第2讲、Tensor高级操作与自动求导详解
1. 前言
在深度学习模型中,Tensor是最基本的运算单元。本文将深入探讨PyTorch中两个核心概念:
- Tensor的广播机制(Broadcasting)
- **自动求导(Autograd)**机制
这些知识点不仅让你更加灵活地操作数据,还为后续搭建神经网络打下坚实基础!
2. Tensor广播(Broadcasting)详解
2.1 什么是广播?
**广播(Broadcasting)**是一种在不同形状的Tensor之间进行数学运算的机制。当我们对两个形状不同的Tensor进行运算时,PyTorch会自动将较小的Tensor扩展到较大Tensor的形状,使它们能够进行元素级的运算。
广播机制的优势在于:
- 无需创建冗余的内存副本
- 代码更简洁高效
- 计算性能更好
2.2 广播规则总结
PyTorch中的广播规则遵循以下原则:
- 维度对齐:从最后一维开始对齐,向前比较
- 自动扩展:当一个Tensor的某维度为1时,它会被自动扩展以匹配另一个Tensor的对应维度
- 无法匹配时报错:如果两个Tensor的对应维度既不相等,也不存在为1的情况,则广播失败
2.3 广播常见案例
让我们通过代码示例来理解广播机制:
import torch# 示例1:小Tensor加大Tensor
a = torch.rand(3, 1) # 形状为[3,1]
b = torch.rand(1, 4) # 形状为[1,4]
c = a + b # 广播后结果是[3,4]
print(f"a shape: {a.shape}, b shape: {b.shape}, c shape: {c.shape}")# 示例2:行向量与列向量相加
row = torch.rand(1, 5) # 形状为[1,5]的行向量
col = torch.rand(4, 1) # 形状为[4,1]的列向量
out = row + col # 结果是[4,5]的矩阵
print(f"row shape: {row.shape}, col shape: {col.shape}, out shape: {out.shape}")# 示例3:标量与矩阵运算
matrix = torch.rand(2, 3)
scalar = torch.tensor(5.0)
result = matrix * scalar # 标量会广播到矩阵的每个元素
print(f"matrix shape: {matrix.shape}, result shape: {result.shape}")
让我们分析一下为什么能这样广播:
对于第一个示例:
a的形状是[3,1]b的形状是[1,4]- 最后一维:1和4不相等,但其中一个是1,所以
a在这一维被扩展为4 - 倒数第二维:3和1不相等,但其中一个是1,所以
b在这一维被扩展为3 - 最终两者都被广播为
[3,4]的形状,然后进行元素级加法
2.4 广播的使用场景
广播在深度学习中有很多实用场景:
- 批量数据处理:对一批数据应用相同的变换
- 添加偏置项:将一维的偏置向量添加到二维矩阵的每一行
- 归一化操作:使用均值和标准差对数据进行归一化
- 掩码操作:使用布尔掩码对数据进行过滤
# 批量归一化例子
batch_data = torch.rand(32, 10) # 32个样本,每个10个特征
batch_mean = batch_data.mean(dim=0, keepdim=True) # 形状[1,10]
batch_std = batch_data.std(dim=0, keepdim=True) # 形状[1,10]
normalized_data = (batch_data - batch_mean) / batch_std # 广播操作
3. PyTorch自动求导(Autograd)详解
3.1 什么是Autograd?
PyTorch的Autograd是一个自动微分系统,它能够自动计算神经网络中所有参数的梯度。这个功能是深度学习框架的核心,因为反向传播算法依赖于对每个参数计算梯度。
简单来说,Autograd可以:
- 自动构建计算图
- 执行反向传播(backward)
- 计算梯度
你只需专注于前向计算,梯度求导PyTorch帮你自动完成!
3.2 Tensor的requires_grad属性
在PyTorch中,每个Tensor都有一个requires_grad属性,它决定了这个Tensor是否需要计算梯度:
import torch# 默认情况下,requires_grad为False
x = torch.tensor([2.0])
print(f"默认requires_grad: {x.requires_grad}")# 创建需要梯度的Tensor
x = torch.tensor([2.0], requires_grad=True)
print(f"设置requires_grad=True: {x.requires_grad}")# 也可以后续修改
x = torch.tensor([2.0])
x.requires_grad_(True) # 注意有下划线
print(f"后续修改requires_grad: {x.requires_grad}")
当requires_grad=True时:
- Tensor会开始追踪所有与它相关的操作
- 执行backward()时,会自动计算梯度
- 梯度值存储在
.grad属性中
3.3 计算图与反向传播
当我们对设置了requires_grad=True的Tensor进行操作时,PyTorch会自动构建一个计算图:
import torch# 创建叶子节点
x = torch.tensor(2.0, requires_grad=True)
y = torch.tensor(3.0, requires_grad=True)# 构建计算图
z = x * y + torch.log(x)# 查看计算图
print(f"z.grad_fn: {z.grad_fn}")
print(f"z的创建者: {z.grad_fn.__class__.__name__}")
执行反向传播计算梯度:
import torch# 创建需要求导的Tensor
x = torch.tensor(2.0, requires_grad=True)# 定义函数: y = x² + 3x + 1
y = x**2 + 3*x + 1# 执行反向传播
y.backward()# 查看x的梯度
print(f"x的梯度: {x.grad}") # 输出应该是 dy/dx = 2x + 3,当x=2时,结果是7
3.4 梯度累积与清零
PyTorch中的梯度是累积的,这意味着多次调用.backward()会导致梯度累加,而不是覆盖:
import torchx = torch.tensor(2.0, requires_grad=True)# 第一次前向传播和反向传播
y = x**2
y.backward()
print(f"第一次反向传播后 x.grad: {x.grad}") # 输出: 4# 第二次前向传播和反向传播(梯度会累加)
y = x**2
y.backward()
print(f"第二次反向传播后 x.grad: {x.grad}") # 输出: 8 (4+4)# 清零梯度
x.grad.zero_()
print(f"清零后 x.grad: {x.grad}") # 输出: 0# 再次计算
y = x**2
y.backward()
print(f"清零后再计算 x.grad: {x.grad}") # 输出: 4
在训练神经网络时,每次更新参数前都需要清零梯度,否则会导致梯度累积:
optimizer.zero_grad() # 清零所有参数的梯度
