【C】初阶数据结构13 -- 快速排序
本篇文章主要讲解经典的排序算法 -- 快速排序算法
目录
1 递归版本的快速排序
1) 算法思想
(1) hoare 版本
(2) 双指针版本
(3) 挖坑法
2) 代码
3) 时间复杂度与空间复杂度分析
(1) 时间复杂度
(2) 空间复杂度
2 非递归版本的快速排序
1) 算法思想
2) 代码
3 快速排序的缺陷以及优化
1) 缺陷
2) 优化
(1) 三路划分
(2) 内省排序(IntroSort)
4 总结
1 递归版本的快速排序
1) 算法思想
快速排序,顾名思义,就是因为该算法排序速度非常快,所以叫做快速排序算法。快速排序是分治算法的一种经典应用。快速排序利用了可以将整个大问题划分为若干个相同的子问题,然后解决子问题,大问题就随之解决的分治算法思想:
a. 假设这里排升序,首先将数组最左边那个值作为 key 值,将对整个数组进行排序划分为两部分,key 值左边的是比 key 值小的部分,key 值右边是比 key 值大的部分
b. 这样对整个数组进行排序就划分成了两个相同子问题,比 key 值小的部分进行排序与比 key 值大的部分进行排序。
所以快速排序的关键就是某个子问题是如何解决的,下面就来讲解某个子问题是如何解决的。
解决某个子问题的有三种算法,分别是 hoare 版本的方法,双指针法以及挖坑法。
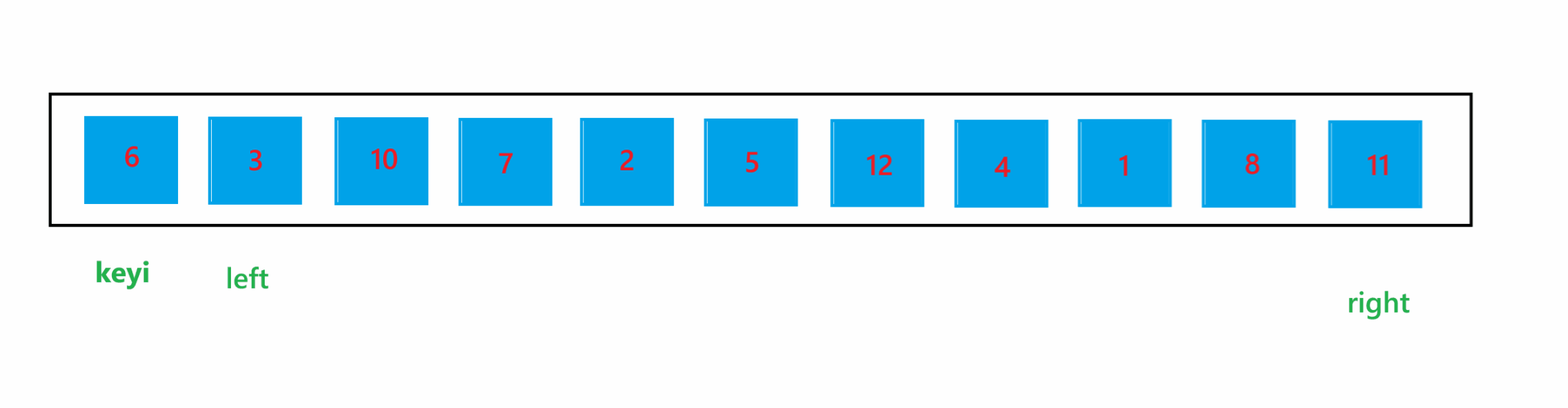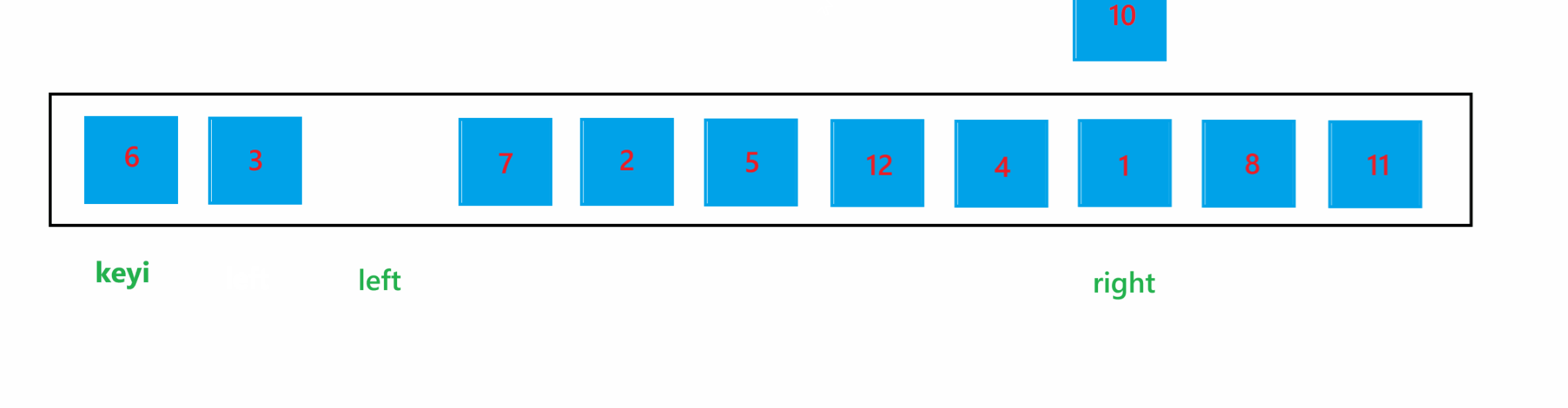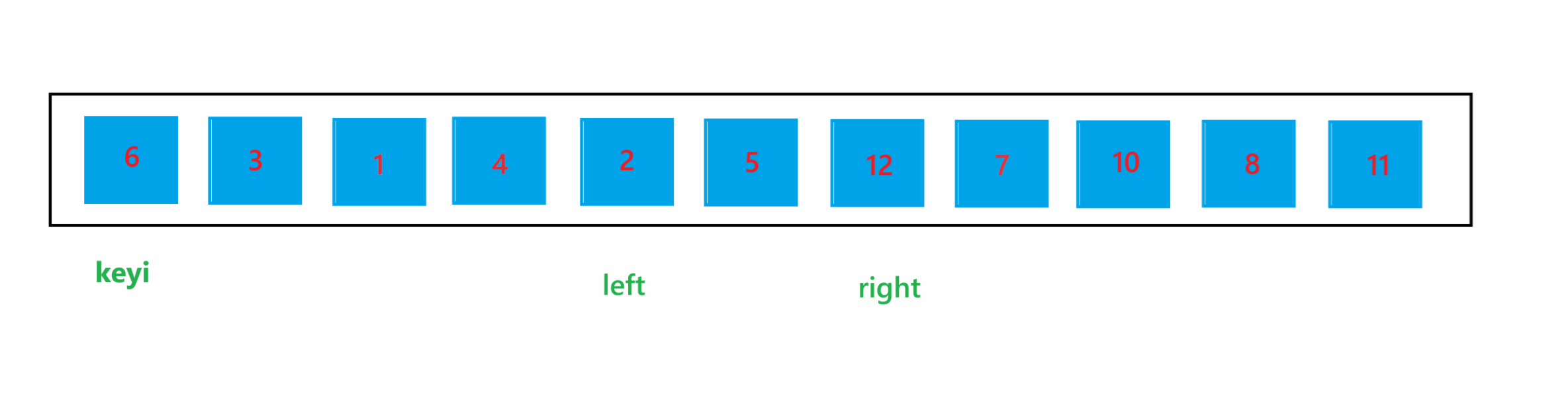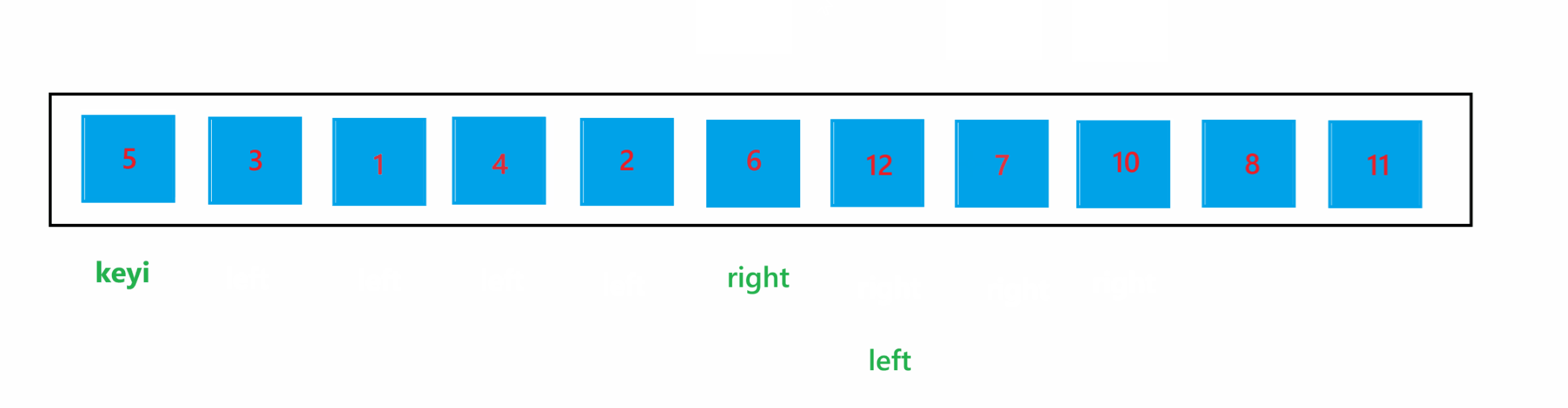
(1) hoare 版本
a. 首先将每个子问题中最左边的下标定义为 left,最右边的下标定义为 right,将 left 下标定义为 keyi ,代表要进行比较的 key 值,然后让 left++
b. 如果 left 下标的值大于 key 值,那就让 left++,这样 left 就会指向比 key 值小的元素;如果 right 下标的值小于 key 值,那就让 right--,这样 right 就会指向比 key 值大的元素,然后交换他们俩,就将大的元素换到了右边,小的元素换到了左边;交换完之后,让 left++,right--
c. 循环上述过程,当循环停止时,比 key 值大的元素就会全都被交换到右边,比 key 值小的元素就会全部被交换到左边。
那么停止条件,就是当 left > right 或者 left >= right的时候,那么具体是哪一个呢?我们来举个例子说明一下,假设对下面这些数据进行排序:
数组元素为 6 1 2 7 8 3,对这堆数据进行快速排序,达到停止条件时结果如图所示:
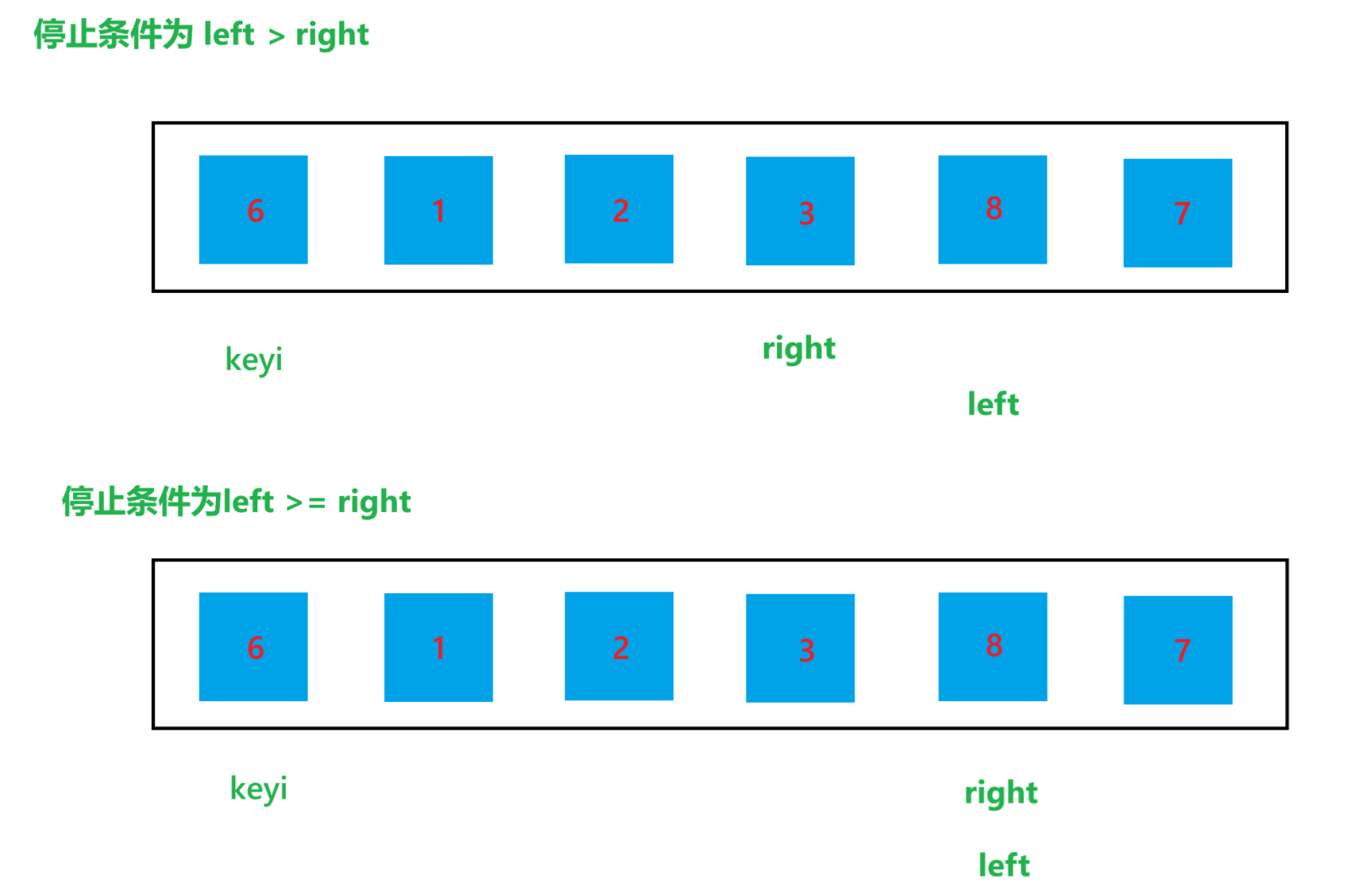
通过上图可以看到,当 left 与 right 相遇时,如果相遇的元素比 key 值大时,如果停止条件为 left >= right 的话,那循环结束之后,就会将该相遇的元素交换到 keyi 位置,那么比 key 值大的元素就被交换到左边了,肯定会导致最终结果混乱了。所以停止条件肯定是为 left > right 的,也就是进入循环的条件为 left <= right。使用 hoare 版本的一次快速排序的过程如图所示:
(2) 双指针版本
在学习快速排序算法的过程中,本人认为双指针版本解决某个子问题是最好理解和代码最好写的一个版本。
a. 首先定义两个整型变量 cur 和 prev(由于这两个整型变量代表某个子问题的数组的下标,看起来像指针一样,所以是双指针版本),假设数组名是 arr,开始先让 prev = left,是第一个元素的下标,cur 定义为 prev + 1
b. 然后 cur 在 arr 数组中遍历,如果 arr[cur] 比 arr[left] 大,那就交换 arr[++prev] 和 arr[cur],然后让 cur++;如果 arr[cur] <= arr[left] ,那就只让 cur++
c. 当 cur > right 时,循环停止,因为如果再继续循环,就超出当前子问题数组的范围了,会导致排序结果混乱
d. 循环结束之后,不要忘记让 arr[left] 放在比 arr[left] 大的元素和 arr[left] 小的元素的分界处,即 prev 所指向位置,所以最后还要交换一下 arr[left] 和 arr[prev]
使用双指针算法解决子问题的过程如图所示:
(3) 挖坑法
挖坑法就是直接赋值,在挖坑法里面没有交换的操作。
