Python----深度学习(基于DNN的PM2.5预测)
一、目标
如何使用 PyTorch 实现一个简单的深度神经网络(DNN)模型,并用于回归任务。该模型通过训练数据集来预测PM2.5。代码通过读取数据集、数据处理、模型训练和模型评估等步骤,详细展示了整个实现过程。
二、数据集介绍
Data 含有 18 项观测数据 AMB_TEMP(环境温度), CH4(甲烷), CO(一氧化碳), NMHC(非甲烷总烃), NO(一氧化氮), NO2(二氧化氮), NOx(氮氧化物), O3(臭氧), PM10, PM2.5, RAINFALL(降雨量), RH(相对湿度), SO2(二氧化硫), THC(总碳氢化合物), WD_HR(小时平均风向), WIND_DIREC(风向), WIND_SPEED(风速), WS_HR(小时平均风速)。纵向为日期从2014/1/1到2014/12/20,其中每月记录20天,横向为每日24小时每一小时的记录。

三、设计思路
3.1、准备工作
导入模块包
import pandas as pd
import numpy as np
import random
import os
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import StandardScaler
from torch.utils.data import TensorDataset, DataLoader设置随机种子保证结果的可重复性
def setup_seed(seed):# 设置 Numpy 随机数种子,确保Numpy生成的随机数序列一致np.random.seed(seed)# 设置Python内置随机数种子,保证Python内置的随机函数生成的随机数一致random.seed(seed)# 设置Python哈希种子,避免不同运行环境下哈希结果不同,影响随机数生成os.environ['PYTHONHASHSEED'] = str(seed)# 设置PyTorch 随机种子,使PyTorch生成的随机数序列可以重复torch.manual_seed(seed)# 检查是否有可用的CUDA设备(GPU)if torch.cuda.is_available():# 设置 CUDA 随机种子,保证在GPU上的随即操作可重复torch.cuda.manual_seed(seed)# 为所有 GPU 设置随机种子torch.cuda.manual_seed_all(seed)# 关闭 cudnn 自动寻找最优算法加速的功能,保证结果可重复torch.backends.cudnn.benchmark = False# 设置 cudnn 为确定性算法,确保每次运行结果一致torch.backends.cudnn.deterministic = True检测是否使用cuda
if torch.cuda.is_available():device = 'cuda'print('CUDA is useful!!')
else:device = 'cpu'print('CUDA is not useful!!')设置 pandas 显示选项
# 最多显示1000列
pd.set_option('display.max_columns', 1000)
# 显示宽度为1000
pd.set_option('display.width', 1000)
# 每列最多显示1000个字符
pd.set_option('display.max_colwidth', 1000)3.2、数据操作
读取数据
train_data = pd.read_csv('train.csv', encoding='big5')选取特征数据
train_data = train_data.iloc[:, 3:]将数组中值为NR的元素替换为0
train_data[train_data == 'NR'] = 0查看缺失情况
print(train_data.isnull().sum())对数据进行维度变换和重塑,转为DataFrame格式
datas = []# 按照 步长为18 分割数据
for i in range(0, 4320, 18):datas.append(numpy_data[i:i+18, :])# 将datas 转换为Numpy数组
datas_array = np.array(datas, dtype=float)# 对数据进行维度变换和重塑,转为DataFrame格式
train_data = pd.DataFrame(datas_array.transpose(1, 0, 2).reshape(18, -1).T)
查看相关性
corr=train_data.corr()
sns.heatmap(corr,annot=True)
plt.show()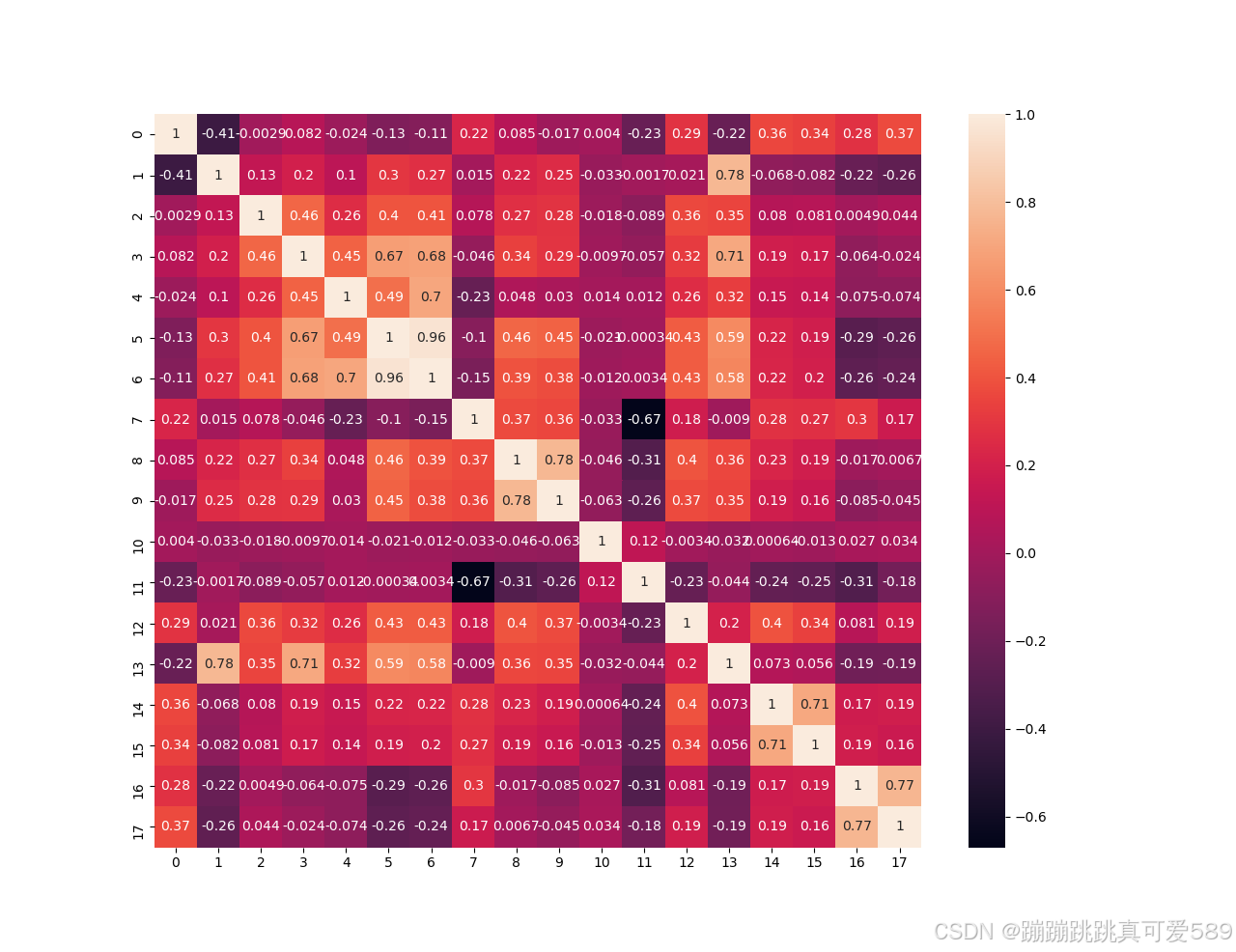
从相关性矩阵里筛选大于0.2的特征
important_features = []
for i in range(len(corr.columns)):if abs(corr.iloc[i, 9]) > 0.2:important_features.append(corr.columns[i])划分特征和目标
X = train_data[important_features].drop(9, axis=1)
# 选取第9列作为目标
y = train_data[9]划分训练集和测试集
# 划分训练集和测试集
train_ratio = 0.8# 训练集特征
X_train = X[:int(train_ratio * len(train_data))]