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新参数
3.5 高阶梯度和链式法则
PyTorch支持高阶导数计算,这对于某些优化算法和研究很有用:
import torchx = torch.tensor(2.0, requires_grad=True)# 计算函数 y = x^3
y = x**3# 计算一阶导数 dy/dx = 3x^2
y.backward(create_graph=True) # 设置create_graph=True以计算高阶导数
print(f"一阶导数 dy/dx: {x.grad}") # 当x=2时,输出应该是12# 计算二阶导数 d²y/dx² = 6x
x.grad.backward()
print(f"二阶导数 d²y/dx²: {x.grad.grad}") # 当x=2时,输出应该是6
PyTorch自动处理链式法则,使得复杂函数的求导变得简单:
import torchx = torch.tensor(2.0, requires_grad=True)# 复合函数: y = sin(x²)
y = torch.sin(x**2)# 计算导数: dy/dx = cos(x²) * 2x
y.backward()
print(f"dy/dx: {x.grad}") # 当x=2时,输出应该接近 cos(4) * 4
4. 实战案例
4.1 使用广播实现批量归一化
import torch# 创建一批数据
batch_size = 100
features = 20
data = torch.randn(batch_size, features)# 计算每个特征的均值和标准差
mean = data.mean(dim=0, keepdim=True) # shape: [1, features]
std = data.std(dim=0, keepdim=True) # shape: [1, features]# 使用广播进行归一化
normalized_data = (data - mean) / stdprint(f"均值接近0: {normalized_data.mean(dim=0)}")
print(f"标准差接近1: {normalized_data.std(dim=0)}")
4.2 手写函数求导例子
让我们计算一个更复杂函数的导数:y = x² + 3x + 1
import torch# 创建一个需要求导的Tensor
x = torch.tensor(2.0, requires_grad=True)# 定义函数
y = x**2 + 3*x + 1# 执行反向传播
y.backward()# 查看x的梯度
print(f"x的梯度: {x.grad}") # 输出应该是 dy/dx = 2x + 3,当x=2时,结果是7# 理论结果验证
theoretical_grad = 2*x.item() + 3
print(f"理论计算的梯度: {theoretical_grad}")
4.3 使用自动求导训练简单线性回归
import torch
import torch.nn as nn
import matplotlib.pyplot as plt# 生成一些带有噪声的数据
x = torch.linspace(0, 10, 100)
y_true = 2*x + 1 + torch.randn(100) * 0.5# 准备数据
x = x.view(-1, 1)
y_true = y_true.view(-1, 1)# 定义模型
class LinearRegression(nn.Module):def __init__(self):super(LinearRegression, self).__init__()self.linear = nn.Linear(1, 1) # 输入和输出维度都是1def forward(self, x):return self.linear(x)# 初始化模型、损失函数和优化器
model = LinearRegression()
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)# 训练模型
epochs = 100
losses = []for epoch in range(epochs):# 前向传播y_pred = model(x)# 计算损失loss = criterion(y_pred, y_true)losses.append(loss.item())# 反向传播optimizer.zero_grad()loss.backward()# 更新参数optimizer.step()if (epoch+1) % 10 == 0:print(f'Epoch {epoch+1}/{epochs}, Loss: {loss.item():.4f}')# 获取参数
w, b = model.linear.weight.item(), model.linear.bias.item()
print(f'学习到的参数: y = {w:.4f}x + {b:.4f}')# 可视化结果
plt.figure(figsize=(10, 6))
plt.scatter(x.numpy(), y_true.numpy(), label='原始数据')
plt.plot(x.numpy(), model(x).detach().numpy(), 'r-', linewidth=2, label=f'拟合线: y = {w:.2f}x + {b:.2f}')
plt.legend()
plt.title('线性回归结果')
plt.show()# 可视化损失下降
plt.figure(figsize=(10, 6))
plt.plot(losses)
plt.title('训练损失')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.show()
4.4 记录中间梯度进行可视化
import torch
import numpy as np
import matplotlib.pyplot as plt# 创建函数 f(x) = x^3 - 3x^2 + 2
def f(x):return x**3 - 3*x**2 + 2# 创建导数函数 f'(x) = 3x^2 - 6x
def df(x):return 3*x**2 - 6*x# 准备数据点进行可视化
x_plot = np.linspace(-1, 3, 100)
y_plot = f(torch.tensor(x_plot)).numpy()
dy_plot = df(torch.tensor(x_plot)).numpy()# 选择几个点计算梯度
x_points = torch.tensor([-0.5, 0.5, 1.0, 2.0], requires_grad=True, dtype=torch.float)
y_points = f(x_points)# 计算每个点的梯度
gradients = []
for i in range(len(x_points)):if i > 0: # 清除之前的梯度x_points.grad.zero_()# 只对一个点的输出调用backwardy = f(x_points[i:i+1])y.backward()# 存储梯度gradients.append(x_points.grad[i].item())# 可视化函数和导数
plt.figure(figsize=(12, 8))# 绘制函数
plt.subplot(2, 1, 1)
plt.plot(x_plot, y_plot, 'b-', label='f(x) = x^3 - 3x^2 + 2')
