ubantu18.04(Hadoop3.1.3)之Flink安装与编程实践(Flink1.9.1)

说明:本文图片较多,耐心等待加载。(建议用电脑)
注意所有打开的文件都要记得保存。
第一步:准备工作
本文是在之前Hadoop搭建完集群环境后继续进行的,因此需要读者完成我之前教程的所有操作。
注意本次实验需要你的虚拟机内存大于4G,硬盘内存大于20G
如果没有满足条件,请到我的ubantu虚拟机专栏里进行扩容操作
以下所有操作均在Master主机进行。
第二步:安装Flink
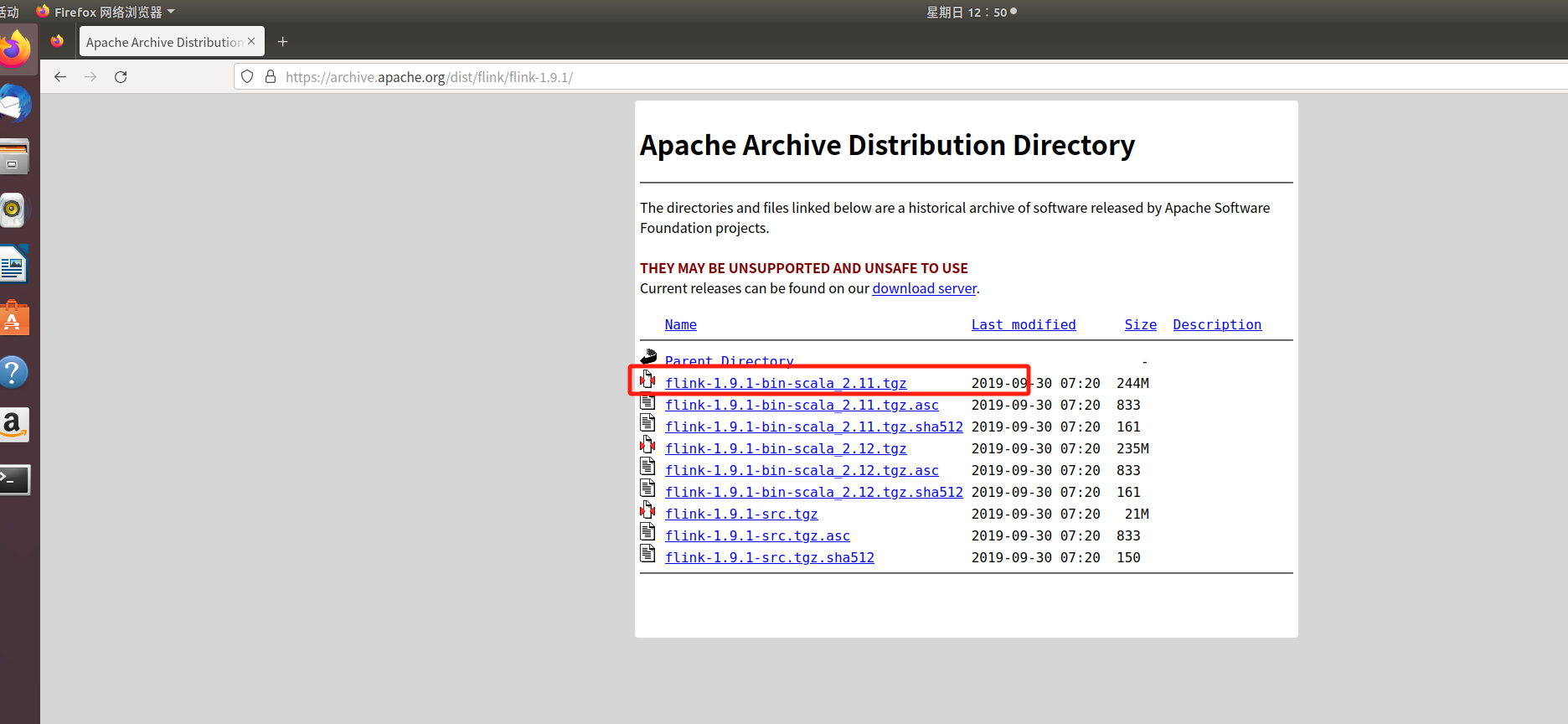
大家直接在虚拟机打开浏览器复制下面的地址,点击下载
Index of /dist/flink/flink-1.9.1
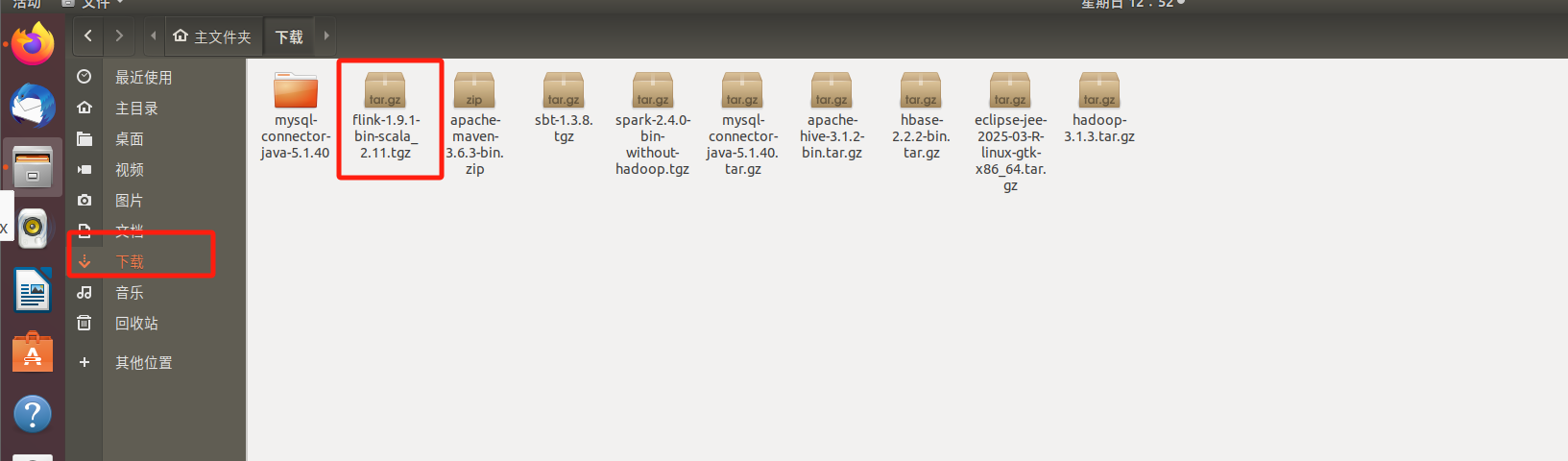
然后我们打开终端输入以下命令:
cd ~/下载
sudo tar -zxvf flink-1.9.1-bin-scala_2.11.tgz -C /usr/local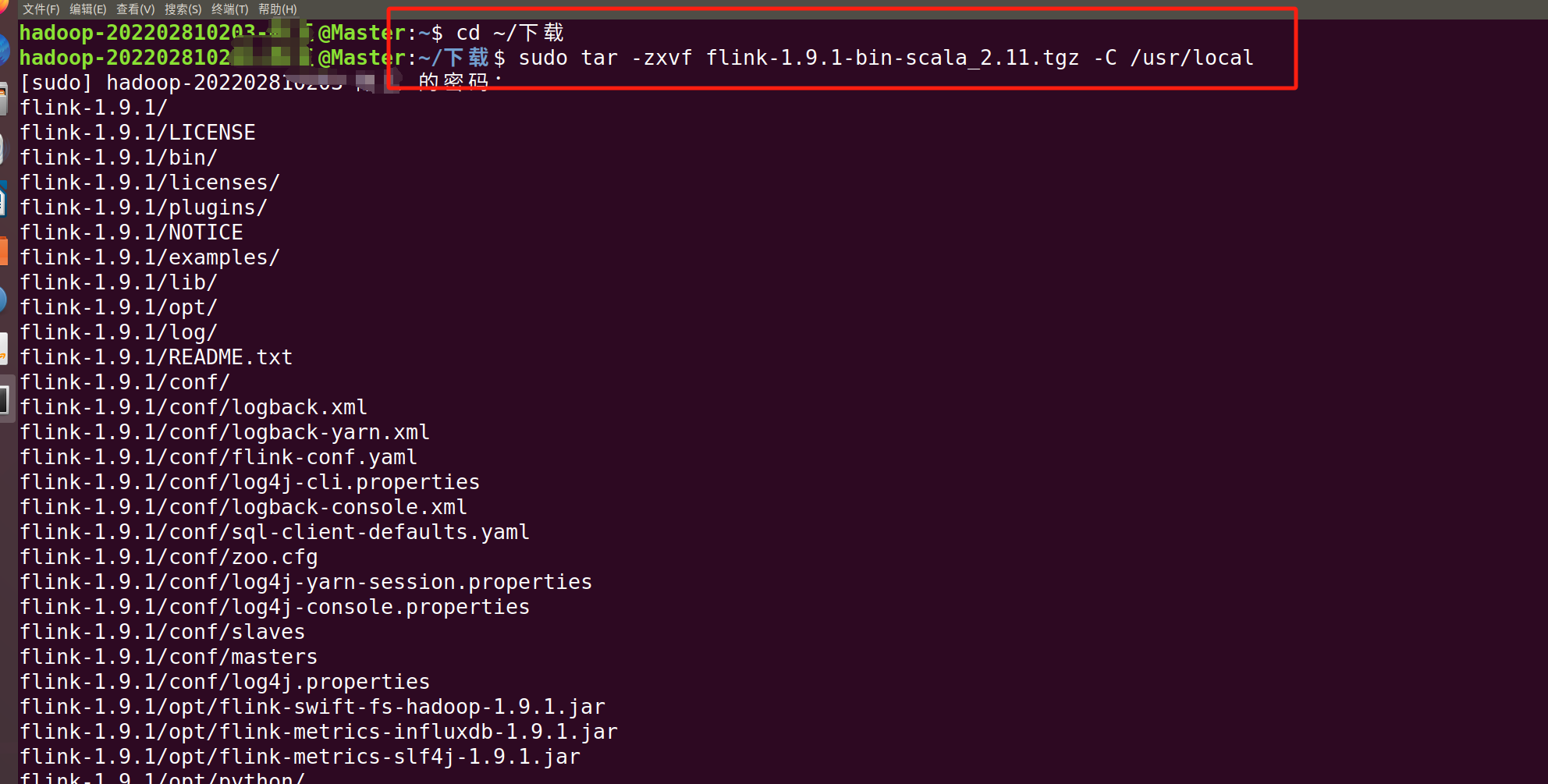
继续在终端输入以下命令:(注意下面的hadoop是你自己的用户名)
cd /usr/local
sudo mv ./flink-1.9.1 ./flink
sudo chown -R hadoop:hadoop ./flink
继续在终端输入以下命令:
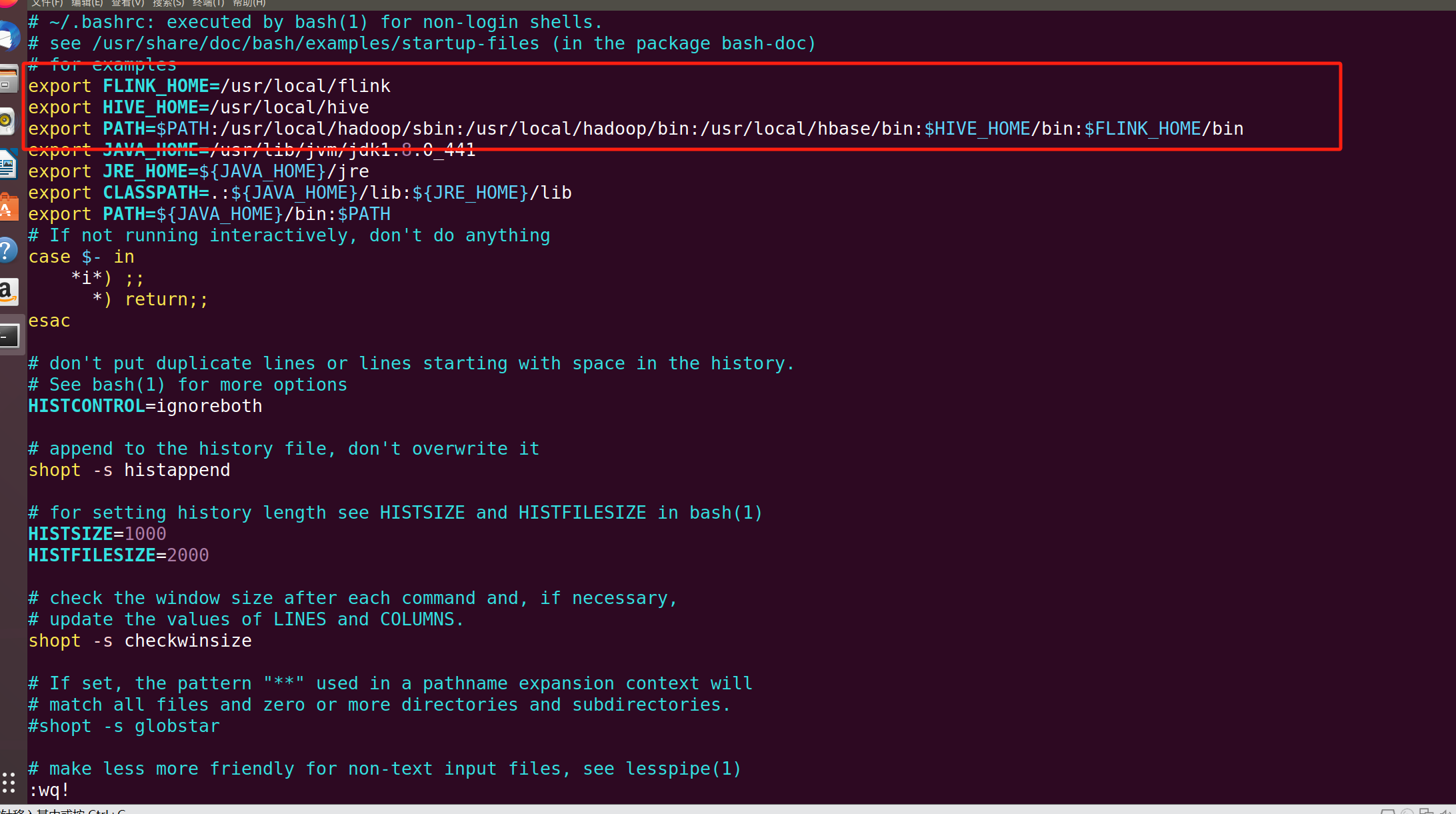
vim ~/.bashrc将之前的内容改为:
export FLINK_HOME=/usr/local/flink
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:/usr/local/hadoop/sbin:/usr/local/hadoop/bin:/usr/local/hbase/bin:$HIVE_HOME/bin:$FLINK_HOME/bin
继续在终端输入以下命令:
source ~/.bashrc
使用如下命令启动Flink:
cd /usr/local/flink
./bin/start-cluster.sh 使用jps命令查看进程:
使用jps命令查看进程:
出现以下内容即为成功。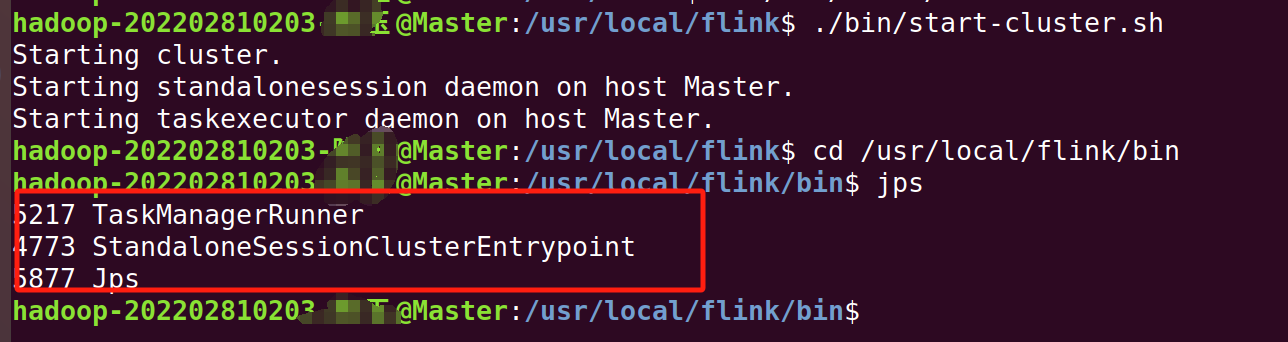
Flink安装包中自带了测试样例,这里可以运行WordCount样例程序来测试Flink的运行效果,具体命令如下:
cd /usr/local/flink/bin
./flink run /usr/local/flink/examples/batch/WordCount.jar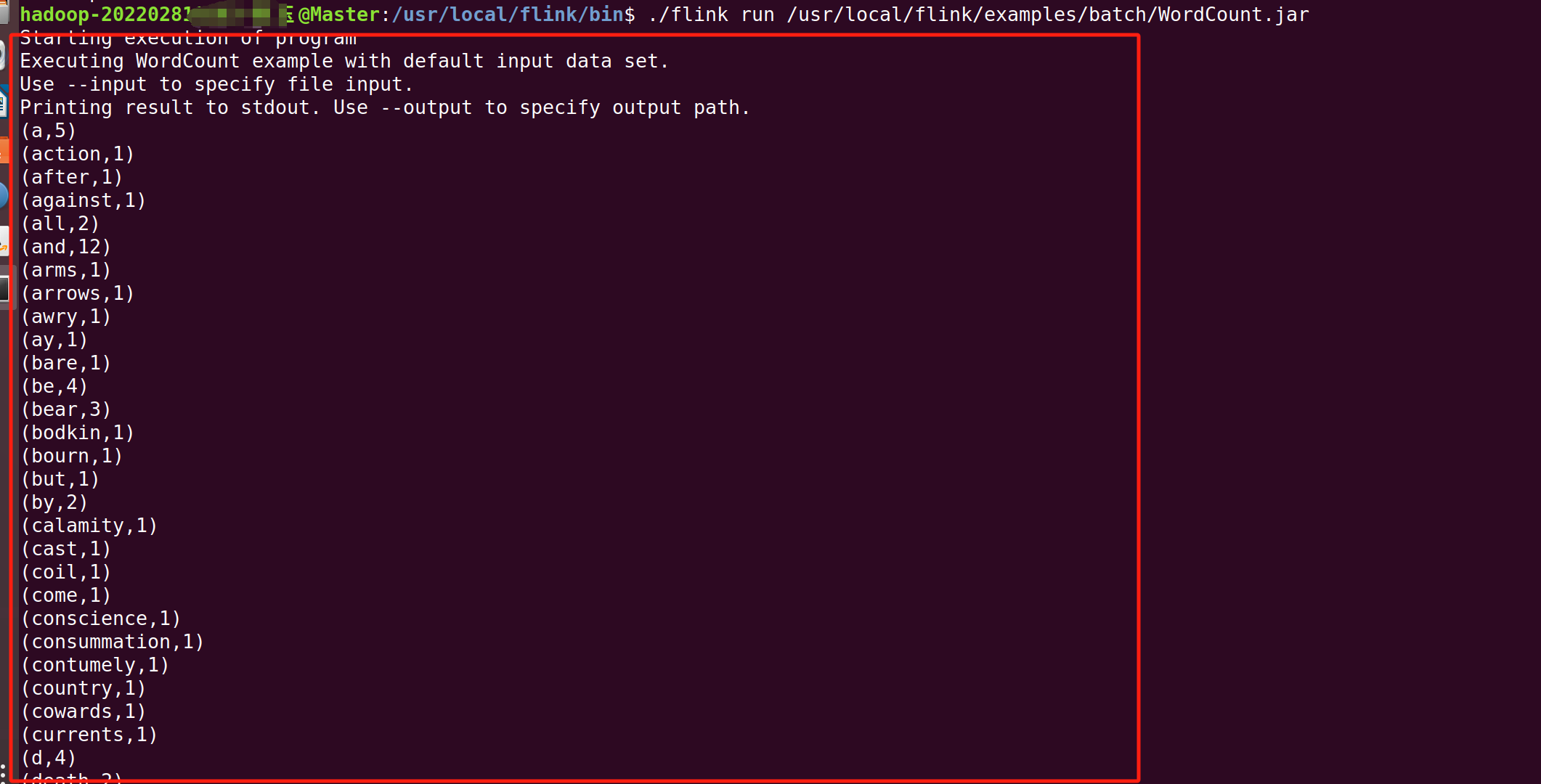 出现以上内容即为成功。
出现以上内容即为成功。
第二步:编程实现WordCount程序
1. 安装Maven
我们之前已经安装过了,这里就不说了,上一章已经搞过了。这里就不需要重新搞了
2. 编写代码
继续在终端输入:
cd ~ #进入用户主文件夹
mkdir -p ./flinkapp/src/main/java 继续在终端输入:
继续在终端输入:
cd /usr/local/flinkapp/src/main/java
vim WordCountData.java
在文本内添加以下内容:
package cn.edu.xmu;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;public class WordCountData {
public static final String[] WORDS = new String[]{
"To be, or not to be,--that is the question:--",
"Whether 'tis nobler in the mind to suffer",
"The slings and arrows of outrageous fortune",
"Or to take arms against a sea of troubles,",
"And by opposing end them?--To die,--to sleep,--",
"No more; and by a sleep to say we end",
"The heartache, and the thousand natural shocks",
"That flesh is heir to,--'tis a consummation",
"Devoutly to be wish'd. To die,--to sleep;--",
"To sleep! perchance to dream:--ay, there's the rub;",
"For in that sleep of death what dreams may come,",
"When we have shuffled off this mortal coil,",
"Must give us pause: there's the respect",
"That makes calamity of so long life;",
"For who would bear the whips and scorns of time,",
"The oppressor's wrong, the proud man's contumely,",
"The pangs of despis'd love, the law's delay,",
"The insolence of office, and the spurns",
"That patient merit of the unworthy takes,",
