记录学习记录学习《手动学习深度学习》这本书的笔记(九)
马不停蹄地来到了第十二章:计算性能……
感觉应该是讲并行计算方面的,比如GPU、CPU、CUDA那些。
第十二章:计算性能
12.1 编译器和解释器
这里先提出了命令式编程和符号式编程的概念。
命令式编程VS符号式编程
目前为止,本书讲的主要是命令式编程,通过直接的方式改变程序的状态,比如"+"、"print"这些,而符号式编程主要通过一些接口,主要关注任务的目的。
问了下ai:命令式编程主要关注每一步要做什么,改变程序状态一步步实现具体功能,达到预期结果;而符号式式编程关注数学符号和逻辑表达式的操作,主要用于逻辑推理。
命令式编程效率不高,因为编译器一步步执行这些操作,却不关注程序整体架构,比如一个函数可能连续调用两次,如果在一个或多个GPU上执行,则开销可能会非常大,并且每走一步都要保留以后可能不会用到的值……总之走一步看一步总是很麻烦的。
考虑另一种符号式编程,它不会马上计算每一步,只在完全定义了整个过程后才执行计算,深度学习的TensorFlow框架就使用了这种编程。
符号式编程流程:
①定义计算流程
②将流程编译成可执行程序
③给定输入,调用编译好的程序执行
而非命令式编程的一步步执行,所以这允许了大量优化,因为编译器在执行之前就可以看到完整的代码,在发现之后不需要某个变量后编译器就可以释放它的内存。
但之前我们一般都是用更好使用更好调试的命令式编程,因为无论是打印中间变量还是使用调试工具命令式编程都更简单。
符号式编程优点在效率高,程序容易移植,甚至可以将python程序移植到与python无关的格式中,使其在非python环境下运行。
混合编程
深度学习编程框架们有使用符号式也有使用命令式的,目前主流的Pytorch(命令式)和Tensorflow(混合式)都有向对方靠拢的趋势。
作者这里拿Pytorch举例(我的书是Pytorch版本的,电子版有Tensorflow版本)。
先构建一个普通MLP:
import torch
from torch import nn
from d2l import torch as d2l# 生产网络的工厂模式
def get_net():net = nn.Sequential(nn.Linear(512, 256),nn.ReLU(),nn.Linear(256, 128),nn.ReLU(),nn.Linear(128, 2))return netx = torch.randn(size=(1, 512)命令式编程版本:
net = get_net()
net(x)符号式编程:
net = torch.jit.script(net)
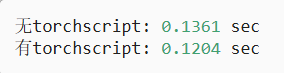
net(x)测试两种编程方法的性能:
#@save
class Benchmark:"""用于测量运行时间"""def __init__(self, description='Done'):self.description = descriptiondef __enter__(self):self.timer = d2l.Timer()return selfdef __exit__(self, *args):print(f'{self.description}: {self.timer.stop():.4f} sec')net = get_net()
with Benchmark('无torchscript'):for i in range(1000): net(x)net = torch.jit.script(net)
with Benchmark('有torchscript'):for i in range(1000): net(x)结果
并且符号式编程要求先定义并编译程序,编译程序的好处之一是可以将模型及其参数序列化保存到磁盘,这样保存的训练好的模型可以迁移到其他设备,与其他前端编程语言结合。
(看到这里想到前几天做的情感计算实验,文件就是有前端有后端,后端训练模型并保存,前端只需调用模型就行,这样提高了计算效率)
12.2 异步计算
Python是单线程的,它不擅长处理并行和异步代码。
(怪不得并行计算课的代码要用C语言实现……)
在深度学习框架中,Tensorflow采用异步编程模式提高性能,Pytorch则采用Python自有的调度器实现不同性能的权衡,GPU操作默认情况下是异步的,调用一个使用GPU的函数时,操作会在特定设备上排队,但之后控制权会立刻返还给使用者,不需要等待GPU完成这个任务再执行后续代码。这允许我们并行执行更多运算。
异步编程通过主动减少计算需求和相互依赖,开发更高效的程序。
作者再次做了个实验比较Pytorch(GPU上)和Numpy中矩阵相乘花费的时间:
with d2l.Benchmark('numpy'):for _ in range(10):a = numpy.random.normal(size=(1000, 1000))b = numpy.dot(a, a)with d2l.Benchmark('torch'):for _ in range(10):a = torch.randn(size=(1000, 1000), device=device)b = torch.mm(a, a)结果:
![]()
因为Numpy的矩阵乘法是在CPU上执行,而Pytorch在GPU上,默认情况是异步的。
其实,Pytorch可以看作分为前端和后端,用户通过Python调用Pytorch,这是前端,而执行计算的后端主要由C++实现。用户调用Pytorch后,操作被传到后端执行,后端有自己的多线程,所以Pytorch支持异步计算。
注意:如果要按上述方式工作,后端必须跟踪整个计算图中各步骤直接依赖关系,因此不可以并行化相互依赖的工作。
这就是为什么编程时要主动减少相互依赖的操作。
作者举了一个很直观的例子:
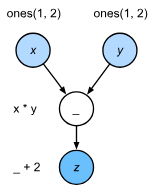
比如这样一段代码:
x = torch.ones((1, 2), device=device)
y = torch.ones((1, 2), device=device)
z = x * y + 2
z内部是这样运行的:
两个构造矩阵的操作可以并行实现,意思是前端只需要将任务返回后端队列,Python前端等待C++后端线程完成计算结果,而不需要实际计算,这样任务就可以并行计算。(前端Python的性能对计算任务没有什么影响)
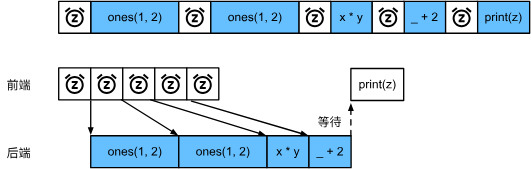
总而言之,异步产生了一个相当灵活的前端。
电子书上还有一个直观的例子:

12.3 自动并行
深度学习框架会在后端自动构建计算图。
比如上面那个例子中,初始化两个张量这个步骤,系统就可以选择并发运行它们。
模拟并行计算
在有多个计算设备的情况下,选择并发运行就可以大大提高效率,接下来作者用代码模拟了系统内部并发和不并发执行任务:
def run(x):return [x.mm(x) for _ in range(50)]
假设这个是我们的任务,也就是让 x 自乘50次。
然后设置两个 x ,分别放在两个GPU设备上。
devices = d2l.try_all_gpus()
x_gpu1 = torch.rand(size=(4000, 4000), device=devices[0])
x_gpu2 = torch.rand(size=(4000, 4000), device=devices[1])torch.cuda.synchronize函数会等待当前设备计算执行结束才往后执行。
于是可以写出串行代码:
with d2l.Benchmark('GPU1 time'):run(x_gpu1)torch.cuda.synchronize(devices[0])with d2l.Benchmark('GPU2 time'):run(x_gpu2)torch.cuda.synchronize(devices[1])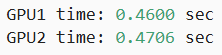
删除俩任务之间的torch.cuda.synchronize,就可以实现俩GPU并行。
并行代码:
with d2l.Benchmark('GPU1 & GPU2'):run(x_gpu1)run(x_gpu2)torch.cuda.synchronize()![]()
可以看出,总执行时间小于两部分执行时间的总和。
所以可以看出,深度学习框架中会默认让两个任务并行执行,提高计算效率。
模拟设备间通信
然后作者又用代码模拟了一个设备之间的通信。
之前我们可以将一个数据迁移到另一个设备上,那么数据可不可以边计算边迁移呢?
def copy_to_cpu(x, non_blocking=False):return [y.to('cpu', non_blocking=non_blocking) for y in x](利用Pytorch中的to函数将某个数据迁移设备)
按照之前的样子,写一个串行执行俩步骤的代码:
with d2l.Benchmark('在GPU1上运行'):y = run(x_gpu1)torch.cuda.synchronize()with d2l.Benchmark('复制到CPU'):y_cpu = copy_to_cpu(y)torch.cuda.synchronize()
这样的话效率不高,但是想想其实可以边运算边迁移,将运算完的部分先迁移过去。
这时候就要to函数中的non_blocking参数了,当这个参数为true时,就可以在不需要同步时调用同步,从而实现一边运算一边迁移。
并行代码:
with d2l.Benchmark('在GPU1上运行并复制到CPU'):y = run(x_gpu1)y_cpu = copy_to_cpu(y, True)torch.cuda.synchronize()![]()
这样做就可以让系统先将运算完的部分先迁移,减少运行时间。
这两个任务看着简单,但在实际应用中要通过Python实现还是非常复杂的,比如一个简单的两层感知机在两个GPU和一个CPU下运行的例子:
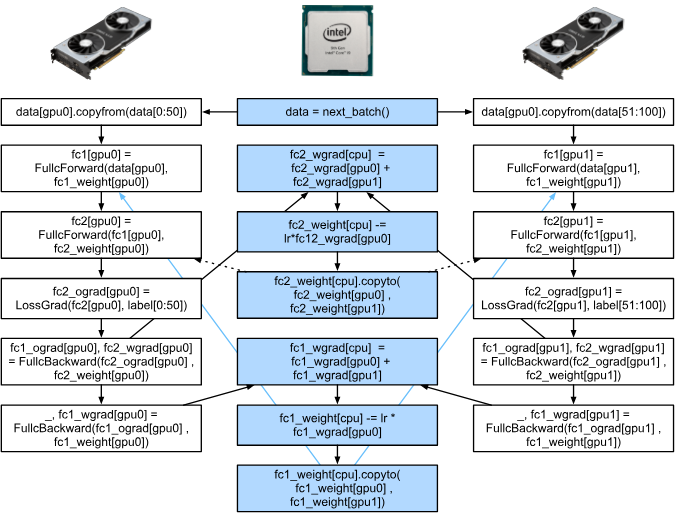
手动调度其实是非常复杂的,这就体现了基于图的计算后端优化的优势了。
12.4 硬件
这一节主要是讲计算机组成方面的内容,理解计算机内部的组成对于实现高性能的算法有很大帮助。
首先,计算机是由以下关键部分组成的:
- 中央处理器(CPU):运行计算机的大部分功能,如操作系统,也能够执行给定的程序。
- 主存(RAM,也叫内存):用于存储计算结果,使CPU可以较快访问到数据。
- 以太网连接:网络。
- 高速扩展总线:用于连接GPU,通常用更高级的方式拓扑连接。
- 持久性存储设备(辅存):固态硬盘(SSD)、硬盘驱动器(HDD),用高速扩展总线连接,提高传输速率。
接下来我们一一讲解这些组成。
1. 高速扩展总线
其中高速扩展总线由多个直连到CPU的通道组成,将CPU与网络、GPU、存储连接到一起。
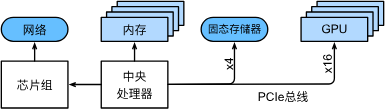
在计算机上执行代码时,需要将数据移到处理器(CPU或GPU)上计算,然后将结果移到主存或辅存上,为了保证无缝衔接,就要拥有一个较快的高速扩展总线;如果是在多台设备上运行,就要有一个较快的以太网连接。
2. 内存
在读取内存方面有两种方式,一种是随机读取,直接跳到指定位置,只读取需要的部分数据;一种是突发读取,以连续的快速读取完成更大片的数据的访问。在数据连续存储的情况下,突发读取效率快得多。
GPU对内存存取速率的要求更高,内存也比CPU小。
3. 存储器
对于存储器,关键特性是带宽和延迟。
硬盘驱动器(HDD)比较古早,最大的优点是便宜,众多缺点之一是灾难性故障和高读取延迟。
主要原因是磁盘转速就那么快,如果太快会因为施加在盘片的离心力过大而破碎,性能很难有较大提升,对于较大数据集很难存储。
固态驱动器(SDD)就可以持久并且更快存储信息,它的设计方式使它必须满足一些条件:
- 以块的方式存储信息。而块只能作为一个整体写入,需要耗费大量时间,按位写入时性能会非常差。
- 存储单元磨损较快,所以不适合用于交换分区文件和大型日志文件。
- 带宽大幅增加,必须与高速扩展总线相连。
还有一种存储器是云存储,虚拟机的存储在数量和速度上可以与用户需求相匹配。
4. CPU
中央处理器是计算机的核心。
它的关键组成部分有处理器核心(用于执行机器代码)、总线(用于连接不同组件)、缓存cache(缓解内存到核心间的传输速率)、向量处理单元(用于辅助高性能线性代数和卷积计算)。
每个处理器都由复杂的组件构成,前端加载指令并尝试预测用哪条路径,然后指令从汇编代码解码为微指令(更低级别的操作),最后才由实际核心处理。
通常执行指令的核心可以同时执行多个操作,所以高效的程序可以在每个时间周期执行多条独立指令。
在这里我们可以知道为什么对任务进行向量化,而不是单个单个求解效率会高很多。
为了满足需求,CPU需要在同一个时钟周期内执行许多操作,这种执行方式是通过向量处理单元实现的,处理单元可以执行单指令多数据(SIMD)操作。
比如八个任务要求将两个整数相加,就可以在一个时钟周期完成:
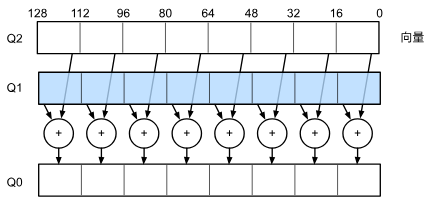
(这张图的意思是八对整数加法,先将八个整数排成向量,将俩向量相加)
然后书里讲了高速缓存Cache的内容,但这部分内容在计组和操作系统课里讲过,就简略带过。
总之Cache主要是缓解CPU核心处理速度过快,而主存到CPU数据传输相对过慢的情况,在两者中间加入速度介于两者之间的缓存,就可以大大缓解这种速度差。
CPU要从主存中读取数据时,先将主存中的一片数据读入Cache,如果将来CPU又要用到这些数据,或者要用到这些数据旁边的数据,就可以直接从Cache中查找。
5. GPU和其他加速卡
GPU对于深度学习非常非常重要。
虽然对于训练(需要反向传播,要求高精度)来说可能没什么,但对于推断(只需前向传播,不需要存储中间数据),我们需要更大的内存和处理能力。
在之前说过向量化能够提高运算效率,当然矩阵化就更好了。利用多个张量核,可以优化矩阵运算的数值精确度。
GPU不太擅长的主要在于稀疏数据和中断。
6. 网络和总线
单个设备不足时就要用到多个设备运算。
平常人们最常用的网络应该是wifi,但是在深度学习中wifi提供的带宽和延迟相对一般,下面介绍几种深度学习中更好用的互连方式。
- PCIe(高速扩展总线):一种专用总线,适合大批量数据传输。
- 以太网:连接计算机时最常用的方式,比上面那位慢,但优点是按照成本低,覆盖距离长。
- 交换机:一种连接多个设备的方式,每一对设备都能同时进行点对点连接。
- NVLink:PCIe的替代品,适用于带宽非常高的互连,纯粹的强大。
(ps:看完这些仿佛又回到了计网……)
12.5 多GPU训练
这一节主要讲如何用多个GPU并行进行神经网络的训练。
有三种思路,第一种是将不同层分配给不同GPU,第二种是将每一层任务拆解到不同GPU,第三种是跨多个GPU对数据进行拆分。
- 第一种:网络并行。可以处理更大的网络,并且每个GPU的内存占用都能得到很好的控制。然而,GPU接口之间的密集同步很难实现,每个GPU间可能需要大量数据传输,总之不太好办。
- 第二种,按层并行。是我们并行计算课实验的内容,比如将矩阵拆分到不同处理单元进行计算,或者按通道划分给不同GPU,这样就可以处理不断变大的网络了。但是,这需要很多同步操作,因为每一层都依赖上一层输出结果,需要传输的数据量不比第一种方法小,总之也不太好办。
- 第三种,数据并行。对数据进行拆分,每个GPU处理小批量数据的部分训练,最后汇总梯度,这种方法最简单并且可以用于任何情况,只需要在每个小批量处理后同步。只不过添加更多GPU并对训练更大的模型没什么帮助。
三种方法的比较图如下:
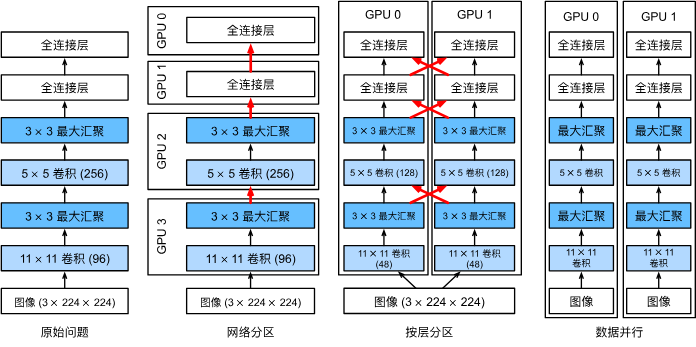
另外,GPU的内存对训练很重要,内存大会很方便,在早期是个很棘手的问题,不过现在已经解决。
因为数据并行最好用且最实用,所以我们将按照数据并行的方法实现并行计算。
数据并行时系统内部大致如下(2个GPU的情况):
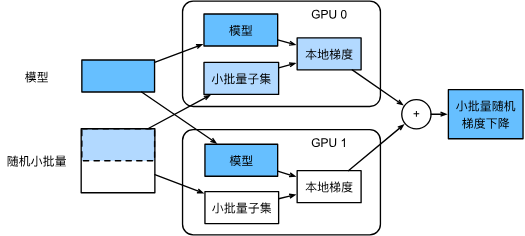
如图,随机小批量数据被分为2个部分,在不同GPU上计算梯度,最后汇总在一起。
k个GPU并行训练过程:
- 小批量数据被均匀分成k个部分,每个部分都被分给不同GPU。
- 每个GPU计算各自部分的损失和梯度。
- 将所有GPU上的梯度汇总,获得当前小批量的梯度。
- 聚合梯度再一次被分成k个部分,分给每个GPU更新参数。
实际中需要将小批量扩大成k的倍数,以便均匀分配,如果会显著增大数据量大小,那么相应可能还要提高学习率(关于为什么可以提高学习率,问了ai但是没有结果,我猜测是因为批量增大,方差更小,数据更稳定,学习率就可以提高),批量规范化也要调整,每个GPU独自进行批量归一化。
然后就是如何用代码实现,这里介绍了几种关键的技术:
1. 数据同步
这里需要构建一个函数,模拟两个GPU同步的过程,也就是两个设备计算出的梯度相加。
def allreduce(data):for i in range(1, len(data)):data[0][:] += data[i].to(data[0].device)for i in range(1, len(data)):data[i][:] = data[0].to(data[i].device)运行结果示例:

2. 数据分发
这里直接借用了Pytorch框架中的函数,将数据分发给每个设备:
split = nn.parallel.scatter(data, devices)其中data是需要分配的数据,devices是设备列表,返回的split是分发结果。
构建一个数据分发的函数:
#@save
def split_batch(X, y, devices):"""将X和y拆分到多个设备上"""assert X.shape[0] == y.shape[0]return (nn.parallel.scatter(X, devices),nn.parallel.scatter(y, devices))然后我们就可以利用构建的这两个辅助函数构造多GPU的数据并行训练函数。
之前说过只要没有互相依赖的关系,系统就会自动并行计算,所以不需要添加什么并行计算的代码,直接用循环让各个设备计算自己的部分就行了。
单个批量训练:
def train_batch(X, y, device_params, devices, lr):X_shards, y_shards = split_batch(X, y, devices)# 在每个GPU上分别计算损失ls = [loss(lenet(X_shard, device_W), y_shard).sum()for X_shard, y_shard, device_W in zip(X_shards, y_shards, device_params)]for l in ls: # 反向传播在每个GPU上分别执行l.backward()# 将每个GPU的所有梯度相加,并将其广播到所有GPUwith torch.no_grad():for i in range(len(device_params[0])):allreduce([device_params[c][i].grad for c in range(len(devices))])# 在每个GPU上分别更新模型参数for param in device_params:d2l.sgd(param, lr, X.shape[0]) # 在这里,我们使用全尺寸的小批量随后的train函数和之前没什么区别,都是对每个批量执行上面的批量训练函数。
12.6 多GPU的简洁实现
也可以使用深度学习框架中的API实现,内部原理和上面差不多。
比起之前的训练函数,主要添加的步骤只有利用API在所有设备上设置模型。
def train(net, num_gpus, batch_size, lr):train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)devices = [d2l.try_gpu(i) for i in range(num_gpus)]def init_weights(m):if type(m) in [nn.Linear, nn.Conv2d]:nn.init.normal_(m.weight, std=0.01)net.apply(init_weights)# 在多个GPU上设置模型net = nn.DataParallel(net, device_ids=devices)trainer = torch.optim.SGD(net.parameters(), lr)loss = nn.CrossEntropyLoss()timer, num_epochs = d2l.Timer(), 10animator = d2l.Animator('epoch', 'test acc', xlim=[1, num_epochs])for epoch in range(num_epochs):net.train()timer.start()for X, y in train_iter:trainer.zero_grad()X, y = X.to(devices[0]), y.to(devices[0])l = loss(net(X), y)l.backward()trainer.step()timer.stop()animator.add(epoch + 1, (d2l.evaluate_accuracy_gpu(net, test_iter),))print(f'测试精度:{animator.Y[0][-1]:.2f},{timer.avg():.1f}秒/轮,'f'在{str(devices)}')即net = nn.DataParallel(net, device_ids=devices)这一步。