# 测试集特征
X_test = X[int(train_ratio * len(train_data)):]
# 训练集标签
y_train = y[:int(train_ratio * len(train_data))]
# 测试集标签
y_test = y[int(train_ratio * len(train_data)):]3.3、标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)3.4、将数据转换为PyTorch的张量
# 训练集的特征张量表示
X_train_tensor = torch.tensor(X_train_scaled, dtype=torch.float32)
# 训练集的标签张量表示
y_train_tensor = torch.tensor(y_train.values, dtype=torch.float32).view(-1, 1)
# 测试集的特征张量表示
X_test_tensor = torch.tensor(X_test_scaled, dtype=torch.float32)
# 测试集的标签张量表示
y_test_tensor = torch.tensor(y_test.values, dtype=torch.float32).view(-1, 1)
3.5、使用DataLoader去加载数据集
# 创建TensorDataset对象,将训练集特征张量与标签一一组合在一起
train_dataset = TensorDataset(X_train_tensor, y_train_tensor)
# 创建DataLoader对象,用于批量加载数据
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)3.6、定义模型
class DNN(nn.Module):def __init__(self, input_size, hidden_size, output_size):# 调用父类的构造函数super(DNN, self).__init__()# 定义第一个Linear层,输入就是input_size,输出维度就是 hidden_sizeself.fc1 = nn.Linear(input_size, hidden_size)# 定义第二个Linear层,输入是hidden_size,输出维度是 hidden_sizeself.fc2 = nn.Linear(hidden_size, hidden_size)# 定义第三个Linear层,输入是hidden_size,输出维度是 hidden_sizeself.fc3 = nn.Linear(hidden_size, hidden_size)# 定义第四个Linear层,输入是hidden_size,输出维度是 output_sizeself.fc4 = nn.Linear(hidden_size, output_size)# 定义激活函数self.relu = nn.ReLU()def forward(self, x):# 输入数据经过第一个Linear和ReLU激活x = self.relu(self.fc1(x))# 输入数据经过第二个Linear和ReLU激活x = self.relu(self.fc2(x))# 输入数据经过第三个Linear和ReLU激活x = self.relu(self.fc3(x))# 输入数据经过第四个Linear进行输出x = self.fc4(x)return xmodel = DNN(X_train_tensor.shape[1], 256,1)
# 将模型放到device上
model.to(device)3.7、定义损失函数和优化器
# 定义损失函数,使用均方误差损失函数,回归任务
criterion = nn.MSELoss()
# 定义优化器
optimizer = optim.Adam(model.parameters(), lr=0.01)3.8、训练模型
for epoch in range(1,1001):# 将模型设置为训练模式model.train()# 初始化总损失total_loss = 0# 循环加载dataLoader,每次获取一个批次的数据和标签for inputs, labels in train_loader:# 清空优化器梯度optimizer.zero_grad()# 将inputs和labels放到device上,即将输入数据放到指定的设备上inputs = inputs.to(device)labels = labels.to(device)# 前向传播,计算输出outputs = model(inputs)# 计算损失loss = criterion(outputs, labels)# 反向传播和优化loss.backward()# 更新参数optimizer.step()# 累加当前批次的损失total_loss += loss# 计算本次epoch的平均损失avg_loss = total_loss / len(train_loader)# 每10个epoch打印一次当前模型的训练情况if (epoch + 1) % 10 == 0:print(f'Epoch [{epoch + 1}/{1000}], Loss: {avg_loss:.4f}')3.9、模型评估
with torch.no_grad():# 将模型设置为评估模式model.eval()# 将测试集放到模型上计算输出predict_test = model(X_test_tensor.to(device))# 计算测试集的损失test_loss = criterion(predict_test, y_test_tensor.to(device))3.10、 可视化
