C++ 基于多设计模式下的同步异步⽇志系统-2项目实现
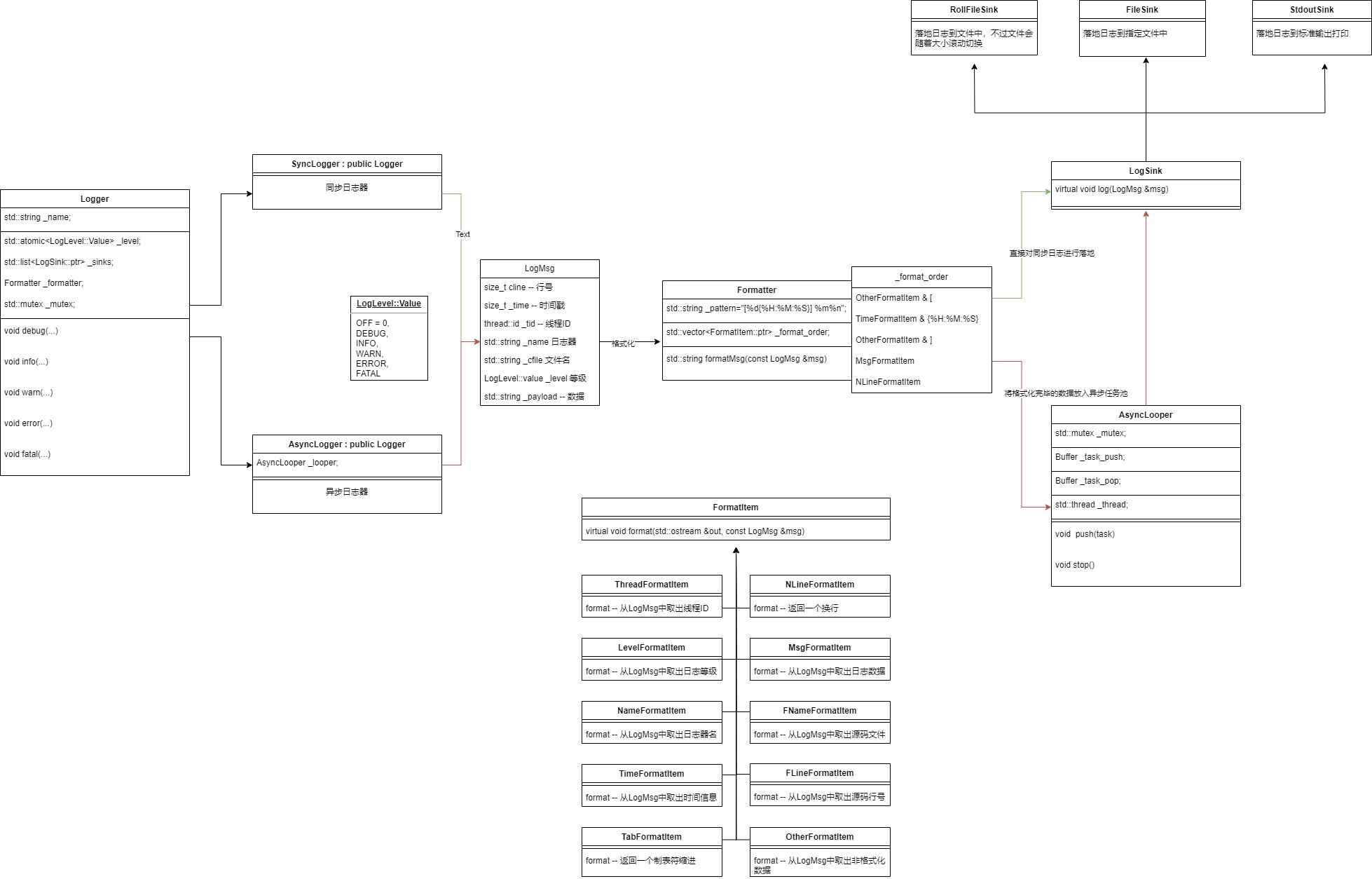
⽇志系统框架设计
1.⽇志等级模块:对输出⽇志的等级进⾏划分,以便于控制⽇志的输出,并提供等级枚举转字符串功能。
◦ OFF:关闭
◦ DEBUG:调试,调试时的关键信息输出。
◦ INFO:提⽰,普通的提⽰型⽇志信息。
◦ WARN:警告,不影响运⾏,但是需要注意⼀下的⽇志。
◦ ERROR:错误,程序运⾏出现错误的⽇志
◦ FATAL:致命,⼀般是代码异常导致程序⽆法继续推进运⾏的⽇志
2.⽇志消息模块:中间存储⽇志输出所需的各项要素信息
◦ 时间:描述本条⽇志的输出时间。
◦ 线程ID:描述本条⽇志是哪个线程输出的。
◦ ⽇志等级:描述本条⽇志的等级。
◦ ⽇志数据:本条⽇志的有效载荷数据。
◦ ⽇志⽂件名:描述本条⽇志在哪个源码⽂件中输出的。
◦ ⽇志⾏号:描述本条⽇志在源码⽂件的哪⼀⾏输出的。
3.⽇志消息格式化模块:设置⽇志输出格式,并提供对⽇志消息进⾏格式化功能。
◦ 系统的默认⽇志输出格式:%d{%H:%M:%S}%T[%t]%T[%p]%T[%c]%T%f:%l%T%m%n
◦ -> 13:26:32 [2343223321] [FATAL] [root] main.c:76 套接字创建失败\n
◦ %d{%H:%M:%S}:表⽰⽇期时间,花括号中的内容表⽰⽇期时间的格式。
◦ %T:表⽰制表符缩进。
◦ %t:表⽰线程ID
◦ %p:表⽰⽇志级别
◦ %c:表⽰⽇志器名称,不同的开发组可以创建⾃⼰的⽇志器进⾏⽇志输出,⼩组之间互不影响。
◦ %f:表⽰⽇志输出时的源代码⽂件名。
◦ %l:表⽰⽇志输出时的源代码⾏号。
◦ %m:表⽰给与的⽇志有效载荷数据
◦ %n:表⽰换⾏
◦ 设计思想:设计不同的⼦类,不同的⼦类从⽇志消息中取出不同的数据进⾏处理。
4.⽇志消息落地模块:决定了⽇志的落地⽅向,可以是标准输出,也可以是⽇志⽂件,
也可以滚动⽂件输出....
◦ 标准输出:表⽰将⽇志进⾏标准输出的打印。
◦ ⽇志⽂件输出:表⽰将⽇志写⼊指定的⽂件末尾。
◦ 滚动⽂件输出:当前以⽂件⼤⼩进⾏控制,当⼀个⽇志⽂件⼤⼩达到指定⼤⼩,则切换下⼀个⽂件进⾏输出
◦ 后期,也可以扩展远程⽇志输出,创建客⼾端,将⽇志消息发送给远程的⽇志分析服务器。
◦ 设计思想:设计不同的⼦类,不同的⼦类控制不同的⽇志落地⽅向。
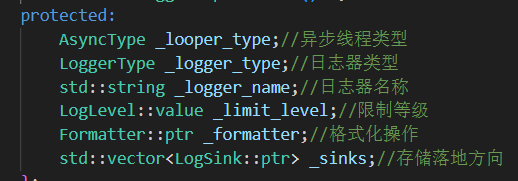
5.⽇志器模块:
◦ 此模块是对以上⼏个模块的整合模块,⽤⼾通过⽇志器进⾏⽇志的输出,有效降低⽤⼾的使⽤难度。
◦ 包含有:⽇志消息落地模块对象,⽇志消息格式化模块对象,⽇志输出等级
6.⽇志器管理模块:
◦ 为了降低项⽬开发的⽇志耦合,不同的项⽬组可以有⾃⼰的⽇志器来控制输出格式以及落地⽅向,因此本项⽬是⼀个多⽇志器的⽇志系统。
◦ 管理模块就是对创建的所有⽇志器进⾏统⼀管理。并提供⼀个默认⽇志器提供标准输出的⽇志输出。
7.异步线程模块:
◦ 实现对⽇志的异步输出功能,⽤⼾只需要将输出⽇志任务放⼊任务池,异步线程负责⽇志的落地输出功能,以此提供更加⾼效的⾮阻塞⽇志输出。
一.实用类设计
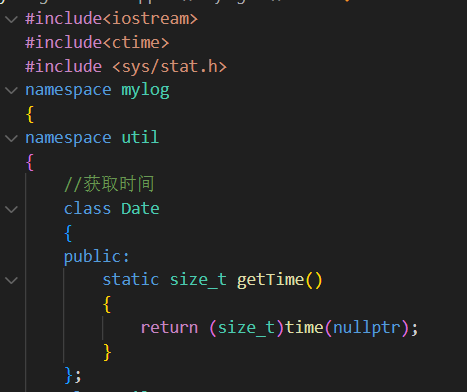
logs/util.hpp
Date类
static size_t getTime()获取当前时间(静态函数)
File类
1.判断文件是否存在
struct stat st;
stat是一个结构体(定义在<sys/stat.h>头文件中)它会被用来存储目标文件或目录的各种信息
比如文件大小、权限、类型(是否是目录)、最后访问时间等
int stat(const char *pathname, struct stat *statbuf)是一个系统调用函数获取路径 pathname 所指文件的信息,并存储在 st 变量中
返回值 含义 0成功,说明文件/目录存在并可访问 ✅ 非 0失败,说明文件/目录不存在或无权限访问 ❌ 2.提取文件路径
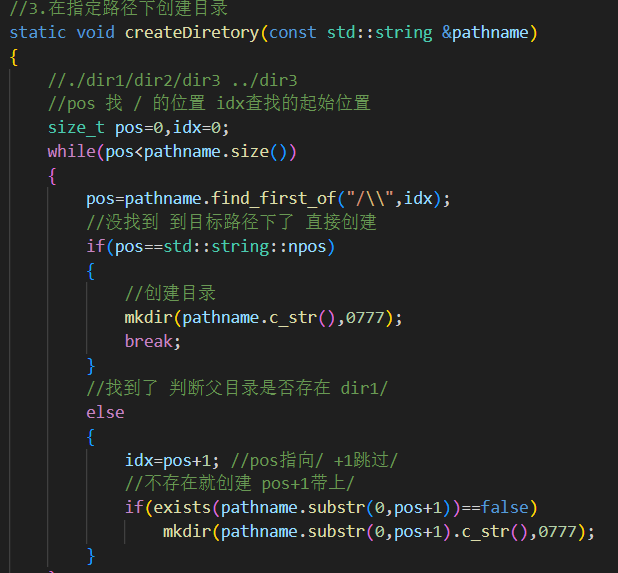
3.递归创建多级目录
找路径分割符,没找到说明已经到最底层的目录了,直接创建目标目录。
找到了判断是否存在该目录,没有就该目录创建。


