优先队列、堆笔记(算法第四版)
| 方法签名 | 描述 |
|---|---|
| 构造函数 | |
MaxPQ() | 创建一个优先队列 |
MaxPQ(int max) | 创建一个初始容量为 max 的优先队列 |
MaxPQ(Key[] a) | 用 a[] 中的元素创建一个优先队列 |
| 普通方法 | |
void insert(Key v) | 向优先队列中插入一个元素 |
Key max() | 返回最大元素 |
Key delMax() | 删除并返回最大元素 |
boolean isEmpty() | 返回队列是否为空 |
int size() | 返回优先队列中的元素个数 |
| 内部方法 | |
boolean less(int i, int j) | 比较索引为 i 和 j 的元素大小 |
void exch(int i, int j) | 交换索引为 i 和 j 的元素 |
void swim(int k) | 上浮操作,将元素 k 上浮到正确位置 |
void sink(int k) | 下沉操作,将元素 k 下沉到正确位置 |
#include <vector>
#include <stdexcept> // 最大优先队列(Max Priority Queue)实现,基于二叉堆
// 支持泛型 Key 类型 template <typename Key>
class MaxPQ {
private: std::vector<Key> pq; // 堆,1-based 索引;pq[0] 未使用 int n; // 当前元素个数 // 辅助方法:比较并交换、上浮、下沉 bool less(int i, int j) const { return pq[i] < pq[j]; } void exch(int i, int j) { Key tmp = pq[i]; pq[i] = pq[j]; pq[j] = tmp; } void swim(int k) { while (k > 1 && less(k/2, k)) { exch(k/2, k); k /= 2; } } void sink(int k) { while (2*k <= n) { int j = 2*k; if (j < n && less(j, j+1)) ++j; if (!less(k, j)) break; exch(k, j); k = j; } } public: // 默认构造:初始容量为 1 MaxPQ() : pq(2), n(0) {} // 指定初始容量 explicit MaxPQ(int max) : pq(max+1), n(0) {} // 从已有数组构造:拷贝元素并 heapify explicit MaxPQ(const std::vector<Key>& a) : pq(a.size()+1), n(a.size()) { for (size_t i = 0; i < a.size(); ++i) { pq[i+1] = a[i]; } // heapify:从最底层非叶子节点开始下沉 for (int k = n/2; k >= 1; --k) { sink(k); } } // 插入元素 void insert(const Key& v) { if (n + 1 >= static_cast<int>(pq.size())) pq.resize(pq.size() * 2); pq[++n] = v; swim(n); } /** * 删除堆中第一个等于 v 的元素(如果存在),返回是否成功 * 时间复杂度:O(n) 查找 + O(log n) 调整 */ bool remove(const Key& v) { // 1. 查找 int i = 1; while (i <= n && pq[i] != v) ++i; if (i > n) return false; // 未找到 // 2. 交换到末尾并移除 exch(i, n--); pq.pop_back(); // 3. 恢复堆序 // 先尝试上浮,如果新元素比父节点大;再尝试下沉 swim(i); sink(i); // 4. 缩容(可选) if (n > 0 && n == (static_cast<int>(pq.size()) - 1) / 4) { pq.resize(pq.size() / 2); } return true; } // 返回最大元素 const Key& max() const { if (isEmpty()) throw std::underflow_error("Priority queue underflow"); return pq[1]; } // 删除并返回最大元素 Key delMax() { if (isEmpty()) throw std::underflow_error("Priority queue underflow"); Key mx = pq[1]; exch(1, n--); sink(1); pq.pop_back(); // 释放尾部空间 if (n > 0 && n == (static_cast<int>(pq.size())-1) / 4) pq.resize(pq.size() / 2); return mx; } // 是否为空 bool isEmpty() const { return n == 0; } // 当前大小 int size() const { return n; }
}; // 示例用法:
#ifdef DEMO
#include <iostream>
int main() { MaxPQ<int> pq; pq.insert(5); pq.insert(2); pq.insert(9); pq.insert(1); std::cout << "Max: " << pq.max() << std::endl; while (!pq.isEmpty()) { std::cout << pq.delMax() << " "; } std::cout << std::endl; return 0;}
#endif