# 将预测值从GPU移动到CPU上再去转换为Numpy
predictions = predict_test.cpu().numpy()
# 将测试集目标值从CPU上移动到CPU上并转换为Numpy
y_test_numpy = y_test_tensor.cpu().numpy()
# 绘制结果,创建一个新的图形窗口
plt.figure(1)
# 绘制散点图,用来显示实际值和预测值的关系
plt.scatter(y_test_numpy, predictions, color='blue')
# 绘制对角线,用来对比
plt.plot([min(y_test_numpy), max(y_test_numpy)], [min(y_test_numpy), max(y_test_numpy)], linestyle='--', color='red', lw=2)
# 设置x轴标签
plt.xlabel('Actual Values')
# 设置y轴标签
plt.ylabel('Predicted Values')
# 设置标题
plt.title('Regression Results')# 绘制实际值和预测值的曲线
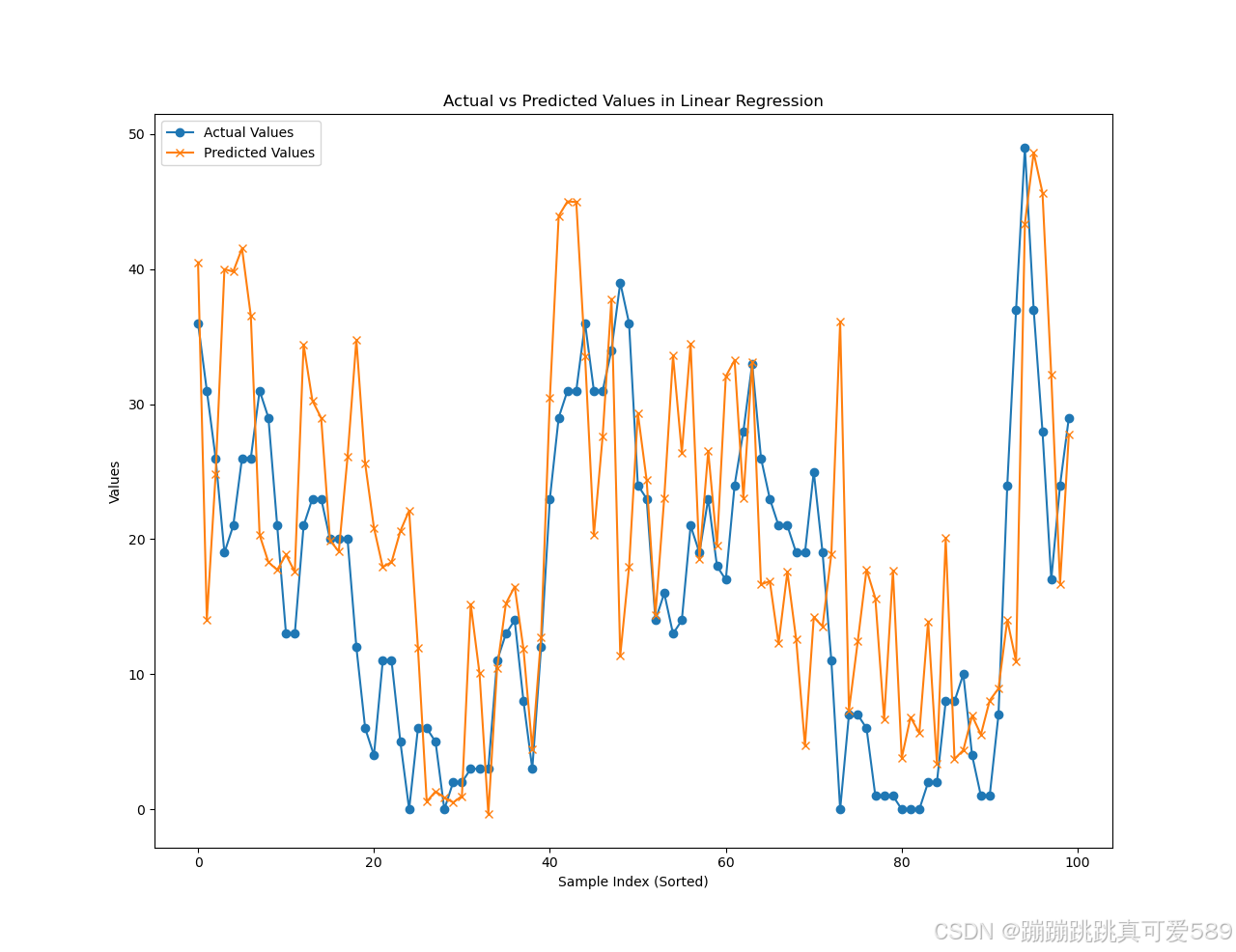
# 创建一个新的图形窗口
plt.figure(2)
# 绘制实际值的曲线,取最后100个样本
plt.plot(y_test_tensor[-100:], label='Actual Values', marker='o')
# 绘制预测值的曲线,取最后100个样本
plt.plot(predictions[-100:], label='Predicted Values', marker='*')
# 设置x轴标签
plt.xlabel('Sample Index')
# 设置y轴标签
plt.ylabel('Values')
# 设置标题
plt.title('Actual vs Predicted Values in Linear Regression')plt.show()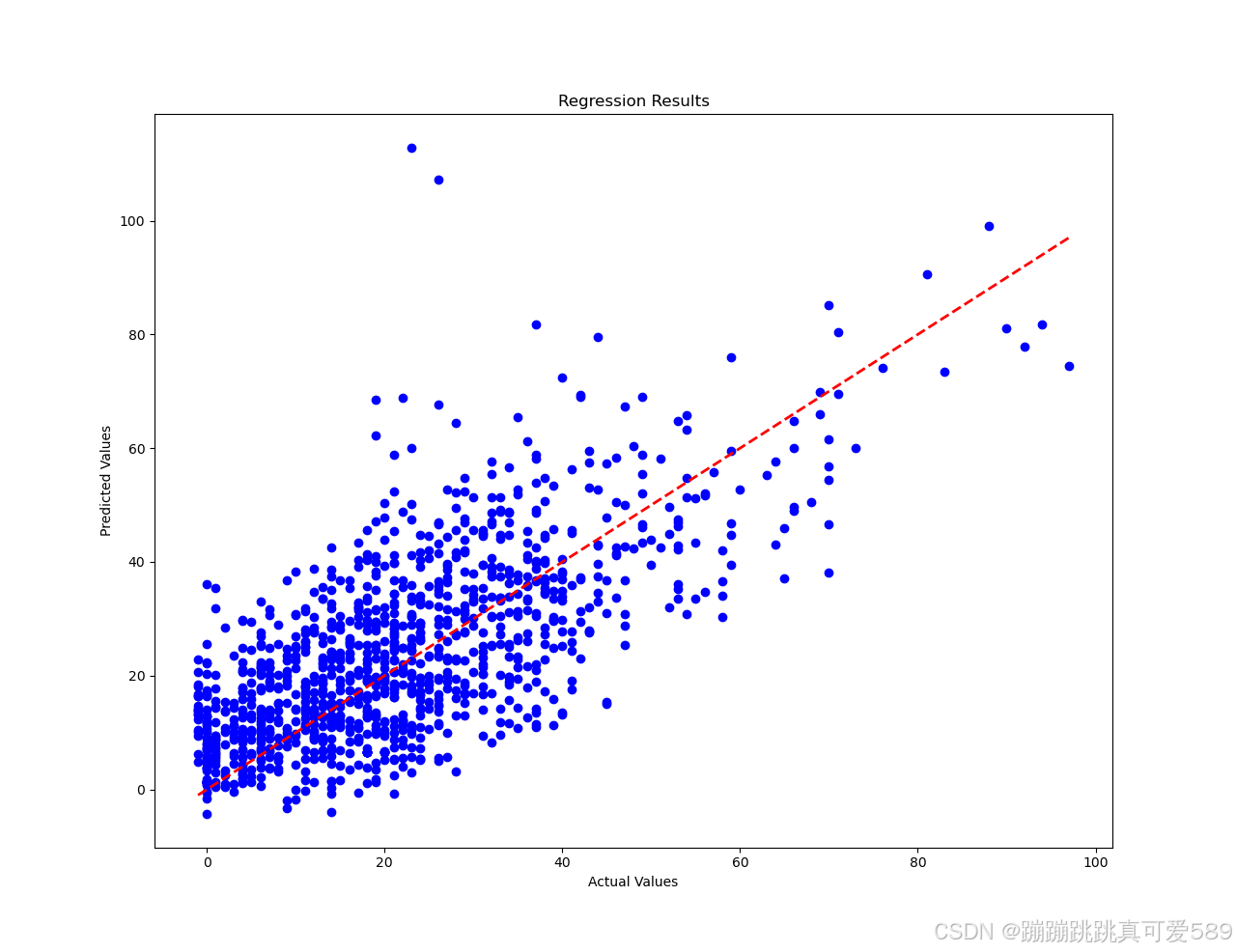
3.11、完整代码
# 导入必要的库
import pandas as pd # 数据处理
import numpy as np # 数值计算
import random # 随机数生成
import os # 操作系统功能
import torch # PyTorch库
import torch.nn as nn # 神经网络模块
import torch.optim as optim # 优化算法
import matplotlib.pyplot as plt # 绘图
import seaborn as sns # 高级可视化工具
from sklearn.preprocessing import StandardScaler # 特征缩放
from torch.utils.data import TensorDataset, DataLoader # 数据集与数据加载器 # 设置随机种子以保证结果的可重复性
def setup_seed(seed): # 设置 Numpy 随机数种子,确保Numpy生成的随机数序列一致 np.random.seed(seed) # 设置Python内置随机数种子,保证Python内置的随机函数生成的随机数一致 random.seed(seed) # 设置Python哈希种子 os.environ['PYTHONHASHSEED'] = str(seed) # 设置PyTorch随机数种子 torch.manual_seed(seed) # 检查CUDA设备 if torch.cuda.is_available(): torch.cuda.manual_seed(seed) # 设置CUDA随机种子 torch.cuda.manual_seed_all(seed) # 为所有GPU设置随机种子 torch.backends.cudnn.benchmark = False # 保证结果可重复 torch.backends.cudnn.deterministic = True # 使用确定性算法 # 检测CPU/GPU可用性
if torch.cuda.is_available(): device = 'cuda' # 使用CUDA print('CUDA is useful!!')
else: device = 'cpu' # 使用CPU print('CUDA is not useful!!') setup_seed(0) # 设置随机种子 # 设置pandas显示选项,以便显示更多列和行
pd.set_option('display.max_columns', 1000) # 最多显示1000列
pd.set_option('display.width', 1000) # 显示宽度为1000
pd.set_option('display.max_colwidth', 1000) # 每列最多显示1000个字符 # 读取数据集
train_data = pd.read_csv('train.csv', encoding='big5') # 注意编码格式
# 查看前5行数据,确保数据读取正确
# print(train_data.head())
# 打印数据集的信息,查看数据集的情况
# print(train_data.info()) # 选取从第3列开始到最后的所有列作为特征数据
train_data = train_data.iloc[:, 3:] # 将数组中值为'NR'的元素替换为0
