dl学习笔记(13):从强化学习到PPO
一、我们为什么要有强化学习
为了更好的有一个宏观感受,下图是DeepMind在2024发表的文章中对AI做出了不同层次的定义
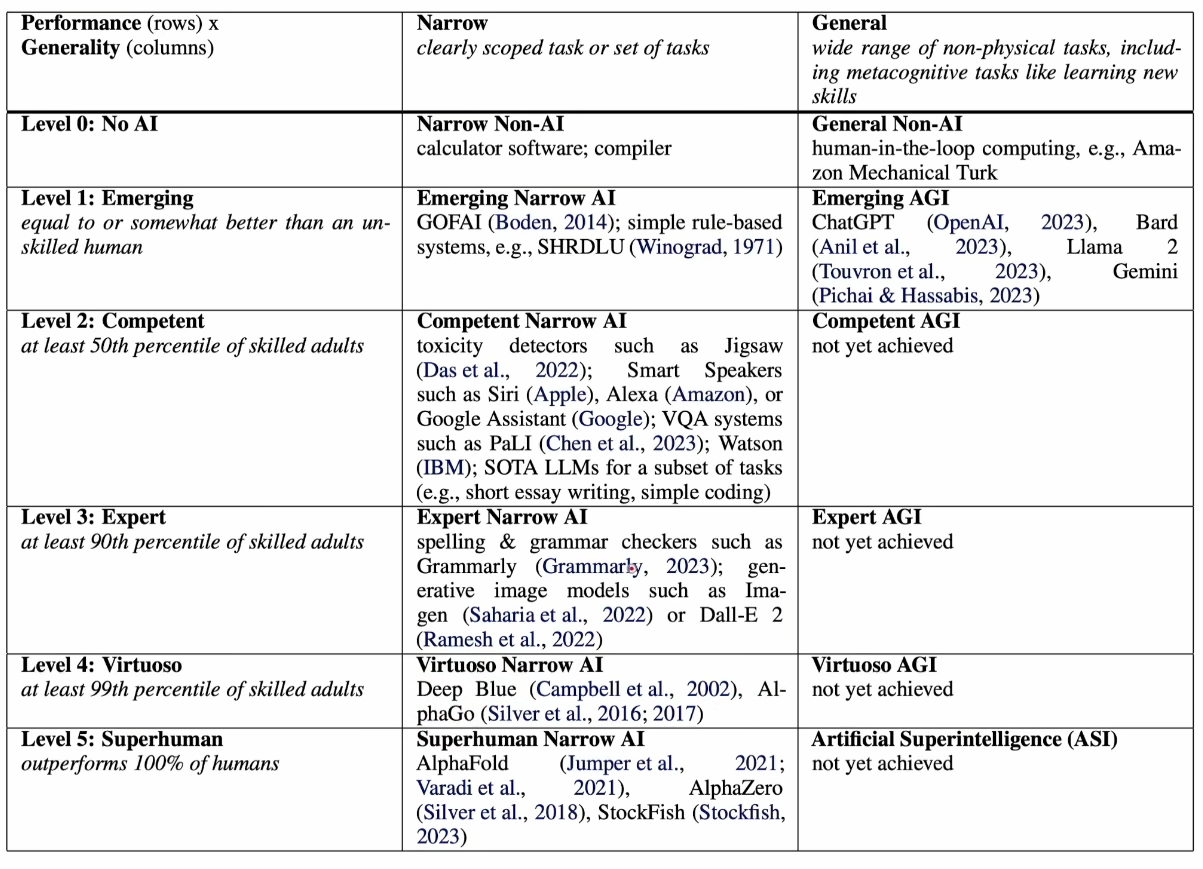
可以看到左边分为了5个不同层次的AI,中间是对于细分的下游任务AI的能力展现,右边则是通用任务的AGI实现。我们可以看到中间的细分任务每个阶段都有AI能完成了,甚至最下面的超过人类的也已经有好几个实现了,而右边的通用还停留在第三个阶段。所以现在的主流任务是在右边往AGI的更深入的发展,而发展AGI具体需要哪些能力呢?
在2024年发表的一篇文章中写道,具体大概有哪些特点:感知,记忆,推理和意识。
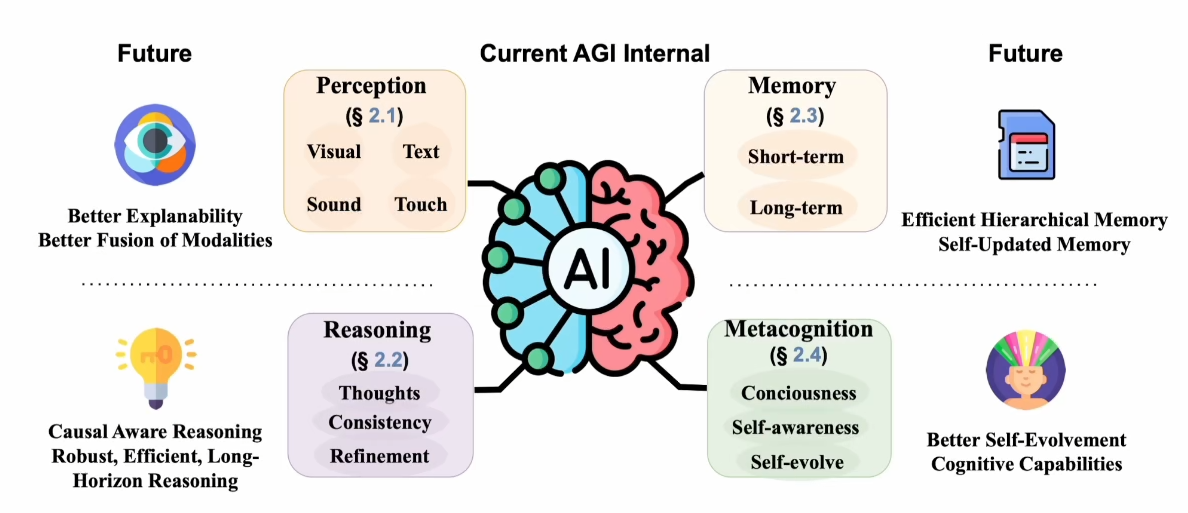
从这里大家就可以大致看到为什么现在很多大厂或者研究都在往推理方向深耕,推理是实现AGI很重要的一部分。而训练推理能力常见的一种方法就是强化学习。
二、AlphaGo
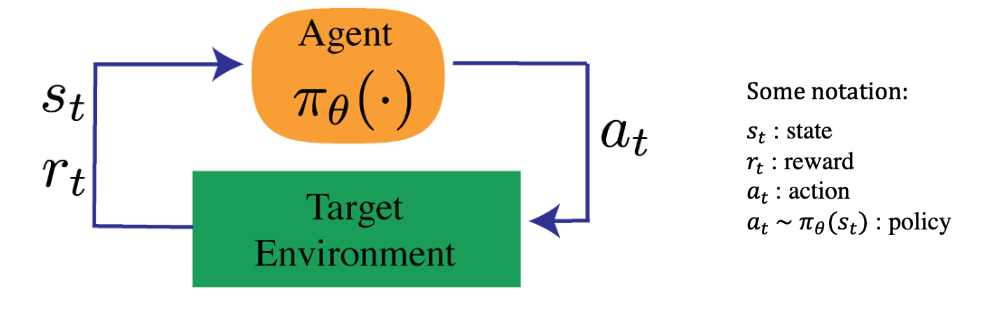
从这张图片中可以看到,强化学习主要有以下几个基本概念:状态,奖励,行动和策略。
举一个有名的强化学习例子:AlphaGo下围棋。状态就是围棋的具体每一步下完之后的棋谱;奖励就是每一步下完之后会对未来有什么影响;行动就是具体下的每一步动作;策略就是具体到下到哪里的一个决策。
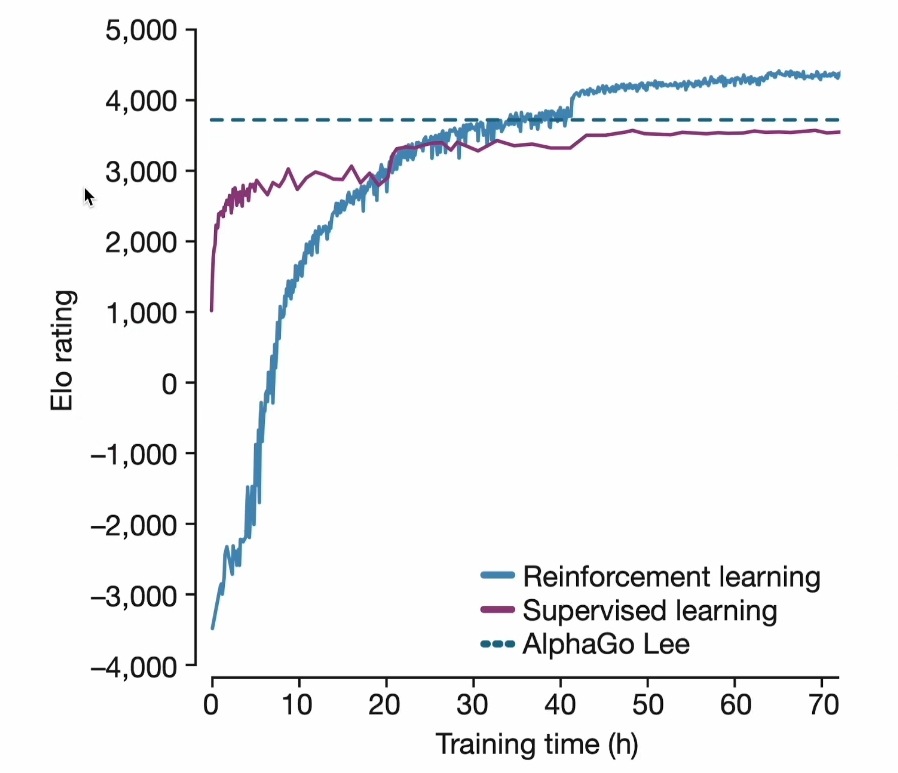
这张图就是AlphaGo的一个训练效果展示图,可以看到正常的监督学习如果以人类下的棋谱作为学习目标的话是永远超出不了人类的水平的,如果使用强化学习的方法,虽然前期效果不如监督学习,但是随着后期的训练积累与探索是可以超过人类的水平的。
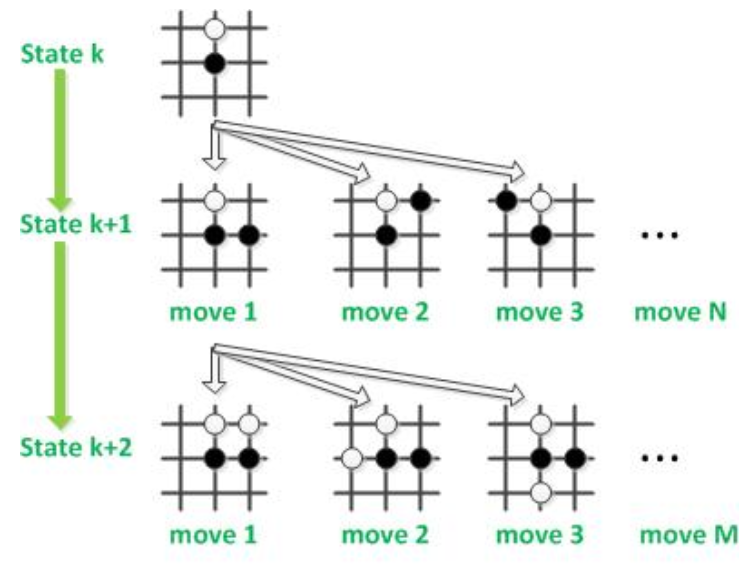
上图就是一个简单的示例,我们把每一步棋子都理解为一个状态,在下完一步之后又有N种别的走法,如果我们把这种结构抽象成多叉树的结构的话,以此类推下棋这个游戏就变成了一种在一个很大的搜索空间中的搜索一条较优路径问题,也就是论文中说的蒙特卡洛树搜索(MCTS)。也就是说这本质上是一个搜索算法,用强化学习来减少搜索空间。
在有了上面的基础后,我们就可以把我们的策略和奖励全部都参数化,用神经网络去拟合变成两个神经网络模型,也就是Policy network和Value network。
具体的训练流程大概分为三个阶段:在第一阶段先进行预训练,用大量的人类玩家棋谱进行训练一个基础的策略网络,从而拥有一定的围棋水平。具体来说输入一个具体的状态,放到神经网络中最后输出一个动作,拟合目标就是人类玩家的先验知识。
第二阶段是强化学习阶段:训练两个策略模型对着下,由于围棋是很容易判断输赢的,所以通过两个策略网络对下收集大量训练样本,已经达到一个很高的水平。
第三个阶段是训练一个价值模型:通过第二阶段得到的大量训练样本,模型可以学习到大量的走法,并且也知道哪些走法赢了哪些走法输了,我们就可以以此来训练一个价值模型用来判断:给定一个状态输出一个最终的可能胜率,然后我们每次都按照胜率最高的走法就形成了循环。
然后DeepMind又推出zero版本,拿掉了第一阶段的预训练的先验知识,通过纯强化学习训练的一个版本,发现让模型从一开始就自己探索也一样获得了很好的效果,插句题外话deepseekR1zero应该就是这么来的。
三、强化学习基础
由于本文的重点不是AlphaGo,所以也不会花费太多篇幅来讲解中间的具体细节,但是我们可以通过上面大致内容可以看到强化学习的一个大概流程以及出现的问题。首先我们可以看到强化学习的核心思想就是选择一个策略能够将未来的期望奖励最大化。其次我们可以发现我们在训练的时候这个奖励在大多数任务下都是是很稀疏的,例如这里下一整盘棋只有最后一个奖励信号也就是输赢。那我们如何知道哪些动作导致了输赢,具体给每个动作分配奖励多少呢?所以很多工作都是关于如何更好的分配奖励。
为了更方便理解,接下来会引用一些来自CS234强化学习课程的部分PPT图片,以及GPT对相关内容的讲解图片。马上发车,坐稳扶好,下面会从强化学习基础概念直通PPO的数学公式。