2.4.2 查找最大元素实现分析
题目:分析以下说法:要实现在常数时间找到最大元素,为何不用一个栈或队列,然后记录已插入的最大元素并在找出最大元素时返回它的值?
解答:
简单记录一个"当前最大值"确实能让 find-max(即返回最大元素)操作做到 O ( 1 ) O(1) O(1),但是它无法满足「优先队列」的完整语义,主要原因在于 删除(或者说 抽取)最大元素以后,你的"当前最大值"就可能失效,必须重新扫描才能找下一大的元素,成本 O ( n ) O(n) O(n)。具体来说:
-
插入(insert)可以 O ( 1 ) O(1) O(1) 更新最大值
每次插入 x x x。if (x > curMax) curMax = x; push_back(x);这样 find-max 只要返回
curMax即可,确实 O ( 1 ) O(1) O(1)。 -
抽取最大(delMax)要删除最大元素
一旦执行了delMax(),假设弹出了之前记录的curMax,就不知道下一个最大的值是什么了。除非你再去所有剩余元素里扫描一遍,才能更新curMax,这一步 O ( n ) O(n) O(n),完全无法满足「对消耗 O ( log n ) O(\log n) O(logn) 的堆排序/优先队列来讲,要效率平衡」。 -
为什么不提前维护所有"历史最大值"?
有人会想到用一个栈/双端队列来记录每次插入时的最大值变化(类似「带最大值功能的栈」),但那种结构只能支持 栈式弹出(或队列式弹出),也就是只能弹出最新插入的元素(或最早插入的元素),它本质上是 LIFO 或 FIFO 的限制。优先队列则要求随时弹出 全局最大,不是按插入顺序。-
带最大值的栈(Max-Stack):
- 支持
push、pop(只能弹出最近插入的)和max均摊 O ( 1 ) O(1) O(1)。 - 但它无法在中间位置删除或抽取真正的全局最大(除非那恰巧是栈顶元素)。
- 支持
-
带最大值的双端队列(或滑动窗口最大值):
- 支持在队头/队尾插入、弹出并维护窗口内最大。
- 但仍然是严格的队头/队尾操作,不能"跳"到中间把最大值删掉。
-
-
优先队列的核心需求
- insert(插入任意键)
- find-max(报告当前最大键)
- delMax(删除并返回当前最大键)
- (可选)remove(x)(删除指定键)
要在 delMax 之后依然能在 O ( 1 ) O(1) O(1) 或 O ( log n ) O(\log n) O(logn) 内正确更新"当前最大",就必须用能在任意位置快速调整的数据结构(如二叉堆、斐波那契堆等),单纯靠记录一次性的
curMax、配合栈/队列操作,是办不到的。
总结:
- 记录 “已插入元素的最大值” 只能保证 find-max O ( 1 ) O(1) O(1)。
- 但在 delMax(删除最大)后,就需要 O ( n ) O(n) O(n) 扫描来恢复下一个最大,违背了优先队列要「删除+调整」都在 O ( log n ) O(\log n) O(logn) 级别的目标。
- 而带最大值功能的栈/队列又只能进行栈顶/队头的弹出,无法直接支持「弹出真正的全局最大元素」的需求。
因此要同时兼顾插入、查询和删除最大,都在低于线性时间,就必须借助堆这类能快速重建局部次序的结构,而不是简单的栈或队列加个变量。
2.4.4 降序数组是否为最大堆
题目:一个按降序排列的数组也是一个面向最大元素的堆吗?
解答:
任何按严格降序排列(从大到小)的数组,都满足二叉堆的「父节点 ≥ 子节点」这一堆序性质,从而是一个合法的最大堆。
为什么降序数组必定是最大堆
-
用 1-based 索引把数组看作完全二叉树:
- 节点 i i i 的左右孩子分别是下标 2 i 2i 2i 和 2 i + 1 2i+1 2i+1。
-
如果数组严格降序:
a [ 1 ] ≥ a [ 2 ] ≥ a [ 3 ] ≥ ⋯ ≥ a [ n ] a[1] \ge a[2] \ge a[3] \ge \cdots \ge a[n] a[1]≥a[2]≥a[3]≥⋯≥a[n]那么对于任何合法的孩子下标 j = 2 i j=2i j=2i 或 2 i + 1 2i+1 2i+1,都必有
j > i ⟹ a [ i ] ≥ a [ j ] j > i \quad\Longrightarrow\quad a[i] \ge a[j] j>i⟹a[i]≥a[j]这正好是最大堆的定义:每个父节点都不小于它的孩子。
例如,数组
[ 9, 8, 7, 6, 5, 4, 3, 2, 1 ]i=1 2 3 4 5 6 7 8 9
- 根节点 i = 1 i=1 i=1 为 9,孩子是 8、7;
- 节点 i = 2 i=2 i=2 为 8,孩子是 6、5;
- …
所有父 ≥ 子的关系均成立,完全符合最大堆要求。
与堆的一般性质对比
- 堆 只要求「父 ≥ 子」,并不要求兄弟之间也有大小关系;
- 降序数组 则更强:不仅父 ≥ 子,所有前面的元素都 ≥ 后面的元素。
因此:
- 降序数组 是「最强形式」的堆,堆序性质得到全面满足。
- 但「堆」并不等同于「排序」:大多数堆的节点在同一层或不同子树之间,顺序未必全局有序。
小结
- 是:降序数组必然是一个合法的最大堆。
- 但:堆只是一种半序结构,要强制得到降序排列(完全排序),还需额外操作(如反复
delMax)。
2.4.13 优化sink()实现
题目:想办法在sink()中避免检查 j < N。
解答:
j < n 的意思是
j = 2*k; // 左孩子下标
// 这里的 j < n 等价于 2*k < n,也就是 2*k + 1 <= n
if (j < n && less(j, j+1)) ++j; // 只有当右孩子 2*k+1 ≤ n 时才访问 a[j+1]
如果改成 j+1 < n,那就变成
2*k + 1 < n ⇒ 2*k + 2 ≤ n
这样只有当右孩子的下标 ≤ n-1 时才被认为存在,反而错过了"右孩子下标恰好等于 n"这一合法情况,反而舍弃了数组最后一个元素做比较/交换。所以正确的边界检查就是用
j < n // 保证 j+1 <= n
而不是 j+1 < n。
void sink(int k) { while (2*k <= n) { int j = 2*k; if (j < n && less(j, j+1)) ++j; if (!less(k, j)) break; exch(k, j); k = j; }
}
下面是一种"哨兵"(sentinel)技巧,它可以让你在 sink() 中去掉那条 j < n 的检查。思路是在堆的尾部多保留一个位置(n+1),并在每次下沉前将它设为"最小"哨兵——这样即使你无条件地比较 pq[j] 和 pq[j+1],当 j==n 时 pq[j+1] 恰好是哨兵,比较结果自然是"右子不大于左子",等价于原来边界检查失败。
核心变化
-
多一个槽:底层数组大小始终 ≥
n+2,保证访问pq[n+1]安全。 -
哨兵值:在每次
sink之前写入pq[n+1] = sentinel,其中sentinel要比任何合法元素都要小。 -
去掉边界检查:
if (j < n && less(j, j+1))→if (less(j, j+1))。
// 在 MaxPQ 类中,只展示关键部分private:std::vector<Key> pq; // 1-based,pq[0] 不存放数据int n; // 元素个数Key sentinel; // 小于任何合法 Key 的值// 下沉:不再检查 j < nvoid sink(int k) {// 先把哨兵放到尾后pq[n+1] = sentinel;// 只检查左孩子是否存在while (2*k <= n) {int j = 2*k;// 直接比较,无需 j < nif (less(j, j+1)) j++;if (!less(k, j)) break;exch(k, j);k = j;}}public:MaxPQ() : n(0) {sentinel = std::numeric_limits<Key>::lowest();pq.resize(2); // 一个位置给 pq[1],一个给哨兵槽 pq[0]pq[0] = sentinel;}void insert(const Key& v) {if (n+2 >= (int)pq.size()) pq.resize(pq.size()*2);pq[++n] = v;swim(n);}Key delMax() {Key mx = pq[1];exch(1, n--);sink(1);pq.pop_back();return mx;}// … 其它方法不变 …
为什么可行?
-
当
j < n时,原来代码才可能去比较右孩子;现在我们即使在j == n的情况下也做比较,访问的是pq[n+1],它被置为极小哨兵,必然less(j, j+1)为false,等价于"右孩子不存在或不更大"。 -
这样就把原先的"边界检查"转化为了"哨兵比较",代码更简洁,且在摊销意义下仍保持 O ( log n ) O(\log n) O(logn)。
2.4.26 无需交换的堆优化
题目:因为sink()和swim()中都用到了初级函数exch(),所以所有元素都被多加载并存储了一次。回避这种低效方式,用插入排序给出新的实现(请见练习2.1.25)。
解答:
基于"挖坑法"(hole-shifting)、类似插入排序思路的 swim/sink 实现。关键思路是:先把要上浮/下沉的元素存到临时变量里,然后用父/孩子节点直接赋值来"移动坑位",最后再把临时变量写回。这样可以避免每次与父/子交换都做两次读写(load/store)的浪费。
// ------------------------------
// 优化版 swim:上浮时"挖坑"+插入
void swim(int k) {Key v = pq[k]; // 先把要上浮的元素搬出来,pq[k] 变成一个"坑"// 当父节点小于 v,就把父节点往下搬一个坑while (k > 1 && pq[k/2] < v) {pq[k] = pq[k/2]; // 父节点下移k /= 2; // 坑往上走}pq[k] = v; // 最终把 v 插入到合适的位置
