多级缓存入门:Caffeine、Lua、OpenResty、Canal
之前写过——Google Guava Cache简介
本文系统学习一下多级缓存
目录
- 0.什么是多级缓存
- 商品查询业务案例导入
- 1.JVM进程缓存
- 初识Caffeine
- 实现JVM进程缓存
- 2.Lua语法入门
- HelloWorld
- 数据类型、变量和循环
- 函数、条件控制
- 3.Nginx业务编码实现多级缓存
- 安装OpenResty
- OpenResty快速入门
- 请求参数处理
- ☆实现OpenResty查询Tomcat
- Redis缓存预热
- ☆实现OpenResty查询Redis缓存
- ☆实现Nginx本地(OpenResty)缓存
- 4.☆缓存同步
- 缓存同步策略
- Canal初识与配置
- 监听Canal实现缓存同步
0.什么是多级缓存
传统的缓存策略一般是请求到达Tomcat后,先查询Redis,如果未命中则查询数据库,如图:
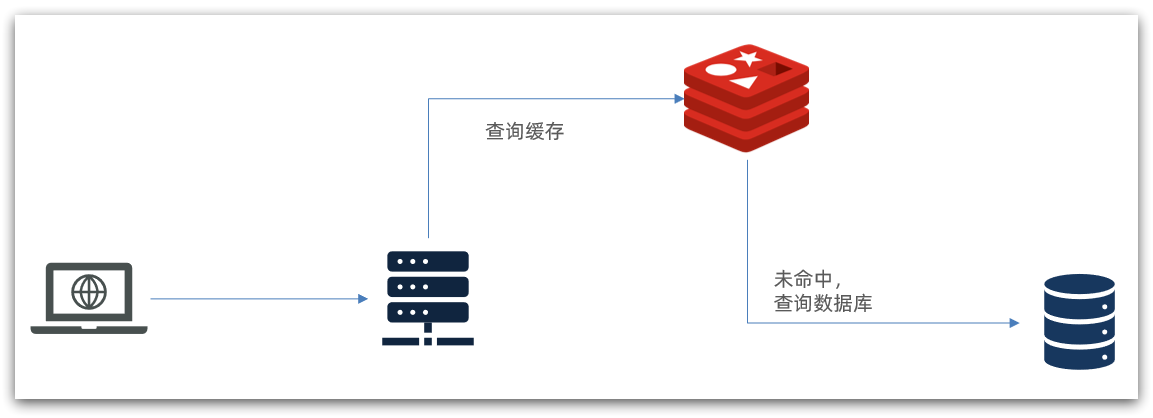
存在下面的问题:
-
请求要经过Tomcat处理,Tomcat的性能成为整个系统的瓶颈
-
Redis缓存失效时,会对数据库产生冲击
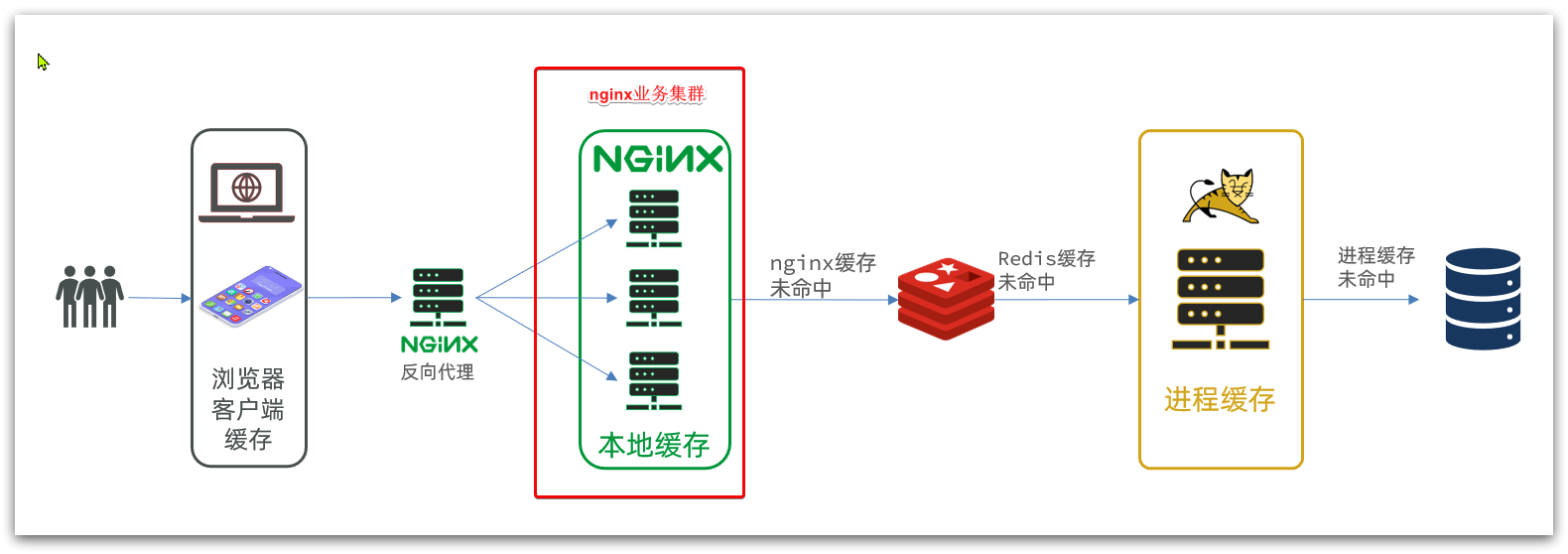
多级缓存就是充分利用请求处理的每个环节,分别添加缓存,减轻Tomcat压力,提升服务性能:
- 浏览器访问静态资源时,优先读取浏览器本地缓存
- 访问非静态资源(ajax查询数据)时,访问服务端
- 请求到达Nginx后,优先读取Nginx本地缓存
- 如果Nginx本地缓存未命中,则去直接查询Redis(不经过Tomcat)
- 如果Redis查询未命中,则查询Tomcat
- 请求进入Tomcat后,优先查询JVM进程缓存
- 如果JVM进程缓存未命中,则查询数据库
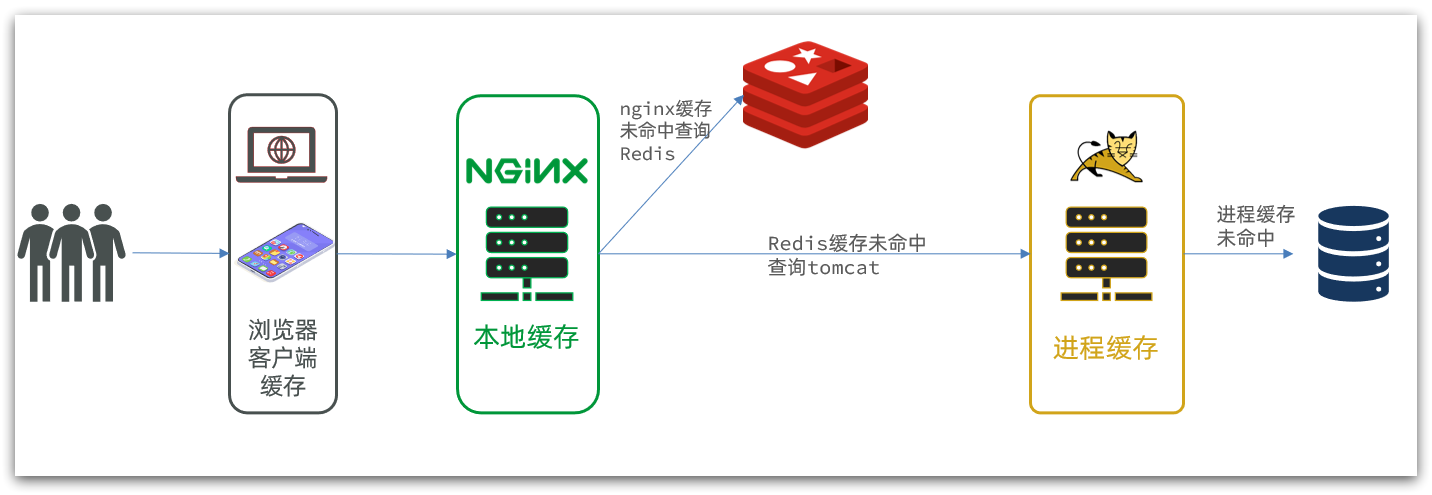
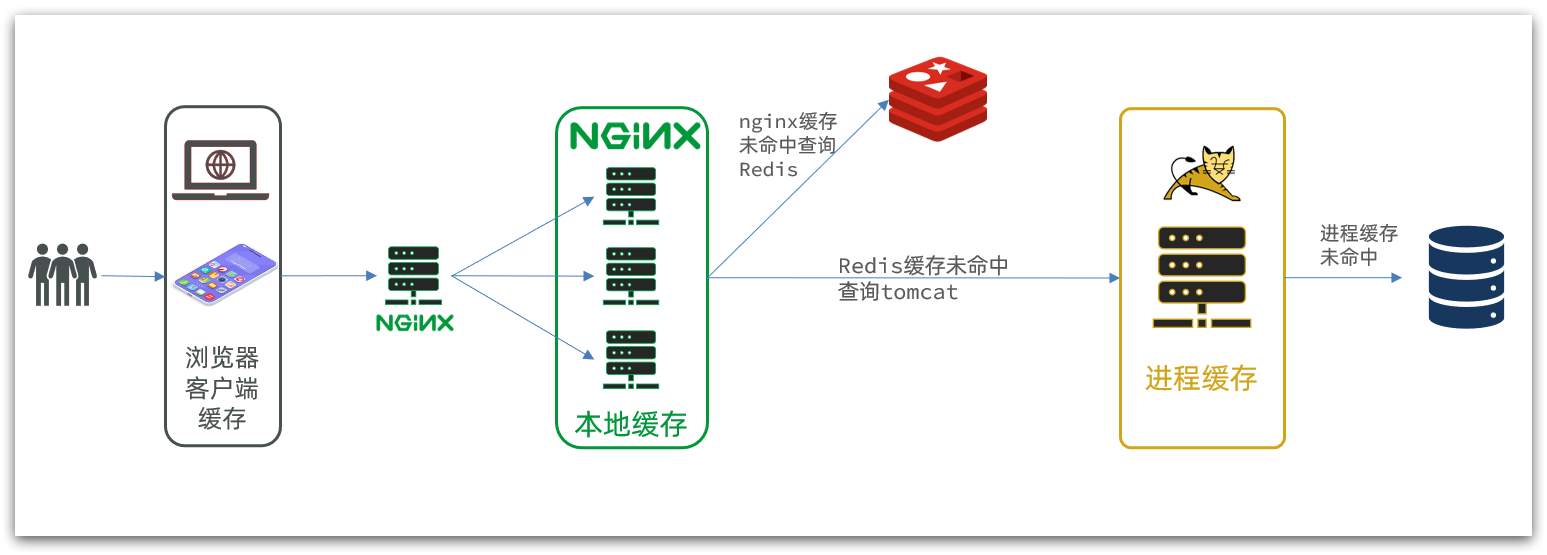
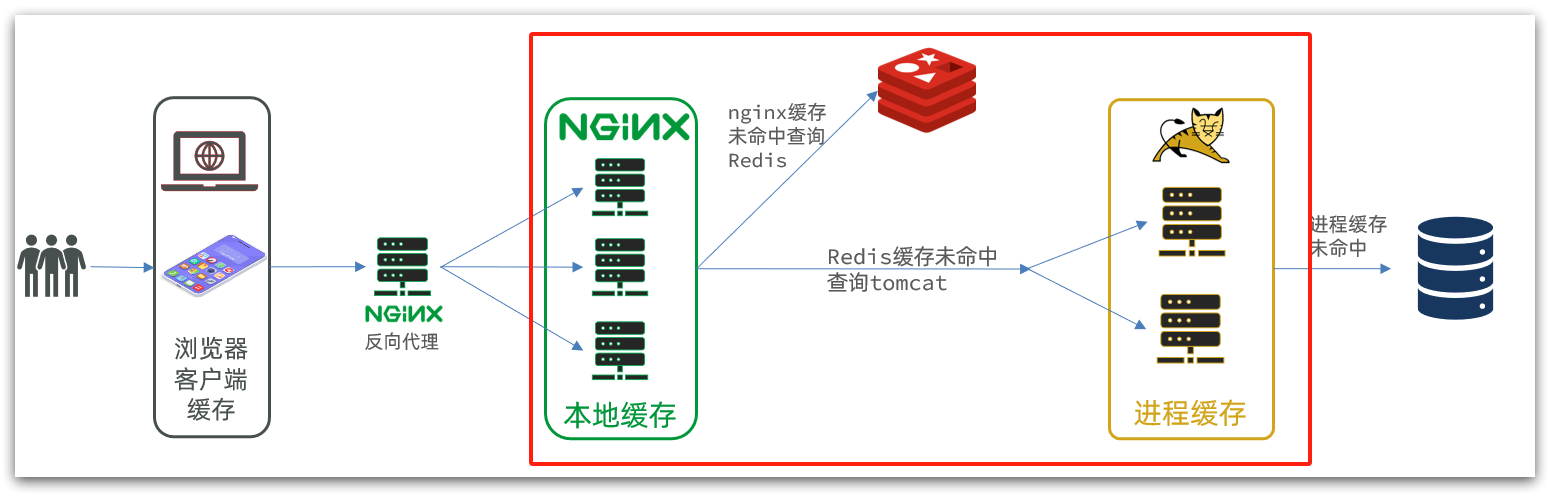
在多级缓存架构中,Nginx内部需要编写本地缓存查询、Redis查询、Tomcat查询的业务逻辑,因此这样的nginx服务不再是一个反向代理服务器,而是一个编写业务的Web服务器了。
因此这样的业务Nginx服务也需要搭建集群来提高并发,再有专门的nginx服务来做反向代理,如图:
另外,我们的Tomcat服务将来也会部署为集群模式:
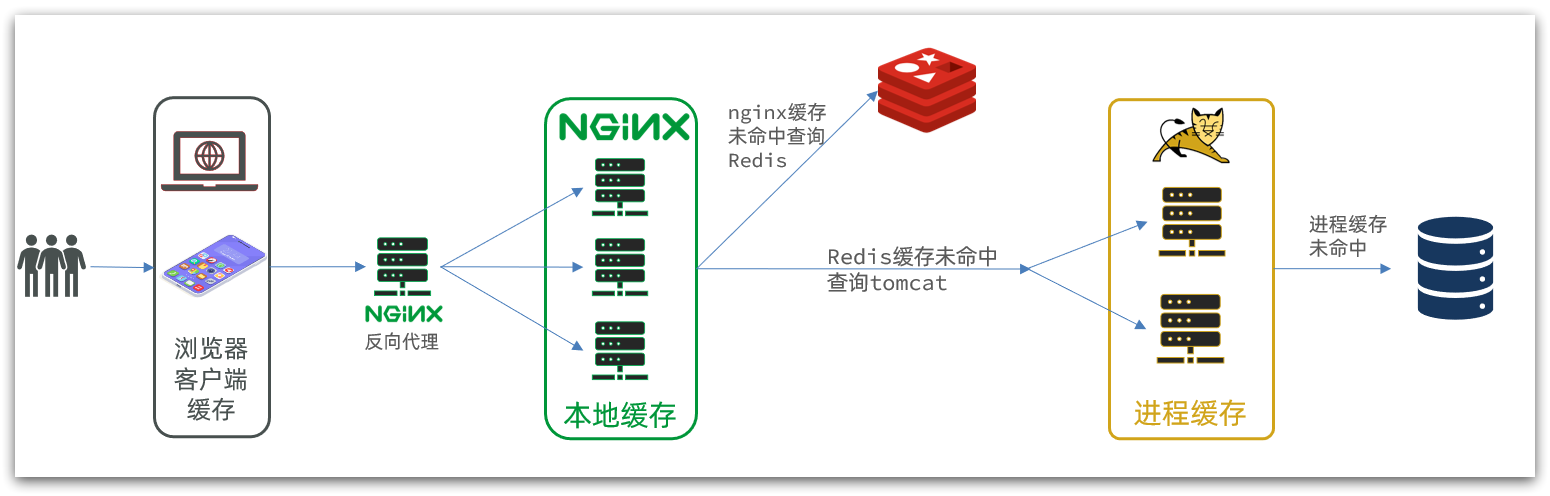
可见,多级缓存的关键有两个:
-
一个是在nginx中编写业务,实现nginx本地缓存、Redis、Tomcat的查询
-
另一个就是在Tomcat中实现JVM进程缓存
其中Nginx编程则会用到OpenResty框架结合Lua这样的语言。
这也是今天学习的难点和重点。
商品查询业务案例导入
为了演示多级缓存,我们先导入一个商品管理的案例,其中包含商品的CRUD功能。我们将来会给查询商品添加多级缓存。
1.安装MySQL
后期做数据同步需要用到MySQL的主从功能,所以需要大家在虚拟机中,利用Docker来运行一个MySQL容器。
1.1.准备目录
为了方便后期配置MySQL,我们先准备两个目录,用于挂载容器的数据和配置文件目录:
# 进入/tmp目录
cd /tmp
# 创建文件夹
mkdir mysql
# 进入mysql目录
cd mysql
1.2.运行命令
进入mysql目录后,执行下面的Docker命令:
docker run \-p 3306:3306 \--name mysql \-v $PWD/conf:/etc/mysql/conf.d \ # 挂载mysql配置文件目录-v $PWD/logs:/logs \ # 挂载mysql日志文件目录-v $PWD/data:/var/lib/mysql \ # 挂载mysql数据文件目录-e MYSQL_ROOT_PASSWORD=123 \ # 指定root账号和密码--privileged \-d \mysql:5.7.25
1.3.修改配置
在/tmp/mysql/conf目录添加一个my.cnf文件,作为mysql的配置文件:
# 创建文件
touch /tmp/mysql/conf/my.cnf
文件的内容如下,都是mysql的默认配置,主要配的就是字符的编码改成utf-8
[mysqld]
# 跳过域名解析,速度加载可以更快
skip-name-resolve
# 字符编码
character_set_server=utf8
# 指定数据库的目录 与我们挂载的目录保持一致
datadir=/var/lib/mysql
# 服务id
server-id=1000
1.4.重启
配置修改后,必须重启容器:
docker restart mysql
2.导入SQL
接下来,利用Navicat客户端连接MySQL,创建新的数据库,然后导入课前资料提供的sql文件:
/*Navicat Premium Data TransferSource Server : 192.168.150.101Source Server Type : MySQLSource Server Version : 50725Source Host : 192.168.150.101:3306Source Schema : heimaTarget Server Type : MySQLTarget Server Version : 50725File Encoding : 65001Date: 16/08/2021 14:45:07
*/SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;-- ----------------------------
-- Table structure for tb_item
-- ----------------------------
DROP TABLE IF EXISTS `tb_item`;
CREATE TABLE `tb_item` (`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '商品id',`title` varchar(264) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '商品标题',`name` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT '' COMMENT '商品名称',`price` bigint(20) NOT NULL COMMENT '价格(分)',`image` varchar(200) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '商品图片',`category` varchar(200) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '类目名称',`brand` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '品牌名称',`spec` varchar(200) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '规格',`status` int(1) NULL DEFAULT 1 COMMENT '商品状态 1-正常,2-下架,3-删除',`create_time` datetime NULL DEFAULT NULL COMMENT '创建时间',`update_time` datetime NULL DEFAULT NULL COMMENT '更新时间',PRIMARY KEY (`id`) USING BTREE,INDEX `status`(`status`) USING BTREE,INDEX `updated`(`update_time`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 50002 CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '商品表' ROW_FORMAT = COMPACT;-- ----------------------------
-- Records of tb_item
-- ----------------------------
INSERT INTO `tb_item` VALUES (10001, 'RIMOWA 21寸托运箱拉杆箱 SALSA AIR系列果绿色 820.70.36.4', 'SALSA AIR', 16900, 'https://m.360buyimg.com/mobilecms/s720x720_jfs/t6934/364/1195375010/84676/e9f2c55f/597ece38N0ddcbc77.jpg!q70.jpg.webp', '拉杆箱', 'RIMOWA', '{\"颜色\": \"红色\", \"尺码\": \"26寸\"}', 1, '2019-05-01 00:00:00', '2019-05-01 00:00:00');