#include<iostream>
#include<ctime>
#include <sys/stat.h>
namespace mylog
{
namespace util
{//获取时间class Date{public:static size_t getTime(){return (size_t)time(nullptr);}};class File{public://1.判断文件是否存在static bool exists(const std::string &pathname){struct stat st;//stat(...) 的返回值为:== 0:说明文件存在 != 0:说明文件不存在或无权限访问return stat(pathname.c_str(),&st)==0;}//2.获取这个文件所处的路径static std::string path(const std::string &pathname){//./dir1/dir2/a.txtsize_t pos=pathname.find_last_of("/\\");//查找"/" "\"(windows下路径分割符)if(pos==std::string::npos) return ".";return pathname.substr(0,pos+1);}//3.在指定路径下创建目录static void createDiretory(const std::string &pathname){//./dir1/dir2/dir3 ../dir3//pos 找 / 的位置 idx查找的起始位置size_t pos=0,idx=0;while(pos<pathname.size()){pos=pathname.find_first_of("/\\",idx);//没找到 到目标路径下了 直接创建if(pos==std::string::npos){//创建目录mkdir(pathname.c_str(),0777);break;}//找到了 判断父目录是否存在 dir1/else{idx=pos+1; //pos指向/ +1跳过///不存在就创建 pos+1带上/if(exists(pathname.substr(0,pos+1))==false)mkdir(pathname.substr(0,pos+1).c_str(),0777);}}}};
}
}二.日志等级类
logs/level.hpp
对输出⽇志的等级进⾏划分,以便于控制⽇志的输出,并提供等级枚举转字符串功能。
#pragma once
namespace mylog
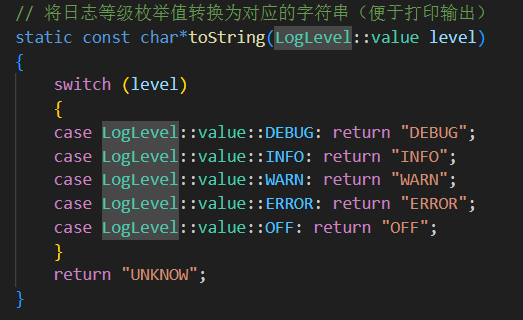
{class LogLevel{public:// 日志等级类,用于表示不同级别的日志输出控制enum class value{UNKNOW = 0, // 未知等级DEBUG, // 调试信息INFO, // 正常运行的信息WARN, // 警告ERROR, // 错误OFF // 关闭日志输出};// 将日志等级枚举值转换为对应的字符串(便于打印输出)static const char*toString(LogLevel::value level){switch (level){case LogLevel::value::DEBUG: return "DEBUG";case LogLevel::value::INFO: return "INFO";case LogLevel::value::WARN: return "WARN";case LogLevel::value::ERROR: return "ERROR";case LogLevel::value::OFF: return "OFF";}return "UNKNOW";}};}三.日志消息类
message.hpp
在什么时间,那个组的日志器 哪个线程 哪个文件 具体在哪一行,什么等级的日志内容
字段名 类型 含义说明 _ctimesize_t日志创建的时间戳(秒),用于记录日志生成的时刻 _levelLogLevel::value日志级别,例如 DEBUG/INFO/WARN/ERROR/OFF,用于日志过滤_linesize_t日志语句所在的代码行号(一般宏传入 __LINE__)_tidstd::thread::id当前线程的 ID,支持多线程日志追踪 _filestd::string源文件名(一般传入 __FILE__),帮助定位日志位置_loggerstd::string日志器名称(如 "root"、"async_logger"),区分多个 logger _payloadstd::string实际日志内容(要输出的文字)
#include<iostream>
#include<thread>
#include<string>
#include"level.hpp"
#include"util.hpp"namespace mylog
{struct LogMesg{size_t _ctime;//日志产生的时间戳LogLevel::value _level;//日志等级size_t _line;//行号std::thread::id _tid;//线程idstd::string _file;//文件名std::string _logger;//日志器名std::string _payload;//有效消息数据LogMesg(LogLevel::value level,size_t line,std::string file,std::string logger,std::string msg): _ctime(util::Date::getTime()),_level(level),_line(line),_tid(std::this_thread::get_id()),_file(file),_logger(logger),_payload(msg){}};}四.⽇志输出格式化类
format.hpp
按照用户给的格式/默认格式,把LogMsg里面的信息格式化放到对应的流中。
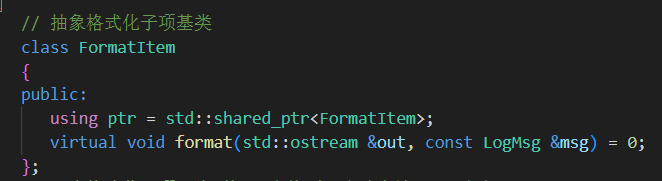
1. FormatItem(抽象基类)
抽象接口,定义日志格式子项的统一接口。
子类会重写
format(),输出指定字段内容。
2. 各种子类(继承自 FormatItem)
不同子类重写format函数,从LogMsg中取出对应的字段的内容输出到对应的out流中。
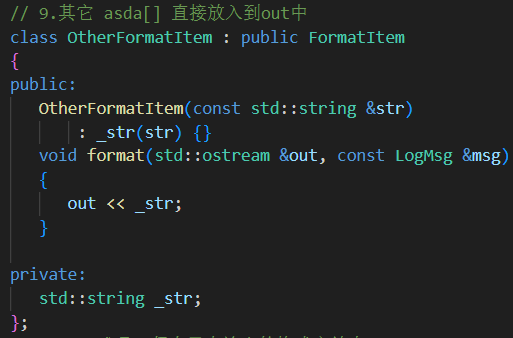
类名 输出内容 LogMsg来源字段格式 MsgFormatItem日志正文内容 _payload%mLevelFormatItem日志等级 _level(转为字符串)%pTimeFormatItem时间戳,支持自定义格式 _ctime%d{fmt}FileFormatItem源文件名 _file%fLineFormatItem行号 _line%lThreadFormatItem线程ID _tid%tLoggerFormatItem日志器名称 _logger%cTabFormatItem制表符 \t无 %TNLineFormatItem换行符 \n无 %nOtherFormatItem原始字符串 构造传入 _str非 %开头字符
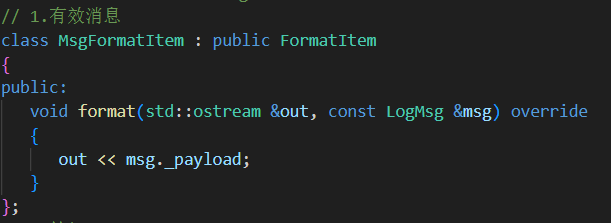
1.消息正文字段
取出消息字段直接输出到out流中
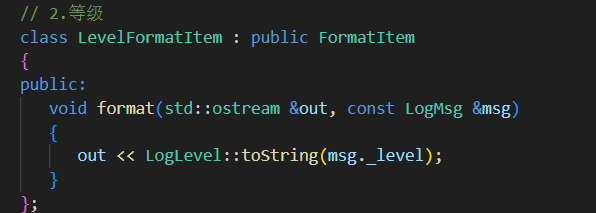
2.等级 调用LogLevel类中的静态函数 把枚举类value类型转换为char*
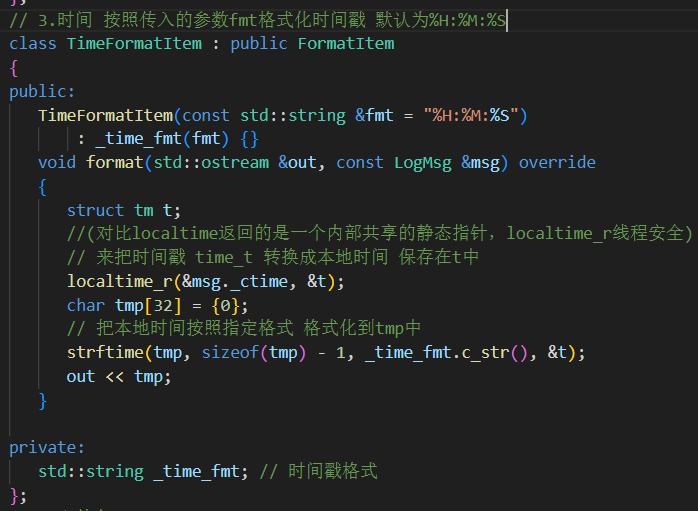
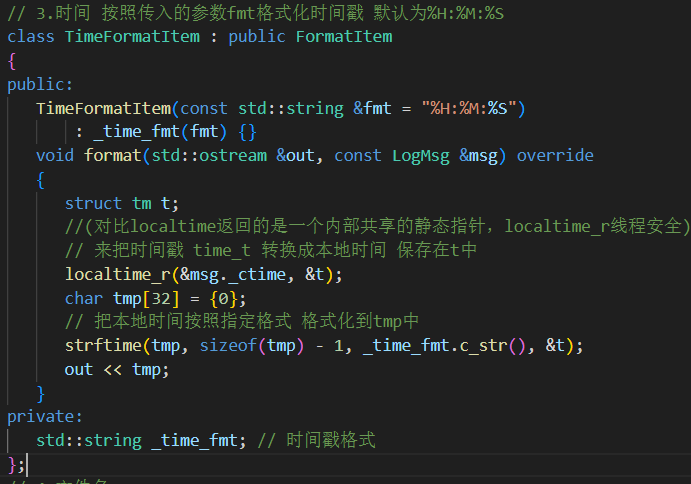
3.时间 可以传入字符串fmt初始化该子类,表示需要打印的时间格式。
localtime():非线程安全
time_t raw = time(nullptr); struct tm* t = localtime(&raw);
它返回的是一个 指向静态内存区域的指针。
这块静态内存通常是函数内部的一个全局变量或
static变量,在整个进程中只有一份共享的副本。每次调用
localtime(),这个内部的struct tm都会被重写。localtime_r():线程安全
time_t raw = time(nullptr); struct tm t; localtime_r(&raw, &t);传入用户自己定义的
struct tm变量,不会发生数据覆盖问题。
其它子类...
// 派生格式化子项子类 从msg中找到对应消息放入out流中// 1.有效消息class MsgFormatItem : public FormatItem{public:void format(std::ostream &out, const LogMsg &msg) override{out << msg._payload;}};// 2.等级class LevelFormatItem : public FormatItem{public:void format(std::ostream &out, const LogMsg &msg){out << LogLevel::toString(msg._level);}};// 3.时间 按照传入的参数fmt格式化时间戳 默认为%H:%M:%Sclass TimeFormatItem : public FormatItem{public:TimeFormatItem(const std::string &fmt = "%H:%M:%S"): _time_fmt(fmt) {}void format(std::ostream &out, const LogMsg &msg) override{struct tm t;//(对比localtime返回的是一个内部共享的静态指针,localtime_r线程安全)// 来把时间戳 time_t 转换成本地时间 保存在t中localtime_r(&msg._ctime, &t);char tmp[32] = {0};// 把本地时间按照指定格式 格式化到tmp中strftime(tmp, sizeof(tmp) - 1, _time_fmt.c_str(), &t);out << tmp;}private:std::string _time_fmt; // 时间戳格式};// 4.文件名class FileFormatItem : public FormatItem{public:void format(std::ostream &out, const LogMsg &msg){out << msg._file;}};// 5.行号class LineFormatItem : public FormatItem{public:void format(std::ostream &out, const LogMsg &msg){out << msg._line;}};// 5.线程idclass ThreadFormatItem : public FormatItem{public:void format(std::ostream &out, const LogMsg &msg){out << msg._tid;}};// 6.日志器名class LoggerFormatItem : public FormatItem{public:void format(std::ostream &out, const LogMsg &msg){out << msg._logger;}};// 7.Tabclass TabFormatItem : public FormatItem{public:void format(std::ostream &out, const LogMsg &msg){out << "\t";}};// 8.换行class NLineFormatItem : public FormatItem{public:void format(std::ostream &out, const LogMsg &msg){out << "\n";}};// 9.其它 asda[] 直接放入到out中class OtherFormatItem : public FormatItem{public:OtherFormatItem(const std::string &str): _str(str) {}void format(std::ostream &out, const LogMsg &msg){out << _str;}private:std::string _str;};3. Formatter 类(格式化核心)
这个类完成的功能就是,根据用户指定的格式,格式化消息输出到指定的流中。
比如说用户传入的格式是"dasd{}[%%[%d{%H:%M:%S}[%t][%c][%f:%l][%p]%T%m%n]"
先对格式化字符串的字符进行分类:
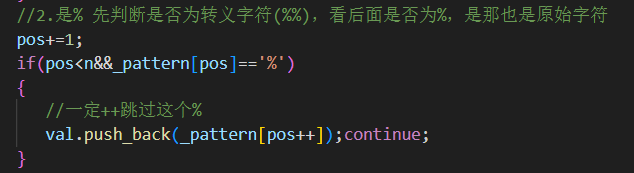
1.dasd{}[ 属于原始字符2.%% 表示转义% 属于原始字符
3.%d d属于格式化字符
4.格式化字符后面的{%H:%M:%S} 属于格式化字符的子格式(“{}”也属于)
1.原始字符 就保持不动 (为了统一处理 原始字符串也是调用FormatItem子类输出到流中)
2.格式化字符 就调用对应的FormatItem子类从LogMsg中取出对应的字段输出到流中。
字段的输出顺序就是用户传入的格式从左向右的顺序,我们可以用一个vecotr<FormatItem::ptr>按顺序保存需要调用的子类,再遍历vecotr数组完成格式化。
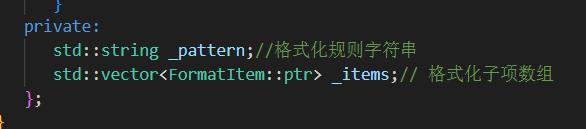
1.构造函数
用户传入 格式化规则字符串 初始化_pattern
并完成字符串解析 assert()强断言
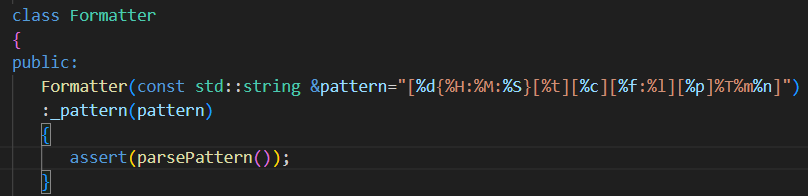
2.createrItem()根据不同的格式化字符 创建不同的子类对象
key格式化字符 val其子格式({ }以及里面的字符串) 或者key=="" val代表原始字符[ ]adc
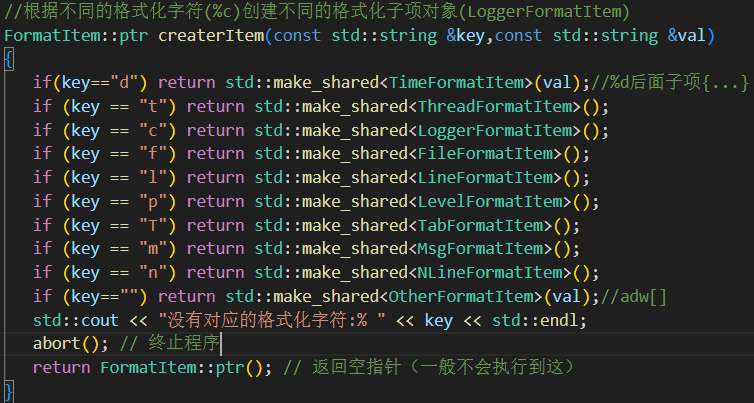
3.bool parsePattern() 对格式化字符串进行解析,将需要调用的子类保存到vector数组中
流程:
输入字符串: [%d{%H:%M:%S}][%p]%T%m%nHello【第一阶段】解析成:("", "[")("d", "%H:%M:%S")("", "][")("p", "")("T", "")("m", "")("n", "")("", "Hello")【第二阶段】根据 key 构建对应的 FormatItem 子类
fmt_order: 暂存格式化字符(key)与其子格式(val)的列表
key: 当前格式化符号(如d)
val: 当前格式化符的子格式(如%H:%M:%S),或原始非格式化文本
pos: 当前扫描位置1.非 % 字符 → 原始字符原样收集 ("", "[") key=="" val+=[
2.%% → 视为转义的 %当作原始字符原样收集 ("", "%")
3.%x → %后面是格式化字符
1.如果val中保存有原始字符 就先放入数组vector中,并clear()为后面保存格式化字符的子格式(如
%H:%M:%S)作准备。2.给key赋值 保存当前的转义字符是什么
原始字符后面对应的子类
4.判断格式化字符是否有 {} 子格式 eg.%d{%H:%M:%S} → key = d,val = {%H:%M:%S}
如果找到最后都没找到与之匹配的 } 说明子规则{}匹配错误 返回false
注意此时{ }也被保存到了val中,但这并不影响后面格式的输出,后面调用对应子类,fmt=val,向流中输出时也会带上{ }。所以前面说格式化字符后面的“{}”也属于子格式,不当作原始字符处理。
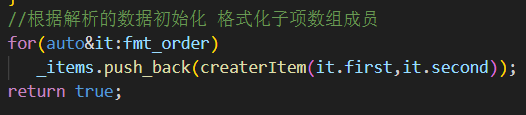
5.保存解析结果 解析完一组 %x{子格式} 或 %x 后,放入 fmt_order
6.字符串解析完 生成格式化项对象
每组 key/val 通过
createrItem()构建出具体的FormatItem派生类实例,如:
%d{}→TimeFormatItem
%p→LevelFormatItem
%m→MsgFormatItem
"["→OtherFormatItem