"When he himself might his quietus make",
"With a bare bodkin? who would these fardels bear,",
"To grunt and sweat under a weary life,",
"But that the dread of something after death,--",
"The undiscover'd country, from whose bourn",
"No traveller returns,--puzzles the will,",
"And makes us rather bear those ills we have",
"Than fly to others that we know not of?",
"Thus conscience does make cowards of us all;",
"And thus the native hue of resolution",
"Is sicklied o'er with the pale cast of thought;",
"And enterprises of great pith and moment,",
"With this regard, their currents turn awry,",
"And lose the name of action.--Soft you now!",
"The fair Ophelia!--Nymph, in thy orisons",
"Be all my sins remember'd."
};public WordCountData() {
}public static DataSet<String> getDefaultTextLineDataset(ExecutionEnvironment env) {
return env.fromElements(WORDS);
}
}
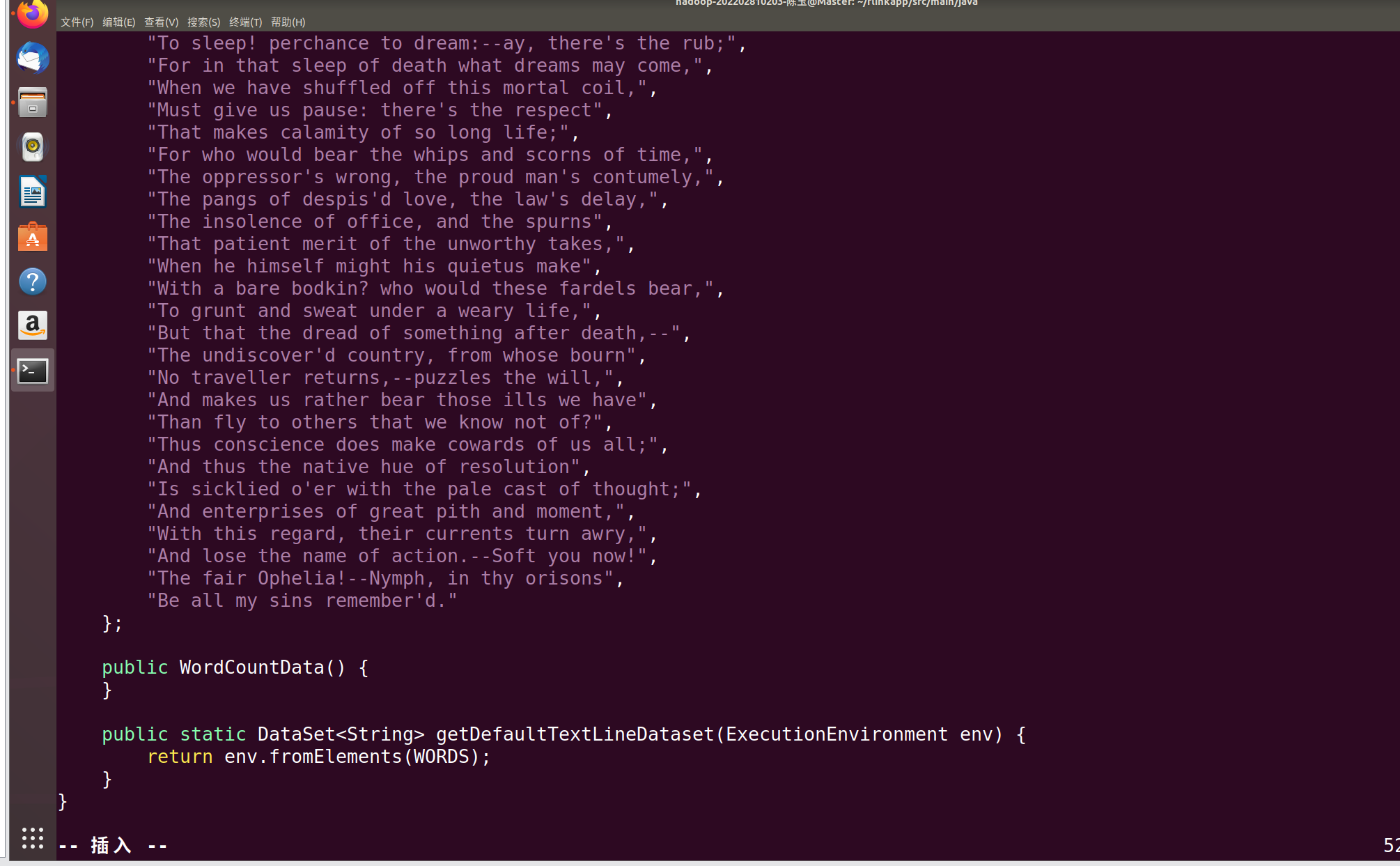 保存退出,继续
保存退出,继续
vim WordCountTokenizer.java在文本内添加以下内容:
package cn.edu.xmu;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;public class WordCountTokenizer implements FlatMapFunction<String, Tuple2<String,Integer>> {
public WordCountTokenizer() {}
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] tokens = value.toLowerCase().split("\\W+");
int len = tokens.length;for (int i = 0; i < len; i++) {
String tmp = tokens[i];
if (tmp.length() > 0) {
out.collect(new Tuple2<String, Integer>(tmp, Integer.valueOf(1)));
}
}
}
}
保存退出,继续
vim WordCount.java在文本内添加以下内容:
package cn.edu.xmu;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.utils.ParameterTool;public class WordCount {
public WordCount() {}
public static void main(String[] args) throws Exception {
ParameterTool params = ParameterTool.fromArgs(args);
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.getConfig().setGlobalJobParameters(params);
Object text;// 如果没有指定输入路径,则默认使用WordCountData中提供的数据
if (params.has("input")) {
text = env.readTextFile(params.get("input"));
} else {
System.out.println("Executing WordCount example with default input data set.");
System.out.println("Use --input to specify file input.");
text = WordCountData.getDefaultTextLineDataset(env);
}AggregateOperator counts = ((DataSet<String>) text)
.flatMap(new WordCountTokenizer())
.groupBy(0)
.sum(1);// 如果没有指定输出,则默认打印到控制台
if (params.has("output")) {
counts.writeAsCsv(params.get("output"), "\n", " ");
env.execute();
} else {
System.out.println("Printing result to stdout. Use --output to specify output path.");
counts.print();
}
}
}
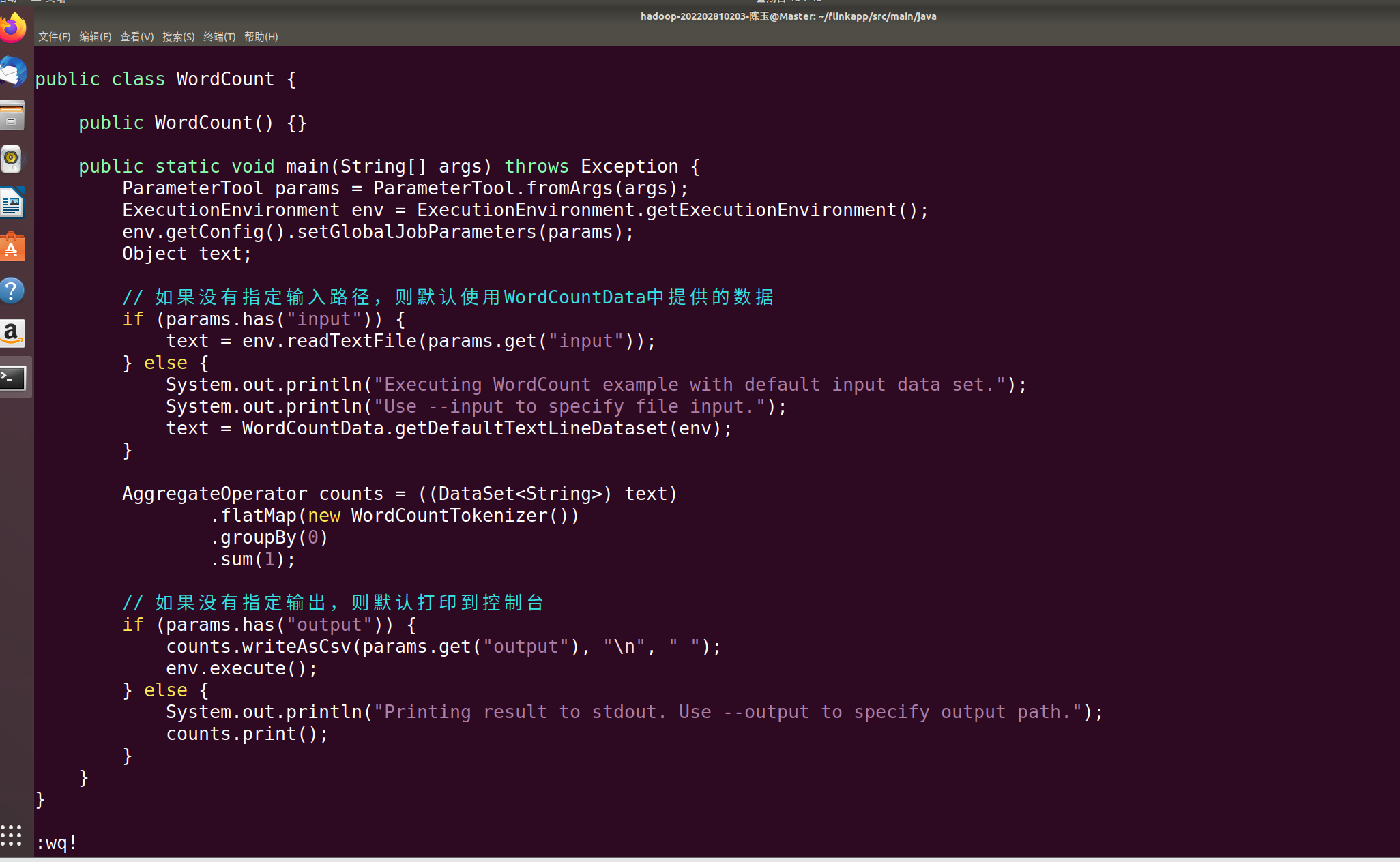