plt.scatter(x_points.detach().numpy(), f(x_points).detach().numpy(), color='red', s=50, label='选中的点')# 绘制切线
for i, x_val in enumerate(x_points):x_v = x_val.item()y_v = f(torch.tensor(x_v)).item()slope = gradients[i]# 绘制切线 (使用点斜式方程)x_tangent = np.array([x_v - 0.5, x_v + 0.5])y_tangent = slope * (x_tangent - x_v) + y_vplt.plot(x_tangent, y_tangent, 'g--')plt.grid(True)
plt.legend()
plt.title('函数及其在选定点的切线')# 绘制导数
plt.subplot(2, 1, 2)
plt.plot(x_plot, dy_plot, 'r-', label='f\'(x) = 3x^2 - 6x')
plt.scatter(x_points.detach().numpy(), np.array(gradients), color='blue', s=50, label='计算的梯度')
plt.grid(True)
plt.legend()
plt.title('导数函数及通过autograd计算的梯度')plt.tight_layout()
plt.show()
5. 注意事项和最佳实践
5.1 自动求导注意事项
-
只有标量(单个数)才能直接执行backward()
# 如果输出是向量,需要提供gradient参数 vector_output = torch.tensor([1.0, 2.0, 3.0], requires_grad=True) vector_output.backward(torch.ones_like(vector_output)) -
.grad属性是累计的
# 每次使用backward()前清零梯度 optimizer.zero_grad() # 或者 x.grad.zero_() -
中断梯度流
# 使用detach()中断梯度流 x = torch.tensor([2.0], requires_grad=True) y = x * 2 z = y.detach() # z不会追踪与x的关系 z = z * 3 z.backward() # 这不会影响x.grad -
with torch.no_grad()上下文
x = torch.tensor([2.0], requires_grad=True) with torch.no_grad():# 在这个上下文中的操作不会被追踪y = x * 2
5.2 广播机制最佳实践
-
在使用广播前了解张量形状
print(f"Tensor shapes: {a.shape}, {b.shape}") -
避免创建不必要的大型中间张量
# 避免这样 a = torch.rand(10000, 1) b = a.expand(10000, 10000) # 创建大矩阵# 更好的方式是直接利用广播 a = torch.rand(10000, 1) c = a + 1 # 广播,不创建中间张量 -
利用unsqueeze和view管理维度
# 添加维度以便广播 a = torch.rand(5) b = torch.rand(3) c = a.unsqueeze(0) + b.unsqueeze(1) # 结果形状为[3, 5]
6. 可视化案例代码
tensor_visualizer.py
import streamlit as st
import torch
import numpy as np
import matplotlib.pyplot as plt
import plotly.graph_objects as go
import plotly.express as px
import matplotlib.font_manager as fm
import matplotlib# 指定中文字体路径(macOS)
font_path = "/System/Library/Fonts/PingFang.ttc" # macOS 中文字体
my_font = fm.FontProperties(fname=font_path)# 设置 matplotlib 默认字体
matplotlib.rcParams['font.family'] = my_font.get_name()
matplotlib.rcParams['axes.unicode_minus'] = False# 设置页面标题
st.title("🚀 PyTorch Tensor可视化工具")
st.caption("作者:何双新 | 环境:Mac M1 + PyTorch")
# st.set_page_config(page_title="PyTorch Tensor可视化", layout="wide")# 侧边栏选项
st.sidebar.header("Tensor设置")
tensor_dim = st.sidebar.radio("选择Tensor维度", [0, 1, 2, 3, 4], index=2)# 根据维度提供不同选项
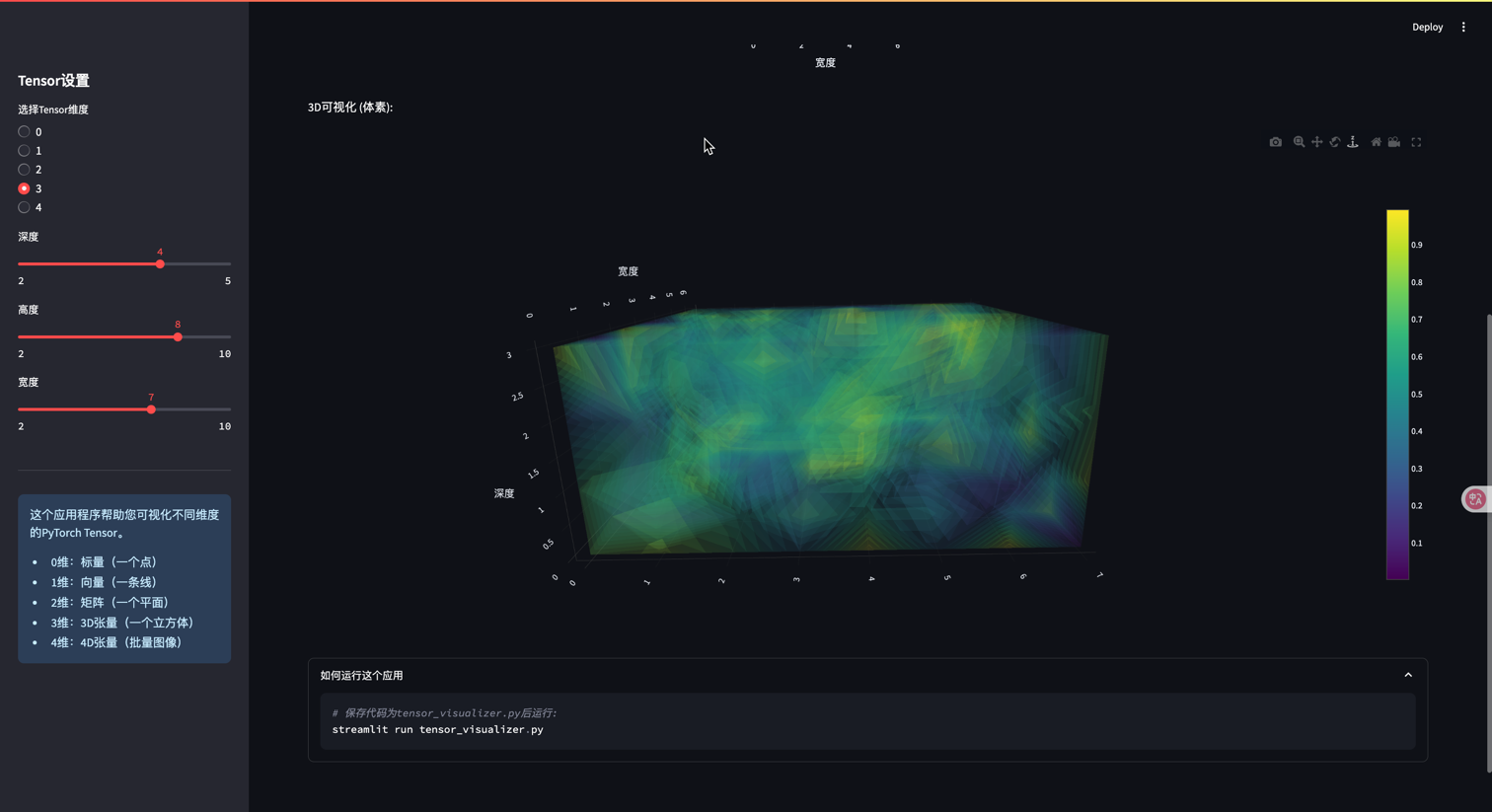
if tensor_dim == 0: # 标量scalar_value = st.sidebar.slider("标量值", -10.0, 10.0, 5.0, 0.1)st.header("0维Tensor (标量)")tensor = torch.tensor(scalar_value)st.code(f"tensor = torch.tensor({scalar_value})")st.write(f"值: {tensor.item()}")st.write(f"形状: {tensor.shape}")# 可视化st.write("可视化: 一个点")fig, ax = plt.subplots(figsize=(3, 3))ax.scatter([0], [0], s=100, c=[scalar_value], cmap='viridis')ax.set_xlim(-1, 1)ax.set_ylim(-1, 1)ax.set_xticks([])ax.set_yticks([])st.pyplot(fig)elif tensor_dim == 1: # 向量vector_size = st.sidebar.slider("向量大小", 2, 20, 10)vector_type = st.sidebar.selectbox("向量类型", ["随机", "线性", "正弦波"])st.header("1维Tensor (向量)")if vector_type == "随机":tensor = torch.rand(vector_size)elif vector_type == "线性":tensor = torch.linspace(0, 10, vector_size)else: # 正弦波tensor = torch.sin(torch.linspace(0, 6.28, vector_size))st.code(f"tensor.shape = {tensor.shape}")st.write("Tensor值:")st.write(tensor)# 可视化st.write("可视化:")fig, ax = plt.subplots(figsize=(10, 