Linux课程五课---Linux进程认识1
作者前言
🎂 ✨✨✨✨✨✨🍧🍧🍧🍧🍧🍧🍧🎂
🎂 作者介绍: 🎂🎂
🎂 🎉🎉🎉🎉🎉🎉🎉 🎂
🎂作者id:老秦包你会, 🎂
简单介绍:🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂
喜欢学习C语言、C++和python等编程语言,是一位爱分享的博主,有兴趣的小可爱可以来互讨 🎂🎂🎂🎂🎂🎂🎂🎂
🎂个人主页::小小页面🎂
🎂gitee页面:秦大大🎂
🎂🎂🎂🎂🎂🎂🎂🎂
🎂 一个爱分享的小博主 欢迎小可爱们前来借鉴🎂
Linux进程
- **作者前言**
- 冯诺依曼体系结构
- 操作系统
- 进程
- 描述进程-PCB
- task_ struct内容分类
- 查看进程
- 创建进程(fork)
- 进程
- 进程排队
- 进程状态
- 运行
- 阻塞
- 挂起
- 进程状态的代码
- 运行状态(R)
- 运行状态(S)
- 运行状态(D)
- 运行状态(T)
- 运行状态(t)
- 运行状态(Z)
- 孤儿进程
- 进程优先级
- 优先级修改
- Linux的调度与切换
- 进程切换
- 寄存器VS寄存器的内容
- 总结
- Linux进程切换的调度算法
- 环境变量
- main参数 ----命令行参数
- 环境变量
- 见见环境变量
- 添加路径
- 环境变量的查看
- 定义环境变量
- 环境变量的特性
- 获取环境变量的方式
- 本地变量
- 删除环境变量
- 环境变量命令总结
- 程序地址
- 虚拟地址
- 进程地址空间结论
- 页表
- 总结
冯诺依曼体系结构
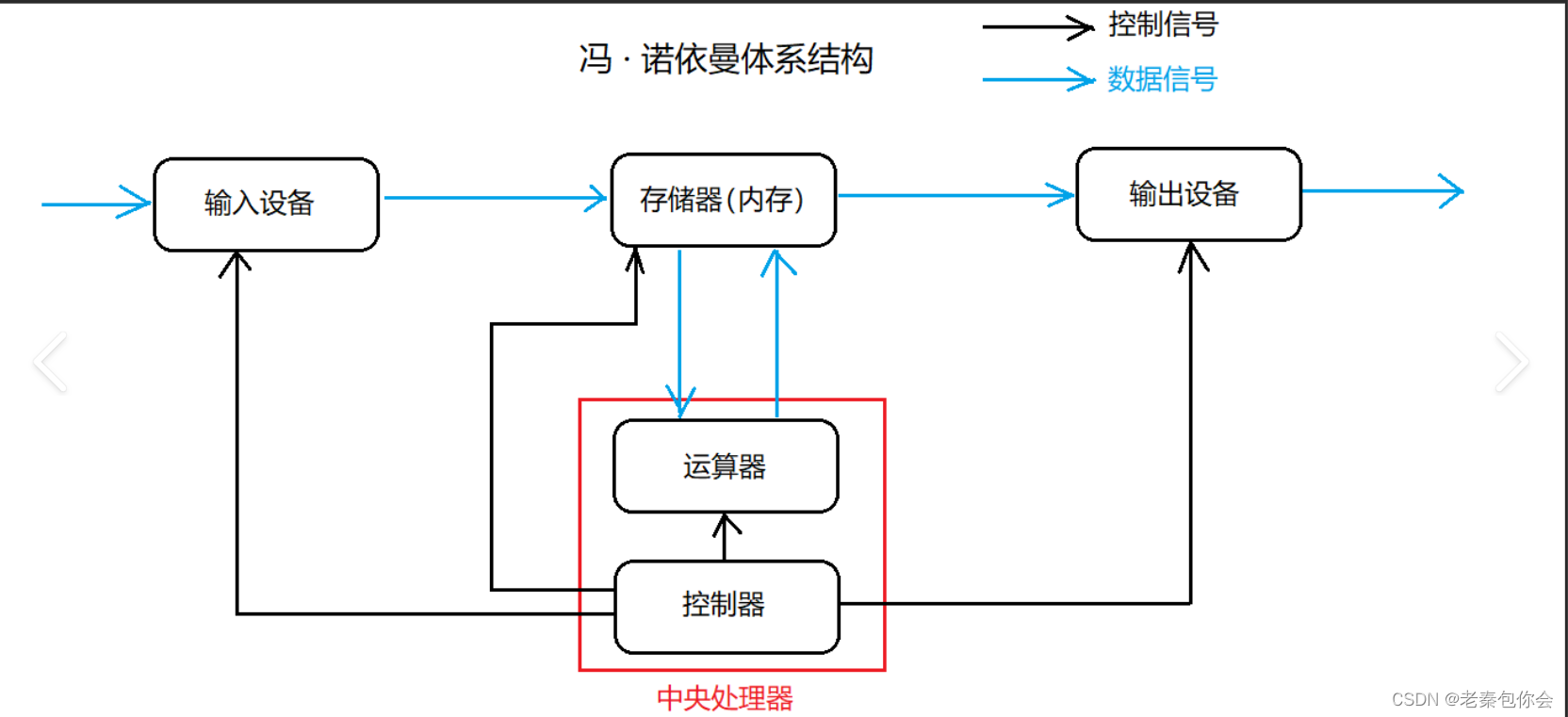
cpu:运算器和控制器组成
内存储器:内存
输入设备:话筒、摄像头、键盘、鼠标、磁盘、网卡
输出设备:声卡、显卡、网卡、磁盘、显示器、打印机,也可能两者都是
目的:通过设备连接进行设备之间数据流动
数据流动:本质就是设备之间会进行数据的来回拷贝,而拷贝的整体速度是决定计算金效率的重要指标
内存金字塔
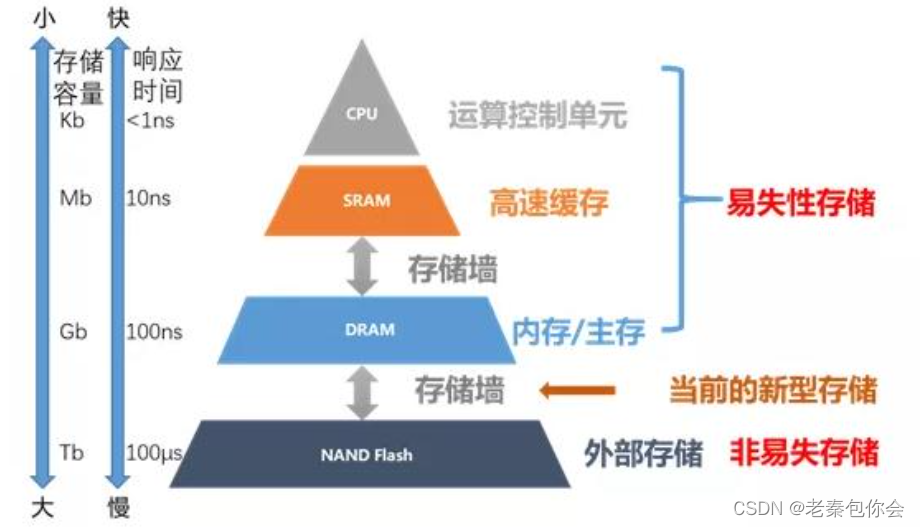
可以看出,接近顶的存储单元效率高,但是造价贵,容量小
为啥要有内存呢?
如果没有内存,cpu的处理速度是很快的,当输入的速度很慢,以至于导致cpu存在很大的时间是空闲的,
内存的引入可以使计算机的效率还不错,造价便宜-
例子:
(1)程序在运行的时候,必须加载到内存里面去
我们知道,程序是一个文件,文件存储在磁盘,而磁盘属于外设,程序最终是要在cpu上运行的,在数据层面,cpu只和内存打交道,而外设只和内存打交道,所以程序要运行,必须加载到内存里面去
操作系统
操作系统是一款进行软硬件管理的软件
当我们打开电脑的时候被加载的就是操作系统
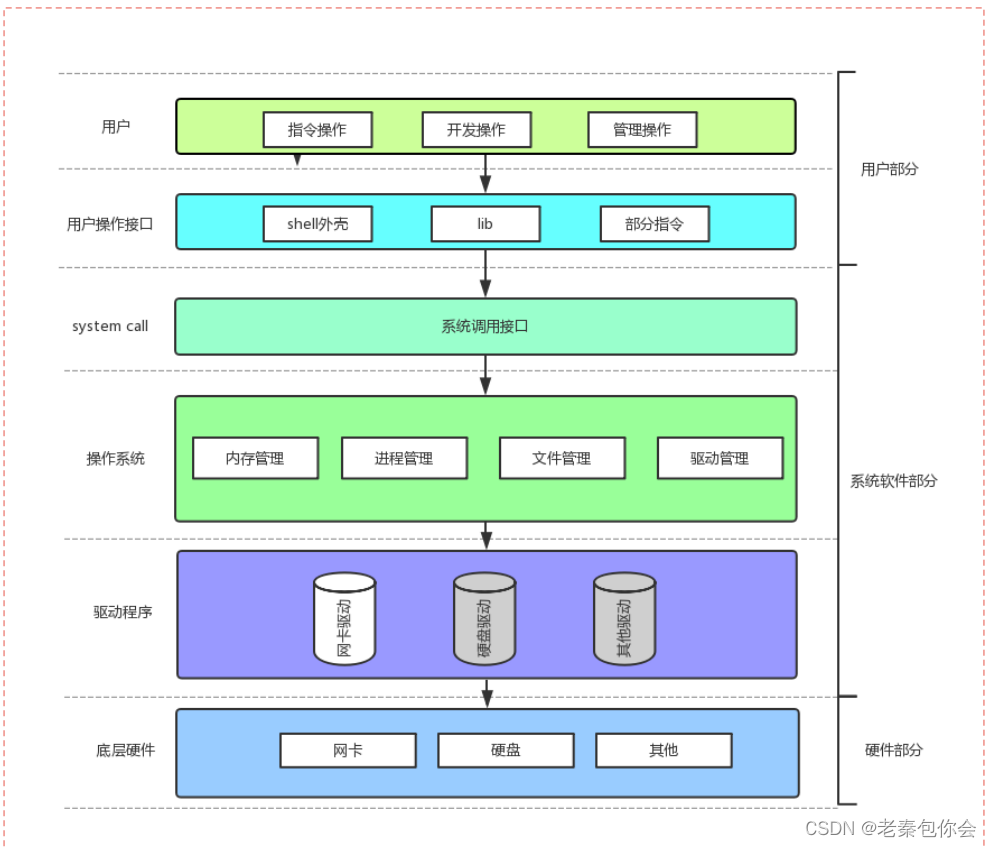
每一款硬件,都有属于自己的驱动程序,而操作系统里面 的软件只有负责调动对应的驱动程序就可以调动对应的硬件
操作系统是管理者,硬件是被管理者,两者不需要见面,本质是对相对应的数据进行管理就行
管理者的核心是做决策,根据数据做决策
对于管理的一个计算机的建模过程:先描述,再组织
计算机管理:
1 .先描述(struct描述)
2.再组织(数据结构)
为啥要有操作系统?
它让计算机运行更为稳定,同时也减少了软件开发者的工作量,因为程序猿只需要考虑操作系统的标准接口,而不需要考虑硬件系统的底层差异
为啥要有操作系统管理:
对下管理好软硬件资源-------手段
对上提供一个良好的运行环境-----目的
系统调用和库函数概念
在开发角度,操作系统对外会表现为一个整体,但是会暴露自己的部分接口,供上层开发使用,这部分由操作系统提供的接口,叫做系统调用。
系统调用在使用上,功能比较基础,对用户的要求相对也比较高,所以,有心的开发者可以对部分系统调用进行适度封装,从而形成库,有了库,就很有利于更上层用户或者开发者进行二次开发。
进程
我们可以看到
- 我们可以同时启动多个进程
- 操作系统要管理多个加载到内存的程序
- 操作系统管理加载到内存的程序是要先描述,再组织
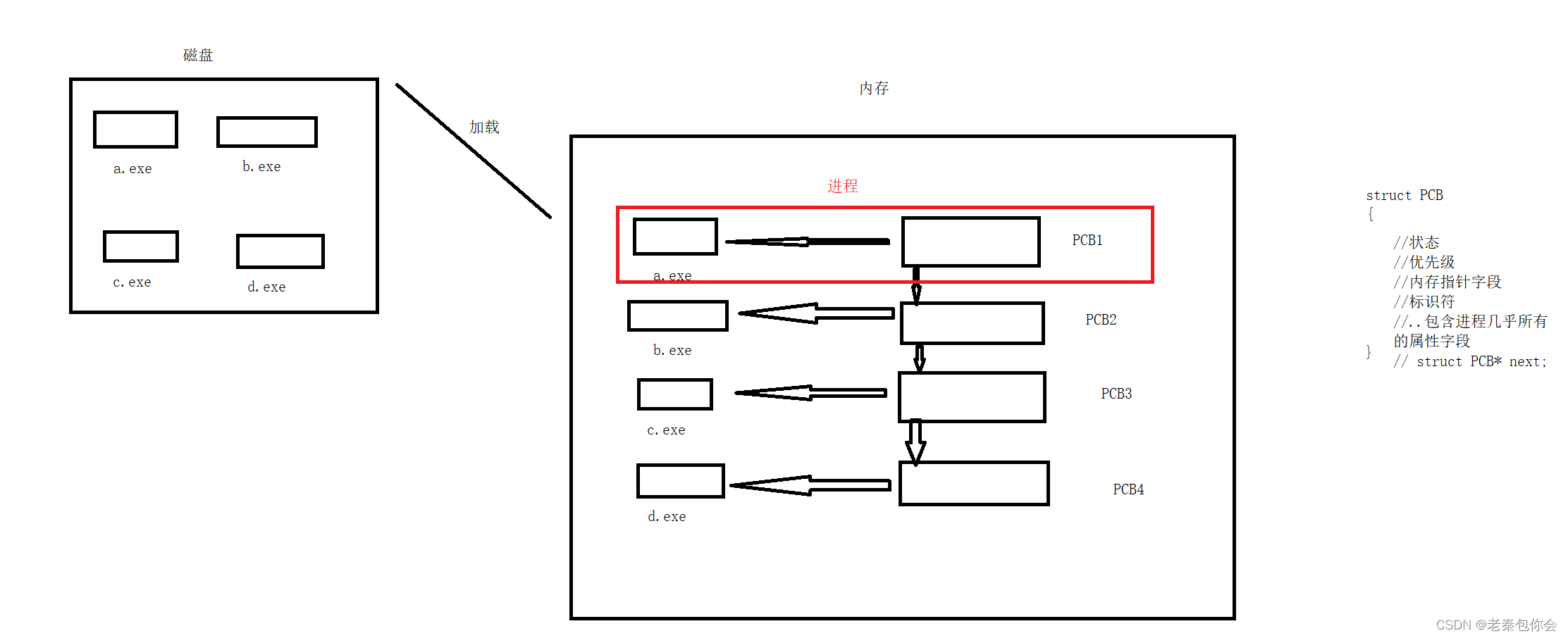
可以看出,可执行文件加载到内存中会形成一个个的PCB对象,所以,进程 = PCB对象+可执行程序
如果是cpu调用一个进程,只需要调用对应的PCB就可以了,
所以,未来对进程的控制和操作,都只和进程的PCB有关,和进程的可执行程序无关
描述进程-PCB
进程信息被放在一个叫做进程控制块的数据结构中,可以理解为进程属性的集合
在Linux中描述进程的结构体叫做task_struct。
task_struct是Linux内核的一种数据结构,它会被装载到RAM(内存)里并且包含着进程的信息。
task_ struct内容分类
标示符: 描述本进程的唯一标示符,用来区别其他进程。
状态: 任务状态,退出代码,退出信号等。
优先级: 相对于其他进程的优先级。
程序计数器: 程序中即将被执行的下一条指令的地址。(就是cpu的pc指针)
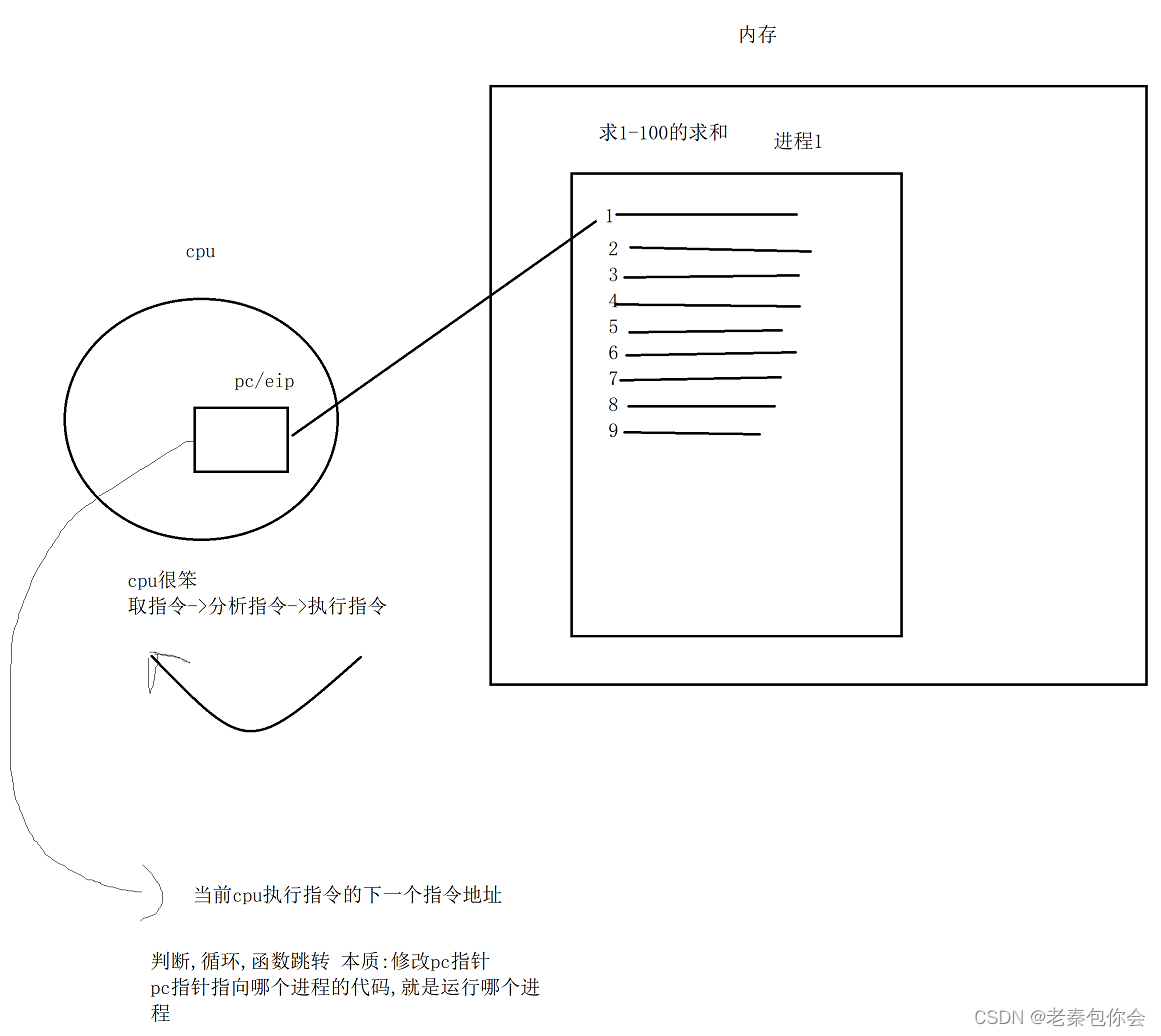
内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针(找到进程)
上下文数据: 进程执行时处理器的寄存器中的数据[休学例子,要加图CPU,寄存器]。
I/O状态信息: 包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。
记账信息: 可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。
其他信息
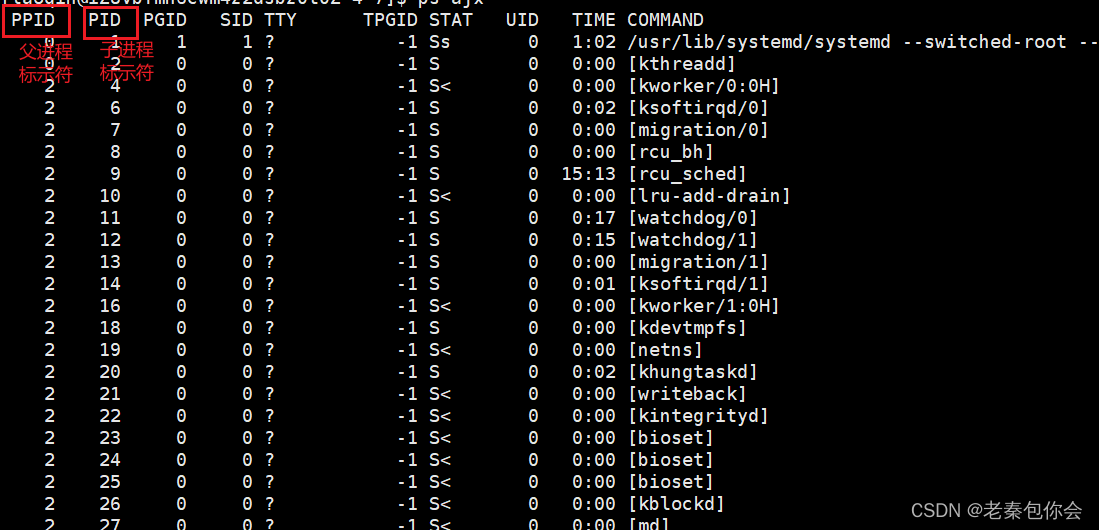
查看进程
ps axj
下面我们可以写一个c的程序进行运行
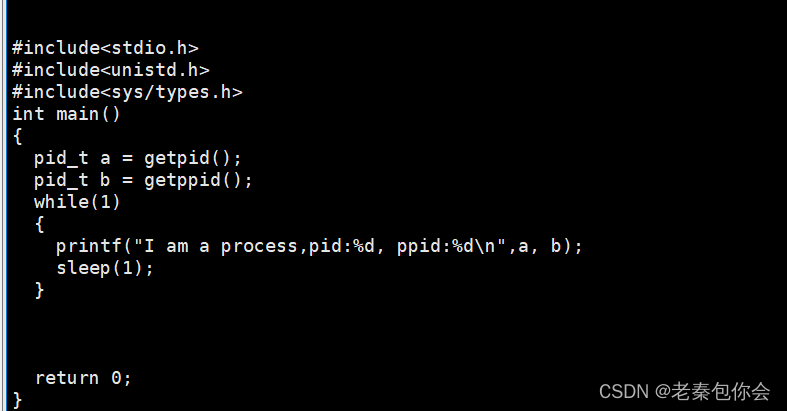
然后运行
ps ajx | head -1 && ps ajx | grep myprocess | grep -v grep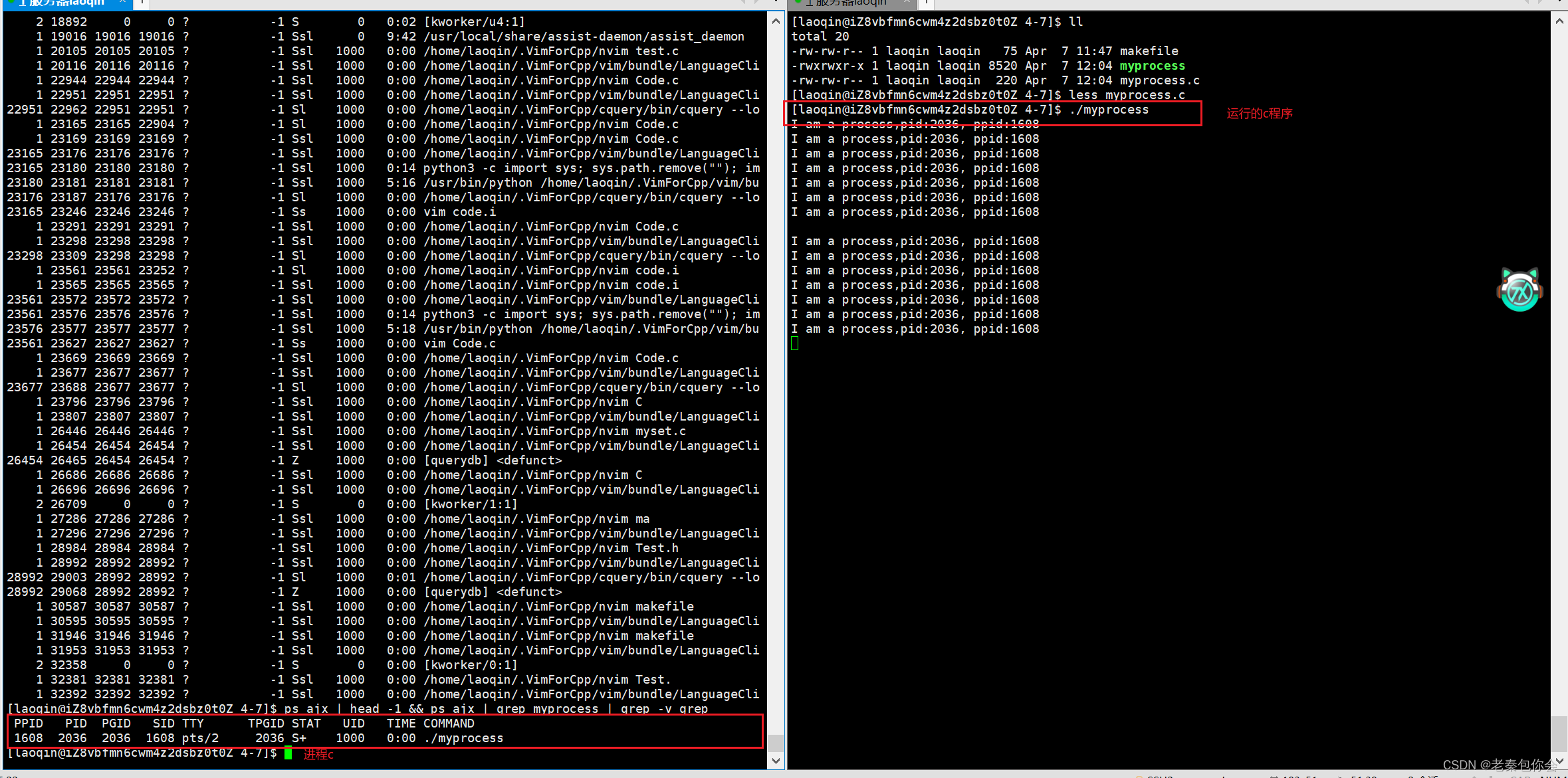
如果我们不断的运行这个程序就会发现该程序的PID是不断变化的,而父进程的PID是不变的,
当我们查看进程PID为父进程的PID的时候