示例分析:[%d{%H:%M:%S}][%p]%T%m%nHello
Step1:fmt_order 内容
[("", "["),("d", "%H:%M:%S"),("", "]["),("p", ""),("T", ""),("m", ""),("n", ""),("", "Hello") ]Step2:生成 _items 内容
[OtherFormatItem("["),TimeFormatItem("%H:%M:%S"),OtherFormatItem("]["),LevelFormatItem(),TabFormatItem(),MsgFormatItem(),NLineFormatItem(),OtherFormatItem("Hello") ]
4.format()
逐个遍历 _items(每个 item 是 FormatItem 的子类,如 TimeFormatItem、MsgFormatItem 等),每个 item 都负责从 LogMsg 提取对应的信息并写入 out。
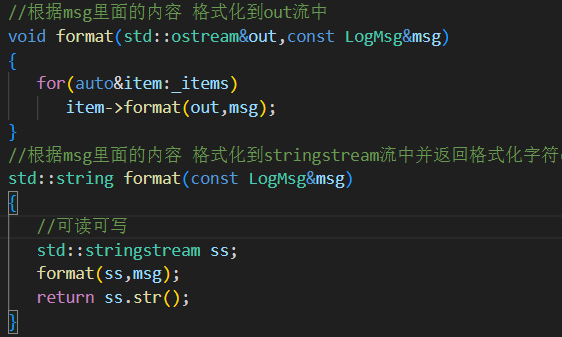
五.⽇志落地(LogSink)类设计(简单⼯⼚模式)
sink.hpp
把日志“落地”(写入)的位置抽象出来,使得用户可以灵活指定日志写到哪里(控制台?文件?滚动文件?)。同时使用简单工厂模式简化使用方式,提升灵活性与扩展性。
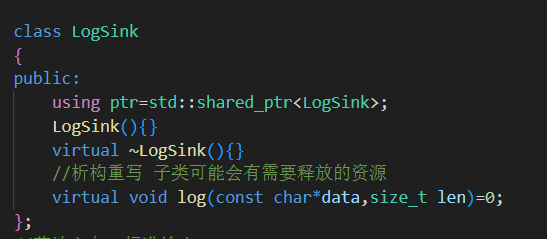
1.LogSink 抽象类设计
定义日志落地的统一接口:只需要实现
log()方法即可。所有具体的日志落地方式都继承自它,符合面向接口编程原则。
使用
shared_ptr管理对象生命周期,便于在异步或多线程中使用。
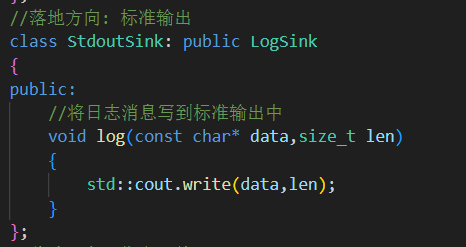
2.三种落地方式的实现
1. 控制台输出:StdoutSink
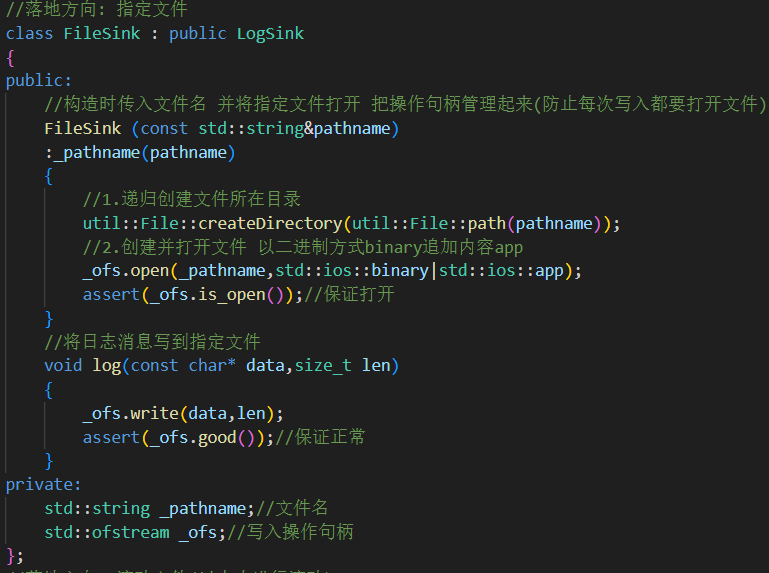
2. 固定文件输出:FileSink
1.初始化传入目录路径+文件名
createDirectory(path()) path()取出目录路径再进行递归创建 createDirectory确保目录路径存在。open()再在对应路径下创建指定文件名(如果不存在)并打开。
3. 按大小滚动输出:RollBySizeSink
文件过大自动滚动,新建文件。
使用时间戳 + 自增后缀保证文件名不重复。
怎么判断需新建文件?
用_cur_fsize记录当前文件的大小,如果超过限制的最大文件大小就新建,注意更新_cur_fsize=0,以及关闭原文件写。
怎么确保新建的文件名不重复?
文件名=base文件名+时间戳(精确到秒)+自增数(新建一个文件++)
这样即使一秒创建两个文件,也不用担心会重复。
//落地方向: 滚动文件(以大小进行滚动)class RollBySizeSink: public LogSink{public:RollBySizeSink(const std::string &basename,const size_t max_size): _basename(basename),_max_fsize(max_size),_cur_fsize(0),_name_count(0){//获取文件所处的路径+文件名std::string pathname=createNewFile();// 1.递归创建文件所在目录util::File::createDirectory(util::File::path(pathname));// 2.创建并打开文件_ofs.open(pathname, std::ios::binary | std::ios::app);assert(_ofs.is_open()); // 保证打开}//将日志消息写到滚动文件中void log(const char* data,size_t len){//超出大小 新建文件if(_cur_fsize>=_max_fsize){//一定要先关闭原文件 防止资源泄漏_ofs.close();_cur_fsize=0;_ofs.open(createNewFile(),std::ios::binary|std::ios::app);assert(_ofs.is_open()); }_ofs.write(data,len);assert(_ofs.good());_cur_fsize+=len;}private://获取新文件名std::string createNewFile(){//获取以时间生成的文件名time_t t=util::Date::now();struct tm lt;localtime_r(&t,<);std::stringstream ss;ss<<_basename;ss<<lt.tm_year+1900;ss<<lt.tm_mon+1 ;ss<<lt.tm_mday;ss<<lt.tm_hour;ss<<lt.tm_min;ss<<lt.tm_sec;ss<<'-';ss<<_name_count++;ss<<".log";return ss.str();}private://文件名=基础文件名+扩展文件名(以时间生成) std::string _basename;//./logs/base-20250421203801 准确到秒size_t _name_count;//防止一秒内生成的文件名重复std::ofstream _ofs;size_t _max_fsize;//文件最大大小size_t _cur_fsize;//当前文件大小 };4. 按时间滚动输出:RollByTimeSink
枚举类
TimeGap表示间隔(秒、分、小时、天)。日志会按时间粒度自动切分,比如每分钟一个文件。
比大小滚动更适合做按时归档(日志分析、ELK 系统对接等)。
怎么判断需要新建文件?
我们是根据时间段进行划分文件的,比如说我们以 1 分钟进行划分,时间段的大小就是60秒,time(NULL)/60 算出来当前时间戳属于第几个时间段。初始化时先保存当前时间戳属于第几个时间段,每次写入时再判断时间段是不是变化了?变化了就,新建并更新当前保存的时间段。
定义一个枚举类来表示 一个时间段的大小
//时间间隔 枚举类enum class TimeGap{GAP_SECOND=1,GAP_MINUTE=60,GAP_HOUR=3600,GAP_DAY=3600*24};//落地方向: 滚动文件(以时间为间隔进行滚动)class RollByTimeSink: public LogSink{public:RollByTimeSink(const std::string &basename,const TimeGap gap_type): _basename(basename),_gap_type((size_t)gap_type){//获取文件所处的路径+文件名std::string pathname=createNewFile();// 1.递归创建文件所在目录util::File::createDirectory(util::File::path(pathname));_cur_gap=(time(NULL)/_gap_type);//获取当前是第几个时间段// 2.创建并打开文件_ofs.open(pathname, std::ios::binary | std::ios::app);assert(_ofs.is_open()); // 保证打开}//将日志消息写到滚动文件中void log(const char* data,size_t len){//出现新的时间段size_t new_gap=((time(NULL)/_gap_type));if(_cur_gap!=new_gap){//一定要先关闭原文件 防止资源泄漏_ofs.close();_cur_gap=new_gap;//更新当前时间段_ofs.open(createNewFile(),std::ios::binary|std::ios::app);assert(_ofs.is_open()); }_ofs.write(data,len);assert(_ofs.good());}private://获取新文件名std::string createNewFile(){//获取以时间生成的文件名time_t t=util::Date::now();struct tm lt;localtime_r(&t,<);std::stringstream ss;ss<<_basename;ss<<lt.tm_year+1900;ss<<lt.tm_mon+1 ;ss<<lt.tm_mday;ss<<lt.tm_hour;ss<<lt.tm_min;ss<<lt.tm_sec;ss<<".log";return ss.str();}private:std::string _basename;std::ofstream _ofs;size_t _gap_type;//时间段大小size_t _cur_gap;//当前是第几个时间段};3.简单工厂类 SinkFactory
利用函数模板和完美转发创建任意
LogSink子类对象。解耦日志使用者与具体实现,符合开放封闭原则。
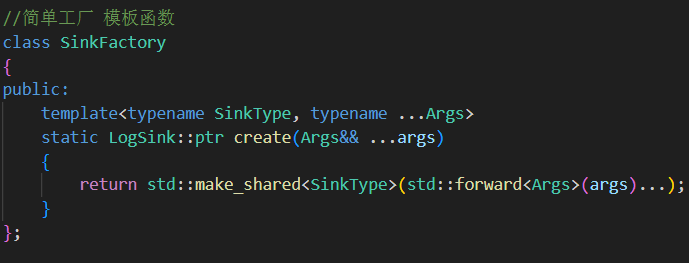
类中定义一个静态的模板函数,不要写成模板类,因为可变参数是给create函数的,不是给类的。
六.⽇志器类(Logger)设计(建造者模式)
logger.hpp
⽇志器主要是⽤来和前端交互, 当我们需要使⽤⽇志系统打印log的时候, 只需要创建Logger对象,调⽤该对象debug、info、warn、error、fatal等⽅法输出⾃⼰想打印的⽇志即可,⽀持解析可变参数列表和输出格式, 即可以做到像使⽤printf函数⼀样打印⽇志。
当前⽇志系统⽀持同步⽇志 & 异步⽇志两种模式,两个不同的⽇志器唯⼀不同的地⽅在于他们在⽇志的落地⽅式上有所不同:
同步⽇志器:直接对⽇志消息进⾏输出。
异步⽇志器:将⽇志消息放⼊缓冲区,由异步线程进⾏输出。
因此⽇志器类在设计的时候先设计出⼀个Logger基类,在Logger基类的基础上,继承出SyncLogger同步⽇志器和AsyncLogger异步⽇志器。
且因为⽇志器模块是对前边多个模块的整合,想要创建⼀个⽇志器,需要设置⽇志器名称,设置⽇志输出等级,设置⽇志器类型,设置⽇志输出格式,设置落地⽅向,且落地⽅向有可能存在多个,整个⽇志器的创建过程较为复杂,为了保持良好的代码⻛格,编写出优雅的代码,因此⽇志器的创建这⾥采⽤了建造者模式来进⾏创建。
1.Logger类
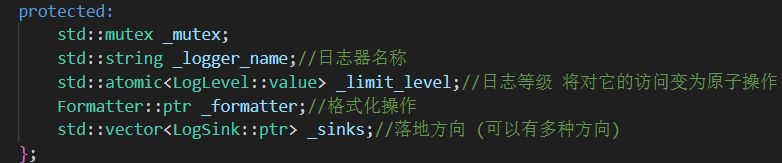
Logger 类主要负责记录日志消息并将其输出到指定的目标(如文件、控制台)。其构造函数接收日志名称、日志级别、格式化器以及落地方向(LogSink):
每次我们调用Logger里面函数进行日志输出时,要判断当前传入的日志是否>=限制的日志等级,只有>=才能进行日志输出。
因此我们保证对日志等级_limit_level的访问操作必须是原子性的,不能在访问的过程中被其它线程进行修改。
怎么保证对该变量的操作是原子性的?
std::atomic可以应用于不同的基本类型,如整数、指针、布尔值等。它的作用是提供一种方式来保证对这些类型的访问是 线程安全的,不需要显式的互斥锁。
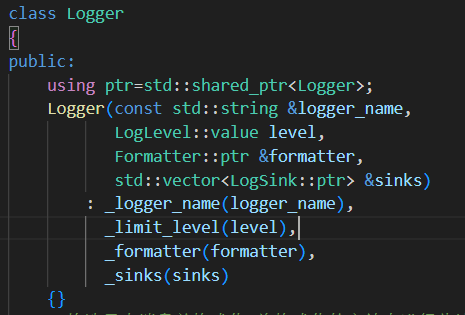
1.构造函数
2.日志记录方法
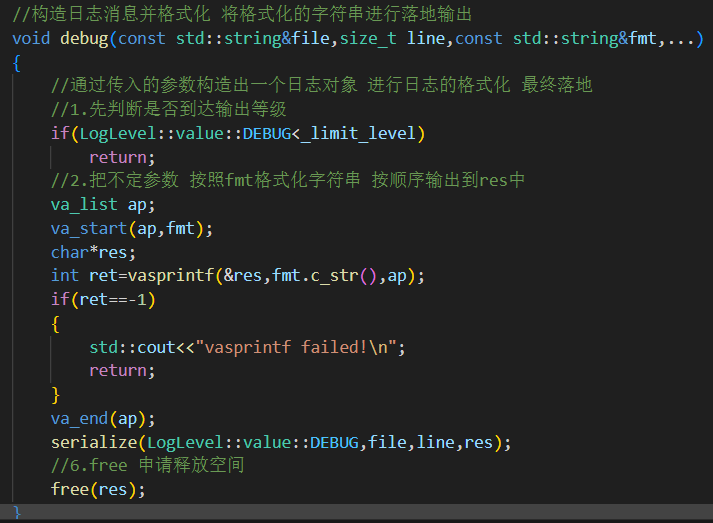
Logger类中定义了多个日志记录方法:debug、info、warn、error、fatal,它们接收文件名、行号、格式化字符串和可变参数。所有这些方法都遵循相似的逻辑:
检查日志级别:首先判断当前日志级别是否符合输出条件,如果不符合则直接返回,不进行日志记录。
格式化日志消息:使用
vasprintf将可变参数格式化成日志消息字符串。调用
serialize方法:serialize方法将格式化后的日志消息封装成LogMsg对象,然后通过指定的格式化器对消息进行格式化,并最终输出到日志目标。eg.debug等级日志输出
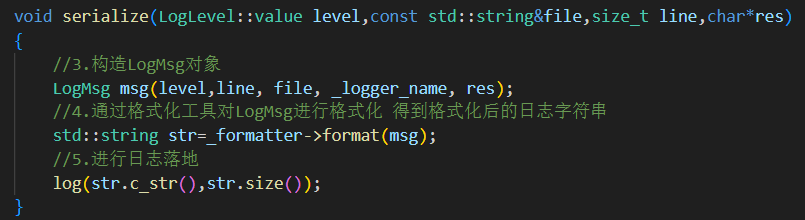
3.具体向哪里输出 log() 由继承的子类日志器(同步 异步)完成