强化学习整个系统大概就分为这几个步骤,我们已经拥有了状态和动作的定义,下一步是建立一个动态模型来描述世界。所以为了更好的描述整个环境,我们需要先对环境进行一个初始建模。
1.MRP
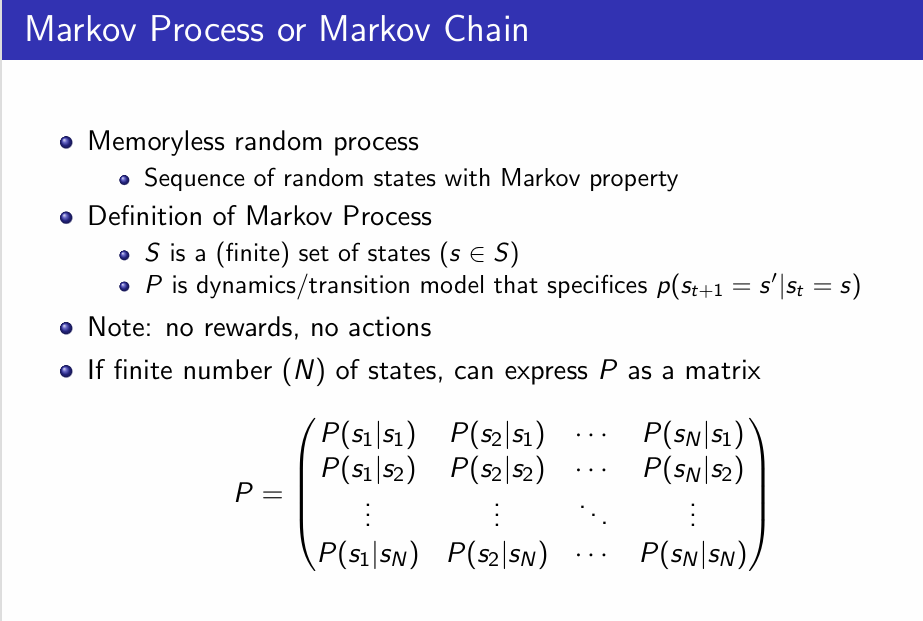
这张PPT把世界建模成一个马尔可夫过程(Markov chain)作为刻画环境的动态模型,也就是假设“下一时刻状态只和当前状态有关,与过去历史无关”,并用转移概率矩阵P来描述从任一状态到下一个状态的概率分布。这就是环境中“状态→状态”转移的动态模型。
而我们之所以假设未来的状态仅依赖于当前状态,而不是整个历史动作。一方面如果不做马尔可夫假设,理论上每一个时刻的决策都要依赖整个历史,那么状态空间和计算成本就会无限膨胀,不利于算法设计与收敛分析;另一方面这也确实符合一些事实的直觉。
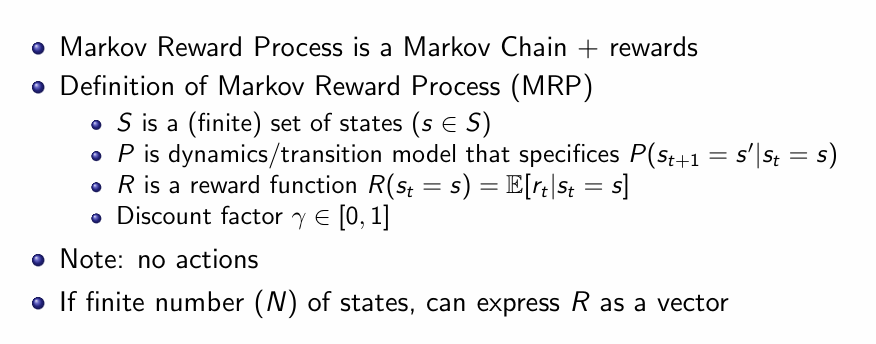
进一步的,我们可以继续定义马尔可夫奖励过程(Markov reward process, MRP),它是在前面“马尔可夫链”基础上加上奖励信号和折扣因子的扩展。我们在前者之上为每个状态赋予了一个“价值”信号(奖励),并引入折扣,从而能定义回报 Gt 和状态值函数 V(s),为后续的策略评估与优化奠定数学基础。