我们可以通过查看系统文件/proc来进行,查找对应的父进程的PID或者普通进程的PID
/proc
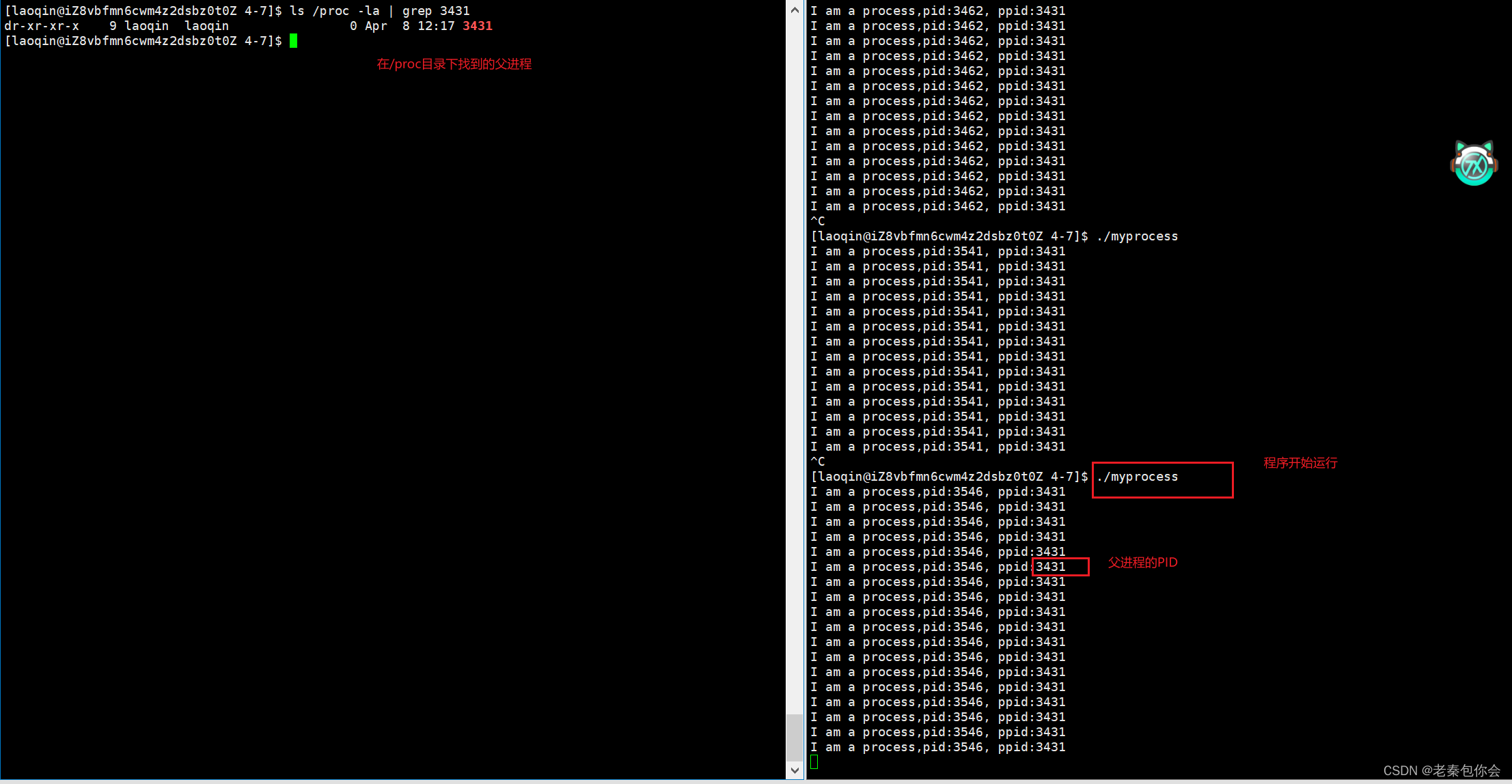
当我们进入到普通进程的文件夹里面
的时候
ls /proc/3546 -la ## 3546是一个进程文件夹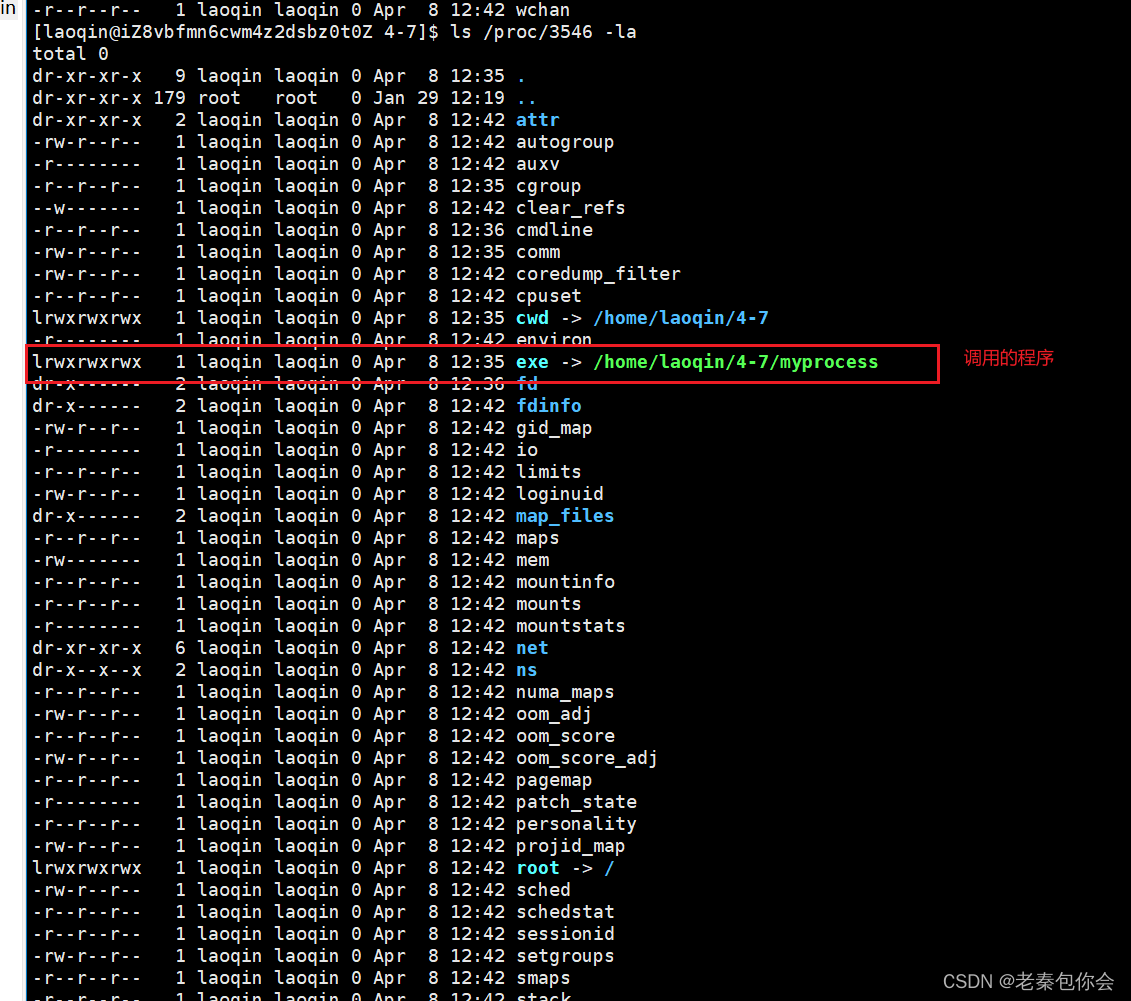
当我们把这个进程运行结束,这个文件夹也就没有了,
图中:

这个就是该程序的所在目录,前面我们学过C语言的fopen函数,就会知道,如果我们往文件写入,如果文件不存在就会在当前目录创建该文件.计算机是怎么知道当前目录的,就是靠这个进程的cwd指向的地方
我们先写一段代码进行实现
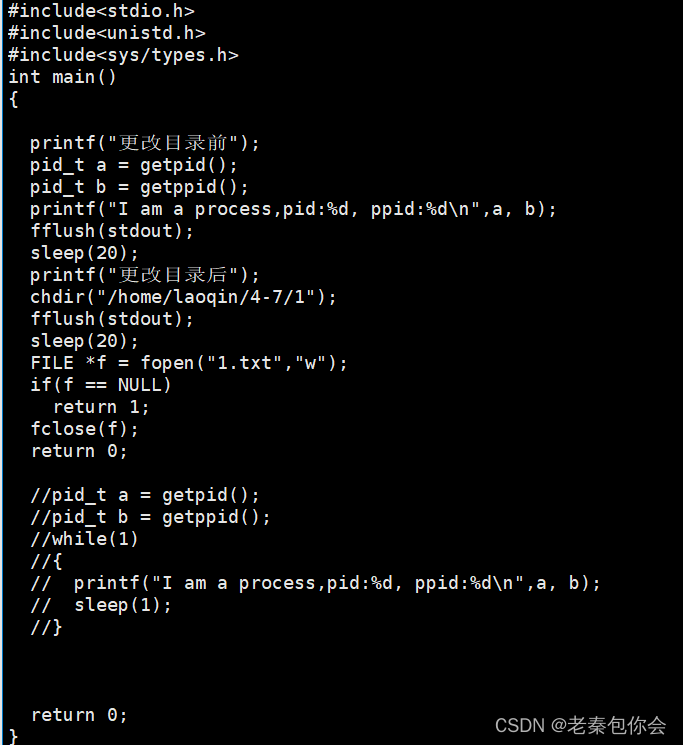
然后运行出来,分别查看更改前和更改后的cwd有没有改变,
更改前:

更改后:

可以发现是更改了,如果取查看对应的目录就会发现,文件也创建好了
创建进程(fork)
一个进程的创建,先创建出来的是PCB,然后再把可执行程序进行加载到内存
认识fork
man 2 fork然后我们写一个,如图的代码
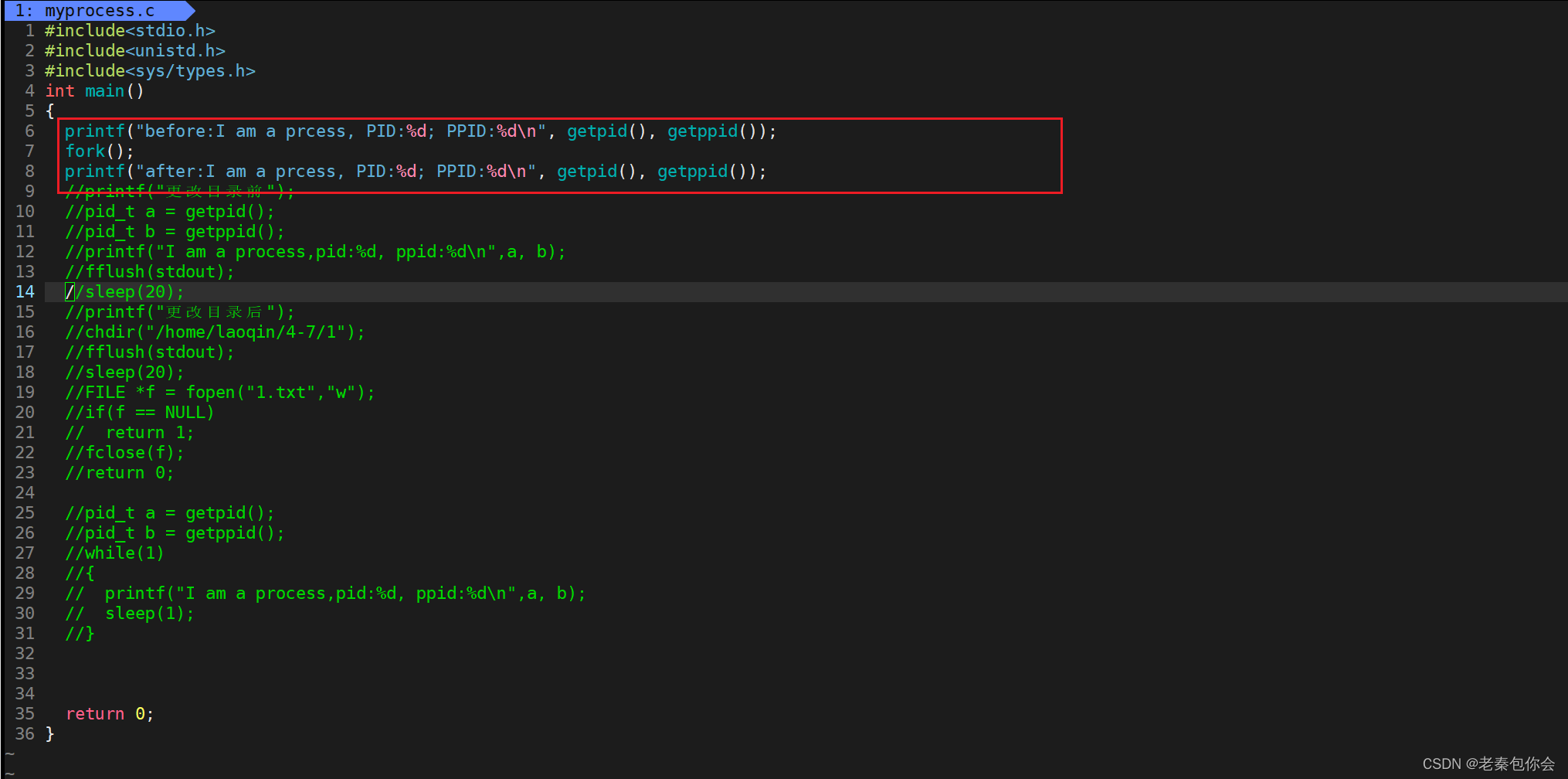
当我们打印出来的时候就是

