【深度学习】多头注意力机制的实现|pytorch

- 博主简介:努力学习的22级计算机科学与技术本科生一枚🌸
- 博主主页: @Yaoyao2024
- 往期回顾:【深度学习】注意力机制| 基于“上下文”进行编码,用更聪明的矩阵乘法替代笨重的全连接
- 每日一言🌼: 路漫漫其修远兮,吾将上下而求索。—屈原🌺
0、前言
在上篇文章中,我们介绍了系统且详细的介绍了注意力机制及其数学原理进行系统且详细的讲解。在本篇博客中,我们围绕 多头注意力的代码实现进行展开。
这篇文章的代码实现还是youtube管博主所提供的worksheet:https://github.com/kilianmandon/alphafold-decoded.git
在本篇博客中,我们会根据worksheet中的内容,依次实现以下:
- MultiHeadAttention:多头注意力机制
- Gated MultiHeadAttention:带门控的注意力机制
- Global Gated MultiHeadAttention:全局+门控注意力机制
最终将其整合到一个注意力模块中,利用传递参数的方法选择使用哪种注意力。不过本篇博客主要是从代码方面进行讲解,让对python和pytorch不是很熟悉的同学也能看懂代码。
1. 模型初始化和qkv准备
1.1 def init
class MultiHeadAttention(nn.Module):"""A MultiHeadAttention module with optional bias and optional gating."""def __init__(self, c_in, c, N_head, attn_dim, gated=False, is_global=False, use_bias_for_embeddings=False):"""Initializes the module. MultiHeadAttention theoretically consists of N_head separate linear layers for the query, key and value embeddings.However, the embeddings can be computed jointly and split afterwards,so we only need one query, key and value layer with larger c_out.Args:c_in (int): Input dimension for the embeddings.c (int): Embedding dimension for each individual head.N_head (int): Number of heads.attn_dim (int): The dimension in the input tensor along whichthe attention mechanism is performed.gated (bool, optional): If True, an additional sigmoid-activated linear layer will be multiplicated against the weighted value vectors before feeding them through the output layer. Defaults to False.is_global (bool, optional): If True, global calculation will be performed.For global calculation, key and value embeddings will only use one head,and the q query vectors will be averaged to one query vector.Defaults to False.use_bias_for_embeddings (bool, optional): If True, query, key, and value embeddings will use bias, otherwise not. Defaults to False."""super().__init__()self.c_in = c_inself.c = cself.N_head = N_headself.gated = gatedself.attn_dim = attn_dimself.is_global = is_global
首先在模型初始化中包含这样几个参数:
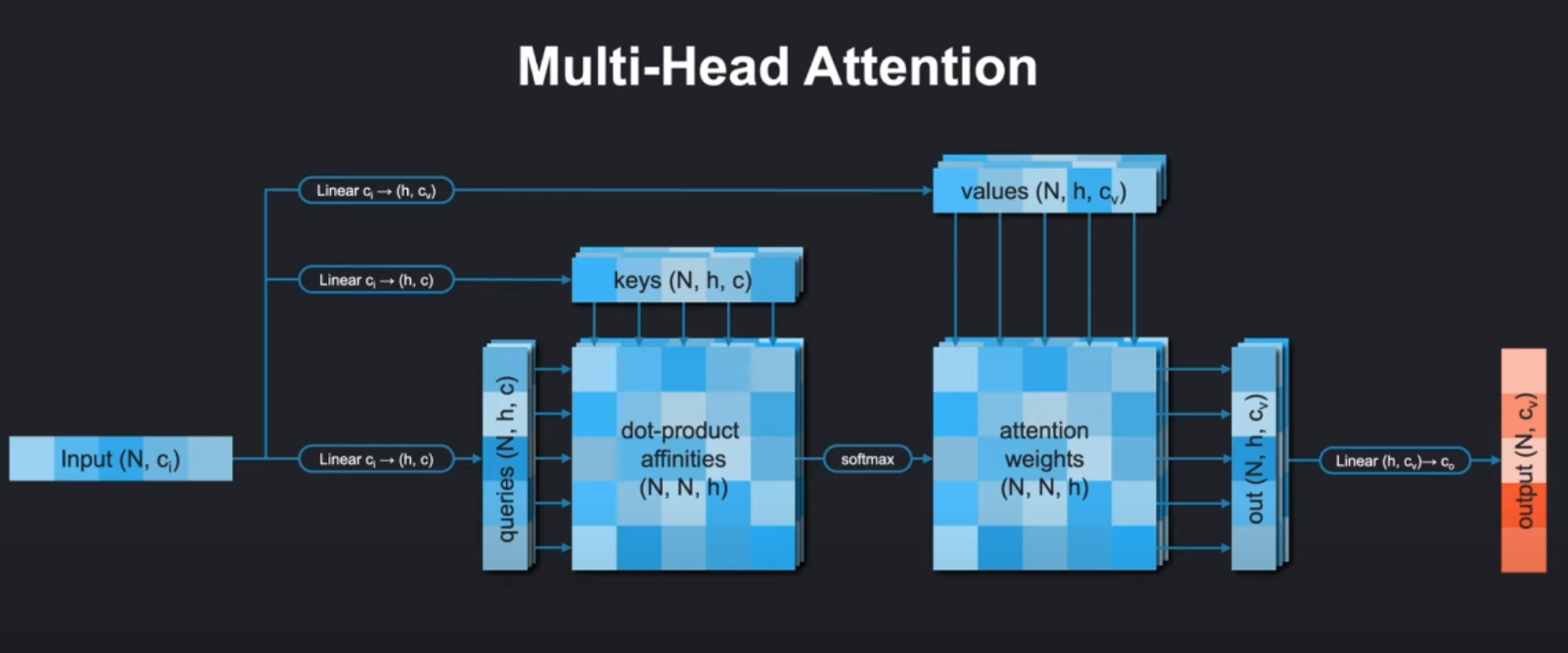
c_in:输入特征维度c:每个注意力头的特征维度N_head:注意力头的数量attn_dim⭐:计算注意力的维度索引,注意力会沿着这个维度去计算不同元素之间的关联。比如对于上图的输入单词序列Input(N,ci),这里N代表token个数也是序列长度,注意力模型会沿着这个维度,去计算各个token之间的关联。
🌸在计算点积亲和度(dot - product affinities )时,是在这个维度上不同位置的查询(queries)、键(keys)向量间进行点积运算,衡量不同位置之间的相关性,从而确定注意力权重 。 比如句子中某个词和其他词之间关联程度计算,就是沿着这个维度展开的。gated:是否使用门控机制is_global:是否使用全局注意力:如果是全局注意力key和value在线性层进行变换后只有一个头,query还是多头,但是会在后面q/k/v准备的时候沿着注意力头的方向被平均掉。use_bias_for_embeddings:是否在Q/K/V线性变换中使用偏置(也就是Linear层要不要加偏置和上图中的在注意力得分后加偏置的意义不同)!
关键组件
-
线性变换层:
linear_q:生成查询(Query)向量,输出维度为c*N_headlinear_k:生成键(Key)向量,全局模式下输出c,否则c*N_headlinear_v:生成值(Value)向量,维度同linear_klinear_o:输出变换层,将多头结果合并回c_in维度
-
门控层(可选):
linear_g:生成门控信号,使用sigmoid激活
########################################################################### TODO: Initialize the query, key, value and output layers. ## Whether or not query, key, and value layers use bias is determined ## by `use_bias` (False for AlphaFold). The output layer should always ## use a bias. If gated is true, initialize another linear with bias. ## For compatibility use the names linear_q, linear_k, linear_v, ## linear_o and linear_g. ###########################################################################
在初始化部分,我们主要是实现模型输入和输出的几个线性层:
self.linear_q = nn.Linear(c_in, c*N_head, bias=use_bias_for_embeddings)c_kv = c if is_global else c*N_headself.linear_k = nn.Linear(c_in, c_kv, bias=use_bias_for_embeddings)self.linear_v = nn.Linear(c_in, c_kv, bias=use_bias_for_embeddings)self.linear_o = nn.Linear(c*N_head, c_in)if gated:self.linear_g = nn.Linear(c_in, c*N_head)