4))ax.plot(tensor.numpy(), marker='o')ax.set_title("1维Tensor可视化")ax.set_xlabel("索引")ax.set_ylabel("值")ax.grid(True)st.pyplot(fig)elif tensor_dim == 2: # 矩阵rows = st.sidebar.slider("行数", 2, 10, 5)cols = st.sidebar.slider("列数", 2, 10, 5)tensor_type = st.sidebar.selectbox("矩阵类型", ["随机", "单位矩阵", "对角矩阵"])st.header("2维Tensor (矩阵)")if tensor_type == "随机":tensor = torch.rand(rows, cols)elif tensor_type == "单位矩阵":tensor = torch.eye(max(rows, cols))[:rows, :cols]else: # 对角矩阵tensor = torch.diag(torch.linspace(1, min(rows, cols), min(rows, cols)))if rows > cols:tensor = torch.cat([tensor, torch.zeros(rows - cols, cols)], dim=0)elif cols > rows:tensor = torch.cat([tensor, torch.zeros(rows, cols - rows)], dim=1)st.code(f"tensor.shape = {tensor.shape}")st.write("Tensor值:")st.write(tensor)# 可视化为热力图st.write("可视化:")fig = px.imshow(tensor.numpy(), labels=dict(x="列", y="行", color="值"),color_continuous_scale='viridis')fig.update_layout(width=600, height=500)st.plotly_chart(fig)elif tensor_dim == 3: # 3D Tensordepth = st.sidebar.slider("深度", 2, 5, 3)height = st.sidebar.slider("高度", 2, 10, 5)width = st.sidebar.slider("宽度", 2, 10, 5)st.header("3维Tensor")tensor = torch.rand(depth, height, width)st.code(f"tensor.shape = {tensor.shape}")# 展示每个深度层st.write("每个深度的切片可视化:")tabs = st.tabs([f"切片 {i}" for i in range(depth)])for i, tab in enumerate(tabs):with tab:fig = px.imshow(tensor[i].numpy(),labels=dict(x="宽度", y="高度", color="值"),color_continuous_scale='viridis')fig.update_layout(width=500, height=400)st.plotly_chart(fig)# 3D可视化st.write("3D可视化 (体素):")# 创建网格X, Y, Z = np.mgrid[0:depth, 0:height, 0:width]values = tensor.numpy().flatten()fig = go.Figure(data=go.Volume(x=X.flatten(),y=Y.flatten(),z=Z.flatten(),value=values,opacity=0.1,surface_count=15,colorscale='viridis'))fig.update_layout(scene=dict(xaxis_title='深度', yaxis_title='高度', zaxis_title='宽度'),width=700, height=700)st.plotly_chart(fig)elif tensor_dim == 4: # 4D Tensorbatch = st.sidebar.slider("批量大小", 1, 5, 2)channels = st.sidebar.slider("通道数", 1, 3, 3)height = st.sidebar.slider("高度", 4, 12, 8)width = st.sidebar.slider("宽度", 4, 12, 8)st.header("4维Tensor (批量图像)")tensor = torch.rand(batch, channels, height, width)st.code(f"tensor.shape = {tensor.shape}")st.write(f"这个Tensor可以表示{batch}张{channels}通道的{height}x{width}图像")# 可视化每个批次的图像batch_tabs = st.tabs([f"批次 {i}" for i in range(batch)])for b, batch_tab in enumerate(batch_tabs):with batch_tab:if channels == 3:# 针对RGB图像的特殊处理img = tensor[b].permute(1, 2, 0).numpy() # 转换为HWC格式st.image(img, caption=f"批次 {b} 的RGB图像", use_column_width=True)else:# 展示每个通道channel_tabs = st.tabs([f"通道 {i}" for i in range(channels)])for c, channel_tab in enumerate(channel_tabs):with channel_tab:fig = px.imshow(tensor[b, c].numpy(),color_continuous_scale='viridis')fig.update_layout(width=400, height=400)st.plotly_chart(fig)# 添加信息部分
st.sidebar.markdown("---")
st.sidebar.info("""
这个应用程序帮助您可视化不同维度的PyTorch Tensor。
- 0维:标量(一个点)
- 1维:向量(一条线)
- 2维:矩阵(一个平面)
- 3维:3D张量(一个立方体)
- 4维:4D张量(批量图像)
""")# 添加代码说明
with st.expander("如何运行这个应用"):st.code("""
# 保存代码为tensor_visualizer.py后运行:
streamlit run tensor_visualizer.py""")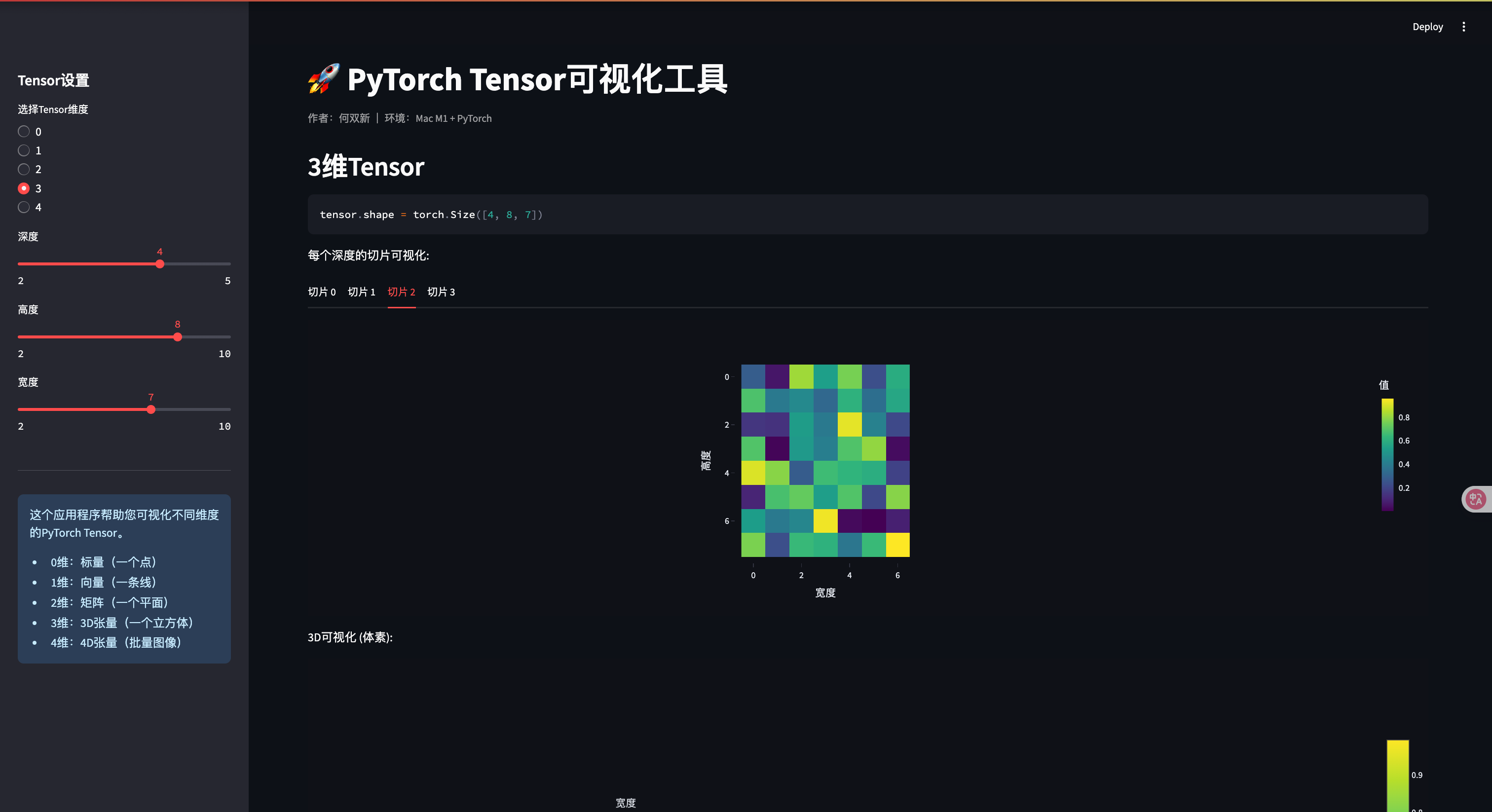
7. 总结
在本篇博客中,我们深入探讨了PyTorch中的两个核心概念:
- Tensor广播机制 - 使不同形状的张量能够进行运算,避免不必要的内存复制,提高代码效率
- 自动求导机制 - 自动构建计算图并执行反向传播,计算各参数的梯度,是深度学习优化的基础
8. 参考资料
- PyTorch官方文档 - 广播语义
- PyTorch官方文档 - Autograd机制
- Deep Learning with PyTorch by Eli Stevens, Luca Antiga, and Thomas Viehmann
相关文章:

第2讲、Tensor高级操作与自动求导详解
1. 前言 在深度学习模型中,Tensor是最基本的运算单元。本文将深入探讨PyTorch中两个核心概念: Tensor的广播机制(Broadcasting)**自动求导(Autograd)**机制 这些知识点不仅让你更加灵活地操作数据&#…...
表的操作)
(MySQL)表的操作
目录 表的创建 语法 创建表的案例 查看表的结构 修改表的操作 修改表名 编辑 添加一个字段(列) 修改一个字段的类型 修改字段名 删除字段名(删除列) 删除指定的表 表的插入数据 数据库的备份和恢复 我们来学习表的操作 表的创建 语法 CREATE TABLE [if not ex…...

函数的使用
函数绑定 fn.call(obj, param1, param2) fn.apply(obj, [param1, param2]) fn.bind(obj, param1, param2)()相同点: 都是借用别人(fn)的方法,替换其中的this(第一个参数)call和apply的不同点:a…...
)
LLM应用于自动驾驶方向相关论文整理(大模型在自动驾驶方向的相关研究)
1、《HILM-D: Towards High-Resolution Understanding in Multimodal Large Language Models for Autonomous Driving》 2023年9月发表的大模型做自动驾驶的论文,来自香港科技大学和人华为诺亚实验室(代码开源)。 论文简介: 本文…...