train_data[train_data == 'NR'] = 0 # 将train_data转换为Numpy数组
numpy_data = train_data.to_numpy() # 创建一个列表,用来存储拆分后的数据
datas = [] # 按照步长为18分割数据
for i in range(0, 4320, 18): datas.append(numpy_data[i:i+18, :]) # 将datas转换为Numpy数组
datas_array = np.array(datas, dtype=float) # 对数据进行维度变换和重塑,转为DataFrame格式
train_data = pd.DataFrame(datas_array.transpose(1, 0, 2).reshape(18, -1).T) # 计算特征相关性矩阵
corr = train_data.corr() # 绘制相关性热图
plt.figure(0)
# 使用seaborn库绘制相关性矩阵的热图
sns.heatmap(corr, annot=True) # 从相关性矩阵里筛选比较重要的特征(绝对值大于0.2的特征)
important_features = []
for i in range(len(corr.columns)): if abs(corr.iloc[i, 9]) > 0.2: important_features.append(corr.columns[i]) # print('比较重要的特征:', important_features) # 定义特征(X)和目标(y)
X = train_data[important_features].drop(9, axis=1) # 选取重要特征,但排除目标特征
y = train_data[9] # 选取第9列
# 划分训练集和测试集
train_ratio = 0.8 # 设定训练集比例# 训练集特征
X_train = X[:int(train_ratio * len(train_data))] # 根据比例切分训练集特征
# 测试集特征
X_test = X[int(train_ratio * len(train_data)):] # 根据比例切分测试集特征
# 训练集标签
y_train = y[:int(train_ratio * len(train_data))] # 根据比例切分训练集标签
# 测试集标签
y_test = y[int(train_ratio * len(train_data)):] # 根据比例切分测试集标签# 使用标准化进行特征缩放
scaler = StandardScaler() # 实例化标准化对象
X_train_scaled = scaler.fit_transform(X_train) # 拟合并转换训练集特征
X_test_scaled = scaler.transform(X_test) # 仅转换测试集特征# 将数据转换为PyTorch的张量
# 训练集的特征张量表示
X_train_tensor = torch.tensor(X_train_scaled, dtype=torch.float32)
# 训练集的标签张量表示
y_train_tensor = torch.tensor(y_train.values, dtype=torch.float32).view(-1, 1)
# 测试集的特征张量表示
X_test_tensor = torch.tensor(X_test_scaled, dtype=torch.float32)
# 测试集的标签张量表示
y_test_tensor = torch.tensor(y_test.values, dtype=torch.float32).view(-1, 1)# 使用DataLoader加载数据集
# 创建TensorDataset对象,将训练集特征和标签一一组合在一起
train_dataset = TensorDataset(X_train_tensor, y_train_tensor)
# 创建DataLoader对象,用于批量加载数据
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)# 构建DNN模型
class DNN(nn.Module):def __init__(self, input_size, hidden_size, output_size):# 调用父类的构造函数super(DNN, self).__init__()# 定义第一个Linear层,输入维度为input_size,输出维度为hidden_sizeself.fc1 = nn.Linear(input_size, hidden_size)# 定义第二个Linear层,输入是hidden_size,输出维度是hidden_sizeself.fc2 = nn.Linear(hidden_size, hidden_size)# 定义第三个Linear层,输入是hidden_size,输出维度是hidden_sizeself.fc3 = nn.Linear(hidden_size, hidden_size)# 定义第四个Linear层,输入是hidden_size,输出维度是output_sizeself.fc4 = nn.Linear(hidden_size, output_size)# 定义激活函数self.relu = nn.ReLU() # ReLU激活函数def forward(self, x):# 输入数据经过各层和激活函数x = self.relu(self.fc1(x)) # 第一个Linear和ReLU激活x = self.relu(self.fc2(x)) # 第二个Linear和ReLU激活x = self.relu(self.fc3(x)) # 第三个Linear和ReLU激活x = self.fc4(x) # 最后一层线性输出return x# 实例化模型model = DNN(X_train_tensor.shape[1], 256, 1) # 输入特征维度、隐藏层节点数和输出维度# 将模型放到指定设备上(GPU或CPU)