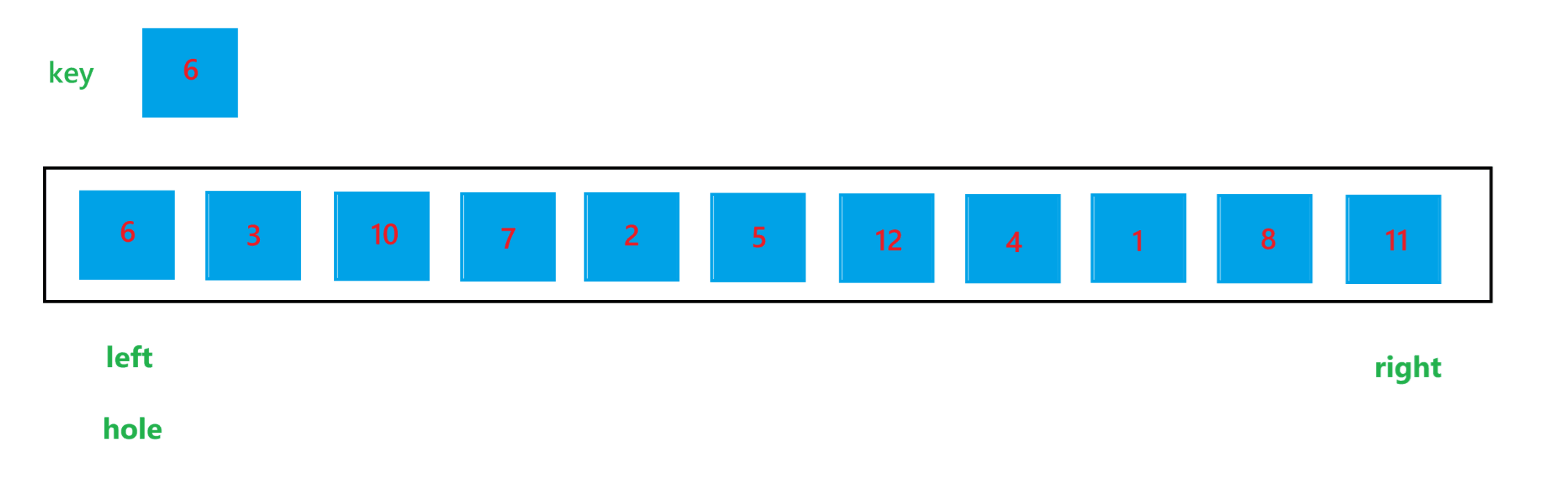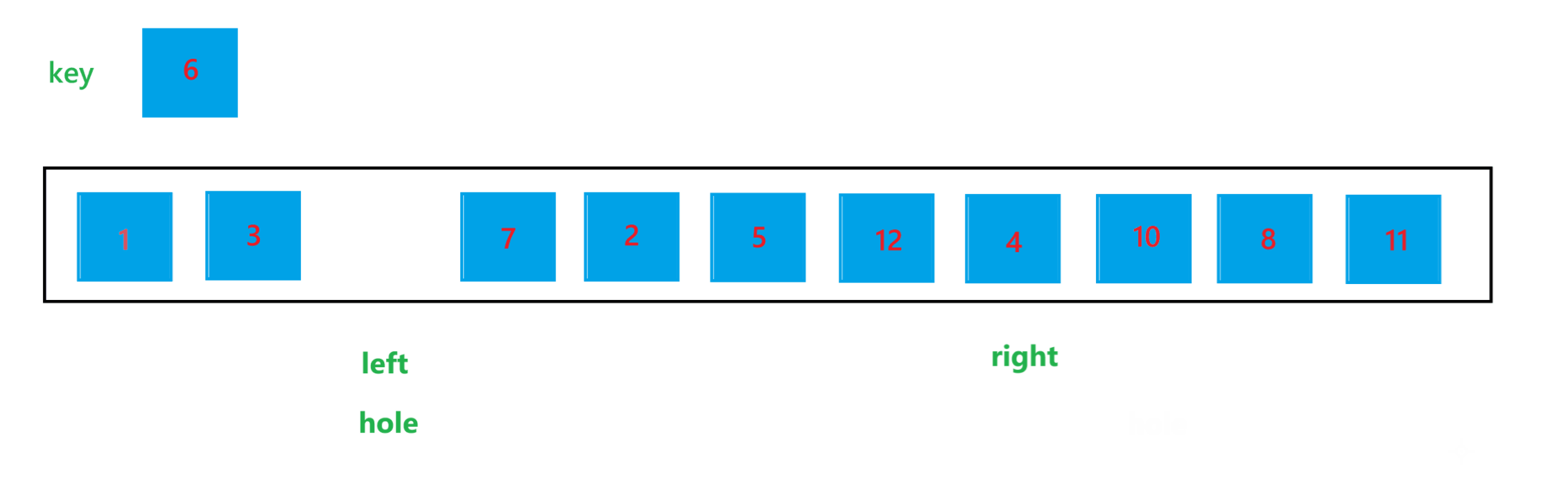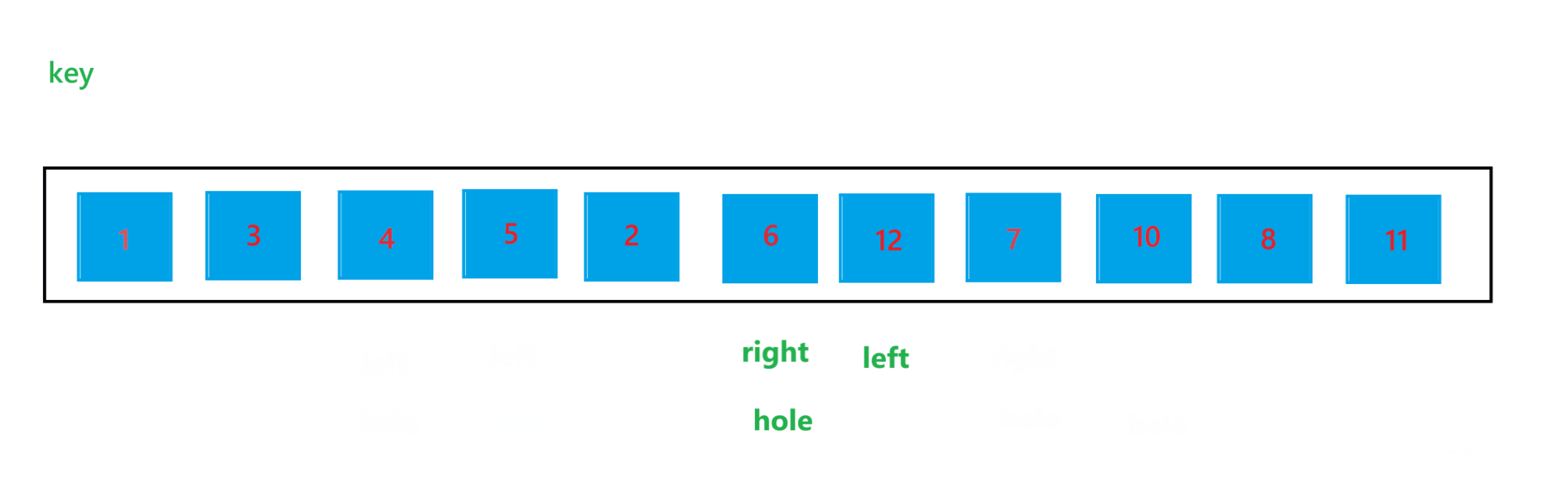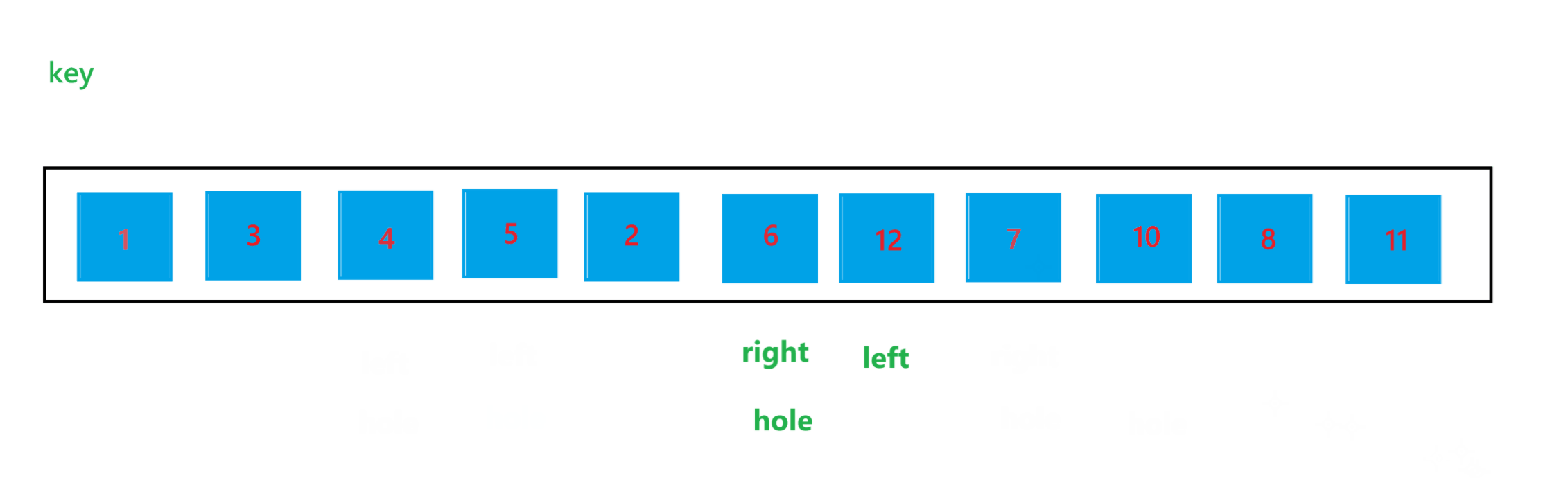
a. 首先定义一个 left 变量为某个子问题最左边元素的下标,一个 right 变量为某个子问题最右边元素的下标,一个整型变量 hole 代表坑位,一个整型变量 key 代表要比较的关键值。
b. 初始定义 hole 为 left,然后让 right 找比 key 小的元素,只要 arr[right] >= key 值,那就让 right--,找到之后,让 arr[hole] = arr[right],然后让 hole = right,让 right 位置变为新的坑位
c. 然后让 left 找比 key 值大的元素,只要 arr[left] <= key,就让 left++,找到之后,让 arr[hole] = arr[left],然后让 hole = left,再让 left 变为新的坑位
d. 依次执行上述过程,直到 left >= right 为止
e. 执行完上述过程之后,hole 所指向元素的左边都是比 key 值小的元素,右边都是比 key 值大的元素,最后不要忘记让 arr[hole] = key
由于每次都是将元素放到 hole 指向的位置,hole 看起来就像一个坑位,所以被形象的称为挖坑法。用挖坑法解决一次子问题的过程如图所示:
2) 代码
快速排序主函数:
void QuickSort(int* arr, int left, int right)
{if (left >= right){return;}int keyi = _QuickSort(arr, left, right);QuickSort(arr, left, keyi - 1);QuickSort(arr, keyi + 1, right);
}
解决某个子问题的子函数:
(1) 双指针法:
void Swap(int* x, int* y)
{int tmp = *x;*x = *y;*y = tmp;
}int _QuickSort(int* arr, int left, int right)
{int prev = left, cur = prev + 1;while (cur <= right){if (arr[cur] < arr[left]){Swap(&arr[cur], &arr[++prev]);}cur++;}//把left的值放到基准值位置Swap(&arr[left], &arr[prev]);return prev;
}(2) hoare版本:
int _QuickSort(int* arr, int left, int right)
{int keyi = left;left++;while (left <= right){//左边找大while (left <= right && arr[left] < arr[keyi])left++;//右边找小while (left <= right && arr[right] > arr[keyi])right--;if (left <= right)Swap(&arr[left++], &arr[right--]);}//再交换right与keyiSwap(&arr[right], &arr[keyi]);return right;
}
(3) 挖坑法:
int _QuickSort(int* arr, int left, int right)
{int hole = left;int key = arr[left];while (left < right){while (left < right && arr[right] >= key) right--;//找比key值小的元素arr[hole] = arr[right];hole = right;while (left < right && arr[left] <= key) left++;//找比key值大的元素arr[hole] = arr[left];hole = left;}arr[hole] = key;//最后不要忘记让坑位 = keyreturn hole;
}测试用例:
#include<stdio.h>
#include<stdlib.h>int main()
{int arr[10] = { 0 };//采用随机数,更加具有普遍性srand(time(NULL));int n = sizeof(arr) / sizeof(arr[0]);for (int i = 0; i < n; i++){arr[i] = rand() % (i + 1);}QuickSort(arr, 0, n - 1);for (int i = 0; i < n; i++){printf("%d ", arr[i]);}return 0;