保存退出,继续
cd ~/flinkapp
vim pom.xml
先执行如下命令检查整个应用程序的文件结构:
find .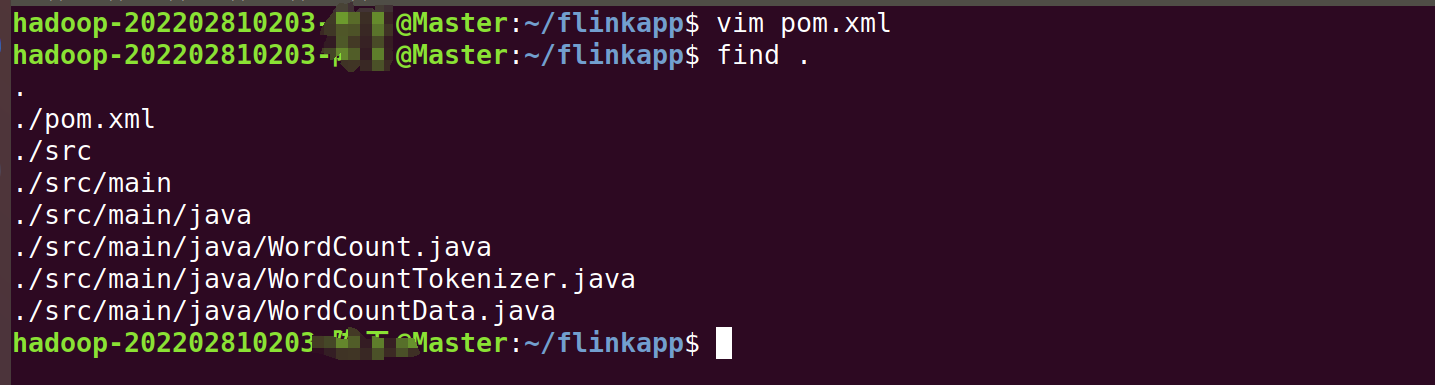
3.使用Maven打包Java程序
继续在终端输入:
/usr/local/maven/bin/mvn package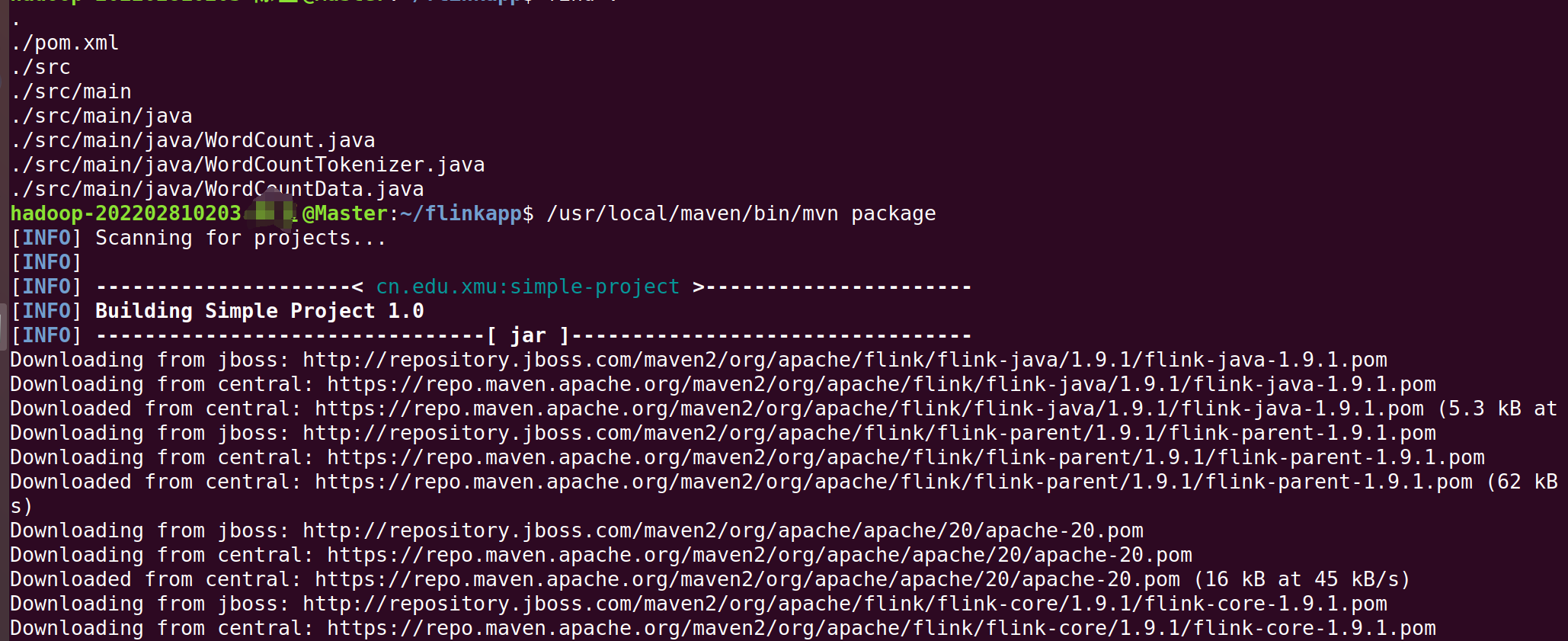
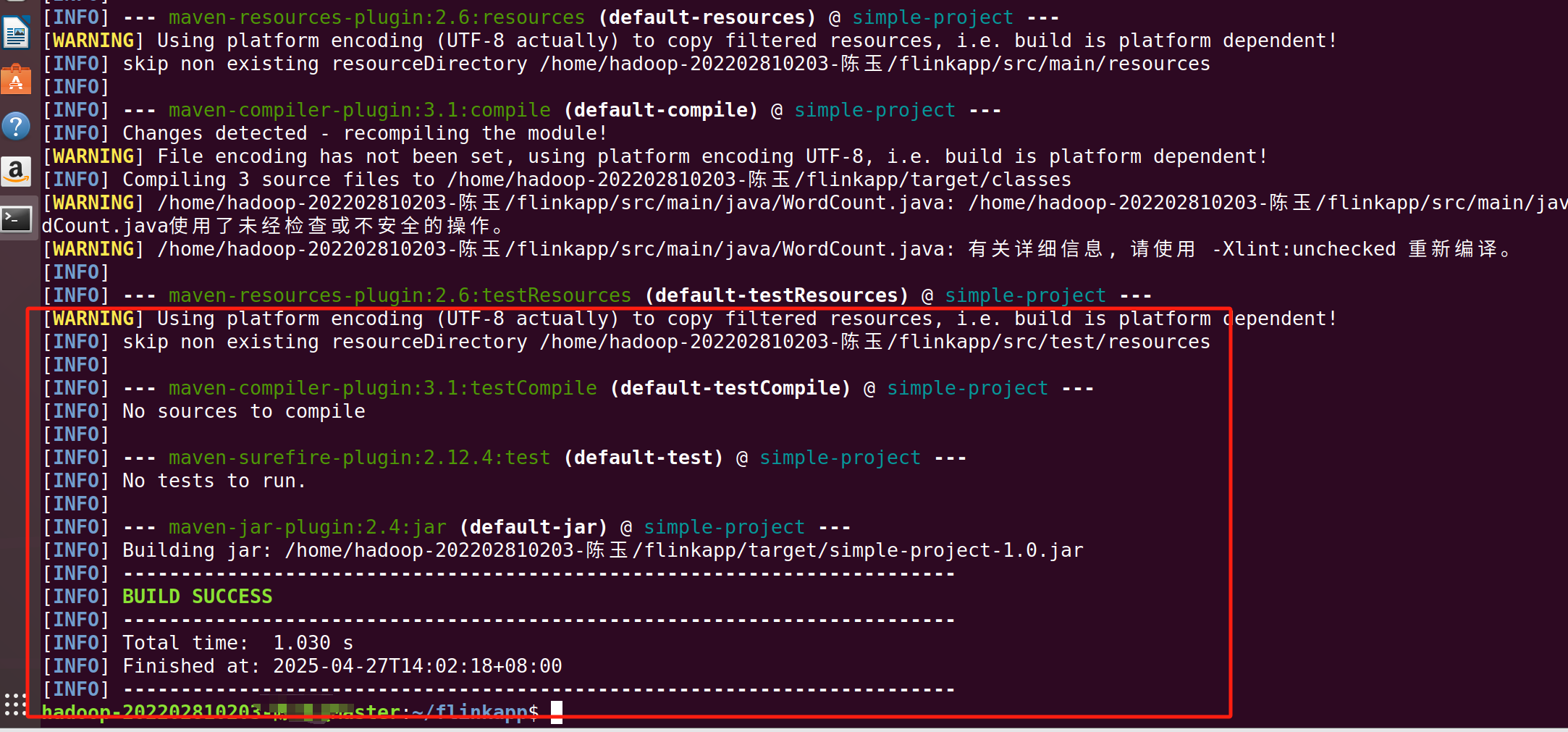 出现上面的内容即为成功
出现上面的内容即为成功
4.通过flink run命令运行程序
最后,可以将生成的JAR包通过flink run命令提交到Flink中运行(请确认已经启动Flink),命令如下:
/usr/local/flink/bin/flink run --class cn.edu.xmu.WordCount ~/flinkapp/target/simple-project-1.0.jar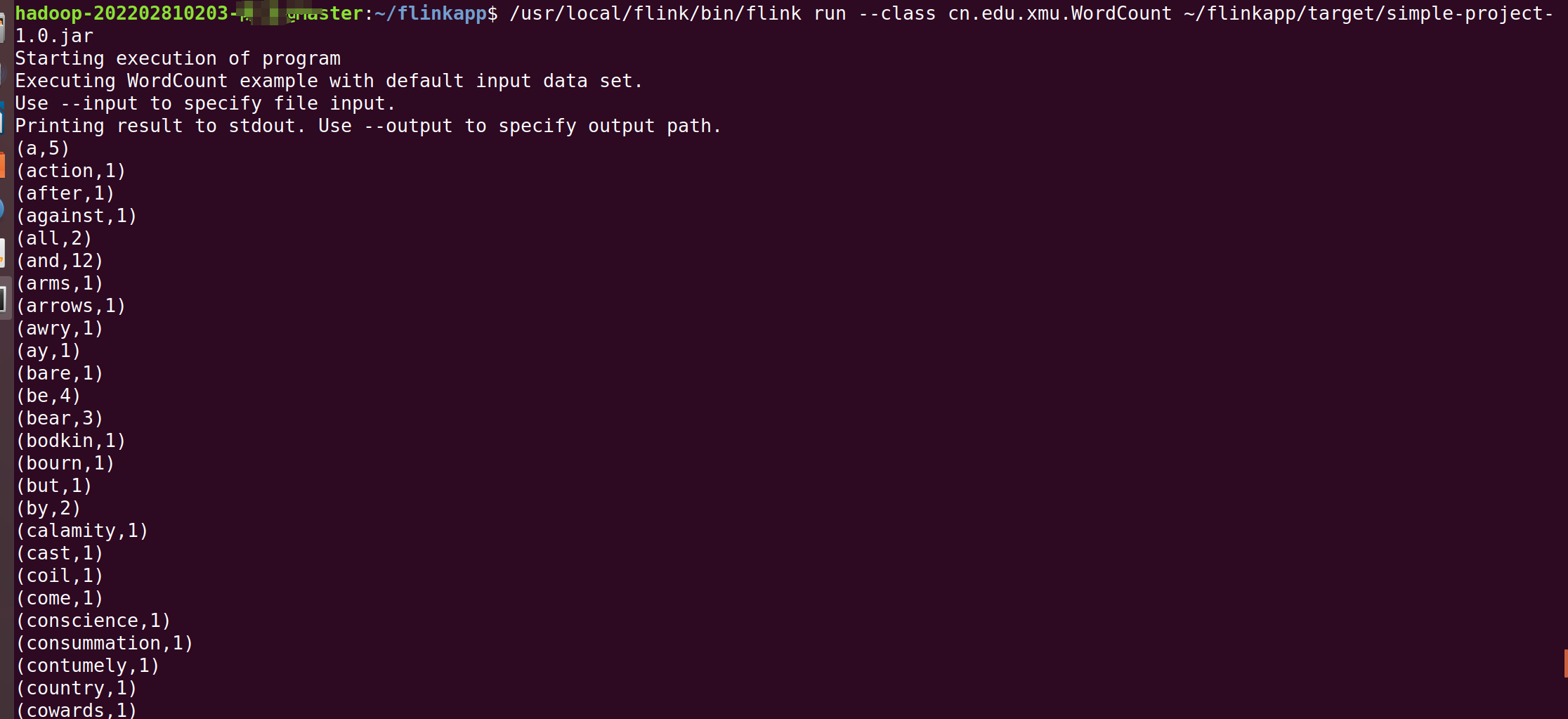
第四步:使用IntelliJ IDEA开发调试WordCount程序
1.安装idea
去博主主页请到我的ubantu虚拟机专栏里进行寻找如何安装idea文章。跟随操作。步步截图
2.在开始本实验之前,首先要启动Flink。
没启动的可以在上面找到去启动的命令。
3.启动进入IDEA,新建一个项目。
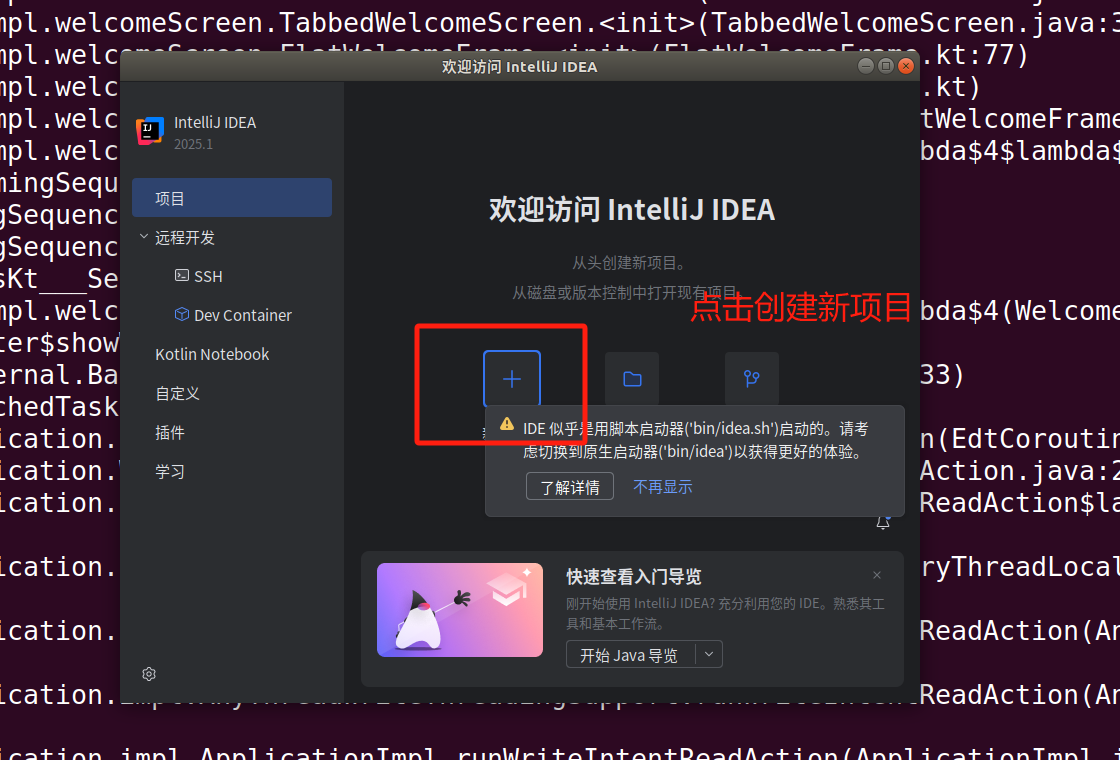
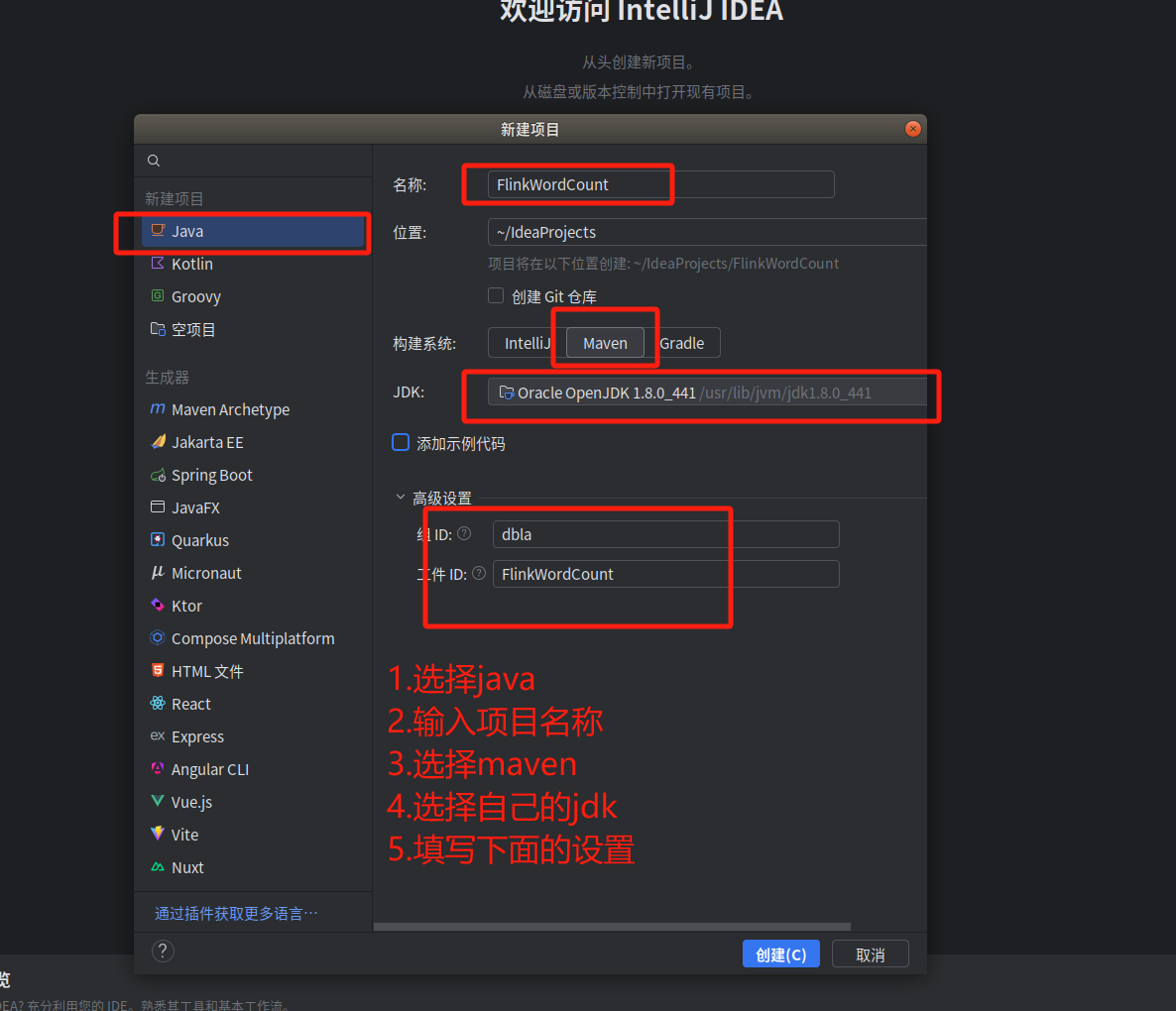 点击创建
点击创建
打开pom.xml文件
将下面的内容粘贴覆盖了原有内容
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>dblab</groupId>
<artifactId>FlinkWordCount</artifactId>
<version>1.0-SNAPSHOT</version><properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties><dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.9.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.9.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.9.1</version>
</dependency>
</dependencies></project>
没有蓝色刷新的图标点击,可以如下图操作,有的话直接点击就行,按右上角的➖就可以关闭这个侧边栏

