Linux——动静态库
目录
1. 动静态库基本原理
2. 认识动静态库
3. 动静态库的特点
3.1 静态库的优缺点
3.2 动态库的优缺点
4. 静态库的打包和使用
4.1 打包
4.2 使用
5. 动态库的打包和使用
5.1 打包
5.2 使用
6. 库的理解与加载
6.1 目标文件
6.2 ELF文件
6.3 ELF形成到加载
6.3.1 ELF形成可执行
6.3.2 ELF可执行文件加载
6.4 理解链接与加载
6.4.1 静态链接
6.4.2 ELF加载与进程地址空间
6.5 动态链接与动态库加载
6.5.1 进程如何看待动态库
6.5.2 进程间如何共享库
6.5.3 动态链接
1. 动静态库基本原理
动静态库的本质是可执行程序的“半成品”。
我们先来介绍可执行程序形成的过程:
step1:预处理
完成头文件展开、去注释、宏替换、条件编译等,最终形成xxx.i文件。
step2:编译
完成词法分析、语法分析、语义分析、符号汇总等,检查无误后将代码翻译成汇编指令,最终形成xxx.s文件。
step3:汇编
将汇编指令转换成二进制指令,最终形成xxx.o文件。
step4:链接
将生成的各个xxx.o文件进行链接,最终形成可执行程序。
上面四个过程,大家可以按照ISO的顺序理解记忆。
例如,用test1.c、test2.c、test3.c、test4.c以及main1.c形成可执行文件,我们需要先得到各个文件的目标文件test1.o、test2.o、test3.o、test4.o以及main1.o,然后再将这写目标文件链接起来,最终形成一个可执行程序。

如果我们在另一个项目当中也需要用到test1.c、test2.c、test3.c、test4.c和项目的main2.c或者main3.c分别形成可执行程序,那么可执行程序生成的步骤也是一样的。
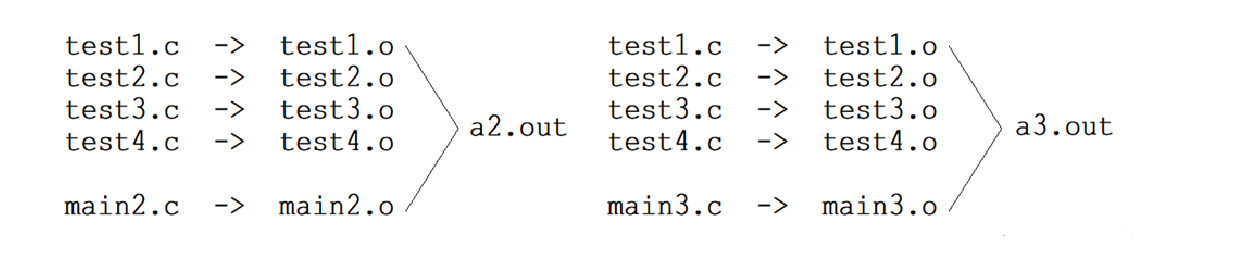
这里大家会发现,我们做了重复的工作,频繁对源文件进行操作,那有没有什么方法可以简化我们的操作呢?这里就要引入“库”的概念了。
这里的test1.c、test2.c、test3.c、test4.c,我们可以将它们的目标文件test1.o、test2.o、test3.o、test4.o进行打包,之后需要用到这四个目标文件时就可以之间链接这个包当中的目标文件了,而这个包实际上就可以称之为一个库。

实际上,所有库本质都是一堆目标文件(xxx.o)的集合,库的文件当中并不包含主函数而只是包含了大量的方法以供调用,所以说动静态库本质是可执行程序的“半成品”。
2. 认识动静态库


这里写了一段很简单的代码,足够让大家认识动静态库。
在这份代码当中我们可以通过调用printf输出Hello Linux,主要原因是gcc编译器在生成可执行程序时,将C标准库也链接进来了。
那什么是C标准库,其实我们可以通过命令查看它;
在Linux下,我们可以通过“ldd 文件名”来查看一个可执行程序所依赖的库文件。

这其中的libc.so.6就是该可执行程序所依赖的库文件,我们通过ls命令可以发现libc.so.6实际上只是一个软链接。

实际上该软链接的源文件/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2和/lib64/ld-linux-x86-64.so.2在同一个目录下,为了进一步了解,我们可以通过“file 文件名”命令来查看/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2的文件类型。

我们可以看到/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2是一个共享目标文件库(动态库又叫作共享库),后面我们可以看到它是动态链接形成的动态库,当我们去掉一个动静态库的前缀lib,再去掉后缀.so或者.a及其后面的版本号,剩下的就是这个库的名字。
- 在Linux当中,以
.so为后缀的是动态库,以.a为后缀的是静态库。 - 在Windows当中,以
.dll为后缀的是动态库,以.lib为后缀的是静态库。
而gcc/g++编译器默认都是动态链接的,若想进行静态链接,可以携带一个-static选项。
cp@hcss-ecs-348a:~/test1$ gcc -o mytest-s mytest.c -static
此时生成的可执行程序就是静态链接的了,可以明显发现静态链接生成的可执行程序的文件大小,比动态链接生成的可执行程序的文件大小要大得多。
静态链接生成的可执行程序并不依赖其他库文件,此时当我们使用ldd 文件名命令查看该可执行程序所依赖的库文件时就会看到以下信息。

此外,当我们分别查看动静态链接生成的可执行程序的文件类型时,也可以看到它们分别是动态链接和静态链接的。

3. 动静态库的特点
3.1 静态库的优缺点
静态库是程序在编译链接的时候把库的代码复制到可执行文件当中的,生成的可执行程序在运行的时候将不再需要静态库,因此使用静态库生成的可执行程序的大小一般比较大。
优点:
- 使用静态库生成可执行程序后,该可执行程序就可以独自运行,不再需要库了。
缺点:
- 使用静态库生成可执行程序会占用大量空间,特别是当有多个静态程序同时加载而这些静态程序使用的都是相同的库,这时在内存当中就会存在大量的重复代码。
3.2 动态库的优缺点
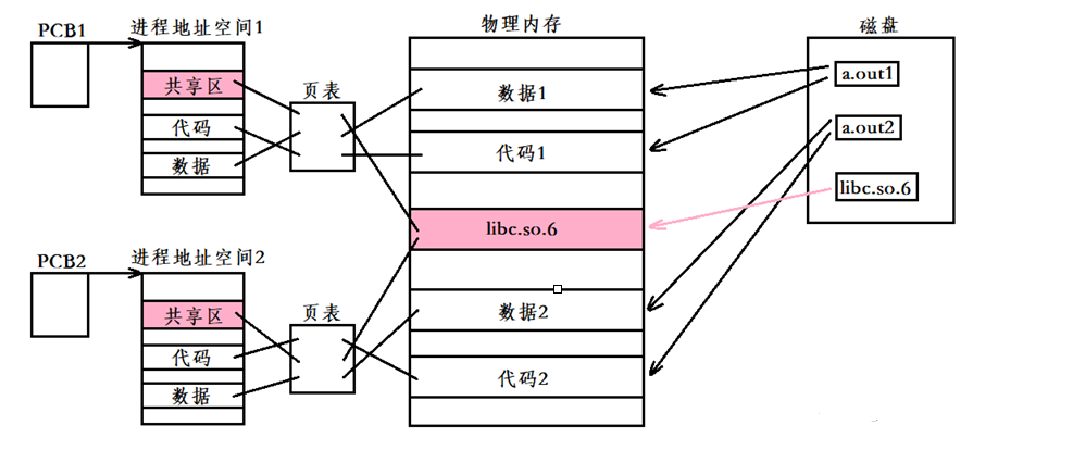
动态库是程序在运行的时候才去链接相应的动态库代码的,多个程序共享使用库的代码。一个与动态库链接的可执行文件仅仅包含它用到的函数入口地址的一个表,而不是外部函数所在目标文件的整个机器码。
在可执行文件开始运行前,外部函数的机器码由操作系统从磁盘上的该动态库中复制到内存中,这个过程称为动态链接。
动态库在多个程序间共享,节省了磁盘空间,操作系统采用虚拟内存机制允许物理内存中的一份动态库被要用到该库的所有进程共用,节省了内存和磁盘空间。
优点:
- 节省磁盘空间,且多个用到相同动态库的程序同时运行时,库文件会通过进程地址空间进行共享,内存当中不会存在重复代码。
- 减少页面交换。
缺点:
- 必须依赖动态库,否则无法运行。
- 运行加载速度相较静态库慢一些。
4. 静态库的打包和使用
4.1 打包
这里我们先来创建几个头文件和源文件。
add.h
#pragma once
extern int add(int x,int y);add.c
#include"add.h"
int add(int x,int y)
{return x+y;
}mul.h
#pragma once
extern int mul(int x,int y);mul.c
#include"mul.h"
int mul(int x,int y)
{return x*y;
}下面我们来进行打包:
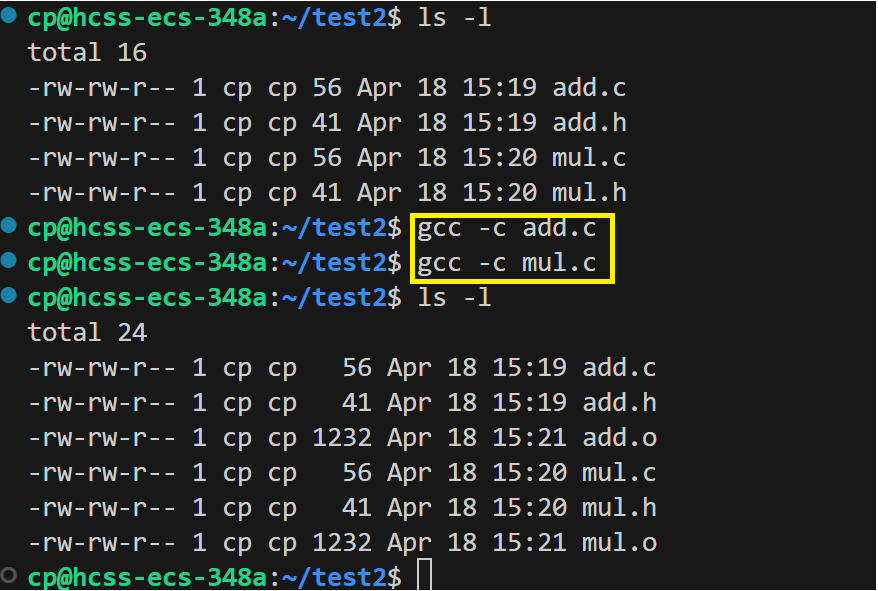
第一步:让所有源文件生成对应的目标文件
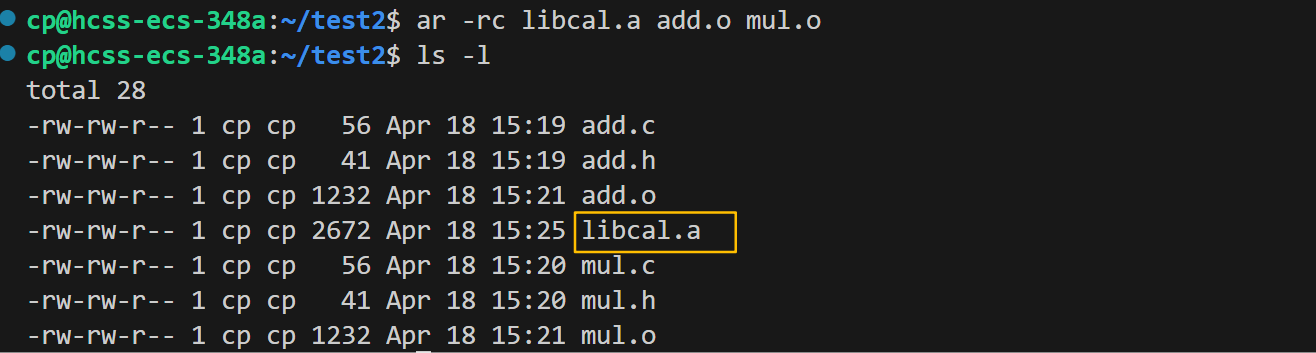
第二步:使用ar命令将所有目标文件打包为静态库
ar命令是gnu的归档工具,常用于将目标文件打包为静态库,下面我们使用ar命令的-r选项和-c选项进行打包。
此外,我们可以用ar命令的-t选项和-v选项查看静态库当中的文件。