整个代码实现如上,用pytorch中的nn.Linear即可。对于当时学到这里的我来说,我并不是很理解在is_global下的处理逻辑:
If True, global calculation will be performed.
For global calculation, key and value embeddings will only use one head,
and the q query vectors will be averaged to one query vector.
Defaults to False.
大致意思是说,k,v使用单头,而q使用多头(然后在和k进行点积计算注意力得分计算之前沿着attn-dim维度进行平均
1.2 prepare_qkv
非全局注意力的q,k,v准备:
def prepare_qkv(self, q: torch.Tensor, k: torch.Tensor, v: torch.Tensor):"""Splits the embeddings into individual heads and transforms the inputshapes of form (*, q/k/v, *, N_head*c) into the shape (*, N_head, q/k/v, c). The position of the q/k/v dimension in the original tensors is given by attn_dim.Args:q (torch.Tensor): Query embedding of shape (*, q, *, N_head*c).k (torch.Tensor): Key embedding of shape (*, k, *, N_head*c).v (torch.Tensor): Value embedding of shape (*, v, *, N_head*c).Returns:tuple: The rearranged embeddings q, k, and v of shape (*, N_head, q/k/v, c) respectively."""########################################################################### TODO: Rearrange the tensors with the following changes: ## - (*, q/k/v, *, N_head*c) -> (*, q/k/v, N_head*c) with movedim # # - (*, q/k/v, N_head*c) -> (*, q/k/v, N_head, c) ## - (*, q/k/v, N_head, c) -> (*, N_head, q/k/v, c) ############################################################################ Transposing to [*, q/k/v, N_head*c]q = q.movedim(self.attn_dim, -2)k = k.movedim(self.attn_dim, -2)v = v.movedim(self.attn_dim, -2)# Unwrapping to [*, q/k/v, N_head, c]q_shape = q.shape[:-1] + (self.N_head, -1)k_shape = k.shape[:-1] + (self.N_head, -1)v_shape = v.shape[:-1] + (self.N_head, -1)q = q.view(q_shape)k = k.view(k_shape)v = v.view(v_shape)# Transposing to [*, N_head, q/k/v, c]q = q.transpose(-2, -3)k = k.transpose(-2, -3)v = v.transpose(-2, -3)########################################################################### END OF YOUR CODE ###########################################################################return q, k, v
1. 移动 attn_dim 维度到倒数第二个位置
self.attn_dim表示查询、键和值维度在原始张量中的位置。movedim方法用于将attn_dim维度移动到倒数第二个位置,这样做是为了方便后续的形状调整操作。经过这一步,张量的形状变为(*, q/k/v, N_head*c)。
在标准的多头注意力计算中,通常会将头的维度放在倒数第三个位置,这样可以更清晰地表示不同的头和每个头的嵌入维度。把 attn_dim 移动到倒数第二个位置,然后再进行后续的维度调整,最终可以得到符合这种习惯的形状,便于后续的注意力计算和代码实现。
2. 将 N_head*c 维度拆分为 N_head 和 c
- 首先,通过
q.shape[:-1] + (self.N_head, -1)构建新的形状元组,将最后一个维度N_head*c拆分为N_head和c。这里的-1表示让 PyTorch 自动计算该维度的大小。 - 然后,使用
view方法将张量的形状调整为(*, q/k/v, N_head, c)。
3. 交换倒数第二个和倒数第三个维度
transpose方法用于交换张量的两个维度。这里交换倒数第二个和倒数第三个维度,将N_head维度移动到倒数第三个位置,最终得到形状为(*, N_head, q/k/v, c)的张量。
1.3 prepare_qkv_global
def prepare_qkv_global(self, q, k, v):"""Prepares the query, key and value embeddings with the following differences to the non-global version:- key and value embeddings use only one head.- the query vectors are contracted into one, average query vector.Args:q (torch.tensor): Query embeddings of shape (*, q, *, N_head*c).k (torch.tensor): Key embeddings of shape (*, k, *, c).v (torch.tensor): Value embeddings of shape (*, v, *, c).Returns:tuple: The rearranged embeddings q, k, and v ofshape (*, N_head, 1, c) for q and shape (*, 1, k, c) for k and v. """########################################################################### TODO: Rearrange the tensors to match the output dimensions. Use ## torch.mean