和我们预期的不一样,为啥呢?
因为fork之后的代码父进程和子进程共享,上图中的子进程的父进程的PID就可以大致猜到一二了,
fork函数有两个返回值,如果是父进程就会读取到子进程的PID,如果是子进程就会读取到0,否则返回失败就返回小于0的数
为啥会这样呢?
因为父进程可以拥有多个子进程,而子进程只有一个父进程,子进程找到父进程很容易,但是父进程找到子进程必须有PID,也就是父进程要知道子进程的PID
为啥fork函数会返回两个值呢?
因为父进程在fork函数返回一次,子进程在fork函数也返回一次,而我们的变量是一个虚拟地址,当我们把C语言代码,变成二进制指令,也就是映射到了物理地址,在Linux中可以使用相同的同名的变量,来表示不同的内存,也就是说,
在操作系统中,fork() 是创建一个新进程的系统调用。在调用 fork() 之后,操作系统会复制父进程的地址空间,并将它分配给子进程。这种机制被称为写时复制(Copy-on-Write)。
在父进程和子进程之间,初始时它们共享相同的物理内存页面。这意味着它们的虚拟地址是相同的,但实际上指向的是相同的物理内存页。这样,父子进程之间可以共享数据,减少内存的开销。
然而,当其中一个进程尝试修改共享的内存页时,操作系统会采取一定的措施来保证数据的一致性。具体来说,当有进程要修改一个被共享的内存页时,操作系统首先会为该进程分配一个新的物理内存页,然后将原来的内存页的内容拷贝到新的内存页中。这样一来,父进程和子进程分别拥有各自的内存页副本,它们的虚拟地址对应的物理内存页就不再相同。
因此,通过 fork() 创建的子进程在修改共享变量时会拥有自己的副本,这就解释了为什么父子进程的公共变量在相同的地址上具有不同的值。
需要注意的是,这种写时复制机制只适用于父进程和子进程之间的直接修改。如果父进程创建了子进程,并且子进程继续创建了更多的子进程,那么它们之间的共享内存仍然是相同的,因为它们共享同一个物理内存页。只有当有进程尝试修改这些共享内存页时,才会进行拷贝操作。
此外,每个操作系统在实现 fork() 和写时复制时可能有所不同,但基本原理是相似的。以上解释是一般情况下对 fork() 和写时复制机制的描述,具体细节可能因操作系统的不同而有所差异。
进程之间是不影响,一个进程结束,不会影响另外一个进程
杀死进程
kill -9 8854进程
进程排队
我们知道进程不会一直运行下去,哪怕放在cpu上,进程排队一定是为了等待某种资源,是进程的PCB进行排队的,进程 = stack_struct + 可执行程序;
PCB可以被多种数据结构连入,就拿我们熟悉的链表形式
在我们平时练习的链表中
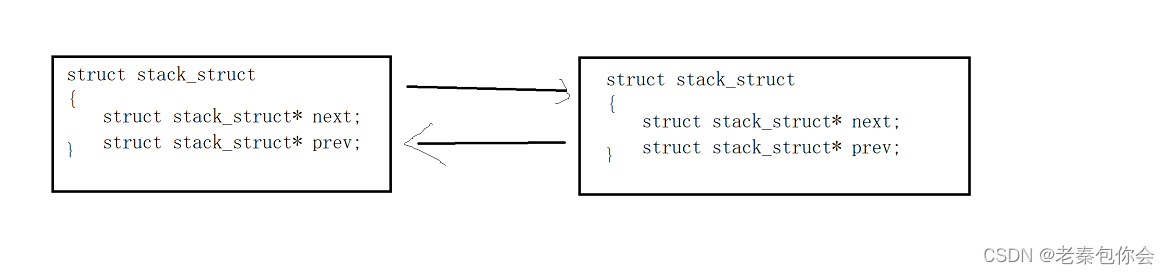
链表的next指向下一个节点的地址
而在Linux中有点不一样
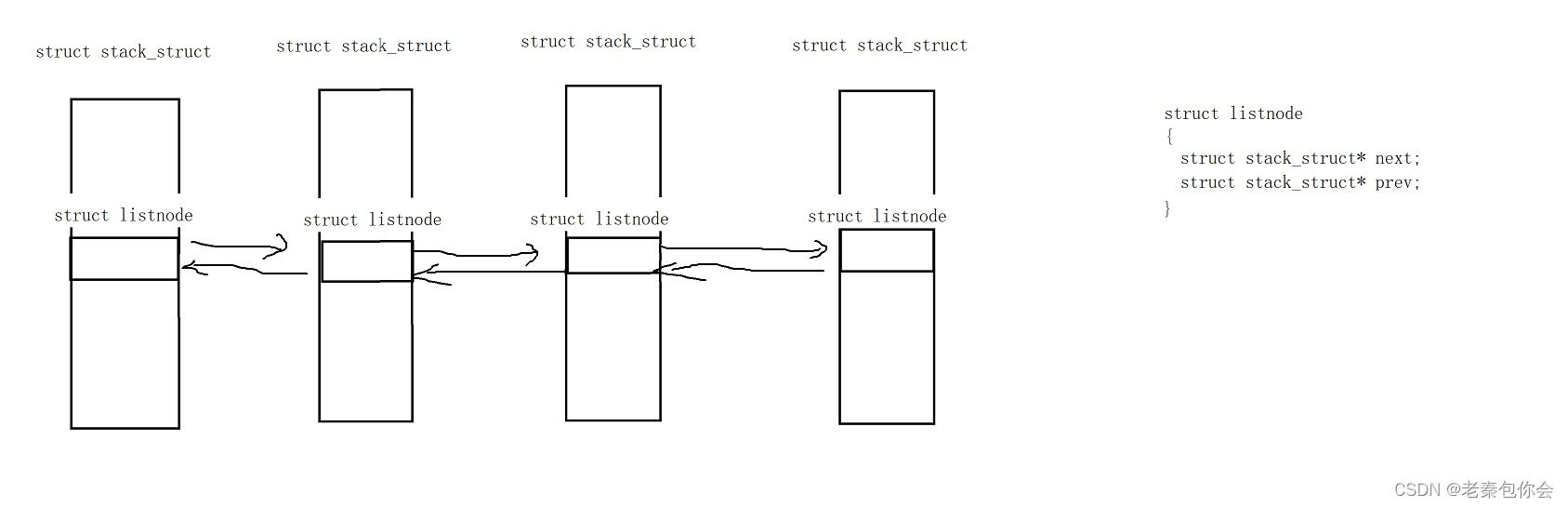
是stack_struct里面一个listnode来进行链接的,
如果要拿到stack_struct的首地址,可以listnode减去偏移量,定义一个listnode结构体变量为n
偏移量
&(((stack_struct*)0)->n)
进程状态
运行
进程处于要么是在运行中要么在运行队列里
所谓的状态就是一个整形变量
#define NEW 1
#define READY 2
#define RUNNING 3
#define BLOCK 4
而状态在stack_struct中,是一个整形变量,这个整形变量的值决定这个进程的状态
进程的状态决定了后续行为
一个cpu一个运行队列
例如
struct runqueue
{int num;stack_struct *q;
}
在运行队列中的进程称为运行状态
阻塞
指的是一个进程在执行过程中,由于某些原因无法继续执行,需要等待某个事件的发生或者资源变得可用后才能继续执行
前面我们讲过,
操作系统要管理软硬件,要先描述,在组织,

然后连入数据结构中进行各种操作
当我们在Linux中写一个简单的输入输出代码
int a = 0;
scanf("%d", &a);
printf("%d\n", a);
运行起来就会发现,程序等待我们输入,为啥会等待,
我们假设一下,这个进程被放入在cpu的运行队列中,运行到scanf中,由于无法进行运行,就会把该进程的状态改为阻塞状态,踢出cpu运行队列中,然后把该进程链入到键盘设备队列(等待队列)中,等到输入数据,就会把这个进程在放到cpu的运行队列里,并把阻塞状态改为运行状态,等待调度
需要注意的是,每个设备都可以有自己的队列,就跟cpu的运行队列是一样的,只是这个队列是等待队列,cpu的是运行队列
总结: 状态的变迁,会引起的是PCB会被OS(操作系统)变迁到不同的队列中
挂起
前提:计算机资源吃紧,
我们知道,一个进程要先运行,必须加载到内存里面去,进程 = PCB+可执行程序,只要我们对对应的PCB进行管理,就可以对对应的代码和数据进行管理,内存拥有很多进程,在运行一些进程时,如果发生内存不足,就会使进程崩溃,为了解决这个问题, 内存就有一个机制,就是把一些目前未在就绪状态的进程(或者没有现阶段不需要运行的进程)中的可执行程序(代码和数据)和磁盘的swap分区进行换入和换出,把内存的空间腾出来、
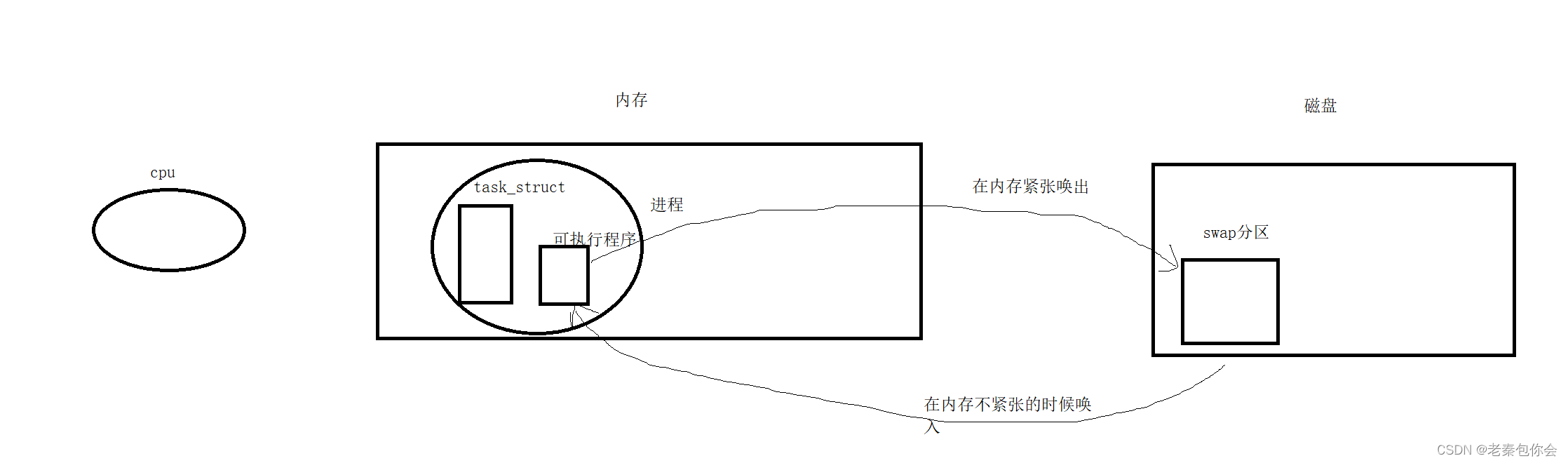
此时这些进程就称为挂起状态
注意:PCB不能唤出,因为唤出,就无法知道这个进程是啥,无法管理,
一个进程的创建,先创建出来的是PCB,然后再把可执行程序进行加载到内存
进程状态的代码
/*
* The task state array is a strange "bitmap" of
* reasons to sleep. Thus "running" is zero, and
* you can test for combinations of others with
* simple bit tests.
*/
static const char * const task_state_array[] = {
"R (running)", /* 0 */
"S (sleeping)", /* 1 */
"D (disk sleep)", /* 2 */
"T (stopped)", /* 4 */
"t (tracing stop)", /* 8 */
"X (dead)", /* 16 */
"Z (zombie)", /* 32 */
};
R运行状态(running): 并不意味着进程一定在运行中,它表明进程要么是在运行中要么在运行队列
里。
S睡眠状态(sleeping): 意味着进程在等待事件完成(这里的睡眠有时候也叫做可中断睡眠
(interruptible sleep))
D磁盘休眠状态(Disk sleep)有时候也叫不可中断睡眠状态(uninterruptible sleep),在这个状态的进程通常会等待IO的结束。
T停止状态(stopped): 可以通过发送 SIGSTOP 信号给进程来停止(T)进程。这个被暂停的进程可以通过发送 SIGCONT 信号让进程继续运行。
X死亡状态(dead):这个状态只是一个返回状态,你不会在任务列表里看到这个状态。
运行状态(R)
我们写一个简单的代码,来运行看看
#include<stdio.h>
#include<stdlib.h>
#include<sys/types.h>
#include<unistd.h>
int main()
{while(1){printf("pid: %d\n", getpid());sleep(2);}return 0;
}运行起来

查看对应的进程
ps ajx | head -1 && ps ajx | grep myprocess|grep -v grep

可以看到进程的pid, STAT表示的就是状态 ,可以看出,这个程序是S+状态,为啥会是这个状态,
因为printf是要访问外设的,还有sleep是在等待,,所以说这个进程处于一种等待状态,printf执行完,sleep执行完,如果要想该进程是R状态,我们可以删除while里面的代码,只进行循环,
这里我选择注释掉,我们运行看看
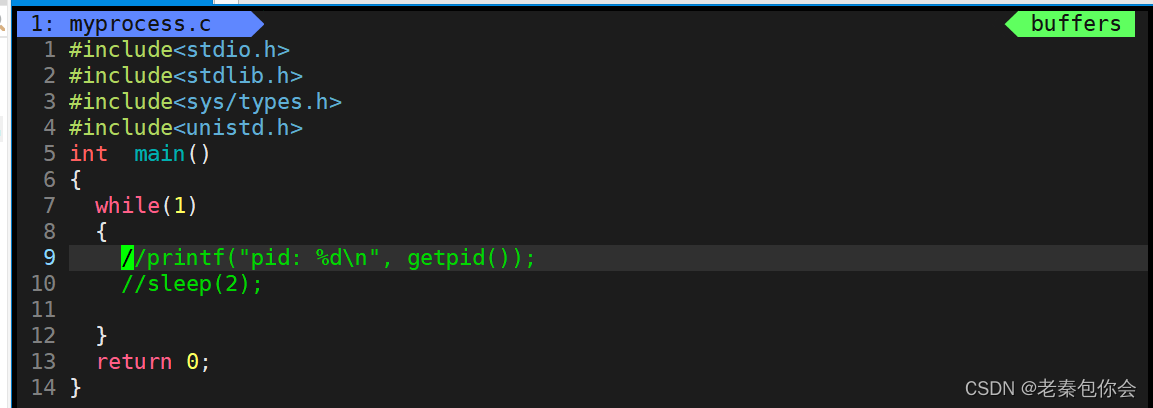

可以看出,这个程序是一直运行, 运行状态,我们添加scanf等这些函数,本身这些函数需要调用到对应的外设就得需要运行对应的外设进程,这些外设进程不一定是就绪状态,需要等待, 虽然我们看到很快,但是cpu的运行速度比外设快很多的
后台进程
需要注意的是: R+中的+表示该进程是前台, 如果要把该进程放在后台
可以在直接在在后面加个 &,表示后台进程
./myprocess &
后台进程需要用kill命令来杀死才行
运行状态(S)
是多种阻塞状态的一种,这种状态是可以终断的,ctrl+c就可以终断
例如:
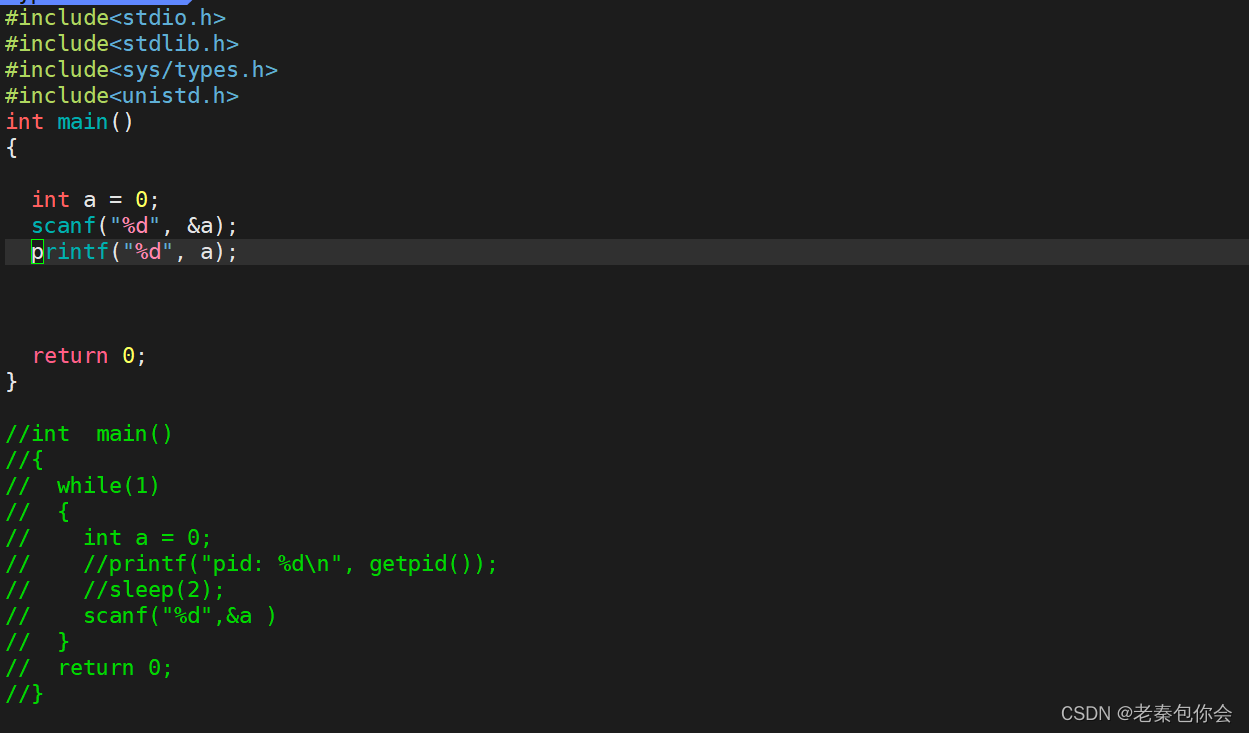
如图,简单代码,然后运行,然后中断