这一个API的具体作用有:
- 将训练数据均匀分给每一个设备。
- 将模型复制到每一个设备。
- 每个GPU独立进行向前向后传播。
- 向前传播时将所有结果汇总到默认第一个GPU上计算损失。
- 向后传播时将所有梯度同步到默认第一个GPU上更新模型参数。
另外,代码中的X, y = X.to(devices[0]), y.to(devices[0])这步,可能是DataParallel会自动将所有在第一个GPU设备上的数据分给其他GPU。
总之,DataParallel会解决一切的(合十)。
12.7 参数服务器
在硬件的那一节我们讲到了设备间不同互连方式,它们的带宽差距可能很大,因此速率差距也很大。
下面会介绍一些提高计算效率的其他方法。
1. 数据并行训练
之前说道,三种并行方法中数据并行是最简单直接有效的,我们可以对它进行改良衍生变体。
比如最后先将所有梯度聚合在第一个GPU上,进行参数更新后又将参数重新广播给GPU们:
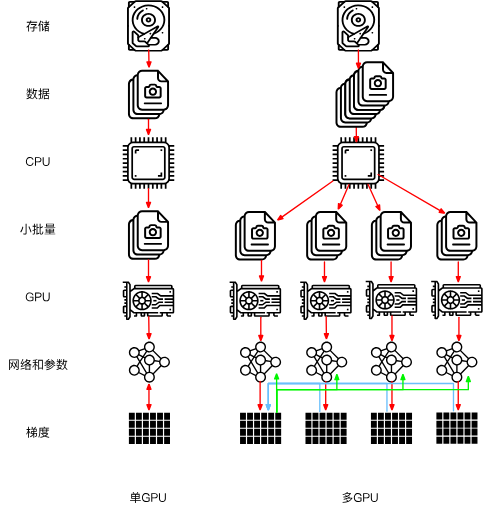
实际上不一定要在第一个GPU上聚合,可以在CPU上聚合,甚至可以依旧分配给不同GPU,在不同设备上聚合。
虽然听起来很梦幻,但它确实是可以实现的。
作者在这里举了一个具体的例子,比较了三种做法(在GPU上聚合、在CPU上聚合,分配给不同设备进行聚合)。
这个例子中的连接设备大概是,一个GPU可以同时为所有其他GPU发送不同数据,但不能两个GPU同时发送数据。
这时候第三种做法就很有优势了,每个GPU轮流将梯度分块分给各个GPU,在每个GPU上完成各自的聚合后再返还给各个GPU,可以实现高效的数据传递。
三种方法比较如下:
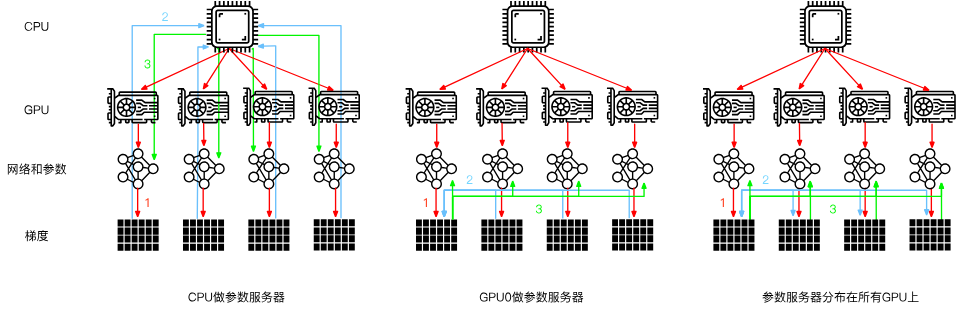
2. 环同步
有一些定制网络连接方式。
比如一些连接,每个GPU通过PCIe连接到CPU,每个GPU还有6个NVLink连接。
大概长这样:
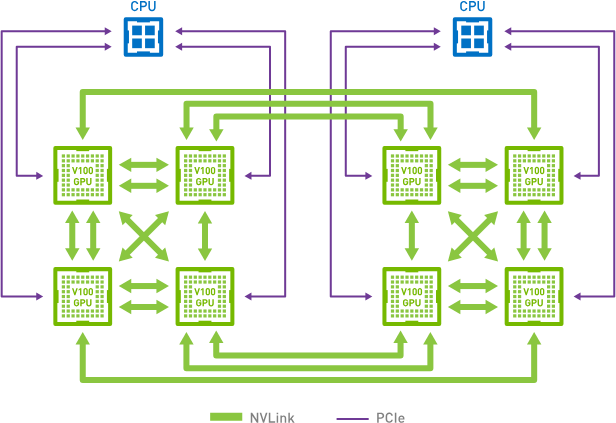
我们可以将这个结构分成环,下面是两种分法:
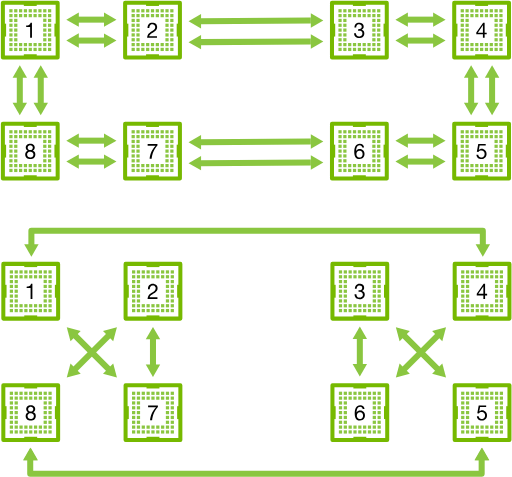
(不管看成哪样的环,总之可以看成一个环)
这样梯度就可以按环传播,从第一个设备开始,它将它的梯度传给 2 设备,然后 2 设备计算自己的梯度和传来的梯度,相加之和给第 3 个设备……最后所有梯度相加的结果返回给第 1 个设备。
但这样很低效,因为计算实际是按照设备数量线性递增的。
然后我们就想到可以用之前那种方法,将梯度分块,每次每个设备传递部分梯度块。
流程如下:
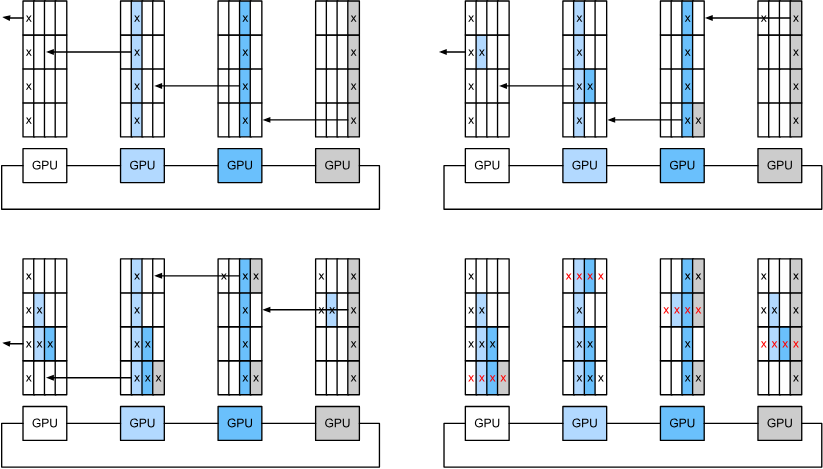
虽然传递数据的时间还是随着节点数线性增加,但是计算可以同步完成,大大提高了效率。
3. 多机训练
在多台机器上训练。其实和之前差不多,只不过每个机器中又有多个GPU,每次计算完这个批量的梯度之和都要将梯度整合后返回中心的参数服务器。
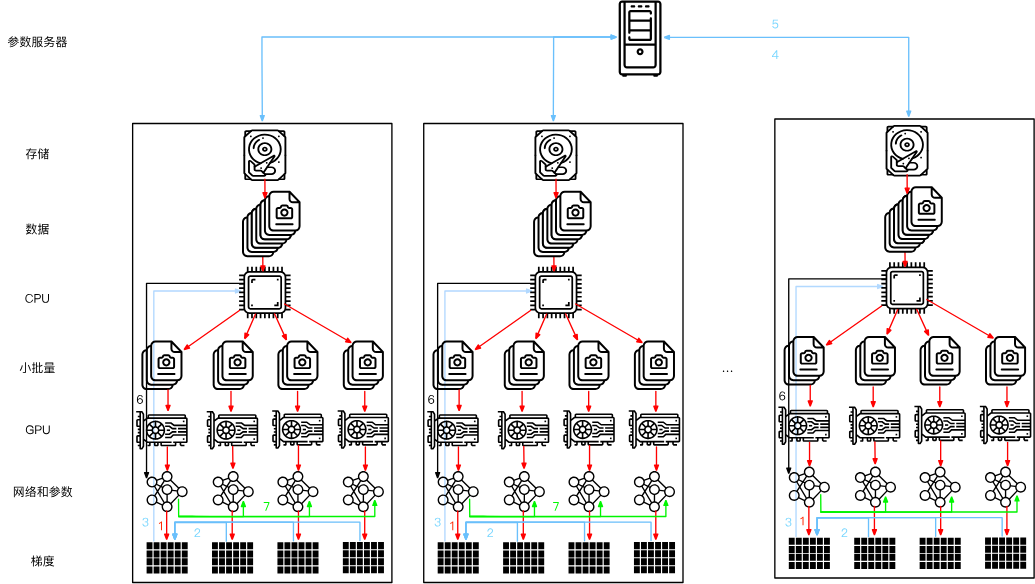
这其中很重要的是同步,就是参数服务器接受多个机器的结果的过程。
但每个服务器的带宽有限,数据传输的时间开销会随着机器数目的增加而线性增长。
可以增加参数服务器数量解决。
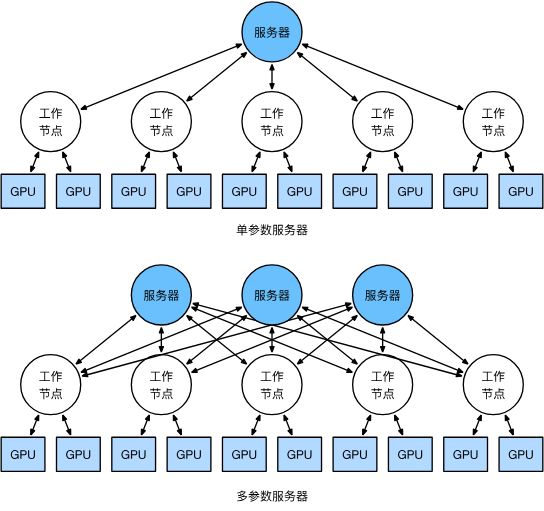
4. 键-值存储
在许多工作节点和GPU中,梯度 i 的计算可定义为:

其中是梯度 i 在工作节点 k ,GPU j 中拆分的梯度。
这样就可以假设 i 是键,gi 就是值。
定义两个操作push(累计梯度)和pull(取得聚合梯度),i 可以代表层。
-
push(key,value)将特定的梯度值从工作节点发送到公共存储,在那里通过某种方式(相加)来聚合值;
-
pull(key,value)从公共存储中取得某种方式(组合来自所有工作节点的梯度)的聚合值。
通过将所有复杂操作转化成这两个操作,就可以方便解释。
相关文章:
)
记录学习记录学习《手动学习深度学习》这本书的笔记(九)
马不停蹄地来到了第十二章:计算性能…… 感觉应该是讲并行计算方面的,比如GPU、CPU、CUDA那些。 第十二章:计算性能 12.1 编译器和解释器 这里先提出了命令式编程和符号式编程的概念。 命令式编程VS符号式编程 目前为止,本书…...

麒麟系统通过 Service 启动 JAR 包的完整指南
🧑 博主简介:CSDN博客专家、CSDN平台优质创作者,高级开发工程师,数学专业,10年以上C/C, C#, Java等多种编程语言开发经验,拥有高级工程师证书;擅长C/C、C#等开发语言,熟悉Java常用开…...

【记录maven依赖规则-dependencyManagement,dependencies】
记录maven依赖规则-dependencyManagement,dependencies 依赖方式 直接依赖 间接依赖 依赖关系 直接依赖: 父级管理定义的版本,并且在中进行引用了的版本。 优先使用dependencyManagement定义的版本。 间接依赖: 如果间接依赖…...

macos下mysql 5.7/8.0版本切换
1、首先安装好mysql 5.7/8.0,可以用brew进行安装 5.7 的原始配置文件路径: /usr/local/Cellar/mysql5.7/5.7.44_1/homebrew.mxcl.mysql5.7.plist 配置内容如下: 对应的.cnf配置文件内容如下: 8.0 的原始配置文件路径࿱…...

FPGA时钟设计
实现功能:基于Verilog的动态显示时钟设计,支持整点(时:00:00)闪烁功能。代码包含时钟计数、动态扫描、整点检测和闪烁控制模块: module dynamic_clock(input clk, // 主时钟(假设50MHz࿰…...

【NVM】管理不同版本的node.js
目录 一、下载nvm 二、安装nvm 三、验证安装 四、配置下载镜像 五、使用NVM 前言:不同的node.js版本会让你在使用过程很费劲,nvm是一个node版本管理工具,通过它可以安装多种node版本并且可以快速、简单的切换node版本。 一、下载nvm htt…...
 / 主持人调度(排序) / 分割等和子集(01背包))
【今日三题】笨小猴(模拟) / 主持人调度(排序) / 分割等和子集(01背包)
⭐️个人主页:小羊 ⭐️所属专栏:每日两三题 很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~ 目录 笨小猴(模拟)主持人调度(排序)分割等和子集(01背包) 笨小猴(模拟) 笨小猴 #include <iostream> #include <string…...

android10 卸载应用出现回退栈异常问题
打开设置,打开APP1,使用adb uninstall 卸载APP1/或者杀掉APP1进程,没有回到设置而是回到了桌面 抓取eventlog,查看ams/wms打印,发现“am_focused_stack: appDied leftTaskHistoryEmpty”源码中搜索“leftTaskHistoryE…...

位置差在坐标系间的相互转换
1 NED转经纬高 (n 系下的北向、东向和垂向位置差异(单位 m)转化为纬度、经度和高程分量的差异) 2 基站坐标转换 纬度、经度、高程 到 ECEF %纬度、经度、高程 到 ECEF clc; clear; glvs; addpath(genpath(E:\GNSSINS\ACES)…...

在线重定义——分区表改造
在数据库管理过程中,随着数据量的不断增长,普通表的查询、维护成本不断上升。为了提升查询性能和管理效率,通常需要将大表进行分区处理。 本文介绍如何使用 Oracle 在线重定义(DBMS_REDEFINITION) 的方式对现有大表进行…...
)
day51—二分法—x 的平方根(LeetCode-69)
题目描述 给你一个非负整数 x ,计算并返回 x 的 算术平方根 。 由于返回类型是整数,结果只保留 整数部分 ,小数部分将被 舍去 。 注意:不允许使用任何内置指数函数和算符,例如 pow(x, 0.5) 或者 x ** 0.5 。 示例 …...

网络安全漏洞现状与风险管理分析
在当今数字化时代,网络安全已成为企业和组织不可忽视的核心问题。网络环境的日益复杂和攻击手段的不断升级,使得漏洞管理成为网络安全战略中的关键环节。下面将详细分析当前网络安全领域的漏洞现状及有效的风险管理策略。 当前网络安全面临的挑战 高危漏…...

二、Web服务常用的I/O操作
一、单个或者批量上传文件 前端: <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>文件…...

Pinia——Vue的Store状态管理库
一、Store 是什么? Store (如 Pinia) 是一个保存状态和业务逻辑的实体,它并不与你的组件树绑定。换句话说,它承载着全局状态。它有点像一个永远存在的组件,每个组件都可以读取和写入它。它有三个概念,state、getter 和…...
适合那些人考?)
生成式人工智能认证(GAI认证)适合那些人考?
在人工智能浪潮席卷全球的今天,你是否曾思考过:当机器开始创作诗歌、设计建筑、撰写代码,甚至模拟人类思维时,我们该如何与这个“新物种”共处?更关键的是,当生成式人工智能(Generative AI)从实验室走向千行百业,谁将成为驾驭这场技术革命的“领航者”?答案或许藏在一…...