for the contraction of q at the end of this function. ###########################################################################q = q.movedim(self.attn_dim, -2)k = k.movedim(self.attn_dim, -2)v = v.movedim(self.attn_dim, -2)q_shape = q.shape[:-1] + (self.N_head, self.c)q = q.view(q_shape)q = q.transpose(-2, -3)k = k.unsqueeze(-3)v = v.unsqueeze(-3)q = torch.mean(q, dim=-2, keepdim=True)########################################################################### END OF YOUR CODE ###########################################################################return q, k, v
因为在上面初始化的时候已经讲到k,v都是单头的,所以在这里无需考虑n-head。但对于q来说,它需要考虑。
其次它的不同是,需要在最后沿着attn-dim的方向进行平均,这样让一个head下只有一个query和key进行矩阵乘法计算注意力得分。
1.4 解释:关于global选项下的qkv
到这里为止,我们把多头注意力的初始化、q/k/v的准备算是讲完了。其实到这里我还有一个疑问:
为什么在考虑Global-attention的时候,只对k/v使用单头?对q保留多头。后来我发现是自己对q/k/v的本身地位没有理解透彻。
如果和cnn类比的话,q相当于卷积核,k/v都是用来表示原始数据的信息。只有卷积核不同,模型才能提取出来各种各样的特征。这里也是类似,只有query不同,模型才能以各个角度去捕捉多样化的信息。k/v可以不用多头,因为它们本质主要为注意力计算提供可匹配信息和实际要聚合的特征。单头足以提供关键信息,多头可能引入过多重复或相似信息,造成资源浪费,单头能更高效地提供必要信息 (主要是采用单头计算,能显著减少线性变换等操作次数)。
1. 核心目的:减少计算量
全局注意力的核心思想是将序列级别的全局信息压缩为一个"概要向量",从而避免计算庞大的 N × N N \times N N×N 注意力矩阵( N N N) 是序列长度)。
- Key/Value单头:所有注意力头共享同一组Key/Value,相当于用单头生成一个"全局记忆池"。
- 计算量从 O ( N 2 ⋅ H ) O(N^2 \cdot H) O(N2⋅H) 降至 O ( N 2 + N ⋅ H ) O(N^2 + N \cdot H) O(N2+N⋅H)( H H H 是头数)。
- Query多头:保留多头设计,让不同头从不同角度"查询"这个全局记忆池,维持特征多样性。
2. 为什么Query需要多头?
即使Key/Value是全局共享的,不同注意力头仍可关注不同的全局模式:
- 举例(蛋白质序列):
- 头1可能关注"保守残基"的全局分布。
- 头2可能关注"疏水残基"的全局密度。
- 头3可能关注"二级结构"(如α螺旋)的周期性。
- 数学上:
多组Query与同一组Key/Value计算注意力,仍会得到不同的加权结果(因Query向量不同)。
3. 为什么Key/Value可以单头?
- 信息冗余假设:
对于超长序列,Key/Value的全局特征(如蛋白质的总体折叠模式)通常不需要多视角编码,一个统一的表示足够。 - 计算效率:
Key/Value矩阵的维度从 N × ( H ⋅ d k ) N \times (H \cdot d_k) N×(H⋅dk) 降至 N × d k N \times d_k N×dk,显存占用大幅减少。
2. Forward
def forward(self, x, bias=None, attention_mask=None):"""Forward pass through the MultiHeadAttention module.Args:x (torch.tensor): Input tensor of shape (*, q/k/v, *, c_in).bias (torch.tensor, optional): Optional bias tensor of shape(*, N_head, q, k) that will be added to the attention weights. Defaults to None.attention_mask (torch.tensor, optional): Optional attention maskof shape (*, k). If set, the keys with value 0 in the mask willnot be attended to.Returns:torch.tensor: Output tensor of shape (*, q/k/v, *, c_in)"""out = Noneq = self.linear_q(x)k = self.linear_k(x)v = self.linear_v(x)if self.is_global:q, k, v = self.prepare_qkv_global(q, k, v)else:q, k, v = self.prepare_qkv(q, k, v)q = q / math.sqrt(self.c)a = torch.einsum('...qc,...kc->...qk', q, k)if bias is not None:bias_batch_shape = bias.shape[:-3]bias_bc_shape = bias_batch_shape + (1,) * (a.ndim-len(bias_batch_shape)-3) + bias.shape[-3:]bias = bias.view(bias_bc_shape)a = a + biasif attention_mask is not None:attention_mask = attention_mask[..., None, None, :]offset = (attention_mask==0) * -1e8a = a + offseta = torch.softmax(a, dim=-1)# o has shape [*, N_head, q, c]o = torch.einsum('...qk,...kc->...qc', a, v)o = o.transpose(-3, -2)o = torch.flatten(o, start_dim=-2)o = o.moveaxis(-2, self.attn_dim)if self.gated:g = torch.sigmoid(self.linear_g(x))o = g * oout = self.linear_o(o)########################################################################### END OF YOUR CODE ###########################################################################return out- 输入预处理: Create query, key and value embeddings,Rearrange the embeddings with prepare_qkv
q = self.linear_q(x)
k = self.linear_k(x)
v = self.linear_v(x)