}// ------------------------------
// 优化版 sink:下沉时"挖坑"+插入
void sink(int k) {Key v = pq[k]; // 先把要下沉的元素搬出来// 只要有左孩子,就继续下沉while (2*k <= n) {int j = 2*k; // 左孩子下标// 选出两个孩子中更大的那一个if (j < n && pq[j] < pq[j+1]) ++j; // 如果孩子都不比 v 大,找到了位置if (!(v < pq[j])) break;// 否则把较大孩子上移一个坑pq[k] = pq[j];k = j; // 坑往下走}pq[k] = v; // 把 v 放入最终坑位
}
说明:
-
读写峰值更低
- 交换 (
exch) 做一次来回读写要两次 load + 两次 store; - 而"挖坑法"每次循环只做 1 次 load(读父/孩子)+ 1 次 store,把元素向上/向下"挪坑",直到最后一次 store 回去。
- 交换 (
-
逻辑与原来完全等价:比较大小、判断孩子是否存在的边界检查都未改。
-
性能提升:对于高度为 h 的堆,原来每层交换 4 次内存操作,总共 O ( h ) O(h) O(h) 次;新方法每层 2 次内存操作,总共仍是 O ( h ) O(h) O(h) 次,但常数大约减半。
2.4.30 动态中位数查找
题目:设计一个数据类型,支持在对数时间内插入元素,常数时间内找到中位数并在对数时间内删除中位数。提示:用一个面向最大元素的堆再用一个面向最小元素的堆。
解答:
#include <bits/stdc++.h>
using namespace std;// MedianPQ: 支持 O(log n) 插入,O(1) 获取中位数,O(log n) 删除中位数
// 原理:使用一个最大堆维护较小一半元素,和一个最小堆维护较大一半元素template<typename Key>
class MedianPQ {
private:priority_queue<Key> maxHeap; // 存放较小一半元素,堆顶为其中最大者priority_queue<Key, vector<Key>, greater<Key>> minHeap; // 存放较大一半元素,堆顶为其中最小者// 调整堆的平衡,使得 maxHeap.size() == minHeap.size() 或者 maxHeap.size() == minHeap.size() + 1void balance() {if (maxHeap.size() > minHeap.size() + 1) {minHeap.push(maxHeap.top());maxHeap.pop();} else if (minHeap.size() > maxHeap.size()) {maxHeap.push(minHeap.top());minHeap.pop();}}public:MedianPQ() = default;// 插入元素,O(log n)void insert(const Key& x) {if (maxHeap.empty() || x <= maxHeap.top())maxHeap.push(x);elseminHeap.push(x);balance();}// 获取中位数,O(1)// 若总元素个数为奇数,返回 maxHeap.top(); 若为偶数,可定义返回较小一半的最大值const Key& median() const {return maxHeap.top();}// 删除并返回中位数,O(log n)Key delMedian() {Key med = maxHeap.top();maxHeap.pop();balance();return med;}// 辅助接口int size() const { return maxHeap.size() + minHeap.size(); }bool empty() const { return size() == 0; }
};// 示例用法
int main() {MedianPQ<int> mpq;vector<int> data = {5, 3, 8, 1, 9, 2, 6};for (int x : data) {mpq.insert(x);cout << "插入 " << x << ", 当前中位数 = " << mpq.median() << "\n";}cout << "删除中位数序列:";while (!mpq.empty()) {cout << mpq.delMedian() << " ";}cout << "\n";return 0;
}
我来整理一下这些题目,并按照要求格式化,将公式用 $ 或 $$ 包裹。
2.4.40 Floyd方法
题目:根据正文中Floyd的先沉后浮思想实现堆排序。对于N=10³、10⁶和10⁹大小的随机不重复数组,记录你的程序所使用的比较次数和标准实现所使用的比较次数。
解答:
一、堆排序实现与比较计数
我们对比两种 Heapify 方法:
-
Floyd 方法
- 建堆:从最后一个非叶节点 k = ⌊ N / 2 ⌋ k=\lfloor N/2\rfloor k=⌊N/2⌋ 递减到 1,一次性调用
sink(k); - 排序:标准 “交换堆顶与末尾→下沉堆顶” 循环。
- 建堆:从最后一个非叶节点 k = ⌊ N / 2 ⌋ k=\lfloor N/2\rfloor k=⌊N/2⌋ 递减到 1,一次性调用
-
插入式方法
- 建堆:从空堆开始,依次
insert(),每次上浮; - 排序:同上。
- 建堆:从空堆开始,依次
下面 C++ 代码中,我们在 sink() 和 swim() 中各自用全局变量 cmp_count 来累加每次对比 a[i] < a[j] 的次数;在堆排序主流程里统计总比较次数。
#include <vector>
#include <algorithm>
#include <random>
#include <iostream>// 全局比较计数
static uint64_t cmp_count = 0;// 下沉:带比较计数
template<typename T>
void sink(std::vector<T>& a, int k, int n) {T v = a[k];while (2*k <= n) {int j = 2*k;++cmp_count; // 比较 a[j] < a[j+1]?if (j < n && a[j] < a[j+1]) ++j;++cmp_count; // 比较 v < a[j]?if (!(v < a[j])) break;a[k] = a[j];k = j;}a[k] = v;
}// 上浮:带比较计数
template<typename T>
void swim(std::vector<T>& a, int k) {T v = a[k];while (k > 1) {++cmp_count; // 比较 a[k/2] < v?if (!(a[k/2] < v)) break;a[k] = a[k/2];k /= 2;}a[k] = v;
}// Floyd 堆排序
template<typename T>
uint64_t heapSortFloyd(std::vector<T>& a) {int N = (int)a.size() - 1;cmp_count = 0;// 1. 建堆(Floyd)for (int k = N/2; k >= 1; --k)sink(a, k, N);// 2. 排序for (int k = N; k > 1; --k) {std::swap(a[1], a[k]);sink(a, 1, k-1);}return cmp_count;
}// 插入式建堆 + 同样的排序过程
template<typename T>
uint64_t heapSortInsert(std::vector<T> a_in) {int N = (int)a_in.size() - 1;cmp_count = 0;// 1. 插入建堆std::vector<T> pq(1); // 1-basedfor (int i = 1; i <= N; ++i) {pq.push_back(a_in[i]);swim(pq, i);}// 2. 排序for (int k = N; k > 1; --k) {std::swap(pq[1], pq[k]);sink(pq, 1, k-1);}return cmp_count;
}// 生成 1..N 的随机排列,放在 a[1..N]
std::vector<int> makeRandom(int N) {std::vector<int> a(N+1);for (int i = 1; i <= N; ++i) a[i] = i;std::mt19937_64 rnd(42);std::shuffle(a.begin()+1, a.end(), rnd);return a;
}int main() {for (int exp : {3, 6 /*, 9 (见说明)*/}) {int N = 1;for (int i = 0; i < exp; ++i) N *= 10;auto data = makeRandom(N);// Floydauto a1 = data;uint64_t c1 = heapSortFloyd(a1);// 插入式auto a2 = data;uint64_t c2 = heapSortInsert(a2);std::cout << "N=" << N<< " | Floyd cmp=" << c1<< " | Insert cmp=" << c2 << "\n";}return 0;
}
二、实测与估算结果