Spring MVC深度解析:从原理到实战
文章目录 一、Spring MVC概述1.1 MVC设计模式1.2 Spring MVC特点 二、Spring MVC核心组件2.1 架构流程图解2.2 核心组件说明 三、环境搭建与配置3.1 Maven依赖3.2 传统XML配置 vs JavaConfig 四、控制器开发实践4.1 基础控制器示例4.2 请求映射注解 五、数据处理与绑定5.1 表单…...

Spark学习全总结
基础概念: Spark 是一个快速、通用的大数据处理引擎,支持多种计算模式,如批处理、流处理、交互式查询和机器学习等。 特点: 速度快:基于内存计算,能将数据缓存在内存中,避免频繁读写磁盘,大幅…...

pytorch写张量pt文件,libtorch读张量pt文件
直接在pytorch中,用torch.save保存的张量,可能因格式差异无法在C中加载。 以下是一个最简单的例子,展示如何在 Pytorch中保存张量到 TorchScript 模块,并在 C 中使用 LibTorch 加载。 Python 代码 (save_tensor.py) import torc…...

关于Android Studio的Gradle各项配置2
好的!你提到的这些文件是 Gradle 构建系统 和 Android 项目 中非常重要的一部分,它们各自有不同的作用,涉及项目的构建配置、Gradle 环境、系统配置等方面。接下来我会为你详细解释每个文件的作用,并提供具体的例子和注释。 1. gr…...

Android Studio中创建第一个Flutter项目
一、Flutter环境验证 创建Flutter项目之前需要验证是否有Flutter环境,如没有Flutter 环境,请参考配置Flutter开发环境 1.1、flutter doctor 验证通过会有以下提示 [√] Flutter (Channel stable, 3.29.3, on Microsoft Windows [版本 10.0.19045.573…...
)
Linux的例行性工作(crontab)
crontab服务 at 命令是在指定的时间只能执行一次任务, crontab 命令可以循环重复的执行定时任务,与 Windows 中的计划任务有些类似 crond 是 Linux 下用来周期地执行某种任务或等待处理某些事件的一个守护进程,在安装完成操 作系统后,默认会安装 crond …...

03 基于 STM32 的温度控制系统
前言 Protues、KeilC 设计内容:使用STM32设计一个空调温度的显示控制系统 设计要求: 1.温度显示范围为16-30摄氏度 2.按键K1实现显示温度加1,按键K2实现显示温度减1,低于16或高于30,显示数值不变 3.正常按键蜂鸣器响一…...
)
23种设计模式-行为型模式之备忘录模式(Java版本)
Java 备忘录模式(Memento Pattern)详解 🧠 什么是备忘录模式? 备忘录模式是一种行为型设计模式,它允许在不暴露对象实现细节的情况下,保存和恢复对象的状态。备忘录模式常常用于需要记录对象状态以便随时…...
:selenium自动化测试常用函数(上))
[三分钟]web自动化测试(二):selenium自动化测试常用函数(上)
文章目录 1.元素定位1.1 cssSelector(选择器)1.2 xpath1.3小示例 2.操作测试对象2.1点击/提交对象-click()2.2 模拟按键输入-sendKeys("")2.3 清除文本内容-clear()2.4 获取文本信息-getText()2.5 获取当前页面标题-getTitle()2.6获取当前页面URL-getCurrentUrl() 3.…...

基于ruoyi-plus实现AI聊天和绘画
项目介绍 基于ruoyi-plus实现AI聊天和绘画功能,打造自己的AI平台。前后端分离,有管理后台,用户端,小程序端。支持对接openai,讯飞星火,通义灵码,deepseek等大语言模型。项目架构 管理后台-前端&…...

假设检验学习总结
目录 一、假设检验1. 两种错误2. z检验和t检验3. t检验3.1 单样本t检验3.2 配对样本t检验3.3 独立样本t检验4 方差齐性检验备注卡方检验样本容量的计算AB测试主要的两种应用场景绝对量的计算公式率的计算公式说明一、假设检验 1. 两种错误 第一类错误 原假设为真,却拒绝了原假…...

