题描述 当使用 Spring Boot 的配置注解(如 ConfigurationProperties、Value、ConditionalOnProperty 等)时,若未…...

MySQL 的ANALYZE与 OPTIMIZE命令
MySQL 的ANALYZE与 OPTIMIZE命令 一、ANALYZE TABLE - 更新统计信息 1. 基本语法与功能 ANALYZE [NO_WRITE_TO_BINLOG | LOCAL] TABLE tbl_name [, tbl_name] ...作用:收集表统计信息用于优化器生成更优的执行计划,主要更新: 索引基数&am…...

【机器学习】人工智能在电力电子领域的应用
摘要: 本文概述了电力电子系统的人工智能 (AI) 应用。设计、控制和维护这三个独特的生命周期阶段与人工智能要解决的一项或多项任务相关,包括优化、分类、回归和数据结构探索。讨论了专家系统、模糊逻辑、元启发法和机器学习四类人工智能的应用。我们对…...

InferType和_checked_type的区别?
在 TVM 的 Relay IR 中,relay.frontend.common.infer_shape(node) 和 node.checked_type.shape 都与**形状(Shape)**信息相关,但它们的用途、实现机制和性能特点有显著区别。以下是详细对比: 1. 功能区别 特性node.ch…...

Flutter 学习之旅 之 flutter 作为 module ,在 Android 端主动唤起 Flutter 开发的界面 简单的整理
Flutter 学习之旅 之 flutter 作为 module ,在 Android 端主动唤起 Flutter 开发的界面 简单的整理 目录 Flutter 学习之旅 之 flutter 作为 module ,在 Android 端主动唤起 Flutter 开发的界面 简单的整理 一、简单介绍 二、Android 端唤起 Flutter …...

vue3 css模拟语音通话不同语音、正在加载等的效果
实现效果如下: 在不同的时间,显示不一样的效果(大小是一样的,截图时尺寸发生了变化) 具体实现代码如下: <script setup> import {ref} from "vue";const max_hight ref(40px) const min…...

【Machine Learning Q and AI 读书笔记】- 01 嵌入、潜空间和表征
Machine Learning Q and AI 中文译名 大模型技术30讲,主要总结了大模型相关的技术要点,结合学术和工程化,对LLM从业者来说,是一份非常好的学习实践技术地图. 本文是Machine Learning Q and AI 读书笔记的第1篇,对应原…...

[Agent]AI Agent入门02——ReAct 基本理论与实战
ReAct介绍 ReAct(Reasoning and Acting)是一种通过协同推理(Reasoning)与行动(Acting)提升大语言模型(LLM)任务解决能力的技术。其核心思想是在解决复杂问题时交替生成推理和动作&a…...
,兼容h5))
uniapp自定义头部(兼容微信小程序(胶囊和状态栏),兼容h5)
很早之前就写过自定义头部,但是那时偷懒写死了,现在用插槽重新写了个 有两种形式: type1是完全自定义的,可以自己去组件改也可以用插槽改 type2是正常的返回标题和右边按钮,使用就是 title"标题" rightClic…...

mybatis的xml ${item}总是更新失败
场景 代码如下 void updateStatus(Param("deviceSerialIdCollection") Collection<String> deviceSerialIdCollection, Param("status") Integer status);<update id"updateStatus">UPDATE gb_monitor SET online#{status} WHERE d…...

数据库- JDBC
标题目录 JDBC基本概念JDBC 接口JDBC 工作原理 JDBC APIJDBC工作过程Driver 接口及驱动加载Connection 接口Statemen 接口ResultSet 接口PreparedStatement 接口 JDBC 基本概念 Java Database Connectivity:java访问数据库的解决方案希望用相同的方式访问不同的数…...

[26] cuda 应用之 nppi 实现图像格式转换
[26] cuda 应用之 nppi 实现图像格式转换 讲述 nppi 接口定义通过nppi实现 bayer 格式转rgb格式官网参考信息:http://gwmodel.whu.edu.cn/docs/CUDA/npp/group__image__color__debayer.html#details1. 接口定义 官网关于转换的原理是这么写的: Grayscale Color Filter Array …...

MYSQL-OCP官方课程学习截图
第一节 介绍...