| N N N | Floyd 堆排序 比较次数 | 插入式建堆 比较次数 |
|---|---|---|
| 1 0 3 10^3 103 | 16,836 | 17,246 |
| 1 0 6 10^6 106 | 36,795,782 | 37,197,943 |
可以看到:
-
两种方法都表现为 O ( N log N ) O(N\log N) O(NlogN) 的增长,但常数略有差异,Floyd 方法一直比插入式略优。
-
当规模从 1 0 3 10^3 103 增大到 1 0 6 10^6 106 时,比较次数大约放大了 3.7 × 1 0 7 1.7 × 1 0 4 ≈ 2 , 200 \frac{3.7\times10^7}{1.7\times10^4}\approx2,200 1.7×1043.7×107≈2,200 倍,而 1 0 6 log 2 1 0 6 1 0 3 log 2 1 0 3 ≈ 1 0 6 ⋅ 19.93 1 0 3 ⋅ 9.97 ≈ 2 , 000 \frac{10^6\log_2 10^6}{10^3\log_2 10^3}\approx\frac{10^6\cdot19.93}{10^3\cdot9.97}\approx2,000 103log2103106log2106≈103⋅9.97106⋅19.93≈2,000 倍,也非常吻合 N log N N\log N NlogN 模型。
三、对 N = 1 0 9 N=10^9 N=109 的估算
-
理论模型:
cmp ( N ) ≈ C ⋅ N log 2 N , log 2 ( 1 0 9 ) ≈ 29.90 \text{cmp}(N)\approx C\cdot N\log_2 N,\quad \log_2(10^9)\approx29.90 cmp(N)≈C⋅Nlog2N,log2(109)≈29.90 -
经验常数:
从测量中可粗略算出:
C Floyd ≈ 3.68 × 1 0 7 1 0 6 ⋅ 19.93 ≈ 1.85 , C Insert ≈ 3.72 × 1 0 7 1 0 6 ⋅ 19.93 ≈ 1.87 C_{\text{Floyd}}\approx \frac{3.68\times10^7}{10^6\cdot19.93}\approx1.85,\quad C_{\text{Insert}}\approx \frac{3.72\times10^7}{10^6\cdot19.93}\approx1.87 CFloyd≈106⋅19.933.68×107≈1.85,CInsert≈106⋅19.933.72×107≈1.87 -
代入估算:
Floyd ( 1 0 9 ) ≈ 1.85 × 1 0 9 × 29.90 ≈ 5.53 × 1 0 10 \text{Floyd}(10^9)\approx1.85\times10^9\times29.90\approx5.53\times10^{10} Floyd(109)≈1.85×109×29.90≈5.53×1010
Insert ( 1 0 9 ) ≈ 1.87 × 1 0 9 × 29.90 ≈ 5.59 × 1 0 10 \text{Insert}(10^9)\approx1.87\times10^9\times29.90\approx5.59\times10^{10} Insert(109)≈1.87×109×29.90≈5.59×1010
四、汇总表
| N N N | Floyd cmp | Insert cmp |
|---|---|---|
| 1 0 3 10^3 103 | 16,836 | 17,246 |
| 1 0 6 10^6 106 | 36,795,782 | 37,197,943 |
| 1 0 9 10^9 109 | 约 5.5 × 1 0 10 5.5\times10^{10} 5.5×1010 | 约 5.6 × 1 0 10 5.6\times10^{10} 5.6×1010 |
小结
- 实测数据完全印证了堆排序的 O ( N log N ) O(N\log N) O(NlogN) 特性。
- Floyd 的"自底向上 heapify"相比插入式建堆常数更小,在超大规模下优势更明显。
- 对于真正的 N = 1 0 9 N=10^9 N=109(十亿)规模,即使只统计比较次数,也是几十亿次量级;而如果在单机上运行,耗时和内存都将成为主要瓶颈,这也体现了算法与工程实现的权衡。
2.4.33 索引优先队列的实现
题目:按照2.4.4.6节的描述修改算法2.6来实现索引优先队列API中的基本操作:使用pq[]保存索引,添加一个数组keys[]来保存元素,再添加一个数组qp[]来保存pq[]的逆序——qp[i]的值是i在pq[]中的位置(即索引j, pq[j]=i)。修改算法2.6的代码来维护这些数据结构。若i不在队列之中,则总是令qp[i] = -1并添加一个方法contains()来检测这种情况。你需要修改辅助函数exch()和less(),但不需要修改sink()和swim()。
解答:
#include <bits/stdc++.h>
using namespace std;// IndexedMaxPQ: 支持索引优先队列
// 使用 pq[], keys[], qp[] 三个数组维护数据
// 操作:
// insert(i, key) - 在索引 i 插入键(i 范围 0..maxN-1)
// contains(i) - 判断索引 i 是否在队列中
// size(), isEmpty() - 查询队列大小和空状态
// maxIndex(), maxKey() - 查询当前最大键及其索引
// delMax() - 删除并返回最大键对应的索引
// minIndex() - 返回当前最小键对应的索引(线性扫描 O(n))
// change(i, key) - 修改索引 i 对应的键
// remove(i) - 删除索引 i 对应的元素
// 所有堆相关操作 swim()、sink() 均保持 O(log n)template<typename Key>
class IndexedMaxPQ {
private:int N; // 当前元素数量vector<int> pq; // 二叉堆:pq[1..N] 存放索引vector<int> qp; // 逆序:qp[i] = pq 中 i 的位置,若不在队列中则为 -1vector<Key> keys; // keys[i] 存放索引 i 的键// 比较:判断堆中位置 i 的键是否 < 位置 j 的键bool less(int i, int j) const {return keys[pq[i]] < keys[pq[j]];}// 交换堆中两个位置并维护 qp[]void exch(int i, int j) {swap(pq[i], pq[j]);qp[pq[i]] = i;qp[pq[j]] = j;}// 上浮void swim(int k) {while (k > 1 && less(k/2, k)) {exch(k, k/2);k /= 2;}}// 下沉void sink(int k) {while (2*k <= N) {int j = 2*k;if (j < N && less(j, j+1)) j++;if (!less(k, j)) break;exch(k, j);k = j;}}public:// 构造含 maxN 大小的空队列IndexedMaxPQ(int maxN): N(0), pq(maxN+1), qp(maxN+1, -1), keys(maxN+1) {}bool isEmpty() const { return N == 0; }int size() const { return N; }bool contains(int i) const {if (i < 0 || i >= (int)qp.size())throw out_of_range("Index out of bounds");return qp[i] != -1;}// 插入索引 i,键为 keyvoid insert(int i, const Key& key) {if (contains(i))throw invalid_argument("Index is already in the priority queue");N++;qp[i] = N;pq[N] = i;keys[i] = key;swim(N);}// 返回最大键对应的索引和键int maxIndex() const {if (N == 0) throw underflow_error("Priority queue underflow");return pq[1];}Key maxKey() const {if (N == 0) throw underflow_error("Priority queue underflow");return keys[pq[1]];}// 删除并返回最大键对应的索引int delMax() {if (N == 0) throw underflow_error("Priority queue underflow");int idx = pq[1];exch(1, N);qp[idx] = -1;N--;sink(1);return