model.to(device)# 定义损失函数,使用均方误差损失函数,适用于回归任务
criterion = nn.MSELoss()
# 定义优化器,使用Adam优化器
optimizer = optim.Adam(model.parameters(), lr=0.01)# 进行训练迭代
for epoch in range(1, 1001):model.train() # 将模型设置为训练模式total_loss = 0 # 初始化总损失# 循环加载DataLoader,每次获取一个批次的数据和标签for inputs, labels in train_loader:# 清空优化器梯度optimizer.zero_grad()# 将inputs和labels放到device上inputs = inputs.to(device)labels = labels.to(device)# 前向传播,计算输出outputs = model(inputs)# 计算损失loss = criterion(outputs, labels)# 反向传播和优化loss.backward() # 反向传播计算梯度optimizer.step() # 更新参数# 累加当前批次的损失total_loss += loss.item() # 获取当前批次的损失,累加到 total_loss# 计算本次 epoch 的平均损失avg_loss = total_loss / len(train_loader)# 每10个epoch打印一次当前模型的训练情况if (epoch + 1) % 10 == 0:print(f'Epoch [{epoch + 1}/{1000}], Loss: {avg_loss:.4f}')# 模型的评估
with torch.no_grad(): # 不计算梯度以提高速度和减少内存使用model.eval() # 将模型切换到评估模式# 将测试集放到模型上计算输出predict_test = model(X_test_tensor.to(device))# 计算测试集的损失test_loss = criterion(predict_test, y_test_tensor.to(device))# 打印测试集的损失
print('MSE:', test_loss.item()) # 打印均方误差# 将预测值和目标值转换为Numpy数组
predictions = predict_test.cpu().numpy() # 将预测值从GPU移到CPU并转换为Numpy
y_test_numpy = y_test_tensor.cpu().numpy() # 将测试集目标值从GPU移动到CPU并转换为Numpy# 绘制结果,创建一个新的图形窗口
plt.figure(1)
# 绘制散点图,用来显示实际值和预测值的关系
plt.scatter(y_test_numpy, predictions, color='blue', label='Predicted Values')
# 绘制对角线,用来对比预测值与实际值的关系
plt.plot([min(y_test_numpy), max(y_test_numpy)], [min(y_test_numpy), max(y_test_numpy)],linestyle='--', color='red', lw=2, label='Ideal Prediction')
# 设置x轴标签
plt.xlabel('Actual Values')
# 设置y轴标签
plt.ylabel('Predicted Values')
# 设置标题
plt.title('Regression Results')
plt.legend() # 显示图例# 绘制实际值和预测值的曲线
plt.figure(2)
# 绘制实际值的曲线,取最后100个样本
plt.plot(y_test_numpy[-100:], label='Actual Values', marker='o')
# 绘制预测值的曲线,取最后100个样本
plt.plot(predictions[-100:], label='Predicted Values', marker='*')
# 设置x轴标签
plt.xlabel('Sample Index')
# 设置y轴标签
plt.ylabel('Values')
# 设置标题
plt.title('Actual vs Predicted Values in Linear Regression')
plt.legend() # 显示图例plt.show() # 显示所有图形相关文章:
)
Python----深度学习(基于DNN的PM2.5预测)
一、目标 如何使用 PyTorch 实现一个简单的深度神经网络(DNN)模型,并用于回归任务。该模型通过训练数据集来预测PM2.5。代码通过读取数据集、数据处理、模型训练和模型评估等步骤,详细展示了整个实现过程。 二、数据集介绍 Data …...