继续
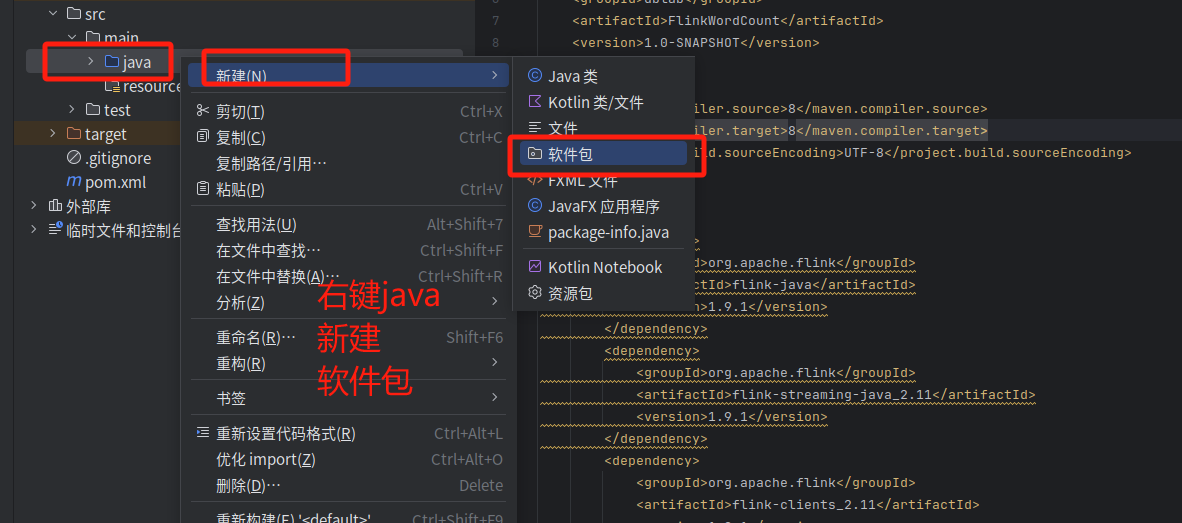 输入包名cn.edu.xmu
输入包名cn.edu.xmu
继续
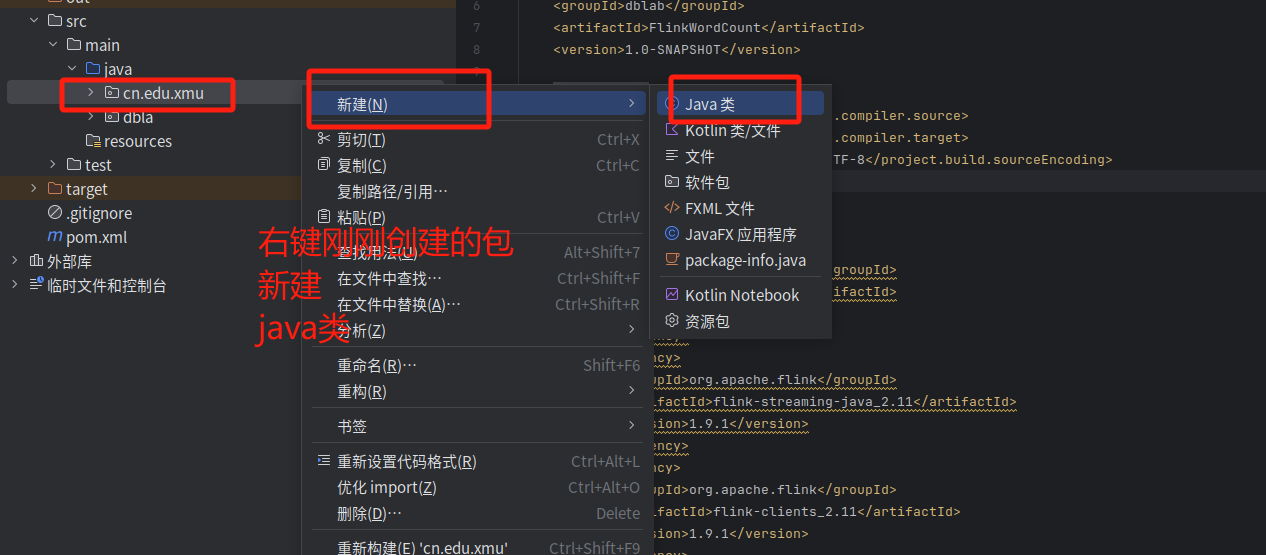 输入类名WordCountData
输入类名WordCountData
然后按回车或者点击类都行。
将下面的内容粘贴进去
package cn.edu.xmu;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;public class WordCountData {
public static final String[] WORDS = new String[]{
"To be, or not to be,--that is the question:--",
"Whether 'tis nobler in the mind to suffer",
"The slings and arrows of outrageous fortune",
"Or to take arms against a sea of troubles,",
"And by opposing end them?--To die,--to sleep,--",
"No more; and by a sleep to say we end",
"The heartache, and the thousand natural shocks",
"That flesh is heir to,--'tis a consummation",
"Devoutly to be wish'd. To die,--to sleep;--",
"To sleep! perchance to dream:--ay, there's the rub;",
"For in that sleep of death what dreams may come,",
"When we have shuffled off this mortal coil,",
"Must give us pause: there's the respect",
"That makes calamity of so long life;",
"For who would bear the whips and scorns of time,",
"The oppressor's wrong, the proud man's contumely,",
"The pangs of despised love, the law's delay,",
"The insolence of office, and the spurns",
"That patient merit of the unworthy takes,",
"When he himself might his quietus make",
"With a bare bodkin? who would these fardels bear,",
"To grunt and sweat under a weary life,",
"But that the dread of something after death,--",
"The undiscovered country, from whose bourn",
"No traveller returns,--puzzles the will,",
"And makes us rather bear those ills we have",
"Than fly to others that we know not of?",
"Thus conscience does make cowards of us all;",