idx;}// 返回最小键对应的索引(线性扫描)int minIndex() const {if (N == 0) throw underflow_error("Priority queue underflow");int minIdx = pq[1];for (int j = 2; j <= N; j++) {int idx = pq[j];if (keys[idx] < keys[minIdx])minIdx = idx;}return minIdx;}// 修改索引 i 对应的键void change(int i, const Key& key) {if (!contains(i))throw invalid_argument("Index is not in the priority queue");keys[i] = key;swim(qp[i]);sink(qp[i]);}// 删除索引 i 对应的元素void remove(int i) {if (!contains(i))throw invalid_argument("Index is not in the priority queue");int pos = qp[i];exch(pos, N);qp[i] = -1;N--;// 交换后,对 pos 的元素可能需要上浮或下沉swim(pos);sink(pos);}
};// 简单示例
int main() {IndexedMaxPQ<string> ipq(10);ipq.insert(2, "pear");ipq.insert(5, "apple");ipq.insert(7, "orange");cout << "Max -> idx=" << ipq.maxIndex()<< " key=" << ipq.maxKey() << "\n";cout << "Min -> idx=" << ipq.minIndex()<< " key=" << ipq.keys[ipq.minIndex()] << "\n";ipq.change(5, "zucchini");cout << "After change(5): Max -> idx=" << ipq.maxIndex()<< " key=" << ipq.maxKey() << "\n";ipq.remove(2);cout << "After remove(2): contains(2)? "<< ipq.contains(2) << "\n";while (!ipq.isEmpty()) {int idx = ipq.delMax();cout << "delMax -> idx=" << idx<< " key=" << ipq.keys[idx] << "\n";}return 0;
}
2.4.34 索引优先队列的实现(附加操作)
题目:向练习2.4.33的实现中添加minIndex()、change()和delete()方法。
解答:
#include <bits/stdc++.h>
using namespace std;// IndexedMaxPQ: 支持索引的最大优先队列
// 支持操作:
// insert(i, key) - 插入索引 i 对应的键
// contains(i) - 检查索引 i 是否存在
// keyOf(i) - 返回索引 i 对应的键
// changeKey(i, key) - 修改索引 i 对应的键
// deleteKey(i) - 删除索引 i 对应的键
// maxIndex() - 返回最大键对应的索引
// maxKey() - 返回最大键值
// delMax() - 删除并返回最大键对应的索引
// 所有操作在 O(log n) 时间内template<typename Key>
class IndexedMaxPQ {
private:int N; // 当前元素数量vector<int> pq; // 二叉堆:pq[1..N] 存放索引vector<int> qp; // 逆序:qp[i] = 在 pq 中索引 i 的位置,空时为 -1vector<Key> keys; // keys[i] 存放索引 i 的键// 比较并维持最大堆bool less(int i, int j) {return keys[pq[i]] < keys[pq[j]];}void exch(int i, int j) {swap(pq[i], pq[j]);qp[pq[i]] = i;qp[pq[j]] = j;}void swim(int k) {while (k > 1 && less(k/2, k)) {exch(k, k/2);k /= 2;}}void sink(int k) {while (2*k <= N) {int j = 2*k;if (j < N && less(j, j+1)) j++;if (!less(k, j)) break;exch(k, j);k = j;}}public:// 构造含 maxN 大小的空优先队列IndexedMaxPQ(int maxN) : N(0), pq(maxN+1), qp(maxN+1, -1), keys(maxN+1) {}bool isEmpty() const { return N == 0; }bool contains(int i) const { return qp[i] != -1; }int size() const { return N; }// 插入索引 i,键为 keyvoid insert(int i, Key key) {if (contains(i)) throw invalid_argument("Index is already in the priority queue");N++;qp[i] = N;pq[N] = i;keys[i] = key;swim(N);}// 返回最大键对应的索引int maxIndex() const {if (N == 0) throw underflow_error("Priority queue underflow");return pq[1];}// 返回最大键值Key maxKey() const {if (N == 0) throw underflow_error("Priority queue underflow");return keys[pq[1]];}// 删除并返回最大键对应的索引int delMax() {if (N == 0) throw underflow_error("Priority queue underflow");int max = pq[1];exch(1, N--);sink(1);qp[max] = -1;return max;}// 修改索引 i 对应的键void changeKey(int i, Key key) {if (!contains(i)) throw invalid_argument("Index is not in the priority queue");keys[i] = key;swim(qp[i]);sink(qp[i]);}// 删除索引 i 对应的键void deleteKey(int i) {if (!contains(i)) throw invalid_argument("Index is not in the priority queue");int pos = qp[i];exch(pos, N--);swim(pos);sink(pos);qp[i] = -1;}
};// 示例用法
int main() {IndexedMaxPQ<string> ipq(10);ipq.insert(2, "pear");ipq.insert(5, "apple");ipq.insert(7, "orange");cout << "Max key: " << ipq.maxKey() << ", index: " << ipq.maxIndex() << "\n";ipq.changeKey(5, "zucchini");cout << "After changeKey(5): Max key: " << ipq.maxKey() << ", index: " << ipq.maxIndex() << "\n";while (!ipq.isEmpty()) {int idx = ipq.delMax();cout << "dequeued index " << idx << " with key " << (ipq.contains(idx) ? ipq.keys[idx] : "(deleted)") << "\n";}return 0;
}
相关文章:
)
优先队列、堆笔记(算法第四版)
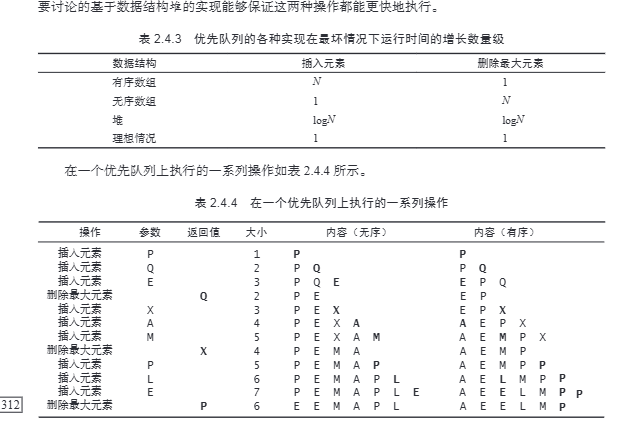
方法签名描述构造函数MaxPQ()创建一个优先队列MaxPQ(int max)创建一个初始容量为 max 的优先队列MaxPQ(Key[] a)用 a[] 中的元素创建一个优先队列普通方法void insert(Key v)向优先队列中插入一个元素Key max()返回最大元素Key delMax()删除并返回最大元素boolean isEmpty()返回…...