Android12源码编译及刷机
由于google的AOSP源码拉取经常失败,编译还经常出现各种问题。这里根据香橙派Orange Pi 5 Plus(Android12电视镜像)源码进行编译演示。 RK芯片的开发板可玩性很高,这里以电视版本android系统为例子,学习的同时还可以当…...

TRO再添新案 TME再拿下一热门IP,涉及Paddington多个商标
4月2日和4月8日,TME律所代理Paddington & Company Ltd.对热门IP Paddington Bear帕丁顿熊的多类商标发起维权,覆盖文具、家居用品、毛绒玩具、纺织用品、游戏、电影、咖啡、填充玩具等领域。跨境卖家需立即排查店铺内的相关产品! 案件基…...

如何使用 Spring Boot 实现分页和排序:配置与实践指南
在现代 Web 应用开发中,分页和排序是处理大量数据时提升用户体验和系统性能的关键功能。Spring Boot 结合 Spring Data JPA 提供了简单而强大的工具,用于实现数据的分页查询和动态排序,广泛应用于 RESTful API、后台管理系统等场景。2025 年&…...

asammdf 库的信号处理和数据分析:深入挖掘测量数据
内容概要: 信号处理的基本操作数据分析和统计数据可视化和报告生成 正文: 信号处理的基本操作 asammdf 提供了对信号的基本操作,包括读取、筛选和转换。 读取信号 with asammdf.MDF(nameexample.mf4) as mdf:engine_speed …...

在springboot项目中,如何进行excel表格的导入导出功能?
以下是使用 Apache POI 和 EasyExcel 实现 Excel 表格导入导出功能的具体代码示例。 1. 使用 Apache POI 实现 Excel 导入导出 添加依赖 在 pom.xml 中添加 Apache POI 的依赖: <dependency><groupId>org.apache.poi</groupId><artifactId…...

【C++11】右值引用和移动语义:万字总结
📝前言: 这篇文章我们来讲讲右值引用和移动语义 🎬个人简介:努力学习ing 📋个人专栏:C学习笔记 🎀CSDN主页 愚润求学 🌄其他专栏:C语言入门基础,python入门基…...

29、简要描述三层架构开发模式以及三层架构有哪些好处?
三层架构开发模式概述 三层架构(3-Tier Architecture)是一种将软件系统按功能模块垂直拆分为三个独立逻辑层的经典设计模式,自20世纪90年代提出以来,已成为企业级应用开发的主流范式。其核心思想是通过职责分离和松耦合设计&…...

PotPlayer,强大的高清视频播放器
PotPlayer 是一款强大的的高清视频播放器,兼容多种音频和视频格式,支持多种硬件加速解码,包括DXVA、CUDA、QuickSync等。支持立体视频播放技术、字幕支持、截屏工具以及视频录制等多种功能。文末获取! 1.鼠标右键【PotPlayer】压…...
)
AI数字人:未来职业的重塑(9/10)
摘要:AI 数字人凭借计算机视觉、自然语言处理与深度学习技术,从虚拟形象进化为智能交互个体,广泛渗透金融、教育、电商等多领域,重构职业生态。其通过降本提效、场景拓展与体验升级机制,替代重复岗位工作,催…...

Qt开发:如何加载样式文件
文章目录 一、加载图片资源二、QSS的使用介绍三、QSS的应用步骤与示例 一、加载图片资源 右键项目->选择"Add New…“之后,会弹出如下界面: 选择Qt->Qt Resource File即可。 点击下一步 点击上图中的LoadImageDemo.qrc文件,右…...
【10分钟读论文】Power Transmission Line Inspections电力视觉水文
标题Power Transmission Line Inspections: Methods, Challenges, Current Status and Usage of Unmanned Aerial Systems 2024 评分一颗星 论文《Power Transmission Line Inspections: Methods, Challenges, Current Status and Usage of Unmanned Aerial Systems》的核心内…...

[详细无套路]MDI Jade6.5安装包下载安装教程
目录 1. 软件包获取 2. 下载安装 3. 启动 4. 问题记录 写在前面: 垂死病中惊坐起,JAVA博主居然开始更博客了~ 最近忙项目了, 没啥更新的动力,见谅~见谅~. 这次博主的化工友友突然让帮安装JADE6.5软件,本来以为不就一个软件,直接拿捏. 不料竟然翻了个小车, 反被拿捏了. 既…...

Spring Boot 参考文档导航手册
📚 Spring Boot 参考文档导航手册 🗺️ ✨ 新手入门 👶 1️⃣ 📖 基础入门:概述文档 | 环境要求 | 安装指南 2️⃣ 🔧 实操教程:上篇 | 下篇 3️⃣ 🚀 示例运行:基础篇 …...

多个请求并行改造
改成 compose 页面的recompose次数 有时候recompose次数没必要优化,除非真的影响到性能了...
)
前端与Rust后端交互:跨越语言鸿沟 (入门系列三)
作为前端开发者,在Tauri应用中与Rust后端交互可能是最陌生的部分。本文将帮助你理解这一过程,无需深入学习Rust即可实现高效的前后端通信。 极简上手项目 apkParse-tauri 命令系统:前端调用Rust函数 Tauri的核心通信机制是"命令系统&q…...