"And thus the native hue of resolution",
"Is sicklied o'er with the pale cast of thought;",
"And enterprises of great pith and moment,",
"With this regard, their currents turn awry,",
"And lose the name of action.--Soft you now!",
"The fair Ophelia!--Nymph, in thy orisons",
"Be all my sins remember'd."
};public WordCountData() {
}public static DataSet<String> getDefaultTextLineDataset(ExecutionEnvironment env) {
return env.fromElements(WORDS);
}
}
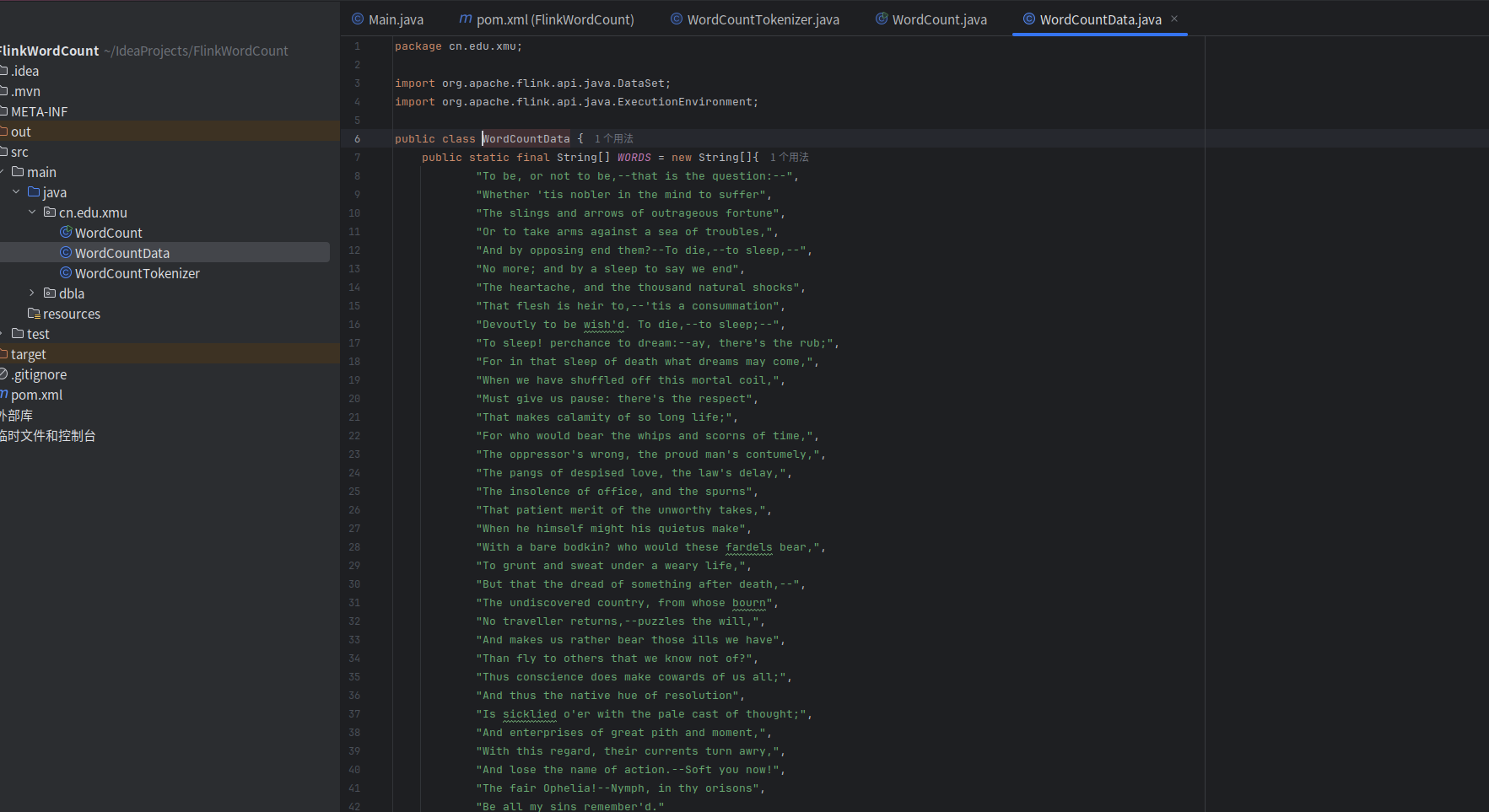
按照刚才同样的操作,创建第2个文件WordCountTokenizer.java。
他的内容如下:
package cn.edu.xmu;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;public class WordCountTokenizer implements FlatMapFunction<String, Tuple2<String, Integer>> {
public WordCountTokenizer() {}
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] tokens = value.toLowerCase().split("\\W+");
int len = tokens.length;for (int i = 0; i < len; i++) {
String tmp = tokens[i];
if (tmp.length() > 0) {
out.collect(new Tuple2<String, Integer>(tmp, Integer.valueOf(1)));
}
}
}
}
按照刚才同样的操作,创建第3个文件WordCount.java。
package cn.edu.xmu;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.utils.ParameterTool;public class WordCount {
public WordCount() {}public static void main(String[] args) throws Exception {
ParameterTool params = ParameterTool.fromArgs(args);
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.getConfig().setGlobalJobParameters(params);
Object text;
// 如果没有指定输入路径,则默认使用WordCountData中提供的数据
if (params.has("input")) {
text = env.readTextFile(params.get("input"));
} else {
System.out.println("Executing WordCount example with default input data set.");
System.out.println("Use --input to specify file input.");