使用cmd来创建数据库和数据库表-简洁步骤
创建数据库和表: 1. 按WinR打开“运行”,输入cmd,回车 2. 登录数据库:mysql -u root -p 然后输入密码 3. 创建数据库create database myblog; myblog为数据库名(自定义你的数据库名) !注意分号不要漏了! …...

微博安卓版话题热度推荐算法与内容真实性分析
微博是目前最受欢迎的社交平台之一,它的推荐算法在推动话题热度和内容传播方面发挥着重要作用。然而,这一算法也引发了对于内容真实性的担忧。本文将通过分析微博安卓版的推荐机制,探讨其对话题热度的影响以及内容真实性问题。 微博的推荐算法…...

助力产业升级 | BMC安全启动方案上新了!
近日,OurBMC 社区联合其理事成员单位中移(苏州)软件技术有限公司,在产业化落地SIG发布计算机系统安全可信创新解决方案——《 BMC 安全启动方案》。该方案为开发者提供了清晰、可实现的技术实施路径,可有效助力开发者提…...

Python中使用Redis的参数
Python中使用Redis通常是通过redis-py这个库来实现的。redis-py是一个Python客户端,它提供了对Redis数据库的完整操作接口。在使用redis-py时,你需要通过连接参数来配置与Redis服务器的连接。下面是一些常用的连接参数及其解释: host 描述&…...

tensorflow使用详解
一、TensorFlow基础环境搭建 安装与验证 # 安装CPU版本 pip install tensorflow# 安装GPU版本(需CUDA 11.x和cuDNN 8.x) pip install tensorflow-gpu# 验证安装 python -c "import tensorflow as tf; print(tf.__version__)"核心概念 Tensor…...

FreeMarker语法深度解析与Node.js集成实践指南
一、FreeMarker核心语法体系 1.1 基础模板结构 <#-- 注释语法 --> ${expression} <#-- 输出表达式 --> <#directive paramvalue> <#-- 指令语法 -->1.2 数据类型处理 标量类型深度处理: <#assign num 123.45?floor> <#--…...
?)
如何实现一个可视化的文字编辑器(C语言版)?
一、软件安装 Visual Studio 2022 Visual Studio 2022 是微软提供的强大集成开发环境(IDE),广泛用于C/C、C#、Python等多种编程语言的开发。它提供了许多强大的工具,帮助开发者编写、调试和优化代码。 1.下载 Visual Studio 202…...

学习海康VisionMaster之路径提取
一:进一步学习了 今天学习下VisionMaster中的路径提取:可在绘制的路径上等间隔取点或查找边缘点 二:开始学习 1:什么是路径提取? 相当于事先指定一段路径,然后在对应的路径上查找边缘,这个也是…...
:MCP与Web框架集成)
【MCP Node.js SDK 全栈进阶指南】中级篇(6):MCP与Web框架集成
背景 在现代Web开发生态中,框架已成为构建高效、可维护应用的核心基础设施。将MCP TypeScript-SDK与流行的Web框架集成,能够充分发挥两者的优势,构建功能丰富、交互智能的现代应用。本文将深入探讨MCP与主流Web框架的集成方法、最佳实践和架构设计,帮助开发者构建强大而灵…...

vue3+vite 项目中使用 Echarts 5.0 按需引入教程
效果图 第一步,封装 ECharts 工具函数 在 utils 目录下新建一个 echarts.js 文件,位置随意这里只引入了 折线图和拼团,需要其他的图自行引入 import * as echarts from "echarts/core"; import { LineChart, PieChart } from "…...

Unreal Engine 实现软件测试方案的仿真体验
以下将以一款模拟物流仓储管理软件的测试为例,详细阐述如何利用 Unreal Engine 实现软件测试方案的仿真体验。 1. 明确测试目标与需求 功能方面:要验证货物出入库管理、库存盘点、货物定位、叉车调度等功能的准确性和稳定性。性能方面:测试…...

蓝绿部署的详细规划文档
一、蓝绿部署概述 蓝绿部署是一种通过运行两套完全相同的生产环境(蓝色和绿色)实现零停机发布的策略。核心流程为:在绿色环境部署新版本并验证通过后,将流量逐步切换至绿色环境,若出现问题可快速回滚至蓝色环境。该策略适用于对可用性要求极高的系统(如金融、电商),可…...

【SpringMVC】概念引入与连接
目录 1.前言 2.正文 2.1SpringMVC是什么 2.2详解RequestMapping注解 2.3创建Spring项目 2.4建立连接 2.5Postman 3.小结 1.前言 哈喽大家好,今天来给大家带来Spring相关的学习,主要内容有概念的讲解以及如何分别通过Java代码和工具Postman来建立…...

NodeJs模块化与JavaScript的包管理工具
Js:模块化规范的文章链接:https://blog.csdn.net/Y1914960928/article/details/131793004?spm1011.2415.3001.5331 一、模块化: 1、导入文件的注意事项: ① 导入路径建议写 相对路径,且不能省略 ./ 和 ../ ② 文件…...

一、接口测试01
目录 一、接口1. 概念2. 接口的类型 二、接口测试1. 概念 三、HTTP协议1. HTTP协议简介2. URL格式2.1 练习 3. HTTP请求3.1 整体格式3.2 fiddler 抓包验证3.3 请求行3.4 请求头3.5 请求体3.6 练习 4. HTTP响应4.1 整体格式4.2 状态行4.3 响应头4.4 响应体4.5 练习 5. 传统风格接…...

CISA、项目管理、信息系统项目等等电子书资料
概述 在数字化转型浪潮中,教育工作者与技术管理者如何把握前沿趋势?我们精选了覆盖教育研究、IT治理与项目管理的系列电子资源,为职场精英打造知识升级方案。资料已整理好:https://pan.quark.cn/s/9c8a32efc89e 内容介绍 包含教…...
)
神经网络(自己记录)
一、神经网络基础 5分钟-通俗易懂 - 神经网络 反向传播算法(手算)_哔哩哔哩_bilibili 二、GAT...