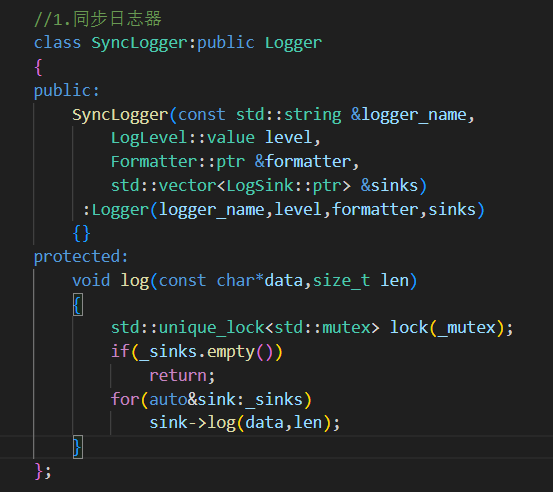
1.SyncLogger 同步日志器类
根据传入的参数初始化Logger日志器
1.先保证落地方向存在
2.遍历落地方向 一个一个打印日志进行输出
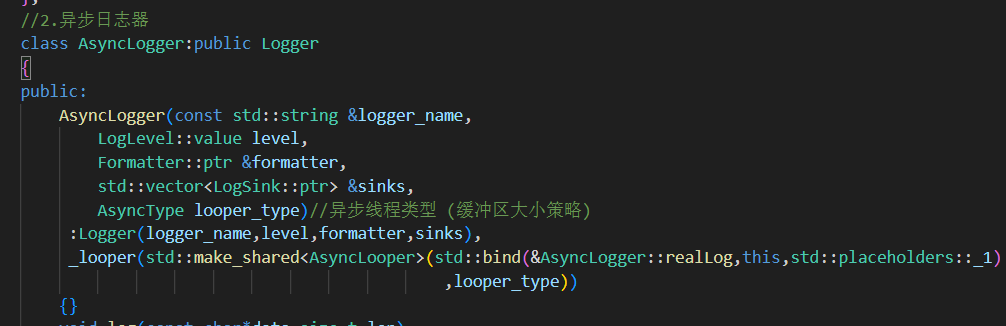
2.AsyncLogger异步日志器类
继承 Logger,重写了 log() 方法,实现了异步写入。
1.构造
创建了异步线程对象
_looper,传入一个回调realLog();当异步线程从缓冲区中取出日志后,会自动调用
realLog(buf)写入文件。
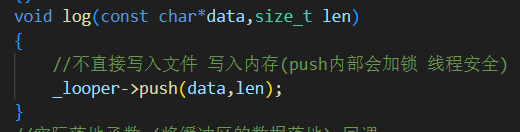
2.log 只向缓冲区中写入数据
主线程只写入缓冲区(非阻塞、线程安全);
具体向哪里 I/O 写入交由
AsyncLooper在线程中处理。
3.realLog
异步线程中处理缓冲区数据的具体逻辑,将内存缓冲区中的日志数据写入到所有配置的落地目标中

2.LoggerBuilder 类(建造者模式)
使用建造者模式来构造日志器 不让用户一个个构造成员变量再构造日志器
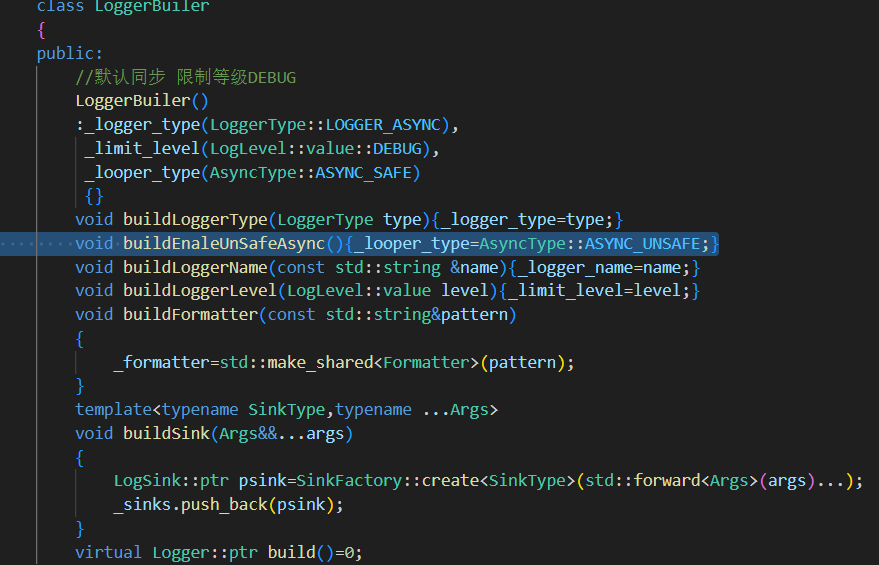
1.抽象一个日志器建造者类 (完成日志器对象所需零部件的构建&&日志器的构建)
1.设置日志器类型(异步 同步)
2.将不同的日志器的创建放到同一个日志器构建者类中完成
2.派生出具体的构造者类 局部日志器的构造者&全局的日志器构造者
构建对应成员遍历的build__函数
在LoggerBuiler进行初始化时完成对日志器类型 日志限制等级的默认构造 异步线程缓冲区的策略(缓冲区大小是否固定,默认固定)
具体创建Logger日志器并返回的build函数,由其子类完成。
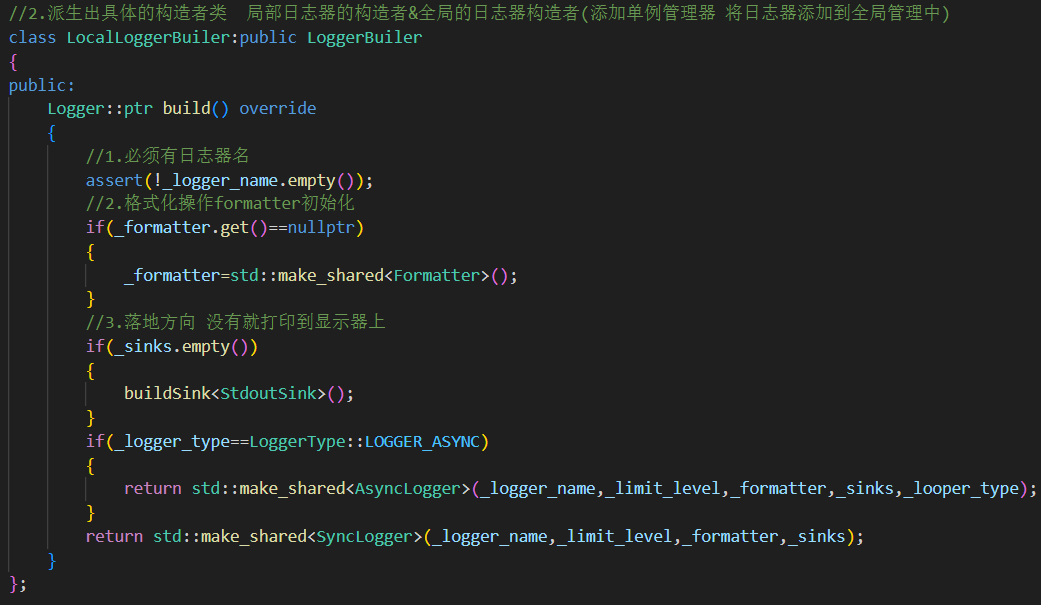
1.LocalLoggerBuiler 局部(本地)日志器类
日志器名称必须有,格式化操作 落地方向可以给默认值
使用方法:
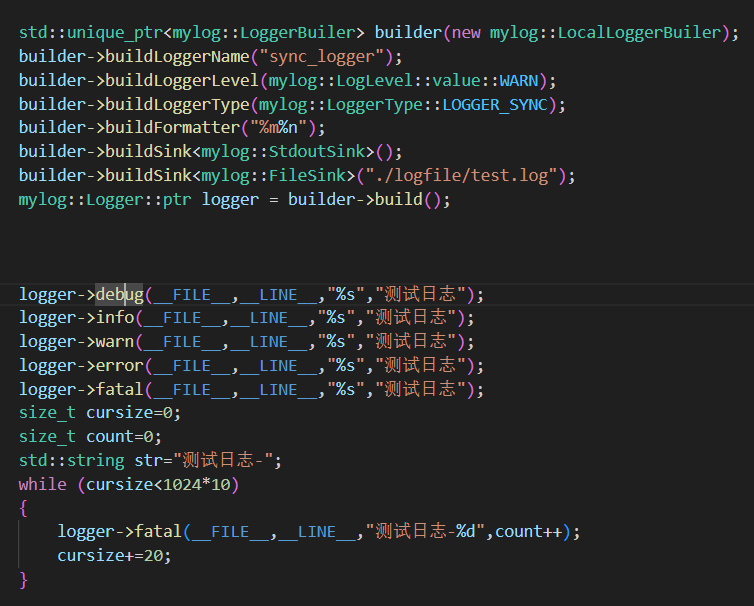
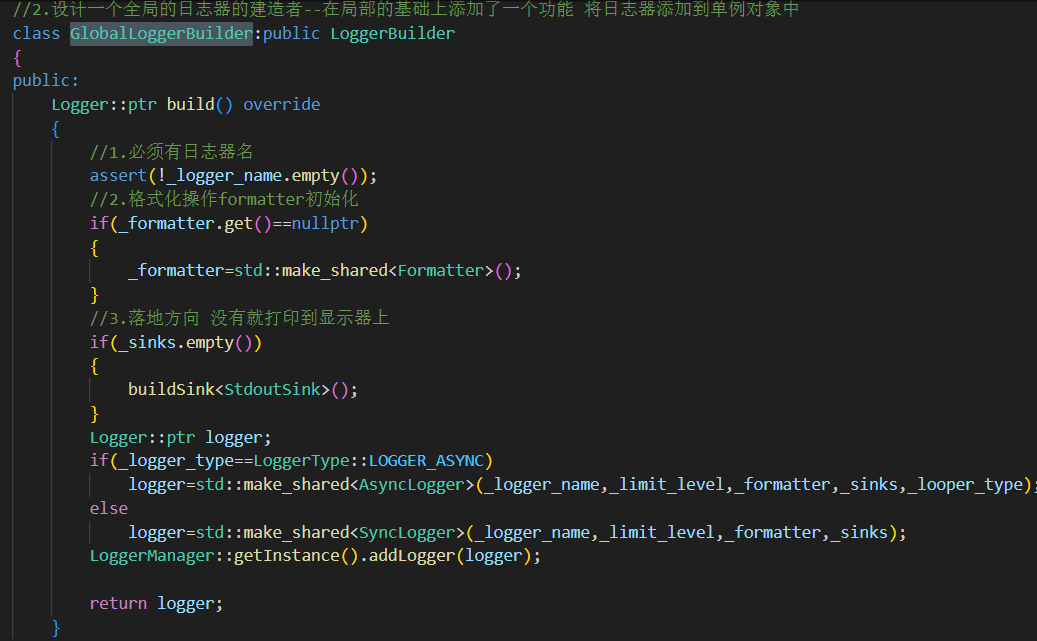
2.GlobalLoggerBuilder全局日志器类
全局日志器其实就是用单例对象管理的局部日志器。单例对象延长了日志器的生命周期,通过获取单例对象查找里面对应的日志器,进行操作。
关键词 含义 局部日志器 是指通过 LoggerBuilder(尤其是LocalLoggerBuilder)手动创建、管理的日志器实例全局日志器 是指通过 GlobalLoggerBuilder创建,并自动注册到单例 LoggerManager 中的日志器单例对象 LoggerManager是懒汉模式的全局单例,统一管理所有日志器,提供注册/查找接口本质 所有日志器(无论本地创建或全局注册)最终其实都是 Logger实例,只是有没有放入LoggerManager的_loggers容器里
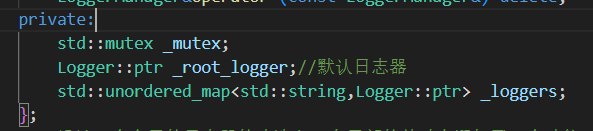
LoggerManager日志器管理类 (懒汉模式)
项目 说明 类型 单例类(懒汉式,局部静态变量) 主要作用 统一管理所有日志器,包括 root 日志器和自定义日志器 核心功能 创建默认 root 日志器、添加日志器、查询日志器、获取日志器 线程安全性 采用 std::mutex加锁保护_loggers容器
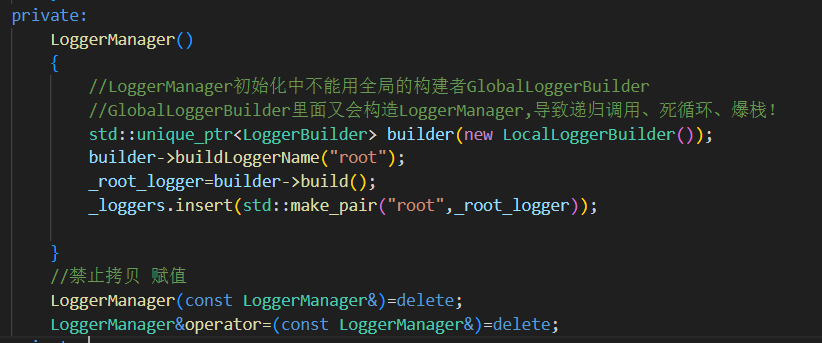
构造函数
在
LoggerManager构造时,创建了一个 root 日志器。使用 LocalLoggerBuilder,避免递归调用(GlobalLoggerBuilder里面又会构造LoggerManager,导致递归调用)。
直接 insert 到
_loggers,保证程序最初始至少有一个可用日志器。
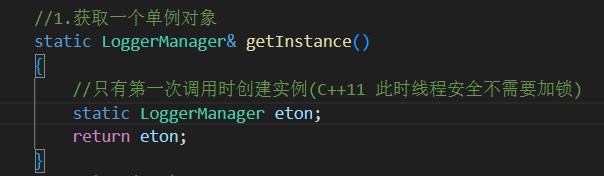
static LoggerManager& getInstance()
采用 C++11 之后线程安全的局部静态变量初始化机制
懒汉模式(第一次用到时再初始化)
线程安全,不会因为多线程导致多次创建
addLogger(Logger::ptr& logger)
加锁保护
_loggers将 logger 插入
_loggers映射表中注意:因为在持锁状态下又调用了 hasLogger(),原来存在死锁风险,所以注释掉了 hasLogger()调用,改为直接 insert
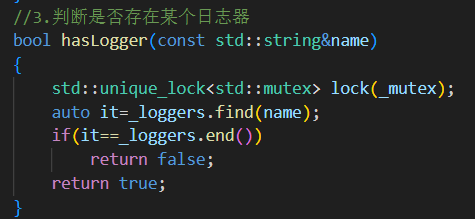
hasLogger(const std::string& name)
单独加锁判断
_loggers中是否存在某名字注意:如果在 addLogger 内部调用,需要避免加锁两次问题(最好解耦锁逻辑)
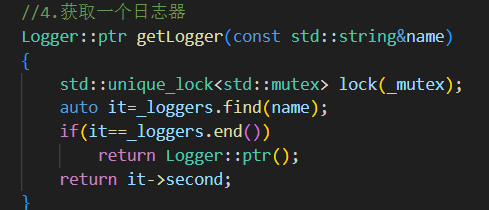
getLogger(const std::string& name)
加锁安全地查询并返回 logger
如果找不到,返回空指针
Logger::ptr()
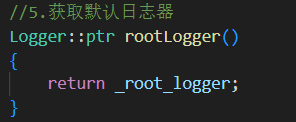
rootLogger()
返回默认的 root 日志器
root 是程序启动时创建的,名字为
"root"