第三步:将头文件和生成的静态库组织起来
当我们把自己的库给别人用的时候,实际上需要给别人两个文件夹,一个文件夹下面放的是一堆头文件的集合,另一个文件夹下面放的是所有的库文件。
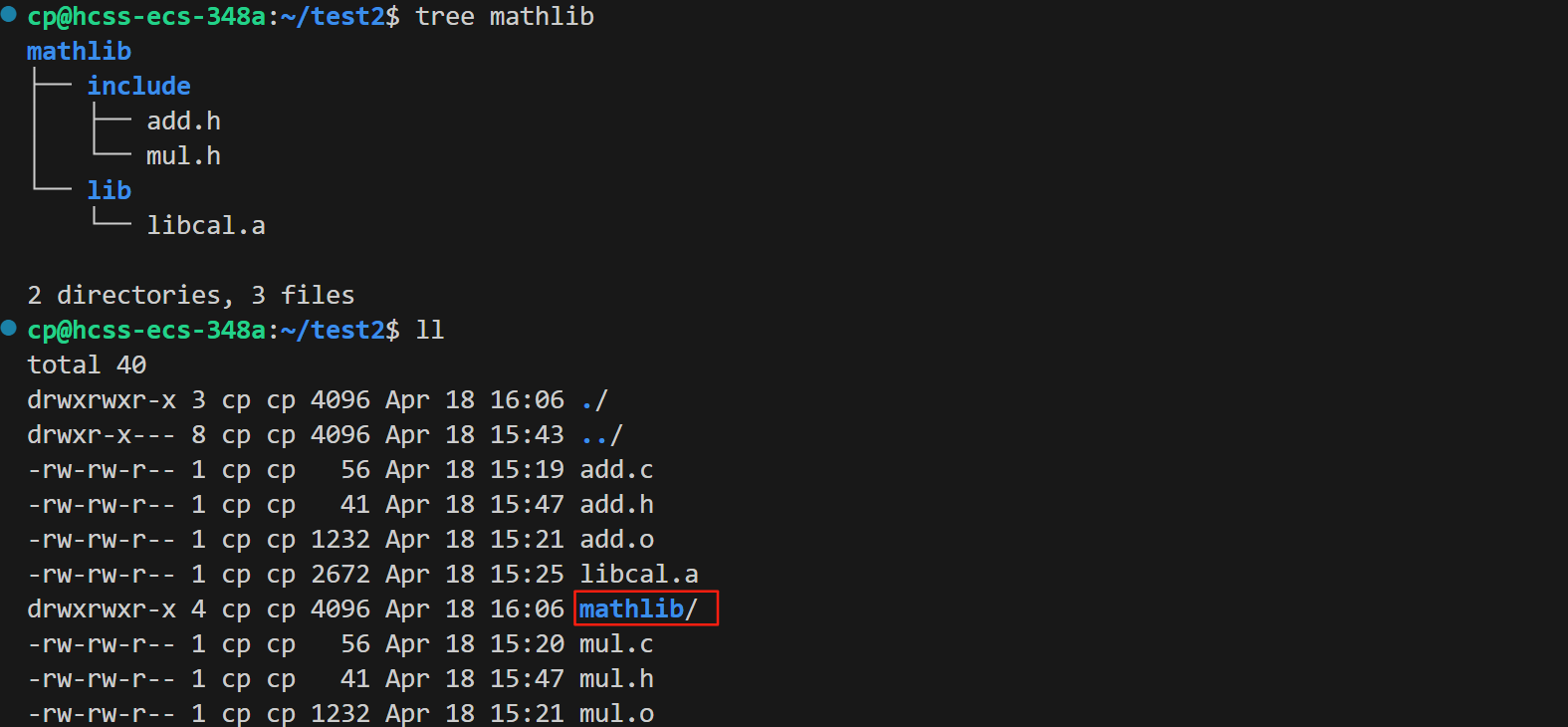
因此,在这里我们可以将add.h和mul.h这两个头文件放到一个名为include的目录下,将生成的静态库文件libcal.a放到一个名为lib的目录下,然后将这两个目录都放到mathlib下,此时就可以将mathlib给别人使用了。

打包完成后,我们可以通过tree命令来查看库结构。
4.2 使用
创建源文件main.c,编写下面这段简单的程序来尝试使用我们打包好的静态库。
#include<stdio.h>
#include<mul.h>
int main()
{int a=5;int b=6;int c=mul(a,b);printf("%d*%d=%d\n",a,b,c);return 0;
}
方法1:使用选项
此时使用gcc编译main.c生成可执行程序时需要携带三个选项:
-I:指定头文件搜索路径。-L:指定库文件搜索路径。-l:指明需要链接库文件路径下的哪一个库。
cp@hcss-ecs-348a:~/test2$ gcc main.c -I./mathlib/include -L./mathlib/lib -lcal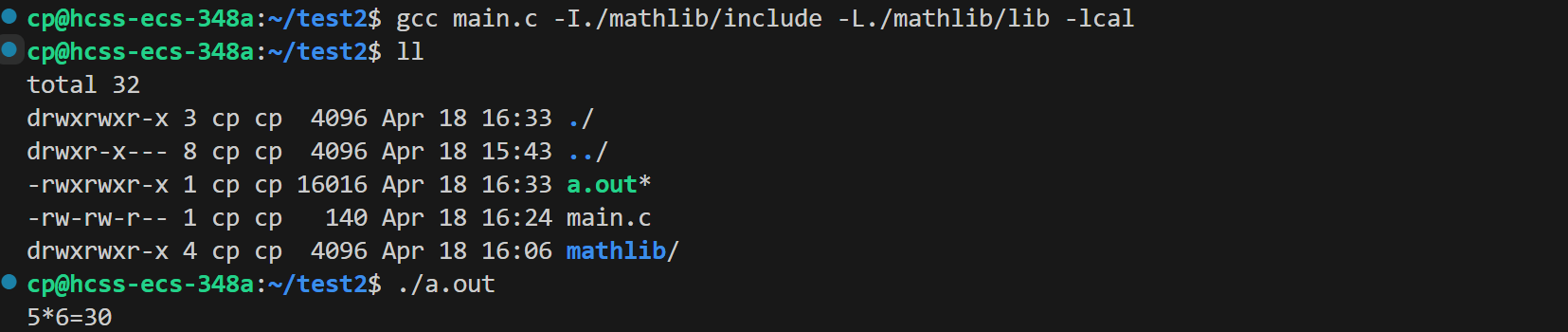
这里我们使用自己制作的库生成了可执行程序,并且完成了计算工作。
几点说明:
1.、因为编译器不知道你所包含的头文件add.h在哪里,所以需要指定头文件的搜索路径。
2.、因为头文件add.h当中只有mul函数的声明,并没有该函数的定义,所以还需要指定所要链接库文件的搜索路径。
3、实际中,在库文件的lib目录下可能会有大量的库文件,因此我们需要指明需要链接库文件路径下的哪一个库。库文件名去掉前缀lib,再去掉后缀.so或者.a及其后面的版本号,剩下的就是这个库的名字。
4、-I(大写i),-L,-l(小写l)这三个选项后面可以加空格,也可以不加空格。
到这里,其实我们已经实现了静态库,但是肯定有人会想,编译一个可执行程序还带那么多选项,是不是太麻烦了,能不能简单一点?答案是OK的,大家来看第二种方法:
方法2:把头文件和库文件拷贝到系统路径下
要实现这个方法,首先大家需要知道系统路径在哪里?


所以我们只需要将我们的头文件和库文件拷贝到系统对应路径下即可。
cp@hcss-ecs-348a:~/test1$ sudo cp mathlib/include/*.h /usr/include/cp@hcss-ecs-348a:~/test1$ sudo cp mathlib/lib/libcal.a /usr/lib/x86_64-linux-gnu
这里我们就只需要说明是哪个库就可以形成可执行程序了。
5. 动态库的打包和使用
5.1 打包
动态库的打包相对于静态库来说有一点点差别,但大致相同,我们还是利用四个文件进行打包演示:

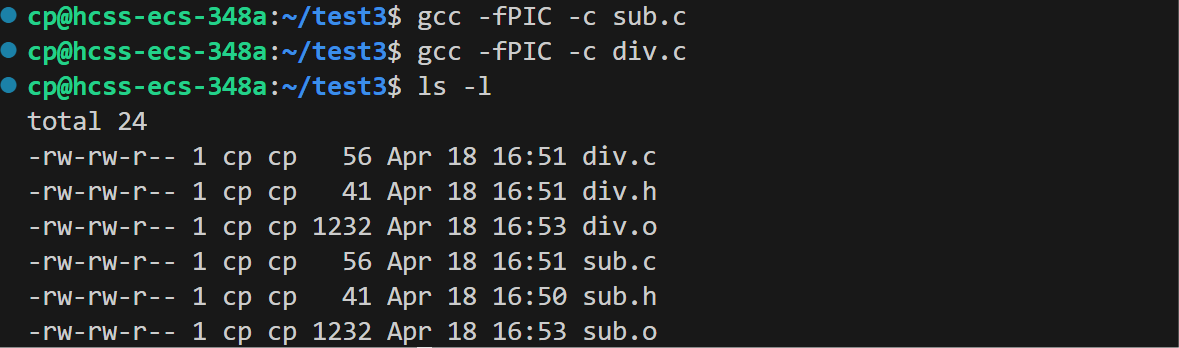
第一步:让所有源文件生成对应的目标文件
此时用源文件生成目标文件时需要携带-fPIC选项:
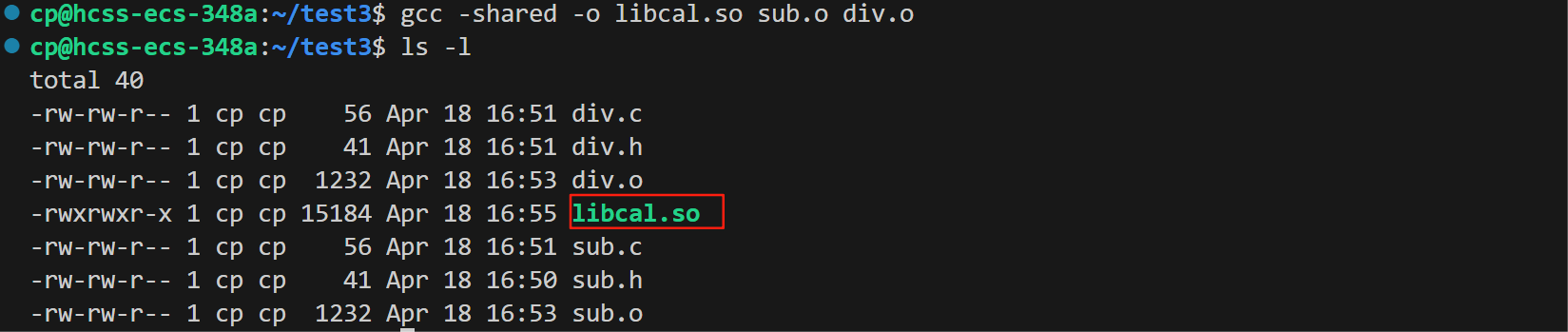
第二步:使用-shared选项将所有目标文件打包为动态库
第三步:将头文件和生成的动态库组织起来
与生成静态库时一样,为了方便别人使用,在这里我们可以将add.h和sub.h这两个头文件放到一个名为include的目录下,将生成的动态库文件libcal.so放到一个名为lib的目录下,然后将这两个目录都放到mylib下,此时就可以将mylib给别人使用了。
这里的操作和上面基本一致,大家可以类比学习。
5.2 使用
与上面一样,我们创建main.c
#include<stdio.h>
#include<div.h>
int main()
{int a=10;int b=2;int c=div(a,b);printf("%d/%d=%d\n",a,b,c);return 0;
} 
下面还是和静态库那里一样,我们使用选项:
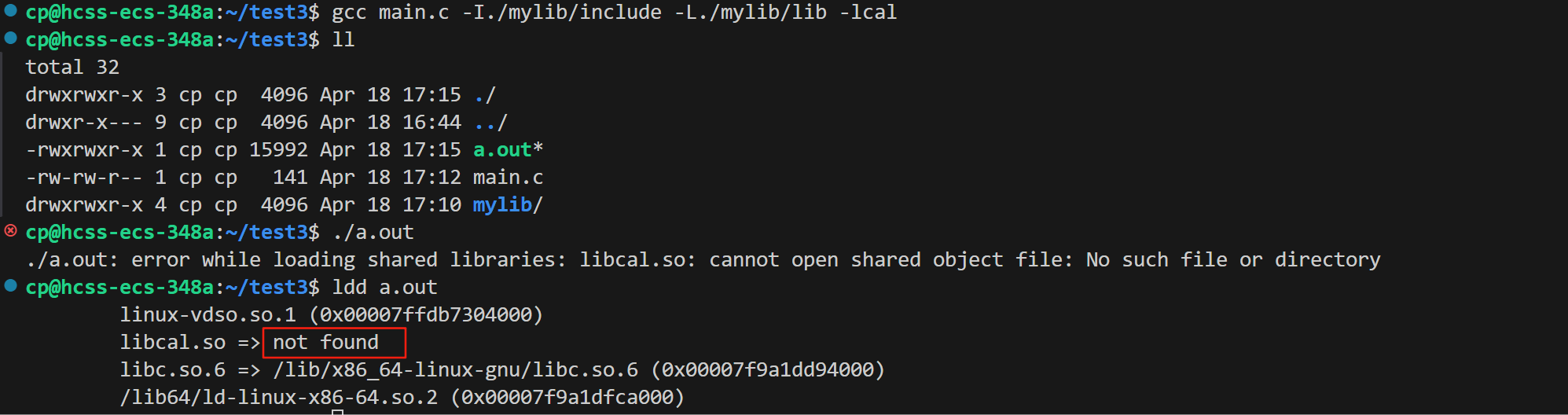
我们使用-I,-L,-l这三个选项都是在编译期间告诉编译器我们使用的头文件和库文件在哪里以及是谁,但是当生成的可执行程序生成后就与编译器没有关系了,相当于我们只告诉了gcc,而没有告诉OS;此后该可执行程序运行起来后,操作系统找不到该可执行程序所依赖的动态库,我们可以使用ldd命令进行查看,如上图所示。
那为啥静态库没有这个问题呢?其实答案前面已经说过了:
静态库是程序在编译链接的时候把库的代码复制到可执行文件当中的。这也就意味着一旦形成可执行程序,它将不再依赖静态库。
那么我们应该怎么解决呢?这里介绍一个比较简单的方法:
既然系统找不到我们的库文件,那么我们直接将库文件拷贝到系统共享的库路径下,这样一来系统就能够找到对应的库文件了。
cp@hcss-ecs-348a:~/test3$ sudo cp mylib/lib/libcal.so /lib/x86_64-linux-gnu