if self.is_global:q, k, v = self.prepare_qkv_global(q, k, v)
else:q, k, v = self.prepare_qkv(q, k, v)
- 通过线性变换生成Query(Q)、Key(K)、Value(V)张量:
(*, N_head, q/k/v, c) - 如果是全局注意力模式(
is_global=True),会调用prepare_qkv_global对KV做特殊处理
- Query缩放:Scale the queries by 1/sqrt( c )
q = q / math.sqrt(self.c)
- 将Query向量除以√d(d是每个头的维度),防止点积结果过大导致softmax梯度消失
- 注意力得分计算
a = torch.einsum('...qc,...kc->...qk', q, k)
- 使用爱因斯坦求和约定计算Q和K的点积
- 结果张量a的形状为
[*, N_head, q, k],表示每个查询位置与每个键位置的相似度
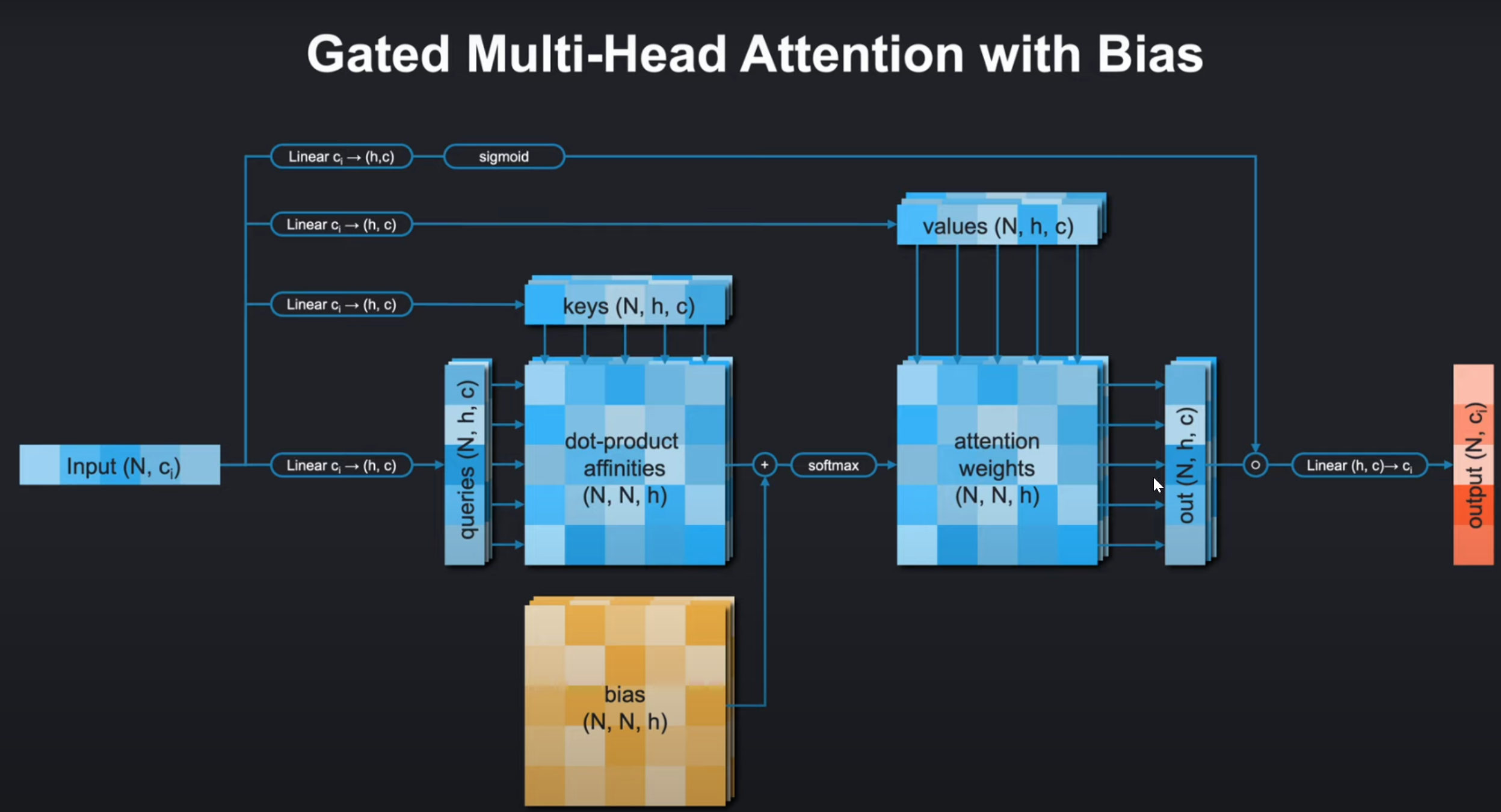
- 偏置处理
if bias is not None:bias_batch_shape = bias.shape[:-3]bias_bc_shape = bias_batch_shape + (1,) * (a.ndim-len(bias_batch_shape)-3) + bias.shape[-3:]bias = bias.view(bias_bc_shape)a = a + bias
- 调整偏置张量的形状使其可以广播到注意力得分矩阵
- 将偏置加到原始得分上(如AlphaFold中用于注入残基对信息)
- 注意力掩码处理
if attention_mask is not None:attention_mask = attention_mask[..., None, None, :]offset = (attention_mask==0) * -1e8a = a + offset
- 对需要屏蔽的位置(attention_mask==0)加上一个很大的负值(-1e8)
- softmax后这些位置的权重会趋近于0
- Softmax归一化
a = torch.softmax(a, dim=-1)
- 对最后一个维度(k)做softmax,得到归一化的注意力权重
- 加权求和
o = torch.einsum('...qk,...kc->...qc', a, v)
- 使用注意力权重对Value向量加权求和
- 输出形状为
[*, N_head, q, c]
- 输出重组
o = o.transpose(-3, -2)
o = torch.flatten(o, start_dim=-2)
o = o.moveaxis(-2, self.attn_dim)
- 转置头维和查询维
- 展平多头输出
- 将特征维度移动到指定位置(attn_dim)
- 门控机制
if self.gated:g = torch.sigmoid(self.linear_g(x))o = g * o
- 如果启用门控,生成0-1之间的门控值
- 按元素相乘控制信息流
- 最终输出变换
out = self.linear_o(o)
- 通过最后一个线性层将维度映射回输入维度
这个forward方法是多头注意力机制的核心计算过程,我将逐步解释它的实现逻辑和关键步骤:
1. 输入预处理
q = self.linear_q(x)
k = self.linear_k(x)
v = self.linear_v(x)
- 通过线性变换生成Query(Q)、Key(K)、Value(V)张量
- 如果是全局注意力模式(
is_global=True),会调用prepare_qkv_global对KV做特殊处理
2. Query缩放
q = q / math.sqrt(self.c)
- 将Query向量除以√d(d是每个头的维度),防止点积结果过大导致softmax梯度消失
3. 注意力得分计算
a = torch.einsum('...qc,...kc->...qk', q, k)
- 使用爱因斯坦求和约定计算Q和K的点积
- 结果张量a的形状为
[*, N_head, q, k],表示每个查询位置与每个键位置的相似度
4. 偏置处理
if bias is not None:bias_batch_shape = bias.shape[:-3]bias_bc_shape = bias_batch_shape + (1,) * (a.ndim-len(bias_batch_shape)-3) + bias.shape[-3:]bias = bias.view(bias_bc_shape)a = a + bias
- 调整偏置张量的形状使其可以广播到注意力得分矩阵
- 将偏置加到原始得分上(如AlphaFold中用于注入残基对信息)
5. 注意力掩码处理
if attention_mask is not None:attention_mask = attention_mask[..., None, None, :]offset = (attention_mask==0) * -1e8a = a + offset
- 对需要屏蔽的位置(attention_mask==0)加上一个很大的负值(-1e8)
- softmax后这些位置的权重会趋近于0(代表不关注这些位置)
6. Softmax归一化
Use softmax to convert the attention scores into a probability distribution.
a = torch.softmax(a, dim=-1)
- 对最后一个维度(k)做softmax,得到归一化的注意力权重。
7. 加权求和
o = torch.einsum('...qk,...kc->...qc', a, v)
- 使用注意力权重对Value向量加权求和
- 输出形状为
[*, N_head, q, c]
8. 输出重组
# - Rearrange the intermediate output in the following way: ## * (*, N_head, q, c) -> (*, q, N_head, c) ## * (*, q, N_head, c) -> (*, q, N_head * c) ## * (*, q, N_head * c) -> (*, q, *, N_head * c) ## The order of these transformations is crucial, as moving q
o = o.transpose(-3, -2)
o = torch.flatten(o, start_dim=-2)
o = o.moveaxis(-2, self.attn_dim)
- 转置头维和查询维
- 展平多头输出
- 将特征维度移动到指定位置(attn_dim)
9. 门控机制
if gated, calculate the gating with linear_g and sigmoid and multiply it against the output.
if self.gated:g = torch.sigmoid(self.linear_g(x))o = g * o
- 如果启用门控,生成0-1之间的门控值
- 按元素相乘控制信息流
10. 最终输出变换
apply linear_o to calculate the final output.
out = self.linear_o(o)
- 通过最后一个线性层将维度映射回输入维度
关键设计特点:
- 高效张量操作:使用
einsum进行批量矩阵运算 - 灵活的维度处理:支持任意批处理维度和自定义注意力维度
- 模块化设计:可插拔的偏置、掩码和门控机制
- 全局注意力支持:通过
is_global标志切换模式
相关文章:

【深度学习】多头注意力机制的实现|pytorch
博主简介:努力学习的22级计算机科学与技术本科生一枚🌸博主主页: Yaoyao2024往期回顾:【深度学习】注意力机制| 基于“上下文”进行编码,用更聪明的矩阵乘法替代笨重的全连接每日一言🌼: 路漫漫其修远兮,吾…...

OceanBase数据库磁盘空间管理
OceanBase数据库磁盘空间管理 日志盘空间管理日志盘容量参数日志盘空间满应急处理 数据盘空间管理数据盘容量参数数据文件自动扩展数据盘空间满应急处理表占用的磁盘空间 日志盘空间管理 日志盘容量参数 🐯 与日志盘redo_dir相关的四个重要参数: log_…...
自然语言处理之机器翻译:Statistical Machine Translation(SMT)的评估方法解析与创新实践
## 机器翻译与评估的重要性 机器翻译(Machine Translation, MT)作为自然语言处理(NLP)的核心任务之一,旨在通过计算机实现跨语言的信息传递。随着全球化进程加速,机器翻译在商业、科研、社交等领域的应用愈发广泛。然而,翻译质量直接决定了其实际价值,因此**翻译质量…...
)
数据集下载(AER 和causaldata R包)
1.AER #install.packages("AER") library(AER)# 引用R包 citation("AER") # 参考文献:Kleiber, Christian, and Achim Zeileis. Applied econometrics with R. Springer Science & Business Media, 2008.# 查看有哪些数据集 data(package …...