GlobalLoggerBuilder
项目 说明 类型 日志器构建器(Builder模式) 主要作用 帮助用户构建自定义日志器,并自动注册到 LoggerManager 特点 build()后不仅返回日志器,还自动 addLogger 线程安全性 依赖 LoggerManager 内部加锁
Logger::ptr build() override
校验日志器名字不为空
如果没有设置 formatter,默认使用一个新建 formatter
如果没有设置 sinks,默认加一个 StdoutSink
根据同步/异步选择创建 SyncLogger 或 AsyncLogger
构建完成后,注册到 LoggerManager 单例中
返回 logger 指针,方便外部继续操作
七.异步工作器设计
1. 为什么要异步输出日志消息?
问题:
同步输出(例如
send()、write())一旦对端或磁盘缓冲区满了会阻塞主线程。频繁系统调用开销大,影响主线程性能。
解决:
业务线程仅负责将日志写入内存缓冲区(生产者角色)。
另有专属异步线程负责将日志落地(写文件、send到网络等),主线程立刻返回,不阻塞。
避免主线程陷入IO,提升系统吞吐量与响应能力。
通常一个日志器对应一个异步处理线程,再多反而浪费系统资源(尤其CPU与上下文切换成本)。
2. 缓冲区存储结构用什么?
队列,因为先进入的消息要先处理.
3. 每次写入/读取都申请释放内存效率太低?
问题:
new/delete太频繁,容易导致内存碎片与系统开销。解决:
提前申请一整块连续内存,作为环形缓冲区或双缓冲区的底层存储空间。
用
_read_index和_write_index控制写入/读取位置,复用空间而不频繁分配。
4.业务线程写数据相当于生产者 异步处理线程取数据相当于消费者,写数据取数据每次进入缓冲区都需要加锁,太过于频繁怎么办? 先分析一下,生产者会有多个线程 而消费者一般一个日志器对应一个,所以主要是生产者和生产者 生产者和消费者冲突.
这样 我们采用双缓冲区的方案,生产者 消费者各一个缓冲区,每当消费者把消费者缓冲区的数据消费完 且生产者缓冲区内有数据 就交换两个缓冲区。就减少了生产者和消费者的锁冲突。
5.我们在缓存区存储的是一个个日志消息结构体 LogMsg吗?不这样频繁创建和析构LogMsg会,降低效率,我们在缓冲区存入的是格式化的日志字符串,这样不用new delete LogMsg对象,而且异步线程一次性把缓冲区的多条日志消息落地减少write次数。
传统方式:
LogMsg结构体直接格式化字符串
每条日志需要创建
LogMsg对象每条日志直接格式化为字符串
内存频繁
new/delete造成碎片写入缓冲区是连续内存操作
异步线程还需重新 format 后输出
异步线程直接写入文件,无需处理
每条日志都需一次 write()
可一次性 write 多条,提高吞吐量
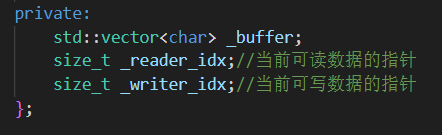
buffer.hpp
Buffer 类
目的: 在内存中维护一块连续的日志写入缓冲区,支持动态扩容、双缓冲交换、快速读写操作,并为异步日志器提供数据中转。
+-------------------------------+
|....已读....|....待读....|....可写....|
0 _reader _writer _buffer.size()
生产者从_writer_idx位置写入到内存中
消费者从_reader_idx位置读取并写入到文件中
当_reader_idx==_writer_idx时 说明已经把缓冲区的数据都写入文件,之后就交换缓冲区继续处理
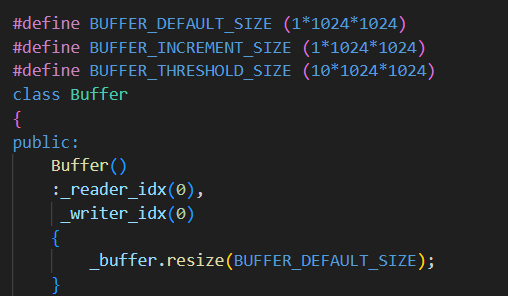
1.构造函数
默认创建一个 1MB 的缓冲区。
使用
std::vector<char>管理内存,避免裸指针和手动new/delete。
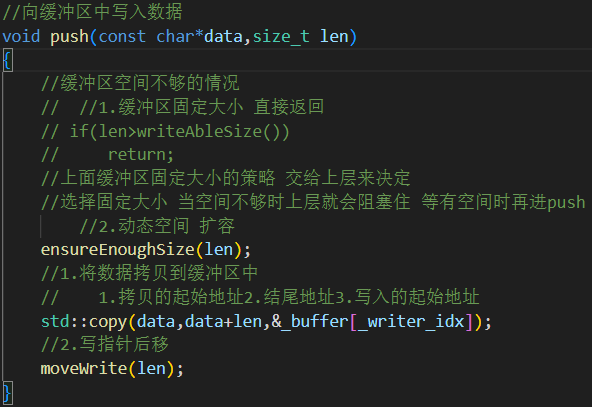
2.push() 生产者写入内存
调用
ensureEnoughSize()确保空间够用(如不够则扩容)。用
std::copy进行内存拷贝(性能高于memcpy在泛型容器中)。更新
_writer_idx写指针。
buffer只考虑扩容,缓冲区大小是否固定由上层进行控制,空间不够上层就会阻塞,不够还不阻塞说明就需要扩容。
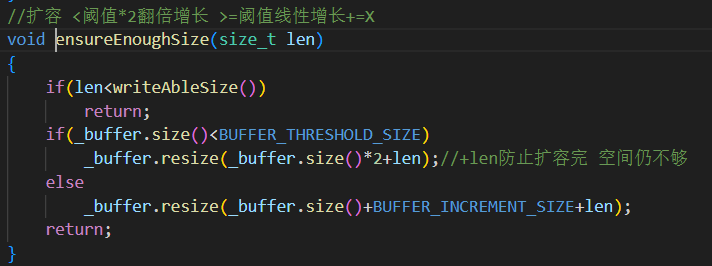
设定阈值
10MB:
小于时采用倍增扩容:性能高、增长快。
大于时改为线性扩容:防止内存爆炸。
总会额外加上
len,确保本次写入不会失败。
3.writeAbleSize() 获取还有多少空间给生产者写入
返回当前缓冲区还剩多少空间可以写。
在异步日志中用于判断是否“生产者需要阻塞等待”。

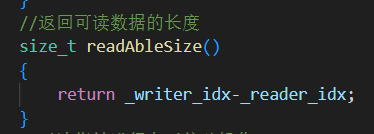
4.readAbleSize() 获取还剩多少数据给消费者处理
返回还未消费的数据长度。
被消费者线程用于“一次性取出所有待写日志数据”。
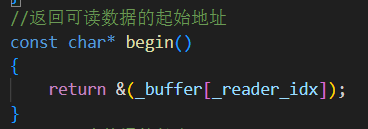
5.begin() 获取数据处理的起始地址给消费者
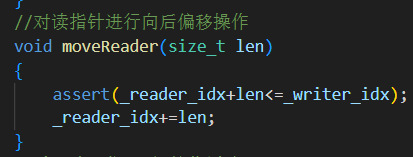
6.moveReader(size_t len)
消费者从缓冲区中读了多少数据,可读指针就向后面偏移多少。但确保不能超过可写指针的位置
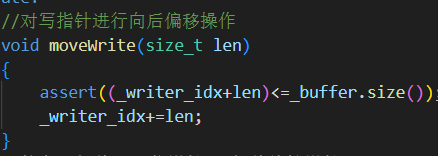
7.moveWrite(size_t len)
同理生产者向缓冲区写了多少数据 可写指针就向后面偏移多少,不能超出缓冲区大小。
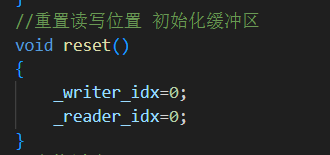
8.reset() 重置缓冲区
表示消费完数据后,清空整个缓冲区,准备下次复用。
重要特性:不重新分配内存,只是重置两个指针,极大减少内存抖动。
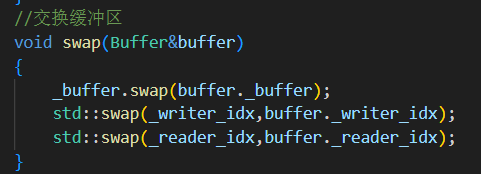
9.swap()
消费者处理完数据 并且生产者缓冲区中有数据才进行交换缓冲区
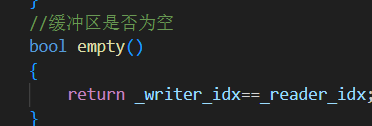
9.empty()
Buffer 是一个高性能、支持自动扩容的环形日志缓冲区,结合 read/write 指针操作和双缓冲技术,能极大降低内存申请与锁粒度,是异步日志系统中极其重要的性能核心模块。
looper.hpp
AsyncLooper类

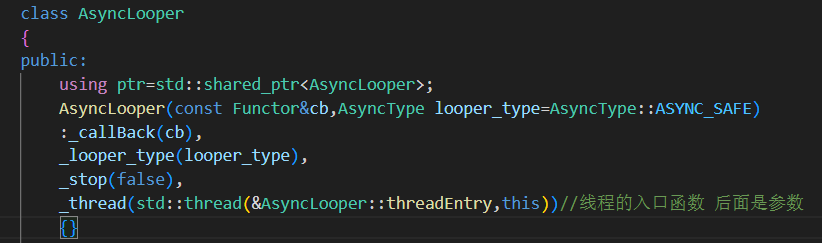
1.构造函数
传入处理日志消息的回调函数cb 以及缓冲区的策略模式
并设置线程的入口函数启动线程
创建时立即启动工作线程,由
threadEntry()开始处理缓冲区数据。线程通过回调函数处理日志内容,完全解耦主逻辑和落地逻辑。
ASYNC_SAFE 安全策略 缓冲区大小固定,空间不够时生产者会wait阻塞直到可写入
ASYNC_UNSAFE 非安全策略 缓冲区可扩容 ,空间不够时会扩容写入不阻塞