运行状态(D)
是阻塞状态的一种,这种状态是不可中断的,不能被杀死
我们可以想像一下,
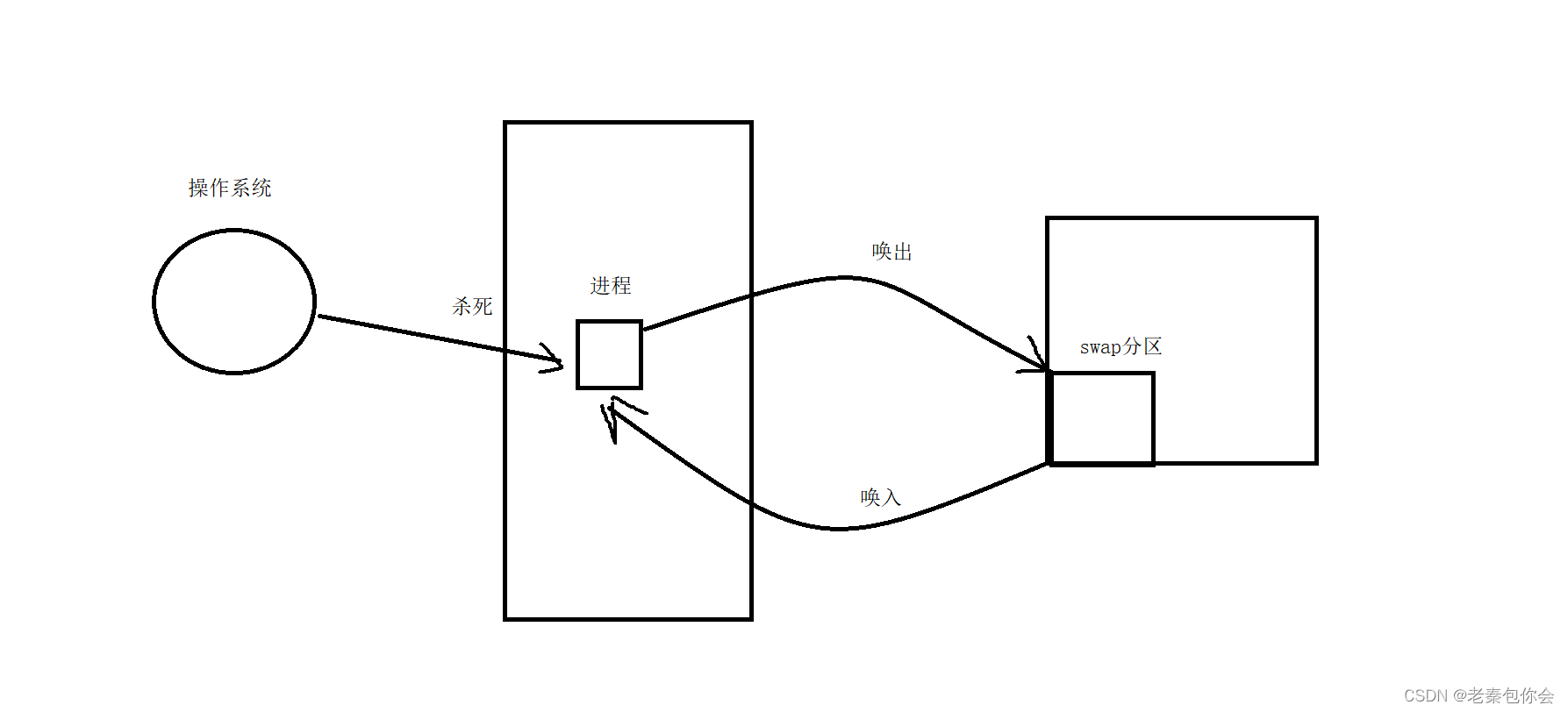
内存很吃紧的状况下, 进程吃着瓜子等数据唤入,操作系统为了内存能腾出空间,就会杀死进程(发生在内存严重不足的情况下),如果刚好在写入swap分区 的数据刚好还差一些数据没有写入,该进程又刚刚杀死了。swap分区就会回收该进程的在swap占据的全部空间,刚好这个进程是一个很重要的进程,就会导致了这部分的数据的丢失,所以为了解决这个问题, 就增加了这个运行状态,
运行状态(T)
也是阻塞状态的一种
这里为了让我们清楚的看到,需要用到kill命令
kill有多种的命令,
查看kill命令相关发
kill -l
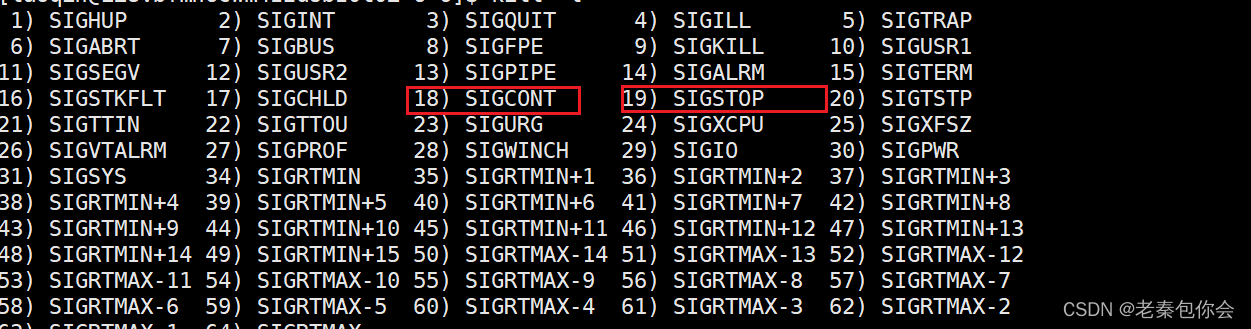
这里我们需要用到18和19,
19命令可以使一个正在运行的进程暂停,
kill -19 17934
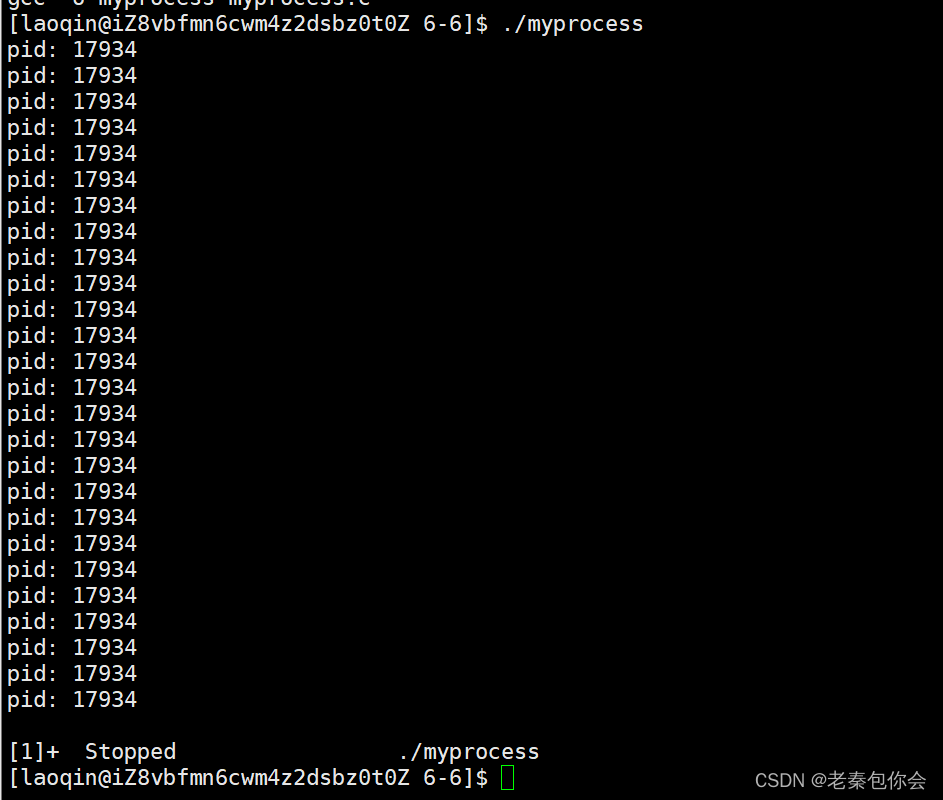
可以看到进程停止了,我们查看进程的状态
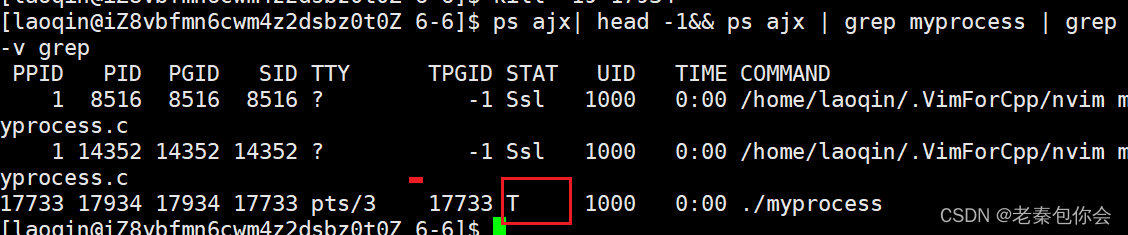
变成了T状态,并且进程由前台变成在后台上,
我们再把该进程运行起来
kill -18 17934结果:
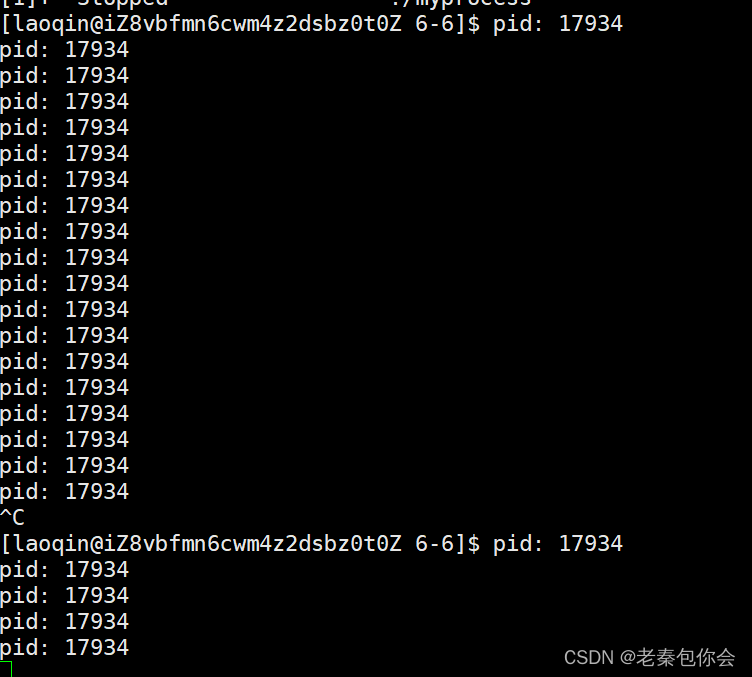
会发现,进程重新运行起来,但是ctrl +c 没有把进程终止掉,查看进程的状态
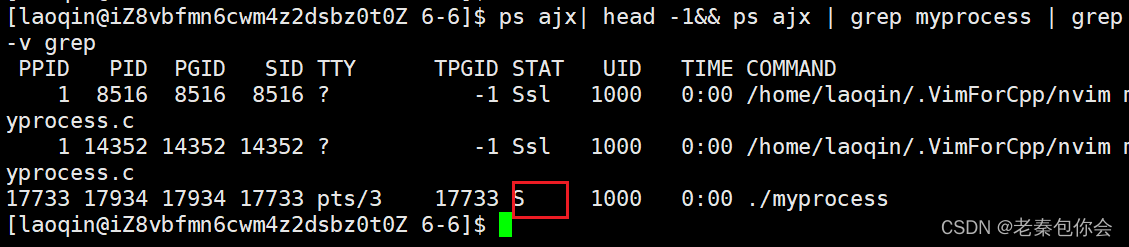
发现进程在后台上,这里后面讲解
运行状态(t)
也是阻塞状态的一种
这也是一种暂停状态,只是这种状态和T状态不一样,有一种属性:被追踪的状态
这里我使用gdb演示一下:
进入gdb:
状态:

调试进程状态是前台睡眠状态(阻塞状态的一种),这个进程不是我们关注的
当我们打个断点运行起来,运行到断点处,我们查看myprocess的进程(该进程是状态为t的进程,不是第一个进程),就会发现状态是t

运行状态(Z)
僵尸状态
简单的理解就是,该进程执行结束了,但是不能马上进行销毁,只有等到父进程或者其他进程获取到该进程的状态,该进程 的PCB就会被释放掉,,如果该进程的状态一直没有被获取,PCB就会一直存在, 但是代码和数据可以释放掉
我们可以写一个程序
2 #include<stdio.h>3 #include<stdlib.h>4 #include<sys/types.h>5 #include<unistd.h>6 int main()7 {8 int a = fork();9 if(a > 0)10 {11 printf("我是父进程,我知道子进程的pid:%d\n", a);12 }13 else if(a == 0){ 14 15 printf("我是子进程,我获取到的for值是:%d\n", a);16 exit(0);17 }18 else{19 printf("我是失败了\n");20 exit(0);21 }22 23 sleep(30);24 25 return 0;26 }
~运行起来的结果如下:

然后我们查看对应的子进程的就会发现,子进程的状态是僵尸状态,如图:

所以我们可以理解为: Z状态是希望这个进程结束后,需要给上层读取, 如果该状态下的进程没有被获取,就会一直占用内存,(内存泄漏), 所有的进程运行结束后,先是Z状态哦
孤儿进程
前面我们知道了。子进程结束后会等待上层获取到,然后子进程才能被释放掉。如果父进程比子进程先结束,则该子进程被称为孤儿进程,父进程会被bash进程回收掉
孤儿进程被1号init进程领养,当然要有init进程回收喽。
例子:
我们可以一个例子,代码如下
1 #include<stdio.h>2 #include<unistd.h>3 #include<sys/types.h>4 int main()5 {6 pid_t it = fork();7 8 if(it)9 {10 int i = 0;11 printf("I am is father, pid: %d ppid:%d\n", getpid(), getppid());12 while(i <5)13 {14 15 printf("I am is father, pid: %d ppid:%d\n", getpid(), getppid());16 i++;17 sleep(1);18 }19 20 }21 else22 {23 int i =0;24 printf("I am is chlid, pid: %d ppid:%d\n", getpid(), getppid());25 26 while(i <20)27 {28 printf("I am is chlid, pid: %d ppid:%d\n", getpid(), getppid()); 29 i++;30 sleep(1);31 }32 }33 return 0;34 }
~运行结果:截图主要分为两部分,左部分是运行程序,右部分是查看进程的
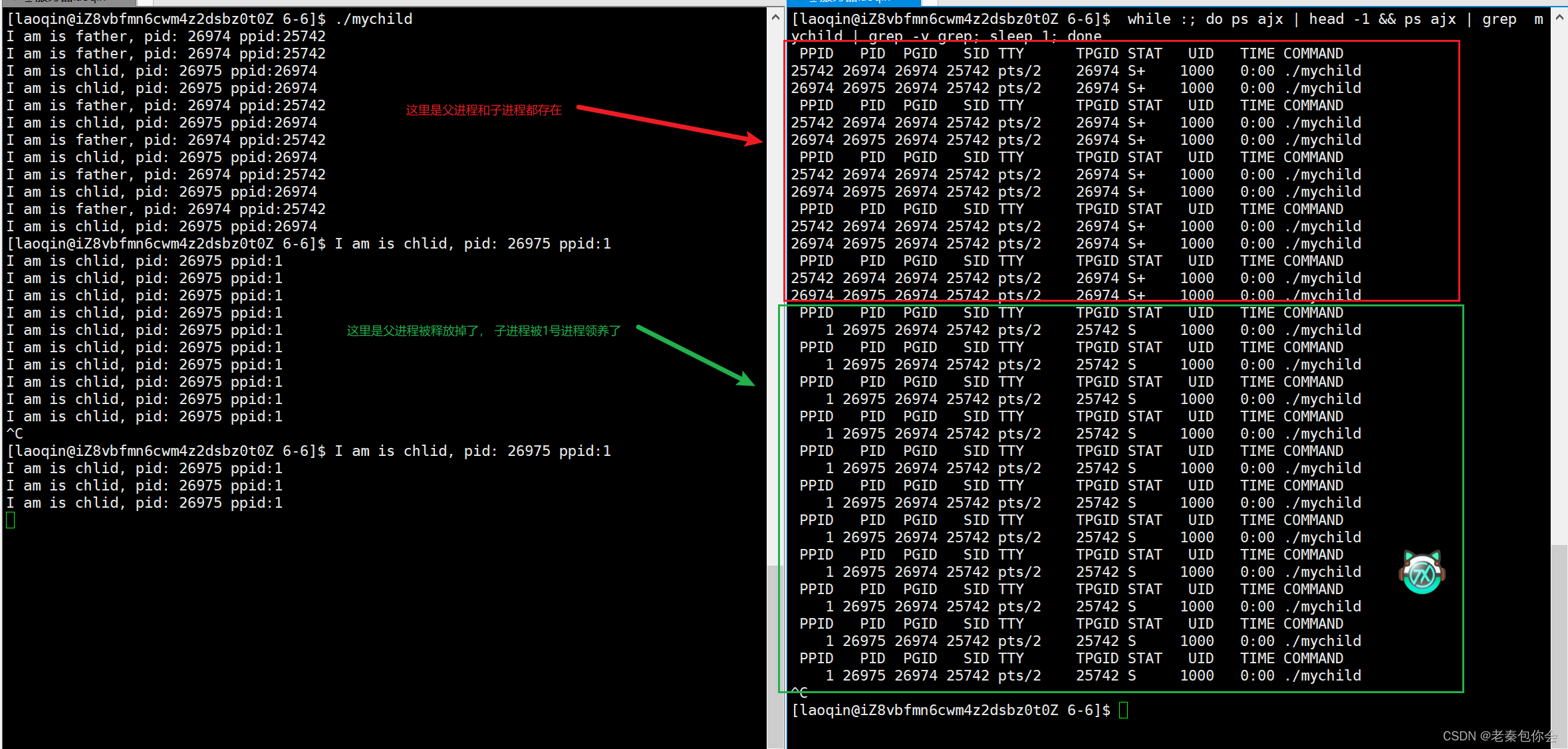
从图中可以看出,父进程比子进程先释放掉,子进程被1号进程领养了,子进程也跟着变成后台进程了
需要被kill -9 来杀死
进程优先级
注意: 优先级和权限是两个不一样的概念,优先级是先后顺序,权限是可不可以做
显示当前用户运行的所有进程
ps -al
如图,
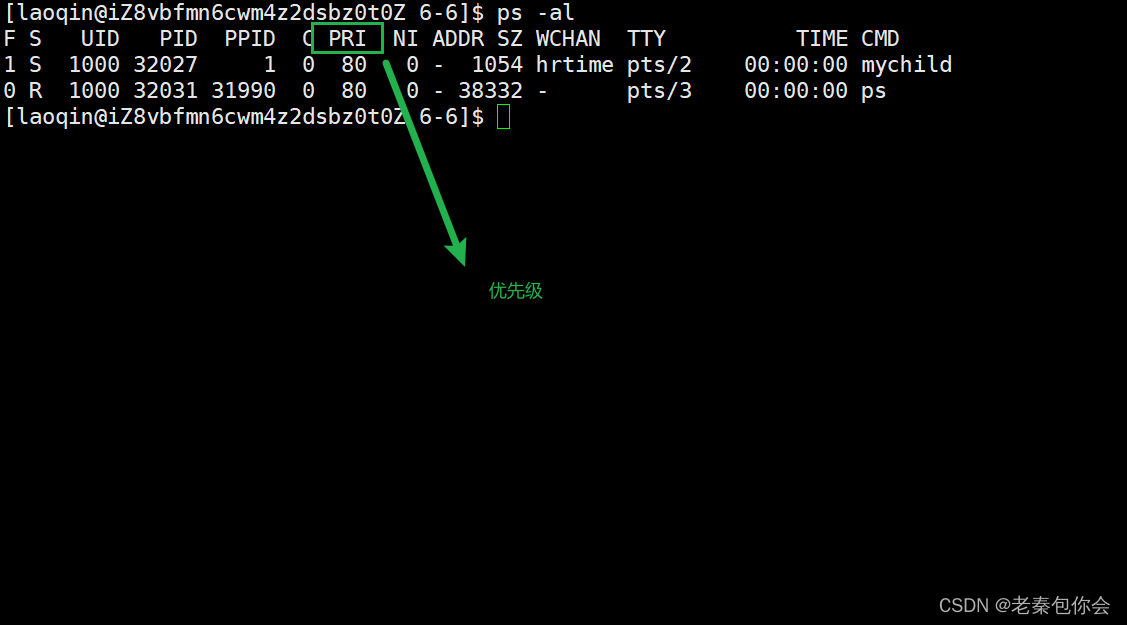
图中的PRI就是优先级,
UID : 代表执行者的身份
PID : 代表这个进程的代号
PPID :代表这个进程是由哪个进程发展衍生而来的,亦即父进程的代号
PRI :代表这个进程可被执行的优先级,其值越小越早被执行
NI :代表这个进程的nice值
相当于一个PCB结构体里面的一个整数

linux里面默认的优先级就是80, linux的优先级的大小是[60,99],优先级是可以修改的
数值越小,优先级越高
优先级修改
进入任务管理器
top
如图:
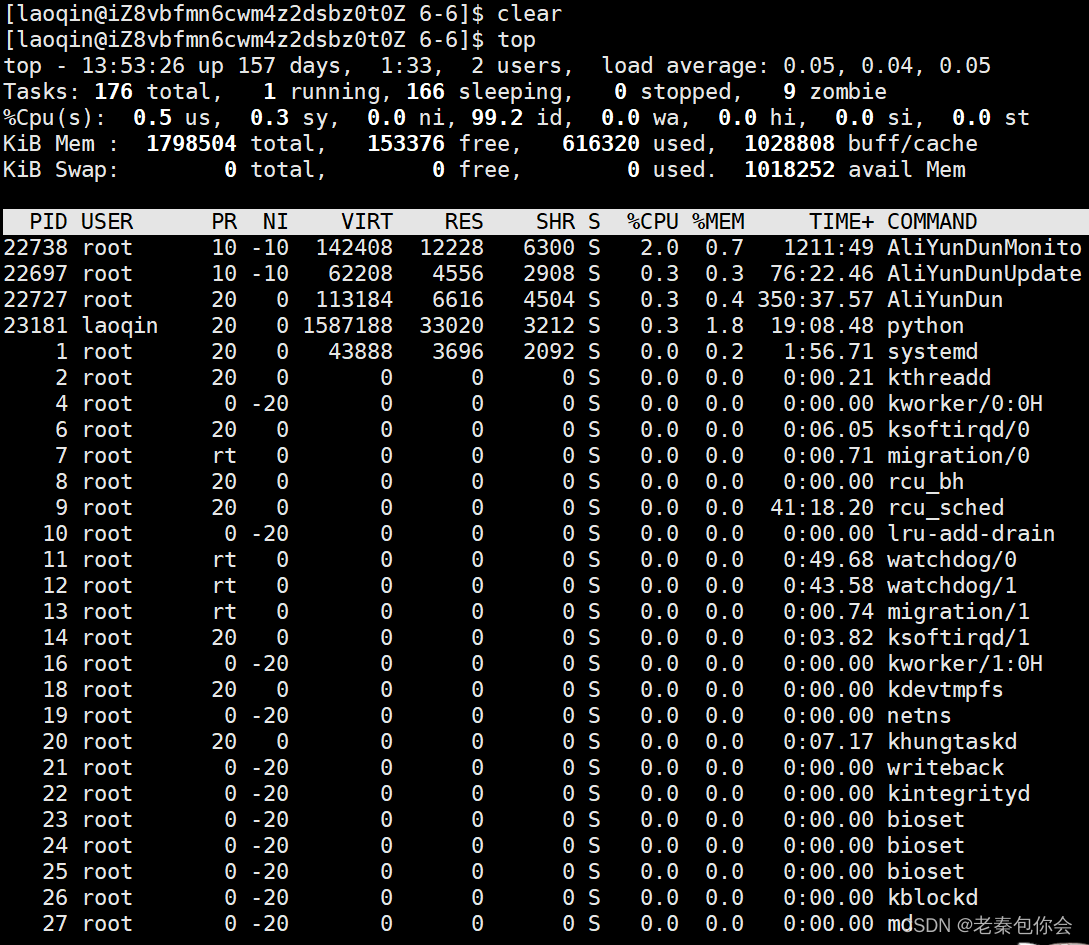
然后输入r键之后就出现下面的提示:

然后输入你要更改哪个进程的pid,然后会有一个提示

然后输入你要增大的数值
.然后查看对应的PRI就行了
其实Linux系统允许用户调整优先级。但是不能直接更改PRI,而是修改nice值,
PRI = PRI(old)+ nice,所以我们在这里更改的就是nice
如图:

其中这个PRI(old) = 80(这个是定的,不能更改),nice值可正可负,会进行极值的判断,nice在[-20, 19]范围,设置这个范围主要是约束程序员的过度把自己的进程调整过高,让一些进程迟迟等不到资源,进而让 造成进程饥饿问题
如果要进行更改nice值,建议 使用
sudo top
这样可以预防无法进程nice负值操作
Linux的调度与切换
在进程运行的时候,不一定是要把代码运行完,因为现代的操作系统中,都是基于时间片进行轮转执行的
- 竞争性: 系统进程数目众多,而CPU资源只有少量,甚至1个,所以进程之间是具有竞争属性的。为了高
- 效完成任务,更合理竞争相关资源,便具有了优先级
- 独立性: 多进程运行,需要独享各种资源,多进程运行期间互不干扰
- 并行: 多个进程在多个CPU下分别,同时进行运行,这称之为并行
- 并发: 多个进程在一个CPU下采用进程切换的方式,在一段时间之内,让多个进程都得以推进,称之为并发
进程切换
我们前面知道,进程加载到内存中,然后由cpu调度,其中cpu有一个属于自己的运行队列,把进程安照队列的形式进行排列,cpu调度进程,调用对应的PCB就可以了,PCB会找到对应的可执行程序(代码)
在cpu中拥有许多品质的寄存器,比如:eax/ebx/ecx/,eds.ecs/fg…等寄存器,
进程在cpu运行中,会产生许多的临时数据,这些数据需要使用寄存器来存储,没有存储到寄存器的数据,我们可以默认是进程的代码。
我们知道,进程的运行是基于时间片来进行轮转的,当一个进程运行的时间,和时间片相等,就会跳到下一个进程中,跳到下一个进程之前,会把在cpu的寄存器(进程运行产生的临时数据都保存在寄存器中, 这些进程的所有临时数据叫做进程的硬件上下文)中的数据保存到对应的PCB(我们目前理解成这个样子),
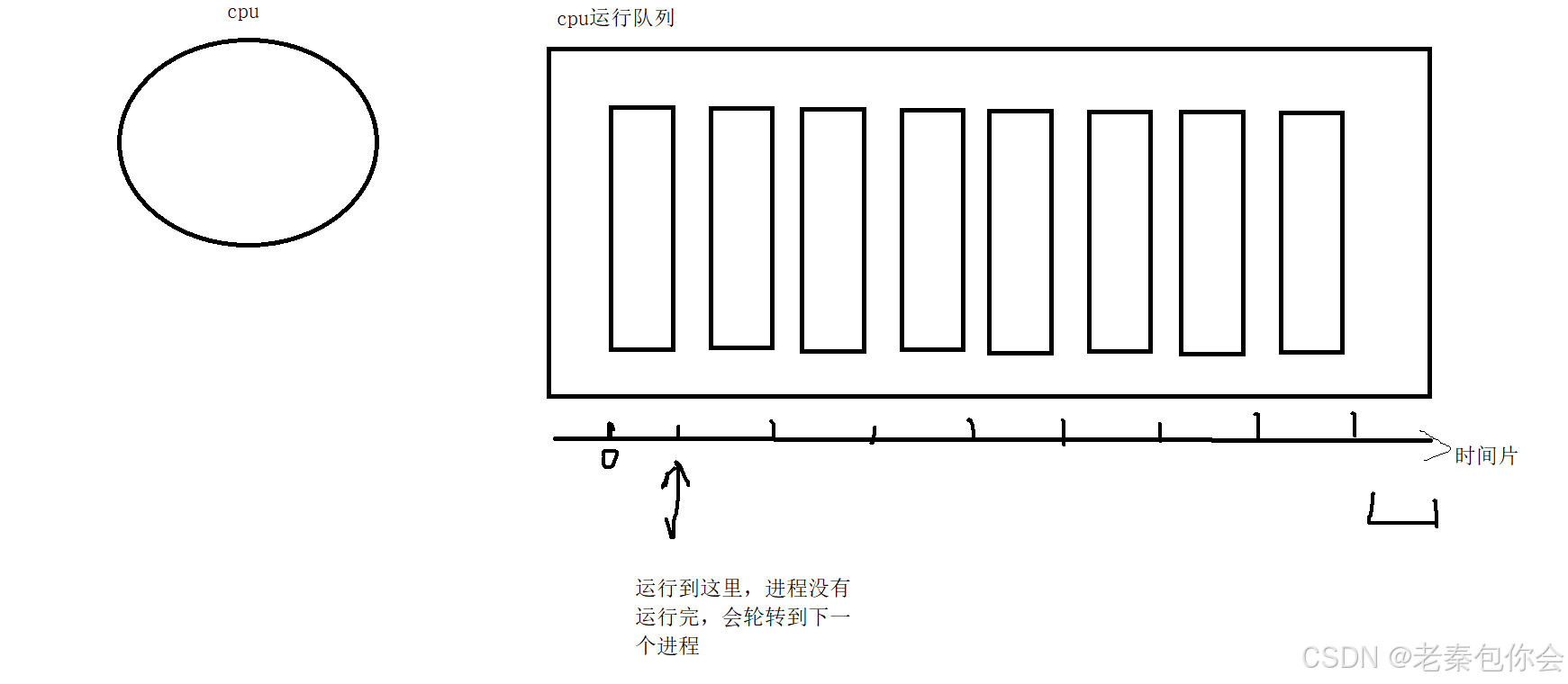
当该进程第二次被执行时,会找出曾经的硬件上下文,进行恢复,然后延续上次运行程度,继续进行
寄存器VS寄存器的内容
cpu内的寄存器只有一套,但是寄存器内部保存的数据可以有多套,因为寄存器存放在一个共享的cpu设备里面,但是所有数据是进程私有的,一个进程有自己的一套私有数据,
总结
一个进程的运行完成,基于时间片, 通常是在不断的进行进程切换,硬件上下文转移的过程,
Linux进程切换的调度算法
要解决进程的优先级、饥饿、效率问题
优先级的解决
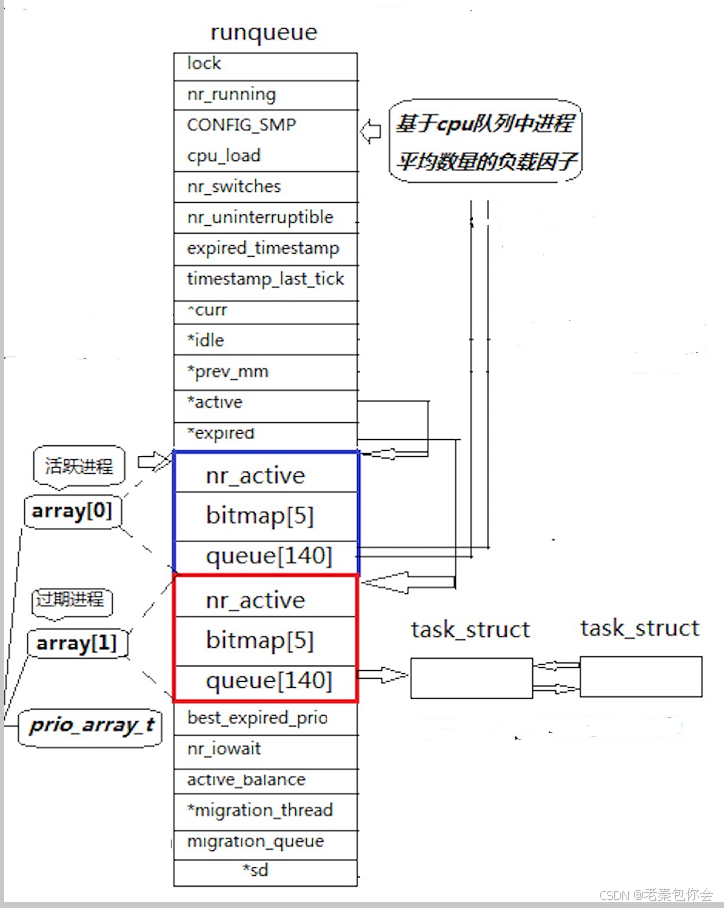
这里我来讲解一下,
图中runqueue是一个cpu的运行队列,这里我讲解红色和蓝色这两个
首先, 红色这个框内中,queue[140],是一个内存指针数组,指向的是进程 task_struct* queue[140],
数组下标0~99是不会使用的,剩下的100~139是使用的,对应的是PRI的范围[60,99],刚好四十个,相当于一个哈希表一样,把优先级相同的进程链入到对应的位置中,100对应的是优先级为60的进程队列,依次往上,
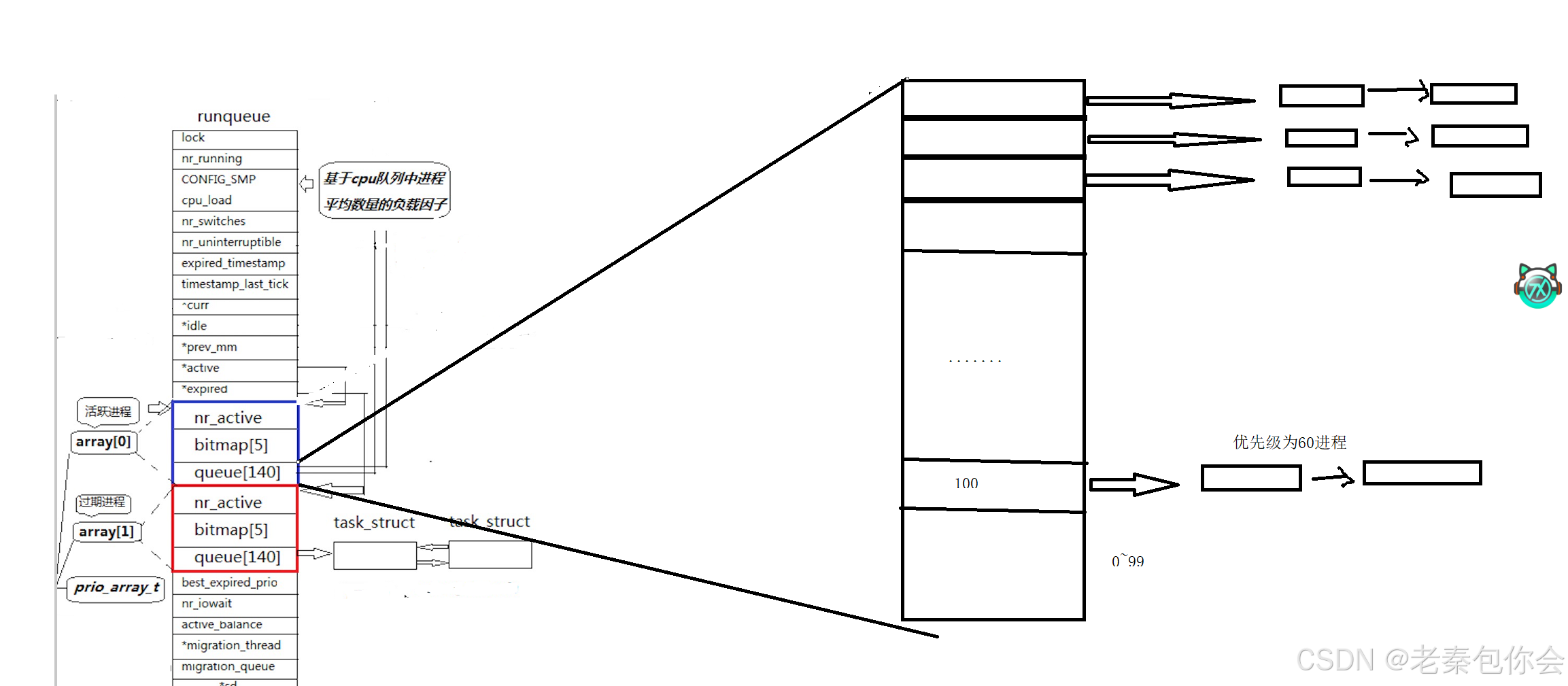
效率解决
在有bitmap[5] ,是一个整形数组, int bitmap[5],设置出这个,主要是为了解决访问queue[140]中的访问问题,
一个整形的大小是32bit,所以这个数组有160个bit,有140个bit一一对应queue的0~139的下标,如果该比特位的值为1,代表对应的queue下标指向的不是NULL,,所以每判断一个bitmap[i],就会决定queue对应的位置的值是否是NULL.不为NULL就运行,
饥饿问题解决
有一些小伙伴可能想到,假如在运行优先级为60的进程的时候,有其他的优先级为60的进程加入,就会导致后面的优先级较低的进程无法得到cpu的运行,造成饥饿问题,为了解决这个问题,就创建出来两个一摸一样的也就是蓝红框的内容,
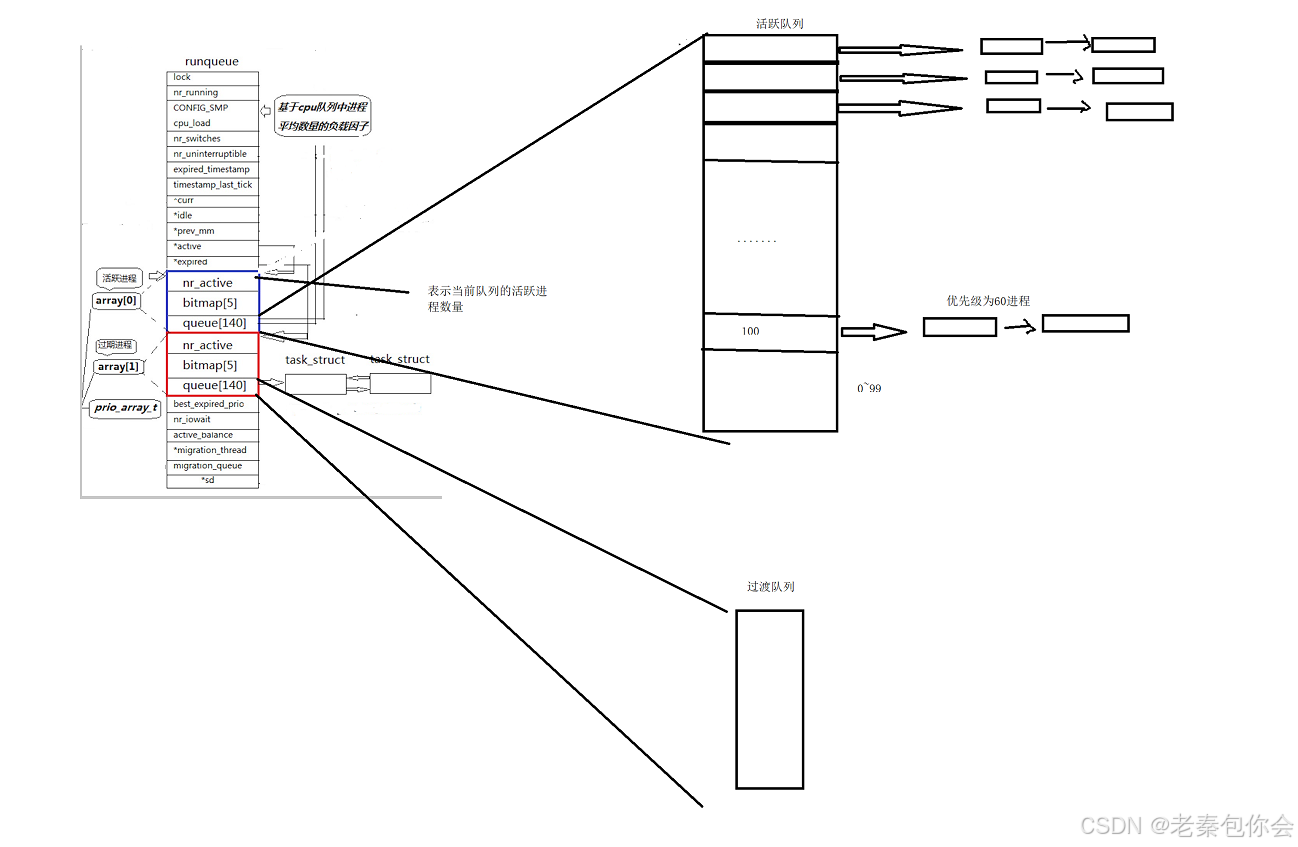
过渡队列主要是解决进程链入,造成饥饿的问题,后面进来的进程直接链入对应的位置,当活跃队列里面的内容都为NULL,活跃队列和过渡队列的身份就会调换过来
还有一些其他的
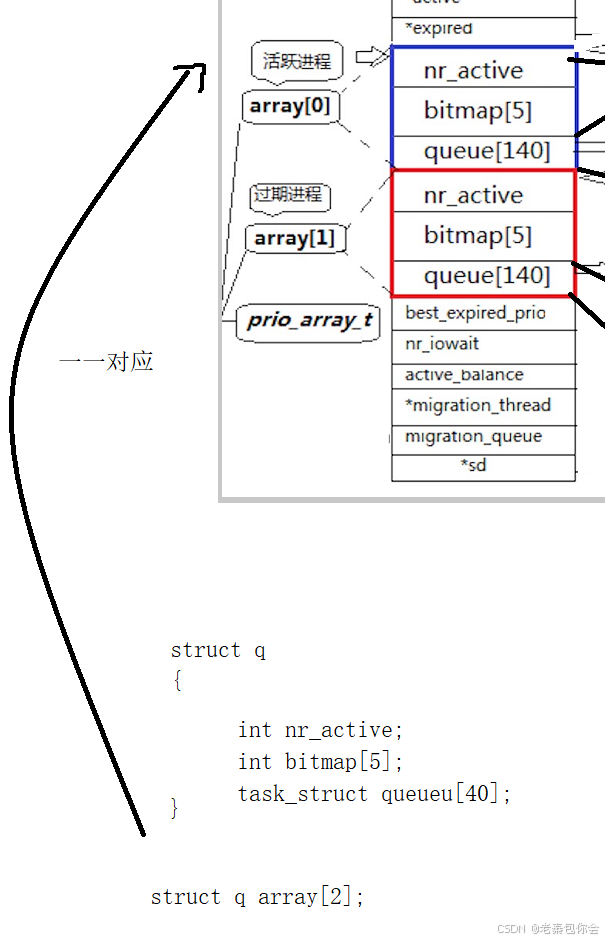
图中的array[0]代表的是活跃进程,所以当活跃进程里面的queue的所有元素都是NULL或者时间片到了,活跃进程就变成了过渡进程,这个是下图中的两个指针来控制的

tack_struct * active = &array[0];
tack_struct * expired = &array[1];
当活跃进程要变成过渡进程,只需active和expired互相交换就行了
环境变量
main参数 ----命令行参数
前面我们知道,一个源文件只有一个主函数main,很多时候,我们写这个main函数的时候,是不写参数的,其实这个main函数是有参数的,
如图:

一个是整形参数argc,一个是字符指针数组,然后我们运行一下图中的代码就会发现

每当我们运行图中代码,就会把命令行的字符全部输出出来,
主要是类似这样
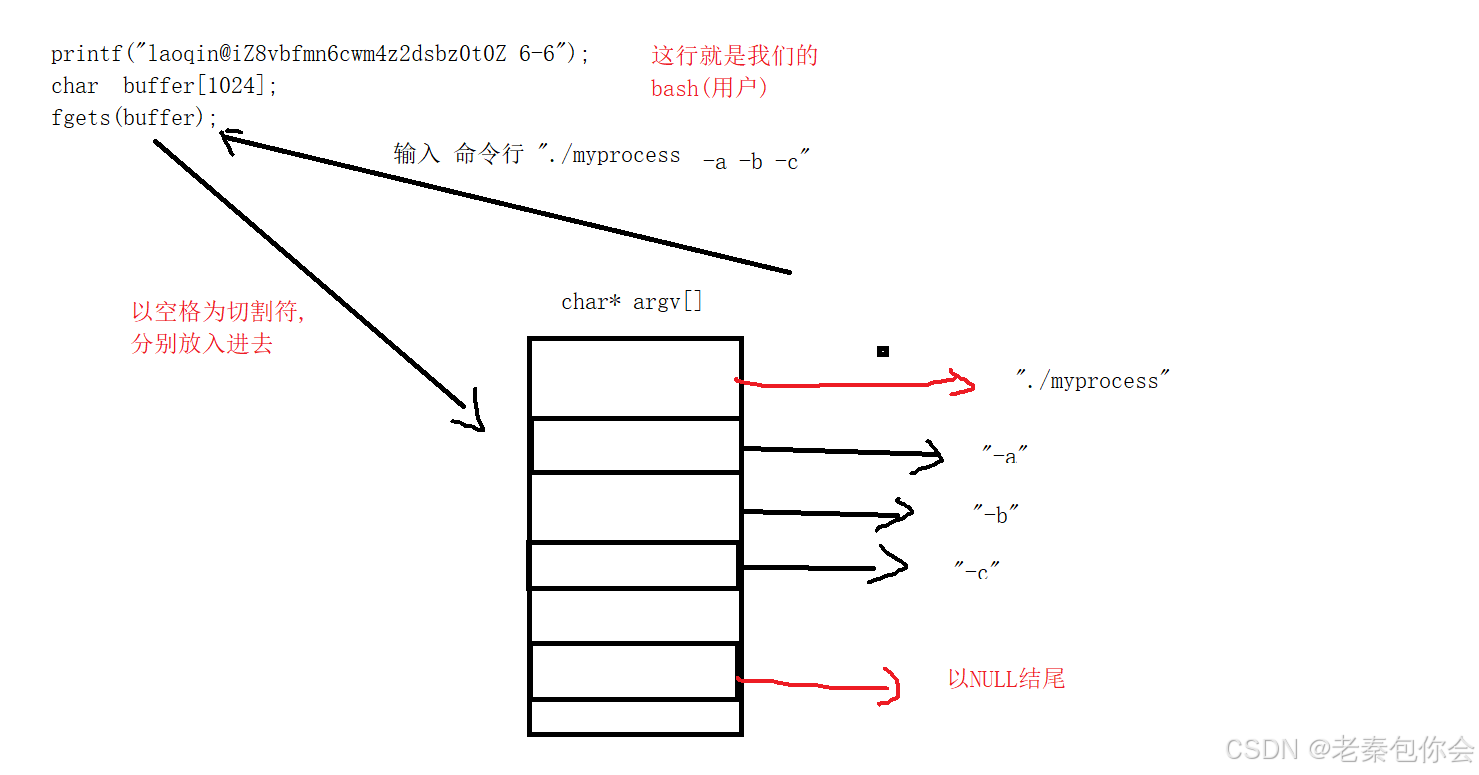
由一个字符数组接收,然后以空格进行切割,分别放入到argv数组中,最后一个元素是NULL, argc的大小就是数组argv的大小减去1, argc = argv长度 - 1,
我们可以利用这个特性去写一个特色的main函数
如图:
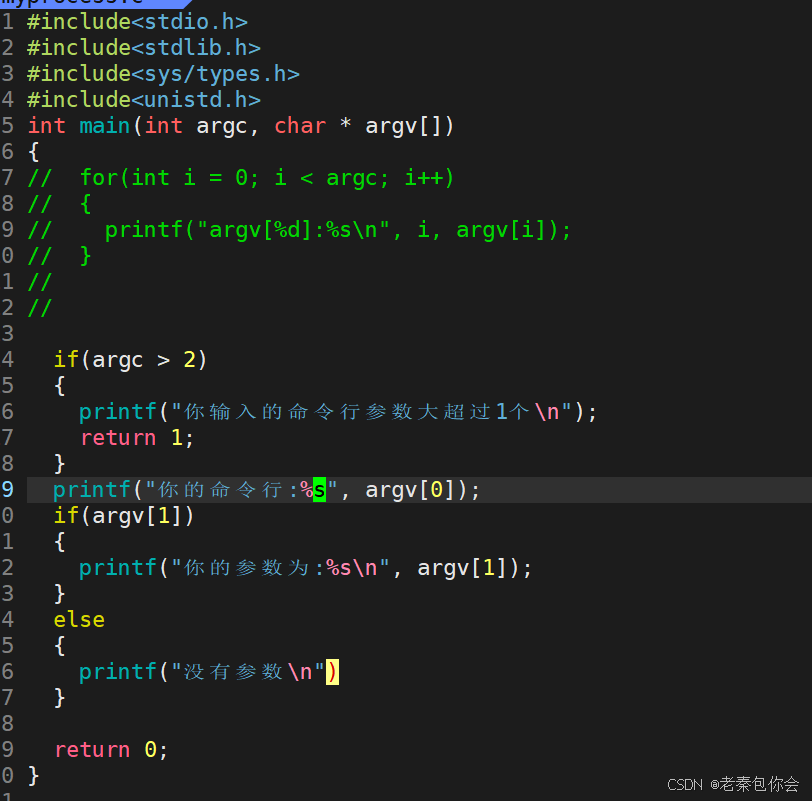
结果:
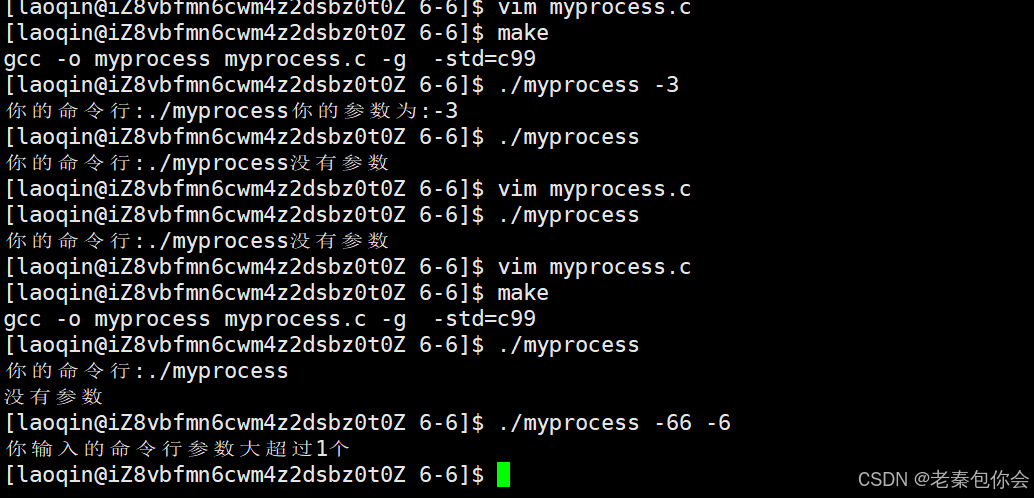
所以我们可以理解 命令+参数可以实现不同的功能了
环境变量
环境变量不是一个,是一堆,彼此之间其实没有关系, 一般是系统内具体特殊用途的变量
我们知道,定义变量的本质就是开辟空间,所以说系统的+环境变量就是系统开辟的一个空间,里面存储着内容
见见环境变量
前面我们写过很多的C语言程序,可以发现,我们可执行文件在运行是必须如图所示:

当我们运行ls这些命令时,不用使用当前路径或者绝对路径就可以运行,如图

这是是因为有一个环境变量PATH,
查看PATH的内容,注意一定要有$
echo $PATH

输出出来的是一个个路径,以:为分隔符进行分割,每一个路径就是默认搜索的路径,
所以说,环境变量里面存放的是程序的位置路径,
添加路径
PATH=/home/laoqin/6-6/:$PATH$PATH是之前的老的内容,这就是一个赋值操作
如果被覆盖了也没问题,直接重启shell就可以了,
为啥启动shell就可以了呢,原因如下:
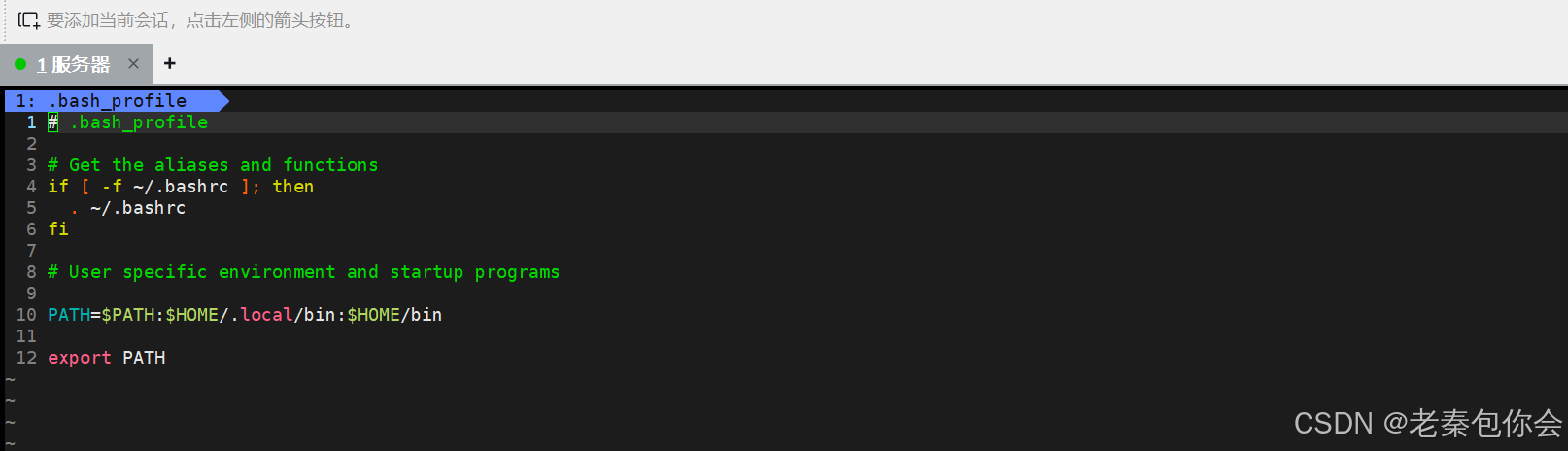
当我们登入进行的使用bash(当前用户)就会读取.bash_profile文件里面的内容,这个文件在用户的家目录下:
内容如下:
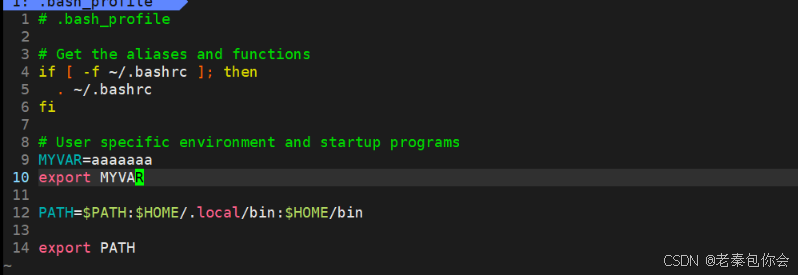
然后我们模拟一下PATH的写法,写一个自己定义的环境变量
MYVAR=aaaaaaa
export MYVAR
效果如下:
保存退出,然后重启Xshell,进行环境变量的查找如下:(我这里定义的是VAR)
环境变量的查看
还要一些其他的环境变量
我们可以通过下面命令进行查看
env
如图:
定义环境变量
export 变量名=值
如图
环境变量的特性
这里再来引入一个main函数的参数 char* env[];
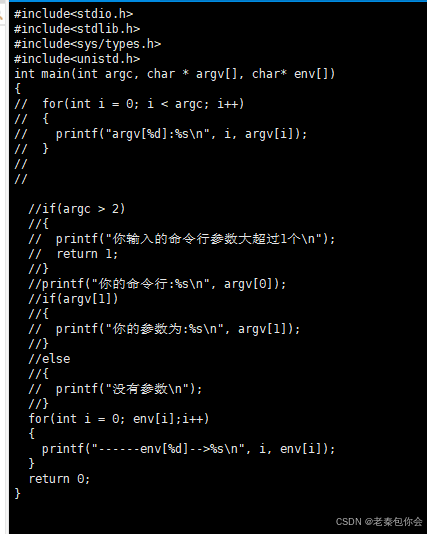
写一个类似的代码,然后输出env数组里面的内容,其中env数组是以NULL结尾的,(最后一个元素是NULL),里面存储的是所有的环境变量,
如同:
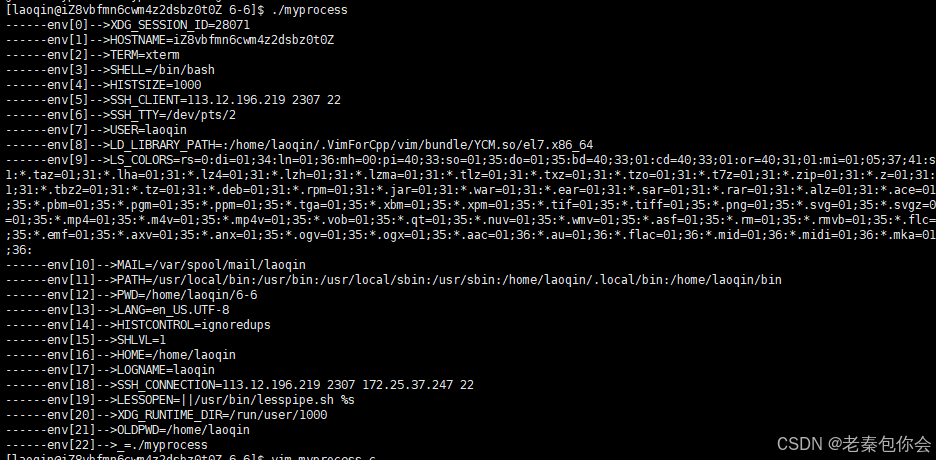
所以main函数控制着两张表,一张是命令行的表格,一张是环境变量表
- 环境变量具有全局属性,可以被子进程和孙子进程继承
下面代码,父进程和子进程都可以输出
#include<stdio.h>#include<stdlib.h>#include<sys/types.h>#include<unistd.h>int main(int argc, char * argv[], char* env[]){printf("I am is fatherproess, pid:%d, ppid: %d", getpid(), getppid());for(int i = 0; env[i];i++){printf("------env[%d]-->%s\n", i, env[i]);}pid_t id = fork();if(id == 0){ printf("I am is childproess, pid: %d, ppid: %d", getpid(), getppid());for(int i = 0; env[i];i++){printf("------env[%d]-->%s\n", i, env[i]);}}return 0;}获取环境变量的方式
除了使用env这个数组还可以使用environ这个变量获取
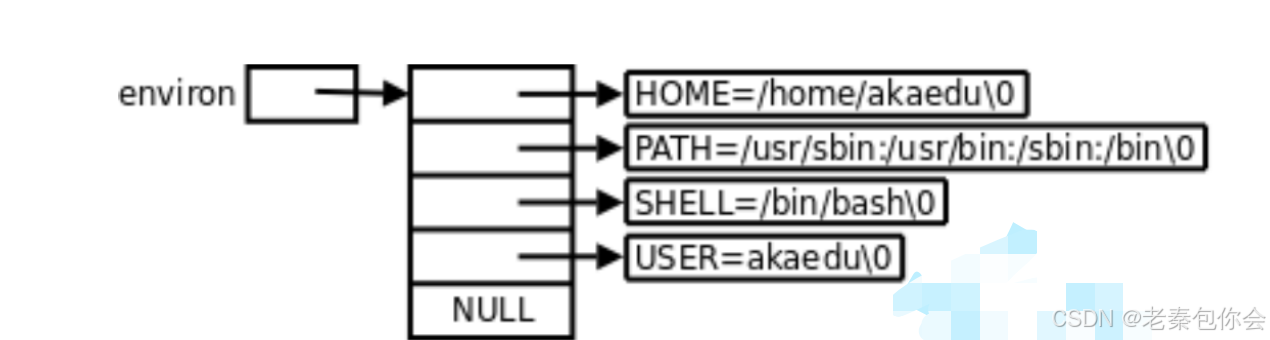
这个变量是一个二级指针,使用之前需要声明这个变量
#include<stdio.h>#include<unistd.h>int main(){extern char** environ;//声明变量for(int i = 0;environ[i];i++){printf("%s\n",environ[i]);} return 0;}但是这两种方式使用情况很少,一般使用如下:
- 获取无参 的main的环境变量
这里要用到函数getenv(const char *name)
#include<stdio.h>
#include<stdlib.h>
#include<sys/types.h>
#include<unistd.h>
#include<string.h>
int main()
{const char* username = getenv("USER");if(strcmp(username, "laoqin")==0){printf("恭喜主人回家\n");}else{printf("有外部人进入\n");}
}这个代码就是获取当前的用户名,如果用户名相等就输出结果
本地变量
写法:
变量名=值
如图:

注意:使用env方法是查找不到的,需要使用set
如下:

本地变量不是环境变量。不会被子进程继承
删除环境变量
写法:
unset 变量名
本地变量也是一样的
环境变量命令总结
和环境变量相关的命令
1. echo: 显示某个环境变量值
2. export: 设置一个新的环境变量
3. env: 显示所有环境变量
4. unset: 清除环境变量
5. set: 显示本地定义的shell变量和环境变量
程序地址
前面我们使用fork创建进程的时候,在不同的进程输出PID是不一样,为啥不一样呢,下面先介绍一下:
程序地址空间图
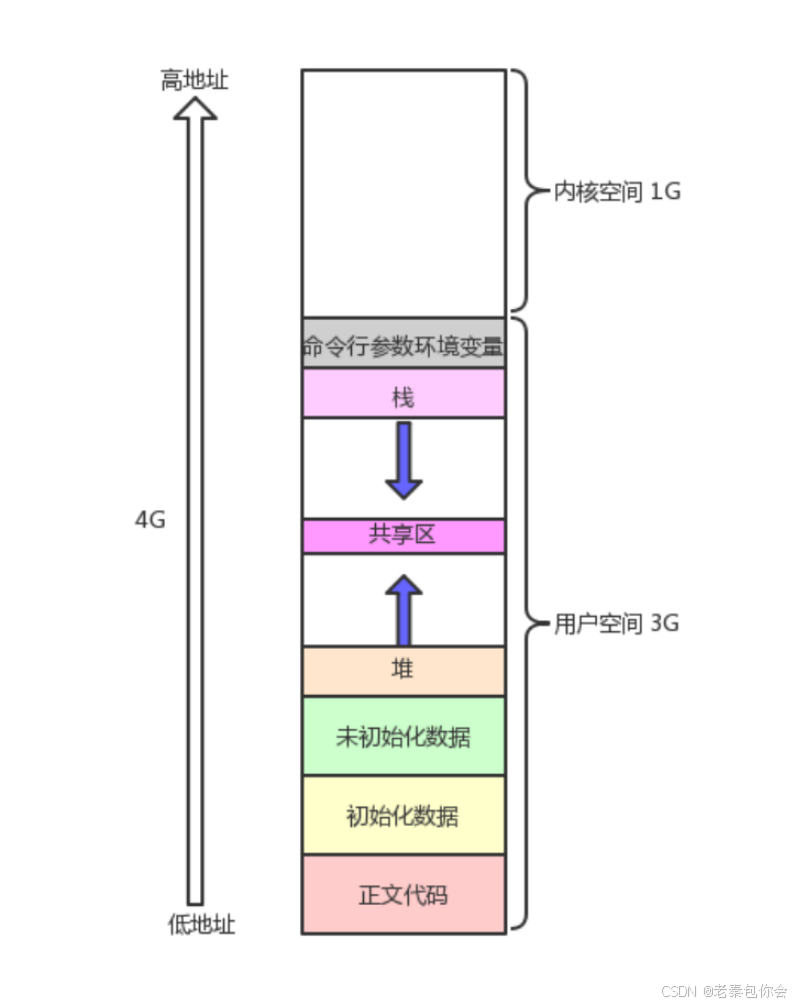
然后我们一一写一下对应的代码看看是否图中的一样
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<vector>using namespace std;
int variable_One;
int variable_Two = 1;int main()
{vector<int>* var = new vector<int>(4,1);printf("正文内容地址: %p\n", main);printf("初始化地址: %p\n", &variable_Two);printf("未初始化地址: %p\n", &variable_One);printf("堆地址: %p\n", var);printf("栈的地址:%p\n", &var);return 0;
}效果图:

可以看到不同类型的地址创建,是先使用低地址,再使用高地址,
我们再写一个同为栈或者堆的地址的创建是先使用啥的,如下:
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<vector>using namespace std;
int variable_One;
int variable_Two = 1;int main()
{vector<int>* var = new vector<int>(4,1);vector<int>* var_1 = new vector<int>(4,1);vector<int>* var_2 = new vector<int>(4,1);vector<int>* var_3 = new vector<int>(4,1);vector<int>* var_4 = new vector<int>(4,1);printf("var:%p\n",&var);printf("var:%p\n",&var_1);printf("var:%p\n",&var_2);printf("var:%p\n",&var_3);printf("var:%p\n",&var_4);printf("stack var:%p\n",var);printf("stack var:%p\n",var_1);printf("stack var:%p\n",var_2);printf("stack var:%p\n",var_3);printf("stack var:%p\n",var_4);return 0;
}效果图:
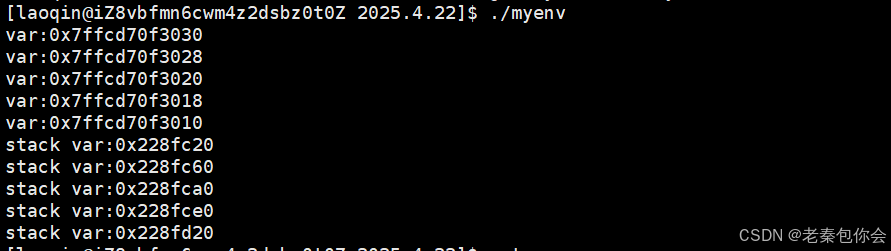
可以看见,堆和栈地址的创建,都是先使用高地址的再使用低地址,
当我们仔细观察栈地址和堆地址的就会发现,栈的地址比堆区的大。
下面我们输出一下对应的命令行和环境变量对应的地址
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
int variable_One;
int variable_Two = 1;
int main(int argc, char* argv[], char* env[])
{ int * var = (int*)malloc(10);int * var_2 = (int*)malloc(10);int * var_3 = (int*)malloc(10);int * var_4 = (int*)malloc(10);printf("var:%p\n",&var);printf("var:%p\n",&var_4);printf("stack var:%p\n",var);printf("stack var:%p\n",var_4);free(var);free(var_2);free(var_3);free(var_4);for(int i = 0; i < argc; i++){printf("argv[%d]地址:%p,值为:%s\n",i , argv+i, *(argv+i) );printf("env[%d]地址:%p,值为:%s\n",i , env+i, *(env+i) );}return 0;
}效果如下:
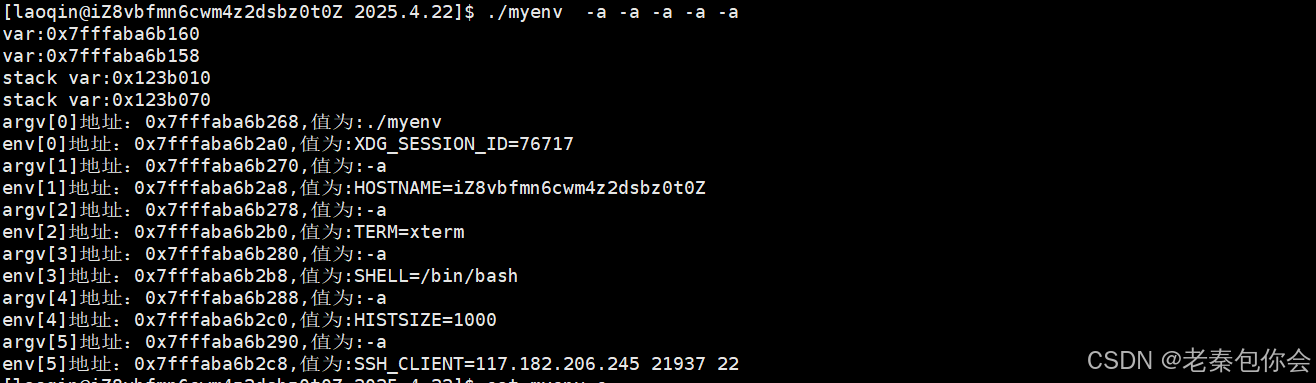
可以看清楚,环境变量的地址比命令行参数的地址可以说明,先有命令行表才有环境变量表
虚拟地址
到这里我们就有一个疑问,这个表中是否是存在内存中的呢?答案不是
下面写一段代码进行验证
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
int g_var = 200;
int main()
{int pid_d = fork();if(pid_d){int variable = 0;while(1){variable++;printf("father: PID: %d, PPID:%d g_var:%d &g_var:%p\n",getpid(), getppid(), g_var, &g_var);sleep(1);if(variable == 5){printf("father: g_var chage 1000\n ");g_var = 1000;}}}else{while(1){printf("child: PID: %d, PPID:%d g_var:%d &g_var:%p\n",getpid(), getppid(), g_var, &g_var);sleep(1);}}return 0;
}效果:
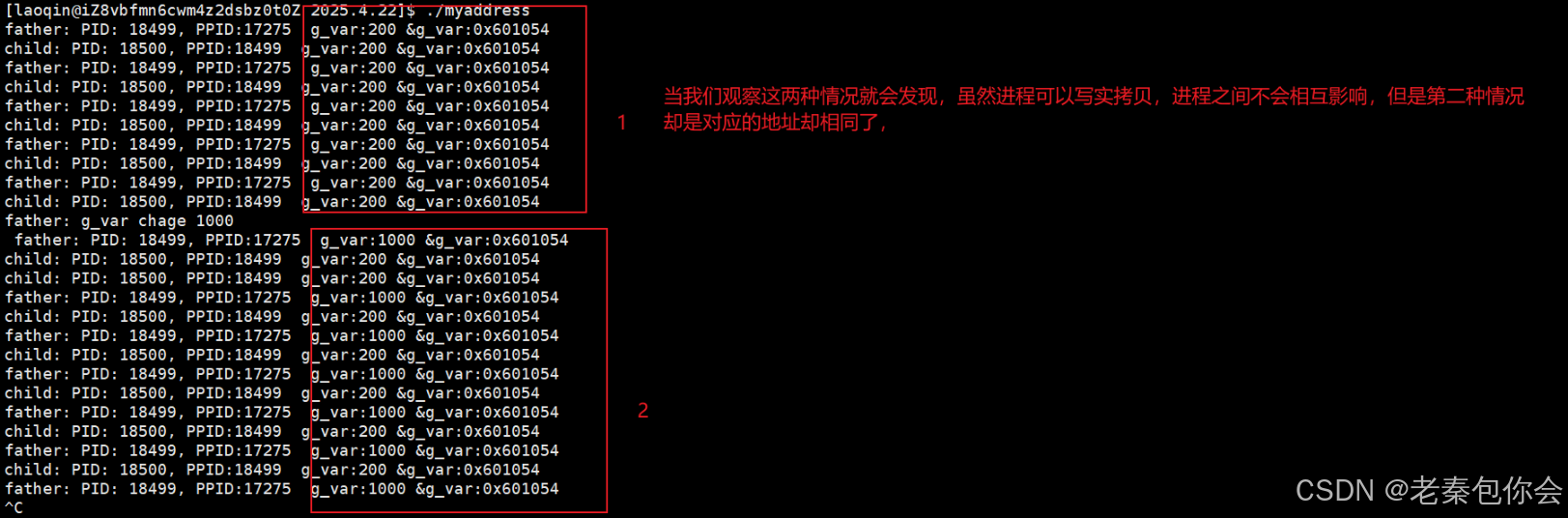
可以观察出,父进程和子进程在变量改变的情况下,地址还是一样,这就说明我们以前C/C++打印出来的地址都是虚拟地址,不是物理地址,所以上面的图不是存在物理内存叫做进程地址空间,所在的地方是操作系统的内部
C/C++的每个进程都有一个对应的进程地址空间
进程地址空间结论
如图:
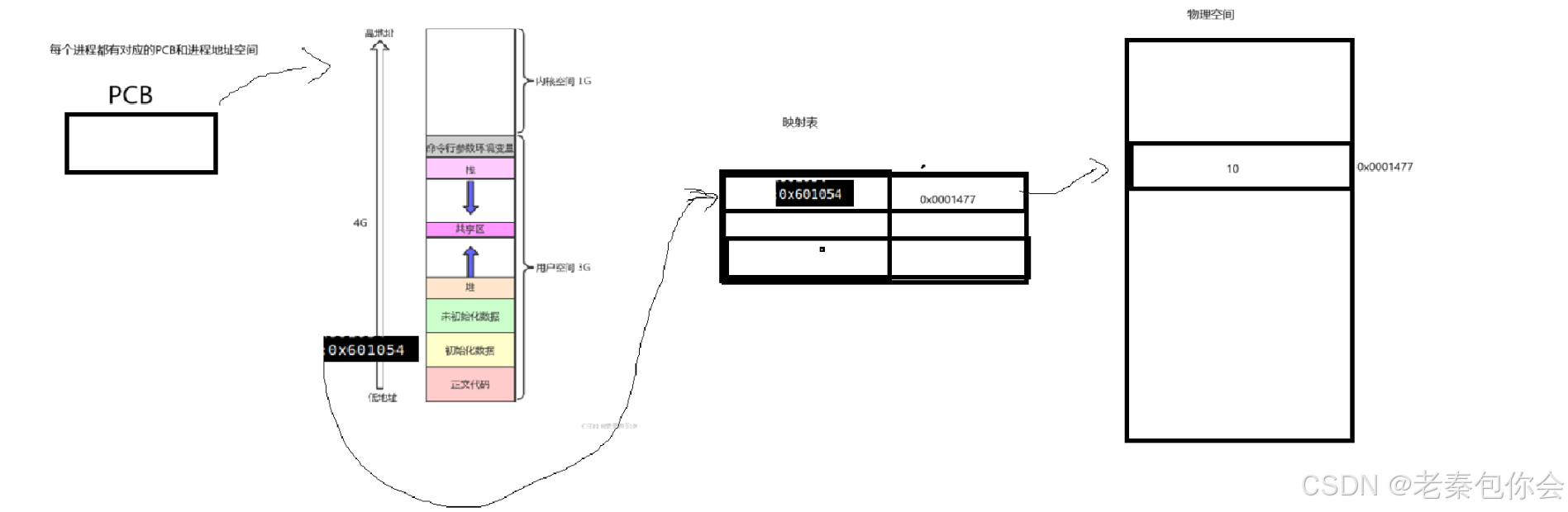
我们知道进程 = PCB+可执行程序,所以说每个进程都有PCB,然后我们还知道,每个进程也有一个进程地址空间, 而在物理内存和进程地址空间之间有一个映射表,通过对应的虚拟地址,查找映射表,找到对应的物理内存地址,然后访问对应的数据,这就是结论,
前面我们创建子进程的情况就是如下:
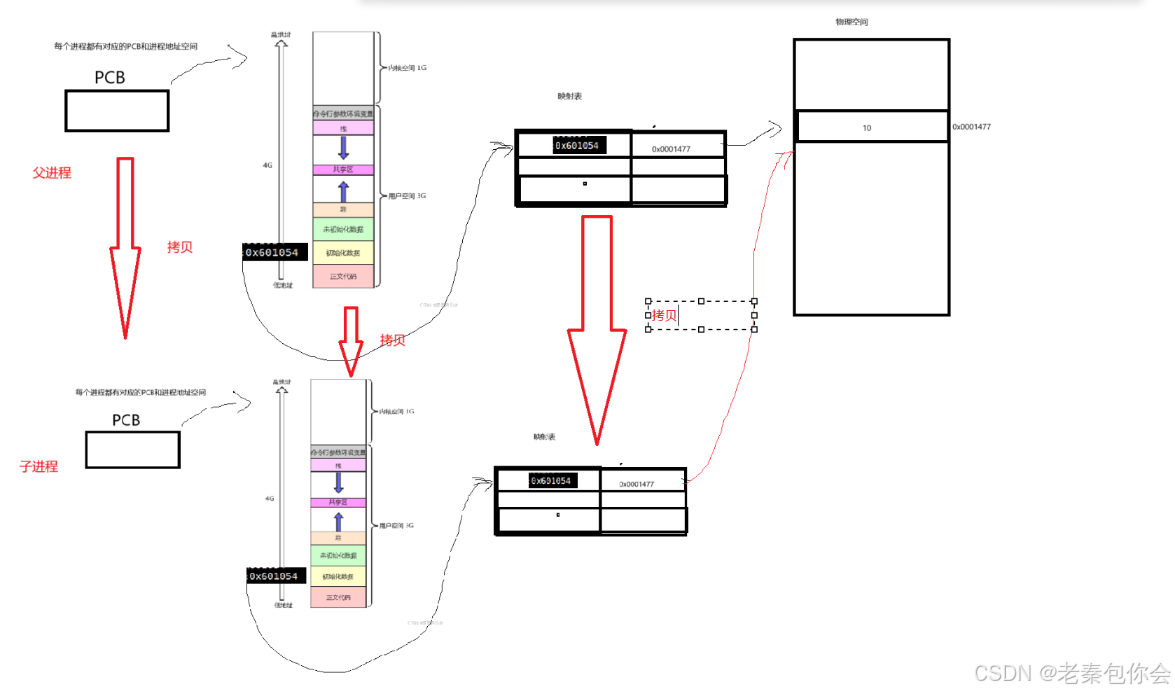
子进程会继承父进程相关的PCB和映射表,这就是前面我写的代码输出的结果,当前父进程修改对应的值的时候,物理内存就会创建一个新的地址,拷贝过来(写时拷贝),修改对应的映射表,如图:
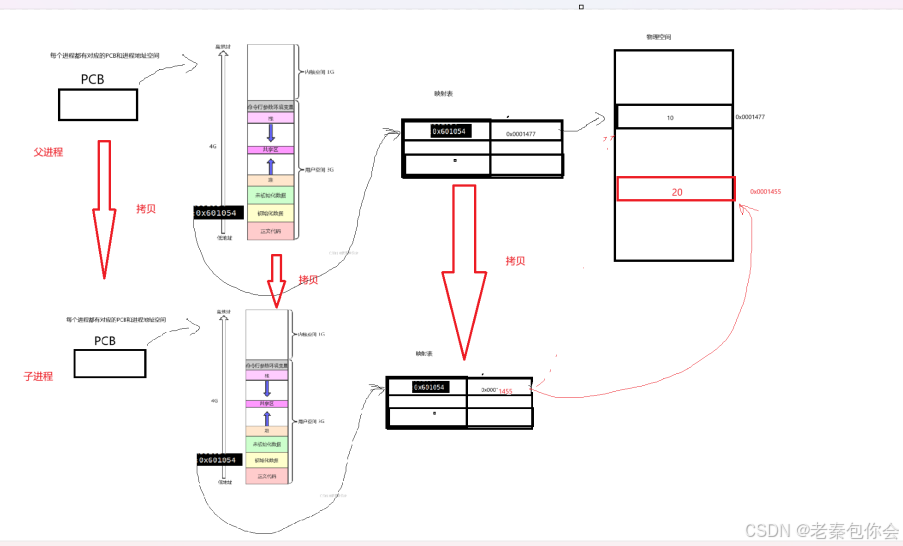
这就解释出来为啥上面的代码输出相同的地址了。也解释出为啥fork()函数返回值的不同。
进程地址空间: 是数据结构, 先描述在组织,具体在进程的PCB就是一个特定的数据结构对象
操作系统需要对进程地址空间进行管理。
下面是大致情况

进程地址空间在内部会进行区域划分,划分的本质不是为了 区分区域,而是为了保证每个地址都能使用到,
地址空间对于我们的代码和数据是不具备保存能力的,保存我们的代码和数据是在物理内存的,所以可以理解为:通过虚拟地址转化到物理内存上,映射表(页表)就是这个重要的媒介。这个映射是CPU进行的,因为CPU有一个CR3的区域,保存着这个页表的物理地址,当PUB读取这个进程的时候,读取到对应的 进程地址空间,就会去找到对应的页表地址进行映射。
进程地址空间是进程拥有的
进程的大致情况如图:
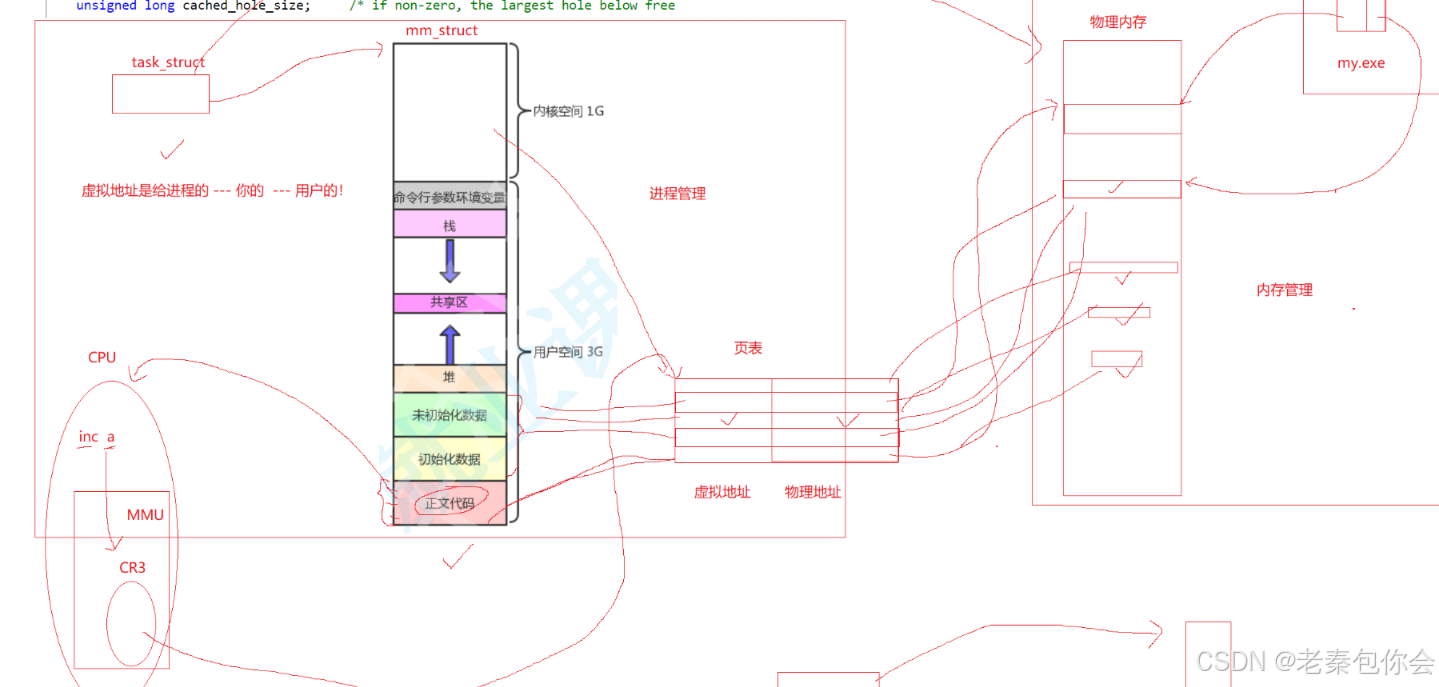
一个进程 = PCB + 可执行程序(exe),图中的左边的就是进程管理,右侧的就是内存管理,
内存管理,把可执行程序的内容加载到物理内存上,然后进程的PCB通过页表映射出对应的内容,把对应的内容拿到进程地址空间中。
有进程地址空间+页表的好处:
- 把物理内存存储数据的无序存储映射到进程地址空间进行有序存储,让进程用统一的视角看待内存
- 将进程管理和内存管理解耦合。
- 是保护内存安全的重要手段。(野指针访问影响的只是进程地址空间)
扩展
4. 前面C/C++使用malloc/new申请的地址不是物理地址而是虚拟地址,在未使用该地址时,对应的页表不会存在对应的物理内存映射关系,物理内存也不会开辟空间,当我们使用该地址的时候,由于没有对应的映射关系,操作系统就会获取到相关操作,期间会进行缺页中断,在物理内存中开辟空间,然后和对应的虚拟地址形成映射关系。然后才能进行使用。
页表
页表不仅仅有虚拟地址和物理地址,还有权限。
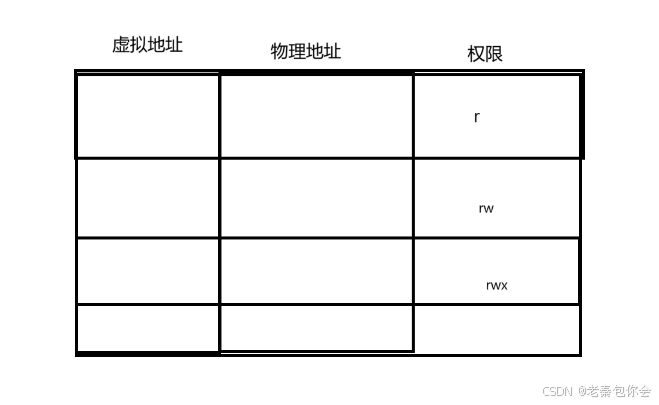
下面我们写一个代码
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
int main()
{char* str = "hello";*str = "H";printf("%s", str);return 0;
}前面我们我们知道,字符串常量是不能修改的,根本上就是对应的虚拟地址映射到物理内存中的权限只是 读取权限,不是具备写入权限,前面我们定义字符串常量是要添加const的,是为了防止在运行时报错,提前把报错放在预编译的时候。,如图:

总结
认识冯诺依曼系统
操作系统概念与定位
深入理解进程概念,了解PCB
学习进程状态,学会创建进程,掌握僵尸进程和孤儿进程,及其形成原因和危害
了解进程调度,Linux进程优先级,理解进程竞争性与独立性。
理解环境变量,熟悉常见环境变量及相关指令, getenv/setenv函数
理解C/C++内存空间分配规律,了解进程内存映像和应用程序区别, 认识地址空间。
相关文章:

Linux课程五课---Linux进程认识1
作者前言 🎂 ✨✨✨✨✨✨🍧🍧🍧🍧🍧🍧🍧🎂 🎂 作者介绍: 🎂🎂 🎂 🎉🎉🎉…...

Nacos简介—4.Nacos架构和原理一
大纲 1.Nacos的定位和优势 2.Nacos的整体架构 3.Nacos的配置模型 4.Nacos内核设计之一致性协议 5.Nacos内核设计之自研Distro协议 6.Nacos内核设计之通信通道 7.Nacos内核设计之寻址机制 8.服务注册发现模块的注册中心的设计原理 9.服务注册发现模块的注册中心的服务数…...
)
splitchunk(如何将指定文件从主包拆分为单独的js文件)
1. 说明 webpack打包会默认将入口文件引入依赖js打包为一个入口文件,导致这个文件会比较大,页面首次加载时造成加载时间较长 可通过splitchunk配置相应的规则,对匹配的规则打包为单独的js,减小入口js的体积 2. 示例 通过正则匹配ÿ…...
)
MCP+A2A协议终极指南:AI系统构建技术全解析(医疗/金融实战+Streamable HTTP代码详解)
简介 2025年,MCP协议与A2A协议成为AI系统互联的核心技术。本文从通信机制到企业级应用,结合Streamable HTTP、零信任安全、多模态处理等最新技术,提供Go/Python/Java多语言实战代码,覆盖医疗诊断、金融风控等场景。含15+完整案例、性能优化方案及安全架构设计,助你掌握下…...

关于定时任务原理
关于定时任务原理 计算机是怎么计时的关于本地定时任务实现小根堆实现时间轮实现 关于分布式任务的实现管理未来的执行时间点 今天来聊一下工作中经常使用的定时任务的底层实现原理 计算机是怎么计时的 计算机内部使用多种方式来计时,主要依赖于硬件时钟࿰…...

【vue3】购物车实战:从状态管理到用户体验的全流程实现
在电商项目中,购物车是核心功能之一,需要兼顾数据一致性、用户体验和逻辑复杂度。 本文结合 Vue3 Pinia 技术栈,详细讲解如何实现一个高效且易用的购物车系统,重点剖析 添加购物车 和 头部购物车预览 的核心逻辑与实现细节。 一…...

日本IT|UIUX主要的工作都是哪些?及职业前景
在日本IT行业中,UI/UX(用户界面/用户体验)设计的工作涵盖从用户研究到界面实现的全流程,尤其在数字化服务、电商、金融科技等领域需求旺盛。 本篇是UI/UX在日本的主要工作内容、行业特点及职业前景分析: 一、UI/UX的主…...
)
Tailwind CSS 实战:基于 Kooboo 构建企业官网页面(二)
基于上篇内容,继续完善企业官网页面: Tailwind CSS 实战:基于 Kooboo 构建企业官网页面(一) 3.3 服务亮点:用于展示企业主要的服务项 1. 整体结构: <section class"py-16">&…...

第7章 内部类与异常类
7.1 内部类 在一个类中定义另一个类,这样的类称为内部类,包含内部类的类称为内部类的外部类。 关系: 内部类的外嵌类的成员变量在内部类中仍然有效,内部类中的方法也可以调用外嵌类中的方法。 内部类的类体中不可以声明类变量和…...
)
优先队列、堆笔记(算法第四版)
方法签名描述构造函数MaxPQ()创建一个优先队列MaxPQ(int max)创建一个初始容量为 max 的优先队列MaxPQ(Key[] a)用 a[] 中的元素创建一个优先队列普通方法void insert(Key v)向优先队列中插入一个元素Key max()返回最大元素Key delMax()删除并返回最大元素boolean isEmpty()返回…...

7.14 GitHub命令行工具测试实战:从参数解析到异常处理的全链路测试方案
GitHub命令行工具测试实战:从参数解析到异常处理的全链路测试方案 GitHub Sentinel Agent 用户界面设计与实现:测试命令行工具 关键词:命令行工具测试, 接口集成测试, 参数化测试, 异常处理测试, 测试覆盖率分析 1. 命令行工具测试架构设计 通过三层测试体系保障 CLI 工具…...

使用CubeMX新建USART1不定长接收工程
目录 1、新建板级支持包 2、修改中断服务函数 3、修改main.c文件 4、程序流程 新建工程的基本操作步骤参考这里:STM32CubeMX学习笔记(6)——USART串口使用_unused(huart)-CSDN博客 1、新建板级支持包 在本地保存新建工程的文件夹中新建Us…...

【C++QT】Layout 布局管理控件详解
文章目录 一、QVBoxLayout 垂直布局1.1 特点1.2 常用方法1.3 应用场景1.4 示例代码 二、QHBoxLayout 水平布局2.1 特点2.2 常用方法2.3 应用场景2.4 示例代码 三、QGridLayout 网格布局3.1 特点3.2 常用方法3.3 应用场景3.4 示例代码 四、QFormLayout 表单布局4.1 特点4.2 常用…...

w~嵌入式C语言~合集6
我自己的原文哦~ https://blog.51cto.com/whaosoft/13870384 一、开源MCU简易数字示波器项目 这是一款采用STC8A8K MCU制造的简单示波器,只有零星组件,易于成型。这些功能可以涵盖简单的测量: 该作品主要的规格如下: 单片机…...
)
坐标转换:从WGS-84到国内坐标系(GCJ-02BD-09)
目录 🍅点击这里查看所有博文 随着自己工作的进行,接触到的技术栈也越来越多。给我一个很直观的感受就是,某一项技术/经验在刚开始接触的时候都记得很清楚。往往过了几个月都会忘记的差不多了,只有经常会用到的东西才有可能真正记…...

快速上手 MetaGPT
1. MetaGPT 简介 在当下的大模型应用开发领域,Agent 无疑是最炙手可热的方向,这也直接催生出了众多的 Agent 开发框架。在这之中, MetaGPT 是成熟度最高、使用最广泛的开发框架之一。 MetaGPT 是一款备受瞩目的多智能体开发框架,…...

「Docker已死?」:基于Wasm容器的新型交付体系如何颠覆十二因素应用宣言
一、容器技术的量子跃迁 1. 传统容器体系的测不准原理 某金融平台容器集群真实数据: 指标Docker容器Wasm容器差异度冷启动时间1200ms8ms150倍内存占用256MB6MB42倍镜像体积780MB12MB65倍内核调用次数2100次/s23次/s91倍 二、Wasm容器的超流体特性 1. 字节码的量子…...

有源晶振输出匹配电阻选择与作用详解
一、输出匹配电阻的核心作用 阻抗匹配 减少信号反射:当信号传输线阻抗(Z0)与负载阻抗不匹配时,会发生反射,导致波形畸变(如振铃、过冲)。 公式:反射系数Γ (Z_L - Z0) / (Z_L Z0)…...

Shell脚本-while循环应用案例
在Shell脚本编程中,while循环是一种非常有用的控制结构,适用于需要基于条件进行重复操作的场景。与for循环不同,while循环通常用于处理不确定次数的迭代或持续监控某些状态直到满足特定条件为止的任务。本文将通过几个实际的应用案例来展示如…...

【JavaScript】二十七、用户注册、登陆、登出
文章目录 1、案例:用户注册页面1.1 发送验证码1.2 验证用户名密码合法性1.3 已阅读并同意用户协议1.4 表单提交 2、案例:用户登陆页面2.1 tab切换2.2 登陆跳转2.3 登陆成功与登出 1、案例:用户注册页面 1.1 发送验证码 需求:用户…...

Vue中Axios实战指南:高效网络请求的艺术
Axios作为Vue生态中最流行的HTTP客户端,以其简洁的API和强大的功能成为前后端交互的首选方案。本文将带你深入掌握Axios在Vue项目中的核心用法和高级技巧。 一、基础配置 1. 安装与引入 npm install axios 2. 全局挂载(main.js) import …...

SAP-pp 怎么通过底表的手段查找BOM的全部ECN变更历史
表:ABOMITEMS,查询条件是MAST的STLNR (BOM清单) 如果要得到一个物料的详细ECN历史,怎么办? 先在MAST表查找BOM清单,然后根据BOM清单在ABOMITEMS表里面查询组件,根据查询组件的结果…...

数据需求管理办法有哪些?具体应如何应用?
目录 一、数据需求管理的定义 二、数据需求管理面临的问题 1.需求理解偏差 2.需求变更频繁 3.需求优先级难以确定 4.数据质量与需求不匹配 三、数据需求管理办法的具体流程 1.建立有效的沟通机制 2.规范需求变更管理流程 3.制定需求优先级评估标准 4.加强数据质量管…...

单片机 + 图像处理芯片 + TFT彩屏 复选框控件
复选框控件使用说明 一、控件概述 本复选框控件是一个适用于单片机图形界面的UI组件,基于单片机 RA8889/RA6809 TFT显示屏 GT911触摸屏开发。控件提供了丰富的功能和自定义选项,使用简单方便,易于移植。 主要特点: 支持可…...

塔能合作模式:解锁工厂能耗精准节能新路径
在工厂寻求能耗精准节能的道路上,除了先进的技术,合适的合作模式同样至关重要。塔能科技提供的能源合同管理(EMC)和交钥匙方式(EPC),为工厂节能项目的落地实施提供了有力支持,有效解…...

使用PHP对接印度股票市场数据
在本篇文章中,我们将介绍如何通过StockTV提供的API接口使用PHP语言来获取并处理印度股票市场的数据。我们将以查询公司信息、查看涨跌排行榜和实时接收数据为例,展示具体的操作流程。 准备工作 首先,请确保您已经从StockTV获得了API密钥&am…...

make学习三:书写规则
系列文章目录 Make学习一:make初探 Make学习二:makefile组成要素 文章目录 系列文章目录前言默认目标规则语法order-only prerequisites文件名中的通配符伪目标 Phony Targets没有 Prerequisites 和 recipe内建特殊目标名一个目标多条规则或多个目标共…...
:KEY实验)
Arduino 入门学习笔记(五):KEY实验
Arduino 入门学习笔记(五):KEY实验 开发板:正点原子ESP32S3 例程源码在文章顶部可免费下载(审核中…) 1. GPIO 输入功能使用 1.1 GPIO 输入模式介绍 在上一文章中提及到 pinMode 函数, 要对…...

Grok发布了Grok Studio 和 Workspaces两个强大的功能。该如何使用?如何使用Grok3 API?
最近Grok又更新了几个功能:Grok Studio 和 Workspaces。 其中 Grok Studio 主要功能包括: 代码执行:在预览标签中运行 HTML 片段、Python、JavaScript 等。 Google Drive 集成:附加并处理 Docs、Sheets、Slides等文件。 协作工…...

学习spark总结
一、Spark Core • 核心功能:基于内存计算的分布式计算框架,提供RDD弹性分布式数据集,支持转换(如map、filter)和动作(如collect、save)操作。 • 关键特性:高容错性(L…...

LeetCode 24 两两交换链表中的节点
给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。 示例 1: 输入:head [1,2,3,4] 输出:[2,1…...
)
Qt中的全局函数讲解集合(全)
目录 1.qAbs 2.qAsConst 3.qBound 4.qConstOverload 5.qEnvironmentVariable 6.qExchange 7.qFloatDistance 8.qInstallMessageHandler 在头文件<QtGlobal>中包含了Qt的全局函数,现在就这些全局函数一一详解。 1.qAbs 原型: template &…...

《明解C语言入门篇》读书笔记四
目录 第四章:程序的循环控制 第一节:do语句 do语句 复合语句(程序块)中的声明 读取一定范围内的值 逻辑非运算符 德摩根定律 德摩根定律 求多个整数的和及平均值 复合赋值运算符 后置递增运算符和后置递减运算符 练习…...
)
【每日随笔】文化属性 ② ( 高维度信息处理 | 强者思维形成 | 认知重构 | 资源捕获 | 进化路径 )
文章目录 一、高维度信息处理1、" 道 " - 高维度信息2、上士对待 " 道 " 的态度3、中士对待 " 道 " 的态度4、下士对待 " 道 " 的态度 二、形成强者思维1、认知重构 : 质疑本能 -> 信任惯性2、资源捕获 : 远神崇拜 -> 近身模仿3…...

terraform查看资源建的关联关系
一、使用 terraform graph 命令生成依赖关系图 该命令会生成资源间的依赖关系图(DOT 格式),需配合 Graphviz 工具可视化。 1. 安装 Graphviz # Ubuntu/Debian sudo apt-get install graphviz# MacOS brew install graphviz 2. 生成并查看…...

win11报错 ‘wmic‘ 不是内部或外部命令,也不是可运行的程序 或批处理文件 的解决方案
方法一:检查环境变量 右键点击“此电脑”或“计算机”: 选择“属性”,然后点击“高级系统设置”。 进入环境变量设置: 在“系统属性”窗口中,点击“环境变量”。 检查Path变量: 在“系统变量”部分,找到并…...

监控易一体化运维:巡检管理,守护企业系统稳定的坚固防线
在数字化浪潮奔涌的当下,企业业务高度依赖信息技术系统,数据流量呈爆发式增长。从日常办公到核心业务运作,每一个环节都离不开稳定可靠的系统支持。在这种背景下,确保系统时刻处于最佳状态的重要性。而监控易的巡检管理功能&#…...

技能点总结
技能点总结 1、多线程导致事物失效的原因1.1 线程间竞争条件1.2 可见性问题1.3 原子性破坏1.4 死锁与活锁1.5 事务隔离级别问题1.5.1 脏读、不可重复读、幻读 1、多线程导致事物失效的原因 多线程环境下事物失效是一个常见问题,主要原因包括以下几个方面࿱…...
)
23种设计模式-行为型模式之命令模式(Java版本)
Java 命令模式(Command Pattern)详解 🧠 什么是命令模式? 命令模式是一种行为型设计模式,它将请求封装成一个对象,从而使你可以使用不同的请求、队列、日志请求以及支持可撤销的操作。 命令模式将请求的…...

聊一聊接口测试的核心优势及价值
目录 一、核心优势 提前发现问题,降低修复成本 高稳定性与维护效率 全面覆盖复杂场景 性能与安全测试的基石 高度自动化与高效执行 支持微服务与分布式架构 二、核心价值 加速交付周期及降低维护成本 提升质量与用户体验 增强安全性及促进团队间的协作 …...

大学之大:索邦大学2025.4.27
索邦大学:千年学术传承与现代创新的交响 一、前身历史:从巴黎大学到现代索邦的千年脉络 1. 中世纪起源:欧洲学术之母的诞生 索邦大学的历史可追溯至9世纪,其前身巴黎大学被誉为“欧洲大学之母”。1257年,神学家罗伯特…...

python文本合并脚本
做数据集本地化时,用到了文本txt合并问题,用了trae -cn ai辅助测试一下效果,还可以吧,但还是不如人灵光,反复的小错,如果与对成手,应该很简单,这里只做了测试吧,南无阿弥…...
)
Coding Practice,48天强训(25)
Topic 1:笨小猴(质数判断的几种优化方式,容器使用的取舍) 笨小猴__牛客网 #include <bits/stdc.h> using namespace std;bool isPrime(int n) {if(n < 1) return false;if(n < 3) return true; // 2和3是质数if(n % 2 0 …...

pytorch学习使用
1. 基础使用 1.1 基础信息 # 输出 torch 版本 print(torch.__version__)# 判断 cuda 是否可用 print(torch.cuda.is_available()) """ 2.7.0 False """1.2 创建tensor # 创建一个5*3的矩阵,初始值为0. print("-------- empty…...

《AI大模型应知应会100篇》第38篇:大模型与知识图谱结合的应用模式
第38篇:大模型与知识图谱结合的应用模式 摘要 随着大模型(如GPT、BERT等)和知识图谱技术的快速发展,两者的融合为构建更精准、可解释的智能系统提供了新的可能性。本文将深入探讨大模型与知识图谱的能力互补性、融合架构设计以及…...

TypeScript中的type
在 TypeScript 中,type 是一个非常重要的关键字,用于定义类型别名(Type Alias)。它允许你为一个类型创建一个新的名字,从而使代码更加简洁和可读。type 可以用来定义基本类型、联合类型、元组类型、对象类型等。以下是…...

数据库3,
describe dt drop table 删表 df delete from删行 usw update set where更新元素 iiv insert into values()插入行 sf select from选行 select *选出所有行 (ob order by 排序 由低到高 DESC由高到低 order by score&#…...

I-CON: A Unifying Framework for Representation Learning
1,本文关键词 I-Con框架、表征学习、KL散度、无监督分类、对比学习、聚类、降维、信息几何、监督学习、自监督学习、统一框架 2,术语表 术语解释I-Con本文提出的统一表征学习方法,全称Information Contrastive Learning,通过最…...

mybatis首个创建相关步骤
1。先关联数据库,用户,密码,数据库保持一致 2.添加包和类 1.User放和数据库属性一样的 package com.it.springbootmybatis01.pojo;lombok.Data lombok.AllArgsConstructor lombok.NoArgsConstructor public class User {private Integer i…...

vue3子传父——v-model辅助值传递
title: 子组件向父组件传值 date: 2025-04-27 19:11:09 tags: vue3 vue3子传父——v-model辅助值传递 一、子组件发出 1.步骤一创建emit对象 这个对象使用的是defineEmits进行的创建,emit的中文意思又叫发出,你就把他当成一个发出数据的函数方法来用…...