这里首先定义了在马尔可夫奖励过程中的奖励是什么,而下面的价值函数就是一个在当前状态下的奖励期望。为了更好的理解这个基本式子,我们还需要理解为什么要这样做。具体来说当我们做出一个行动后,奖励就分为两个部分:即时奖励和未来奖励。所以为了平衡即时奖励和未来的奖励,这里以指数衰减的形式通过折扣因子进行了平衡,形成了一个几何级数。这样做的主要原因有几个:首先当 γ<1时必然收敛,从而使得价值函数可被良好定义和计算;其次在真实环境里,越往后得到的奖励往往越不确定,比如模型可能失配、环境发生变化,通过对越远的回报打越低的折扣可以自然地“更看重”近期奖励,弱化远期噪声对策略评估的影响。

所以当等于0的时候就退化成只考虑当前的即时奖励,当等于1时为每个动作分配一样的权重。
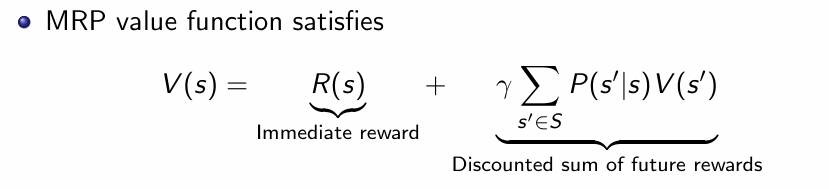
进一步的我们可以计算MRP的价值函数,这里S'表示下一个动作,为了更好的理解,下面放一张GPT对此做出的解释:

最后我们也可以同样的定义策略:

策略就是代理人在每个状态下“做什么动作”的规则,它可以有两种形式:
-
确定性策略:对每个状态s都固定地选一个动作 a=π(s);
-
随机策略:对每个状态s给出一个动作分布,代理人按照这个分布采样动作。
为了在数学上既能覆盖两种情况,又方便后续用期望和概率的语言来统一推导,通常把策略写成条件概率。
最后就引出了我们最后的优化目标:
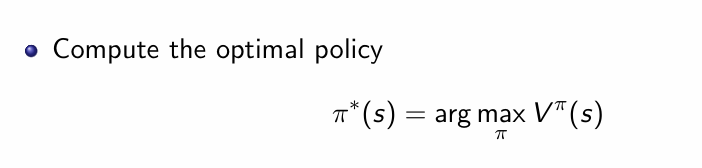
即找到能使价值函数最大化的策略。
2.MDP
在对环境进行建模之后,MRP并没有将动作和策略纳入进来,所以MDP和MRP最主要的区别就在此。总的来说,MRP是不含动作的“被动”随机过程模型,侧重值函数评估;而MDP则是含动作的“主动”决策过程模型,既要评估也要控制,是强化学习算法设计的核心。
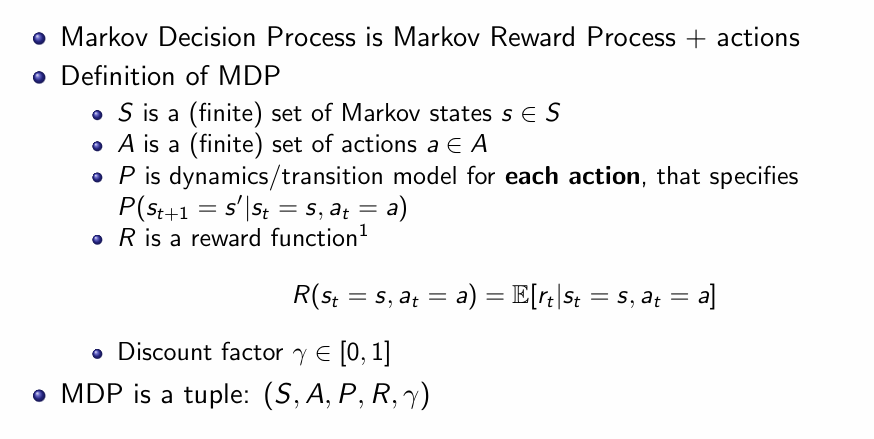
这张“Markov Decision Process (MDP)”的PPT把之前的马尔可夫奖励过程再加上动作这一维度,正式定义了强化学习的核心模型。它由五个部分组成:
-
状态集 S:系统可能处于的所有离散状态的集合;
-
动作集 A:代理人在每个状态下可选择的所有动作;
-
转移模型 P:给定当前状态s和选定动作a,下一时刻变到状态s′的概率分布;
-
奖励函数 R(s,a):在状态s执行动作a后,获得即时回报的期望值;
-
折扣因子 γ∈[0,1]:对未来奖励进行指数衰减,以保证无穷期望回报的收敛并表达对即时回报的偏好。
综合起来,MDP 被表示为一个五元组 (S,A,P,R,γ),它既能描述环境的随机动态,也给出了代理人通过选择动作来影响状态演化和累积回报的数学框架。基于这个模型,我们既可以进行策略评估(在固定策略下归约为 MRP 计算值函数),也可以进行最优控制(通过策略迭代或价值迭代寻找最大化长期回报的最优策略)。

在求解一个给定 MDP 的最优策略时,最直观的做法是 枚举所有可能的确定性策略,计算它们各自的值函数,再挑出回报最高的那个。这种穷举方法虽然思路简单,但面临两个致命问题:
-
策略空间指数级增长
如果状态数为∣S∣,每个状态下可选动作数为∣A∣,那么所有可能的确定性映射数量就是。只要∣S∣或∣A∣略微增大,策略总数就会以天文数字暴涨,根本没法在有限时间或内存中逐一评估。
-
计算与存储开销巨大
即便硬件足够强大,单纯评估每个策略对应的长期折扣回报 Vπ也要花费大量时间。把它乘以指数级的策略数,就完全不现实。
相比之下,策略迭代(Policy Iteration) 则用到了动态规划的“评价–改进”循环,通常只需多次迭代,并且每一轮都能严格或不变地提升策略质量,并且在有限状态空间内保证最终收敛到最优策略。整体复杂度通常在多项式范围内,远比枚举所有策略高效得多。

在MDP中由于多了动作维度,所以相应的添加多了动作维度的Q函数定义: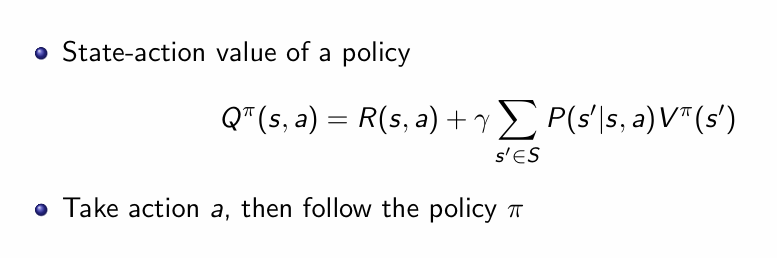
其中第一项是立刻因为执行动作a而得到的即时奖励,第二项是“折扣后的、从下一个状态s′开始再按照策略π行动所能获得的未来回报”(也就是下一个状态的值函数)。由于后面是又回到了固定策略π,所以后面的部分又退化成前面MRP中的V函数定义。
所以我们的策略更新就分成了两步走:
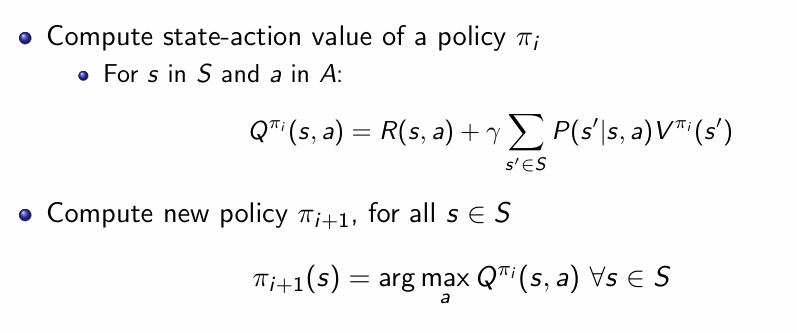
先计算每个动作的Q函数,然后在找到里面最大的作为下一个动作。需要注意这里与V函数之间的区别:当我们手上已经有了当前策略 πi对应的状态值函数Vπ(s)时,可以对“如果此刻在状态s强制执行一个不同的动作a,然后再回归到原策略 πi”这一情形做精确评估,这个Q值告诉我们“先选动作a再按πi”能拿到多少期望回报,从而可以直接在各动作之间比较,选出最优者。
我们可以首先证明这个迭代方法至少不比原来的差:

下一步证明每一步都有一个单调的改进:
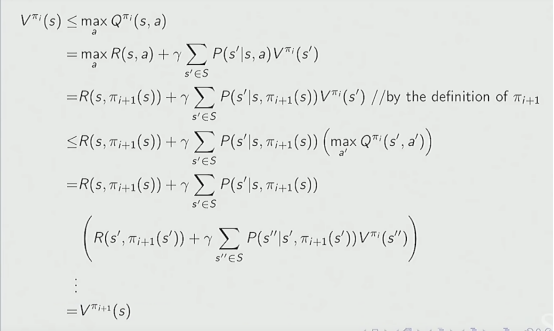
同样的为了方便理解插一段GPT对此的解释:

3.Model-Free Policy Evaluation
由于前面的MRP和MDP都是对环境世界进行建模状态转移矩阵,如果我们并不知道环境从一个状态转移到另一个状态的概率是多少(大多数情况都不知道),那就需要通过采样来模拟环境世界的运行。
3.1Monte Carlo policy evaluation

蒙特卡洛估计的核心思想
-
“Value = mean return”:既然Vπ(s)就是回报的期望,那么最简单的做法是采样多条由π生成的、并且都能终止的完整轨迹,把它们从第一次出现s起的回报Gt全部算出来,然后求平均,就得到对Vπ(s)的蒙特卡洛估计
首次访问的版本具体实现如下:

同样的插入GPT的一段

同样的我们可以实现增量版的蒙特卡洛估计:

增量MC的精髓在于:把批量求平均转成在线、累积式的“旧值+步长×误差”更新。

缺点:
-
方差通常很高
-
因为一次更新要等到整个情节结束才计算回报,单条轨迹的Gt本身会累积很多随机误差;
-
要把均值的方差降下来,往往需要采集大量完整的情节样本——如果环境交互代价高、数据难以获取或出错成本大,MC 可能不切实际。
-
-
只能用在情节型(episodic)任务
-
MC 必须等到“情节结束”才能算出那条轨迹的Gt,才能进行更新;
-
对于没有明确终止条件的无限时域任务,就无法得到有限长度的回报样本,MC就无法应用。
-
3.2Temporal Difference
为了解决无法及时更新必须等到采样完毕的问题,于是TD他来了,我们开始逐渐变成PPO的模样。

我们看到在增量式蒙特卡洛中,之所以不能及时更新就是因为Gt的存在,我们需要一直采样到结尾才能给出完整的折扣奖励求和。而V函数本身就是对折扣奖励的期望,所以很自然的就会想到用下一时刻的V函数对Gt做进一步的近似,这样就能实现像动态规划那样迭代更新。


4.Policy Gradient
在我们对价值函数有了MC和TD两种方法估计之后,下一步我们就能更新我们的策略了。在做具体的更新之前,我们可以先对策略进行参数化,使用一个神经网络来拟合这个策略,所以根据价值函数更新策略的目标就转变为找到最佳参数去拟合最佳策略,也是后面PPO用到的的基础思想。
-
策略参数化
我们把原本“黑箱”的策略π(a∣s)用可微的参数向量θ映射成一个类函数πθ(s,a),从而把“找最优策略”变成“找最优参数”——也就是在参数空间里做更新优化。 -
需要一个性能度量
既然要“找最优”,就必须给每组参数θ定义一个分数,告诉我们这套策略“好不好”。这个分数通常就是在环境中执行策略πθ后所能获得的期望总回报,也就是前面说的价值函数,这就和前面的连在一起了。

由于要找的策略式最大化价值函数,所以这里使用梯度上升去寻找最大值,这就是完整的数学框架

下面是两种表示方法的对比:

由于我们这里主要讨论的是无环境模型的情况,所以只会讲解第二种。
下面就可以使用第二种表示方法来带入到前面的数学框架中:

下一步就是通过求解梯度来更新参数,通过一些恒等变形得到初始梯度表达式:
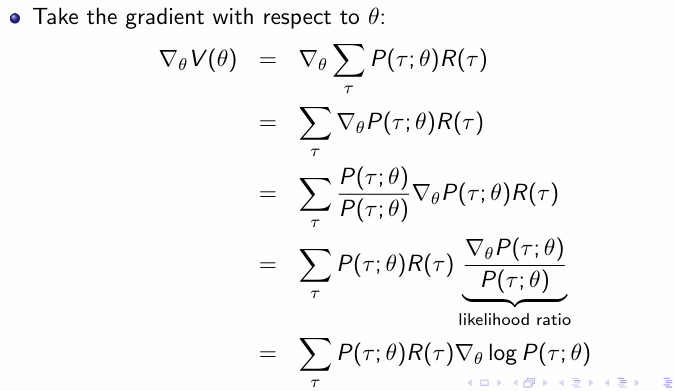
进一步的我们先通过采样来得到前面部分的近似,然后展开做恒等变形:

插入一段GPT对于这段推导的解释:

而最后这里动作选择的方法又主要分为3种:Softmax,Gaussian,Neural networks。它描述的是“在状态s下以怎样的概率选择某个动作”,下面只放softmax这一种常用的,高斯分布在课程课件中也有提到,而神经网络是自动求导。

至此我们完成了梯度数学表达式的所有推导,下面是完整的梯度表示:
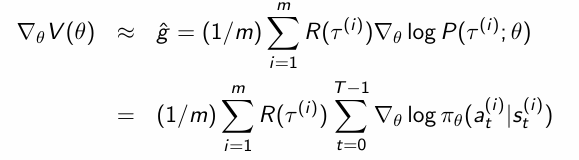
最后我们再在这个基础上加上时间和基线两步来减少方差:

为了更近一步减少方差,我们可以引进一个基线:

这里的b函数只要满足不和参数θ相关即可,这里假设只和状态相关的一个函数。当然也可以不仅仅是和状态相关,并且保证估计依然是无偏的,在平均角度并没有改变梯度估计。
下面我们可以证明并不改变无偏性:
既然都不改变偏差,那我们选择什么作为基线呢,这里选择Q函数作为基线正好符合要求是奖励求和的期望,回顾一下Q函数的定义:

其实我们可以推导得出这里令为价值函数也是为了方差最小化的一个近似,会发现Q函数确实是一个很好的基线,值得注意的是GRPO中的主要改动就是改变了这里的基线:

终于我们得到了优势函数以及完整表达式:
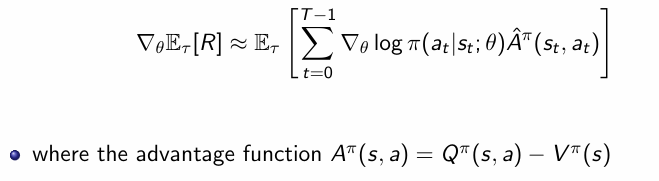
最后我们可以引入TD的思路:由于Q函数是最纯粹的蒙特卡洛回报,理论上无偏但方差极大。
所以我们可以通过引入价值函数的迭代来降低方差,但是会带来一点偏差

四、PPO
我们可以注意到:当k越大时,估计偏差越小(更接近完整回报),但是方差越大;反之k越小就方差低而偏差高。PPO中的GAE 通过引入一个额外的 参数 λ∈[0,1],把所有k-步优势估计按指数衰减地混合起来:

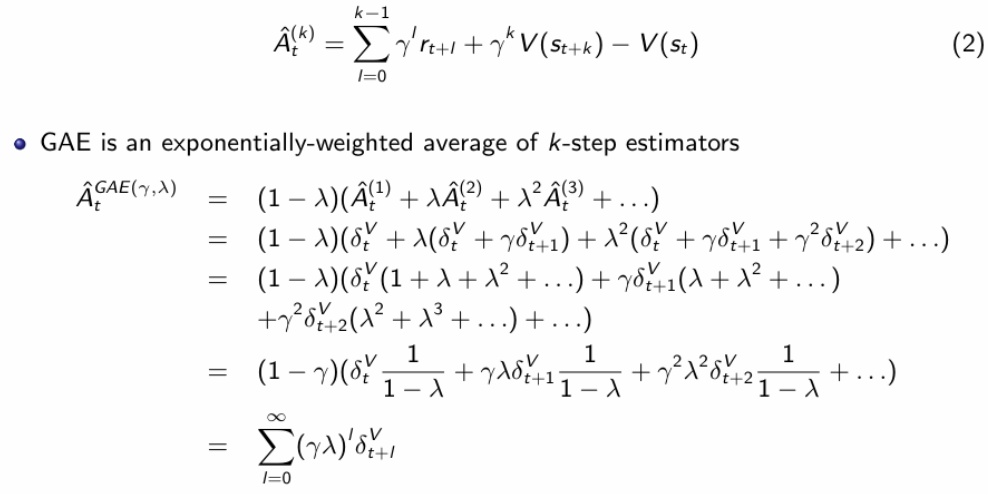
PPO为了防止参数过度更新,还进行了CLIP和KL惩罚的两层保护,这里的CLIP就是限制在这个区间内的操作:
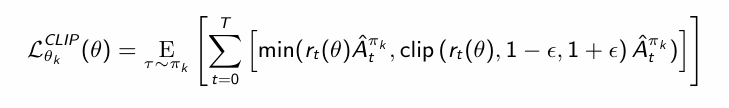
下面PPO在损失函数中进一步引入KL散度惩罚,KL散度就是衡量两个分布之间的差距:
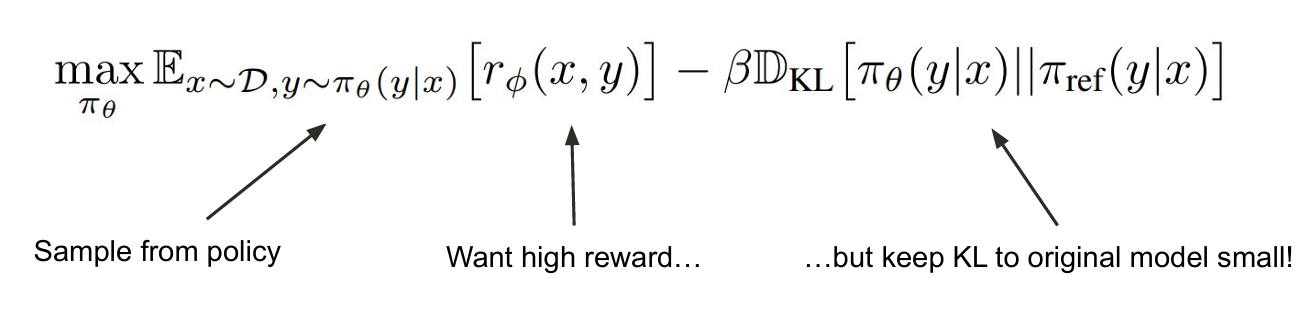
终于我们得到了PPO的损失函数,在这篇文章中只是刚刚讲到PPO的数学公式,具体的RLHF实现流程以及DPO和GRPO等则会在下篇文章中具体讲解。
相关文章:
:从强化学习到PPO)
dl学习笔记(13):从强化学习到PPO
一、我们为什么要有强化学习 为了更好的有一个宏观感受,下图是DeepMind在2024发表的文章中对AI做出了不同层次的定义 可以看到左边分为了5个不同层次的AI,中间是对于细分的下游任务AI的能力展现,右边则是通用任务的AGI实现。我们可以看到中间…...

【运维】云端掌控:用Python和Boto3实现AWS资源自动化管理
《Python OpenCV从菜鸟到高手》带你进入图像处理与计算机视觉的大门! 解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界 在云计算时代,AWS(Amazon Web Services)作为领先的云服务平台,其资源管理的高效性对企业至关重要。本文深入探讨如何利用Python的boto3…...

数字技术驱动下教育生态重构:从信息化整合到数字化转型的路径探究
一、引言 (一)研究背景与问题提出 在当今时代,数字技术正以前所未有的速度和深度渗透到社会的各个领域,教育领域也不例外。从早期的教育信息化整合到如今的数字化转型,教育系统正经历着一场深刻的范式变革。 回顾教…...

《数据库系统工程师》-B站-视频截图整理-2021-23
在2024年准备软考《数据库系统工程师》,跟着B站UP主学习的视频截图记录,当然考试也顺利通过了(上午下午都是50多分)。 在视频评论区还愿下面看到有人问我的截图资源。 我当时学习用的钉钉的teambition做的记录,在线文档…...
——function-mf_dataset.py)
【PINN】DeepXDE学习训练营(5)——function-mf_dataset.py
一、引言 随着人工智能技术的飞速发展,深度学习在图像识别、自然语言处理等领域的应用屡见不鲜,但在科学计算、工程模拟以及物理建模方面,传统的数值方法仍然占据主导地位。偏微分方程(Partial Differential Equations, PDEs&…...

lnmp1.5+centos7版本安装php8
1、问题: 1nmp1.5不支持php8 解决办法: 下载lnmp2.1,进入到2.1版本执行安装php多版本命令,选择php8 2、编译安装php8时报C错误问题 解决办法: 安装php8.0报错A compiler with support for C17 language features is required…...

Netmiko 源码解析
1. 源码结构概览 Netmiko 的代码库主要分为以下核心模块: netmiko/ ├── base_connection.py # 连接基类(核心逻辑) ├── cisco/ # Cisco 设备实现类 ├── juniper/ # Juniper 设备实现类 ├── hp_…...

WPF大数据展示与分析性能优化方向及代码示例
WPF大数据展示与分析性能优化指南 一、大数据展示性能优化方向 1. 虚拟化技术 核心思想:只渲染可见区域的数据,动态加载/卸载数据项 实现方式: 使用VirtualizingStackPanel(WPF内置)自定义虚拟化容器(如VirtualizingWrapPanel)代码示例: &…...

Redis的ZSet对象底层原理——跳表
我们来聊聊「跳表(Skip List)」,这是一个既经典又优雅的数据结构,尤其在 Redis 中非常重要,比如 ZSet(有序集合)底层就用到了跳表。 🌟 跳表(Skip List)简介 …...

SpringCloud组件——OpenFeign
一.使用 1.为什么要使用 OpenFeign是⼀个声明式的WebService客户端。它让微服务之间的调用变得更简单,类似controller调用service, 只需要创建⼀个接口,然后添加注解即可使用OpenFeign。 2.引入依赖 加下面的依赖引入到服务消费者中&…...