ClickHouse查询执行与优化
SQL语法扩展与执行计划分析 特殊函数与子句 WITH子句:定义临时表达式(CTE),复用中间结果。 WITH tmp AS (SELECT ...) SELECT * FROM tmp ANY修饰符:在JOIN时仅保留第一个匹配的行(避免笛卡尔积爆炸&…...
)
[Kaggle]:使用Kaggle服务器训练YOLOv5模型 (白嫖服务器)
【核知坊】:释放青春想象,码动全新视野。 我们希望使用精简的信息传达知识的骨架,启发创造者开启创造之路!!! 内容摘要:最近需要使用 YOLOv5 框架训练一个识别模型…...

Debian安装避坑
Debian安装避坑 不要联网安装不支持root直接登陆默认没有ssh服务默认没有sudo命令 不要联网安装 安装系统的时候不要联网安装, 直接关闭网卡 否则在线下载最新的包非常耗时间. 不支持root直接登陆 ssh <创建的普通用户名>机器ip默认没有ssh服务 # 安装ssh服务 apt ins…...

Android Gradle插件开发
文章目录 1. Gradle插件是什么2. 为什么需要插件3. 编写插件位置4. 编写插件5. 自定义插件扩展5.1 订阅扩展对象5.2 把扩展添加给Plugin并使用5.3 配置参数5.4 嵌套扩展5.4.1 定义扩展5.4.2 获取扩展属性5.4.3 使用5.4.4 执行5.4.5 输出 6. 编写在单独项目里6.1 新建Module6.2 …...

goweb项目结构以及如何实现前后端交互
项目结构 HTML模板 使用ParseFiles可以解析多个模板文件 func ParseFiles(filenames ...string)(*Teplate,error){return parseFiles(nil,filenames...) }把模板信息响应写入到输入流中 func (t *Template) Exwcute(wr io.Writer,data interface{})error{if err:t.escape();…...

Astro canvas大屏从iotDA上抽取设备影子的参数的详细操作实施路径
目录 🛠 场景: 🎯 核心思路 🗺 详细操作实施路径(针对小白版) 🚛 第1步:配置桥接器(建立连接通道) 📋 第2步:配置数据集…...

Ardunio学习
程序书写 Ardunio程序安装 在 Arduino的官方网站上可以下载这款官方设计的软件及源码、教程和文档。Arduino IDE的官方下载地址 为:http://arduino.cc/en/Main/Software。登录官网,下载软件并安装。 https://www.arduino.cc/。 安装成功后࿰…...
:从强化学习到PPO)
dl学习笔记(13):从强化学习到PPO
一、我们为什么要有强化学习 为了更好的有一个宏观感受,下图是DeepMind在2024发表的文章中对AI做出了不同层次的定义 可以看到左边分为了5个不同层次的AI,中间是对于细分的下游任务AI的能力展现,右边则是通用任务的AGI实现。我们可以看到中间…...

【运维】云端掌控:用Python和Boto3实现AWS资源自动化管理
《Python OpenCV从菜鸟到高手》带你进入图像处理与计算机视觉的大门! 解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界 在云计算时代,AWS(Amazon Web Services)作为领先的云服务平台,其资源管理的高效性对企业至关重要。本文深入探讨如何利用Python的boto3…...

数字技术驱动下教育生态重构:从信息化整合到数字化转型的路径探究
一、引言 (一)研究背景与问题提出 在当今时代,数字技术正以前所未有的速度和深度渗透到社会的各个领域,教育领域也不例外。从早期的教育信息化整合到如今的数字化转型,教育系统正经历着一场深刻的范式变革。 回顾教…...

《数据库系统工程师》-B站-视频截图整理-2021-23
在2024年准备软考《数据库系统工程师》,跟着B站UP主学习的视频截图记录,当然考试也顺利通过了(上午下午都是50多分)。 在视频评论区还愿下面看到有人问我的截图资源。 我当时学习用的钉钉的teambition做的记录,在线文档…...
——function-mf_dataset.py)
【PINN】DeepXDE学习训练营(5)——function-mf_dataset.py
一、引言 随着人工智能技术的飞速发展,深度学习在图像识别、自然语言处理等领域的应用屡见不鲜,但在科学计算、工程模拟以及物理建模方面,传统的数值方法仍然占据主导地位。偏微分方程(Partial Differential Equations, PDEs&…...

lnmp1.5+centos7版本安装php8
1、问题: 1nmp1.5不支持php8 解决办法: 下载lnmp2.1,进入到2.1版本执行安装php多版本命令,选择php8 2、编译安装php8时报C错误问题 解决办法: 安装php8.0报错A compiler with support for C17 language features is required…...

Netmiko 源码解析
1. 源码结构概览 Netmiko 的代码库主要分为以下核心模块: netmiko/ ├── base_connection.py # 连接基类(核心逻辑) ├── cisco/ # Cisco 设备实现类 ├── juniper/ # Juniper 设备实现类 ├── hp_…...

WPF大数据展示与分析性能优化方向及代码示例
WPF大数据展示与分析性能优化指南 一、大数据展示性能优化方向 1. 虚拟化技术 核心思想:只渲染可见区域的数据,动态加载/卸载数据项 实现方式: 使用VirtualizingStackPanel(WPF内置)自定义虚拟化容器(如VirtualizingWrapPanel)代码示例: &…...

Redis的ZSet对象底层原理——跳表
我们来聊聊「跳表(Skip List)」,这是一个既经典又优雅的数据结构,尤其在 Redis 中非常重要,比如 ZSet(有序集合)底层就用到了跳表。 🌟 跳表(Skip List)简介 …...