最后再总结一些结论
1. gcc/g++默认使用动态库(动静态库同时存在时)。如果非要静态链接,就要带-static,而且必须有静态库的存在。 如果只存在静态库,那么对于该库就只能静态链接了。
2. Linux中,默认安装的大部分都是动态库。
3. 库:应用程序=1:n
6. 库的理解与加载
6.1 目标文件
⽬标⽂件(.o文件)是⼀个⼆进制的文件,文件的格式是 ELF ,是对二进制代码的⼀种封装。
$ file hello.o
hello.o: ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV), not stripped
## file命令⽤于辨识⽂件类型。tip:动静态库、可执行程序、.o文件都是ELF格式。
6.2 ELF文件
• 可重定位文件(Relocatable File) :即xxx.o文件。包含适合于与其他⽬标文件链接来创建可执行文件或者共享⽬标文件的代码和数据。
• 可执行文件(Executable File) :即可执行程序。
• 共享⽬标文件(Shared Object File) :即xxx.so⽂件。
• 内核转储(core dumps) ,存放当前进程的执行上下文,用于dump信号触发。
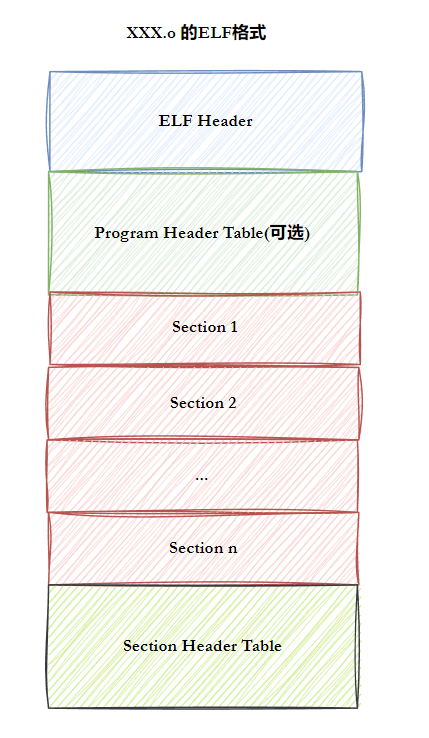
⼀个ELF文件由以下四部分组成:
• ELF头(ELF header) :描述⽂件的主要特性。其位于⽂件的开始位置,它的主要⽬的是定位⽂件的其他部分。
• 程序头表(Program header table) :列举了所有有效的段(segments)和他们的属性。表⾥记着每个段的开始的位置和位移(offset)、长度,毕竟这些段,都是紧密的放在⼆进制文件中, 需要段表的描述信息,才能把他们每个段分割开。
• 节头表(Section header table) :包含对节(sections)的描述。
• 节(Section ):ELF⽂件中的基本组成单位,包含了特定类型的数据。ELF⽂件的各种信息和 数据都存储在不同的节中,如代码节存储了可执行代码,数据节存储了全局变量和静态数据等。
6.3 ELF形成到加载
6.3.1 ELF形成可执行
• step-1:将多份 C/C++ 源代码,翻译成为⽬标 .o 文件。
• step-2:将多份 .o ⽂件section进行合并。
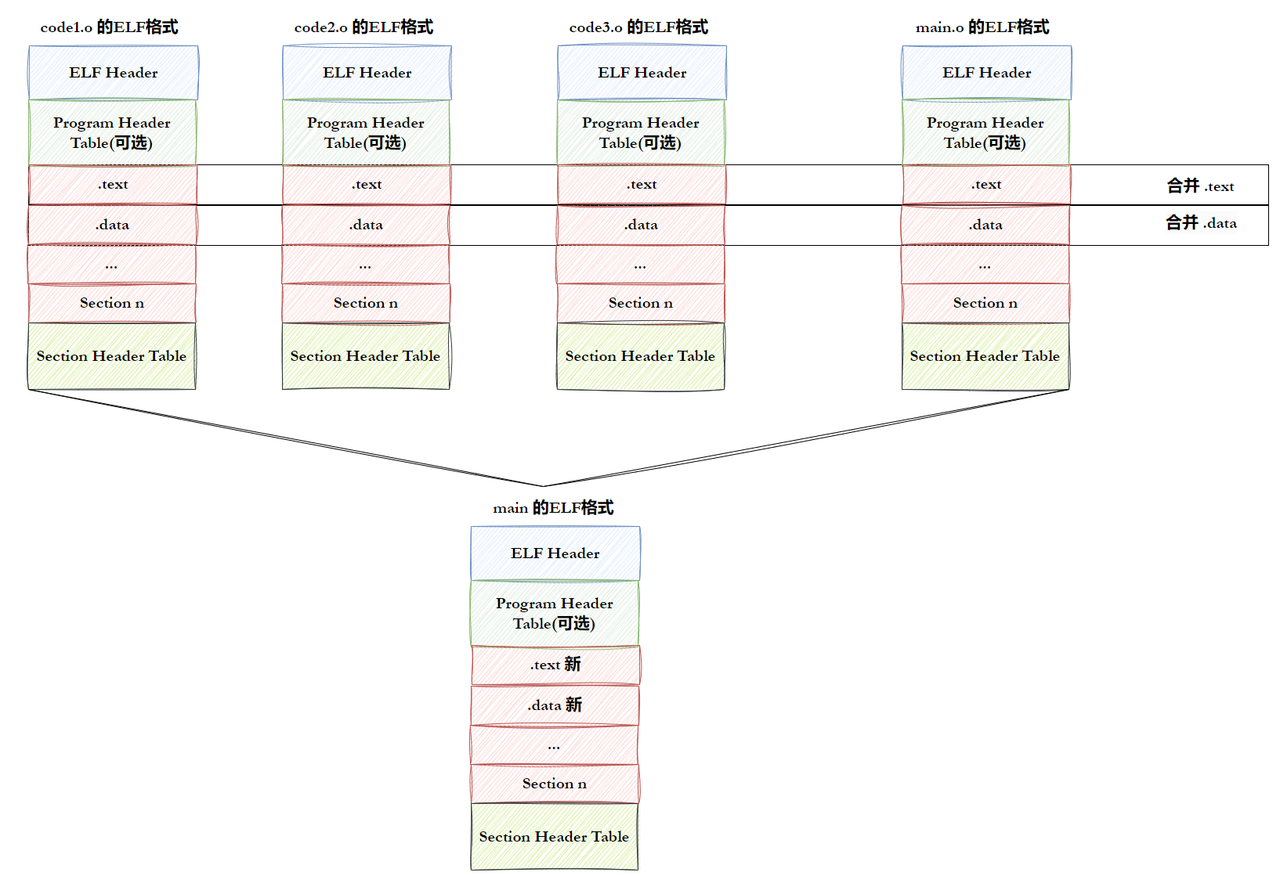
注意: • 实际合并是在链接时进行的,但是并不是这么简单的合并,也会涉及对库合并,此处不做 过多追究。
6.3.2 ELF可执行文件加载
• ⼀个ELF会有多种不同的Section,在加载到内存的时候,也会进⾏Section合并,形成segment
• 合并原则:相同属性,⽐如:可读,可写,可执⾏,需要加载时申请空间等.
• 这样,即便是不同的Section,在加载到内存中,可能会以segment的形式,加载到⼀起
• 很显然,这个合并工作也已经在形成ELF的时候,合并⽅式已经确定了,具体合并原则被记录在了 ELF的 程序头表(Program header table) 中。
# 查看可执⾏程序的section
$ readelf -S a.out
There are 31 section headers, starting at offset 0x19d8:
Section Headers:[Nr] Name Type Address OffsetSize EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 000000000000000000000000 0000000000000000 0 0 0[ 1] .interp PROGBITS 0000000000400238 00000238000000000000001c 0000000000000000 A 0 0 1[ 2] .note.ABI-tag NOTE 0000000000400254 000002540000000000000020 0000000000000000 A 0 0 4[ 3] .note.gnu.build-i NOTE 0000000000400274 000002740000000000000024 0000000000000000 A 0 0 4[ 4] .gnu.hash GNU_HASH 0000000000400298 00000298000000000000001c 0000000000000000 A 5 0 8[ 5] .dynsym DYNSYM 00000000004002b8 000002b80000000000000048 0000000000000018 A 6 1 8[ 6] .dynstr STRTAB 0000000000400300 000003000000000000000038 0000000000000000 A 0 0 1[ 7] .gnu.version VERSYM 0000000000400338 000003380000000000000006 0000000000000002 A 5 0 2[ 8] .gnu.version_r VERNEED 0000000000400340 000003400000000000000020 0000000000000000 A 6 1 8[ 9] .rela.dyn RELA 0000000000400360 000003600000000000000018 0000000000000018 A 5 0 8[10] .rela.plt RELA 0000000000400378 000003780000000000000018 0000000000000018 AI 5 24 8[11] .init PROGBITS 0000000000400390 00000390...
# 查看section合并的segment
$ readelf -l a.out
Elf file type is EXEC (Executable file)
Entry point 0x4003e0
There are 9 program headers, starting at offset 64
Program Headers:Type Offset VirtAddr PhysAddrFileSiz MemSiz Flags AlignPHDR 0x0000000000000040 0x0000000000400040 0x00000000004000400x00000000000001f8 0x00000000000001f8 R E 8INTERP 0x0000000000000238 0x0000000000400238 0x00000000004002380x000000000000001c 0x000000000000001c R 1[Requesting program interpreter: /lib64/ld-linux-x86-64.so.2]LOAD 0x0000000000000000 0x0000000000400000 0x00000000004000000x0000000000000744 0x0000000000000744 R E 200000LOAD 0x0000000000000e10 0x0000000000600e10 0x0000000000600e100x0000000000000218 0x0000000000000220 RW 200000DYNAMIC 0x0000000000000e28 0x0000000000600e28 0x0000000000600e280x00000000000001d0 0x00000000000001d0 RW 8NOTE 0x0000000000000254 0x0000000000400254 0x00000000004002540x0000000000000044 0x0000000000000044 R 4GNU_EH_FRAME 0x00000000000005a0 0x00000000004005a0 0x00000000004005a00x000000000000004c 0x000000000000004c R 4GNU_STACK 0x0000000000000000 0x0000000000000000 0x00000000000000000x0000000000000000 0x0000000000000000 RW 10GNU_RELRO 0x0000000000000e10 0x0000000000600e10 0x0000000000600e100x00000000000001f0 0x00000000000001f0 R 1Section to Segment mapping:Segment Sections...00 01 .interp 02 .interp .note.ABI-tag .note.gnu.build-id .gnu.hash .dynsym .dynstr
.gnu.version .gnu.version_r .rela.dyn .rela.plt .init .plt .plt.got .text
.fini .rodata .eh_frame_hdr .eh_frame 03 .init_array .fini_array .jcr .dynamic .got .got.plt .data .bss 04 .dynamic 05 .note.ABI-tag .note.gnu.build-id 06 .eh_frame_hdr 07 08 .init_array .fini_array .jcr .dynamic .got
为什么要将section合并成为segment?
• Section合并的主要原因是为了减少⻚⾯碎⽚,提⾼内存使⽤效率。如果不进行合并, 假设页面大小为4096字节(内存块基本⼤小,加载,管理的基本单位),如果.text部分为4097字节,.init部分为512字节,那么它们将占⽤3个⻚⾯,⽽合并后,它们只需2个页面。
• 此外,操作系统在加载程序时,会将具有相同属性的section合并成⼀个大的 segment,这样就可以实现不同的访问权限,从⽽优化内存管理和权限访问控制。
• 链接视图(Linking view) -对应节头表 Section header table
◦ ⽂件结构的粒度更细,将⽂件按功能模块的差异进⾏划分,静态链接分析的时候⼀般关注的是链接视图,能够理解ELF⽂件中包含的各个部分的信息。
◦ 为了空间布局上的效率,将来在链接⽬标⽂件时,链接器会把很多节(section)合并,规整成可执⾏的段(segment)、可读写的段、只读段等。合并了后,空间利⽤率就⾼了,否则,很小的⼀段,未来物理内存也浪费太⼤(物理内存页分配⼀般都是整数倍⼀块给 你,比如4k),所以,链接器趁着链接就把小块们都合并了。
• 执行视图(execution view) -对应程序头表 Program header table
◦ 告诉操作系统,如何加载可执行文件,完成进程内存的初始化。⼀个可执行程序的格式中, ⼀定有 program header table 。
• 说白了就是:⼀个在链接时作用,⼀个在运行加载时作⽤。
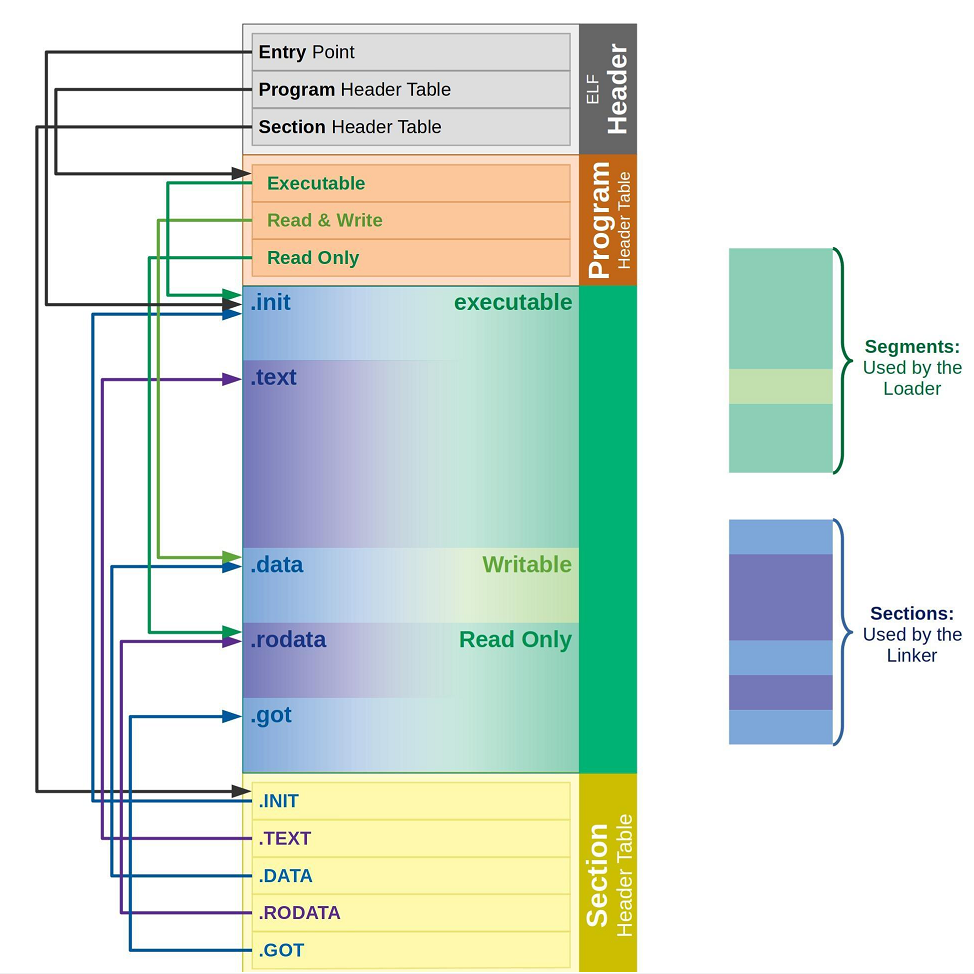
从链接视图来看:
• 命令 readelf -S hello.o 可以帮助查看ELF⽂件的节头表。
• .text节 :是保存了程序代码指令的代码节。
• .data节 :保存了初始化的全局变量和局部静态变量等数据。
• .rodata节 :保存了只读的数据,如⼀⾏C语⾔代码中的字符串。由于.rodata节是只读的,所以只能存在于⼀个可执行⽂件的只读段中。因此,只能是在text段(不是data段)中找到.rodata 节。
• .BSS节 :为未初始化的全局变量和局部静态变量预留位置
• .symtab节 :Symbol Table符号表,就是源码⾥⾯那些函数名、变量名和代码的对应关系。
• .got.plt节 (全局偏移表-过程链接表):.got节保存了全局偏移表。.got节和.plt节⼀起提供了对导入的共享库函数的访问入口,由动态链接器在运行时进行修改。对于GOT的理解,我们后面会说。
◦ 使⽤ readelf 命令查看.so⽂件可以看到该节。
从执行视图来看:
• 告诉操作系统哪些模块可以被加载进内存。
• 加载进内存之后哪些分段是可读可写,哪些分段是只读,哪些分段是可执行的。
我们可以在 ELF头中找到文件的基本信息,以及可以看到ELF头是如何定位程序头表和节头表的。
// 查看可执⾏程序
$ gcc *.o
$ readelf -h a.out
ELF Header:Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00 Class: ELF64Data: 2's complement, little endianVersion: 1 (current)OS/ABI: UNIX - System VABI Version: 0Type: DYN (Shared object file)Machine: Advanced Micro Devices X86-64Version: 0x1Entry point address: 0x1060Start of program headers: 64 (bytes into file)Start of section headers: 14768 (bytes into file)Flags: 0x0Size of this header: 64 (bytes)Size of program headers: 56 (bytes)Number of program headers: 13Size of section headers: 64 (bytes)Number of section headers: 31Section header string table index: 30
对于 ELF HEADER 这部分来说,我们只⽤知道其作⽤即可,它的主要目的是定位文件的其他部分。
6.4 理解链接与加载
6.4.1 静态链接
• ⽆论是自己的.o,还是静态库中的.o,本质都是把.o文件进行链接的过程。
• 所以:研究静态链接,本质就是研究.o是如何链接的。
链接其实就是将编译之后的所有⽬标⽂件连同⽤到的⼀些静态库运行时库组合,拼装成⼀个独⽴ 的可执行文件。其中就包括地址修正,当所有模块组合在⼀起之后,链接器会根据我 们的.o⽂件或者静态库中的重定位表找到那些需要被重定位的函数全局变量,从⽽修正它们的地址。这 其实就是静态链接的过程。
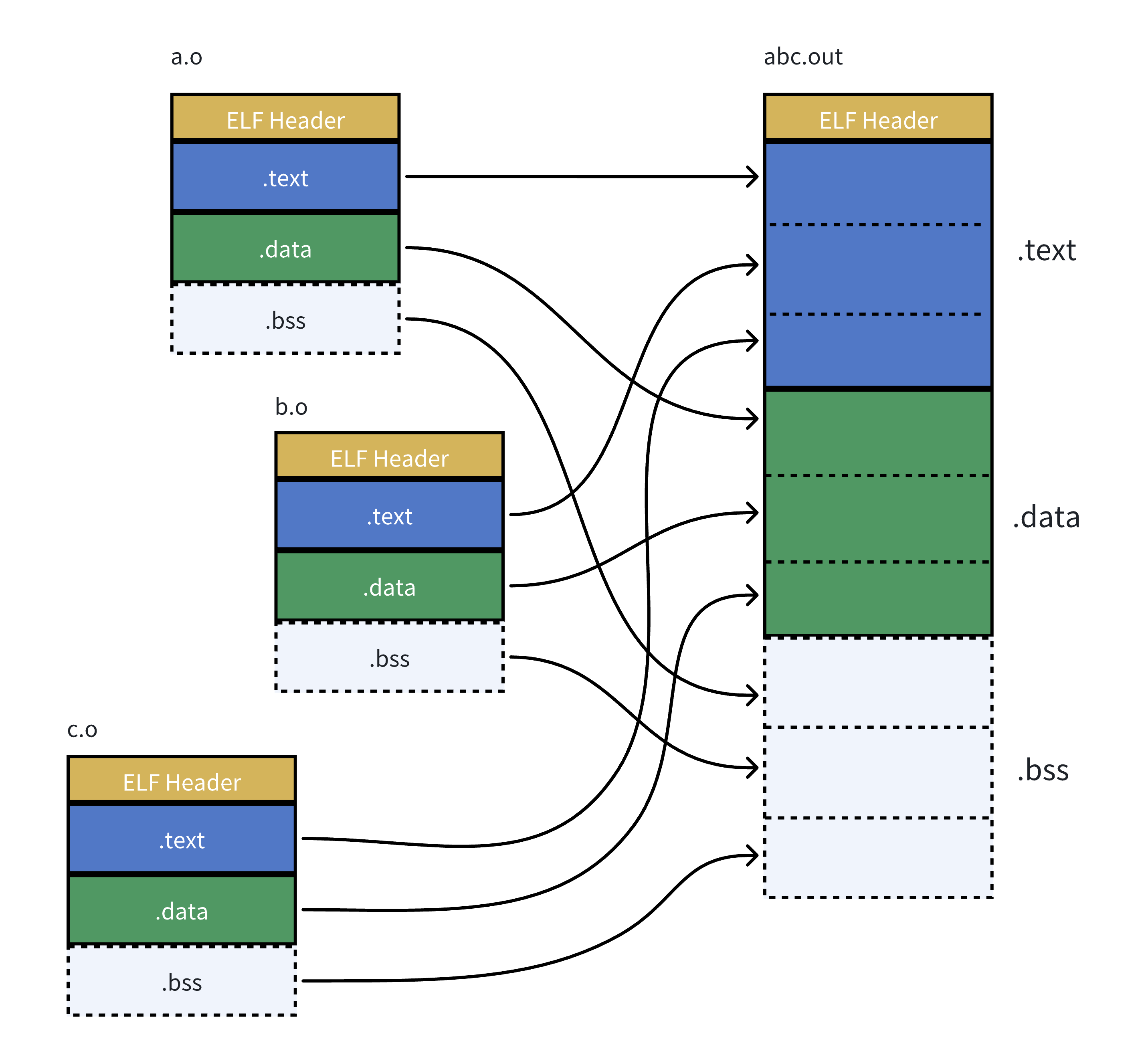
所以,链接过程中会涉及到对.o中外部符号进行地址重定位。
6.4.2 ELF加载与进程地址空间
这里首先来问大家两个问题:
• ⼀个ELF程序,在没有被加载到内存的时候,有没有地址呢?
• 进程mm_struct、vm_area_struct在进程刚刚创建的时候,初始化数据从哪里来的?
答案:
• ⼀个ELF程序,在没有被加载到内存的时候,本来就有地址,当代计算机工作的时候,都采⽤"平坦 模式"进行⼯作。所以也要求ELF对自己的代码和数据进行统⼀编址,下⾯是 objdump -S 反汇编之后的代码。