text = WordCountData.getDefaultTextLineDataset(env);
}AggregateOperator counts = ((DataSet) text)
.flatMap(new WordCountTokenizer())
.groupBy(new int[]{0})
.sum(1);// 如果没有指定输出,则默认打印到控制台
if (params.has("output")) {
counts.writeAsCsv(params.get("output"), "\n", " ");
env.execute();
} else {
System.out.println("Printing result to stdout. Use --output to specify output path.");
counts.print();
}
}
}
最后的效果,这三个文件在同一位置下。
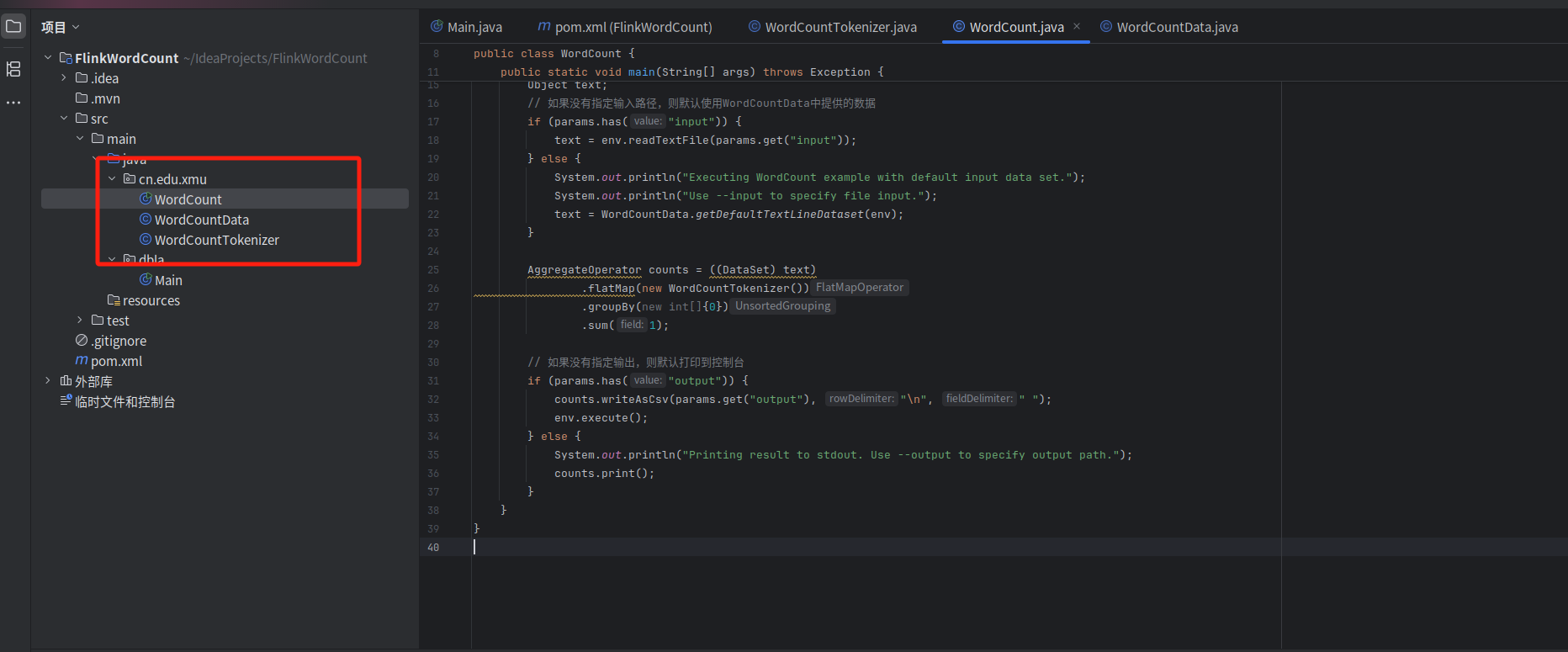
继续
 继续
继续
继续
方法一:
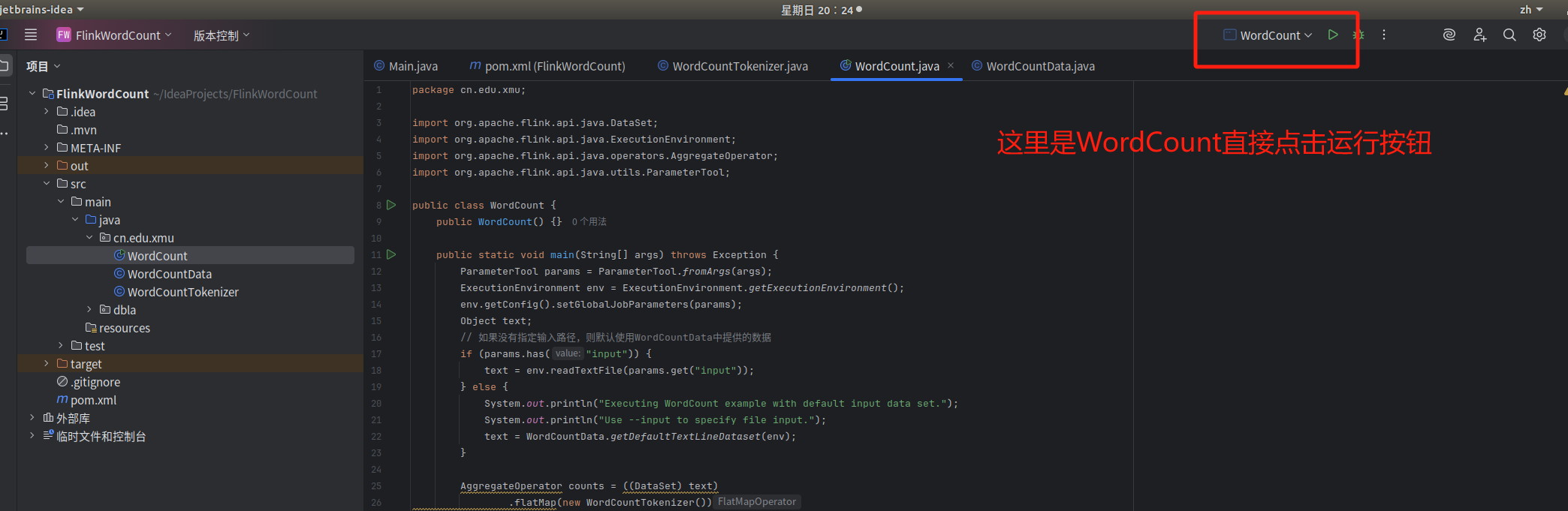
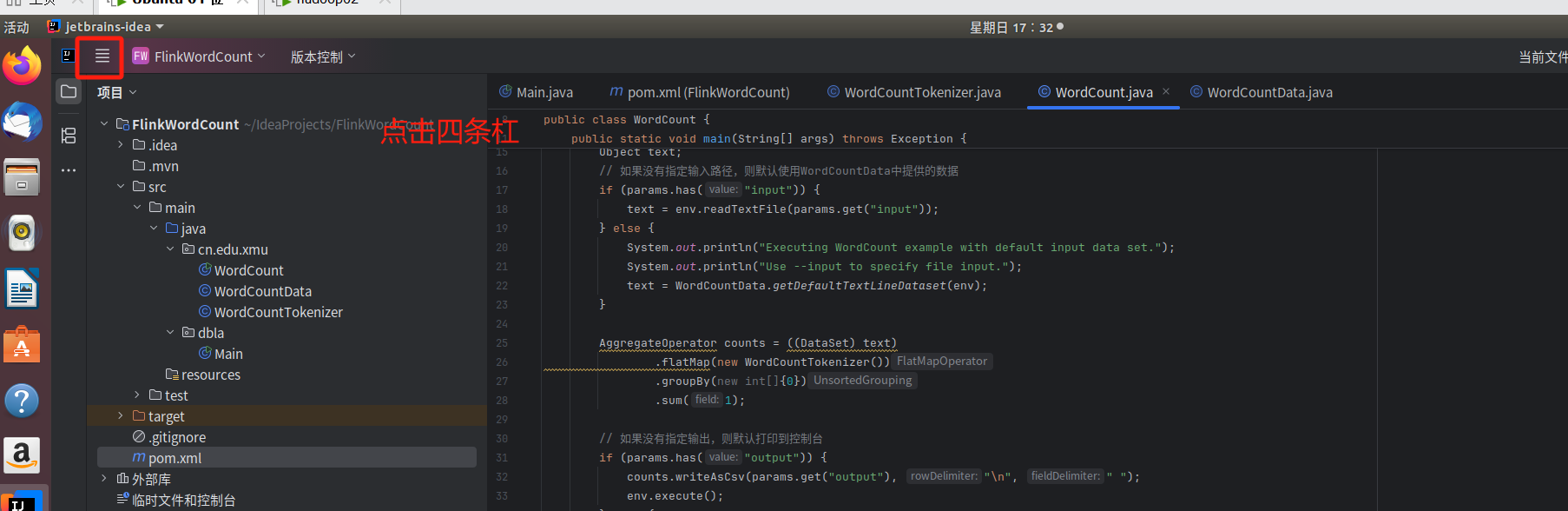
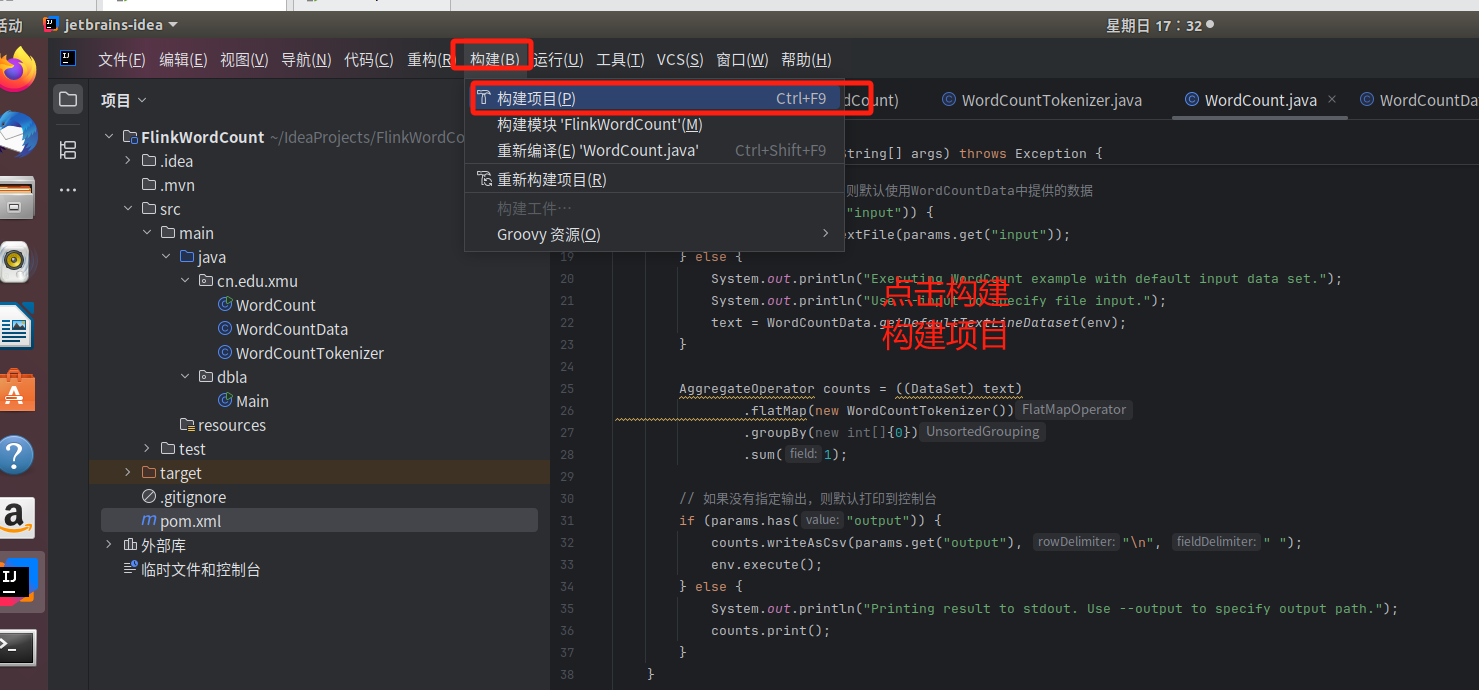
大家也可以用下面的方法 , 方法二:
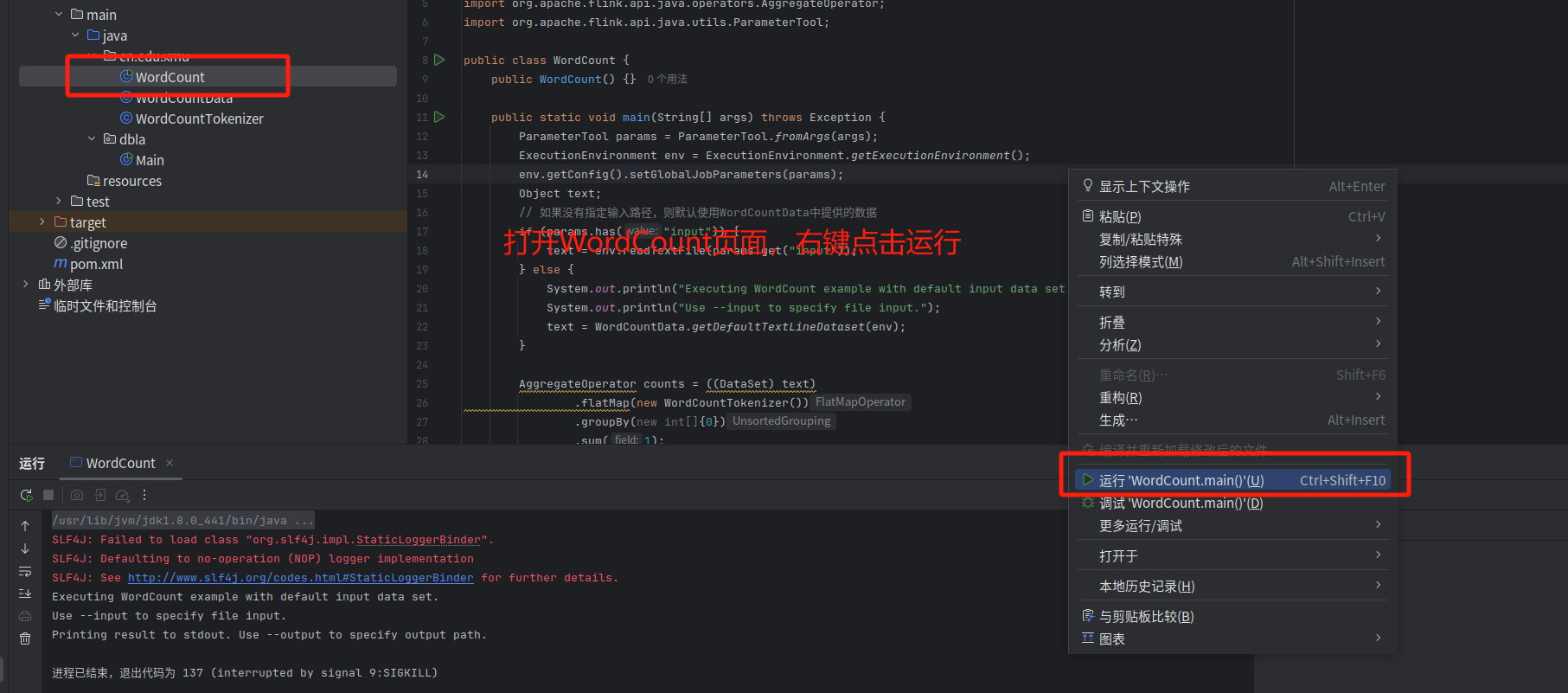
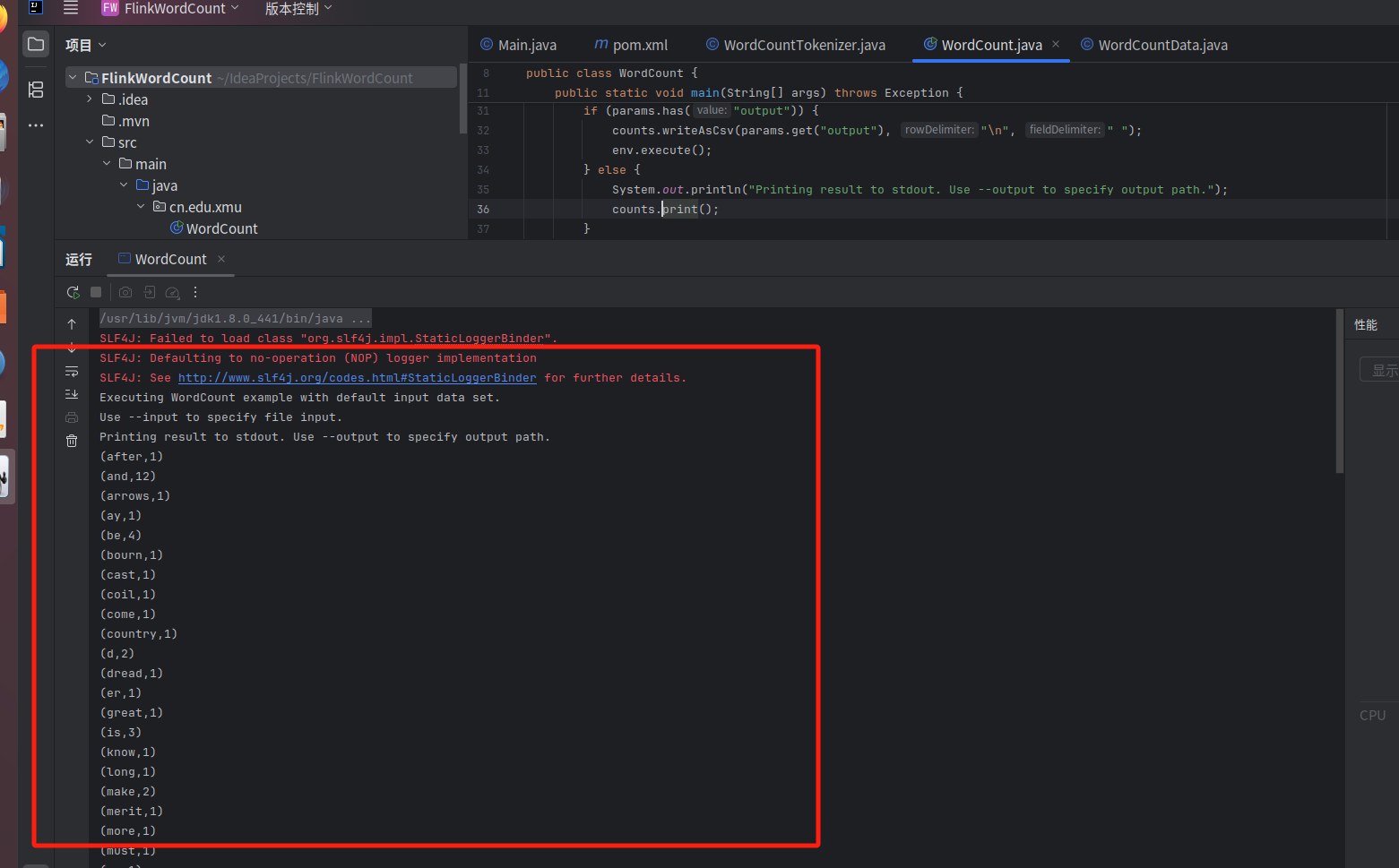 执行成功以后,可以看到词频统计结果。
执行成功以后,可以看到词频统计结果。
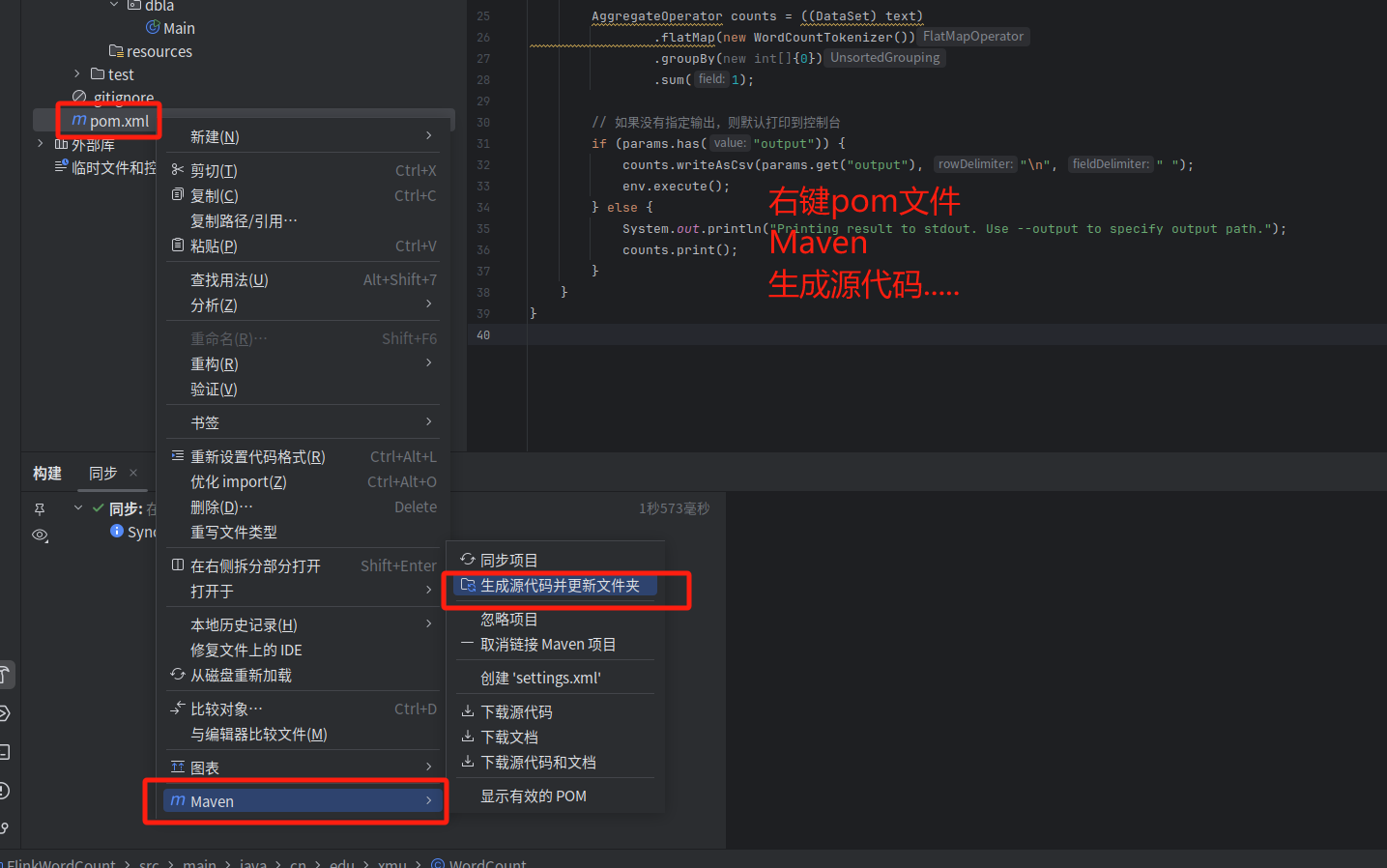
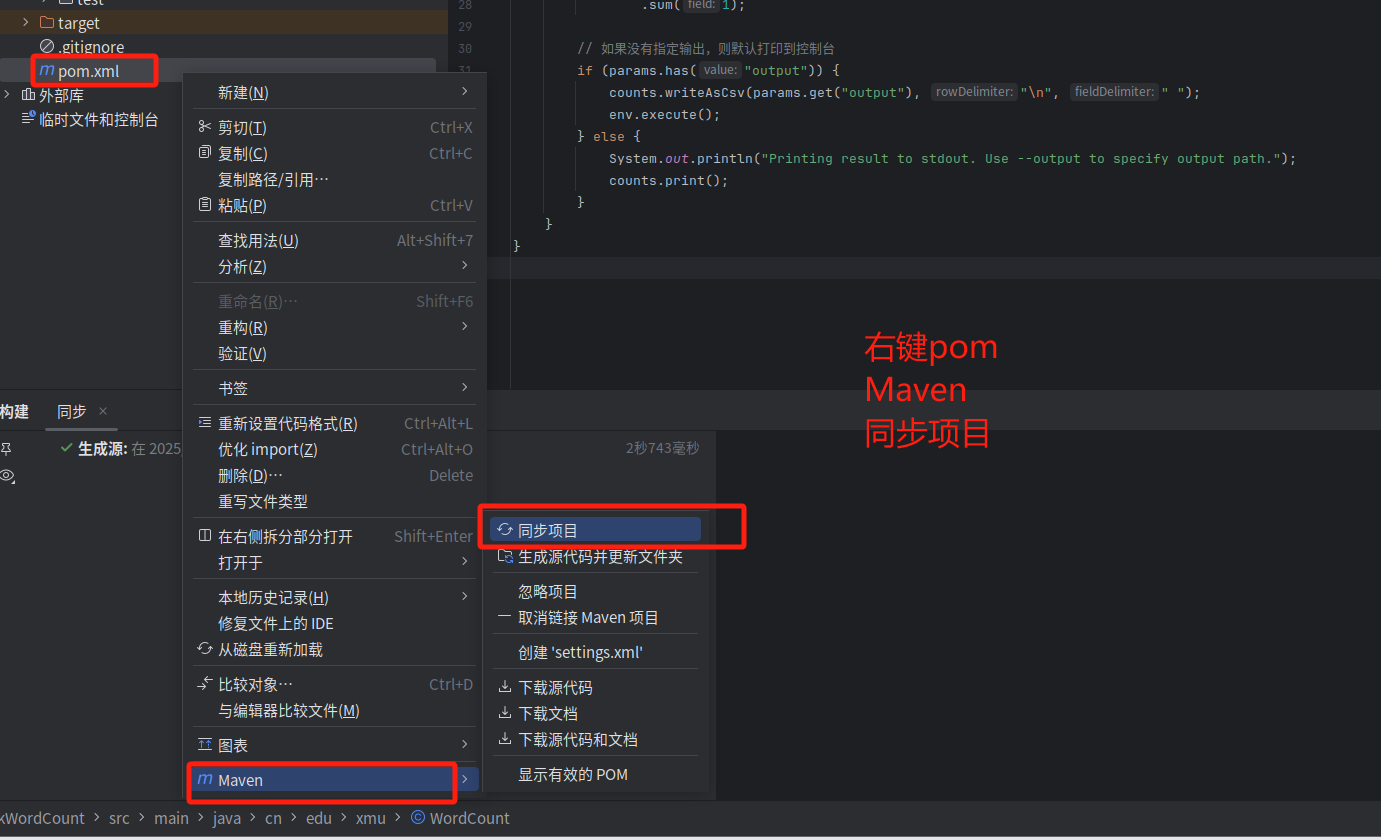
4.下面要把代码进行编译打包,打包成jar包。
没有文件的可以点四条杠。
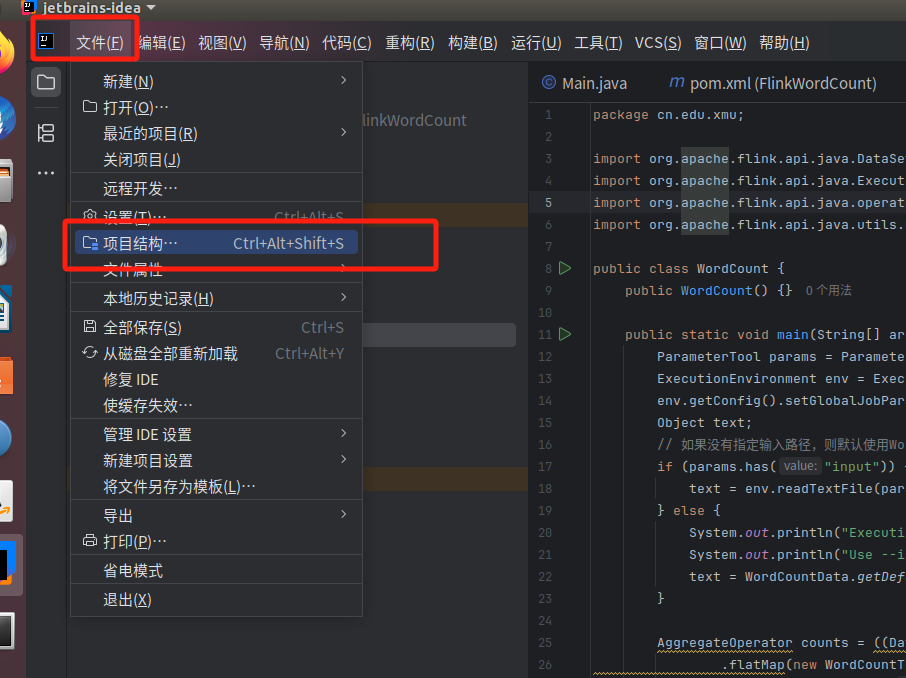
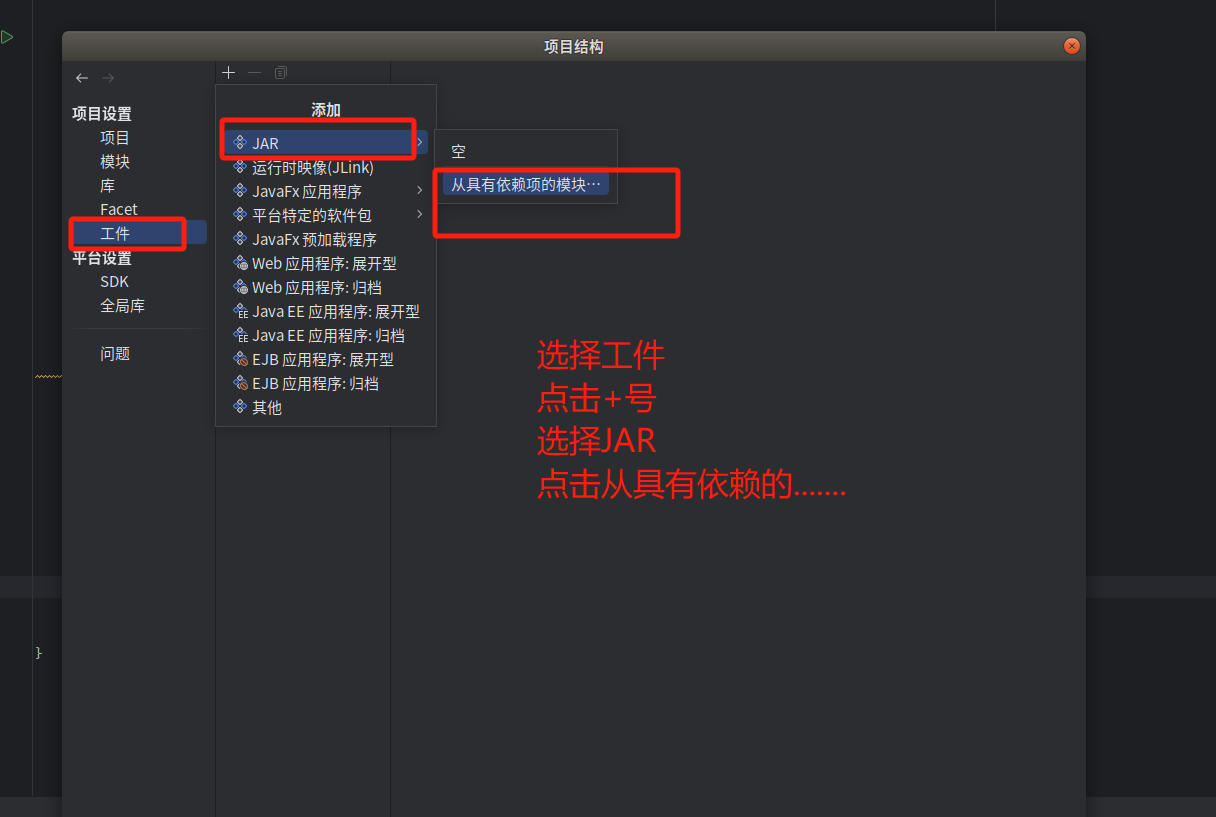
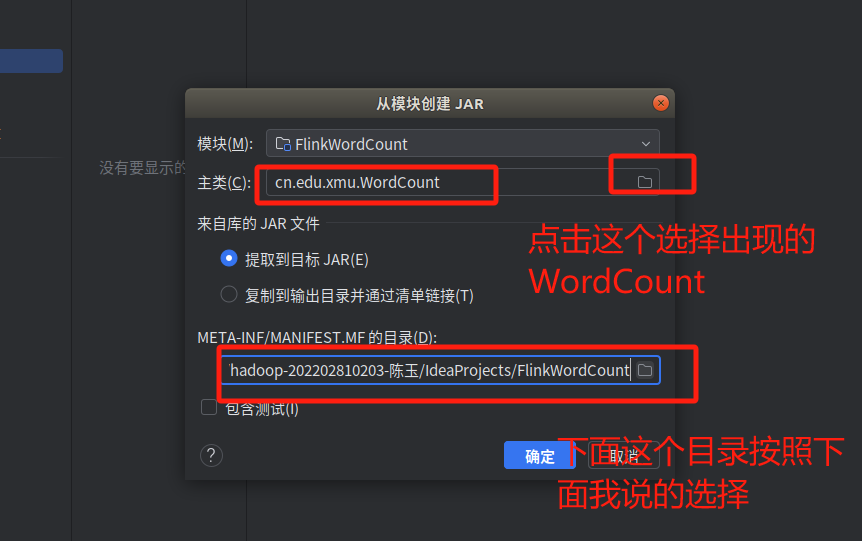
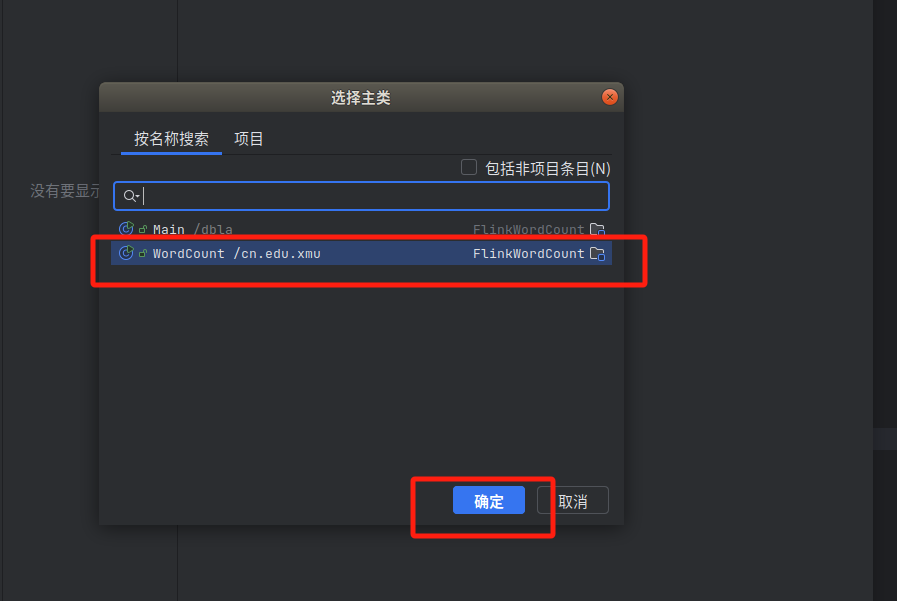
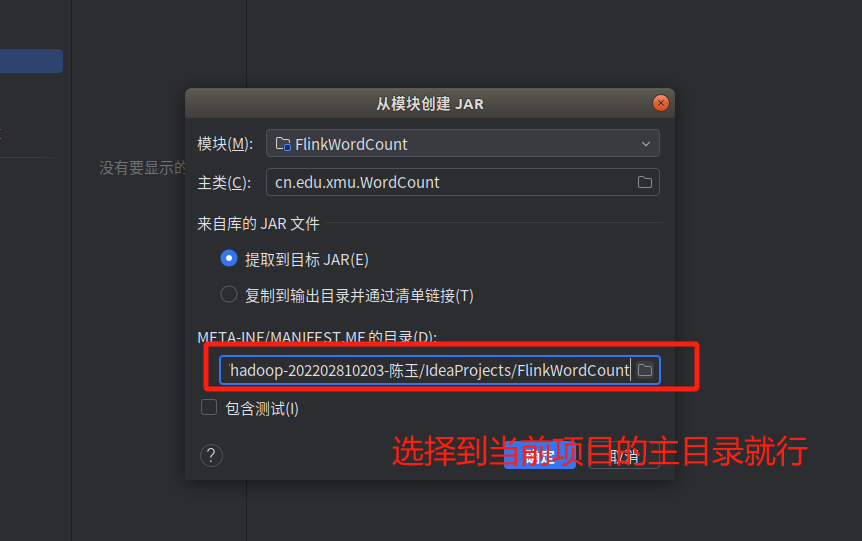
继续
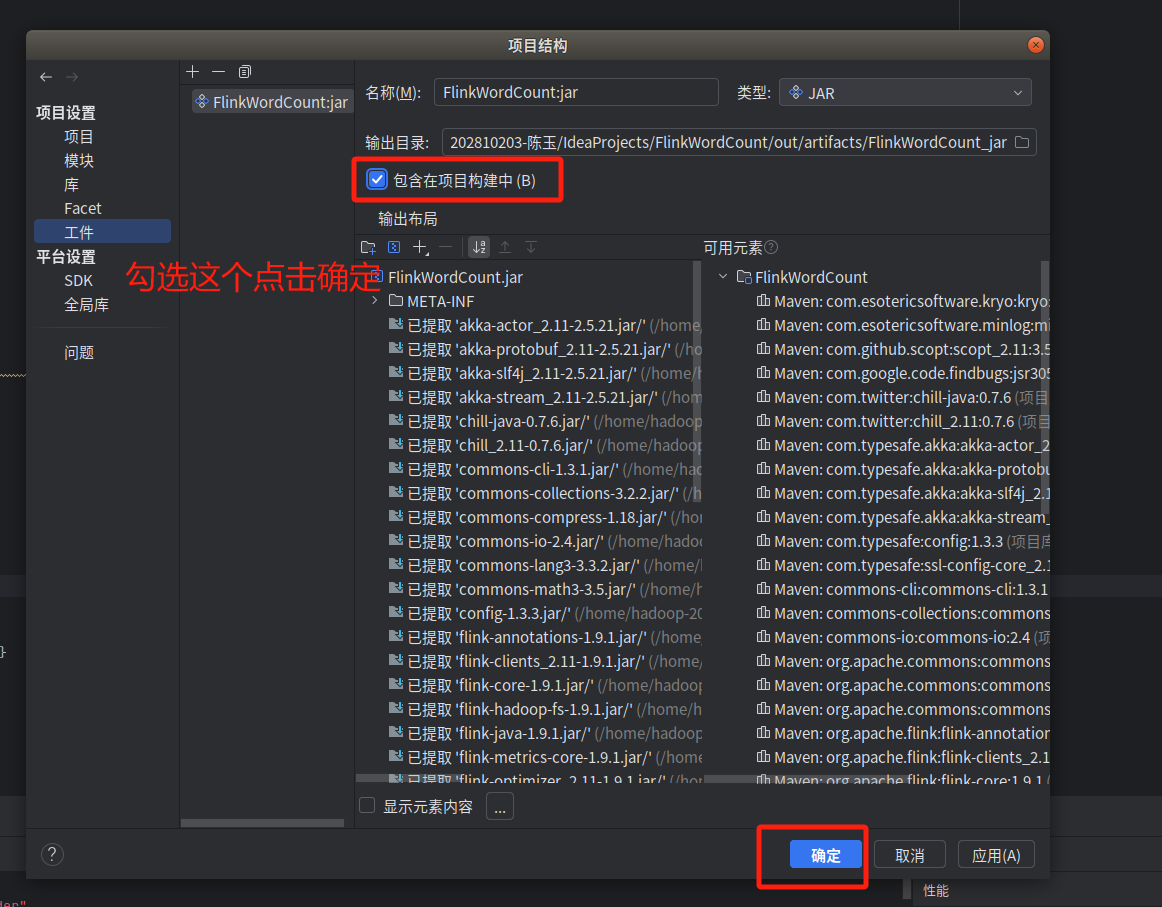 继续
继续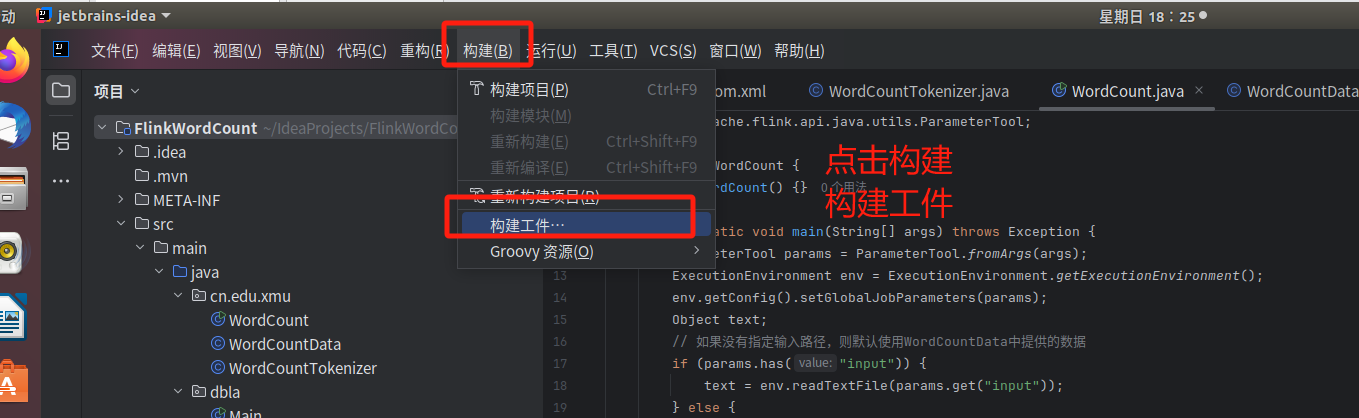
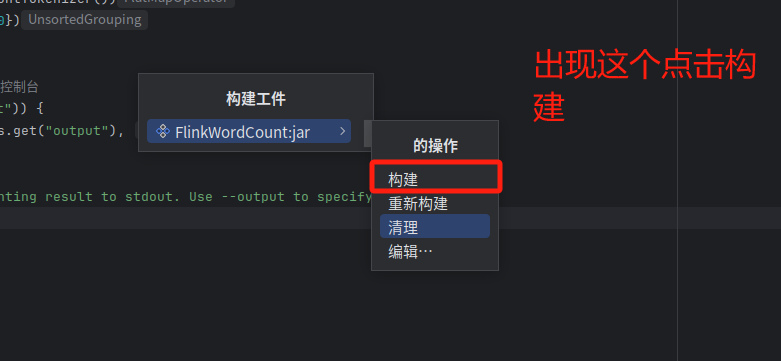 然后就可以看到
然后就可以看到
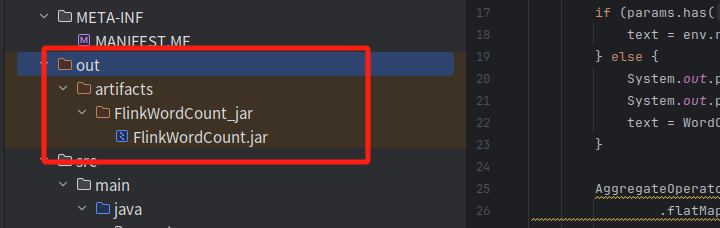
最后来到终端输入以下命令,运行jar包
注意下面的hadoop是你自己的用户名。
./bin/flink run /home/hadoop-202202810203/IdeaProjects/FlinkWordCount/out/artifacts/FlinkWordCount.jar
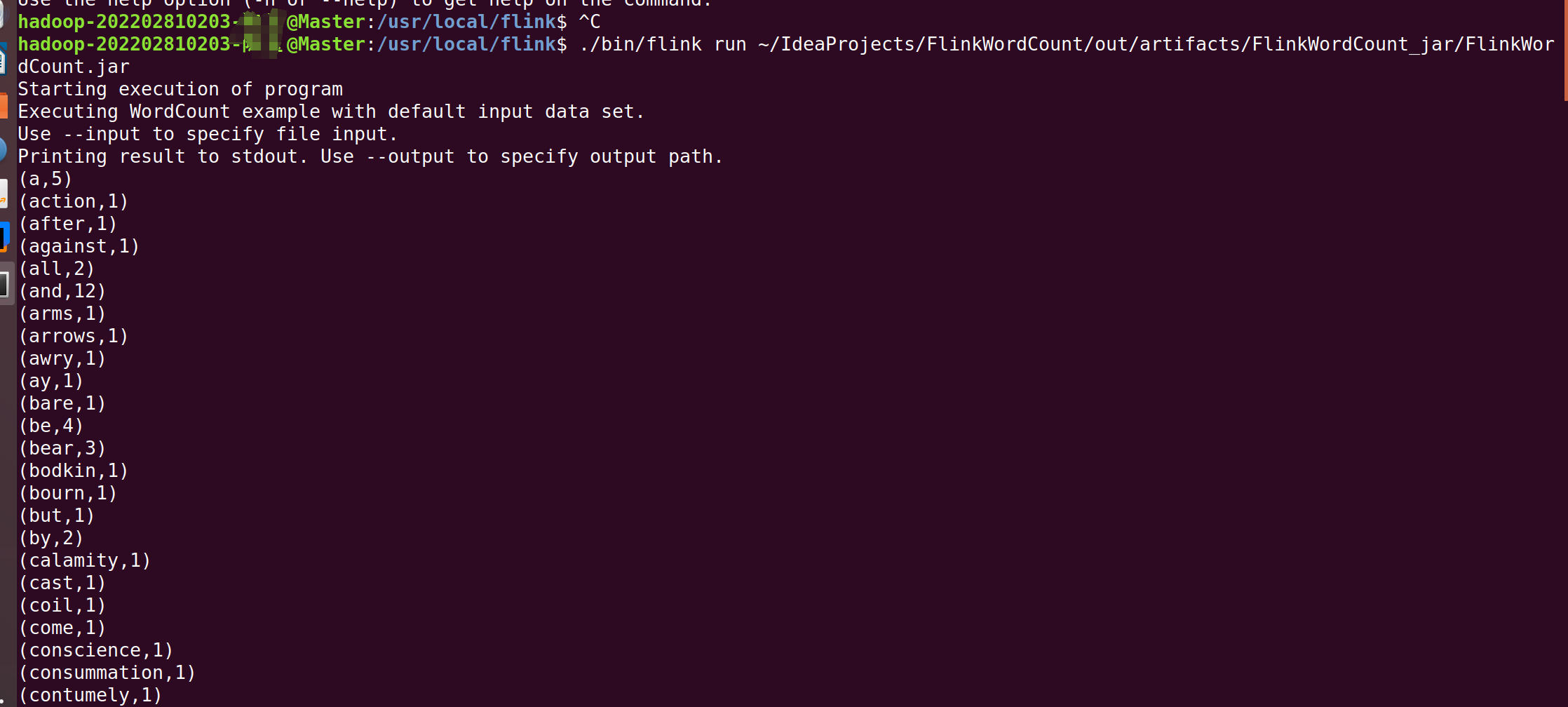
结语:但此为止,资料里的林子雨老师的实验,已全部在我的博客更完,并且步步都有截图,完结散花!!
相关文章:
之Flink安装与编程实践(Flink1.9.1))
ubantu18.04(Hadoop3.1.3)之Flink安装与编程实践(Flink1.9.1)
说明:本文图片较多,耐心等待加载。(建议用电脑) 注意所有打开的文件都要记得保存。 第一步:准备工作 本文是在之前Hadoop搭建完集群环境后继续进行的,因此需要读者完成我之前教程的所有操作。 注意本次实…...