SpringCloud组件——OpenFeign
一.使用 1.为什么要使用 OpenFeign是⼀个声明式的WebService客户端。它让微服务之间的调用变得更简单,类似controller调用service, 只需要创建⼀个接口,然后添加注解即可使用OpenFeign。 2.引入依赖 加下面的依赖引入到服务消费者中&…...

C#里使用libxl来创建EXCEL文件然后发送到网络
前面一个例子说明了从网络直接读取EXCEL数据的方法, 本例子就说明怎么样创建一个EXCEL文件,也可以直接发送到网络,而不需要保存到文件,直接在内存里高效操作。 在这里要使用函数SaveRaw,输入参数是保存数据缓冲区和缓冲区的大小,返回数据和大小。 例子如下: private…...

物联网安全运营概览
这是第二篇博客文章,概述了实施物联网安全及其运行之前所需的内容。上次,我们概述了物联网安全。为了让您更具体地了解它是什么,我们将首先解释它是如何工作的,然后介绍设备 ID、部署选项和许可的概念。 物联网安全各个组件之间的关系如下图所示:基于此图,我们先来看一下…...

如何给GitHub项目提PR(踩坑记录
Fork 项目 (Fork the Repository): 在你使用的代码托管平台(如 GitHub、GitLab)上,找到你想要贡献的原始项目仓库。点击 "Fork" 按钮。这会在你自己的账户下创建一个该项目的完整副本(你的 Fork 仓库)。 克…...

Redux和MobX有什么区别
Redux 和 MobX 都是用于 React 应用的全局状态管理库,但它们在设计理念、使用方式和适用场景等方面存在明显的区别,下面为你详细分析: 1. 设计理念 Redux:基于 Flux 架构,遵循单向数据流和纯函数式编程的理念。状态是…...

测试模板x
本篇技术博文摘要 🌟 引言 📘 在这个变幻莫测、快速发展的技术时代,与时俱进是每个IT工程师的必修课。我是盛透侧视攻城狮,一名什么都会一丢丢的网络安全工程师,也是众多技术社区的活跃成员以及多家大厂官方认可人员&a…...

dubbo 隐式传递
隐式传递 隐式传递的应用 传递请求流水号,分布式应用中通过链路追踪号来全局检索日志传递用户信息,以便不同系统在处理业务逻辑时可以获取用户层面的一些信息传递凭证信息,以便不同系统可以有选择性地取出一些数据做业务逻辑,比…...

深入解析 ASP.NET Core 中的 ResourceFilter
在现代 Web 开发中,ASP.NET Core 提供了强大的过滤器(Filters)机制,用于在处理请求的不同阶段执行特定的代码逻辑。ASP.NET Core 中的 ResourceFilter 是一种非常有用的过滤器类型,允许开发人员在请求到达控制器操作方…...

Java进阶--面向对象设计原则
设计模式 概念 设计模式,又称软件设计模式,是一套被反复使用,经过分类编目的,代码设计经验的总结。描述了在软件设计过程中的一些不断重复发生的问题,以及该问题的解决方。它是解决特定问题的一系列套路,是…...

java每日精进 4.26【多租户之过滤器及请求处理流程】
一月没更,立誓以后断更三天我就是狗!!!!!!!! 研究多租户框架中一条请求的处理全流程 RestController RequestMapping("/users") public class UserControlle…...

【学习笔记】Stata
一、Stata简介 Stata 是一种用于数据分析、数据管理和图形生成的统计软件包,广泛应用于经济学、社会学、政治科学等社会科学领域。 二、Stata基础语法 2.1 数据管理 Stata 支持多种数据格式的导入,包括 Excel、CSV、文本文件等。 从 Excel 文件导入…...

[MySQL数据库] 事务与锁
🌸个人主页:https://blog.csdn.net/2301_80050796?spm1000.2115.3001.5343 🏵️热门专栏: 🧊 Java基本语法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12615970.html?spm1001.2014.3001.5482 🍕 Collection与…...
)
Rule.issuer(通过父路径配置loader处理器)
说明 正常在设置loader配置规则时,都是通过文件后缀来配置的 issuer的作用是可以通过父级的路径,设置生效的匹配规则 与rule的差别 test: 匹配当前模块的路径(如 .css 文件) issuer: 匹配引入当前模块的父模块的路径࿰…...

MyBatis 插件开发的完整详细例子
MyBatis 插件开发的完整详细例子 MyBatis 插件(Interceptor)允许开发者在已映射语句执行过程中的某一点进行拦截调用,从而实现自定义逻辑。以下是一个完整的 MyBatis 插件开发示例,涵盖所有使用场景,并附有详细注释和总…...

树状数组底层逻辑探讨 / 模版代码-P3374-P3368
目录 功能 实现 Q:但是,c[x]左端点怎么确定呢? Q:那么为什么要以二进制为基础呢? Q:为什么是补码 - ? 区间查询 树形态 性质1.对于x<y,要么c[x]和c[y]不交,要么c[x]包含于c[y] 性质2.c[x] 真包含 于c[x l…...

Eigen库入门
Eigen是一个C模板库,用于线性代数运算,包括矩阵、向量、数值求解和相关算法。它以其高性能、易用性和丰富的功能而闻名。 安装与配置 Eigen是一个纯头文件库,无需编译,只需包含头文件即可使用。 下载Eigen:从官方网站…...

力扣HOT100——102.二叉树层序遍历
给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。 示例 1: 输入:root [3,9,20,null,null,15,7] 输出:[[3],[9,20],[15,7]] /*** Definition for a bi…...

客户案例 | 光热+数智双驱动!恒基能脉的数字化协同与技术创新实践
光热先锋 智领未来 恒基能脉新能源科技有限公司: 创新驱动,智造光热未来行业领航者 恒基能脉新能源科技有限公司是一家立足于光热发电核心技术产品,专注于“光热” 多能互补项目的国家高新技术企业,其核心产品定日镜广泛应用于光热发电、储…...