INSERT INTO `tb_item` VALUES (10002, '安佳脱脂牛奶 新西兰进口轻欣脱脂250ml*24整箱装*2', '脱脂牛奶', 68600, 'https://m.360buyimg.com/mobilecms/s720x720_jfs/t25552/261/1180671662/383855/33da8faa/5b8cf792Neda8550c.jpg!q70.jpg.webp', '牛奶', '安佳', '{\"数量\": 24}', 1, '2019-05-01 00:00:00', '2019-05-01 00:00:00');
INSERT INTO `tb_item` VALUES (10003, '唐狮新品牛仔裤女学生韩版宽松裤子 A款/中牛仔蓝(无绒款) 26', '韩版牛仔裤', 84600, 'https://m.360buyimg.com/mobilecms/s720x720_jfs/t26989/116/124520860/644643/173643ea/5b860864N6bfd95db.jpg!q70.jpg.webp', '牛仔裤', '唐狮', '{\"颜色\": \"蓝色\", \"尺码\": \"26\"}', 1, '2019-05-01 00:00:00', '2019-05-01 00:00:00');
INSERT INTO `tb_item` VALUES (10004, '森马(senma)休闲鞋女2019春季新款韩版系带板鞋学生百搭平底女鞋 黄色 36', '休闲板鞋', 10400, 'https://m.360buyimg.com/mobilecms/s720x720_jfs/t1/29976/8/2947/65074/5c22dad6Ef54f0505/0b5fe8c5d9bf6c47.jpg!q70.jpg.webp', '休闲鞋', '森马', '{\"颜色\": \"白色\", \"尺码\": \"36\"}', 1, '2019-05-01 00:00:00', '2019-05-01 00:00:00');
INSERT INTO `tb_item` VALUES (10005, '花王(Merries)拉拉裤 M58片 中号尿不湿(6-11kg)(日本原装进口)', '拉拉裤', 38900, 'https://m.360buyimg.com/mobilecms/s720x720_jfs/t24370/119/1282321183/267273/b4be9a80/5b595759N7d92f931.jpg!q70.jpg.webp', '拉拉裤', '花王', '{\"型号\": \"XL\"}', 1, '2019-05-01 00:00:00', '2019-05-01 00:00:00');-- ----------------------------
-- Table structure for tb_item_stock
-- ----------------------------
DROP TABLE IF EXISTS `tb_item_stock`;
CREATE TABLE `tb_item_stock` (`item_id` bigint(20) NOT NULL COMMENT '商品id,关联tb_item表',`stock` int(10) NOT NULL DEFAULT 9999 COMMENT '商品库存',`sold` int(10) NOT NULL DEFAULT 0 COMMENT '商品销量',PRIMARY KEY (`item_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = COMPACT;-- ----------------------------
-- Records of tb_item_stock
-- ----------------------------
INSERT INTO `tb_item_stock` VALUES (10001, 99996, 3219);
INSERT INTO `tb_item_stock` VALUES (10002, 99999, 54981);
INSERT INTO `tb_item_stock` VALUES (10003, 99999, 189);
INSERT INTO `tb_item_stock` VALUES (10004, 99999, 974);
INSERT INTO `tb_item_stock` VALUES (10005, 99999, 18649);SET FOREIGN_KEY_CHECKS = 1;
其中包含两张表:
- tb_item:商品表,包含商品的基本信息
- tb_item_stock:商品库存表,包含商品的库存信息
之所以将库存分离出来,是因为库存是更新比较频繁的信息,写操作较多。而其他信息修改的频率非常低,如果放在一起,每次修改整条数据作废,那么缓存失效的频率就太高了,所以需要做数据分离,真实的商品数据可能要有好几张表,将来有好几个不同的缓存。
3.导入Demo工程
下面导入课前资料提供的工程,项目结构如图所示:

其中的业务包括:
- 分页查询商品
- 新增商品
- 修改商品
- 修改库存
- 删除商品
- 根据id查询商品
- 根据id查询库存
业务全部使用mybatis-plus来实现
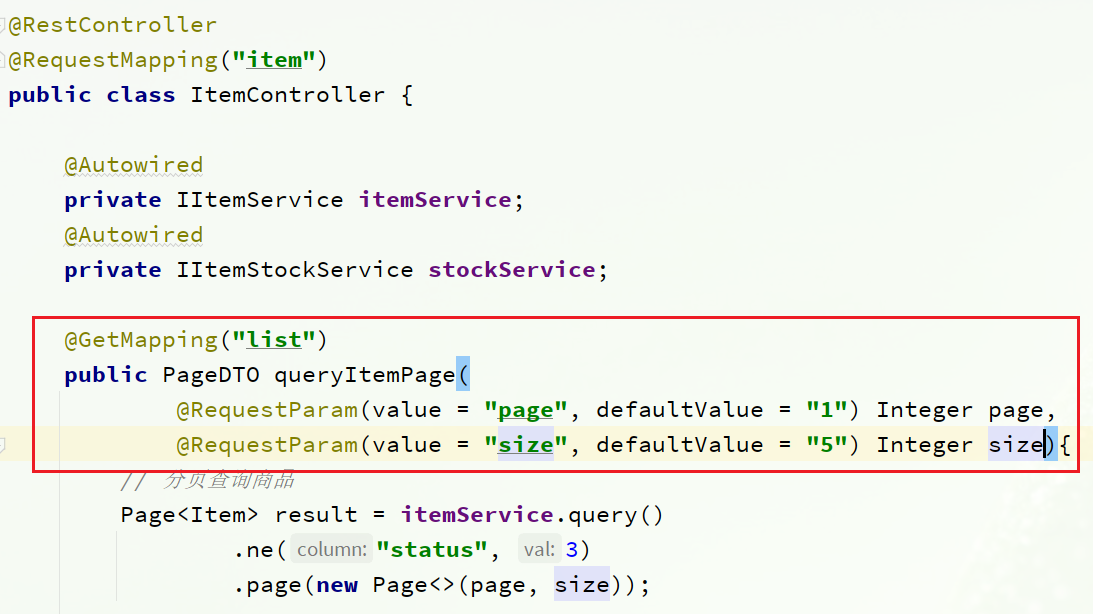
3.1.分页查询商品
在com.heima.item.web包的ItemController中可以看到接口定义:
3.2.新增商品
在com.heima.item.web包的ItemController中可以看到接口定义:

3.3.修改商品
在com.heima.item.web包的ItemController中可以看到接口定义:

3.4.修改库存
在com.heima.item.web包的ItemController中可以看到接口定义:

3.5.删除商品
在com.heima.item.web包的ItemController中可以看到接口定义,这里是采用了逻辑删除,将商品状态修改为3。

3.6.根据id查询商品
在com.heima.item.web包的ItemController中可以看到接口定义,这里只返回了商品信息,不包含库存

3.7.根据id查询库存
在com.heima.item.web包的ItemController中可以看到接口定义

3.8.启动
注意修改application.yml文件中配置的mysql地址信息,需要修改为自己的虚拟机地址信息、还有账号和密码。
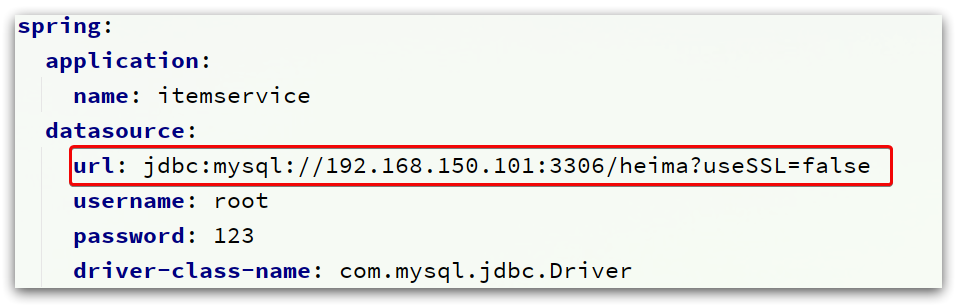
修改后,启动服务,访问:http://localhost:8081/item/10001即可查询商品数据,访问http://localhost:8081/item/stock/10001即可查询商品对应库存。
4.导入商品查询页面
商品查询是购物页面,与商品管理的页面是分离的。部署方式如图:
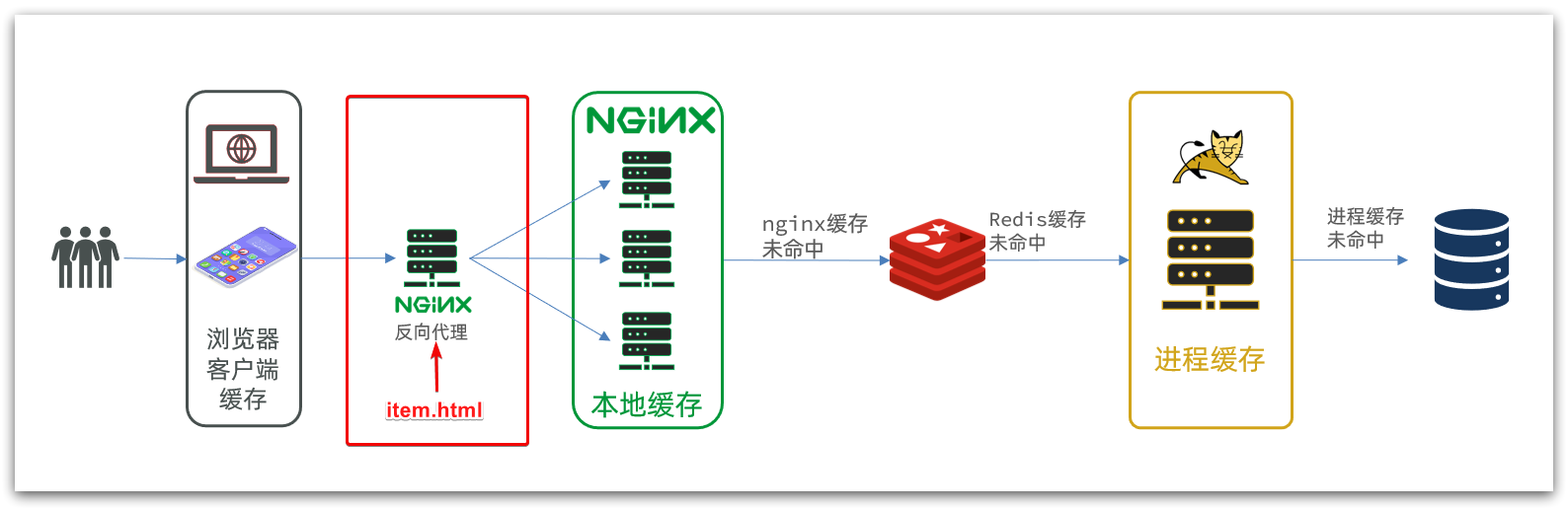
我们需要准备一个反向代理的nginx服务器,如上图红框所示,将静态的商品页面放到nginx目录中。
页面需要的数据通过ajax向服务端(nginx业务集群)查询。
4.1.运行nginx服务
这里我已经给大家准备好了nginx反向代理服务器和静态资源。
我们找到课前资料的nginx目录:
将其拷贝到一个非中文目录下,其中html目录存放着页面资源:
运行这个nginx服务。运行命令:
start nginx.exe
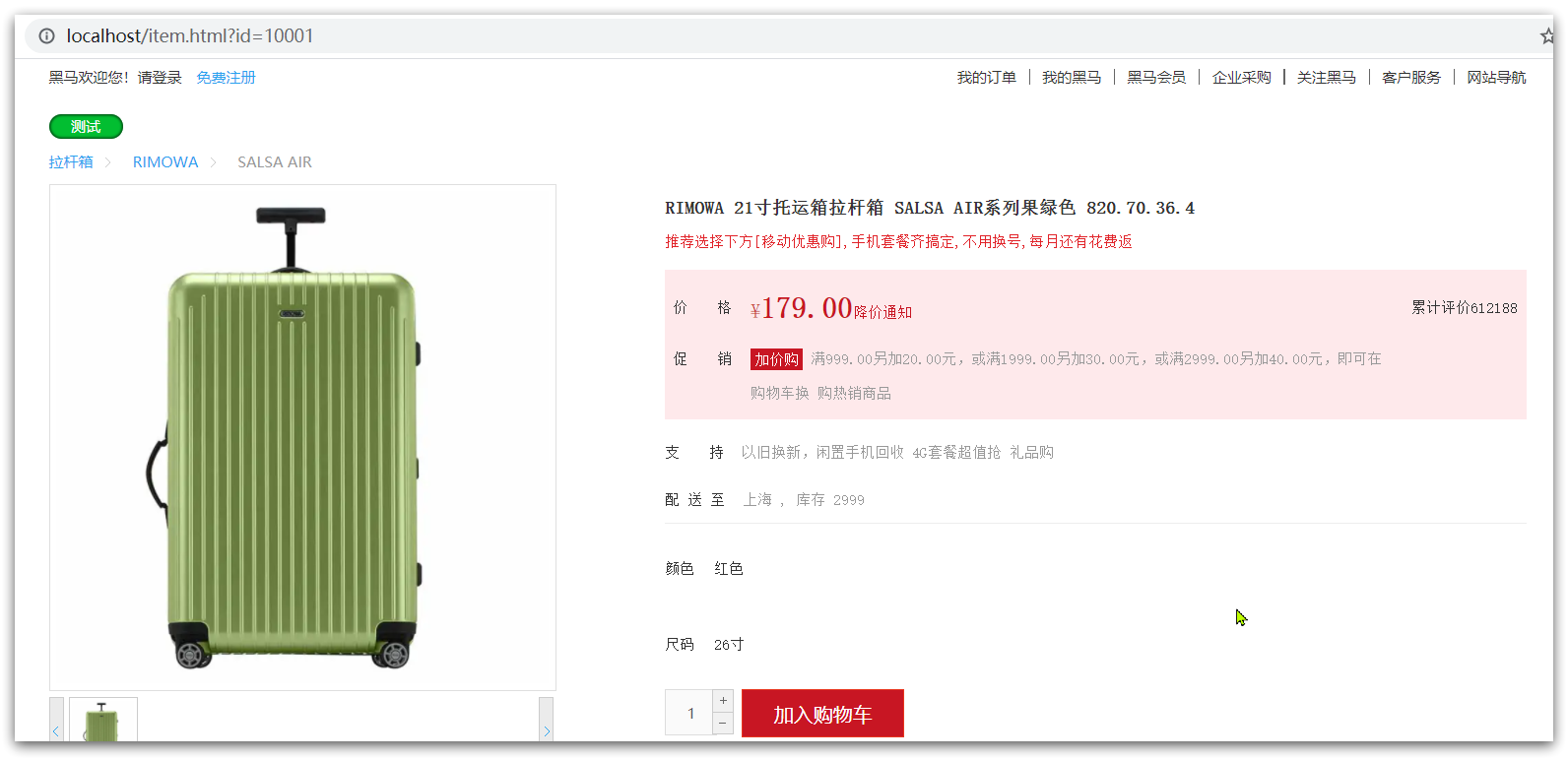
然后访问 http://localhost/item.html?id=10001即可访问商品:
4.2.反向代理
但是现在,页面是假数据展示的(前端写死)。我们需要向服务器发送ajax请求,查询商品数据。
打开控制台,可以看到页面有发起ajax查询数据:
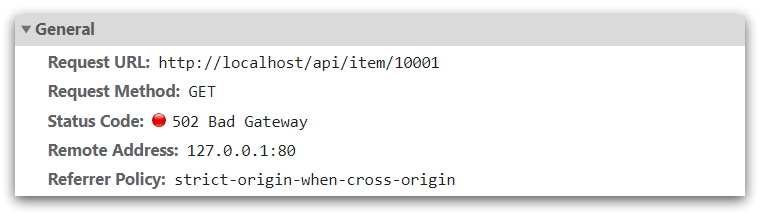
而这个请求地址同样是80端口(没加端口默认html是80,也是Nginx 默认监听端口),所以被当前的nginx反向代理了,所以我们需要在当前的nginx做反向代理的配置。
查看nginx的conf目录下的nginx.conf文件:
其中的关键配置如下:
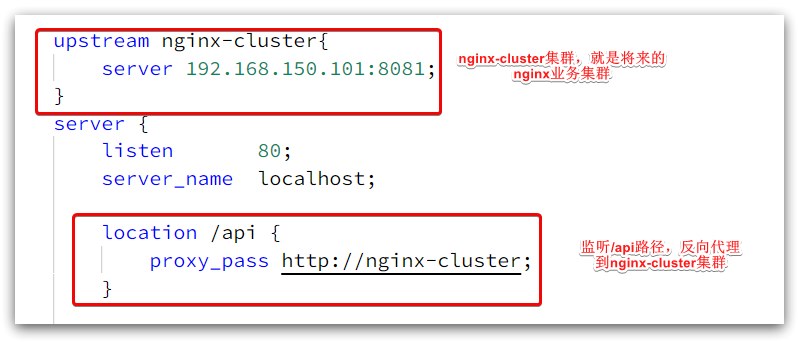
其中的192.168.150.101是我的虚拟机IP,也就是我的Nginx业务集群要部署的地方:
完整内容如下:
#user nobody;
worker_processes 1;events {worker_connections 1024;
}http {include mime.types;default_type application/octet-stream;sendfile on;#tcp_nopush on;keepalive_timeout 65;# nginx的业务集群(在这里做nginx本地缓存、redis缓存、tomcat查询等)upstream nginx-cluster{# 还没做集群 先配一个 这里ip是我的虚拟机ipserver 192.168.150.101:8081;}server {listen 80;server_name localhost;# /api接口反向代理到/nginx-cluster(nginx里的负载均衡的配置,在上面定义了)location /api {proxy_pass http://nginx-cluster;}location / {root html;index index.html index.htm;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}
}
以上就是整个商品查询案例的导入了,我们把架子搭好了。tomcat有了,数据有了,反向代理服务器也准备好了,浏览器也有了,现在差的是下面框内的部分,下面我们去实现。
1.JVM进程缓存
初识Caffeine
缓存在日常开发中启动至关重要的作用,由于是存储在内存中,数据的读取速度是非常快的,能大量减少对数据库的访问,减少数据库的压力。我们把缓存分为两类:
- 分布式缓存,例如Redis:
- 优点:存储容量更大(Redis本身可以搭建集群)、可靠性更好(哨兵、主从)、可以在集群间共享(多台tomcat都可以访问同一个Redis缓存)
- 缺点:访问缓存有网络开销(独立于tomcat之外)
- 场景:缓存数据量较大、可靠性要求较高、需要在集群间共享
- 进程本地缓存,例如HashMap、GuavaCache:
- 优点:读取本地内存,没有网络开销,速度更快
- 缺点:存储容量有限(上限就是这台tomcat服务器的JVM堆内存上限,而且不能独占,否则程序运行有问题)、可靠性较低(tomcat重启、宕机则数据丢失)、无法共享(tomcat与tomcat之间)
- 场景:性能要求较高,缓存数据量较小
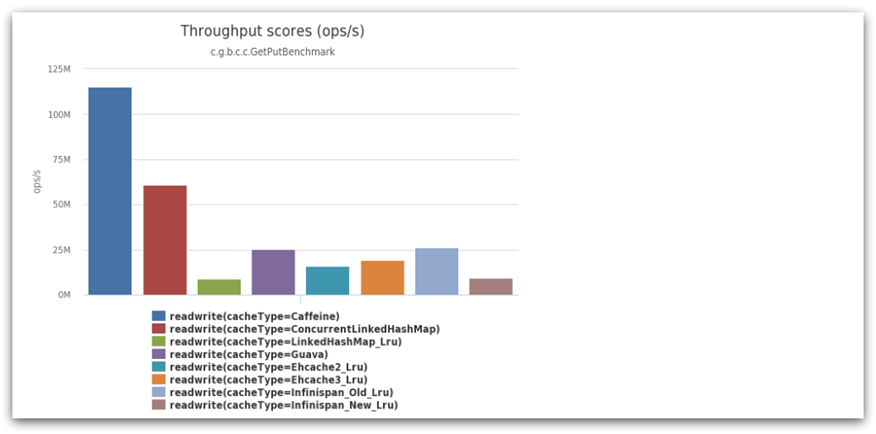
我们今天会利用Caffeine框架来实现JVM进程缓存。Caffeine是一个基于Java8开发的,提供了近乎最佳命中率的高性能的本地缓存库。目前Spring内部的缓存使用的就是Caffeine。GitHub地址
Caffeine的性能非常好,下图是官方给出的性能对比,可以看到Caffeine的性能遥遥领先
缓存使用的基本API:
@Test
void testBasicOps() {// 构建cache对象Cache<String, String> cache = Caffeine.newBuilder().build();// 存数据cache.put("gf", "迪丽热巴");// 取数据,不存在则返回nullString gf = cache.getIfPresent("gf");System.out.println("gf = " + gf);// 上面的取法不是用的最多的,因为一般缓存没命中要去查数据库,查完后再写到缓存里,把结果返回给用户// 去Caffeine也提供了这样的一个api取数据,包含两个参数:// 参数一:缓存的key// 参数二:Lambda表达式,表达式的参数就是缓存的key,方法体是自定义的后续逻辑(例如查询数据库),查询到的结果会被存入缓存,并且返回给调用者。// 优先根据key查询JVM缓存,如果未命中,则执行参数二的Lambda表达式,并将查询到的结果存入缓存中String defaultGF = cache.get("defaultGF", key -> {// 根据key去数据库查询数据return "柳岩";});System.out.println("defaultGF = " + defaultGF);
}
相关文章:

多级缓存入门:Caffeine、Lua、OpenResty、Canal
之前写过——Google Guava Cache简介 本文系统学习一下多级缓存 目录 0.什么是多级缓存商品查询业务案例导入1.JVM进程缓存初识Caffeine实现JVM进程缓存2.Lua语法入门HelloWorld数据类型、变量和循环函数、条件控制3.Nginx业务编码实现多级缓存安装OpenRestyOpenResty快速入门…...
的三种类型)
在AWS Glue中实现缓慢变化维度(SCD)的三种类型
根据缓慢变化维度(SCD)的三种核心类型(类型1、类型2、类型3),以下是基于AWS Glue的实现设计、步骤及测试用例: 一、AWS Glue实现SCD的设计与步骤 1. SCD类型1(覆盖旧值) 设计目标&…...

业务校验工具包-validate-utils介绍
validate-utils介绍 1. 概述 validate-utils是一个基于Hibernate Validator的轻量级校验框架,旨在简化和增强Java应用程序中的数据校验工作。该工具包提供了一系列常见的校验场景,帮助开发人员快速实现数据验证,提高代码的可维护性和可靠性。 2. 功能特性 2.1 集合数据量…...

参数规模:衡量大语言模型体量的标尺
大语言模型的体量差异通过参数数量呈现。业界标杆如GPT-3拥有1750亿参数,Grok-1更达到3140亿级别,而Llama系列则提供70亿至700亿参数的轻量化选择。这里的"70B"并非指训练数据量,而是模型内部结构的复杂度指标——每个参数如同微型…...

JS 中call、apply 和 bind使用方法和场景
call 方法 核心特性 立即执行函数,并显式指定 this 值和逐个传递参数。语法:func.call(thisArg, arg1, arg2, …) 使用场景 借用其他对象的方法 const person { name: "Alice" }; function greet(greeting) {console.log(${greeting}, ${t…...

ZeroGrasp:零样本形状重建助力机器人抓取
25年4月来自CMU、TRI 和 丰田子公司 Woven 的论文“ZeroGrasp: Zero-Shot Shape Reconstruction Enabled Robotic Grasping”。 机器人抓取是具身系统的核心能力。许多方法直接基于部分信息输出抓取结果,而没有对场景的几何形状进行建模,导致运动效果不…...

第2讲、Tensor高级操作与自动求导详解
1. 前言 在深度学习模型中,Tensor是最基本的运算单元。本文将深入探讨PyTorch中两个核心概念: Tensor的广播机制(Broadcasting)**自动求导(Autograd)**机制 这些知识点不仅让你更加灵活地操作数据&#…...
表的操作)
(MySQL)表的操作
目录 表的创建 语法 创建表的案例 查看表的结构 修改表的操作 修改表名 编辑 添加一个字段(列) 修改一个字段的类型 修改字段名 删除字段名(删除列) 删除指定的表 表的插入数据 数据库的备份和恢复 我们来学习表的操作 表的创建 语法 CREATE TABLE [if not ex…...