医院信息管理系统全解析
目录 一、医院信息管理系统是什么 1. 概念阐释 2. 核心功能概述 二、医院信息管理系统的种类 1. 医院信息系统(HIS) 2. 电子病历系统(EMR) 3. 实验室信息管理系统(LIS) 三、医院信息管理系统的实际…...
:技术解析与生态发展)
模型上下文协议(MCP):技术解析与生态发展
一、概念与目标 模型上下文协议(Model Context Protocol,MCP)是由Anthropic于2024年11月推出的开源协议,旨在为大语言模型(LLM)与外部工具、数据源提供标准化的双向通信框架。其核心目标是打破数据孤岛&am…...

laravel中layui的table翻页不起作用问题的解决
本地测试是好的,部署的时候就发现,翻页不起作用了。但lay_num序号是可以变化的,查看api接口传递的数据,发现数据没有变化,加上page2等翻页,也是不起作用,看来是url参数返回给后台,后…...

python上测试neo4j库
安装完了neo4j库后,如何使用。用python来小试牛刀 1.从其他博客上找来demo #coding:utf-8 from py2neo import Graph,Node,Relationship##连接neo4j数据库,输入地址、用户名、密码 graph Graph(bolt://xx.xx.xx.xx:7687,userneo4j,passwordneo4j1234)…...

云原生周刊:Kubernetes v1.33 正式发布
开源项目推荐 Robusta Robusta 是一个开源的 K8s 可观测性与自动化平台,旨在增强 Prometheus 告警的智能化处理能力。它通过规则和 AI 技术对告警进行丰富化处理,自动附加相关的 Pod 日志、图表和可能的修复建议,支持智能分组、自动修复和高…...

网络安全入门综述
引言 在数字化时代,网络安全(Cybersecurity)已成为保护个人、企业和政府机构免受数字威胁的关键领域。随着互联网的普及、云计算的兴起以及物联网(IoT)设备的激增,网络攻击的频率和复杂性不断增加。从数据…...
)
LLaMA-Factory部署以及大模型的训练(细节+新手向)
LLaMA-Factory 经过一段时间的探索,从手动编写训练代码到寻求框架辅助训练,遇到了各种各样的问题。前面我介绍了dify的部署,但是并没有详细介绍使用方式,是因为我在尝试利用dify的时候碰到了很多困难,总结下来首先就是…...

ASP.NET MVC 入门指南四
21. 高级路由配置 21.1 自定义路由约束 除了使用默认的路由约束,你还可以创建自定义路由约束。自定义路由约束允许你根据特定的业务逻辑来决定一个路由是否匹配。例如,创建一个只允许特定年份的路由约束: csharp public class YearRouteCo…...

rabbitmq-集群部署
场景:单个pod,部署在主节点,基础版没有插件,进阶版多了一个插件 基础版本: --- apiVersion: v1 kind: PersistentVolume metadata:name: rabbitmq-pv spec:capacity:storage: 5GiaccessModes:- ReadWriteOncestorage…...

明远智睿SSD2351开发板:开启工业控制新征程
在工业控制领域,对开发板的性能、稳定性和扩展性有着极高的要求。明远智睿的SSD2351开发板凭借其卓越的特性,为工业控制带来了全新的解决方案。 SSD2351开发板搭载四核1.4GHz处理器,强大的运算能力使其在处理工业控制中的复杂任务时游刃有余。…...
GD32VF103 MCU架构了解)
RISCV学习(5)GD32VF103 MCU架构了解
RISCV学习(5)GD32VF103 MCU架构了解 1、芯片内核功能简介 GD32VF103 MCU架构,采用Bumblebee内核,芯来科技(Nuclei System Technology)与台湾晶心科技(Andes Technology)联合开发&am…...

IDEA2022.3开启热部署
1、开启IDEA的自动编译 1.1 具体步骤:打开顶部工具栏 File -> Settings -> Build,Execution,Deployment -> Compiler 然后勾选 Build project automatically 。 1.2 打开顶部工具栏 File -> Settings -> Advanced Settings -> Compiler -> 然…...

《算法吞噬幻想乡:GPT-4o引发的艺术平权运动与版权核爆》
一、引言:现象级AI艺术事件的社会回响 GPT - 4o吉卜力风格刷屏现象 在当今数字化浪潮中,GPT - 4o吉卜力风格的作品在网络上掀起了一阵刷屏热潮。吉卜力工作室以其独特的水彩质感、奇幻氛围和孤独美学,在全球范围内拥有大量粉丝。而GPT - 4o强…...

yolov5 源码 +jupyter notebook 笔记 kaggle
YOLOv5 | Kaggle 直接用的githuab的源码,git clone 后output才有文件 直接gitclone他的源码用Vscode看 好久没见过16g了 怎么这么便宜 https://gadgetversus.com/graphics-card/nvidia-tesla-p100-pcie-16gb-vs-nvidia-geforce-rtx-4060/#google_vignette 好的&am…...