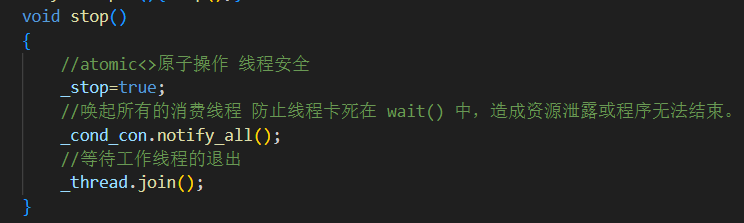
2.stop():安全终止线程
_thread.join等待异步线程处理完数据再退出,。没有它,异步线程可能中途被杀,数据丢失,资源泄漏。
必须唤醒消费者线程(可能正
wait()阻塞),否则线程可能挂死。退出条件为
_stop == true && _pro_buf.empty(),确保剩余数据处理完。
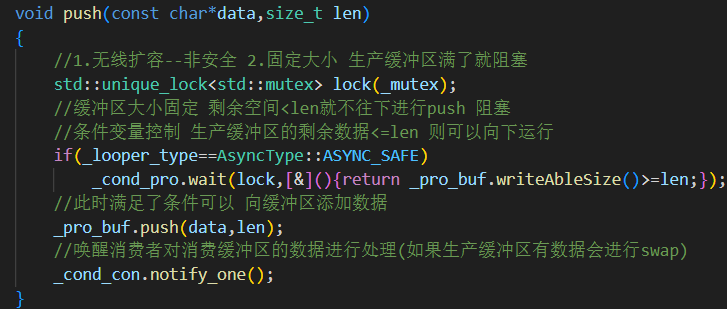
3.push():生产者写入缓冲区
加锁保护
_pro_buf,确保线程安全。如果是安全模式(ASYNC_SAFE),写不下就阻塞等待消费者释放空间,直到可以写入。
写入完成后
notify_one()唤醒消费线程处理。
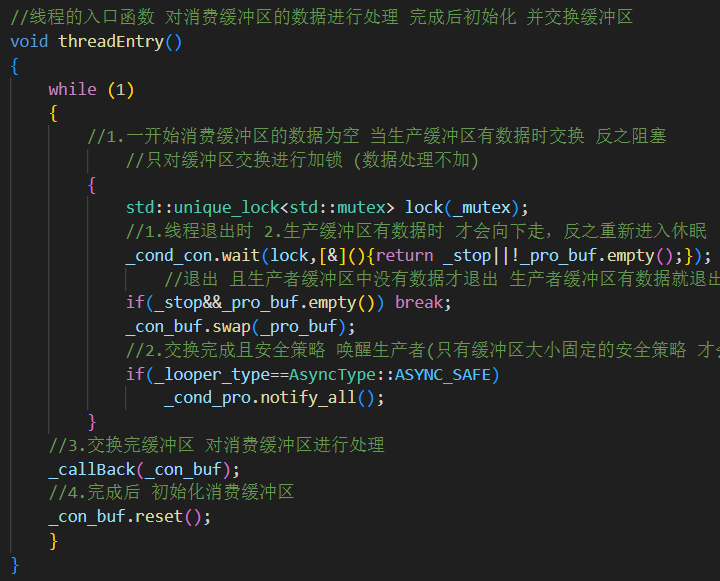
4.threadEntry(): 消费者线程主循环
步骤 动作 1️⃣ 等待 _pro_buf有数据,或者收到_stop信号2️⃣ 如果满足退出条件(且没有残留数据)→ break 3️⃣ 否则交换缓冲区: _pro_buf→_con_buf,如果是安全策略 唤醒可能阻塞住的生产者4️⃣ 解锁后执行 _callBack(_con_buf)把内存数据写入文件5️⃣ 最后 reset()清空消费缓冲区
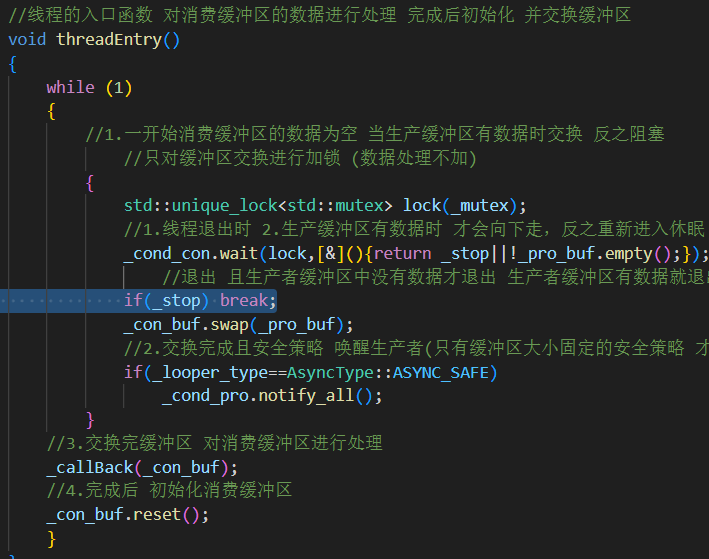
异步线程的退出时机设计
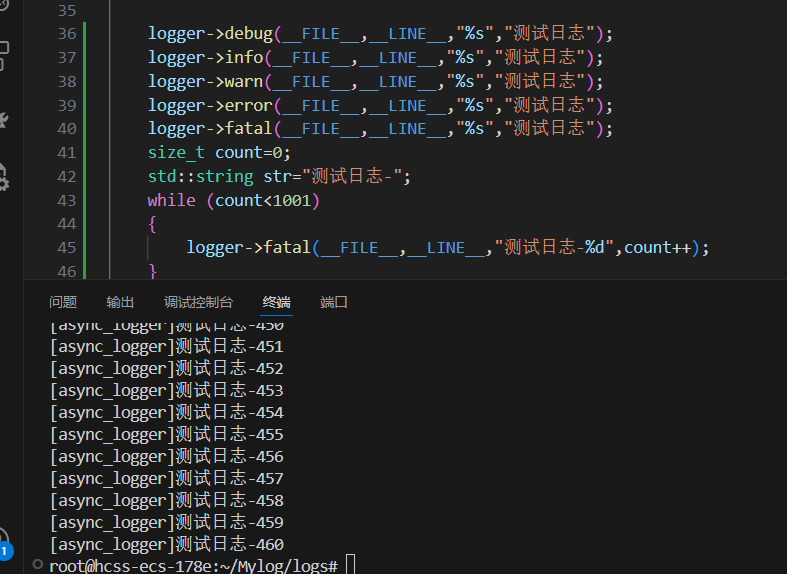
第一次编写时,当我选择向显示器打印日志,按理来说while()循环会打印1000条fatal等级的日志。但为什么只打印了460条就终止了呢?
因为我一开始写的时候,异步处理线程中收到终止信号就直接break,打破循环,此时处理完消费者缓冲区的数据就直接退出了,但此时生产者缓冲区的数据并没有swap处理完,进而导致了数据没有处理完全。
我用 join() 保证主线程等待异步线程结束再退出,但日志还是只打了一半,最后发现是线程收到 stop() 后立刻退出,后面只处理完了消费者缓冲区的数据,没处理完生产者缓冲区的数据,所以把while循环的退出条件再加上消费者缓冲区为空才解决。
八.日志系统的全局接口和宏封装
九.性能测试
#include "../logs/mylog.h"
#include <chrono>namespace mylog
{//1.线程名称 2.线程个数 3.日志条数 4.一条日志大小void bench(const std::string &logger_name,size_t thr_count,size_t msg_count,size_t msg_len){//1.获取日志器mylog::Logger::ptr logger=mylog::getLogger(logger_name);if(logger.get()==nullptr)return;std::cout<<"测试日志:"<<msg_count<<" 条,总大小:"<<(msg_count*msg_len)/1024<<"KB\n";//2.组织指定长度的日志消息std::string msg(msg_len-1,'A');// \n占一个字节//3.创建指定数量的线程std::vector<std::thread> threads;std::vector<double> cost_arry(thr_count); //每个线程的写日志的时间size_t msg_per_thr=msg_count/thr_count; //每个线程平均要写的日志条数for(int i=0;i<thr_count;i++){//i按值捕获 不引用(每个线程保存自己的i)threads.emplace_back([&,i](){//4.线程函数内部开始计时auto start=std::chrono::high_resolution_clock::now();//5.开始循环写日志for(int j=0;j<msg_per_thr;j++)logger->fatal("%s",msg.c_str());//6.结束计时auto end=std::chrono::high_resolution_clock::now();std::chrono::duration<double> cost=end-start;cost_arry[i]=cost.count();//.count得到时间长度(单位秒)std::cout<<"\t线程"<<i<<":\t输出数量"<<msg_per_thr<<"耗时:"<< cost_arry[i]<<"s\n";});}//等待所有线程退出for(int i=0;i<thr_count;i++){threads[i].join();}//7.计算总时间 (因为线程并行 所有总时间为最长的线程运行时间)double max_cost=0;for(int i=0;i<thr_count;i++)max_cost=max_cost>cost_arry[i]?max_cost:cost_arry[i];//每秒输出日志数=总条数/总时间size_t msg_per_sec=msg_count/max_cost;//每秒输出日志大小=总大小/(总时间*1024 ) 单位KBsize_t size_per_sec=(msg_count*msg_len)/(max_cost*1024);//8.进行输出打印std::cout<<"\t总耗时"<<max_cost<<"s"<<std::endl;std::cout<<"\t每秒输出日志数量"<<msg_per_sec<<" 条"<<std::endl;std::cout<<"\t每秒输出日志大小"<<size_per_sec<<" KB"<<std::endl;}//同步void sync_bench(){std::unique_ptr<mylog::LoggerBuilder> builder(new mylog::GlobalLoggerBuilder());builder->buildLoggerName("sync_logger");builder->buildFormatter("%m%n");builder->buildLoggerType(mylog::LoggerType::LOGGER_SYNC);builder->buildSink<mylog::FileSink>("./logfile/sync.log");builder->build();bench("sync_logger",16,200000,1024*16);}//异步void async_bench(){std::unique_ptr<mylog::LoggerBuilder> builder(new mylog::GlobalLoggerBuilder());builder->buildLoggerName("async_logger");builder->buildFormatter("%m%n");builder->buildEnaleUnSafeAsync();builder->buildLoggerType(mylog::LoggerType::LOGGER_ASYNC);builder->buildSink<mylog::FileSink>("./logfile/async.log");builder->build();bench("async_logger",8,200000,1024*10);}}
int main()
{mylog::async_bench();return 0;
}同步写入磁盘的过程
在开始前我们先了解一下同步模式下,日志数据写入磁盘的全过程。
1.程序格式化日志内容(用户态)
先把日志内容组织好,变成一块连续的内存数据
2.调用 write() 系统调用
这时候,程序要做一件重要的事:
从用户态切换到内核态(陷入系统内核)
调用内核的
sys_write系统调用3.数据写入内核缓冲区(Page Cache)
注意:向内核缓冲区写完就返回了,继续执行。后面是Linux后台异步写回线程 完成阻塞并刷新到磁盘的过程。日志线程不会卡在等待flush磁盘上!(只有你显式调用fsync(),线程才会因为刷新磁盘而阻塞)
内核接收到
write请求,不是直接写磁盘!它首先把数据写到Page Cache,也就是内核管理的一块内存缓存区。
4.Page Cache 决定什么时候真正写磁盘
内核什么时候把 Page Cache 里的内容同步到磁盘呢?
缓冲区满了(比如写入太多数据)
过了一定时间(定时flush)(比如默认5秒一次)
用户调用 fsync() 强制刷盘
系统负载很低,后台自动同步
真正触发刷盘时,内核才会:
把缓存中的数据,提交给磁盘驱动
磁盘控制器接收数据,最终物理写入磁盘
细节 解释 write() 返回了,是不是代表数据已经写到磁盘? 不是!只是到了内核Page Cache里,真正落盘可能还要等一段时间 write() 过程慢不慢? 通常快(因为只是内存拷贝),除非Page Cache满了或I/O很忙 真正慢的是哪一步? Page Cache flush到磁盘时才真正慢,但通常不是同步日志线程在等待 调用fsync()会怎样? 强制刷新Page Cache到磁盘,非常慢(阻塞)
单线程同步vs多线程同步
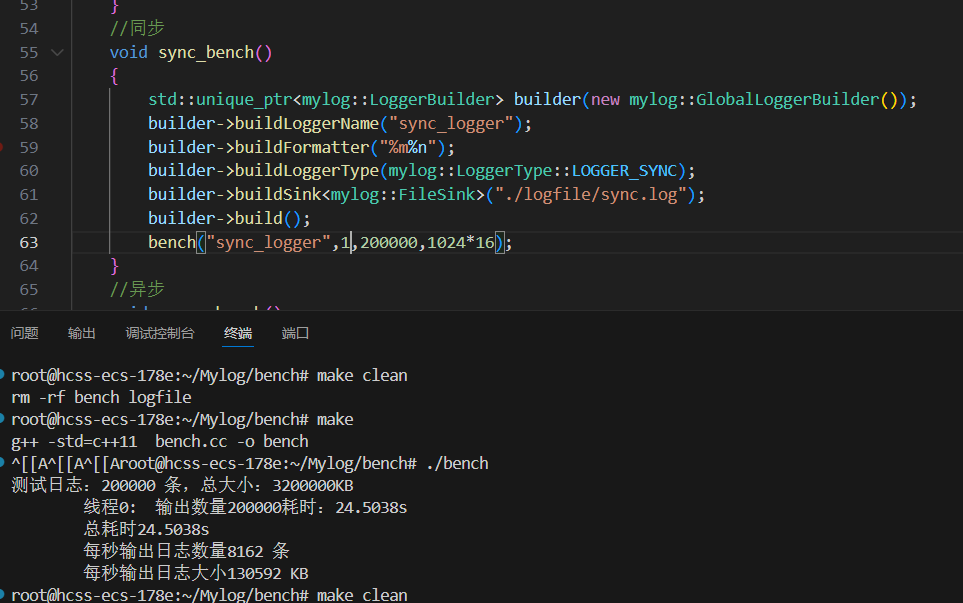
在同步模式下,我们一般会选择单线程,因为多线程会出现锁冲突导致效率下降。
但在我的2核4G服务器测试中,发现多线程反而比单线程更快。
1.单线程同步
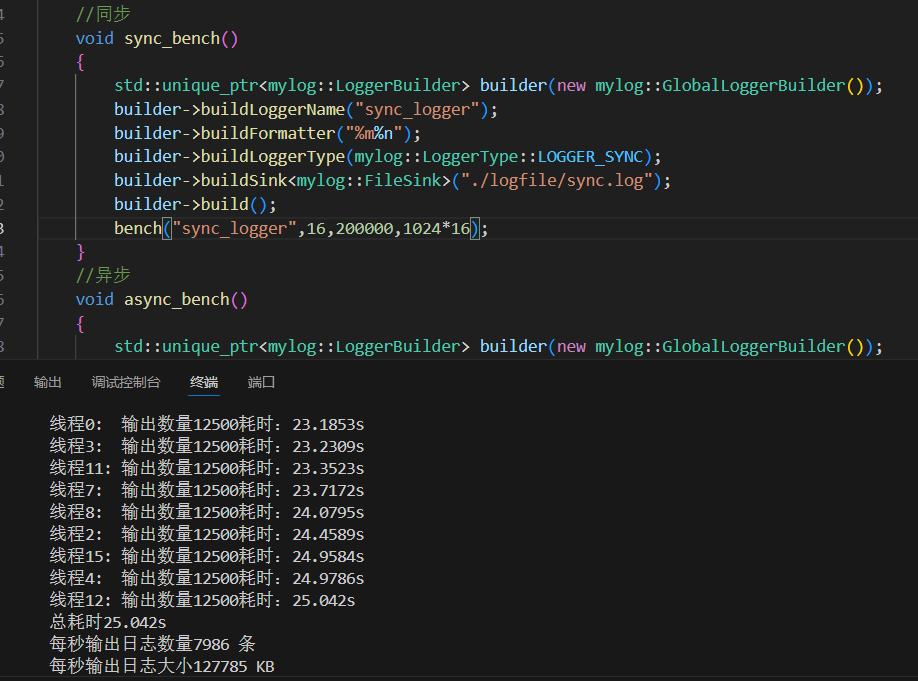
2.多线程同步
接下来我们进行原因分析,为什么同步模式下多线程有锁冲突还是比单线程快?
简单来说:多线程充分利用CPU提高的效率大,且锁冲突降低的效率低
1. 单条日志很小
每条日志体积只有几十到一百字节。
write()写入过程极短,锁持有时间非常短。所以即使多线程竞争锁,每次持锁时间很快释放,锁冲突不明显。
2. 总日志数据量小
总写入数据量只有几十MB到100MB左右。
内核Page Cache能完全hold住所有数据。
向磁盘真正flush的次数很少(内核异步回写)(这个过程也需要加锁)
没有真正暴露磁盘I/O延迟,系统调用
write()只拷贝到内存,很快返回。
3. 多线程数量适中
只开了2~4个线程,并未远远超出CPU核心数(2核)。
多线程合理分摊到不同CPU核上执行,CPU利用率提升。
并行执行带来的加速效果,大于锁竞争导致的损失。
锁冲突分类:
反过来我们也可以从这三点入手,1.增加单条日志大小 2.增加日志总量 3.增加线程数量
类型 解释 特点 锁持有时间长型冲突(Lock Holding Contention) 一个线程拿着锁很久,其他线程只能苦等 比如一次write操作太慢,锁持有时间过长 锁等待排队型冲突(Lock Waiting Contention) 很多线程抢锁,排队抢占,虽然每次持锁很短 比如多线程短写日志,锁很快释放,但抢锁的人太多
方法 目的 ① 增加单条日志大小 加重单次write开销 ② 增加日志总量 提高Page Cache压力、增加flush次数 ③ 增加线程数量 提高锁竞争和CPU切换开销 总结:起到两个方面的作用
1.增加锁冲突
1.增加锁持有时间 1.增加单条日志大小 write()写入内核缓冲区速度下降。2.日志总量增加,增加write()写入缓冲区阻塞的概率,以及增加缓冲区数据向磁盘刷新的次数。
2.增加线程排队时间,增加线程数量 线程抢锁排队,等待时间变长,整体吞吐下降。
2.增加CPU切换开销 (降低CPU利用率)
增加线程,因为CPU轮询机制,每个线程都会被调用且运行一段时间换下一个。导致CPU在不同线程之间频繁切换,浪费大量CPU时间,总耗时增加,吞吐下降。
1.单线程
2.多线程
有的线程17秒就输出完了,有的线程24秒多才完成。 为什么同步多线程测试中,不同线程完成时间差很多?
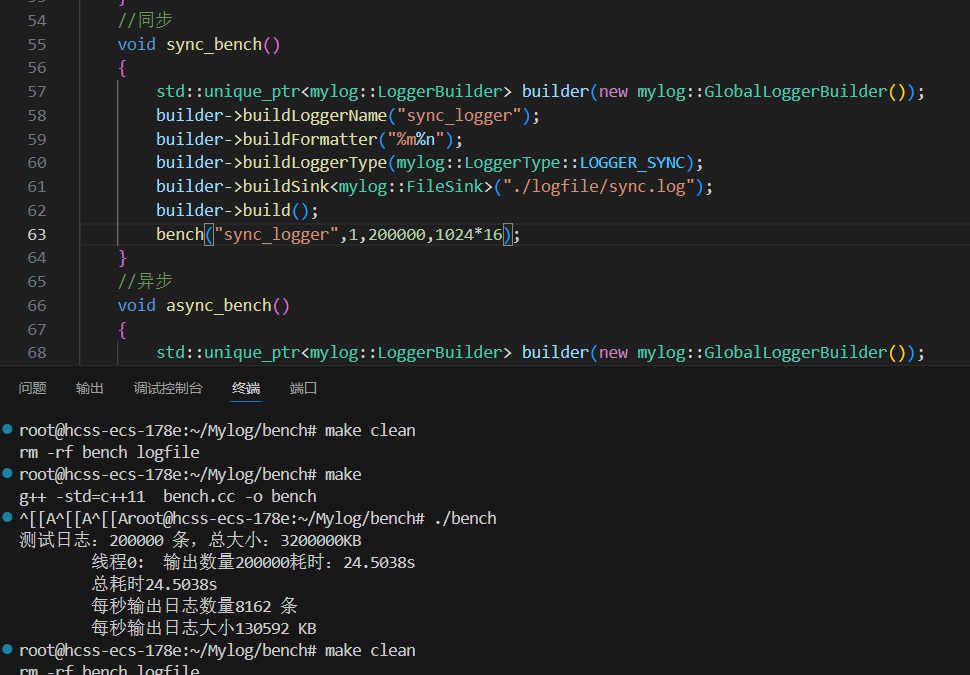
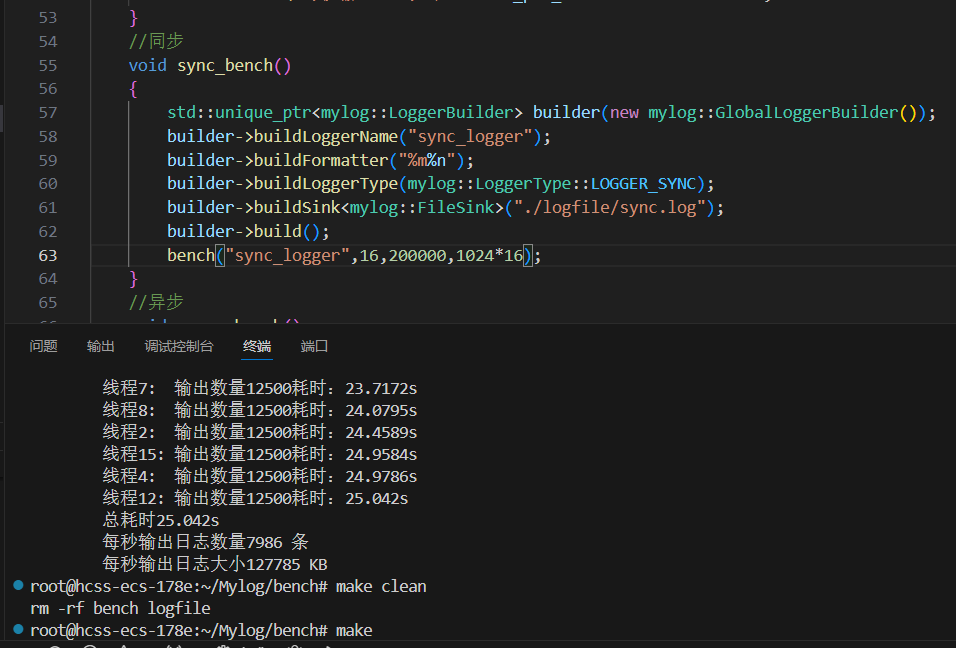
项目 单线程同步日志 多线程同步日志(16线程) 总日志条数 200,000条 200,000条 每条大小 16KB 16KB 总数据量 3.2GB 3.2GB 总耗时 24.5038秒 25.042秒 每秒输出条数 8162条/s 7986条/s 每秒输出日志大小 130592 KB/s 127785 KB/s
多线程同步日志,大家写日志都要抢一把锁(通常是
std::mutex保护的)。
std::mutex在Linux底层是非公平锁(抢到就用,不保证排队顺序)。结果就是:
某些线程运气好,连续抢到锁,疯狂输出
某些线程运气差,总在锁外苦等,一直排队
原因 现象 影响 锁抢占不公平 有的线程连续拿锁,有的线程苦等 导致完成时间天差地别 CPU调度不均 某些线程抢到CPU多,跑得快 执行速率不同 Page Cache刷盘堵塞 后期线程write变慢 后期线程完成时间普遍更长
异步写入磁盘的过程
1. 【主线程】格式化日志内容
2.【主线程】push日志到异步缓冲区
在
log()函数内部做的事情:
加锁(保护缓冲区,通常是
std::mutex)把日志数据拷贝到生产缓冲区(内存区域)
解锁
条件变量 notify_one 通知异步线程:有新日志来了
push动作只涉及:
加锁保护
内存拷贝(拷贝到内部缓冲区)
通知后台线程
没有系统调用(没有write())
push很快完成,主线程立刻继续跑业务,不受I/O影响。
3. 【异步线程】被唤醒
4. 【异步线程】交换缓冲区
5. 【异步线程】处理消费缓冲区数据
这一步才真正发生了系统调用(write)
6. 【内核】处理write动作
7. 【异步线程】处理完成,继续睡眠等待下一波日志
所以说异步日志,就是让异步线程完成耗费时间多的write(),但为了让异步线程获取到数据,还得再建一个缓冲区,多一步拷贝到缓冲区的内容。对比同步,异步主线程相当于把write()换成了一次push拷贝(以及其它的细节开销 比如说缓冲区交换时会加锁 唤醒线程的系统调用notify等)。
对比同步模式,可以理解为:
同步日志主线程需要:
格式化 + write()(系统调用,可能慢)
异步日志主线程需要:
格式化 + push拷贝 + notify异步线程(全在用户态完成,极快)
✅ 异步日志相当于把主线程的 write() 开销换成了一次轻量级的 push拷贝,
✅ 再加上一些很轻的锁和notify开销。
单线程同步vs单线程异步
如果需要调用的write()次数很少,那么单线程异步 同步差距不明显,但需要频繁调用write()才能处理完数据,还是异步更快一点 。
单线程异步vs多线程异步
异步模式下 单线程和多线程对比,和同步模式一样,异步模式下多线程也会出现锁竞争,但不用自己调用write() push写入buffer缓冲区不够会自动扩容不会阻塞住,push写入速度很快,导致锁竞争并不大 只有在push写入时加锁,速度很快。
多线程异步最主要的优势在于:对日志消息格式化的过程多线程是并行的,虽然push串行有细微锁开销,但总体的效率还是比单线程快的。单线程push写入少稳定 多线程短时间push大量数据。
利用多核CPU,加速日志格式化
格式化(如:时间戳、线程ID、日志级别、文本拼接)本身是有一定开销的。
单线程异步时,所有格式化工作由一个线程做,受限于单核CPU速度。
多线程异步时,不同线程可以在不同核上并行进行格式化。
格式化速率大大提高,总体日志生产能力上升。
1.单线程异步
2.多线程异步 8
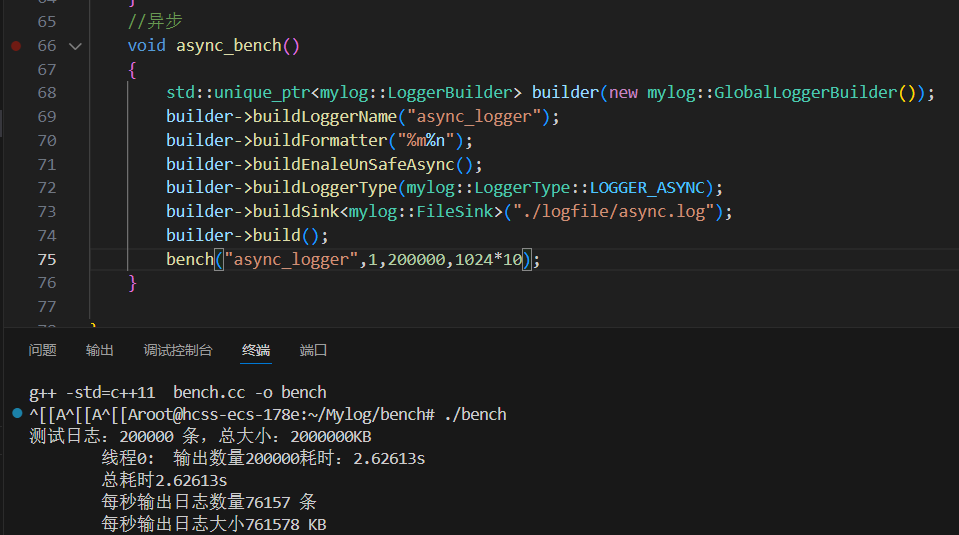
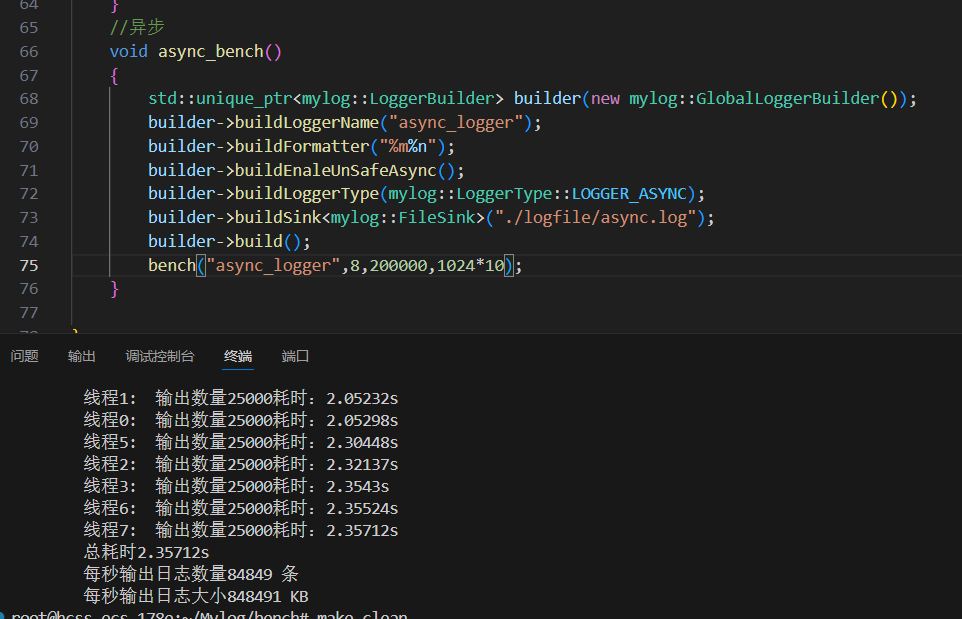
测试 线程数 总日志条数 总大小 总耗时 每秒输出条数 每秒输出大小 第一次 1线程(单线程异步) 200,000条 2GB 2.62613秒 76,157条/s 761,578 KB/s 第二次 8线程(多线程异步) 200,000条(每线程25,000条) 2GB 2.35712秒 84,849条/s 848,491 KB/s
总结:
条件 推荐日志模式 原因 每秒日志量小(≤几千条) 同步单线程 系统开销最小,结构最简单 每秒日志量中等(几万条) 异步单线程 主线程减少阻塞,异步线程批量处理 每秒日志量大(十万条以上) 异步多线程 并行格式化 + 快速push + 批量write,极限提升吞吐
总结:
| 模块 | 功能 |
|---|---|
| Logger类 | 日志器,统一管理日志级别、格式化器、输出目的地 |
| Formatter类 | 日志消息格式化(支持自定义格式) |
| Sink类 | 日志落地(支持stdout/file等多种输出) |
| Builder模式 | 统一构建日志器(配置LoggerName、LoggerType、Formatter、Sink等) |
| LoggerManager(单例) | 全局日志器管理中心,负责创建、查找日志器实例 |
| 异步模块(AsyncLogger) | 实现缓冲区管理、异步push和write,减少主线程I/O阻塞 |
| 同步模块(SyncLogger) | 简单直接的日志同步落地,适合小量数据低延迟需求 |
难点:
异步模式下push和write之间的速率平衡问题
由于push本身非常快(只是内存拷贝),
而异步线程的write动作相对慢(需要系统调用,将数据从用户态写入内存缓冲区),
如果主线程push频率太高,异步线程write跟不上,就会导致缓冲区积压,最终push阻塞(安全模式),影响主线程业务流程。针对这个问题,我做了几层优化设计:
1. 双缓冲区结构
减少消费者和生产者的锁冲突,提高异步线程write()处理速率。
主线程push到生产缓冲区;
异步线程消费交换后的缓冲区;
交换期间加锁,数据处理期间无锁,减少锁冲突时间。
2. 条件变量+批处理机制
push完成数据立刻用条件变量notify通过异步线程处理,异步线程一次性批量write,减少系统调用次数,提升磁盘写入效率。
主线程push时,用
std::condition_variable::notify_one()唤醒异步线程;异步线程wait时只在缓冲区有数据或stop信号时醒来;
一次消费整个缓冲区内所有日志,批量write,减少系统调用次数,提升磁盘写入效率。
3. 支持安全异步与非安全异步模式
生产者push太快就选安全模式 阻塞push,等有空间时再push
在业务量爆发时,可以选择:
安全异步模式(生产缓冲区满了就阻塞push,保护内存)
非安全异步模式(无限扩容缓冲区,保证主线程push不卡顿,牺牲内存)
相关文章:

C++ 基于多设计模式下的同步异步⽇志系统-2项目实现
⽇志系统框架设计 1.⽇志等级模块:对输出⽇志的等级进⾏划分,以便于控制⽇志的输出,并提供等级枚举转字符串功能。 ◦ OFF:关闭 ◦ DEBUG:调试,调试时的关键信息输出。 ◦ INFO:提⽰,普通的提⽰…...
)
Tauri窗口与界面管理:打造专业桌面应用体验 (入门系列五)
窗口管理是桌面应用的核心特性之一,良好的窗口管理可以显著提升用户体验。在Web开发中,我们通常被限制在浏览器窗口内,但Tauri允许前端开发者控制应用窗口的方方面面,从而创造出更加原生的体验。 窗口配置基础 初始窗口配置 在…...
和 channel(管道) 案例解析)
golang goroutine(协程)和 channel(管道) 案例解析
文章目录 goroutine和channel概念开启线程与channel简单通信流程多个工作协程并发执行流程 goroutine和channel概念 goroutine(协程),一般我们常见的是进程,线程,进程可以理解为一个软件在运行执行的过程,线程跟协程比较类似&…...
)
底层源码和具体测试解析HotSpot JVM的notify唤醒有序性(5000字详解)
在大家的认知里,或者大家也可能搜过,notify唤醒机制到底是随机的呢?还是顺序的呢?在网上其实也有很多人说notify的唤醒机制就是随机的,但实际上并不是这样的,notify的唤醒机制是先进先出的! 目…...
)
Jenkins(CI/CD工具)
1. 什么是 Jenkins? Jenkins 是一个开源的持续集成(CI)和持续交付/部署(CD)工具,用于自动化软件构建、测试和部署过程。 2. Jenkins 优势 (1)开源免费:社区活跃&#…...

Apache Sqoop数据采集问题
Sqoop数据采集格式问题 一、Sqoop工作原理二、Sqoop命令格式三、Oracle数据采集格式问题四、Sqoop增量采集方案 Apache Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql…)间进行数据的传递,可以将一个关系型数据库&…...
)
再学GPIO(二)
GPIO寄存器 每个GPI/O端口有两个32位配置寄存器(GPIOx_CRL,GPIOx_CRH),两个32位数据寄存器(GPIOx_IDR和GPIOx_ODR),一个32位置位/复位寄存器(GPIOx_BSRR),一个16位复位寄存器(GPIOx_BRR)和一个32位锁定寄存器(GPIOx_LCKR)。 GPIO…...

err: Error: Request failed with status code 400
好的,今天学习ai的时候从前端发送请求,实在是想不通为啥会啥是一个坏请求,后来从前端方法一个一个找参数,传递的值都有,然后想到我这边需要传递的是一个对象,那么后端使用的RequestParam就接收不到json对象…...