}3) 时间复杂度与空间复杂度分析
(1) 时间复杂度
对于具有递归函数的时间复杂度,我们总是先分析在递归过程中,解决某个子问题的函数的时间复杂度,然后乘上递归的深度,就是带有递归的函数的时间复杂度。
首先我们先来分析解决某个子问题所使用的函数的时间复杂度。我们来看双指针版本的时间复杂度,由于仅有一层循环,最坏情况下,就是找最开始要进行排序的整个数组的 key 值,假设数组长度为 n,所以解决一个子问题的时间复杂度 T(n) = O(n)。
再来看递归的深度,递归的深度主要是看其递归树的高度(递归树就是将其递归展开图画出来之后,其递归过程所形成的一棵树),如果不是极端情况下,每次都基本上是在中间位置对每个子问题整个数组划分为两部分,那么其递归树是一棵二叉树,且高度是 层,所以递归的深度就是 logn 级别的。
所以快速排序的时间复杂度为 T(n) = O(nlogn)。
(2) 空间复杂度
递归函数的空间复杂度是与递归深度有关的,因为每递归一次就会为该函数开辟一次函数栈帧,所以递归深度决定了额外使用空间的次数,在时间复杂度里,我们分析了递归深度为 次,所以空间复杂度 S(n) = O(logn) 的。
2 非递归版本的快速排序
1) 算法思想
一般情况下,递归是可以与迭代(循环)相互转换的,只不过有时候使用递归比较方便,有时候使用迭代比较方便。所以,快速排序也是可以使用迭代来实现的。
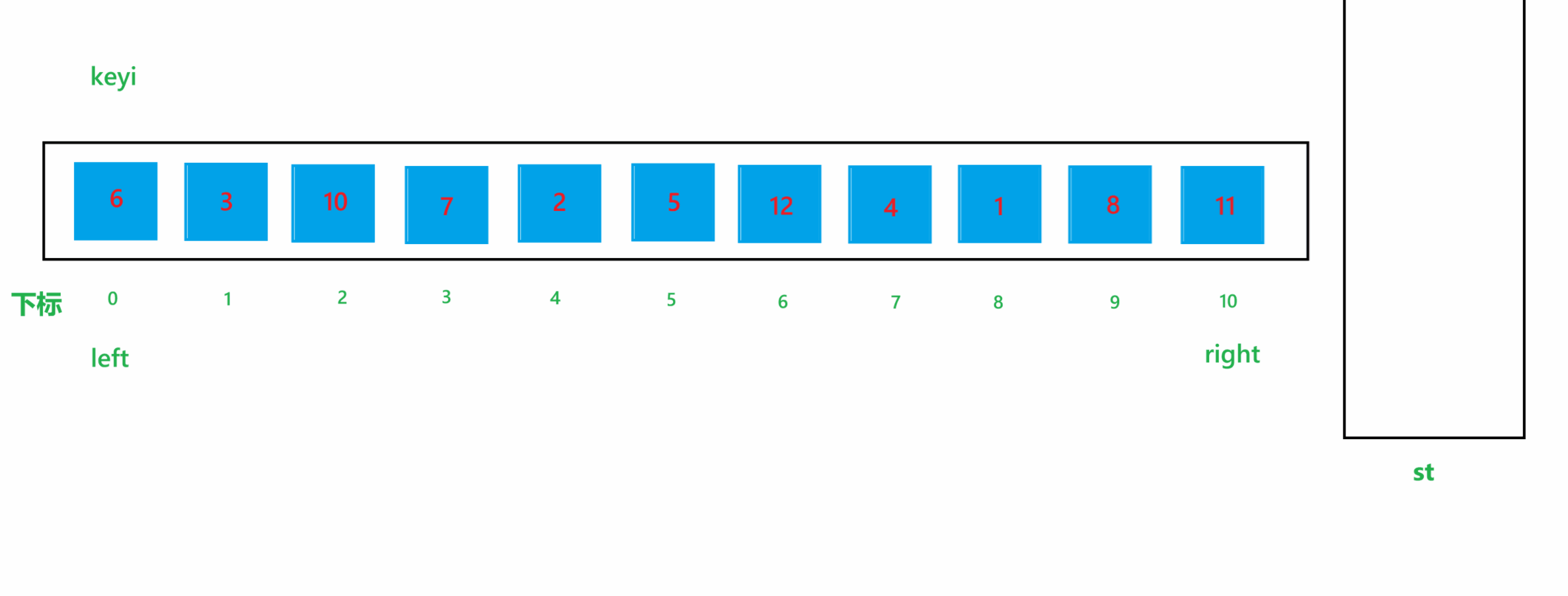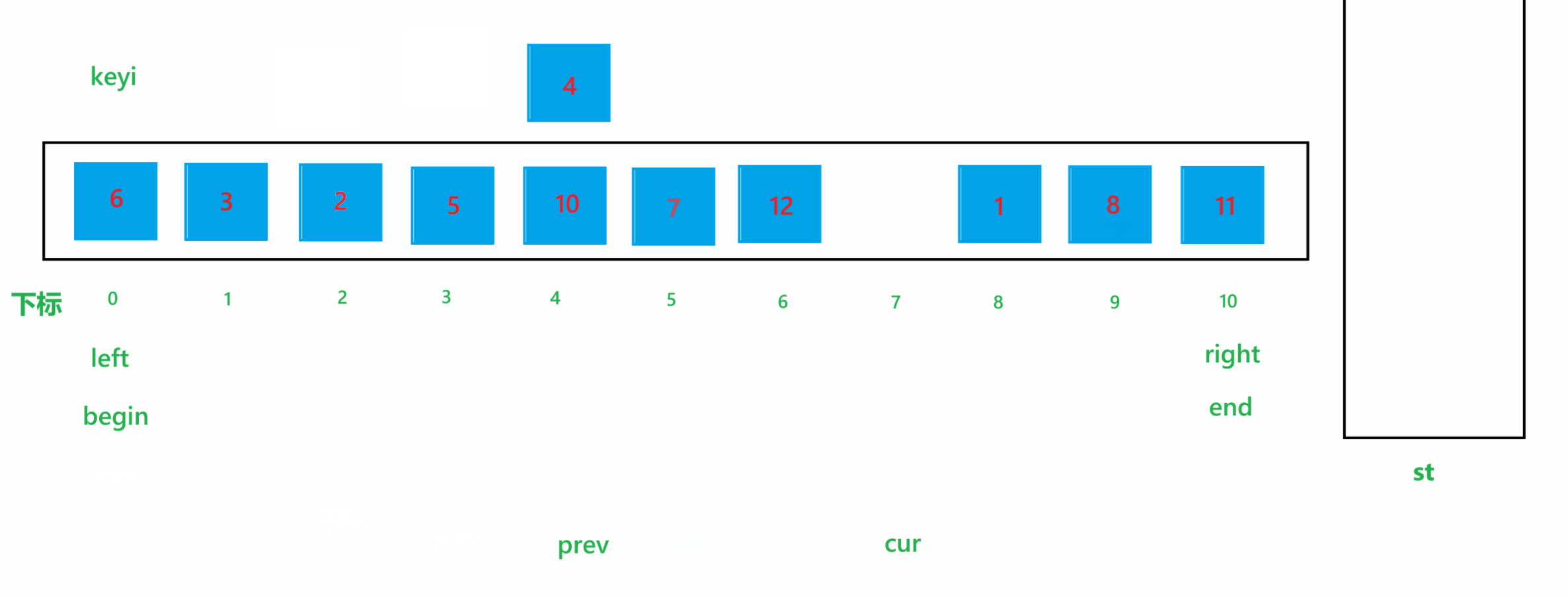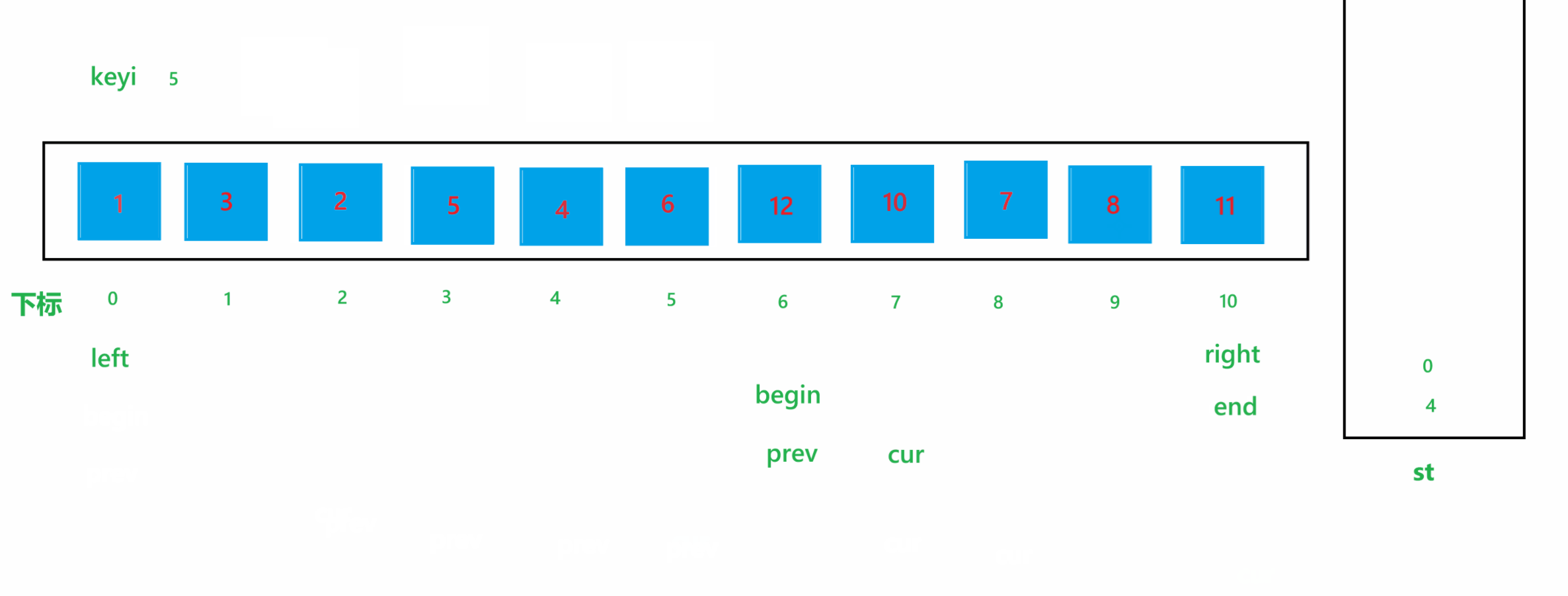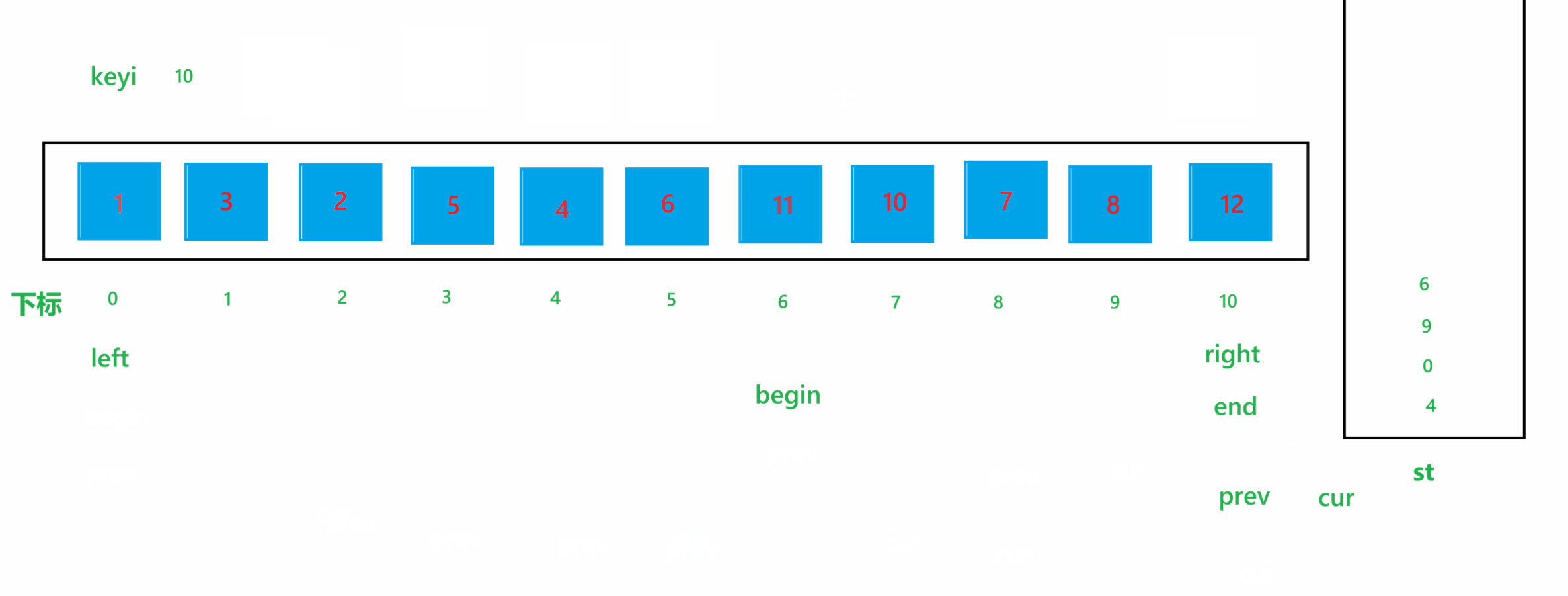
在递归版本中,我们是将对整个数组进行排序的大问题划分为对若干个子数组(数组中一段连续的区间,如大数组下标为 0~9,那么子数组的下标可以是 1~5,也可以是2~6)小问题来实现的,在迭代版本的快速排序中,我们也可以利用这一思想,但是在迭代版本中,我们是用过利用栈存储每一个子问题中子数组的左右下标来实现的:
a. 首先我们创建一个栈 st,方便后面存储下标,开始我们先让整个数组的最右边的下标 right 入栈,再让整个数组最左边的下标 left 入栈
b. 在每次循环里面,先取出栈中的第一个元素 begin ,代表某个子问题中数组的最左边的下标,然后让栈顶元素出栈
c. 再取出栈中的第二个元素 end ,代表某个子问题中数组的最右边的下标,然后让栈顶元素出栈
d. 这样就得到了要解决的子问题的数组,然后解决该子问题(这里可以使用双指针法,也可以使用挖坑法,也可使用hoare版本的方法,可以看上面的讲解)
e. 解决完子问题之后,会得到一个 key 值的下标 keyi ,之后先让 keyi - 1 入栈,再让 begin 入栈;然后再让 end 入栈,keyi + 1 入栈。
但是入栈这里有两个需要注意的点:
(1) 在每次入栈的时候需要先让每个数组的右下边先入栈,再让左下标入栈。因为之前去栈顶元素的时候,是先取出左边下标 begin,再取出右边下标 end,遵循栈后进先出的原则,需要先入栈右边下标,再入栈左边下标。
(2) 入栈之前,需要先做一次判断,判断右边下标是否严格大于左边下标。因为需要解决的子问题是一个子数组,当一个子问题不是一个子数组或者子数组中只有一个元素的时候,是不需要再排序的,所以右边的下标需要严格大于左边的下标。
最后还有一个点,就是循环的结束条件。这里的结束条件也比较好想到,就是当栈不为空时,代表还有需要解决的子问题,需继续循环,当栈为空时,代表所有的子问题已经全部解决,那么整个大问题也就全部解决了,所以就不需要循环了。最后不要忘记将栈给销毁,否则会造成内存泄漏现象。快速排序的部分迭代过程如下图所示:
2) 代码
void QuickSortNorR(int* arr, int left, int right)
{//初始化栈Stack st;StackInit(&st);//让左右序号入栈StackPush(&st, right);StackPush(&st, left);//判断栈为不为空while (!StackEmpty(&st)){//取前两个栈顶元素,作为左边和右边的元素int begin = StackTop(&st);StackPop(&st);int end = StackTop(&st);StackPop(&st);//找基准值int keyi = left;int prev = left;int cur = prev + 1;while (cur <= end){if (arr[cur] < arr[keyi] && ++prev != cur)Swap(&arr[prev], &arr[cur]);cur++;}Swap(&arr[prev], &arr[keyi]);keyi = prev;//如果基准值左边的下标大于begin,那就入栈if (keyi - 1 > begin){StackPush(&st, keyi - 1);StackPush(&st, begin);}if (keyi + 1 < end){StackPush(&st, end);StackPush(&st, keyi + 1);}}//销毁栈StackDestroy(&st);