聊天室系统:多任务版TCP服务端程序开发详细代码解释
1. 需求 目前我们开发的TCP服务端程序只能服务于一个客户端,如何开发一个多任务版的TCP服务端程序能够服务于多个客户端呢? 完成多任务,可以使用线程,比进程更加节省内存资源。 2. 具体实现步骤 编写一个TCP服务端程序,循环等…...
迭代器和生成器)
Python(15)迭代器和生成器
在 Python 编程领域中,迭代器和生成器是两个强大且独特的概念,它们为处理数据序列提供了高效且灵活的方式。这篇博客将结合菜鸟教程内容,通过丰富的代码示例,深入学习 Python3 中的迭代器与生成器知识,方便日后复习回顾…...

无刷空心杯电机及机器人灵巧手的技术解析与发展趋势
一、无刷空心杯电机结构与技术解析 1. 核心结构设计 无刷空心杯电机的核心设计突破在于无铁芯转子与电子换向系统的结合。其结构由以下关键部分构成: 定子组件:采用印刷电路板(PCB)或柔性电路板(FPC)作为绕组载体,通过三维绕线技术形成空心杯状绕组,彻底消除齿槽效应…...

如何修复卡在恢复模式下的 iPhone:简短指南
Apple 建议使用恢复模式作为最后的手段,以便在 iPhone 启动循环或显示 Apple 标志时恢复 iPhone。这是解决持续问题的简单方法,但您很少使用。但是,当您的 iPhone 卡住恢复模式本身时,您会怎么做?虽然 iPhone 卡在这种…...

蒋新松:中国机器人之父
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 蒋新松:中国机器人之父 一、生平简介 1. 早年经历与求学道路 蒋新松出生…...

[Windows] MousePlus 5.5.9
[Windows] MousePlus 链接:https://pan.xunlei.com/s/VOOwKJ281kDaZV5_MpP1COd_A1?pwdn69c# MousePlus是一款轻便小巧的鼠标右键增强工具,使用鼠标右键拖动即可唤醒鼠标轮盘,这个功能界面和quicker的轮盘软件界面一样,操作逻辑…...

BT131-ASEMI无人机专用功率器件BT131
编辑:ll BT131-ASEMI无人机专用功率器件BT131 型号:BT131 品牌:ASEMI 封装:TO-92 批号:最新 引脚数量:3 特性:双向可控硅 工作温度:-40℃~150℃ 在智能化浪潮中,…...

ETL架构、数据建模及性能优化实践
ETL(Extract, Transform, Load)和数据建模是构建高性能数据仓库的核心环节。下面从架构设计、详细设计、数据建模方法和最佳实践等方面系统阐述如何优化性能。 一、ETL架构设计优化 1. 分层架构设计 核心分层: 数据源层:对接O…...

30分钟上架鸿蒙原生应用,即时通信IM UI组件库全面适配HarmonyOS 原
自去年 10 月 8 日鸿蒙5开启公测以来,鸿蒙操作系统不断迭代,生态趋向稳健。当前,支持HarmonyOS操作系统的设备数量已超过 10 亿,上架HarmonyOS 5 应用市场的鸿蒙原生应用和元服务已超过2万个。这无疑为广大开发者提供了丰富的应用…...

【虚幻5蓝图Editor Utility Widget:创建高效模型材质自动匹配和资产管理工具,从3DMax到Unreal和Unity引擎_系列第二篇】
虚幻5蓝图Editor Utility Widget 一、基础框架搭建背景:1. 创建Editor Utility Widget2.根控件选择窗口3.界面功能定位与阶段4.查看继承树5.目标效果 二、模块化设计流程1.材质替换核心流程:2.完整代码如下 三、可视化界面UI布局1. 添加标题栏2. 构建滚动…...
)
机器学习第三篇 模型评估(交叉验证)
Sklearn:可以做数据预处理、分类、回归、聚类,不能做神经网络。原始的工具包文档:scikit-learn: machine learning in Python — scikit-learn 1.6.1 documentation数据集:使用的是MNIST手写数字识别技术,大小为70000,数据类型为7…...

php数据库连接
前言 最近在学习php,刚好学习到了php连接数据库记录一下 总结 //1、与mysql建立连接$conn mysql_connect("127.0.0.1","root","root");//设置编码mysql_set_charset(utf8);//2、选择要操作的数据库mysql_select_db("xuesheng…...

Android Studio学习记录1
Android Studio打包APK 本文为个人学习记录,仅供参考,如有错误请指出。本文主要记录在Android Studio中开发时遇到的问题和回答。 随着学习的深入,项目完成并通过测试之后免不了需要进入打包环节。这篇文章主要记录一下尝试打包APK的过程。我…...