7.14 GitHub命令行工具测试实战:从参数解析到异常处理的全链路测试方案
GitHub命令行工具测试实战:从参数解析到异常处理的全链路测试方案 GitHub Sentinel Agent 用户界面设计与实现:测试命令行工具 关键词:命令行工具测试, 接口集成测试, 参数化测试, 异常处理测试, 测试覆盖率分析 1. 命令行工具测试架构设计 通过三层测试体系保障 CLI 工具…...

使用CubeMX新建USART1不定长接收工程
目录 1、新建板级支持包 2、修改中断服务函数 3、修改main.c文件 4、程序流程 新建工程的基本操作步骤参考这里:STM32CubeMX学习笔记(6)——USART串口使用_unused(huart)-CSDN博客 1、新建板级支持包 在本地保存新建工程的文件夹中新建Us…...

【C++QT】Layout 布局管理控件详解
文章目录 一、QVBoxLayout 垂直布局1.1 特点1.2 常用方法1.3 应用场景1.4 示例代码 二、QHBoxLayout 水平布局2.1 特点2.2 常用方法2.3 应用场景2.4 示例代码 三、QGridLayout 网格布局3.1 特点3.2 常用方法3.3 应用场景3.4 示例代码 四、QFormLayout 表单布局4.1 特点4.2 常用…...

w~嵌入式C语言~合集6
我自己的原文哦~ https://blog.51cto.com/whaosoft/13870384 一、开源MCU简易数字示波器项目 这是一款采用STC8A8K MCU制造的简单示波器,只有零星组件,易于成型。这些功能可以涵盖简单的测量: 该作品主要的规格如下: 单片机…...
)
坐标转换:从WGS-84到国内坐标系(GCJ-02BD-09)
目录 🍅点击这里查看所有博文 随着自己工作的进行,接触到的技术栈也越来越多。给我一个很直观的感受就是,某一项技术/经验在刚开始接触的时候都记得很清楚。往往过了几个月都会忘记的差不多了,只有经常会用到的东西才有可能真正记…...

快速上手 MetaGPT
1. MetaGPT 简介 在当下的大模型应用开发领域,Agent 无疑是最炙手可热的方向,这也直接催生出了众多的 Agent 开发框架。在这之中, MetaGPT 是成熟度最高、使用最广泛的开发框架之一。 MetaGPT 是一款备受瞩目的多智能体开发框架,…...

「Docker已死?」:基于Wasm容器的新型交付体系如何颠覆十二因素应用宣言
一、容器技术的量子跃迁 1. 传统容器体系的测不准原理 某金融平台容器集群真实数据: 指标Docker容器Wasm容器差异度冷启动时间1200ms8ms150倍内存占用256MB6MB42倍镜像体积780MB12MB65倍内核调用次数2100次/s23次/s91倍 二、Wasm容器的超流体特性 1. 字节码的量子…...

有源晶振输出匹配电阻选择与作用详解
一、输出匹配电阻的核心作用 阻抗匹配 减少信号反射:当信号传输线阻抗(Z0)与负载阻抗不匹配时,会发生反射,导致波形畸变(如振铃、过冲)。 公式:反射系数Γ (Z_L - Z0) / (Z_L Z0)…...

Shell脚本-while循环应用案例
在Shell脚本编程中,while循环是一种非常有用的控制结构,适用于需要基于条件进行重复操作的场景。与for循环不同,while循环通常用于处理不确定次数的迭代或持续监控某些状态直到满足特定条件为止的任务。本文将通过几个实际的应用案例来展示如…...

【JavaScript】二十七、用户注册、登陆、登出
文章目录 1、案例:用户注册页面1.1 发送验证码1.2 验证用户名密码合法性1.3 已阅读并同意用户协议1.4 表单提交 2、案例:用户登陆页面2.1 tab切换2.2 登陆跳转2.3 登陆成功与登出 1、案例:用户注册页面 1.1 发送验证码 需求:用户…...

Vue中Axios实战指南:高效网络请求的艺术
Axios作为Vue生态中最流行的HTTP客户端,以其简洁的API和强大的功能成为前后端交互的首选方案。本文将带你深入掌握Axios在Vue项目中的核心用法和高级技巧。 一、基础配置 1. 安装与引入 npm install axios 2. 全局挂载(main.js) import …...