【Linux系统】详解Linux权限
文章目录 前言一、学习Linux权限的铺垫知识1.Linux的文件分类2.Linux的用户2.1 Linux下用户分类2.2 创建普通用户2.3 切换用户2.4 sudo(提升权限的指令) 二、Linux权限的概念以及修改方法1.权限的概念2.文件访问权限 和 访问者身份的相关修改(…...

Go语言--语法基础4--基本数据类型--字符串类型
在 Go 语言中,字符串也是一种基本类型。相比之下, C/C 语言中并不存在原 生的字符串类型, 通常使用字符数组来表示,并以字符指针来传递。 Go 语言中字符串的声明和初始化非常简单,举例如下: var str st…...

分布式GPU上计算长向量模的方法
分布式GPU上计算长向量模的方法 当向量分布在多个GPU卡上时,计算向量模(2-范数)需要以下步骤: 在每个GPU上计算本地数据的平方和跨GPU通信汇总所有平方和在根GPU上计算总和的平方根 实现方法 下面是一个完整的CUDA示例代码,使用NCCL进行多…...

项目班——0422——日志
...

【音视频】音频编码实战
FFmpeg流程 从本地⽂件读取PCM数据进⾏AAC格式编码,然后将编码后的AAC数据存储到本地⽂件。 示例的流程如下所示。 关键函数说明: avcodec_find_encoder:根据指定的AVCodecID查找注册的编码器。avcodec_alloc_context3:为AVCod…...

Git Bash 下使用 SSH 连接出现 “Software caused connection abort” 问题
目录 一、检查网络环境和防火墙设置(失败)二、尝试使用 GitHub 的备用 SSH 端口 443(成功)三、检查 SSH Key 是否被正确加载四、检查是否多个 SSH 进程干扰或者服务异常五、使用 HTTPS 方式临时解决(非 SSH)…...

K8S Pod 常见数据存储方案
假设有如下三个节点的 K8S 集群: k8s31master 是控制节点 k8s31node1、k8s31node2 是工作节点 容器运行时是 containerd 一、理论介绍 1.1、Volumes 卷 Kubernetes 的卷是 pod 的⼀个组成部分,因此像容器⼀样在 pod 的规范(pod.spec&#x…...

JavaScript 模板字符串:更优雅的字符串处理方式
什么是模板字符串? 模板字符串(Template Literals)是 ES6(ES2015)引入的一种新的字符串表示方式,它提供了更强大、更灵活的字符串拼接功能。与传统的字符串使用单引号()或双引号&am…...
:基于区域人口数量绘制地图散点-大模型搜集数据NL2SQL加工数据)
DeepSeek智能时空数据分析(五):基于区域人口数量绘制地图散点-大模型搜集数据NL2SQL加工数据
序言:时空数据分析很有用,但是GIS/时空数据库技术门槛太高 时空数据分析在优化业务运营中至关重要,然而,三大挑战仍制约其发展:技术门槛高,需融合GIS理论、SQL开发与时空数据库等多领域知识;空…...

PostSwigger 的 CSRF 漏洞总结
本文所提供的关于 web 安全的相关信息、技术讲解及案例分析等内容,仅用于知识分享与学术交流目的,旨在提升读者对 web 安全领域的认知与理解。以下仅仅是作者对 PostSwigger Web 安全的知识整理和分享,严禁任何非法犯罪活动。 限制 CSRF 的三…...

vue项目页面适配
vue项目页面适配 目的:结合动态设置根字体大小的脚本(如通过 JavaScript 监听屏幕尺寸变化),实现页面元素在不同设备上的自适应缩放 1、安装postcss-pxtorem ### 若项目未集成 postcss,需同步安装: npm …...

AI-Browser适用于 ChatGPT、Gemini、Claude、DeepSeek、Grok的客户端开源应用程序,集成了 Monaco 编辑器。
一、软件介绍 文末提供程序和源码下载学习 AI-Browser适用于 ChatGPT、Gemini、Claude、DeepSeek、Grok、Felo、Cody、JENOVA、Phind、Perplexity、Genspark 和 Google AI Studio 的客户端应用程序,集成了 Monaco 编辑器。使用 Electron 构建的强大桌面应用程序&a…...

Flutter Dart新特性NulI safety late 关键字、空类型声明符?、非空断言!、required 关键字
目录 late 关键字 required关键词: 常用的Model对象使用required Null safety翻译成中文的意思是空安全 null safety 可以帮助开发者避免一些日常开发中很难被发现的错误,并且额外的好处是可以改善性能后的版本都要求使用nul1 safety。Flutter2.2.0(2021年5月19日…...

CF2096G Wonderful Guessing Game 构造
题解 首先考虑没有 ? ? ? 回答的时候,答案是多少。 猜猜需要多少个询问。 ⌈ log 2 n ⌉ ? ⌈ log 3 n ⌉ ? \lceil \log_2n\rceil ? \lceil \log_3n\rceil ? ⌈log2n⌉?⌈log3n⌉? 可以构造一个表,行表示不同的询问,…...