最左侧的就是ELF的虚拟地址,其实,严格意义上应该叫做逻辑地址(起始地址+偏移量),但是我们 认为起始地址是0。也就是说,其实虚拟地址在我们的程序还没有加载到内存的时候,就已经把可执行程序进行统一编址了。
• 进程mm_struct、vm_area_struct在进程刚刚创建的时候,初始化数据从哪里来的?
从ELF各个 segment来,每个segment有自己的起始地址和自己的长度,用来初始化内核结构中的[start,end]等范围数据,另外在用详细地址,填充页表.。
所以:虚拟地址机制,不光光OS要支持,编译器也要支持。
说到这里,我们需要来重新认识一下虚拟地址空间;
ELF在被编译好之后,会把自己未来程序的入口地址记录在ELF的header的Entry字段中:
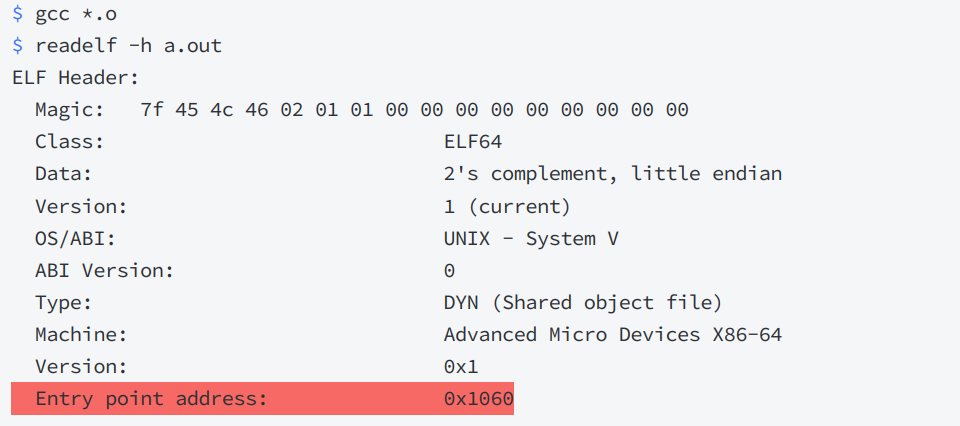