} 3 快速排序的缺陷以及优化
1) 缺陷
前面我们提到过,快速排序的时间复杂度度是 O(nlogn) 的,但是当数组中的元素为降序或者有大量的重复元素时,其时间复杂度是会退化为 O(n^2) 的。因为如果元素是降序的话,那么就不会在中间位置划分子问题,而是只存在比 key 值小子数组的子问题,不存在比 key 值大子数组的子问题,此时的递归树就由二叉树退化为了单叉树,如:
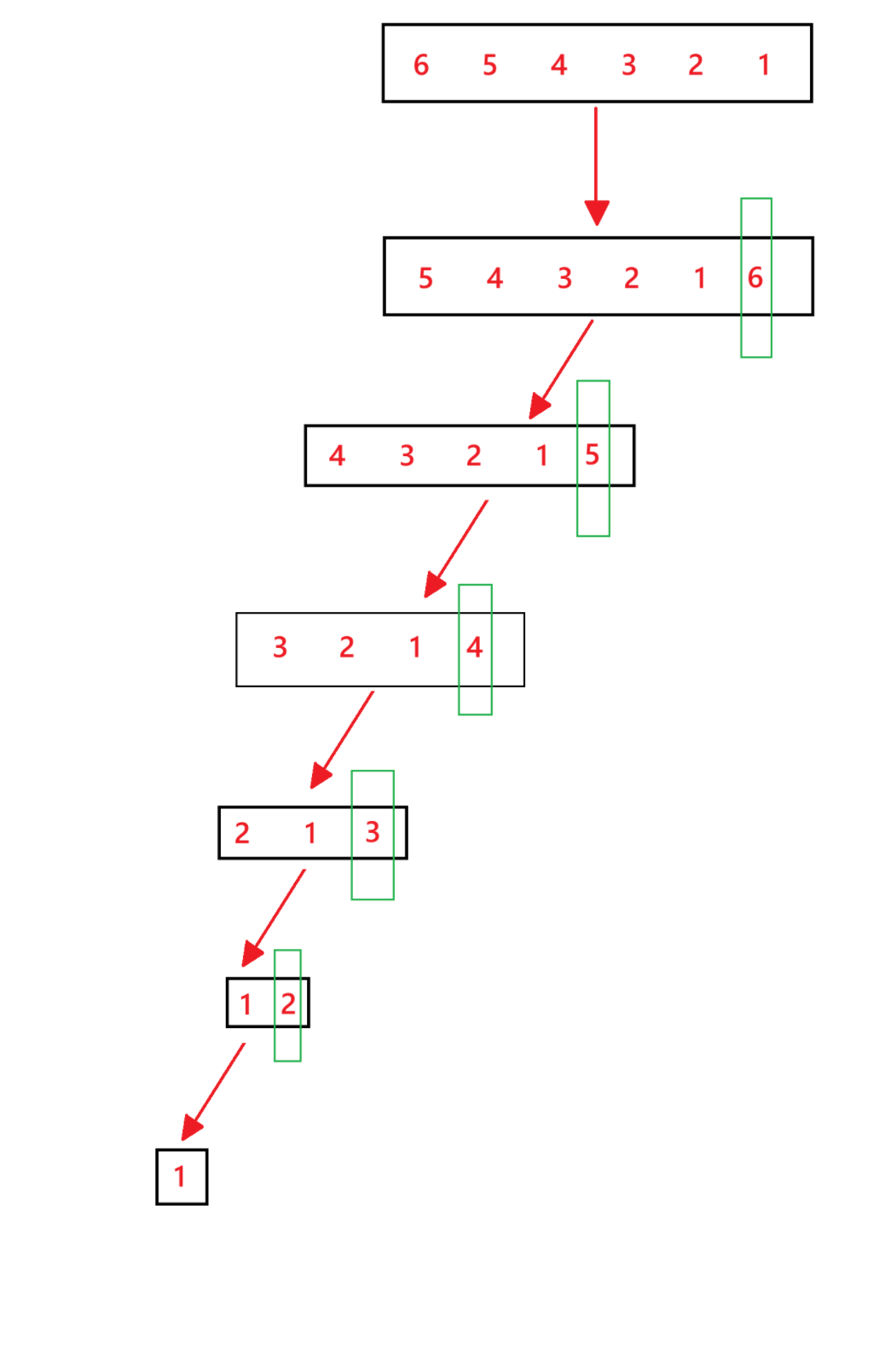
此时递归树的深度就会变为 n,而不是 logn 了。所以当数组中的元素为降序时,快速排序的时间复杂度就会退化为 O(n^2)。有大量重复元素也类似于是数组中的元素是降序的情况,可以自己试着分析一下。
2) 优化
(1) 三路划分
三路划分主要是应用于优化数组中有大量重复值的情况下导致快速排序性能下降的一种优化方法。三路主要是指将数组中的元素划分为三部分,一部分是比 key 值小的部分,一部分是与 key 值相等的部分,一部分是比 key 值大的部分,由于数组被划分为了三部分,所以叫做三路划分。其算法思想为:
a. 定义某个子问题的数组(这里假设数组为 arr)最左边元素的下标为 left ,最右边元素的下标为 right,最左边的元素值为 key,定义 cur = left + 1,begin = left,end = right
b. 当 arr[cur] < key 时,就交换 arr[cur] 和 arr[left] ,然后 cur++,left++
c. 当 arr[cur] > key 时,就交换 arr[right] 和 arr[cur] ,然后只让 right--
d. 当 arr[cur] == key 时,只让 cur++
e. 当 cur > right 时,结束循环
等循环结束之后,left 和 right 就会指向与 key 值相等的区间,那么再对 [begin, left - 1] 和 [right + 1, end] 继续递归就可以了。这里给大家一个测试用例,执行过程大家可以自己试着画一下:
数组元素: 6 1 7 6 8 6 6 9
代码
void Swap(int* x, int* y)
{int tmp = *x;*x = *y;*y = tmp;
}void QuickSort(int* arr, int left, int right)
{if (left >= right){return;}int key = arr[left];int begin = left, end = right;int cur = left + 1;while (cur <= right){if (arr[cur] < key)Swap(&arr[cur++], &arr[left++]);else if (arr[cur] > key)Swap(&arr[cur], &arr[right--]);else++cur;}//数组被划分为 [begin, left - 1] [left, right] [right + 1, end]QuickSort(arr, begin, left - 1);QuickSort(arr, right + 1, end);
}测试用例:
int main()
{int arr[] = { 2, 2, 2, 2, 1, 9, 10, 2, 2, 6, 8, 7 };int n = sizeof(arr) / sizeof(arr[0]);QuickSort(arr, 0, n - 1);for (int i = 0; i < n; i++){printf("%d ", arr[i]);}return 0;
}(2) 内省排序(IntroSort)
内省排序,英文全称为 Introspective Sort,是由 David R.Musser 在1997年提出的一中排序算法。内省排序,顾名思义,就是这个排序会自我反省,当递归深度过深,导致性能下降时,该排序算法就会采用别的排序算法来提高性能。该算法的算法思想为:
a. 开始先使用快速排序算法,不过会设计两个变量 logn 和 depth 来记录数组元素个数的 logn 是多少以及当前递归的深度
b. 当子问题的数组元素不大于 16 个元素时,采用直接插入排序