制作一款打飞机游戏26:精灵编辑器
虽然我们基本上已经重建了Axel编辑器,但我不想直接使用它。我想创建一个真正适合我们当前目的的编辑器,那就是编辑精灵(sprites)。这将是今天的一个大目标——创建一个基于模板的编辑器,用它作为我们实际编辑器的起点。…...

深入Java JVM常见问题及解决方案
1. 简介 Java虚拟机(JVM)是Java程序运行的核心环境,但其复杂性可能导致内存泄漏、性能下降、类加载失败等问题。本文从内存管理、垃圾回收、性能调优、异常处理四大方向,结合工具使用与实战案例,详解JVM问题的排查与解…...

【MySQL】Java代码操作MySQL数据库 —— JDBC编程
目录 1. Java的JDBC编程 1.1 Java的数据库编程:JDBC 1.2 JDBC工作原理 1.3 如何在项目中导入数据库驱动包 如何下载数据库驱动包 jar包如何引入项目中 2. 编写JDBC代码 1. 创建并初始化一个数据源(DataSource) 2. 和数据库服务器建立连接 3. 构造 SQL 语句…...

Marmoset Toolbag 5.0 中文汉化版 八猴软件中文汉化版 免费下载
八猴安装包下载链接 https://pan.baidu.com/s/1Mgy3Mrlrb3Tvtc8w7Zn1nA?pwd6666 提取码:6666 Marmoset Toolbag是由Monkey公司推出一款专业动画渲染软件,也叫做八猴渲染器。该软件主要特征功能是可以进行实时模型观察、材质编辑和动画预览,…...

Java编程中常见错误的总结和解决方法
1. 找不到文件 问题描述:尝试编译一个名为ChangeCha.java的文件,但编译器找不到这个文件。错误信息:javac: 找不到文件: ChangeCha.java解决方法:检查文件名是否正确,文件是否存在于当前目录,或者路径是否…...

【GESP】C++三级练习 luogu-B2114 配对碱基链
GESP三级练习,字符串练习(C三级大纲中6号知识点,字符串),难度★✮☆☆☆。 题目题解详见:https://www.coderli.com/gesp-3-luogu-b2114/ 【GESP】C三级练习 luogu-B2114 配对碱基链 | OneCoderGESP三级练…...

C++类设计新思路:封装结构体成员变量
C++类设计新思路:封装结构体成员变量 引言 在C++编程里,类是封装数据和行为的重要手段。常规的类设计直接把成员变量定义在类中,再通过成员函数访问和修改这些变量。不过,有时候我们可以采用不同的设计思路,例如将成员变量封装到结构体里,这样可能会带来一些好处。本文…...

图像预处理-形态学变换
针对二值化图像,其有两个输入,一个输出:输入为原图像、核(结构化元素),输出为形态学变换后的图像。基本操作有腐蚀和膨胀。 一.核 联想到之前的卷积核,也是一种核。 此时的核就跟卷积核不太一…...

关于百度模型迭代个人见解:技术竞速下的应用价值守恒定律
就在前天,在 2025 年 4 月 25 日的百度 Create 开发者大会上,文心大模型 4.5 Turbo 与 X1 Turbo 的发布再次将 AI 行业带入 "涡轮加速" 时代。这两款模型不仅在多模态理解、逻辑推理等核心指标上实现突破,更以80% 的价格降幅重塑行…...

从基础到实战的量化交易全流程学习:1.3 数学与统计学基础——概率与统计基础 | 基础概念
从基础到实战的量化交易全流程学习:1.3 数学与统计学基础——概率与统计基础 | 基础概念 第一部分:概率与统计基础 第1节:基础概念:随机变量、概率分布、大数定律与中心极限定理 一、随机变量与概率分布:用数学描述市场…...

混沌工程领域常用工具的对比分析
以下是混沌工程领域常用工具的对比分析,涵盖主流工具的核心功能、优势、适用场景及局限性,帮助技术团队根据自身需求选择合适的工具: 一、故障注入工具对比 工具核心特点优势适用场景局限性生态集成开源/付费Chaos MonkeyNetflix 开源,随机终止生产环境实例,模拟硬件/进程…...
- 安装软件)
LINUX的使用(2)- 安装软件
0.防火墙相关 启动防火墙: sudo systemctl start firewalld #查看防火墙列表 firewall-cmd --list-ports 设置防火墙开机自启: sudo systemctl enable firewalld 检查防火墙状态: sudo firewall-cmd --state 允许某个端口(如端…...

一主多从+自组网络,无线模拟量信号传输专治布线PTSD
无线模拟量信号传输模块通过无线方式实现模拟量信号的传输,采集工业现场标准4~20mA电流信号,并将其转换为无线信号进行传输。 以下是关于无线模拟量信号传输模块实现无线模拟量信号传输的详细介绍: 一、模块原理 无线模拟量信号传输模块的…...

IDEA中使用Git
Git工作流程 创建远程仓库 现在我们已经在本地创建了一个Git仓库,但是这只能满足我们单人开发,如果想要团队协作,还需要一个远程仓库 目前比较流行的远程仓库,有下面这两个: github:https://github.com …...

Go RPC 服务方法签名的要求
在 Go 中,RPC 方法的签名有严格的要求,主要是为了保证方法的调用能够通过网络正确地传输和解析。具体要求如下: 1. 方法必须是导出的 RPC 服务的方法必须是导出的(即首字母大写)。这是因为 Go 的反射机制要求服务方法…...
安装笔记)
Ant(Ubuntu 18.04.6 LTS)安装笔记
一、前言 本文与【MySQL 8(Ubuntu 18.04.6 LTS)安装笔记】同批次:先搭建数据库,再安装JDK,后面肯定就是部署Web应用。其中Web应用的部署使用 Ant 方式,善始善终,特以笔记。 二、准备 …...