C#里使用libxl来创建EXCEL文件然后发送到网络
前面一个例子说明了从网络直接读取EXCEL数据的方法, 本例子就说明怎么样创建一个EXCEL文件,也可以直接发送到网络,而不需要保存到文件,直接在内存里高效操作。 在这里要使用函数SaveRaw,输入参数是保存数据缓冲区和缓冲区的大小,返回数据和大小。 例子如下: private…...

物联网安全运营概览
这是第二篇博客文章,概述了实施物联网安全及其运行之前所需的内容。上次,我们概述了物联网安全。为了让您更具体地了解它是什么,我们将首先解释它是如何工作的,然后介绍设备 ID、部署选项和许可的概念。 物联网安全各个组件之间的关系如下图所示:基于此图,我们先来看一下…...

如何给GitHub项目提PR(踩坑记录
Fork 项目 (Fork the Repository): 在你使用的代码托管平台(如 GitHub、GitLab)上,找到你想要贡献的原始项目仓库。点击 "Fork" 按钮。这会在你自己的账户下创建一个该项目的完整副本(你的 Fork 仓库)。 克…...

Redux和MobX有什么区别
Redux 和 MobX 都是用于 React 应用的全局状态管理库,但它们在设计理念、使用方式和适用场景等方面存在明显的区别,下面为你详细分析: 1. 设计理念 Redux:基于 Flux 架构,遵循单向数据流和纯函数式编程的理念。状态是…...

测试模板x
本篇技术博文摘要 🌟 引言 📘 在这个变幻莫测、快速发展的技术时代,与时俱进是每个IT工程师的必修课。我是盛透侧视攻城狮,一名什么都会一丢丢的网络安全工程师,也是众多技术社区的活跃成员以及多家大厂官方认可人员&a…...

dubbo 隐式传递
隐式传递 隐式传递的应用 传递请求流水号,分布式应用中通过链路追踪号来全局检索日志传递用户信息,以便不同系统在处理业务逻辑时可以获取用户层面的一些信息传递凭证信息,以便不同系统可以有选择性地取出一些数据做业务逻辑,比…...

深入解析 ASP.NET Core 中的 ResourceFilter
在现代 Web 开发中,ASP.NET Core 提供了强大的过滤器(Filters)机制,用于在处理请求的不同阶段执行特定的代码逻辑。ASP.NET Core 中的 ResourceFilter 是一种非常有用的过滤器类型,允许开发人员在请求到达控制器操作方…...

Java进阶--面向对象设计原则
设计模式 概念 设计模式,又称软件设计模式,是一套被反复使用,经过分类编目的,代码设计经验的总结。描述了在软件设计过程中的一些不断重复发生的问题,以及该问题的解决方。它是解决特定问题的一系列套路,是…...

java每日精进 4.26【多租户之过滤器及请求处理流程】
一月没更,立誓以后断更三天我就是狗!!!!!!!! 研究多租户框架中一条请求的处理全流程 RestController RequestMapping("/users") public class UserControlle…...

【学习笔记】Stata
一、Stata简介 Stata 是一种用于数据分析、数据管理和图形生成的统计软件包,广泛应用于经济学、社会学、政治科学等社会科学领域。 二、Stata基础语法 2.1 数据管理 Stata 支持多种数据格式的导入,包括 Excel、CSV、文本文件等。 从 Excel 文件导入…...

[MySQL数据库] 事务与锁
🌸个人主页:https://blog.csdn.net/2301_80050796?spm1000.2115.3001.5343 🏵️热门专栏: 🧊 Java基本语法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12615970.html?spm1001.2014.3001.5482 🍕 Collection与…...
)
Rule.issuer(通过父路径配置loader处理器)
说明 正常在设置loader配置规则时,都是通过文件后缀来配置的 issuer的作用是可以通过父级的路径,设置生效的匹配规则 与rule的差别 test: 匹配当前模块的路径(如 .css 文件) issuer: 匹配引入当前模块的父模块的路径࿰…...

MyBatis 插件开发的完整详细例子
MyBatis 插件开发的完整详细例子 MyBatis 插件(Interceptor)允许开发者在已映射语句执行过程中的某一点进行拦截调用,从而实现自定义逻辑。以下是一个完整的 MyBatis 插件开发示例,涵盖所有使用场景,并附有详细注释和总…...

树状数组底层逻辑探讨 / 模版代码-P3374-P3368
目录 功能 实现 Q:但是,c[x]左端点怎么确定呢? Q:那么为什么要以二进制为基础呢? Q:为什么是补码 - ? 区间查询 树形态 性质1.对于x<y,要么c[x]和c[y]不交,要么c[x]包含于c[y] 性质2.c[x] 真包含 于c[x l…...

Eigen库入门
Eigen是一个C模板库,用于线性代数运算,包括矩阵、向量、数值求解和相关算法。它以其高性能、易用性和丰富的功能而闻名。 安装与配置 Eigen是一个纯头文件库,无需编译,只需包含头文件即可使用。 下载Eigen:从官方网站…...

力扣HOT100——102.二叉树层序遍历
给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。 示例 1: 输入:root [3,9,20,null,null,15,7] 输出:[[3],[9,20],[15,7]] /*** Definition for a bi…...

客户案例 | 光热+数智双驱动!恒基能脉的数字化协同与技术创新实践
光热先锋 智领未来 恒基能脉新能源科技有限公司: 创新驱动,智造光热未来行业领航者 恒基能脉新能源科技有限公司是一家立足于光热发电核心技术产品,专注于“光热” 多能互补项目的国家高新技术企业,其核心产品定日镜广泛应用于光热发电、储…...

第十六周蓝桥杯2025网络安全赛道
因为只会web,其他方向都没碰过,所以只出了4道 做出来的: ezEvtx 找到一个被移动的文件,疑似被入侵 提交flag{confidential.docx}成功解出 flag{confidential.docx} Flowzip 过滤器搜索flag找到flag flag{c6db63e6-6459-4e75-…...

构造函数有哪些种类?
构造函数用于对象的初始化。 1.默认构造函数:没有参数,执行默认的初始化操作; 2.参数化构造函数:传入参数的构造函数,允许构造函数初始化成员变量; 3.拷贝构造函数:将同一类型的实例化对象作…...

第十六届蓝桥杯大赛软件赛省赛 C/C++ 大学B组 [京津冀]
由于官方没有公布题目的数据, 所以代码仅供参考 1. 密密摆放 题目链接:P12337 [蓝桥杯 2025 省 AB/Python B 第二场] 密密摆放 - 洛谷 题目描述 小蓝有一个大箱子,内部的长宽高分别是 200、250、240(单位:毫米)&…...

关于调度策略的系统性解析与物流机器人应用实践
关于调度策略的系统性解析与物流机器人应用实践 一、调度策略的定义与核心目标 调度策略是用于在复杂环境中协调资源分配、任务排序及路径规划的决策框架,旨在通过优化资源利用率和任务执行效率,实现系统整体性能的最优解。其核心目标包括: 动态适应性:应对实时变化(如订…...