C++ 基于多设计模式下的同步异步⽇志系统-2项目实现
⽇志系统框架设计 1.⽇志等级模块:对输出⽇志的等级进⾏划分,以便于控制⽇志的输出,并提供等级枚举转字符串功能。 ◦ OFF:关闭 ◦ DEBUG:调试,调试时的关键信息输出。 ◦ INFO:提⽰,普通的提⽰…...
)
Tauri窗口与界面管理:打造专业桌面应用体验 (入门系列五)
窗口管理是桌面应用的核心特性之一,良好的窗口管理可以显著提升用户体验。在Web开发中,我们通常被限制在浏览器窗口内,但Tauri允许前端开发者控制应用窗口的方方面面,从而创造出更加原生的体验。 窗口配置基础 初始窗口配置 在…...
和 channel(管道) 案例解析)
golang goroutine(协程)和 channel(管道) 案例解析
文章目录 goroutine和channel概念开启线程与channel简单通信流程多个工作协程并发执行流程 goroutine和channel概念 goroutine(协程),一般我们常见的是进程,线程,进程可以理解为一个软件在运行执行的过程,线程跟协程比较类似&…...
)
底层源码和具体测试解析HotSpot JVM的notify唤醒有序性(5000字详解)
在大家的认知里,或者大家也可能搜过,notify唤醒机制到底是随机的呢?还是顺序的呢?在网上其实也有很多人说notify的唤醒机制就是随机的,但实际上并不是这样的,notify的唤醒机制是先进先出的! 目…...
)
Jenkins(CI/CD工具)
1. 什么是 Jenkins? Jenkins 是一个开源的持续集成(CI)和持续交付/部署(CD)工具,用于自动化软件构建、测试和部署过程。 2. Jenkins 优势 (1)开源免费:社区活跃&#…...

Apache Sqoop数据采集问题
Sqoop数据采集格式问题 一、Sqoop工作原理二、Sqoop命令格式三、Oracle数据采集格式问题四、Sqoop增量采集方案 Apache Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql…)间进行数据的传递,可以将一个关系型数据库&…...
)
再学GPIO(二)
GPIO寄存器 每个GPI/O端口有两个32位配置寄存器(GPIOx_CRL,GPIOx_CRH),两个32位数据寄存器(GPIOx_IDR和GPIOx_ODR),一个32位置位/复位寄存器(GPIOx_BSRR),一个16位复位寄存器(GPIOx_BRR)和一个32位锁定寄存器(GPIOx_LCKR)。 GPIO…...

err: Error: Request failed with status code 400
好的,今天学习ai的时候从前端发送请求,实在是想不通为啥会啥是一个坏请求,后来从前端方法一个一个找参数,传递的值都有,然后想到我这边需要传递的是一个对象,那么后端使用的RequestParam就接收不到json对象…...

解决qnn htp 后端不支持boolean 数据类型的方法。
一、背景 1.1 问题原因 Qnn 模型在使用fp16的模型转换不支持类型是boolean的cast 算子,因为 htp 后端支持量化数据类型或者fp16,不支持boolean 类型。 ${QNN_SDK_ROOT_27}/bin/x86_64-linux-clang/qnn-model-lib-generator -c ./bge_small_fp16.cpp -b …...
:Pod亲和性详解)
k8s学习记录(五):Pod亲和性详解
一、前言 上一篇文章初步探讨了 Kubernetes 的节点亲和性,了解到它在 Pod 调度上比传统方式更灵活高效。今天我们继续讨论亲和性同时Kubernetes 的调度机制。 二、Pod亲和性 上一篇文章中我们介绍了节点亲和性,今天我们讲解一下Pod亲和性。首先我们先看…...

MongoDB与PHP7的集成与优化
MongoDB与PHP7的集成与优化 引言 随着互联网技术的飞速发展,数据库技术在现代软件开发中扮演着越来越重要的角色。MongoDB作为一种流行的NoSQL数据库,以其灵活的数据模型和强大的扩展性受到众多开发者的青睐。PHP7作为当前最流行的服务器端脚本语言之一,其性能和稳定性也得…...

maven相关概念深入介绍
1. pom.xml文件 就像Make的MakeFile、Ant的build.xml一样,Maven项目的核心是pom.xml。POM(Project Object Model,项目对象模型)定义了项目的基本信息,用于描述项目如何构建,声明项目依赖,等等。…...

以科技之力,启智慧出行 —— 阅读《NVIDIA 自动驾驶安全报告》及观看实验室视频有感
作为中南民族大学通信工程专业的学生,近期研读《NVIDIA 自动驾驶安全报告》并观看其实验室系列视频后,我深刻感受到自动驾驶技术不仅是一场交通革命,更是一次社会生产力的解放与民族精神的升华。这场变革的浪潮中,我看到了科技如何…...

2P4M-ASEMI机器人功率器件专用2P4M
编辑:LL 2P4M-ASEMI机器人功率器件专用2P4M 型号:2P4M 品牌:ASEMI 封装:TO-126 批号:最新 引脚数量:3 封装尺寸:如图 特性:双向可控硅 工作结温:-40℃~150℃ 在…...
回归)
基础的贝叶斯神经网络(BNN)回归
下面是一个最基础的贝叶斯神经网络(BNN)回归示例,采用PyTorch实现,适合入门理解。 这个例子用BNN拟合 y x 噪声 的一维回归问题,输出均值和不确定性(方差)。 import torch import torch.nn a…...

小黑享受思考心流: 73. 矩阵置零
小黑代码 class Solution:def setZeroes(self, matrix: List[List[int]]) -> None:"""Do not return anything, modify matrix in-place instead."""items []m len(matrix)n len(matrix[0])for i in range(m):for j in range(n):if not m…...

整合 | 大模型时代:微调技术在医疗智能问答矩阵的实战应用20250427
🔎 整合 | 大模型时代:微调技术在医疗智能问答矩阵的实战应用 一、引言 在大模型技术高速变革的背景下,数据与微调技术不再是附属品,而是成为了AI能力深度重构的核心资产。 尤其在医疗行业中,微调技术改写了智能分诊和…...

Web安全:威胁解析与综合防护体系构建
Web安全:威胁解析与综合防护体系构建 Web安全是保护网站、应用程序及用户数据免受恶意攻击的核心领域。随着数字化转型加速,攻击手段日益复杂,防护需兼顾技术深度与系统性。以下从威胁分类、防护技术、最佳实践及未来趋势四个维度࿰…...

spring项目rabbitmq es项目启动命令
应该很多开发者遇到过需要启动中间件的情况,什么测试服务器挂了,服务连不上nacos了巴拉巴拉的,虽然是测试环境,但也会手忙脚乱,疯狂百度。 这里介绍一些实用方法 有各种不同的场景,一是重启,服…...