相机DreamCamera2录像模式适配尺寸
在开发中遇到 一个问题,相机切换视频模式时,预览时,界面不能充满屏幕两侧有黑边,客户要求修改,在此记录 一问题现象: 系统相机在视频模式下预览时如下现象如图1,期望现象如图2: 图1 …...

Animate 中HTMLCanvas 画布下实现拖拽、释放、吸附的拼图游戏
1.舞台上物体拖拽 2.松手以后,检查是否移动到范围内,是则自动吸附 3.播放音效 4.变量1,显示在舞台的动态文本中 1.实现拖拽 下面代码实现拖拽和释放 地图模块 //记录原始位置 var OriXthis.my_mc.x; var OriYthis.my_mc.y;this.my_mc.on(&q…...

第十一章-PHP表单传值
第十一章-PHP表单传值 一,核心概念 1. 表单的基本结构(HTML) 通过HTML的<form>标签定义表单,关键属性包括: action: 指定处理表单数据的PHP脚本路径(如action"process.php")…...

互联网大厂Java求职面试:从Java核心到微服务的深度探索
场景引入: 在一个阳光明媚的早上,谢飞机满怀信心地走进了一家知名互联网大厂的面试房间。面试官坐在桌子的另一端,手中拿着一份简历,面带微笑地开始了今天的面试。 第一轮提问:核心语言与平台 面试官: "谢飞机,你好。我看到你熟悉Java SE,能不能简单介绍一下Ja…...
---入口网关子服务)
微服务即时通信系统(十二)---入口网关子服务
目录 功能设计 模块划分 业务接口/功能示意图 服务实现流程 网关HTTP接口 网关WebSocket接口 总体流程 服务代码实现 客户端长连接管理封装(connectionManage.hpp) proto文件的编写 身份鉴权proto 事件通知proto 各项请求的URL的确定 服务端完成入口网关服务类…...

ES练习册
es索引结构和数据实例 这里提供索引结构和数据实例提供给大家使用练习,希望大家能够一起成长进步~~~~ #添加索引 PUT /ecommerce_products {"settings": {"number_of_shards": 3,"number_of_replicas": 1,"analysis": {&…...

运算符分为哪几类?哪些运算符常用作判断?简述运算符的优先级
运算符主要分为以下几类: 算术运算符:用于执行基本的数学运算,如加、减、乘、除、取模等。例如:、-、*、/、%。赋值运算符:用于将值赋给变量。例如:、、-、*、/、%。比较运算符ÿ…...

shell编程基础知识及脚本示例
文章目录 前言一、shell变量1.命名规则2.定义及使用变量 二、shell传递参数1.位置参数2. 任意参数 三、shell一维数组0.定义方式1.定义并获取数组的单个元素2.定义并获取数组的所有元素3.定义并获取数组的元素个数4.定义并获取数组的元素索引 四、shell条件判断语法五、shell常…...
)
再学GPIO(一)
GPIO输出模式 STM32的GPIO(General Purpose Input Output 通用输入输出)引脚支持多种输出模式,不同模式决定了引脚的驱动能力和信号特性。STM32的GPIO输出模式主要分为以下4种: 推挽输出(Push-Pull Output)…...

OpenCV彩色图像分割
OpenCV计算机视觉开发实践:基于Qt C - 商品搜索 - 京东 灰度图像大多通过算子寻找边缘和区域生长融合来分割图像。彩色图像增加了色彩信息,可以通过不同的色彩值来分割图像,常用彩色空间HSV/HIS、RGB、LAB等都可以用于分割。本节使用inRange…...

django filter 排除字段
在Django中,当你使用filter查询集(QuerySet)时,通常你会根据模型的字段来过滤数据。但是,有时你可能想要排除某些特定的字段,而不是过滤这些字段。这里有几种方法可以实现这一点: 使用exclude方…...
)
多模态大语言模型arxiv论文略读(四十五)
CAT: Enhancing Multimodal Large Language Model to Answer Questions in Dynamic Audio-Visual Scenarios ➡️ 论文标题:CAT: Enhancing Multimodal Large Language Model to Answer Questions in Dynamic Audio-Visual Scenarios ➡️ 论文作者:Qil…...

Vue3 通过Vue3-Print-Nb在线工单打印 模板打印 自定义打印 打印下载
介绍 通过在应用中集成打印功能,用户可以直接从页面打印工单,不用导出文件或使用其他外部工具。节省时间,提高效率,特别是当需要大量打印时。同时也可以将文件模板上传到数据库,提供给部门工作自行下载。 开源文档&am…...

视觉“解锁”触觉操控:Franka机器人如何玩转刚柔物体?
集智联机器人(Plug & Play Robotics),简称PNP机器人,是Franka Robotics和思灵机器人金牌合作伙伴,集智联机器人团队成员均来自于国内外机器人行业知名企业,具有较强的学术背景。PNP机器人致力于为客户提…...

FlinkUpsertKafka深度解析
1. 设计目标与工作机制 Upsert-Kafka Connector 核心功能:支持以 Upsert(插入/更新/删除) 模式读写 Kafka 数据,适用于需要动态更新结果的场景(如聚合统计、CDC 数据同步)。数据流类型: 作为 …...

百度Create大会深度解读:AI Agent与多模态模型如何重塑未来?
目录 百度Create大会亮点全解析:从数字人到Agent生态布局 数字人商业化:从"拟人"到"高说服力"的进化 Agent生态:从"心响"App看百度的Agent战略布局 "心响"App的技术架构与创新点 多模态大模型&a…...