函数的使用
函数绑定 fn.call(obj, param1, param2) fn.apply(obj, [param1, param2]) fn.bind(obj, param1, param2)()相同点: 都是借用别人(fn)的方法,替换其中的this(第一个参数)call和apply的不同点:a…...
)
LLM应用于自动驾驶方向相关论文整理(大模型在自动驾驶方向的相关研究)
1、《HILM-D: Towards High-Resolution Understanding in Multimodal Large Language Models for Autonomous Driving》 2023年9月发表的大模型做自动驾驶的论文,来自香港科技大学和人华为诺亚实验室(代码开源)。 论文简介: 本文…...

Spring MVC深度解析:从原理到实战
文章目录 一、Spring MVC概述1.1 MVC设计模式1.2 Spring MVC特点 二、Spring MVC核心组件2.1 架构流程图解2.2 核心组件说明 三、环境搭建与配置3.1 Maven依赖3.2 传统XML配置 vs JavaConfig 四、控制器开发实践4.1 基础控制器示例4.2 请求映射注解 五、数据处理与绑定5.1 表单…...

Spark学习全总结
基础概念: Spark 是一个快速、通用的大数据处理引擎,支持多种计算模式,如批处理、流处理、交互式查询和机器学习等。 特点: 速度快:基于内存计算,能将数据缓存在内存中,避免频繁读写磁盘,大幅…...

pytorch写张量pt文件,libtorch读张量pt文件
直接在pytorch中,用torch.save保存的张量,可能因格式差异无法在C中加载。 以下是一个最简单的例子,展示如何在 Pytorch中保存张量到 TorchScript 模块,并在 C 中使用 LibTorch 加载。 Python 代码 (save_tensor.py) import torc…...

关于Android Studio的Gradle各项配置2
好的!你提到的这些文件是 Gradle 构建系统 和 Android 项目 中非常重要的一部分,它们各自有不同的作用,涉及项目的构建配置、Gradle 环境、系统配置等方面。接下来我会为你详细解释每个文件的作用,并提供具体的例子和注释。 1. gr…...

Android Studio中创建第一个Flutter项目
一、Flutter环境验证 创建Flutter项目之前需要验证是否有Flutter环境,如没有Flutter 环境,请参考配置Flutter开发环境 1.1、flutter doctor 验证通过会有以下提示 [√] Flutter (Channel stable, 3.29.3, on Microsoft Windows [版本 10.0.19045.573…...
)
Linux的例行性工作(crontab)
crontab服务 at 命令是在指定的时间只能执行一次任务, crontab 命令可以循环重复的执行定时任务,与 Windows 中的计划任务有些类似 crond 是 Linux 下用来周期地执行某种任务或等待处理某些事件的一个守护进程,在安装完成操 作系统后,默认会安装 crond …...

03 基于 STM32 的温度控制系统
前言 Protues、KeilC 设计内容:使用STM32设计一个空调温度的显示控制系统 设计要求: 1.温度显示范围为16-30摄氏度 2.按键K1实现显示温度加1,按键K2实现显示温度减1,低于16或高于30,显示数值不变 3.正常按键蜂鸣器响一…...
)
23种设计模式-行为型模式之备忘录模式(Java版本)
Java 备忘录模式(Memento Pattern)详解 🧠 什么是备忘录模式? 备忘录模式是一种行为型设计模式,它允许在不暴露对象实现细节的情况下,保存和恢复对象的状态。备忘录模式常常用于需要记录对象状态以便随时…...
:selenium自动化测试常用函数(上))
[三分钟]web自动化测试(二):selenium自动化测试常用函数(上)
文章目录 1.元素定位1.1 cssSelector(选择器)1.2 xpath1.3小示例 2.操作测试对象2.1点击/提交对象-click()2.2 模拟按键输入-sendKeys("")2.3 清除文本内容-clear()2.4 获取文本信息-getText()2.5 获取当前页面标题-getTitle()2.6获取当前页面URL-getCurrentUrl() 3.…...

基于ruoyi-plus实现AI聊天和绘画
项目介绍 基于ruoyi-plus实现AI聊天和绘画功能,打造自己的AI平台。前后端分离,有管理后台,用户端,小程序端。支持对接openai,讯飞星火,通义灵码,deepseek等大语言模型。项目架构 管理后台-前端&…...

假设检验学习总结
目录 一、假设检验1. 两种错误2. z检验和t检验3. t检验3.1 单样本t检验3.2 配对样本t检验3.3 独立样本t检验4 方差齐性检验备注卡方检验样本容量的计算AB测试主要的两种应用场景绝对量的计算公式率的计算公式说明一、假设检验 1. 两种错误 第一类错误 原假设为真,却拒绝了原假…...

C++ 基于多设计模式下的同步异步⽇志系统-2项目实现
⽇志系统框架设计 1.⽇志等级模块:对输出⽇志的等级进⾏划分,以便于控制⽇志的输出,并提供等级枚举转字符串功能。 ◦ OFF:关闭 ◦ DEBUG:调试,调试时的关键信息输出。 ◦ INFO:提⽰,普通的提⽰…...
)
Tauri窗口与界面管理:打造专业桌面应用体验 (入门系列五)
窗口管理是桌面应用的核心特性之一,良好的窗口管理可以显著提升用户体验。在Web开发中,我们通常被限制在浏览器窗口内,但Tauri允许前端开发者控制应用窗口的方方面面,从而创造出更加原生的体验。 窗口配置基础 初始窗口配置 在…...
和 channel(管道) 案例解析)
golang goroutine(协程)和 channel(管道) 案例解析
文章目录 goroutine和channel概念开启线程与channel简单通信流程多个工作协程并发执行流程 goroutine和channel概念 goroutine(协程),一般我们常见的是进程,线程,进程可以理解为一个软件在运行执行的过程,线程跟协程比较类似&…...
)
底层源码和具体测试解析HotSpot JVM的notify唤醒有序性(5000字详解)
在大家的认知里,或者大家也可能搜过,notify唤醒机制到底是随机的呢?还是顺序的呢?在网上其实也有很多人说notify的唤醒机制就是随机的,但实际上并不是这样的,notify的唤醒机制是先进先出的! 目…...
)
Jenkins(CI/CD工具)
1. 什么是 Jenkins? Jenkins 是一个开源的持续集成(CI)和持续交付/部署(CD)工具,用于自动化软件构建、测试和部署过程。 2. Jenkins 优势 (1)开源免费:社区活跃&#…...

Apache Sqoop数据采集问题
Sqoop数据采集格式问题 一、Sqoop工作原理二、Sqoop命令格式三、Oracle数据采集格式问题四、Sqoop增量采集方案 Apache Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql…)间进行数据的传递,可以将一个关系型数据库&…...
)
再学GPIO(二)
GPIO寄存器 每个GPI/O端口有两个32位配置寄存器(GPIOx_CRL,GPIOx_CRH),两个32位数据寄存器(GPIOx_IDR和GPIOx_ODR),一个32位置位/复位寄存器(GPIOx_BSRR),一个16位复位寄存器(GPIOx_BRR)和一个32位锁定寄存器(GPIOx_LCKR)。 GPIO…...

err: Error: Request failed with status code 400
好的,今天学习ai的时候从前端发送请求,实在是想不通为啥会啥是一个坏请求,后来从前端方法一个一个找参数,传递的值都有,然后想到我这边需要传递的是一个对象,那么后端使用的RequestParam就接收不到json对象…...