AI辅助编程-cursor开发煤矿持证上岗管理程序需求与设计篇
Cursor 是一款由人工智能驱动的智能代码编辑器,深度融合AI技术以提升开发效率。其核心功能基于GPT-4等先进模型,支持代码生成、错误修复、智能补全及自然语言编程。开发者可通过对话交互直接描述需求,AI即时生成对应代码片段,显…...

如何使用极狐GitLab 议题看板?
极狐GitLab 是 GitLab 在中国的发行版,关于中文参考文档和资料有: 极狐GitLab 中文文档极狐GitLab 中文论坛极狐GitLab 官网 议题看板 (BASIC ALL) 议题看板是一个软件项目管理工具,用于计划、组织和可视化功能或产品发布的工作流程。它可…...
)
计网分层体系结构(包括OSI,IP,两者对比和相关概念)
1. 应用层: 用户与网络的界面,FTP,SMTP, HTTP 2. 表示层(Presentation Layer): 解决用户信息的语法表示问题 数据压缩,加密解密 表示变换 3. 对话层(Session Layer): 功能:允许不同主机的各个进…...

爬虫过程中如何确保数据准确性
在爬虫过程中,确保数据的准确性是非常重要的。数据不准确可能会导致分析结果的偏差,甚至影响决策。以下是一些确保爬虫数据准确性的方法和技巧: 一、验证数据来源 确保数据来源的可靠性是确保数据准确性的第一步。选择信誉良好的网站作为数…...