ARCGIS PRO 在地图中飞行
一、要将飞行添加到地图,请确保动画选项卡已处于打开状态。 如有必要,请单击视图选项卡上动画组中的添加动画 ,如图: 二、在动画选项卡的创建组中,单击追加下拉菜单并验证过渡类型是固定还是线性。 三、将照相机导航到…...

Java 消息代理:企业集成的 5 项基本技术
大家好,这里是架构资源栈!点击上方关注,添加“星标”,一起学习大厂前沿架构! Java 消息代理通过实现分布式系统之间的可靠通信路径,改变了企业集成。我广泛使用了这些技术,发现它们对于构建可有…...

SpringBoot自动装配
自动装配就是自动地把其他组件中的Bean装载到IOC容器中,不需要开发人员再去配置文件中添加大量的配置 源码分析 EnableAutoConfiguration:SpringBoot实现自动化配置的核心注解 AutoConfigurationImportSelector类分析 public class AutoConfigurationIm…...

【项目篇之垃圾回收】仿照RabbitMQ模拟实现消息队列
实现垃圾回收 消息垃圾回收为什么要去实现垃圾回收如何实现这个垃圾回收? 编写代码编写触发垃圾回收的条件触发垃圾回收的条件约定新文件所在的位置实现垃圾回收的算法(重点) 总结 消息垃圾回收 为什么要去实现垃圾回收 由于当前会不停地往消息文件中写入新消息&a…...

【Redis】服务端高并发分布式结构演进之路
文章目录 前景概念架构演进 现在说起服务端,经常听到的就是分布式、集群、微服务这类词汇,这些到底是什么呢?又是如何而来的呢?本篇博客记录相关学习 前景概念 在认识上述架构之前,需要有些前景知识 应用(Applicatio…...

【SpringMVC文件上传终极指南:从基础配置到云存储集成】
🎥博主:程序员不想YY啊 💫CSDN优质创作者,CSDN实力新星,CSDN博客专家 🤗点赞🎈收藏⭐再看💫养成习惯 ✨希望本文对您有所裨益,如有不足之处,欢迎在评论区提出…...

windows安装docker教程
1、参考博客 - 安装教程: https://blog.csdn.net/GoodburghCottage/article/details/131413312 - docker详解: https://www.cnblogs.com/yaok430/p/16738002.html 2、设计目标 - 提供一个简单的应用程序打包工具,可以将应用程序…...

基于物理信息的神经网络在异常检测Anomaly Detection中的应用:实践指南
物理信息神经网络(PINNs)代表了一种令人兴奋的新建模范式,这种范式正在各行各业迅速崭露头角。 PINNs 最有前景的应用之一是复杂物理系统中的异常检测Anomaly Detection。这一应用尤其值得关注,因为它解决了传统机器学习方法在实践中一直难以克服的几个关键痛点。 在这篇…...

Spark阶段学习总结
一、Spark 是什么 Spark 是一种基于内存的快速、通用、可扩展的大数据分析计算引擎,也可说是分布式内存迭代计算框架。 二、Spark 四大特点 速度快(内存计算) 易于使用 通用性强 运行方式多 三、与hadoop的核心差异 数据通信…...

统信操作系统使用默认yum源安装 Docker 的踩坑
事件 在使用 docker 运行 es 的时候,es 报错 ulimit 的值为1024,但是服务器已经设置成了65535。 排查结果 在装完 docker 之后发现 docker systemd 的启动命令引用了 /etc/sysconfig/docker 这个文件里面设定了 ulimit 为 1024 如下: [ro…...
)
HK1RBOX K8 RK3528 Via浏览器_插件_央视频的组合验证(失败)
文章目录 前言软件和设备信息过程方案插件代码 运行效果问题 前言 实践的结果为失败,设备性能不满足, 无法流畅播放视频 软件和设备信息 via浏览器, 版本4.9.1HK1RBOX K8 RK3528设备win10, 逍遥游安卓虚拟机(开发插件)央视频官网(不是cctv那个) 过程 方案 浏览器设置央视…...

XMOS直播声卡——可支持实时音频DSP处理的低延迟音频方案
对于游戏玩家和短视频直播工作者来说,声卡不可或缺。它除了能将计算设备的数字信号转换为声音信号,还能够提供各种逼真的或者定制的3D音效,提升游戏的沉浸感,特别是在大型开放联网游戏或射击游戏中,声音细节直接影响玩…...

DB2备份恢复操作文档及其注意事项
备份BACKUP 备份语法: 在线备份:db2 backup db MYDB online to /tmp/backup_db2_20250326 离线备份:db2 backup db MYDB to /tmp/backup_db2_20250326 需要注意,在执行在线备份时需要开启归档,即执行db2 get db cfg f…...

flask uri 怎么统一加前缀
在 Flask 中为 URI 统一添加前缀,可以通过多种方式实现,下面为你详细介绍几种常见的方法。 方法一:使用 Blueprint(推荐) Blueprint(蓝图)是 Flask 中组织路由的一种方式,它可以将…...

创建一个springboot的项目-简洁步骤
1. 打开IDEA,新建项目: 2. 设置项目的基本信息,其中注意jdk版本要与Java版本匹配,这里使用jdk17和java17 3. 选择SpringBoot版本,选择项目依赖(依赖也可以创建完项目后在pom文件中修改) 这里选…...
题解)
杭电oj(1008、1012、1013、1014、1017)题解
目录 编辑 1008 题目 思路 代码 1012 题目 思路 代码 1013 题目 思路 代码 1014 题目 思路 代码 1017 题目 思路 处理每组测试数据 计算满足条件的整数对数量 代码 1008 题目 思路 s a[0];:初始化 s 为数组的第一个元素,即电…...

VRRP与BFD在冗余设计中的核心区别:从“备用网关”到“毫秒级故障检测”
(本文完全由deepseek生成,特此声明) 在网络冗余设计中,VRRP(Virtual Router Redundancy Protocol)和BFD(Bidirectional Forwarding Detection)是两种关键协议,但它们的定…...

蓝桥杯 2. 确定字符串是否是另一个的排列
确定字符串是否是另一个的排列 原题目链接 题目描述 实现一个算法来识别一个字符串 str2 是否是另一个字符串 str1 的排列。 排列的解释如下:如果将 str1 的字符拆分开,重新排列后再拼接起来,能够得到 str2,那么就说字符串 st…...