c. 当 depth > 2 * logn 时(这里可以自己设定,1 * logn 或者 3 * logn 都可以),采用堆排序
代码
void Swap(int* x, int* y)
{int tmp = *x;*x = *y;*y = tmp;
}//直接插入排序
void InsertSort(int* arr, int n)
{for (int i = 1; i < n; i++){int end = i - 1;int tmp = arr[i];while (end >= 0){if (tmp < arr[end]){arr[end + 1] = arr[end];--end;}else break;}arr[end + 1] = tmp;}
}//向下调整函数
void AdjustDown(int* arr, int n, int parent)
{int child = 2 * parent + 1;if (child + 1 < n && arr[child] < arr[child + 1]){child++;}while (child < n){if (arr[child] > arr[parent]){Swap(&arr[parent], &arr[child]);parent = child;child = 2 * parent + 1;}elsebreak;}
}//堆排序
void HeapSort(int* arr, int n)
{for (int i = (n - 1 - 1) / 2; i >= 0; i--){AdjustDown(arr, n, i);}int end = n - 1;while (end >= 0){Swap(&arr[0], &arr[end--]);AdjustDown(arr, end + 1, 0);}
}//内省排序
void IntroSort(int* arr, int left, int right, int depth, int defaultdepth)
{if (left >= right) return;//数组元素不超过16个时,采用直接插入排序if (right - left + 1 <= 16){InsertSort(arr + left, right - left + 1);return;}//如果递归深度超过标准,采用堆排序if (depth > defaultdepth){HeapSort(arr + left, right - left + 1);return;}//采用快速排序++depth;//递归深度需要 +1int prev = left, cur = left + 1;while (cur <= right){if (arr[cur] < arr[left] && ++prev != cur) Swap(&arr[cur], &arr[prev]);++cur;}Swap(&arr[left], &arr[prev]);//[left, prev - 1] prev [prev + 1, right]IntroSort(arr, left, prev - 1, depth, defaultdepth);IntroSort(arr, prev + 1, right, depth, defaultdepth);
}//快排主函数
void QuickSort(int* arr, int left, int right)
{int depth = 0;//记录当前递归的深度int logn = 0;//记录数组元素个数的 logn 是多少int N = right - left + 1;for (int i = 1; i < N; i *= 2){logn++;}IntroSort(arr, left, right, depth, 2 * logn);
}测试用例:
int main()
{int arr[100] = { 0 };//采用随机数,更加具有普遍性srand(time(NULL));int n = sizeof(arr) / sizeof(arr[0]);for (int i = 0; i < n; i++){arr[i] = rand() % (i + 1);}QuickSort(arr, 0, n - 1);for (int i = 0; i < n; i++){printf("%d ", arr[i]);}return 0;
}4 总结
快速排序是特别重要的一个排序算法,因为其排序性能特别好,所以在许多语言官方的排序函数底层都是使用的快速排序的算法思想,比如:C++ 中 STL (后面C++ 会讲解)里面的sort函数,使用的就是内省排序算法思想。所以,大家一定要把快速排序学好,对于后面学习非常有帮助。
相关文章:

【C】初阶数据结构13 -- 快速排序
本篇文章主要讲解经典的排序算法 -- 快速排序算法 目录 1 递归版本的快速排序 1) 算法思想 (1) hoare 版本 (2) 双指针版本 (3) 挖坑法 2) 代码 3) 时间复杂度…...

Spring Boot 3.4 实战指南:从性能优化到云原生增强
一、核心新特性概览 Spring Boot 3.4 于 2024 年 11 月正式发布,带来 6 大维度的 28 项改进。以下是实战开发中最具价值的特性: 1. 性能革命:虚拟线程与 HTTP 客户端优化 虚拟线程支持:Java 21 引入的虚拟线程在 Spring Boot 3…...

Git分支重命名与推送参数解析
这两个参数的解释如下: git branch -M master 中的 -M 参数 -M 是 --move --force 的组合简写,表示强制重命名当前分支为 master。如果当前分支已经存在名为 master 的分支,-M 会强制覆盖它(慎用,可能导致数据丢失&…...

深度学习中的预训练与微调:从基础概念到实战应用全解析
摘要 本文系统解析深度学习中预训练与微调技术,涵盖核心概念、技术优势、模型复用策略、与迁移学习的结合方式,以及微调过程中网络参数更新机制、模型状态分类等内容。同时深入分析深层神经网络训练难点如梯度消失/爆炸问题,为模型优化提供理…...