人工智能期末复习1
该笔记为2024.7出版的人工智能技术应用导论(第二版)课本部分的理论总结。 一、人工智能的产生与发展 概念:人工智能是通过计算机系统和模型模拟、延申和拓展人类智能的理论、方法、技术及应用系统的一门新的技术科学。 发展:19…...
)
深入理解指针(5)
字符指针变量 对下述代码进行调试 继续go,并且观察p2 弹出错误: 为什么报错呢? 因为常量字符串是不能被修改的,否则,编译器报错。 最后,打印一下: 《剑指offer》中收录了⼀道和字符串相关的笔试题&#…...
)
新魔百和CM311-5_CH/YST/ZG代工_GK6323V100C_2+8G蓝牙版_强刷卡刷固件包(可救砖)
新魔百和CM311-5_CH/YST/ZG代工_GK6323V100C_28G蓝牙版_强刷卡刷固件包(可救砖) 1、准备一个优盘卡刷强刷刷机,用一个usb2.0的8G以下U盘,fat32,2048块单分区格式化(强刷对ÿ…...

磁盘清理git gc
#!/bin/bash find / -type d -name “.git” 2>/dev/null | while read -r git_dir; do repo_dir ( d i r n a m e " (dirname " (dirname"git_dir") echo “Optimizing r e p o d i r " c d " repo_dir" cd " repodir"cd&…...

django admin AttributeError: ‘UserResorce‘ object has no attribute ‘ID‘
在 Django 中遇到 AttributeError: ‘UserResource’ object has no attribute ‘ID’ 这类错误通常是因为你在代码中尝试访问一个不存在的属性。在你的例子中,错误提示表明 UserResource 类中没有名为 ID 的属性。这可能是由以下几个原因造成的: 拼写错…...

现代Python打包工具链
现代Python打包工具如Poetry、Flit和Hatch提供了更简单、更强大的方式来管理项目依赖和打包流程。下面我将通过具体示例详细介绍这三种工具。 1. Poetry - 全功能依赖管理工具 Poetry是最流行的现代Python项目管理工具之一,它集依赖管理、虚拟环境管理和打包发布于一…...
 吴恩达版提示词工程 8. 聊天机器人 (聊天格式设计,上下文内容,点餐机器人))
(done) 吴恩达版提示词工程 8. 聊天机器人 (聊天格式设计,上下文内容,点餐机器人)
视频:https://www.bilibili.com/video/BV1Z14y1Z7LJ/?spm_id_from333.337.search-card.all.click&vd_source7a1a0bc74158c6993c7355c5490fc600 别人的笔记:https://zhuanlan.zhihu.com/p/626966526 8. 聊天机器人(Chatbot) …...

Maven概述
1.maven是什么? Maven 是一个基于项目对象模型(Project Object Model,POM)概念的项目构建工具,主要用于 Java 项目的构建、依赖管理和项目信息管理。(跨平台的项目管理工具,用于构建和管理任何…...

SKLearn - Biclustering
文章目录 Biclustering (双聚类)谱二分聚类算法演示生成样本数据拟合 SpectralBiclustering绘制结果 Spectral Co-Clustering 算法演示使用光谱协同聚类算法进行文档的二分聚类 Biclustering (双聚类) 关于双聚类技术的示例。 谱…...

使用c++实现一个简易的量子计算,并向外提供服务
实现一个简易的量子计算模拟器并提供服务是一个相对复杂的过程,涉及到量子计算的基本概念、C编程以及网络服务的搭建。以下是一个简化的步骤指南,帮助你开始这个项目: 步骤 1: 理解量子计算基础 在开始编码之前,你需要对量子计算…...

京东攻防岗位春招面试题
围绕电商场景,以下是5道具有代表性的技术面试题及其解析,覆盖供应链、电商大促、红蓝对抗等场景。 《网安面试指南》https://mp.weixin.qq.com/s/RIVYDmxI9g_TgGrpbdDKtA?token1860256701&langzh_CN 5000篇网安资料库https://mp.weixin.qq.com/s?…...

Kafka批量消费部分处理成功时的手动提交方案
Kafka批量消费部分处理成功时的手动提交方案 当使用Kafka批量消费时,如果500条消息中只有部分处理成功,需要谨慎处理偏移量提交以避免消息丢失或重复消费。以下是几种处理方案示例: 方案1:记录成功消息并提交最后成功偏移量 Co…...

消息中间件
零、文章目录 消息中间件 1、中间件 (1)概述 中间件(Middleware)是位于操作系统、网络与数据库之上,应用软件之下的一层独立软件或服务程序,其核心作用是连接不同系统、屏蔽底层差异,并为应…...

vue3直接操作微信小程序云开发数据库,web网页对云数据库进行增删改查
我们开发好小程序以后,有时候需要编写一个管理后台网页对数据库进行管理,之前我们只能借助云开发自带的cms网页,但是cms网页设计的比较丑,工作量和代码量也不够,所以我们今天就来带大家实现用vue3编写管理后台直接管理…...

重塑编程体验边界:明基RD280U显示器深度体验
重塑编程体验边界:明基RD280U显示器深度体验 写在前面 本文将以明基RD280U为核心,通过技术解析、实战体验与创新案例,揭示专业显示器如何重构开发者的数字工作台。 前言:当像素成为生产力的催化剂 在GitHub的年度开发者调查中&…...

Linux命令-iostat
iostat 命令介绍 iostat 是一个用于监控 Linux 系统输入/输出设备加载情况的工具。它可以显示 CPU 的使用情况以及设备和分区的输入/输出统计信息,对于诊断系统性能瓶颈(如磁盘或网络活动缓慢)特别有用。 语法: iostat [options…...