Maven多模块工程版本管理:flatten-maven-plugin扁平化POM
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,精通Java编…...

数据库基础与核心操作:从概念到实战的全面解析
目录 1 基本概念2 基本操作2.1 DCL2.2 DDL2.3 DML2.4 DQL(高级查询) 3 高级功能3.1 视图(无参函数)3.2 存储过程(有参函数)3.3 触发器 4 约束4.1 主键约束4.2 UNIQUE KEY(唯一键约束)4.3 FOREIGN KEY(外键约束…...
)
网络原理 - 10(HTTP/HTTPS - 1)
前面的网络原理 1 - 9,按照 TCP/IP 五层协议栈,介绍了各个层次的核心协议。 应用层:自定义协议(xml,json....) 传输层:UDP/TCP 网络层:IP 数据链路层:以太网 我们这…...

UDP协议详解+代码演示
1、UDP协议基础 1. UDP是什么? UDP(User Datagram Protocol,用户数据报协议)是传输层的核心协议之一,与TCP并列。它的主要特点是: 无连接:通信前不需要建立连接(知道对端的…...

QT事件Trick
拖动 void DWidget::mousePressEvent(QMouseEvent *event) {if(event->button()Qt::LeftButton){QListWidgetItem *selItem currentItem();if(selItem! nullptr){m_startPosevent->pos(); //记录鼠标按下时的起始位置}}QListWidget::mousePressEvent(event); }void DW…...
)
解答UnityShader学习过程中的一些疑惑(持续更新中)
一、坐标系相关 shader中会有几种空间: 模型空间:以物体自己为中心原点 世界空间:就是unity的世界坐标 观察空间(视图空间):以相机为中心的坐标系 裁剪空间:是一个4d空间,有x,y,z,w…...

【图论 拓扑排序 bfs】P6037 Ryoku 的探索|普及+
本文涉及知识点 C图论 CBFS算法 P6037 Ryoku 的探索 题目背景 Ryoku 对自己所处的世界充满了好奇,她希望能够在她「死」之前尽可能能多地探索世界。 这一天,Ryoku 得到了一张这个世界的地图,她十分高兴。然而,Ryoku 并不知道…...

Spring Boot定时任务
在 Spring Boot 中实现定时任务主要依赖于Scheduled注解和 Spring 调度器。 基本概念 定时任务,简单来说就是在特定的时间点或按照一定的时间间隔自动执行的任务。在 Spring Boot 中,实现定时任务主要依赖于 Spring 框架提供的 Scheduled 注解和 TaskSc…...

如何使用electron-forge开发上位机ui
Electron Forge是一个用于快速构建、打包和发布Electron应用程序的工具。它提供了一种简单的方式来设置Electron项目,并使用现代工具和最佳实践来管理应用程序的开发和部署过程。使用Electron Forge,开发人员可以轻松地创建跨平台的桌面应用程序…...

idea启动springboot方式及web调用
使用以下方式启动springboot. 我这里是微服务, 本地调试需要启动程序使用 1. 通过maven检测到Profile配置 2. web调用 我这里直接用 apifox接口调用, 带着token和一些必要参数。有这几点: 请求头要加的token需要是网页上F12获取到的 如果是微服务本地调用。url需要…...

利用EMQX实现单片机和PyQt的数据MQTT互联
https://www.dong-blog.fun/post/2050 基于MQTT的设备监控与控制系统设计 引言 物联网(IoT)设备的远程监控与控制是现代智能系统的基础需求。本文将介绍一个基于MQTT协议的设备监控与控制系统,该系统由两部分组成:模拟单片机设备和PyQt客户端。我们将…...
)
C#/.NET/.NET Core技术前沿周刊 | 第 36 期(2025年4.21-4.27)
前言 C#/.NET/.NET Core技术前沿周刊,你的每周技术指南针!记录、追踪C#/.NET/.NET Core领域、生态的每周最新、最实用、最有价值的技术文章、社区动态、优质项目和学习资源等。让你时刻站在技术前沿,助力技术成长与视野拓宽。 欢迎投稿、推荐…...

Context7 MCP:提供实时、版本特定的文档以解决AI幻觉问题
在实际开发中,使用AI辅助编码常常出现令人沮丧的问题:AI提供的API调用建议往往已经过时,或者根本不存在。 特别是当您使用最新版库时,这个问题尤为明显。 Upstash团队开发的Context7开源工具正是为解决这一痛点而生。 版本不匹配导致的API错误 现代开发库迭代速度快,常…...
-PDP的研究)
电路研究9.3.2——合宙Air780EP中的AT开发指南:HTTP(S)-PDP的研究
按照推荐的GPRS模块的学习顺序,现在需要研究的是HTTP(S)了,所以我们就继续学习吧。 9.5.2 HTTP(S)应用指南 应用概述 4G 模块支持 HTTP 和 HTTPS 协议(这个确实也考虑过了,但是不知道合不合适呢,而且我们计划的通讯是只…...

K8S ConfigMap 快速开始
一、什么是 ConfigMap? ConfigMap 是 Kubernetes 中用于存储非敏感配置数据的 API 对象,支持以键值对(Key-Value)或文件的形式存储配置,允许将配置与镜像解耦,实现配置的集中管理和动态更新。 二、主要用…...

【星海出品】K8S调度器leader
发现K8S的技术资料越写越多,独立阐述一下K8S-Scheduler-leader 调度器通过Watch机制来发现集群中【新创建】且尚未被调度【unscheduled】到节点上的pod。 由于 Pod 中的容器和 Pod 本身可能有不同的要求,调度程序会过滤掉任何不满足 Pod 特定调度需求的…...

第十二届蓝桥杯 2021 C/C++组 空间
目录 题目: 题目描述: 题目链接: 思路: 思路详解: 代码: 代码详解: 题目: 题目描述: 题目链接: 空间 - 蓝桥云课 思路: 思路详解&#…...

通过深度学习推进增材制造:当前进展与未来挑战综述
通过深度学习推进增材制造:当前进展与未来挑战综述 原文信息: 标题:Advancing Additive Manufacturing through Deep Learning: A Comprehensive Review of Current Progress and Future Challenges 作者:Amirul Islam Saimon, Emmanuel Yangue, Xiaowei Yue, Zhenyu (…...
详解:省电机制与移动特性)
深入蜂窝物联网 第三章 LTE-M(Cat-M1)详解:省电机制与移动特性
1. 前言与应用场景 在蜂窝物联网阵营中,LTE-M(Cat-M1) 兼具低功耗和中速率,且支持移动场景下的无缝切换,因而成为物流追踪、可穿戴设备、智能路灯、共享单车等场景的首选。 本章将系统剖析: 核心特性:PSM、eDRX 与移动性保障; 协议流程:简化的 RRC/NAS 步骤; 时序图…...

软件设计师速通其一:计算机内部数据表示
考试资料推荐 ,这也是大部分图片的出处。本文章主要将视频原本讲的不详细、不便于理解的东西摆开揉碎了给到读者。相信本文能帮您更好更快的学习知识。本文也是您考前快速复习的不二之选。本文会用星星来表示每个考点的重要性,其中一颗★表示课外拓展&am…...

Kubernetes》》k8s》》Taint 污点、Toleration容忍度
污点 》》 节点上 容忍度 》》 Pod上 在K8S中,如果Pod能容忍某个节点上的污点,那么Pod就可以调度到该节点。如果不能容忍,那就无法调度到该节点。 污点和容忍度的概念 》》污点等级——>node 》》容忍度 —>pod Equal——>一种是等…...
)
【爬虫】一文掌握 adb 的各种指令(adb备忘清单)
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 入门设备基础Logcat文件管理远程 Shell包安装Paths手机信息包信息设备相关命令权限Logs常见的 ADB 命令将文件推送到 Android 设备的下载文件夹列出所有已安装的包并获取完整路径从安卓设备中提取文件从主机安装 APK 到…...

1.7无穷级数
引言 无穷级数是考研数学一的核心内容,涵盖数项级数、幂级数、傅里叶级数等核心概念。本文系统梳理4大考点,结合公式速查与实战示例,助你高效突破级数难点! 考点一:数项级数敛散性判定 1️⃣ 正项级数 (1) 比较审敛…...

vitest | 测试框架vitest | 总结笔记
测试框架 vitest 介绍 网址:Vitest | Next Generation testing framework 特点:①支持vite的生态系统,②兼容jest语法 ③HMR测试(速度快) ④ ESM(js的原生支持) 安装 Vitest: npm …...

使用 ELK 实现全链路追踪:从零到一的实践指南
前言 在现代分布式系统中,随着服务数量的增加,系统的复杂性也呈指数级增长。为了快速定位问题、分析性能瓶颈,全链路追踪成为一项必不可少的能力。本文将详细介绍如何利用 ELK(Elasticsearch Logstash Kibana) 实现…...

AI智能体开发实战:从概念到落地的全流程解析
一、AI智能体:重新定义人机协作 什么是AI智能体? AI智能体是具备感知-思考-行动闭环能力的程序实体,能够通过传感器(如文本输入、图像识别)获取信息,基于大模型推理决策,并通过API、机器人等执…...

如何搭建spark yarn 模式的集群
搭建Spark on YARN集群的步骤 Spark on YARN模式允许Spark作业在Hadoop YARN资源管理器上运行,这样可以更好地与Hadoop生态系统集成并共享集群资源。以下是搭建Spark YARN集群的详细步骤: 前提条件 已安装并配置好Hadoop集群(包括HDFS和YAR…...

DDoS 攻击如何防护?2025最新防御方案与实战指南
一、DDoS 攻击的致命威胁:你的业务离瘫痪有多近? 1. 2024 年 DDoS 攻击现状 攻击规模:全球日均攻击峰值突破7.2Tbps,混合型攻击占比超 65%(来源:Cloudflare)行业重灾区: 行业攻击占…...

3D架构图软件 iCraft Editor 正式发布 @icraft/player-react 前端组件, 轻松嵌入3D架构图到您的项目
安装 pnpm install icraft/player-react --saveimport { ICraftPlayer } from "icraft/player-react";export default function MyScene() {return <ICraftPlayer srcyour-scene.iplayer />; }icraft/player-react 为开发者提供了一站式的3D数字孪生可视化解决…...

esm使用-包括esmfold和embedding
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言零、安装一、esmfold的使用二、esm2的embedding1.模型加载与准备2.读入数据3.提取残基级表示4.生成序列级表示(均值池化)5.可视化自注意力接触图6.潜在问题与改进建议7.小结总结前言 主要参…...

【Nginx】 使用least_conn负载均衡算法是否能将客户端的长连接分散到不同的服务器上demo
为了验证Nginx在关闭HTTP Keepalive的情况下,使用least_conn负载均衡算法是否能将客户端的长连接分散到不同的服务器上,我们可以搭建一个简单的环境。这个环境包括: 一个Nginx服务器作为负载均衡器。两个后端服务器(可以使用简单…...
:共同作者)
TMI投稿指南(三):共同作者
IEEE 作者编辑风格手册 --- IEEE Editorial Style Manual for Authors 投稿之后检查路径: IEEE 作者门户:登录 --- IEEE Author Gateway: Login 共同第一作者:在许多领域,被视为成为第一作者是件好事。但只有一个人可以是第一作…...

Java多线程入门案例详解:继承Thread类实现线程
本文通过一个简单案例,讲解如何通过继承 Thread 类来实现多线程程序,并详细分析了代码结构与运行机制。 一、前言 在 Java 中,实现多线程主要有两种方式: 继承 Thread 类 实现 Runnable 接口 本文以继承 Thread 类为例&#x…...
Transformer Prefill阶段并行计算:本质、流程与思考
Transformer Prefill阶段并行计算:本质、流程与思考 “为什么Transformer在Prefill阶段可以并行?并行到什么程度?哪里还需要同步?今天讲清楚!” 引子 在大语言模型(LLMs)爆发的时代,…...

KUKA机器人自动备份设置
在机器人的使用过程中,对机器人做备份不仅能方便查看机器人的项目配置与程序,还能防止机器人项目和程序丢失时进行及时的还原,因此对机器人做备份是很有必要的。 对于KUKA机器人来说,做备份可以通过U盘来操作。也可以在示教器上设…...

Lua 第13部分 位和字节
13.1 位运算 Lua 语言从 5.3 版本开始提供了针对数值类型的一组标准位运算符。与算术运算符不同的是,位运算符只能用于整型数。位运算符包括 &( 按位与)、|(按位或)、~(按…...

下载同时返回其他参数
一般情况下下载的接口是没有返回值的,直接返回一个文件 浏览器直接触发文件下载 但是有一些奇葩需求,除了文件外还需要一些其他字段返回。这个时候就只能把文件转成字符串返回,然后再由前端做下载或者展示 后台获取字符 byte[] byte[] bo…...

240428 leetcode exercises
240428 leetcode exercises jarringslee 文章目录 240428 leetcode exercises[25. K 个一组翻转链表 ](https://leetcode.cn/problems/reverse-nodes-in-k-group/solutions/3663828/xian-fan-zhuan-lian-biao-zai-kyi-ge-zu-f-lgaj/)🔁 探宗求源 其义自见 [75. 颜色…...

SQLMesh 审计与测试:确保数据质量的利器
在数据科学项目中,确保数据质量和准确性至关重要。SQLMesh 提供了审计和测试两种工具来验证数据。本文将介绍 SQLMesh 的审计功能,并与测试进行对比,帮助您更好地理解如何在项目中使用这些工具。 SQLMesh 审计 SQLMesh 的审计功能可以帮助您…...

SQL Server 存储过程开发规范
SQL Server 存储过程开发规范(高级版) 1. 总则 1.1 目标 本规范旨在: 提高存储过程的事务一致性、异常可追踪性、错误透明度。 统一日志记录、错误码管理、链路追踪(Trace ID)。 支持复杂事务场景(嵌套…...

图像处理篇---信号与系统的应用
文章目录 前言一、信号表示层面图像作为二维信号二、系统特性分析线性移变系统建模采样系统理论应用时域采样定理在帧率选择中的应用三、变换域处理多维傅里叶分析小波变换与多分辨率分析四、系统响应特性人类视觉系统(HVS)建模摄像机系统响应五、编码系统中的信号处理预测编…...

什么是 Web 标准?为什么它们对 SEO 和开发很重要?
网页标准为何重要?谷歌解析SEO优势 在当今数字营销领域,搜索引擎优化(SEO)是网站提升可见性和吸引自然流量的关键策略。然而,许多网站管理员和营销人员可能忽略了一个重要的SEO因素——网页标准。谷歌的SEO专家深入解…...

Python 正则表达式 re 包
一、常见正则表达式符号 符号含义示例.匹配任意单个字符(除了换行)r"a.c" 可匹配 "abc"、"a1c" 等\d匹配任何数字(0-9)r"\d" 匹配 "123"、"56"\w匹配字母、数字或下…...

leetcode0230. 二叉搜索树中第 K 小的元素-medium
1 题目:二叉搜索树中第 K 小的元素 官方标定难度:中 给定一个二叉搜索树的根节点 root ,和一个整数 k ,请你设计一个算法查找其中第 k 小的元素(从 1 开始计数)。 示例 1: 输入:r…...

Linux环境变量配置与std访问环境变量
文章目录 前言1. 用户环境变量快速配置1.2 **以上语句的具体解释:**1.3 $PATHNAME实现增量式添加 2.系统级永久配置与避坑指南2.1 特殊字符处理2.2 动态PATH管理2.3 敏感信息保护2.4 环境调试命令 3. cstd中访问环境变量 前言 首先介绍一下Linux下各目录操作符的含…...