大家仔细观察上面这张图,当可执行程序加载到内存之前,在磁盘上已经采用“平坦模式”进行统一编址了,在磁盘上叫“逻辑地址”,到了内存里就叫“虚拟地址”,本质上的一个东西。那么可执行程序加载到内存里,其代码和数据本身就占有了对应的物理地址,我们前面学习虚拟地址空间时说过,OS会为我们构建页表来建立虚拟地址和物理地址映射关系;与此同时,在mm_struct中的代码段会被segment中起始地址初始化,也就是确定了代码段的start和end;并且,可执行程序将其入口地址填充到CPU的EIP寄存器中,这样一来CPU就知道了可执行程序从哪里开始执行,然后通过MMU,再加上页表,找到对应程序语句的物理地址,执行语句,如果语句中还在调用其他地方的语句,那么CPU会得到相应的虚拟地址,然后继续查页表,去找到对应物理地址,所以总结来说,进入CPU的都是虚拟地址,出来的都是物理地址。
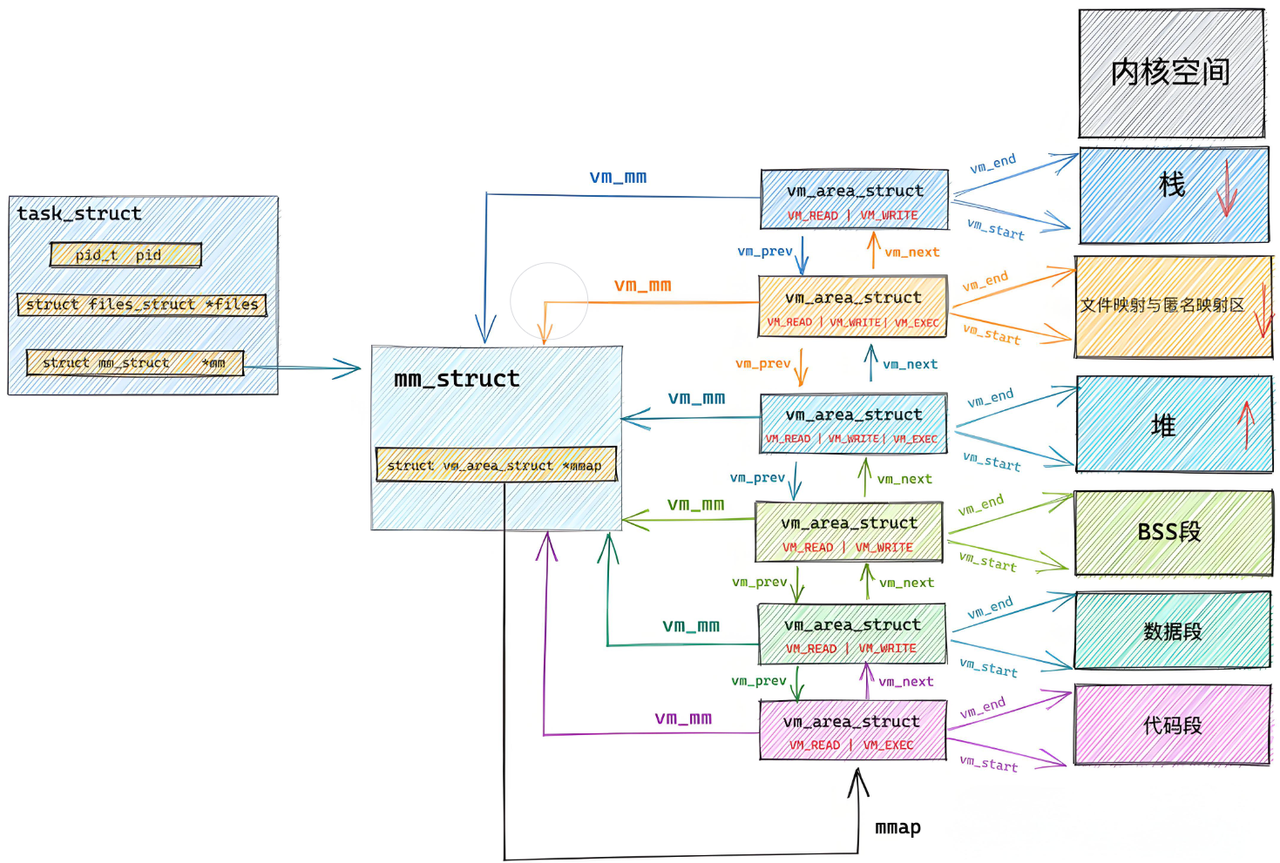
上图中vm_area_struct中的start和end就是由ELF中的segment初始化的,每个segment加载进来之前就已经经过编址了,所以就用它们上面的起始位置来初始化vm_area_struct。
6.5 动态链接与动态库加载
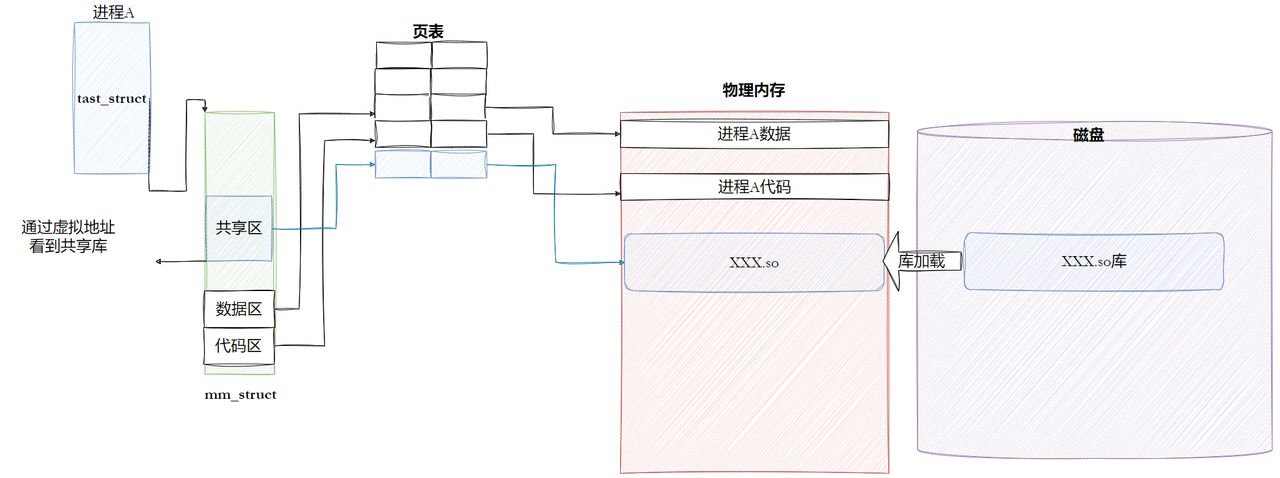
6.5.1 进程如何看待动态库
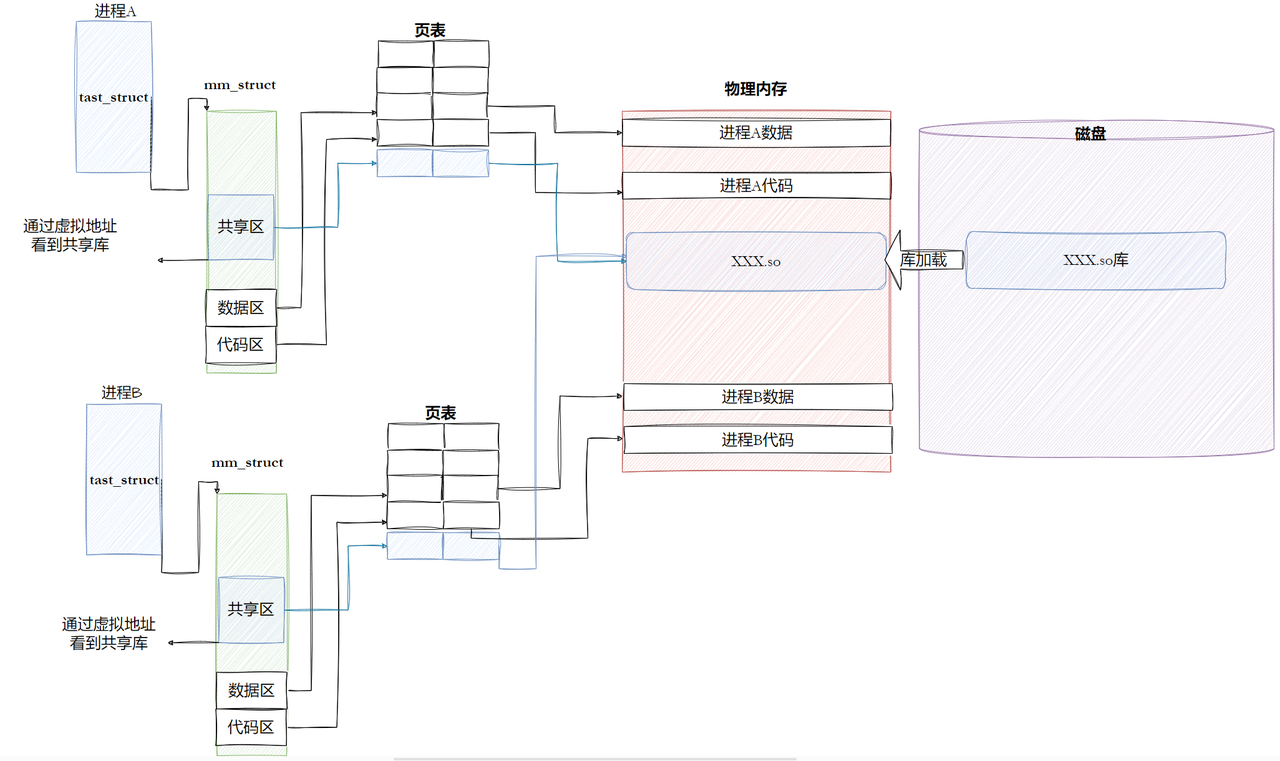
6.5.2 进程间如何共享库
6.5.3 动态链接
首先要交代⼀个结论,动态链接实际上将链接的整个过程推迟到了程序加载的时候。
静态链接最大的问题在于生成的文件体积大,并且相当耗费内存资源。
在C/C++程序中,当程序开始执⾏时,它⾸先并不会直接跳转到 main 函数。实际上,程序的⼊⼝点 是 _start ,这是⼀个由C运⾏时库(通常是glibc)或链接器(如ld)提供的特殊函数。在 _start 函数中,会执⾏⼀系列初始化操作,这些操作包括:
1. 设置堆栈:为程序创建⼀个初始的堆栈环境。
2. 初始化数据段:将程序的数据段(如全局变量和静态变量)从初始化数据段复制到相应的内存位 置,并清零未初始化的数据段。
3. 动态链接:这是关键的⼀步, _start 函数会调⽤动态链接器的代码来解析和加载程序所依赖的 动态库(shared libraries)。动态链接器会处理所有的符号解析和重定位,确保程序中的函数调 ⽤和变量访问能够正确地映射到动态库中的实际地址。
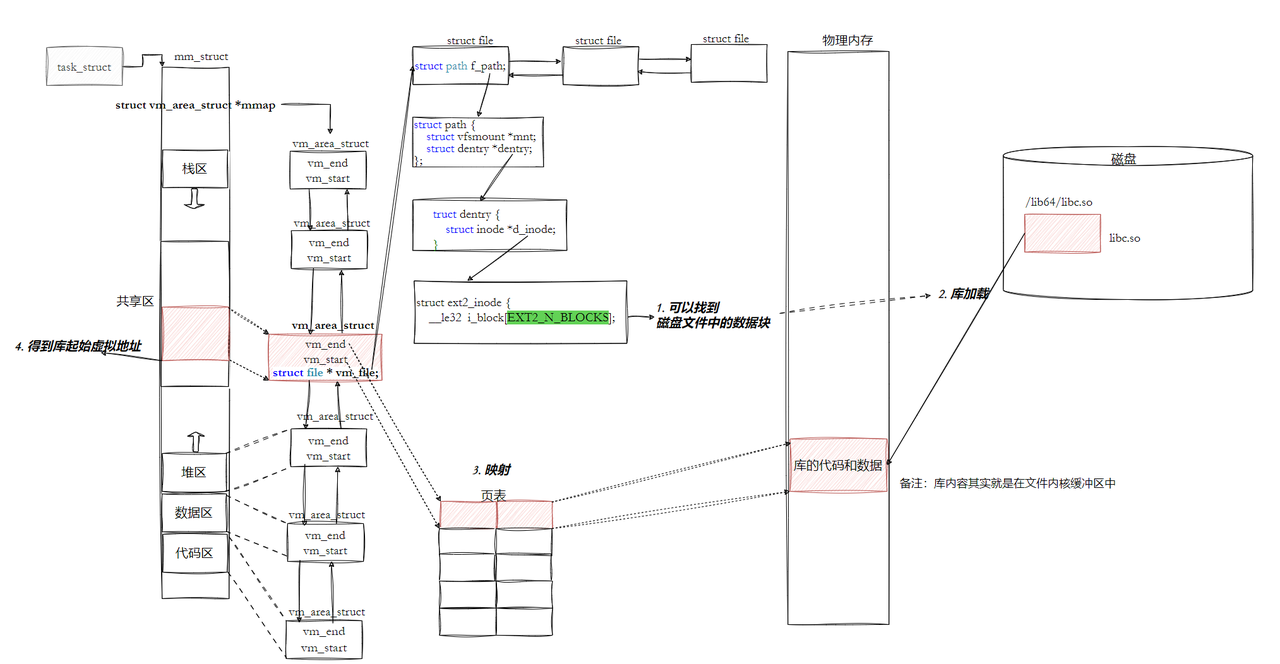
我们的程序,怎么进行库函数调用?
• 库已经被我们映射到了当前进程的地址空间中。
• 库的虚拟起始地址我们也已经知道了。
• 库中每⼀个⽅法的偏移量地址我们也知道。
• 所以:访问库中任意方法,只需要知道库的起始虚拟地址+方法偏移量即可定位库中的方法。
• 而且:整个调用过程,是从代码区跳转到共享区,调用完毕在返回到代码区,整个过程完全在进程地址空间中进行的。
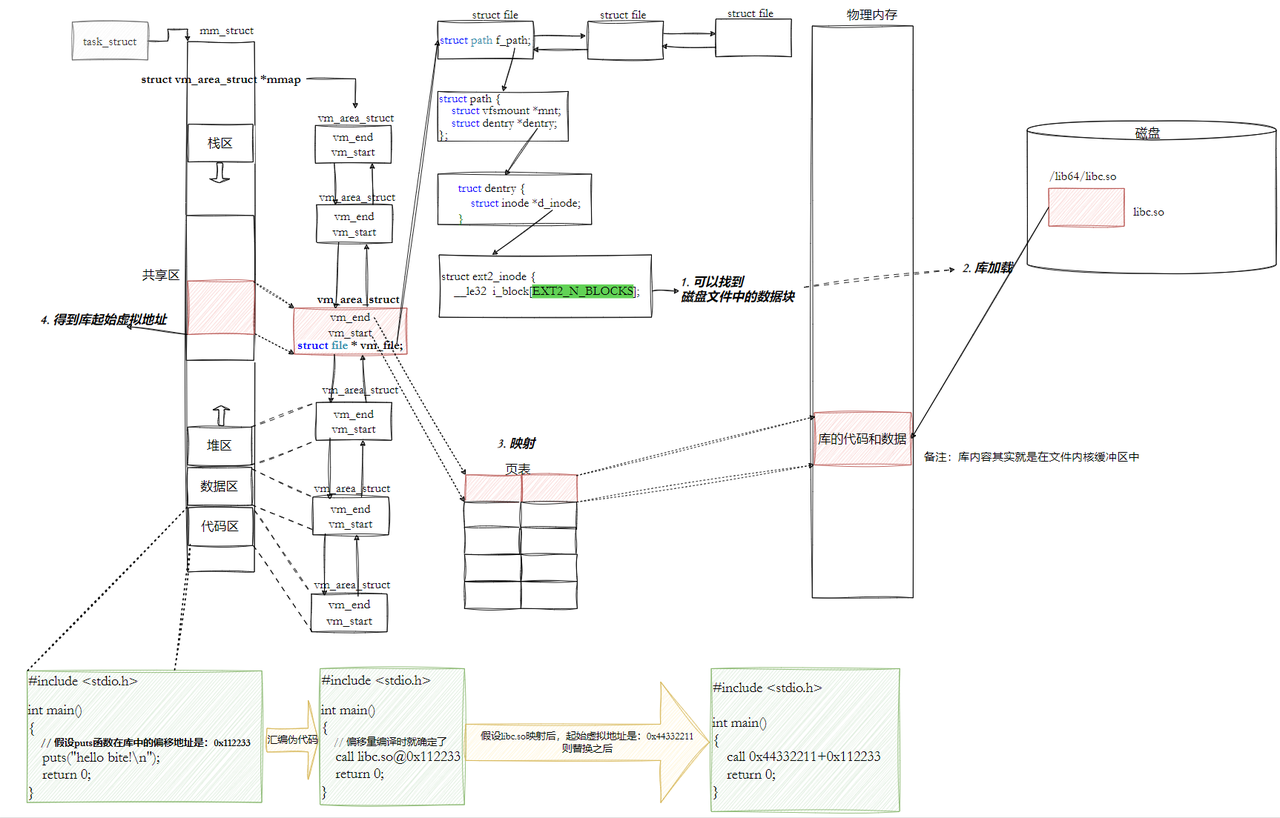
• 也就是说,我们的程序运行之前,先把所有库加载并映射,所有库的起始虚拟地址都应该提前知道。
• 然后对我们加载到内存中的程序的库函数调用进行地址修改,在内存中二次完成地址设置 (这个叫做加载地址重定位)。
• 但是这里就有问题了,修改的是代码区?不是说代码区在进程中是只读的吗?怎么修改?能修改吗?
这里首先可以明确,代码区肯定不能被修改,这是基本原则,那么这个是怎么实现的呢?
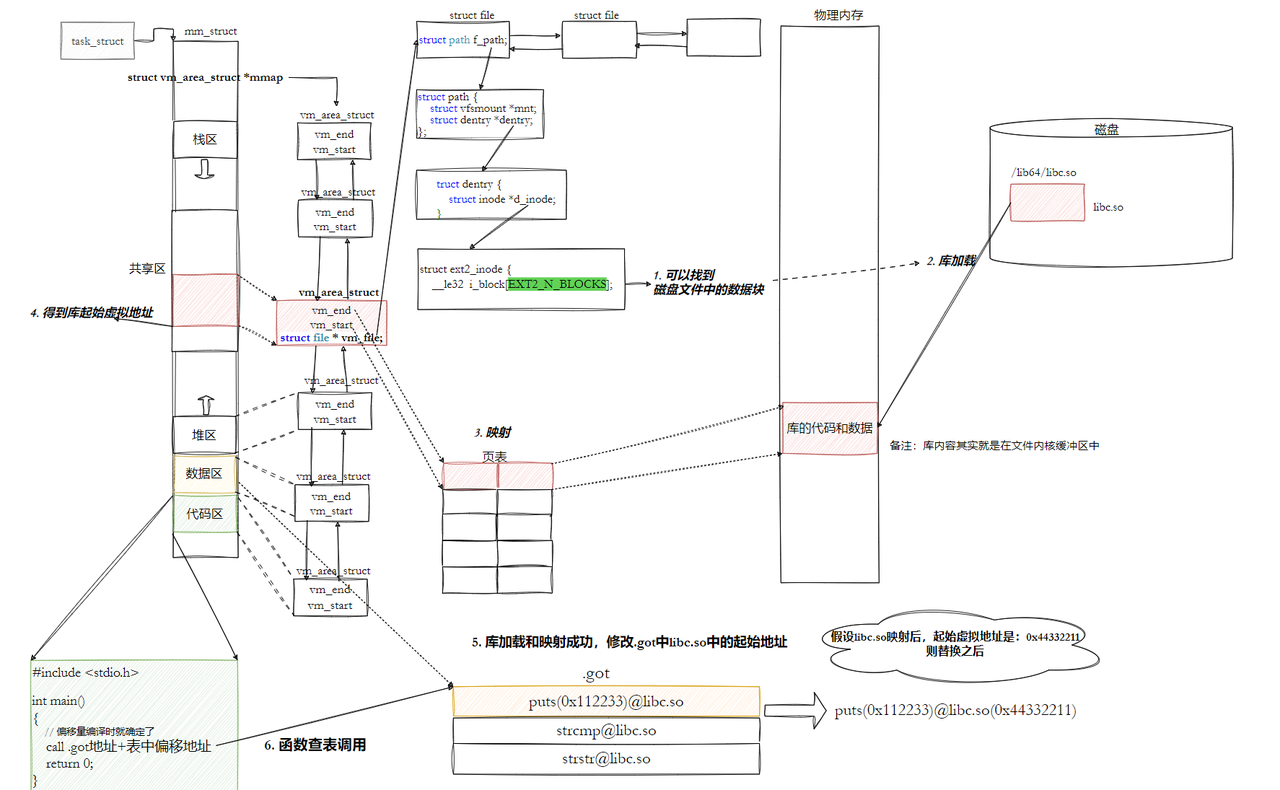
1、动态链接采用的做法是在 .data (可执行程序或者库自己)中专门预留⼀片区域用来存放函数的跳转地址,它也被叫做全局偏移量表GOT,表中每⼀项都是本运行模块要引用的⼀个全局变量或函数 的地址。因为.data区域是可读写的,所以可以支持动态进行修改。
2、由于代码段只读,我们不能直接修改代码段。但有了GOT表,代码便可以被所有进程共享。但在不同进程的地址空间中,各动态库的绝对地址、相对位置都不同。反映到GOT表上,就是每个进程的 每个动态库都有独立的GOT表,所以进程间不能共享GOT表。
3、 在单个.so下,由于GOT表与 .text 的相对位置是固定的,我们完全可以利⽤CPU的相对寻址来找到GOT表。
4、在调用函数的时候会首先查表,然后根据表中的地址来进行跳转,这些地址在动态库加载的时候会被修改为真正的地址。
5、 这种方式实现的动态链接就被叫做 PIC 地址无关代码 。换句话说,我们的动态库不需要做任何修 改,被加载到任意内存地址都能够正常运⾏,并且能够被所有进程共享,这也是之前我们给编译器指定-fPIC参数的原因,PIC=相对编址+GOT。
相关文章:

Linux——动静态库
目录 1. 动静态库基本原理 2. 认识动静态库 3. 动静态库的特点 3.1 静态库的优缺点 3.2 动态库的优缺点 4. 静态库的打包和使用 4.1 打包 4.2 使用 5. 动态库的打包和使用 5.1 打包 5.2 使用 6. 库的理解与加载 6.1 目标文件 6.2 ELF文件 6.3 ELF形成到加载…...

从频域的角度理解S参数:
从频域的角度理解S参数: S参数是一种频域模型,在频域的每一个频点都可以通过该频点的S参数来得到入射信号和反射信号之间的一组关系。这种方法不关注网络内部的具体结构,无论网络内部结构是什么,只要网络是线性不变的,就可以当作“…...

Java 安全:如何保护敏感数据?
Java 安全:如何保护敏感数据? 在当今数字化时代,数据安全成为了软件开发中至关重要的课题。对于 Java 开发者而言,掌握如何在 Java 应用中保护敏感数据是必备的技能。本文将深入探讨 Java 安全领域,聚焦于敏感数据保护…...

PySpark实现ABC_manage_channel逻辑
问题描述 我们需要确定"ABC_manage_channel"列的逻辑,该列的值在客户连续在同一渠道下单时更新为当前渠道,否则保留之前的值。具体规则如下: 初始值为第一个订单的渠道如果客户连续两次在同一渠道下单,则更新为当前渠…...

栈与堆的演示
1、栈与堆的演示 (1)网页视图 (2)代码 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, in…...
)
【Kafka】Windows环境下生产与消费流程详解(附流程图)
1. 背景说明 在搭建基于Kafka的数据流通系统(例如流式推荐、实时日志采集)时,常见的操作是: 生产者 Producer 向 Kafka Topic 写入消息消费者 Consumer 从 Kafka Topic 读取消息本文以Windows本地环境 + Kafka 2.8.1版本为例,手把手演示生产消费流程。 2. 准备条件 Kafka…...

基于FFmpeg命令行的实时图像处理与RTSP推流解决方案
前言 在一些项目开发过程中需要将实时处理的图像再实时的将结果展示出来,此时如果再使用一张一张图片显示的方式展示给开发者,那么图像窗口的反复开关将会出现窗口闪烁的问题,实际上无法体现出动态画面的效果。因此,需要使用码流…...

神经网络笔记 - 感知机
一 感知机是什么 感知机(Perceptron)是一种接收输入信号并输出结果的算法。 它根据输入与权重的加权和是否超过某个阈值(threshold),来判断输出0还是1。 二.计算方式 感知机的基本公式如下: X1, X2 : …...

【双指针】专题:LeetCode 15题解——三数之和
三数之和 一、题目链接二、题目三、题目解析四、算法原理解法一:排序 暴力枚举 利用set去重解法二:排序 双指针处理细节问题1、去重越界问题 2、不漏 五、编写代码六、时间复杂度和空间复杂度 一、题目链接 三数之和 二、题目 三、题目解析 i ! j …...

如何创建一个导入模板?全流程图文解析
先去找到系统内可以上传东西的按钮 把你的模板上传上去,找到对应的fileName 图里的文字写错了,是复制粘贴"filePath"到URL才能下载...

JS自动化获取网站信息开发说明
一、自动获取信息的必要性 1. 提高效率与节省时间 批量处理:自动化可以快速抓取大量数据,比人工手动操作快得多。 24/7 运行:自动化工具可以全天候工作,不受时间限制。 减少重复劳动:避免人工反复执行相同的任务&am…...

Python爬虫-爬取汽车之家各品牌月销量榜数据
前言 本文是该专栏的第54篇,后面会持续分享python爬虫干货知识,记得关注。 在本文中,笔者已整理19篇汽车平台相关的爬虫项目案例。对此感兴趣的同学,可以直接翻阅查看。 而本文,笔者将以汽车之家平台为例子。基于Python爬虫,实现批量爬取“各品牌月销量榜”的数据。废话…...

WPF 调用 OpenCV 库
WPF 调用 OpenCV 库指南 OpenCV 是一个强大的计算机视觉库,WPF 是 Windows 平台的 UI 框架。将两者结合可以实现强大的图像处理和计算机视觉应用。本文将详细介绍如何在 WPF 应用程序中集成和使用 OpenCV 库。 一、准备工作 1. 安装 OpenCV 方法一:通过 NuGet 安装 在 Vi…...
技术的最新进展可总结)
LLM(大语言模型)技术的最新进展可总结
截至2025年4月26日,LLM(大语言模型)技术的最新进展可总结为以下关键方向: 1. 架构创新与性能突破 多模态能力深化:GPT-4o等模型通过统一架构支持文本、图像、音频和视频的跨模态推理,显著提升复杂场景下的…...

Fedora 43 计划移除所有 GNOME X11 相关软件包
Fedora 43 计划移除所有 GNOME X11 相关软件包,这是 Fedora 项目团队为全面拥抱 Wayland 所做的重要决策。以下是关于此计划的详细介绍: 提案内容:4 月 23 日,Neal Gompa 提交提案,建议从 Fedora 软件仓库中移除所有 G…...

解构与重构:“整体部分”视角下的软件开发思维范式
在软件开发的复杂图景中,整体与部分的关系始终是决定项目成败的关键命题。《人月神话》“整体部分”一章以深邃的洞察力,揭示了软件开发过程中系统设计与实现的内在逻辑,不仅探讨了规格说明、设计方法等技术层面的核心要素,更深入…...

NdrpConformantVaryingArrayUnmarshall函数分析--重要
第一部分: void NdrpConformantVaryingArrayUnmarshall( PMIDL_STUB_MESSAGE pStubMsg, uchar ** ppMemory, PFORMAT_STRING pFormat, uchar fMustCopy, uchar fMustAlloc ) { uchar * …...
:基于 BRAM 的 PS、PL 数据交互)
ZYNQ笔记(十四):基于 BRAM 的 PS、PL 数据交互
版本:Vivado2020.2(Vitis) 实验任务: PS 将字符串数据写入BRAM,再将数据读取出来;PL 从 BRAM 中读取数据,bing。通过 ILA 来观察读出的数据,与前面串口打印的数据进行对照࿰…...

月之暗面开源 Kimi-Audio-7B-Instruct,同时支持语音识别和语音生成
我们向您介绍在音频理解、生成和对话方面表现出色的开源音频基础模型–Kimi-Audio。该资源库托管了 Kimi-Audio-7B-Instruct 的模型检查点。 Kimi-Audio 被设计为通用的音频基础模型,能够在单一的统一框架内处理各种音频处理任务。主要功能包括: 通用功…...