解决qnn htp 后端不支持boolean 数据类型的方法。
一、背景 1.1 问题原因 Qnn 模型在使用fp16的模型转换不支持类型是boolean的cast 算子,因为 htp 后端支持量化数据类型或者fp16,不支持boolean 类型。 ${QNN_SDK_ROOT_27}/bin/x86_64-linux-clang/qnn-model-lib-generator -c ./bge_small_fp16.cpp -b …...
:Pod亲和性详解)
k8s学习记录(五):Pod亲和性详解
一、前言 上一篇文章初步探讨了 Kubernetes 的节点亲和性,了解到它在 Pod 调度上比传统方式更灵活高效。今天我们继续讨论亲和性同时Kubernetes 的调度机制。 二、Pod亲和性 上一篇文章中我们介绍了节点亲和性,今天我们讲解一下Pod亲和性。首先我们先看…...

MongoDB与PHP7的集成与优化
MongoDB与PHP7的集成与优化 引言 随着互联网技术的飞速发展,数据库技术在现代软件开发中扮演着越来越重要的角色。MongoDB作为一种流行的NoSQL数据库,以其灵活的数据模型和强大的扩展性受到众多开发者的青睐。PHP7作为当前最流行的服务器端脚本语言之一,其性能和稳定性也得…...

maven相关概念深入介绍
1. pom.xml文件 就像Make的MakeFile、Ant的build.xml一样,Maven项目的核心是pom.xml。POM(Project Object Model,项目对象模型)定义了项目的基本信息,用于描述项目如何构建,声明项目依赖,等等。…...

以科技之力,启智慧出行 —— 阅读《NVIDIA 自动驾驶安全报告》及观看实验室视频有感
作为中南民族大学通信工程专业的学生,近期研读《NVIDIA 自动驾驶安全报告》并观看其实验室系列视频后,我深刻感受到自动驾驶技术不仅是一场交通革命,更是一次社会生产力的解放与民族精神的升华。这场变革的浪潮中,我看到了科技如何…...

2P4M-ASEMI机器人功率器件专用2P4M
编辑:LL 2P4M-ASEMI机器人功率器件专用2P4M 型号:2P4M 品牌:ASEMI 封装:TO-126 批号:最新 引脚数量:3 封装尺寸:如图 特性:双向可控硅 工作结温:-40℃~150℃ 在…...
回归)
基础的贝叶斯神经网络(BNN)回归
下面是一个最基础的贝叶斯神经网络(BNN)回归示例,采用PyTorch实现,适合入门理解。 这个例子用BNN拟合 y x 噪声 的一维回归问题,输出均值和不确定性(方差)。 import torch import torch.nn a…...

小黑享受思考心流: 73. 矩阵置零
小黑代码 class Solution:def setZeroes(self, matrix: List[List[int]]) -> None:"""Do not return anything, modify matrix in-place instead."""items []m len(matrix)n len(matrix[0])for i in range(m):for j in range(n):if not m…...

整合 | 大模型时代:微调技术在医疗智能问答矩阵的实战应用20250427
🔎 整合 | 大模型时代:微调技术在医疗智能问答矩阵的实战应用 一、引言 在大模型技术高速变革的背景下,数据与微调技术不再是附属品,而是成为了AI能力深度重构的核心资产。 尤其在医疗行业中,微调技术改写了智能分诊和…...

Web安全:威胁解析与综合防护体系构建
Web安全:威胁解析与综合防护体系构建 Web安全是保护网站、应用程序及用户数据免受恶意攻击的核心领域。随着数字化转型加速,攻击手段日益复杂,防护需兼顾技术深度与系统性。以下从威胁分类、防护技术、最佳实践及未来趋势四个维度࿰…...

spring项目rabbitmq es项目启动命令
应该很多开发者遇到过需要启动中间件的情况,什么测试服务器挂了,服务连不上nacos了巴拉巴拉的,虽然是测试环境,但也会手忙脚乱,疯狂百度。 这里介绍一些实用方法 有各种不同的场景,一是重启,服…...

人工智能期末复习1
该笔记为2024.7出版的人工智能技术应用导论(第二版)课本部分的理论总结。 一、人工智能的产生与发展 概念:人工智能是通过计算机系统和模型模拟、延申和拓展人类智能的理论、方法、技术及应用系统的一门新的技术科学。 发展:19…...
)
深入理解指针(5)
字符指针变量 对下述代码进行调试 继续go,并且观察p2 弹出错误: 为什么报错呢? 因为常量字符串是不能被修改的,否则,编译器报错。 最后,打印一下: 《剑指offer》中收录了⼀道和字符串相关的笔试题&#…...
)
新魔百和CM311-5_CH/YST/ZG代工_GK6323V100C_2+8G蓝牙版_强刷卡刷固件包(可救砖)
新魔百和CM311-5_CH/YST/ZG代工_GK6323V100C_28G蓝牙版_强刷卡刷固件包(可救砖) 1、准备一个优盘卡刷强刷刷机,用一个usb2.0的8G以下U盘,fat32,2048块单分区格式化(强刷对ÿ…...

磁盘清理git gc
#!/bin/bash find / -type d -name “.git” 2>/dev/null | while read -r git_dir; do repo_dir ( d i r n a m e " (dirname " (dirname"git_dir") echo “Optimizing r e p o d i r " c d " repo_dir" cd " repodir"cd&…...

django admin AttributeError: ‘UserResorce‘ object has no attribute ‘ID‘
在 Django 中遇到 AttributeError: ‘UserResource’ object has no attribute ‘ID’ 这类错误通常是因为你在代码中尝试访问一个不存在的属性。在你的例子中,错误提示表明 UserResource 类中没有名为 ID 的属性。这可能是由以下几个原因造成的: 拼写错…...

现代Python打包工具链
现代Python打包工具如Poetry、Flit和Hatch提供了更简单、更强大的方式来管理项目依赖和打包流程。下面我将通过具体示例详细介绍这三种工具。 1. Poetry - 全功能依赖管理工具 Poetry是最流行的现代Python项目管理工具之一,它集依赖管理、虚拟环境管理和打包发布于一…...
 吴恩达版提示词工程 8. 聊天机器人 (聊天格式设计,上下文内容,点餐机器人))
(done) 吴恩达版提示词工程 8. 聊天机器人 (聊天格式设计,上下文内容,点餐机器人)
视频:https://www.bilibili.com/video/BV1Z14y1Z7LJ/?spm_id_from333.337.search-card.all.click&vd_source7a1a0bc74158c6993c7355c5490fc600 别人的笔记:https://zhuanlan.zhihu.com/p/626966526 8. 聊天机器人(Chatbot) …...

Maven概述
1.maven是什么? Maven 是一个基于项目对象模型(Project Object Model,POM)概念的项目构建工具,主要用于 Java 项目的构建、依赖管理和项目信息管理。(跨平台的项目管理工具,用于构建和管理任何…...

SKLearn - Biclustering
文章目录 Biclustering (双聚类)谱二分聚类算法演示生成样本数据拟合 SpectralBiclustering绘制结果 Spectral Co-Clustering 算法演示使用光谱协同聚类算法进行文档的二分聚类 Biclustering (双聚类) 关于双聚类技术的示例。 谱…...

使用c++实现一个简易的量子计算,并向外提供服务
实现一个简易的量子计算模拟器并提供服务是一个相对复杂的过程,涉及到量子计算的基本概念、C编程以及网络服务的搭建。以下是一个简化的步骤指南,帮助你开始这个项目: 步骤 1: 理解量子计算基础 在开始编码之前,你需要对量子计算…...

京东攻防岗位春招面试题
围绕电商场景,以下是5道具有代表性的技术面试题及其解析,覆盖供应链、电商大促、红蓝对抗等场景。 《网安面试指南》https://mp.weixin.qq.com/s/RIVYDmxI9g_TgGrpbdDKtA?token1860256701&langzh_CN 5000篇网安资料库https://mp.weixin.qq.com/s?…...

Kafka批量消费部分处理成功时的手动提交方案
Kafka批量消费部分处理成功时的手动提交方案 当使用Kafka批量消费时,如果500条消息中只有部分处理成功,需要谨慎处理偏移量提交以避免消息丢失或重复消费。以下是几种处理方案示例: 方案1:记录成功消息并提交最后成功偏移量 Co…...

消息中间件
零、文章目录 消息中间件 1、中间件 (1)概述 中间件(Middleware)是位于操作系统、网络与数据库之上,应用软件之下的一层独立软件或服务程序,其核心作用是连接不同系统、屏蔽底层差异,并为应…...

vue3直接操作微信小程序云开发数据库,web网页对云数据库进行增删改查
我们开发好小程序以后,有时候需要编写一个管理后台网页对数据库进行管理,之前我们只能借助云开发自带的cms网页,但是cms网页设计的比较丑,工作量和代码量也不够,所以我们今天就来带大家实现用vue3编写管理后台直接管理…...

重塑编程体验边界:明基RD280U显示器深度体验
重塑编程体验边界:明基RD280U显示器深度体验 写在前面 本文将以明基RD280U为核心,通过技术解析、实战体验与创新案例,揭示专业显示器如何重构开发者的数字工作台。 前言:当像素成为生产力的催化剂 在GitHub的年度开发者调查中&…...

Linux命令-iostat
iostat 命令介绍 iostat 是一个用于监控 Linux 系统输入/输出设备加载情况的工具。它可以显示 CPU 的使用情况以及设备和分区的输入/输出统计信息,对于诊断系统性能瓶颈(如磁盘或网络活动缓慢)特别有用。 语法: iostat [options…...

Hyper-V安装Win10系统,报错“No operating system was loaded“
环境: Win10专业版 Hyper-V 问题描述: Hyper-V安装Win10系统,报错"No operating system was loaded" 已挂载ISO但仍无法启动的深度解决方案 🔧如果已确认ISO正确挂载且启动顺序已调整,但虚拟机仍提…...

Zabbix
zabbix官网: https://www.zabbix.com zabbix中文操作手册:https://www.zabbix.com/documentation/5.0/zh/manual/introduction/features 1、SERVER Zabbix server 是 Zabbix 软件的核心组件。Zabbix Agent 向Zabbix server报告可用性、系统完整性信息和统计信息。…...

NEPCON China 2025 | 具身智能时代来临,灵途科技助力人形机器人“感知升级”
4月22日至24日,生产设备暨微电子工业展(NEPCON China 2025)在上海如期开展。本届展会重磅推出“人形机器人拆解展区”,汇聚35家具身智能产业链领军企业,围绕机械结构、传感器布局、驱动系统与AI算法的落地应用…...

css响应式布局设置子元素高度和宽度一样
css响应式布局设置子元素高度和宽度一样 常常遇到响应式布局 其中父元素(类名为.list)包含多个子元素(类名为.item),每个子元素中显示一张图片,并且这些图片能够根据子元素的宽度和高度进行自适应调整。 …...

【AI论文】RefVNLI:迈向可扩展的主题驱动文本到图像生成评估
摘要:主题驱动的文本到图像(T2I)生成旨在生成与给定文本描述一致的图像,同时保留参考主题图像的视觉特征。 尽管该领域具有广泛的下游适用性——从增强图像生成的个性化到视频渲染中一致的角色表示——但该领域的进展受到缺乏可靠…...

信创系统 sudoers 权限配置实战!从小白到高手
好文链接:实战!银河麒麟 KYSEC 安全中心执行控制高级配置指南 Hello,大家好啊!今天给大家带来一篇关于信创终端操作系统中 sudoers 文件详解的实用文章!在 Linux 系统中,sudo 是一项非常重要的权限控制机制…...

用户行为检测技术解析:从请求头到流量模式的对抗与防御
用户行为检测是反爬机制的核心环节,网站通过分析请求特征、交互轨迹和时间模式,识别异常流量并阻断爬虫。本文从基础特征检测与高级策略分析两个维度,深入解析用户行为检测的技术原理与对抗方案。 一、基础特征检测:请求头与交互…...

关于Android Studio的AndroidManifest.xml的详解
AndroidManifest.xml 是 Android 项目的核心配置文件,它定义了应用的基本信息、所需权限、组件、功能等。它为 Android 系统提供了关于应用如何运行的重要信息。每个 Android 应用程序必须包含这个文件,而且这个文件的配置直接影响到应用的行为和安装要求…...

全栈自动化:从零构建智能CI/CD流水线
1. 基础架构:GitLab Kubernetes 1.1 GitLab CI/CD核心配置 GitLab通过.gitlab-ci.yml定义流水线阶段。以下是一个基础模板: stages:- build- test- deploybuild_job:stage: buildscript:- echo "Compiling the code..."- make…...

xe-upload上传文件插件
1.xe-upload地址:文件选择、文件上传组件(图片,视频,文件等) - DCloud 插件市场 2.由于开发app要用到上传文件组件,uni.chooseFile在app上不兼容,所以找到了xe-upload,兼容性很强&a…...

PySpark中DataFrame应用升阶及UDF使用
目录 1. 加载数据2. 列常见操作2.1 添加新列2.2 重命名列2.3 删除指定列2.4 修改数据 3 空值处理3.1 丢弃空值3.2 空值填充 4 聚合操作4.1 分组聚合 5 用户自定义函数(UDF)5.1 传统UDF函数5.2 Pandas UDF(向量化UDF) 参考资料 imp…...

C++ ——引用
引用定义 引用是一个已存在的变量的别名。 用法 类型 & 别名 引用指向的变量名 关于别名的理解: 别名可以理解为绰号或者小名,比如美猴王、齐天大圣、斗战胜佛等,指的都是孙悟空。 这意味着: ①别名和别名指向的变量其实是同…...
图像结构分析和形状描述符------拟合二维点集的直线函数 fitLine2D())
OpenCV 图形API(65)图像结构分析和形状描述符------拟合二维点集的直线函数 fitLine2D()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 拟合一条直线到2D点集。 该函数通过最小化 ∑ i ρ ( r i ) \sum_i \rho(r_i) ∑iρ(ri)来将一条直线拟合到2D点集,其中 ri 是第…...

k8s生成StarRocks集群模版
集群由1个fe3个be组成,满足以下要求: 1、由3个pod组成,每pod分配2c4g 2、第一个pod里有一个be与一个fe,同在一个容器里,fe配置jvm内存设置为1024mb,be的jvm内存设置为1024MB 3、第二第三个pod里分别有一…...

web基础+HTTP+HTML+apache
目录 一.web基础 1.1web是什么 1.2HTTP 1.2.1HTTP的定义 1.2.2 HTTP请求过程 1.2.3 HTTP报文 1 请求报文 2 响应报文 1.2.4 HTTP协议状态码 1.2.5 HTTP方法 1.2.6 HTTP协议版本 二.HTML CSS和JavaScript 2.1HTML 2.1.1HTML的概述 2.1.2 HTML中的部分基本标签&…...