EMC-148.5MHz或85.5辐射超标-HDMI
EMC 148.5MHz或85.5辐射超标-HDMI 遇到了一台设备过不了EMC ,经排查主要是显示器的HDMI问题 解决办法看看能否更换好一点的HDMI线缆...
:团队协作最佳实践)
DeepSeek系列(9):团队协作最佳实践
团队知识库构建 在知识经济时代,团队知识的有效管理和传递是组织核心竞争力的关键。DeepSeek可以成为打造高效团队知识库的得力助手,让知识管理从繁重工作变为自动化流程。 知识库架构设计 多层次知识结构 一个高效的团队知识库应具备清晰的层级结构,DeepSeek可以协助:…...

信息系统项目管理工程师备考计算类真题讲解十
一、立项管理 1)折现率和折现系数:折现也叫贴现,就是把将来某个时间点的金额换算成现在时间点的等值金额。折现时所使用的利率叫折现率,也叫贴现率。 若n年后能收F元,那么这些钱在现在的价值,就是现值&am…...

第1章 基础知识
1.1 机器语言 1.2 汇编语言的产生 用汇编语言编写程序的工作过程如下: 1.编写程序:汇编程序包括汇编指令、伪指令、其他符号,如下图。其中,“伪指令”并不是由计算机直接执行的指令,而是帮助编译器完成“编译”的符号。 2.编译:将汇编程序转换成机器码。 3.计算机执行。 …...

16.【.NET 8 实战--孢子记账--从单体到微服务--转向微服务】--微服务基础工具与技术--Github Action
GitHub Actions 是 GitHub 提供的持续集成和持续部署(CI/CD)平台,它允许我们自动化软件开发工作流程。通过 GitHub Actions,我们可以构建、测试和部署代码,而无需手动干预。 一、基本概念 1.1 Workflow(工作流) 工作…...

MySQL 事务隔离级别详解
以下是 MySQL 支持的四种事务隔离级别及其特性,按并发安全性从低到高排列: 1. 读未提交 (Read Uncommitted) 问题: 脏读 (Dirty Read):事务可读取其他事务未提交的数据。不可重复读 (Non-repeatable Read)&am…...

A. Ambitious Kid
time limit per test 1 second memory limit per test 256 megabytes Chaneka, Pak Chaneks child, is an ambitious kid, so Pak Chanek gives her the following problem to test her ambition. Given an array of integers [A1,A2,A3,…,AN][A1,A2,A3,…,AN]. In one o…...

C19-while循环及for循环等价引入
一 while的表达式 //while的表达式有三个 #include <stdio.h> int main() { int sum; int data1; //第一个表达式,条件的初始值while(data<100){ //第二个表达式,条件的临界值sumsumdata;data; //第三个表达式,条件变化}printf("0至100的和是:%d\n",sum);…...

华为盘古OS深度评测:构建AI自进化系统的实践密码
华为盘古OS通过分布式AI内核与自适应学习框架的深度耦合,重新定义操作系统级智能能力。实测显示其AI任务调度效率较传统系统提升17倍,本文从智能体编排、持续学习机制、端云协同架构三个维度,解析如何基于DevKit 3.0打造具备认知进化能力的下…...

SpringBoot UserAgentUtils获取用户浏览器 操作系统设备统计 信息统计 日志入库
介绍 UserAgentUtils 是于处理用户代理(User-Agent)字符串的工具类,一般用于解析和处理浏览器、操作系统以及设备等相关信息,这些信息通常包含在接口请求的 User-Agent 字符串中。 这个库可以用于解析用户代理头,以提…...

PCL绘制点云+法线
读取的点云ASCII码文件,每行6个数据,3维坐标3维法向 #include <iostream> #include <fstream> #include <vector> #include <string> #include <pcl/point_types.h> #include <pcl/point_cloud.h> #include <pc…...

DataStreamAPI实践原理——计算模型
引入 Apache Flink 是一个框架和分布式处理引擎,用于在 无边界 和 有边界 数据流上进行有状态的计 算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。Flink可以处理批数据也可以处理流数据,本质上,流处理…...
)
【那些年踩过的坑】Docker换源加速详细教程(截至2025年4月)
由于各种网络政策,在国内访问DockerHub速度会非常缓慢,大家一般都会采取更换镜像源的方式来进行加速。但是,2024.6之后,由于政策的加强,大部分常见的镜像源已经无法使用,可能在更换镜像源后出现如下报错信息…...

【MCP】详细了解MCP协议:和function call的区别何在?如何使用MCP?
本文介绍了MCP大模型上下文协议的的概念,并对比了MCP协议和function call的区别,同时用python sdk为例介绍了mcp的使用方式。 1. 什么是MCP? 官网:https://modelcontextprotocol.io/introduction 2025年,Anthropic提出…...
)
交换机之配置系统基本信息(Basic Information of the Configuration System for Switches)
交换机之配置系统基本信息 本文章中的信息都是基于一些特定实验环境写的。文章中使用的所有设备最初均采用缺省配置启动。如果不按初始配置,有可能会导致本文中的部分或全部步骤失败。如果您使用的是真实网络设备,请确保您已经了解所有使用过的命令影响。…...

贝叶斯算法学习
贝叶斯算法学习 贝叶斯算法基础与原理应用场景主要分类优缺点简单示例代码实现 贝叶斯算法是基于贝叶斯定理的一种统计学习方法,在机器学习、数据挖掘、自然语言处理等领域有广泛应用。以下是其原理、应用和示例的详细介绍: 贝叶斯算法基础与原理 贝…...

Java 日志:掌握本地与网络日志技术
日志记录是软件开发中不可或缺的一部分,它为开发者提供了洞察应用程序行为、诊断问题和监控性能的手段。在 Java 生态系统中,日志框架如 Java Util Logging (JUL)、Log4j 和 Simple Logging Facade for Java (SLF4J) 提供了丰富的功能。然而,…...

线程池单例模式
线程池的概念 线程池是一种线程使用模式。 一种线程使用模式。线程过多会带来调度开销,进而影响缓存局部性和整体性能。而线程池维护着多个线程,等待着监督管理者分配可并发执行的任务。…...

物联网安全解决方案介绍:有效利用现有的下一代防火墙
管理物联网设备安全的挑战 如今,随着IoT(物联网)的普及,可以集中管理相机、打印机、传感器、电器、机床等各种设备,并分析和有效利用从这些设备收集的数据。这些设备已成为商业环境中不可或缺的一部分,但设备的多样化使其难以管理。与PC、服务器和网络设备不同,识别物联…...

Java社区门诊系统源码 SaaS医院门诊系统源码 可上线运营
Java社区门诊系统源码 SaaS医院门诊系统源码 医院门诊系统适用于:社区卫生服务站、门诊部、诊所、村卫生室等,有上百家医疗机构正常使用;包括医保结算。 系统功能 (一)后端管理系统功能 用户管理:提供用…...