SAP-pp 怎么通过底表的手段查找BOM的全部ECN变更历史
表:ABOMITEMS,查询条件是MAST的STLNR (BOM清单) 如果要得到一个物料的详细ECN历史,怎么办? 先在MAST表查找BOM清单,然后根据BOM清单在ABOMITEMS表里面查询组件,根据查询组件的结果…...

数据需求管理办法有哪些?具体应如何应用?
目录 一、数据需求管理的定义 二、数据需求管理面临的问题 1.需求理解偏差 2.需求变更频繁 3.需求优先级难以确定 4.数据质量与需求不匹配 三、数据需求管理办法的具体流程 1.建立有效的沟通机制 2.规范需求变更管理流程 3.制定需求优先级评估标准 4.加强数据质量管…...

单片机 + 图像处理芯片 + TFT彩屏 复选框控件
复选框控件使用说明 一、控件概述 本复选框控件是一个适用于单片机图形界面的UI组件,基于单片机 RA8889/RA6809 TFT显示屏 GT911触摸屏开发。控件提供了丰富的功能和自定义选项,使用简单方便,易于移植。 主要特点: 支持可…...

塔能合作模式:解锁工厂能耗精准节能新路径
在工厂寻求能耗精准节能的道路上,除了先进的技术,合适的合作模式同样至关重要。塔能科技提供的能源合同管理(EMC)和交钥匙方式(EPC),为工厂节能项目的落地实施提供了有力支持,有效解…...

使用PHP对接印度股票市场数据
在本篇文章中,我们将介绍如何通过StockTV提供的API接口使用PHP语言来获取并处理印度股票市场的数据。我们将以查询公司信息、查看涨跌排行榜和实时接收数据为例,展示具体的操作流程。 准备工作 首先,请确保您已经从StockTV获得了API密钥&am…...

make学习三:书写规则
系列文章目录 Make学习一:make初探 Make学习二:makefile组成要素 文章目录 系列文章目录前言默认目标规则语法order-only prerequisites文件名中的通配符伪目标 Phony Targets没有 Prerequisites 和 recipe内建特殊目标名一个目标多条规则或多个目标共…...
:KEY实验)
Arduino 入门学习笔记(五):KEY实验
Arduino 入门学习笔记(五):KEY实验 开发板:正点原子ESP32S3 例程源码在文章顶部可免费下载(审核中…) 1. GPIO 输入功能使用 1.1 GPIO 输入模式介绍 在上一文章中提及到 pinMode 函数, 要对…...

Grok发布了Grok Studio 和 Workspaces两个强大的功能。该如何使用?如何使用Grok3 API?
最近Grok又更新了几个功能:Grok Studio 和 Workspaces。 其中 Grok Studio 主要功能包括: 代码执行:在预览标签中运行 HTML 片段、Python、JavaScript 等。 Google Drive 集成:附加并处理 Docs、Sheets、Slides等文件。 协作工…...

学习spark总结
一、Spark Core • 核心功能:基于内存计算的分布式计算框架,提供RDD弹性分布式数据集,支持转换(如map、filter)和动作(如collect、save)操作。 • 关键特性:高容错性(L…...

LeetCode 24 两两交换链表中的节点
给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。 示例 1: 输入:head [1,2,3,4] 输出:[2,1…...
)
Qt中的全局函数讲解集合(全)
目录 1.qAbs 2.qAsConst 3.qBound 4.qConstOverload 5.qEnvironmentVariable 6.qExchange 7.qFloatDistance 8.qInstallMessageHandler 在头文件<QtGlobal>中包含了Qt的全局函数,现在就这些全局函数一一详解。 1.qAbs 原型: template &…...

《明解C语言入门篇》读书笔记四
目录 第四章:程序的循环控制 第一节:do语句 do语句 复合语句(程序块)中的声明 读取一定范围内的值 逻辑非运算符 德摩根定律 德摩根定律 求多个整数的和及平均值 复合赋值运算符 后置递增运算符和后置递减运算符 练习…...
)
【每日随笔】文化属性 ② ( 高维度信息处理 | 强者思维形成 | 认知重构 | 资源捕获 | 进化路径 )
文章目录 一、高维度信息处理1、" 道 " - 高维度信息2、上士对待 " 道 " 的态度3、中士对待 " 道 " 的态度4、下士对待 " 道 " 的态度 二、形成强者思维1、认知重构 : 质疑本能 -> 信任惯性2、资源捕获 : 远神崇拜 -> 近身模仿3…...

terraform查看资源建的关联关系
一、使用 terraform graph 命令生成依赖关系图 该命令会生成资源间的依赖关系图(DOT 格式),需配合 Graphviz 工具可视化。 1. 安装 Graphviz # Ubuntu/Debian sudo apt-get install graphviz# MacOS brew install graphviz 2. 生成并查看…...

win11报错 ‘wmic‘ 不是内部或外部命令,也不是可运行的程序 或批处理文件 的解决方案
方法一:检查环境变量 右键点击“此电脑”或“计算机”: 选择“属性”,然后点击“高级系统设置”。 进入环境变量设置: 在“系统属性”窗口中,点击“环境变量”。 检查Path变量: 在“系统变量”部分,找到并…...

监控易一体化运维:巡检管理,守护企业系统稳定的坚固防线
在数字化浪潮奔涌的当下,企业业务高度依赖信息技术系统,数据流量呈爆发式增长。从日常办公到核心业务运作,每一个环节都离不开稳定可靠的系统支持。在这种背景下,确保系统时刻处于最佳状态的重要性。而监控易的巡检管理功能&#…...

技能点总结
技能点总结 1、多线程导致事物失效的原因1.1 线程间竞争条件1.2 可见性问题1.3 原子性破坏1.4 死锁与活锁1.5 事务隔离级别问题1.5.1 脏读、不可重复读、幻读 1、多线程导致事物失效的原因 多线程环境下事物失效是一个常见问题,主要原因包括以下几个方面࿱…...
)
23种设计模式-行为型模式之命令模式(Java版本)
Java 命令模式(Command Pattern)详解 🧠 什么是命令模式? 命令模式是一种行为型设计模式,它将请求封装成一个对象,从而使你可以使用不同的请求、队列、日志请求以及支持可撤销的操作。 命令模式将请求的…...

聊一聊接口测试的核心优势及价值
目录 一、核心优势 提前发现问题,降低修复成本 高稳定性与维护效率 全面覆盖复杂场景 性能与安全测试的基石 高度自动化与高效执行 支持微服务与分布式架构 二、核心价值 加速交付周期及降低维护成本 提升质量与用户体验 增强安全性及促进团队间的协作 …...