文件操作及读写-爪哇版
文章目录 前言 初识文件文件路径里的符号文件分类文件操作方法文件读写字节流输入输出输入输出 字符流输入输出输入输出 前言 Windows用户需知:“/”和“\”, 文件路径分隔符一般都用“/”,但Windows系统一直保留着“\”,这两种符…...

【matlab】绘制maxENT模型的ROC曲线和omission curve
文章目录 一、maxENT模型二、ROC曲线三、实操3.1 数据提取3.2 绘制ROC曲线3.3 绘制遗漏曲线3.4 多次训练的ROC和测试的ROC 一、maxENT模型 前面的文章已经详细讲过了。 maxENT软件运行后,会生成一个html报告,里面有ROC曲线,但我们往往需要自…...
、 撤销、取消撤销 等等功能,))
个人电子白板(svg标签电子画板功能包含正方形、文本、橡皮 (颜色、尺寸、不透明度)、 撤销、取消撤销 等等功能,)
在Http开发中,svg标签电子画板功能包含正方形、文本、橡皮 (颜色、尺寸、不透明度)、 撤销、取消撤销 等等功能, 效果图 代码如下: <!DOCTYPE html> <html lang"en"> <!--<link href&qu…...

Pygame终极项目:从零开发一个完整2D游戏
Pygame终极项目:从零开发一个完整2D游戏 大家好!欢迎来到本期的Pygame教程。今天,我们将从零开始开发一个完整的2D游戏。通过这个项目,你将学习到如何使用Pygame库来创建游戏窗口、处理用户输入、绘制图形、管理游戏状态、实现碰撞检测和音效等。无论你是初学者还是有一定…...

在应用运维过程中,业务数据修改的证据留存和数据留存
在应用运维过程中,业务数据修改的证据留存和数据留存至关重要,以下是相关介绍: 一、证据留存 操作日志记录 : 详细记录每一次业务数据修改的操作日志,包括操作人员、操作时间、修改内容、修改前后数据的对比等。例如,某公司业务系统中,操作日志会精确记录员工小张在 2…...

JAVA JVM面试题
你的项目中遇到什么问题需要jvm调优,怎么调优的,堆的最小值和最大值设置为什么不设置成一样大? 在项目中,JVM调优通常源于以下典型问题及对应的调优思路,同时关于堆内存参数(-Xms/-Xmx)的设置逻…...

C盘爆红如何解决
deepseek来试用一下! 一、快速释放空间 1. 清理临时文件 - **Win R** 输入 %temp% → 删除文件夹内所有内容。 - **Win S** 搜索 “磁盘清理”** → 选择C盘 → 勾选“临时文件”“系统缓存”等 → 点击“清理系统文件”(可额外清理Windows…...

在 Ubuntu24.04 LTS 上 Docker 部署英文版 n8n 和 部署中文版 n8n-i18n-chinese
一、n8n 简介 n8n 是一个低代码(Low-Code)工作流自动化平台,可以帮助用户以非常简单的方式创建自动化流程,连接不同的应用程序和服务。n8n的设计理念是为了让复杂的工作流变得简单易用,同时也支持高度的自定义…...

软件设计案例分析学习笔记
1.软件设计师内容小考 一、单选题 1.(单选题,1.0 分) 下列内聚种类中,内聚程度最高的是 ( )。 A. 功能内聚 B. 逻辑内聚 C. 偶然内聚 D. 过程内聚 第 1 题: 答案:A 解析:功能内聚是指模块内所有元素共同完成一个功能&a…...

魔百盒CM311-3-YST代工-晨星MSO9385芯片-2+8G-免拆卡刷通刷固件包
魔百盒CM311-3-YST代工-晨星MSO9385芯片-28G-免拆卡刷通刷固件包 刷机前准备: 准备一个8G或一下容量的优盘将其格式化为fat32格式;(切记不要用做过电脑系统的优盘,不然刷机直接变砖); 优盘卡刷强刷刷机&am…...
)
nginx 504 (Gateway Time-out)
目录 1. 后端处理超时 2. Nginx 代理超时设置不足 3. 服务未响应或崩溃 4. 请求体过大 5. 重启nginx 原本代理服务器用的是微软的Kestrel ,今天给项目换用了nginx,然后有个接口请求报了 (504 Gateway Timeout) 请求发送到了…...

WPF 实现PLC数据采集
WPF 数据采集网关系统设计与实现 一、系统概述 本系统是一个基于 WPF 的数据采集网关,支持主流 PLC(可编程逻辑控制器)的数据采集,并将采集到的数据汇总存储到数据库中。系统采用模块化设计,具有良好的扩展性和可维护性。 二、系统架构 1. 整体架构 +---------------…...

llama factory怎么命令行推理图片
根据LLaMA-Factory多模态数据处理规范,配置图片输入需注意以下核心要点: --- **一、本地图片路径配置** 1. 绝对路径配置: json "images": ["/home/user/project/data/mllm_demo_data/1.jpg"] *适用场景*…...
--应用层协议原理)
计算机网络 | 应用层(1)--应用层协议原理
💓个人主页:mooridy 💓专栏地址:《计算机网络:自定向下方法》 大纲式阅读笔记 关注我🌹,和我一起学习更多计算机的知识 🔝🔝🔝 目录 1. 应用层协议原理 1.1 …...
 笔记 1.1~1.3 (台大机器人学-林沛群))
刚体运动 (位置向量 - 旋转矩阵) 笔记 1.1~1.3 (台大机器人学-林沛群)
目录 1. 理解刚体的“自由度”(Degrees of Freedom, DOF) 1.1 平面运动 (2D) 1.2 空间运动 (3D) 2. 统一描述:引入“体坐标系”(Body Frame) 3. 从“状态”到“运动”:引入微分 3.1 补充:…...
)
MES系列-MOM(Manufacturing Operations Management,制造运营管理)
MES系列文章目录 ISA-95制造业中企业和控制系统的集成的国际标准-(1) ISA-95制造业中企业和控制系统的集成的国际标准-(2) ISA-95制造业中企业和控制系统的集成的国际标准-(3) ISA-95制造业中企业和控制系统的集成的国际标准-(4) ISA-95制造业中企业和控制系统的集成的国际标准…...

矩阵系统私信功能开发技术实践,支持OEM
在短视频矩阵系统中,私信功能是连接运营者与用户、用户与用户的重要桥梁。它不仅能提升用户粘性,还能为精准营销提供支持。本文将从需求分析、技术选型、核心功能实现到性能优化,全面解析矩阵系统私信功能的开发过程。 一、功能需求分析 &am…...

leetcode 26和80
leetcode 26. Remove Duplicates from Sorted Array 代码: class Solution { public:int removeDuplicates(vector<int>& nums) {int len nums.size();int slowIdx 1;for(int firstIdx 1; firstIdx < len;firstIdx){if(nums[firstIdx] ! nums[firs…...

微信小程序 template 模版详解
一、什么时候使用template ? 代码复用,维护方便,提高性能 二、模版的基本使用 三、模版样式的使用 四、使用模版 五、使用模版定义的样式,需要在引入的wxml 样式文件中导入样式 六、template模版...扩展符数据传递 可以根据自己…...
北斗导航 | 基于Transformer+LSTM+激光雷达的接收机自主完好性监测算法研究
基于Transformer+LSTM+激光雷达的接收机自主完好性监测算法研究 接收机自主完好性监测(RAIM)是保障全球导航卫星系统(GNSS)定位可靠性的核心技术。传统RAIM算法依赖最小二乘残差法,存在故障漏检、对复杂环境适应性差等问题。结合Transformer、LSTM与激光雷达的多模态融合…...

ASP.NET CORE部署IIS的三种方式
ASP.NET Core 部署方式对比 本文档对比了三种常见的 ASP.NET Core 应用(如你的 DingTalkApproval 项目)部署到 Windows 10 上 IIS 服务器的方式:dotnet publish(手动部署)、Web Deploy(直接发布到 IIS&…...

推荐三款GitHub上高星开源的音乐搜索平台
文章目录 一、Spottube 1. 展示 2. 功能 3. 安装 二、YesPlayMusic 1. 展示 2. 功能 2. 安装 三、Navidrome 1. 展示 2. 功能 3. 安装 一、Spottube 一个开源的跨平台 Spotify 客户端,兼容多个平台,利用 Spotify 的数据 API 和 YouTube、P…...

Linux基础指令【上】
Linux的基本操作 , 是通过指令来执行的! 小贴士:指令很多,但一定要摒弃那种看到知识点就全部死记硬背的坏习惯(因为就算背,也背不完) , 一定要以理解为主,练习为辅 &…...

GPT系列模型-20250426
文章目录 🧠 GPT-4o(Omni)🔬 GPT-4.5(研究预览)🧩 o3 模型系列(o3、o3-mini、o3-mini-high)🧠 o4-mini 和 o4-mini-high🧠 GPT-4o mini🧾 总结对比表🧠 GPT-4o(Omni) 特点:全能型模型,支持文本、图像、音频和视频输入输出,具备强大的多模态处理能力。…...
)
高精度运算(string函数)
高精度加法 #include<iostream> #include<string> #include<algorithm> using namespace std; string _add(string s1,string s2); int main() {string a,b;cin>>a>>b;cout<<_add(a,b);return 0; } string _add(string s1,string s2) {re…...

探索 AI 在文化遗产保护中的新使命:数字化修复与传承
文化遗产是人类文明的瑰宝,承载着历史的记忆与文化的灵魂。然而,随着时间的推移和自然环境的影响,许多珍贵的文化遗产正面临着损毁和消失的威胁。在这样的背景下,人工智能(AI)技术的出现为文化遗产的保护和…...
)
Python----深度学习(基于DNN的PM2.5预测)
一、目标 如何使用 PyTorch 实现一个简单的深度神经网络(DNN)模型,并用于回归任务。该模型通过训练数据集来预测PM2.5。代码通过读取数据集、数据处理、模型训练和模型评估等步骤,详细展示了整个实现过程。 二、数据集介绍 Data …...

Android12源码编译及刷机
由于google的AOSP源码拉取经常失败,编译还经常出现各种问题。这里根据香橙派Orange Pi 5 Plus(Android12电视镜像)源码进行编译演示。 RK芯片的开发板可玩性很高,这里以电视版本android系统为例子,学习的同时还可以当…...

TRO再添新案 TME再拿下一热门IP,涉及Paddington多个商标
4月2日和4月8日,TME律所代理Paddington & Company Ltd.对热门IP Paddington Bear帕丁顿熊的多类商标发起维权,覆盖文具、家居用品、毛绒玩具、纺织用品、游戏、电影、咖啡、填充玩具等领域。跨境卖家需立即排查店铺内的相关产品! 案件基…...

如何使用 Spring Boot 实现分页和排序:配置与实践指南
在现代 Web 应用开发中,分页和排序是处理大量数据时提升用户体验和系统性能的关键功能。Spring Boot 结合 Spring Data JPA 提供了简单而强大的工具,用于实现数据的分页查询和动态排序,广泛应用于 RESTful API、后台管理系统等场景。2025 年&…...

asammdf 库的信号处理和数据分析:深入挖掘测量数据
内容概要: 信号处理的基本操作数据分析和统计数据可视化和报告生成 正文: 信号处理的基本操作 asammdf 提供了对信号的基本操作,包括读取、筛选和转换。 读取信号 with asammdf.MDF(nameexample.mf4) as mdf:engine_speed …...