解决qnn htp 后端不支持boolean 数据类型的方法。
一、背景 1.1 问题原因 Qnn 模型在使用fp16的模型转换不支持类型是boolean的cast 算子,因为 htp 后端支持量化数据类型或者fp16,不支持boolean 类型。 ${QNN_SDK_ROOT_27}/bin/x86_64-linux-clang/qnn-model-lib-generator -c ./bge_small_fp16.cpp -b …...
:Pod亲和性详解)
k8s学习记录(五):Pod亲和性详解
一、前言 上一篇文章初步探讨了 Kubernetes 的节点亲和性,了解到它在 Pod 调度上比传统方式更灵活高效。今天我们继续讨论亲和性同时Kubernetes 的调度机制。 二、Pod亲和性 上一篇文章中我们介绍了节点亲和性,今天我们讲解一下Pod亲和性。首先我们先看…...

MongoDB与PHP7的集成与优化
MongoDB与PHP7的集成与优化 引言 随着互联网技术的飞速发展,数据库技术在现代软件开发中扮演着越来越重要的角色。MongoDB作为一种流行的NoSQL数据库,以其灵活的数据模型和强大的扩展性受到众多开发者的青睐。PHP7作为当前最流行的服务器端脚本语言之一,其性能和稳定性也得…...

maven相关概念深入介绍
1. pom.xml文件 就像Make的MakeFile、Ant的build.xml一样,Maven项目的核心是pom.xml。POM(Project Object Model,项目对象模型)定义了项目的基本信息,用于描述项目如何构建,声明项目依赖,等等。…...

以科技之力,启智慧出行 —— 阅读《NVIDIA 自动驾驶安全报告》及观看实验室视频有感
作为中南民族大学通信工程专业的学生,近期研读《NVIDIA 自动驾驶安全报告》并观看其实验室系列视频后,我深刻感受到自动驾驶技术不仅是一场交通革命,更是一次社会生产力的解放与民族精神的升华。这场变革的浪潮中,我看到了科技如何…...

2P4M-ASEMI机器人功率器件专用2P4M
编辑:LL 2P4M-ASEMI机器人功率器件专用2P4M 型号:2P4M 品牌:ASEMI 封装:TO-126 批号:最新 引脚数量:3 封装尺寸:如图 特性:双向可控硅 工作结温:-40℃~150℃ 在…...
回归)
基础的贝叶斯神经网络(BNN)回归
下面是一个最基础的贝叶斯神经网络(BNN)回归示例,采用PyTorch实现,适合入门理解。 这个例子用BNN拟合 y x 噪声 的一维回归问题,输出均值和不确定性(方差)。 import torch import torch.nn a…...

小黑享受思考心流: 73. 矩阵置零
小黑代码 class Solution:def setZeroes(self, matrix: List[List[int]]) -> None:"""Do not return anything, modify matrix in-place instead."""items []m len(matrix)n len(matrix[0])for i in range(m):for j in range(n):if not m…...

整合 | 大模型时代:微调技术在医疗智能问答矩阵的实战应用20250427
🔎 整合 | 大模型时代:微调技术在医疗智能问答矩阵的实战应用 一、引言 在大模型技术高速变革的背景下,数据与微调技术不再是附属品,而是成为了AI能力深度重构的核心资产。 尤其在医疗行业中,微调技术改写了智能分诊和…...

Web安全:威胁解析与综合防护体系构建
Web安全:威胁解析与综合防护体系构建 Web安全是保护网站、应用程序及用户数据免受恶意攻击的核心领域。随着数字化转型加速,攻击手段日益复杂,防护需兼顾技术深度与系统性。以下从威胁分类、防护技术、最佳实践及未来趋势四个维度࿰…...

spring项目rabbitmq es项目启动命令
应该很多开发者遇到过需要启动中间件的情况,什么测试服务器挂了,服务连不上nacos了巴拉巴拉的,虽然是测试环境,但也会手忙脚乱,疯狂百度。 这里介绍一些实用方法 有各种不同的场景,一是重启,服…...

人工智能期末复习1
该笔记为2024.7出版的人工智能技术应用导论(第二版)课本部分的理论总结。 一、人工智能的产生与发展 概念:人工智能是通过计算机系统和模型模拟、延申和拓展人类智能的理论、方法、技术及应用系统的一门新的技术科学。 发展:19…...
)
深入理解指针(5)
字符指针变量 对下述代码进行调试 继续go,并且观察p2 弹出错误: 为什么报错呢? 因为常量字符串是不能被修改的,否则,编译器报错。 最后,打印一下: 《剑指offer》中收录了⼀道和字符串相关的笔试题&#…...
)
新魔百和CM311-5_CH/YST/ZG代工_GK6323V100C_2+8G蓝牙版_强刷卡刷固件包(可救砖)
新魔百和CM311-5_CH/YST/ZG代工_GK6323V100C_28G蓝牙版_强刷卡刷固件包(可救砖) 1、准备一个优盘卡刷强刷刷机,用一个usb2.0的8G以下U盘,fat32,2048块单分区格式化(强刷对ÿ…...

磁盘清理git gc
#!/bin/bash find / -type d -name “.git” 2>/dev/null | while read -r git_dir; do repo_dir ( d i r n a m e " (dirname " (dirname"git_dir") echo “Optimizing r e p o d i r " c d " repo_dir" cd " repodir"cd&…...

django admin AttributeError: ‘UserResorce‘ object has no attribute ‘ID‘
在 Django 中遇到 AttributeError: ‘UserResource’ object has no attribute ‘ID’ 这类错误通常是因为你在代码中尝试访问一个不存在的属性。在你的例子中,错误提示表明 UserResource 类中没有名为 ID 的属性。这可能是由以下几个原因造成的: 拼写错…...

现代Python打包工具链
现代Python打包工具如Poetry、Flit和Hatch提供了更简单、更强大的方式来管理项目依赖和打包流程。下面我将通过具体示例详细介绍这三种工具。 1. Poetry - 全功能依赖管理工具 Poetry是最流行的现代Python项目管理工具之一,它集依赖管理、虚拟环境管理和打包发布于一…...
 吴恩达版提示词工程 8. 聊天机器人 (聊天格式设计,上下文内容,点餐机器人))
(done) 吴恩达版提示词工程 8. 聊天机器人 (聊天格式设计,上下文内容,点餐机器人)
视频:https://www.bilibili.com/video/BV1Z14y1Z7LJ/?spm_id_from333.337.search-card.all.click&vd_source7a1a0bc74158c6993c7355c5490fc600 别人的笔记:https://zhuanlan.zhihu.com/p/626966526 8. 聊天机器人(Chatbot) …...

Maven概述
1.maven是什么? Maven 是一个基于项目对象模型(Project Object Model,POM)概念的项目构建工具,主要用于 Java 项目的构建、依赖管理和项目信息管理。(跨平台的项目管理工具,用于构建和管理任何…...

SKLearn - Biclustering
文章目录 Biclustering (双聚类)谱二分聚类算法演示生成样本数据拟合 SpectralBiclustering绘制结果 Spectral Co-Clustering 算法演示使用光谱协同聚类算法进行文档的二分聚类 Biclustering (双聚类) 关于双聚类技术的示例。 谱…...

使用c++实现一个简易的量子计算,并向外提供服务
实现一个简易的量子计算模拟器并提供服务是一个相对复杂的过程,涉及到量子计算的基本概念、C编程以及网络服务的搭建。以下是一个简化的步骤指南,帮助你开始这个项目: 步骤 1: 理解量子计算基础 在开始编码之前,你需要对量子计算…...