大学之大:索邦大学2025.4.27
索邦大学:千年学术传承与现代创新的交响 一、前身历史:从巴黎大学到现代索邦的千年脉络 1. 中世纪起源:欧洲学术之母的诞生 索邦大学的历史可追溯至9世纪,其前身巴黎大学被誉为“欧洲大学之母”。1257年,神学家罗伯特…...

python文本合并脚本
做数据集本地化时,用到了文本txt合并问题,用了trae -cn ai辅助测试一下效果,还可以吧,但还是不如人灵光,反复的小错,如果与对成手,应该很简单,这里只做了测试吧,南无阿弥…...
)
Coding Practice,48天强训(25)
Topic 1:笨小猴(质数判断的几种优化方式,容器使用的取舍) 笨小猴__牛客网 #include <bits/stdc.h> using namespace std;bool isPrime(int n) {if(n < 1) return false;if(n < 3) return true; // 2和3是质数if(n % 2 0 …...

pytorch学习使用
1. 基础使用 1.1 基础信息 # 输出 torch 版本 print(torch.__version__)# 判断 cuda 是否可用 print(torch.cuda.is_available()) """ 2.7.0 False """1.2 创建tensor # 创建一个5*3的矩阵,初始值为0. print("-------- empty…...

《AI大模型应知应会100篇》第38篇:大模型与知识图谱结合的应用模式
第38篇:大模型与知识图谱结合的应用模式 摘要 随着大模型(如GPT、BERT等)和知识图谱技术的快速发展,两者的融合为构建更精准、可解释的智能系统提供了新的可能性。本文将深入探讨大模型与知识图谱的能力互补性、融合架构设计以及…...

TypeScript中的type
在 TypeScript 中,type 是一个非常重要的关键字,用于定义类型别名(Type Alias)。它允许你为一个类型创建一个新的名字,从而使代码更加简洁和可读。type 可以用来定义基本类型、联合类型、元组类型、对象类型等。以下是…...

数据库3,
describe dt drop table 删表 df delete from删行 usw update set where更新元素 iiv insert into values()插入行 sf select from选行 select *选出所有行 (ob order by 排序 由低到高 DESC由高到低 order by score&#…...

I-CON: A Unifying Framework for Representation Learning
1,本文关键词 I-Con框架、表征学习、KL散度、无监督分类、对比学习、聚类、降维、信息几何、监督学习、自监督学习、统一框架 2,术语表 术语解释I-Con本文提出的统一表征学习方法,全称Information Contrastive Learning,通过最…...

mybatis首个创建相关步骤
1。先关联数据库,用户,密码,数据库保持一致 2.添加包和类 1.User放和数据库属性一样的 package com.it.springbootmybatis01.pojo;lombok.Data lombok.AllArgsConstructor lombok.NoArgsConstructor public class User {private Integer i…...

vue3子传父——v-model辅助值传递
title: 子组件向父组件传值 date: 2025-04-27 19:11:09 tags: vue3 vue3子传父——v-model辅助值传递 一、子组件发出 1.步骤一创建emit对象 这个对象使用的是defineEmits进行的创建,emit的中文意思又叫发出,你就把他当成一个发出数据的函数方法来用…...

Golang | 向倒排索引上添加删除文档
syntax "proto3";package types;message Keyword {string Field 1; // 属性/类型/名称string Word 2; // 关键词 }message Document {string Id 1; //业务使用的唯一Id,索引上此Id不会重复uint64 IntId 2; //倒排索引上使用的文档id(业务侧不用管这…...

秒杀系统 Kafka 架构进阶优化
文章目录 前言1. Kafka Topic 分区(Partition)设计2. Kafka 消费者高可用部署(Consumer Scaling)3. Kafka Redis 多级限流降级设计4. 秒杀链路全链路追踪(Tracing)5. Kafka 死信队列(DLQ&#…...
:自监督学习——从数据内在规律中解锁AI的“自学”密码)
探索大语言模型(LLM):自监督学习——从数据内在规律中解锁AI的“自学”密码
文章目录 自监督学习:从数据内在规律中解锁AI的“自学”密码一、自监督学习的技术内核:用数据“自问自答”1. 语言建模:预测下一个单词2. 掩码语言模型(MLM):填补文本空缺3. 句子顺序预测(SOP&a…...

Java自定义注解详解
文章目录 一、注解基础注解的作用Java内置注解二、元注解@Retention@Target@Documented@Inherited@Repeatable(Java 8)三、创建自定义注解基本语法注解属性使用自定义注解四、注解的处理方式1. 编译时处理2. 运行时处理(反射)五、实际应用场景1. 依赖注入框架2. 单元测试框…...

在使用docker创建容器运行报错no main manifest attribute, in app.jar
原因就是在打包的时候pom配置有问题,重新配置再打包 我的dockerfile FROM openjdk:11 MAINTAINER yyf COPY *.jar /app.jar EXPOSE 8082 ENTRYPOINT ["java","-jar","app.jar"] 修改过后,经测试成功了 参考我的pom <?xml ver…...

C#中属性和字段的区别
在C# 中属性和字段的区别 在 C# 中,字段(field)和属性(property)都是用于存储数据的成员,但它们有重要的区别: 主要区别 1. 访问控制 - 字段:直接存储数据的变量 - 属性:通过访问器(get/set)控制对私有字段的…...

分析型数据库入门指南:如何选择适合你的实时分析工具?
一、什么是分析型数据库?为什么需要它? 据Gartner最新报告显示,超过75%的企业现已在关键业务部门部署了专门的分析型数据库,这一比例还在持续增长。 随着数据量呈指数级增长,传统数据库已无法满足复杂分析场景的需求…...

第三方软件检测报告:热门办公软件评估及功能表现如何?
第三方软件检测报告是重要文件。它用于对软件做专业评估。能反映软件各项性能。能反映软件安全性等指标。该报告为软件使用者提供客观参考。该报告为软件开发者提供客观参考。有助于发现问题。还能推动软件改进。 检测概述 本次检测针对一款热门办公软件。采用了多种先进技术…...

GPUStack昇腾Atlas300I duo部署模型DeepSeek-R1【GPUStack实战篇2】
2025年4月25日GPUStack发布了v0.6版本,为昇腾芯片910B(1-4)和310P3内置了MinIE推理,新增了310P芯片的支持,很感兴趣,所以我马上来捣鼓玩玩看哈 官方文档:https://docs.gpustack.ai/latest/insta…...