探索具身智能协作机器人:技术、应用与未来
具身智能协作机器人:概念与特点 具身智能协作机器人,简单来说,就是将人工智能技术与机器人实体相结合,使其能够在与人类共享的空间中进行安全、高效协作的智能设备。它打破了传统机器人只能在预设环境中执行固定任务的局限&#…...

毕业项目-Web入侵检测系统
1. 项目简介 系统主要分为两大板块:靶标站点和入侵检测系统。靶标站点是系统的被监测对象,而入侵检测系统则是用于检测靶标站点的流量是否存在异常,以及在检测到异常时进行告警。 入侵检测系统的实现过程简述如下: 数据获取与分…...

【分布式系统中的“瑞士军刀”_ Zookeeper】二、Zookeeper 核心功能深度剖析与技术实现细节
在分布式系统的复杂生态中,Zookeeper 凭借其强大的核心功能,成为保障系统稳定运行的关键组件。上篇文章我们了解了 Zookeeper 的基础概念与安装配置,本文将继续深入剖析 Zookeeper 的核心功能,包括分布式锁、配置管理、命名服务和…...
自定义组件控制自己的css)
前端学习笔记(四)自定义组件控制自己的css
1、前言及背景 自己写的一个组件有至少3个页面在使用,组件中的部分文字颜色需要统一修改需要根据一个状态字段来显示不同颜色且不希望受父组件影响 注意:博主学习vue截止目前也就半年,如有知识错误之处还请指出不胜感激,祝学习开…...

从描述语言,非功能性需求,需求和架构的一致性三个方面,说明软件需求到架构的映射存在哪些难点
软件需求到架构的映射是软件工程中的关键环节,其难点主要体现在描述语言差异、非功能性需求的复杂性以及需求与架构的一致性维护三个方面。以下是具体分析: 1. 描述语言的差异 难点:需求与架构使用不同的抽象语言描述,导致语义鸿…...

linux blueZ 第五篇:高阶优化与性能调优——蓝牙吞吐、延迟与功耗全攻略
本篇面向已有实战经验的读者,深入探讨 Classic Bluetooth 与 BLE 在 BlueZ 平台上的性能优化和调优方法,包括连接参数、MTU 调整、PHY 选择、缓存管理、并发策略,以及 HCI 抓包、功耗测量与自动化基准测试,助你打造高吞吐、低延迟、超低功耗的蓝牙应用。 目录 为何要做性能…...
)
linux的例行性工作(at)
使用场景: 生活中,我们有太多场景需要使用到闹钟,比如早上 7 点起床,下午 4 点开会,晚上 8 购物,等等 在 Linux 系统里,我们同样也有类似的需求。比如我们想在凌晨 1 点将文件上传服务器&#…...
:执剑人·降维打击的终极审判)
JVM考古现场(二十六):执剑人·降维打击的终极审判
楔子:二向箔的颤动——当修真文明遭遇降维打击 "警告!老年代发生维度坍缩!"我腰间悬挂的昆仑镜突然迸发幽蓝光芒,终南山巅的河图洛书大阵中,GC日志正以《奇门遁甲》的格局疯狂演化: // 降维打击…...

腾讯云物联网平台
文档:物联网开发平台 MQTT.fx 快速接入物联网开发平台_腾讯云...

Unity之基于MVC的UI框架-含案例
Unity之基于MVC的UI框架-含案例 使用案例:类《双人成行》3D动作益智冒险类双人控制游戏开发教程 资源地址:https://learn.u3d.cn/tutorial/3d-adventure-william-anna 一、MVC框架概览 本框架以MVC的方式搭建,以View视口的方式展现数据&am…...

【Token系列】01 | Token不是词:GPT如何切分语言的最小单元
文章目录 01 | Token不是词:GPT如何切分语言的最小单元?一、什么是 Token?二、Token 是怎么来的?——BPE算法原理BPE核心步骤: 三、为什么不直接用词或字符?四、Token切分的实际影响五、中文Token的特殊性六…...

C++学习之路,从0到精通的征途:List类的模拟实现
目录 一.list的介绍 二.list的接口实现 1.结点 2.list结构 3.迭代器 (1)begin (2)end 4.修改 (1)insert (2)push_back (3)push_front ࿰…...

Java大师成长计划之第4天:Java中的泛型
📢 友情提示: 本文由银河易创AI(https://ai.eaigx.com)平台gpt-4o-mini模型辅助创作完成,旨在提供灵感参考与技术分享,文中关键数据、代码与结论建议通过官方渠道验证。 在现代软件开发中,类型安…...

计算机学报 2024年 区块链论文 录用汇总 附pdf下载
计算机学报 Year:2024 1 Title: 区块链中的公钥密码:设计、分析、密评与展望 Authors: Key words: 区块链;公钥密码算法;算法设计;复杂性分析;密评 Abstract: 比特币的成功,吸引了人们研…...

【Castle-X机器人】三、紫外消杀模块安装与调试
持续更新。。。。。。。。。。。。。。。 【Castle-X机器人】紫外消杀模块安装与调试 三、紫外消杀模块安装与调试2.1 安装2.2 调试2.2.1 紫外消杀模块话题2.2.2 测试 三、紫外消杀模块安装与调试 2.1 安装 使用相应工具将紫外消杀模块固定在Castle-X机器人底盘 2.2 调试 2.2…...
:深入剖析电子商务商业模式)
精益数据分析(29/126):深入剖析电子商务商业模式
精益数据分析(29/126):深入剖析电子商务商业模式 在创业和数据分析的学习道路上,我们始终在探索如何更精准地把握商业规律,提升业务的竞争力。今天,我们依旧怀揣着共同进步的愿望,深入解读《精…...

AI图像编辑器 Luminar Neo 便携版 Win1.24.0.14794
如果你对图像编辑有兴趣,但又不想花费太多时间学习复杂的软件操作,那么 Luminar Neo 可能就是你要找的完美工具。作为一款基于AI技术的创意图像编辑器,Luminar Neo简化了复杂的编辑流程,即使是没有任何图像处理经验的新手…...

在Mybatis中为什么要同时指定扫描mapper接口和 mapper.xml 文件,理论单独扫描 xml 文件就可以啊
设计考虑因素 历史兼容性: MyBatis早期版本主要依赖XML配置,后来才引入接口绑定方式同时支持两种方式可以保证向后兼容 明确性: 显式指定两种路径可以使映射关系更加明确减少因命名不一致导致的潜在问题 性能考虑: 同时扫描可…...
)
MyBatis XML 配置完整示例(含所有核心配置项)
MyBatis XML 配置完整示例(含所有核心配置项) 1. 完整 mybatis-config.xml 配置文件 <?xml version"1.0" encoding"UTF-8" ?> <!DOCTYPE configurationPUBLIC "-//mybatis.org//DTD Config 3.0//EN""htt…...