如何在 Windows 10 中使用 WSL 和 Debian 安装 Postgresql 和 Postgis
安装 Postgresql 和 Postgis 的常规方法需要设置多个二进制文件,并且工作流程通常在图形用户界面 (GUI) 上进行。我们希望找到一种在 Windows 10 中安装 Postgresql 和 Postgis 的方法,同时保留 Linux 的 shell 体验。本教程展示了在 Windows 10 中的 De…...

[论文解析]Mip-Splatting: Alias-free 3D Gaussian Splatting
Mip-Splatting: Alias-free 3D Gaussian Splatting 论文地址:https://arxiv.org/abs/2403.17888 源码地址:https://github.com/autonomousvision/mip-splatting 项目地址:https://niujinshuchong.github.io/mip-splatting/ 论文解读 两个主…...

MongoDB 入门使用教程
MongoDB 入门使用教程 MongoDB 是一个开源的 NoSQL 数据库,使用文档(JSON-like)存储数据,与传统的关系型数据库不同,它不依赖表结构和行列的约束。MongoDB 提供了强大的查询能力,支持高效的数据存储和检索…...

PowerBI动态路径获取数据技巧
PowerBI动态路径获取数据技巧 场景一:同事接力赛——不同电脑共用模板 (想象一下:小王做完报表要传给小李,结果路径总对不上怎么办?) 这种情况就像接力赛交接棒,每台电脑的账户名不同࿰…...

【数据结构】优先级队列
目录 1. 优先级队列概念 2. 优先级队列的模拟实现 2.1 堆的概念 2.2 堆的存储方式 2.3 堆的创建 2.3.1 向下调整的时间复杂度 2.3.2 建堆时间复杂度 2.3.3 向上调整的时间复杂度 2.4 堆的插入与删除 3. 堆的应用 4. 常用接口介绍 4.1 PriorityQueue的特性 4.2 Pri…...

Myweb项目——面试题总结
一.项目描述 项⽬概述:本项⽬在云服务上开发了⼀个后端服务器与前端⻚⾯为⼀体的⾳乐专辑 鉴赏⽹站,旨在为⽤⼾提供丰富的⾳乐专辑信息展⽰和优 质的浏览体验。 主要内容及技术: 后端开发:利⽤ C 语⾔构建后端服务器,…...
)
用高德API提取广州地铁线路(shp、excel)
目录 结果示例html文件——直观看出输出的效果excel文件——包括地铁的具体信息完整代码网络上现有的地铁数据要么过于老旧且不便于更新,要么过于定制化限定于具体的城市无法灵活调整得到自己真正想要的那部份数据。而使用高德的API可以非常方便得到全国各地的地铁数据,而且可…...

leetcode110 平衡二叉树
一棵高度平衡二叉树定义为:一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过1。 二叉树节点的深度:指从根节点到该节点的最长简单路径边的条数。二叉树节点的高度:指从该节点到叶子节点的最长简单路径边的条数。 递归:…...

二、信息时代社会结构的转变
到了信息时代,以及在核武器的前提下,上述的社会结构的逻辑,就有了一个根 本性的转变,就是暴力的成本和收益,都在下降。 暴力的成本在降低。比如说枪支,它的制造和分发都变得非常容易。现在我们都 知道有 3D 打印,它就好像工业时代的印刷机,印刷圣经或者书籍,使知识更加 普及和容…...

Vue2+ElementUI实现无限级菜单
使用Vue2和ElementUI实现无限级菜单,通常菜单数据以树形结构存储,每个菜单包含多个子菜单 ,子菜单又可以继续包含更深层次的子菜单项。所以,需要使用递归形式,完成子项菜单的渲染。 这里,结合Element UI界面的el-menu和el-submenu组件来构建菜单结构,有子菜单时使用el-s…...

YTJ笔记——FFT、NCC
FFT算法 快速傅里叶算法 为了计算两个多项式相乘(卷积),将多项式系数表示法转换成点值表示法 F(g(x)∗f(x))F(g(x))F(f(x)) 超详细易懂FFT(快速傅里叶变换)及代码实现_傅立叶变换编程-CSDN博客 NCC算法…...

模型 隐含前提
系列文章分享模型,了解更多👉 模型_思维模型目录。隐藏的思维地基,决策的无声推手。 1 隐含前提模型的应用 1.1 金融投资决策—科技股估值隐含前提的验证 行业:金融投资 应用方向:投资逻辑验证 背景解读࿱…...

大模型微调与蒸馏的差异性与相似性分析
大模型微调与蒸馏的差异性分析 一、定义与核心目标差异 大模型微调 在预训练大模型基础上,通过少量标注数据调整参数,使模型适应特定任务需求。核心目标是提升模型在特定领域的性能,例如医疗影像分析或金融预测。该技术聚焦于垂直场景的精度…...
)
Ubuntu下安装vsode+qt搭建开发框架(一)
Ubuntu下安装vsode+qt搭建开发框架(一) g++的编译环境,这里不介绍,可点击这里查看 查看一下当前的g++环境 g++ --version g++ (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0 Copyright (C) 2021 Free Software Foundation, Inc. This is free software; see the source for copyin…...

单片机-89C51部分:3、创建工程
飞书文档https://x509p6c8to.feishu.cn/wiki/Mzhnwb1qni6YkykJtqXc17XMnre 创建工程 首先创建一个文件夹,用来存放工程文件,文件夹名称最好为英文,例如Demo1。 打开软件KEIL,上方菜单栏选择Project ->new uVision Project&am…...

从零实现 registry.k8s.io/pause:3.8 镜像的导出与导入
以下是为 registry.k8s.io/pause:3.8 镜像的导出与导入操作定制的完整教程,适用于 Kubernetes 集群中使用 containerd 作为容器运行时的场景。本教程包含详细步骤、常见问题解析及注意事项。 从零实现 registry.k8s.io/pause:3.8 镜像的导出与导入 背景说明 Kuber…...

详解Adobe Photoshop 2024 下载与安装教程
Adobe Photoshop下载安装和使用教程 Adobe Photoshop,简称“PS”,是由Adobe Systems开发和发行的图像处理软件。Photoshop主要处理以像素所构成的数字图像。使用其众多的编修与绘图工具,可以有效地进行图片编辑和创造工作,…...

thinking-intervention开源程序用于DeepSeek-R1等推理模型的思维过程干预,有效控制推理思考过程
一、软件介绍 文末提供程序和源码下载 thinking-intervention开源程序用于DeepSeek-R1等推理模型的思维过程干预,有效控制推理思考过程。基于论文 《Effectively Controlling Reasoning Models through Thinking Intervention》 实现的思维干预技术,用于…...

Qt 5.15 编译路径吐槽点
在Qt 5.15以前,勾选“Shadow build”会自动将编译文件放在同一个目录下(区分编译器类型、Qt版本、debug和release等),可将代码文件和编译文件区分开,用户不用操心。但是奇葩的是,这个功能Qt 5.15居然失效了…...

【机器学习-线性回归-3】深入浅出:简单线性回归的概念、原理与实现
在机器学习的世界里,线性回归是最基础也是最常用的算法之一。作为预测分析的基石,简单线性回归为我们理解更复杂的模型提供了完美的起点。无论你是机器学习的新手还是希望巩固基础的老手,理解简单线性回归都至关重要。本文将带你全面了解简单…...
:MCP客户端高级开发)
【MCP Node.js SDK 全栈进阶指南】中级篇(5):MCP客户端高级开发
在前面的系列文章中,我们主要关注了服务器端的开发,包括基础服务器构建、资源设计、身份验证与授权以及错误处理与日志系统。本篇文章将转向客户端,探讨MCP TypeScript-SDK在客户端开发中的高级应用。 客户端开发是MCP应用的重要组成部分,它连接了用户与服务器,提供了交互…...

RASP技术在DevOps中的安全应用
随着新技术的不断演进,DevOps开发模式不断被利用,Web应用程序的开发相比过往更高效。随之而来的是保护这些应用程序同样面临着巨大挑战,黑客的攻击手段不断多变,而DevOps团队成员却不都是安全专家,难以保证应用程序的安…...

2025.04.26-饿了么春招笔试题-第三题
📌 点击直达笔试专栏 👉《大厂笔试突围》 💻 春秋招笔试突围在线OJ 👉 笔试突围OJ 03. 魔法网格变换计数 问题描述 LYA是一位魔法研究学者,她正在研究一种特殊的魔法网格。这个网格有 n n n...

Linux线程与进程:探秘共享地址空间的并发实现与内
Linux系列 文章目录 Linux系列前言一、线程的概念二、线程与地址空间2.1 线程资源的分配2.2 虚拟地址到物理地址的转换 三 、线程VS进程总结 前言 在Linux操作系统中,线程作为CPU调度的基本单位,起着至关重要的作用。深入理解线程控制机制,是…...

数据结构手撕--【堆】
目录 编辑 定义结构体: 初始化: 插入数据: 删除: 取堆顶元素: 堆销毁: 判断堆是否为空: TopK问题: 堆其实是完全二叉树 物理结构:二叉树的层序遍历(…...

MySQL基本命令--系统+用户+表
前言:在当今数据驱动的时代,关系型数据库依然是构建信息系统的中坚力量,而MySQL作为开源领域中最广泛使用的数据库管理系统之一,以其高性能、稳定性和易用性赢得了开发者和企业的青睐。无论是在小型博客系统中承担数据存储职责&am…...